DOI:10.32604/cmc.2021.013457
| Computers, Materials & Continua DOI:10.32604/cmc.2021.013457 | |
| Article |
Intelligent Fusion of Infrared and Visible Image Data Based on Convolutional Sparse Representation and Improved Pulse-Coupled Neural Network
1School of Artificial Intelligence, Nanjing University of Information Science & Technology, Nanjing, 210044, China
2School of Computer and Software, Nanjing University of Information Science & Technology, Nanjing, 210044, China
3Western University, London, N6A 3K7, Canada
*Corresponding Author: Ling Tan, Email: cillatan0@nuist.edu.cn
Received: 07 August 2020; Accepted: 12 September 2020
Abstract: Multi-source information can be obtained through the fusion of infrared images and visible light images, which have the characteristics of complementary information. However, the existing acquisition methods of fusion images have disadvantages such as blurred edges, low contrast, and loss of details. Based on convolution sparse representation and improved pulse-coupled neural network this paper proposes an image fusion algorithm that decompose the source images into high-frequency and low-frequency subbands by non-subsampled Shearlet Transform (NSST). Furthermore, the low-frequency subbands were fused by convolutional sparse representation (CSR), and the high-frequency subbands were fused by an improved pulse coupled neural network (IPCNN) algorithm, which can effectively solve the problem of difficulty in setting parameters of the traditional PCNN algorithm, improving the performance of sparse representation with details injection. The result reveals that the proposed method in this paper has more advantages than the existing mainstream fusion algorithms in terms of visual effects and objective indicators.
Keywords: Image fusion; infrared image; visible light image; non-downsampling shear wave transform; improved PCNN; convolutional sparse representation
Infrared imaging sensors have a strong ability to identify low-illuminance or camouflage targets by thermal radiation imaging of target scenes, while their imaging clarity is relatively low. Correspondingly, visible light imaging sensors are imaged by reflection of the target scenes, with higher spatial resolution and clarity, but their imaging quality is easily affected by factors such as harsh environment [1]. It is believed that the fusion of infrared images and visible light images can make full use of their advantages, which can contribute to applications in many fields such as military operations, resource detection, and security monitoring [2].
Since the beginning of the 21st century, image fusion algorithms have rapidly developed in various fields to achieve better results. However, most existing image fusion methods are introduced under the framework of multi-scale transform (MST). Furthermore, methods of image conversion [3] and fusion techniques of separated sub-bands are two significant research topics in the field of MST-based fusion methods. A large number of literatures have shown that the performance of MST-based fusion methods can be significantly improved by selecting appropriate conversion methods and designing effective fusion technique. Specifically, the NSST algorithm proposed by Xia et al. [4] is remarked as great local time domain feature, multi-directionality and translation invariance, which can effectively save and extract details from source images. A study conducted by Ding et al. [5] fuses high-frequency subbands by PCNN, successfully combining important details from different source images. In addition, Singh et al. [6] suggested to add PCNN in the NSST framework to draw the key details of source images, ignoring the complexity of setting a large number of parameters in PCNN. Yang et al. [7] proposed an image fusion method based on sparse representation (SR), which improves the productivity of image fusion, but it only performs sparse representation on the low-frequency coefficients in four directions and does not fully represent characteristics and details of source images.
Furthermore, another SR-based denoising method, which was proposed by Liu et al. [8], improves the performance of the traditional MST-based method. However, this method still has two shortcomings, namely the limited ability to save details and high sensitivity to registration errors. Subsequently, a CSR algorithm was developed by Liu et al. [9], which can solve the two problems of sparse representation and achieve image fusion by implementing sparse representation of the entire image. In the research of Chen et al. [10], an image segmentation method based on simplified pulse coupled neural network model (SPCNN) was proposed, which can automatically set its free parameters for better segmentation results. Based on the optimization of the SPCNN model, Ma obtained an IPCNN for image fusion [11].
Based on the analysis of existing image fusion algorithms, especially IPCNN and CSR, this study proposes a new image fusion algorithm, namely NSST-IPCNN-CSR, which can retain the global features of source images and characteristics of each pixel point, and highlight the edges of the images to achieve a better visual perception of fusion results.
2.1 Non-subsampled Shearlet Transform (NSST)
Easley et al. [12] suggested NSST based on Shearlet transform which has no translation invariance. NSST achieves the multi-scale decomposition of an image through the non-subsampling pyramid set (NSP) and then obtains the coefficients of the images in various scales using the shear filter bank (SF) for directional decomposition, thereby obtaining the coefficients of the images in different scales and directions [13]. The NSP generates k + 1 sub images made of a low-frequency sub image and k high-frequency sub images with the same size as the source images, where k represents the decomposition order. In image decomposition and reconstruction, no up and down sampling is performed on the image, and NSST not only has good frequency doIn general, non-standard acronyms/abbreviations must be defined at their first mention in the Abstract and in the main text and used consistently thereafter. For non-standard acronyms/abbreviations mentioned once, only the full form must be used.
Main localisation characteristics and multi-directionality, but also translation invariance for suppressing the pseudo-Gibbs phenomenon. Fig. 1 shows the schematic of NSST multi-scale multi-directional decomposition.
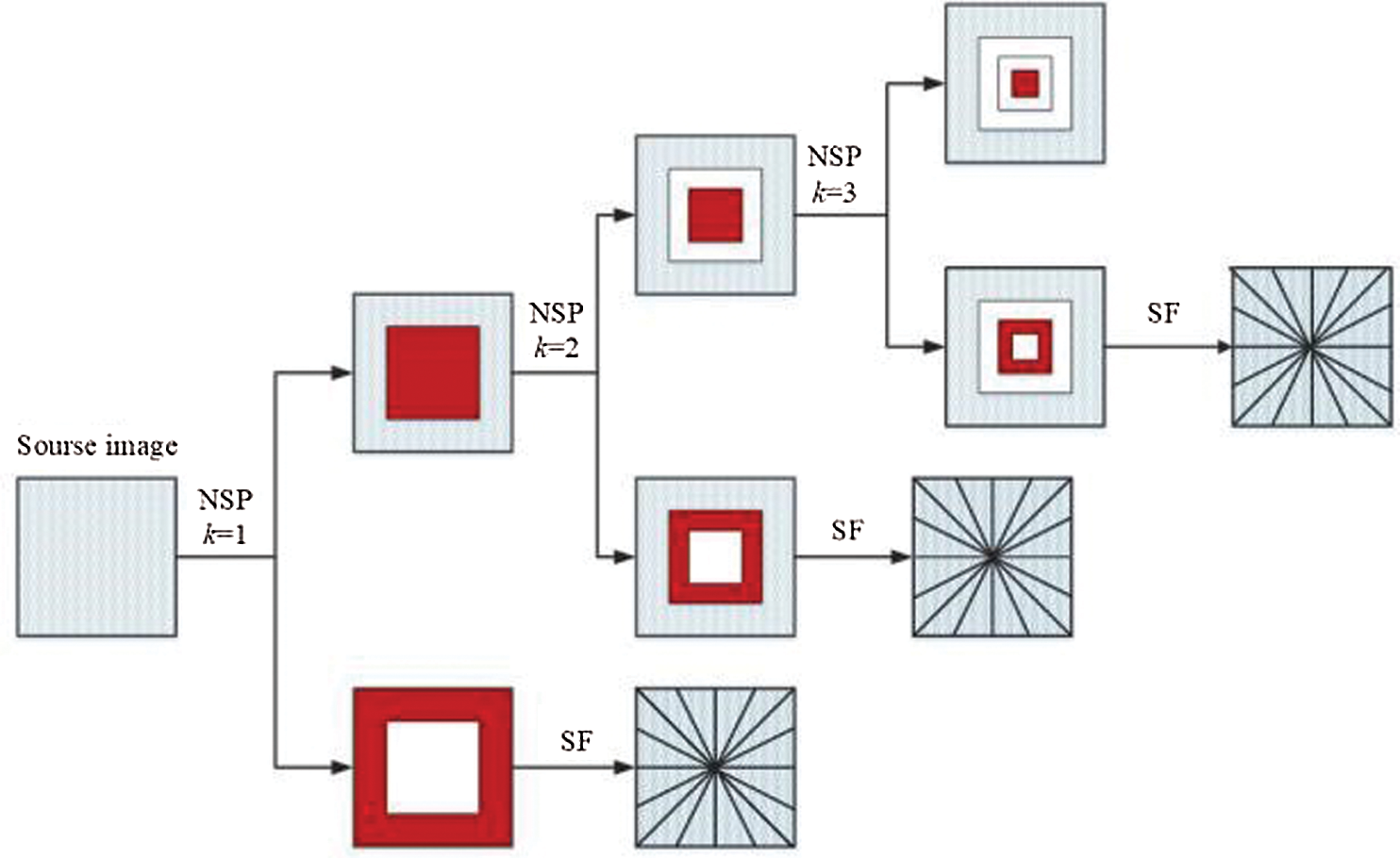
Figure 1: Schematic of NSST multi-scale multi-directional decomposition
Setting the size of free parameters, such as the connection strength, is a significant problem in the traditional PCNN model. To overcome the difficulty of setting these parameters manually, Ma [11] recently proposed an improved PCNN model (IPCNN) and an automatic parameter setting method for image segmentation. We believe that it has the same effect on image fusion. Furthermore, the high-frequency coefficients obtained by applying the IPCNN model to the fusion of multiscale transform (MST) are reasonable.
The IPCNN model is described as follows:
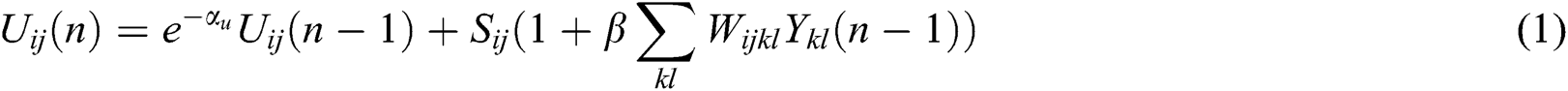


The improved PCNN model uses the ignition conditions of the standard PCNN model,  , and retains the feedback input and link input modes of the standard PCNN model and connection strength coefficient
, and retains the feedback input and link input modes of the standard PCNN model and connection strength coefficient  which reflects the degree of influence between the domain neurons.
which reflects the degree of influence between the domain neurons.
The working mechanism of the IPCNN model is improved compared with that of the traditional PCNN model. In the IPCNN model, dynamic threshold 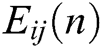 is affected by the combination of previous state
is affected by the combination of previous state 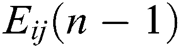 and previous state output
and previous state output 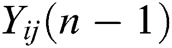 . When the internal activity item of current state
. When the internal activity item of current state 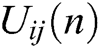 is better than that of the dynamic threshold (
is better than that of the dynamic threshold (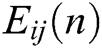 ) of the current state, ignition is performed, and the output is
) of the current state, ignition is performed, and the output is 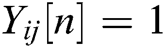 . The source image is defined as S. In the IPCNN model, the decay time constant of parameter feedback
. The source image is defined as S. In the IPCNN model, the decay time constant of parameter feedback 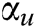 and input
and input  is changed to the decay time constant of the internal activity item which can more accurately express the meaning of each item in the model and further unify the expression of this model.
is changed to the decay time constant of the internal activity item which can more accurately express the meaning of each item in the model and further unify the expression of this model.
The IPCNN model has four tuneable parameters, i.e., 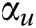 ,
, 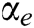 ,
, 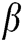 and
and 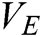 , and a synaptic connection matrix (W).
, and a synaptic connection matrix (W). 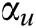 and
and 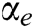 are the exponential decay constants for the internal activity terms and the dynamic thresholds, respectively;
are the exponential decay constants for the internal activity terms and the dynamic thresholds, respectively; 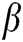 is the connection strength; and
is the connection strength; and 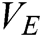 is the magnitude of the dynamic threshold. The choice of these parameters greatly affects the image processing.
is the magnitude of the dynamic threshold. The choice of these parameters greatly affects the image processing.
The above model is mainly used in image segmentation and is effective for image fusion. Currently, 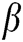 is usually constant in many image processing applications. However, the response to regions with significant features should be stronger than that to regions with insignificant features, depending on human visual characteristics. Therefore, assigning
is usually constant in many image processing applications. However, the response to regions with significant features should be stronger than that to regions with insignificant features, depending on human visual characteristics. Therefore, assigning 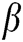 a constant value is unreasonable. Parameter
a constant value is unreasonable. Parameter 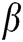 indicates the connection strength of the neighbouring neurons in the IPCNN model. The magnitude of
indicates the connection strength of the neighbouring neurons in the IPCNN model. The magnitude of 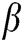 indicates the degree of interaction between neighbouring neurons. The larger the value is, the greater the interaction between adjacent neurons will be, making the internal activity items more volatile, and vice versa. At present,
indicates the degree of interaction between neighbouring neurons. The larger the value is, the greater the interaction between adjacent neurons will be, making the internal activity items more volatile, and vice versa. At present, 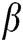 is normally set manually by empirical value in image processing applications. To integrate infrared visible images better, we adjust
is normally set manually by empirical value in image processing applications. To integrate infrared visible images better, we adjust 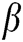 to construct the local-direction contrast model and then apply the model to
to construct the local-direction contrast model and then apply the model to 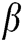 as follows to determine its value:
as follows to determine its value:

where 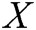 indicates the source image that must be fused,
indicates the source image that must be fused,  indicates the coefficient of the
indicates the coefficient of the 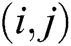 position in the r sub-band at the K NSP decomposition level, and
position in the r sub-band at the K NSP decomposition level, and 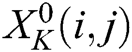 indicates the local average of the low-frequency coefficients of image X at the Kth decomposition level and is expressed as follows:
indicates the local average of the low-frequency coefficients of image X at the Kth decomposition level and is expressed as follows:
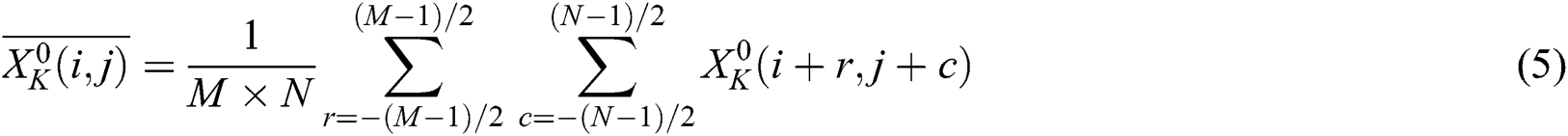
where M is generally assumed to be equal to N, and M × N is the area of the neighbourhood within the centre of  .
.
2.3 Convolutional Sparse Representation (CSR)
CSR is a convolutional form of SR [9], i.e., the convolutional sum of filter dictionary and representative response is used instead of the product of redundant dictionary and sparse coefficient, sparsely encoding the image in the ‘entirety’ unit. The CSR model can be expressed as
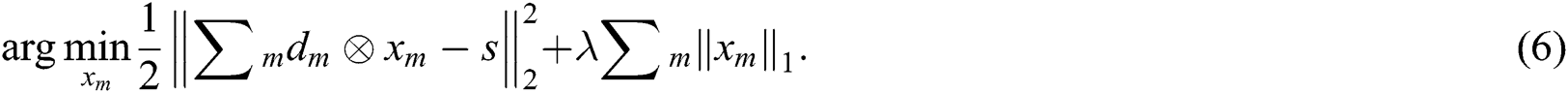
In Eq. (6), 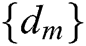 represents an M-dimensional convolution dictionary,
represents an M-dimensional convolution dictionary,  is the symbol of convolution operation,
is the symbol of convolution operation, 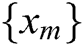 represents the representative response, and s represents the source image. The alternating direction method of multipliers (ADMM) is a dual convex optimisation algorithm that can solve the convex programming problem with a separable structure by alternately solving several sub-problems. Considering that the ADMM algorithm can solve the basis pursuit denoising problem well, the literature [14] proposes a Fourier domain ADMM algorithm for solving the sparse convolution model. In this algorithm, dictionary learning is defined as the optimisation problem of Eq. (7).
represents the representative response, and s represents the source image. The alternating direction method of multipliers (ADMM) is a dual convex optimisation algorithm that can solve the convex programming problem with a separable structure by alternately solving several sub-problems. Considering that the ADMM algorithm can solve the basis pursuit denoising problem well, the literature [14] proposes a Fourier domain ADMM algorithm for solving the sparse convolution model. In this algorithm, dictionary learning is defined as the optimisation problem of Eq. (7).
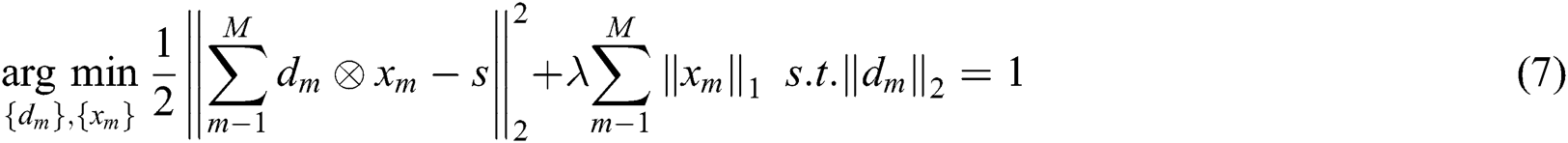
In the literature [9], CSR is applied to image fusion for the first time; CSR is considered an improved form of SR for the sparse representation of the entire picture. The CSR algorithm addresses the weak points of traditional sparse representations with limited detail preservation capacity and high sensitivity to registration errors. The algorithm is also useful in low-frequency sub-bands fusion. The low-frequency sub-bands obtained by NSST decomposition represent the general description of the picture and there is generous with approximate value of 0, sparsely representing the low-frequency details in the image. Thus, we introduce the CSR model in low-frequency sub-bands fusion.
Fig. 2 shows the specific fusion framework of this work. The framework is divided into four steps: NSST decomposition, fusion of high-frequency sub-bands, fusion of low-frequency sub-bands and NSST reconstruction.
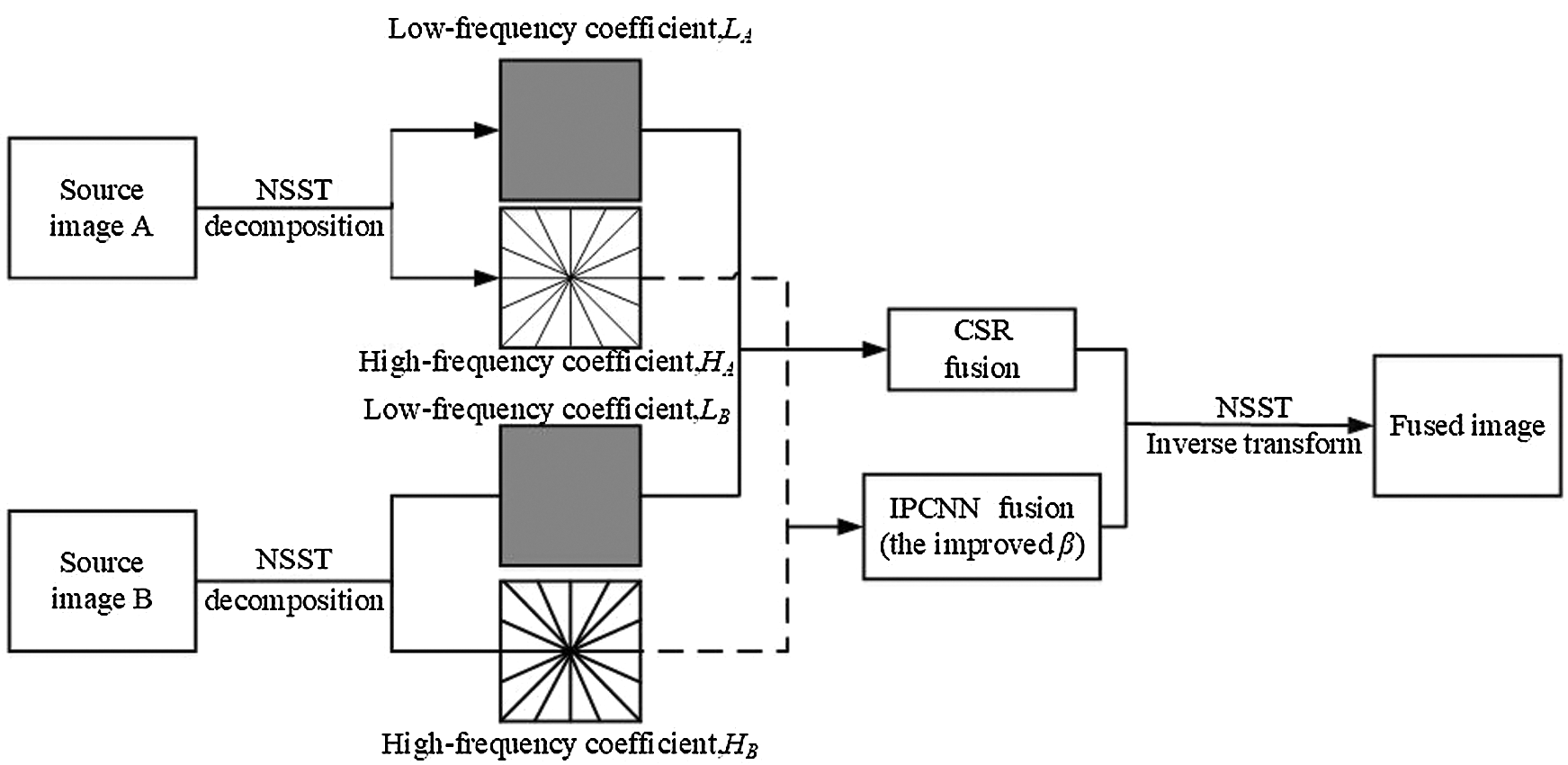
Figure 2: The image fusion algorithm used in this paper
Step 1 NSST Decomposition
Source images A and B are disassembled by the L-level NSST model to obtain their low-frequency coefficients 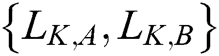 and high-frequency coefficients
and high-frequency coefficients 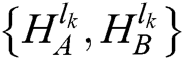 , where K is the multiscale decomposition level, l is the decomposition order, k is the decomposition direction, and
, where K is the multiscale decomposition level, l is the decomposition order, k is the decomposition direction, and 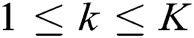 .
.
Step 2 Fusion of High-frequency Sub-bands
The IPCNN model is used to fuse high-frequency sub-bands [15]. The normalisation coefficients of high-frequency coefficients 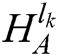 and
and 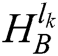 are taken as the feed input, and the value of the local direction contrast model as the joint strength according to Eq. (4). In the entire iterative process, the total emission time is applied to measure the activity level of the high-frequency coefficients. In line with the IPCNN model described by Eq. (1)–Eq. (3), the trigger time accumulates by adding the following steps at the end of each iteration:
are taken as the feed input, and the value of the local direction contrast model as the joint strength according to Eq. (4). In the entire iterative process, the total emission time is applied to measure the activity level of the high-frequency coefficients. In line with the IPCNN model described by Eq. (1)–Eq. (3), the trigger time accumulates by adding the following steps at the end of each iteration:

The excitation time of each neuron is 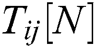 , where N is the total number of iterations, in correspondence to high-frequency sub-bands
, where N is the total number of iterations, in correspondence to high-frequency sub-bands 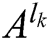 and
and 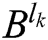 . The IPCNN times of
. The IPCNN times of 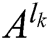 and
and 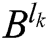 could be respectively calculated as
could be respectively calculated as 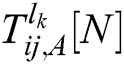 and
and 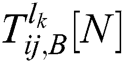 . The final fusion coefficients are obtained as follows:
. The final fusion coefficients are obtained as follows:

where 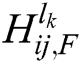 is the fusion coefficient of the high-frequency sub-bands. If
is the fusion coefficient of the high-frequency sub-bands. If 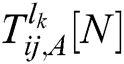 is larger than
is larger than 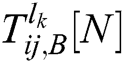 , than the pixel at
, than the pixel at 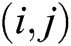 in image A has more obvious characteristics than the pixel at the same position in image B; therefore, the former is chosen as the pixel in the fused image, and vice versa.
in image A has more obvious characteristics than the pixel at the same position in image B; therefore, the former is chosen as the pixel in the fused image, and vice versa.
Step 3 Fusion of Low-frequency Sub-bands
The low-frequency sub-bands fusion strategy also has a significant impact on the final fusion effect. Literature [16] fused low-frequency sub-bands with a convolutional sparse representation. Low-frequency sub-bands are assumed after the decomposition of 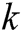 source images and set as
source images and set as 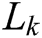 ,
,  , and a group of dictionary filters
, and a group of dictionary filters 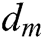 ,
, 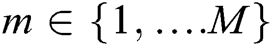 is assumed. Fig. 3 shows the low-frequency sub-bands fusion based on CSR.
is assumed. Fig. 3 shows the low-frequency sub-bands fusion based on CSR.

Figure 3: Low-frequency coefficients fusion map
Step 4 NSST reconstruction
Finally, we perform NSST reconstruction on fusion band 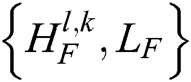 to obtain the final results (F).
to obtain the final results (F).
The NSST-IPCNN-CSR algorithm is compared with five typical methods, namely, contrast Algorithm 1: the IPCNN [15], contrast Algorithm 2: CSR [17], contrast Algorithm 3: MST [18], contrast Algorithm 4: adaptive weighted average [19] and contrast Algorithm 5: the sparse representation and pulse coupled neural network (SR-NSCT-PCNN) [20].
4.2 Objective Evaluation Index
The evaluation method of image fusion quality is divided into subjective visual and objective index evaluations. Objective index evaluation selects relevant indices to measure the effect of the human visual system on image quality perception. To quantitatively evaluate the performance of different methods, six accepted objective fusion evaluation indices were selected in the experiment, i.e., entropy (EN), edge information retention (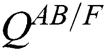 ), mutual information (MI), average gradient (AG), space frequency (SF) and standard deviation (SD). Entropy characterises the amount of information available in the source and fused images; edge information retention characterises the amount of edge detail information in the source image injected into the fused image; mutual information is used to measure the information of the fused image containing the source image; average gradient can be used to represent the sharpness of the image, and the larger the value is, the clearer the image will be; space frequency reflects the overall activity of the image in the space domain, and its size is proportional to the image fusion effect; standard deviation reflects the dispersion degree of the pixel and mean values of the image, and the greater the deviation is, the better the quality of the image will be. In general, the larger the six objective indices are, the higher the quality of the fused image and the clearer the image will be.
), mutual information (MI), average gradient (AG), space frequency (SF) and standard deviation (SD). Entropy characterises the amount of information available in the source and fused images; edge information retention characterises the amount of edge detail information in the source image injected into the fused image; mutual information is used to measure the information of the fused image containing the source image; average gradient can be used to represent the sharpness of the image, and the larger the value is, the clearer the image will be; space frequency reflects the overall activity of the image in the space domain, and its size is proportional to the image fusion effect; standard deviation reflects the dispersion degree of the pixel and mean values of the image, and the greater the deviation is, the better the quality of the image will be. In general, the larger the six objective indices are, the higher the quality of the fused image and the clearer the image will be.
To verify the effectiveness of the proposed method, three pairs of multi-focus images were used in our experiments. These source images were collected from the Lytro Multi-focus Dataset and have the same spatial resolution of 256 × 256 pixels. The source images in each pair have been accurately registered. The experiments were conducted on a PC equipped with an Intel(R) Core(TM) i7-6700 K CPU (4.00 GHz) and 32-GB RAM. The MATLAB R2013b software was installed on a Win 7 64-bit operating system.
To verify the availability of NSST-IPCNN-CSR, three sets of infrared and visible images with a pre-registration size of 256 × 256 were selected as the experimental data. The three sets of source images have different complexities in terms of target and scene expressions. Group 1 represents complex objects under a single scene; Group 2 represents single object under a single scene; Group 3 represents complex objects under a complex scene. Fig. 4 illustrates the fusion results of Group 1, and the objective evaluation indexes are illustrated in Tab. 1.
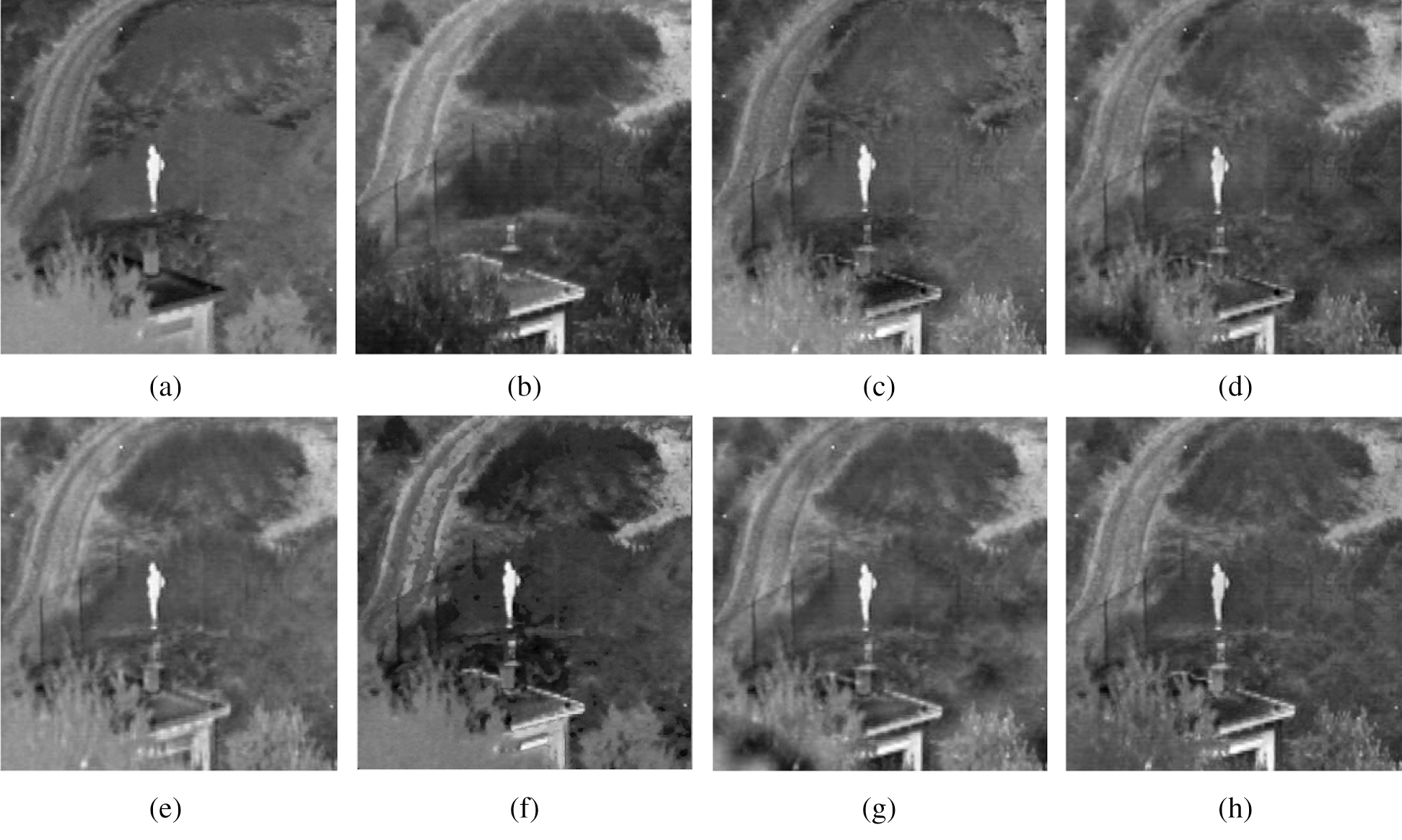
Figure 4: Group 1 image fusion results. (a) Infrared image, (b) Visible image, (c) Algorithm 1, (d) Algorithm 2, (e) Algorithm 3, (f) Algorithm 4, (g) Algorithm 5, (h) Proposed
Table 1: Group 1 image fusion quality evaluation

The fusion results in Figs. 4(c)–4(h) clearly indicate that these compared methods can effectively complete complementary information fusion from source images, but their abilities to capture feature information vary. In Algorithm 1, the fusion results indicate that the contrast between the character and the scene is low, the texture of the open space in the upper right image is unclear, and the details of the visible image cannot be displayed well. In Algorithm 2, the road, the railing, the house and the tree are enhanced in layering, but plaque shadows and unclear textures can be observed in the shrub. In Algorithm 3, the details of the road, the railing and the house are seriously lost, resulting in the unclear road and railing edges and blurred house edges. In Algorithm 4, the bushes are not textured clearly, and the house exhibits a clear ‘block effect’ phenomenon. The details of the house and the road in the fusion results of Algorithm 5 are prominent, but ‘discontinuity’ can be observed in the space. In the fusion result of the NSST-IPCNN-CSR algorithm, the grey level, the brightness and the sharpness optimally match those of the source images, and the overall texture structure is obvious, with a desirable visual effect on human eyes.
The performance indicators in Tab. 1 clearly show that except for the MI value of Algorithm 3 that is slightly larger than that of the proposed algorithm, the evaluation indicators of the proposed algorithm are better than those of the contrast algorithm. Therefore, based on the subjective visual evaluation of Fig. 4, when a single source image is targeted under a complex scene, the proposed algorithm can conserve the serviceable parts of the source image excellently and has a good visual effect.
The fusion results of Group 2 are shown in Fig. 5, and Tab. 2 shows the objective quality evaluation indicators.

Figure 5: Group 2 image fusion results. (a) Infrared image, (b) Visible image, (c) Algorithm 1, (d) Algorithm 2, (e) Algorithm 3, (f) Algorithm 4, (g) Algorithm 5, (h) Proposed
Table 2: Group 2 image fusion quality evaluation

Figs. 5(c)–5(h) clearly indicate that the above methods can effectively fuse the target and scene information, but the visual qualities of the fusion images vary. In the fusion results of Algorithm 1, the target vessel information is prominent, but the scene information is ambiguous. In Algorithm 2, the target vessel information is prominent, but a serious ‘plaque effect’ phenomenon can be observed. In Algorithm 3, the target vessel contour is blurred, and a slight plaque can be observed on the fused image. In Algorithm 4, the detailed information of the infrared light is displayed poorly, and the scene information is too smooth. In Algorithm 5, the detailed features of the image are prominent, and a ‘discontinuity’ phenomenon can be observed in the space, with poor visual effects. In the NSST-IPCNN-CSR algorithm, the target vessel information is prominent, and the background information structure features are obvious, with a great visual effect.
The performance indicators in Tab. 2 indicate that the proposed algorithm is inferior to Algorithm 6 in terms of edge information retention and better than other contrast algorithms in terms of the other five evaluation indicators. The proposed algorithm has good visual effects and performance indicators according to both subjective visual and objective quality evaluations. Furthermore, its fusion effect has good recognisability.
The fusion results of Group 3 are shown in Fig. 6, and Tab. 3 shows the objective quality evaluation indicators.

Figure 6: Group 3 image fusion results. (a) Ir, (b) Vis, (c) Algorithm 1, (d) Algorithm 2, (e) Algorithm 3, (f) Algorithm 4, (g) Algorithm 5, (h) Proposed
Table 3: Group 3 image fusion quality evaluation

Figs. 6(c)–6(h) clearly show that these above methods can effectively complete infrared/visible images fusion, but their detail expression capabilities vary. In the fusion results of Algorithm 1, the contrast of the image is enhanced, although the target feature information is seriously lost, and the text information on the billboard is nearly impossible to distinguish. In Algorithm 2, the contrast of the image is weak, and a slight ‘discontinuity’ phenomenon can be observed in the space. In Algorithm 3, the image contrast is enhanced, but the details are displayed poorly. In Algorithm 4, the detailed information of the infrared images cannot be displayed well, and the scene information is too smooth. In Algorithm 5, the overall image contrast is low, the edge of the target object is blurred, and the loss of detail feature information is serious. In the fusion results of the NSST-IPCNN-CSR algorithm, the layering of the image is enhanced, the continuity is good, the edge contour texture is clear, and the text information on the billboard can be recognised well.
We propose the application of a new algorithm called NSST-IPCNN-CSR to medical image fusion. The novelty of the proposed algorithm is primarily reflected in two aspects. First, IPCNN model was used for the first time in high-frequency sub-band fusion in which all required parameters could be calculated adaptively in line with the input high-frequency sub-bands. Moreover, local direction contrast model was used to adjust parameter 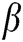 to its optimal value, and the IPCNN model was adjusted to function better in image fusion. Second, we fused low-frequency sub-bands by convolutional sparse representation, addressing two matters in sparse representation, i.e., the insufficient ability to save detail texture information and the high sensitivity to mismatch rate, and performing better in low-frequency sub-bands fusion. Three sets of source images and five sets of comparison algorithms were used for experiments. The results demonstrate that the NSST-IPCNN-CSR algorithm can effectively express the details in the image, i.e., presenting the required details clearly and making smooth edges; retain the useful information of the source image and capture its geometric structure at a deeper level; and perform well in visual perception and objective effect evaluation.
to its optimal value, and the IPCNN model was adjusted to function better in image fusion. Second, we fused low-frequency sub-bands by convolutional sparse representation, addressing two matters in sparse representation, i.e., the insufficient ability to save detail texture information and the high sensitivity to mismatch rate, and performing better in low-frequency sub-bands fusion. Three sets of source images and five sets of comparison algorithms were used for experiments. The results demonstrate that the NSST-IPCNN-CSR algorithm can effectively express the details in the image, i.e., presenting the required details clearly and making smooth edges; retain the useful information of the source image and capture its geometric structure at a deeper level; and perform well in visual perception and objective effect evaluation.
Acknowledgement: We would like to solemnly thank those who helped generously during the research. They are the instructors who offered pertinent suggestions on revision and the classmates who helped build the dataset. With their support and encouragement, this paper can be successfully completed.
Funding Statement: This work was supported in part by the National Natural Science Foundation of China under Grant 41505017.
Conflicts of Interest: The authors of this paper declare no conflict of interest regarding the publication of this paper.
References
1. W. Zhang, W. Li and J. Zhao. (2017). “A method of visible and infrared image fusion based on sparse representation,” Electronics Optics & Control, vol. 24, pp. 47–52.
2. S. Chen and S. Shan. (2015). “Research on infrared and visible image fusion method based on NSCT,” Laser & Optoelectronics Progress, vol. 52, pp. 1–6.
3. X. Chen, D. Zhong and F. Bao. (2019). “A GLCM-feature-based approach for reversible image transformation,” Computers, Materials & Continua, vol. 59, no. 1, pp. 239–255.
4. J. M. Xia, Y. M. Chen and Y. C. Chen. (2019). “Medical image fusion based on sparse representation and PCNN in NSCT domain,” Computational and Mathematical Methods in Medicine, vol. 6, pp. 1–12.
5. S. Ding, Y. Bi and Y. He. (2017). “Infrared and visible image fusion based on sparse features,” Acta Photonica Sinica, vol. 47, pp. 1–10.
6. S. Singh, D. Gupta and R. S. Anand. (2015). “Nonsubsampled shearlet based CT and MR medical image fusion using biologically inspired spiking neural network,” Biomedical Signal Processing and Control, vol. 18, pp. 91–101.
7. B. Yang and S. Li. (2010). “Multi-focus image fusion and restoration with sparse representation,” IEEE Transactions on Instrumentation and Measurement, vol. 59, no. 4, pp. 884–892.
8. Y. Liu and Z. Wang. (2016). “Simultaneous image fusion and denoising with adaptive sparse representation,” IET Image Processing, vol. 9, no. 5, pp. 347–357.
9. Y. Liu, X. Chen and R. K. Ward. (2016). “Image fusion with convolutional sparse representation,” IEEE Signal Processing Letters, vol. 23, no. 12, pp. 1882–1886.
10. L. Chen, S. K. Park and D. Ma. (2010). “A new automatic parameter setting method of a simplified PCNN for image segmentation,” IEEE Transactions on Neural Networks, vol. 22, no. 6, pp. 880–892. [Google Scholar]
11. R. Ma, “Research on pulse coupled neural networks with self-adapting parameter setting and its application in image processing,” M.S. dissertation, Lanzhou University, China, 2017. [Google Scholar]
12. G. Easley, D. Labate and W. Q. Lim. (2008). “Sparse directional image representations using the discrete shearlet transform,” Applied and Computational Harmonic Analysis, vol. 25, no. 1, pp. 25–46. [Google Scholar]
13. L. Li, L. Wang and X. Wang. (2019). “A novel medical image fusion approach based on nonsubsampled shearlet transform,” Journal of Medical Imaging and Health Informatics, vol. 9, no. 9, pp. 1815–1826. [Google Scholar]
14. M. Chen, M. Xia and C. Chen. (2018). “Infrared and visible image fusion based on sparse representation and NSCT-PCNN,” Electronics Optics & Control, vol. 25, pp. 1–6. [Google Scholar]
15. W. Kong and P. Liu. (2013). “Technique for image fusion based on nonsubsampled shearlet transform and improved pulse-coupled neural network,” Optical Engineering, vol. 52, no. 1, 017001-1–017001-12. [Google Scholar]
16. B. Wohlberg. (2015). “Efficient algorithms for convolutional sparse representations,” IEEE Transactions on Image Processing, vol. 25, no. 1, pp. 301–315. [Google Scholar]
17. Y. Dong, B. Su and B. Zhao. (2018). “Infrared and visible image fusion based on convolution sparse representation,” Laser & Infrared, vol. 48, pp. 1547–1553. [Google Scholar]
18. H. Lin, “Research on infrared and visible image fusion based on multi-scale transform,” University of Chinese Academy of Sciences, 2019. [Google Scholar]
19. M. Zhen and P. Wang. (2019). “Adaptive weighted average fusion of visible and infrared images,” Infrared Technology, vol. 41, pp. 341–346. [Google Scholar]
20. P. Liu and Y. Fang. (2007). “Infrared image fusion algorithm based on contourlet transform and improved pulse coupled neural network,” Journal of Infrared and Millimeter Waves, vol. 26, pp. 217–221. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |