DOI:10.32604/cmc.2022.018547
| Computers, Materials & Continua DOI:10.32604/cmc.2022.018547 | |
| Article |
Automated COVID-19 Detection Based on Single-Image Super-Resolution and CNN Models
1Department Electronics and Electrical Communications, Faculty of Electronic Engineering, Menoufia University, Menouf, 32952, Egypt
2Alexandria Higher Institute of Engineering & Technology (AIET), Alexandria, Egypt
3Department of Information Technology, College of Computer and Information Sciences, Princess Nourah Bint Abdulrahman University, Riyadh, 84428, Saudi Arabia
*Corresponding Author: Naglaa F. Soliman. Email: nfsoliman@pnu.edu.sa
Received: 12 March 2021; Accepted: 26 May 2021
Abstract: In developing countries, medical diagnosis is expensive and time consuming. Hence, automatic diagnosis can be a good cheap alternative. This task can be performed with artificial intelligence tools such as deep Convolutional Neural Networks (CNNs). These tools can be used on medical images to speed up the diagnosis process and save the efforts of specialists. The deep CNNs allow direct learning from the medical images. However, the accessibility of classified data is still the largest challenge, particularly in the field of medical imaging. Transfer learning can deliver an effective and promising solution by transferring knowledge from universal object detection CNNs to medical image classification. However, because of the inhomogeneity and enormous overlap in intensity between medical images in terms of features in the diagnosis of Pneumonia and COVID-19, transfer learning is not usually a robust solution. Single-Image Super-Resolution (SISR) can facilitate learning to enhance computer vision functions, apart from enhancing perceptual image consistency. Consequently, it helps in showing the main features of images. Motivated by the challenging dilemma of Pneumonia and COVID-19 diagnosis, this paper introduces a hybrid CNN model, namely SIGTra, to generate super-resolution versions of X-ray and CT images. It depends on a Generative Adversarial Network (GAN) for the super-resolution reconstruction problem. Besides, Transfer learning with CNN (TCNN) is adopted for the classification of images. Three different categories of chest X-ray and CT images can be classified with the proposed model. A comparison study is presented between the proposed SIGTra model and the other related CNN models for COVID-19 detection in terms of precision, sensitivity, and accuracy.
Keywords: Medical images; SIGTra; GAN; CT and X-ray images; SISR; TCNN
Pneumonia is a disease that affects one or both lungs and aggravates air sacs. Fluid or pus (purulent material) fill the bags with air, affecting pus or phlegm to cough, fever, breathing, and chills difficulties. Pneumonia may be hard to identify because of the variability of symptoms and the occurrence of Pneumonia with cold and flu cases. Hence, Pneumonia is detected, and the germ causing the disease is determined by medical professionals. Both physical examination, laboratory testing (e.g., blood or urine testing), and psychological assessment can be useful in the diagnosis process. Popular diagnostic tests include chest X-ray images to look for the lung location and extent of inflammation. The CT scan of chest is required to give a clear view of the lungs and a look for other problems with them [1].
At the end of 2019, an outbreak of COVID-19 occurred. COVID-19 can be transferred from person to person in the world. Data from the World Health Organization (WHO) justify why quarantine action is needed. The WHO declared some classification procedures needed to deal with COVID-19 based on medical images [2]. In most third-world countries, due to the lack of funding for healthcare, there is a dire need for Artificial Intelligence (AI) tools that can perform the diagnosis task accurately in a short time. The need to interpret radiographic images rapidly inspired researchers to introduce a series of deep learning AI systems [3], which have shown promising accuracy levels for detecting COVID-19 cases using radiographic imagery [4–6].
With the growing number of infected patients, radiologists find it increasingly difficult to finish the diagnosis process in a limited time [7]. Analyzing medical images is one of the most important fields of study for decision-making about all cases. Machine learning and AI approaches are the basis for automated or Computer-Aided Diagnostic (CAD) systems. X-ray image classification with transfer learning has been applied using CCNs, which succeeded largely in the classification task [8]. Recently, a competitive generalized gamma mixture model for medical image diagnosis was presented in [9].
An overview of some significant works for COVID-19 detection is presented in this section. In [10], a Deep Learning (DL) approach for classifying chest CT scans based on a CNN model and ensemble techniques was presented. It depends on light-weight transfer learning with the EfficientNet-B3 model. In [11], the authors suggested a self-developed model for the diagnosis of COVID-19, namely CTnet-10. In [12], a DL-assisted approach for quick diagnosis of COVID-19 from X-ray images was presented. Eight pre-trained CNN models were assessed for this purpose. In [13], the authors presented transfer learning and the adversarial network on CT scans to annotate COVID-19 and Pneumonia images.
An alternative modeling system described as DeTraC was suggested in [14]. The presented work in [15] aims to fine-tune the Inception-v3 with multimodal learning for COVID-19 detection from CT scans and X-ray images. In [16], the authors introduced a two-stage data enhancement method to classify images from six categories, including COVID-19 images. In [17], the authors suggested an efficient general Gamma Mixture Model (gGMM) to classify X-ray and CT images. In [18], the authors proposed a multi-scale classification model of COVID-19 from Pneumonia Chest X-ray (CXR) images, namely MAG-SD. In [19], the authors proposed a merged semi-supervised shallow neural network architecture with an automated segmentation network for CT images, namely PQIS-Net. In [20], different deep learning approaches have been employed to classify COVID-19, namely a deep extraction function and a fine-tuning pre-trained convolution neural network.
In [21], different pre-trained models for learning of features from CT images were used. A pre-trained fusion algorithm followed by discriminatory correlation analysis was employed. In [22], the authors presented a method for generating CXR synthetic images by developing a CovidGAN-based model that depends on an Auxiliary Generative Classification Network (ACGAN). Three main scenarios for transfer learning were introduced in [23]. The first one is shallow tuning, which takes only the final classification layer to manage the new task, and freezes the remaining layer parameters without training. The second is fine tuning, which aims to progressively train more layers by changing the learning parameters until a significant performance improvement is achieved. The last one is deep tuning, which aims to retrain all layers in a previously trained network.
High Resolution (HR) image estimation is a complicated assignment developed on the corresponding Low Resolution (LR) image. This process is known as image Super-Resolution (SR). The image SR has gained a significant attention, and has a wide variety of applications. The latest researches have been concentrated on reducing the average square error of restoration. However, these researches often lack concentration on high-frequency information, and their results are perceptually unsatisfactory. Generally, these research works do not satisfy the requirements of SR reconstruction. Hence, in this work, a GAN is introduced for medical image SR to improve the subsequent classification accuracy.
After reviewing the related studies, we can deduce that deep learning can effectively help in the detection of Pneumonia and COVID-19 from CXR and CT images. However, detail enhancement in images has not been considered, deeply. Different medical datasets may display similarity as in the cases of Pneumonia. This, in turn, affects the accuracy of DL classification models. Hence, this paper introduces a hybrid CNN model, namely SIGTra for generating SR versions of COVID-19, Pneumonia, and normal images. It depends on a GAN for the SISR reconstruction problem. Different pre-trained TCNN frameworks (DenseNet121, Densenet169, Dense-Net201 [24], ResNet50, ResNet152 [25], VGG16, VGG19 [26], and Xception [27]), and different full-trained models (CNN model, LeNet-5 [28], AlexNet [29], VGG16, Inception naïve v1 [30], and Inception v2 with multiple layers [30]) are considered for the classification task. In addition, more comparative studies are introduced between the proposed work and the other related CNN models for COVID-19 and Pneumonia detection. This research work has the following contributions:
• A comprehensive study of the classification process of X-ray and CT images is presented. Several sources of images are utilized to distinguish between normal and abnormal cases.
• Classification process is studied with and without the proposed SIGTra model for SR image reconstruction.
• A detailed comparison is presented between the different classification models presented in this paper with different training/testing ratios.
• A comparison is presented between the best classification results obtained with the proposed models on SR images and those of different state-of-the-art models.
The rest of this research work is coordinated as follows. The suggested SIGTra model is presented in Section 2. The simulation and comparison results are presented and analyzed in Section 3. The conclusion and future work are presented in Section 4.
This section presents the proposed hybrid SIGTra model that comprises the SISR based on GAN and the TCNN. It distinguishes between COVID-19 and Pneumonia cases. As demonstrated in Fig. 1, it has three stages: pre-processing, SR, and classification. The pre-processing stage begins with reading the image dataset, and resizing the images as they come from different sources. Therefore, the input image size becomes 64 × 64 × 3. The normalization of images between 0 and 1 is also performed to allow higher efficiency in the following stages. The second stage is to produce a 256 × 256 × 3 HR image from each LR image. The third stage is responsible for the classification task using CNNs and transfer learning models with and without SR.

Figure 1: General steps of the SIGTra model
A significant category of image processing techniques in computer vision and image processing is image SR, which belongs to retrieving HR images from LR ones. It has various applications in the real world, such as medical imaging, surveillance, and defense. It also helps to enhance other computer vision functions, apart from enhancing the perceptual image consistency. Since there are often numerous HR images related to a single LR image, this problem is dramatically complicated. A single image SR-GAN algorithm has been suggested based on photo-realistic and natural images [31,32]. To the best of our knowledge, this original algorithm depends on inference for obtaining photo-realistic images with an up-scaling factor of 4. We adopt this algorithm for medical image SR to allow an efficient classification process. A perceptual loss function comprising content loss and adversarial loss is used as shown in Fig. 2. The objective is to generate HR medical images from the LR ones using the GAN, a generator, and a discriminator. To produce the HR images, the LR images are fed to the generator. The GAN loss is used during the training for weight update to generate the HR images. The proposed SR-GAN model is developed based on that of [31,32] with some adjustments represented in normalization, inclusion of content loss, and modification of the generator and discriminator according to medical image characteristics. These modifications will be discussed in detail in the following sub-sections.
The deep ResNet [25] architecture is adopted in this paper with the principles of GANs to allow SISR of medical images. We develop a new strategy for medical image SISR with an up-scaling factor of 4. Both Structural Similarity (SSIM), Mean Square Error (MSE), and Peak Signal-to-Noise Ratio (PSNR) metrics are used for the quality assessment of the obtained images. An SR-GAN model is developed based on a new perceptual loss. The MSE-based content loss is replaced by the loss of the DenseNet121 model [24], which is more invariant to the pixel space changes [33]. This model is tested on two different medical image datasets for a successive classification task.

Figure 2: Steps of the modified SR-GAN algorithm
We define a discriminator network
The general concept behind this formulation is that a generative model (G) can be trained to deceive a distinguishable discriminator (D) trained to distinguish SR images from authentic input images. Our employed generator can be trained to construct SR images that are remarkably similar to authentic digital medical images. So, it is hard to distinguish by (D). This method allows a superior perceptual quality belonging to the complex subspace of natural digital images, unlike SR solutions that depend on decreasing pixel-wise error metrics, such as MSE.
Fig. 3 illustrates the proposed architecture that comprises generator and discriminator networks. The generator consists of 8 residual blocks with an identical design. Each block has two convolutional layers consisting of (3 × 3) kernels and 64 filters followed by a sigmoid activation function and batch-normalization layers [36]. These residual blocks, inspired by [37], are followed by four up-sampling blocks and two max-pooling layers. Hence, an up-scaling by 4 is achieved. This method enables the generator to be trained effectively by reducing and increasing the resolution to generate HR images. The architectural guidelines introduced in [38] are followed, and the ReLU activation is used to allow normalization of pixel values between 0 and 1. The discriminator network is trained and prepared to solve the maximization problem presented in Eq. (1). It consists of four convolutional layers with 3 × 3 kernels and 64, 128, 256, and 512 filters. The number of features is doubled in each layer. So, max-pooling is used to reduce the features. After that, four fully-connected layers that contain feature maps of 4096 features and a definitive sigmoid activation function are used to obtain the classification likelihood.

Figure 3: The proposed architecture of the generator/discriminator networks with an equivalent kernel size (k), number of feature maps (F), stride (S), and the same padding (SP) for every convolutional layer
The concept of perceptual loss
Probable options for the content loss
• Content Loss
The MSE pixel-wise loss is determined as follows:
where
The MSE is the frequently utilized metric for the optimization of image SR [31,40]. However, while achieving high PSNR, MSE optimization leads to excessively smooth textures that may be perceptually unsatisfactory. A loss function that is closer to perceptual similarity is utilized instead of depending on pixel-wise losses. In [41], the authors used the VGG loss based on ReLU activation layers of the VGG-19 pre-trained network. In this work, we use the DenseNet121 loss based on ReLU activation layers of the pre-trained DenseNet121. The feature map obtained by the jth convolution (after concatenation) is referred to as
Within the DenseNet121 network,
• Adversarial Loss (GAN Loss)
The generative loss of our SR-GAN model is also added to the perception loss, including the content loss discussed previously. By attempting to deceive the discriminator network, the generator network enhances the features of LR images. The generative loss
where
2.2 Proposed TCNN and Full Learning Models
In our work, several pre-trained CNN and full-training models are employed to examine the robustness and effectiveness of the proposed TCNN model with and without the SR-GAN model. Fine tuning is used to train more layers by changing the parameters of learning until a significant performance improvement is achieved. DenseNet121, Densenet169, Dense-Net201 [24], ResNet50, ResNet152 [25], VGG16, VGG19 [26], and Xception [27] are checked. Full training and deep tuning are performed to retrain all layers in a previously trained network. The proposed CNN model, LeNet-5 [28], AlexNet [29], VGG16, Inception naïve v1 [30], and Inception v2 with multiple layers [30] are compared. The proposed CNN model is a full learning model consisting of batch normalization followed by four convolution layers with 16, 32, 64, and 256 filters in consequence, and ReLU functions. Four fully-connected layers are dropped out. Finally, a SoftMax classification layer is utilized as shown in Fig. 4.

Figure 4: The proposed classification architecture based on (F) feature maps, kernel size (k), stride (S), and the same padding (SP) for each convolutional layer
In the simulation scenarios, we change all parameters in the last fully-connected layers in transfer learning through a fine-tuning process. All convolution layers and fully-connected layers remain as in the deep tuning scenario. All these scenarios are discussed to validate the suggested work with and without the GAN-based SISR model. The loss of the model is determined by computing the following sum:
where
The ReLU function is used to replace any obtained negative pixel values with zero. It can be expressed as follows:
where x is the input value.
A large number of medical images is required for successful training and classification, but this is costly. This challenge can be treated through transfer learning, which involves tuning of millions of parameters in CNN architectures. The SIGTra model can be applied on images with similar features, and hence it is adopted in this paper. We apply transfer learning from a generic image recognition task to a medical image classification task.
3 Experimental Results and Comparison
Our contribution in this paper is the automatic classification of chest CT and X-ray datasets [42–45]. The datasets and the simulation experiments are summarized in the subsequent sub-sections.
For testing the suggested DL frameworks, we used the following image datasets:
a) COVID-19 CT Dataset Repository on GitHub [42]. This dataset includes 349 axial CT COVID-19 images and 397 axial CT Non-COVID-19 images.
b) The Data COVID-19 Collection Image Repository on GitHub [43]. Dr Joseph Cohen haunts this dataset.
c) Chest X-Ray Images (Pneumonia) Challenge Detection Dataset [44]. It is accessible on Kaggle.
d) Extensive COVID-19 X-Ray and CT Chest Images Dataset [45]. This data collection is available on Mendeley.
All medical scans are resized to a size of 224 × 224 × 3 or 299 × 299 × 3 according to the employed DL model. Based on the adopted interpolation technique, the appropriate algorithm is selected. The INTER_AREA method is used from the OpenCV library. It allows resampling based on pixel/area relation [46]. To prevent over-fitting, because the number of CT scans is small, we have employed data processing strategies like arbitrary transformations. Such transformations comprise the range of rotation, the range of changes in width, and the brightness range. The transformation parameters are generated randomly for each training sample, and data augmentation is applied identically for every slice in the tested medical image. For the division of data, we used different ratios of training/testing [80%/20%], [70%/30%], and [60%/40%] to ensure that the model works well with various training/testing ratios.
3.3 Training/Classification Dataset
Data augmentation, splitting, and pre-processing procedures are used to expand the training dataset. Feature maps are extracted with the DL models and sent to the multilayer perceptron for classification. The suggested model efficiency is assessed by using the trained network on the test medical images. Every experiment is repeated three times, and then the average outcomes are calculated.
The utilized medical images of all datasets are resized to 224 × 224 except the Xception images, which are resized to 299 × 299 for the classification process. For the proposed SR-GAN model, we begin with images of size 64 × 64. To train the proposed DL models, we test different batch sizes. The validation-to-training ratios are correspondingly set to different values. After several trials to choose the best optimizer, Adam’s optimizer was used due to its high efficiency and short training time. For the classification models, we have used β1 = 0.9 and β2 = 0.999. On the other hand, for the SR-GAN model, we have used β1 = 0.5 and β2 = 0.999. The learning rate is firstly set to 0.00001 and then reduced to 0.000001 for the classification process. On the other hand, it is set to 0.0002 for the SR-GAN model.
A drop-out strategy is adopted to decrease the overfitting probability of the employed DL models. The realization of the DL models was accomplished through Kaggle that provides notebook editors with free access to NVIDIA TESLA P100 GPUs and 13 GB RAM operating on Professional Windows Microsoft 10 (64-bit). For simulation tests, Python 3.7 was utilized. In addition, TensorFlow and Keras were employed as DL backend.
Through our assessment, we use accuracy, recall, f1 score, precision [47], Area Under Curve of the Receiver Operating Characteristic (AUC ROC) [48], and log loss [49] as evaluation metrics. More details about their theoretical and physical meanings, definitions, and mathematical expressions can be found in [47–49].
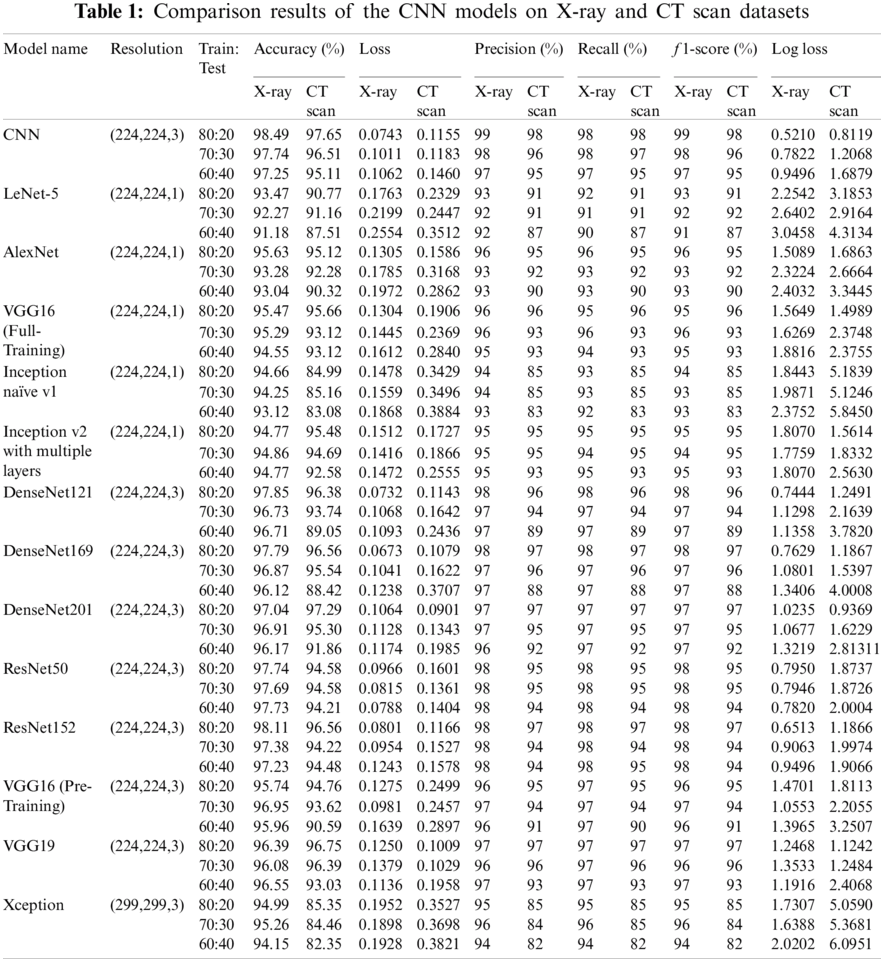
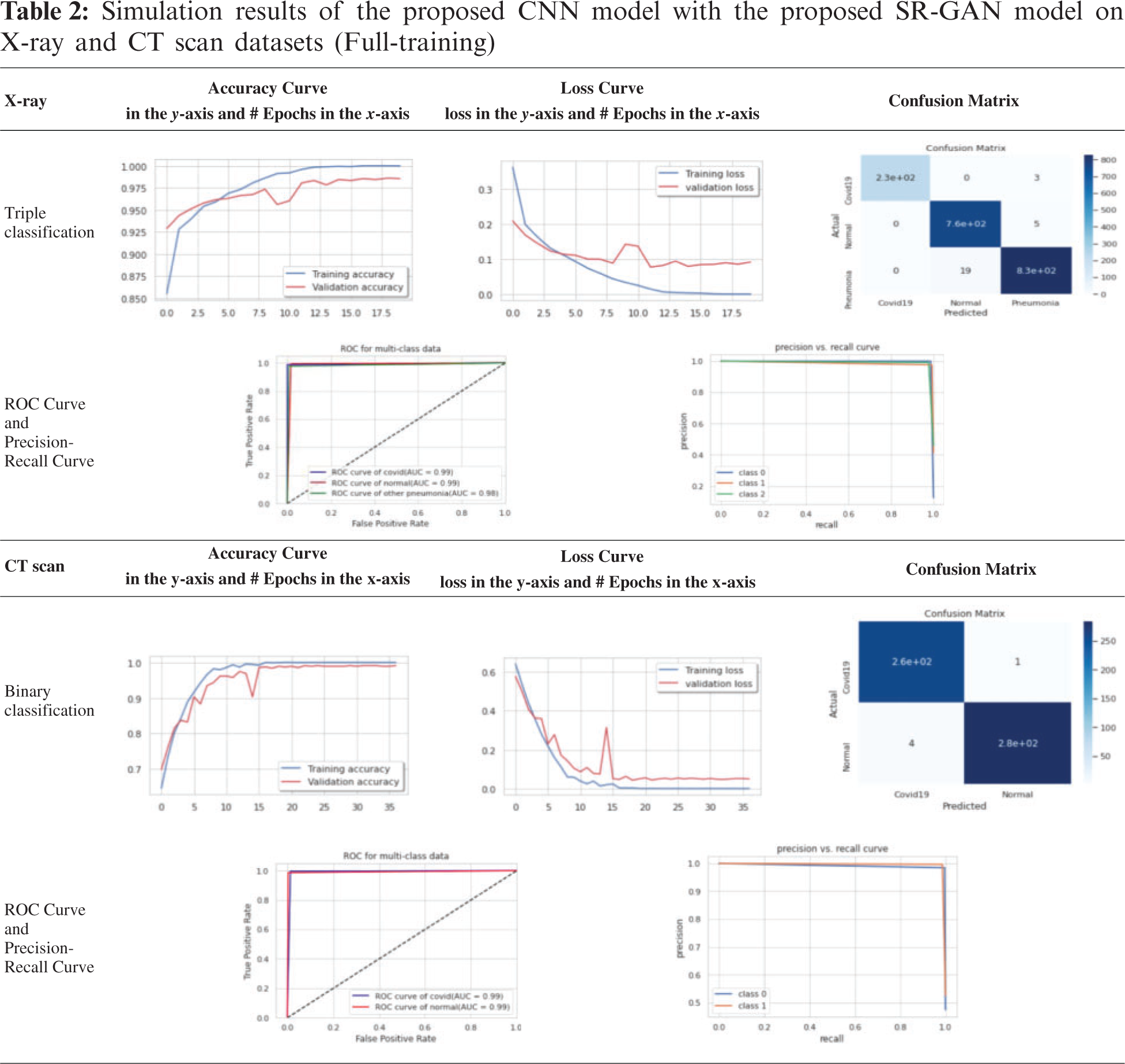
The results of the binary and ternary classification are presented in this section for the chest CT and X-ray images with the different DL models including full training of all layers of the proposed CNN model, LeNet-5, AlexNet, VGG16, Inception naïve v1, and Inception v2 with multiple layers. In addition, fine tuning of the top layers of the DenseNet121, Densenet169, DenseNet201, ResNet50, ResNet152, VGG16, VGG19, and Xception is also considered. Additionally, to verify the robustness of all DL models, numerous tests are performed on the chest CT and X-ray scan datasets. We have presented two different scenarios in the simulation results as illustrated in Sub-sections 3.6.1 and 3.6.2. These scenarios are classification with and without implementing the SR-GAN model. Tabs. 1 and 3 present the results of both scenarios. It is clear that the proposed SR-GAN model enhances the classification performance.
The test or validation curve is obtained based on a validation hold-out dataset. The loss of validation and training is known as the number of miscalculations produced for every instance of training or invalidation. Generally, the best DL model is a model that can be generalized well and that has neither over-fitting nor under-fitting. The confusion matrix reflects the overall performance, as presented in Tab. 2.
3.6.1 Classification Results of the TCNN and DL Models Without the SR-GAN Model
Tab. 1 presents the outcomes of various CNN models for ternary and binary classification with different training/testing ratios (80:20, 70:30, 60:40) on the X-ray and CT scan datasets without the SR-GAN model. The comparison is made in terms of f1 score, loss, log loss, recall, accuracy, and precision in the test phase only.
3.6.2 Classification Results of the TCNN and DL Models with the SR-GAN Model
For simplicity, we present only the curves and confusion matrices for the 80:20 training/testing ratio with the SIGTra model. Tab. 2 presents the classification results of X-ray and CT scans. From the obtained results on the X-ray dataset in Tab. 2, it is noticed the proposed hybrid SIGTra model (CNN + SR − GAN) achieves a training accuracy of 99.99%, a testing accuracy of 98.53%, a training loss of 0.0008, and a testing loss of 0.091 for 20 epochs. From the confusion matrix, it is observed that the proposed model can classify 230 images accurately, but three images of the first class (COVID-19) are labeled as Pneumonia. Similarly, the proposed model can classify 760 images accurately, but five images of the second class (Normal) are labeled as Pneumonia. In the same way, the proposed model can classify 830 images accurately, but 19 images of the third class (Pneumonia) are labeled as Normal. The ROC curve demonstrates that the TPR (true positive rate) and FPR (false positive rate) are nearly equal to 1, which means that the proposed SIGTra model can efficiently classify different images. Precision-Recall curve reveals a high AUC with a high level of precision and a high level of recall.
From the obtained results on the CT scan dataset in Tab. 2, it is noticed the proposed hybrid SIGTra model achieves a training accuracy of 100%, a testing accuracy of 99.08%, a training loss of 0.0003 and a testing loss of 0.0496 for 36 epochs. From the obtained confusion matrix, it is observed that the proposed model can classify 260 images accurately for the first class (COVID-19). Similarly, the proposed model can classify 280 images, accurately. The ROC curve demonstrates that the TPR and FPR are nearly equal to 0.99. The Precision-Recall curve reveals a high AUC with a high level of precision and a high level of recall. Therefore, the obtained outcomes for the proposed model on the X-ray and CT scan datasets prove that it has a little under-fitting and higher accuracy in testing. It remains nearly stable with different training/testing ratios compared to other DL models as illustrated in Tab. 3 that presents the outcomes of various CNN models for ternary and binary classification with the SR-GAN model. The given results in Tab. 3 prove the superiority of the classification process in terms of f1 score, loss, precision, log loss, recall, and accuracy with the proposed hybrid SIGTra model (CNN + SR − GAN) compared to that with the TCNN model without SR-GAN.
3.7 Discussions and Comparisons
In this study, the binary classification (COVID-19, Normal) and ternary classification (COVID-19, Normal, and Pneumonia) are investigated on different CT and X-ray scans with transfer learning and full training using recent DL models to compare with the proposed model with SR-GAN. From Tabs. 1 and 3, it is noticed that the TCNN model and the fine-tuned versions of the DensNet121, DensNet169, DensNet201, ResNet152, and VGG19 models achieve a good performance on CT and X-ray datasets. They outperform the LeNet-5, AlexNet, VGG16 full-training models and the Inception naïve v1, Inception v2 with multiple layers, ResNet50, and VGG16 pre-training models. The Xception model presents the lowest performance. Some of these DL models present high performance on CT scans, but low performance on X-ray images. It is also observed from the results in Tabs. 1 and 3 that the proposed SR-GAN model enhances the classification results.
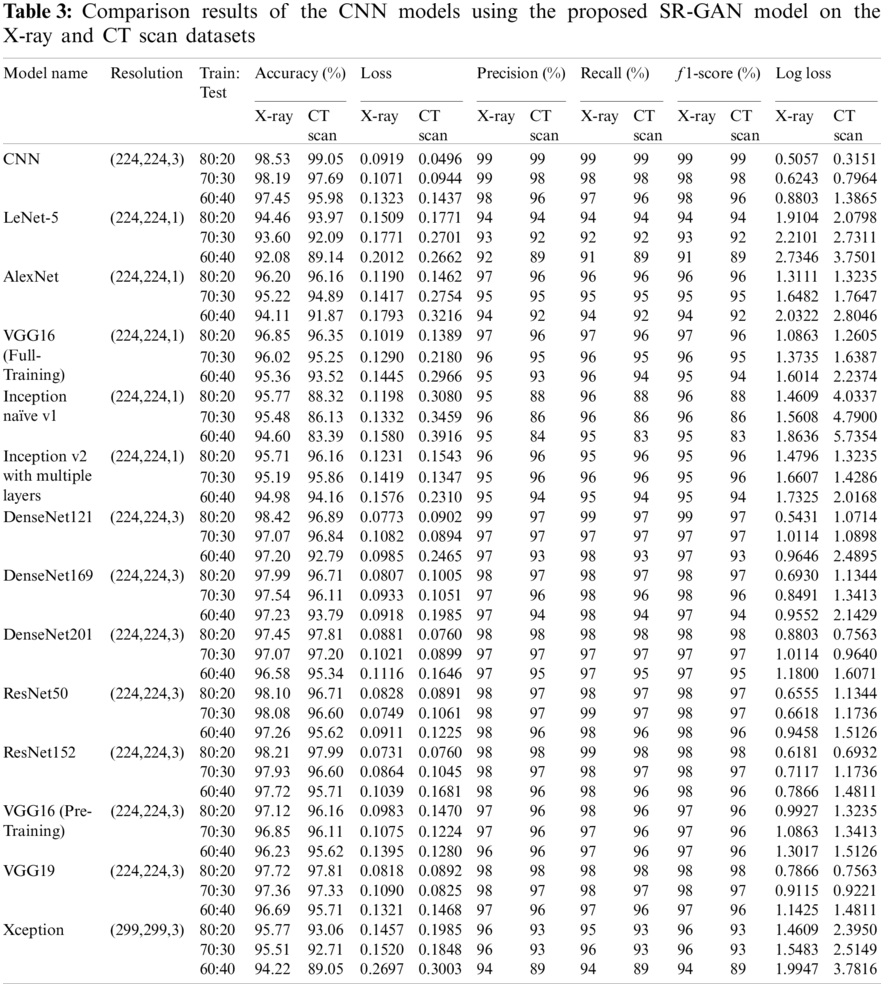
To further prove the classification efficacy of the suggested SIGTra model, we compared it with other recent related works as presented in Tab. 4 in terms of the achieved accuracy, recall, precision, and f1 score. It is demonstrated that the proposed model exceeds all other recent related models in terms of all used evaluation metrics. In addition, the accuracy of the proposed CNN model is compared to those of various pre-trained transfer learning models with and without employing the proposed SR-GAN. It is noticed that the proposed hybrid SIGTra model achieves a superior classification accuracy compared to those of other models. It achieves an accuracy of 98.53% on X-ray images and 99.05% on CT scans.

This paper presented a proposed hybrid SIGTra model to classify chest X-ray images and CT scans into Normal, COVID-19, and Pneumonia classes. The proposed SIGTra model is used to improve the classification process with an SISR stage based on the SR-GAN. The paper introduced comprehensive comparisons between different DL models including the proposed model, LeNet-5, AlexNet, VGG16, Inception naïve v1, Inception v2 with multiple layers, DenseNet121, DenseNet169, DenseNet201, ResNet50, ResNet152, VGG16, VGG19, and Xception. Several experimentations have been performed on chest X-ray and CT images. The proposed SIGTra model leads to superior results compared to other DL models. Future research may include developing a complete Pneumonia classification system through deep learning, super-resolution, and classification. Moreover, the classification process can be performed on more datasets, with more advanced techniques. Efficient sub-pixel and Very Deep SR (VDSR) can also be considered as new tools for SISR.
Acknowledgement: The authors would like to thank the support of the Deanship of Scientific Research at Princess Nourah Bint Abdulrahman University.
Funding Statement: This research was funded by the Deanship of Scientific Research at Princess Nourah Bint Abdulrahman University through the Fast-track Research Funding Program.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. L. Qun, M. Med, G. Xuhua, D. Ph, W. Peng et al., “Early transmission dynamics in Wuhan, China, of novel coronavirus-infected pneumonia,” New England Journal of Medicine, vol. 382, pp. 1199–1207, 2020. [Google Scholar]
2. N. Zhang, L. Wang, X. Deng, R. Liang, M. Su et al., “Recent advances in the detection of respiratory virus infection in humans,” Journal of Medical Virology, vol. 92, no. 4, pp. 408–417, 2020. [Google Scholar]
3. Y. LeCun, Y. Bengio and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015. [Google Scholar]
4. O. Gozes, M. Frid-Adar, H. Greenspan, P. D. Browning, H. Zhang et al., “Rapid AI development cycle for the coronavirus (COVID-19) pandemic: Initial results for automated detection & patient monitoring using deep learning CT image analysis,” Radiology: Artificial Intelligence, vol. 5, pp. 1–22, 2020. [Google Scholar]
5. L. Li, L. Qin, Z. Xu, Y. Yin, X. Wang et al., “Artificial intelligence distinguishes COVID-19 from community acquired pneumonia on chest CT,” Radiology, vol. 296, no. 2, pp. E65–E71, 2020. [Google Scholar]
6. C. Butt, J. Gill, D. Chun and B. A. Babu, “Deep learning system to screen coronavirus disease 2019 pneumonia,” Applied Intelligence, vol. 10, pp. 1122–1129, 2020. [Google Scholar]
7. G. Zhang, W. Wang, J. Moon, J. Pack and S. Jeon, “A review of breast tissue classification in mammograms,” in Proc. of ACM Sym. on Research in Applied Computation, New York, NY, USA, Association for Computing Machinery, pp. 232–237, 2011. [Google Scholar]
8. A. Abbas, M. Abdelsamea and M. Gaber, “DeTrac: Transfer learning of class decomposed medical images in convolutional neural networks,” IEEE Access, vol. 8, pp. 74901–74913, 2020. [Google Scholar]
9. S. Bourouis, H. Sallay and N. Bouguila, “A competitive generalized gamma mixture model for medical image diagnosis,” IEEE Access, vol. 9, pp. 13727–13736, 2021. [Google Scholar]
10. H. Alhichri, “CNN ensemble approach to detect covid-19 from computed tomography chest images,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3581–3599, 2021. [Google Scholar]
11. V. Shah, R. Keniya, A. Shridharani, M. Punjabi, J. Shah et al., “Diagnosis of COVID-19 using CT scan images and deep learning techniques,” Emergency Radiology, vol. 9, pp. 1–9, 2021. [Google Scholar]
12. S. Nayak, D. Nayak, U. Sinha, V. Arora and R. Pachori, “Application of deep learning techniques for detection of COVID-19 cases using chest X-ray images: A comprehensive study,” Biomedical Signal Processing and Control, vol. 64, pp. 1–9, 2021. [Google Scholar]
13. A. Oluwasanmi, M. Aftab, Z. Qin, S. Ngo, T. Doan et al., “Transfer learning and semisupervised adversarial detection and classification of COVID-19 in CT images,” Complexity, vol. 13, pp. 1–11, 2021. [Google Scholar]
14. A. Abbas, M. Abdelsamea and M. Gaber, “Classification of COVID-19 in chest X-ray images using DeTraC deep convolutional neural network,” Applied Intelligence, vol. 51, no. 2, pp. 854–864, 2021. [Google Scholar]
15. S. El-bana, A. Al-Kabbany and M. Sharkas, “A multi-task pipeline with specialized streams for classification and segmentation of infection manifestations in COVID-19 scans,” PeerJ Computer Science, vol. 6, pp. 1–27, 2020. [Google Scholar]
16. Ş. Öztürk, U. Özkaya and M. Barstuğan, “Classification of coronavirus (COVID-19) from X-ray and CT images using shrunken features,” International Journal of Imaging Systems and Technology, vol. 31, no. 1, pp. 5–15, 2021. [Google Scholar]
17. S. Bourouis, H. Sallay and N. Bouguila, “A competitive generalized gamma mixture model for medical image diagnosis,” IEEE Access, vol. 9, pp. 13727–13736, 2021. [Google Scholar]
18. J. Li, Y. Wang, S. Wang, J. Wang, J. Liu et al., “Multiscale attention guided network for COVID-19 diagnosis using chest X-ray images,” IEEE Journal of Biomedical and Health Informatics, vol. 3, pp. 1–9, 2021. [Google Scholar]
19. D. Konar, B. Panigrahi, S. Bhattacharyya and N. Dey, “Auto-diagnosis of COVID-19 using lung CT images with semi-supervised shallow learning network,” IEEE Access, vol. 9, pp. 28716–28728, 2021. [Google Scholar]
20. A. Ismael and A. Şengür, “Deep learning approaches for COVID-19 detection based on chest X-ray images,” Expert Systems with Applications, vol. 164, pp. 1–29, 2021. [Google Scholar]
21. S. Wang, D. Nayak, D. Guttery, X. Zhang and Y. Zhang, “COVID-19 classification by CCSHNet with deep fusion using transfer learning and discriminant correlation analysis,” Information Fusion, vol. 68, pp. 131–148, 2021. [Google Scholar]
22. A. Waheed, M. Goyal, D. Gupta, A. Khanna, F. Al-Turjmanet al., “COVIDGAN: Data augmentation using auxiliary classifier GAN for improved COVID-19 detection,” IEEE Access, vol. 8, pp. 91916–91923, 2020. [Google Scholar]
23. S. Wu, H. Zhang and C. Ré, “Understanding and improving information transfer in multi-task learning,” arXiv preprint, arXiv: 2005.00944, pp. 1–28, 2020. [Google Scholar]
24. G. Huang, Z. Liu, L. Van and K. Weinberger, “Densely connected convolutional networks,” in Proc. IEEE Conf. on Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 2261–2269, 2017. [Google Scholar]
25. K. He, X. Zhang, S. Ren and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, pp. 770–778, 2016. [Google Scholar]
26. K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint, arXiv: 1409.1556, pp. 1–14, 2014. [Google Scholar]
27. F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” in Proc. IEEE Conf. on Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 1800–1807, 2017. [Google Scholar]
28. Y. LeCun, L. Bottou, Y. Bengio and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998. [Google Scholar]
29. A. Krizhevsky, I. Sutskever and G. Hinton, “Imagenet classification with deep convolutional neural networks,” Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017. [Google Scholar]
30. C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed et al., “Going deeper with convolutions,” in Proc. IEEE Conf. on Computer Vision and Pattern Recognition, Boston, MA, USA, pp. 1–9, 2015. [Google Scholar]
31. C. Ledig, L. Theis, F. Huszár, J. Caballero and A. Cunningham, “Photo-realistic single image super-resolution using a generative adversarial network,” in Proc. IEEE Conf. on Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 105–114, 2017. [Google Scholar]
32. B. Demiray, M. Sit and I. Demir, “D-SRGAN: DEM super-resolution with generative adversarial network,” SN Computer Science, vol. 2, no. 1, pp. 1–11, 2021. [Google Scholar]
33. I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley et al., “Generative adversarial nets,” in Proc. of the 27th Int. Conf. on Neural Information Processing Systems, (NIPS’14Cambridge, MA, USA, MIT Press, pp. 2672–2680, 2014. [Google Scholar]
34. S. Gross and M. Wilber, “Training and investigating residual nets,” Facebook AI Research, vol. 6, pp. 1–7, 2016. [Google Scholar]
35. S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” Pattern Machine Learning Recognition, vol. 5, pp. 448–456, 2015. [Google Scholar]
36. C. Nwankpa, W. Ijomah, A. Gachagan and S. Marshall, “Activation functions: Comparison of trends in practice and research for deep learning,” Neural Computing and Applications, vol. 7, pp. 1–19, 2018. [Google Scholar]
37. Y. Yu, Z. Gong, P. Zhong and J. Shan, “Unsupervised representation learning with deep convolutional neural network for remote sensing images,” in Proc. Int. Conf. on Image and Graphics, Cham, Springer, pp. 97–108, 2017. [Google Scholar]
38. J. Johnson, A. Alahi and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in Proc. European Conf. on Computer Vision, Cham, Springer, pp. 694–711, 2016. [Google Scholar]
39. W. Shi, J. Caballero, F. Huszár, J. Totz and A. P. Aitken, “Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network,” in Proc. IEEE Conf. on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, pp. 1874–1883, 2016. [Google Scholar]
40. K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint, arXiv: 1409.1556, pp. 1–14, 2014. [Google Scholar]
41. COVID DatasetOne, 2020. [Online]. Available: https://github.com/UCSD-AI4H/COVID-CT, last access on 25-12-2020. [Google Scholar]
42. COVID DatasetTwo, 2020. [Online]. Available: https://github.com/ieee8023/covid-chestxray-dataset, last access on 25-12-2020. [Google Scholar]
43. COVID and Pneumonia Dataset, 2020. [Online]. Available: https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia, last access on 25-12-2020. [Google Scholar]
44. COVIDDataset, 2020. [Online]. Available: https://data.mendeley.com/datasets/8h65ywd2jr/1?fbclid=IwZLb04fZMx4CX7fU1B6Ln1D, last access on 25-10-2020. [Google Scholar]
45. A. Blum and S. Chawla, “Learning from labeled and unlabeled data using graph mincuts,” in Proc. of the Eighteenth Int. Conf. on Machine Learning, San Francisco, CA, USA, pp. 19–26, 2001. [Google Scholar]
46. Open CV library, 2020. [Online]. Available: https://opencv.org/, last access on 10-2-2020. [Google Scholar]
47. D. Hand and R. Till, “A simple generalization of the area under the ROC curve for multiple class classification problems,” Machine Learning, vol. 45, no. 2, pp. 171–186, 2001. [Google Scholar]
48. C. Bishop, Pattern recognition and machine learning. New York, NY: Springer, 2006. [Google Scholar]
49. Scikit library, 2020. [Online]. Available: https://scikit-learn.org/stable/auto_examples/model_selection/plot_precision_recall.html, last access on 25-11-2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |