DOI:10.32604/cmc.2021.014429
| Computers, Materials & Continua DOI:10.32604/cmc.2021.014429 | |
| Article |
A Knowledge-Based Pilot Study on Assessing the Music Influence
1Faculty of Computer Science, University Alexandru Ioan Cuza, Iasi, 700706, Romania
2Faculty of Economics and Business Administration, University Alexandru Ioan Cuza, Iasi, 700706, Romania
*Corresponding Author: Octavian Dospinescu. Email: doctav@uaic.ro
Received: 20 September 2020; Accepted: 19 October 2020
Abstract: A knowledge-driven approach is proposed for assessing the music influence on university students. The proposed method of modeling and conducting the interactive pilot study can be useful to convey other surveys, interviews, and experiments created in various phases of the user interface (UI) design processes, as part of a general human-computer interaction (HCI) methodology. Benefiting from existing semantic Web and linked data standards, best practices, and tools, a microservice-oriented system is developed as a testbed platform able to generate playlists in a smart way according to users’ music preferences. This novel approach could bring also benefits for user interface adaptation by using semantic Web techniques. Statistical analysis based on the ANOVA method and post-experiment survey data led to the conclusion that music listened has a significant impact on students’ cognitive abilities in various contexts. All obtained results were semantically enhanced by using different conceptual models in order to create a knowledge graph providing support for automated reasoning. Also, a knowledge-based persona Web smart editor was implemented in order to include music preferences for certain categories of the potential users operating a specific interactive system.
Keywords: HCI; knowledge; conceptual model; methodology; music; pilot study
In order to properly envision a user interaction to a certain—conventional, Web, mobile—complex application, various software engineering approaches are used. The article proposes a knowledge-driven method in modeling HCI (Human–Computer Interaction) surveys, interviews and experiments—such as user research, usability evaluation, field study, controlled experiment, etc. These processes are performed in different phases: A-priori (discovery, alpha, beta) and/or a-posteriori (during the actual deployment) of a given interactive application. The paper also illustrates the pragmatic use of schema.org conceptualizations [1] in HCI context, especially for annotation of music digital artefacts (i.e., playlists) and for specifying useful metadata with respect to HCI engineering processes.
By using well-known semantic Web standards [2]—such as expressing data as triples denoted by Web addresses (RDF—Resource Description Framework), remotely querying these triples (via SPARQL standard language), conceiving knowledge models represented by meta-data vocabularies, taxonomies, thesauri, ontologies (OWL—Web Ontology Language), performing automated reasoning with help from specific logics, our aim is to describe a methodology able to specify, annotate and publish all useful assets and datasets associated to a given HCI experiment: research questions, contextual research (problem domain), participants, performed tasks, results, and others. This method is inspired by Negru et al. [3] which describe a knowledge-based system able of making decisions towards personalizing UIs based on user needs and preferences. A larger context has as foundation the concept-driven interaction design research [4].
As a real example, a pilot study was conducted to analyze the influence of listening to music on the efficiency of cognitive processes of students from technical specializations—in this case, Computer Science. Given that many students nowadays are used to listening to music while performing cognitive activities (learning, acquiring knowledge, solving tests and questions, interpreting texts and visual information) in the academic context, the present study is based on an experiment that highlights how these cognitive capacities are enhanced by simultaneous listening to music. Several kinds of studies related to this issue have been conducted in the literature, but our aim is to assess—with the help of the present-day semantic Web initiatives—how students’ cognitive abilities are affected in two distinct situations: Listening to their favorite music genre and listening to a totally unpleasant music genre.
The obtained results were integrated into a persona Web editor able to create and manage classes of potential users of an interactive system in the phases of design practice and/or design exploration. This tool also makes use of current semantic Web standards in order to manage and suggest personas to be used in designing user interfaces.
The paper is structured as follows. Next section discusses several related approaches concerning the use of knowledge in the HCI areas, plus investigating how music has influence on users in various contexts.
The following section details the proposed methodology used for performing experiments—in order to study how students’ cognitive abilities are affected by the preferred/unwanted background music. This section outlines our most significant contributions:
• The conceptualization of preliminary data gathered in the pre-experiment survey in order to group the involved participants according to their music genre preferences and demographics.
• Generating playlists, in an intelligent and novel manner, by using our microservice-oriented Web system adopting the functional (FaaS—Functions As A Service) serverless paradigm [4,5]; this prototype, deployed on a popular cloud computing platform, was developed to manage knowledge about user preferences of music genres. This approach could bring also benefits for user interface adaptation by using semantic Web techniques.
• Performing the statistical analysis of the data gathered from the conducted experiment and from the post-experiment survey, in order to offer insights and discuss the expected outcome.
The article continues with a presentation of an interactive Web application conceived to create personas in a smart way, including suggestions regarding the music preferences for each category of potential users. The purposes regarding the tool design and development are focused on two main directions: (1) Creating and managing knowledge about personas—modelling, editing, validation, annotation; and (2) Learning and understanding persona design methods—exploration, search, filtering, explanation. The tool has mainly an educational purpose and is currently used to specify personas for various HCI projects by post-graduate students enrolled in our “Human–Computer Interaction” discipline (MSc studies), stimulating design research activities and digital creativity. A case study on rule-based recommendations for performing certain tasks (in our experiment, suggesting to meet a person having a similar music taste) is also included.
Last section presents the conclusions and various future directions of research.
2.1 Using Semantic Web Technologies in the HCI Context
There are relatively few proposals of using current semantic Web technologies for designing interactive systems or representing certain aspects of interest: UI components, interaction methods, personas, tasks, user behavior (e.g., gestures, emotions), context of use, processes (quality evaluation, user testing, usability experiments), and others [1,6,7].
We considered also various papers describing certain knowledge models able to express, among others:
User-centered design process—an approach for designing usable products and systems, which encompasses a collection of techniques, procedures, and methods focused on the user. The proposal considers the use of HTML5 microdata (i.e., the schema.org model) and an ontological specification to denoted such processes [3].
Persona—a pragmatic solution to express the main categories of potential users for a given interactive application (demographic profile, preferences, needs and goals, frustrations and requirements) [8]. Several public conceptualizations are available such as an ontology (PersonaOnto) and a HTML5 template capturing data about a certain proposed persona [4].
Human needs—a family of ontologies for representing human needs is proposed in order to represent, enrich and query the results of a needs assessment study in a local citizen community [5].
Body movements—especially, gestures, and postures—performed by users in the context of interacting to certain devices (for example, Kinect) [6].
User emotions and affective states—a number of 20 ontologies are compared in order to assess the expressivity of denoting user behaviors driven by emotions, moods, and sentiments [9].
Concerning user interface adaptation, a high-level architectural proposal is discussed in Partarakis et al. [10] with respect to how semantic Web initiatives could be used to provide support for designing adaptable Web-based interfaces.
Regarding learning environments, a knowledge/rule-based e-learning ecosystem is described by Ouf et al. [7]. Unfortunately, the user preferences and motivations are not considered.
Several other research solutions concerning the adoption of semantic models to be used in various HCI systems and contexts are described in Hussein et al. [11].
None of these studies reflects the music influence on involved users.
2.2 Music and Cognitive Activities
A variety of studies have been conducted in the literature, with respect to the relation between music and cognitive activities [12–14], including the effects of background music on human subjects from various fields like education [15–17], or concerning different cognitive tasks [18–20].
We also reviewed the existing literature regarding the effects of background music on human subjects from various areas.
In the educational field, an interesting result was obtained by Taylor et al. [16] who researched the effect of Mozart’s music on the performance of students having to solve trigonometry problems. The students who took the tests while listening to Mozart’s music achieved significantly better results than those who took the test without background music. Concerning the “bullying” phenomenon, background music has a significant effect—under certain conditions, bullying may increase even with music played at a low volume [17].
An interesting study [15] analyzed how listening to music during learning activities helps reduce stress and anxiety for students. The results obtained from scientific research have shown that listening to music during learning activities does not contribute to lowering anxiety levels. Moreover, the authors suggest that listening to music during learning could actually be a disturbing factor.
Another research focused on the effects of background music on cognitive tasks in four different environmental conditions: noise, silence, music with lyrics, music without lyrics. The study was unable to show notable results in terms of music influence for the proposed tasks [21].
In terms of task performances, a concern is whether background music affects human work concentration (subjects having background music versus no ambient music) [22]. The results showed that changes in performance depend less on the type of music and rather on preferences of workers to listen or not to music. The effects of music listened to in offices were investigated by performing empirical studies to highlight musical habits, the effects of music on work appreciation, and the impression of employees on their own activities. Based on a variety of music styles, the study concludes that there are no significant influences on performance-related tasks [18]. Also, music can have both positive and negative effects on different employees in different situations. According to the study, office music can be considered as having the role of blurring the boundaries between private space and public space and also it has the role of bringing personal habits into the official work space to improve personal comfort in public spaces [23].
The effects of background music have been examined by Sengupta et al. [19] to investigate how the users’ performance regarding text editing tasks changes. The results showed that the presence of background music caused an increase in the rate of typing errors, but at the same time there was a significant relaxation process for users, which caused a 23% lower force in keyboard operation.
Music can also have effects on behavior when analyzing human interaction over the phone. In a call center, customers are less aggressive in days when background music is instrumental and become more aggressive when background music contains lyrics [21].
Unfortunately, all mentioned studies and experimental endeavors do not benefit from a conceptual (formal) model defined with the help of current semantic Web standards. Our proposed knowledge-based approach could be a proper solution to rigorously specify the main aspects with respect to various HCI experiments.
3.1 A Knowledge-Based Experiment of Assessing the Role of Music in Performing Specific Tasks
Our approach is to assess how students’ cognitive abilities are affected by background music in two distinct situations: listening to their favorite music and listening to a totally unpleasant style of music. We choose to adopt a method of investigation based on knowledge modelling techniques specific to actual semantic Web directions of research.
By following the methodological proposals presented in Jawaheer et al. [24,25], the main steps of the conducted non-invasive study are: (1) Selecting a random sample of voluntary participants. (2) Performing a pre-experiment to obtain useful demographics, plus favorite/undesirable music styles. (3) Grouping respondents according to the classification criteria: preferred music style versus unwanted music style. (4) Performing the experiment, by giving two tests conducted when the participants had their favorite music in the background, and the other set of tests was administered with undesirable background music. (5) Analyzing and discussing the results.
3.2 Conducting the Pre-Experiment
The study was conducted on a random sample of 40 university students—22 female students and 18 male students, aged between 21 and 25, enrolled in the final year of undergraduate studies on Computer Science at the Faculty of Economy and Business Administration. All respondents signed a consensus statement agreeing to participate in this experiment and agreeing to have their data taken and analyzed by the authors of the study, including filming.
Each student was given a pre-experiment on-line survey to obtain useful demographics (gender, age, rural/urban origin) and favorite/undesirable music styles, including preferred songs and/or artists, in order to create suitable playlists and to avoid the cold start of recommended items of interest (in this case, musical compositions).
There are various proposals regarding how user preferences could be formally modelled in order to be properly used in the context of recommender systems.
The preliminary data can be formalized as tuples Ds, s ∈ S, where D is the set of gathered preferences and demographics for a given participant, and S represents the set of subjects (all participants in the experiment; in this case, students).
Each Ds has the following structure: <pgs(m), pcs, g, a, o>, where pgs : M → R denotes the preference of the subject (student) s for a music genre m—an element of the taxonomy of all considered music genres (m ∈ M). R signifies the set of expected ratings—for example, using a scale from 1 (“I totally dislike”) to 10 (“I totally like”) or other (symbolic) conventions. The pcs construct represents the list of preferred music compositions (usually, songs) or artists (musicians such as singers, pop stars, rock bands, coral ensembles, symphonic orchestras, etc.) stated by the subject s, and has a similar definition to pgs.
The last three items—g, a, and o—indicate demographic information: gender, age, and origin, respectively.
Using the description logics formalism [26], a preference could be considered as a functional property having as a domain the set M and as a range R, where M is a (sub)class from a conceptual model (i.e., a taxonomy or an ontology) related to music genres and other things of—for instance, MusicMoz1 (see below) or Music Ontology2, and R denotes the class Rating defined by the schema.org specification. A similar approach is used to specify user demographics.
As we shall describe below, these models are useful to easily group the subjects according to the most (un)liked music genres.
3.2.2 A RDF-Based Conceptualization of User Music Preferences
Gathered data from this survey are semantically annotated with schema.org semantic constructs [27] and modelled as RDF3 triples: < subject, predicate, object >, typically denoted by Web addresses—URIs (Uniform Resource Identifiers) or IRIs (Internationalized Resource Identifiers).
The following example, adopting the standardized Turtle4 format of the RDF abstract model, asserts that a given subject (subject33) is a female person who loves pop and dislikes jazz music genres. Also, she has as a preferred song a techno piece by Moby (Richard Melville Hall). Techno genre represents a subclass of the electronic dance music. In order to make further assumptions and automated reasoning, each concept is uniquely denoted by Wikidata’s URLs. The “ex” prefix denotes our own vocabulary regarding the knowledge about the conducted experiments and schema corresponds to the schema.org conceptual model.

We also asked participants to state their preferences and opinions on several topics such as:
Listening to music by using various types of speakers: standalone speakers, laptop speakers, or headphones. Unsurprisingly, the majority of subjects prefer to use headphones. We also learn that only 27% of subjects choose to listen to music at a high volume.
Listening to music in the academic context (for example, when studying lecture notes or working on homework)—results: 15.4% never, 65.4% sometimes, 19.2% often.
Opinion on personal efficiency with respect to listened music (i.e., if music makes work more efficient) on a scale of 0 to 10, where 0 denotes “I don’t know” or “I don’t want to respond to this question”. In our case, the arithmetic mean value was 5.92, the median value was 7, and the mode (most frequent value in the dataset) was 8.
Preferring foreign or national music: 53.8% foreign, 42.3% any, and only 3.9% countrywide music. This denotes a higher grade of musical cosmopolitanism among younger generation.
With respect to urban/rural origin, 54% of subjects are from urban areas and 36% from rural regions.
3.3 Conducting the Pilot Study
3.3.1 Distributing Subjects According to Music Preferences
Respondents were divided into three distinct groups (see Tab. 1) according to the classification criterion: the preferred music style versus the unwanted music style. To distribute respondents according to musical genres, an adaptation of the taxonomy provided by MusicMoz was made, inspired by Ferwerda et al. [25].
Table 1: Groups of respondents according to their music style preferences

Thus, the groups of musical genres that were considered are: blues, classical (including opera, ballet, etc.), dance (including electronica, techno), easy listening (including new age, movie music, ambient), folk, hip-hop/rap, jazz, pop (including europop, synthpop), country, soul & R’n’B (including funk and disco), rock (alternative, classic rock, progressive, post-rock, etc.), world (ethnic).
By following [28], we analyze the pre-experiment gathered data and found that female subjects prefer classical music and male participants like rock. Pop is also preferred by women, and is correlated to dance, but not to rock. Usually, classical music is correlated to the easy listening genre. Rock music—somehow strange—is not correlated to blues (both genres share a common root), but is correlated to preferences for hip-hop/rap music. Subjects from urban areas have hip-hop/rap, pop, and classical as most liked music genres, and dislike folk, world, and soul & R’n’B. Respondents having a rural origin prefer dance, easy listening, and pop music, but manifest aversion to rock, soul & R’n’B, and hip-hop/rap genres.
3.3.2 Recommending Music Playlists
A knowledge-based Web system was designed as a serverless platform5 and developed by using microservices in order to recommend suitable playlists with favorite/unpleasant music genres. The general software architecture is presented in Fig. 1. Having multiple benefits—such as maintainability, scalability, complexity reduction and others [28,29], the microservice architectural pattern [29] was considered the best solution to accomplish our goals. All microservices, aligned to the serverless functional paradigm (FaaS) [30], were deployed on the AWS Lambda cloud platform6.
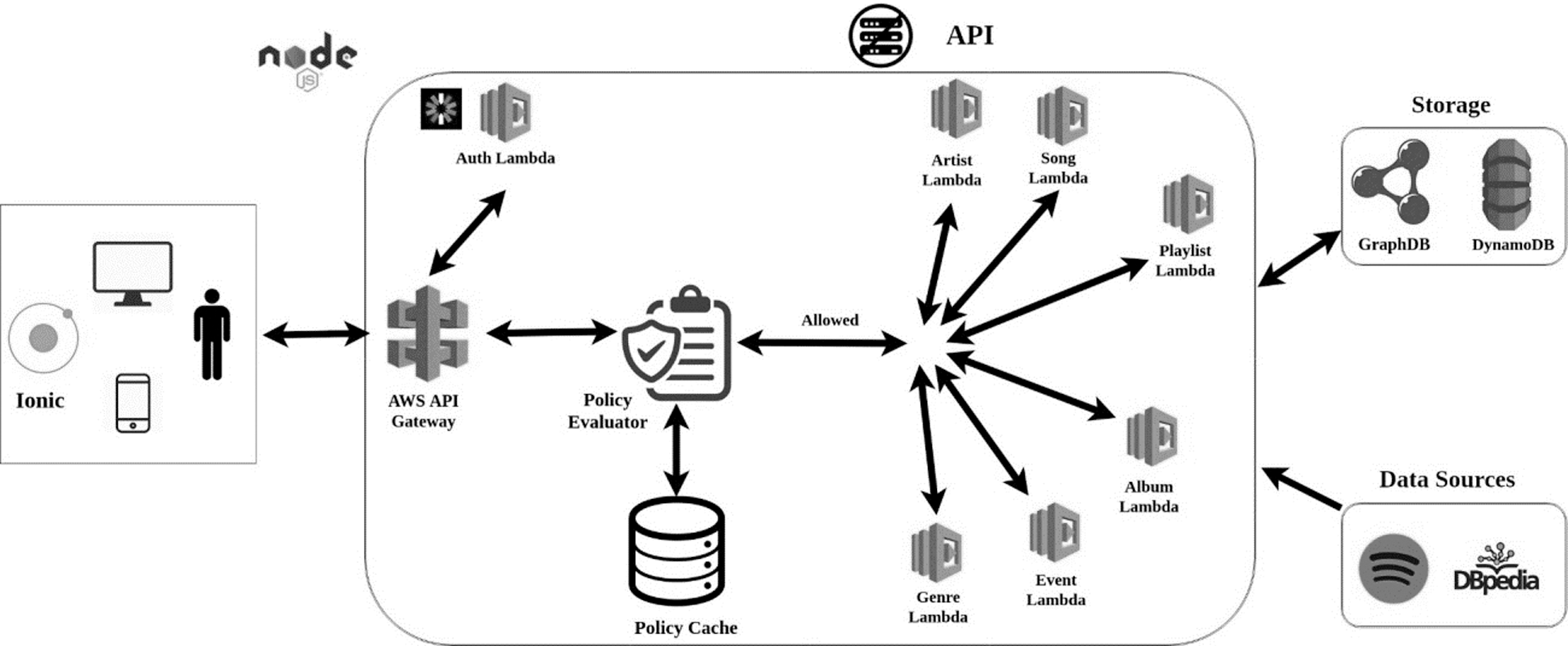
Figure 1: Overall architecture of the knowledge-based playlist recommendation system
To recommend tracks (songs) of interest to be included in a playlist, several aspects were taken into account: (1) Music genre, including related (sub)genres—those preferred by users and/or automatically discovered by software (see discussion below). (2) Avoiding repetitions (e.g., already chosen tracks) and monotony—for this, various constraints were formulated: selecting only less that 5-minute long tracks, using similar artists to preferred ones, generating playlists no longer than a given duration (i.e., the duration of the experiment itself), etc. (3) Popularity—choosing actual popular songs from each considered genre.
The Wikipedia’s machine processable knowledge provided by DBpedia [31] and Wikidata [32] was used to find and recommend resources of interest, including music entities (e.g., musicians and compositions) and relationships between these entities. This solution could be considered as an alternative to well-known methods from the music information retrieval field [33].
Additionally, an internal ontology, based on concepts from DBpedia and schema.org, was envisioned to properly model knowledge about music genres and playlists. An excerpt of this ontological model is displayed in Fig. 2, where the “dbo” prefix specifies the DBpedia ontology and “dbc” denotes a concept defined via SKOS (Simple Knowledge Organizational System)7, a standard for defining thesauri for machine processing.
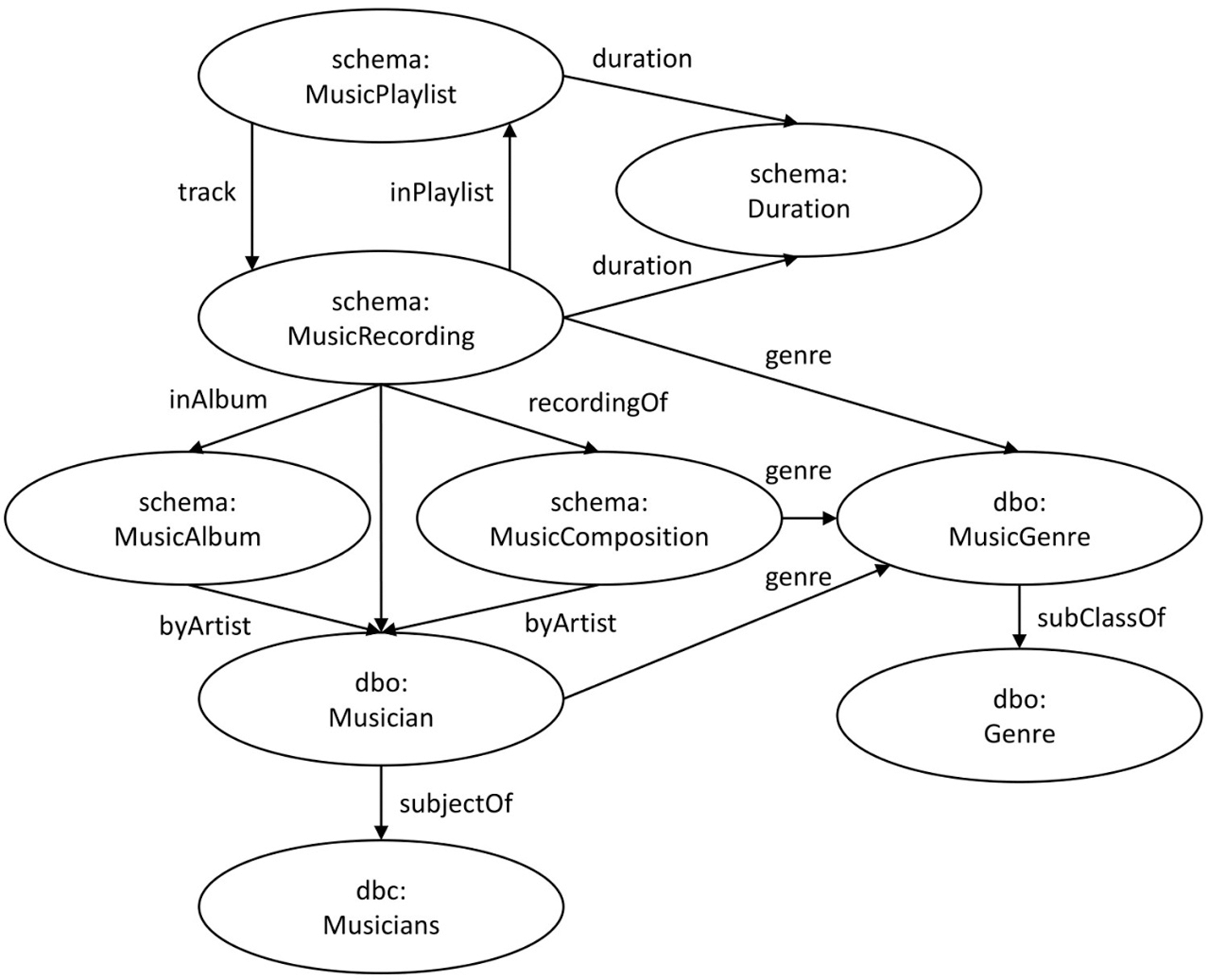
Figure 2: Main concepts involved in recommending a suitable playlist
Key classes defined to suit our aims are described below.
MusicPlaylist includes instances (tracks) from the MusicRecording class. MusicRecording is a subclass of CreativeWork and can have specified, among other things, a certain music genre defined by the MusicGenre class. MusicComposition is connected to MusicRecording via recordingOf property and can have links to one or more instances of the Musician class. Musician denotes the musically talented persons having skills like performing, conducting, singing, composing, and others. A musician can be associated to one or more musical genres—i.e., instances of MusicGenre class. MusicGenre class could be aligned to any conceptual model concerning music-related knowledge, such as MusicMoz taxonomy or Music Ontology.
Each entity is internally stored in a knowledge base—in this case, a semantic graph database management system: Ontotext GraphDB8.
The implemented Web application can also suggest entities (artists, events of interest, songs) and can offer playlist recommendations expressed in RDF and based on various criteria (search keywords, already added songs in the personal playlists, historical data). Generated playlists can be accessed via a SPARQL endpoint (service) that will provide a way of accessing data from the RDF data management system.
For example, by using the musicSubgenre relation, our application generates specific queries to obtain from DBpedia the sub-genres of a music genre (following the provided conceptualization, surf music and post-punk are related to rock music). Additional relations defined by the DBpedia ontology—such as stylisticOrigin, musicFusionGenre, and derivative—are also utilized to provide simple yet straightforward recommendations.
In order to play the recommended music and to discover the current popular songs/artists for each music style, a streaming popular service was used—in this case, Spotify accessed via the provided API (Application Programming Interface)9. Being based on microservices, our software platform is flexible enough to accommodate other streaming solutions.
For reusing purposes, the playlists can also be imported/exported by using XSPF (XML Shareable Playlist Format) or JSPF (JSON Shareable Playlist Format)10.
The experiment itself had no invasive character and the participants were told from the beginning that they can quit the experiment anytime they feel uncomfortable. All respondents went through the experiment until the end. The participants were given 2 sets of 20-question tests, and the time set for each set of tests was 20 minutes. The tests were different, but with the same degree of difficulty. The tests were administered using the BlackBoard Learn e-learning platform—an already familiar e-learning system among the students, according to [34].
Three types of questions were used: (1) Technical questions (from the current IT curricula of the target respondents). (2) Logical questions—similar to the standardized tests designed to assess human intelligence. (3) Questions of cognitive interpretation of an unfamiliar text containing new information—for example, medium-level descriptive articles about physics, biology, medicine, and others.
For each group of participants indicated in Tab. 1, the background music—preferred versus unwanted genre—was the same and was generated based on the generated playlists (a process described above). The music was broadcast via external speakers and the sound level varied between 30 and 35 decibels, the level being considered safe according to international regulations, specialized scientific studies [35], and from the perspective of national regulations imposed by the Ministry of Health.
Students had their own workstation each and did not visually interact with other colleagues, having their own individual work space in the experiment—a snapshot taken during the experiment is presented in Fig. 3. At the end of the experiment, subjects were symbolically rewarded.

Figure 3: Several participants to the experiment
To properly process the knowledge about the HCI experiment, an RDF dataset was generated by using additional conceptual models—mainly, a set of concepts provided by schema.org (such as Question, Answer, PeopleAudience). The dataset itself was annotated by using various properties related to Dataset concept. Multiple datasets regarding our experiments could be organized into a data collection expressed by DataCatalog constructs. An alternative solution is to adopt the Evaluation and Report Language (EARL) format11.
In addition, our own Usability Testing extensions [3] to schema.org model were adopted.
For instance, the following facts are denoted: The experiment has Group1 (a group of persons) as audience target (an instance of Audience class specified by schema.org ontology) for assessing behavior during performing an action—e.g., denoted by ListenAction concept. For this particular case, the participants are listening to tracks belonging to classical and easy listening music while performing various tasks (instances of ControlAction class defined by schema.org).
One of the tracks included into the generated playlist specifies a variety of (meta-)data about the played melody. For example, the track is a well-known aria from Adriana Lecouvreur, an opera by Francesco Cilea, performed by Angela Gheorghiu. Following the LOD (Linked Open Data) principles [36], for each item of interest several external Web addresses pointing to other public datasets are provided in order to expand the knowledge about a given resource. Using this method, further processing can discover, in a smart manner, that Angela Gheorghiu is a Romanian opera soprano and appears on various professional organizations’ Websites such as Carnegie Hall12 and Discogs13. Using these Web identifiers, a software agent can automatically learn about biography, released albums and public appearances of a particular artist.
A task from the designed HCI experiment represents an instance of ControlAction class and should be rescheduled since it is failed. Estimated time to perform this task is 20 minutes—expressed in a machine-friendly standardized format.
From our point of view, this annotated data/knowledge is very useful to be further processed in order to prepare similar experiments or to schedule or propose assessment tests regarding the behavior of users involved in specific interactive tasks.
Following the experiment, the number of correct answers provided by the respondents was counted in both cases: favorite versus unwanted music. Considering that the same 40 students participated in the experiment in two different situations from the point of view of the listened music, we can say that the series of analyzed data are dichotomous. The number of questions each student answered correctly in the two tests is statistically frequent within the set of the analyzed data.
4 Results, Analysis and Statistical Processing
From these perspectives of considered hypotheses, we were interested in finding descriptive statistics values at the following levels (globally, male gender, female gender):
Globally—the data obtained from all respondents for all questions.
H0: For the group of all respondents, the average of correct answers is equal for both playlists of background music (preferred versus undesirable genres). H1: For the group of all respondents, the average of correct answers differs significantly for the considered music genres.
The descriptive statistical values were calculated using the ANOVA method (see Tab. 2). In the case of subjects listening to unpleasant music, the average of correct answers was 9.1—variance: 5.12. The other case provided an average of 14.1 correct answers—variance: 9.63.

At the male gender level—i.e., data obtained from male respondents for all questions.
H0: For the male respondents’ group, the average of correct answers is equal for the two playlists of music. H1: For the male respondents’ group, the average of correct answers differs significantly for each of the two playlists.
In this particular situation, the results are: For the 18 male subjects listening to unpleasant music, the average of correct answers was 8.89—variance: 3.87. In the case of favorite music, the average of correct answers was 14.22, with a variance of 8.89. These findings are presented in Tab. 3.
Table 3: ANOVA—male respondents

At the female gender level—data obtained from female respondents for all questions.
H0: For the female respondents’ group, the average of the correct answers is equal for all music listened to. H1: For the female respondents’ group, the average of the correct answers differs significantly for the two musical backgrounds.
The obtained results are presented in Tab. 4. For the 22 female subjects listening to undesirable music, the average of correct answers was 9.27—variance: 6.30. Regarding the opinion on pleasant music, the average of correct answers was 14, with a variance of 10.67.
Table 4: ANOVA—female respondents

By analyzing the above data, it is observed that all three values of the p-value are less than α = 0.01. Therefore, based on the ANOVA tests, we can conclude that all H0 hypotheses are rejected for a 99% significance threshold.
Additionally, to verify the results obtained by the ANOVA type test, the chi-squared and t-test were performed, choosing α = 0.01. The obtained results are presented in Tab. 5.
Table 5: Chi-squared and t-test results

We notice that the p-value < α condition is met for each of the three groups. Corroborated with the ANOVA test results, this condition allows us to reject the null hypothesis, paving the way for the alternative hypothesis.
The statistical interpretation of the experiment shows that the 40 students had better results when they perceive their favorite music in the background, compared to the situation when the unpleasant music was played in the background. Therefore, the music listened to has a significant influence on students’ cognitive abilities.
4.2 Analyzing the Post-Experiment Survey Data
Additionally, after the experiment was concluded, all participants were asked to frankly give responses to several questions regarding the following aspects:
The difficulty of performed tasks, using a scale from 1 (not at all difficult) to 10 (very difficult)—for unwanted music, the average value was 3.65 (median = 4) versus preferred music, where the average was 3.2 (median = 3.5); in conclusion, from the participants’ subjective point of view, the tasks were perceived as being much more difficult if the background music was annoying.
How music influenced the test on a scale from 0 (none) to 10 (maximum impact)—in the case of undesirable music, average = 5.5 (median = 5) and for enjoyable music, average = 6.85 (median = 7); therefore, participants considered that the pleasant music had a greater influence.
The emotion/mood/sentiment experienced during the test—subjects had the opportunity to freely express their feelings regarding the experiment; using the Tone Analyzer service provided by IBM Watson Developer Cloud services, we processed all terms (translated into English) denoting a positive/negative sentiment—for example, “relaxed”, “happiness”, “peace” versus “nervous”, “pressure”, “irritation”, “stress”. We found only 45% occurrences of positive terms in the case of listening to undesirable music, in contrast to 75% occurrences when participants listened to a playlist delivering pleasant music. Therefore, these user-oriented findings also confirm the statistical analysis detailed in previous section.
If the perceived grade of effectiveness depended on the music listened to during the experiment—for results, see the chart depicted in Fig. 4.
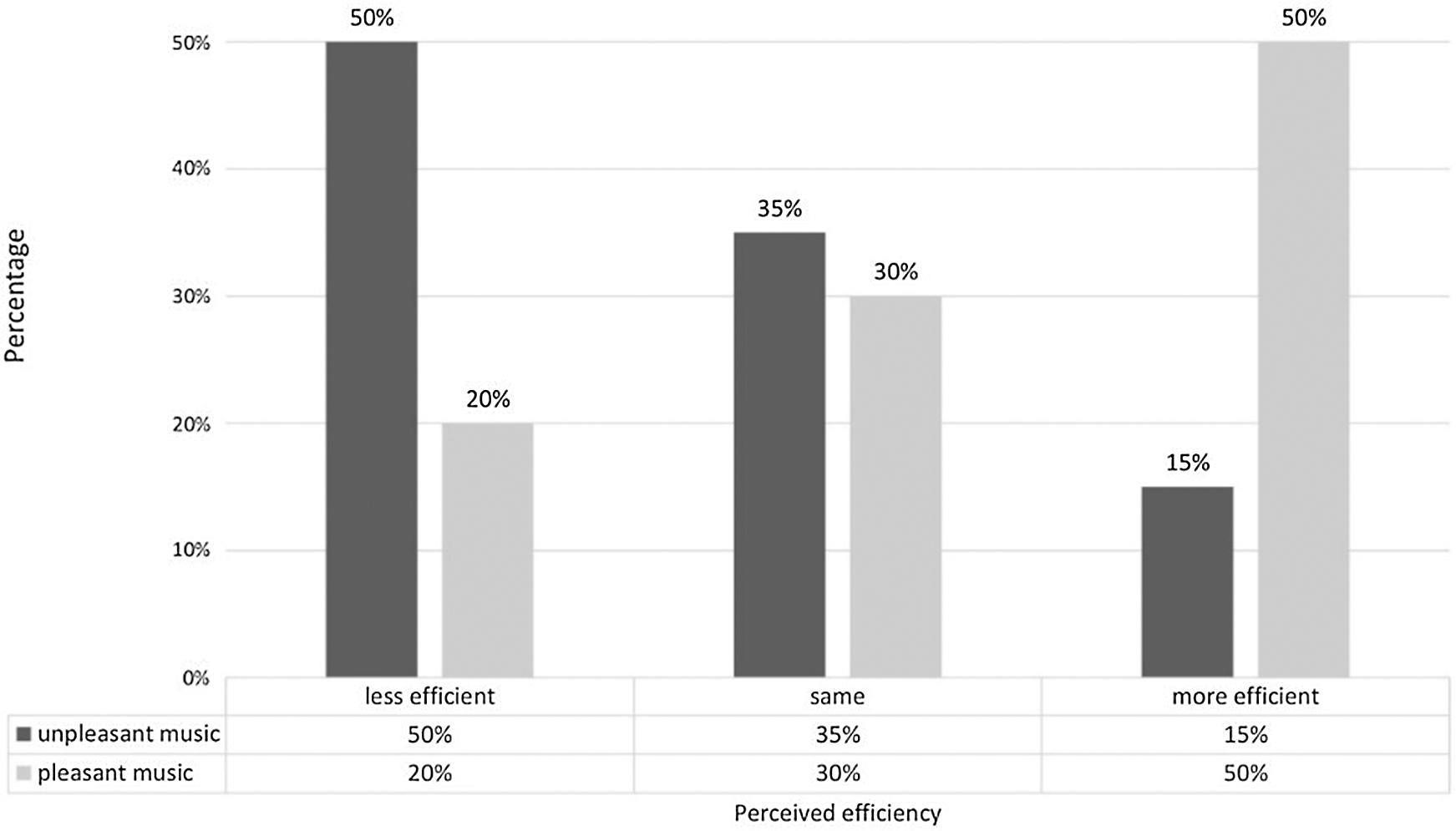
Figure 4: Grade of effectiveness by music
5 Discussion: Incorporating Music Preferences in Personas
By using the above findings, a knowledge-based Web editor was built in order to provide support for creating and experimenting with set of personas.
Persona method is one of the popular processes for analyzing user research data in user-centered design [4,37,38]. A persona represents user archetypes, giving a precise description of the user of an interactive system, and of what (s)he wishes to accomplish—i.e., user goals, needs, and preferences. Also, a persona offers reliable and realistic representations of the key audience segments for a given interactive system and could add empathetic focus to the design.
There are numerous studies on using persona method for multiple purposes and in many contexts, from common disciplines and domains of practice to “exotic” areas. Several interesting pragmatic usages include healthcare [39], assistive technologies for wireless applications [40], mobile medication selfcare [39], and many others.
Knowledge-driven procedures are usually not taken into consideration.
By incorporating music preferences and adopting the PersonasOnto ontology, a modular Web editor was designed. This software prototype primary manages the concept of Persona denoted by a class having attached a list of properties expressing knowledge about: (1) Identity (name, plus photos), demographic information + personality, disability (if any), education background, frustrations (if any), etc. (2) Goals—depending on each persona type (primary, secondary, additional), could be categorized into business goals, personal (life goals), experience goals, technical goals, etc. (3) Technology level—typical values: none, novice, intermediate, advanced, expert. (4) Occupation—an additional conceptual model, adapted from HRM Ontology14, is used to represent most frequent professions. (5) Group—denotes a user entourage (e.g., a research team or a club for opera music aficionados).
We extended this knowledge model in order to accommodate the concepts regarding the music preferences (i.e., preferred/unwanted music genres, songs, artists).
Our developed Web application provides a Web form—using HTML5 semantic mark-ups and schema.org microdata denoting PersonasOnto constructs—to be filled in with requested information about a given persona specified for a given UI/UX design project.
All provided data is converted into RDF triples and stored by using a dedicated storage solution.
Various persona profiles can be created, edited, filtered, and visualized according to user needs. Also, support for defining specific team groups is provided, in order to facilitate a collaborative approach in designing personas for a given HCI project. In addition, persona recommendations are suggested according to selected criteria: Type, age, occupation, music preferences, demographic factors, etc.
A microservice architecture was adopted. All operations are exposed by a REST API in order to reuse the functionalities in various multi-platform scenarios. All knowledge-based processing is performed by using Apache Jena15, a well-known open-source framework for building semantic Web applications.
Using these enriched datasets and the proposed semantic Web-based tool, one of the next steps is to give insights—for example, to suggest (proto-)personas [8]— in designing the interaction means with a platform concerning music recommendations for specific tasks.
The following use case concerns a multi-device adaptive and customizable tool able to determine (e.g., learn) and recommend the ideal weekday and time for performing a set of desired actions—for example, initiating a teleconference—in a real context of use, including music preferences of a given user.
An example of a primary persona—defined by our tool and considered as a most significant user for the designed application—is a young PhD student, researcher at the University of Oxford. His music preferences consist of classical and opera genres. A photo and other realistic random data (e.g., name, location, date of birth) are automatically generated. Each information of interest is denoted by a specific concept, according to the formal models chosen to express the desired knowledge.
For each persona, several usage scenarios could be described by the designer in order to stimulate brainstorms during some phases of the adopted UI/UX methodology.
The algorithm—using automated reasoning techniques—of recommending a better schedule for performing a certain task (in this circumstance, calling an old friend sharing common music interests) takes into consideration the music preferences by using the conceptual models presented below. For example, using the rule-based reasoning support provided by Jena framework16, a suggestion is made to initiate a videoconference between a group of persons by taking into account their mutual preferred music genre(s) and composition(s), plus an interval of spare time.
6 Conclusions and Further Work
The paper presented an original approach in conducting HCI experiments in a systematic manner. Our aim was to perform a pilot study for assessing music’s influence on students enrolled in Computing Studies. To accomplish this goal, various conceptualizations and best practices were adopted with the help of the existing (semantic) Web standards and technologies.
Our experimental findings confirmed the fact that music has a significant impact on the cognitive abilities of participants in the controlled experiment. By using these results, a persona editor was developed in order to suggest suitable personas for specific interactive applications. Using this knowledge-based tool, the paper describes a multi-device Web application focused on providing suitable intervals of time for performing various actions according to users’ needs and preferences, including music ones.
All involved data and knowledge were modelled as RDF datasets conforming to the Linked Data principles [36] in order to facilitate the discoverability of additional music-related resources available on the Web. Therefore, a future direction of research is to consider the complex user behavior manifested during the experiment, especially in the context of COVID-19 pandemic situation.
The current study will be continued and deepened by analyzing the influence of music on cognitive capacities considering different age categories. It would also be interesting to explore whether the level of music intensity has an effect on differences in cognitive capabilities. Also, the experiment should be conducted on a broader palette of subjects, in order to study the influence of music on cognitive abilities for persons with a background in other areas such as arts, social sciences, engineering, and others.
Funding Statement: The author(s) received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. C. Pesquita, V. Ivanova, S. Lohmann and P. Lambrix. (2018). “A framework to conduct and report on empirical user studies in semantic web contexts,” in Int. Conf. on Knowledge Engineering and Knowledge Management—EKAW 2018, Nancy, France. [Google Scholar]
2. D. Allemang and D. J. Hendler. (2020). Semantic Web for the Working Ontologist. 3rd edition, Morgan Kaufmann, Massachusetts, United States of America. [Google Scholar]
3. S. Negru and S. Buraga. (2013). “A knowledge-based approach to the user-centered design process,” in IC3K 2012: Knowledge Discovery, Knowledge Engineering and Knowledge Management, Communications in Computer and Information Science, vol. 415, pp. 165–178. [Google Scholar]
4. S. Negru and S. Buraga. (2012). “Towards a conceptual model for describing the personas methodology, ” in IEEE 8th Int. Conf. on Intelligent Computer Communication and Processing, Cluj-Napoca, Romania. [Google Scholar]
5. S. Human, F. Fahrenbach, F. Kragulj and V. Savenkov. (2017). “Ontology for representing human needs,” in Int. Conf. on Knowledge Engineering and the Semantic Web, Vienna, Austria. [Google Scholar]
6. M. Ousmer, J. Vanderdonckt and S. Buraga. (2019). “An ontology for reasoning on body-based gestures,” in The 11th ACM SIGCHI Symp. on Engineering Interactive Computing Systems, Valencia, Spain. [Google Scholar]
7. S. Ouf, M. Ellatif, S. Salama and Y. Helmy. (2017). “A proposed paradigm for smart learning environment based on semantic web,” Computers in Human Behaviour, vol. 72, pp. 796–818. [Google Scholar]
8. L. Neilsen. (2019). Personas—User Focused Design. 2nd edition, London, UK, Springer. [Google Scholar]
9. R. Abaalkhail, B. Guthier, R. Alharthi and A. El Saddik. (2018). “Survey on ontologies for affective states and their influences,” Semantic Web, vol. 9, no. 4, pp. 441–458. [Google Scholar]
10. N. Partarakis, C. Doulgeraki, A. Leonidis and M. Antona. (2009). “User interface adaptation of web-based services on the semantic web,” in Proc. of the 5th Int. Conf. on Universal Access in Human-Computer Interaction (Part IISan Diego, USA, pp. 711–719. [Google Scholar]
11. T. Hussein, H. Paulheim, S. Lukosch, J. Ziegler and G. Calvary. (2013). Semantic Models for Adaptive Interactive Systems, Springer, London, UK. [Google Scholar]
12. A. Amaral and D. Langers. (2017). “The relevance of task-irrelevant sounds: Hemispheric lateralization and interactions with task-relevant streams,” Frontiers in Neuroscience, vol. 7, no. 264, pp. 1–14. [Google Scholar]
13. C. Bernardino, M. Toscano Rico and J. Parmar. (2017). Effects of Music on Student’s Concentration Levels. Frankfurt: European School Frankfurt am Main.
14. E. Falcon. (2017). The Relationship Between Background Classical Music and Reading Comprehension on 7th and 8th Grade Students. Florida: St. Thomas University, Miami Gardens. [Google Scholar]
15. R. Rastogi and E. Silver. (2014). “Association of music with stress, test anxiety, and test grades among high school students,” Journal of Young Investigators, vol. 26, no. 5, pp. 32–38. [Google Scholar]
16. J. Taylor and B. Rowe. (2012). “The ‘Mozart Effect’ and the mathematical connection,” Journal of College Reading and Learning, vol. 42, no. 2, pp. 51–66. [Google Scholar]
17. N. Ziv and E. Dolev. (2013). “The effect of background music on bullying: A pilot study,” Children & Schools, vol. 35, no. 2, pp. 83–90. [Google Scholar]
18. G. Myles. (2017). Effects of Background Music on Cognitive Tasks. Ontario: University of Western, Ontario. [Google Scholar]
19. A. Sengupta and X. Jiang. (2015). “Effect of background music in a computer word processing task,” Occupational Ergonomics, vol. 12, no. 4, pp. 165–177. [Google Scholar]
20. R. Huang and Y. Shih. (2011). “Effects of background music on concentration of workers,” Work, vol. 38, no. 4, pp. 383–387. [Google Scholar]
21. K. Niven. (2014). “Can music with prosocial lyrics heal the working world? A field intervention in a call center,” Journal of Applied Social Psychology, vol. 45, no. 3, pp. 132–138. [Google Scholar]
22. N. Perham and J. Vizard. (2011). “Can preference for background music mediate the irrelevant sound effect?,” Applied Cognitive Psychology, vol. 25, no. 4, pp. 625–631. [Google Scholar]
23. A. Haake. (2010). Music Listening in UK Offices: Balancing Internal Needs and External Considerations. Sheffield: University of Sheffield. [Google Scholar]
24. G. Jawaheer, P. Weller and P. Kostkova. (2014). “Modeling user preferences in recommender systems: A classification framework for explicit and implicit user feedback,” ACM Transactions on Interactive Intelligent Systems, vol. 4, no. 2, pp. 1–26. [Google Scholar]
25. B. Ferwerda, E. Yang, M. Schedl and M. Tkalcic. (2015). “Personality traits predict music taxonomy preferences,” in 33rd Annual ACM Conf. Extended Abstracts on Human Factors in Computing Systems, Seoul, Republic of Korea. [Google Scholar]
26. F. Baader, D. Calvanese, D. McGuinness, P. Patel-Schneider and D. Nardi. (2003). The Description Logic Handbook: Theory, Implementation and Applications, Cambridge University Press, Cambridge, UK. [Google Scholar]
27. R. Guha, D. Brickley and S. Macbeth. (2016). “Schema.org: Evolution of structured data on the web,” Communications of the ACM, vol. 59, no. 2, pp. 44–51. [Google Scholar]
28. D. Taibi, V. Lenarduzzi and C. Pahl. (2017). “Processes, motivations, and issues for migrating to microservices architectures: An empirical investigation,” IEEE Cloud Computing, vol. 5, no. 5, pp. 22–32. [Google Scholar]
29. N. Dragoni, S. Giallorenzo, A. Lafuente, M. Mazzara, F. Montesi et al. (2017). , “Microservices: Yesterday, today, and tomorrow,” Present and Ulterior Software Engineering, vol. 1, pp. 195–216. [Google Scholar]
30. N. Savage. (2018). “Going serverless,” Communications of the ACM, vol. 61, no. 2, pp. 15–16. [Google Scholar]
31. J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas et al. (2015). , “DBpedia—A large-scale, multilingual knowledge base extracted from Wikipedia,” Semantic Web, vol. 6, no. 2, pp. 167–195. [Google Scholar]
32. D. Vrandecic and M. Krotzsch. (2014). “Wikidata: A free collaborative knowledgebase,” Communications of the ACM, vol. 57, no. 10, pp. 78–85. [Google Scholar]
33. P. Knees and M. Schedl. (2013). “A survey of music similarity and recommendation from music context data,” ACM Transactions on Multimedia Computing, Communications, and Applications, vol. 10, no. 1, pp. 1–21. [Google Scholar]
34. N. Dospinescu, M. Tatarusanu, G. Butnaru and L. Berechet. (2011). “The perception of students from the economic area on the new learning methods in the knowledge society,” Economics Amphitheatre, vol. 13, no. 30, pp. 527–543. [Google Scholar]
35. T. Potter, S. Li, T. Nguyen, N. Ince and Y. Zhang. (2017). “Characterization of volume-based changes in cortical auditory evoked potentials and pre-pulse inhibition,” Scientific Reports, vol. 7, no. 1, pp. 1–9. [Google Scholar]
36. T. Heath and C. Bizer. (2011). “Linked data: Evolving the web into a global data space, synthesis lectures on the semantic web,” Theory and Technology, vol. 1, no. 1, pp. 1–136. [Google Scholar]
37. A. Neate, A. Bourazeri, A. Roper and S. Stumpf. (2019). “Co-created personas: Engaging and empowering users with diverse needs within the design process,” in CHI Conf. on Human Factors in Computing Systems, Glasgow, UK. [Google Scholar]
38. M. Lilley, A. Pyper and S. Attwood. (2012). “Understanding the student experience through the use of personas,” Innovation in Teaching and Learning in Information and Computer Sciences, vol. 11, no. 1, pp. 4–13. [Google Scholar]
39. B. Sedlmayr, J. Schöffler, H. Prokosch and M. Sedlmayr. (2019). “User-centered design of a mobile medication management,” Informatics for Health and Social Care, vol. 44, no. 2, pp. 152–163. [Google Scholar]
40. J. Mueller, M. Jones, L. Broderick and V. Haberman. (2005). “Assessment of user needs in wireless technologies,” Assistive Technology, vol. 17, no. 1, pp. 57–71. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |