DOI:10.32604/cmc.2021.016099
| Computers, Materials & Continua DOI:10.32604/cmc.2021.016099 | |
| Article |
Web Attack Detection Using the Input Validation Method: DPDA Theory
1Al-Nahrain University, Al-Nahrain Nano Renewable Energy Research Center, Baghdad, Iraq
2Department of Management Information Systems, Faculty of Science & Information Technology, Cyprus International University, Nicosia, Cyprus
3Department of Computer Science, College of Computers and Information Systems, Umm Al-Qura University, Makkah, Saudi Arabia
4Department of Computer Science, College of Computers and Information Technology, Taif University, Taif, 21944, Saudi Arabia
5Department of Information Technology College of Computers and Information Technology, Taif University, Taif, 21944, Saudi Arabia
*Corresponding Author: Munsif Sokiyna. Email: Munsif.sokiyna@gmail.com
Received: 22 December 2020; Accepted: 12 March 2021
Abstract: A major issue while building web applications is proper input validation and sanitization. Attackers can quickly exploit errors and vulnerabilities that lead to malicious behavior in web application validation operations. Attackers are rapidly improving their capabilities and technologies and now focus on exploiting vulnerabilities in web applications and compromising confidentiality. Cross-site scripting (XSS) and SQL injection attack (SQLIA) are attacks in which a hacker sends malicious inputs (cheat codes) to confuse a web application, to access or disable the application’s back-end without user awareness. In this paper, we explore the problem of detecting and removing bugs from both client-side and server-side code. A new idea that allows assault detection and prevention using the input validation mechanism is introduced. In addition, the project supports web security tests by providing easy-to-use and accurate models of vulnerability prediction and methods for validation. If these attributes imply a program statement that is vulnerable in an SQLIA, this can be evaluated and checked for a set of static code attributes. Additionally, we provide a script whitelisting interception layer built into the browser’s JavaScript engine, where the SQLIA is eventually detected and the XSS attack resolved using the method of input validation and script whitelisting under pushdown automatons. This framework was tested under a scenario of an SQL attack and XSS. It is demonstrated to offer an extensive improvement over the current framework. The framework’s main ability lies in the decrease of bogus positives. It has been demonstrated utilizing new methodologies, nevertheless giving unique access to sites dependent on the peculiarity score related to web demands. Our proposed input validation framework is shown to identify all anomalies and delivers better execution in contrast with the current program.
Keywords: Static; dynamic; detection; prevention; input validation; deterministic push down automata
Online applications that utilize database-driven substances now form a typical and widely used innovation. These often give revised content in the wake of gathering data (from a client and by speaking with databases that contain data, for example, client names, inclinations, Mastercard numbers, and buy orders). Consequently, it is crucial that web applications keep would-be attackers from gaining unapproved access to the system, obtaining private data, or essentially denying assistance. Applications are straightforward, direct, crucial undertakings, and handle sensitive client information. As the size of these applications build, execution vulnerabilities—for example, SQL infusions and cross-scripting assault (XSS)—become significant security challenges [1]. A substantial number of these vulnerabilities come from an absence of approval of sources of information; that is, web applications utilize vindictive information as a component of a primary procedure without adequate checking or purifying of the information values. SQLIA and XSS target databases that are sufficiently open through a web front-end, and likewise exploit rationale defects in web segment approval.
However, simple script injection attacks, which are especially virulent for SQLIA and XSS [2], can easily breach and disable these protective steps. The SQLIA and XSS relate to an online application that uses the SQL database server back-end, recognizes user data, and uses the input to formulate questions dynamically. In such a compromised environment, the SQLIA uses malformed user input, which changes the SQL query supplied to gain unauthorized access to the database.
XSS is one of the most common faults in web applications. Hence, it is sometimes referred to as “Internet buffer overflow.” Halfond et al. propose a whitelisting approach to JavaScript-driven XSS attacks [3], in contrast to standard practice, to avoid unauthorized execution of native code. The goal of this paper is to identify and remove the input validation method for XSS and SQLIA, and additionally, to provide a script whitelisting interception layer built into the browser’s JavaScript engine. This layer is designed to detect XSS attacks from any route on any script that enters the client and to compare it to a list of valid scripts for the accessed site or page. It prevents the execution of scripts that are not on the list. Eventually, SQL injections and XSS are detected and resolved using input validation under pushdown automatons (PDAs).
The remainder of the paper is organized as follows. In Section 2, related work is described. Section 3 explains the proposed methodology and Section 4 explains the proposed input validation. Section 5 describes the detailed results of the experiment, and Section 6 concludes the article.
Cybersecurity problems have grown rapidly in recent years and pose a significant concern in the evolving global economy. As the world becomes increasingly interconnected, e-business survival and individual data protection are becoming ever more critical. The thanks to potential revenue generation, mobile applications are lucrative targets for hackers and crackers [4]. By considering the context of a domain application, the semantic-based detection method proposed in this research can help make effective decisions. By collecting the history of a web application and its underlying protocols, it offers a practical and effective security mechanism against web application attacks. It involves a training method focused on fine-grained, contextual script fingerprints to counter the increasing threat of XSS attacks driven by JavaScript. The “defense-in-depth” strategy is flexible, as it requires different elements to create a fingerprint, depending on accuracy and convenience tradeoffs. Another advantage of our approach is that it manages all scripts from any web location and any route [5]. A variety of risks can be avoided in this way. The overhead levied by the layer does not significantly affect the browsing experience of the user. Significantly, unlike other systems, we do not require developers to alter the code of the web application to apply our strategy.
Our new method for detecting SQLIA compares static SQL queries with dynamically generated questions after the attribute values have been deleted. Also, drawing on research on fragile web applications, we assess the efficacy of the proposed mechanism, contrasting our approach with other systems of detection and demonstrating the effectiveness of our proposed method [6]. The solution suggested essentially removes the attribute values used in SQL queries, and thus makes this independent of the database management system (DBMS). In the proposed method, complex operations such as parse trees or unique libraries are not necessary. The suggested solution can not only be extended to web applications but also be applied to any database-connected device.
In previous research on PHP web applications, we first demonstrated that many forms of vulnerabilities can be identified using the proposed IVS attributes, including SQL injection bugs, cross-site scripting, remote execution of code, and inclusion of files [7]. We also demonstrated that semi-supervised learning is a realistic alternative to supervised learning with a limited number of sinks with known vulnerabilities available when it comes to training the predictive model [8]. In experiments on eight test subjects, each of the proposed attributes demonstrated a discriminative power for at least one subject between vulnerable and non-vulnerable program statements. Our best forecast model (MLP) for anticipating vulnerabilities in SQLI and XSS depends on completely proposed normal traits
Across all comparisons, it is clear that Crawler XSS performed better than other web vulnerability scanners in terms of accuracy and the false-positive rate [9]. It was just an elective as the architecture indicated the number of vulnerabilities found. Implementation of a Fuzzy Inference Process may be related to improved indices of performance. There are several web-based intrusion detection solutions for input validation attacks (IVAs). The networks-based intrusion detection system (NIDS) did not find any unknown attacks on web applications. However, the proposed web application intrusion detection system (WAIDS) can use an extended global sequence alignment algorithm to detect anonymous irregular web requests and to minimize false positives [10]. Our system uses an extended algorithm of alignment to construct a typical profile on the web request; during runtime, it can also detect unusual requests. The experimental results indicate a higher detection rate for our system compared with the previous process.
The suggested framework focuses on the initial application creator’s expectations as well as the constraints enforced by the security administrator. Vulnerability testing is not an essential part of the framework [11]. The reports produced during an attempted attack will help to address the root cause of the vulnerability. The technique also aims to reduce the disparity between the security models that the application itself enforces and those enforced from outside by the application management administrators. Detecting and recognizing input validation attacks in web apps is highly necessary [12]. We obtain more accurate information in the detection process by using efficient metrics for identification of attacks and allocating ranks. As a result, the next phases become more manageable.
The cloud model is increasingly utilized for product advancement organizations. It empowers the advancement of omnipresent applications that will conceivably be used by a large number of clients from essential web customers [13]. In addition, the appearance of a new cloud item advancement permits programming designers to construct pivotal instruments not, at this point, restricted to existing working systems [14,15]. Current solutions for defending customary frameworks are not always adequate to explain the cloud worldview and frequently leave end clients liable for ensuring key assistance aspects [16–19]. Current ways to deal with maintaining a strategic distance from XSS assaults on helpless applications were additionally investigated, focusing on points of interest and drawbacks. If it is managing determined or non-relentless XSS assaults, there are at present some fascinating arrangements that provide intriguing ways to tackle the issue. In any case, these strategies have a few inconveniences. Some of them are not appropriately verified and can be handily skirted, while others are not helpful.
An SQLIA leads to significant problems in systems and websites. In addition, the end user will often not be aware of these attacks, such as:
• hacking another person’s account
• stealing and copying a website’s or a system’s sensitive data
• changing a system’s sensitive data
• deleting a system’s sensitive data
• a user logging in to the application as another user, even as an administrator
• a user viewing private information belonging to other users (e.g., details of other users’ profiles, transaction details)
• a user changing application configuration information and data of other users
• a user modifying the structure of a database; even deleting tables in the application database
• a user taking control of the database server and executing commands on it at will.
a. Cross-site scripting attack (XSS)
An XSS attack is often used because 60% of the users of web applications are more vulnerable to such attacks because they have various forms such as JavaScript commands on the web server by pushing the script somewhere on the parameter value in the URL [20–22]. A simple sample of a fair attack is shown below.
<img””””””><script>alert(“XSS”)<\script>”>
b. Buffer overflow attack (BOA)
This type of attack exploits common security vulnerabilities in web servers such as the input not being properly validated. The buffer overflow occurs at the same time of program execution because this is when a large amount of data is copied into a buffer of fixed size. This leads to data being overwritten to adjacent memory locations, depending on what is stored in it. A simple example of (BOA) is shown below.
http://localhost/Test.php?
nachaicnainciancainininivr
ivnrivnrivrnvirnvivnivrnvir
nvirnvrvnrvirnvrivnrivnriv
c. Path traversal attack (PTA)
This attack exploits the vulnerability related to the web server path directory; its purpose is to gain access to files and data that are not intended to be accessed by unauthorized persons. It works by using the user’s input, so that this is used in a path to access lost files and data. In simple terms, special characters are entered in the URL to modify the meaning of the path. A simple example is shown below.
In our web application, vulnerability attacks damaged network data without user knowledge. The input validation process was used to detect and remove the XSS and SQLIA and avoid bugs on both the client-side and the server-side based on the deterministic pushdown automation. The malicious attack was identified by our proposed methodology.
3.1 Deterministic Pushdown Automata
A pushdown automaton is comparable to a finite automata theistic evolutionist, but has other attributes than a deterministic finite automata (DFA). The data structure used to enforce a pushdown automata (PDA) was a stack; a PDA seems to have an output bound to each input. All inputs either were tossed into a stack or completely overlooked. In a stack used for a PDA, a developer undertakes simple push and pop operations. Some of the risks associated with DFAs include that several entries provided as input to the system were not capable of making a list. PDA avoids this issue since it uses a stack that also provides us with this facility acknowledged as the preferred mechanism for preventing the exploitation of XSS vulnerabilities.
3.2 Detecting XSS and SQL Attack Using Input Validation
SQL injection is a flaw in the network security framework that allows an attacker to interfere with queries that an application makes to its database. It generally allows an attacker to view data that they usually cannot retrieve. These may include data from other users, or other data that could be available to the application itself. An intruder may alter or delete these data in certain situations, causing permanent changes to the content or actions of the application. In some cases, an attacker can escalate the SQLIA to compromise the underlying server or other back-end infrastructure or execute a denial-of-service attack. The SQLIA can lead to unauthorized access to sensitive data, such as passwords, credit card numbers, or personal user data. There are many high-profile infringements of data as it validates the storage that stack in which the data can be stored to solve this problem using input validation.
Vulnerability in computer protection usually occurs in web applications. XSS attacks allow an attacker to insert client-side scripts into web pages that another user can access. Attackers may use a cross-site scripting vulnerability to circumvent access controls, such as the same-origin policy. Web-based applications, their servers, or the plug-in systems on which they rely are vulnerable. Taking advantage of one of these, attackers incorporate malicious code into the code distributed from the compromised platform. When the resulting combined content arrives with the finite state of the client-side web browser and the stack’s queueing level is increased, all of it has been delivered from the trusted source, and thus operates under the permissions given to that device. Through seeking ways to insert malicious scripts into web pages, attackers may increase their access rights to sensitive page content, session cookies, and a range of other details held on behalf of the user by the client.
Cross-site scripting attacks are code-injection cases. They tend to be more competent than finite-state machines but less efficient than Turing machines. Predetermined automatic pushdowns should only comprehend deterministic context-free languages, although non-deterministic ones should identify all context-free languages, mostly used in parser design beforehand. The languages that describe strings that have overlapping parentheses may be a context-free language. We assume that a compiler has created a valid code or parentheses. Another solution would be to feed the code (as strings) into a PDA equipped with conversion functions that execute context-free grammar for compatible language parentheses. Unless the code is right, and all parentheses match, the PDA will “recognize” the feature. When there are skewed brackets, the PDA will be able to leave the code to the programmer since it is not valid. This is one of the behind-computing theoretical concepts.
The PDA can be represented as follows:
• The transformation relationship, which is quadrangular, is a finite subset of
• The limited parameter while the complete subset is infinite by variable
When the current iteration is p, the string at the top of the stack is
Where
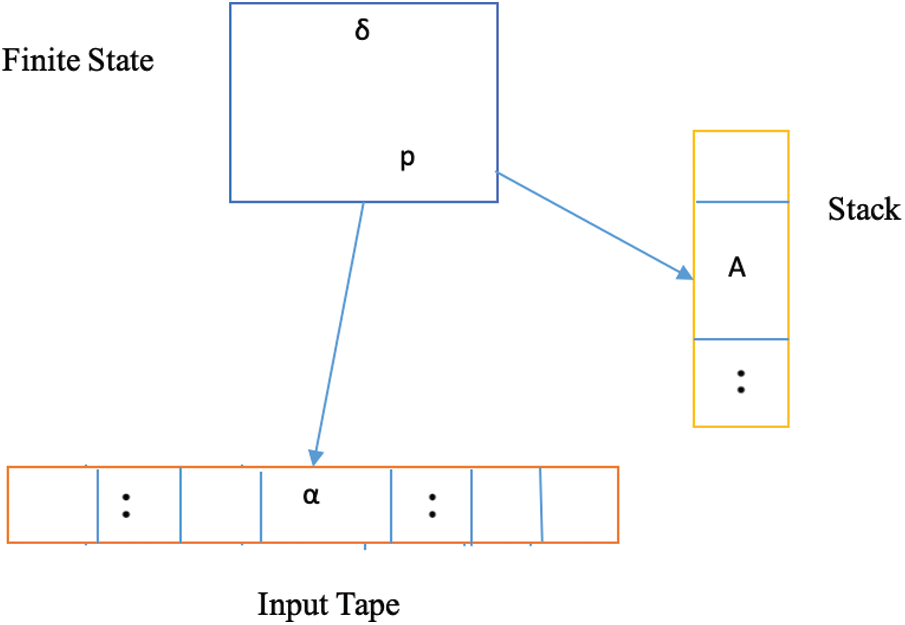
Figure 1: The pushdown automaton program
Every 3-tuple A finite set Q of states, with a set of initial states
The stack overflow in the finite state and the automata generation with the tuple set variations to be queued and the data to be altered due to these problems. The next state’s generation in finite automata is stopped to solve these attacks. The proposed input validation, also termed information validation, provides appropriate screening of user-or software-supplied content. Output validation prohibits the inclusion of unintentionally shaped data into a software system. Since it is difficult to determine an unauthorized user seeking to assault apps, any content placed into such a program will be checked and reviewed by the applications.
Validation of input occurs if data are obtained via an unknown party; notably, if the data come from untrusted sources. Erroneous validation of the data will escalate to threats on the injection, memory leakage, and compromised systems. Following validation, the information will be either whitelisted or blacklisted, with whitelist data preferable. The objective of data validation is to provide well-defined health, accuracy, and reliability assurances for a few of the various types of input into software or an automated system. Data validation rules can be specified using a number of different methodologies and applied across a number of different contexts.
The actual learning process begins by passing each value of a given parameter to any validator type possible. If a validator accepts a value, as shown in Fig. 2, then the corresponding entry in the score vector of that parameter is incremented by one. If no validator accepts a value, the analytics engine will allocate the free-text form to the parameter and will stop processing its values.
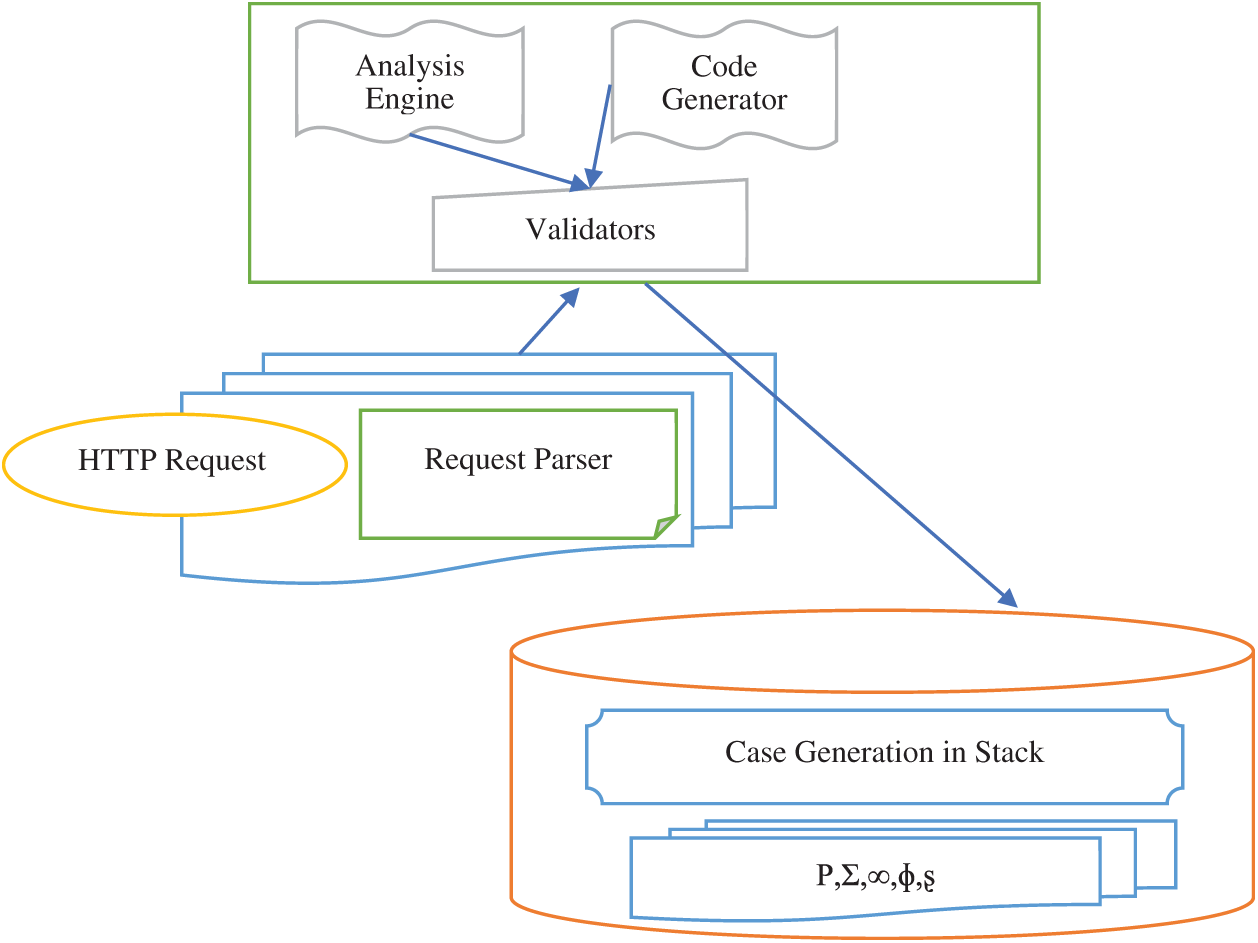
Figure 2: Input validation process
Suppose the information field originates from an assortment of fixed decisions. In that case, a drop-down rundown or radio catches at that point first, and the information must precisely match one of the qualities given to the client. Approval of sources of info is not an essential safeguard against cross-site scripting. If clients type punctuation or not exactly sign < in their remark region, they may have a good reason for that, and the task of the developer is to manage this properly during the entire data lifecycle, including for parameters such as
4.1 Input Validation Should be Implemented on Both Syntactic and Semantic Bases
Syntactic approval should authorize correct punctuation of organized fields (e.g., SSN, date, cash image).
Semantic approval should authorize the accuracy of their qualities in the particular business setting (e.g., start date is before the end date, the cost is inside anticipated range).
In handling the user’s (attacker’s) request, it is often recommended to stop attacks as early as possible. Validation can be used to detect unauthorized data before the application processes it. It is a typical mix-up to utilize boycott approval to endeavor to recognize potentially malicious characters and examples; for example, the character of the punctuation
In Proposition, it will be exhibited that each root u(t) of
a) Normalization: Guarantees an approved compression algorithm is used in the document because there are no incorrect characters.
b) Character category whitelisting: Unicode permits the whitelisting of classes, for example, “decimal digits” or “letters” covering the Latin letter set as well as numerous different contents utilized all-inclusively (e.g., Arabic, Cyrillic, or Chinese, Japanese, Korean (CJK) ideographs).
c) Individual character whitelisting: Used to allow letters and ideographs in names, or an apostrophe for Irish names, but without having to use the entire accentuation system.
Consider the site test portion; for example, the disinfection of execution as shown in Fig. 2. Here, both the h1 and p Document Object Model (DOM) kid hubs are interjected with untrusted data, just as in the quality of the h1 thing kind. At the very least, a good yield sanitizer can ensure that dangerous characters such as “ < ” and “and” do not appear in the added qualities unscaled, whereas more complex whitelisting’ factor strategies can also be implemented. Similarly, the yield sanitizer should be aware of the setting; it would naturally perceive, for example, that “characters” should be encoded before interjecting untrusted information into a component specification. The yield sanitizer listed here should be kept away from assaults that may prevent acceptance of inputs. Information verified as accurate, for example, may now also be related. The primary input validation means for the input of free-form text is as follows:
a) All user-managed data must be encoded to prevent malicious data (e.g., XSS) from being executed when returned to the HTML page; for example, it will return < script > as & lt; script >.
b) The encoding style is specific for the context of the page where the developer-controlled data are placed. In context, encoding the HTML entity is sufficient for data set within the HTML body; however, for precise output, user data placed in a script will need JavaScript encoding.
This allows for a broad definition of what is legal, with anything that does not fit that description condemned. The rules specifying what is legal, and implicitly denying all else, are known as a whitelist. In general, it is not recommended to do the inverse and it is not recommended to endeavor to recognize what is illicit and to compose code to dismiss those cases. This flawed strategy, where the developer looks to list whatever should be acknowledged, is called boycotting; the rundown of sources of information that should be recognized is called a boycott. Boycotting, for the most part, prompts shortcomings in security, since the developer will probably neglect to manage at least one instance of unlawful information. Inappropriate approval of information is such a common reason for vulnerabilities that it has its own the Common Weakness Enumeration CWE identifier, CWE-20.
However, there is a genuine motivation to characterize “illicit” values, and this should take the form of a progression of checks to ensure the approval code is extensive. There are many well-recognized checks that should always be present, and some new ones that will emerge in each context At the point when we set up an information channel, we test our whitelist’ with a couple of unlawful qualities pre-recognized to guarantee that any good unlawful attributes do not get past. Contingent on the information, here are a few instances of fundamental “illicit” values that your information channels may need to stay away from: the vacant string, “,” “
The code should not search for “evil” values; this should be done mentally to ensure that the input values are ruthlessly limited to traditional values by the design. On the unlikely probability that the example is not sufficiently small, it may be necessary to rethink carefully to see whether there are any complications. It may be useful to limit the most extreme length of character (and, if necessary, the least length) and ensure control is not lost when those lengths are exceeded. Below, we offer a few specific forms of details to be checked before use from an untrusted customer:
Characterize the valid characters or legitimate string examples (e.g., as a standard articulation) and reject anything that is sometimes short for that type. Uncommon problems occur when strings contain control characters mainly line feed or nothing or zero or unspecified entry (NIL) or metacharacters (particularly shell metacharacters); it is better to “escape” these metacharacters after receiving the information so that such characters are not sent inadvertently. The Computer Emergency Response Team (CERT) advises erasing all characters that are not in a list of characters that do not have to get out. Remember that the finishing line encoding varies across different PCs: Unix-based frameworks utilize 0x0a (line feed), while CP/M and DOS-based frameworks restrict all numbers to insignificant (regularly zero) and greatest permitted values.
A complete email address checker is extraordinarily challenging, because there are heritage structures that complicate acceptance considerably when supporting them. For a normal articulation to search if an email address is valid (as per the individual), an ordinary “straightforward” articulation is 4,724 characters and an “advanced” articulation. Also, even that usual articulation is not great; it cannot perceive nearby email addresses, and in the remarks, it cannot handle settled enclosures (as permitted by the individual). You may also disentangle and simply allow the “mainstream” Internet address classes.
Uniform Resource Identifiers (URIs) should be tested for legitimacy (counting the URLs). If you are working in a straightforward manner on a URI (i.e., you are actualizing a web server or web-server-like program and the URL is a solicitation for your information), ensure that the URI is correct, and consider URIs that endeavor to “escape” the foundation of the record (the filesystem locale to which the server reacts). The most mainstream approaches to get away from the foundation of the archive are through “..” or a representative connection, so most servers themselves search any “..” indexes and overlook emblematic connections, except if expressly coordinated. Continuously recollect to initially disentangle any encoding (using URL encoding or UTF-8 encoding), or sneak past an encoded “..” URIs are not expected to have UTF-8 encoding. Thus, the best choice is to overlook any URIs that contain high-piece characters.
If a program that utilizes the URI/URL as data is executed, it is important to ensure that vindictive clients do not have the option to embed URIs that hurt other clients. When tolerating, it’s a single word which means like a package or integrated services that stack esteems, provided that you test the space an incentive for each treat you use is the one you anticipate. Additionally, caricature treats might be put on a (perhaps broken) connection. The server at victim.cracker.edu will recognize that the subsequent treatment was not the one that originated from understanding that the area quality is not for itself and that it is disregarded. If you have your record for them, the examples of lawful character will not contain symbols or successions of characters that are of specific hugeness to either the inward framework or the possible yield:
First: A succession of characters might be highly critical for the inside stockpiling organization of the application. For example, if you store information (inside or remotely) in delimited strings, ensure that information esteems are excluded from the delimiters. Various projects store information in a comma (,) or a colon (:) delimited content documents; embeddings the delimiters in the information might be an issue except if it is represented by the program (i.e., forestalling or encoding it here and there). Different characters regularly cause these issues to incorporate single and twofold statements (utilized for encompassing strings), and the not precisely sign “ < ” (utilized in SGML, XML, and HTML to demonstrate a label’s start; this is significant if you store information in these configurations). Most information positions have a break grouping to deal with these cases; use this, or channel such input information.
Second: A character succession may have extraordinary significance whenever sent pull out to a client. A typical case of this is allowing HTML labels in information input that will later be presented on different browsers. However, the issue is considerably broader. These tests should, for the most part, be brought together in one spot with the goal that the legitimacy tests can be effectively inspected for accuracy later. Fig. 3 shows the HTML parsing.
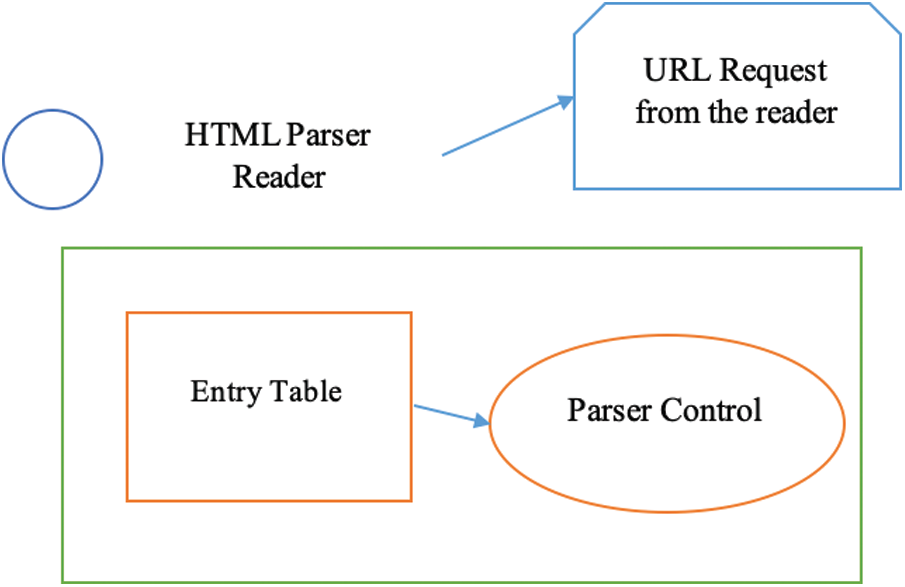
Figure 3: HTML parsing
Ensure the legitimacy test is correct; this is especially difficult when testing input that will be utilized by another program (e.g., a filename, email address, or URL). Similarly, these tests may make inconspicuous blunders, in the form of purported “appointee issues” (where the testing program makes different presumptions than the product that utilizes the information). It is recommended to assess whether there is a comparable standard, and moreover, to verify whether the product has alterations that you should consider. The validation tests are carefully and honestly assessed, and select the best method to manage each specific issue. When assessing a calculation, time intricacy and space multifaceted nature should be considered. Time-multifaceted nature of analysis measures the time that an estimate takes to run as an element of the length of the information. Similarly, the space intricacy of a calculation measures the room or memory that a calculation would take to run as an aspect of the length of knowledge.
Time and space complexity depend on several factors, such as hardware, operating system, and processor. It is not recommended to include any of these variables when testing the algorithm—only take the algorithm execution period into account. T(n) is limited by a value that does not rely on the information size; for instance, it sets aside consistent effort to arrive at a single thing in a cluster, because just a single activity is expected to find it. Similarly, it is the principal component that sees the base incentive in an exhibit requested in the rising request. Finding the base incentive in an unordered cluster is not a steady time activity, as filtering is required over every component in the exhibit to decide the base worth. Hence, it is a straight time activity that takes O(n) time. If the quantity of components is resolved ahead of time and does not change, it may, in any case, be expected that such a calculation would run inconsistently.
Measurement is supposed to be of scalar-time if its runtime is upper limited by an algebraic articulation of the information measurement of the calculation; for example, for some constant positive k,
If the second of these conditions is not met, P is represented as proportional to k in the space used to describe the input, and thus exponential rather than polynomial. Therefore, that calculation cannot be performed on a Turing machine in polynomial time, but the polynomial can determine other arithmetic operations.
Assume that a cluster (A) and a number x are given, and you need to make sense of whether x is the full stack beam as the length assault to be checked happens in (A). A straightforward answer for this is to experience the whole of an exhibit and test if any component is equivalent to x.
Each in-PC activity takes an approximately consistent time. Let every action take c effort to finish. Then the number of lines of code executed relies on the estimation of x.
During the calculation investigation, we should locate the most direct outcome possible; for example, at the point when x is absent in cluster (A). In the most pessimistic scenario, the condition runs N times where N is the cluster length (A). Further, in the most pessimistic scenario, aggregate execution time (N * c + c) would be N * c for the if condition, and c for the arrival articulation (which does not have specific tasks; for example, I task).
The implementation for development is how the time of execution relies on the length of the information; we can observe that the time of execution depends directly on the length of the exhibit. The request for development will assist us with computing the running time efficiently. The lower request terms will be overlooked, since these are generally immaterial for huge amounts of information, and utilize distinctive documentation to depict the constraining conduct of a capacity.
Here, the O-notation is utilized to signify the asymptotic maximum breaking point, as shown in Fig. 4 below. For a given capacity g(n), indicate the arrangement of capacities by O(g(n)): that makes the constants
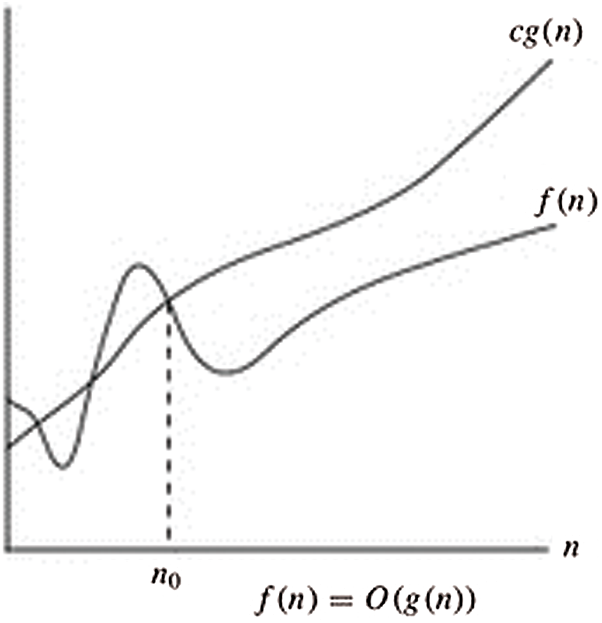
Figure 4: O-notation
It is smart to delete all rights immediately when processing user input, or even build separate processes (with the parser having permanently lowered privileges, and the other process conducting security checks against the parser requests). This is particularly true if the parsing function is complex (e.g., if you are using a lex-like or you-like tool), or if the programming language does not protect against buffer overflows (e.g., C and C++). For more detail on reducing rights, we should make sure to utilize reliable systems when utilizing the information for security choices (e.g., “let this client in”). For example, on an open Internet do not merely use the PC IP address or port number as the sole method to validate clients, as the (potentially malicious) client will set these in many conditions.
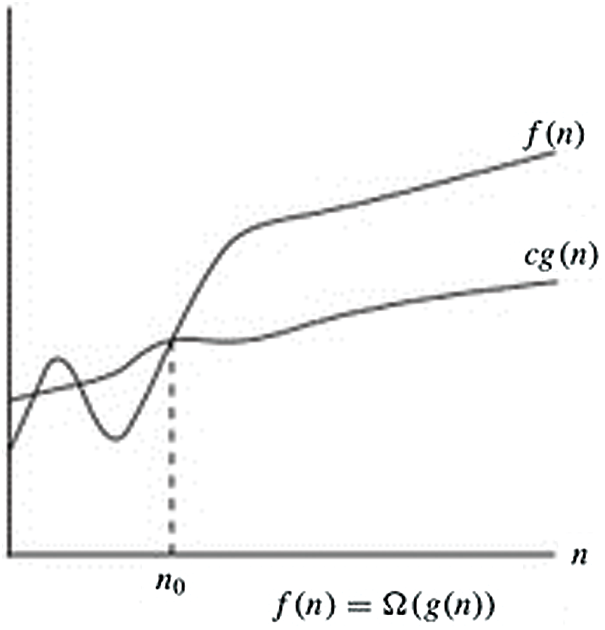
Figure 5:
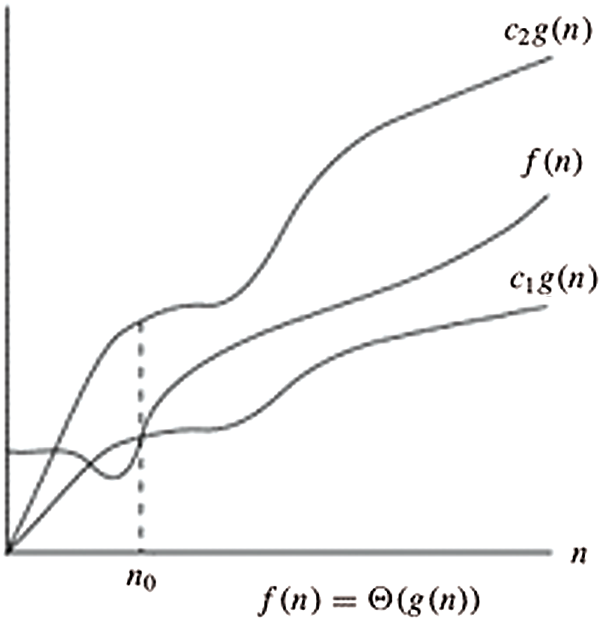
Figure 6:
The grammar language
If parses
A new predicate for this purpose is added, written
At that point, the fundamental adequacy invariant can be expressed as follows: if the parser has devoured the information word w and if the present stack is s, at that point
Thus, the annotations needed by the safety validator (and which must be generated by the parser generator) form a definition of the invariant variables. Such annotations are 1. for each non-initial state Š a symbol series, written past symbols (
The requesting of the postfix between two arrangements of images is commonly characterized: that is,
Input
A free language syntax setting consisting of all strings over a, b containing an inconsistent range of a’s and b’s:
The nonterminal T will deliver all strings with a comparable number of a’s as b’s, the nonterminal U will make all strings with many more a’s than b’s, and the nonterminal V will create all strings with fewer a’s than b’s. Blocking the third route in the standard U and V does not confine the language structure.
For example, on the grammar:
With the following derivation, this can be extracted from the start symbol S:
It follows a strategy that deterministically selects the next nonterminal to be rewritten:
Given such a technique, the sequence of rules applied defines a derivation together; for example, one derivation left-most of the same string is
One right-most derivation is:
F is the string “1+1+an” determined by the furthest left induction referenced over, the string structure would be:
This framework was tried for an SQL attack and cross-site scripting, and it was shown to bring an extensive improvement over the current framework. The framework’s main strength is to decrease bogus positives. It has been demonstrated utilizing new methodologies, notwithstanding giving unique access to sites dependent on the peculiarity score related to web demands. Our proposed input validation framework is shown to identify all anomalies and delivers better execution contrasted with the current program.
Fig. 7 shows a comparison of the number of anomalies identified dependent on the quantity of queries sent between our framework and the existing Intrusion Detection System (IDS) framework. This chart demonstrates that our framework identifies a greater number of anomalies than the current framework.
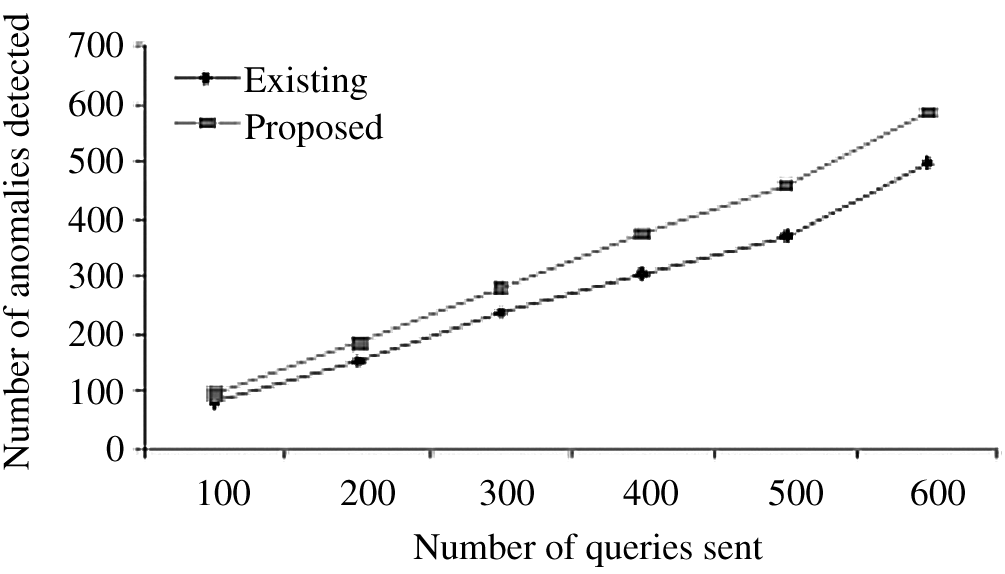
Figure 7: Comparison of our framework for input validation with the existing IDS method
The main objective of this paper was to define the SQLIA and XSS. In addition, the project supports web security tests by providing easy-to-use and accurate models for vulnerability prediction and methods for validation, if these attributes imply a program statement vulnerable to SQLIA, and to evaluate and check it for a set of static code attributes. Additionally, we provided a script whitelisting interception layer built into the browser’s JavaScript engine, where the SQLIA is eventually detected, and the cross-site scripting attack is resolved using the method of input validation and script whitelisting under PDAs.
Acknowledgement: We acknowledge Taif University for supporting this study through the Taif University Researcher Support Project (TURSP-2020/115), Taif University, Taif, Saudi Arabia.
Funding Statement: Taif University supported this study through Taif University Researcher Support Project (TURSP-2020/115).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. Y. S. Jang and J. Y. Choi, “Detecting SQL injection attacks using query result size,” Computer and Security, vol. 44, no. 4, pp. 104–118, 2014. [Google Scholar]
2. P. Bisht, P. Madhusudan and V. N. Venkatakrishnan, “CANDID: Dynamic candidate evaluations for automatic prevention of SQL injection attacks,” ACM Transactions on Information System Security, vol. 13, no. 2, pp. 1–39, 2010. [Google Scholar]
3. W. G. J. Halfond, A. Orso and P. Manolios, “WASP: Protecting web applications using positive tainting and syntax-aware evaluation,” IEEE Transactionson Software Engineering, vol. 34, no. 1, pp. 65–81, 2008. [Google Scholar]
4. A. Razzaq, K. Latif, H. Farooq Ahmad, A. Hur, Z. Anwar et al., “Semantic security against web application attacks,” Information Science. (NY), vol. 254, no. 3, pp. 19–38, 2014. [Google Scholar]
5. D. Mitropoulos, K. Stroggylos, D. Spinellis and A. D. Keromytis, “How to train your browser: Preventing XSS attacks using contextual script fingerprints,” ACM Transactionson Privacy and Security, vol. 19, no. 1, pp. 1–31, 2016. [Google Scholar]
6. P. R. McWhirter, K. Kifayat, Q. Shi and B. Askwith, “SQL injection attack classification through the feature extraction of SQL query strings using a gap-weighted string subsequence kernel,” Journal of Information Security and Applications, vol. 40, no. 2, pp. 199–216, 2018. [Google Scholar]
7. L. K. Shar, L. C. Briand and H. B. K. Tan, “Web application vulnerability prediction using hybrid program analysis and machine learning,” IEEE Transactionson Dependable and Security Computing, vol. 12, no. 6, pp. 688–707, 2015. [Google Scholar]
8. K. N. Durai, R. Subha and A. Haldorai, “A novel method to detect and prevent SQLIA using ontology to cloud web security,” in Wireless Personal Communications, Basel, Switzerland: MDPI, pp. 1–20, 2020. [Google Scholar]
9. B. K. Ayeni, J. B. Sahalu and K. R. Adeyanju, “Detecting cross-site scripting in web applications using fuzzy inference system,” Journal of Computer Networks and Communications, vol. 2018, no. 12, pp. 1–10, 2018. [Google Scholar]
10. W. Said and A. M. Mostafa, “Towards a hybrid immune algorithm based on danger theory for database security,” IEEE Access, vol. 8, pp. 145332–145362, 2020. [Google Scholar]
11. V. Prokhorenko, K. K. R. Choo and H. Ashman, “Intent-based extensible real-time PHP supervision framework,” IEEE Transactionson Information. Forensics and Security, vol. 11, no. 10, pp. 2215–2226, 2016. [Google Scholar]
12. S. Khan Amit Saxena TIET and B. Tieit, “Detecting input validation attacks in web application,” 2015. [Online]. Available: www.browsewebapplication.com/signon.aspx?username= (Accessed: Dec. 19, 2020). [Google Scholar]
13. V. Nithya, S. L. Pandian and C. Malarvizhi, “A survey on detection and prevention of cross-site scripting attack,” International Journal of Security and its Applications, vol. 9, no. 3, pp. 139–152, 2015. [Google Scholar]
14. R. R. Nithya, “A survey on SQL injection attacks, their detection and prevention techniques,” International Journal of Engineering and Computer Science. 2013. [Online]. Available: http://103.53.42.157/index.php/ijecs/article/view/528 (Accessed Dec. 19, 2020). [Google Scholar]
15. Y. Alotaibi, “A new database intrusion detection approach based on hybrid meta-heuristics,” Computers, Materials & Continua, vol. 66, no. 2, pp. 1879–1895, 2021. [Google Scholar]
16. I. Hydara, A. B. M. Sultan, H. Zulzalil and N. Admodisastro, “Current state of research on cross-site scripting (XSS)–A systematic literature review,” Information and Software Technology, vol. 58, pp. 170–186, 2015. [Google Scholar]
17. A. F. Subahi, Y. Alotaibi, O. I. Khalaf and F. Ajesh, “Packet drop battling mechanism for energy aware detection in wireless networks,” Computers, Materials & Continua, vol. 66, no. 1, pp. 2077–2086, 2020. [Google Scholar]
18. K. A. Ogudo, D. Muwawa, J. Nestor, O. I. Khalaf and H. D. Kasmaei, “A device performance and data analytics concept for smartphones’ IoT services and machine-type communication in cellular networks,” Symmetry, mdpi.com, vol. 11, no. 4, pp. 593, 2019. [Google Scholar]
19. G. Muttasher Abdulsaheb, O. Ibrahem Khalaf, G. Muttashar Abdulsahib and O. Ibrahim Khalaf, “Comparison and evaluation of cloud processing models in cloud-based networks,” International Journal of Simulation Systems Science and Technology, vol. 19, pp. 2/2, 2018. [Google Scholar]
20. S. Khan and O. I. Khalaf, “Urban water resource management for sustainable environment planning using artificial intelligence techniques,” Environmental Impact Assessment Review, vol. 86, pp. 106515, 2020. [Google Scholar]
21. O. I. Khalaf, D.-N. Le, S. K. Prasad, J. Rachna, O. I. Khalaf et al., “Map matching algorithim real time location tracking for smart security application,” Telecommunications and Radio Engineering, vol. 79, no. 13, pp. 1–14, 2020. [Google Scholar]
22. M. Sokiyna, M. J. Aqel and O. A. Naqshbandi, “Cloud computing technology algorithms capabilities in managing and processing big data in business organizations: Mapreduce, hadoop, parallel programming,” Journal of Information Technology Management, vol. 12, no. 3, pp. 100–113, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |