DOI:10.32604/cmc.2022.029326
| Computers, Materials & Continua DOI:10.32604/cmc.2022.029326 | |
| Article |
Deep Transfer Learning Driven Oral Cancer Detection and Classification Model
1Department of Information Systems, College of Computer and Information Sciences, Princess Nourah Bint Abdulrahman University, Riyadh, 11671, Saudi Arabia
2Department of Computer Sciences, College of Computer and Information Sciences, Princess Nourah Bint Abdulrahman University, Riyadh, 11671, Saudi Arabia
3Department of Computer Science, College of Science & Art at Mahayil, King Khalid University,Saudi Arabia
4Department of Computer Sciences, College of Computing and Information System, Umm Al-Qura University, Saudi Arabia
5Department of Natural and Applied Sciences, College of Community-Aflaj, Prince Sattam Bin Abdulaziz University, Saudi Arabia
6Department of Computer Science, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11835, Egypt
7Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam Bin Abdulaziz University, AlKharj, Saudi Arabia
*Corresponding Author: Manar Ahmed Hamza. Email: ma.hamza@psau.edu.sa
Received: 01 March 2022; Accepted: 26 April 2022
Abstract: Oral cancer is the most commonly occurring ‘head and neck cancers’ across the globe. Most of the oral cancer cases are diagnosed at later stages due to absence of awareness among public. Since earlier identification of disease is essential for improved outcomes, Artificial Intelligence (AI) and Machine Learning (ML) models are used in this regard. In this background, the current study introduces Artificial Intelligence with Deep Transfer Learning driven Oral Cancer detection and Classification Model (AIDTL-OCCM). The primary goal of the proposed AIDTL-OCCM model is to diagnose oral cancer using AI and image processing techniques. The proposed AIDTL-OCCM model involves fuzzy-based contrast enhancement approach to perform data pre-processing. Followed by, the densely-connected networks (DenseNet-169) model is employed to produce a useful set of deep features. Moreover, Chimp Optimization Algorithm (COA) with Autoencoder (AE) model is applied for oral cancer detection and classification. Furthermore, COA is employed to determine optimal parameters involved in AE model. A wide range of experimental analyses was conducted on benchmark datasets and the results were investigated under several aspects. The extensive experimental analysis outcomes established the enhanced performance of AIDTL-OCCM model compared to other approaches with a maximum accuracy of 90.08%.
Keywords: Oral cancer detection; image classification; artificial intelligence; machine learning; deep learning
Oral cancer is one of the leading cancers across the globe based on its morbidity rate, late diagnoses, and high mortality rate. Tobacco and excessive alcohol usage are major risk factors that cause oral lesions [1]. Betel quid consumption is the most important causal factor behind high oral cancer prevalence in South and Southeast Asia. Betel quid usually contains tobacco, slaked lime, areca nut, and betel leaf [2–4]. At present, betel quid is commercially available in sachets and is commonly consumed in public because of its dynamic marketing strategy. Oral lesion is widely related to delay in presentation i.e., over two-third present at later stage which consequently results in poor survival rate [5]. Lesion management, particularly at later stages, is expensive [6]. Lack of knowledge and public awareness concern the medical experts since oral lesion is a major cause for late diagnosis [7]. Late detection does not define the characteristics of the lesion, since oral lesion is frequently headed by visible oral lesion named as Oral Potentially Malignant Disorder (OPMD). This is diagnosed during routine screening through Clinical Oral Examination (COE) conducted by dental specialists. When an apprehensive cancer is recognized, the patient is recommended for professional examination for further management and confirmation of diagnosis.
Prior research in India reveals that screening and earlier diagnoses have reduced the mortality rates and down-staging of disease among individuals who use alcohol and tobacco [8]. The screening programs for oral lesions must be vigorous, cost-effective and efficient since there is an ongoing constraint exists in terms of health resources and healthcare professionals. In this background, technology, in the form of telemedicine, can be a feasible method for early diagnosis. Advancements in the fields of Deep Learning (DL) and Computer Vision (CV) offer effective methods to design adjunctive technology that can automatically screens the oral cavity of an individual and provide feedback to medical professionals during patient examination and to the individual for self-examination [9]. The study conducted earlier [10] on image-based automated diagnoses of oral cancer has mainly focused on the usage of imaging techniques such as hyperspectral imaging, auto fluorescence imaging, and optical coherence tomography. While one or two studies have implemented white-light photographic image, almost all of the studies conducted earlier focus on the recognition of specific kinds of oral lesion.
The current study introduces Artificial Intelligence (AI) with Deep Transfer Learning Driven Oral Cancer detection and Classification Model (AIDTL-OCCM). The primary goal of the proposed AIDTL-OCCM model is to recognize the oral cancer using AI and image processing techniques. Firstly, the proposed AIDTL-OCCM model performs fuzzy-based contrast enhancement approach to perform data pre-processing. In addition, densely-connected networks (DenseNet-169) model is employed to produce a useful set of features. Moreover, Chimp Optimization Algorithm (COA) with Autoencoder (AE) model is applied for detection and classification of oral cancer. Furthermore, COA is employed to determine the optimal parameters involved in AE model. A wide range of experimental analyses was conducted on benchmark datasets and the results were investigated under several aspects.
Rest of the paper is organized as follows. Section 2 offers the works related to the domain and Section 3 introduces the proposed model. Next, Section 4 provides experimental validation and Section 5 concludes the study.
In literature [11], a new approach was proposed to combine the bounding box annotation from several clinicians. In addition, Deep Neural Network (DNN) was also utilized to create automated systems, where difficult patterns are created as a result to tackle this complex task. Since the primary data collected under this case is utilized, two DL-based CV methods were considered for automated recognition and classification of oral lesions. Jeyaraj et al. [12] established a DL technique for automated and computer-aided oral cancer identification method in which patient hyperspectral image is considered. In order to validate the presented regression-based partitioned DL technique, its performance was compared with other approaches in terms of classifier sensitivity, accuracy, and specificity. To achieve accurate medicinal image classification, a novel infrastructure named partitioned deep Convolution Neural Network (DCNN) was presented with two partitioned layers for labeling and classified by labeling the Region Of Interest (ROI) from multi-dimensional hyperspectral images.
Jubair et al. [13] established a lightweight DCNN for binary classification of oral lesions so as to segregate benign and malignant or potentially-malignant lesions using normal real-time medical images. The data set of 716 medical images was utilized for training and testing the presented method. Tanriver et al. [14] found that both CV and DL approaches have enormous potential in oral cancer detection through photographic images. They analyzed the diagnostic outcomes of automated schemes to identify the potential oral-malignant disorder with a 2-phase pipeline. The initial outcomes demonstrate the possibility of DL-based techniques for automated recognition and classification of oral lesions from real time.
Lin et al. [15] projected an effectual smartphone-based image analysis approach controlled by DL technique to address the automatic detection challenges of oral diseases. It can be conducted as a retrospective analysis. An easy yet effectual centered-rule image-capturing technique is presented in this study to gather oral cavity images. Next, according to this technique, a medium-sized oral data set with five types of diseases are generated, and a resampling approach is projected to alleviate the effect of images’ variability in hand-held smartphone cameras. Eventually, a new DL network (HRNet) has been established to evaluate the performance of the proposed technique in terms of oral cancer recognition. Nanditha et al. [16] established an automated system to analyze oral lesions with the help of DL approaches. An ensemble DL technique that integrates the advantages of Resnet-50 and visual geometry group (VGG)-16 was established in this study. This method was trained with augmented data set of oral lesion images. This technique was compared and contrasted with other commonly-utilized DL approaches in terms of implementing the classifier of oral images.
The current study has developed a novel AIDTL-OCCM model for effectual recognition and classification of oral cancer. The presented AIDTL-OCCM technique undergoes a series of operations (as shown in Fig. 1) such as fuzzy-enabled pre-processing, DenseNet-169 feature extraction, AE-based classification, and COA-based parameter optimization. Furthermore, COA is employed to determine the optimal parameters involved in AE model.
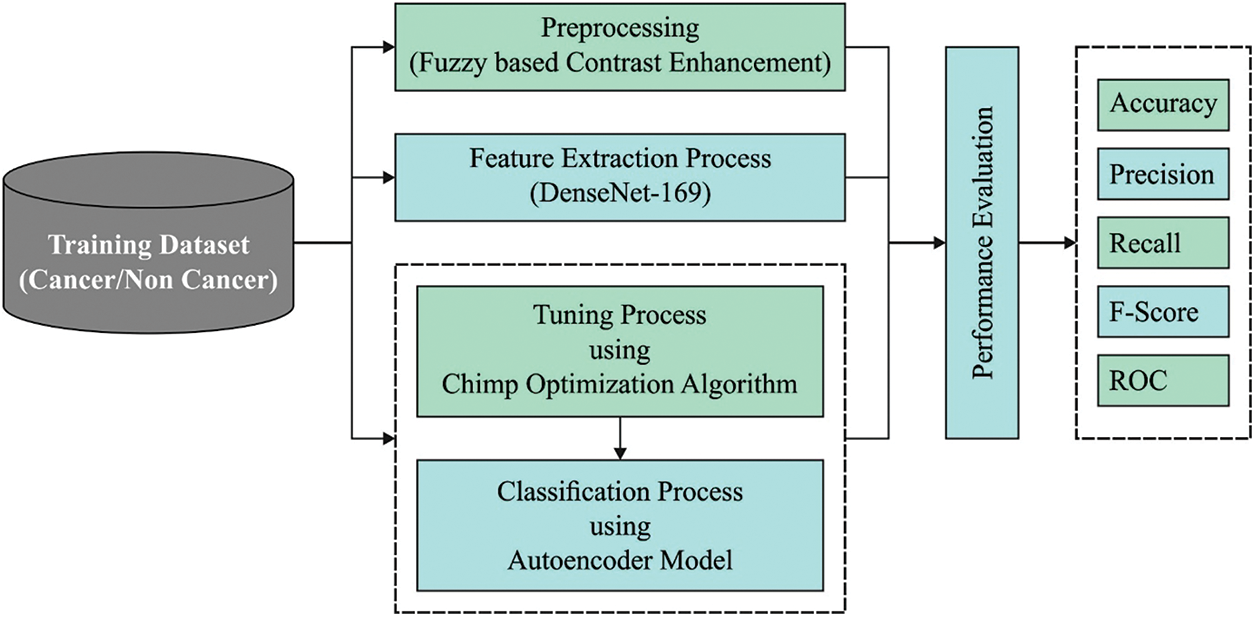
Figure 1: Workflow of AIDTL-OCCM model
3.1 Fuzzy Based Contrast Enhancement
In order to enhance the contrast level of images, Histogram Equalization (HE) is employed. Fuzzy-enabled image pre-processing helps in generating highly-sophisticated image divergence compared to input images. High resolution medical images are difficult to understand due to which image pre-processing is carried out to improve the quality of the image. A major benefit of this model is the transformation of color images into grayscale ones. In order to visualize the image with high clarity, fuzzy-based Contrast Limited Adaptive Histogram Equalization (CLAHE) model is used.
3.2 Dense-169 Based Feature Extraction
Followed by, DenseNet-169 model processes the pre-processed images to create a set of feature vectors [17]. DCNN is a highly efficient framework in image recognition process due to the existence of particular kinds of pooling layer and convolution layer. Nonetheless, when the system goes in-depth, the input data or gradient that passes by the layer gets disappeared with the time, the previous layer of the network is obtained. DenseNet overcomes the challenge of vanishing gradients by interconnecting each layer with equivalent feature-size straightaway with one another. The main objective of utilizing DenseNet model, as a feature extractor is that deeper the network, more generic feature can be attained. DenseNet-169 model includes one pooling and convolutional layer at first followed by three transition layers and four dense blocks. After this layer, the last layer i.e., classification layer exists. The layered architecture is depicted in Fig. 2.
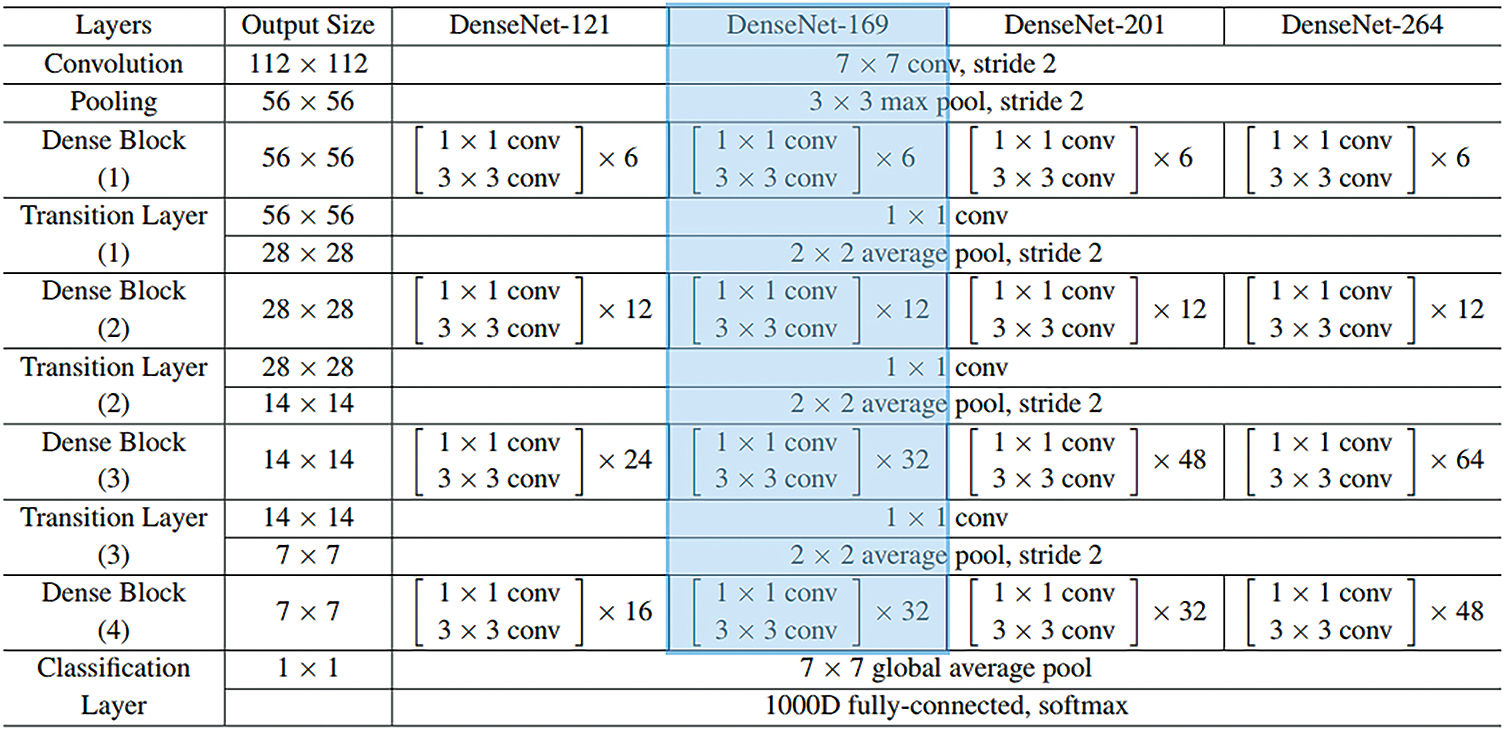
Figure 2: Layers in DenseNet model
The initial convolution layer executes 7 × 7 convolution with stride 2 and 3 × 3 max pooling utilized by stride 2. Next, the network comprises of a dense block and three sets of them contain a dense block and a transition layer. The dense connectivity in DenseNet is established by transporting a direct connection from one layer to another. The lth layer receives the feature-map of each previous layer, thereby, ameliorating the flow of gradient all over the network. This needs the concatenation of feature-map of the preceding layer that could not be completed except the case in which every feature-map is of the similar size. However, Convolution Neural Network mainly intends toward the downsampling of size of the feature-map. The DenseNet model is separated into several densely-connected dense blocks as mentioned above. The layer between these dense blocks is represented as a transition layer. All the transition layers contain 2 × 2 average pooling layer, batch normalization layer, and 1 × 1 convolution layer which employs a stride of 2. As mentioned above, there are four dense blocks and all of them comprise of two convolutional layers, 1 × 1 and 3 × 3 sizes. The size of each 4 dense block in DenseNet169 model pre-trained on ImageNet is 6, 12, 32, and 32. Then, the last layer is the classification layer that implements the global average pooling of 7 × 7 whereas the last FC layer employs ‘softmax’ as the activation.
At the time of classification process, AE model is used to properly determine the class labels for test images [18]. AE consists of a hidden layer of
whereas,
In this work, the subsequent constraints exist
Consider that AE has tied weight that assists in halving the model parameter. Therefore, there are three classes of variables that remains to learn:
In which
After training the network, the reconstructed layer and the parameter are eliminated whereas the learned features in hidden node could be consequently utilized for classification or as input of high layers for the production of deep features.
3.4 COA-Based Parameter Optimization
At the time of parameter optimization process, COA is employed to identify the parameter values of AE model. In the event of non-uniform irradiance conditions (i.e., partial shading), COA utilizes the approach to drive and chase the neighborhood for maximal global functioning points with respect to voltage, as given herewith [19]:
At this point, ‘i’ refers to the iteration number, and
At this point,
and
At this point after upgrading the place of all the chimps, the optimum voltage is as follows.
where
The experimental validation was conducted for the proposed AIDTL-OCCM model using the benchmark dataset from Kaggle repository as illustrated in Fig. 3 (available at https://www.kaggle.com/shivam17299/oral-cancer-lips-and-tongue-images). The dataset holds lips and tongue images under two classes namely, cancer (87 images) and non-cancer (44 images).
Figure 3: Sample images
Fig. 4 illustrates the set of confusion matrices generated by the proposed AIDTL-OCCM model under five runs. The figure points out that AIDTL-OCCM model recognized the oral cancer effectually under every run. For instance, with run-1, the proposed AIDTL-OCCM model classified 81 images under cancer and 37 images under non-cancer. Similarly, with run-2, the proposed AIDTL-OCCM model classified 84 images under cancer and 28 images under non-cancer. Likewise, with run-5, the proposed AIDTL-OCCM model classified 81 images under cancer and 35 images under non-cancer.

Figure 4: Confusion matrices of AIDTL-OCCM model
Tab. 1 showcases the overall oral cancer classification outcomes of the proposed AIDTL-OCCM model after five runs of execution. The experimental values indicate that the proposed AIDTL-OCCM model has accomplished superior outcomes under all the runs.
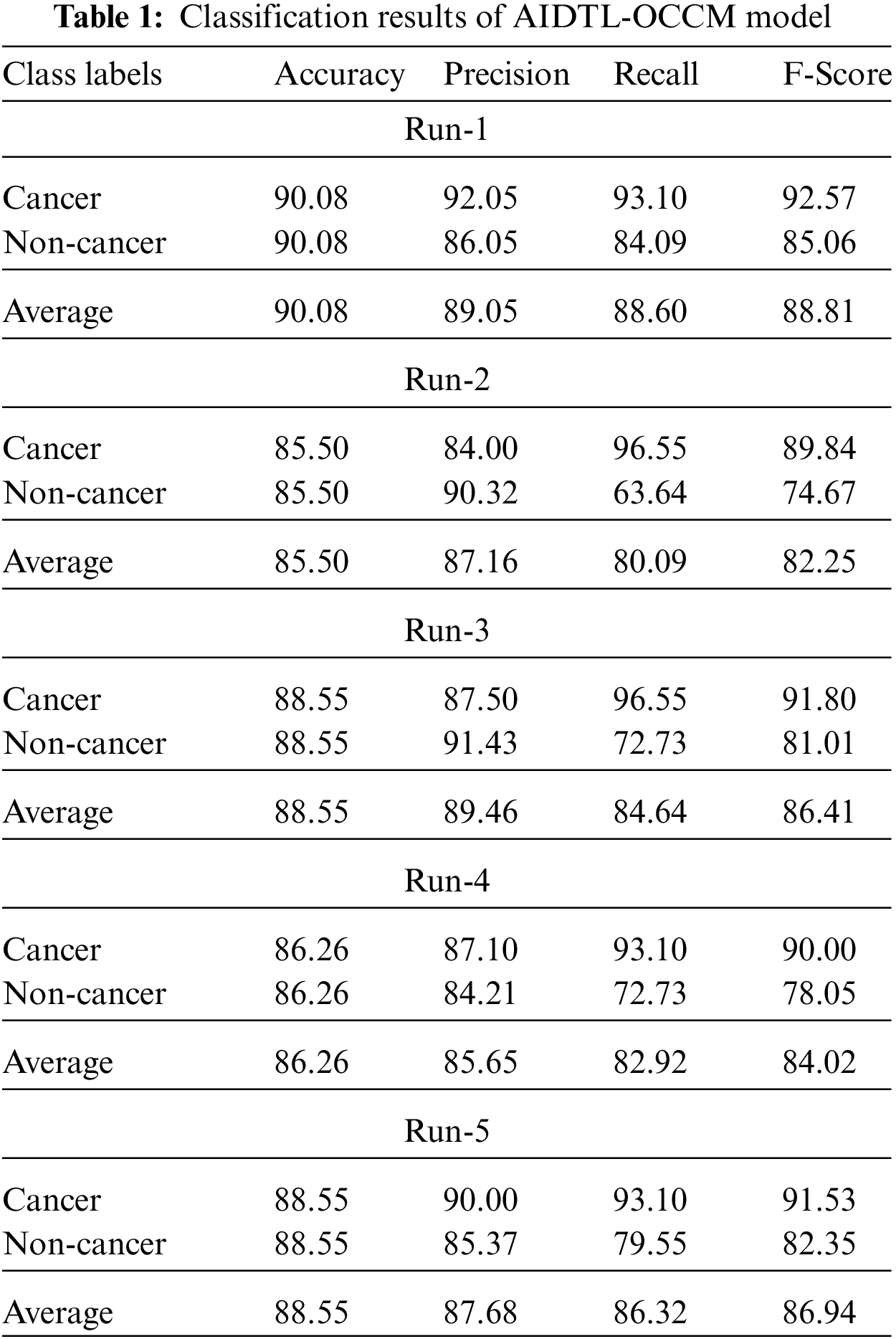
Fig. 5 demonstrates the
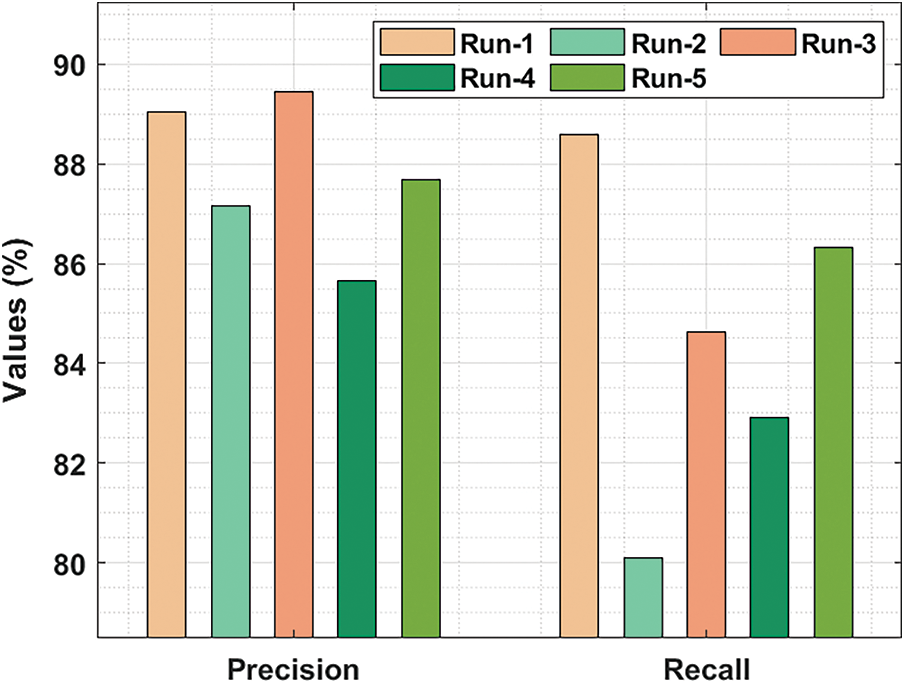
Figure 5:
Fig. 6 demonstrates the
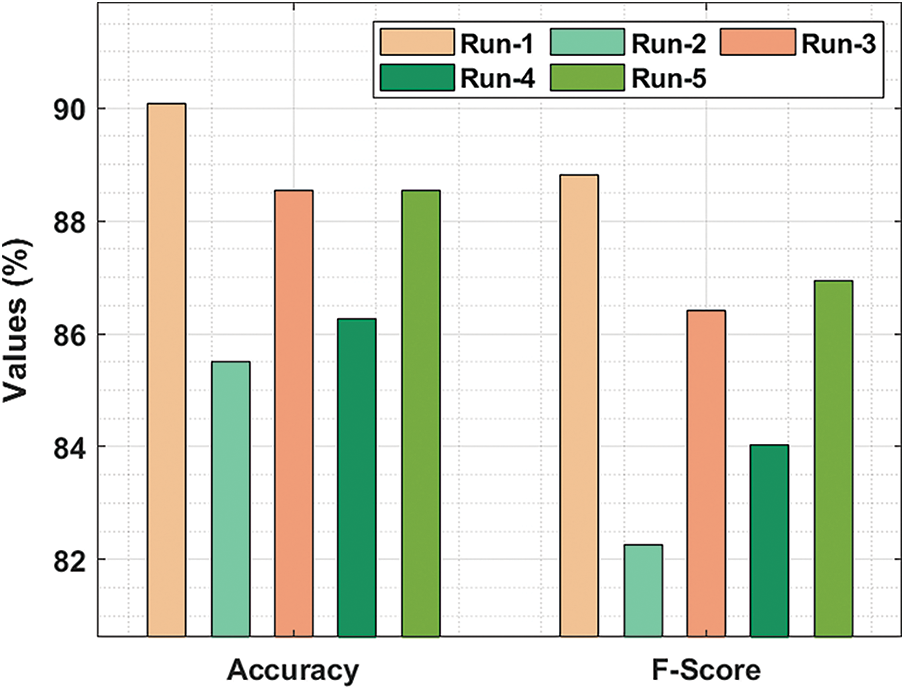
Figure 6:
Tab. 2 highlights the average oral cancer classifier outcomes accomplished by the proposed AIDTL-OCCM model with five runs. With run-1, AIDTL-OCCM model achieved average
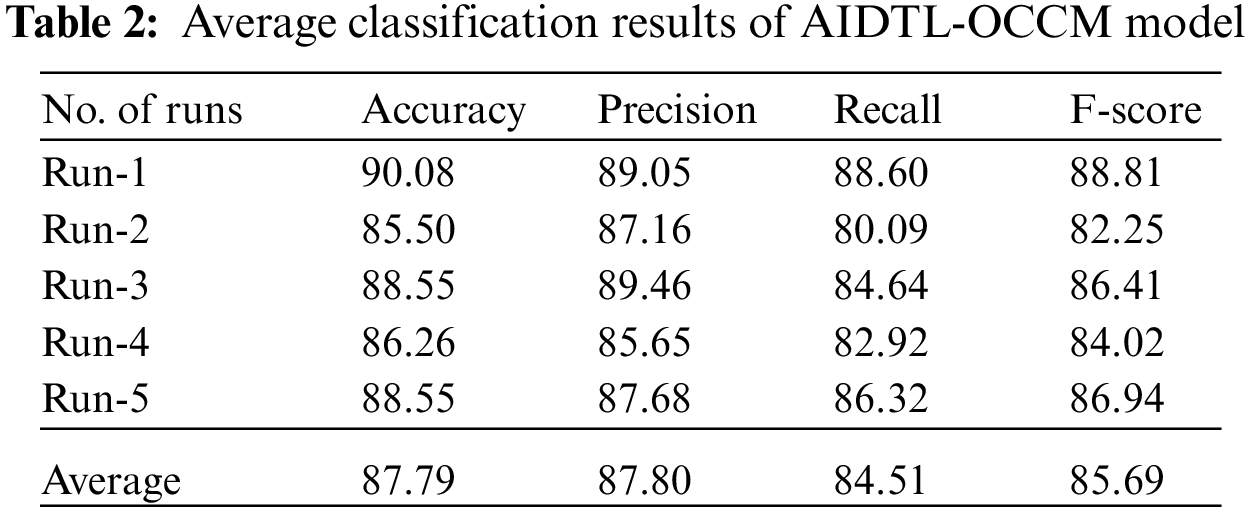
Fig. 7 reports the results from precision-recall curve analysis achieved by AIDTL-OCCM model under five runs. The figure indicates that AIDTL-OCCM model produced effectual outcomes under all five runs.
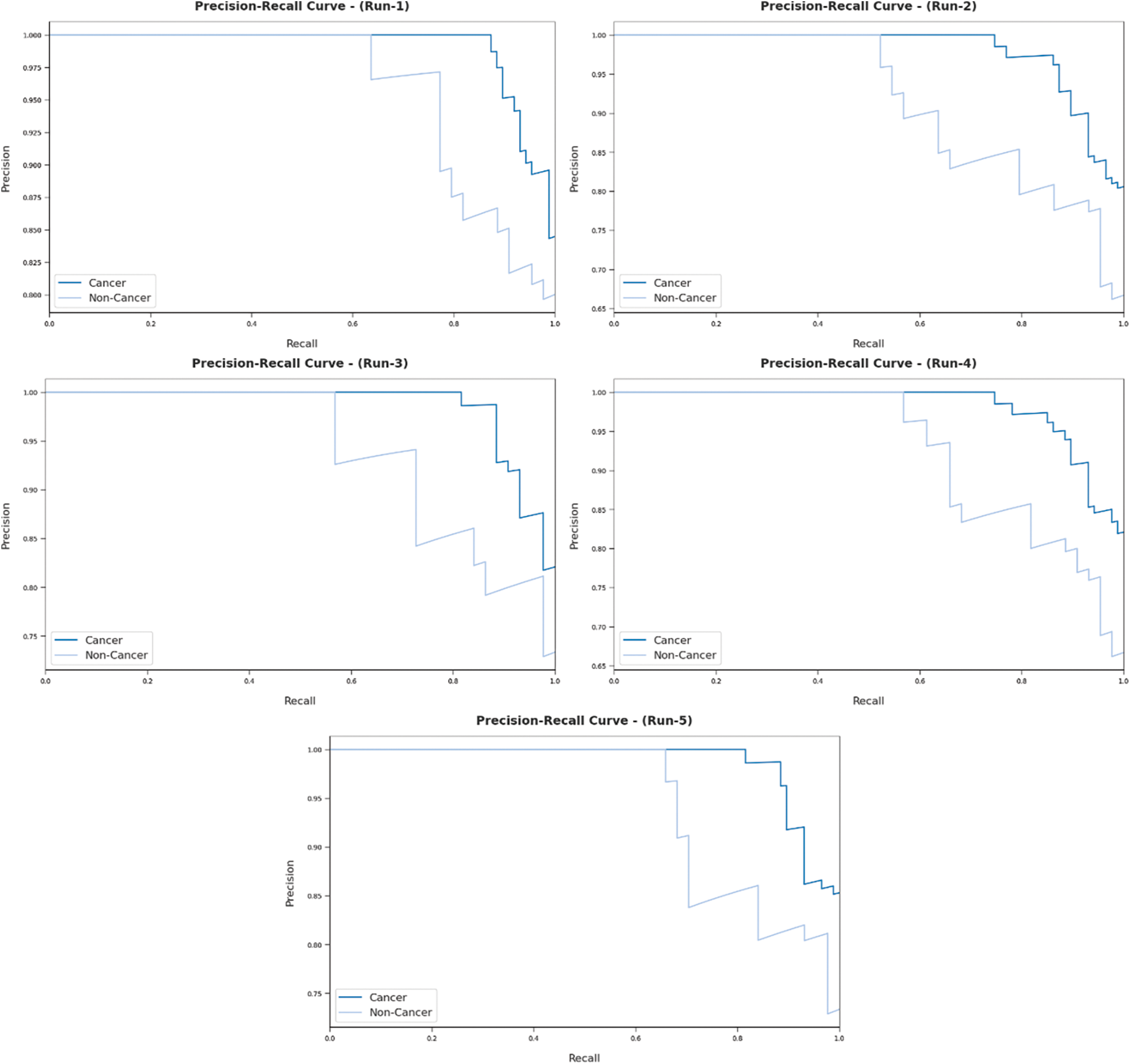
Figure 7: Precision recall analysis results of AIDTL-OCCM model
Fig. 8 portrays ROC analysis results of AIDTL-OCCM model in classifying two classes under five runs. The figure indicates that the proposed AIDTL-OCCM model produced the maximum ROC values during the categorization of cancer and non-cancer images.
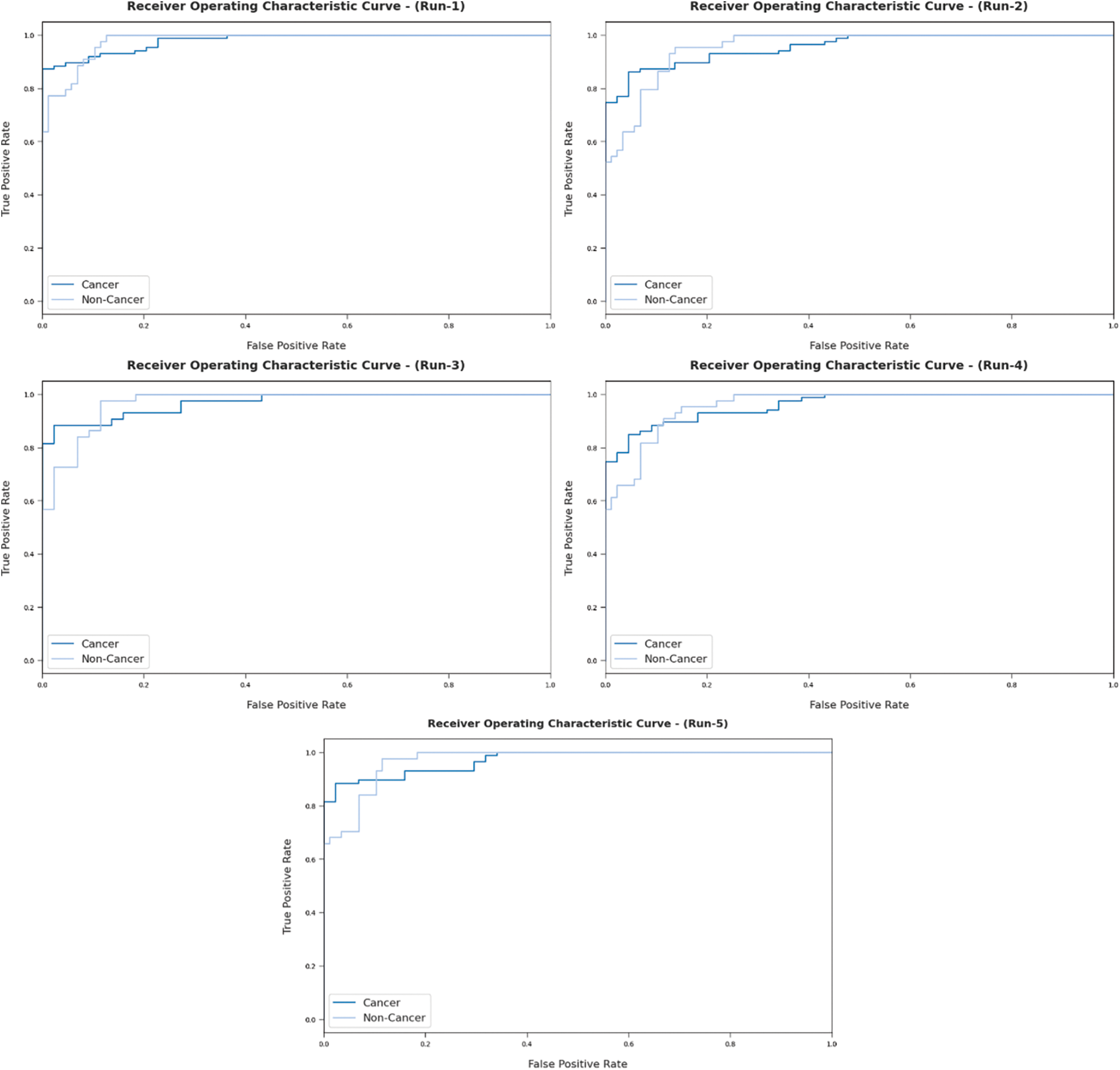
Figure 8: ROC analysis results of AIDTL-OCCM model
Fig. 9 illustrates a set of training and validation accuracy/loss graph plotted by AIDTL-OCCM model under five runs. In this figure, it can be observed that the validation accuracy is higher and validation loss is lower compared to training accuracy/loss.
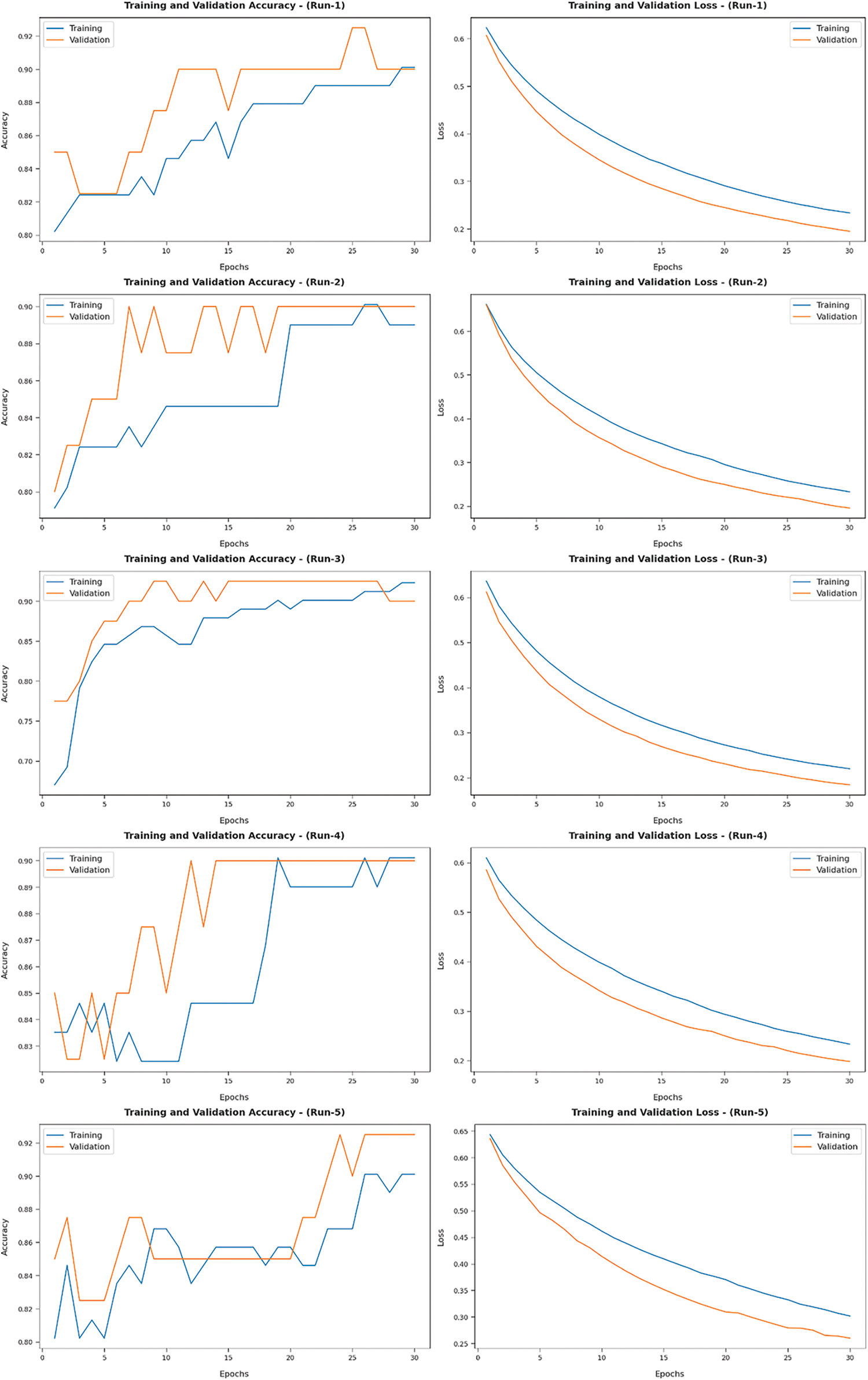
Figure 9: Training and validation accuracy/loss results of AIDTL-OCCM model
In order to demonstrate the superior outcomes of AIDTL-OCCM model, a brief comparison study was conducted and the results are shown in Tab. 3 and Fig. 10 [20]. The experimental values infer that Inception-v4 model produced the least classification outcomes. Followed by, DenseNet-161 and ensemble models resulted in slightly improved classification outcomes.
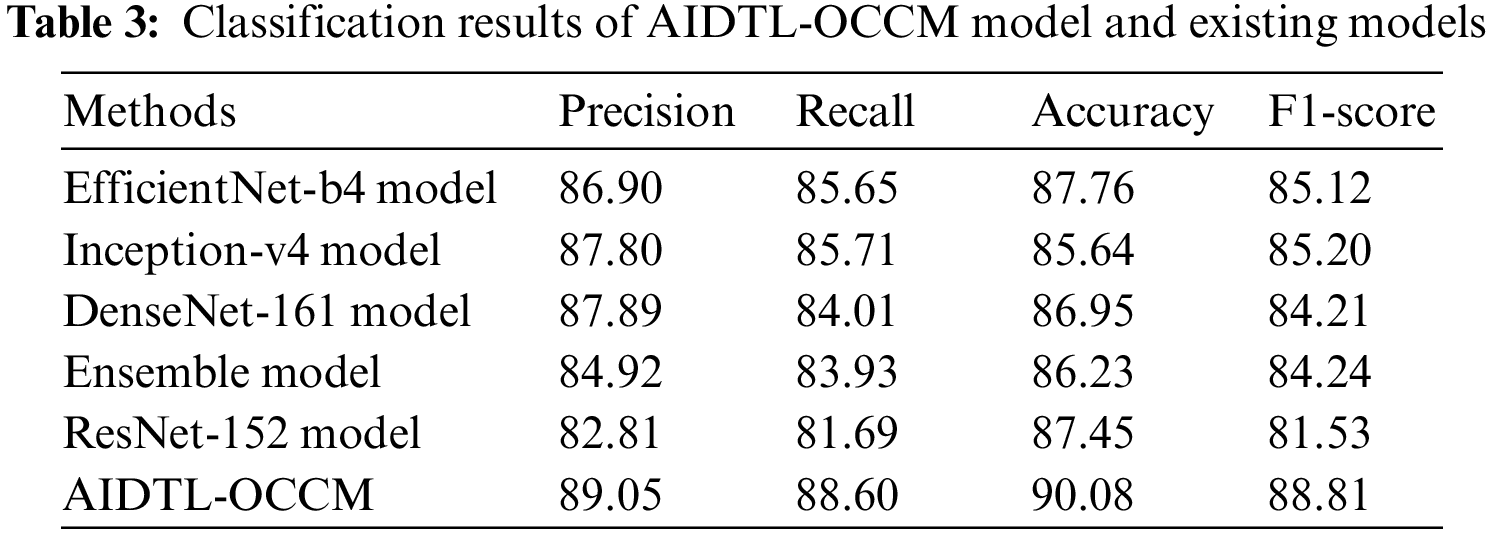
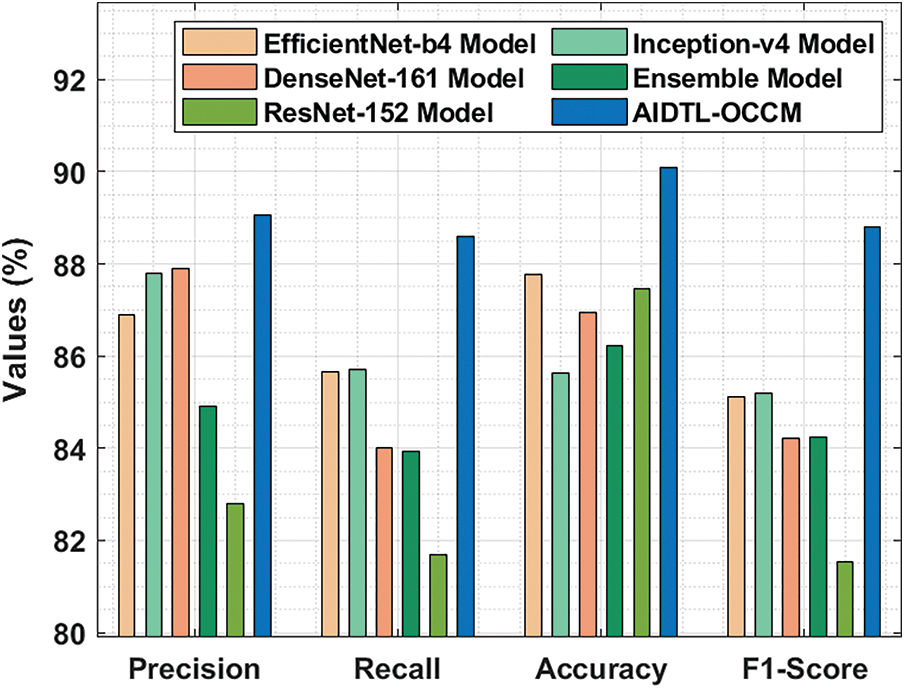
Figure 10: Comparative oral cancer classification outcomes of AIDTL-OCCM model
At the same time, EfficientNet-b4 and ResNet-152 models accomplished reasonable performance. However, the proposed AIDTL-OCCM model produced superior results with maximum
In current study, the researchers developed a novel AIDTL-OCCM model for effectual recognition and classification of oral cancer. In the presented AIDTL-OCCM technique, various functions are involved such as fuzzy-enabled pre-processing, DenseNet-169 feature extraction, AE-based classification, and COA-based parameter optimization. Furthermore, COA is employed to determine the optimal parameters involved in AE model. A wide range of experimental analyses was conducted on benchmark datasets and the results were investigated under several aspects. The results from extensive experimental analysis established the enhanced performance of the proposed AIDTL-OCCM model over other recent approaches with a maximum accuracy of 90.08%. Therefore, AIDTL-OCCM technique can be applied as an efficient tool in oral cancer classification. In future, advanced DL models can be used for the classification of medical images to diagnose oral cancer.
Funding Statement: The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work under grant number (RGP 1/322/42). Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R161), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4310373DSR06).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. R. K. Gupta, M. Kaur and J. Manhas, “Tissue level based deep learning framework for early detection of dysplasia in oral squamous epithelium,” Journal of Multimedia Information System, vol. 6, no. 2, pp. 81–86, 2019. [Google Scholar]
2. J. Rajan, S. Rajan, R. Martis and B. Panigrahi, “Fog computing employed computer aided cancer classification system using deep neural network in internet of things based healthcare system,” Journal of Medical Systems, vol. 44, no. 2, pp. 1–10, 2019. [Google Scholar]
3. P. Yang, G. Liu, X. Li, L. Qin and X. Liu, “An intelligent tumors coding method based on drools,” Journal of New Media, vol. 2, no. 3, pp. 111–119, 2020. [Google Scholar]
4. X. R. Zhang, J. Zhou, W. Sun and S. K. Jha, “A lightweight CNN Based on transfer learning for COVID-19 diagnosis,” Computers, Materials & Continua, vol. 72, no. 1, pp. 1123–1137, 2022. [Google Scholar]
5. N. Das, E. Hussain and L. B. Mahanta, “Automated classification of cells into multiple classes in epithelial tissue of oral squamous cell carcinoma using transfer learning and convolutional neural network,” Neural Networks, vol. 128, no. 2, pp. 47–60, 2020. [Google Scholar]
6. X. Liu, L. Faes, A. UKale, S. K. Wagner, D. J. Fu et al., “A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: A systematic review and meta-analysis,” The Lancet Digital Health, vol. 1, no. 6, pp. e271–e297, 2019. [Google Scholar]
7. H. Yang, E. Jo, H. J. Kim, I. Cha, Y. S. Jung et al., “Deep learning for automated detection of cyst and tumors of the jaw in panoramic radiographs,” Journal of Clinical Medicine, vol. 9, no. 6, pp. 1839, 2020. [Google Scholar]
8. B. Ilhan, P. Guneri and P. Wilder-Smith, “The contribution of artificial intelligence to reducing the diagnostic delay in oral cancer,” Oral Oncology, vol. 116, no. 7, pp. 105254, 2021. [Google Scholar]
9. S. Corbella, S. Srinivas and F. Cabitza, “Applications of deep learning in dentistry,” Oral Surgery, Oral Medicine, Oral Pathology and Oral Radiology, vol. 132, no. 2, pp. 225–238, 2021. [Google Scholar]
10. S. B. Khanagar, S. Naik, A. A. A. Kheraif, S. Vishwanathaiah, P. C. Maganur et al., “Application and performance of artificial intelligence technology in oral cancer diagnosis and prediction of prognosis: A systematic review,” Diagnostics, vol. 11, no. 6, pp. 1004, 2021. [Google Scholar]
11. R. A. Welikala, P. Remagnino, J. H. Lim, C. S. Chan, S. Rajendran et al., “Automated detection and classification of oral lesions using deep learning for early detection of oral cancer,” IEEE Access, vol. 8, pp. 132677–132693, 2020. [Google Scholar]
12. P. Jeyaraj and E. S. Nadar, “Computer-assisted medical image classification for early diagnosis of oral cancer employing deep learning algorithm,” Journal of Cancer Research and Clinical Oncology, vol. 145, no. 4, pp. 829–837, 2019. [Google Scholar]
13. F. Jubair, O. Al-karadsheh, D. Malamos, S. Al Mahdi, Y. Saad et al., “A novel lightweight deep convolutional neural network for early detection of oral cancer,” Oral Disease, 2021. [Google Scholar]
14. G. Tanriver, M. S. Tekkesin and O. Ergen, “Automated detection and classification of oral lesions using deep learning to detect oral potentially malignant disorders,” Cancers, vol. 13, no. 11, pp. 2766, 2021. [Google Scholar]
15. H. Lin, H. Chen, L. Weng, J. Shao and J. Lin, “Automatic detection of oral cancer in smartphone-based images using deep learning for early diagnosis,” Journal of Biomedical Science, vol. 26, no. 08, 2021. [Google Scholar]
16. B. R. Nanditha, A. Geetha, H. S. Chandrashekar, M. S. Dinesh and S. Murali, “An ensemble deep neural network approach for oral cancer screening,” International Association of Online Engineering, vol. 17, no. 02, pp. 121, 2021. [Google Scholar]
17. D. Varshni, K. Thakral, L. Agarwal, R. Nijhawan and A. Mittal, “Pneumonia Detection using cnn based feature extraction,” in 2019 IEEE Int. Conf. on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, pp. 1–7, 2019. [Google Scholar]
18. M. U. Salur and I. Aydin, “A novel hybrid deep learning model for sentiment classification,” IEEE Access, vol. 8, pp. 58080–58093, 2020. [Google Scholar]
19. M. Elahi, H. Ashraf and C. Kim, “An improved partial shading detection strategy based on chimp optimization algorithm to find global maximum power point of solar array system,” Energies, vol. 15, no. 4, pp. 1549, 2022. [Google Scholar]
20. R. A. Welikala, P. Remagnino, J. H. Lim, C. S. Chan, S. Rajendran et al., “Automated detection and classification of oral lesions using deep learning for early detection of oral cancer,” IEEE Access, vol. 8, pp. 132677–132693, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |