| Computer Modeling in Engineering & Sciences |
DOI: 10.32604/cmes.2021.017321
ARTICLE
A GPU-Based Parallel Algorithm for 2D Large Deformation Contact Problems Using the Finite Particle Method
1College of Civil Engineering and Architecture, Zhejiang University, Hangzhou, 310058, China
2Center for Balance Architecture, Zhejiang University, Hangzhou, 310028, China
3Architectural Design and Research Institute of Zhejiang University Co., Ltd., Hangzhou, 310028, China
*Corresponding Author: Yaozhi Luo. Email: luoyz@zju.edu.cn
Received: 01 May 2021; Accepted: 26 July 2021
Abstract: Large deformation contact problems generally involve highly nonlinear behaviors, which are very time-consuming and may lead to convergence issues. The finite particle method (FPM) effectively separates pure deformation from total motion in large deformation problems. In addition, the decoupled procedures of the FPM make it suitable for parallel computing, which may provide an approach to solve time-consuming issues. In this study, a graphics processing unit (GPU)-based parallel algorithm is proposed for two-dimensional large deformation contact problems. The fundamentals of the FPM for planar solids are first briefly introduced, including the equations of motion of particles and the internal forces of quadrilateral elements. Subsequently, a linked-list data structure suitable for parallel processing is built, and parallel global and local search algorithms are presented for contact detection. The contact forces are then derived and directly exerted on particles. The proposed method is implemented with main solution procedures executed in parallel on a GPU. Two verification problems comprising large deformation frictional contacts are presented, and the accuracy of the proposed algorithm is validated. Furthermore, the algorithm's performance is investigated via a large-scale contact problem, and the maximum speedups of total computational time and contact calculation reach 28.5 and 77.4, respectively, relative to commercial finite element software Abaqus/Explicit running on a single-core central processing unit (CPU). The contact calculation time percentage of the total calculation time is only 18% with the FPM, much smaller than that (50%) with Abaqus/Explicit, demonstrating the efficiency of the proposed method.
Keywords: Finite particle method; graphics processing unit (GPU); parallel computing; contact algorithm; large deformation
The numerical simulation of large deformation contact problems plays an important role in engineering fields. These problems generally involve geometric nonlinearity, material nonlinearity, and contact nonlinearity. Several numerical methods are available for these problems, among which the finite element method (FEM) is one of the most widely used methods. Computational contact mechanics using the FEM has been developed by many scholars since the 1970s and can be found in the literature [1,2]. Recently, some elaborated contact algorithms in the FEM context, such as the mortar method [3] and the surface smoothing method [4], have been developed, mainly to improve the accuracy of contact constraints; the computational efficiency of these algorithms, however, has drawn less attention. In fact, contact algorithms generally account for a considerable proportion of the overall computational cost [5]. Specifically, according to Wriggers [1], the time complexities of contact search algorithms are generally of the order from
The finite particle method (FPM) [10], derived from vector mechanics [11–13], is another feasible method for solving large deformation contact problems. In the FPM, a physical body is discretized into a number of particles and elements in space, and the motion path of each particle in time is modeled by a sequence of time steps, as illustrated in Fig. 1. The particles in the FPM are assumed to carry structural variables such as mass, velocity, and displacement. Within each time step, Newton's second law is adopted to formulate the motion of particles, and explicit time integration schemes are used to solve the equations of motion. In recent years, numerical methods based on vector mechanics have been successfully applied to various types of structural analyses, such as the analysis of shell structures [14], multiple body kinematic movements involving large displacements and rotations [15,16], progressive collapse simulations of structures [17], shape analysis of tensile structures [18], train-bridge interaction simulation [19], and fluid-solid interaction simulation [20].
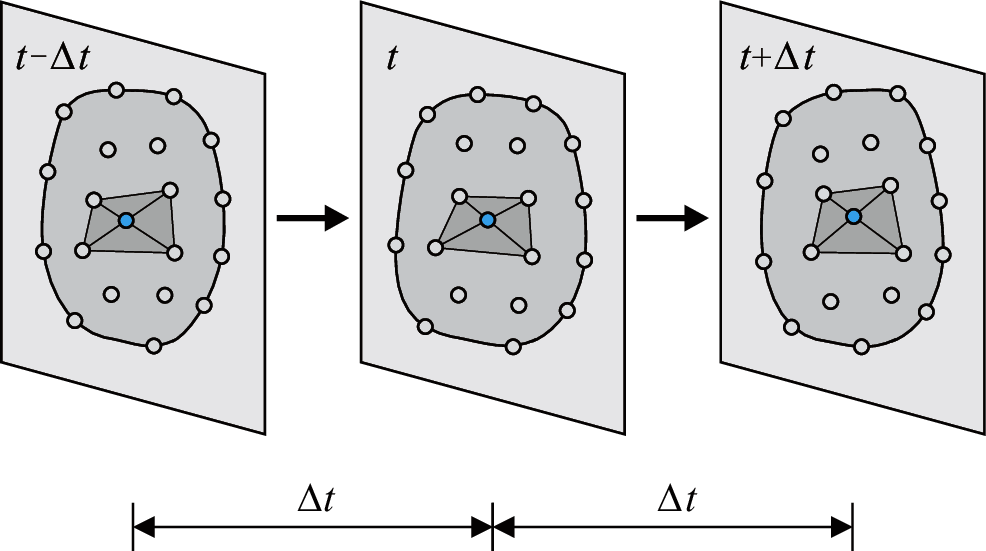
Figure 1: Discrete model of the FPM in space and time (only elements connected to the highlighted particle are depicted for brevity)
When dealing with large deformation problems, the FPM is effective in separating the pure deformation of elements from their total motion by using the fictitious reverse motion technique [10], which makes it suitable for solving large deformation contact problems. In addition, contact algorithms based on the explicit FEM, such as the one proposed by Hallquist et al. [21], can easily be adopted by the FPM due to the similar mechanisms of these two methods. However, contact calculation via the serially computed FPM is still time-consuming, mainly due to the small time step size for ensuring conditional stability of the method and the time-consuming contact search process. This problem can be effectively alleviated by using parallel acceleration for the FPM. In fact, no global stiffness matrix is assembled in the FPM, and the main solution procedures of the FPM are decoupled in nature; thus, the FPM is intrinsically suitable for parallel implementation with a high degree of parallelism.
Many parallel architectures are based on central processing unit (CPU) technology, e.g., open multiprocessing (OpenMP) [22,23] for multiple CPUs and message passing interface (MPI) for multiple computer hosts. However, the hardware costs of CPU-based parallel architectures are very high, and the quantitative restriction of CPU cores in personal computers makes concurrently processing a large number of procedures a difficult task. Recently, thanks to the development of graphics processing units (GPUs) with unified architectures and the introduction of specialized programming models, such as Compute Unified Device Architecture (CUDA) designed by NVIDIA, general-purpose computing on GPU (GPGPU) has become an increasingly adopted computing technique in engineering simulations [24–26]. While a CPU is designed to excel at executing a single thread as fast as possible, a GPU is designed to excel at executing thousands of threads in parallel [27]. As a result, GPUs provide higher instruction throughput and memory bandwidth at a lower cost than CPUs [28]. Therefore, the GPU architecture is more appropriate for parallel implementation of the FPM.
In this paper, a two-dimensional GPU-based parallel contact algorithm using the FPM is proposed and implemented based on the GPU-accelerated software developed in our previous study [24]. The algorithm takes full advantage of the parallel architecture of GPUs, and the main computational procedures of the algorithm, including evaluating elemental internal forces, searching contact pairs, detecting contact states, calculating contact forces, and solving the equations of motion, are executed in parallel on a GPU. There are four contributions of the current work compared to our previous study [24]: (1) two new quadrilateral elements FPM-Q4 and FPM-Q4R are developed for 2D large deformation problems; (2) a contact algorithm for 2D large deformation problems is proposed and incorporated into FPM; (3) The proposed contact algorithm is parallelized based on GPU; (4) the parallel contact algorithm is verified and its performance is fully tested.
This paper is structured as follows. The fundamentals of the parallelized FPM for planar solids are briefly introduced in Section 2. The parallel contact algorithm is discussed in Section 3, including the contact detection process and calculation of the contact forces. The GPU implementation of the proposed algorithm is presented in Section 4. Two verification examples and two performance tests are presented in Section 5 to demonstrate the accuracy and efficiency of the proposed contact algorithm. Finally, conclusions are given in Section 6.
2 Fundamentals of the Parallelized FPM for Planar Solids
The fundamentals of the FPM for planar solids are briefly described in this section, including the equations of motion of particles and the internal forces of quadrilateral elements. Readers are referred to the literature [12] for more details. The parallel algorithm for planar solids is presented in Section 2.3.
2.1 Equations of Motion of Particles
A planar solid, as shown in Fig. 2a, can be discretized into 20 particles and 12 quadrilateral elements. For an arbitrary particle
where
where
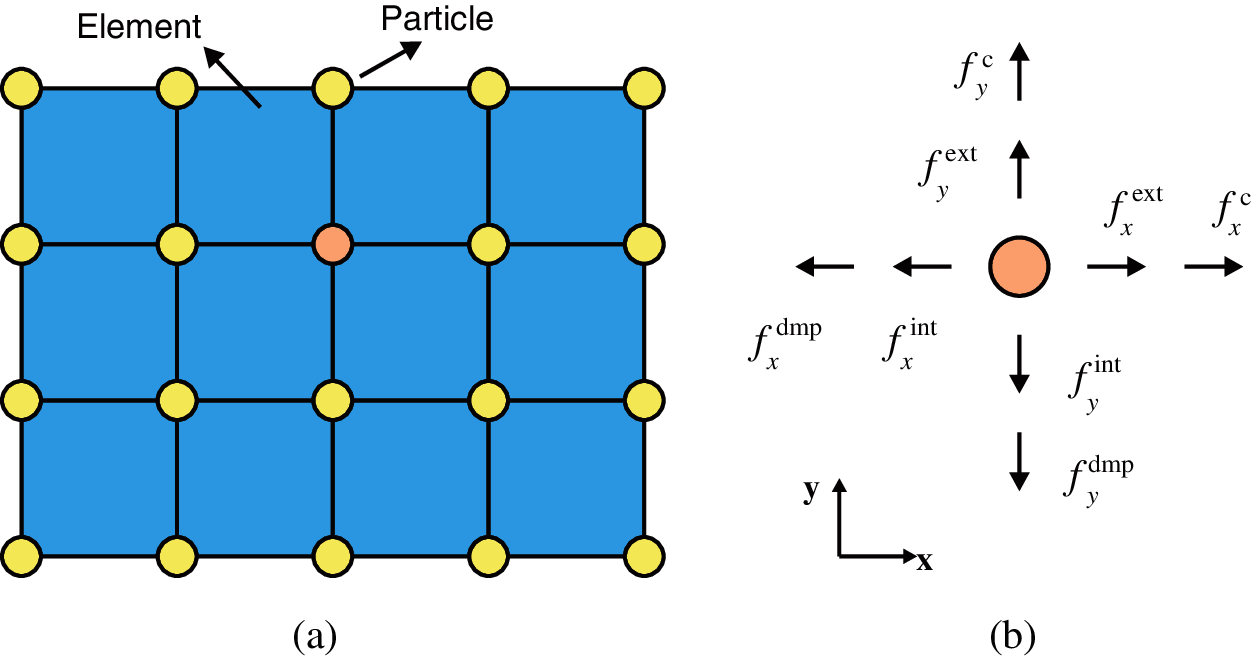
Figure 2: Discretization of a planar solid: (a) Particles and elements; (b) Particle forces
The central difference method is adopted to solve Eq. (1) because of its low computational cost and sufficient accuracy. According to the literature [29], the central difference method has the highest accuracy and maximum stability limit for any second-order accurate explicit method. Other explicit time integration algorithms such as generalized-α algorithm [30] can also be utilized in the FPM, but more computational time will be taken when using those algorithms. Thus, the central difference method is adopted in this paper to solve the equations of motion of particles. Given the particle displacements at times
where
2.2 Internal Forces of Quadrilateral Elements
The internal forces of quadrilateral elements are derived in this section. First, the pure deformation is approximated by using fictitious reverse motion, and a local coordinate system (LCS) is introduced based on the pure deformation vector. Subsequently, the strain and stress increments are computed in the LCS, and the internal forces are derived using the principle of virtual work.
As shown in Fig. 3a, a quadrilateral element moves from time
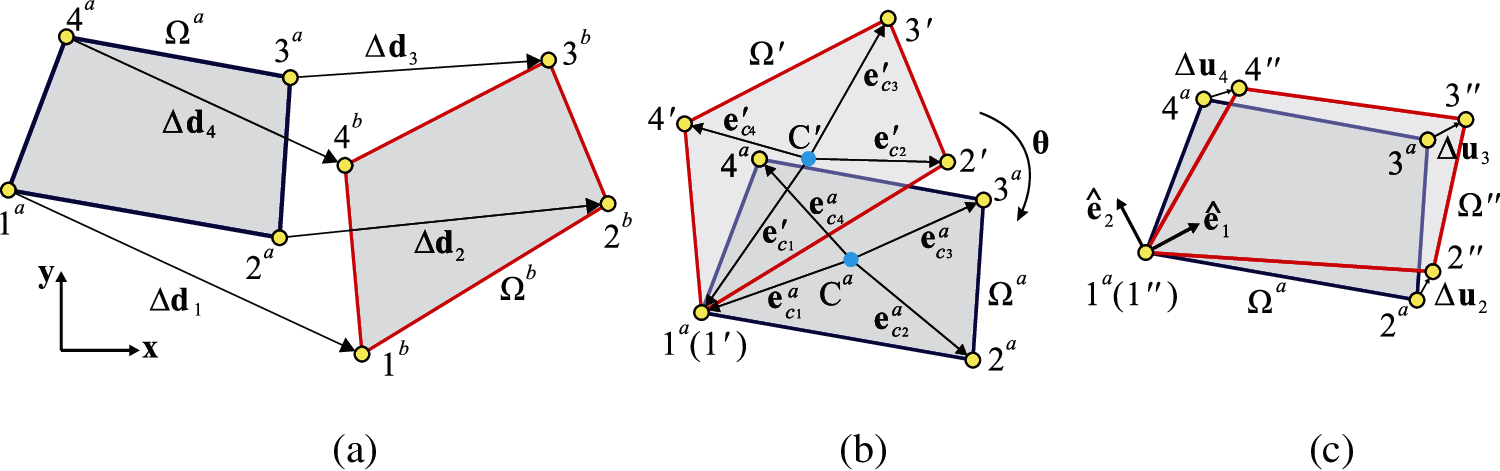
Figure 3: Fictitious reverse motion for calculating pure deformation: (a) Configurations
To separate the rigid-body motion from the total displacement, a fictitious reverse motion technique based on vector mechanics [12] is adopted, and the procedures are described as follows:
Step 1: Fictitious reverse translation. In the following, particle 1 is chosen as a reference particle. The configuration
Step 2: Fictitious reverse rotation. The configuration
where
where
Step 3: Pure deformation approximation. Since the rigid motion is separated from the total displacement through the fictitious reverse motion, the pure deformation matrix of the element is approximated as
with
Step 4: Definition of the LCS. An LCS with axes
where
2.2.2 Strain and Stress Increments
After obtaining the pure deformation, the concepts of shape function and isoparametric transformation developed in the conventional FEM are introduced to the FPM to describe the strain and stress distributions within each quadrilateral element. The strain increment vector at each integration point in the LCS is given as
where
The stress increment vector at each integration point in the LCS can be evaluated as
where
where
The principle of virtual work is adopted to derive the internal forces of elements. For each element, the variation of the external work,
and the variation of the internal work,
Considering that
Note that the internal forces of elements in the LCS should be transformed back to the GCS by
The equivalent internal force of particle
where n denotes the number of elements connected to particle
Two integration schemes of elemental internal forces are adopted in this paper. The first one is the selective integration technique (also called the B bar method) proposed by Hughes [35], which provides good accuracy for both compressible and nearly incompressible media by using a onepoint integration for volumetric stresses and a twopoint quadrature in each direction for the deviatoric stresses. The corresponding elements of the B bar method are called FPM-Q4 and used in Section 5.1. The other integration scheme is the uniform reduced integration with hourglass control developed by Flanagan et al. [36]. The corresponding elements with this reduced integration technique are called FPM-Q4R and used in Section 5.2.
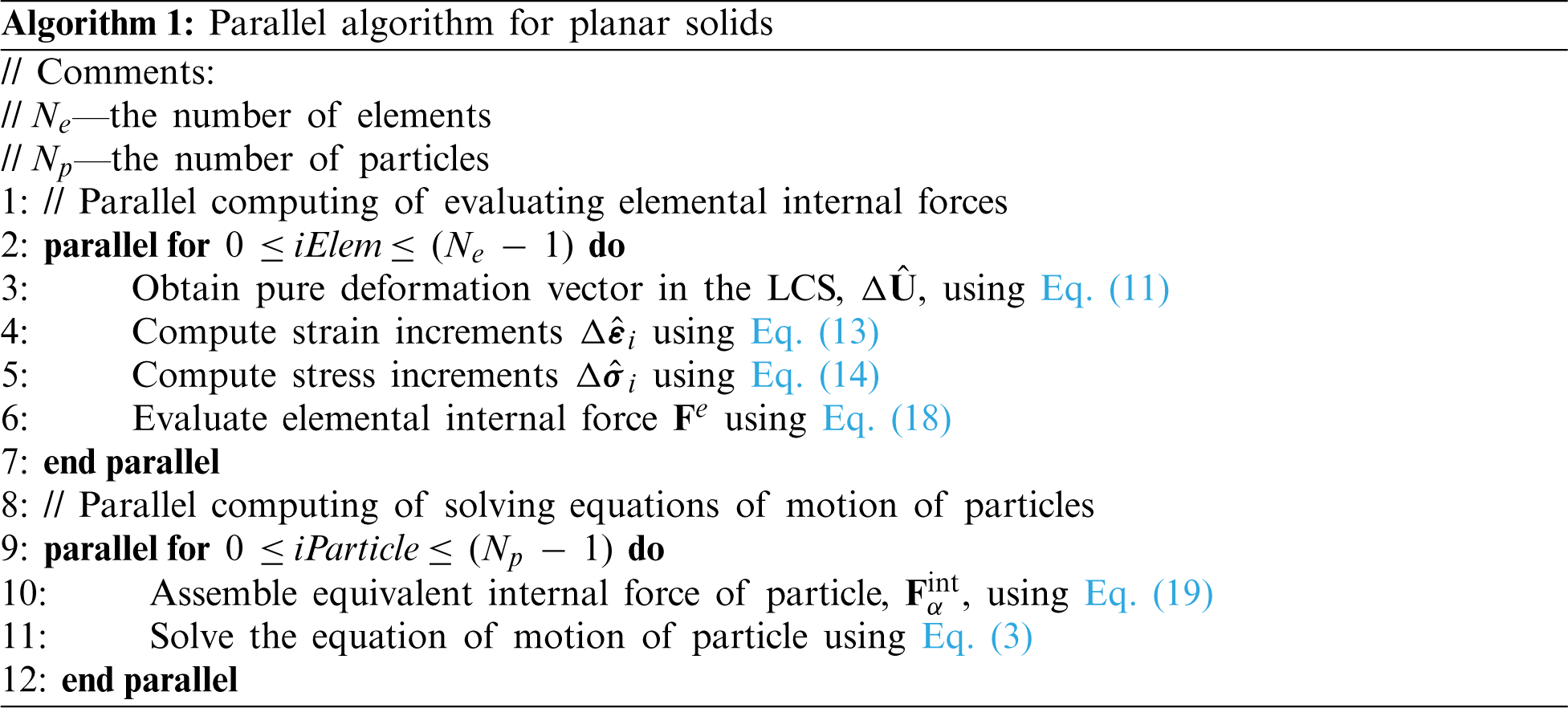
2.3 Parallel Algorithm for Planar Solids
The parallel algorithm for planar solids is presented in Algorithm 1. Note that the keyword pair “parallel for … end parallel” indicates that the codes within it are executed in parallel on GPU threads. The equation of motion of each particle is solved individually, and the evaluations of the elemental internal forces are self-reliant between elements; thus, the FPM can be accelerated by GPGPU techniques with a high degree of parallelism. The corresponding GPU implementation for planar solids is given in Section 4.
3 Parallel Contact Algorithm Based on the FPM
The contact between two deformable bodies is considered. The contact surface on one body is selected as the master and the contact surface on the other body as the slave, as shown in Fig. 4, and this master-slave pair is called a contact surface pair. The node-to-segment (NTS) [21] technique is adopted for discretizing contact surfaces into contact particles and contact segments, as shown in Fig. 4. After discretizing contact bodies, the particles on the master surface are defined as master particles while the particles on the slave surfaces as slave particles. Note that proper selection of the master and slave surfaces is significant for NTS contact discretization. According to the literature [4], the selection of master and slave surfaces should satisfy that the slave nodes cannot penetrate into the master surface, while the master nodes are free to penetrate into the slave surface. Thus, the contact surface of the stiffer body should be the master surface. More details about choosing the master and slave surfaces can be found in the literature [4].
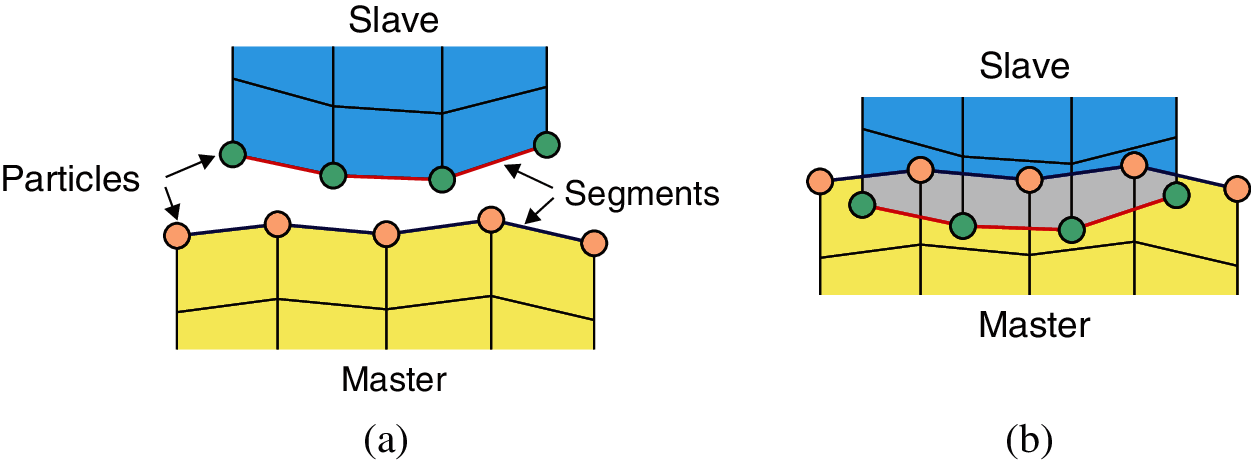
Figure 4: Discretization of contact surfaces: (a) Separation state; (b) Penetration state
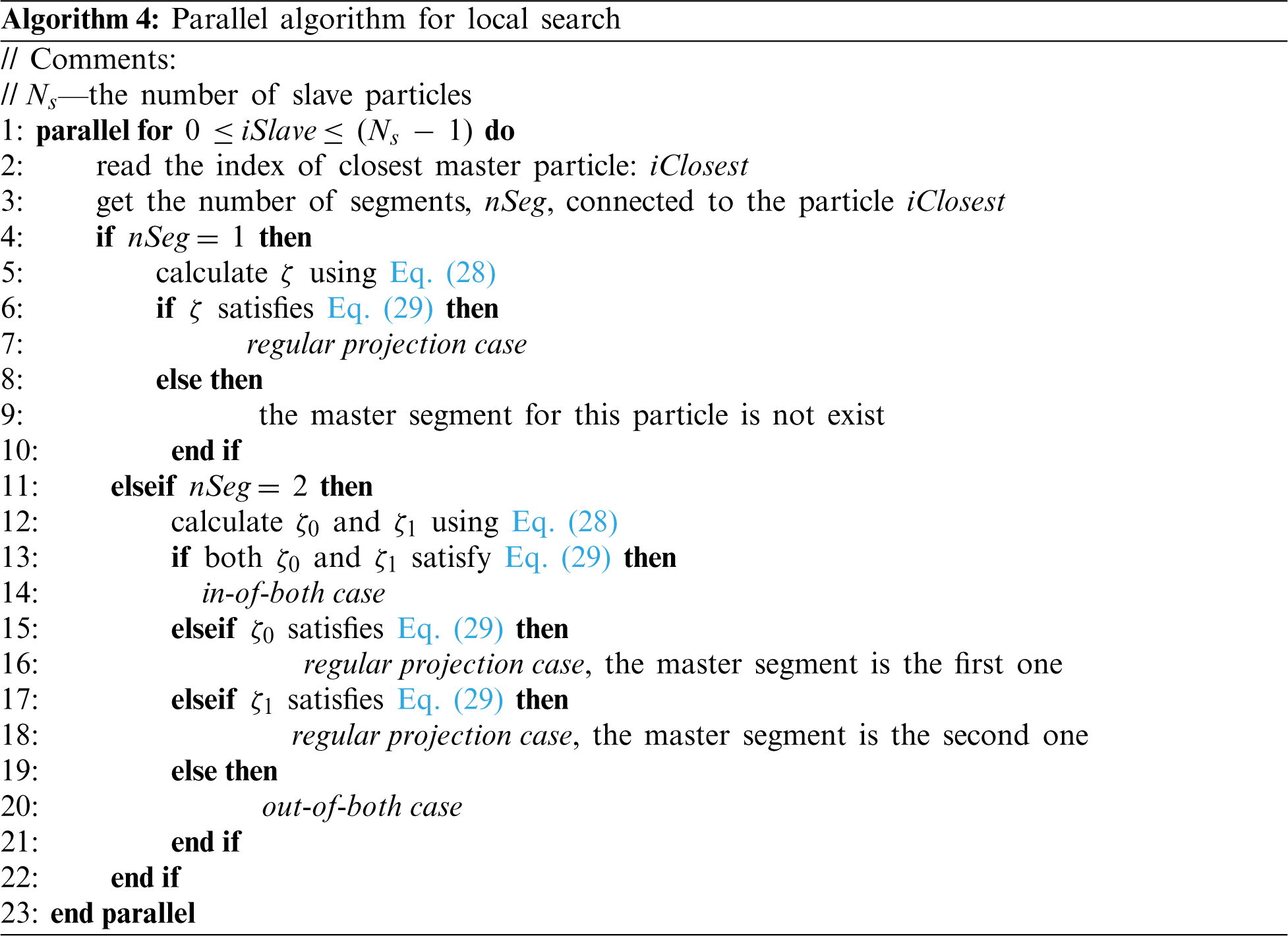
The contact search algorithms of contact surfaces are typically decomposed into two distinct phases: global search and local search. The purpose of global search is to first collect master segment candidates for each slave particle, and the aim of local search is to choose the exact master segment for each slave particle and detect the contact state. Note that global search can be performed every n time steps to reduce the computational time, while local search needs to be performed at every time step. To make this contact search algorithm more suitable for parallel computing, a linked-list data structure represented by two arrays [37] is used.
For a two-body contact problem, the potential range of a contact surface pair in space is represented by a bounding box, as illustrated in Fig. 5. The coordinates of the bottom-left and top-right corners of the bounding box are denoted as
where
where
Subsequently, each particle of the contact surface pair can be mapped into a cell, and the cell index is calculated by
where

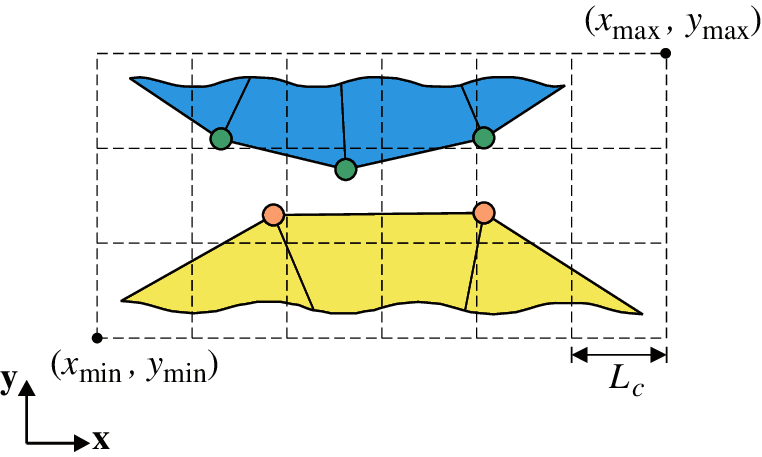
Figure 5: Space decomposition of the bounding box of a contact surface pair
A linked-list data structure [37] is adopted to store the particles in each cell. This data structure is beneficial to the parallel global search process and suitable for the coalescence access of GPU memory. A bounding box that is divided into 16 cells is taken as an example, as shown in Fig. 6, with 20 contact particles located within these cells. Two arrays are used to construct the linked list, as illustrated in Fig. 7a. The array d_head is used to store the first contact particle index in each cell, and the array d_next is used to link the remaining particle indices in the same cell [38]. Note that each element in array d_next indicates the index of the next particle until −1 is encountered. For example, particles 10, 8, and 7 are located in the 6th cell (
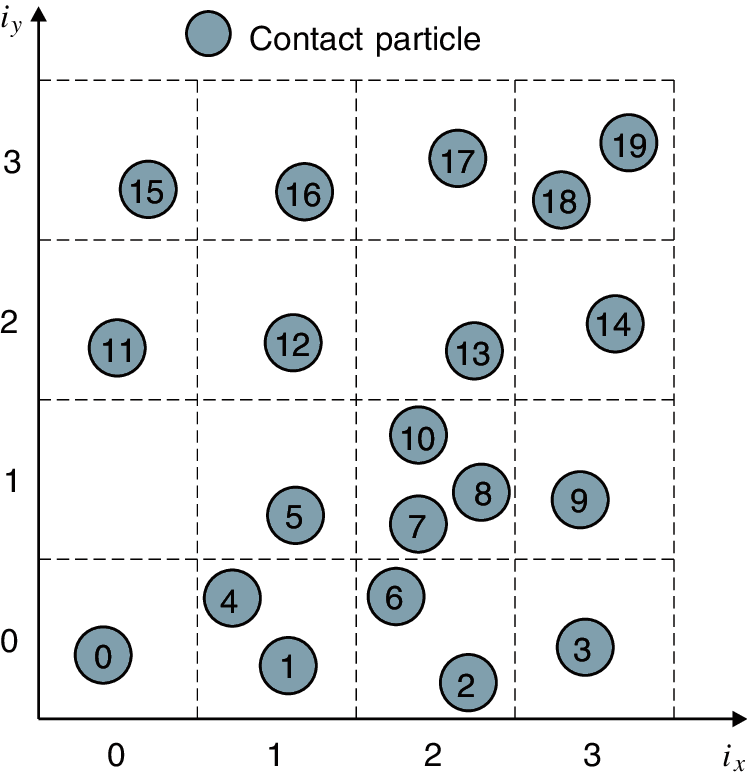
Figure 6: Mapping of contact particles into cells
The main steps for constructing the data structure for a contact surface pair are described in Algorithm 2. The elements of arrays d_head and d_next are initialized to −1. The indices of particles located in the same cell are stored in the linked list one by one. Note that the function b = atomicExch(addr, a) is an atomic function in the CUDA toolkit to replace the value at the address addr with value a and then return the old value b, which performs a read-modify-write atomic operation in a thread and guarantees no interference with other threads [27]. For multiple surface pairs, the contact particles of all pairs can be stored in a single linked-list data structure, as shown in Fig. 7b. This data structure ensures the efficiency of parallel contact search for contact problems with multiple surface pairs, which is validated in Section 5.2.
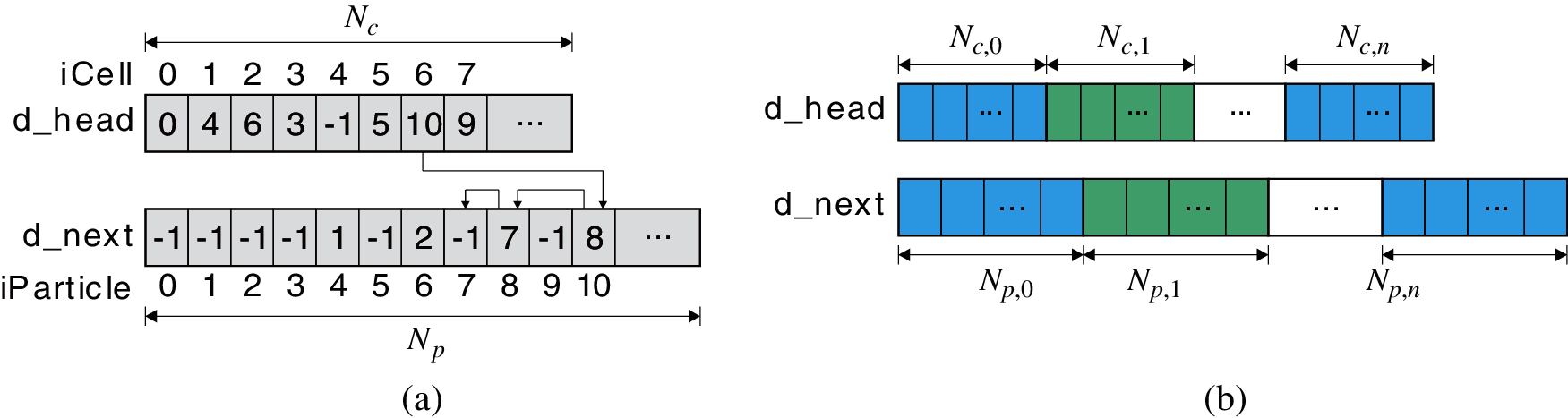
Figure 7: Linked-list data structure: (a) One surface pair; (b) Multiple surface pairs
The global search consists of two steps: (1) find the closest master particle for each slave particle and (2) choose the segments connected to this master particle as master segment candidates. The closest master particle can be identified by looping for all master particles, which is time-consuming. To improve the efficiency, only particles located in the nine (3
where
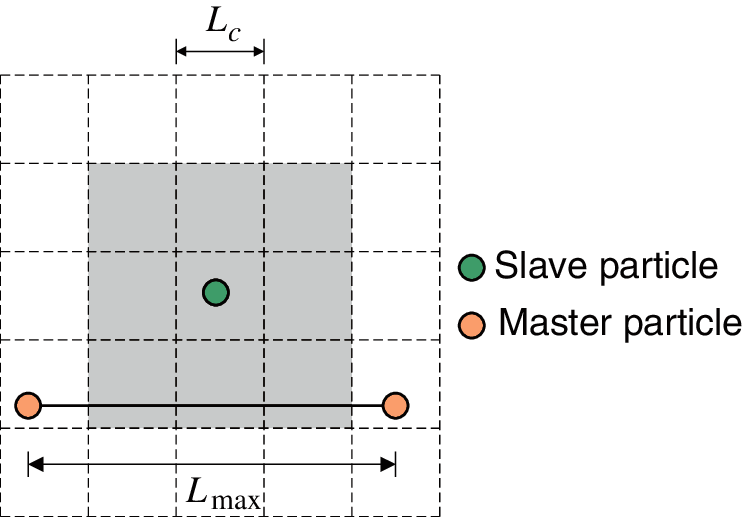
Figure 8: Minimum cell size length requirement

To choose the exact master segment, projections of the slave particle onto each segment candidate should be performed first. Fig. 9 illustrates the projection of a slave particle S onto a master segment candidate CM. Particle C is the closest master particle to particle S. The position vectors of these three particles are denoted by
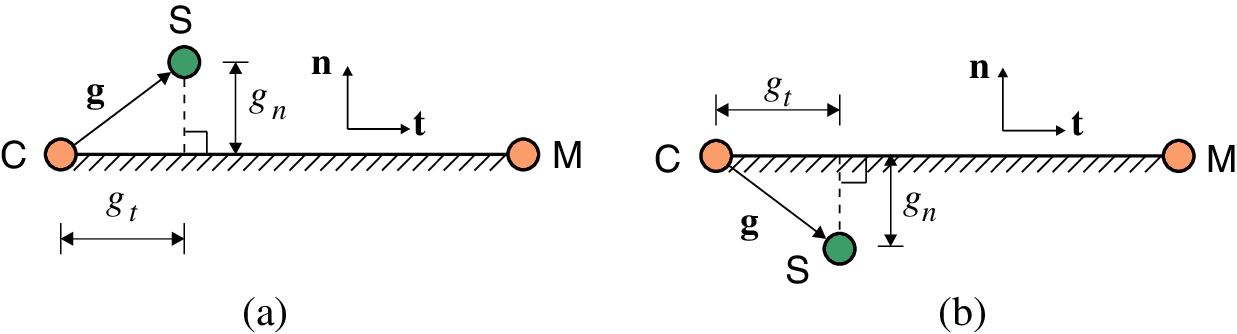
Figure 9: Projection of slave particle onto a master segment candidate: (a) Open gap
An LCS with unit vectors
where
where
and the range of
where
Generally, three projection cases exist, as illustrated in Fig. 10, i.e., a regular case and two special cases: the “in-of-both” case and “out-of-both” case. For the regular case shown in Fig. 10a,
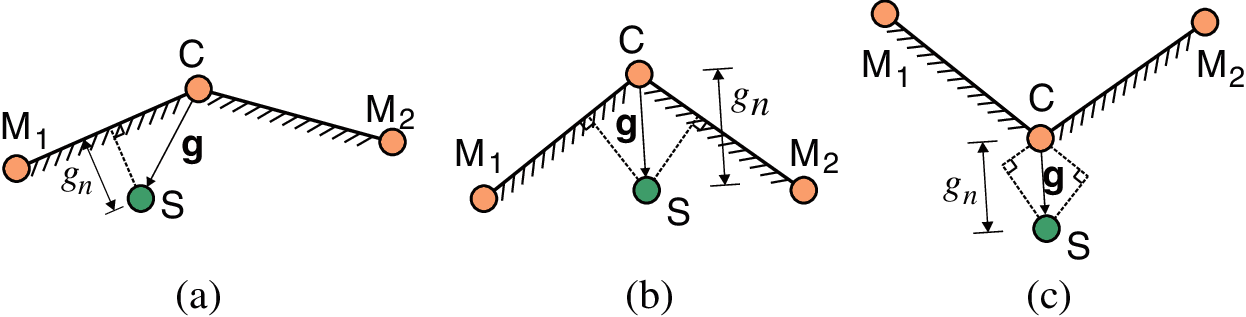
Figure 10: Projection cases: (a) Regular case; (b) “In-of-both” case; (c) “Out-of-both” case
Once the master segment has been identified, the gap status (open or closed) can be determined by checking the sign of
The penalty method is adopted to calculate the contact forces of particles due to its simplicity and ease of implementation. The calculations of the normal contact force and tangential contact force (i.e., friction force) using the penalty method are discussed in Sections 3.2.1 and 3.2.2, respectively. Note that the contact forces are calculated in parallel for each slave particle, and then the reaction forces are applied in parallel to the corresponding master particles.
The magnitude of the normal contact force calculated by the penalty method is proportional to the amount of penetration, as shown in Fig. 11. For a contact pair composed of slave particle S and master segment CM, assuming that its projection case is regular (see Fig. 10a), the normal contact force is determined by
where
where K is the bulk modulus of segment CM, A is the area of the segment, V is the volume of the element that contains segment CM,
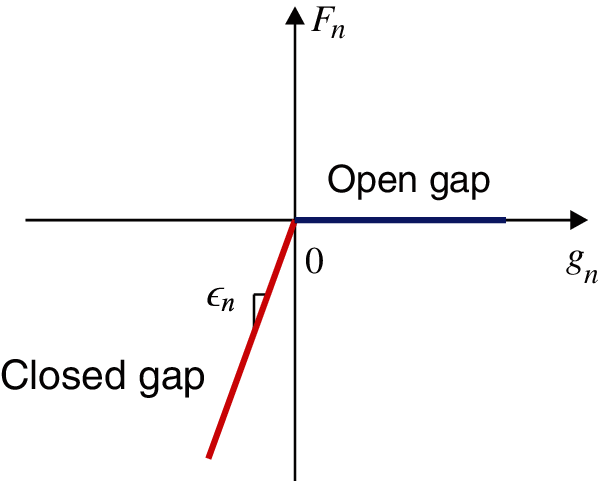
Figure 11: The relation between the normal contact force and normal gap
For the other two special projection cases, as shown in Figs. 10b and 10c,
The most commonly used friction model is the classic Coulomb friction model [41]. However, the friction force of the Coulomb model is discontinuous at zero velocity, which may lead to oscillation results. A smoothed friction model [5] is adopted in this study. The friction force calculation is an adaptation of the radial return algorithm for elastic-perfectly plastic materials and can be described as follows:
Let
1. Compute the magnitude of the maximum static friction force:
(2) Calculate the trial friction force:
where
where
(3) If the trial force does not exceed the maximum friction force, the friction is identified as static, and the friction force at time t is equal to thitrial force; otherwise, the friction is identified as kinetic, and the magnitude of the friction force at time t should equal
Note that the friction force is considered only in the regular projection case (see Fig. 10a).
Once the normal and tangential contact forces of slave particle S have been obtained, the resultant contact force, as shown in Eq. (1), is cculated by
As shown in Fig. 12a, the reaction contact forces applied to the particles of the master segment CM in the regular case can be calculated by
In the other two special projection cases, the reaction force applied to the closest master particle C has the same magnitude but opposite direction compared to
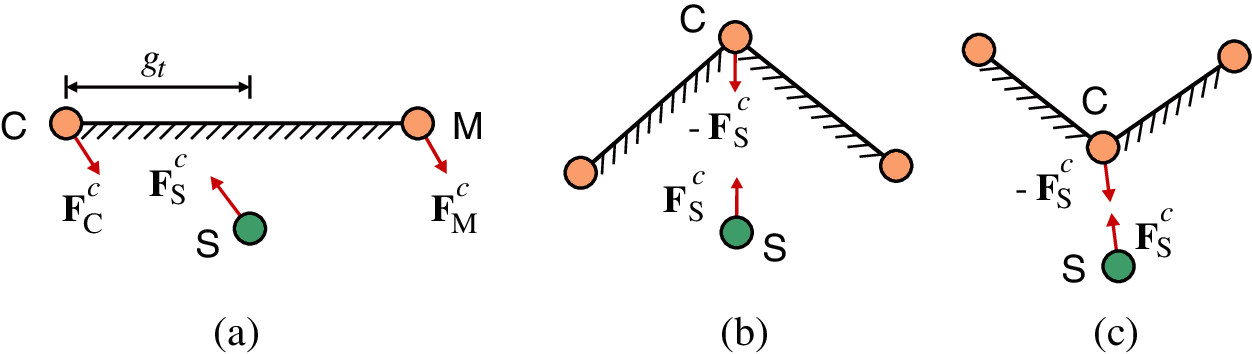
Figure 12: Reaction contact force of master particles: (a) Regular case; (b) “In-of-both” case; (c) “Out-of-both” case
The proposed contact algorithm based on the FPM is suitable for parallel implementation, as described in Sections 2 and 3. The GPU architecture is more appropriate than the CPU architecture for the parallel implementation of the FPM, as mentioned in Section 1. The parallel contact algorithm is implemented in the GPU-accelerated software developed in our previous study [24]. The algorithm is executed on NVIDIA GPUs powered by CUDA. The CUDA programming model is briefly introduced in Section 4.1, and the GPU implementation of the algorithm is presented in Section 4.2.
A generic CUDA application mainly consists of two parts: host code, running serially on a CPU, and device code, running in parallel on a GPU, as illustrated in Fig. 13. The host code is responsible for organizing host and device memories and managing the transfer of data between them. The device code consists of several device functions, named kernels, that are executed on GPU threads. The threads are organized into n-dimensional blocks, which are then organized into an n-dimensional grid (where n can be 1, 2, or 3), as depicted in Fig. 13. For a more detailed description of the CUDA programming model, the reader is referred to the literature [27].
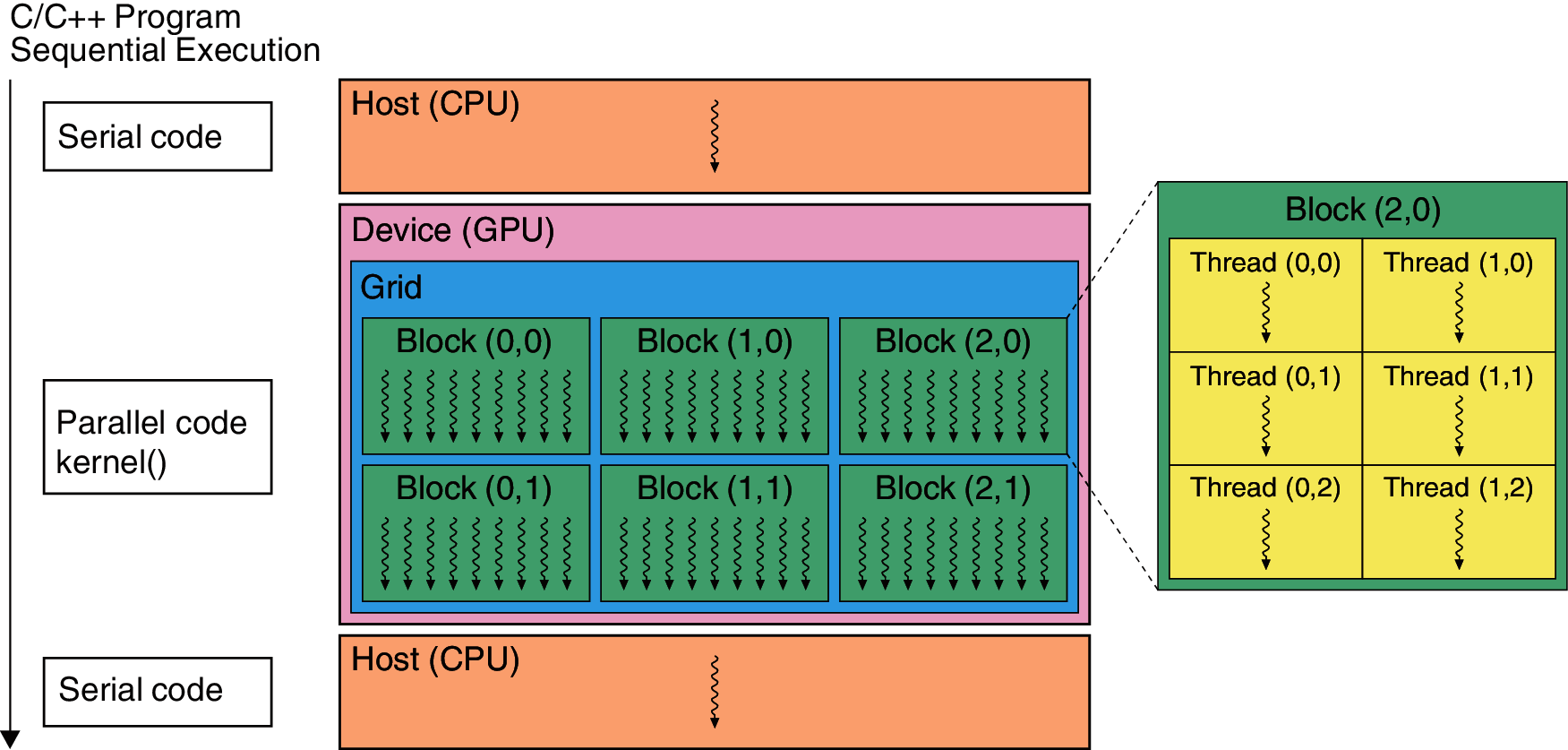
Figure 13: Schematic illustration of the CUDA programming model
4.2 GPU Implementation of the Algorithm
The flowchart of the parallel contact algorithm implemented in the FPM software is presented in Fig. 14. After preprocessing, the model data and variables are organized in the host memory and transferred to the device memory. A sequence of time steps is then performed for the analysis. Within each time step, the computational procedures are executed in a series of CUDA kernels managed by three FPM solvers: element solver, contact solver, and particle solver. Typically, the solution procedures consist of four main steps:
(1) Element solver: evaluate the elemental internal forces in parallel for each element, as described in Section 2.2.
(2) Contact solver:
i. Parallel global search: search for master segment candidates for each slave particle, as discussed in Section 3.1.2.
ii. Parallel local search: choose the master segment for each slave particle from the candidates, and calculate the gap vector, as described in Section 3.1.3.
iii. Parallel contact force calculation: calculate the normal and tangential contact forces for each slave particle, and apply the reaction contact forces to the corresponding master particles, as discussed in Section 3.2.
(3) Particle solver: solve the equation of motion in parallel for each particle using Eq. (3).
(4) Time step controller: if the current time step is the last one, stop the calculation; otherwise, go to Step (1) and start the iteration for the next time step.
As described in our previous study [24], memory management is important to achieve satisfactory performance of the FPM solvers. Among all memory spaces available in CUDA, global device memory is the most widely used for all FPM solvers because it has the largest storage capacity. The global memory can be accessed by all threads using aligned memory transactions. The optimization of global memory throughput can be achieved if the memory access patterns are suitable for coalescence [25], which requires adjacent threads to access successive memory addresses. To achieve this coalescence of memory accesses, an adaptation of the structure-of-arrays (SoA) storage pattern [42] is adopted to manage all data buffers in global memory. In addition to memory management, the thread block size impacts the kernel performance. Based on performance tests for most of the kernels implemented in this study, 128 threads per block results in the best efficiency; thus, for convenience, the thread block size is set to a constant value of 128 for all kernels.
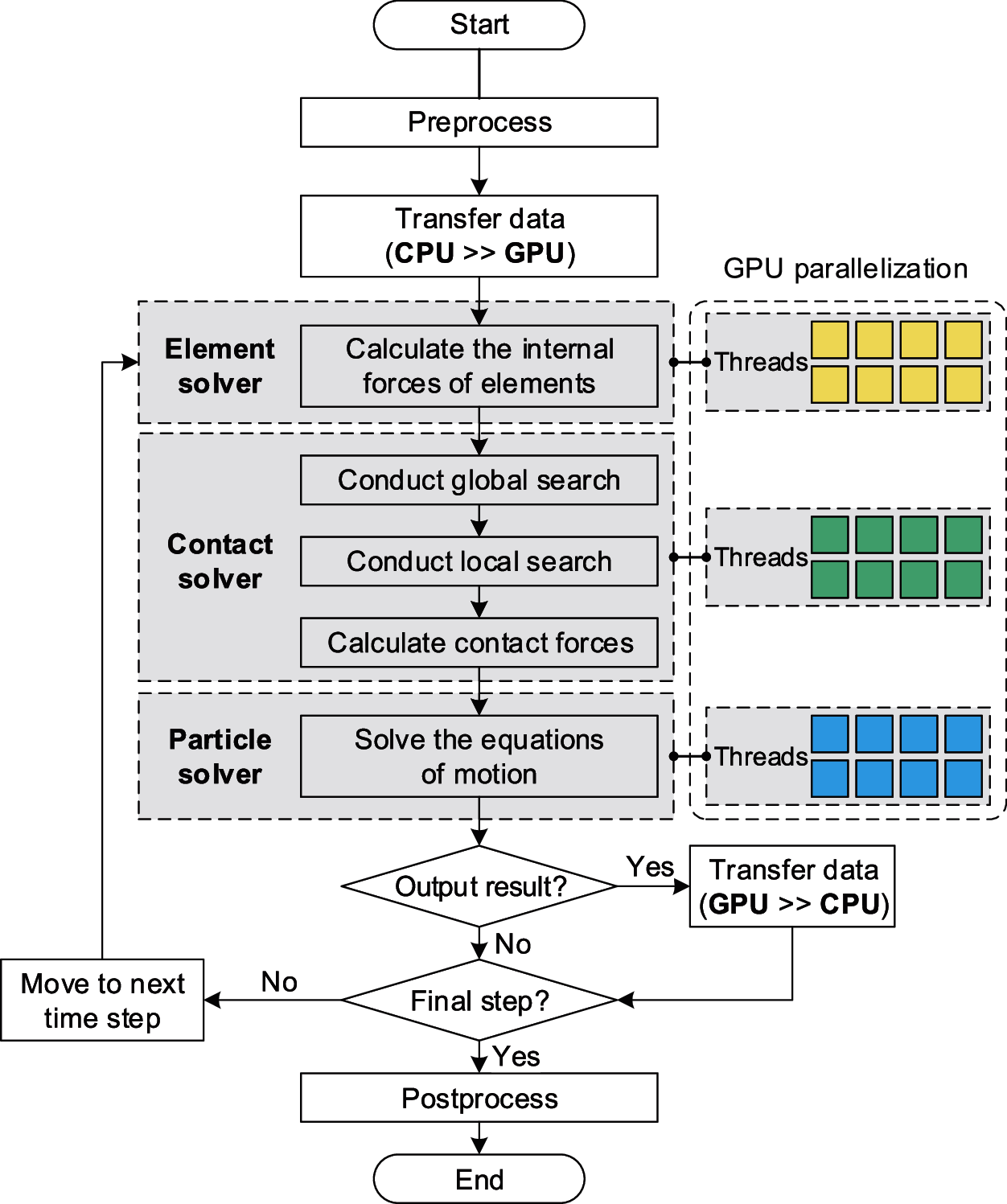
Figure 14: Flowchart of the GPU-based parallel contact algorithm
The effectiveness of the proposed contact algorithm is verified by two examples as presented in Section 5.1. Subsequently, the performance of the algorithm is tested in Section 5.2. All examples are computed under the assumption of a plane strain condition with a unit thickness of 1.0.
In this section, two verification examples are presented to demonstrate the accuracy of the proposed contact algorithm. These two examples focus on the frictional contact between two deformable bodies undergoing large sliding and large deformation. The first example involves elastic behavior, while the second example involves elastoplastic behavior. Fictitious mass damping is used in the verification examples to obtain static solutions. The quadrilateral element FPM-Q4, as described in Section 2.2.4, is used for the analyses in this section.
5.1.1 Contact in Elastic Problem
This numerical example is the so-called frictional ironing problem, which was previously studied in the literature [4,43]. The example comprises the sliding of a deformable block along an elastic slab, as illustrated in Fig. 15. The slab is fixed at its bottom surface, whereas the block is subjected to an imposed displacement at its upper surface. There are two load steps. From 0 to 1 s, a downward displacement
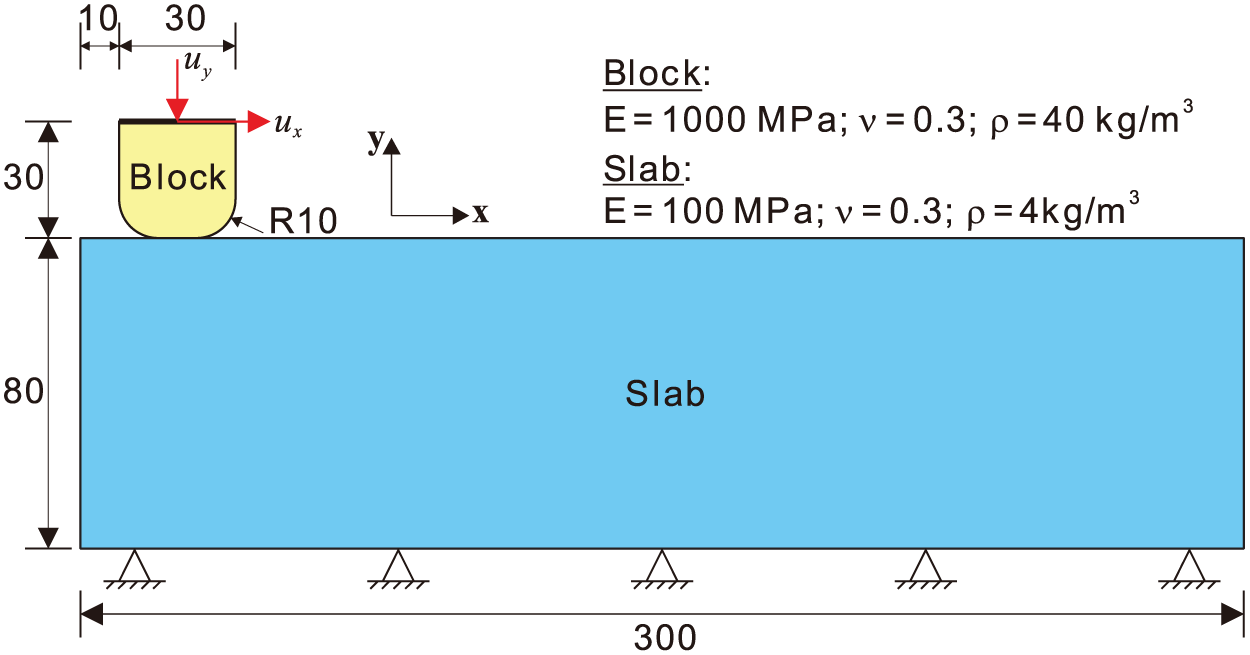
Figure 15: Geometry and material properties of the ironing problem (unit of length: mm)
The deformed configurations with a shear stress distribution are presented in Fig. 16 for three typical instants. In addition, the evolution of the total contact force components between the contacting bodies is presented in Fig. 17. From 0 to 1 s, as the vertical displacement of the block increases, the normal contact force gradually increases. The deformed configuration of the slab is not symmetrical; thus, the horizontal force component is not equal to zero. Starting from 1 s, the block begins to slide on the slab. The normal contact force increases slightly and remains constant afterwards. The horizontal force increases sharply after 1 s due to the contribution of the friction force and remains constant afterwards. Both contact force components drop slightly when the block reaches the right end of the slab. The results calculated by the FPM agree well with those obtained by Neto et al. using the surface smoothing method [4]. Thus, this example demonstrates the effectiveness of the proposed contact algorithm in elastic problems.
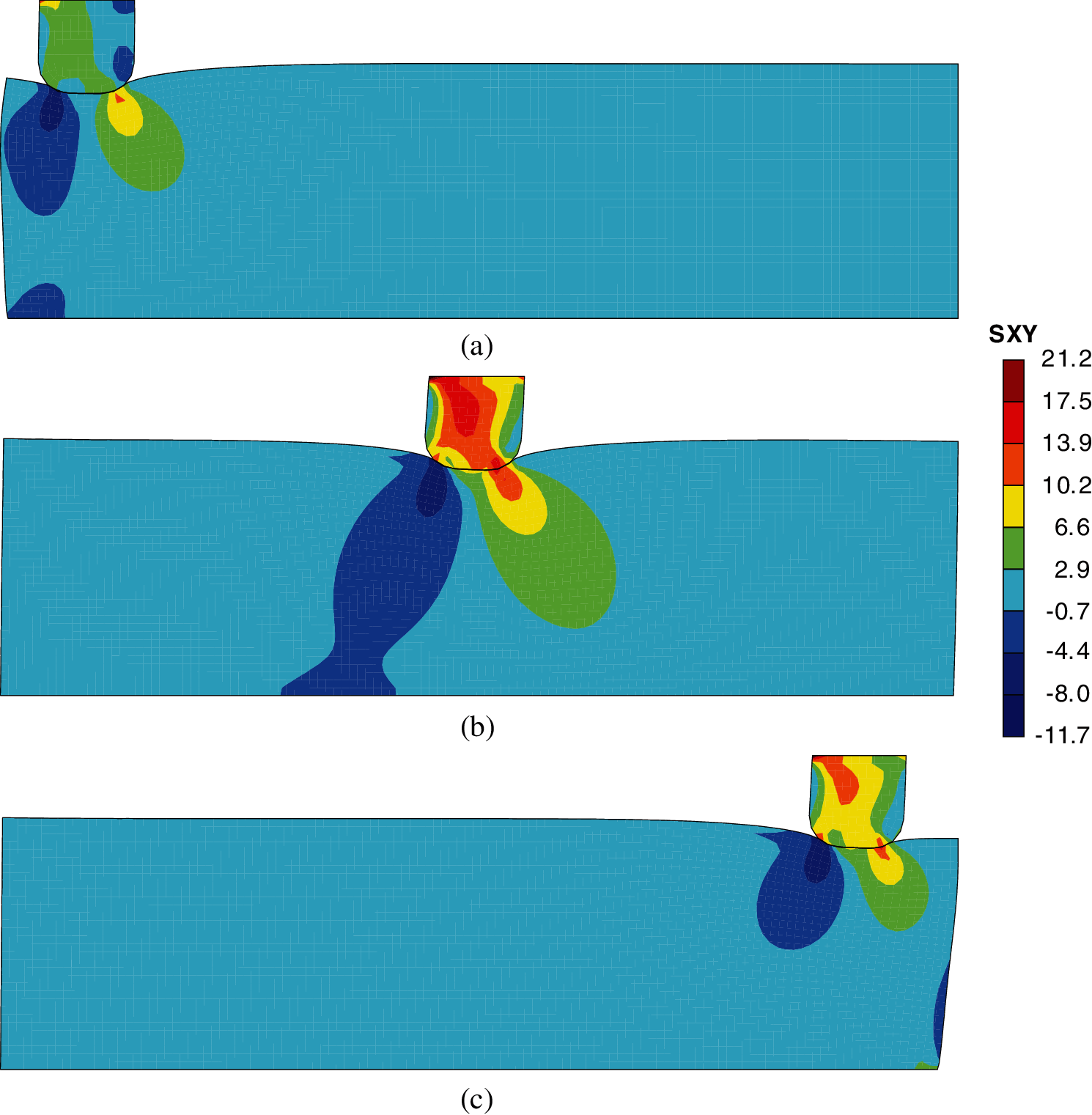
Figure 16: Contour plots of shear stress (unit: MPa) at three instants: (a) 1.0 s; (b) 1.5 s; (c) 2.0 s
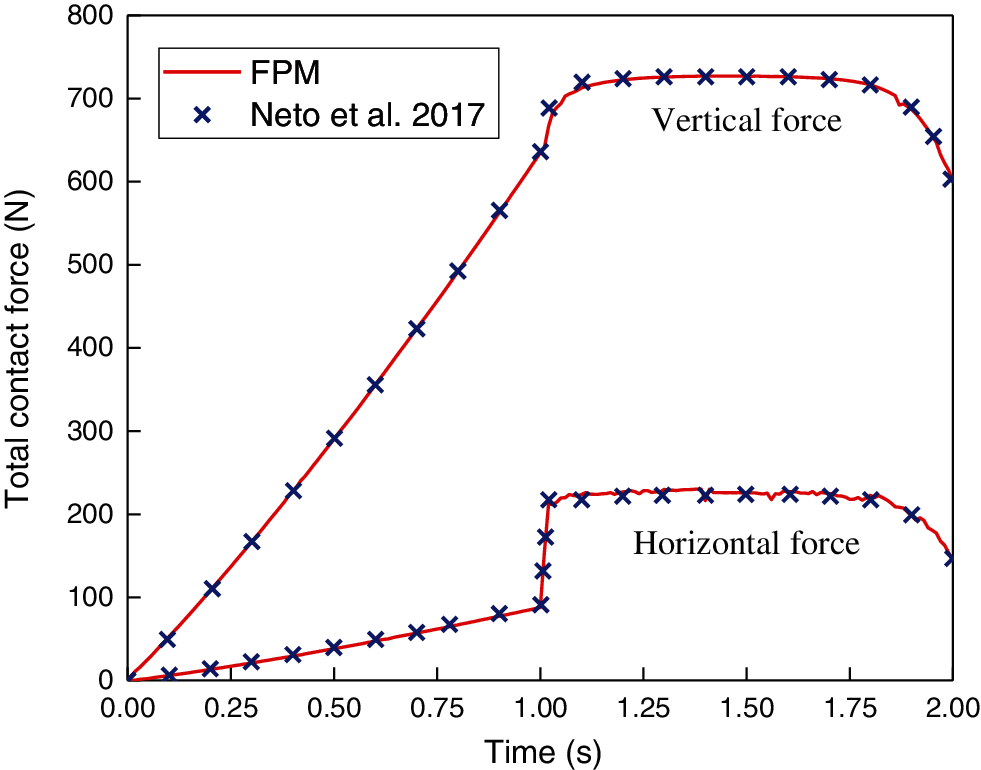
Figure 17: Contact forces obtained by the FPM and surface smoothing method [4]
5.1.2 Contact in Elastoplastic Problem
The second example was proposed by Yang et al. [44] and comprises contact between two curved beams, as shown in Fig. 18. The lower beam is fixed at its bottom surface, while the upper beam is subjected to a horizontal displacement
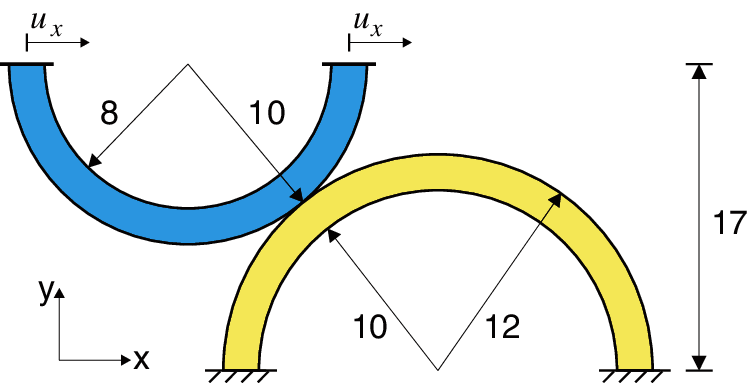
Figure 18: Geometry of the contact problem between two curved beams (unit of length: mm)
Deformed configurations of the beams for 15 mm of prescribed displacement on the upper beam are depicted in Fig. 19 for both frictionless and frictional cases, with the arrows illustrating the nodal contact forces subjected by the lower beam. The contact forces in the frictionless case are normal to the contact surface, while the contact forces in the other two frictional cases comprise tangential components. A higher friction coefficient leads to a higher friction force.
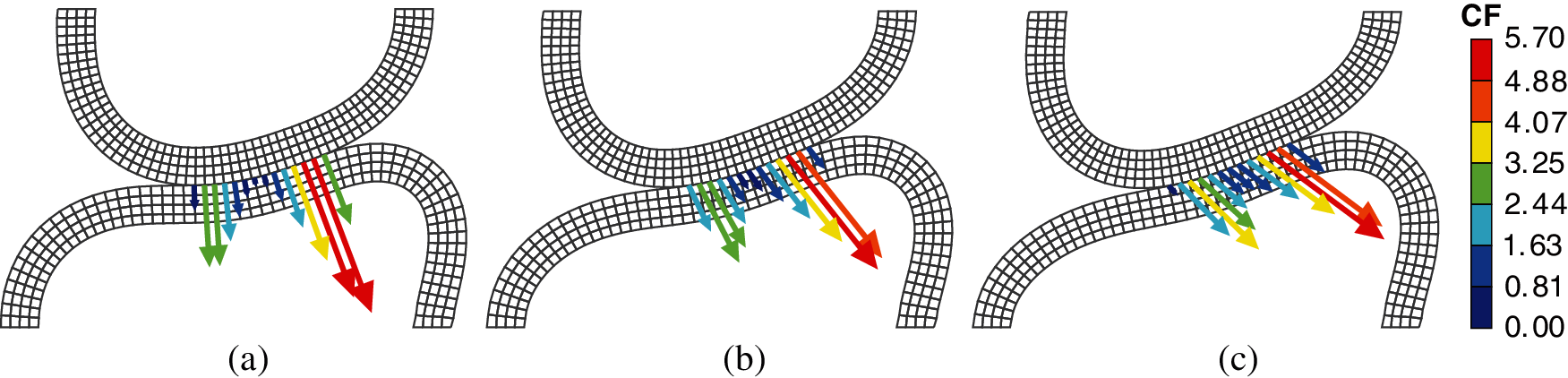
Figure 19: Deformed configurations of the beams and nodal contact forces (unit: N) of the lower beam: (a) μ = 0.0; (b) μ = 0.3; (c) μ = 0.6
The evolution of the total contact force components for the upper beam is presented in Fig. 20. Both the horizontal and vertical contact forces calculated by the FPM agree well with the results obtained by Neto et al. using the surface smoothing method [45]. Given higher values of friction coefficient, the amplitude of contact forces increases, the inflection points of the curves occur later, and contact forces decrease faster. These phenomena are related to the deformation mode of the lower beam due to the friction force.
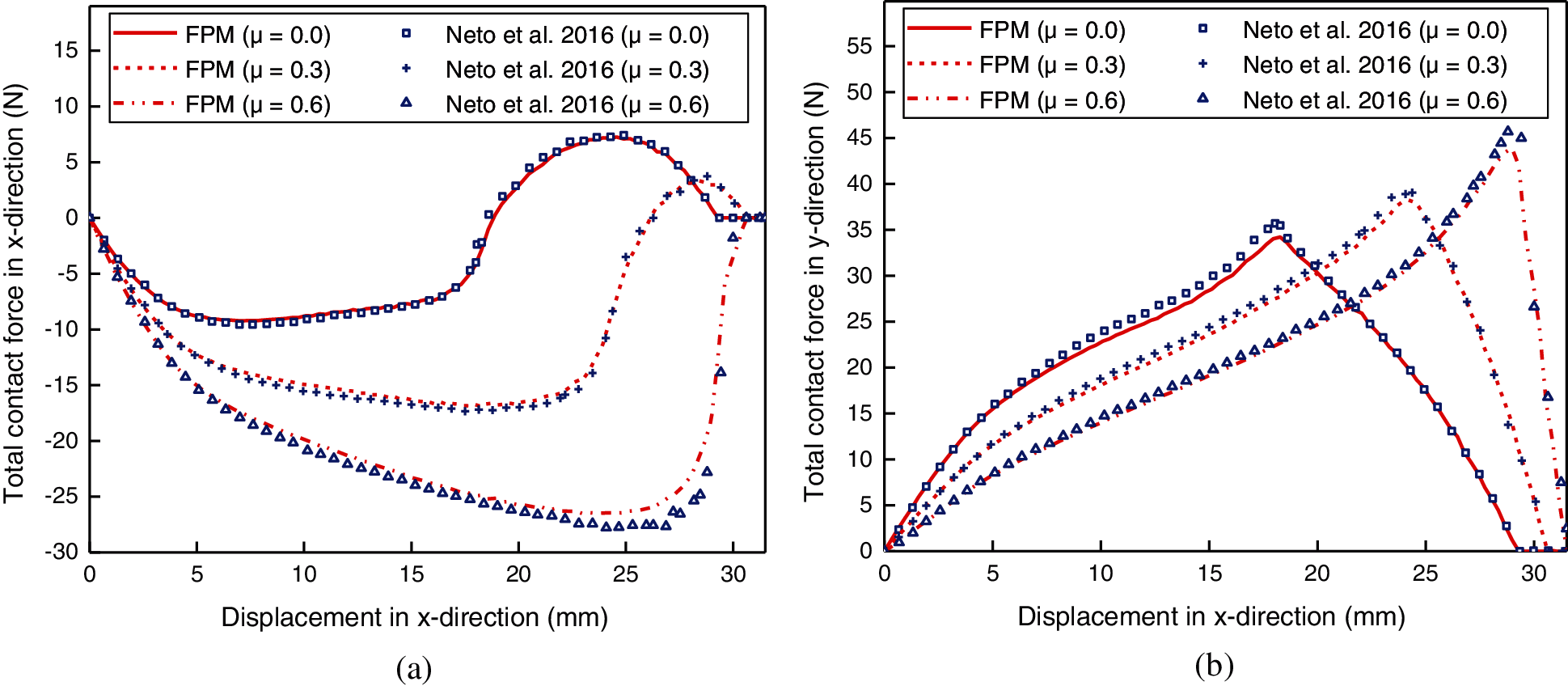
Figure 20: Contact forces obtained by the FPM and surface smoothing method [45]): (a) x-direction; (b) y-direction
The deformed configuration of the beams with contour plots of equivalent plastic strain is presented in Fig. 21, which is similar to the results in the literature [45,46]. The plastic regions mainly appear in the lower beam due to its larger diameter. Besides, the equivalent plastic strain in the region near the contact area is lower given higher values of friction coefficient. This can be explained by the different deformation shapes of the lower beam, as shown in Fig. 19.
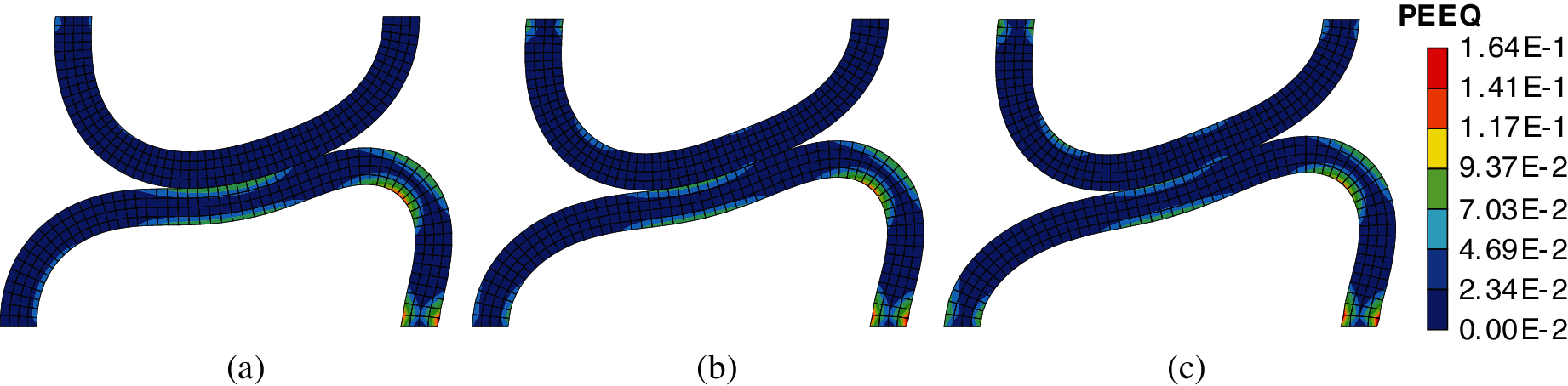
Figure 21: Contour plots of equivalent plastic strain: (a) μ = 0.0; (b) μ = 0.3; (c) μ = 0.6
In conclusion, the proposed contact algorithm is also effective in analyzing elastoplastic problems.
The performance of the proposed method is tested in this section. The performances of parallel element and particle solvers are studied first via a benchmark problem without contact calculation in Section 5.2.1. Then the performance of the parallel contact solver is investigated via a large-scale contact problem in Section 5.2.2. The performances of the parallel FPM solvers are compared with the performances of Abaqus/Explicit solvers and our serial FPM solvers. Note that the kernel codes in the serial FPM solvers are almost identical to the codes in the parallel solvers, but they run serially on a CPU. The efficiency of the parallel implementation is quantified by introducing speedup ratio S, which is defined as
where
The quadrilateral element FPM-Q4R in the FPM as described in Section 2.2.4 is used in the performance test, while the 4-node quadrilateral element with reduced integration CPE4R in Abaqus/Explicit is used for comparison. The performance test is carried out on a PC equipped with an Intel® CoreTM i7-4790 K quad-core 4.00 GHz CPU, an NVIDIA Titan V GPU with 5120 CUDA cores and 12 GB HBM2 memory, and a Windows 10 (64-bit platform) operating system.
5.2.1 Test on Parallel Element and Particle Solvers
As shown in Fig. 22, a cantilever beam is fixed at one edge and subjected to a tip load. The load (P = 100 N) is applied at time t = 0 and then kept constant during the whole simulation. The beam is 100 mm long and 20 mm height. It is made of an elastic material characterized by Young's modulus E = 2000 MPa, Poisson's ratio ν = 0.3, and density
Figure 22: Geometry of cantilever beam
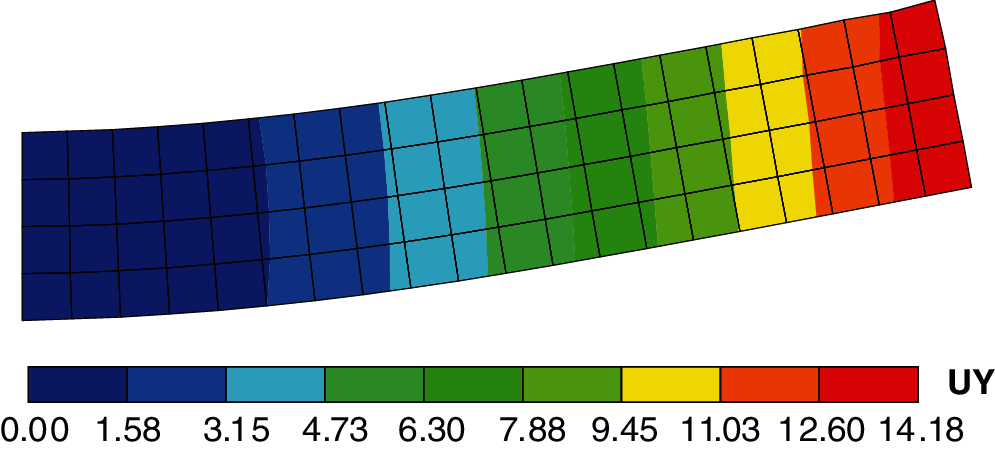
Figure 23: Vertical displacement contour of cantilever beam (unit of length: mm)
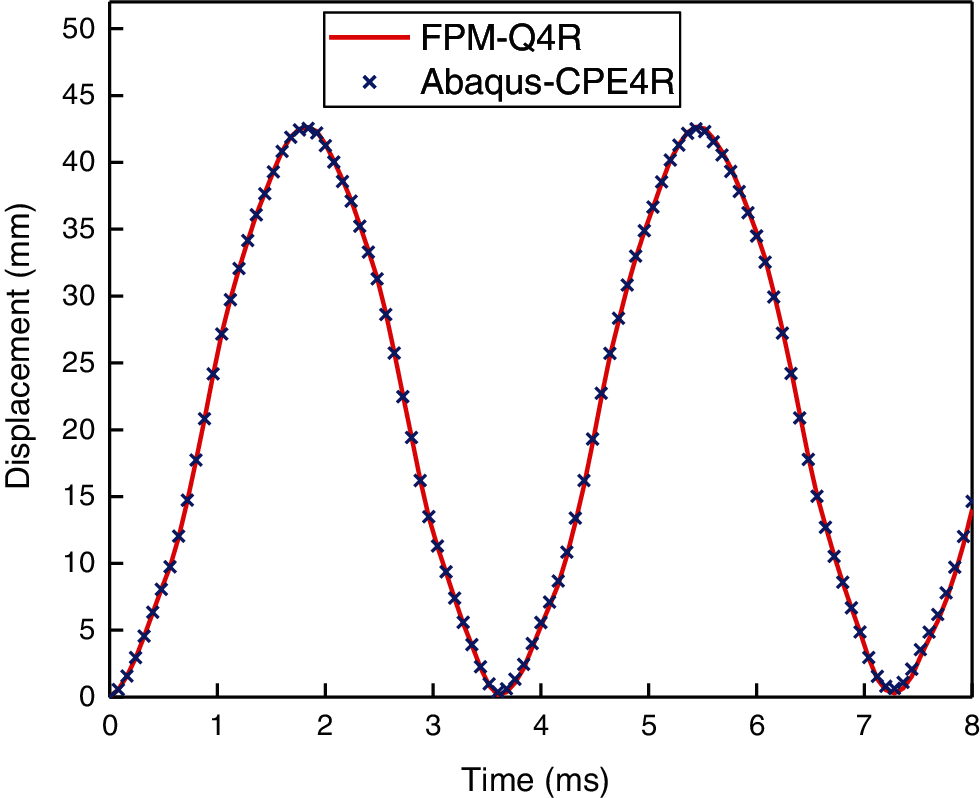
Figure 24: Vertical displacement of the tip node of the cantilever beam
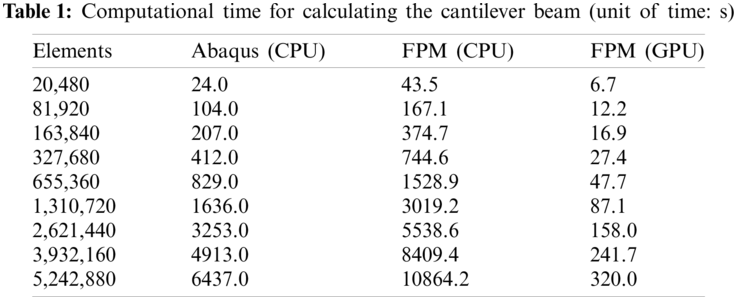
To compare the performances of parallel FPM solvers relative to serial FPM solvers and the Abaqus/Explicit solver, different meshes of the cantilever are tested. Each mesh is performed with a simulation of 0.1 ms with a fixed time step size of 1.0
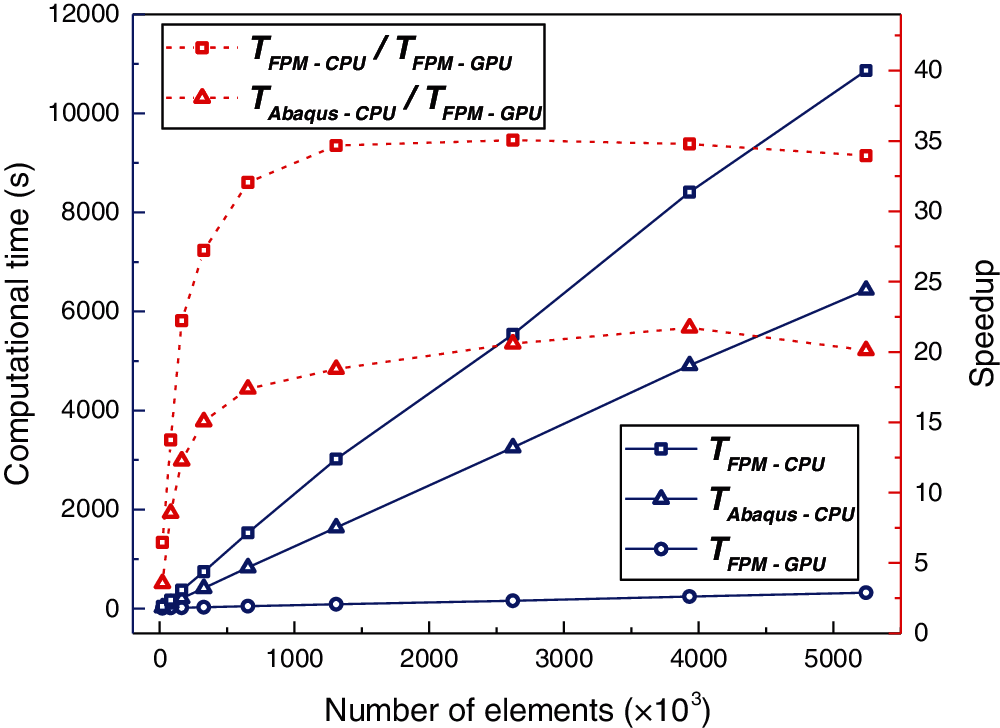
Figure 25: Comparison of computational time for calculating the cantilever beam
5.2.2 Test on Parallel Contact Solver
A two-dimensional simplification of the dynamic impact problem proposed by [38] is considered in this test, as shown in Fig. 26. A half-tube is moving toward a multilayer sheet with a prescribed displacement
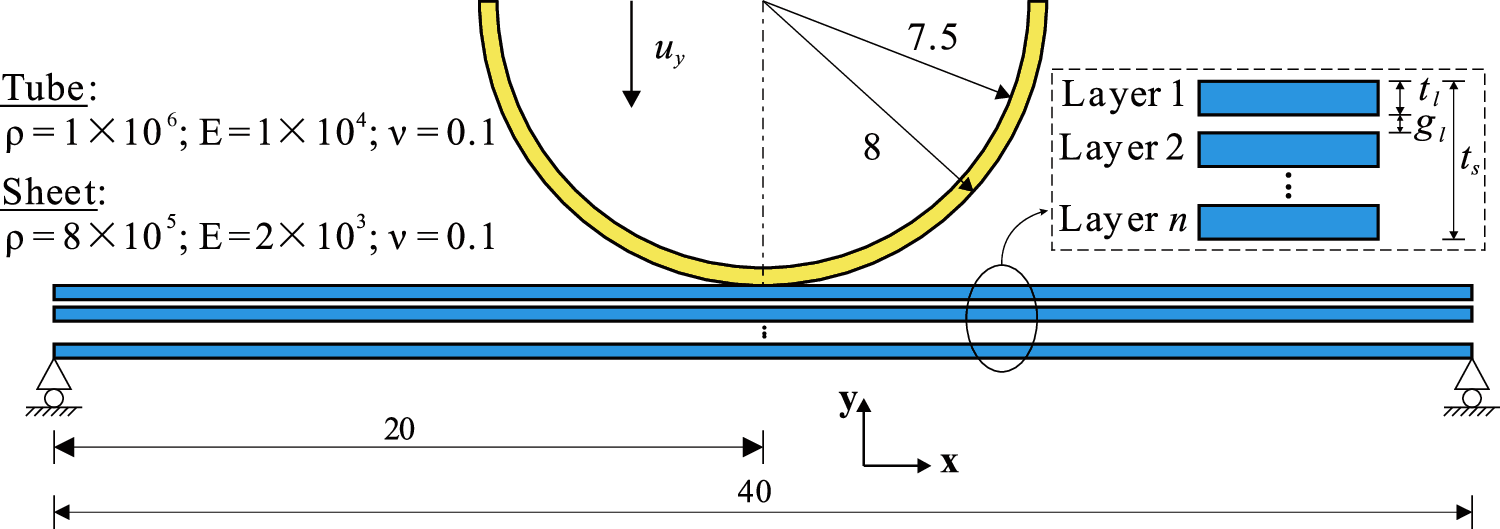
Figure 26: Contact between a half-tube and a multilayer sheet: Geometry and material properties (unit of length: mm; unit of density: kg/m3; unit of modulus: MPa)
A three-layer sheet is taken as an example to demonstrate the results, where
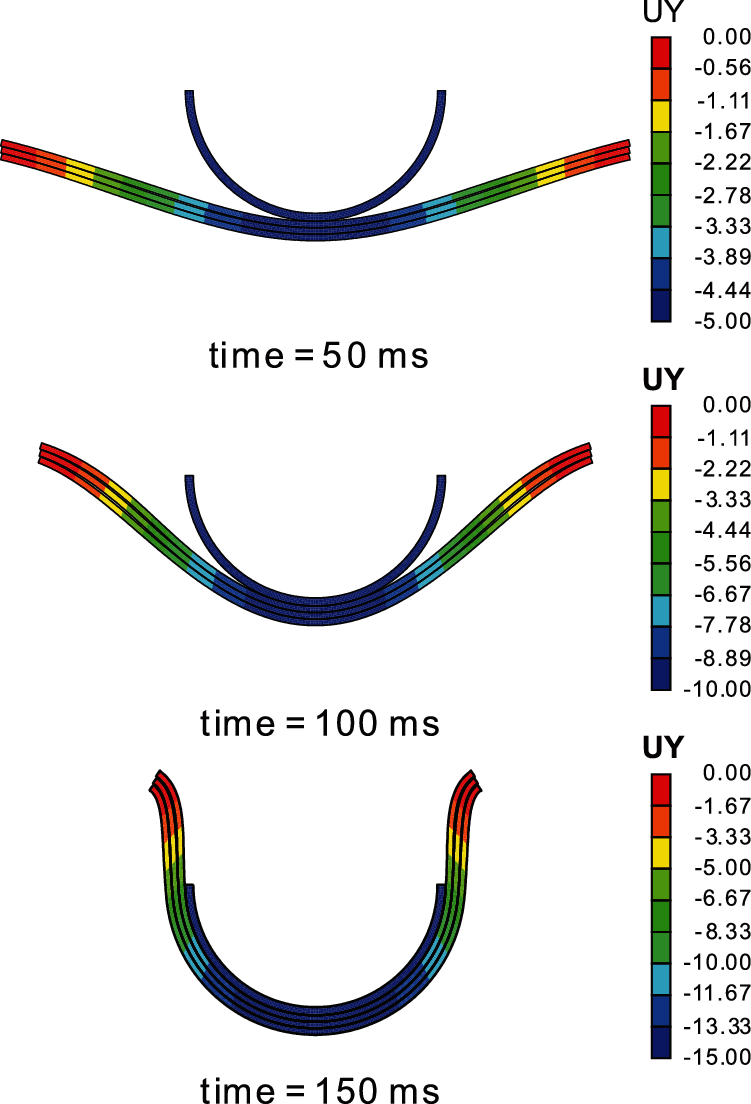
Figure 27: Vertical displacement contour at three instants (unit of length: mm)
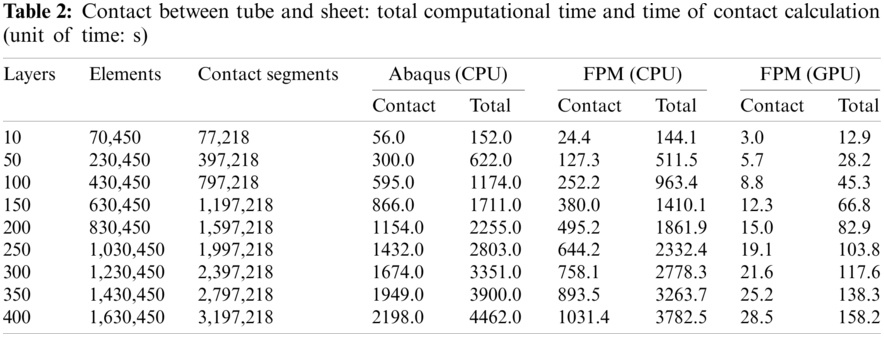
To test the performance and efficiency of the proposed contact algorithm, sheets with different numbers of layers are tested. The layer thickness is set to
The times of both total calculation and contact calculation taken by Abaqus/Explicit and both serial and parallel FPM solvers are listed in Tab. 2. Note that the time of contact calculation taken by Abaqus/Explicit cannot be extracted directly, and it is approximated by subtracting the time of calculation without contact from the time of calculation with contact.
The computational time of contact calculation and the corresponding speedups are shown in Fig. 28. As the number of contact segments increases, the speedup of the parallel FPM contact solver relative to the serial one increases accordingly and reaches 36.1 when the number of contact segments exceeds 3,000,000, and the speedup relative to the Abaqus contact solver reaches 77.4 when the number of contact segments exceeds 2,000,000. It can be concluded that the serial FPM contact solver is more efficient than the Abaqus contact solver due to the proposed contact algorithm that consists of efficient global search and local search processes. The efficiency of the parallel FPM contact solver is further dramatically improved due to its high degree of parallelism.
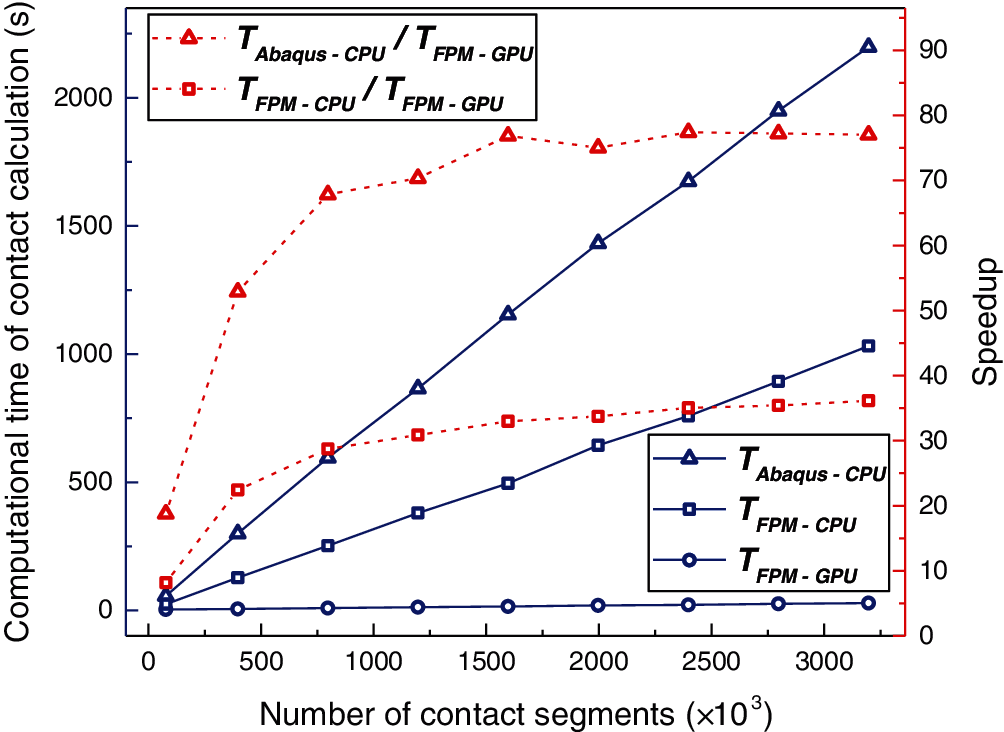
Figure 28: Contact between tube and sheet: computational time of contact calculation
The total computational time and the corresponding speedups are shown in Fig. 29. The speedup of the parallel FPM solvers relative to the serial ones reaches 23.9, and that relative to Abaqus reaches 28.5. Figs. 28 and 29 also indicate that when the number of contact segments exceeds 3,000,000, the GPU cores are fully used. Note that the maximum speedup depends heavily on the GPU hardware, and higher speedup can be achieved by using more advanced GPUs.
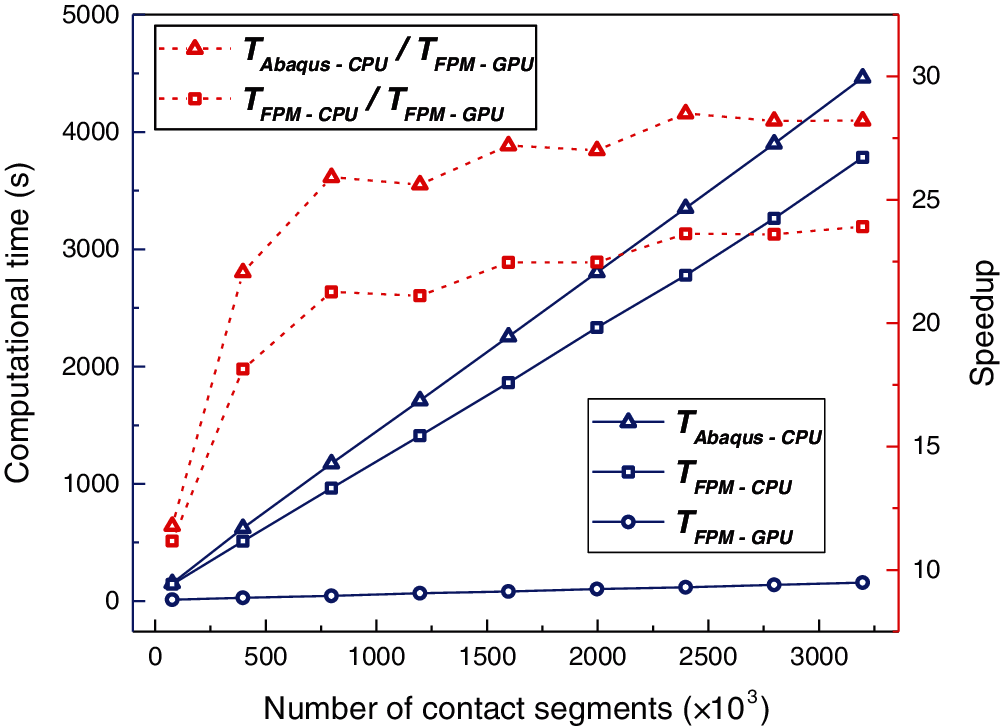
Figure 29: Contact between tube and sheet: total computational time
The percentages of contact calculation time in total calculation time are compared in Fig. 30. As the number of contact segments increases, the three curves remain nearly constant. Contact calculation accounts for approximately 50% of the total computational time in Abaqus, while the percentages in serial and parallel FPMs are only 27% and 18%, respectively. This indicates that the proposed GPU-based parallel contact algorithm can remarkably decrease the time consumption of contact calculation compared to the CPU-based serial contact algorithm.
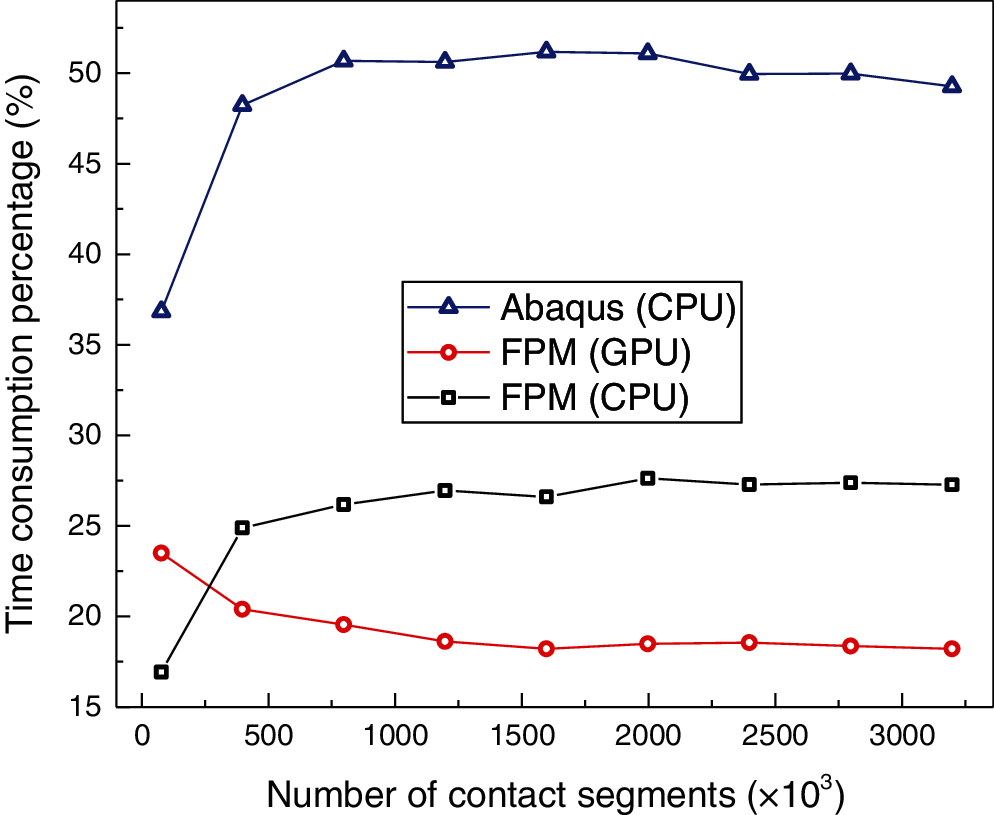
Figure 30: Contact between tube and sheet: time consumption percentages of contact calculation
The time consumption percentages of both serial and parallel FPM solvers are given in Fig. 31. In both serial and parallel cases, the element solvers are the most time-consuming solvers, while the particle solvers account for the smallest proportion. The serial contact solver accounts for a larger proportion than the parallel contact solver, demonstrating the effectiveness of the proposed parallel contact algorithm.
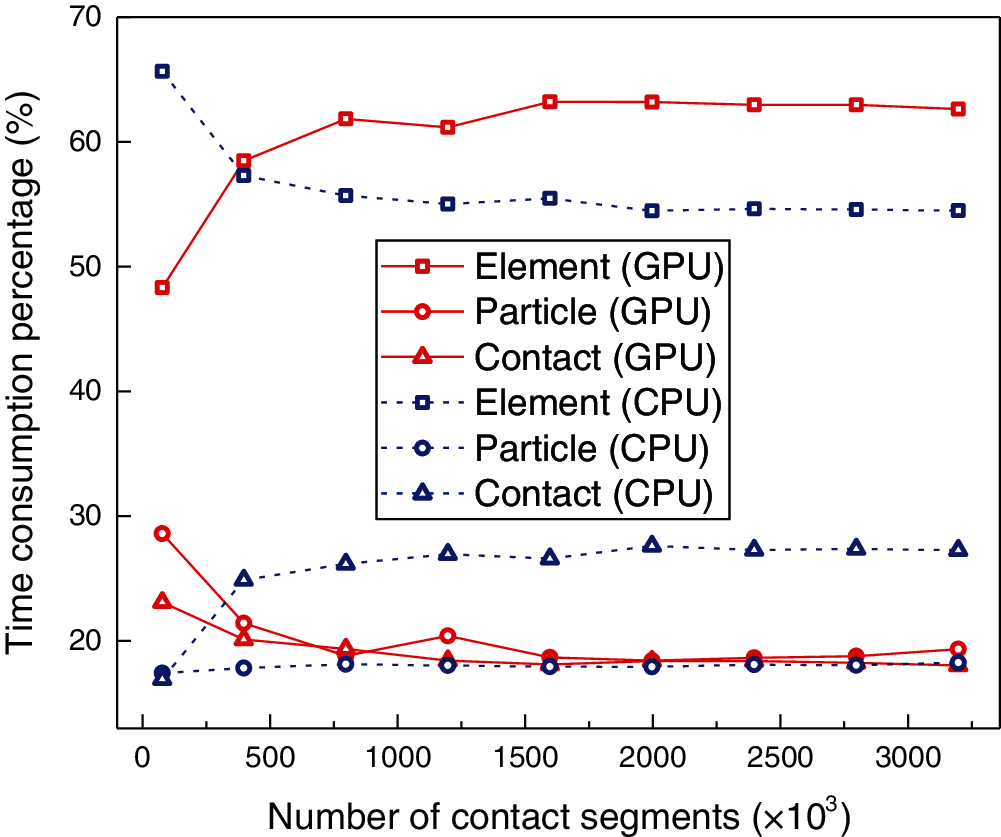
Figure 31: Contact between tube and sheet: time consumption percentages of serial and parallel FPM solvers
This paper presents a 2D GPU-based parallel contact algorithm using the FPM. A data structure suitable for parallel contact detection is introduced, and parallel global search and local search procedures are proposed. The main computational procedures, including elemental internal forces calculation, contact calculation, and solution of equations of motion, are executed in parallel on a GPU. Two verification examples and two performance tests are demonstrated, and the following conclusions can be made:
• Two typical verification examples involving large deformation frictional contacts and both elastic and elastoplastic behaviors are presented, and the results obtained by FPM agree well with those in the literature, indicating the accuracy of the FPM quadrilateral elements and the proposed contact algorithm.
• The performances of parallel element and particle solvers are studied first via a benchmark problem without contact calculation, and a maximum speedup of approximately 21.7 is achieved relative to Abaqus/Explicit when the number of elements approaches 4,000,000, and a maximum speedup of approximately 35.0 is achieved relative to serial FPM solvers when the number of elements approaches 3,000,000. Thus, the efficiency of the parallel element and particle solvers is proven.
• A large-scale contact problem is investigated. The speedup of the parallel FPM contact solver relative to the serial FPM contact solver reaches 36.1 when the number of contact segments exceeds 3,000,000, and that relative to the Abaqus contact solver reaches 77.4 when the number of segments exceeds 2,000,000. Thus, the efficiency of the parallel FPM contact solver has been proven. With respect to the total computational time, the speedup of parallel FPM solvers relative to serial FPM solvers reaches 23.9, and that relative to Abaqus reaches 28.5, demonstrating the efficiency of the parallel FPM solvers for solving large-scale contact problems.
• The percentages of contact calculation time in the total calculation time are 18% in parallel FPM, 27% in serial FPM and 50% in Abaqus/Explicit, which indicates the effectiveness of the proposed GPU-based parallel contact algorithm in reducing the time consumption proportion of contact calculation in the total calculation.
Funding Statement: This work was supported by the National Key Research and Development Program of China [Grant No. 2016YFC0800200]; the National Natural Science Foundation of China [Grant Nos. 51778568, 51908492, and 52008366]; and Zhejiang Provincial Natural Science Foundation of China [Grant Nos. LQ21E080019 and LY21E080022]. This work was also supported by the Key Laboratory of Space Structures of Zhejiang Province (Zhejiang University) and the Center for Balance Architecture of Zhejiang University.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. Wriggers, P. (2006). Computational contact mechanics. Berlin: Springer-Verlag. [Google Scholar]
2. Laursen, T. A. (2003). Computational contact and impact mechanics: Fundamentals of modeling interfacial phenomena in nonlinear finite element analysis. Berlin, Heidelberg: Springer-Verlag. [Google Scholar]
3. Puso, M. A., Solberg, J. M. (2020). A dual pass mortar approach for unbiased constraints and self-contact. Computer Methods in Applied Mechanics and Engineering, 367(1), 113092. DOI 10.1016/j.cma.2020.113092. [Google Scholar] [CrossRef]
4. Neto, D. M., Oliveira, M. C., Menezes, L. F. (2017). Surface smoothing procedures in computational contact mechanics. Archives of Computational Methods in Engineering, 24(1), 37–87. DOI 10.1007/s11831-015-9159-7. [Google Scholar] [CrossRef]
5. Benson, D. J., Hallquist, J. O. (1990). A single surface contact algorithm for the post-buckling analysis of shell structures. Computer Methods in Applied Mechanics and Engineering, 78(2), 141–163. DOI 10.1016/0045-7825(90)90098-7. [Google Scholar] [CrossRef]
6. Zhang, R., Pang, H., Dong, W. C., Li, T., Liu, F. et al. (2020). Three-dimensional discrete element method simulation system of the interaction between irregular structure wheel and lunar soil simulant. Advances in Engineering Software, 148(1), 102873. DOI 10.1016/j.advengsoft.2020.102873. [Google Scholar] [CrossRef]
7. Wang, S. Q., Zhang, Q., Ji, S. Y. (2021). GPU-Based parallel algorithm for super-quadric discrete element method and its applications for non-spherical granular flows. Advances in Engineering Software, 151(1), 102931. DOI 10.1016/j.advengsoft.2020.102931. [Google Scholar] [CrossRef]
8. Fu, T. F., Xu, T., Heap, M. J., Meredith, P. G., Mitchell, T. M. (2020). Mesoscopic time-dependent behavior of rocks based on three-dimensional discrete element grain-based model. Computers and Geotechnics, 121(1), 103472. DOI 10.1016/j.compgeo.2020.103472. [Google Scholar] [CrossRef]
9. Xu, T., Fu, T. F., Heap, M. J., Meredith, P. G., Mitchell, T. M. et al. (2020). Mesoscopic damage and fracturing of heterogeneous brittle rocks based on three-dimensional polycrystalline discrete element method. Rock Mechanics and Rock Engineering, 53(12), 5389–5409. DOI 10.1007/s00603-020-02223-y. [Google Scholar] [CrossRef]
10. Yu, Y., Paulino, G., Luo, Y. Z. (2010). Finite particle method for progressive failure simulation of truss structures. Journal of Structural Engineering, 137(10), 1168–1181. DOI 10.1061/(ASCE)ST.1943-541X.0000321. [Google Scholar] [CrossRef]
11. Ting, E. C., Shih, C., Wang, Y. K. (2004). Fundamentals of a vector form intrinsic finite element: Part I. Basic procedure and a plane frame element. Journal of Mechanics, 20(2), 113–122. DOI 10.1017/S1727719100003336. [Google Scholar] [CrossRef]
12. Ting, E. C., Shih, C., Wang, Y. K. (2004). Fundamentals of a vector form intrinsic finite element: Part II. Plane solid elements. Journal of Mechanics, 20(2), 123–132. DOI 10.1017/S1727719100003348. [Google Scholar] [CrossRef]
13. Shih, C., Wang, Y. K., Ting, E. C. (2004). Fundamentals of a vector form intrinsic finite element: Part III. Convected material frame and examples. Journal of Mechanics, 20(2), 133–143. DOI 10.1017/S172771910000335X. [Google Scholar] [CrossRef]
14. Wu, T. Y. (2013). Dynamic nonlinear analysis of shell structures using a vector form intrinsic finite element. Engineering Structures, 56(Supplement C), 2028–2040. DOI 10.1016/j.engstruct.2013.08.009. [Google Scholar] [CrossRef]
15. Zheng, Y. F., Yang, C., Wan, H. P., Luo, Y. Z., Li, Y. et al. (2020). Dynamics analysis of spatial mechanisms with dry spherical joints with clearance using finite particle method. International Journal of Structural Stability and Dynamics, 20(3), 2050035. DOI 10.1142/S0219455420500352. [Google Scholar] [CrossRef]
16. Zheng, Y. F., Wan, H. P., Zhang, J. Y., Yang, C., Luo, Y. Z. et al. (2021). Local-coordinate representation for spatial revolute clearance joints based on a vector-form particle-element method. International Journal of Structural Stability and Dynamics, 21(7), 2150093. DOI 10.1142/S0219455421500930. [Google Scholar] [CrossRef]
17. Yu, Y., Zhu, X. Y. (2016). Nonlinear dynamic collapse analysis of semi-rigid steel frames based on the finite particle method. Engineering Structures, 118(1), 383–393. DOI 10.1016/j.engstruct.2016.03.063. [Google Scholar] [CrossRef]
18. Yang, C., Shen, Y. B., Luo, Y. Z. (2014). An efficient numerical shape analysis for light weight membrane structures. Journal of Zhejiang University Science A, 15(4), 255–271. DOI 10.1631/jzus.A1300245. [Google Scholar] [CrossRef]
19. Duan, Y. F., Wang, S. M., Wang, R. Z., Wang, C. Y., Shih, J. Y. et al. (2018). Vector form intrinsic finite-element analysis for train and bridge dynamic interaction. Journal of Bridge Engineering, 23(1), 04017126. DOI 10.1061/(ASCE)BE.1943-5592.0001171. [Google Scholar] [CrossRef]
20. Liu, F. H., Yu, Y., Wang, Q. H., Luo, Y. Z. (2020). A coupled smoothed particle hydrodynamic and finite particle method: An efficient approach for fluid-solid interaction problems involving free-surface flow and solid failure. Engineering Analysis with Boundary Elements, 118(1), 143–155. DOI 10.1016/j.enganabound.2020.03.006. [Google Scholar] [CrossRef]
21. Hallquist, J., Goudreau, G., Benson, D. (1985). Sliding interfaces with contact-impact in large-scale lagrangian computations. Computer Methods in Applied Mechanics and Engineering, 51(1–3), 107–137. DOI 10.1016/0045-7825(85)90030-1. [Google Scholar] [CrossRef]
22. Yu, P. C., Peng, X. Y., Chen, G. Q., Guo, L. X. (2020). Openmp-based parallel two-dimensional discontinuous deformation analysis for large-scale simulation. International Journal of Geomechanics, 20(7), 04020083. DOI 10.1061/(ASCE)GM.1943-5622.0001705. [Google Scholar] [CrossRef]
23. Peng, X. Y., Chen, G. Q., Yu, P. C., Zhang, Y. B., Zhang, H. et al. (2020). A full-stage parallel architecture of three-dimensional discontinuous deformation analysis using OpenMP. Computers and Geotechnics, 118(1), 103346. DOI 10.1016/j.compgeo.2019.103346. [Google Scholar] [CrossRef]
24. Tang, J. Z., Zheng, Y. F., Yang, C., Wang, W., Luo, Y. Z. (2020). Parallelized implementation of the finite particle method for explicit dynamics in GPU. Computer Modeling in Engineering & Sciences, 122(1), 5–31. DOI 10.32604/cmes.2020.08104. [Google Scholar] [CrossRef]
25. Bartezzaghi, A., Cremonesi, M., Parolini, N., Perego, U. (2015). An explicit dynamics GPU structural solver for thin shell finite elements. Computers & Structures, 154(1), 29–40. DOI 10.1016/j.compstruc.2015.03.005. [Google Scholar] [CrossRef]
26. Cao, X. G., Cai, Y., Cui, X. Y. (2020). A parallel numerical acoustic simulation on a GPU using an edge-based smoothed finite element method. Advances in Engineering Software, 148(1), 102835. DOI 10.1016/j.advengsoft.2020.102835. [Google Scholar] [CrossRef]
27. NVIDIA (2021). CUDA C++ programming guide. Santa Clara, CA: NVIDIA. [Google Scholar]
28. Cai, Y., Wang, G. P., Li, G. Y., Wang, H. (2015). A high performance crashworthiness simulation system based on GPU. Advances in Engineering Software, 86(1), 29–38. DOI 10.1016/j.advengsoft.2015.04.003. [Google Scholar] [CrossRef]
29. Chung, J. T., Lee, J. M. (1994). A new family of explicit time integration methods for linear and non-linear structural dynamics. International Journal for Numerical Methods in Engineering, 37(23), 3961–3976. DOI 10.1002/nme.1620372303. [Google Scholar] [CrossRef]
30. Hulbert, G. M., Chung, J. T. (1996). Explicit time integration algorithms for structural dynamics with optimal numerical dissipation. Computer Methods in Applied Mechanics and Engineering, 137(2), 175–188. DOI 10.1016/S0045-7825(96)01036-5. [Google Scholar] [CrossRef]
31. Chen, S. Y., Wang, G. H., Li, X. M., Zhang, Q. Y., Shi, Z. P. et al. (2020). Formalization of camera pose estimation algorithm based on rodrigues formula. Formal Aspects of Computing, 32(4), 417–437. DOI 10.1007/s00165-020-00520-5. [Google Scholar] [CrossRef]
32. Liu, G. R., Quek, S. S. (2013). The finite element method: A practical course. Oxford: Butterworth-Heinemann. [Google Scholar]
33. Simo, J. C., Hughes, T. J. (1998). Computational inelasticity. New York: Springer-Verlag. [Google Scholar]
34. Borja, R. I. (2013). Plasticity: Modeling & computation. Berlin, Heidelberg: Springer-Verlag. [Google Scholar]
35. Hughes, T. J. R. (1980). Generalization of selective integration procedures to anisotropic and nonlinear media. International Journal for Numerical Methods in Engineering, 15(9), 1413–1418. DOI 10.1002/nme.1620150914. [Google Scholar] [CrossRef]
36. Flanagan, D. P., Belytschko, T. (1981). A uniform strain hexahedron and quadrilateral with orthogonal hourglass control. International Journal for Numerical Methods in Engineering, 17(5), 679–706. DOI 10.1002/nme.1620170504. [Google Scholar] [CrossRef]
37. Munjiza, A., Andrews, K. R. F. (1998). NBS contact detection algorithm for bodies of similar size. International Journal for Numerical Methods in Engineering, 43(1), 131–149. DOI 10.1002/(SICI)1097-0207(19980915)43:1<131::AID-NME447>3.0.CO;2-S. [Google Scholar] [CrossRef]
38. Chen, H., Lei, Z., Zang, M. Y. (2014). LC-Grid: A linear global contact search algorithm for finite element analysis. Computational Mechanics, 54(5), 1285–1301. DOI 10.1007/s00466-014-1058-5. [Google Scholar] [CrossRef]
39. Zang, M. Y., Gao, W., Lei, Z. (2011). A contact algorithm for 3D discrete and finite element contact problems based on penalty function method. Computational Mechanics, 48(5), 541–550. DOI 10.1007/s00466-011-0606-5. [Google Scholar] [CrossRef]
40. Zavarise, G., de Lorenzis, L. (2009). The node-to-segment algorithm for 2D frictionless contact: Classical formulation and special cases. Computer Methods in Applied Mechanics and Engineering, 198(41–44), 3428–3451. DOI 10.1016/j.cma.2009.06.022. [Google Scholar] [CrossRef]
41. Pennestrì, E., Rossi, V., Salvini, P., Valentini, P. P. (2016). Review and comparison of dry friction force models. Nonlinear Dynamics, 83(4), 1785–1801. DOI 10.1007/s11071-015-2485-3. [Google Scholar] [CrossRef]
42. Lacasta, A., Morales-Hernández, M., Murillo, J., García-Navarro, P. (2014). An optimized GPU implementation of a 2D free surface simulation model on unstructured meshes. Advances in Engineering Software, 78(1), 1–15. DOI 10.1016/j.advengsoft.2014.08.007. [Google Scholar] [CrossRef]
43. Hammer, M. E. (2013). Frictional mortar contact for finite deformation problems with synthetic contact kinematics. Computational Mechanics, 51(6), 975–998. DOI 10.1007/s00466-012-0780-0. [Google Scholar] [CrossRef]
44. Yang, B., Laursen, T. A., Meng, X. (2005). Two dimensional mortar contact methods for large deformation frictional sliding. International Journal for Numerical Methods in Engineering, 62(9), 1183–1225. DOI 10.1002/nme.1222. [Google Scholar] [CrossRef]
45. Neto, D. M., Oliveira, M. C., Menezes, L. F., Alves, J. L. (2016). A contact smoothing method for arbitrary surface meshes using nagata patches. Computer Methods in Applied Mechanics and Engineering, 299(1), 283–315. DOI 10.1016/j.cma.2015.11.011. [Google Scholar] [CrossRef]
46. Areias, P., Rabczuk, T., de Melo, F. Q., de Sá, J. C. (2015). Coulomb frictional contact by explicit projection in the cone for finite displacement quasi-static problems. Computational Mechanics, 55(1), 57–72. DOI 10.1007/s00466-014-1082-5. [Google Scholar] [CrossRef]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |