DOI:10.32604/cmc.2021.016113
| Computers, Materials & Continua DOI:10.32604/cmc.2021.016113 | |
| Article |
A Hybrid Model Using Bio-Inspired Metaheuristic Algorithms for Network Intrusion Detection System
Department of Computer Network and Information Systems, The World Islamic Sciences and Education University, Amman, 11947, Jordan
*Corresponding Author: Omar Almomani. Email: omar.almomani@wise.edu.jo
Received: 23 December 2020; Accepted: 24 January 2021
Abstract: Network Intrusion Detection System (IDS) aims to maintain computer network security by detecting several forms of attacks and unauthorized uses of applications which often can not be detected by firewalls. The features selection approach plays an important role in constructing effective network IDS. Various bio-inspired metaheuristic algorithms used to reduce features to classify network traffic as abnormal or normal traffic within a shorter duration and showing more accuracy. Therefore, this paper aims to propose a hybrid model for network IDS based on hybridization bio-inspired metaheuristic algorithms to detect the generic attack. The proposed model has two objectives; The first one is to reduce the number of selected features for Network IDS. This objective was met through the hybridization of bio-inspired metaheuristic algorithms with each other in a hybrid model. The algorithms used in this paper are particle swarm optimization (PSO), multi-verse optimizer (MVO), grey wolf optimizer (GWO), moth-flame optimization (MFO), whale optimization algorithm (WOA), firefly algorithm (FFA), and bat algorithm (BAT). The second objective is to detect the generic attack using machine learning classifiers. This objective was met through employing the support vector machine (SVM), C4.5 (J48) decision tree, and random forest (RF) classifiers. UNSW-NB15 dataset used for assessing the effectiveness of the proposed hybrid model. UNSW-NB15 dataset has nine attacks type. The generic attack is the highest among them. Therefore, the proposed model aims to identify generic attacks. My data showed that J48 is the best classifier compared to SVM and RF for the time needed to build the model. In terms of features reduction for the classification, my data show that the MFO-WOA and FFA-GWO models reduce the features to 15 features with close accuracy, sensitivity and F-measure of all features, whereas MVO-BAT model reduces features to 24 features with the same accuracy, sensitivity and F-measure of all features for all classifiers.
Keywords: IDS; metaheuristic algorithms; PSO; MVO; GWO; MFO; WOA; FFA; BAT; SVM; J48; RF; UNSW-NB15 dataset
Computer network operations have been developing rapidly due to an increase in the number of computers and mobile devices. In light of that, the number of network attacks has been overgrowing as well. According to “the European Union Agency for Network and Information Security (ENISA),” the attacks complexity and the malicious sophistication has been increasing. Therefore, network security has been receiving greater attention [1,2]. The techniques used for ensuring network security are prevention, detection, and mitigation techniques. Prevention is a proactive technique that serves as the first-line procedure for protecting the network. It aims to avoid the attacks. If the prevention fails to protect the network, the detection technique is employed. It is utilized to monitor the network and detect potential attacks. Finally, mitigation techniques used to keep devices on while it is under attack. Detection techniques are categorized into two kinds based on the place of detection or type of detection. Place of detection can be host-based detection or network-based detection. In contrast, the type of detection can be a signature or anomaly-based detection [3]. Host-based detection monitors the internal operations of the computer system to detect any illegal access to its resources. The network-based detection monitors the network traffic logs in real-time for identifying the potential intrusions launched against the network. Signature-based detection technique searches for specific trends, or signatures. The use of this technique preferred for detecting known attacks, however, this technique is not able to detect new attacks.
On the other hand, anomaly-based detection aims to identify the normal behaviour of the network and producing a warning every time a deviation occurs through using a predefined threshold. Anomalies detection defined as a two-class classifier that classifies each sample as a normal or abnormal sample. The current IDS suffers from several efficiency-related problems, such as the low rates of detection accuracy and high rates of false detection [4]. To improve the IDS performance, feature selection is a significant step in any IDS. Feature selection for IDS can be done using several approaches. One of these approaches is bio-inspired metaheuristic algorithms.
Feature selection contributes to reducing the dimensional data by removing the duplicate and unnecessary features from the dataset. In addition to that, it deletes the least essential feature from the dataset to improve the classification accuracy. Feature selection approaches play a significant role in building an optimized IDS with fewer features. Feature selection model can be either filter-based, wrapper-based and embedded-based. In this paper wrapper-based used.
Bio-inspired metaheuristic algorithms are algorithms based on certain physical and biological standards. They are classified into two types, population and single solution based algorithms [5]. Population-based detectors are deemed more suitable than single solution-based algorithms. Population-based bio-inspired metaheuristic algorithms used in this study are PSO [6–10], MVO [11], GWO [7,12], MFO [13], WOA [14], FFA [7,15] and BAT [16,17].
Through the present paper, a hybrid model based on PSO, MVO, GWO, MFO, WOA, FFA, and BAT algorithms for network IDS proposed to reduce feature selection. That main objective of this study is to enhance the network IDS performance by reducing the number of the selected features to get high detection accuracy for large scale datasets with consuming less time. The effectiveness of the proposed model tested by using well-known machine learning SVM, J48 and RF classifiers.
The new contributions of the paper include:
a) The present study offers a proposed hybrid model for network IDS through the hybridization of every couple of PSO, MVO, GWO, MFO, WOA, FFA, and BAT algorithms to reduce the number of the selected feature to improve NIDS performance.
b) The present study evaluates the reduced dataset of the proposed hybrid model based on SVM, J48, and RF machine learning classifiers.
The paper organized as follows: Section 2 provides a review of the relevant literature that is related to anomaly detection by using bio-Inspired Metaheuristic algorithms. Section 3 presents a discussion about the proposed model. Section 4 provides information about the performance evaluation metrics. Section 5 presents several experimental results about the proposed model. Section 6 offers a conclusion
During recent years, the feature selection model for network IDS has been receiving much attention from researchers. The researchers proposed many models to improve network IDS performance using different approaches such as filter, wrapper, data processing, optimization, machine learning techniques, and Bio-inspired Metaheuristic algorithms. Bio-inspired Metaheuristic algorithms are used to improve the network IDS performance due to its ability to find the most effective solutions within the minimum time. Each bio-Inspired metaheuristic algorithm has its drawbacks and advantages. Through hybridization, each algorithm can take advantage of the strengths and address the weaknesses of other algorithms. Many recent studies suggest that hybridization improves the bio-Inspired metaheuristic algorithm performance. This section explains some of these recent studies.
Kim et al. [18] developed a hybrid IDS which includes an anomaly detection model based on multiple 1-class SVM. It consists of a misuse detection model based on the C4.5 decision tree algorithm. NSL-KDD dataset used for validating the proposed hierarchical model in terms of detection accuracy and false alarm rate of unknown and known attacks. In comparison to other models, the proposed model can effectively reduce the false positive rate and the duration needed for the testing and training processes. In addition to that, the proposed model significantly reduces the time required for training processes by 50% and the time required for the testing process by 40%.
Ghanem et al. [19] proposed a hybrid IDS to classify anomalies in large-scale datasets through employing the Genetic Algorithm (GA) detectors and multi-start metaheuristic system. The proposed model uses a negative selection-based detector generation method. It was evaluated by employing the NSL-KDD dataset. Based on the results of the evaluation, the model is useful in generating an appropriate number of detectors. The accuracy rate of this model is 96.1%, and the false positive rate is 3.3.
Eesa et al. [20] developed a hybrid model that includes the cuttlefish optimization algorithm (CFA) and the decision tree classifier. It aims to detect network intrusions. In this model, the CFA employed for selecting significant features, while the decision tree algorithm used for identifying the types of abnormal events. The performance of this model tested on the KDDCup99 Dataset. The results showed that, when the number of features is less than 20, the detection rate and accuracy is significantly high.
Asahi-Shahri et al. [21] developed a hybrid model that includes GA and SVM. This model reduced the features from 45 to 10 features. The GA algorithm categorized those features into three types based on priority. This model shows an outstanding true positive value and a low false-positive value using the KDD 99 dataset. The results of the proposed hybrid model showed a true positive value of 0.973 and the false-positive value is 0.017.
Guo et al. [22] developed a two-level hybrid model to detect the intrusions by utilizing the strengths of the misuse-based and anomaly-based detection approach. This model consists of two anomaly detection components (ADCs) and one misuse detection component (MDC). ADC one detects abnormal connections by employing the ADBCC method. After that, the declared abnormal and normal links sent to the ADC two and the MDC respectively in parallel to be assessed by K-NN. This hybrid approach tested experimentally using KDDCup99 and the Kyoto University Benchmark Dataset (KUBD). Based on the results of the trial using the dataset of KDD99, the proposed model can effectively detect unknown attacks and known ones. It can effectively detect network anomalies by showing a high detection accuracy value and a low false-positive rate value. Based on the results of the experiment using the dataset of KUBD, the proposed model was highly effective in collecting attack traffics without having a specific label compared to KDDcup99 and KDD99.
Al-Yaseena et al. [23] developed a multi-level hybrid IDS that employs extreme learning machine (ELM) and SVM which they were used to improve the performance efficiency of the model in detecting known and unknown attacks. The proposed model tested using the KDDCup99 dataset. Based on the results of the trial, the accuracy of the proposed model is 95.75%. The false alarm rate of the model is 1.87%.
Hajisalem et al. [24] developed a hybrid classification model based on an artificial bee colony (ABC) and artificial fish swarm (AFS) algorithm. The performance level of the model assessed by employing two datasets (NSL-KDD and UNSW-NB15). Based on the results of the trial, the detection accuracy of the model is 99%. The false-positive rate is 0.01%.
Li et al. [25] developed a model that includes the Gini index. This model consists of the gradient boosting decision tree (GBDT) and PSO. The optimal feature subset was chosen by Gini index. The gradient lifting decision tree algorithm was used to detect a network attack. The parameters of GBDT were optimized using the PSO algorithm. The model assessed in terms of detection rate, accuracy, F1-score, precision, and false alarm rate. Such an assessment conducted by employing the NSL-KDD Dataset. Based on the results, it was found that the model is accurate and able to detect intrusion effectively. The detection rate of the model was 78.48%, the precision rate was 96.44%, the F1-score was 86.54% and the false acceptance rate was 3.83%.
Hosseini et al. [26] developed a hybrid model for detecting intrusion. This model consists of two phases. The first phase is the feature selection phase. The second phase is the attack detection phase. Through the first phase, a wrapper method called (MGA-SVM) employed. This model includes features of SVM and GA with multi-parent crossover and multi-parent mutation (MGA). In the second phase, an artificial neural network (ANN) employed for detecting attacks. A hybrid gravitational search (HGS) conducted, and a PSO is used to improve the performance of the proposed model. The proposed model is named MGA-SVMHGS-PSO-ANN. The performance of MGA-SVMHGS-PSO-ANN compared to the performance of GS-ANN, DT, GD-ANN, GAANN, PSO-ANN, and GSPSO-ANN. Using the NSL-KDD Dataset, data showed that the proposed MGA-SVMHGS-PSO-ANN model has a high detection accuracy rate of 99.3%. The features of NSL-KDD reduced from 42 to 4 features and the training time of this model is 3 seconds maximum.
Khraisat et al. [27] developed a hybrid IDS (HIDS) model, which includes a C5.0 decision tree classifier and a one-class support vector machine (OC-SVM). HIDS used the strengths of the Signature-based IDS and the anomaly-based IDS. The signature-based IDS created based on the C5.0 decision tree classifier, while the anomaly-based IDS established based on the OC-SVM. It aims to identify the well-known intrusions and zero-day attacks by showing a high level of detection accuracy and a low false-alarm rate. The proposed HIDS assessed by employing the NSL-KDD datasets and the Australian defence force academy (ADFA) datasets. It found that the performance of HIDS has improved compared to Signature-based IDS and anomaly-based IDS in terms of the detection rate, false alarm rate, true negative rate, false-negative rate, false-positive rate, recall rate, precision, sensitivity, and F-Measure.
Mohmmadzadeh et al. [28] proposed a new hybrid model combining WOA and flower pollination algorithm (FPA). This model is called HWOAFPA. It employs natural processes of WOA and FPA for solving the problem of feature selection optimization. On the other hand, it operates the opposition-based learning (OBL) method to ensure that the convergence rate and accuracy of the proposed model are high. In fact, in the proposed model, WOA creates solutions in their search space by using the prey siege and encircling process, bubble invasion. It searches for prey methods and seeks to enhance the solutions of the feature selection problem; along with this model. FPA improves the solution of the issue of the feature selection by carrying out two global and local search processes in an opposite space with the solutions of the WOA. WOA and FPA using all the possible solutions to solve the feature selection problem. They assessed the level of the proposed model performance using an experiment consisting of two stages. Through the 1st stage, the investigation carried out on ten feature selection datasets that obtained from the UCI data repository, and in the second stage, WOA and FPA assessed the performance level of the model in terms of detecting spam email messages. Based on the results obtained from the first stage, the model performance on ten UCI datasets is more effective than other basic metaheuristic algorithms in terms of the average size of selection and classification accuracy, whereas in the second stage, the proposed model shows higher accuracy than other similar algorithms in terms of having spam emails detected.
This model aims to increase the performance efficiency of the network IDS by hybridizing the following PSO, MVO, GWO, MFO, WOA, FFA, and BAT meta-heuristic algorithms. Fig. 1 presents a proposed hybrid model architecture. The performance efficiency is enhanced by reducing the number of effective features in classifying the dataset to detect generic attacked. The following subsection illustrates each stage of the proposed model in detail.
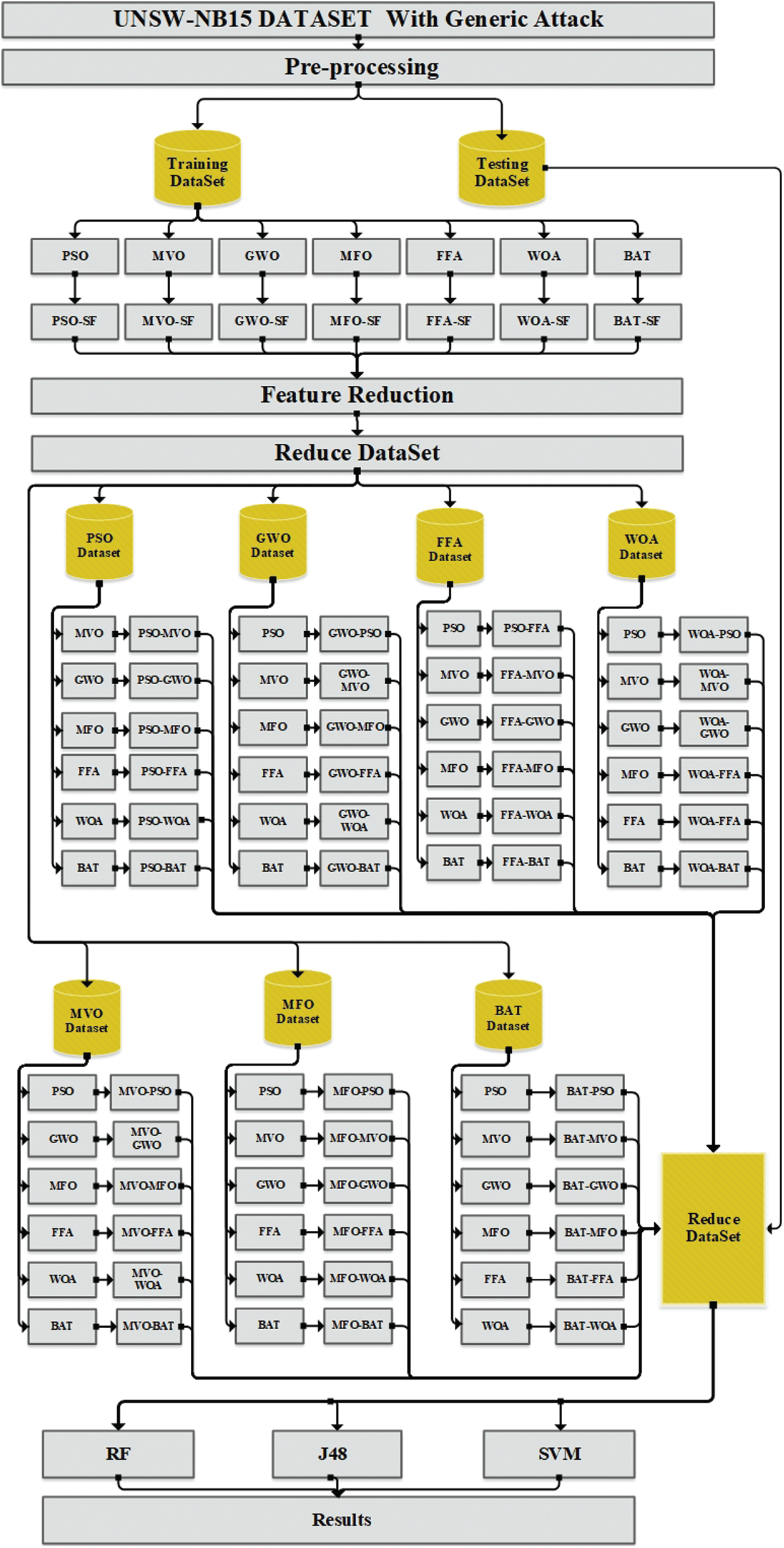
Figure 1: The proposed hybrid model architecture
The UNSW-NB15 dataset [29] created by utilizing an IXIA PerfectStorm tool. A tcpdump tool used to capture 100 GB of raw network traffic (pcap files). Each pcap file contains 1000 MB to make the analysis of the packets easier. Argus and Bro-IDS techniques were used, and 12 procedures carried out to generate 49 features with the class label. This dataset divided into a training set and a testing set. The training set includes 175,341 records, while the testing set contains 82,332 records and these records can be either attack or normal. The relevant attacks launched against the UNSW-NB15 dataset are 9 types which include; analysis, backdoor, DoS, Exploits, Fuzzers, Generic, Reconnaissance, Shellcode and Worms. The generic attack represented by 18,8712 records in the testing set and 40,000 records in the training set which is the highest attacks among other attacks. Tab. 1 presents a list of features that are in UNSW-NB15 dataset.
Table 1: UNSW-NB15 dataset features list

The UNSW-NB15 dataset has to go through the following pre-processing steps to use the EvoloPy-FS optimization framework [30–33]:
a) The label removal: Each feature in the original UNSW-NB15 dataset has a label. It’s necessary to remove this label to adapt the dataset with the EvoloPy-FS context.
b) The removal of features: The original UNSW-NB15 Dataset has 45 features, 2 of these include class labels i.e attack cat and label. The attack cat is not considered as a feature, thus, deleting it is necessary.
c) Label encoding: Within the Dataset, the labels i.e state, protocol, and service type have string values and it is crucial to have these values encoded in numerical values.
d) Binarisation of data: The numerical data in the dataset poses challenges over the classifier in the training process. Thus, it is very important to standardize the values in each feature. Therefore, the minimum value should be 0 in each feature and the maximum value should be 1 in each feature. This will make the group more homogeneous and maintain the contrast between the values of every feature.
3.3 Bio-Inspired Metaheuristic Algorithms
Selecting the features was done based on the following Bio-inspired metaheuristic algorithms:
PSO created by Eberhart et al. [6]. Through PSO, the information gets optimized through having social contact within the community; the learning is considered personal and social. PSO based on the ability to interpret each solution in the swarm as a particle. Regarding each particle as a position in the search space that represented as follows:
D refers to the search space dimensionality. Particles move to search for the optimal solutions within the search space, considering each particle has a velocity which is identified as follows
Regarding each particle, it has its position and velocity, such a position and velocity updated throughout the movement of the position. The best initial position of the particle reported as the best personal pbest. The best position of the population is called gbest. PSO looks for optimal solutions based on gbest-pbest. It looks for them through having the velocity and position of each particle updated by the equations below:
t denotes the tth iteration within the process of evolutionary. d
MVO is a new metaheuristic algorithm that was developed by Mirjalili et al. [11]. It mimics the principles of a multi-versa theory. It was developed based on the idea of multiple existences universes that include white, black and wormholes and their interactions. Regarding the algorithm, it is a stochastic algorithm that based on the population. It approximates the optimum global for problem optimization with a solution collection.
MVO has two parameters for having the solution updated. Those parameters are wormhole existence probability (WEP) and travelling distance rate (TDR). They determine how much and how often the solutions change during the process of optimization. WEP is calculated based on the equation below:
Where the minimum is b, the maximum is a current iteration is t, and the maximum number of allowed iterations is T. TDR i is calculated based on the equation below:
where the exploitation accuracy is p. Finally, the position of the solutions modified after calculating WEP and TDR.
GWO developed based on a social hierarchy and the hunting approach of grey wolves. It proposed by Mirjalili et al. [12]. It consists of four levels.
Level-1: Alpha (
Level-2: Beta (
Level-3: Delta (
Level-4: Omega (
GWO mathematics model has three parts. Those parts are encircling, hunting and attaching behaviour. the encircling behaviour, it represented in the equation below:
whereas:
The hunting behaviour defined in the equation below
The attaching behaviour represented in the equation below
MFO proposed by Mirjalili [13]. Regarding Moth, an insect related to the butterflies’ family. It starts carrying out its primary activities at night. The primary concept for MFO comes from investigating the moth cycle when looking for light in nature, that’s called transverse orientation. The moth location is regulated based on a fixed angle of motion concerning the incoming light. Moths travel in a spiral shape and seek to hold angle that similar to the angle of the light produced by man. They update their location for a specific flame according to the following equation:
Whereas:
Di Euclidian distance of the i moth for the j flame. It calculated as follows:
Mi is i Moth, Fj is j flame, t refers to any random value that is within the range of [ −1, 1]. Where the number of the flames inside MFO calculate as follows:
l stands for the number of iterations, N stands for the maximum number of flames, T stands for the maximum number of iterations
FFA created by Yang et al. [34]. It based on tropical firefly’s communication behaviour. This behaviour described by using three idealized rules. These rules are:
a) Regarding all the fireflies as unisex.
b) The brightness of the fireflies is proportionate to their attractiveness.
c) The firefly’s brightness is determined and influenced by the environment of the objective functions.
The movement of a firefly i that is attracted to firefly j represented in the equation below:
Where:
(rand −0.5) is a random number that is within the range of [ −0.5 −0.5],
Whereas:
xi refers to the position of firefly I, xj refers to the position of firefly j.
A WOA created by Mirjalili [14]. It imitates the natural behaviour of the humpback whales. The simulation of this algorithm involves three operators simulating the prey search (exploration phase), the encircling prey, and the humpback whales behaviour of bubble-net foraging (exploitation phase). The encircling prey, it represented in the equation below:
Where:
The phase of exploitation: This phase is also called the attacking bubble-net. It works with two approaches: Shrinking encircling and spiral updating position. Both shrinking circlings in a spiral updating position are applying in whale movement in the direction of its prey.
BAT proposed by Yang [16]. It represents the behaviour of the bats, which is described by employing three idealized rules as follows:
a) All the bats use echolocation to predict the distance. They know in some magical manner the difference between food/prey and background barriers.
b) A bat bi flies randomly at velocity vi with a specific frequency fmin at position xi, varying wavelength
c) Loudness varies in several aspects. It differs from a large positive A0 to a minimum constant value Amin as it’s suggested by Yang [12].
Virtual bat movement updates its velocity and position through using the following equations:
where:
ß is a random number that is within the range of [0, 1], Xi stands for the initial position, Vi stands for the velocity, Fi stands for the initial frequency
The proposed model selects important features as follow:
a) Binariz data [ −1, 1]
b) Define a set of binary individuals.
c) Individual and population represented by [1-D, 2-D] array.
d) Reduce dataset generated where 1s indicates to feature selected, and 0s mean feature not selected feature.
e) Knn classifier used to evaluate the suitable solution and produce fitness value of reducing dataset.
f) Finally, repeat these steps to reach the maximum number of iterations.
3.5 Hybrid Bio-Inspired Metaheuristic Model
Tab. 2 presents the hybridization of bio-inspired metaheuristic algorithms hybridization.
Table 2: Hybridization of bio-inspired metaheuristic algorithms

3.6 Machine Learning Classifiers
Classifier employed for classifying the incoming data as abnormal data or a normal. The present study sheds light on J48, SVM and RF classifiers. These classifiers were select because they are the most famous classifiers used in the literature for network IDS [21,35–39].
SVM is a binary classifier. In SVM, the data gets divided into two class through the use of statistical methods, fixed rules and quadratic equations. The binary classification of the data is carried out through employing a separating hyperplane to maximize the space of the margin based on the functions of the kernel, and the extracted data are stored in the vector, leading to the best solution for the problem. Due to its use for the structural risk minimization method, the SVM has a strong generalization capability. Several previous [21,35,36] studies showed that SVM is a highly effective classifier.
The algorithm of J48 is considered a tree classifier that was proposed by Quinlan [40]. It employed the improved technique of tree pruning for reducing the number of classification-related errors. It follows the following steps for creating a decision tree:
a) Selecting the attribute as root that has the enormous gain value.
b) Building a branch for any value.
c) Repeating the procedure for each branch until the branches have the same class for all the cases.
Several researchers explored the influence of employing the J48 algorithm for enhancing the accuracy level of IDS [36,37].
RF classifier proposed by L.Breiman [41]. It is a tree-based ensemble learning classifier [42]. It constructed by combining the predictions of various trees, each of which trained in individual. The decision takes by RF classifier is based on most of the trees selected. The RF classifier has several benefits, for instance, it has the chance of over-fitting and it is associated with less duration of time for the training process. It shows a high level of accuracy and it runs efficiently in large databases. Through predicting of the missing data, it makes highly accurate predictions. Several previous studies [38,39], showed that the RF classifier has a significant positive impact on the accuracy of IDS.
4 Performance Evaluation Metrics
For assessing the performance efficiency of the proposed model, the following metrics were used: true-positive (TP), true-negative (TN), false-positive (FP) and false-negative (FN) rates [43,44]. The confusion matrix presented in Tab. 3. Based on these metrics, other metrics are calculated, such as sensitivity, precision, accuracy, F-measure and building time.

Metrics calculated as below:
5.1 First Experiment: Features Selection
The experiment was done using anaconda python open-source. Tab. 4 presents the simulation parameters setting.
Table 4: Simulation parameters

Tab. 5 presents the results of selected features based on the hybridization of Bio-Inspired metaheuristic algorithms.
Table 5: Selected features-based hybridization model


Tab. 5 presents the results of selected features based on the hybridization of Bio-Inspired metaheuristic algorithms. Based on Tab. 5, it was found that PSO-MVO model reduces the number of features into 12 features. In contrast, MVO-WOA, GWO-MVO and GWO-MFO model reduces the number of features into 14 features, while MFO-PSO and MFO-MVO model reduces the number of features into 12 features. Meanwhile, WOA-GWO minimizes the number of features into 9 features, FFA-MVO model reduces the number of features into 8 features and BAT-GWO reduces features to 18 features.
5.2 Second Experiment: Classification
The hybrid model in Tab. 5 evaluated based on three ML classifiers. These classifiers are J48, SVM and RF classifier. The results of the J48, SVM and RF classifier shown in Tab. 6.
Table 6: Results of J48, SVM and RF

Based on obtained results from Tab. 6, it was found that PSO-BAT model with 19 features outperformed other PSO combination in terms of accuracy, sensitivity and F-measure, concerning J48, SVM and RF classifiers. In terms of building time, PSO-BAT required less time to compare all features and J48 needed the lowest time than SVM and RF. Whilst MVO-BAT model with 24 features outperformed other MVO combination and gave the same accuracy, sensitivity and F-measure of all features for all mentioned classifiers. MVO-BAT model needed less building time to compare all features and J48 needed the lowest time compared to the other classifiers. Regarding GWO combination model, the GWO-PSO and GWO-WOA models with 17 features performed better than other GWO combination and required less building time of all features, GWO-PSO and GWO-WOA models produced close accuracy, sensitivity and F-measure to all features. J48 again required less time than SVM and RF. In the case of the MFO combination, the MFO-WOA model reduces feature to 15, it outperformed other MFO combination with respect to accuracy, sensitivity and F-measure. The time required to build MFO-WOA model with J48 classifier is less than SVM and RF. The WOA-BAT model reduces feature to 19, it produces better performance compare to other WOA combination in terms of accuracy, sensitivity and F-measure. J48 needed less time to build WOA-BAT model than SVM and RF. Regarding FFA combination, the FFA-GWO with 15 features has the best performance among other FFA combination concerning the accuracy, sensitivity and F-measure for J48, SVM and RF classifiers. The FFA-GWO model builds takes less time compare to SVM and RF. Finally, BAT-PSO model reduces features to 22 and shows the best results among other BAT combination. Again J48 shows a higher efficiency relative to SVM and RF in term of needed time to build the model.
My data suggest that the proposed hybrid models improve network IDS by reducing features and time required to build a detection model. In addition to that my results show the dominance of J48 on SVM and RF in term of the required time. Concerning the features reduction and the classification, results show that the MFO-WOA and FFA-GWO models reduce features to 15 features with close accuracy, sensitivity and F-measure of all features, whereas MVO-BAT model reduces features to 24 features with the same accuracy, sensitivity and F-measure of all features for all classifiers.
Using metaheuristic algorithms can help to find optimal features sets. Hybridization of metaheuristic algorithms can reduce the number of features and improve the accuracy of the classification process with less time. Therefore, In this study, a hybrid model based on metaheuristic algorithms is developed to reduce selected features for network IDS. PSO, MVO, GWO, MFO, WOA, FFA and BAT algorithms used by this study. The proposed hybrid model was evaluated using UNSW-NB15 dataset and J48, SVM, RF classifier. The experiment conducted throughout two phases. The first phase aims to choose features through using Metaheuristic algorithm and the second phase is represented in evaluating proposed hybrid models based on R48, SVM and RF classifiers. The results obtained of the first phase showed that proposed hybrid models reduce the number of features. The results of the second phase show the dominance of J48 on SVM and RF in terms of required time to build the model. MFO-WOA and FFA-GWO models reduce features to 15 features with good classification rate. Finally, the MVO-BAT model reduces features to 24 features with the same results of all features. The proposed hybrid model is capable to detect generic attack more effectively.
Funding Statement: This work was funded by The World Islamic Sciences and Education University.
Conflicts of Interest: The author declares that they have no conflicts of interest.
1. M. Adil, M. A. Almaiah, A. Omar Alsayed and O. Almomani. (2020). “An anonymous channel categorization scheme of edge nodes to detect jamming attacks in wireless sensor networks,” Sensors, vol. 20, no. 8, pp. 2311–2330. [Google Scholar]
2. A. almaiah and O. Almomani. (2020). “An investigator digital forensics frequencies particle swarm optimization for detection and classification of apt attack in fog computing environment (IDF-FPSO),” Journal of Theoretical and Applied Information Technology, vol. 98, no. 7, pp. 937–952. [Google Scholar]
3. H. Rajadurai and U. D. Gandhi. (2020). “A stacked ensemble learning model for intrusion detection in wireless network,” Neural Computing and Applications, S.I.: New Trends in Brain Computer Interface, pp. 1–9. [Google Scholar]
4. A. El Omri and M. Rida. (2019). “An efficient network ids for cloud environments based on a combination of deep learning and an optimized self-adaptive heuristic search algorithm,” 7th Int. Conf. in Networked Systems, NETYS 2019, vol. 11704, pp. 235–249. [Google Scholar]
5. G. Dhiman. (2019). “ESA: A hybrid bio-inspired metaheuristic optimization approach for engineering problems,” Engineering with Computers, vol. 37, no. 1, pp. 1–31. [Google Scholar]
6. J. Kennedy and R. Eberhart. (1995). “Particle swarm optimization,” ICNN’95—Int. Conf. on Neural Networks, vol. 4, pp. 1942–1948. [Google Scholar]
7. O. Almomani. (2020). “A feature selection model for network intrusion detection system based on PSO, GWO, FFA and GA algorithms,” Symmetry (Basel), vol. 12, no. 6, pp. 1046. [Google Scholar]
8. F. Marini and B. Walczak. (2015). “Particle swarm optimization (PSO). A tutorial,” Chemometrics and Intelligent Laboratory Systems, vol. 149, pp. 153–165. [Google Scholar]
9. A. K. Al Hwaitat, M. A. Almaiah, O. Almomani, M. Al-Zahrani, R. M. Al-Sayed et al. (2020). , “Improved security particle swarm optimization (PSO) algorithm to detect radio jamming attacks in mobile networks,” International Journal of Advanced Computer Science and Applications, vol. 11, no. 4, pp. 614–625. [Google Scholar]
10. A. H. Mohammad, T. Alwada’n and O. Al-Momani. (2016). “Arabic text categorization using support vector machine, Naïve Bayes and neural network,” GSTF Journal on Computing, vol. 5, no. 1, pp. 108–115. [Google Scholar]
11. S. Mirjalili, S. M. Mirjalili and A. Hatamlou. (2016). “Multi-verse optimizer: A nature-inspired algorithm for global optimization,” Neural Computing & Applications, vol. 27, no. 2, pp. 495–513. [Google Scholar]
12. S. Mirjalili, S. M. Mirjalili and A. Lewis. (2014). “Grey wolf optimizer,” Advances in Engineering Software, vol. 69, pp. 46–61. [Google Scholar]
13. S. Mirjalili. (2015). “Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm,” Knowledge-Based System, vol. 89, pp. 228–249. [Google Scholar]
14. S. Mirjalili and A. Lewis. (2016). “The whale optimization algorithm,” Advances In Engineering Software, vol. 95, no. 12, pp. 51–67. [Google Scholar]
15. X. S. Yang. (2010). “Firefly algorithm, stochastic test functions and design optimisation,” International Journal of Bio-Inspired Computation, vol. 2, no. 2, pp. 78–84. [Google Scholar]
16. X. S. Yang. (2011). “Bat algorithm for multi-objective optimisation,” International Journal of bio-inspired computation, vol. 3, no. 5, pp. 267–274. [Google Scholar]
17. X. S. Yang. (2010). “A new metaheuristic bat-inspired algorithm,” in Nature Inspired Cooperative Strategies for Optimization (NICSO 2010), Berlin, Germany: Springer, pp. 65–74. [Google Scholar]
18. G. Kim, S. Lee and S. Kim. (2014). “A novel hybrid intrusion detection method integrating anomaly detection with misuse detection,” Expert Systems with Applications, vol. 41, no. 4, pp. 1690–1700. [Google Scholar]
19. T. F. Ghanem, W. S. Elkilani and H. M. Abdul-Kader. (2015). “A hybrid approach for efficient anomaly detection using metaheuristic methods,” Journal of Advanced Research, vol. 6, no. 4, pp. 609–619. [Google Scholar]
20. A. S. Eesa, Z. Orman and A. M. A. Brifcani. (2015). “A novel feature-selection approach based on the cuttlefish optimization algorithm for intrusion detection systems,” Expert Systems with Applications, vol. 42, no. 5, pp. 2670–2679. [Google Scholar]
21. B. M. Aslahi-Shahri, R. Rahmani, M. Chizari, A. Maralani, M. Eslami et al. (2016). , “A hybrid method consisting of GA and SVM for intrusion detection system,” Neural Computing and Applications, vol. 27, no. 6, pp. 1669–1676. [Google Scholar]
22. C. Guo, Y. Ping, N. Liu and S.-S. Luo. (2016). “A two-level hybrid approach for intrusion detection,” Neurocomputing, vol. 214, pp. 391–400. [Google Scholar]
23. W. L. Al-Yaseen, Z. A. Othman and M. Z. A. Nazri. (2017). “Multi-level hybrid support vector machine and extreme learning machine based on modified K-means for intrusion detection system,” Expert Systems with Applications, vol. 67, no. 4, pp. 296–303. [Google Scholar]
24. V. Hajisalem and S. Babaie. (2018). “A hybrid intrusion detection system based on ABC-AFS algorithm for misuse and anomaly detection,” Computer Networks, vol. 136, pp. 37–50. [Google Scholar]
25. L. Li, Y. Yu, S. Bai, J. Cheng and X. Chen. (2018). “Towards effective network intrusion detection: A hybrid model integrating Gini index and GBDT with PSO,” Journal of Sensors, vol. 2018, no. 6, pp. 1–9. [Google Scholar]
26. S. Hosseini and B. M. H. Zade. (2020). “New hybrid method for attack detection using combination of evolutionary algorithms, SVM, and ANN,” Computer Networks, vol. 173, pp. 107–168. [Google Scholar]
27. A. Khraisat, I. Gondal, P. Vamplew, J. Kamruzzaman and A. Alazab. (2020). “Hybrid intrusion detection system based on the stacking ensemble of C5 decision tree classifier and one class support vector machine,” Electronics, vol. 9, no. 1, pp. 173–191. [Google Scholar]
28. H. Mohmmadzadeh and F. S. Gharehchopogh. (2020). “A novel hybrid whale optimization algorithm with flower pollination algorithm for feature selection: Case study Email spam detection,” Preprints, pp. 1–28, . https://doi.org/10.1111/coin.12397. [Google Scholar]
29. N. Moustafa and J. Slay. (2016). “The evaluation of network anomaly detection systems: statistical analysis of the UNSW-NB15 data set and the comparison with the KDD99 data set,” Information Security Journal: A Global Perspective, vol. 25, no. 1–3, pp. 18–31. [Google Scholar]
30. H. Faris, I. Aljarah, S. Mirjalili, P. A. Castillo and J. J. M. Guervós. (2016). “EvoloPy: An open-source nature-inspired optimization framework in python,” in 8th Int. Conf. on Evolutionary Computation Theory and Applications IJCCI, Portugal, pp. 171–177. [Google Scholar]
31. H. Faris, A. A. Heidari, A. Z. Ala’M, M. Mafarja, I. Aljarah et al. (2020). , “Time-varying hierarchical chains of salps with random weight networks for feature selection,” Expert Systems with Applications, vol. 140, no. 5, pp. 1–17. [Google Scholar]
32. R. A. Khurma, I. Aljarah, A. Sharieh and S. Mirjalili. (2020). “EvoloPy-FS: An open-source nature-inspired optimization framework in python for feature selection,” in Evolutionary Machine Learning Techniques, Berlin, Germany: Springer, pp. 131–173. [Google Scholar]
33. I. Aljarah, M. Mafarja, A. A. Heidari, H. Faris, Y. Zhang et al. (2018). , “Asynchronous accelerating multi-leader salp chains for feature selection,” Applied Soft Computing, vol. 71, no. 3, pp. 964–979. [Google Scholar]
34. X. S. Yang. (2008). “Firefly algorithm,” Nature-Inspired Metaheuristic Algorithms, vol. 20, pp. 79–90. [Google Scholar]
35. P. Nagar, H. K. Menaria and M. Tiwari. (2020). “Novel approach of intrusion detection classification deep learning using SVM,” in Int. Conf. on Sustainable Technologies for Computational Intelligence, Singapore: Springer, pp. 365–381. [Google Scholar]
36. M. Madi, F. Jarghon, Y. Fazea, O. Almomani and A. Saaidah. (2020). “Comparative analysis of classification techniques for network fault management,” Turkish Journal of Electrical Engineering and Computer Sciences, vol. 28, no. 3, pp. 1442–1457. [Google Scholar]
37. S. Aljawarneh, M. B. Yassein and M. Aljundi. (2019). “An enhanced J48 classification algorithm for the anomaly intrusion detection systems,” Cluster Computing-the Journal of Networks Software Tools and Applications, vol. 22, no. 5, pp. 10549–10565. [Google Scholar]
38. P. Negandhi, Y. Trivedi and R. Mangrulkar. (2019). “Intrusion detection system using random forest on the NSL-KDD dataset,” Emerging Research in Computing, Information, Communication and Applications, Springer, vol. 906, pp. 519–531. [Google Scholar]
39. N. Farnaaz and M. A. Jabbar. (2016). “Random forest modeling for network intrusion detection system,” Procedia Computer Science, vol. 89, no. 1, pp. 213–217. [Google Scholar]
40. J. R. Quinlan. (2014). C4.5: Programs for Machine Learning, Amsterdam, Netherlands: Elsevier. [Google Scholar]
41. L. Breiman. (2001). “Random forests,” Machine Learning, vol. 45, no. 1, pp. 5–32. [Google Scholar]
42. O. Alzubi, J. Alzubi, S. Tedmori, H. Rashaideh and O. Almomani. (2018). “Consensus-Based combining method for classifier ensembles,” International Arab Journal of Information Technology, vol. 15, no. 1, pp. 76–86. [Google Scholar]
43. S. Smadi, N. Aslam and L. Zhang. (2018). “Detection of online phishing email using dynamic evolving neural network based on reinforcement learning,” Decision Support Systems, vol. 107, pp. 88–102. [Google Scholar]
44. J. Cheng, R. M. Xu, X. Y. Tang, V. S. Sheng and C. T. Cai. (2018). “An abnormal network flow feature sequence prediction approach for DDoS attacks detection in big data environment,” Computers, Materials & Continua, vol. 55, no. 1, pp. 95–119. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |