DOI:10.32604/cmc.2021.016348
| Computers, Materials & Continua DOI:10.32604/cmc.2021.016348 | |
| Article |
Location-Aware Personalized Traveler Recommender System (LAPTA) Using Collaborative Filtering KNN
1School of Information Technology, Asia Pacific University, Kuala Lumpur, 57000, Malaysia
2Department of Computer and Information Sciences, Universiti Teknologi PETRONAS, Seri Iskandar, 32160, Malaysia
3Department of Information Systems, Prince Sultan University, Riyadh, 11586, Saudi Arabia
*Corresponding Author: Amgad Muneer. Email: muneeramgad@gmail.com
Received: 30 December 2020; Accepted: 8 April 2021
Abstract: Many tourists who travel to explore different cultures and cities worldwide aim to find the best tourist sites, accommodation, and food according to their interests. This objective makes it harder for tourists to decide and plan where to go and what to do. Aside from hiring a local guide, an option which is beyond most travelers’ budgets, the majority of sojourners nowadays use mobile devices to search for or recommend interesting sites on the basis of user reviews. Therefore, this work utilizes the prevalent recommender systems and mobile app technologies to overcome this issue. Accordingly, this study proposes location-aware personalized traveler assistance (LAPTA), a system which integrates user preferences and the global positioning system (GPS) to generate personalized and location-aware recommendations. That integration will enable the enhanced recommendation of the developed scheme relative to those from the traditional recommender systems used in customer ratings. Specifically, LAPTA separates the data obtained from Google locations into name and category tags. After the data separation, the system fetches the keywords from the user’s input according to the user’s past research behavior. The proposed system uses the K-Nearest algorithm to match the name and category tags with the user’s input to generate personalized suggestions. The system also provides suggestions on the basis of nearby popular attractions using the Google point of interest feature to enhance system usability. The experimental results showed that LAPTA could provide more reliable and accurate recommendations compared to the reviewed recommendation applications.
Keywords: LAPTA; recommender system; KNN; collaborative filtering; users’; preference; mobile application; location awareness
Nowadays, travel is one of the preferred habits for many people globally for different purposes (i.e., business, leisure, or tourism). The number of travelers worldwide has experienced a steady increase annually [1,2]. Statistics show an increase of travelers from 530 million in 2015 to 1.3 billion in 2017, and this figure was expected to reach 1.8 billion in 2020. However, many travelers face serious challenges during their journeys, like finding suitable accommodation, good quality food, and proper guidance to tourist sites. These issues affect the traveler experience and lead to a noticeable impact on the tourism industry in the visited country. That impact emerges from the traveler reviews and word-of-mouth through websites and mobile applications.
Since 2015, the usage of mobile devices has increased dramatically and has surpassed desktop and laptop usage [1]. Therefore, we are living in the era of mobile computing. This claim is supported by statistics in [3,4] which show that by the end of 2015, the number of mobile users globally was approximately 4.15 billion and the expected figure is five billion users by 2020.
Therefore, as everyone has a mobile device, the travelers immediately share what they encounter in their journey with their relatives, friends, and even with potential travelers through different platforms, including booking.com, Agoda, and TripAdvisor. For instance, travelers may find the accommodation, which they reserve online, cramped, dirty, or with insufficient hotel facilities, or unfriendly or uncooperative staff [5,6]. Such issues are serious concerns for any traveler and may spoil his/her whole trip as they desire comfort and peace and tried his/her best to plan carefully to choose among a variety of options to meet their expectations and avoid any disturbance. Food is also a significant factor that measures the traveler’s trip experience, as many visitors would travel around to try various food dishes from different origins. However, authors in [7] claim that various factors affect tourists’ food consumption and selection as one of the main determinants is the difference of culture and religion. Moreover, authors in [7,8] agreed that the health and hygiene of restaurants exert a considerable effect on food consumption and restaurant selections among tourists. Tourists primarily prefer to eat in renowned international fast food restaurant chains rather than in local or street food restaurants that are cramped or dirty. Another issue that travelers face while traveling abroad is transportation [9].
Furthermore, many tourists who travel to explore different cultures and cities worldwide aim to find the best tourist sites such as museums, historical sites, temples, and other places according to their interests. This situation makes it harder for tourists to decide and plan where to go and what to do. Consequently, many tourists tend to look for local tour guides or tourist agencies to obtain information about their destination, a task which might be time-consuming and financially costly [10]. Thus, recommender systems are proposed in many travel platforms to overcome these issues and recommend the point of interests (POI) on the basis of the traveler’s preferences.
Recommender systems (RSs) represent a subclass of information filtering systems that predict user preferences when the user rates an item. RSs are used widely in commercial websites/applications to suggest products with high demand to users who show interest in similar products [11,12]. The idea behind the RS is that they function at the forefront of user-friendly systems to extract relevant information from a massive amount of data [13] and provide suggestions in line with the extracted information to expedite the search process, even when encountering the dramatic growth of a large amount of data. A prime example is a book RS that allows users to pick a book to read. As a well-known website, Amazon.com uses an RS to personalize each customer’s online store [14]. As recommendations are typically customized, non-personalized recommendations exist for multiple users or user groups to obtain benefits from various suggestions. Therefore, in RSs, machine learning (ML) algorithms provide better recommendations to users compared to those from data mining techniques. However, no precise classification exists for the algorithms in the ML region, mainly because of the number of approaches employed in the literature [15]. As a result, selecting an appropriate ML algorithm becomes challenging and unclear [16]. Moreover, some additional techniques such as the threshold algorithm (TA) are required to ensure the scalability in RSs.
Thus, this study aimed to develop a one-stop center mobile application that provides information about places according to user preferences. This work primarily provides a threefold contribution.
• We gave a clear overview of RSs and explained the various problems in the traditional RSs. Then, we explained the development of travel RSs along with the techniques and interface types.
• We proposed a location-aware traveler assistance (LAPTA) that employs user preferences to generate personalized recommendations using a K-Nearest Neighbor Item-Based Collaborative Filtering.
• The proposed system is scalable, which means it maintains an acceptable performance level when the workload increases.
The remainder of this paper is structured as follows. Section 2 discusses related work on different RSs. Section 3 provides a summary of the methods adopted for the present study and describes the approach employed. Section 4 presents and examines the results. Lastly, Section 5 concludes the study and highlights future work.
2.1 Location Awareness Mobile Applications
With the rapid advancement in telecommunication and the Internet since the 1990s, all businesses have changed to adopt to-of-the-art technologies, thereby leading to rising new business models with thoughtful impact on such businesses. According to [17], the travel and tourism industry is no exception in relation to the influence of the Internet. That influence contributes to the evolution of travel and tourism started by adopting online airline ticketing through the web. Moreover, smartphones have become fully integrated into public lives over time. Thus, the travel and tourism industry were rearticulated by enhancing traveler behaviors and travel experience, including the searching for information, on-site decision-making, the sharing of journey details, and documenting travel experiences [18]. One of the recent directions in the mobile applications of travel and tourism involves location-based applications that allow travelers to provide information and services to users according to their current location [19]. Furthermore, mobile device features like GPS location, Bluetooth, and WLAN hotspots enables the applications to guide travelers toward nearby POIs while they explore indoor and outdoor environments [20]. Those features attract travelers to use the mobile devices to make their journey enjoyable.
RSs constitute one of the artificial intelligence fields that provides suggestions to users in line with their interests and search histories [21]. According to [22,23], RSs utilize different techniques such as data mining and prediction algorithms to forecast the interests of users in various aspects such as information, products, and services. Three types of RSs exist: content-based filtering, collaborative filtering (CF), and hybrid filtering. Content-based filtering is one of the oldest approaches and is the most popular RS type [24,25]. Those approaches track the user rating for an item and then recommends similar products according to two criteria: the user’s profile preference and the item description with a high rating by the user [26]. However, the main limitation of the content-based filtering approaches is that the user should rate an item to see recommended ones. If the user did not rate a product, then he/she will not be able to see the recommended item list. Another popular technique is the CF approach, which predicts users’ interests by gathering various users’ preferences or desired information from different sources and integrating these various preferences to predict the user’s interest [21,26]. The CF approaches can be classified into two classes. First, memory-based approaches use the fundamental similarities between users and/or items to make predictions. Second, model-based approaches use only a set of ratings to train the model which, in turn, is employed to predict the users’ rating of an unrated item or group of items [27]. Despite the wide application of content-based and CF approaches, both methods suffer from serious issues of precision and scalability, as the data of products and users have grown tremendously lately, thereby resulting in inaccurate recommendations. Thus, a robust and scalable RS approach in handling huge data that expands by the second is needed. As a solution for this issue, the hybrid filtering approach utilizes both content-based and CF techniques to enhance and improve recommendation results. According to [28], a range of methods has been developed to integrate different filtering approaches, including CF, content-based filtering, and knowledge-based demographics. The most popular combination is the hybridization between content-based and CF. Such a hybrid approach is usually applied in commercial RSs and can address and overcome issues of standard methods the unrated items such as the new item has not been rated by any user [29].
Personalization is an important aspect of producing good recommendations for users and communities. Therefore, the integration of the RS with the advancement in mobile devices/applications plays a crucial role in personalization [30]. Since its invention until now, RSs were incorporated with various technologies to help the users decide in choosing their preferred items such as clothes [31], movies [32,33], and restaurants [34]. The literature presents some initiatives for such an integration for the sake of personalization. The authors in [35] proposed a Location-Based Personalized Restaurant Recommendation System for Mobile Environments. That system introduces the merging of mobile technology and context awareness with RSs. ML algorithms have been used to study user behavior while the user keeps exploring restaurants through social media applications. Such a combination may help enhance dining experiences, but this system has an issue in data gathering as it relies on the Foursquare application to gather users’ behaviors data, which is social-driven data with missing and unvalidated details. Likewise, the authors in [36] proposed a location-content-aware RS to recommend nearby locations on the basis of personal interest and local preference that aims to facilitate the travel experience for those who visit different cities. Furthermore, the authors used an ML algorithm named LCALDA to learn users’ interests and the local preference of each city by gathering item pattern convergence, content exploiting, and the learning interest of the querying user. Then, the results are combined automatically with the local preference of the querying city to produce top-k recommendations. Nevertheless, the classical TA in [36] is extended by a scalable query processing technology and evaluates the recommended item. Additionally, the authors used Foursquare and DoubaneEvent datasets to increase the efficiency and the effectiveness of the RS. To overcome the data sparsity problem and supervise the user preferences, utilizing local preference and item content information to enhance the recommendation efficiency further and provide the online recommendation is necessary. A scalable-based TA query processing technique has been implemented in the current research.
2.4 K Nearest Neighbor (KNN) Algorithm
ML techniques have been widely used in various scientific fields for classification or prediction purposes. Among these techniques, the KNN is one of the simplest supervised ML approaches [37] and is commonly applied to solve classification and regression problems. KNN classifies the unlabeled data instance by assigning them to another class with similar labelled examples according to the nearest calculated distance between the data instance and the classes. In the context of RSs, the authors in [38] utilized and trained the KNN algorithm to build an automatic web usage data mining and RS in line with user behavior on the basis of user clickstream data on a newly developed elementary syndication reader (RSS) website. Moreover, authors in [38] claimed that KNN could be utilized in RSs for the following reasons:
• The KNN overcomes various common scalability problems that occur within various algorithms, i.e., the tree technique, by handling massive training data to fit in the memory.
• KNN is easy to implement as it uses the Euclidean distance equation to measure the similarities even with the absence of prior knowledge about data distribution. It also produces accurate recommendations for end-users on the basis of the straightforward application of similarity or distance for classifications.
• It is fast with a lower error rate caused by inaccuracy in assumptions.
3 The Proposed Location-Aware Personalized Traveler Assistance (LAPTA) Recommender System
In this section, the proposed RS for travelers will be discussed in detail. The collected data, system architecture, and process flow of the developed system will be explored.
Unlike requirement analysis, which focuses more on collecting the proper requirements, requirement validation ensures that the gathered requirements are complete, consistent, and reflective of the users’ expectations and needs according to the collected data from end-users [39]. In the data gathering through primary research questionnaires, the gathered data should be analyzed and validated to assist in creating a clear idea of the study objectives and the proposed system. In this research, the authors conducted an online survey to extract the system requirements through the respondents’ opinions. The survey involved 65 respondents globally who are adults and travel at an average of 2–3 times a year. After the data collection, validation was conducted to ensure the completeness of all the survey sections. The following figures depict the survey results with analysis.
Fig. 1a indicates that 89.2% of the participants plan their trips using the Internet and other options (such as travel agents) constitute the remaining 10.8%. Therefore, most people rely on the Internet to plan their trips. Regarding the most convenient way to plan a trip, 67.7% of participants chose using the Internet, 16.9% selected the help of a friend, and 13.8% indicated the services of travel agents (Fig. 1b). Thus, the majority prefer to use the Internet as a convenient approach to plan a trip.
Fig. 2a shows that 86.2% of respondents utilize the Internet during their trip to search for a particular location, 7.7% depend on travel local guides, and 6.2% ask the nearby local people for suggestions. Thus, people started to rely on the Internet to search for locations during their trip rather than using other options like local guides.
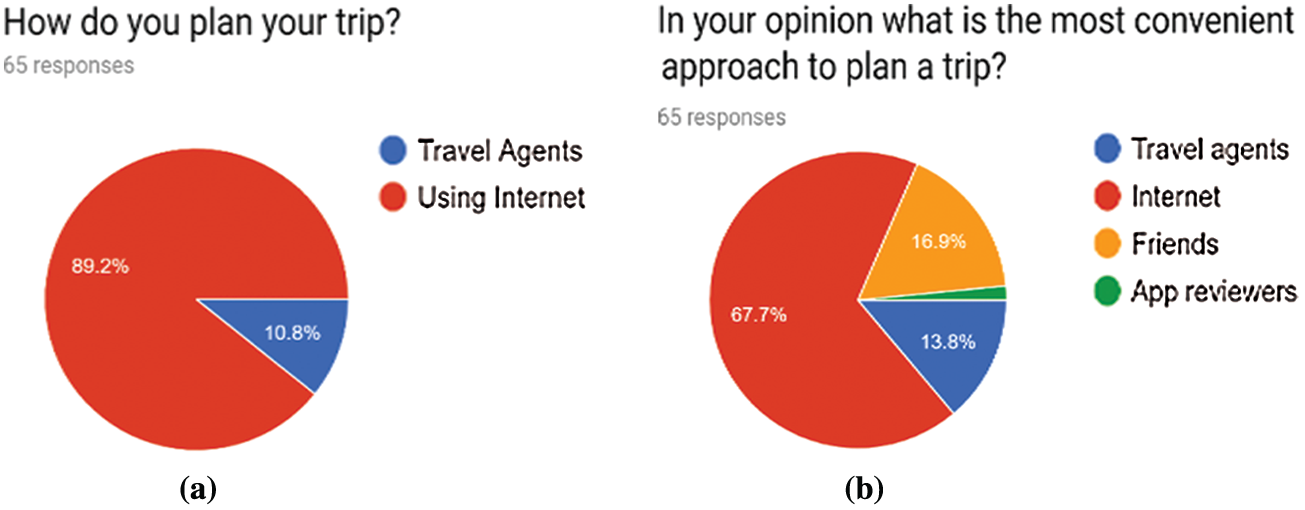
Figure 1: Survey results: (a) travel planning and (b) convenient planning methods according to the users
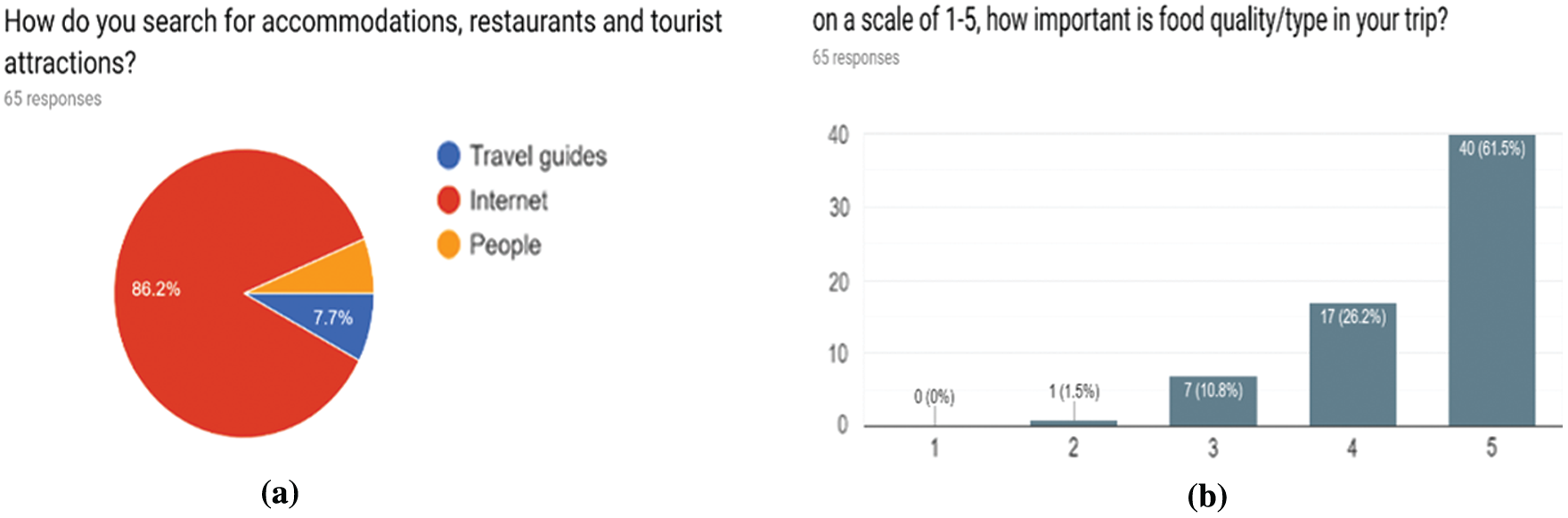
Figure 2: Results of users experience in: (a) searching for places and tourist attractions and (b) importance of food quality/types for the traveler
As depicted in Fig. 2b, 61.5% of respondents found that food quality is essential, 26.2% find that food quality is quite important, 10.8% have neutral thoughts about the quality of food during the trip, and only 1.5% do not think that quality of food is essential. Thus, more than 80% of respondents find that their food quality is critical during their trip.
According to the question in Fig. 3a, the respondents consider their trip satisfactory on various factors. For example, travelers consider their trip satisfactory due to good accommodation (47.7%), food quality and safety (46.2%), attractions and tourist sites (33.8%), finding friendly people around the city (16.9%), and 38.5% of participants reveal that all the above factors are critical during the trip. Fig. 3b shows that 76.9% of participants always rely on their mobile phones, 13.8% use their mobile phone often, 6.2% rarely use their phones, and 3.1% rarely use their phone during their trips. Thus, more than 80% of the participants reach for and depend on their mobile phones for various reasons.
Fig. 4a indicates that 60% of participants find mobile phones strongly helpful to recommend nearby hotels, restaurants, tourist attractions, and public transportation locations; 32.3% find them quite helpful; 3.1% consider them as neutral, and 4.6% find them entirely unhelpful. Therefore, approximately 93% of respondents need an application that would help them find and would recommend nearby locations. Fig. 4b displays the responses on the necessity of a location awareness personalized assistance application for travelers. The results are as follows: strongly agree (47.7%), agree (43.1%), neutral (7.7%), and disagree (1.5%). Accordingly, a location awareness personalized assistance mobile application would bring value and assistance to travelers throughout their trips.
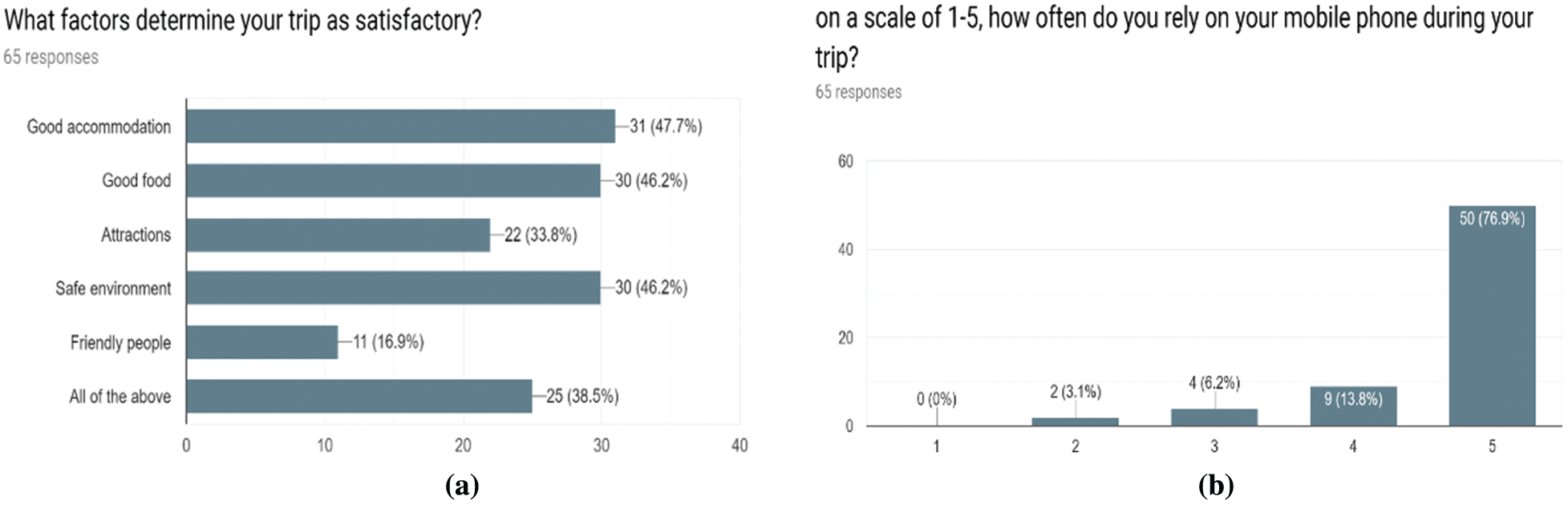
Figure 3: Results of users experience: (a) factors influencing users’ trip satisfaction and (b) usage rate of mobile phone during trips
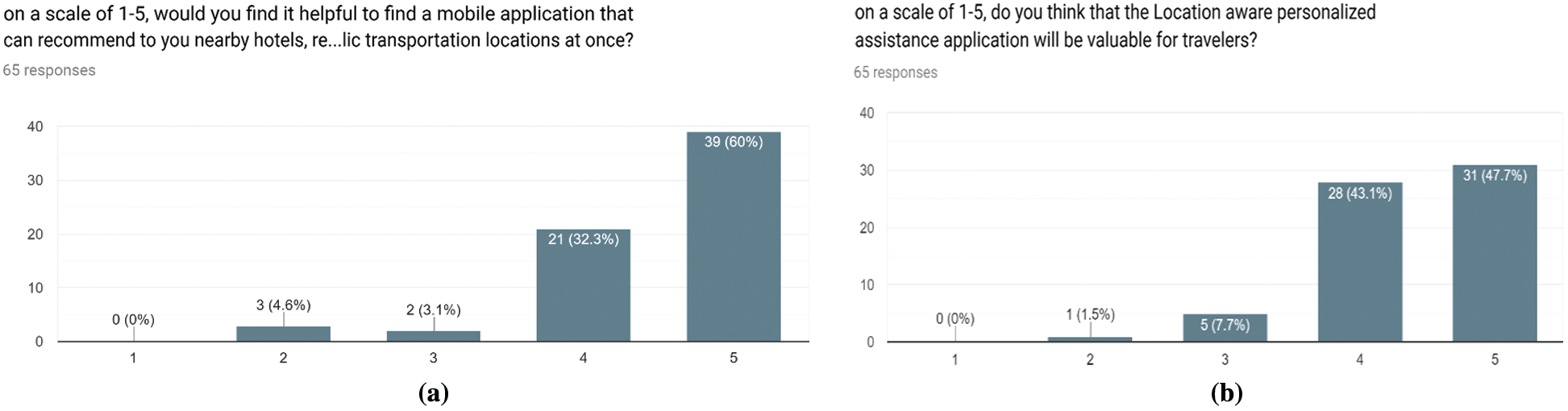
Figure 4: Results of: (a) Importance of recommender system mobile app and (b) evaluations of application necessity
Fig. 5a reveals that 83.1% of respondents would use a location-based app, 13.8% are unsure, and 3.1% would not download and use a location awareness personalized assistance mobile application. Therefore, this outcome shows the necessity, significance, and feasibility of the application to people. Fig. 5b shows the respondents’ thoughts on the features that may be included in the LAPTA, and 78.5% of respondents believe that a current local map view with nearby locations should be included, 75.4% want to view reviews of a particular location, 61.5% want to have the ability to search and view locations, 49.2% want to have the ability to add reviews and ratings about a particular location, 46.2% require the ability to provide feedback about the mobile application, 44.6% thinks that displayed ratings on a particular location would be valuable, and 40% wish for displayed price tags on locations. This outcome endows the researchers with a clear picture of the features to be considered while developing the proposed LAPTA application.

Figure 5: Results of: (a) Evaluation of application necessity and (b) Important features to be implemented in LAPTA application
The implemented approach in this study is the KNN-based CF Algorithm. The principle of the proposed approach is to evaluate the user’s rating of the POI m, and then according to the user ratings, u, the approach finds other POIs which are like POI m. To decide the similarity of POIs, the similarity function (similarity metric) has been formulated as in [40] and utilizes the modified cosine similarity between POIs a and b:
where R
where
One primary step in the CF algorithm is to measure the similarity between locations and pick the most similar items. The fundamental idea in measuring similarities between I and J is to isolate users who rated these POIs and then use the similarity calculation technique to evaluate the similarity si, j. This process has been demonstrated in Fig. 6, where the matrix rows represent users, and the columns represent items.
Several tricks in data post-processing could also be applied simultaneously to enhance the performance of RSs [41]. One of the “tricks” employed in this study is item-based correction, which explicitly defines the item-based rating mean as given in Eq. (3).
where U(m) is defined in Eq. (5). For the proposed CF approach, the item-based prediction mean is calculated as
where Nu is the number of users. We correct the prediction by
Thus, Eq. (5) provides the item-based correction formula. The item-based correction increases the RMSE by approximately 0.03 on the basis of the testing conducted.
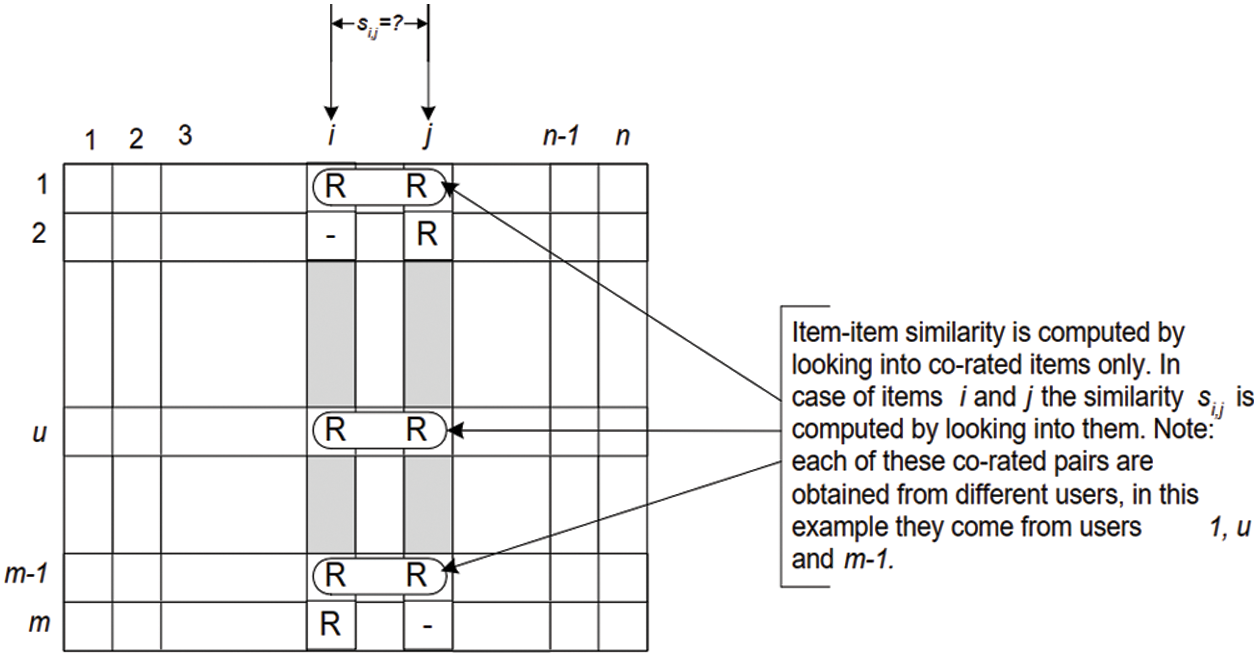
Figure 6: Isolation of the co-rated items and similarity computation [40]
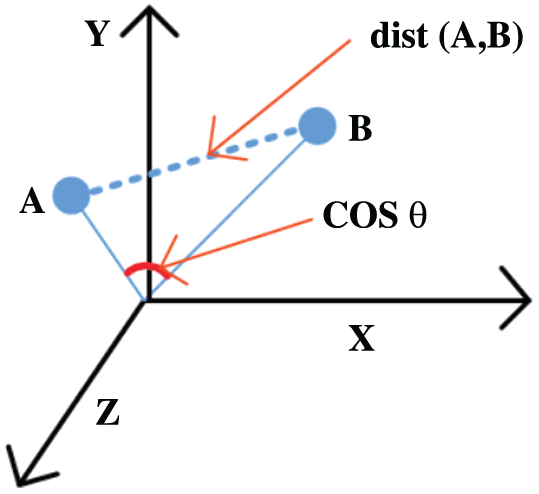
Figure 7: Recommender system using k-nearest neighbors–-cosine similarity [42]
Fig. 8 depicts the LAPTA overall architecture and how it operates. LAPTA consists of two modules: the online and offline modules. In the online module, the user interacts with the system, such as by searching for current locations and viewing locations according to the current detected location. By contrast, the offline module stores users’ past search behavior and matches it with the locations to generate a user preference. Likewise, the stored user preference dataset assists the recommendation engine in generating personalized suggestions in line with the preferences generated from users’ past search behaviors.
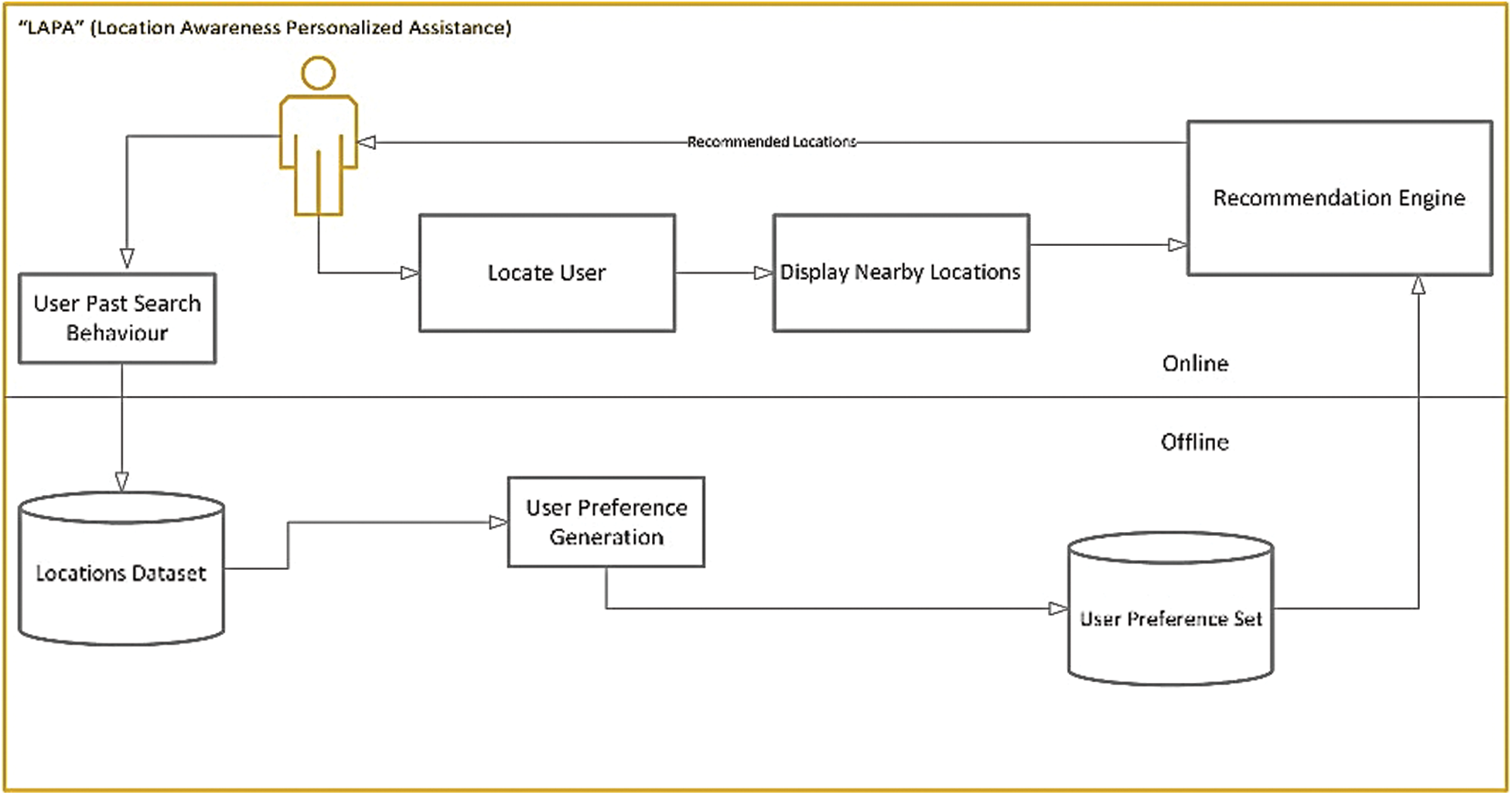
Figure 8: Overall System Architecture of LAPTA
The CF approach creates a model on the basis of past user behaviors (similar locations previously visited or given good numerical ratings) and similar decisions taken by other users. This model is then utilized to predict locations based on KNN (or POI ratings) that may be of interest to the user. The technique then utilizes a database in which data points are divided into various clusters to make inferences for new POIs. Therefore, KNN does not claim the underlying data distribution but relies on the featured item’s similarity. As it makes an inference about the POI, KNN calculates the “distance” between the target POI and every other POI in its database. It ranks the distances and returns the closest neighbor K top POIs to the most similar POI recommendations. Fig. 9 presents an example of how KNN classifies the new POI.
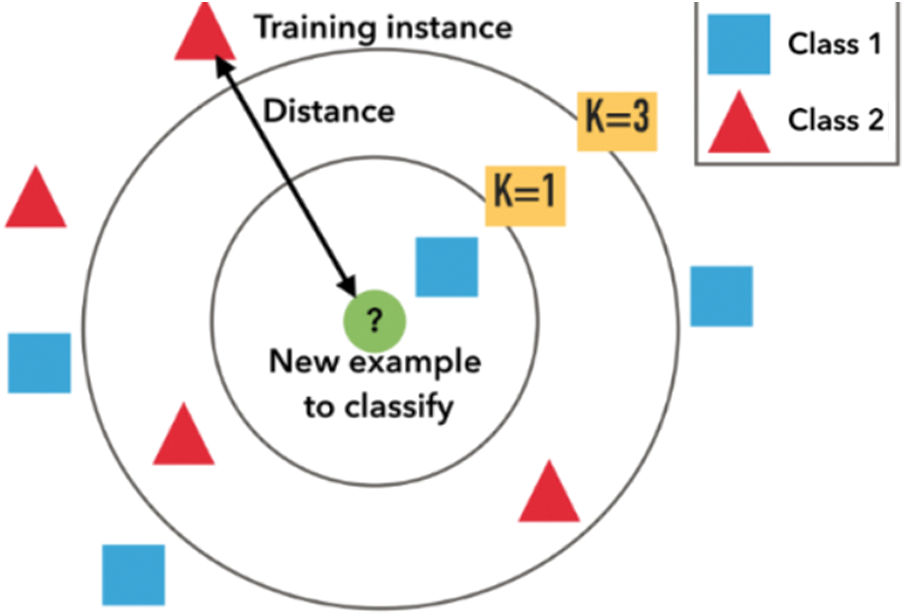
Figure 9: Classification of a new POI using the KNN
3.4 Process Flow of the Proposed Approach
The proposed approach creates recommendations by identifying places that travelers rated highly or provided them with good experiences. Two places can be identical if most of these two places’ visitors gave similar ratings or share the same experiences. Per this explanation, this suggested approach is an item-centric technique as it identifies and measures distances between the places on the basis of user experiences. For instance, the traveler can receive a personal recommendation from the proposed approach by considering the POI that the user prefers the most. This preferred POI can be represented by its vector of contact with each user (the corresponding column in the interaction matrix). Subsequently, the approach measures the similarities between the current POI and all the other POIs. Once the similarities are computed, KNN starts selecting the best POI. Tab. 1 shows the process flow of the proposed algorithm.

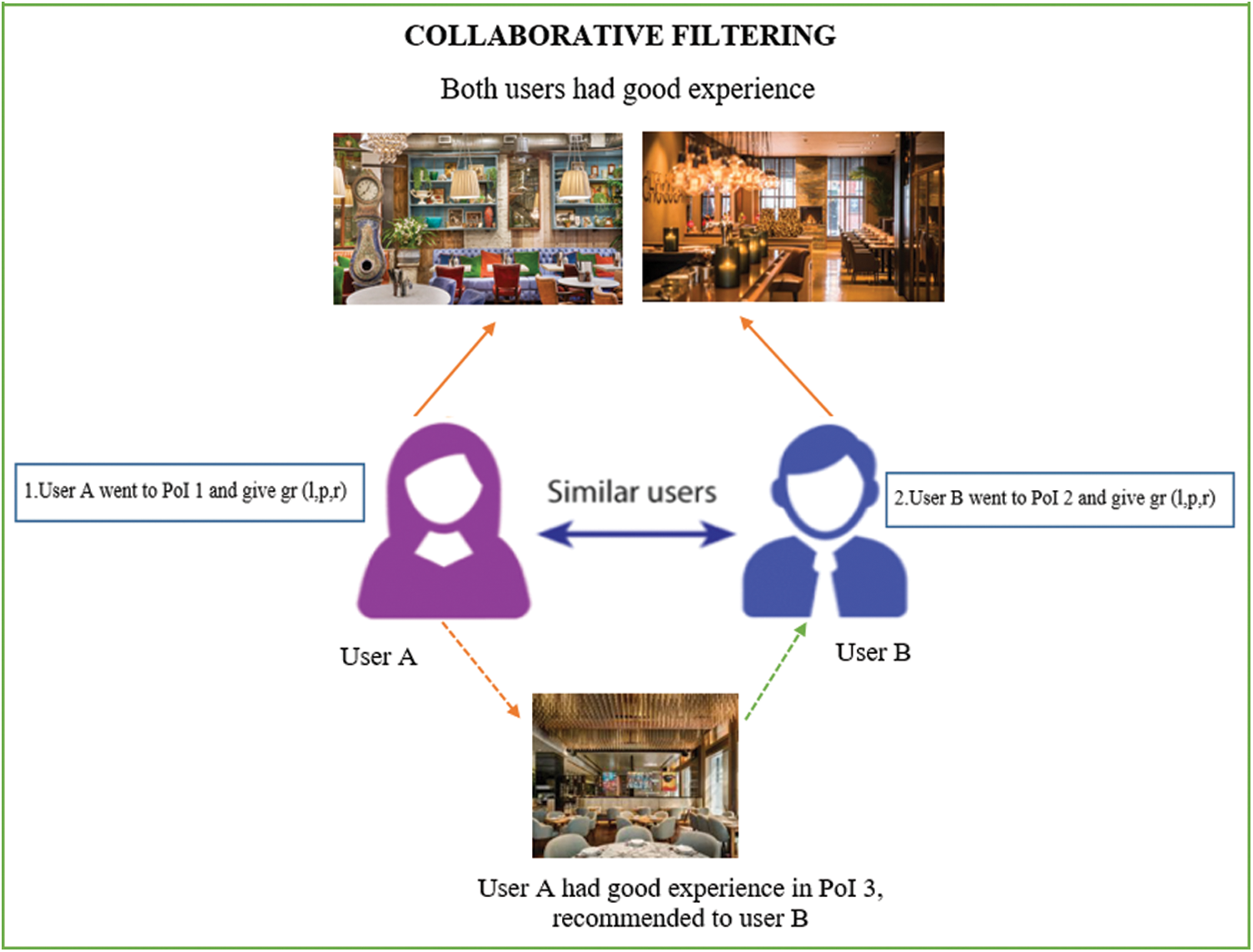
Figure 10: Collaborative filtering approach using KNN in this study
3.5 The Proposed Algorithm Description
CF systems work by collecting user feedback in the form of user ratings POIs in a given domain and then employing the similarities of the rating behavior among several users to recommend a new POI. In the proposed system, the CF model was developed using the KNN algorithm, an ML algorithm, to predict the user’s ratings of unrated items. The KNN algorithm is non-parametric, so it does not make any assumptions on the underlying data distribution but relies on POI feature similarity calculations. The KNN recommends a POI by calculating the distance between the target POI and every other POI in its database. Then, it ranks its distances and returns the top KNN POIs as the most similar POIs in the recommendation list. Fig. 10 depicts the proposed algorithm whereby Users A and B have a good experience in two different POIs. Subsequently, the proposed approach recommends a new POI to User B on the basis of past experiences and user preference/rating. In other words, KNN classifies any data point by a majority vote of its neighbors, and then the data point will be assigned to the class having the most common nearest neighbors as measured by a distance function (categorical variable).
In this section, the proposed LAPTA approach is tested for effectiveness, efficiency, and performance. Experiments on an ASUS core i7-5500U@3,00 GHz device with 16 GB memory on 64-bit Windows OS were performed in Python 3.8.0. The mobile app of the proposed approach was then examined and implemented in a mobile Android environment.
The main objective of this experiment is to evaluate the performance and efficiency of the proposed RS according to location recommendations. The evaluation was measured using two metrics, namely, mean absolute error and root mean absolute error.
4.1.1 Mean Absolute Error (MAE)
The metric MAE computes the deviation between predicted ratings and actual ratings, as shown in Eq. (6). Thus, a lower MAE value is more beneficial for our model.
where
4.1.2 Root Mean Square Error (RMSE)
The metric RMSE is like the MAE but places greater emphasis on a larger deviation. Thus, the residual’s absolute value is squared. The square root of the entire term is taken for comparison. The RMSE metric given in Eq. (7).
The results obtained from a cosine-based similarity test with different neighborhood sizes are presented in Tab. 2. When the cosine similarity with neighborhood size 20 is adjusted, the MAE and RMSE values are minimal. Both evaluation metrics showed similar improvements in rating accuracy when the neighborhood size increases. RMSE shows that neighborhood size 20 provides the highest accuracy, but MAE achieves the corresponding outcome with neighborhood size 10.

4.2 Comparison with the Literature
Tab. 3 provides the results of comparison of the proposed approach with those of recent studies [40,43–45]. For instance, the authors in [40] proposed an item-based CF recommendation algorithm which was evaluated with a MAE value of 0.7392, and the authors in [43] suggested a cluster-based CF RS for cardiac patients. The approach in [43] obtained the best results by employing CF with a clustering algorithm as the MAE achieved 0.2510 with a neighborhood size 15. Authors in [44] also presented an item-based CF RS where the MAE and RMSE values were 0.920979 and 0.717344, respectively. In [45], authors proposed various approaches, including an item-based CF with the corresponding MAE and RMSE values of 0.8222 and 0.8927. Comparatively, the suggested technique in this study combines content-based and item-based filtering, a scheme which outperforms the RSs suggested by [40,44,45]. However, the RS proposed by [43] remains optimal as it obtained a better result relative to our work.

For security purposes, the LAPTA system was equipped with an authentication page which requires valid user credentials to access the application. In case the user entered the wrong credentials, an alert message will notify users to insert the valid ones. Alternatively, the user can use Google ID to access the system using the Google Sign-in feature. After logging in, the user will be redirected to the main page, which is the map view page, as depicted in Fig. 11. In the map view page, the user can explore all nearby POIs (e.g., restaurants and shopping malls) and explore the POIs under particular categories by selecting those classifications from a dropdown list (left side, Fig. 11). The user can also click on the location icon on the map to display the distance between the user’s location and the selected location.
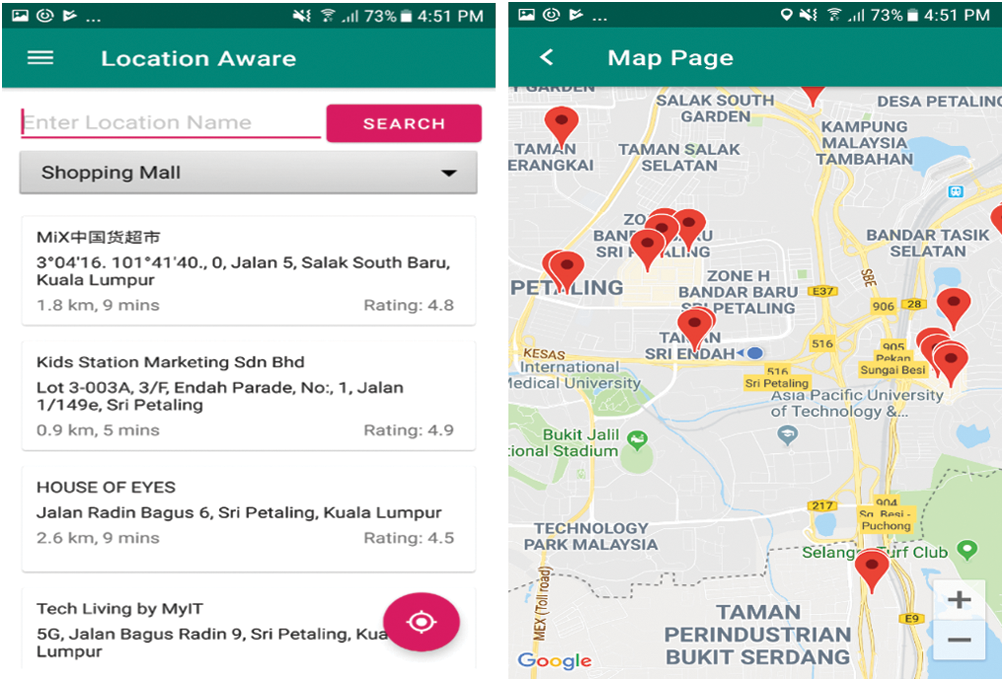
Figure 11: Map View with various POIs
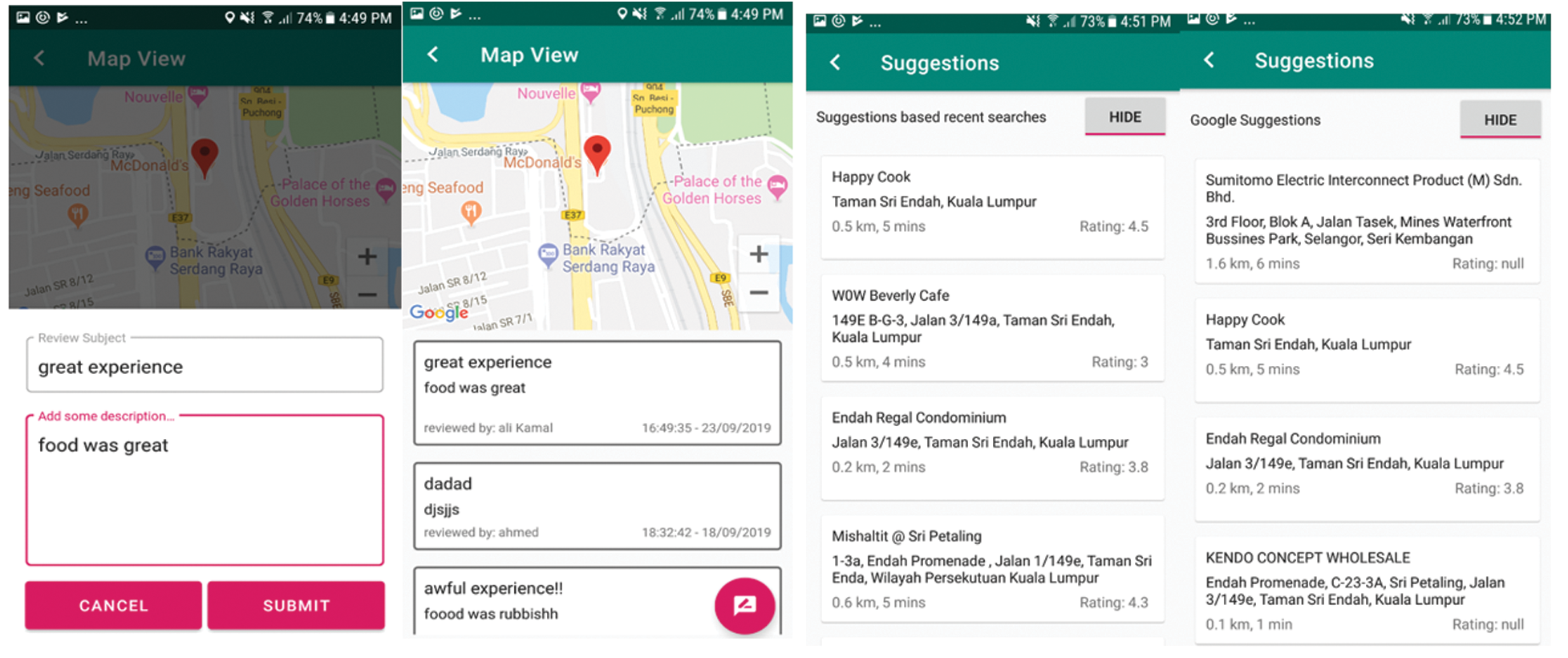
Figure 12: Proposed mobile app results: (a) the view and add reviews feature and (b) the suggestions panel according to user preferences
Furthermore, users can add and view feedback and reviews on locations, as shown in Fig. 12a. In the page for location viewing (e.g., restaurant), users can read current reviews about that location. If the user needs to write a review, he/she can click on the reviews button located at the bottom of the screen and add the desired feedback. Once the review is saved, the user can immediately view their reviews. Additionally, LAPTA has a navigation drawer through which the user can navigate the application to access different features (e.g., profiles, suggestions, and maps) and logout from the application.
LAPTA also has an interesting feature which displays Google provided suggestions and the recommendations generated by the system itself. As discussed in Section 3, the system uses a KNN-based CF algorithm to provide suggestions according to user preferences like search behavior and the most popular or top-rated nearby locations. Those suggestions are displayed as shown in Fig. 12b. As an example, we assume the user searches for nearby shopping malls and McDonald’s restaurants (Fig. 11). Once the user navigates to the suggestions panel, several suggestions would be created in line with the user searches and locations, as in Fig. 12a. Those generated suggestions include similar nearby POIs under the same tag.
The crucial role of mobile devices and applications in people’s daily lives is undeniable. Nowadays, mobile applications contribute to the different sectors like entertainment, E-Commerce, E-Government, and tourism and travelling. That contribution to the tourism industry leads to a considerable change in the concept of travel by enhancing the travelers’ experience by searching, selecting, and sharing information about different locations. Thus, this study examined this area through surveys and in the academic literature to explore the different issues and develop a proper solution to help the travelers enjoy their journeys with less disturbance. To address the issue of finding the suitable POIs for the travelers, RSs were proposed to allow the travelers to select the convenient POIs according to the personal preferences and others user ratings. This work utilized RSs and a mobile device location-based feature to build the LAPTA system, which integrates user preferences and GPS to generate personalized and location-aware recommendations. The recommendations were generated using a KNN-based CF approach which considers the user’s rating and behavior profile to show recommended POIs. The experimental results showed the superiority of the proposed system over those in related works in terms of the MAE and RMSE values. However, the authors feel that the system needs further improvements. Thus, future enhancements can be made to improve the application’s efficiency by exploring more ML filtering algorithms and technologies that could improve response time and improve the system’s effectiveness. Moreover, a GPS navigation system and a language translator could be implemented as a future upgrade to increase the application’s usability and enhance the user’s experience.
Funding Statement: The authors would like to acknowledge the support of Prince Sultan University for paying the Article Processing Charges (APC) of this publication.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. S. R. Department, “Number of mobile phone users worldwide from 2015 to 2020,” 2016. [Online]. Available: https://www.statista.com/statistics/274774/forecast-of-mobile-phone-users-worldwide. [Google Scholar]
2. B. Stringam and J. Gerdes, “An analysis of word-of-mouse ratings and guest comments of online hotel distribution sites,” Journal of Hospitality Marketing & Management, vol. 19, no. 7, pp. 773–796, 2010. [Google Scholar]
3. S. R. Department, “Smartphone travel bookers in the United States 2012–2018,” 2018. [Online]. Available: https://www.statista.com/statistics/183721/us-travellers-researching-or-booking-a-travel-online-since-2010/. [Google Scholar]
4. S. Philippines, “1.3 billion people traveled the world in 2017,” 2018. [Online]. Available: https://www.sunstar.com.ph/article/417102/Sports/13-billion-people-traveled-the-world-in-2017. [Google Scholar]
5. B. Sparks and V. Browning, “The impact of online reviews on hotel booking intentions and perception of trust,” Tourism Management, vol. 32, no. 6, pp. 1310–1323, 2011. [Google Scholar]
6. M. Alsarayreh and A. Al Matarneh, “Communication problems among tourists and community form the tourist perspective, a case study form karak governorate,” Tourismos An International Multidisciplinary Journal of Tourism, vol. 8, no. 1, pp. 19–34, 2013. [Google Scholar]
7. A. Mak, M. Lumbers, A. Eves and R. Chang, “Factors influencing tourist food consumption,” International Journal of Hospitality Management, vol. 31, no. 3, pp. 928–936, 2012. [Google Scholar]
8. E. Cohen and N. Avieli, “Food in tourism: Attraction and impediment,” Annals of Tourism Research, vol. 31, no. 4, pp. 755–778, 2004. [Google Scholar]
9. D. Scott, “Why sustainable tourism must address climate change,” Journal of Sustainable Tourism, vol. 19, no. 1, pp. 17–34, 2011. [Google Scholar]
10. L. Caldito, F. Dimanche and S. Ilkevich, “Tourist behaviour and trends,” in Tourism in Russia: A Management Handbook, 1st ed., vol. 1. West Yorkshire, England: Springer, pp. 101–130, 2015. [Google Scholar]
11. R. Burke, “Hybrid web recommender systems,” in The Adaptive Web, vol. 12. Berlin, Heidelberg: Springer, pp. 377–408, 2007. [Google Scholar]
12. F. Ricci, L. Rokach and B. Shapira, “Recommender systems: Introduction and challenges,” in Recommender Systems Handbook, 2nd ed., vol. 1. Boston: Springer, pp. 1–34, 2015. [Google Scholar]
13. M. Ramachandran and V. Chang, “Recommendations and best practices for cloud enterprise security,” in Proc. of the 2014 IEEE 6th Int. Conf. on Cloud Computing Technology and Science, Singapore, 2014. [Google Scholar]
14. G. Linden, B. Smith and J. York, “Amazon.com recommendations: Item-to-item collaborative filtering,” IEEE Internet Computing, vol. 7, no. 1, pp. 76–80, 2003. [Google Scholar]
15. H. Lv and H. Tang, “Machine learning methods and their application research,” in 2011 2nd Int. Symp. on Intelligence Information Processing and Trusted Computing, Hubei, China, pp. 108–110, 2011. [Google Scholar]
16. I. Portugal, P. Alencar and D. Cowan, “The use of machine learning algorithms in recommender systems: A systematic review,” Expert Systems with Applications, vol. 97, no. 3, pp. 205–227, 2018. [Google Scholar]
17. C. Standing, J. Tang-Taye and M. Boyer, “The impact of the internet in travel and tourism: A research review 2001–2010,” Journal of Travel & Tourism Marketing, vol. 31, no. 1, pp. 82–113, 2014. [Google Scholar]
18. D. Wang, Z. Xiang and D. Fesenmaier, “Smartphone use in everyday life and travel,” Journal of Travel Research, vol. 55, no. 1, pp. 52–63, 2014. [Google Scholar]
19. Y. Yang, Y. Zhang, P. Xia, B. Li and Z. Ren, “Mobile terminal development plan of cross-platform mobile application service platform based on ionic and cordova,” in 2017 Int. Conf. on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration, Wuhan, China, pp. 100–103, 2017. [Google Scholar]
20. Y. Dari, S. Suyoto and P. Pranowo, “Capture: Mobile based indoor positioning system using wireless indoor positioning system,” International Journal of Interactive Mobile Technologies, vol. 12, no. 1, pp. 61–72, 2018. [Google Scholar]
21. F. Dafedar and K. F. Bharati, “A fast collaborative filtering approach for web personalized recommendation system,” in 2017 Int. Conf. on Information Communication and Embedded Systems, Chennai, India, pp. 1–7, 2017. [Google Scholar]
22. S. Gandhi and M. Gandhi, “Hybrid recommendation system with collaborative filtering and association rule mining using big data,” in 2018 3rd Int. Conf. for Convergence in Technology, Pune, India, pp. 1–5, 2018. [Google Scholar]
23. M. Ilhami, “Film recommendation systems using matrix factorization and collaborative filtering,” in 2014 Int. Conf. on Information Technology Systems and Innovation, Bandung, Indonesia, pp. 1–5, 2014. [Google Scholar]
24. P. B. Thorat, R. M. Goudar and S. Barve, “Survey on collaborative filtering, content-based filtering and hybrid recommendation system,” International Journal of Computer Applications, vol. 110, no. 4, pp. 31–36, 2015. [Google Scholar]
25. F. Isinkaye, Y. Folajimi and B. Ojokoh, “Recommendation systems: Principles, methods and evaluation,” Egyptian Informatics Journal, vol. 16, no. 3, pp. 261–273, 2015. [Google Scholar]
26. H. Zarzour, Z. Al-Sharif, M. Al-Ayyoub and Y. Jararweh, “A new collaborative filtering recommendation algorithm based on dimensionality reduction and clustering techniques,” in 2018 9th Int. Conf. on Information and Communication Systems, Irbid, Jordan, pp. 102–106, 2018. [Google Scholar]
27. W. Chen, X. Xia and Y. G. Shi, “A collaborative filtering recommendation algorithm based on contents genome,” in IET Int. Conf. on Information Science and Control Engineering 2012, Shenzhen, China, pp. 1–4, 2012. [Google Scholar]
28. R. Chen, Q. Hua, Y. S. Chang, B. Wang, L. Zhang et al., “A survey of collaborative filtering-based recommender systems: From traditional methods to hybrid methods based on social networks,” IEEE Access, vol. 6, pp. 64301–64320, 2018. [Google Scholar]
29. Z. Li, J. Hu, J. Shen and Y. Xu, “A scalable recipe recommendation system for mobile application,” in 3rd Int. Conf. on Information Science and Control Engineering, Beijing, China, pp. 19–94, 2016. [Google Scholar]
30. S. Ilarri, R. Hermoso, R. Trillo-Lado and M. D. C. Rodríguez-Hernández, “A review of the role of sensors in mobile context-aware recommendation systems,” International Journal of Distributed Sensor Networks, vol. 11, no. 11, pp. 1–30, 2015. [Google Scholar]
31. X. Hu, W. Zhu and Q. Li, “A hybrid clothes recommender system based on user ratings and product feature,” arXiv preprint arXiv, pp. 270–274, 2014. https://doi.org/10.1109/ICMeCG.2013.60. [Google Scholar]
32. R. Ahuja, A. Solanki and A. Nayyar, “Movie recommender system using k-means clustering and k-nearest neighbor,” in 9th Int. Conf. on Cloud Computing, Data Science & Engineering, Noida, India, pp. 263–268, 2019. [Google Scholar]
33. R. Katarya and O. P. Verma, “An effective collaborative movie recommender system with cuckoo search,” Egyptian Informatics Journal, vol. 18, no. 2, pp. 105–112, 2017. [Google Scholar]
34. L. Sun, J. Guo and Y. Zhu, “Applying uncertainty theory into the restaurant recommender system based on sentiment analysis of online chinese reviews,” World Wide Web, vol. 22, no. 1, pp. 83–100, 2019. [Google Scholar]
35. A. Gupta and K. Singh, “Location based personalized restaurant recommendation system for mobile environments,” in Int. Conf. on Advances in Computing, Communications and Informatics, Mysore, India, pp. 507–511, 2013. [Google Scholar]
36. H. Yin, B. Cui, Y. Sun, Z. Hu and L. Chen, “Lcars: A spatial item recommender system,” ACM Transactions on Information Systems, vol. 32, no. 3, pp. 1–37, 2014. [Google Scholar]
37. Z. Zhang, “Introduction to machine learning: K-nearest neighbors,” Annals of Translational Medicine, vol. 4, no. 11, pp. 1–7, 2016. [Google Scholar]
38. D. Adeniyi, Z. Wei and Y. Yongquan, “Automated web usage data mining and recommendation system using k-nearest neighbor (KNN) classification method,” Applied Computing and Informatics, vol. 12, no. 1, pp. 90–108, 2016. [Google Scholar]
39. M. Kamalrudin and S. Sidek, “A review on software requirements validation and consistency management,” International Journal of Software Engineering and its Applications, vol. 9, no. 10, pp. 39–58, 2015. [Google Scholar]
40. B. Sarwar, G. Karypis, J. Konstan and J. Riedl, “Item-based collaborative filtering recommendation algorithms,” in Proc. of the 10th Int. Conf. on World Wide Web, NY, USA, pp. 1–11, 2001. [Google Scholar]
41. I. Portugal, P. Alencar and D. Cowan, “The use of machine learning algorithms in recommender systems: A systematic review,” Expert Systems with Applications, vol. 79, no. 3, pp. 205–227, 2018. [Google Scholar]
42. L. Wang, Z. Chen and J. Wu, “An opportunistic routing for data forwarding based on vehicle mobility association in vehicular ad hoc networks,” Information-an International Interdisciplinary Journal, vol. 8, no. 4, pp. 140, 2017. [Google Scholar]
43. A. Mustaqeem, S. M. Anwar and M. Majid, “A modular cluster based collaborative recommender system for cardiac patients,” Artificial Intelligence in Medicine, vol. 102, no. 4, pp. 101761, 2020. [Google Scholar]
44. S. Najafi and Z. Salam, “Evaluating prediction accuracy for collaborative filtering algorithms in recommender systems,” B.Sc. thesis, Dept. Computer Science and Communication (CSCKTH Royal Institute of Technology School of Computer Science and Communication, Stockholm, Sweden, 2016. [Google Scholar]
45. I. K. Pradeep and M. JayaBhaskar, “Comparative analysis of recommender systems and its enhancements,” International Journal of Engineering & Technology, vol. 7, no. 3, pp. 304–310, 2018. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |