| Computer Modeling in Engineering & Sciences |
DOI: 10.32604/cmes.2022.019069
ARTICLE
N-SVRG: Stochastic Variance Reduction Gradient with Noise Reduction Ability for Small Batch Samples
School of Information Science and Engineering, Fudan University, Shanghai, 200433, China
*Corresponding Author: Lirong Zheng. Email: lrzheng@fudan.edu.cn
Received: 01 September 2021; Accepted: 11 October 2021
Abstract: The machine learning model converges slowly and has unstable training since large variance by random using a sample estimate gradient in SGD. To this end, we propose a noise reduction method for Stochastic Variance Reduction gradient (SVRG), called N-SVRG, which uses small batches samples instead of all samples for the average gradient calculation, while performing an incremental update of the average gradient. In each round of iteration, a small batch of samples is randomly selected for the average gradient calculation, while the average gradient is updated by rounding of the past model gradients during internal iterations. By suitably reducing the batch size B, the memory storage as well as the number of iterations can be reduced. The experiments are compared with the state-of-the-art Mini-Batch SGD, AdaGrad, RMSProp, SVRG and SCSG, and it is demonstrated that N-SVRG outperforms SVRG and SASG, and is on par with SCSG. Finally, by exploring the relationship between the small values of different parameters n. B and k and the effectiveness of the algorithm, we prove that our N-SVRG algorithm has some stability and can achieve sufficient accuracy even in the case of small batch size. The advantages and disadvantages of various methods are experimentally compared, and the stability of N-SVRG is explored by parameter settings.
Keywords: Machine learning; SGD; SVRG; memory storage
The variance problem introduced by the stochastic nature of the SGD algorithm becomes the main problem of optimization algorithms nowadays. The introduction of variance makes SGD reach only sublinear convergence speed with a fixed step size [1], while the stochastic algorithm accuracy is positively related to the sampling variance, and when the variance tends to 0, the deviation of the algorithm will also be 0. In this case, the SGD can still be fast even with a large step size convergence. Therefore, how to reduce the variance of the stochastic gradient in the stochastic algorithm has become an important issue studied by scholars [2].
For SGD variance problem, there are three mainstream methods to reduce the variance of sampling at present that include importance sampling, hierarchical sampling method and control variable method. The objective function in machine learning is usually solved using the Batch Gradient Descent (BGD) or SGD [3]. BGD algorithm computes the gradients of all samples for each iteration to perform the weight update, and the latter randomly selects one training sample at a time to update the parameters by computing the sample gradients. Then came the improved Mini-Batch SGD (MBGD) algorithm, where MBGD computes the gradient and performs weight update by randomly selecting m data samples in the original data for each iteration. SGD has the advantage that each step relies only on a simple random sample gradient, so the computational consumption is only a fraction of that of the standard GD [4]. However, it has the disadvantage that a constant step size leads to slow convergence in the case of variance introduced by randomness.
In recent years, many scholars have carried out research based on SGD algorithm, for example, momentum algorithm [5], which is based on the idea of gradient momentum accumulation and uses exponential weighted average to reduce the swing amplitude of the gradient. Two concepts of velocity and friction are introduced into momentum algorithm. The function of the gradient is to change velocity, and friction is to gradually reduce the velocity. In the whole training process, the increase and attenuation of momentum are simulated to achieve the purpose of convergence. AdaGrad (Adaptive Gradient) is proposed to learn by gradually decreasing the step size [6]. By accumulating gradients, the learning rate of each weight is related to the value of their previous gradient. However, the consequence of accumulating gradients is that as the training increases, the step size decreases and eventually the training stalls. To address the training stagnation problem that occurs with AdaGrad, Hinton, G. proposed RMSProp (Root Mean Square Prop) to calculate the cumulative gradient using a moving average method that only accumulates the gradient of one window, making the change in step size adapt to the current gradient thus achieving better optimization [7,8]. And for SGD stochasticity introduces the variance problem, where SVRG is used to correct the gradient used for each model update using the global average gradient information [9]. Theoretical analysis and experiments demonstrated that SVRG produced linear convergence with reducing variance. Subsequently, Zhao et al. [10] proposed the SASG (Stochastic Average Gradient Average) algorithm, which has the same thematic idea as SVRG, with the difference that a piece of memory is used to store the original gradients of all samples, and the global average gradient is updated by constantly updating the original gradients during training, which requires a large amount of memory consumption throughout the training [11]. The SCSG (Stochastically Controlled Sto-chastic Gradient) algorithm was proposed, SCSG is to calculate the average gradient by randomly selecting a part of the sample gradient as the global gradient, but when performing the weight update, randomly selecting the number of updates will make the calculation more variable and tedious, and the computation is large [12]. Subsequently, a series of algorithms [13] such as the novel Mini-Batch SCSG [14,15], b-NICE, SAGA [16,17] were generated based on the idea of variance reduction.
However, there is another structural risk minimization problem in machine learning, which is composed of “loss function + regularization term”, and different forms of regularization terms lead to different complex problems, such as Overlapping group lasso, Graph-guided fused lasso etc. [18], which are very complex for SGD-based theoretical approaches, while the ADMM algorithm is applied to a wider range of models and its excellent performance proves itself to be an effective optimization tool. Several variance reduction algorithms have been proposed in combination with ADMM, including SAG-ADMM [19], SDCA-ADMM [20], and SVRG-ADMM [21]. All three algorithms are improved algorithms generated based on the update strategy of ADMM. Then [22] proposed the APA-SVRG, which is trained on the basis of SVRG using proximity averaging, and the experimental results show that the APA-SVRG algorithm is comparable to SVRG-ADMM. The neighborhood stochastic L-BFGS [23] methods, on the other hand, an improved algorithm based on Newton’s method, which is trained mainly on loss functions that are smooth functions. Meanwhile, the specular stochastic sub-gradient descent [24] method is used to train on the loss function that is a non-smooth function. However, these schemes compute the gradient unbiased estimation using the average gradient of a small batch of samples, which cannot reduce the total complexity linearly, and the computational cost and memory consumption increase, and the computation and update of the gradient of a small batch of samples increase the computational consumption of the whole algorithm [25].
In order to address the above challenges, we propose a noise reduction method of stochastic gradient method, and then use the idea of small sample average gradient instead of global average gradient to design the algorithm N-SVRG that selects small samples for training while updating the average gradient to achieve variance reduction, and introduce the algorithm flow and convergence analysis of N-SVRG algorithm in detail, and compare it with the mainstream Mini-Batch SGD The N-SVRG algorithm is compared with the mainstream Mini-Batch SGD, AdaGrad, RMSProp, SVRG and SCSG algorithms, and it is proved that the N-SVRG algorithm outperforms SVRG, SASG and other algorithms, and is equal to SCSG. Finally, by exploring the relationship between the small values of different parameters n. B and k and the effectiveness of the algorithm, we prove that the N-SVRG algorithm has some stability and can achieve sufficient accuracy even in the case of low back size. Experimentally comparing the advantages and disadvantages of various methods and exploring the stability of the N-SVRG algorithm through parameter settings.
The contributions of this paper are as follows:
* We propose N-SVRG that uses small batches samples instead of all samples for the average gradient calculation, while performing an incremental update of the average gradient. By suitably reducing the batch size B, the memory storage as well as the number of iterations can be reduced.
* The convergence analysis of the proposed algorithm shows that the algorithm can stably converge to a certain lower limit, and find the saddle point with smooth gradient descent in the whole training process of neural network. It also enables the algorithm in this paper to reduce the computational cost and memory burden.
* The experiments are compared with the state-of-the-art demonstrate that N-SVRG outperforms baseline. Exploring the relationship between the small values of different parameters n. B and k and the effectiveness of the algorithm, we prove that our N-SVRG algorithm has some stability and can achieve sufficient accuracy even in the case of low batch size.
For the supervised learning problem in machine learning [2,26]: assume that there is a functional model l in the space L for each model input x, i.e., there is a prediction l(x). That is, given n training data
Experience risk:
Expected risk:
where w represents the parameters in the function model, and
Empirical risk minimization is solving for w such that the empirical risk is minimized:
However, during the training process, the model may have a strong performance capability because it has a large number of parameters itself, but the data provided for training are insufficient. Insufficient data for training, then the model may overfit during a large number of repeated training sessions, i.e., “the learned model is so well suited to a specific set of data that it does not reliably fit other data or future observations”. In order to reduce the impact of overfitting [4,27] to some extent, a regularization term is added to the empirical risk to limit the complexity of the model, which constitutes a structural risk minimization [28] in the form of “loss function + regularization term” problem:
where λ > 0 is a hyperparameter that balances the weight of the regularization term by its own numerical size, and the larger λ is set, the heavier the penalty on the weight. r(w) picks different forms depending on the effect, which include L1 parametrization, L2 parametrization [29], and L~∞ parametrization. The most common form is the L2 parametrization, i.e., r(w) = ‖ w ‖ 2, which can be calculated using
The loss function in machine learning is a non-negative real function
Logarithmic loss function:
Mean square error loss function:
0-1 Loss function:
Cross-entropy error loss function:
The use of these loss functions should be chosen according to the specific problem, for example, the cross-entropy error loss function can be used with the Softmax function to form a Softmax-with-Loss layer for training and learning the classification problem [31].
To facilitate the subsequent analysis and study, we give the relevant basic concepts that will be covered in the paper as well as the definitions. There is an iterative sequence
1) If μ = 1, the algorithm achieves sublinear convergence;
2) If 0 < μ < 1, the algorithm achieves linear convergence [32];
3) If μ = 0, the algorithm achieves superlinear convergence.
Let set
Let set
f (x) is a convex function defined on a convex set C.
For a function f(y) with step η > 0, its proximal operator at the point x [33] (Proximal Operator) is defined as:
If
Then:
That is, the proximity operator of the function f(y) at x can be viewed as the Euclidean projection of x on the set C.
Assume (Lipschitz continuous target gradient) that the objective function F:
Ensures that the gradient of F does not change arbitrarily fast with respect to the parameter vector. This assumption is essential for the convergence analysis of most gradient-based methods; without it, the gradient will not be a good indication of the distance to reduce F.
Assumption 1: If the function
The constant L is called the Lipschitz constant and is generally used to measure the smoothness of a function. The function satisfies L smoothness in case it itself satisfies the Lipschitz continuity condition. For a fixed
If the function
4.1 Controlled Variable Method
This section describes the specific implications of the control variables approach [34]. It is assumed that we need to use Monte Carlo [35] sampling method to estimate the expectation μ of the random variable X, i.e., E[X] = μ. Also assume that we have been able to be able to estimate relatively easily the expectation τ of another random variable Y, i.e., E[Y] = τ. We construct a new random variable:
where
It can be easily obtained by calculation that Var(Z) is minimum at
where
SVRG is a new variance reduction method formed based on the control variable method, which itself does not construct control variables from similar samples, but from the perspective of optimizing variables. Its iterative approach is:
where
SVRG itself is a periodic algorithm, with the increase of iterations,
The SVRG algorithm steps are as follows:
Step 1: Given the initialization weight
Step 2: Calculate the global average gradient
Step 3: j = 0, select a random sample
Step 4: t = t + 1, go to Step 2 until t = T, output: Choice 1:
Assuming that all
Expectation of geometric convergence [21] for SVRG:
Proof: For any i, consider that there is
science
Because
So
When i = 1,2, …, n, the cumulative inequality (21) is added. And using
Give way
Make
The first inequality uses
The first inequality uses the previously obtained inequality
The second inequality uses the strong convexity property, thus obtaining
So get
The SASG algorithm is a memory-consuming algorithm in the SVRG family of algorithms. Although the computational cost of the SVRG algorithm is huge when computing the average of all sample gradients, it can be computed in parallel during the computation because it can use matrix operations itself. the difference between the SASG and SVRG algorithms is that the SASG algorithm requires one memory block to store all sample gradients, which not only increases the computational cost (because matrix parallelism cannot be used), but also increases the memory burden of the computer. In order to reduce the computational cost and memory burden, we designed the back decimation update gradient [2,33].
In the SASG algorithm, a piece of memory is used to store the original gradients of all samples, while a new gradient
The small batch average gradient in SCSG and the SGD update approach in the SASG algorithm inspired our algorithm. n-SVRG algorithm discards the calculation of the global average gradient for all samples and consistently samples a small batch of samples from the sample, and replaces the global average sample gradient for all by calculating the batch average gradient, i.e.,
The N-SVRG algorithm steps are as follows:
Step 1: Given the initialization model parameters
Step 2: Randomly and consistently sample a batch of
Step 3: Calculate the gradient
Step 4: Calculate
Step 5: Compute
Step 6: t = t + 1, go to Step 2 until t = T, output:
As can be seen from Step 5 to
5.2 Algorithm Convergence Analysis
For simplicity, we only consider the case where each
Assume that P(w) is a strongly convex function
The expectation in Step 3 of the SVRG algorithm is
In the algorithm of this paper, the same SVRG is wanted to be achieved by updating
Then
From the literature it is clear that
We can take the expectation for
Since
The first three inequalities are used
Set
The first inequality uses
The second inequality uses the strongly convex property (38), and we thus obtain
We have the convergence of N-SVRG
The convergence of the N-SVRG algorithm shows that the convergence rate of the algorithm is related to the selection of parameters B and k.
Regarding the selection of parameters B and k on the stability of the algorithm and the convergence speed exploration we will explain in detail in the experimental section.
6 Experimental Design and Experimental Results
MNIST [35] is a handwritten digit image dataset that was collected with the aim of logarithmically enabling the recognition of handwritten digits, as shown in Fig. 1. This dataset has been widely used in machine learning and deep learning since 1998 by Yan LeCun in the LeNet-5 network to test the effectiveness of algorithms such as SVM, Linear Classifiers, Neural Nets, KNN [31,35], etc.

Figure 1: Example of MNIST dataset
The dataset consists of a training set and a test set, where the training set contains 60,000 handwritten digital images and the digital labels corresponding to the digital images. Similarly, the test set contains a total of 10,000 handwritten digital images and digital labels corresponding to the digital images. The data set is composed of digital images from 0 to 9, each of which is a single-channel gray scale image of 28 pixels by 28 pixels, and each pixel is a uint 8 data type, i.e., an 8-bit unsigned integer with a value between 0 and 255. Each image is labeled with “1”, “3”, “5”, etc.
The experimental dataset is a MNIST dataset. In the experimental preprocessing stage, we need to regularize and expand the images in one dimension so that when we use batch processing, we can transform a batch of digital image samples into a two-dimensional array for computation. At the same time, we encode the data labels as one-hot. One-hot encoding is an array where the correct solution label is 1 and all others are 0. For example, like label ‘7’ in one-hot encoding array is 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0.
All program networks are structured as 728 × 40 × 10, the input layer is 728 neurons with input function only, the implicit layer is 40 neurons containing the Relu function, and the output layer is a Softmax-with-Loss layer with 10 neurons. In the output layer we use a Softmax-with-Loss layer for learning.
The algorithm is done by Python3.6, for the implementation of the algorithm for the structure in [15,17] is consulted. The device used in this paper is CPU: Inter(R) Core(TM) i5-7500 CPU@3.40 GHz with 16.00 GB of RAM.
The experiment consists of two parts in total. The first part is mainly the evaluation comparison between the algorithm of this paper and the current mainstream algorithm; the second part is mainly the exploration of the relationship between the parameters of the algorithm of this paper.
The N-SVRG algorithm is programmed in PyCharm using Python3.6, and is compared with the mainstream Mini-Batch SGD, AdaGrad, RMSProp, SVRG and SCSG algorithms.
Parameter setting of each algorithm: Mini-Batch SGD:
Maximum number of iterations 4800, per batch size 250;
AdaGrad: 4800 iterations maximum, 250 per batch size;
RMSProp: 4800 iterations maximum, 250 per batch size;
SVRG: Maximum epoch count 20 times, SGD steps 5000;
SCSG: Maximum number of iterations 4800, batch size 250, number of SGD steps 250;
N-SVRG: Maximum number of iterations 4800, batch size 250, number of SGD steps 249.
The following points can be seen in Fig. 2 and Table 1:
(1) N-SVRG, RMSProp and SCSG all reach around 65% accuracy by the first epoch of iteration, while SVRG, Mini-Batch SGD and AdaGrad only reach below 40%. As the iteration proceeds, N-SVRG, RMSProp and SCSG reach 80% or more accuracy after only 7 epochs, SVRG reaches 65%, and Mini-Batch SGD and AdaGrad reach only 50%. Batch SGD and AdaGrad.
(2) N-SVRG, RMSProp and SCSG all achieve high accuracy smoothly and quickly. In terms of accuracy, the difference between N-SVRG and SCSG is 0.26%, and the difference between RMSProp and SCSG is 1.13%. The detection accuracy of SVRG is slightly lower than the previous three algorithms, but it is still better than Mini-Batch SGD and AdaGrad.
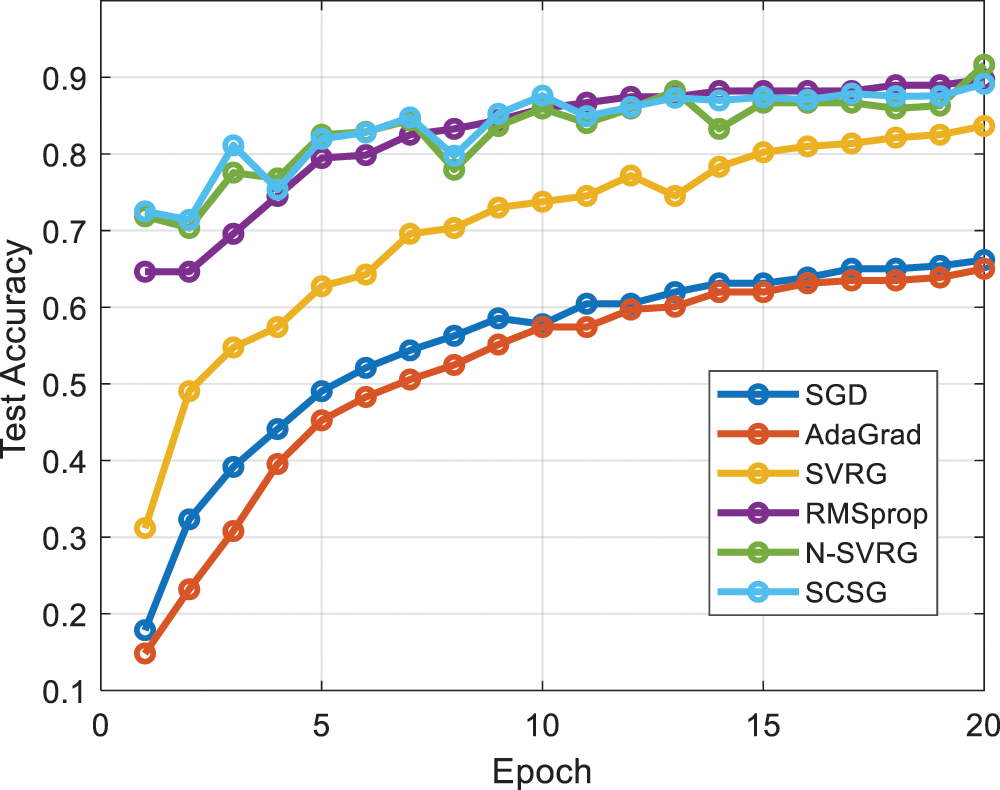
Figure 2: Comparison of algorithm accuracy

The stability of the N-SVRG algorithm is mainly affected by two factors: the size of each batch B and the number of SGD steps k. The size of B directly affects the computational cost and storage cost of the algorithm, while an appropriate B can enable the algorithm to achieve better accuracy while converging quickly, and the number of SGD steps k has a similar effect with B. Also, the size relationship between k and B is what we need to discuss. Inspired by [24], this paper focuses on two aspects of the experimental investigation, namely, the relationship between the number of training samples B and n ratio and the relationship between B and k the ratio.
B and n ratio exploration:
In the experiment to explore the effect of B and n scaling relationship on the algorithm, in order to make the experimental sample size diversity, we need to take 10,000, 8,000, 4,000 samples from MNIST data one by one for training and B ∈ n/2, n/4, n/8, n/16, n/32, set k = B − 1 for the experiment.
The following can be seen from Fig. 3 and Table 2:
(1) The proportional relationship between B and n has a certain relationship with the effect of the algorithm, the larger B is the smaller the training accuracy, and the longer the training time will be because of the number of substitutions due to the setting of k;
(2) Relatively best accuracy at
(3) Although it can be seen from the detection accuracy that the size of B has a relationship with the convergence speed and the accuracy of the algorithm, especially
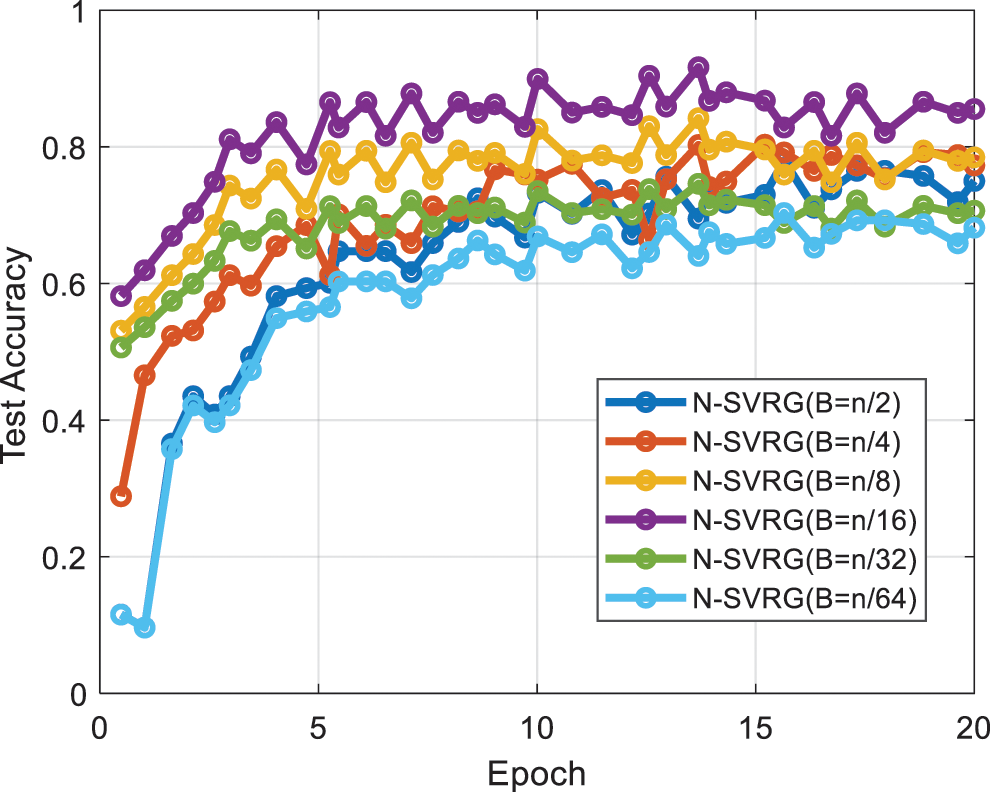
Figure 3: Results of the B vs. n ratio investigation

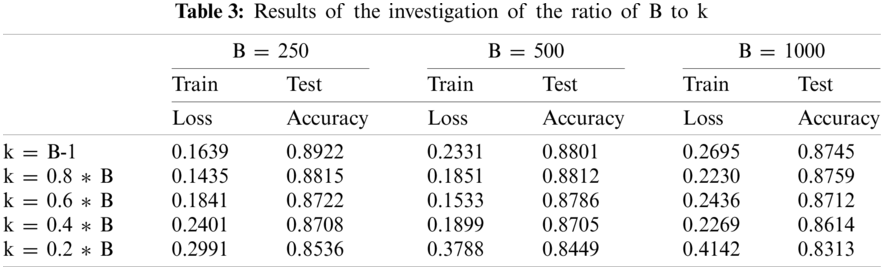
In the experiments exploring the effect of the relationship between B and k scaling on the algorithm, we directly use the complete MNIST dataset and consistently sample small batches of samples of sizes 250, 500, and 1000, respectively. while we set the number of SGD steps k ∈ B-1, 0.8 × B 0.6 × B 0.4 × B 0.2 × B for the experiments.
The following can be seen in Fig. 4 and Table 3:
(1) The relationship between the size of k and B is positively related to the accuracy of the algorithm, the closer k is to B, the higher the testing accuracy of the algorithm, and vice versa, the accuracy decreases, and this phenomenon does not change with the size of B.
(2) From the cross-observation of the data, it is clear that when k is a constant (k = 200), the accuracy decreases with the increase of B, which confirms the above point.
(3) Comparing the results of two experiments, Experiment B with n-proportional probe and Experiment B with k-proportional probe, we can see that the N-SVRG algorithm is robust and maintains high experimental results for general optimization problems when the batch size is too small.
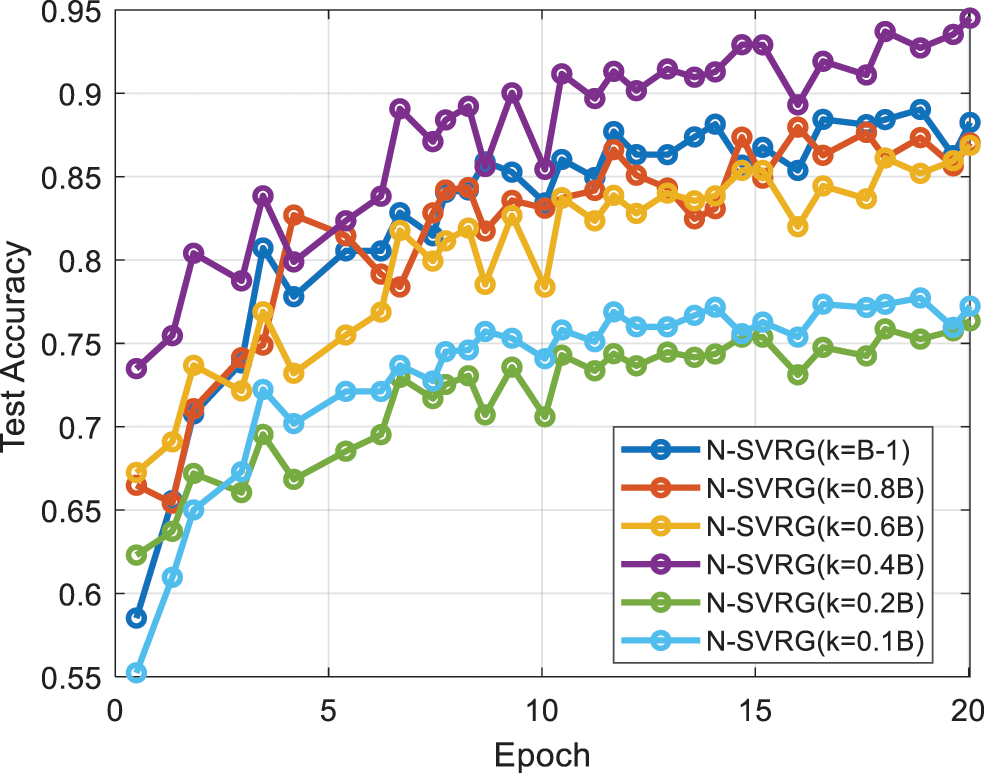
Figure 4: Results of the B vs. k ratio exploration
Through the experiments we can find that the N-SVRG algorithm is outstanding in convergence speed and accuracy compared with Mini-Batch SGD, AdaGrad and SVRG, and is comparable to RMSProp and SCSG. We can know that N-SVRG algorithm is a relatively stable algorithm, although there are two parameters B and k affect the accuracy of the algorithm, from the experiment we can see that the change of B shows a trend of the smaller the value, the higher the accuracy of the algorithm, this nature is the algorithm is suitable for general optimization problems.
In this paper, we propose a noise reduction method for SVRG, which uses a small batch of samples instead of all samples for average gradient computation and incremental update of the average gradient. The experiments are compared with the mainstream Mini-Batch SGD, AdaGrad, RMSProp, SVRG and SCSG algorithms, and it is proved that the N-SVRG algorithm outperforms SVRG and SASG, and is equal to SCSG. Finally, by exploring the relationship between the small values of different parameters n, B and k and the algorithm effect, we prove that the N-SVRG algorithm has some stability.
Funding Statement: This work was supported by the National Natural Science Foundation of China under Grant 62076066.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. Jain, P., Nagaraj, D. M., Netrapalli, P. (2021). Making the last iterate of SGD information theoretically optimal. SIAM Journal on Optimization, 31(2), 1108–1130. DOI 10.1137/19M128908X. [Google Scholar] [CrossRef]
2. Hu, B., Seiler, P., Lessard, L. (2020). Analysis of biased stochastic gradient descent using sequential semidefinite programs. Mathematical Programming, 187(5), 1–26. DOI 10.1007/s10107-020-01486-1. [Google Scholar] [CrossRef]
3. Prashanth, L. A., Korda, N., Munos, R. (2021). Concentration bounds for temporal difference learning with linear function approximation: The case of batch data and uniform sampling. Machine Learning, 110(3), 559–618. DOI 10.1007/s10994-020-05912-5. [Google Scholar] [CrossRef]
4. Pan, H., Zheng, L. (2021). DisSAGD: A distributed parameter update sheme based on variance reduction. Sensors, 21(15), 5124. DOI 10.3390/s21155124. [Google Scholar] [CrossRef]
5. Xie, Y., Li, P., Zhang, J., Ogiela, M. R. (2021). Differential privacy distributed learning under chaotic quantum particle swarm optimization. Computing, 103(3), 449–472. DOI 10.1007/s00607-020-00853-2. [Google Scholar] [CrossRef]
6. Yao, J., Wang, J., Tsang, I. W., Zhang, Y., Sun, J. et al. (2019). Deep learning from noisy image labels with quality embedding. IEEE Transactions on Image Processing, 28(4), 1909–1922. DOI 10.1109/TIP.2018.2877939. [Google Scholar] [CrossRef]
7. Yang, Z. (2021). Variance reduced optimization with implicit gradient transport. Knowledge-Based Systems, 212, 106626. DOI 10.1016/j.knosys.2020.106626. [Google Scholar] [CrossRef]
8. Khamaru, K., Pananjady, A., Ruan, F., Wainwright, M. J., Jordan, M. I. (2021). Is temporal difference learning optimal? An instance-dependent analysis. SIAM Journal on Mathematics of Data Science, 3(4), 1013–1040. DOI 10.1137/20M1331524. [Google Scholar] [CrossRef]
9. Zhang, C., Xie, T., Yang, K., Ma, H., Xie, Y. et al. (2019). Positioning optimisation based on particle quality prediction in wireless sensor networks. IET Networks, 8(2), 107–113. DOI 10.1049/iet-net.2018.5072. [Google Scholar] [CrossRef]
10. Zhao, H., Wu, D., Su, H., Zheng, S., Chen, J. (2021). Gradient-based conditional generative adversarial network for non-uniform blind deblurring via DenseResNet. Journal of Visual Communication and Image Representation, 74(10), 102921. DOI 10.1016/j.jvcir.2020.102921. [Google Scholar] [CrossRef]
11. Meng, X., Bradley, J., Yavuz, B., Sparks, E., Venkataraman, S. et al. (2016). Mllib: Machine learning in apache spark. The Journal of Machine Learning Research, 17(1), 1235–1241. [Google Scholar]
12. Loey, M., Manogaran, G., Taha, M. H. N., Khalifa, N. E. M. (2021). Fighting against COVID-19: A novel deep learning model based on YOLO-v2 with ResNet-50 for medical face mask detection. Sustainable Cities and Society, 65(3), 102600. DOI 10.1016/j.scs.2020.102600. [Google Scholar] [CrossRef]
13. Duchi, J. C. (2018). Introductory lectures on stochastic optimization. The Mathematics of Data, 25, 99–185. DOI 10.1090/pcms/025. [Google Scholar] [CrossRef]
14. Xie, T., Zhang, C., Zhang, Z., Yang, K. (2018). Utilizing active sensor nodes in smart environments for optimal communication coverage. IEEE Access, 7, 11338–11348. DOI 10.1109/ACCESS.2018.2889717. [Google Scholar] [CrossRef]
15. Gower, R. M., Richtárik, P., Bach, F. (2021). Stochastic quasi-gradient methods: Variance reduction via Jacobian sketching. Mathematical Programming, 188(1), 135–192. DOI 10.1007/s10107-020-01506-0. [Google Scholar] [CrossRef]
16. Garcia, N., Kawan, C., Yüksel, S. (2021). Ergodicity conditions for controlled stochastic nonlinear systems under information constraints: A volume growth approach. SIAM Journal on Control and Optimization, 59(1), 534–560. DOI 10.1137/20M1315920. [Google Scholar] [CrossRef]
17. Metel, M. R., Takeda, A. (2021). Stochastic proximal methods for non-smooth non-convex constrained sparse optimization. Journal of Machine Learning Research, 22(115), 1–36. [Google Scholar]
18. Yang, Z., Wang, C., Zhang, Z., Li, J. (2019). Mini-batch algorithms with online step size. Knowledge-Based Systems, 165, 228–240. DOI 10.1016/j.knosys.2018.11.031. [Google Scholar] [CrossRef]
19. Gower, R. M., Richtárik, P., Bach, F. (2021). Stochastic quasi-gradient methods: Variance reduction via Jacobian sketching. Mathematical Programming, 188(1), 135–192. DOI 10.1007/s10107-020-01506-0. [Google Scholar] [CrossRef]
20. Zhang, J., Tu, H., Ren, Y., Wan, J., Zhou, L. et al. (2018). An adaptive synchronous parallel strategy for distributed machine learning. IEEE Access, 6, 19222–19230. DOI 10.1109/ACCESS.2018.2820899. [Google Scholar] [CrossRef]
21. Vlaski, S., Sayed, A. H. (2021). Distributed learning in non-convex environments—Part II: Polynomial escape from saddle-points. IEEE Transactions on Signal Processing, 69, 1257–1270. DOI 10.1109/TSP.2021.3050840. [Google Scholar] [CrossRef]
22. Dean, J., Corrado, G., Monga, R., Chen, K., Devin, M. et al. (2012). Large scale distributed deep networks. Advances in Neural Information Processing Systems, 25, 1223–1231. [Google Scholar]
23. Wei, J., Zhang, X., Ji, Z., Li, J., Wei, Z. (2021). Deploying and scaling distributed parallel deep neural networks on the Tianhe-3 prototype system. Scientific Reports, 11(1), 1–14. DOI 10.1038/s41598-021-98794-z. [Google Scholar] [CrossRef]
24. Wang, X., Fan, N., Pardalos, P. M. (2017). Stochastic subgradient descent method for large-scale robust chance-constrained support vector machines. Optimization Letters, 11(5), 1013–1024. DOI 10.1007/s11590-016-1026-4. [Google Scholar] [CrossRef]
25. Xing, E. P., Ho, Q., Dai, W., Kim, J. K., Wei, J. et al. (2015). Petuum: A new platform for distributed machine learning on big data. IEEE Transactions on Big Data, 1(2), 49–67. DOI 10.1109/TBDATA.2015.2472014. [Google Scholar] [CrossRef]
26. Pu, S., Nedić, A. (2021). Distributed stochastic gradient tracking methods. Mathematical Programming, 187(1), 409–457. DOI 10.1007/s10107-020-01487-0. [Google Scholar] [CrossRef]
27. Zhou, Q., Guo, S., Lu, H., Li, L., Guo, M. et al. (2021). A comprehensive inspection of the straggler problem. Computer, 54(10), 4–5. DOI 10.1109/MC.2021.3099211. [Google Scholar] [CrossRef]
28. Skoraczyński, G., Dittwald, P., Miasojedow, B., Szymkuć, S., Gajewska, E. P. et al. (2017). Predicting the outcomes of organic reactions via machine learning: Are current descriptors sufficient? Scientific Reports, 7(1), 1–9. DOI 10.1038/s41598-017-02303-0. [Google Scholar] [CrossRef]
29. Nguyen, L. M., Scheinberg, K., Takáč, M. (2021). Inexact SARAH algorithm for stochastic optimization. Optimization Methods and Software, 36(1), 237–258. DOI 10.1080/10556788.2020.1818081. [Google Scholar] [CrossRef]
30. Lu, H., Freund, R. M. (2021). Generalized stochastic Frank-Wolfe algorithm with stochastic substitute gradient for structured convex optimization. Mathematical Programming, 187(1), 317–349. DOI 10.1007/s10107-020-01480-7. [Google Scholar] [CrossRef]
31. Schmidt, M., Le Roux, N., Bach, F. (2017). Minimizing finite sums with the stochastic average gradient. Mathematical Programming, 162(1–2), 83–112. DOI 10.1007/s10107-016-1030-6. [Google Scholar] [CrossRef]
32. Konečný, J., Liu, J., Richtárik, P., Takáč, M. (2015). Mini-batch semi-stochastic gradient descent in the proximal setting. IEEE Journal of Selected Topics in Signal Processing, 10(2), 242–255. DOI 10.1109/JSTSP.2015.2505682. [Google Scholar] [CrossRef]
33. Xin, R., Khan, U. A., Kar, S. (2021). An improved convergence analysis for decentralized online stochastic non-convex optimization. IEEE Transactions on Signal Processing, 69, 1842–1858. DOI 10.1109/TSP.2021.3062553. [Google Scholar] [CrossRef]
34. Guo, Y., Liu, Y., Bakker, E. M., Guo, Y., Lew, M. S. (2018). CNN-RNN: A large-scale hierarchical image classification framework. Multimedia Tools and Applications, 77(8), 10251–10271. DOI 10.1007/s11042-017-5443-x. [Google Scholar] [CrossRef]
35. Shetty, A. B., Ail, N. N., Sahana, M., Bhat, V. P. (2021). Recognition of handwritten digits and English texts using MNIST and EMNIST datasets. International Journal of Research in Engineering, Science and Management, 4(7), 240–243. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |