DOI:10.32604/cmc.2022.019291
| Computers, Materials & Continua DOI:10.32604/cmc.2022.019291 | |
| Article |
Hybrid Evolutionary Algorithm Based Relevance Feedback Approach for Image Retrieval
1College of Applied Computer Science, King Saud University (Almuzahmiyah Campus), Riyadh, 11543, Saudi Arabia
2Shaheed Zulfikar Ali Bhutto Institute of Science and Technology (Islamabad Campus), 44000, Pakistan
3University of Engineering and Technology Taxila, Pakistan
4International Islamic University, Islamabad, 44000, Pakistan
5Faculty of Sciences and Technology, University of Kairouan, Sidi Bouzid, 4352, Tunisia
6Department of Software Engineering, Foundation University Islamabad, Islamabad, 44000, Pakistan
*Corresponding Author: Awais Mahmood. Email: mawais@ksu.edu.sa
Received: 08 April 2021; Accepted: 14 May 2021
Abstract: Searching images from the large image databases is one of the potential research areas of multimedia research. The most challenging task for nay CBIR system is to capture the high level semantic of user. The researchers of multimedia domain are trying to fix this issue with the help of Relevance Feedback (RF). However existing RF based approaches needs a number of iteration to fulfill user's requirements. This paper proposed a novel methodology to achieve better results in early iteration to reduce the user interaction with the system. In previous research work it is reported that SVM based RF approach generating better results for CBIR. Therefore, this paper focused on SVM based RF approach. To enhance the performance of SVM based RF approach this research work applied Particle Swarm Optimization (PSO) and Genetic Algorithm (GA) before applying SVM on user feedback. The main objective of using these meta-heuristic was to increase the positive image sample size from SVM. Firstly steps PSO is applied by incorporating the user feedback and secondly GA is applied on the result generated through PSO, finally SVM is applied using the positive sample generated through GA. The proposed technique is named as Particle Swarm Optimization Genetic Algorithm- Support Vector Machine Relevance Feedback (PSO-G A-SVM-RF). Precisions, recall and F-score are used as performance metrics for the assessment and validation of PSO-GA-SVM-RF approach and experiments are conducted on coral image dataset having 10908 images. From experimental results it is proved that PSO-GA-SVM-RF approach outperformed then various well known CBIR approaches.
Keywords: Feature selection; image retrieval; particle swarm optimization
In this era of information technology due to various personal devices such as Digital camera, Smart phones, there is an increase in number of images, photos, videos and uploads on social media. Due to these activities the volume of digital content are increasing day by day in various achieves. To extract the related information from this vast amount of data the retrieval techniques need to accurately identify the relevant information by extracting various potential features. The searching performance form the textual data reached to the maturity level, However, the techniques used for visual search or multimedia data are consider still young due to rich multimedia contents [1] research areas.
The most common methods for searching from multimedia contents is the use of information associated with the images such as keywords, labels, tags and timestamp where retrieval is performed through text based. User enters a keyword to the system and then system search the images annotated with that keywords. Manual annotation of huge image repository required large amount of time which makes it expensive task is also not an effective approach in comparing with the semantic contents richness because of subjectivity of the task. Besides this, every person perceive each image differently, the person who annotate an image having building and car may perceive it as building image but the one who is searching may perceive the same image as car image, similarly the one words can have different meaning which may create confusion. Usually the manual annotation provides the general information but is loosely connected to the specific visual content of the image which means a textual query can generate the multiple results with diverse semantic meaning.
To overcome these drawbacks of textual searching various automatic methods which performed the analysis of image contents have been proposed. The leverage of mid-level and low level features like color, share and texture features are used in the content based approach. From the query image, features are extracted and then a mapping process is perfumed with the image database based on these features then relevant images are then indexed based on the similarly of these features between the database images & the query image. This becomes very active research fields since 20 years [2–5] and is known as Content Based Image Retrieval (CBIR).
However, these low level features cannot always describe the image directly according to the usual understating of the use about the image. Images based on the physical characteristics such as textures, shapes and colors or emotions and memories can be perceived by the human being. Computer considers an image simply a set of pixels with various colors and various intensities. The early CBIR approaches based on the low level features are easy to implement and generates good results for simple images. These low level features are actually the numeric values which describe the color, shape and texture information of the image. When two images needs to be compared to measure their similarity actually the similarity of their numeric features is computed. For example if similarity between the lemon and orange needs to be computed, you may get good results and verse results as well because if the searching is based on the shape features both images will be considered from the same class, however in color based searching both images will be considered from the different classes [6,7]. These findings focused the researchers of multimedia to use the various types of features simultaneously. However these low level features may not elaborate the visual semantic of the image. Identification of semantic information perceived by human beings from the images to bridge the gap between low level features and the high level features, researchers adopted the relevance feedback methodology from the domain of information searching. The reason to adopt the Relevance feedback (RF) is to incorporate the human perception subjectivity by involving the user into retrieval process which enhanced the retrieval results.
In CBIR systems user is involved in the searching process through RF where user first enter an image to the system which is consider as query image, system then find the similar images from the image database based on the low level features and returns top N images to the user and user labels the interested image as relevant and rest of the images are considered as irrelevant, further system consider the relevant images marked by the user as an additional examples to specify the query image. This way system can improve the learning in each iteration which improved the system performance. RF is an emerging technique in CBIR but still it faces some issues such as user needs to record the feedback for various times which may result of user frustration. Researchers of multimedia domain have explored various classification techniques to enhance the performance of RF in image retrieval process but mostly researchers focused on SVM supported RF. However, SVM supported RF also facing different issues such as imbalanced feedback reported by the user i.e., user mark only few images as relevant from displayed images and rest of all the images are considered as irrelevant so the number of relevant samples are few where as irrelevant samples is very large [8]. One other problem of RF is user interaction if user has to interact with the system for various time which takes a lot of time of user. Therefore there is need to propose a technique which reduce the user interaction with the system.
This papers proposes a new methodology to overcome the abovementioned problem using Genetic Algorithm (GA), Particle Swarm Optimization (PSO) and Support Vector Machine (SVM). The proposed technique is called as PSO-GA-SVM-RF. PSO-GA-SVM-RF increased the number of relevant images marked by the user during feedback process through GA and PSO. The concept of using GA is to extend the feature set on the basis of existing feature through evolutionary process. PSO is used to increase the relevant samples selected by the user. Once the relevant samples are increased then SVM classify the relevant and irrelevant images from the image database. This way GA and PSO resolved the imbalance set of feedback labeling for SVM.
In order to engage the user in the image retrieval process, Young and Huang introduced the concept of relevance feedback in the field of CBIR. Now a day's number of researchers is using relevance feedback to enhance the performance of their algorithms in CBIR. A detail of RF process is already mentioned in the introduction section. A neural network was trained on the basis of user feedback for searching relevant images from a huge image database by Koskela et al. [9].
Relevance feedback was also adopted by Bordogona et al. [10] for the training of neural network to retrieve similar images against any query image. To improve the RF's performance researchers also explored the graph theory. The major motivation behind using graph theory was to reduce the navigational process needed in RF process.
To make RF process fast, random walker method was introduced by [11]. In this approach positive and negative marked images by the user are considered as seed nodes for random walker algorithm.
Even though various techniques have been proposed to improve the performance of RF mechanism, SVM based RF process is considered as more robust [12]. In SVM base RF approach, SVM is trained on using positive and negative samples availed during RF process [13]. To further improve the performance of RF Yildizer [14] presented the ensemble classifier. We have discussed few problems being faced by SVM based RF technique. These issues arise as user marked few images as relevant therefore the training set is very small specifically positive samples which make SVM unstable and it may include biasness as well due to small set of positive samples. The objective of this study is to fix these issues of SVM based RF by applying PSO and GA before the startup of SVM process. The reason of using PSO and GA is to strengthen the training set specifically increase the images in positive sample set.
2.2 Particle Swarm Optimization
Particle Swarm Optimization (PSO) was proposed by Kennedy and Eberhart to solve the optimization problems [15]. PSO has resemblance with other evolutionary computing algorithms in nature. The idea of PSO is inspired by the flock of bird on the way to search bets food. The motivation was to search global optimum through flying particles. A particle in the environment of PSO can be represented with term
In these equations
Despite the fact that PSO is considered as good optimizer algorithm, however to further improve its performance various researchers work on it [16–20]. A detailed study on the PSO variants was presented by Imran et al. [21]. It was successfully employed to solve variety of industry oriented problems [22] and various domains such as digital content classification [23], sensor network [24], design of arrays antenna [25] and to optimize the weights of neural network [26]. Despite of others fields PSO served CBIR to improve its performance. In CBIR it was used to optimize the feature map by Chandramouli [27]. PSO was used by [28] to improve the performance of relevance feedback in content based image retrieval. ANN weight optimization is performed by PSO to improve the performance of content based image retrieval [29]. Ranking of image retrieval was also improved by though PSO in [30]. To grasp the user semantic it was used in CBIR by Broilo [31].
Genetic Algorithm is an evolutionary algorithm which is based on the natural evolution procedures and also recognized as machine learning algorithm [32]. Population of GA is individually called as chromosome, and these chromosomes are initialized in the start of genetic procedure. After the initialization procedure new chromosome is generated through existing chromosome in each iteration which actually means new population is generated. New population is generated on the hope that new population will be better than existing population to find the optimum solution. After the new population generation fitness of each chromosome is computed using a fitness function, different pairs of chromosomes having better fitness value are selected which are called as parents to generate the new chromosomes (called as Childs). Mutation & the crossover operators are used to generate the child chromosomes through parent chromosomes.
Various domains are benefited by GA [33,34] including CBIR [35,36]. GA was used for feature optimization [37] with SVM and CNN. Great deluge algorithm combined with GA [38] to improve the performance of GA. This study also utilized the GA with combination of PSO to improve the performance of CBIR. The output generated by GA as two sub set of images relevant and irrelevant used by SVM to enhance the CBIR performance. Detail is available in subsequent sections.
Proposed methodology consists of 4 phases, information collection, working of PSO, processing of GA finally training of SVM and classification, which starts after basic image retrieval process. Initially users read the query image in system then the system will pull out the image features and compute the similarity between query image feature and the database image features using Manhattan distance measuring technique. Based on this distance, similar images are ranked and then the results are shown to user. At this stage user feedback is collected in the form of irrelevant images as well as relevant images. On the basis of user feedback swarms of PSO are initialized and the process of PSO starts. During PSO process a fitness function is used to find the relevant images, PSO generates the two sub set of images relevant an irrelevant. Then process of Genetic algorithm is starts, for this purpose output generated through PSO is used by GA to further increase the relevant samples size. SVM is trained using result generated by GA for classification purpose. Flow chart of the proposed methodology is displayed in Fig. 1. Further detail including feature extraction is presented in subsequent sections.
One of the basic key success factors of CBIR is the image representation in the form of image features. Various types of features from the image can be extracted such as texture, Color and shape features [39,40]. Even though image description is not focus of this study, however, the paper will remain incomplete without the discussion of image description. This study adopted Homogeneous Texture Descriptor (HTD) from the MPEG-7 standard for image representation [40], as the HTD is reported as the efficient and performing well as texture descriptor and global features [41]. The feature extraction process is performed in offline mode and stored as feature database. The detail is presented in the next section of Swarm representation.
As the initial process of PSO is Swarm representation and initialization. In this study the HTD feature vector of image is represented as swarm of PSO.
HTD define the regularity coarseness and directionality of pattern of the image. Basically HTD figure out, energy, energy deviation, standard deviation and mean value of the image. Principally HTD vector which is a complete image descriptor is based on 52 values where initial two values are reserve for mean & standard deviation and the rest 60 values are energy and energy deviation. Following two equations are used to compute the mean and standard deviation.
In these equations
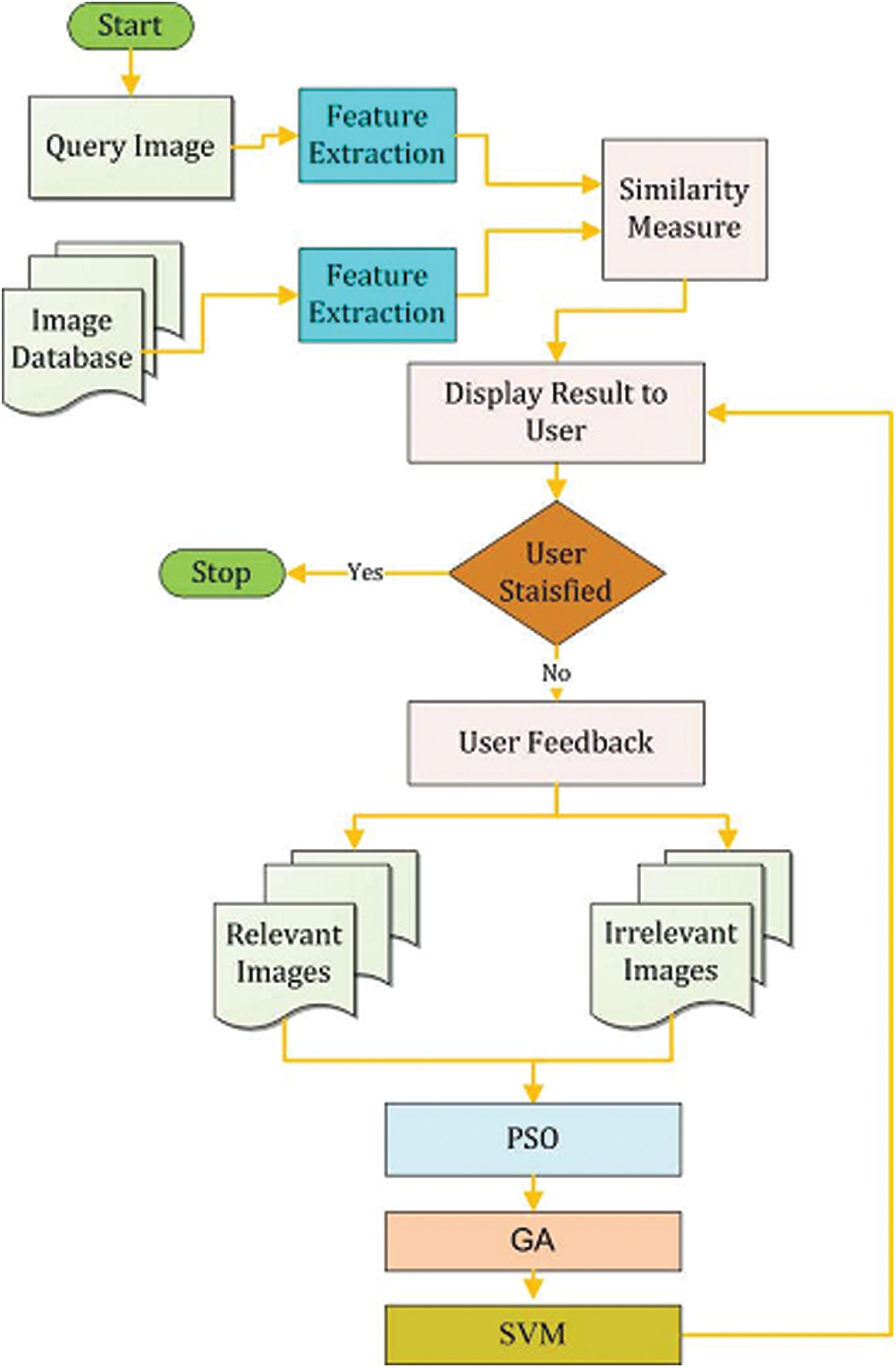
Figure 1: Flow chart of proposed methodology
Image is converted into frequency domain to compute the energy & energy deviation. To compute energy & energy deviation image is split into 30 channels in frequency domain dividing octave division & angular direction as well as radial direction equally. The procedure to extract these 60 features is given below.
1. To represent image in the polar coordinates
2. To strength the information obtained from image, Gabor filter is deployed which is expressed in term
3. The wedge & energy feature of each of the individual channel is calculated. The Gabor feature can be calculated as
Polar coordinates point value is denoted by
Here, r denotes index of angle
where, s is the radius index.
where
3.3 Calculating Distance and User Feedback
The first step of image retrieval after entering query to the system is to compute the distance between query image feature and features of database images.
In this proposed methodology the image is represented using Eq. (10)
where MNHT is the Manhattan distance calculated between the query image and database images. Once the distance between the query image and the database image is computed the ranked results available for user and then user can record his feedback by marking interested images as relevant and remaining images are automatically considered as irrelevant. This way, the displayed images are divided into two groups which are
3.4 Swarm Initialization and Fitness Evolutions
As already established in earlier sections that a swarm is represented using feature vector of the image, the next step is swarms initialization. Therefore, feature vector of all the images recorded during the RF process by user are used to initialize the feature vector.
The total number of particles/Swarms are expressed as
In the above equation,
3.5 Swarm Evolution and Termination Criteria
As in PSO, swarm evolution process is started after swarm initialization. In standard PSO personal and global best for each particle must be defined before start of swarm evolution process. However in this approach the updating of personal and global is different contrast to standard PSO. In this PSO-GA-SVM-RF approach query image entered by the user is considered as global best and updated as the subset of relevant image and each image for this subset is selected using following equation.
For each relevant image, the image having the minimum sum of distances with other relevant images is selected
Here r1 and r2 are nothing but two random numbers in the range of [0, 1], the value of inertia weight w is 0.4, C1 = 0.5 and C2 = 0.9 are considered as learning factors. Once the velocity is updated the next step is to update the position of the particle using following equation
The process of particle's velocity and position update is carried out during each iteration. Eq. (12) is used to compute the particle's fitness in case it is lower than its previous fitness it is considered as the best particle. In this way images are ranked based on the fitness, the image having lower fitness remain top on the list and relevant image library is updated.
3.6 Implementation Detail of GA
As described in earlier section the main objective of this study is to optimize the image retrieval process. The relevant feedback mechanism optimizes by minimizing the user interaction. For this purpose the output generated by PSO is used by GA. As in GA it is important to establish that how the structure of chromosome will be. The detail of GA process such as chromosome construction, Population Evolution in GA and fitness function used by GA is presented in following sections.
Initially the chromosome of GA in this study is defined as
Here in this Equation N is used to represent the total number of genes in a chromosome and M represent total size of population which means total number of chromosomes. Initially the feature vector positive image set generated by PSO and query image are considered as initial chromosome of GA and represented as in following equation.
where k = 1, 2, 3,…, 62 are the features obtained using HTD.
GA uses two operator crossover and mutation for the population evolution. In this study new population is generated through crossover and mutation operators using following equation
Here
This test helps us to select the chromosomes which have less distance from best parents. Here ‘n’ shows the numbers of remaining offspring which can become influential other than the original parents. mutation rate in this study is set as 0.05.
As Fitness function is considered as core of any evolutionary computing algorithm. This study adopts the fitness function form [33ow] and is defined by following equation.
where
Here C shows the maximum possible relevant images in a database. Pth member from
So if result of fitness function is 1 it means system match the users solution, however, if it is 0 then no match.
The performance of proposed approach PSO-GA-SVM-RF is assessed and validated through experiments. These experiments are perfumed on real data set. to validate the GA-SVM-RF its results are compared with other well-known CBIR techniques with RF. The detail of dataset and experiments is described in following subsections.
4.1 Image Database and Performance Metrics
Experiments were performed on coral image data set [36]. As there are two version of coral image data set. One of which has 1000 images and the other has 9908 images. Both data sets were merged into single data set. The final data set has 10908 images from various categories such as Elephants, Buses, Beaches butterfly and texture etc.
Experiments were perfumed by executing the simulation on Matlab 2010b release to assess the proposed approach. For this purpose initially 300 images are selected rand omly and considered as query image. Most relevant images for any query images are displayed to the user. The process of RF is executed automatically during the simulation where relevant images are considered as positive while rest of the images are considered as negative samples. To make sure that PSO-GA-SVM-RF performance is best a rich experiments was performed for different top retrieval such as top as (10, 20, 30,…, 100) where top 10 means user wants to display 10 most similar images, same for top 20 means user is interested to display the 20 most similar images during each experiment 9 times automatic RF is repeated.
Precision, Recall and F-Score were used as performance metric to measure the performance of PSO-GA-SVM-RF. Where Precision is calculated by dividing “Number of relevant images” with the “Total Number of retrieved images” and Recall is calculated by dividing “Total number of relevant retrieved images” with the “Total number relevant images in the database.” The performance of the any technique depends on the precision where maximum value of precision is 1.0 and minimum value is 0.1. So if the precision value is higher it means the performance of the system is good and vice versa. Similarly this can be measure in percentage if precision value is 0.1 it means 10% while 1.0 means 100%. To check the robustness of the GAPSO-SVM-RF we have calculated the recall, where it is important to note that the precision is high in case of less top retrieval and low recall, but when the number of top retrievals is increased then the recall is increased &precision is decreased.
4.2 Precision Based Performance Comparison
Kernel biased marginal convex machine (KBMCM) [4], ABRSVM [9], GOSVM [42], semi-BDEE [43] and DBA [44] are selected to compare with PSO-GA-SV-RF approach. The result of these previous well known techniques are adopted from [38] and similar experimental setup is adopted to generate the result of PSO-GA-SVM-RF. Comparison of PSO-GA-SVM-RF based on the precision values is presented in Fig. 1.
From Fig. 2 it is clear that the PSO-GA-SVM-RF approach achieved 100% accuracy in 4th iteration while rest of all well-known techniques are fail to achieve 100% accuracy. From this figure it is also obvious that PSO-GA-SVM-RF achieved its claimed objective that is to minimize the user interaction with the system as it achieved 100% accuracy only in 4th iteration.
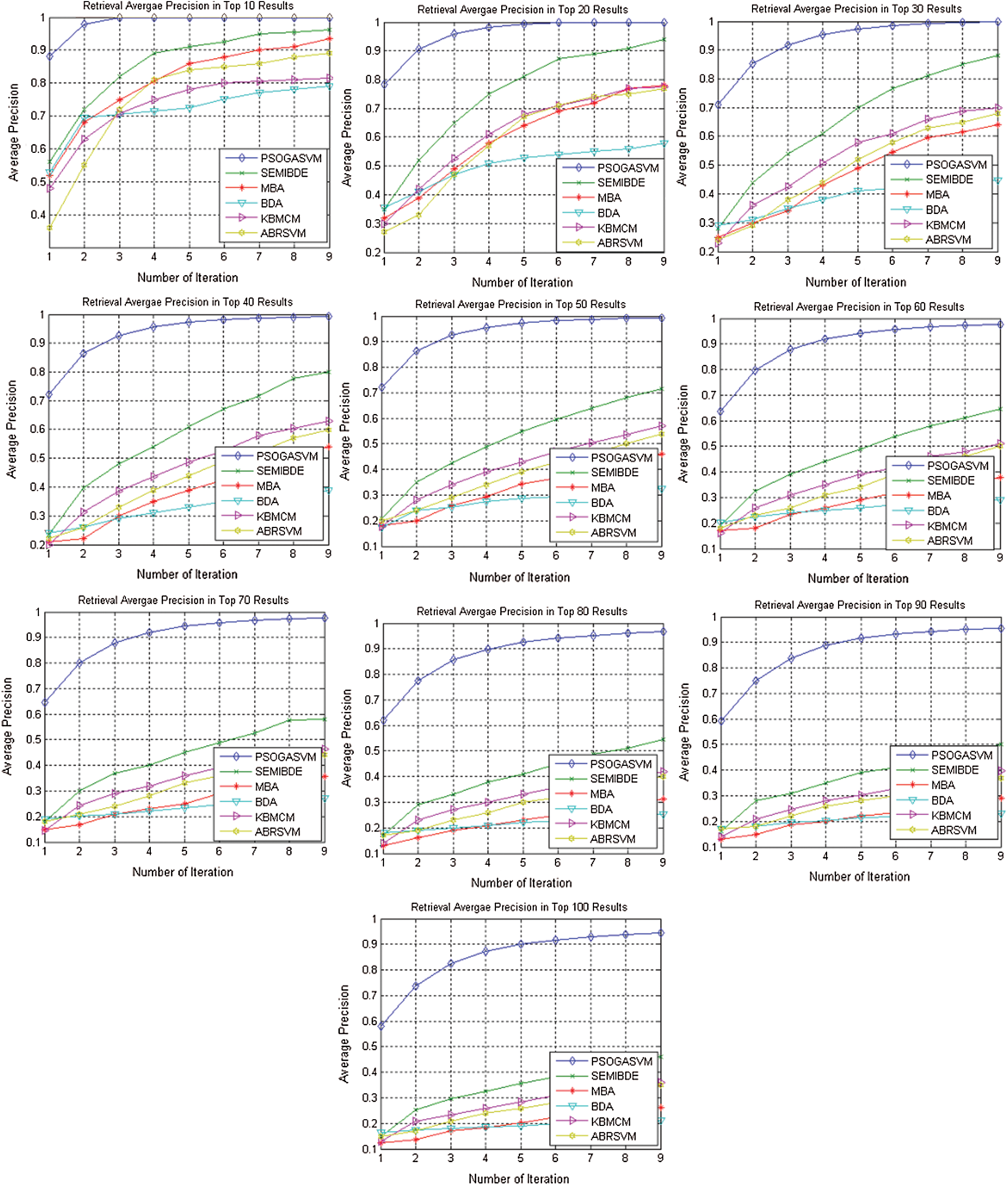
Figure 2: Performance of the proposed GAPSO-SVM-RF compared against existing algorithms, i.e., SEMIBDEE, MBA, BDA, KBMCM and ABRSVM. All algorithms are evaluated over nine RF iterations
In case of top 20 retrieval the accuracy achieved by PSO-GA-SVM-RF is also very good, its reaches 100% in 6th iteration however the other techniques can achieve only 90% accuracy after 9th iteration.
When user request to see the 30 most relevant images the PSO-GA-SVM-RF achieved 70% accuracy in first attempt but in 8th iteration successfully achieved 100% accuracy, however other competitors such as MBA, DBA, KBMCM and ABRSVM are fail to achieved 70 or less than 70% accuracy level even in final iteration.
The performance of PSO-GA-SVM-RF for the top 40 retrievals presented in Fig. 1 shows that the PSO-GA-SVM-RF approach succeeded to achieve 98% accuracy in final iteration, however the performance of other techniques is not good. Only GOSVM and SEMIBDE were able to achieve 82% in final iteration.
Similarly PSO-GA-SVM-RF approach was able to achieve the accuracy of 98% in final iteration for top 50 retrievals while other techniques except GOSVM and SEMIBDE achieved very low accuracy rate in final iteration. GOSVM and SEMIBDE achieved 80% and 71% respectively in final iteration. However in the initial iterations their performance was not good as well.
When user requested to see the 60 and 70 most similar images against any query image the accuracy of PSO-GA-SVM-RF is initial iteration was 63% however gradually it increases and in final iteration system was able to achieve the 97% accuracy in 8th and 9th iteration. Among other competitors only GOSVM and SEMIBDE achieved 80% and 64% accuracy in final iteration respectively while other techniques such as KBMCM, BDA and MBA were unable to achieve even 50% accuracy in final iteration.
In case of top 80 retrievals the PSO-GA-SVM-RF approach achieved accuracy of 90% in 4th iteration but in final two iterations successfully achieved 96% accuracy while among other techniques only GOSVM and SEMIBDE achieved more than 50% in final iteration.
While retrieving 90 most similar images the PSO-GA-SVM-RF achieved 95% accuracy level in final iteration where rest of the techniques were unable to achieve good accuracy level such as GOSVM and SEMIBDE achieve 60% and 50% accuracy respectively in final iteration. However all other techniques were failed to achieve 50% accuracy in the final iteration.
Last graph in Fig. 1 depicts that the performance of PSO-GA-SVM-RF approach remains very good for the top 100 retrievals, as it achieved 94% in final iteration where other techniques were fail to achieve 60% accuracy in final iteration. Some of the techniques such as MBA and DBA achieved 26% and 21% respectively in final iteration.
Finally above discussion can be summarized as PSO-GA-SVM-RF approach successfully achieved good performance in all top retrievals. It is clearly observed that for all top retrievals the accuracy achieved by proposed approach was more than 94% in final iteration. But from other techniques only GOSVM and SEMIBDE was able to achieve 90% accuracy in final iteration for top 10-top 30 retrievals only. one important point to note is that PSO-GA-SVM-RF approach successfully achieved more than 90% accuracy in just 3rd for top 10-top 80 retrievals while it just need only one other iteration to achieve 90% accuracy for top 90 and top 100 retrievals. This trend clearly indicates that PSO-GA-SVM-RF can easily fulfill the user requirements in image retrieval.
4.3 Performance Comparison Based on f-Score
Precision and recall cannot just tell the robustness of any image retrieval system. Therefore, F-score is also computed where both precision and recall are combined, F-Score is also considered as the harmonic means of precision and recall. In this study F-Score is calculated using precision and recall value recorded in the final iteration for top-10-top 100 retrievals differently. The best value of F-score is 1.0 while 0 is considered as worst. The F-Score measurements of PSO-GA-SVM-RF, GOSVM, SEMIBDE and other CBIR techniques are presented in Tab. 1.
From Tab. 1 it is obvious that F-Score measurement of PSO-GA-SVM-RF is greater than all other techniques from top-10 to top-100 retrievals. Few techniques such as MBA, BDA and KBMCM achieved very less F-Score in all top retrievals. One can observe that the value of F-Score is increasing from top 10 to top 100 retrievals means F-Score of top 20 retrievals is greater than F-Score of top 10 retrievals for all techniques while in case of precision it is vice versa. Its reason is the value of recall is increases from top 10 to top 100 retrievals.

Performance of PSO-GA-SVM-RF is good in the case of precision as well as F-Score which shows that the proposed methodology is more robust than other techniques.
As mentioned in earlier section proposed PSO-GA-SVM-RF approach is validated by comparing its results with kernel biased marginal convex machine (KBMCM) [4], ABRSVM [9], semi-BDEE [43] and DBA [44]. For the purpose of validation results of previous techniques are collected from [43].
Following observations can be concluded from the results presented in Fig. 2. 1) There is consistency in the performance of PSO-GA-SVM-RF over other techniques as it remains best in all iterations for all top retrievals. 2) The proposed methodology achieved a very good precision rate in earlier iterations which means user desired results can achieve quickly. This was also objective of the proposed methodology to minimize the user interaction with the system. 3) Among the other techniques GOSVM and SEMIBDE performance remains good in all experiments. ABRSVM, KBMCM, BDA and MBA achieved satisfactory results only for top 10-top 50 retrievals. Based on the presented results it's easy to conclude that PSO-GA-SVM-RF is more robust and stable technique than other competitors.
This study proposed a new methodology for image retrieval to minimize the user interaction with system in RF based approaches. The proposed approach used PSO, GA and SVM to achieve the aforementioned objective. In this approach SVM is trained on the best image selected by PSO and GA process. PSO and GA are used to increase the relevant image subset to resolve the SVM training problem and this is the reason why proposed technique outperformed then other approaches. The other objective of proposed approach was to bridge the gap between low level features and high level semantics. To establish the authenticity of proposed approach a rich experiments were performed on the coral dataset having more than 10000 images. Through experiments it is clear that with the help of proposed approach the number of RF iterations can be decreased and a good accuracy level can be achieved in only three iterations which is a significant improvement in RF based image retrieval systems.
As the experiments were performed on top 10-top 100 retrievals, PSO-GA-SVM-RF achieved 100% accuracy level for top 10-top 50 retrievals and for top 60–100 image retrievals the accuracy achieved by proposed methodology was 94% which is obviously a very good number. This shows that the proposed methodology is a robust and stable technique.
Acknowledgement: This work was supported by the Deanship of Scientific Research at King Saud University through the Research Group under Grant RG-1438-071.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. C. Kofler, M. Larson and A. Hanjalic “User intent in multimedia search: A survey of the state of the art and future challenges,” ACM Computing Surveys, vol. 49, no. 2, pp. 1–37, 2016. [Google Scholar]
2. A. W. M. Smeulders, M. Worring, S. Santini, A. Gupta and R. Jain, “Content-based image retrieval at the end of the early years,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 22, no. 12, pp. 1349–1380, 2000. [Google Scholar]
3. M. S. Lew, N. Sebe, C. Djeraba and R. Jain, “Content-based multimedia information retrieval: State of the art and challenges,” ACM Transactions on Multimedia Computing, Communications, and Applications, vol. 2, no. 1, pp. 1–19, 2006. [Google Scholar]
4. R. Datta, D. Joshi, J. Li and J. Z. Wang, “Image retrieval: Ideas, influences, and trends of the new age,” ACM Computing Surveys, vol. 40, no. 2, pp. 1–60, 2008. [Google Scholar]
5. R. Zinko, C. P. Furner, H. B. Woodman, P. Johnson and A. Sluhan, “The addition of images to eWOM in the travel industry: An examination of hotels, cruise ships and fast food reviews,” Journal of Theoretical and Applied Electronic Commerce Research, vol. 16, no. 3, pp. 525–541, 2021. [Google Scholar]
6. M. L. Kher and D. Ziou, “Relevance feedback for cbir: A new approach based on probabilistic feature weighting with positive and negative examples,” IEEE Transactions on Image Processing, vol. 15, no. 4, pp. 1017–103, 2006. [Google Scholar]
7. H. H. Bhatt and A. P. Mankodia, “A comprehensive review on content-based image retrieval system: Features and challenges,” Data Science and Intelligent Applications, vol. 1, pp. 63–74, 2021. [Google Scholar]
8. D. Tao, X. Li and S. Maybank, “Negative samples analysis in relevance feedback,” IEEE Transactions on Knowledge and Data Engineering, vol. 19, no. 4, pp. 568–580, 2007. [Google Scholar]
9. M. Koskela, J. Laaksonen and E. Oja, “Use of image subset features in image retrieval with self-organizing maps,” in Proc. of 3rd Int. Conf. on Image and Video Retrieval, USA, pp. 508–516, 2004. [Google Scholar]
10. G. Bordogna and G. Pasi, “A user-adaptive neural network supporting a rule-based relevance feedback,” Fuzzy Sets and Systems, vol. 82, pp. 201–211, 1996. [Google Scholar]
11. S. R. Bul, M. Rabbi and M. Pelillo, “Content-based image retrieval with relevance feedback using random walks,” Pattern Recognition, vol. 44, no. 9, pp. 2109–2122, 2011. [Google Scholar]
12. D. Tao, X. Tang, X. Li and X. Wu, “Asymmetric bagging and random subspace for support vector machines-based relevance feedback in image retrieval,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 28, no. 7, pp. 1088–1099, 2006. [Google Scholar]
13. D. Djordjevic and E. Izquierdo, “An object- and user-driven system for semantic-based image annotation and retrieval,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 17, no. 3, pp. 313–323, 2007. [Google Scholar]
14. E. Yildizer, A. M. Balci, M. Hassan and R. Alhajj, “Efficient content based image retrieval using multiple support vector machines ensemble,” Expert Systems with Applications, vol. 39, pp. 2385–2396, 2012. [Google Scholar]
15. J. Kennedy and R. Eberhart, “Particle swarm optimization,” IEEE Int. Conf. on Neural Networks, vol. 4, pp. 1942–1948, 1995. [Google Scholar]
16. H. S. N. Alwerfali, M. A. Elaziz, M. A. A. Al-Qaness, A. A. Abbasi, S. Lu et al.., “A multilevel image thresholding based on hybrid salp swarm algorithm and fuzzy entropy,” IEEE Access, vol. 7, no. 1, pp. 181405–181422, 2019. [Google Scholar]
17. H. Lu, P. Sriyanyong, Y. H. Song and T. Dillon, “Experimental study of a new hybrid PSO with mutation for economic dispatch with non-smooth cost function,” International Journal of Electrical Power & Energy Systems, vol. 32, no. 9, pp. 921–935, 2010. [Google Scholar]
18. W. Dong, L. Kang and W. Zhang, “Opposition-based particle swarm optimization with adaptive mutation strategy,” Soft Computing, vol. 21, no. 17, pp. 5081–5090, 2017. [Google Scholar]
19. D. Tian and Z. Shi, “MPSO: Modified particle swarm optimization and its applications,” Swarm and Evolutionary Computation, vol. 41, no. 2, pp. 49–68, 2018. [Google Scholar]
20. R. Anum, M. Imran, R. Hahsim, A. Mahmood and S. Majeed, “A hybrid particle swarm optimization (PSO) with Chi-square and stable mutation jump strategy,” International Journal of Advanced and Applied Sciences, vol. 3, no. 12, pp. 49–54, 2016. [Google Scholar]
21. M. Imran, R. Hashim and N. E. A. Khalid, “An overview of particle swarm optimization variants,” Procedia Engineering, vol. 53, pp. 491–496, 2013. [Google Scholar]
22. K. E. Parsopoulos and M. N. Vrahatis, “Recent approaches to global optimization problems through particle swarm optimization,” Natural Computing, vol. 1, pp. 235–306, 2002. [Google Scholar]
23. C. S. Wickramasinghe, K. Amarasinghe and M. Manic, “Deep self-organizing maps for unsupervised image classification,” IEEE Transactions on Industrial Informatics, vol. 15, no. 11, pp. 5837–5845, 2019. [Google Scholar]
24. H. Jin, A. A. Abbasi and S. Wu, “Pathfinder: Application-aware distributed path computation in clouds,” International Journal of Parallel Programming, vol. 45, no. 6, pp. 1273–1284, 2017. [Google Scholar]
25. T. Sadad, A. Rehman, A. Hussain, A. A. Abbasi and M. Q. Khan, “A review on multi-organs cancer detection using advanced machine learning techniques,” Current Medical Imaging, vol. 3, no. 2, pp. 180–192, 2020. [Google Scholar]
26. R. Brits, A. P. Engelbrecht and F. Bergh, “Locating multiple optima using particle swarm optimization,” Applied Mathematics and Computation, vol. 189, no. 2, pp. 1859–1883, 2007. [Google Scholar]
27. Y. Shi, K. Wang, C. Chen, L. Xu and L. Lin, “Structure-preserving image super-resolution via contextualized multitask learning,” IEEE Transactions on Multimedia, vol. 19, no. 12, pp. 2804–2815, 2017. [Google Scholar]
28. Y. Zhu, J. Jiang, W. Han, Y. Ding and Q. Tian, “Interpretation of users’ feedback via swarmed particles for content-based image retrieval,” Information Sciences, vol. 375, pp. 246–257, 2017. [Google Scholar]
29. R. B. Kumar and P. Marikkannu, “An efficient content based image retrieval using an optimized neural network for medical application,” Multimed Tools and Applications, vol. 79, pp. 22277–22292, 2020. [Google Scholar]
30. M. Okayama, N. Oka and K. Kameyama, “Relevance Optimization in Image Database Using Feature Space Preference Mapping and Particle Swarm Optimization,” in Neural Information Processing, Berlin, Heidelberg: Springer-Verlag, pp. 608–617, 2008. [Google Scholar]
31. M. Broilo and F. G. B. De Natale, “A stochastic approach to image retrieval using relevance feedback and particle swarm optimization,” IEEE Transactions on Multimedia, vol. 12, no. 4, pp. 267–277, 2010. [Google Scholar]
32. G. D'Angelo and F. Palmieri, “GGA: A modified genetic algorithm with gradient-based local search for solving constrained optimization problems,” Information Sciences, vol. 54, no. 7, pp. 136–162, 2021. [Google Scholar]
33. F. E. Batool, M. Attique, M. Sharif, K. Javed, M. Nazir et al., “Offline signature verification system: A novel technique of fusion of GLCM and geometric features using SVM,” Multimedia Tools and Applications, vol. 14, no. 5, pp. 120–150, 2020. [Google Scholar]
34. M. A. Khan, K. Javed, S. A. Khan, T. Saba, U. Habib et al., “Human action recognition using fusion of multiview and deep features: An application to video surveillance,” Multimedia Tools and Applications, vol. 14, no. 5, pp. 1–27, 2020. [Google Scholar]
35. S. B. Cho and J. Y. Lee, “A human-oriented image retrieval system using interactive genetic algorithm,” IEEE Transactions on Systems, Man and Cybernetics, vol. 32, no. 3, pp. 452–458, 2002. [Google Scholar]
36. S. Baddeti and Y. Rao, “An effective similarity measure via genetic algorithm for content based image retrieval with extensive features,” International Arab Journal of Information Technology, vol. 10, no. 2, pp. 143–151, 2013. [Google Scholar]
37. M. J. J. Ghrabat, M. Guangzhi, I. Y. Maolood, S. S. Alresheedi and Z. A. Abduljabbar, “An effective image retrieval based on optimized genetic algorithm utilized a novel SVM-based convolutional neural network classifier,” Human-centric Computing and Information Sciences, vol. 9, no. 31, pp. 1–29, 2019. [Google Scholar]
38. R. Guha, M. Ghosh, S. Kapri, S. Shaw, S. Mutsuddi et al., “Deluge based genetic algorithm for feature selection,” Evolutionary Intelligence, vol. 14, pp. 1–11, 2019. [Google Scholar]
39. B. Syam and Y. S. Rao, “An effective similarity measure via genetic algorithm for content-based image retrieval with extensive features,” International Journal of Signal and Imaging Systems Engineering, vol. 5, no. 1, pp. 18–28, 2012. [Google Scholar]
40. T. Sikora, “The mpeg-7 visual standard for content description-an overview,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 11, no. 6, pp. 696–702, 2001. [Google Scholar]
41. M. Saadatmand-Tarzjan and H. A. Moghaddam, “A novel evolutionary approach for optimizing content-based image indexing algorithms,” IEEE Transactions on Systems, Man, and Cybernetics, vol. 37, no. 1, pp. 139–153, 2007. [Google Scholar]
42. J. Wang, J. Li and G. Wiederhold, “Simplicity: Semantics-sensitive integrated matching for picture libraries,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 23, no. 9, pp. 947–963, 2001. [Google Scholar]
43. B. Manjunath, J. -R. Ohm, V. Vasudevan and A. Yamada, “Color and texture descriptors,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 11, no. 6, pp. 703–715, 2001. [Google Scholar]
44. R. R. Yager, “Golden rule and other representative values for atanassov type intuitionistic membership grades,” IEEE Transactions on Fuzzy Systems, vol. 23, no. 6, pp. 2260–2269, 2015. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |