DOI:10.32604/cmc.2021.015405
| Computers, Materials & Continua DOI:10.32604/cmc.2021.015405 | |
| Article |
AI-Based Culture Independent Pervasive M-Learning Prototype Using UI Plasticity Design
1Xiamen University Malaysia, Malaysia
2Wrexham Glyndŵr University, UK
3Epoka University, Albania
4REVE Systems Limited, Bangladesh
*Corresponding Author: Mahdi H. Miraz. Email: m.miraz@ieee.org
Received: 05 November 2020; Accepted: 16 December 2020
Abstract: This paper explains the development of a culturally inclusive ubiquitous M-Learning platform (“Mobile Academy”) with an AI-based adaptive user interface. The rationale and need for this research and development are justified by the continuing widespread adoption of the Internet and Internet enabled devices, especially smartphones. The M-learning platform was designed from the onset for the global traveller. The characteristics and limitations of the application are also discussed. The Mobile Academy, proof of concept prototype, was created to facilitate teaching and learning on the move or in environments where the use of a desktop computer is inconvenient or simply impossible. The platform’s primary objective was cross-cultural usability through the use of a combination of AI and plasticity of user interface design techniques. The usability evaluation plan was comprehensive and the results obtained were studied in detail. This also included consideration of the results of the SVM (Support Vector Machine) classifiers’ performance and cross-device evaluation. The AI-based adaptive interface prototype has been tested and evaluated to show its merits and capabilities in terms of its usability, inclusivity and effectiveness of the interface. From the results, it was concluded that such a culture independent application was also affordable.
Keywords: Cross-cultural usability; inclusive design; mobile learning; plasticity of user interface design
This paper presents the development of the “Mobile Academy” [1] prototype - an AndroidTM-based mobile learning (M-Learning) application (app). The app can be considered a proof of concept to achieve cross-cultural usability [2] through a combination of AI and plasticity of user interface design techniques. The application has been developed to investigate the feasibility of an affordable culture-independent inclusive interface for mobile application development, focusing on Mobile Learning. The project comprises three major phases: requirement analysis, application development and testing and evaluation. To satisfy the first phase, a detailed ethnographic study was first conducted in order to investigate how people from different cultural backgrounds use mobile devices, especially for learning purposes.
Despite the predictions of some sceptics, the growth of computational power continues in broad accordance with Moore’s Law [3–5]. On the other hand, the prices of computing and networking equipment per unit performance metric (e.g., TFLOPs, MIPs or Mbit/s) and charges to access the Internet continues to decrease at an inversely exponential rate. This price decline includes the purchasing cost of mobile devices and hence the usage of the Internet almost anywhere in the Developed (and increasingly in the Developing) World—which has become a norm. Furthermore, the widespread adoption of smartphones and, more recently, the concept of the Internet of Everything (IoE) [6] have led to the inspiration of using mobile devices for any kind of Internet usage, including even financial transactions. Such widespread mobile usage of digital electronic techniques, technologies and applications holds huge promise to widen the international ubiquity of teaching and learning, especially through M-Learning.
Previous ethnographic surveys and literature reviews conducted by the researcher partially fulfil the requirements analysis and suggest the development of an M-Learning platform with AI-based adaptive user interfaces to be simultaneously used, in particular, by people with affiliations across different national boundaries: this cross-national (or cross-cultural) aspect is believed to distinguish this presented work from other examples currently known.
The usability evaluation plan and results obtained were detailed, which also included the consideration of the results of the SVM classifiers’ performance and cross-device evaluation. However, developing a complete mobile learning application was not a primary goal of the research: the object was rather to explore the problems and potentials of applying solutions that answer the requirements. As it was a prototype application, it had some limitations, which are also explained. Testing the robustness of the application was also not the target of the research; rather the AI-based adaptive interface prototype has been tested to evaluate usability, inclusivity and effectiveness of the interface. Along with the rationale of selecting the mobile learning app to be developed, the characteristics, development platform and limitations of the application are explained in the following sections.
2 Rationale for Focusing on the Mobile Learning Prototype
Mobile learning is seen as one of the leading-edge teaching and learning technologies [7]. However, there has been no formal definition of mobile learning thus far and hence the perception of it varies among individuals. However, the definition as outlined by Sharples et al. [8] can be considered a working one. According to them, mobile learning is considered as the “process of coming to know through conversations across multiple contexts among people and personal interactive technologies” [8]. The supportive technologies here include any form of handheld devices that can support learning and teaching, such as smartphones, personal digital assistants (PDAs), tablets or even a simple mobile phone. Although it is obvious that laptops are somewhat mobile, they are excluded from the list [9]: They are sometimes classified as “nomadic,” to distinguish them from truly mobile devices.
Due to the pervasive adoption [10] of popular internet and networking modalities such as Social Media, Social Networking, Mobile instant messaging and the like, as part of a continuous development process, universities and other higher education providers are under competitive pressure to become accustomed to, and to adopt them to facilitate learning and education. Mobile communication, simultaneously with other Internet communication technologies, is becoming widespread as a means of education and is expected to bridge the gap [11] between formal and informal learning and teaching methodologies. The stakeholders now have to pay attention to how people embrace and live with the new technologies [12], as this trend will greatly contribute to the dramatic transformation of the education systems’ characteristics and traits.
The multidimensional and exponentially increasing use of mobile technology is influencing cultural practice and is facilitating novel contexts for learning [13], although the integration of mobile technologies in teaching is observing a somewhat slower rate of growth than social media, due to the fact that the instructors themselves first need to be equipped with the knowledge of how to use them [14]. However, from the way that mobile devices and networking technologies are becoming a routine part of daily life, it can be foreseen that M-Learning will soon be widely adopted by the education sectors around the globe. As a result, it is very important to research the impact on this domain of the cross-cultural usability issues and to develop a culture-independent pervasive platform to accommodate users from a wide range of cultural backgrounds.
However, like any other technologies, mobile phones and other handheld devices suffer from technical limitations, which should be carefully considered. These limitations have been categorised into three major groups [15], based on the users’: Pedagogical, psychological and technical limitations. The aim of the work was to specifically address these limitations, especially those related to cross-cultural usability.
3 Research Methodology and Design Process
The Requirements Analysis phase involved identifying the needs of both the students and teachers. Opinions from both the end users were sought and an extensive survey of existing M-Learning apps was conducted. Thus, based on the needs identified, strategies for developing the required functionalities to satisfy the requirements were developed, as described in Tab. 1; use case diagrams, as shown in Fig. 1, were also utilised.
Table 1: The functionality requirement analysis

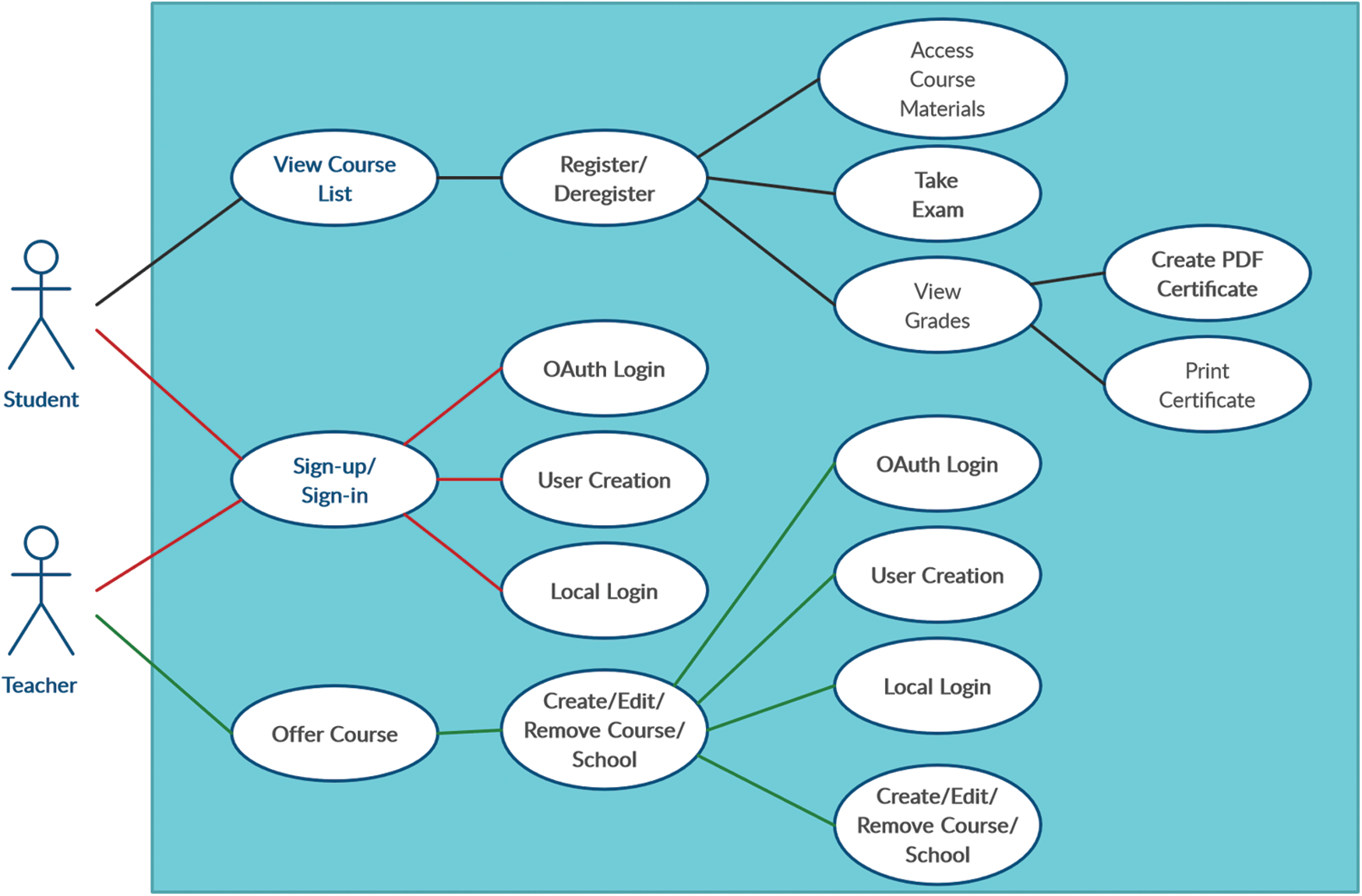
Figure 1: Use case diagram for the first iteration of the Mobile Academy app
The second phase of the project involved designing and developing the app: Some coding was also involved at this stage. The overall functionalities and navigation while using the app can be best described using the following flowchart, as shown in Fig. 2.

Figure 2: Functionality and navigation flowchart of the Mobile Academy app
The third phase of the exercise was to test and evaluate the prototype, especially adopting the usability testing. The following sub-sections cover the three stages of the prototype development: 1. Design Process, 2. Used Techniques and Technologies and 3. Features and Functionalities of the prototype.
This section details the process associated with the design and development of the prototype, including the interface design. The User-centred Design (UCD) [16] method was followed throughout the whole project of the prototype development. The following sub-sections give a short portrayal of the overall process.
User-Centred Design (UCD) [16], also known as User-Sensitive Design or its acronym USD [17,18], is an array of design techniques and methods enabling developers to emphasise the users of the system to be the main focus within the design process. Adopting the five central phases of the UCD method, as presented in Fig. 3, the overall design process can be accomplished with the users’ participation and evaluation. UCD also facilitates the use of empirical methods within each phase of the design process. Thus, a robust user involvement can be attained, especially throughout the period of the analysis and evaluation phase, as this research demands. Due to the fact that there exists a “cultural and experimental gap” between the designer(s) and users, particularly multi-cultural users [19,20], such involvement of the users in the design process plays a vital role [21].
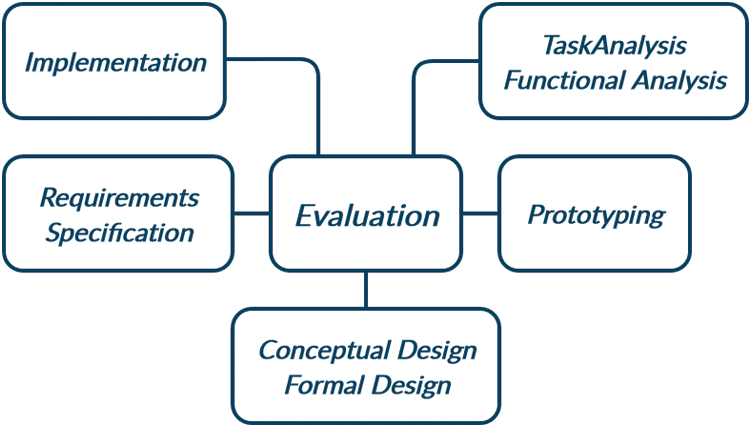
Figure 3: Model incorporating user-sensitive design [18], adapted from [17]
A detailed usability evaluation was planned and extensive usability tests were conducted to measure the satisfaction level of the users. The cross-cultural usability issues [22], which were identified, were taken into consideration while developing this app.
Fig. 4 demonstrates the use of universally known symbols, instead of textual descriptions, to increase cross-cultural usability. In fact, the app itself has been developed to further research the cross-cultural usability aspects of the design process. The findings of these tests were included.

Figure 4: Use of universally known symbols to increase cross-cultural usability
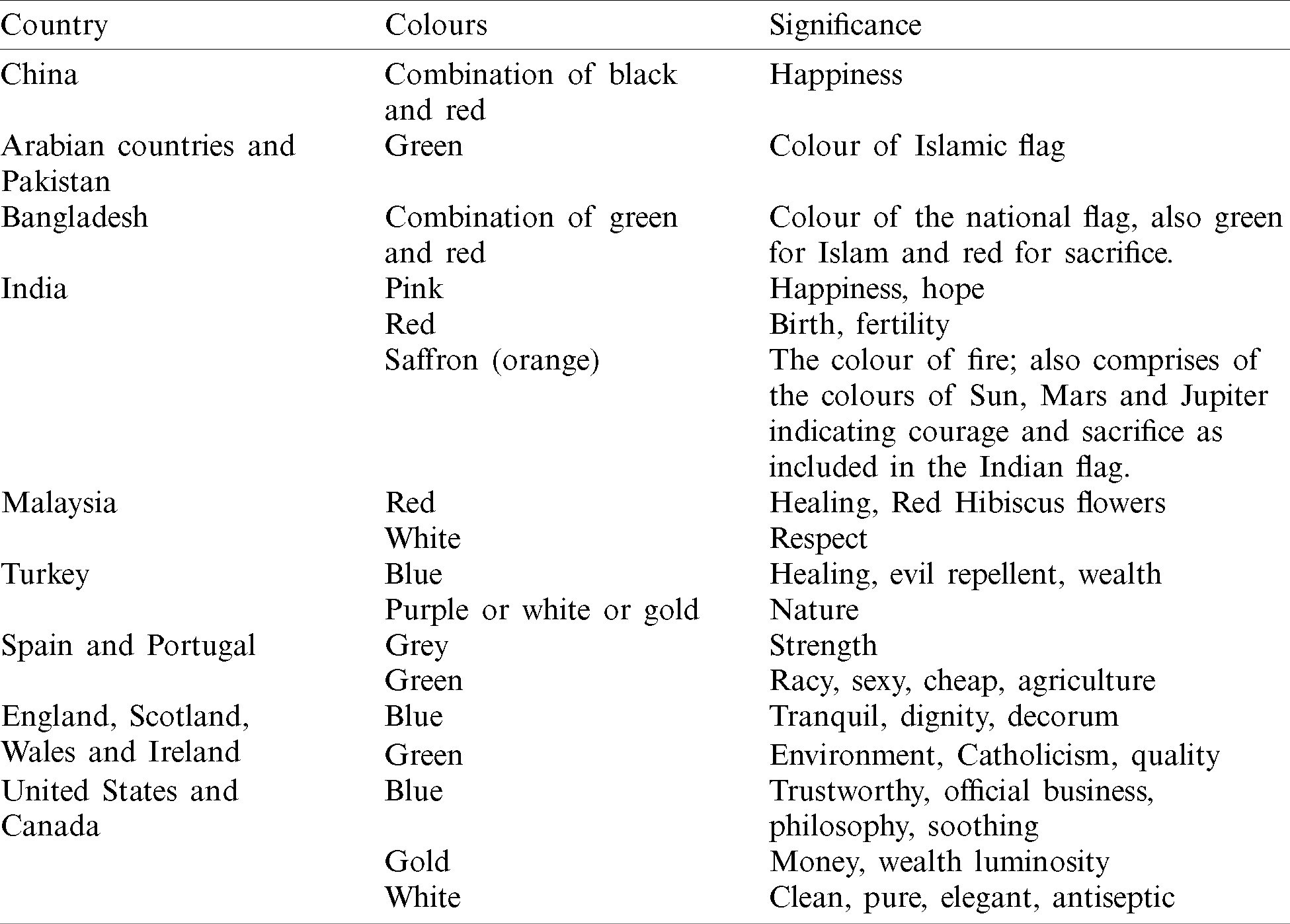
The Mobile Academy is a simple but novel and innovative application to offer culture-based tailored user interfaces using AI-based adaptive user interface design techniques. To test the plan, several interfaces were designed based on a colour scheme, language preferences, image control and text flow, whether right-to-left or vertically. These choices of colours were taken into consideration as they are intricately attached to certain cultures [23]. Colour-associated affective meaning is strongest with East Asians, whereas this is less strong with Northern American and Latin American groups, based on the findings of many researchers [23–25] in the field of association of colour with country and/or culture. This has been tabulated and is shown in Tab. 2, below. The countries were grouped based on similar cultural affinities and/or geographical adjacencies.
Table 2: The significance of colour amongst the ethnic groups
The prototype that was created inferred the users’ cultural background by using AI techniques, and a tailored interface was subsequently offered according to the identified cultural background. A similar methodology was used to offer the language of the interface. A snapshot of one of such interfaces is displayed in Fig. 5. The colour of the adaptive interface is associated with the inferred culture of Arabian Countries and Pakistan, Arabic is the predicted preferred language.

Figure 5: OAuth (Gmail) based login page
The Mobile Academy app was developed as a prototype, based on findings from the analysis of the review and initial research findings. One of the findings was to develop an AI-based application that could offer interfaces to each user according to the relevant cultural background and thus enhance cross-cultural usability. Considering the previous findings, the following techniques and technologies were used to develop the Mobile Learning application.
Mobile and cellular phones have gained a huge popularity for their diverse uses, starting from making phone calls to sending SMS as well as acting as a platform for running converged applications and third-party software. Due to the enormous diffusion of mobile devices and applications, mobile technologies have become a topic of a large number of wide-ranging research efforts. The open source operating system, Android, introduced by Google, is a platform, which is already offering a complete software package, including operating system and middleware as well as core applications. In addition, it has an SDK (Software Development Kit), which provides the necessary tools for developing various applications in platform [26]. Application markets such as Apple’s App Store and Google’s Play Store provide point and click access to hundreds of thousands of both, paid-for and free applications. Such stores streamline software marketing, installation, and update, thereby creating low barriers to bring applications to market, and even lower barriers for users to obtain and use them. The ease of design is very encouraging for developers and users of new applications, as witnessed by the growing Android market. The application communication model of Android further promotes the development of rich applications. Android developers can leverage existing data and services provided by other applications while still giving the impression of a single, seamless application [27]. For example, a restaurant review application can ask other applications to provide a display of the restaurant’s website, provide a map with the restaurant’s location and call the restaurant. This communication model reduces the developers’ burdens and promotes functionality reuse. Android achieves this by dividing applications into components and providing a message passing system so that components can communicate within and across application boundaries [28]. Since Android is Google’s latest open source operating system (OS) software platform for mobile devices having already attained enormous popularity, it was chosen to develop the targeted app, along with SQLite for the database.
As part of the app is Web based, Apache server with MySQL database was also used. To create PDF results, iText library [29] was used.
5.2 AI-Based Adaptive Interface
Smartphones, due to their rising popularity, are predicted to account for a 50% share of the global market for mobile phones by the end of the year 2017 [30]. Many other smart handheld devices, such as tablets, provide similar benefits with bigger screens. These smart devices bring various benefits to the users, greatly enhanced by mobile applications, more commonly known as apps. Apps serve as a fundamental part of the ecosystems of smartphones. These apps can be either provided by the manufacturers or by various third parties. The aim in the present work was to identify the users’ cultural preferences, using the snapshots of installed apps, and to offer the users interfaces more relevant to their cultures. This was achieved with the help of supervised learning methods, together with minimal external data. The use of this inferenced approach may be extended to offer numerous other services such as delivering personalised content or even developing recommender engines [31] for users.
Usually users install apps on their smart mobile devices based on their personal and professional requirements as well as social and cultural preferences. These installed apps thus can be instinctively considered as potential indicators of their culture and other personal traits.
As part of legal requirements, apps have to obtain explicit permissions to get access to users’ possible confidential data such as contacts and location. Android-based apps seek this permission at the time of installation whereas iOS based apps obtain permission on their first attempt to access such information. However, the user has complete control over whether to allow or deny such permissions or even review and modify previously granted ones. In contradistinction to this, the Android system approves the obtaining of the list of installed apps without the user/s permission, as it appears that this is not deemed to be ‘confidential data’. iOS also to some extent allows the obtainment of such lists even though the process is not as straightforward as it is in Android [32]. In the past, some of the advertisement libraries have reportedly used this approach to gather information regarding the users’ personal traits using the list of installed apps [33].
This section demonstrates how a single snapshot of installed apps on smart mobile devices can be used to capture the probable preferences of the user with a greater rate of precision and thus develop a pervasive M-Learning platform based on adaptive user interface design techniques. This method functions as a practical profiling method, eliminating the need of incessantly tracking, monitoring and recording users’ activities such as their use of the Internet or their smart devices. However, the way the popular operating systems of the smart devices allow access to the list of installed apps may pose risks to the users’ privacy. For the purposes of the present research it is convenient to exploit this weakness: If in the future access to the list of apps were to be controlled it would be a simple and safe matter to just ask the user for permission to access it as a one-off event to determine cultural preferences.
5.3 Justification of the Chosen Method
With the massive increase in use of the Internet and Internet-based technologies, the use of data mining, especially data obtained from Social Media and Smart devices, have become a customary trend in the recent past. This is especially so for the purpose of forecasting the users’ traits, such as personal interests, moods, installation and use of future applications, shopping preferences etc. [34–39].
Chittaranjan et al. [34] have studied the correlation between the users’ behavioural characteristics obtained from analysing smartphone data and personality traits obtained by a self-report study. The study analysed a dataset stemming from eight month’s usages of smartphones by 83 participants. This was pioneering work to examine whether the hypothesis that aggregated features acquired from the data based on smartphone usage can be good indicators of the Big-Five personality traits [40]: Extraversion, Agreeableness, Conscientiousness, Neuroticism, Openness to Experience. Their developed automatic method, by deploying a data mining mechanism and machine learning techniques to the users’ apps, SMS usage, and call logs to infer the personality type—achieved a very significant accuracy rate of 75.9%.
MoodScope [35], an app designed for iPhone users, acts as a “sensor” to infer the mental state (“mood”) of a smartphone user based on their communication history and application usage pattern. A formative statistical mood study was conducted using smartphone-logged data such as apps used, voice call logs, websites visited, email logs and SMS logs, over two months from 32 participants. MoodScope achieved an initial accuracy of 66%, which gradually improved up to 93% through a personalised training period of two months. However, the sample size used was very small and limited to only China and the USA.
Several researchers, such as Shepard et al. [41] and Böhmer et al. [42], investigated the dependency of app usage on some contextual variables e.g., the time, day and location of use. Such contextual variables were also used to predict the research users’ future app usage [37–39]. Pan et al. [36] further advanced such research by establishing that aggregated data of externally gathered information (e.g., friendship and affiliation) and smartphone usage logs, including call, app installation and Bluetooth logs, can be utilised to encapsulate the users’ behaviour related to possible future installations of apps.
Predicting the users’ demographic information by using and observing the browsing history either from the server side [43] or even from the client side [44] has also been investigated.
However, such applications always pose a risk to data privacy and privacy leakage, especially through advertisement libraries installed by third parties, accessing users’ information by taking undue advantages of over-permission [45,46]. The term ‘over-permission’ has been applied to situations where permissions are exploited to access information, beyond that reasonably required for the overt requirements for operation of the app. If the findings of Leontiadis et al. [45] are accurate, 73% of the freely available apps from Google Play Store seek at least one such permission, which may be considered a potential privacy risk. However, such risks of information leakage, can in principle, be controlled, as the user is always free to choose whether to install or not, any apps seeking over-permissions.
The approach adopted in this prototype was to harmonise with the works of Kosinski et al. [47] and based on the work of Seneviratne et al. [32]. However, Kosinski proposed a method to predict a variety of highly sensitive user attributes, including ethnicity, personality traits, political and religious views, sexual orientation, gender, age, happiness, use of addictive substances, intelligence and parental separation, using single snapshot of a user’s Facebook likes. Their research involved analyses of a dataset of more than 58,000 Facebook users’ ‘Likes’, along with detailed demographic profiles, as well as several psychometric test scores using logistic/linear regression to predict the users’ psycho-demographic profiles. In their research, relationships between users’ attributes and Facebook ‘Likes’ were exemplified and concerns regarding online personalisation versus privacy, were discussed.
On the other hand, Seneviratne et al. [32] put forward a method to identify the users’ preferred country (for culture-orientation purposes) by using a list of app ratings by country, published by the Appbrain website. However, this app rating is available for only 23 countries and the majority of the sample countries identified as desirable for the present work, are not included in that list. Moreover, their method does not consider the scenario where one user may have affiliations in two countries or may simply install any app of an alien country while visiting that country. The approach pursued in the present work not only overcomes this problem but also focused on a slightly different aspect, the identification of the cultural background based on countries of interests or affiliations. This extended to the grouping together of countries of common cultural preferences; for instance, instead of listing all the countries of the Middle East, they were grouped together under the generic description ‘Arab’.
The contributions of this section can be summarised as follows:
• To demonstrate that a single snapshot of installed apps can be used to foresee the users’ preferences, especially the social and cultural ones;
• To offer an adaptive user interface, with colour-based themes, according to the inferred culture;
• To make use of machine learning techniques (such as SVM Classifiers) to predict the users’ cultural background for interface design;
• To develop a culturally universal M-Learning prototype, using adaptive user interface techniques;
• Evaluating the SVM Classifier Performance used in the developed prototype.
5.4 Datasets and Associated Classifiers
To achieve the desired aim, the developmental work focused on the following two user preferences: the preferred language and the country of affiliation-as the cultural background. These are discussed in detail, in the following two subsections:
As the proffered language can be different from the language of the operating system, it can also be different from the mother tongue and hence extra caution is required while predicting the preferred language.
A commonly used API, “getDisplayLanguage” [48], was used to identify the Language of the Operating System (OS) of the mobile device. However, the language of the OS may not be the locale or preferred language of the users. There are two major reasons for this:
Most commonly, the OS is pre-installed on the mobile device and the users keep using the pre-installed language without changing it, a result of the very common factor of “inertia.” Alternatively, although the users would like to change the language, they may find that the OS does not support the preferred language. So, the language of the OS cannot be taken as the language of preference, with any certainty. However, in the software that was developed, this was used as a back-up option in case the prototype could not predict the preferred language.
As a result, the language found having the highest number of instances amongst the installed apps was forecasted as being the preferred language. As a logical precaution, pre-installed apps by the manufacturer of the smart mobile devices were excluded from this list.
To identify the preferred language, languages of installed apps can be identified using any of the existing APIs for natural language processing. With the help of numerous existing software libraries as well as Web services, the language of any app can be identified using the app description text as an input. This prototype made use of the Detect Language API [49], which can correctly detect 160 languages including all the languages considered in this research. This API accepts the descriptive text of the apps through GET or POST and provides JSON output with scores as an associated confidence value.
Google Play (formerly Android Market) was queried for the description of the app. Other alternative markets such as Appbrain and Appaware were also searched for those apps not appearing on Google Play. This query also checked to see whether the app was freely available or for sale. Some applications, such as TalknRoam, were found to be not to be even indexed in either the Google Play Store or the alternative app market. Four possible reasons for this could be:
• The app could have been developed by the user;
• The app could have originated from an obscure source or market;
• The app could have been discontinued and
• The app could have been removed from the market for various reasons.
5.4.2 Country of Affiliation as Cultural Background
Like language, the country to which the users feel the strongest affiliation, based on their cultural preferences, may be different from the country of origin or residence.
Data collected from two different sources were required to evaluate the user trait classifiers: the list of installed apps and the ground truth data. Ground truth data, of 253 smartphone users, has been obtained as part of the usability questionnaire.
For identifying the country of affiliation, indicating cultural background, nine binary SVM [50] classifiers, one for each cultural background as subcategory, were trained. The SVM classifiers accept the description of the apps as input and forecast whether the particular app is relevant to that specific trait or not.
The first major step to train and evaluate the classifiers was to form a characterised dataset comprising both positive and negative examples. Positive examples may include the apps that actually belong to a particular trait and vice-versa for negative ones. The methodology adopted for the formation of characterised datasets by identifying both positive and negative examples for the nine binary SVM classifiers is described below.
For each cultural background trait, Google Play (store) was manually searched, by inspecting the app description texts for relevance, identifying positive examples and then forming a list of the top 50 apps to train the SVM classifiers. However, because English is not widely spoken in many countries, text pre-processing was also done, with particular use of the snapshot feature to generate the list of the installed applications and the Detect Language app, which can identify over 160 languages. This resulted in a list of 450 apps and their corresponding app descriptions manually classified as positive examples for the Cultural Background trait.
These apps were basically from the corresponding country’s Electronic Media sources, Internet Service Providers and Mobile Operators, Banks, Supermarkets or E-commerce Facilitators, Government Services etc. However, the possibility of having overlapped apps was also considered and any overlapped app found was discarded from the list. To refine the accuracy of the prototype, pre-installed apps such as Google Maps, Google Play, Facebook, WhatsApp, Instagram and those from the manufacturers or the operators were excluded from the positive list examples. Manual investigations of some commonly-owned Android phones from various manufacturers were conducted for this purpose.
For any cultural background trait, the apps identified as positive examples for other than the intended trait can be used as negative examples. However, due to the diversity of the app space, to safeguard the accuracy performance of the prototype, 150 more non-relevant apps (the top 50 pre-installed apps, the top 50 paid apps and the top 25 free apps) were selected to be additionally included as sources of negative examples.
For each cultural background category, the texts of the app descriptions (for 50 positive and 500 negative examples) were pre-processed following standard data-mining techniques such as stemming, eliminating the stop words and characterising the apps by ‘tf–idf’ (term frequency–inverse document frequency) vector term. 70% of this pre-processed data was then used for training while the remaining 30% was used for testing the SVM classifiers, adopting the machine learning tool known as ‘Weka’ [51] which makes use of sequential minimal optimisation [52] for SVM implementation. Linear kernels were also used as, according to [53], linear kernels are likely to generate better results for text-mining related tasks.
5.5 Performance Evaluation of SVM Classifiers
Grounded on the value of information gain [54], the performances of the SVM classifiers were evaluated using the two traditional measures used in scoring: precision and recall metrics, as suggested by Russell and Norvig [55].
Precision, also known as the Positive Predictive Value, is the measure of the ratio of items in the result set that are truly relevant to the total number of retrieved items in the set. It can be calculated using the following formula:
Recall, also known as Sensitivity, is the measure of the ratio of all the relevant items in the collection that are in the retrieved item set to all the relevant items. It can be calculated using the following formula:
Both precision and recall are traditionally expressed in percentage and often used together to measure relevance. However, a system may trade off precision against recall. A high precision algorithm returns more relevant terms, whilst a high recall algorithm returns most of the relevant terms.
For identification of the preferred language, a 100% precision was achieved with 23% recall. For cultural background, 88% precision was achieved with 22% recall. However, these results may vary, based on the number of installed apps used for the evaluation process. The precision was found to increase and the recall decrease with the increase of installed apps as observed in our experimental experience. Intuitively, the accuracy of the result also depends on the number of installed apps matching a user trait. With the increase of the number, the chances of the user actually possessing that particular trait also increase.
6 Features, Characteristics and Functionalities
The Mobile Academy app was developed as a prototype based on findings from the analysis of the review and initial research findings. Taking into account the research objectives as well as findings, the Mobile Academy app has the following major features, characteristics and functionalities:
Considering the widely divergent choices of the users, two types of login/registration options were deployed:
Google OAuth: If the device is configured with a Gmail account, the prototype can automate and ease the login and registration using that account’s information. Fig. 5 demonstrates OAuth (Gmail) base login.
Application Login: The user has to register or login to this application using his/her personal and private information such as name, email, password, etc.
Like any other M-Learning apps, this application is to be used by both the instructors and students. As a result, the functionalities of the app are role-based:
Teachers: This role allows users to create, run, edit and delete schools as well as courses under schools. Running a course may involve uploading course materials, linking to external links for playing videos or podcasts, setting up enrolment keys, conducting and grading exams, issuing certificates etc.
Students: This role allows the users to enrol in any courses provided that the course is public or the users possess an enrolment key for private ones. Taking a course may involve downloading the course materials, studying the materials using the app, completing exams, viewing grades, printing results or certificates, etc.
Courses, either public or private, are to be created under schools. Enrolment in public courses is freely open to everyone but students are required to obtain an enrolment key set by the instructors for private courses. Upon successful completion of the course by any students, instructors can issue certificates.
As shown in Fig. 6, students can download files directly from the server by clicking appropriate links provided in the course. These hyperlinked files, including videos and audios, may be opened using the device’s installed applications.
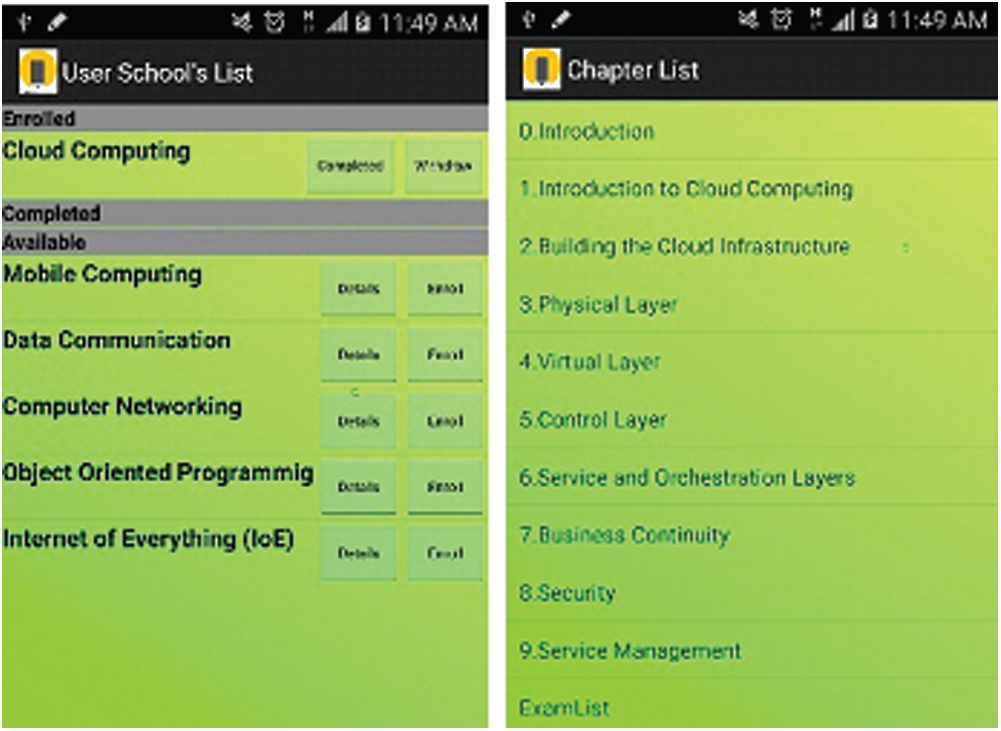
Figure 6: Enrolling and accessing course materials using student account
As an example, the creation of a new school as well as new school instances within the app, using a teacher’s account, was implemented with tick and cross boxes. The teachers can set the questions and the answers so that, upon completion, the results are immediately calculated by the system and displayed. Optionally, the examination can be protected by instructor set keys (password) and can be validated for a specific time only. The grades are saved into the students’ records.
All information about the student is stored in the database on the server. The grades and certificates (upon successful completion of any course) can be viewed on-screen, saved as PDF, printed using installed wireless printers or emailed to the students by themselves.
Although the app has been designed by adopting themes based on colours associated with the users’ respective cultures, it may not be equally applicable to everyone due to differences in psychology or even personal choices. As described in Section 5.4, there may be a mismatch between the offered themes and actual preferences too. Hence, a customisation option will provide users with the facility to personalise the system as they prefer, by selecting from UI Modes of: Default; Adaptive or Adaptable. It also facilitated to get users’ responses, especially for comparing the offered and default interfaces.
6.6 Cross-Device Testing and Evaluation
As the app was developed using Android 4.2 (Jelly Bean), it is thus expected to be compatible with any handheld devices running Android 2.3 (Gingerbread) or above. However, this does not guarantee full compatibility and hence, to confirm such compatibility, cross-device tests were conducted: Satisfactory results were obtained. Some devices, especially smartphones with much smaller screens, suffered some usability problems at the first iteration of the app. This was then solved by modifying the overall design of the app. An example app of video playing, while conducting the cross-device compatibility tests, video lecture uploaded by the teacher was evaluated. The functionalities of the app were thoroughly tested and any other bugs found were resolved. However, a detailed usability evaluation, especially cross-cultural usability, was also conducted [56].
The Mobile Academy app being a prototype and proof-of-concept has some limitations when compared with a complete, commercially available product. As internal functionality of the tasks was not the main focus of the research, some æsthetic and performance issues may be evident.
User Centric Design (UCD) and other design and development methods of Human-Computer Interaction (HCI) were deployed at this stage. However, this application is a prototype only, as a proof of concept and knowledge. The design, development and functionality of the app is not comparable with any commercial product.
Based on the manufacturers’ preferences, origin and point or intended point of sale of the device, it is possible that some of the pre-installed apps may be in a language other than the one the user actually prefers. These apps may have an influence on the accuracy of the results by incorrectly identifying that language as the preferred language of the user. In fact, such pre-installed apps were removed from the list before processing. However, this was not exhaustive as it is impractical for a prototype to cover all the manufacturers and operators’ factory default settings and customisations.
Furthermore, it cannot be guaranteed that the language detection API used for the prototype will perform with 100% accuracy and may actually classify the given text as the wrong language. However, the chances of getting such an error is very low, unless the user language is one that is not listed in its database of 160 languages, e.g., Aramaic or Chaldean, due to it being extinct or being very rare.
There is a direct relationship between the performance of the classification method utilised and the number and diversity of installed apps. For devices with only pre-installed apps or a limited number of optionally installed apps, the system is expected to be less effective, for obvious reasons, and this may result in lower recall values. However, this is expected as there are only temporary limitations for a limited number of new/re-set devices or naïve users. Users are expected to gradually install a diverse range of apps as time passes which will eliminate these temporal limitations of the prototype.
This paper has presented the development cycle of a culturally inclusive adaptive user interface system through creation of a prototype application ‘Mobile Academy’. The prototype has the characteristics of being affordable. It is not yet, however, a market-ready application, but rather a prototype or proof of concept. The application was developed primarily and initially for the purpose of the research studies in this research. The project involved designing, developing and testing an M-Learning app to be used by a wide range of users from differing backgrounds. The prototype has been tested for proper functionalities as well as cross-device compatibility. However, the investigation will continue to improve the app in order for it to be able to be adopted for a wider range of real-world usage. In fact, a Culturally Inclusive Adaptive User Interface (CIAUI) [57] framework has been derived from this project, which can be applied for multifaceted future research and development, including those for other operating systems and platforms. The CIAUI framework is one of the major deliverables of this project.
As far as can be ascertained, this is the first prototype actually based on SVM classifiers. This allows customisation of the user interface, making prediction based on the snapshot of the installed apps. By using the ground truth of 253 smartphone users, this research demonstrates that cultural background of the smart device users can indeed be accurately predicted with a precision rate of 88% and the Language of Preference can be predicted with as high as 100% precision rate using only the list of installed apps. The prototype can be further used to infer other personality traits, such as: gender, age and many more. This method can also be used for micro-targeted advertising, recommender systems and other similar projects, eliminating the need for user profiling by tracking and observing user activity, logged for a long period. It can even be used in parallel with other tracking systems in order to address the cold-start problem, where it is difficult to build an accurate profile, until the required amount of data has been gathered over a long period of observation. Thus, the Mobile Academy prototype reported in this article, along with the derived CIAUI framework, can lead to numerous future research directions, as mentioned above.
Funding Statement: This work is supported by the fund of Xiamen University Malaysia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. M. H. Miraz, S. Khan, M. Bhuiyan and P. Excell. (2014). “Mobile academy: A ubiquitous mobile learning (mLearning) platform,” in Proc. of the Int. Conf. on eBusiness, eCommerce, London, UK: University of Greenwich, pp. 89–95. [Google Scholar]
2. M. H. Miraz, M. Ali and P. Excell. (2021). “Adaptive user interfaces and universal usability through plasticity of user interface design,” Computer Science Review, vol. 40, no. May, pp. 100363–100388, . [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1574013721000034. [Google Scholar]
3. G. E. Moore. (1965). “Cramming more components onto integrated circuits,” Electronics, vol. 38, no. 8, pp. 114–117. [Google Scholar]
4. G. E. Moore. (2006). “Lithography and the future of Moore’s law,” IEEE Solid-State Circuits Society Newsletter, vol. 11, no. 5, pp. 37–42. [Google Scholar]
5. G. E. Moore. (2006). “Progress in digital integrated electronics,” IEEE Solid-State Circuits Society Newsletter, vol. 11, no. 3, pp. 36–37. [Google Scholar]
6. M. H. Miraz, M. Ali, P. Excell and R. Picking. (2015). “A review on internet of things (IoTinternet of everything (IoE) and internet of nano things (IoNT),” in Proc. of the Fifth Int. IEEE Conf. on Internet Technologies and Applications, Wrexham, North East Wales, UK. [Google Scholar]
7. W. Wu, Y. J. Wu, C. Chen and C. Lin, H. Kao et al. (2012). , “Review of trends from mobile learning studies: A meta-analysis,” Computers and Education, vol. 59, no. 2, pp. 817–827. [Google Scholar]
8. M. Sharples, J. Taylor and G. Vavoula. (2007). “A theory of learning for the mobile age,” in The SAGE Handbook of e-Learning Research, 1st ed., vol. 12. London, United Kingdom: SAGE Publications Ltd., pp. 221–247. [Google Scholar]
9. O. Viberg and Å. Grönlund. (2012). “Mobile assisted language learning: A literature review,” Proc. of the 11th Int. Conf. on Mobile and Contextual Learning 2012, vol. 955, pp. 9–16. [Google Scholar]
10. A. Kukulska-Hulme. (2012). “How should the higher education workforce adapt to advancements in technology for teaching and learning?,” Internet and Higher Education, vol. 15, no. 4, pp. 247–254. [Google Scholar]
11. P. P. Rau, Q. Gao and L. Wu. (2008). “Using mobile communication technology in high school education: Motivation, pressure, and learning performance,” Computers & Education, vol. 50, no. 1, pp. 1–22. [Google Scholar]
12. J. C. Cronjé. (2011). “Using Hofstede’s cultural dimensions to interpret cross-cultural blended teaching and learning,” Computers & Education, vol. 56, no. 3, pp. 596–603. [Google Scholar]
13. N. Pachler, B. Bachmair and J. Cook. (2010). Mobile Learning: Structures, Agency, Practices, 1st ed., New York, NY, USA: Springer US. [Google Scholar]
14. A. Kukulska-Hulme and L. Shield. (2008). “An overview of mobile assisted language learning: From content delivery to supported collaboration and interaction,” ReCALL, vol. 20, no. 3, pp. 271–289. [Google Scholar]
15. J. Cheon, S. Lee, S. M. Crooks and J. Song. (2012). “An investigation of mobile learning readiness in higher education based on the theory of planned behavior,” Computers and Education, vol. 59, no. 3, pp. 1054–1064. [Google Scholar]
16. D. A. Norman and S. W. Drape. (1986). User Centered System Design: New Perspectives on Human-Computer Interaction, 1st ed., Hillsdale, New Jersey, USA: Lawrence Erlbaum Associates, Inc., Publishers (CRC Press). [Google Scholar]
17. H. R. Hartson and D. Hix. (1989). “Toward empirically derived methodologies and tools for human-computer interface development,” International Journal of Man-Machine Studies, vol. 31, no. 4, pp. 477–494. [Google Scholar]
18. A. S. Helal, M. Mokhtari and B. Abdulrazak. (2008). The Engineering Handbook of Smart Technology for Aging, Disability and Independence, 1st ed., New York, USA: John Wiley & Sons, Inc. [Google Scholar]
19. M. H. Miraz, M. Ali and Peter Excell. (2013). “Multilingual website usability analysis based on an international user survey,” in Proc. of the Fourth Int. Conf. on Internet Technology and Applications, Wrexham, UK, pp. 236–244. [Google Scholar]
20. M. H. Miraz, P. S. Excell and M. Ali. (2016). “User interface (UI) design issues for multilingual users: A case study,” International Journal of Universal Access in the Information Society, vol. 15, no. 3, pp. 431–444. [Google Scholar]
21. R. Eisma, A. Dickinson, J. Goodman, A. Syme, L. Tiwari et al. (2004). , “Early user involvement in the development of information technology-related products for older people,” Universal Access in the Information Society, vol. 3, no. 2, pp. 131–140. [Google Scholar]
22. M. H. Miraz, M. Ali and P. Excell. (2018). “Cross-cultural usability issues in e/m-learning,” Annals of Emerging Technologies in Computing, vol. 2, no. 2, pp. 46–55. [Google Scholar]
23. L. D. Geboy. (1996). “Color makes a better message,” Journal of Health Care Marketing, vol. 16, no. 2, pp. 52–54. [Google Scholar]
24. O. Akcay and Q. S. Sun. (2013). “Cross-cultural analysis of gender difference in product color choice in global markets,” Journal of International Business and Cultural Studies, vol. 7, pp. 1–12. [Google Scholar]
25. R. P. Grossman and J. Z. Wisenblit. (1999). “What we know about consumers’ color choices,” Journal of Marketing Practice: Applied Marketing Science, vol. 5, no. 3, pp. 78–88. [Google Scholar]
26. J. Raphel. (2010). “Google: Android wallpaper apps were not security threats,” Computerworld, . [Online]. Available: https://www.computerworld.com/article/2468678/google–android-wallpaper-apps-were-not-security-threats.html. [Google Scholar]
27. S. Gezici, Zhi Tian, G. B. Giannakis, H. Kobayashi, A. F. Molisch et al. (2005). , “Localization via ultra-wideband radios: A look at positioning aspects for future sensor networks,” IEEE in Signal Processing Magazine, vol. 22, no. 4, pp. 70–84. [Google Scholar]
28. D. Zhang, F. Xia, Z. Yang, L. Yao and W. Zhao. (2010). “Localization Technologies for Indoor Human Tracking,” in 5th Int. Conf. on Future Information Technology (FutureTechBusan, Korea. [Google Scholar]
29. iText. (2020). “API documentation: iText 7 Java, iText PDF,” . [Online]. Available: https://itextpdf.com/en/resources/api-documentation/itext-7-java. [Google Scholar]
30. eMarketer. (2013). “Smartphone Adoption Tips Past 50% in Major Markets Worldwide,” eMarketer Daily Newsletter, . [Online]. Available: http://www.emarketer.com/Article/Smartphone-Adoption-Tips-Past-50-Major-Markets-Worldwide/1009923. [Google Scholar]
31. A. Corallo, G. Lorenzo and G. Solazzo. (2006). “A semantic recommender engine enabling an eTourism scenario,” in Knowledge-Based Intelligent Information and Engineering Systems, vol. 4253. NY, USA: Springer-Verlag, pp. 1092–1101. [Google Scholar]
32. S. Seneviratne, A. Seneviratne, P. Mohapatra and A. Mahanti. (2014). “Predicting user traits from a snapshot of apps installed on a smartphone,” ACM SIGMOBILE Mobile Computing and Communications Review, vol. 18, no. 2, pp. 1–8. [Google Scholar]
33. M. C. Grace, W. Zhou, X. Jiang and A. Sadeghi. (2012). “Unsafe exposure analysis of mobile in-app advertisements,” in Proc. of the Fifth ACM Conf. on Security and Privacy in Wireless and Mobile Networks, Tucson, AZ, USA, pp. 101–112. [Google Scholar]
34. G. Chittaranjan, J. Blom and D. Gatica-Perez. (2011). “Who’s who with big-five: Analyzing and classifying personality traits with smartphones,” in Proc. of the 2011 15th Annual Int. Symp. on Wearable Computers, San Francisco, CA, USA, pp. 29–36. [Google Scholar]
35. R. LiKamWa, Y. Liu, N. D. Lane and L. Zhong. (2013). “MoodScope: Building a mood sensor from smartphone usage patterns,” in Proc. of the 11th Annual Int. Conf. on Mobile systems, Applications, and Services, Taipei, Taiwan, pp. 389–402. [Google Scholar]
36. W. Pan, N. Aharony and A. S. Pentland. (2011). “Composite social network for predicting mobile apps installation,” in Proc. of the Twenty-Fifth Conf. on Artificial Intelligence, San Francisco, California, USA, pp. 821–827. [Google Scholar]
37. T. Yan, D. Chu, D. Ganesan, A. Kansal and J. Liu. (2012). “Fast app launching for mobile devices using predictive user context,” in Proc. of the 10th Int. Conf. on Mobile systems, Applications, and Services, Ambleside, United Kingdom, pp. 113–126. [Google Scholar]
38. A. Parate, M. Böhmer, D. Chu, D. Ganesan and B. M. Marlin. (2013). “Practical prediction and prefetch for faster access to applications on mobile phones,” in Proc. of the 2013 ACM Int. Joint Conf. on Pervasive and Ubiquitous Computing, Zurich, Switzerland, pp. 275–284. [Google Scholar]
39. Y. Xu, M. Lin, H. Lu, G. Cardone, N. D. Lane et al. (2013). , “Preference, context and communities: A multi-faceted approach to predicting smartphone app usage patterns,” in Proc. of the 2013 Int. Symp. on Wearable Computers, Zurich, Switzerland, pp. 69–76. [Google Scholar]
40. R. R. McCrae and O. P. John. (1992). “An introduction to the five-factor model and its applications,” Journal of Personality, vol. 60, no. 2, pp. 175–215. [Google Scholar]
41. C. Shepard, A. Rahmati, C. Tossell, L. Zhong and P. Kortum. (2010). “LiveLab: Measuring wireless networks and smartphone users in the field,” ACM SIGMETRICS Performance Evaluation Review, vol. 38, no. 3, pp. 15–20. [Google Scholar]
42. M. Böhmer, B. Hecht, J. Schöning, A. Krüger and G. Bauer. (2011). “Falling asleep with Angry Birds, Facebook and Kindle—A large scale study on mobile application usage,” in Proc. of the 13th Int. Conf. on Human Computer Interaction with Mobile Devices and Services, Stockholm, Sweden, pp. 47–56. [Google Scholar]
43. J. Hu, H. Zeng, H. Li, C. Niu and Z. Chen. (2007). “Demographic prediction based on user’s browsing behavior,” in Proc. of the 16th Int. Conf. on World Wide Web, Banff, Alberta, Canada, pp. 151–160. [Google Scholar]
44. S. Goel, J. M. Hofman and M. I. Sirer. (2012). “Who does what on the web: A large-scale study of browsing behavior,” in Proc. of the Sixth Int. AAAI Conf. on Weblogs and Social Media, Dublin, Ireland. [Google Scholar]
45. I. Leontiadis, C. Efstratiou, M. Picone and C. Mascolo. (2012). “Don’t kill my ads! balancing privacy in an ad-supported mobile application market,” in Proc. of the Twelfth Workshop on Mobile Computing Systems & Applications (HotMobile ’12San Diego, CA, USA, pp. 28–29. [Google Scholar]
46. S. Shekhar, M. Dietz and D. S. Wallach. (2012). “AdSplit: Separating smartphone advertising from applications,” in Proc. of the 21st USENIX Conf. on Security Symp. (Security’12Berkeley, CA, USA, pp. 553–567. [Google Scholar]
47. M. Kosinski, D. Stillwell and T. Graepel. (2013). “Private traits and attributes are predictable from digital records of human behavior,” Proc. of the National Academy of Science of the United States of America, vol. 110, no. 15, pp. 5802–5805. [Google Scholar]
48. Android. (2020). “Android Developers,” . [Online]. Available: http://developer.android.com/reference/java/util/Locale.html#getDisplayLanguage [Google Scholar]
49. Detect Language. (2020). “Language Detection API,” . [Online]. Available: https://detectlanguage.com/. [Google Scholar]
50. C. Cortes and V. Vapnik. (1995). “Support-vector networks,” Machine Learning, vol. 20, no. 3, pp. 273–297. [Google Scholar]
51. M. Hall, E. Frank, G. Holmes, B. Pfahringer, P. Reutemann et al. (2009). , “The WEKA data mining software: An update,” ACM SIGKDD Explorations Newsletter, vol. 11, no. 1, pp. 10–18. [Google Scholar]
52. J. C. Platt. (1999). “Fast training of support vector machines using sequential minimal optimization,” in Advances in Kernel Methods, Cambridge, MA, USA: MIT Press, pp. 185–208. [Google Scholar]
53. L. M. Manevitz and M. Yousef. (2001). “One-class SVMs for document classification,” Journal of Machine Learning Research, vol. 2, no. 12, pp. 139–154. [Google Scholar]
54. Y. Yang and J. O. Pedersen. (1997). “A comparative study on feature selection in text categorization,” in Proc. of the Fourteenth Int. Conf. on Machine Learning, Nashville, Tennessee, USA, pp. 412–420. [Google Scholar]
55. S. Russell and P. Norvig. (2003). Artificial Intelligence: A Modern Approach, 2nd ed., NJ, USA: Pearson Educat., Inc. [Google Scholar]
56. M. H. Miraz, M. Ali and P. S. Excell. (2021). “Cross-cultural inclusivity and usability evaluation of mobile academy prototype,” Future Generation Computer Systems [submitted for review]. [Google Scholar]
57. M. H. Miraz, P. S. Excell and M. Ali. (2021). “Culturally inclusive adaptive user interface (CIAUI) framework: Exploration of plasticity of user interface design,” International Journal of Information Technology & Decision Making, vol. 20, no. 1, pp. 1–26, . [Online]. Available: https://www.worldscientific.com/doi/10.1142/S0219622020500455. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |