DOI:10.32604/cmc.2022.019246
| Computers, Materials & Continua DOI:10.32604/cmc.2022.019246 | |
| Article |
Artificial Intelligence in Medicine: Real Time Electronic Stethoscope for Heart Diseases Detection
1Al-Farabi Kazakh National University, Almaty, Kazakhstan
2Khoja Akhmet Yassawi International Kazakh-Turkish University, Turkistan, Kazakhstan
3Abai Kazakh National Pedagogical University, Kazakhstan
4NARXOZ University, Almaty, Kazakhstan
*Corresponding Author: Batyrkhan Omarov. Email: batyahan@gmail.com
Received: 07 April 2021; Accepted: 12 June 2021
Abstract: Diseases of the cardiovascular system are one of the major causes of death worldwide. These diseases could be quickly detected by changes in the sound created by the action of the heart. This dynamic auscultations need extensive professional knowledge and emphasis on listening skills. There is also an unmet requirement for a compact cardiac condition early warning device. In this paper, we propose a prototype of a digital stethoscopic system for the diagnosis of cardiac abnormalities in real time using machine learning methods. This system consists of three subsystems that interact with each other (1) a portable digital subsystem of an electronic stethoscope, (2) a decision-making subsystem, and (3) a subsystem for displaying and visualizing the results in an understandable form. The electronic stethoscope captures the patient’s phonocardiographic sounds, filters and digitizes them, and then sends the resulting phonocardiographic sounds to the decision-making system. The decision-making system classifies sounds into normal and abnormal using machine learning techniques, and as a result identifies abnormal heart sounds. The display and visualization subsystem demonstrates the results obtained in an understandable way not only for medical staff, but also for patients and recommends further actions to patients. As a result of the study, we obtained an electronic stethoscope that can diagnose cardiac abnormalities with an accuracy of more than 90%. More accurately, the proposed stethoscope can identify normal heart sounds with 93.5% accuracy, abnormal heart sounds with 93.25% accuracy. Moreover, speed is the key benefit of the proposed stethoscope as 15 s is adequate for examination.
Keywords: Stethoscope; phonocardiogram; machine learning; classification; heart diseases; PCG
As is known, the most dangerous and common diseases are currently cardiovascular diseases (CVD) [1]. Cardiovascular diseases is the leading cause of death worldwide [2]. This determines the relevance of scientific and practical justification and development of effective methods of treatment, rehabilitation and prevention, and, above all, ensuring reliable early diagnosis of cardiovascular diseases in the presence of minimal symptoms (complaints or feelings of the patient) [3]. The main requirements for such methods are simplicity of implementation, informativeness and reliability.
There are many methods for diagnosing cardiovascular diseases [4]. Among them, the most common method is electrocardiography, which allows you to evaluate the work of the heart using an electrocardiogram (ECG) [5]. However, the ECG characterizes the state of the heart directly at the time of registration. In addition, in some cases, the ECG does not reflect all the existing disorders (for example, the presence of heart murmurs), and requires special conditions for registration [6].
A good addition to electrocardiography is phonocardiography (PCG), which allows investigating and detecting the presence of disorders in the activity of the heart and its valvular apparatus [7]. Phonocardiograms are acoustic measurements of the sound generated by the systolic and diastolic phases of the heart. The method is based on the recording and analysis of sounds that occur when the heart contracts and relaxes. This method is an affordable and relatively easy way to diagnose the functional state of the cardiovascular diseases. The source of diagnostic information here is the phonocardiosignal, the recording method of which is called phonocardiography.
Recently, a large number of studies using data analysis have been conducted in cardiology. The accumulated data on electrocardiography and phonocardiography are analyzed for the correct diagnosis [8–11]. Auscultation of the heart continues to play an important diagnostic role in the assessment of heart health [12]. All this has led to the development of diagnostic strategies that reasonably reduce the need for non-invasive diagnosis of heart disease [13]. One of these approaches is the creation of predictive models that characterize the existence of pathology in the patient. For such tasks, the machine learning technique is most suitable.
Machine learning (ML) methods are considered to be the main tools of artificial intelligence and are increasingly used in diagnostic and prognostic studies in clinical cardiology, including in patients with heart diseases. At the same time, there is a small number of scientific studies in which these methods are used to assess the pre-test probability of obstructive coronary artery disease and non-obstructive coronary artery disease in patients with various clinical variants of heart disease. At the same time, most publications on this issue emphasize that the improvement of machine learning technologies can be implemented only on the basis of interdisciplinary scientific cooperation.
This paper organized as follows: Section 2 reviews state of the art literatures in this area. Section 3 explains characteristics of heart sounds. In the Section 4, we explain architecture of electronic stethoscope and its components. Section 5 considers applying machine-learning methods for heart sound classification problem. The Section 6 demonstrates experiment results. After the results, we discuss the received results and opportunities. In the end, we conclude our paper by identifying further research directions.
Detection of cardiac diseases is crucial and they must be identified in the early stage utilizing regular auscultation evaluation with high accuracy. Cardiac auscultation is a method that uses an electronic stethoscope to analyze and listen to heart sounds. This PCG signal contains important information about the heart’s functioning and health, thus it may be used to investigate and diagnose cardiac problems using a variety of signal processing and machine learning techniques. The cardiac sound signal may be categorized into two groups based on the PCG signal: normal and pathological. Son et al. [14] compiled a database of five types of cardiac sound signals (PCG signals) from diverse sources, one of which is normal and the other four are abnormal. From the heart sound data, the authors employed Mel Frequency Cepstral Coefficient (MFCCs) and Discrete Wavelets Transform (DWT) features, as well as support vector machine (SVM), deep neural network (DNN), and centroid displacement-based k closest neighbor for learning and classification.
Reference [15] offers a prototype concept of an electronic stethoscope system that can detect and identify aberrant cardiac sounds in real-time. This system comprises of two modules: a portable stethoscope and a decision-making part that connects wirelessly utilizing Bluetooth technology. The portable subsystem records the patient’s phonocardiography signals, filters and digitizes them, and delivers them wirelessly to a personal computer for visualization and additional processing to determine if the heartbeats are normal or abnormal. They claim that a cost-adjusted optimal ensemble method can diagnose normal and abnormal heartbeats with 88 percent and 97 percent accuracy, respectively.
A stethoscope described in [16] distinguishes between normal and abnormal PCG signals in four different types of heart valve disease. The system developed on a personnel computer and portable hardware platforms. A portable heart valve disease screening device with an electronic stethoscope as the input is made using a multimedia board with a single board computer, audio codec, and graphic LCD. Both systems have a 96.3 percent specificity rating. However, the portable device’s sensitivity and accuracy are only 77.78 percent and 87.04 percent, respectively, compared to the PC platform’s sensitivity and accuracy of more than 90 percent.
Varghees et al. [17] offer a unified PCG signal delineation and murmur classification approach for automated detection and classification of heart sounds and murmurs that do not need the usage of a reference signal. The authors use empirical decomposition of the PCG signal based on the wavelet transform, Shannon entropy envelope extraction, heart sound, and murmur parameter extraction to identifying heart murmurs. For cardiac sound segmentation, the suggested technique obtains an average sensitivity of 94.38 percent, positive predictivity of 97.25 percent, and prediction accuracy of 91.92 percent.
To boost the loudness of the input PCG received by the stethoscope, [18] uses an acoustic stethoscope, microphone, and preamplifier module. To identify aberrant cardiac sounds, the authors employ the harmonic distribution of Amplitude and Phase. Babu et al. [19] suggest using SVM and KNN algorithms to identify and classify systolic and diastolic patterns in phonocardiograms.
There are some researches that apply deep learning and deep neural networks in heartbeat abnormality detection [19–23]. Despite the high accuracy, deep learning architectures are limited with the decision-making time, since the electronic stethoscope must make a decision promptly.
3 Characteristics of Heart Sounds
The heart sounds S1 and S2 are high-frequency sounds and are clearly audible from the diaphragm of the stethoscope. S1 of normal heart changes between 50 to 60 Hz, and normal S2 changes between 80 to 90 Hz [24]. S3 is a pre-diastolic low signal that has bandwidth limit about 20–30 Hz. S4 is also low signal that takes place at the end of diastole and is well characterized by a stethoscope. The abnormal S4 has a frequency of less than 20 Hz [24].
Although they are audible, S1 and S2 have their amplitude varying and sometimes becoming very faint and not audible because of anomalies. S1 and S2 do not have fixed frequencies, but are in different frequency ranges at different heart periods. Such limitations of heart sound segmentation have led researchers to develop a very specific approach [24].
Fig. 1 lists the full categories and functions of the HSs. There is one or two HSs correlated with each heart condition. Any miscellaneous heart sounds create a noisy high-pitched sound after a first high-pitched sound tricuspid stenosis (TS). The most popular early systolic sound that arises from irregular sudden stopping of the semilunar cusps when they open during early systole is the ejection sound (ES). The mid-systolic click (MSC) is a mid-systole HF signal that comes from the sudden stopping of the excursion of prolapsing mitral valve leaflets into the atrium by chordae [25].
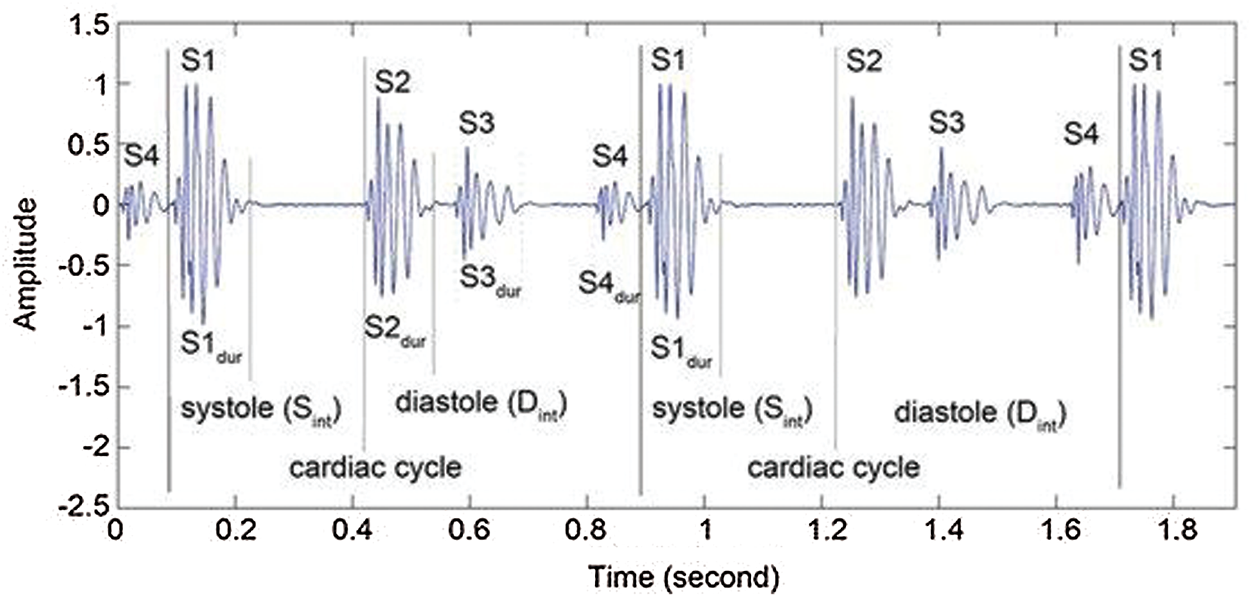
Figure 1: Heart sounds
The doctors are involved in irregular heart sounds and may offer valuable details for diagnosis.
4 Electronic Stethoscope Structure
Fig. 2 illustrates a scheme of the proposed stethoscopic system using machine-learning techniques. The phonocardiographic signals are acquired by the stethoscope, which then amplifies and filters it using analogue front end before digitizing and transmitting the raw data to the decision-making subsystem. The analogue front end must have a high signal-to-noise ratio, good commonmode rejection, and little baseline drift and saturation. The pre-amplifier circuit amplifies the extremely weak cardiac sound signals captured by a microphone to the appropriate level.

Figure 2: Block-diagram of the system
For the computer based cardiac disorder monitoring device utilizing electronic stethoscope, there are three major modules, such as data collection module, pre-processing module and signal processing module (Fig. 3). The electronic stethoscope monitors the HS, and the pre-processing module transforms it into digital signals. In the pre-processing node, the noise-reduced and less interfering full-frame HS signal is normalized and segmented. Function extraction and classification is performed by the signal processing tools. This framework offers outputs of clinical diagnostic decision making. A comprehensive overview of the three the three key sections, sub-parts, etc. of the module is given.
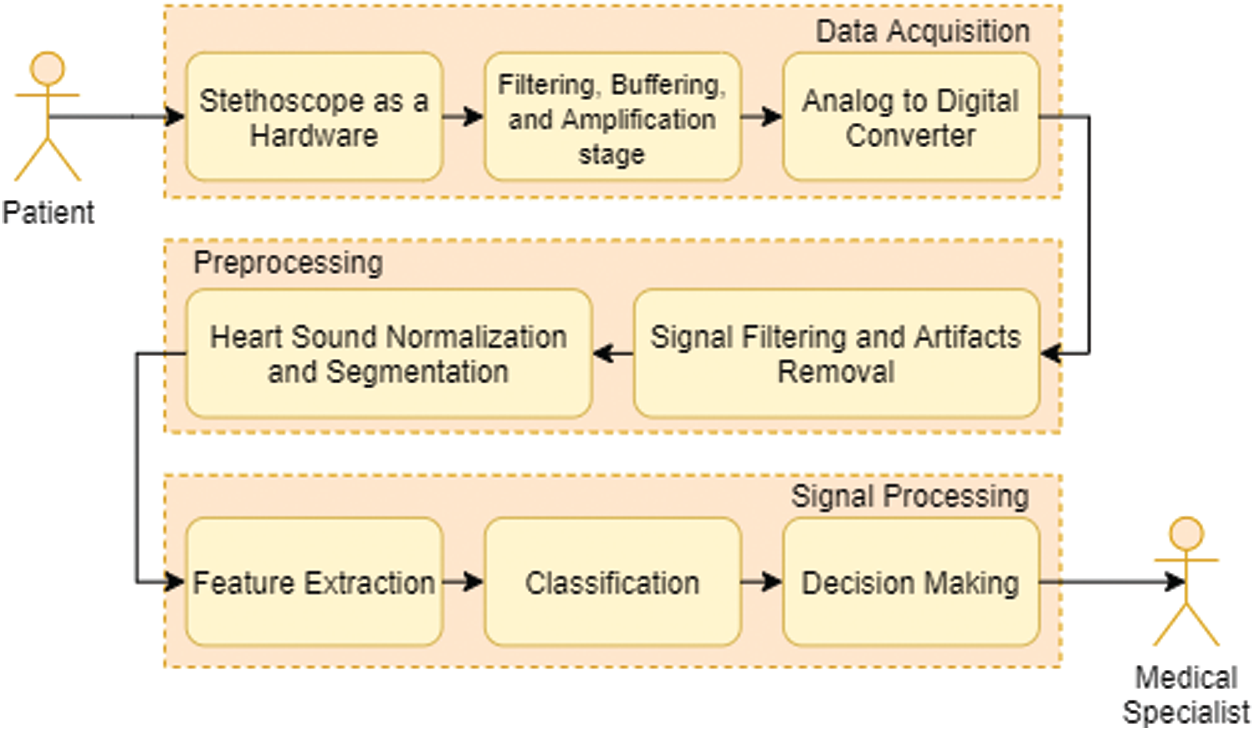
Figure 3: Typical flow chart for heart sound signal acquisition, processing and analysis
4.1 Heart Sound Data Acquisition Module
The heart sound acquisition phase produces the automated heart sound data to use as a base for more processing.
Electronic Stethoscope Sensor. The cardiac tones are taken using a digital stethoscope from patients (Fig. 4). In the stethoscope, certain people might use an automated sound device, piezoelectric disk or wind suction. The electrical signals produced by the heart are transformed to a sound by the system.

Figure 4: Electronic sensor stethoscope
Amplifier and Filter. Amplification and filtering systems are essential in all types of communications systems. To decrease the noise interference from power lines, a low pass filter is used. Next, to minimize aliasing, a smoothing filter is used. The filtering device is designed as a low-pass filter in certain system architectures that has the frequency range of most high-speed heart sound signals. It prevents aliasing by using band-pass filtering for passband selection. After amplification, an analog to digital conversion further digitally collects the signal.
Analog-to-digital Converter. The analog signal is translated into a digital format by the converter. These can be selected in advance by the device manufacturer. Higher bit rate and sample speeds would provide better levels of accuracy using less bandwidth and less power usage.
4.2 Information Collection Module
The digital heart-sound signal is decreased, standardized and segmented in this phase.
Signal Denoising Unit. Often, a digital filter is used to separate from the noisy data the signal inside the frequency range of interest. Some sophisticated reduction methods are used in general, such that the performance signal-to-noise ratio (SNR) can be more increased, to provide the device with even stronger denoising.
Normalization and Segmentation. Different sampling and processing sites usually result in a signal variance in data acquisition. The heart sound signals are then normalized to a certain dimension, such that data collection positions and multiple samples do not influence the predicted amplitude of the signal. The heart sound signals are segmented into cycles after the normalized signals are obtained, which are ready for identification of heart sound components and extraction of functionality.
4.3 Heart Sound Signal Processing Module
In this step, the extraction and classification of features are performed.
Feature Extraction. Signal processing requires the translation of analog data into digital format. This kind of parametric representation is derived and used for further study and production.
Classification. Once the collected features are inserted into a classifier, it can be used as a method to identify the data and support the medical professional for diagnosis and care plans.
The centers of the processor cores (shown in Fig. 4) are the central units of a device capable of processing digitized signal and processing the signal. Based on exhaustive studies, we noted that the thesis concentrated primarily on three stages for the automated detection of different cardiac pathological conditions and heart sound signal diseases: (1) HS process of acquisition and sensor design (2) denoising and segmentation of heart sound signals, and (3) sufficient extraction of feature and automatic analysis of HS.
5 Applying Machine Learning for Heart Sound Classification
In the analysis of the rhythms, limits, duration and information of the strength of the heart tones, the database is an obligatory prerequisite. We collected data and created a dataset utilizing samples from all its patients with heart failure, especially those in the cardiologist department of cardiology center in Almaty. An electronic stethoscope was used to pick up the requisite biothermography measurements of heart tones. For one subject, five samples were taken from the heart apex regions with a needle, (Fig. 5).
Figure 5: Working principle of the smart stethoscope
It is important to have the consistency of the database to train the model. Therefore, only the heart tones of patients that have already been confirmed with heart diseases have been registered.
5.1 Detection of Special Characteristics
Function identification is used to illustrate the heart tone’s signature characteristics, enabling you to distinguish sounds and added heart tones. In Python, which was used to introduce signal processing operations, the feature extraction algorithm was developed. To achieve the best possible precision, the function detection algorithm uses 8 steps and has the potential to accumulate an appropriate number of properties from a single heart sound, since they can represent each patient independently during the optimum processing period. The feature detector algorithm uses the amount of resolutions and thresholds obtained statically to conduct cardiac sound analysis.
Methods for defining the key components of cardiac sound (first cardiac signal (S1) and second heart sound tone (S2)) and measuring the limits of S1, S2, systole and diastole are available in most literature references (Fig. 6).
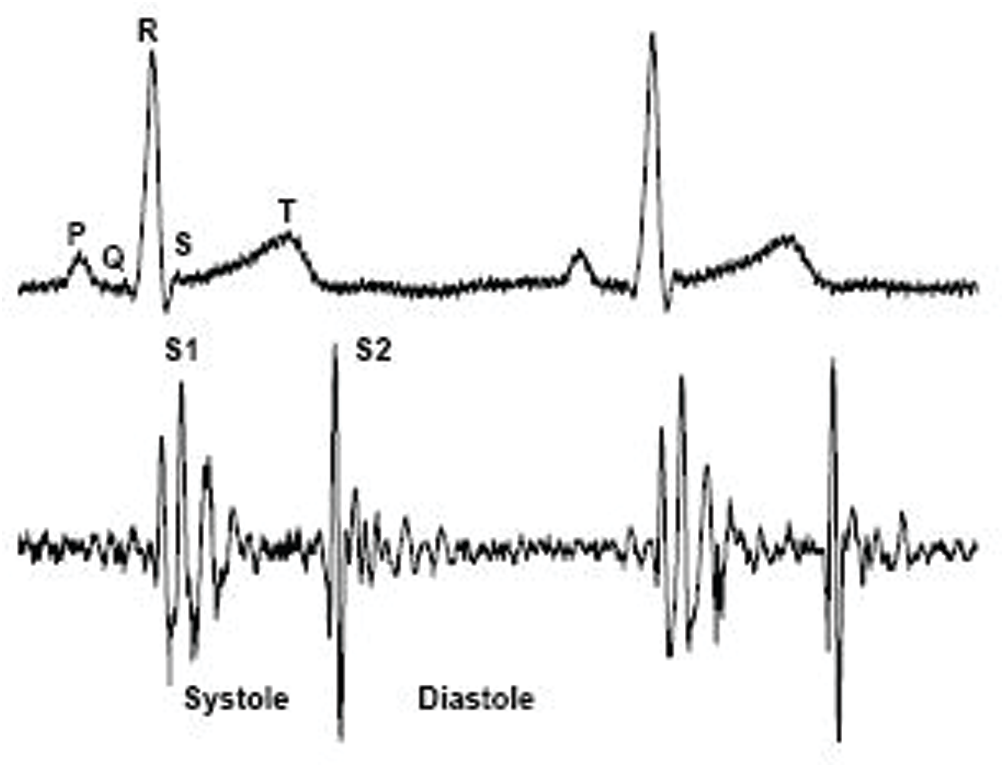
Figure 6: Key components of cardiac sound [26]
Step 1: A standardized root-mean-square curve lasting 10 s is obtained. Since heart sounds are non-stationary, to avoid missing special characteristics that are irregularly distributed over abnormal heart tones, 10-s-long signals have been extracted from the original recorded sound. To increase the illumination of the S1 and S2 peaks by reducing noise interference, uniform RMS energy curves of the above obtained waves were then achieved.
Step 2: Find the elevated peak. Finding strong peaks between the S1 and S2 tones. The resolution of the parameters was used to determine the peaks, and if the distances between the peaks identified were not within a sufficient range, the process of assessing high peaks would be performed over and over again, changing the resolution to obtain an appropriate amount of continuous peaks. The premise behind this repeated algorithm [27] is that every heart tone’s frequency will differ from person to person. The required resolution for each heart tone is then related to the patient’s accompanying heart rhythm. As a consequence, before an exact match is identified, each heart signal must loop through different resolutions.
Step 3: The Maximum Peak Segmentation. Next, all zero wave crossings for the measured threshold were analyzed and the approximate peaks for the highest boundary were plotted. Then, after the verification phase, the whole process was restored to identify a high peak with a different resolution if the amount of correctly segmented peaks was not at an acceptable stage.
Step 4: The shortest peak is described. Waves were collected between correctly segmented, continuous high-peak thresholds, and the maximum point in the period was taken as the short peak of importance. The test then calculated the distances between the short peaks described and the high peaks correlated with them and checked for acceptable standard deviations. Otherwise, the short peak, the highest deviation of which is the direction, was substituted by the peak, which has the lowest deviation impact at the same interval. The maximum continuous short peaks are achieved following the same approach, and if the number is not sufficient, the whole process returns to the measurement of high peaks [28].
Step 5: Segmentation of short peaks. For the assumed threshold, zero intersections of the extracted waves were measured between the boundaries of the high peaks. Afterwards, they were contrasted to the short peaks measured. There, the segmentation of the short peaks will be repeated by changing the threshold if the limits of the short peaks were incorrectly calculated, even if there was some overlap.
Step 6: Final time-frame estimation and final verification. Ultimately, both of the above results were used in multiple arrays to calculate the distribution of peak values from high to low and peak values from short to high. To ensure high accuracy, any peak or period that caused overlap or inappropriate variance was excluded when checked. Even if the amount of peaks or intervals recorded is not sufficient, the protocol for classifying high peaks has been reinstated, but in either case, the mechanism has been broken by adopting all the specified high-pitch detection resolutions to guarantee 100% precision of the results. This termination occurs only in cardiac tones that are highly disturbed by noise.
Step 7: S1, S2, the systolic and diastolic groups. All sections and intervals collected have been classified as S1, S2, systole, and diastole in compliance with the finding that the systolic length is shorter than the diastolic time for heart tones.
Step 8: Functions extract. Only samples which passed final verification were followed by extracted features.
5.2 Information Collection Module
A statistical analysis was conducted to classify trends that vary depending on diseases, based on the characteristic features obtained using the algorithm, and using certain derived features, such as the square of the fourth wavelet information coefficient. For each systole and diastole separately, the square of the fourth wavelet information coefficient was computed. For each form of disorder, a range of this value with a trust level of 87 percent was obtained.
5.3 Applying Machine Learning for Abnormal Heartbeat Detection
Fig. 7 demonstrates the collection of the classification model with the signal pre-processing work flowchart and the implementation of the machine learning methods. The heart sound data from the collection was segmented into datasets for a model training and testing. Using Python, signal pre-processing and automated segmentation were performed, and the statistics and machine learning model training and classification of heart tone were performed. The heart sound pre-processing measures are summarized in the review portion. The segmented cardiac sound data derived multiple time (t)-domain, frequency (f)-domain, and Mel frequency cepstral coefficients (MFCC) characteristics. Before it was fed into the machine learning model for testing, the training dataset underwent preprocessing measures.
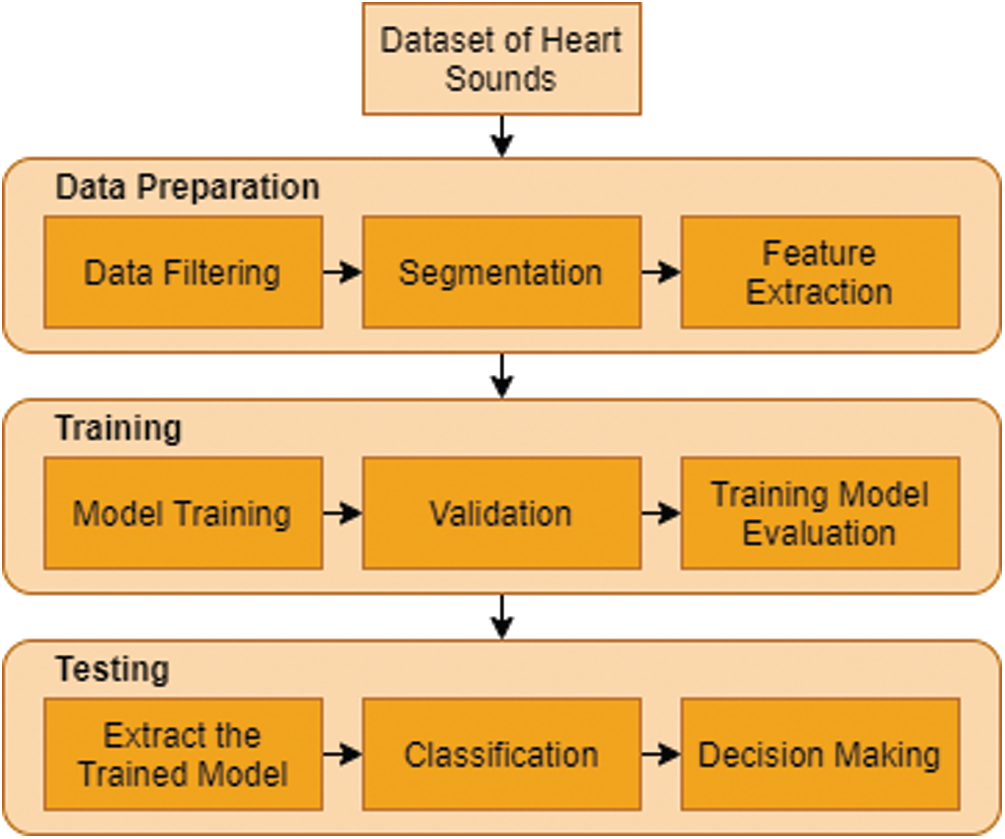
Figure 7: Machine learning-based heart tone abnormality detection mechanism flow map
For classification purpose, we applied k-nearest neighbor classifier. In the study, we used number of neighbours and distance as a hyperparameters. We continue to recognize heart sounds after analyzing and removing the noises in the signals. The findings were issued after detecting regular and irregular heart sounds in Tabs. 1 and 2. We split the dataset into two sections, as we mentioned earlier, with 200 irregular to 200 regular heart sounds. In conjunction, 80 percent to 20 percent of the training and testing data are broken.


The dataset is separated into a dataset for testing and a validation dataset. In order to minimize the error, the former trains the machine learning model with samples that have instructor principles. The above checks the network on examples that it has not “seen,” showing that on fresh evidence the model should be utilized. The instruction collection contains 48 impulse responses and the evaluation set includes 46 for the original pilot analysis of 12 patients.
The heart sound data was buffered for 10 s for real-time execution and then the baseline drift was corrected, segmented into heart sound beats and Python 3.5 band-limited filtering. In order to obtain, buffer, real-time pre-process, and identify the heart sound data on the host machine, a multi-threaded python script was written. Using Numpy, scikit-learn, and Matplotlib libraries, signal pre-processing and segmentation were implemented on a PC. For real-time classification using PyBrain and Scikit learn libraries, the best-performing algorithm was then implemented on the PC.
6 Experiment Results and Analysis
6.1 Hardware and Software User Interface
Smartphones will encourage regular work for health care through the exponential growth of mobile technologies. Applications involve the usage of mobile devices to capture clinical data, supply physicians, researchers and patients with diagnostic records, track the vital signs of patients in real time, and provide direct medical services.
Using the smallest components: a stethoscope, a smartphone application and a portable device, the device is constructed as simply as possible. In order to produce sound, an electronic microphone is placed into the stethoscope vent. To minimize the noise factor, the hose is blocked at all other ends, except the reception section. Fig. 8 demonstrates components of the proposed stethoscope.

Figure 8: Components of the proposed stethoscope (a) Components (b) Stethoscope as a device
After receiving the pulse sounds via the stethoscope, Fig. 9 demonstrates the cardiac anomalies identification mechanism using a smartphone. The proposed stethoscope that analyses the sound obtained from the stethoscope is the first. A qualified algorithm that analyzes extraneous noise is the second. The third is the method of classification. Moreover, the possible diagnosis is indicated by the performance.
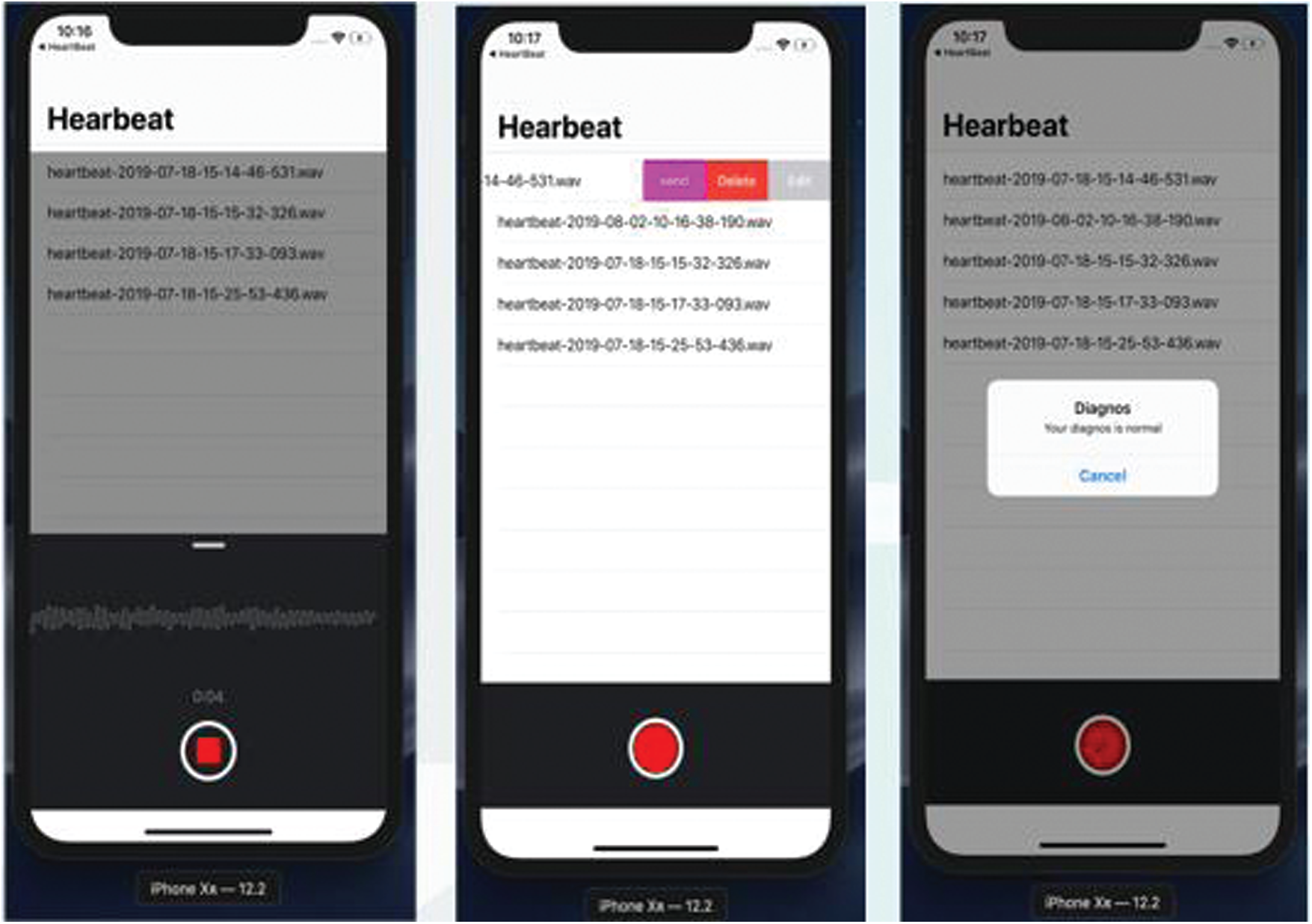
Figure 9: Heartbeat abnormality detection
The signal power spectral in Fig. 10 indicates that for regular and pathological phonocardiogram, the power spectral density peaks occur at various frequencies. In comparison, the higher frequency power spectral density has no peak for the typical phonocardiogram, whereas this is not the case for pathological PCG signals, and from 300 to 600 Hz there are several peaks. This reflects that in classifying the phocardiography signals, the simple frequency domain function can aid greatly. More t-domain, f-domain, and Mel frequency cepstral coefficients (MFCC) however offer visibility into the signal when compensating for the artifacts of noise or motion. In addition, it has been shown in the literature that the features of the MFCC will greatly lead to the classification of sound waves.
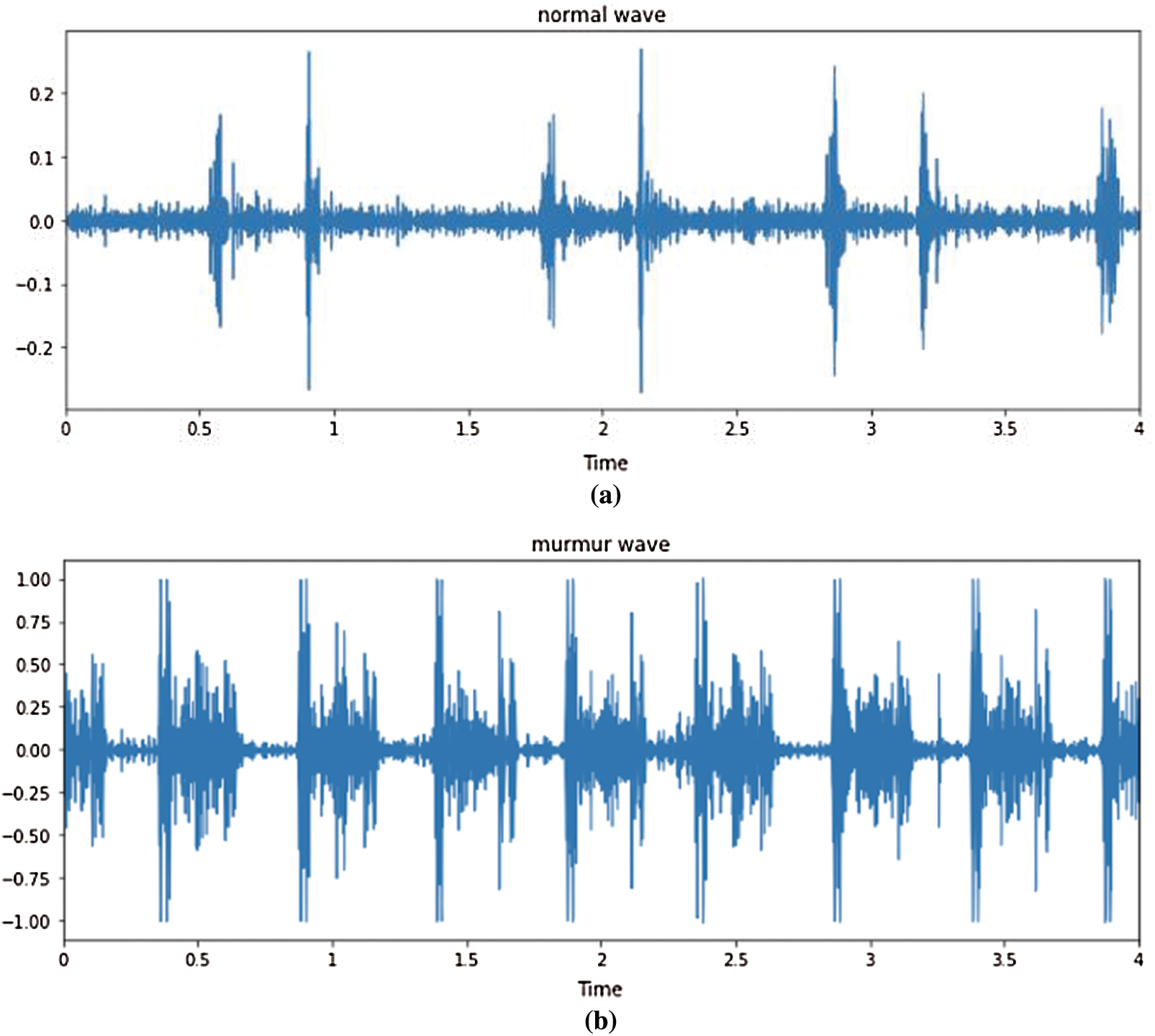
Figure 10: Time domain PCG trace and its power spectral density for normal and abnormal heart rate (a) Normal heart rate (b) Abnormal heart rate
In evaluation, the priority is on identifying as many cases as possible from a community for a screening procedure, and so false negatives ought to be minimized, at the risk of rising false positives. Therefore, it is important to determine three major parameters: true positive rate (TPR), false positive rate (FP) and accuracy (ACC). The first parameter in medical terminology is represented as sensitivity (SEN), specified as:
where the number of true negatives is TP, and the number of true positive instances is P.
The estimation of the second term, false positive rate, is:
The percentage of false positives is FP, and the cumulative number of negative events in the population is N. This statistic, however, is best interpreted as the ratio of true negative to actual negative, represented as the specificity (SPEC) in medical terms, which is specified as:
where the number of true negative cases is TN, and the cumulative number of true negative cases is N.
Finally, the equilibrium between true positives and true negatives is defined by precision. Where the number of positive and negative cases is not equivalent, this can be a very beneficial statistic. This is articulated as:
where the definitions follow as before.
Finally, to measure the efficiency of the algorithm and to be used as a way to record the maximum sensitivity and minimum FPR together, a ratio between the FPR and TPR was developed.
Criteria is set to determine the efficiency of the algorithm and the current state of the ANN is preserved until they are met (i.e., weights, bias and training time). These will refer to each run of the training of the algorithm. The three conditions are:
• Where the ratio of false positives to true positives exceeds a minimum of (initiated when it falls below 0.7).
• Until full specificity is met.
• When the training error has sunk below a point.
The first criteria is to establish that the procedure can be used to reliably diagnose OP cases as a screening method. The second is to analyze whether the strategy is capable of separating the healthy subjects well enough and reducing the false negatives and positives. The third is the algorithm’s stop criterion, which would mean that overfitting is starting to happen.
Fig. 11 illustrates different types of heartbeats. Normal: healthy heart sounds; Murmur: extra noises that arise while there is a vibration in the blood supply that creates extra vibrations that can be heard; Extrahls: supplementary sound; Artifacts: there is a broad variety of various sounds.
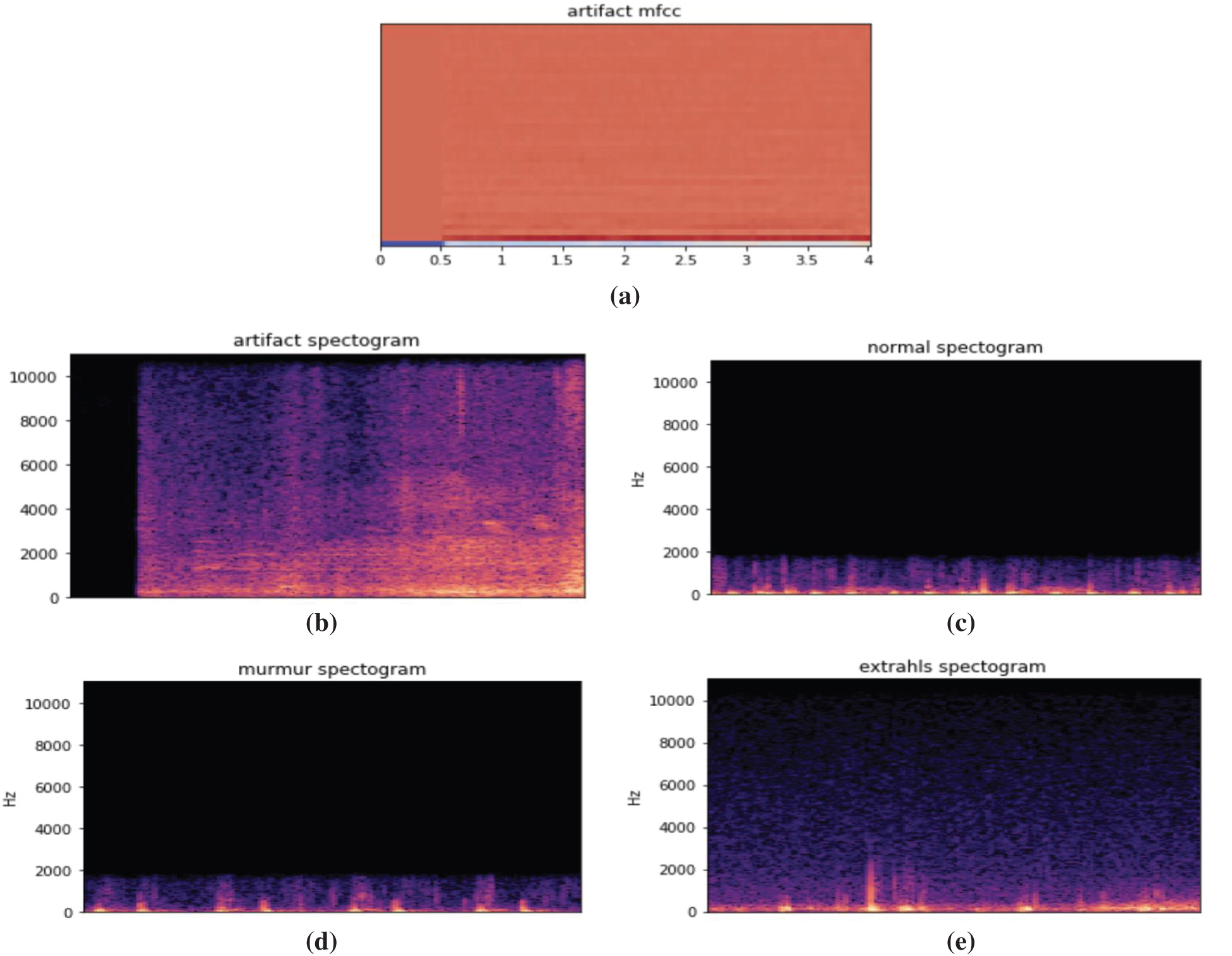
Figure 11: Time domain PCG trace and its power spectral density for different types of heart sounds. (a) Artificial mfcc (b) Artificial spectrogram (c) Normal spectrogram (d) Murmur spectrogram (e) Extrahls spectogram
Fig. 12 demonstrates model training and validation for abnormal heart rate detection. The figure shows the training and validation accuracy results up to 300 epochs. Fig. 13 demonstrates training loss and validation loss results during the training epochs. After about 100 epochs training and validation loss show steady state.
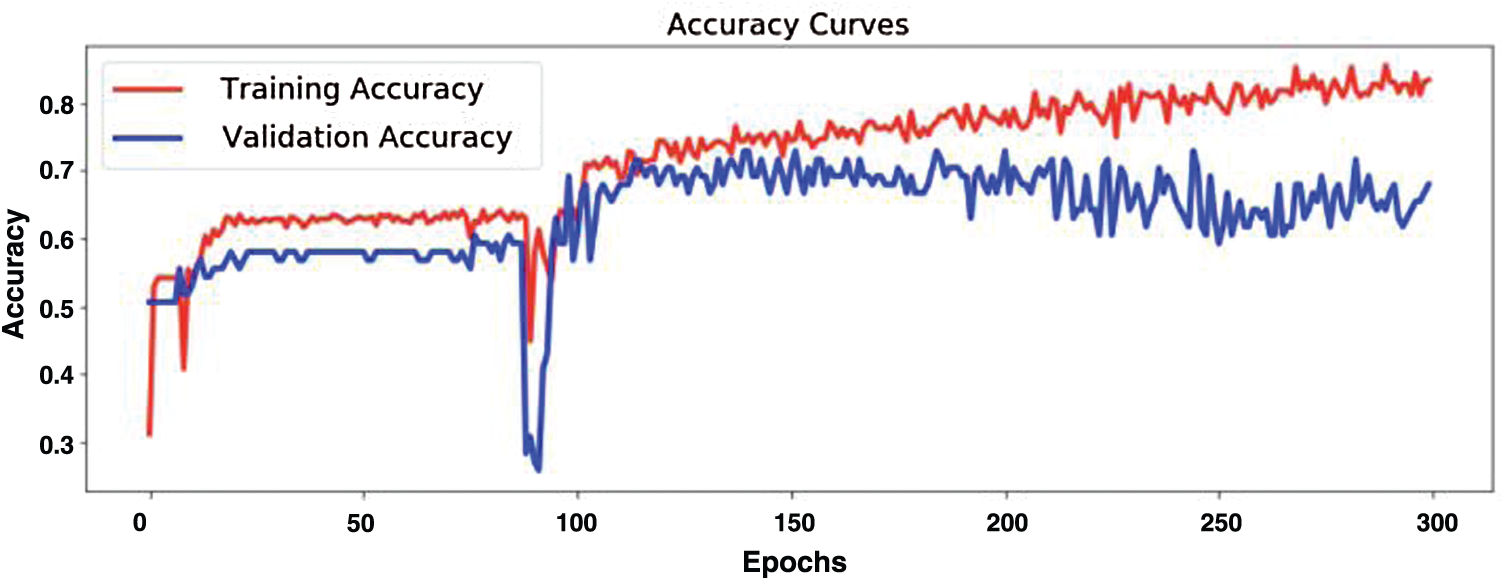
Figure 12: Model training and validation for abnormal heartbeat detection
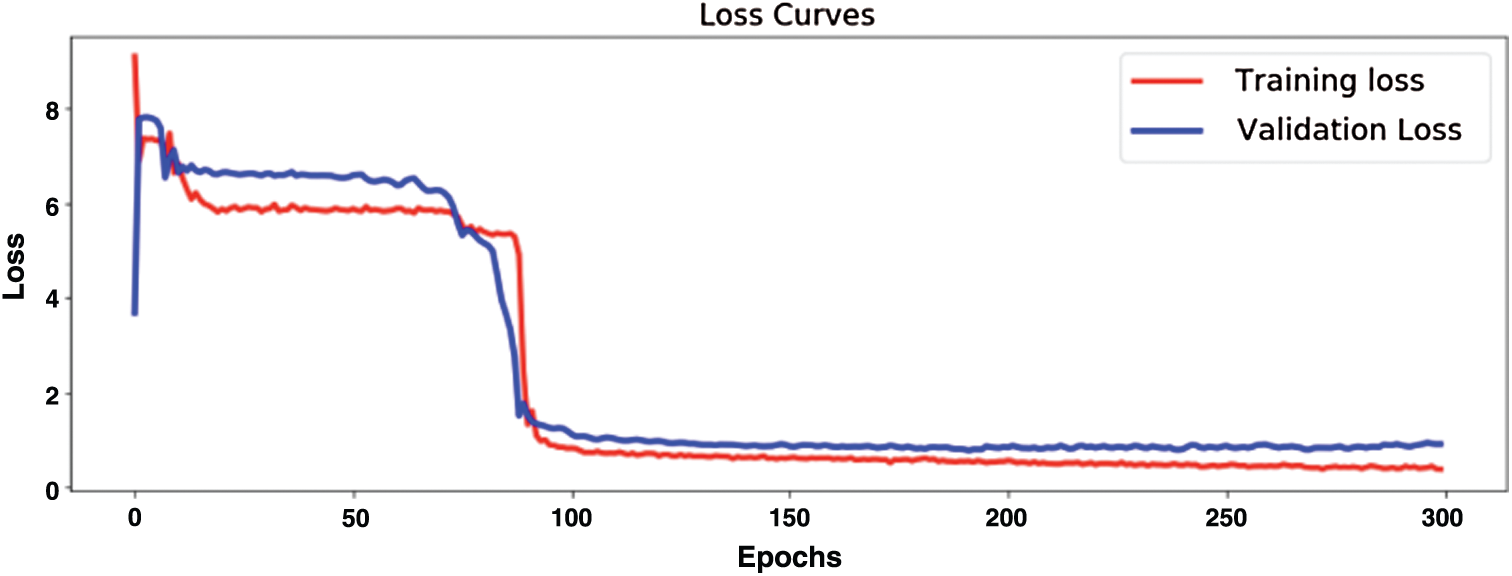
Figure 13: Evaluation of model training loss and validation loss
Fig. 14 shows confusion matrix when detecting five types of heartbeat condition as normal heartbeat, murmur, extrasystole, extrahls, and artifacts. The results show high accuracy in heartbeat sounds classification and abnormal heartbeat detection.
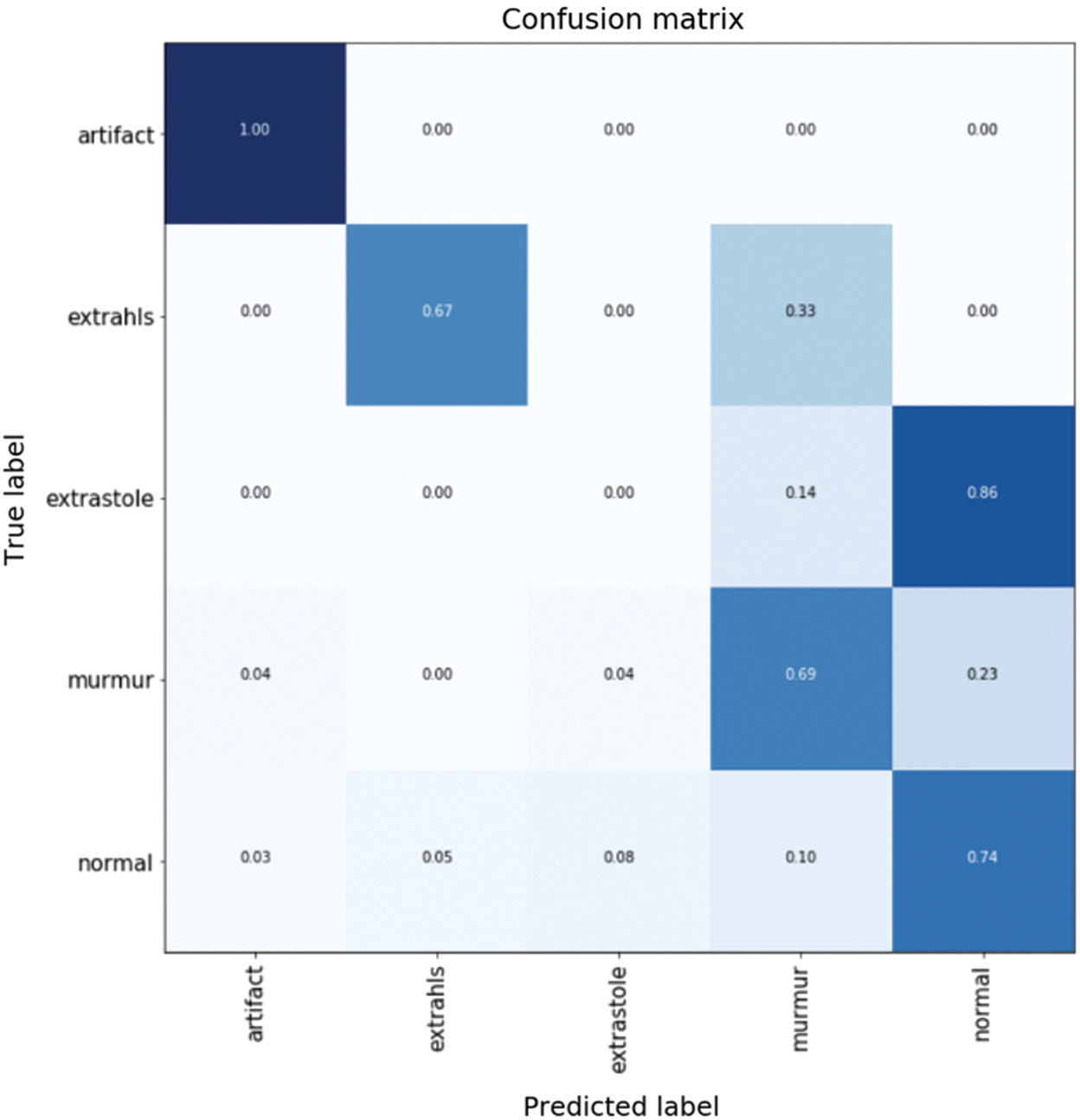
Figure 14: Confusion matrix for different types of heart sound classification
Tabs. 1 and 2 demonstrate classification result of normal and abnormal heart sounds. As shown in the tables, our model can detect abnormal heartbeats with 93.25% accuracy in testing.
The present invention relates to a method and device for determining the frequency ranges of cardiac noise for the classification of pathological heart murmurs. Having a large database of verified phonocardiosignals with known pathologies of cardiac activity classified by other methods, it is possible to identify similar signs in the signals of patients with identical diseases, create templates of signal sections corresponding to the disease, and add them to the general comparative template.
In order to diagnose cardiac pathology, the paper provides a paradigm for identifying abnormal trends in phonocardiograms. The study of audio signals is primarily concerned with issues such as signal weakness, limited band bandwidth, noise contamination, randomness, the need to isolate the mixed signals into a single signal, etc. Heart tones are often subject to the law as complicated signals. Based on sound perception, heart valve vibrations, the loading and emptying of ventricles and lungs, and the distortion between these sounds and a small frequency spectrum render it impossible to diagnose heart-related complications.
The availability of accurate signs, such as ECGs, has, on the other hand, prompted experts to focus on them for heart disease diagnosis. Although the PCG signal can be used to diagnose multiple inappropriate disorders and cardiac arrest functions in an inexpensive and simple way as an independent tool. In recent years, while there have been many algorithms for identifying heart sounds, owing to the existence of audio signals, each of them has several barriers.
We must also have a system for segmenting and detecting heart sounds as clinically relevant fragments and defining their correspondence to heart cycles in order to be able to use the phonocardiogram signal as a diagnostic device in the area of heart disease. When the signal is used separately as a diagnostic tool, the importance of this algorithm and method improves, instead of only influencing the ECG signal. Of course, because the complementary technique is used together, it is often appropriate to use one of these approaches.
A computerized phonocardiogram, as a non-invasive acoustic system for detecting heart abnormalities, is a useful method for doctors and for patients too. It can also open up opportunities for checking the heart condition of patients through teleconsultation. It should be noted that, although a digital phonocardiogram alone cannot provide all the information necessary, for example, to make a decision about the feasibility of heart surgery, it can significantly reduce the unnecessary use of echocardiography, which is a more expensive and time-consuming method. In addition, early diagnosis of heart abnormalities in patients can eliminate the need for further surgical operations, if appropriate medical procedures are used.
In this study, we present an electronic stethoscope that receives heart sounds from a patient, processes them, classifies them using machine learning techniques, and as a result, diagnoses the patient in real time, showing whether a patient has a pathology in the heart or not. The proposed full functional stethoscope system includes three subsystem as portable digital electronic stethoscope, decision-making system that applied machine learning to classify heart sounds, and subsystem for visualizing and displaying the results in an understandable form. Next main difference of the proposed system from the other researches is its ability to identify abnormal heart sounds a short period of time with high accuracy. The proposed stethoscope can detect abnormal heartbeat in 15 s. In addition, the proposed stethoscope system does not transmit server info, because anything on your phone is saved. It is necessary to supply the doctor with audio recordings without complications. Accuracy has hit 93.5% in normal heartbeat detection, and 93.25% in abnormal heartbeat detection. Thus, the solution of the problem of classification of phonocardiograms using machine learning methods is currently possible and provides high efficiency.
In conclusion, we would like to conclude that it is very simple and realistic for such technology. We can enhance the precision of the stethoscope in the future to raise the amount of cardiac disorders that an intelligent stethoscope will detect.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. M. E. Chowdhury, A. Khandakar, K. Alzoubi, S. Mansoor, A. Tahir et al., “Real-time smart-digital stethoscope system for heart diseases monitoring,” Sensors, vol. 19, no. 12, pp. 2781, 2019. [Google Scholar]
2. M. Elhilali and J. E. West, “The stethoscope gets smart: Engineers from Johns Hopkins are giving the humble stethoscope an AI upgrade,” IEEE Spectrum, vol. 56, no. 2, pp. 36–41, 2019. [Google Scholar]
3. M. N. Türker, Y. C. Çağan, B. Yildirim, M. Demirel, A. Ozmen et al., “Smart Stethoscope,” in 2020 Medical Technologies Congress, Izmir, Turkey, pp. 1–4, 2020. [Google Scholar]
4. Y. J. Lin, C. W. Chuang, C. Y. Yen, S. H. Huang, P. W. Huang et al., “An intelligent stethoscope with ECG and heart sound synchronous display,” in 2019 IEEE Int. Symp. on Circuits and Systems, Sapporo, Japan, pp. 1–4, 2019. [Google Scholar]
5. B. Omarov, A. Batyrbekov, A. Suliman, B. Omarov, Y. Sabdenbekov et al., “Electronic stethoscope for detecting heart abnormalities in athletes,” in 2020 21st Int. Arab Conf. on Information Technology, Giza, Egypt, pp. 1–5, 2020. [Google Scholar]
6. V. T. Tran and W. H. Tsai, “Stethoscope-sensed speech and breath-sounds for person identification with sparse training data,” IEEE Sensors Journal, vol. 20, no. 2, pp. 848–859, 2019. [Google Scholar]
7. A. A. Shkel and E. S. Kim, “Continuous health monitoring with resonant-microphone-array-based wearable stethoscope,” IEEE Sensors Journal, vol. 19, no. 12, pp. 4629–4638, 2019. [Google Scholar]
8. H. Bello, B. Zhou and P. Lukowicz, “Facial muscle activity recognition with reconfigurable differential stethoscope-microphones,” Sensors, vol. 20, no. 17, pp. 4904, 2020. [Google Scholar]
9. Ş. Tekin, “Is big data the new stethoscope? Perils of digital phenotyping to address mental illness,” Philosophy & Technology, vol. 1, pp. 1–15, 2020. [Google Scholar]
10. K. A. Babu and B. Ramkumar, “Automatic detection and classification of systolic and diastolic profiles of PCG corrupted due to limitations of electronic stethoscope recording,” IEEE Sensors Journal, vol. 21, no. 4, pp. 5292–5302, 2020. [Google Scholar]
11. V. Arora, R. Leekha, R. Singh and I. Chana, “Heart sound classification using machine learning and phonocardiogram,” Modern Physics Letters B, vol. 33, no. 26, pp. 1950321, 2019. [Google Scholar]
12. S. Vernekar, S. Nair, D. Vijaysenan and R. Ranjan, “A novel approach for classification of normal/abnormal phonocardiogram recordings using temporal signal analysis and machine learning,” in 2016 Computing in Cardiology Conf., Vancouver, BC, Canada, pp. 1141–1144, 2016. [Google Scholar]
13. M. N. Homsi and P. Warrick, “Ensemble methods with outliers for phonocardiogram classification,” Physiological Measurement, vol. 38, no. 8, pp. 1631–1644, 2017. [Google Scholar]
14. G. Son and S. Kwon, “Classification of heart sound signal using multiple features,” Applied Sciences, vol. 8, no. 12, pp. 2344, 2018. [Google Scholar]
15. M. Chowdhury, A. Khandakar, K. Alzoubi, S. Mansoor, A. Tahir et al., “Real-time smart-digital stethoscope system for heart diseases monitoring,” Sensors, vol. 19, no. 12, pp. 2781, 2019. [Google Scholar]
16. M. Suboh, M. Yaakop, M. Ali, M. Mashor, A. Saad et al., “Portable heart valve disease screening device using electronic stethoscope,” Indonesian Journal of Electrical Engineering and Computer Science, vol. 15, no. 1, pp. 122–132, 2019. [Google Scholar]
17. V. Varghees and K. Ramachandran, “Effective heart sound segmentation and murmur classification using empirical wavelet transform and instantaneous phase for electronic stethoscope,” IEEE Sensors Journal, vol. 17, no. 12, pp. 3861–3872, 2017. [Google Scholar]
18. J. Roy, T. Roy and S. Mukhopadhyay, “Heart sound: Detection and analytical approach towards diseases, Smart Sensors,” Measurement and Instrumentation, vol. 29, no. 1, pp. 103–145, 2019. [Google Scholar]
19. K. Babu and B. Ramkumar, “Automatic detection and classification of systolic and diastolic profiles of PCG corrupted due to limitations of electronic stethoscope recording,” IEEE Sensors Journal, vol. 21, no. 4, pp. 5292–5302, 2021. [Google Scholar]
20. A. Alqudah, H. Alquran and I. Qasmieh, “Classification of heart sound short records using bispectrum analysis approach images and deep learning,” Network Modeling Analysis in Health Informatics and Bioinformatics, vol. 9, no. 1, pp. 1–16, 2020. [Google Scholar]
21. S. Singh, T. Meitei and S. Majumder, “Short PCG classification based on deep learning,” in Deep Learning Techniques for Biomedical and Health Informatics, Basingstoke, United Kingdom, pp. 141–164, 2020. [Google Scholar]
22. Y. Khalifa, J. Coyle and E. Sejdić, “Non-invasive identification of swallows via deep learning in high resolution cervical auscultation recordings,” Scientific Reports, vol. 10, no. 1, pp. 1–13, 2020. [Google Scholar]
23. H. Li, X. Wang, C. Liu, Q. Zeng, Y. Zheng et al., “A fusion framework based on multi-domain features and deep learning features of phonocardiogram for coronary artery disease detection,” Computers in Biology and Medicine, vol. 120, no. 25, pp. 103733, 2020. [Google Scholar]
24. F. D. L. Hedayioglu, “Heart sound segmentation for digital stethoscope integration,” Master’s Thesis. University of Porto, Porto, Portugal, 2011. [Google Scholar]
25. H. Li, G. Ren, X. Yu, D. Wang and S. Wu, “Discrimination of the diastolic murmurs in coronary heart disease and in valvular disease,” IEEE Access, vol. 8, pp. 160407–160413, 2020. [Google Scholar]
26. A. Yadav, A. Singh, M. K. Dutta and C. M. Travieso, “Machine learning-based classification of cardiac diseases from PCG recorded heart sounds,” Neural Computing and Applications, vol. 32, no. 24, pp. 1–14, 2019. [Google Scholar]
27. R. Banerjee, S. Biswas, S. Banerjee, A. D. Choudhury, T. Chattopadhyay et al., “Time-frequency analysis of phonocardiogram for classifying heart disease,” in 2016 Computing in Cardiology Conf., Vancouver, BC, Canada, pp. 573–576, 2016. [Google Scholar]
28. L. G. Durand and P. Pibarot, “Most recent advancements in digital signal processing of the phonocardiogram,” Critical ReviewsTM in Biomedical Engineering, vol. 45, no. 1–6, pp. 1–6, 2017. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |