DOI:10.32604/cmc.2021.020324
| Computers, Materials & Continua DOI:10.32604/cmc.2021.020324 | |
| Article |
CNN-Based Forensic Method on Contrast Enhancement with JPEG Post-Processing
1Institute of Information Science, Beijing Jiaotong University, Beijing, 100044, China
2Beijing Key Laboratory of Advanced Information Science and Network Technology, Beijing Jiaotong University, Beijing, 100044, China
3Electrical Engineering and Computer Science Department, University of Tennessee Knoxville, Knoxville, 37996, TN, USA
*Corresponding Author: Rongrong Ni. Email: rrni@bjtu.edu.cn
Received: 19 May 2021; Accepted: 23 June 2021
Abstract: As one of the most popular digital image manipulations, contrast enhancement (CE) is frequently applied to improve the visual quality of the forged images and conceal traces of forgery, therefore it can provide evidence of tampering when verifying the authenticity of digital images. Contrast enhancement forensics techniques have always drawn significant attention for image forensics community, although most approaches have obtained effective detection results, existing CE forensic methods exhibit poor performance when detecting enhanced images stored in the JPEG format. The detection of forgery on contrast adjustments in the presence of JPEG post processing is still a challenging task. In this paper, we propose a new CE forensic method based on convolutional neural network (CNN), which is robust to JPEG compression. The proposed network relies on a Xception-based CNN with two preprocessing strategies. Firstly,unlike the conventional CNNs which accepts the original image as its input, we feed the CNN with the gray-level co-occurrence matrix (GLCM) of image which contains CE fingerprints, then the constrained convolutional layer is used to extract high-frequency details in GLCMs under JPEG compression, finally the output of the constrained convolutional layer becomes the input of Xception to extract multiple features for further classification. Experimental results show that the proposed detector achieves the best performance for CE forensics under JPEG post-processing compared with the existing methods.
Keywords: Contrast enhancement forensics; convolutional neural networks; robust forensics; JPEG compression
As the image editing techniques rapidly developed and the media processing software improves, some malicious users can generate forged images easily with powerful editing tools such as Photoshop, etc. In addition, social networking has accelerated the dissemination of forged images which may cause detrimental effect on our society. Hence, answering the originality and integrity of images becomes increasingly fundamental. In order to determine whether the image is modified and understand what has happened during the tampering, many kinds of forensic techniques for detecting different types of image manipulations were invented.
Contrast enhancement (CE), one of the most popular and efficient image processing operations, is frequently used by malicious image attackers to conceal traces of forgery. CE can improve the visual quality of the forged images by eliminating inconsistent brightness of tampered images. As a consequence, verifying the authenticity and integrity of digital images in CE forensics has always been of great interest for image forensics community.
Many techniques have been proposed to detect contrast-enhanced image in recent years. Earlier traditional CE forensic methods are based on histogram. Stamm et al. [1–3] observed that peak and gaps artifacts occur in the histogram of the contrast-enhanced image, whereas the histogram of the natural image does not follow these features. To detect CE in images which are JPEG compressed and then contrast enhanced, Cao et al. [4] introduced a slightly different observation on the histogram. However, these simple first-order statistics evidences are easy to be concealed after a further processing. Some anti-forensic techniques [5,6] add a pixel-wise random noise to the image to eliminate the visual clues in histogram. To against these anti-forensic methods, De Rosa et al. [7] proposed a CE forensic algorithm that based on gray-level co-occurrence matrix (GLCM), they found that the GLCM of a CE image has empty rows and columns caused by CE operation, in contrast, the GLCM of unenhanced image does not have these gaps artifacts. The method that uses second-order statistics of the image is shown to be effective against anti-forensic techniques targeted at histogram-based detectors. Besides, the steganography field method Spatial Rich Models (SRM) [8] has shown promising performance in image forensics tasks. SRM can extract powerful steganalytic features from pixel domain. Li et al. [9] and Qiu et al. [10] use SRM features to identify multiple image processing operations including CE, the experiments show SRM has great performance on detecting various different image manipulations.
With the development of deep learning-based technique, many deep learning-based methods [11–13] have been successfully applied to many fields. Convolutional neural networks (CNNs) such as XceptionNet [14], one of the most classical networks, shown impressive performance in various tasks. Inspired by this, many forensics researchers proposed forensics method based on designed CNNs, such as H-CNN [15], Laplacian CNN [16], etc. Bayar et al. [17] proposed a universal image manipulation detector called “MISLnet” which based on CNN, they added a new type of convolutional layer with the constrained kernel in the network, called a constrained convolutional (Cons-conv) layer. Sun et al. [18] proposed a novel CE forensic method based on CNN. They feed the CNN with the gray-level co-occurrence matrix (GLCM) of the image. It outperforms the conventional forensic methods in terms of forgery detection accuracy, especially in dealing with counter-forensic attacks.
However, all these methods are failed to detect CE in images which are contrast enhanced with JPEG post-processing. As JPEG is the most common image format, contrast-enhanced (CE) images are distributed in compressed formats to reduce the overheads of both storage and network traffic in practice. The previous effective CE forensic fingerprints in the uncompressed images are modified after JPEG compression, so it is much difficult to classify CE images. In this case, handcrafted feature-based approach is difficult to capture effective fingerprints. Within a data-driven learning framework, Barni et al. [19] proposed a patch-based CNN for generic contrast adjustment, which is robust to JPEG compression. However, they only explored the case under mild JPEG compression, while do not consider the compression images with lower quality factors (QFs).
In order to improve the JPEG-robustness of CE forensic method over a range of Quality Factors (QFs), we propose a novel Xception-based CNN detector. The Network is directly fed with the GLCM of image instead of pixels, which suppresses the interference of the image content. Furthermore, it contains traceable features for CE forensics tasks. Since JPEG compression reduced the artifacts features of GLCM, making it becomes more difficult to detect CE, we add a constrained convolutional (Cons-conv) layer [17] in front of the Xception. It can adaptively learn manipulation traces through extracting high-frequency details in GLCMs, therefore the feature maps show more differences between two classes and improve classification performance. Then Xception network extracts higher-level residual CE features under JPEG compression from Cons-conv layer output. Experiments show that our method achieves significant improvements over a range of QFs compared to the existing methods.
The remaining part of the paper is organized as follow. In Section 2, we will describe the proposed CNN-based network architecture. Experimental settings and results will be present in Section 3. Section 4 provides the conclusion.
In traditional computer vision research, classification tasks tend to learn features from image content. While in the manipulation forensics research, tasks tend to extract traces left by image operations instead of image content, in that case image content becomes redundant information. Therefore, the traditional CNN cannot be directly applied to the task of image forensics. To solve this problem, the network usually added preprocessing layers.
As presented in Fig. 1, the architecture of the proposed detection scheme is based on Xception, and two preprocessing measures are integrated in our method. Firstly, the workflow preprocesses the input images to achieve the GLCM. Then the grayscale GLCM image is fed into the network. Secondly, we make use of a constrained convolutional layer learns manipulation traces in GLCMs. This layer can learn pixel value dependency traces induced by manipulation and constrains CNN to learn prediction error features in the first layer. The Cons-conv layer consists of three constrained convolutional filters of size 5 × 5 and operates with a stride of size 1, the weights can be adaptively learned while training the CNN. The output feature maps size of Cons-conv layer is 252 × 252 × 3, which means that the number of feature maps is 3 and the resolution of each feature map is 252 × 252. These are still low-level pixel value dependency features. In order to learn higher-level prediction error features, we use a Xception network to extract high-dimensional features from the output of Cons-conv layer.
Xception is a deep convolution neural network structure inspired by Inception [20], in which the Inception module has been replaced by the depthwise separable convolution module. Xception also uses residual connections [21]. Xception can be divided into three parts as seen in Fig. 1, the previously learned hierarchical features first goes through the entry flow, then the second part is the middle flow which block2 repeats eight times, and last part is the exit flow.
Detailed introduction and analysis of the network is described as follows.
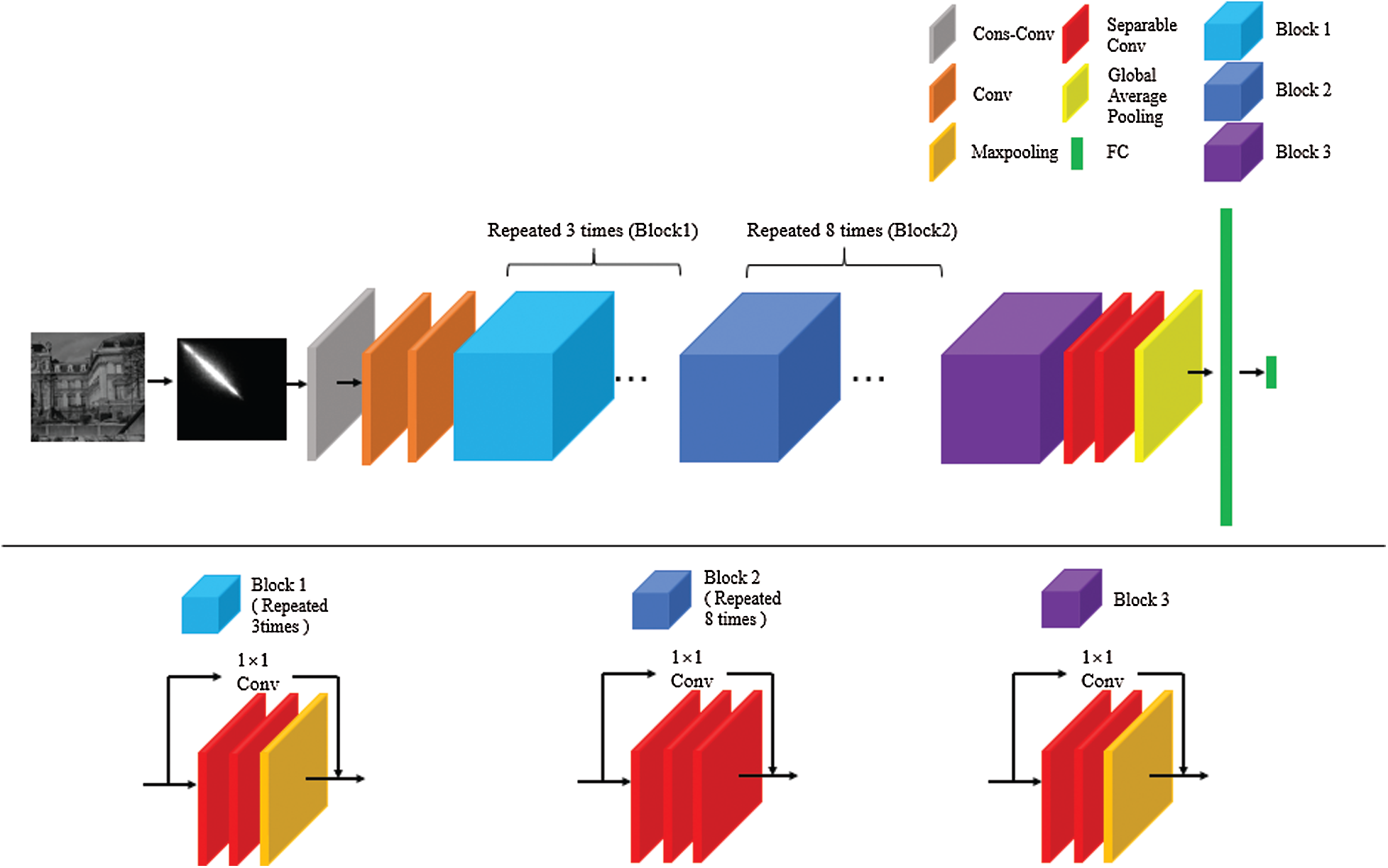
Figure 1: The framework of the proposed CNN model
2.1 Gray-Level Co-Occurrence Matrix
As mentioned earlier, the existing traditional CNN tends to learn features related to the content of the image. When CNN of this form is directly used for image manipulation forensics, it will cause the classifier to identify the scene content associated with the training data. CE just changes the brightness and contrast of an image, rather than the image content. Therefore, we use the GLCM as a preprocessing measure instead of using the image directly.
A gray-level co-occurrence matrix [22] can be shown as an image consisting of 256 × 256 pixels, which is the second-order statistics of the image. This matrix represents the distribution of the pixel intensity pairs consisting of the intensity values of a pixel and its neighboring pixels, the value at coordinate (i, j) obtained by accumulating the number of occurrences of a gray-value (i, j). The GLCM is defined as:
where f(·) is an indicator function that returns a value of 1 if the condition in the parentheses is satisfied, and 0 otherwise. I(p, q) denote a grayscale image of size M × N, and (∆x, ∆y) is a spatial offset. In our experiments, GLCMs are computed with eight different offsets, O = {(0, 1), (0, −1), (1, 0), (−1, 0), (1, 1), (1, −1), (−1, 1), (−1, −1)}, Then add the eight GLCMs to get one accumulated GLCM.
When CE is executed, the brightness range in the image will contract or expand. Therefore, the previous adjacent pixel values will be mapped to the same value or mapped separately. This results in some peak or empty rows and columns in the GLCM of the CE image. GLCM is second-order statistics of an image, which has more information than histogram, and it always has the same size, even for different resolutions input images. As shown in Fig. 2, the left image represents the GLCM of an original image, the right one is the GLCM of CE image which has peaks and empty rows, columns caused by CE operation.

Figure 2: GLCM of original image (left) and CE image (right)
Hence, we use the GLCM of the image as the input of the network, which suppresses the interference caused by image content and also contains traceable fingerprints left by CE.
2.2 Constrained Convolutional Layer
Under the case of JPEG post-processing, it cannot get the expected performance when directly use GLCM as the input of traditional CNNs. The reason may be attributed to that the gaps and peaks of GLCM of a CE image have reduced after JPEG operation, it causes tremendous loss of CE fingerprints in GLCM, therefore the difference between the CE images and CE with JPEG post-processing (CE-JPEG) images is narrowed. As shown in Fig. 3, the left image represents the GLCM of a CE image, the right one is the GLCM of CE image with JPEG post-processing, which we can observe that the gaps and peaks are much less than the one without the JPEG compression. Hence, we add a constrained convolutional (Cons-conv) layer to adaptively learn manipulation traces and extract high-frequency details in GLCMs.

Figure 3: GLCM of CE image (left) and CE image with JPEG post-processing (right)
The constrained convolutional layer [17] is a new type of convolutional layer with the constrained kernel, which is designed to suppress an image’s content and adaptively learn image manipulation traces. In the proposed method, the Cons-conv layer is applied with 3 filters, the kernel size is 5 × 5 and stride is 1. The prediction error filter constraints in the constrained convolutional layer are enforced through the following training process. After update filter weights through optimization algorithm and backpropagate errors at each training iteration, filters are enforced to set the central weight to −1. Next, the remaining weights are normalized so that their sum is equal to 1. Thus, the constrained convolutional layer can capture a number of different types of high-frequency information from the input, then it can adaptively learn good predictors for feature extraction through backpropagation.
In order to validate the constrained convolutional layer can actually capture high-frequency components from the input GLCM, the Cons-conv layer’s feature maps are displayed in Fig. 4. The leftmost column represents the input GLCM, the remaining three columns represent three different high-frequency feature maps obtained from the input GLCM. It can be observed that the high-frequency filter constrained kernels in the Cons-conv layer extract the high-frequency features of GLCM and amplify the detailed information, which is more effective for CE forensic training.
Figs. 5 and 6 show the difference between the features of JPEG images and CE-JPEG images. Fig. 5 represents the case that only using GLCM of two classes images, the left 3 columns are GLCM of JPEG images, the right 3 columns are GLCM of CE-JPEG images. It can be observed that the features in GLCM domain of JPEG image are similar to CE-JPEG images. JPEG compression destroyed the gap artifacts in GLCM, it reduced the difference between the two types of images. Fig. 6 represents the case that using Cons-conv layer, the left columns are the feature maps of JEPG images, the right columns represent the first channel feature maps of the CE-JPEG images, it’s been enlarged with a certain multiple for the convenience of display. It’s obvious that Cons-conv layer extracted the high-frequency features of GLCM and the details of different parts, the feature maps contain richer information and show more perceptible differences compared to the case that only using GLCM, such as the different magnification of the feature map and other differences in details.

Figure 4: GLCM and corresponding feature maps generated from Cons-conv layer
The constrained convolutional layer can adaptively extract high-frequency components and amplify the details of GLCM. It can enlarge the difference between two kinds of images. The corresponding experimental results showed in Section 3.2.
3.1 Database and Experimental Setups
In the experiments, 10000 raw images were obtained from BossBase v1.01 [23]. To get larger scale dataset, each image was firstly cropped into multiple 128 × 128 pixel patches with non-overlapping. Then we randomly chose a total of 20000 images as ORG. To generate contrast enhanced (CE) images, we considered two CE operators: Gamma Correction (GC) and Histogram Stretching (HS). Then we split the 20000 ORG images into five groups of 4000 images. In GC, we applied the GC with different gamma values (γ = 0.6, 0.8, 1.2, 1.4) for each of four groups. HS was performed on the last group images. In the case of HS, the input pixel values were linearly mapped, such that the lowest 1% of the total pixels were saturated at an intensity value of 0, and the highest 1% at an intensity value of 255. Then we obtained 20000 CE data as ORG-CE acquired from ORG.

Figure 5: GLCM of JPEG image (left) and CE-JPEG image (right)
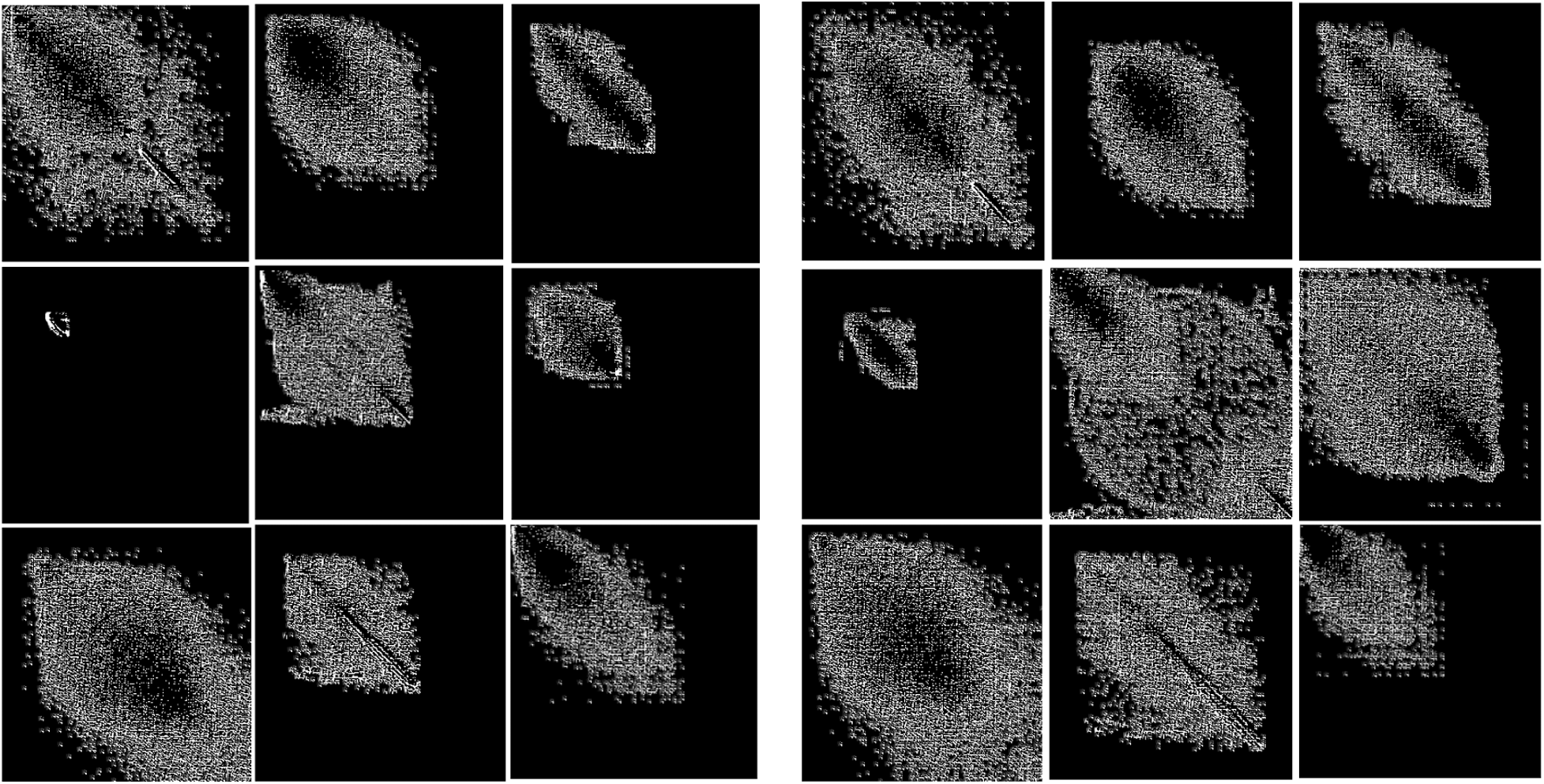
Figure 6: Cons-conv layer’s feature maps of JPEG image (left) and CE-JPEG image (right)
To obtained JPEG compression datasets, we selected QF = {50, 70, 90, 95} to compress ORG respectively to get ORG-50, ORG-70, ORG-90, ORG-95. Do the same processing for ORG-CE to get ORG-CE-50, ORG-CE-70, ORG-CE-90, ORG-CE-95. We also consider ORG/ORG-CE compressed with all three QFs 50, 70 and 90, then get ORG-Mix and ORG-CE-Mix. Finally, we get four sets of corresponding experimental data.
For each positive-negative set, we randomly selected 16000 ORG-JPEG images and 16000 ORG-CE-JEPG images for training set, 2000 ORG-JPEG images and 2000 ORG-CE-JPEG images as validation set, then assigned the remaining 2000 pairs as the test dataset. All the grayscale GLCM image with a size of 256 × 256 is fed into the network, the maximum gray level is 255. The final fully-connected layer applied with 2048 input neurons, and 2 output neurons, followed by a softmax layer.
All the experiments trained on a machine equipped with a GPU card of type GeForce RTX 2080 manufactured by Nvidia. We set the batch size for training and testing to 32, and maximum iteration is setting to 30 epochs. The training parameters of the Adam solver were set as follows: momentum is 0.99, the learning rate is initialized to 0.001 and multiplied by 0.1 after 10 epochs, as the training time increased, the learning rate decreased gradually.
3.2 Contrast Enhancement Detection with JPEG Post Processing
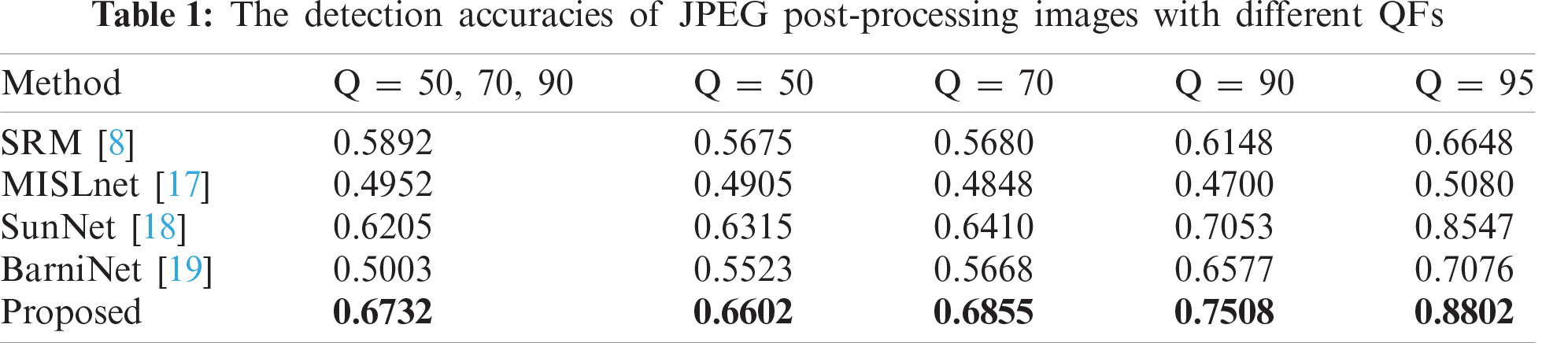
In this section, we evaluate the performance of our proposed method for CE forensics under JPEG compression. We also compared with other CNN-based detectors, MISLnet [17], SunNet [18], BarniNet [19]. Additionally, SRM also have been successfully used to perform universal image manipulation detection. In order to compare with traditional methods, we add SRM associated ensemble classifier for training.
The detection results of the experiments are presented in Tab. 1. The first column represents the results of the mixed quality factors, the other columns represent the corresponding quality factor results. It shows that the proposed method achieved the best performance and it is much higher than BariNet both with higher and lower QF. MLSNet has failed in all the tasks. In addition, we observe that the detection accuracy of GLCM-based models including the proposed method and SunNet are higher than other detectors. The experiments demonstrate that under the complex CE forensics environment, GLCM is still a relatively effective preprocessing strategy for CE detection.
In this section, to verify the feasibility of using GLCM and Cons-conv layer to achieve feature extraction and classification, we test the performance of the proposed model when there is only one preprocessing that means method using GLCM or Cons-conv.
The results of the experiments are shown in Tab. 2. The first method means, the CNN is directly fed with image pixels, the architecture of network is still a Cons-conv layer with the Xception. The second method means, using the GLCM as the input of the network, the network is Xception that without Cons-conv layer. Both the detection accuracy of these models is lower than the proposed method, the second method has better performance than the first one, which also shows the GLCM is more effective than Cons-conv, and only combine the two preprocessing can achieve the best performance.
Principal component analysis (PCA) is a helpful algorithm in statistical signal processing because it can reduce the dimensionality of datasets for purposes such as data interpretation. Fig. 7 illustrates the calculation PCA results of different model’s output when quality factor is 95, the left graph represents the model without the Cons-conv layer, the right one is the model with Cons-conv layer. In the graph, black data represent ORG-JPEG, red data represent ORG-CE-JPEG, test data has a total of 2000 images, the number of each class is 1000. It can be observed that under the effect of Cons-conv layer, the red and black data have higher intra-class and lower inter-class similarities compared with the case that only using GLCM.

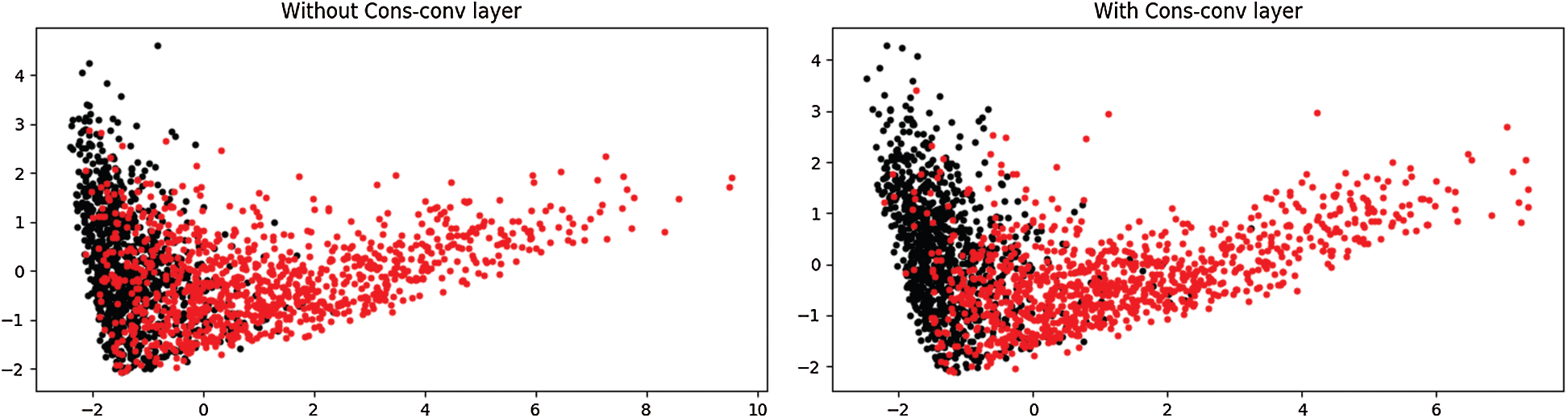
Figure 7: Results of PCA mapping with/out Cons-conv layer
In this paper, we propose a novel Xception-based network to cope with the challenging task which is the detection of contrast adjusted images in the presence of JPEG post-processing. The design of the overall framework makes the network more robust to CE detection when JPEG post-processing exist. We use the GLCM of image as the input of the network, GLCM can suppress the interference of the image content and contain the trace of CE forensic features. By adding a constrained convolutional layer in front of Xception, the high-frequency components in GLCMs under JPEG compression extracted, then feed it into the Xception. As a powerful CNN, Xception significantly extracts higher-level manipulation detection features for further classification. Experimental results show that the performance of proposed method has greatly improved compared with the existing method, it also demonstrates that GLCM-based preprocessing plays an important role in the improvement of CE forensics under the JPEG post processing.
Funding Statement: This work was supported in part by the National Key Research and Development of China (2018YFC0807306), National NSF of China (U1936212, 61672090), and Beijing Fund-Municipal Education Commission Joint Project (KZ202010015023).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. M. C. Stamm and K. R. Liu, “Blind forensics of contrast enhancement in digital images,” in IEEE Int. Conf. on Image Processing, San Diego, CA, USA, pp. 3112–3115, 2008. [Google Scholar]
2. M. C. Stamm and K. R. Liu, “Forensic detection of image manipulation using statistical intrinsic fingerprints,” IEEE Transactions on Information Forensics and Security, vol. 5, no. 3, pp. 492–506, 2010. [Google Scholar]
3. M. C. Stamm and K. R. Liu, “Forensic estimation and reconstruction of a contrast enhancement mapping,” in IEEE Int. Conf. on Acoustics, Speech and Signal Processing, Dallas, TX, USA, pp. 1698–1701, 2010. [Google Scholar]
4. G. Cao, Y. Zhao, R. Ni and X. Li, “Contrast enhancement-based forensics in digital images,” IEEE Transactions on Information Forensics and Security, vol. 9, no. 3, pp. 515–525, 2014. [Google Scholar]
5. G. Cao, Y. Zhao, R. Ni and H. Tian, “Anti-forensics of contrast enhancement in digital images,” in ACM Workshop Multimedia and Security, Roma, Italy, pp. 9–10, 2010. [Google Scholar]
6. C. W. Kwok, O. C. Au and S. H. Chui, “Alternative anti-forensics method for contrast enhancement,” in Int. Workshop Digital Watermarking, Atlantic City, NY, USA, pp. 23–26, 2011. [Google Scholar]
7. A. De Rosa, M. Fontani, M. Massai, A. Piva and M. Barni, “Second-order statistics analysis to cope with contrast enhancement counter-forensics,” IEEE Signal Process Letters, vol. 22, no. 8, pp. 1132–1136, 2015. [Google Scholar]
8. J. Fridrich and J. Kodovsky, “Rich models for steganalysis of digital images,” IEEE Transactions on Information Forensics and Security, vol. 7, no. 3, pp. 868–882, 2012. [Google Scholar]
9. H. Li, W. Luo, X. Qiu and J. Huang, “Identification of various image operations using residual-based features,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 1, pp. 31–45, 2016. [Google Scholar]
10. X. Qiu, H. Li, W. Luo and J. Huang, “A universal image forensic strategy based on steganalytic model,” in ACM Workshop on Information Hiding and Multimedia Security, Salzburg, Austria, pp. 165–170, 2014. [Google Scholar]
11. L. Xiang, S. Yang, Y. Liu, Q. Li and C. Zhu, “Novel linguistic steganography based on character-level text generation,” Mathematics, vol. 8, no. 9, pp. 1558, 2020. [Google Scholar]
12. L. Xiang, G. Guo, Q. Li, C. Zhu, J. Chen et al., “Spam detection in reviews using LSTM-based multi-entity temporal features,” Intelligent Automation & Soft Computing, vol. 26, no. 6, pp. 1375–1390, 2020. [Google Scholar]
13. Z. Yang, S. Zhang, Y. Hu, Z. Hu and Y. Huang, “VAE-stega: Linguistic steganography based on variational auto-encoder,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 880–895, 2021. [Google Scholar]
14. F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” in IEEE Conf. on Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 1800–1807, 2017. [Google Scholar]
15. P. Yang, R. Ni, Y. Zhao and W. Zhao, “Robust contrast enhancement forensics using pixel and histogram domain CNNs,” arXiv preprint arXiv:1803.04749v3, 2019. [Google Scholar]
16. P. Yang, R. Ni and Y. Zhao, “Recapture image forensics based on laplacian convolutional neural networks,” in Int. Workshop on Digital Watermarking, Beijing, China, pp. 119– 128, 2016. [Google Scholar]
17. B. Bayar and M. C. Stamm, “Constrained convolutional neural networks: A new approach towards general purpose image manipulation detection,” IEEE Transactions on Information Forensics and Security, vol. 13, no. 11, pp. 2691–2706, 2018. [Google Scholar]
18. J. Sun, S. Kim, S. Lee and S. Ko, “A novel contrast enhancement forensics based on convolutional neural networks,” Signal Processing: Image Communication, vol. 63, no. C, pp. 149–160, 2018. [Google Scholar]
19. M. Barni, A. Costanzo, E. Nowroozi and B. Tondi, “Cnn-based detection of generic contrast adjustment with jpeg post-processing,” in IEEE Int. Conf. on Image Processing, Athens, Greece, pp. 3803–3807, 2018. [Google Scholar]
20. C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens and Z. Wojna, “Rethinking the inception architecture for computer vision,” in IEEE Conf. on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, pp. 2818–2826, 2016. [Google Scholar]
21. K. He, X. Zhang, S. Ren and J. Sun, “Deep residual learning for image recognition,” in IEEE Conf. on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, pp. 770–778, 2016. [Google Scholar]
22. R. M. Haralick, K. Shanmugan and I. Dinstein, “Textural features for image classification,” IEEE Trans. Systems, Man, and Cybernetics, vol. 3, no. 6, pp. 610–621, 1973. [Google Scholar]
23. P. Bas, T. Filler and T. Pevný, “Break our steganographic system: The ins and outs of organizing BOSS,” in Int. Workshop on Information Hiding, Prague, Czech Republic, pp. 59–70, 2011. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |