| Computer Modeling in Engineering & Sciences |
DOI: 10.32604/cmes.2022.020331
ARTICLE
B-PesNet: Smoothly Propagating Semantics for Robust and Reliable Multi-Scale Object Detection for Secure Systems
1School of Information and Software Engineering, University of Electronic Science and Technology of China, Chengdu, 610054, China
2Yangtze Delta Region Institute (Huzhou), University of Electronic Science and Technology of China, Huzhou, 313000, China
*Corresponding Author: Yunbo Rao. Email: raoyb@uestc.edu.cn
Received: 17 November 2021; Accepted: 26 January 2022
Abstract: Multi-scale object detection is a research hotspot, and it has critical applications in many secure systems. Although the object detection algorithms have constantly been progressing recently, how to perform highly accurate and reliable multi-class object detection is still a challenging task due to the influence of many factors, such as the deformation and occlusion of the object in the actual scene. The more interference factors, the more complicated the semantic information, so we need a deeper network to extract deep information. However, deep neural networks often suffer from network degradation. To prevent the occurrence of degradation on deep neural networks, we put forth a new model using a newly-designed Pre-ReLU, which inserts a ReLU layer before the convolution layer for the sake of preventing network degradation and ensuring the performance of deep networks. This structure can transfer the semantic information more smoothly from the shallow to the deep layer. However, the deep networks will encounter not only degradation, but also a decline in efficiency. Therefore, to speed up the two-stage detector, we divide the feature map into many groups so as to diminish the number of parameters. Correspondingly, calculation speed has been enhanced, achieving a balance between speed and accuracy. Through mathematical demonstration, a Balanced Loss (BL) is proposed by a balance factor to decrease the weight of the negative sample during the training phase to balance the positives and negatives. Finally, our detector demonstrates rosy results in a range of experiments and gains an mAP of 73.38 on PASCAL VOC2007, which approaches the requirement of many security systems.
Keywords: Object detection; Pre-ReLU; CNN; Balanced loss
In recent years, computer vision has thrived with the support of deep learning [1 –7]. Object detection manifests great practical and research value in many subfields of computer vision. Many object detection approaches proposed in earlier years [8,9] were built based on designing features manually. The shortcoming of those detectors is a lack of generalization. Now, more and more state-of-the-art detection models using convolution neural networks (CNNs) [10,11] were presented. By combining with CNN, object detectors display great power by addressing complex tasks. There are two kinds of detectors: (1) two-stage method [12–20] and (2) one-stage method [21–30]. As for the two-stage detector, firstly, the detector tries to find a set of candidate boxes containing objects. These boxes will introduce important semantic information to classification and regression in the second part. Two-stage methods obtained a better accuracy on PASCAL VOC [31] and MSCOCO [32] than one-stage detectors. Object classification and bounding box regression will take place simultaneously in one-stage approaches. These are very important in building a secure system using image detection.
A new framework termed region proposal network (RPN) was proposed by Ren et al. [15] in 2017. They made a detector titled Faster R-CNN, which used RPN to find the bounding box. Object detection was regarded as a regression other than classification task in which you look only once (YOLO) by Redmon et al. [22], which splits the input image into multiple parts for predicting the object. Liu et al. [21] merged features from different layers to make an object prediction in a detector, called single shot detector (SSD). SSD has a better performance in comparison with YOLO. Pang et al. [25] exposed some imbalances during the phase of detection: sample imbalance and feature imbalance. Consequently, the IoU-balanced, feature pyramid and a new loss function termed L1 loss is proposed to moderate those imbalances in Libra R-CNN. Despite its attempts to improve themselves, two-stage detectors were still better than one-stage detectors till the advent of RetinaNet. Lin et al. [24] depicted that the severe imbalance between the foreground and background samples is the critical determinant to influencing the accuracy of one-stage detectors, and a newly-designed loss function termed focal loss was proposed to relieve such imbalance.
However, the one-stage approaches and two-stage approaches mentioned above have some weaknesses. The main limitation of the popular methods is the insensitivity to multi-scale objects. First, in most detection datasets, the scales of objects vary a wide range. What is worse, there are some extremely big or small objects. Such scale variation will make it difficult for detectors to take into account the different scales, hence weakening the accuracy of those detectors. All of the methods summarized above have to reshape the input image to a small size at the beginning of training, which inevitably misses some semantic information. Furthermore, more information will be lost in the following convolution process. Accordingly, traditional detectors have lousy performance for this multi-scale object detection. Second, there is a class imbalance problem in existing datasets. The amount of easily classified samples is much more than those hard to classify. Consequently, the detector is not robust enough.
Based on the above shortcoming of those networks, a new network entitled balanced Pre-ReLU ResNet (B-PesNet) is proposed in our work. As a significant idea, we propose a Pre-ReLU residual block that aims to prevent the degeneration of the deep networks, and then we could build a deeper network without losing semantic information and a new loss function for addressing the extremely class imbalance. The main contributions of our work are from two aspects:
(i) A new residual block within a Pre-ReLU is proposed, which is proven to mitigate the degradation problem of deep neural networks when the network becomes deeper. The reason for the degradation of deep neural networks is that too much semantic information is lost in the repeated convolution process. However, our Pre-ReLU retains shallow semantic information so that the deep neural unit can also use shallow information to calculate, thus solving the degradation problem. This brings a more reliable model for many secure systems.
(ii) Balanced Loss (BL) is suggested for solving class imbalance and helping produce a model more reliable than YOLOv2 [27], YOLOv3 [28], and YOLOv4 [26]. Compared with YOLOv5 [33], we found that the accuracy of B-PesNet is comparable, and the speed is slightly inferior. By introducing weight factor
The following content in this paper is summarized as follows. We concisely retrospect the research concerned with our work in Section 2. Then, particulars of our approach are given in Section 3, where we introduce our B-PesNet. In Section 4, we will state our datasets and evaluation metrics. Experimental results are listed in Section 5. Finally, Section 6 sums up our outcomes and offers some standpoints for future work.
With the widespread utilization of deep learning, object detection approaches have evolved from traditional algorithms based on manual design to automatic extraction of features based on deep learning. Modern object detectors can be approximately divided into one-stage [21–24,26–30] and two-stage algorithms [12 –20].
The one-stage method combines extraction and detection into a whole. One-stage approaches will not explicitly extract candidate regions but directly obtain the final detection result. Liu et al. [21] proposed Single Shot Multi-Box Detector (SSD), which utilizes fused features from different layers of the network. Redmon et al. [22] proposed You Only Look Once (YOLO). YOLO integrates the information of the entire image to predict the object at each position. It regards the entire image as input and predicts in the original image: the category and positioning-related information of each part in the area. Lin et al. [23] proposed feature pyramid networks (FPN). The main problem of this method is the insufficiency of object detection in dealing with multi-scale changes. This network architecture can increase the feature map with various semantic information, but rich spatial information is integrated under the premise of less calculation.
The working method of the two-stage detection method is to first generate a set of region proposals and then classify and regress these proposals. Compared with the one-stage method, the two-stage method is more accurate but less efficient. Firstly, 2000 region proposals were selected through selective search, and each region proposal will be input into CNN to extract features. And then, the classifier will utilize these features to classify. Subsequently, Girshick et al. [12] proposed an improved version of R-CNN, which is termed Fast R-CNN. For R-CNN, the disadvantage is that the efficiency begins to decline during preprocessing. For instance, use selective search to track potential bounding boxes as input. This search method will make the model spend much time on useless data. Fast R-CNN introduces a new layer of the network, named ROI Pooling, which cleverly puts regression into the network and fuses it with classification into a multi-task model. Ren et al. [15] proposed Faster R-CNN. On the basis of Fast R-CNN, they added a newly-designed structure termed region proposal network (RPN). Therefore, the model will utilize RPN to find candidate boxes, which further improves efficiency.
In this section, we firstly introduce the B-PesNet. Then BL is proposed to balance the class imbalance during the network training.
ResNet [34] solved the degradation problem of deep neural networks. However, after deepening the network without limitation, the network degradation problem still exists. It is considering that the residual structure tackles the problem of network degradation by the skip connection, which retains the shallow information. After a large number of experiments and rigorous mathematical verification, it has been found that if we put the ReLU [35] layer in front of the convolution layer, we can get a Pre-ReLU residual block, and improve its performance.
We introduce the Pre-ReLU residual block starting from the standard residual unit:
where xl is the input of the l th residual unit, and Wl means a set of weight factors associated with the l th residual unit. f denotes the ReLU, h means a skip connection:
Then, if f is a skip connection: xl+1 = yl, we can convert Eq. (2) into Eq. (1):
For the whole network, it becomes:
where xL means the input of any residual unit that is behind the l th unit. Then, we found that, for any unit, the information is able to be propagated from one unit to the others.
In order to build a gate, which is able to propagate information without loss from shallow to deep layer, we put a ReLU layer in front of the convolution layer. As we assumed, the Pre-ReLU residual block builds a clean pathway from shallower to a deeper layer. Then more features can be reserved during convoluting.
To decrease the number of parameters and enhance the running speed, we split the feature map into many groups.
First, we divide the feature map into an equal dimension at the dimension level and divide it into multiple groups with the same dimension. The workflow is shown in Fig. 1.
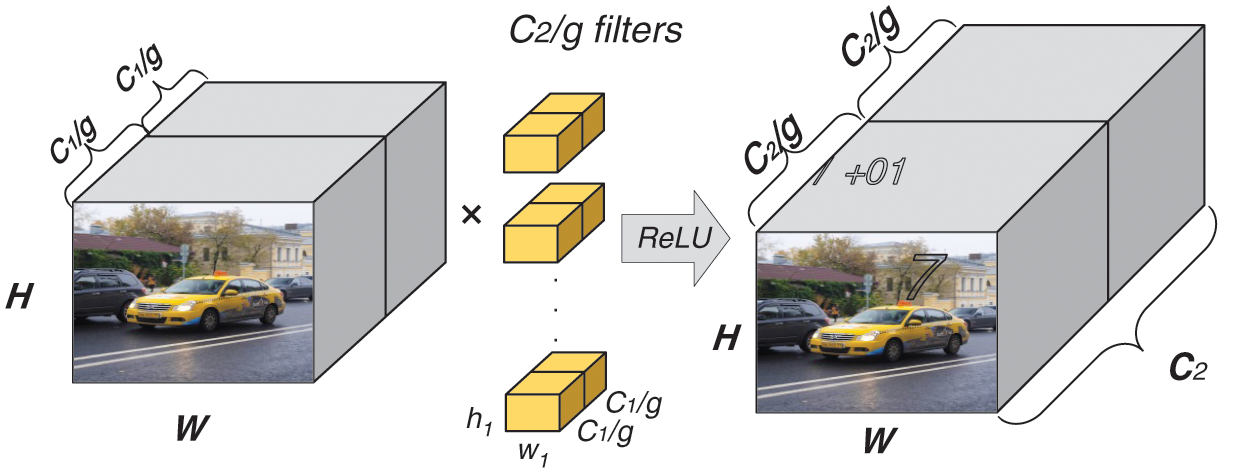
Figure 1: The workflow of dividing. H represents the height of the feature map, and W means the width of the feature map.
Assume the size of the input image is
Pre-ReLU residual block contains three convolutional layers. The architecture of the block is shown in Fig. 2, and the convolution kernel sizes are
The number of parameters required for this convolution operation decreases in inverse proportion to the number of groups.
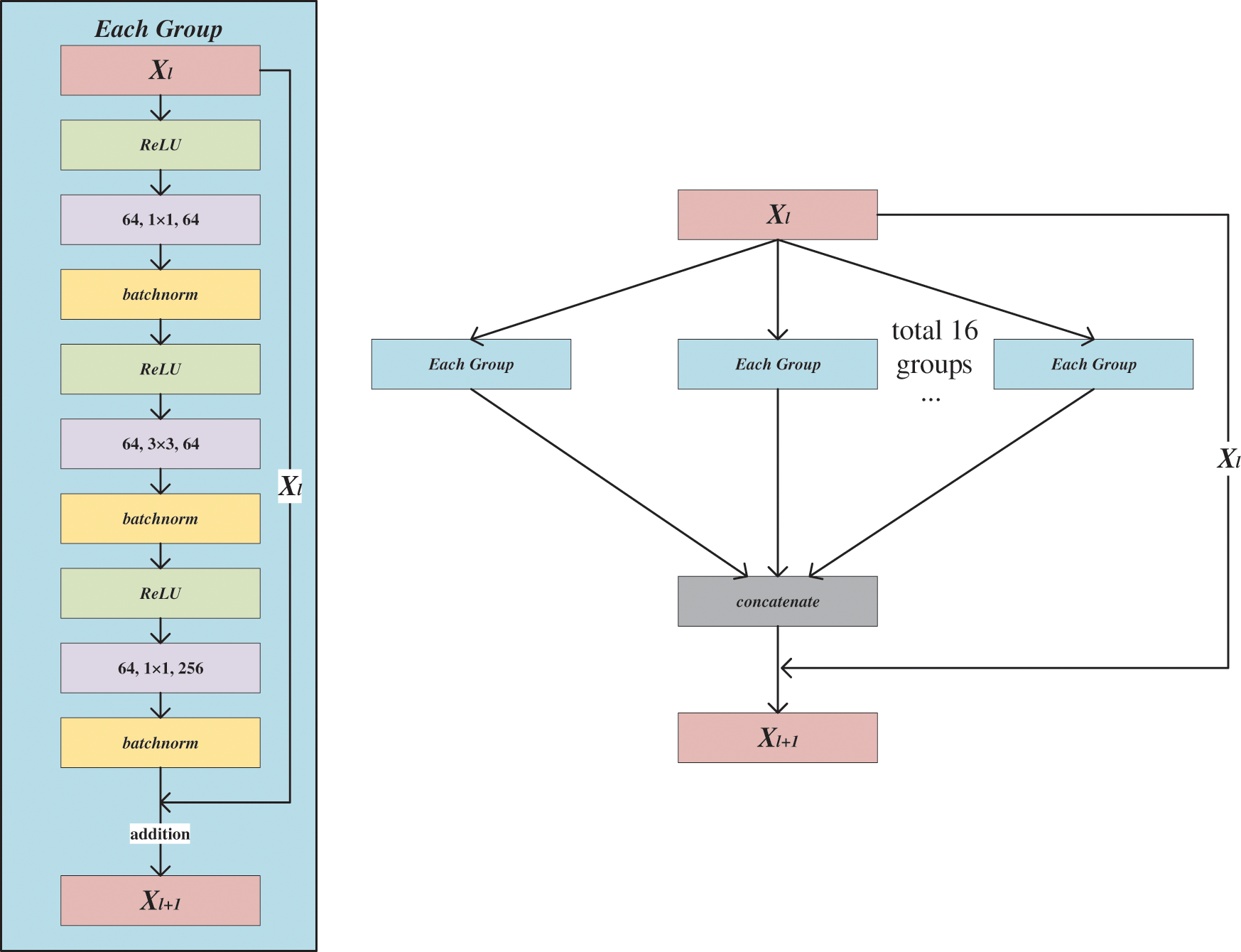
Figure 2: The architecture of the Pre-ReLU residual block

The output of the l th convolution layer is:
where xj is the i th output,
The output of the M th pooling layer is:
where the summation of the entire feature matrix is
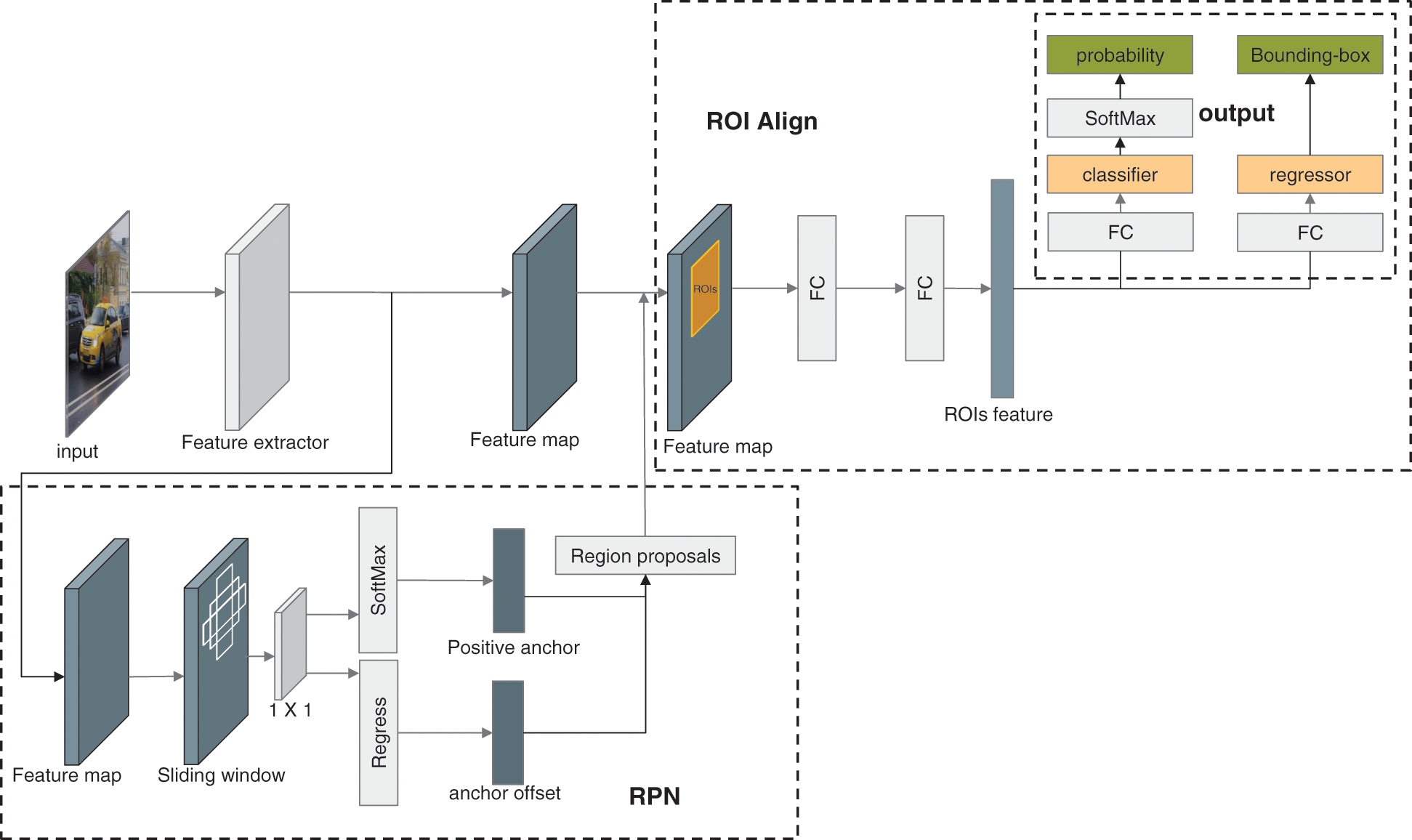
Figure 3: The architecture of B-PesNet
The input of the region proposal network (RPN) is a feature map, which is also used in the region of interest (ROI) Align layer. And the output of RPN is a set of rectangular regions named region proposals. We adopt the sliding window method to select a region titled anchor by sliding a window on the input feature map to obtain the region proposals. In each sliding window, multiple anchors are predicted simultaneously, and the maximum possible anchors of each pixel point are denoted by K . In this paper, K is set to 9 since there are 3 scales anchors, and each scale has 3 anchors with a different shape. Each anchor will be sent to SoftMax and classified it is positive or negative. At the same time, all anchors will perform a regress to get more actual coordinates. Then, the RPN will output the region proposals, which will be sent to the ROI Align layer. ROI Align reduces and normalizes those region proposals, extracts the ROIs feature vectors. And then, sends these vectors into the subsequent layer. The ROIs feature vector obtains the regression results and classification results through the Fully Connected and SoftMax layers.
The classifier and regressor in the output layer work are as follows:
Classifier: This layer will output the probability of objects in region proposals. The classifier will calculate the probability Pi of each element in the feature map i , which contains the object after thoroughly scanning the feature map.
Regressor: In this layer, the intersection of union (IoU) will be utilized to measure the accuracy of the bounding box (b-box). Then, the regressor will output the coordinates
where A and B are the area of two region proposals.
Suppose the coordinates of the center point in the region proposal is
Then the loss function of the regressor can be written as:
here the ROI feature vector is
3.4 Balance the Classes with an Improved Cross-Entropy Loss
The balanced loss (BL) is designed to handle the severe imbalance between foreground and background classes during the training phase, and the class imbalance overwhelms the cross-entropy (CE) loss. Quickly classified negatives cover the majority of the loss and dominate the gradient. Whereas, we propose to reshape the loss function to down-weight easy negatives, and then the network focuses on hard negatives during the training stage.
We introduce our BL starting from the standard CE loss:
here
then rewrite
A common method to address the imbalance of classes is to introduce a hyperparameter. In our method, we introduce a weight coefficient
Then both positive/negative examples will dominate the gradient while
and rewrite BL to
The loss is a simple but effective extension to the standard CE loss, as our follow-up experiments show.
4 Data Processing and Evaluation Metrics
The data set trained, validated, and tested in this paper is the public dataset PASCAL VOC2007. It is composed of 21 classes, 20 foregrounds, and 1 back-ground.
Objects in real life are often under various interferences and are not as simple as the samples in the data set. A model trained with a simple data set will be challenging to apply to complex and changeable real-world scenarios, i.e., generalization is not strong. In order to overcome such a problem, online data enhancement operations will be introduced before training. Whether it is the human eye or the shooting device, it is possible to observe the object from any angle in the real world. The object might present a vastly different appearance due to the perspective. Accordingly, we warp the picture without changing the relevant information of the label. Twist operation can improve the generalization of the model in this respect. Besides this, there may be various interferences in the actual scene, such as intense light, haze, stains, etc. Therefore, we artificially highlight and blur the image to enhance the generalization of the model in such scenarios.
We utilize some common evaluation criteria to evaluate our detector in this paper. We utilize IoU, Precision, and Recall to evaluate our detector, and find the average of these experiments through multiple experiments and evaluations, which are
and
In Eqs. (16) and (17), TP indicates the number of samples for which the prediction is a positive example, which is a positive example. FP expresses that the prediction is positive, which is the number of samples for negative cases. FN represents that the prediction is negative, which is the number of samples for positive cases. Accordingly, Precision expresses how many of the predicted positive samples are genuinely correct, and Recall means how many of the predicted samples are genuinely correct.
In Eq. (18) [7], C represents the number of categories included in the model, N means the number of thresholds used as a reference, and k indicates the currently used threshold. P means the precision rate, R expresses the recall rate, and AP indicates the area under the precision-recall curve. The higher AP represents a better classifier. The average value of APs is mAP , where APs mean the sum of different classes. The value of mAP is within
5 Experimental Results and Analysis
We adopt VOC2007 as the training set and perform data augmentation, which adds artificial noise to each image. Moreover, we scale all inputs into the size of
TM
5.2 Calculation Results Using Different Backbones
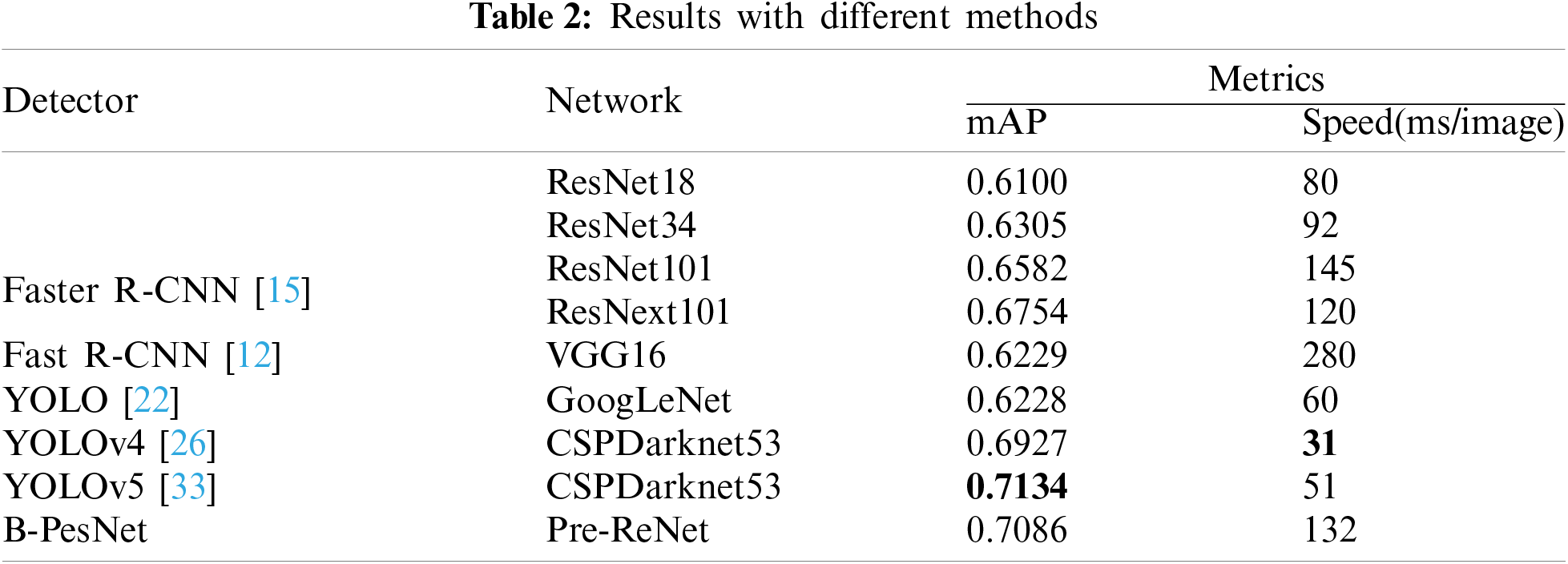
To test the impact of different backbones used in the detector, we have carried out experiments on different feature extractors to compare the difference of mAP. The mAP and calculating speed in the different condition is shown in Table 2. It is evident that the accuracy of our method is higher than the others except for YOLOv5. The accuracy of our proposed B-PesNet is inferior to YOLOv5 cause the network structure of YOLOv5 is more complex than B-PesNet. From this point of view, our B-PesNet is still valuable and meaningful. The B-PesNet obtain a balance between accuracy and speed.
5.3 Results by Different Detection and Recognition Approaches
To demonstrate the effect of the BL, we test some networks using BL or not. Table 3 shows the mAP for each condition. In this table, the value of
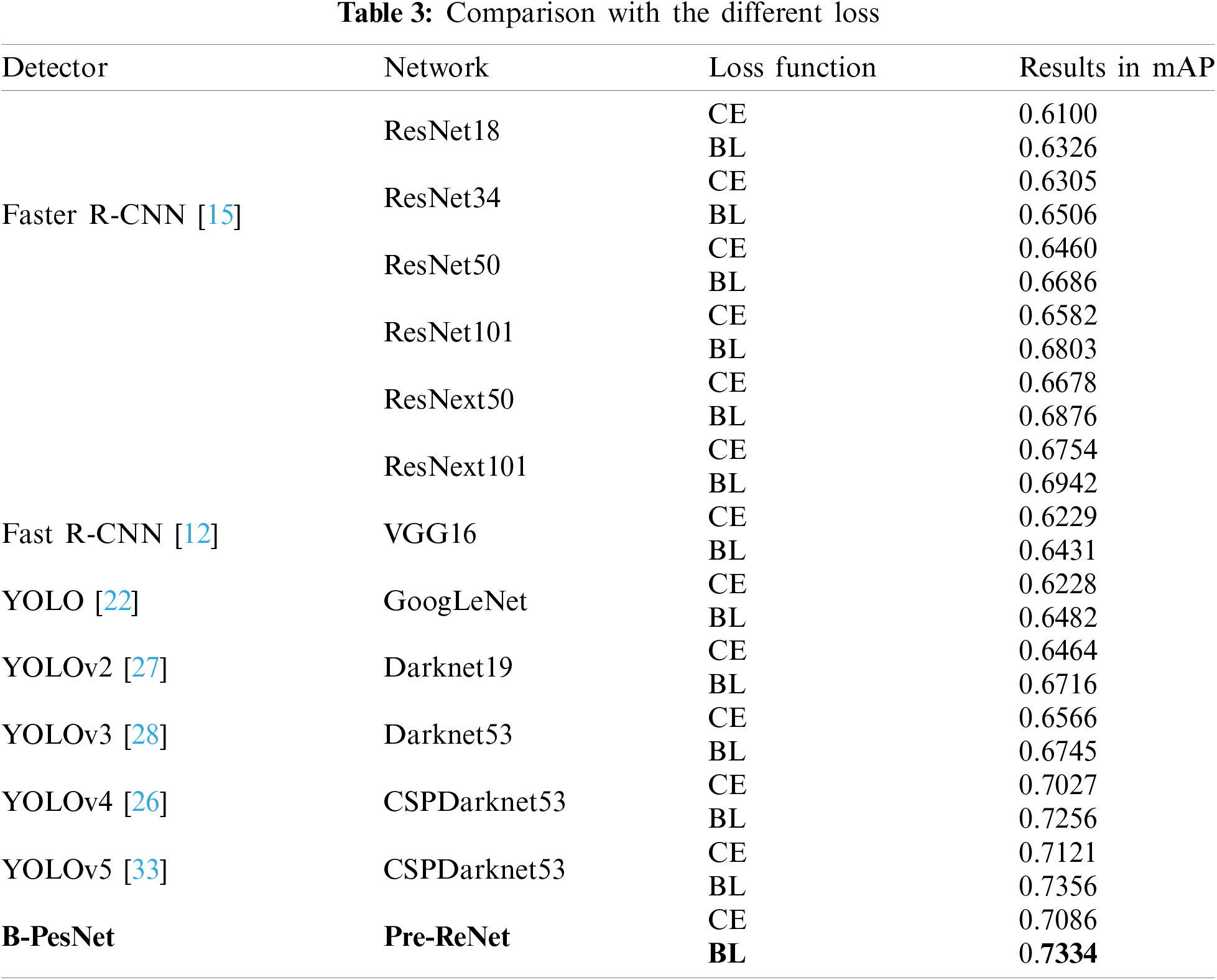
Figure 4: The loss curve of object classification. The blue one represents our B-PesNet with BL, and the orange one means our B-PesNet with CE. Obviously, the loss of B-PesNet with BL is lower and converges more quickly
5.4 Results by Using Different Hyper-Parameters
We chose 20 different values of
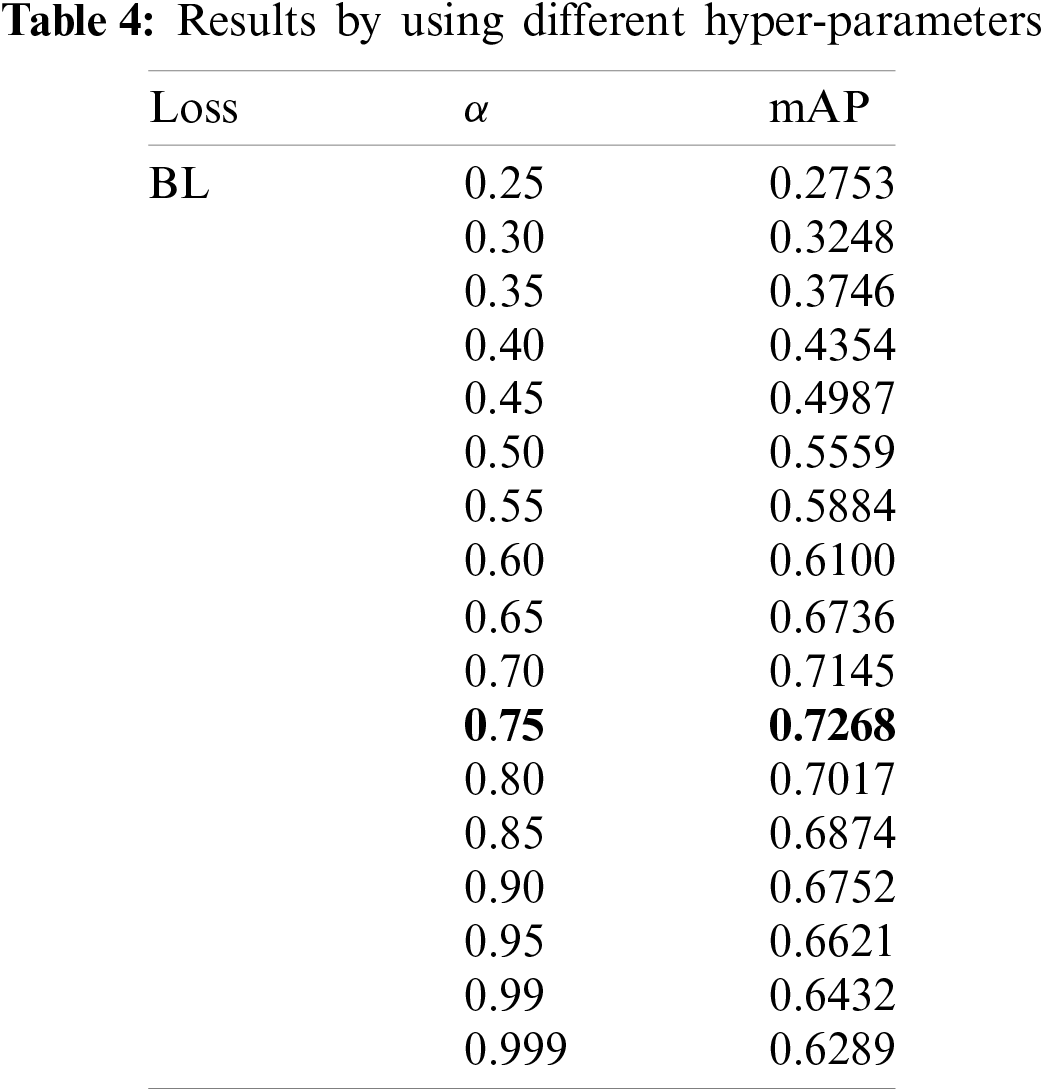

Figure 5: The detection results of B-PesNet. The detected target in the figure is marked by a green bounding box, and the mAP of the target is displayed on the upper part of the bounding box. The detection results of these actual scenes show that our B-PesNet has a good performance in a complex environment with interference factors such as occlusion and deformation
According to the results, we can infer that the semantic information is completely extracted, and the objects are accurately detected. From Table 3, it can be seen that our B-PesNet gets a balance between speed and accuracy. Table 3 shows that BL can tackle the class imbalance problem and improve the accuracy of the detector from the perspective of data. This shows that the research of deep learning can still start from data. As shown in Table 4, the parameters have a significant influence on BL performance. It is considering the definition of the formula,
We propose a method that improves the performance of the existing state-of-the-art two-stage object detection framework by enriching semantic information in shallow layers and introducing a new loss function, then demonstrate its effectiveness on the benchmark datasets. Our newly-designed network outperforms the previous neural network frameworks. The proposed B-PesNet shows above 1% mAP better than those typical object detectors. Compared with the existing approaches, the image processing speed of our method is also boosted. Greater efficiency imparts a higher practical value to the proposed method. This leads to a reliable solution for the applications of detection in security systems. In the future, we are interested in applying this detector to more specific scenarios, e.g., Internet of Things (IoT) applications in healthcare and health [36] and Blockchain-enabled IoMT [37].
Funding Statement: This research was supported by the Science and Technology Project of Sichuan (Nos. 2019YFG0504, 2021YFG0314, 2020YFG0459), and the National Natural Science Foundation of China (Grant Nos. 61872066 and U19A2078).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. Zeng, N., Wang, Z., Zhang, H., Liu, W., Alsaadi, F. E. (2016). Deep belief networks for quantitative analysis of a gold immunochromatographic strip. Cognitive Computation, 8(4), 684–692. DOI 10.1007/s12559-016-9404-x. [Google Scholar] [CrossRef]
2. Zeng, N., Zhang, H., Song, B., Liu, W., Li, Y. et al. (2018). Facial expression recognition via learning deep sparse autoencoders. Neurocomputing, 273, 643–649. DOI 10.1016/j.neucom.2017.08.043. [Google Scholar] [CrossRef]
3. Jiao, L., Zhang, F., Liu, F., Yang, S., Li, L. et al. (2019). A survey of deep learning-based object detection. IEEE Access, 7, 128837–128868. DOI 10.1109/Access.6287639. [Google Scholar] [CrossRef]
4. Wang, H., Gong, D., Li, Z., Liu, W. (2019). Decorrelated adversarial learning for age-invariant face recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3527–3536. Long Beach. [Google Scholar]
5. Huang, H., Feng, Y., Zhou, M., Qiang, B., Yan, J. et al. (2021). Receptive field fusion retinanet for object detection. Journal of Circuits, Systems and Computers, 30(10), 2150184. DOI 10.1142/S021812662150184X. [Google Scholar] [CrossRef]
6. Zheng, S., Wu, Z., Xu, Y., Wei, Z., Xu, W. et al. (2021). Pillar number plate detection and recognition in unconstrained scenarios. Journal of Circuits, Systems and Computers, 30(11), 2150201. DOI 10.1142/S0218126621502017. [Google Scholar] [CrossRef]
7. Wan, S., Goudos, S. (2020). Faster R-CNN for multi-class fruit detection using a robotic vision system. Computer Networks, 168, 107036. DOI 10.1016/j.comnet.2019.107036. [Google Scholar] [CrossRef]
8. Dalal, N., Triggs, B. (2005). Histograms of oriented gradients for human detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol. 1, pp. 886–893. San Diego. [Google Scholar]
9. Felzenszwalb, P., McAllester, D., Ramanan, D. (2008). A discriminatively trained, multiscale, deformable part model. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8. Anchorage. [Google Scholar]
10. Wu, X., Sahoo, D., Hoi, S. C. (2020). Recent advances in deep learning for object detection. Neurocomputing, 396, 39–64. DOI 10.1016/j.neucom.2020.01.085. [Google Scholar] [CrossRef]
11. Oksuz, K., Cam, B. C., Kalkan, S., Akbas, E. (2020). Imbalance problems in object detection: A review. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(10), 3388–3415. DOI 10.1109/TPAMI.2020.2981890. [Google Scholar] [CrossRef]
12. Girshick, R. (2015). Fast R-CNN. Proceedings of the IEEE International Conference on Computer Vision, pp. 1440–1448. Santiago. [Google Scholar]
13. He, K., Zhang, X., Ren, S., Sun, J. (2015). Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(9), 1904–1916. DOI 10.1109/TPAMI.2015.2389824. [Google Scholar] [CrossRef]
14. Cai, Z., Fan, Q., Feris, R. S., Vasconcelos, N. (2016). A unified multi-scale deep convolutional neural network for fast object detection. European Conference on Computer Vision, pp. 354–370. Amsterdam. [Google Scholar]
15. Ren, S., He, K., Girshick, R., Sun, J. (2017). Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6), 1137–1149. DOI 10.1109/TPAMI.2016.2577031. [Google Scholar] [CrossRef]
16. Cheng, B., Wei, Y., Shi, H., Feris, R., Xiong, J. et al. (2018). Revisiting RCNN: On awakening the classification power of faster RCNN. European Conference on Computer Vision, pp. 473–490. Munich. [Google Scholar]
17. Girshick, R., Donahue, J., Darrell, T., Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 580–587. Columbus. [Google Scholar]
18. Cao, J., Cholakkal, H., Anwer, R. M., Khan, F. S., Pang, Y. et al. (2020). D2det: Towards high quality object detection and instance segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 11485–11494. Seattle. [Google Scholar]
19. Lu, X., Li, B., Yue, Y., Li, Q., Yan, J. (2019). Grid R-CNN. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7363–7372. Long Beach. [Google Scholar]
20. He, Y., Zhu, C., Wang, J., Savvides, M., Zhang, X. (2019). Bounding box regression with uncertainty for accurate object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2888–2897. Long Beach. [Google Scholar]
21. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S. et al. (2016). Ssd: Single shot multibox detector. European Conference on Computer Vision, 21–37. Amsterdam. [Google Scholar]
22. Redmon, J., Divvala, S., Girshick, R., Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788. Las Vegas. [Google Scholar]
23. Lin, T. Y., Dollár, P., Girshick, R., He, K., Hariharan, B. et al. (2017). Feature pyramid networks for object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2117–2125. Honolulu. [Google Scholar]
24. Lin, T. Y., Goyal, P., Girshick, R., He, K., Dollár, P. (2017). Focal loss for dense object detection. Proceedings of the IEEE International Conference on Computer Vision, pp. 2980–2988. Venice. [Google Scholar]
25. Pang, J., Chen, K., Shi, J., Feng, H., Ouyang, W. et al. (2019). Libra R-CNN: Towards balanced learning for object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 821–830. Long Beach. [Google Scholar]
26. Bochkovskiy, A., Wang, C. Y., Liao, H. Y. M. (2020). YOLOV4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934. [Google Scholar]
27. Redmon, J., Farhadi, A. (2017). YOLO9000: Better, faster, stronger. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7263–7271. Honolulu. [Google Scholar]
28. Redmon, J., Farhadi, A. (2018). Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767. [Google Scholar]
29. Zhang, S., Wen, L., Bian, X., Lei, Z., Li, S. Z. (2018). Single-shot refinement neural network for object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4203–4212. Salt Lake City. [Google Scholar]
30. Pang, Y., Wang, T., Anwer, R. M., Khan, F. S., Shao, L. (2019). Efficient featurized image pyramid network for single shot detector. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7336–7344. Long Beach. [Google Scholar]
31. Everingham, M., van Gool, L., Williams, C. K., Winn, J., Zisserman, A. (2010). The pascal visual object classes (voc) challenge. International Journal of Computer Vision, 88(2), 303–338. DOI 10.1007/s11263-009-0275-4. [Google Scholar] [CrossRef]
32. Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P. et al. (2014). Microsoft coco: Common objects in context. European Conference on Computer Vision, pp. 740–755. Zurich. [Google Scholar]
33. Jocher, G., N. K. M. T. V. R. (2020). YOLOV5. https://github.com/ultralytics/yolov5. [Google Scholar]
34. He, K., Zhang, X., Ren, S., Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778. Las Vegas. [Google Scholar]
35. Nair, V., Hinton, E. G. (2010). Rectified linear units improve restricted boltzmann machines. International Conference on Machine Learning, pp. 807–814. Haifa. [Google Scholar]
36. Xiong, H., Hou, Y., Huang, X., Zhao, Y., Chen, C. M. (2021). Heterogeneous signcryption scheme from IBC to PKI with equality test for WBANS. IEEE Systems Journal, Early Access, (1), 1–10. DOI 10.1109/JSYST.4267003. [Google Scholar] [CrossRef]
37. Xiong, H., Jin, C., Alazab, M., Yeh, K. H., Wang, H. et al. (2021). On the design of blockchain-based ecdsa with fault-tolerant batch verication protocol for blockchain-enabled iomt. IEEE Journal of Biomedical and Health Informatics, Early Access(1), 1–9. DOI 10.1109/JBHI.2021.3112693. [Google Scholar] [CrossRef]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |