DOI:10.32604/cmc.2022.020437
| Computers, Materials & Continua DOI:10.32604/cmc.2022.020437 | |
| Article |
Generating A New Shilling Attack for Recommendation Systems
1Department of Computer Science & Engineering, National Institute of Technology, Durgapur, India
2Graduate School, Duy Tan University, Da Nang, Vietnam
3Faculty of Information Technology, Duy Tan University, Da Nang, Vietnam
4Department of Computer Science, College of Computers and Information Technology, Taif University, Taif, 21944, Saudi Arabia
*Corresponding Author: Anand Nayyar. Email: anandnayyar@duytan.edu.vn
Received: 24 May 2021; Accepted: 27 June 2021
Abstract: A collaborative filtering-based recommendation system has been an integral part of e-commerce and e-servicing. To keep the recommendation systems reliable, authentic, and superior, the security of these systems is very crucial. Though the existing shilling attack detection methods in collaborative filtering are able to detect the standard attacks, in this paper, we prove that they fail to detect a new or unknown attack. We develop a new attack model, named Obscure attack, with unknown features and observed that it has been successful in biasing the overall top-N list of the target users as intended. The Obscure attack is able to push target items to the top-N list as well as remove the actual rated items from the list. Our proposed attack is more effective at a smaller number of k in top-k similar user as compared to other existing attacks. The effectivity of the proposed attack model is tested on the MovieLens dataset, where various classifiers like SVM, J48, random forest, and naïve Bayes are utilized.
Keywords: Shilling attack; recommendation system; collaborative filtering; top-N recommendation; biasing; shuffling; hit ratio
Recommendation systems are used by e-commerce companies to provide the best services to their customers by recommending items that they would like [1]. Appropriate recommendations have become a challenging task in the presence of overwhelmed data. In such a scenario, the recommendation systems employ a variety of filtering techniques to retrieve useful information from a huge amount of data. A recommendation system identifies a set of n specific items which are supposed to be the most appealing to the user and is termed as the top-N recommendation for that user [2–4]. Collaborative filtering is frequently used for recommending top-N items by considering the preferences of top-k similar users to the target user. User-based collaborative filtering techniques adopt similarity calculation to find the top-k similar users, and then the ratings given by these top-k similar users are utilized in the rating prediction for an unrated item [5]. In item-based collaborative filtering techniques, several item-based top-N recommendation algorithms are proposed, which utilize the rating information of users and similarity values between items [6]. The overall top-N list assures the most suitable products as it includes the best items across all the items in the system. However, the generated top-N lists by the predicted rating may be vulnerable in the presence of shilling attackers. A shilling attack involves inserting fake user profiles into a database to change the recommended top-N list of items [7]. The general objective of the attacker is to bias the overall top-N list as well as the top-N recommendation of a user.
1.1 Effects of Shilling Attacks in Collaborative Filtering Based Recommendation Systems
Attackers may change the list of the target users’ nearest neighbors. Since, in collaborative filtering based recommendation system, users get item recommendation that very much depends on their nearest neighbors. Therefore, if the neighbor list is changed by a shilling attack, the recommendation is also affected accordingly. Due to this, the non-desirable items may be recommended to the users, and the loyalty of the recommendation system may decrease significantly. To elaborate on the effect of shilling attacks in the recommendation system, let us consider the following two scenarios.
Scenario 1: Let us assume there are four users and their rating vectors for ten items are as shown in Tab. 1. Here, 0 denotes that a user did not rate the particular item, the sets of Authentic users = {


Scenario 2: Suppose we want to change the authentic item recommendation list of the target users. For example, let's say, from Tab. 3, the attackers aim to remove

1.2 Purpose of Developing a New Shilling Attack
From Tab. 2, it can be concluded that though the existing shilling attacks can change the target users’ nearest neighbors to some extent they are not successful in every case. Here, the Obfuscated attack, proposed by Chad et al. [8], seems to have the best performance, though not optimal. Similarly, from Tabs. 2 and 3, we can note that all other shilling attacks achieve the target to some extent, except Segment attack, but no attacks fulfill all the targets in the computed scenario. This opens up the scope for a new attack which can disrupt the list of nearest neighbors of any target user to the intended extent.
1.3 Implications of a New Shilling Attack
Attacking a system is not always ill-purposed. Attacks may be generated to test and make the system more robust and attack-proof. The positive implications and take away of a shilling attack on a recommendation system include:
• Although there are numerous works in the field of collaborative filtering based recommendation systems to detect shilling attacks, existing feature-based detection schemes may fail in the case of unknown attacks. An authorized person can use a new attack model as ethical hacking to reveal vulnerabilities in the collaborative filtering based recommendation system.
• A new shilling attack model may suggest how to protect the recommendation system, what are the attack entry points, and what can be done to improve the performance of the recommendation system from this type of attack.
• If a suitable item that meets the quality of Top-N recommended items is initially poorly rated or not rated at all by the users, then over time, it would eventually be removed from the recommended list. In this case, good or niche products may invisible to the consumers as they have never been reviewed or did not get a chance to get into the Top-N list for recommendation. A new shilling attack model may be used to mitigate the aforesaid condition, i.e., a long-tail problem.
Therefore, despite the fact that the term “attack” often refers to a negative operation, a new shilling attack can be used to increase the consistency and quality of the recommendation systems.
1.4 Contribution of This Paper
In this paper, we generate a new attack model with unknown features and prove the failure of the known feature-based detection techniques in identifying them. The major contributions of this paper are as below:
• Design and generate a new shilling attack for recommender systems.
• Compare the biasing, shuffling, and hit ratio of different attacks on the top-N list to find the attack size.
• Apply feature-based attack detection schemes to the known and proposed attacks on the calculated attack size and compare the results.
The requisite theoretical backgrounds that include the basic terms related to shilling attacks, attributes/features of attackers, and the metrics for assessing the effectiveness of shilling attacks, are discussed in Section 2. Section 3 includes the related work. Section 4 represents the proposed attack model with its validation. In Section 5, an experimental analysis of the effect of the proposed attack on the recommendation system is discussed. And finally, the conclusion and future work is presented in Section 6.
The basic structure of the collaborative filtering based recommendation system is depicted in Fig. 1. Data Collection, rating prediction using computed similarity, and top-N recommendation are the key components of this framework [9].

Figure 1: Conceptual framework of collaborative filtering
2.1 Basic Terms Related to Shilling Attacks
An attack is launched by creating a number of fake profiles. Based on the intent, an attack could either be a push or a nuke [10]. The target items are accordingly rated higher or lower than their average rating in order to have a strong impact on the weighted sum [11]. The target item is usually assigned the highest (for a push attack) or the lowest rating (for a nuke attack). The attackers must mimic the behavior of the authentic users to look normal and become the nearest neighbors of the target users. The attacker's profiles have to be designed in such a way that meets the above-mentioned requirements.
2.1.1 Components of an Attacker's Profile
Every attacker's profile is comprised of the following four parts [12]:
Target items (
Selected items (
Filler items (
Unrated items (
2.1.2 Standard Shilling Attacks
Different attack models exist due to the differences in the rating functions and selection of
Random attack:
Average attack: In the average attack
Bandwagon attack:
Segment attack:
The attack profiles are usually created based on the standard attack models and hence tend to show some kind of similarity between them. Many researchers have already mentioned that it is impossible for an attacker to have complete knowledge of the rating database.
Consequently, the attack profiles will differ statistically from those of genuine users. These differences and similarities can be expressed in terms of the attributes/features. Several attributes prevalent in the user profiles have been derived. The most common attack features generally used for detection are Rating Deviation from Mean Agreement (RDMA) [10], Weighted Deviation from Mean Agreement (WDMA) [18], Weighted Deviation from Agreement (WDA) [18], Length Variance (LENVAR) [19], Degree of Similarity (DEGSIM) [18], Filler Mean Target Difference (FMTD) [18], Filler Mean Difference (FMD), Mean-Variance (MEANVAR) [18], and Target Model Focus (TMF) [18]. These attributes tend to show different patterns in the case of genuine users and attackers. Thus, they have been successfully utilized in identifying whether a profile belongs to an authentic user or an attacker. Tab. 4 represents the notations used in the equations of the attribute that can be categorized into generic attributes and model-specific attributes, as shown in Tab. 5.


2.3 Metrics Used to Check the Effectiveness of Shilling Attacks on Top-N Recommendations
Typically, three parameters are used to assess the effect of the attacks on the top-N recommendation of the target users, as discussed below.
Hit ratio: The hit ratio metric measures the average likelihood of a pushed item to be present in the top-N recommendation of a user [12]. Let,
where,
Biasing: In the context of the overall top-N list, a push attacker would want the
where,
Shuffling: Some attacks do not intend to push or nuke items but simply destroy the integrity of the recommendations. In the case of the overall top-N list, interchanging the positions of the items without injecting a target item deteriorates the accuracy of a recommendation system. The item ranked 1 is undoubtedly better and more preferred than the item ranked 3rd or 4th, even if they constitute the overall top-N list. Let, T be the overall top-N list before the attack and
where,
The objective of our designed model is to create attacks that bias the overall top-N list as well as the personalized top-N recommendation of every target user and escape from the feature-based detection. The attacks described are prone to detection due to their highly correlated nature [11–20]. Our model aims to reduce the DEGSIM. Instead of dropping the similarity value to −1, we just reduce it by rating the selected items with the least correlated ratings. The correlation between any two attackers based on these ratings is minimal. Hence, the combined effect of filler and selected items diminish the high correlation, i.e., rendering low DEGSIM values.
Paul et al. [21] mentioned that RDMA values for attackers would be high for attacks of small size, but once the attack size increases, several normal users show bigger RDMA values than the attackers. This is partly because an attack of such a large size is enough to radically increase the average rating for the target items (push) so that regular users who rated these items with the minimum rating would get an increased RDMA. Paul et al. also used the strategy of calculating DEGSIM first and segregating a set of users whose average similarity is less than half of the highest average similarity among users. The ratings of this set of users participate in calculating the average rating of each item. As the DEGSIM has been reduced in our model, the attack profiles also participate in calculating the average rating leading to a biased average value for the target items. The attack profiles do not deviate much from the average ratings rendering low RDMA values while computing. The variants of RDMA, WDMA, and WDA also give low values on account of this.
LENVAR has been considered a critical attribute in distinguishing real users from fake ones since very few real users would rate anything close to all the items available [19]. Since attackers hold no knowledge about the average length of a profile, they create lengthy profiles. It is highly anomalous that an authentic user would rate so many items manually. Attackers can still derive the number of items that are present in the system. We exploit this information to create profiles whose length is less than half the number of items in the system. This significantly reduces the LENVAR. We observe that reducing the filler items below a certain level reduces the attack effect, which means the attackers fail to become the nearest neighbors of the target users. Therefore, we constrain the number of filler items up to that level where the profile length is considerably less than the number of items, but it renders a good hit ratio at the same time. If the attack was only intended to bias the overall top-N items list, the profile length could be reduced to any length without a constraint as filler items do not play a major role in this context.
The attack feature called MEANVAR and its variant FMTD help to detect average attacks where the filler items are rated with a normal distribution centred around the mean rating of each filler item leading to very little difference between their ratings and the average ratings of the corresponding items.
For MEANVAR, every profile is searched for items with extreme ratings, which are labeled as target items for that profile. The remaining ones constitute the filler items. As target items in our model do not have extreme ratings, they will be labeled as filler items along with the selected items. The ratings of target and selected items will exhibit a greater deviation from their corresponding average ratings. Though the filler items will have less variance from their average ratings, the overall MEANVAR will increase due to the presence of the target and the selected items in the group.
For FMTD, every profile will be partitioned into
TMF works on the insight that an attack cannot be launched using a single attack profile. To push or nuke an item, several attack profiles are needed to rate the target item as a group. As already mentioned, the target items in our model will escape suspicion due to non-extreme ratings. In addition, the disguised items will play their part. Owing to their peak ratings, they get wrongly suspected and labeled as target items. The policy that two attackers can share disguised items, but no three attackers can share any, yields uncommon target items between attackers. This disrupts the effectiveness of this attribute.
Zhou et al. [22] suggested a method for detecting shilling attacks based on the assumption of a negative correlation among group users at various time periods. Lam and Riedl [16] investigated the answers to a few questions that could be useful in detecting attacks. The following are the questions: what algorithm is utilized to implement the recommendation system? Where is it utilized as an application? How can recommender system operators identify attacks? What properties do things with attackable properties have? Shriver et al. [23] developed a fuzzy-based model to test the recommender system's stability. For the evaluation of the recommendation system, Bansal and Baliyan [24] employed only segment attacks.
Our research differs significantly from the previously stated works. Instead of giving a method to detect existing shilling attacks, it provides a future opportunity to improve the efficacy or discover the limitations of the recommendation system by proposing a new shilling attack. Furthermore, unlike the aforementioned works that only use some of the attacks; this study examines feature-based shilling attacks as well as the unknown attack.
The closest to the presented work in this paper is of the Obfuscating attack where attackers inject their fallacious profiles into the recommendation system. These camouflaged profiles impersonate as genuine profiles, which confuse the attack detection schemes and are difficult to detect. Though the Obfuscating attack is very much effective to bias the recommendation process by disrupting the recommendation system, it is not so effective in a targeted attack.
4 Experimental Design of the Proposed Obscure Attack Model
Following the direction obtained from the concluding observations in Section 3, we designed a new attack model, where the popularly known attack features, as discussed in Section 2.2, lose their effectiveness in detecting it. We named the attack as the Obscure attack. In this section, we present the theoretical concepts and step-by-step procedure for generating the proposed Obscure attack, and afterward, we validate the effectivity of it.
4.1 Theoretical Consideration of the Obscure Attack
An Obscure attack consists of an additional set of items called the disguised items (


The algorithm for generating the Obscure attack is divided into the following steps:
1)Target item and target user selection: Our aim is to bias the overall top-N list. For this, some high-ranked items from the overall top-N list are selected as the target items in a nuke attack, and some low-ranked items are selected in a push attack. Unlike the standard attack profiles, which assign peak ratings to target items, we rate the target items randomly with 3 or 4 in a push attack, and similarly, the target items are rated randomly with 2 or 3 in a nuke attack. This strategy is followed as users assigning peak ratings are most likely to be suspected as attackers. In contrast, in the Obfuscated attack, the target shifting is done by reducing the rating of the target item by one step from the maximum rating in a push attack and raising the rating of the target item by one step in a nuke attack.
2)Generation of filler items: In order to become the nearest neighbors of the target users (

3) Generation of selected items: The selected items play a significant role in our designed attack model. Since

The purpose of the selected items was to reduce the similarity between the attackers. The attackers will have a zero correlation based on their ratings of selected items. Hence, the correlation matrix of attackers based on selected items will be an identity matrix I, denoting that every attacker has a zero correlation with other attackers and a correlation of 1 with itself. Every attacker has to rate all selected items; hence, the ratings of selected items will be generated as a matrix of size
Let, n be the number of attackers and
where,
A matrix, Selecteditems of size IS x n is generated, where all ratings are randomly picked up from 2 and 3. Here, uncorrelated ratings of selected items, S =
4) Generation of disguised items: To conceal the identity of the attackers, we create a set of disguised items to which the attackers assign extreme ratings. This set consists of some high-rated items and some least rated items apart from the target items. The high-rated items are rated with 5, while the least rated items are rated with 1. Every attacker rates not more than two or three disguised items. A strategy is followed where two attackers can share the disguised items, but no three attackers can share any such item. The procedure for generating the disguised items is given in Algorithm 3.

4.2 Generating the Obscure Attack
To generate the proposed Obscure attack, we used the dataset given in Tab. 1. To attain the assumption of Section 1 (Scenario 2), we assume
Step 1: All attackers give 2 or 3 ratings randomly to

Step 2: Here,
a) Calculate the Correlation matrix (C), as shown in Tab. 9.
b) Generate a 2x4 matrix (no. of selected items = 2 and no. of attackers = 4) whose values are randomly in between the interval (1, 4).
c) Multiply the Cholesky factorization of C with the matrix generated in step (b).
d) Take the transpose of the resultant matrix, which is obtained in step (c). After that, we get the final ratings of selected items, as shown in Tab. 10.


Step 3: Here, we consider I5, I6, and I7 as the filler items. For item I5, mean = 4,

Step 4: For the ratings of disguised items I3 and I4, we have to notice that no three attackers rate the same items. Attackers give a high rating to I3 and low ratings to I4 because based on the ratings, I3 gets a greater number of high ratings than I4. The resultant ratings of disguised items are shown in Tab. 12.
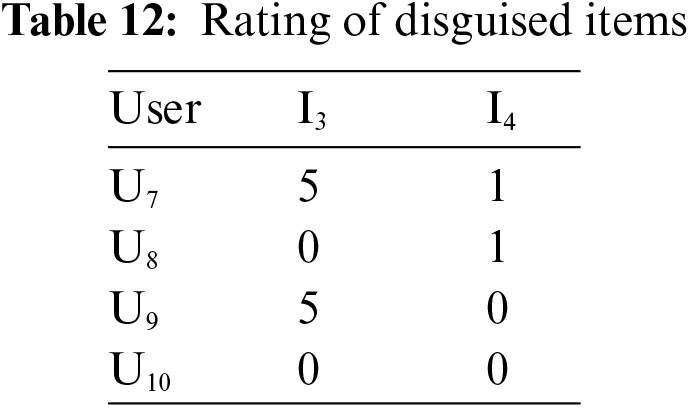
Step 5: However, I10 is considered in an IN set; therefore, no attackers rate I10.
After applying all steps (steps 1 to 5), the resultant ratings of all attackers for all items are shown in Tab. 13.

4.3 Validation of the Proposed Obscure Attack
To show the efficacy of the Obscure attack, Tab. 14 shows the top-3 similar users of the target items, and the recommended items, before and after the attack. From the table, we note that all target users have modified their top-3 similar neighbors after using Obscure attacks, while other shilling attacks fail. Other than that, in the Obscure attack, our predefined assumption is fulfilled.

5 Experimental Analysis of the Effect of the Proposed Attack on Recommendation System
We collected the MovieLens dataset to provide a generalized solution that detects all types of attacks. The collected dataset is found to be attack-free due to the non-existence of any standard attack features. Therefore, it can be concluded that the MovieLens dataset contains only the ratings of the authentic users. This dataset consists of 943 users, 1682 movies, and 1,00,000 ratings [25–27]. These ratings are integer values between 1 and 5, where 1 denotes the lowest rating and 5 denotes the highest rating. Every user has given ratings to at least 20 movies.
The experimental results are divided into the following two phases:
a) Phase 1: In this phase, we show the biasing and shuffling effects of the standard attack model (such as random, average, bandwagon, and segment attack) and the new attacks (Obfuscated attack and our designed Obscure attack).
b) Phase 2: In this phase, we use the same attack size as like as phase 1 and compare the experimental results using Binary classifiers, trained with known attacks and tested with the known and unknown attacks.
The standard metrics such as precision and recall have been used to measure the performance of different attacks. These metrics are calculated using Eqs. (2) and (3).
where, TP (true positive) is the number of attack profiles correctly classified as attackers, FP (false positive) is the number of authentic profiles wrongly classified as attackers, and FN (false negative) is the number of attack profiles wrongly classified as authentic users [13].
In addition to that, we computed the hit ratio values after the detection process has been performed.
5.1 Comparison of the Biasing, Shuffling, and Hit Ratio of Different Attacks on the Overall Top-N List
We generated different sizes of standard attacks of the push type. The biasing and shuffling effect of these different sizes of attacks create changes in the overall top-N list for recommendation. The attack sizes are gradually incremented to obtain the threshold ts where the values of biasing, shuffling, and hit ratio become 1.
Fig. 2 compares the biasing, shuffling, and hit ratio of standard attacks on the overall top-N list. The biasing value and shuffling value of all standard attacks reach 1, at 25% and 20% attack sizes, respectively. We use a maximum 25% attack size for plotting the results of hit ratio and different filler sizes of standard attack because biasing and shuffling both values will reach 1. Hence, Fig. 2 represents the hit ratio of all attacks at different attack sizes across various filler sizes.
5.2 Comparative Analysis of Obscure Attack with Other Shilling Attacks
For training and testing, the dataset is divided into 60%−40%, respectively. In the training process, the binary classifiers are trained with the ratings given by authentic users and known attackers, which are labeled as authentic and attacker, respectively. The testing process contains the test set, which comprises ratings given by the authentic users and the known and unknown attackers.
The classifier detects the authentic users, attackers, and the effect of attacks on the top-N list of recommendations, on the test dataset using precision, recall, and hit ratio. Tab. 15 shows the precision, recall, and hit ratio of different classifiers on the detection of various attacks across four different filler sizes (such as 15%, 20%, 25%, and 40%). All classifiers provide a decent result in feature-based attack detection due to high precision, high recall values, and low hit ratio across four different filler sizes. But for the unknown attacks, all the classifiers attained low recall value and high hit ratio. Low recall value denotes the low detection rate of attackers from the test dataset, and high hit ratio represents the more effect on the top-N recommendation list. From Tab. 15, it can be observed that the Obscure attack provides more effect on the top-N list than the Obfuscated attack at 40% filler size for all the classifiers. The Obscure attack works better than the Obfuscated attack in escaping attack detection.

Figure 2: Biasing and Shuffling effects and the hit ratio of the standard attacks across various filler sizes on the overall top-N list

For further evaluation, we computed the accuracy of the attack detection when the models are trained and tested with the ratings of users under various scenarios. The accuracy (%) of attack detection is defined by Eq. (7).
Fig. 3 portrays the accuracy of four different classifiers on the feature-based detection of different known and unknown attacks. It can be clearly observed that all classifiers obtain high detection accuracy on feature-based detection schemes at different filler sizes, whereas the detection accuracy is significantly decreased in case of unknown attacks. It can be observed that the detection accuracy of the Obscure attack is lowest compared to all other attacks.

Figure 3: Detection accuracy of different attacks (known and unknown)
Due to their effectiveness and popularity, recommendation systems have been the target of the attackers. They use shilling attacks to disrupt the list of recommendable items. The malicious user profiles created by the attackers closely match with the real users. To keep the recommendation systems reliable, the authenticity and security of these systems are very crucial.
In this paper, we generated a new attack model with unknown features and proved that though the existing shilling attack detection methods can detect the standard shilling attacks, they fail to detect the new attacks with unknown features. Our proposed attack is more effective compared to other existing attacks.
This paper measures the rating pattern of the attackers and the authentic users based on standard attack features. We considered only three attackers with the same ratings for a particular item. Due to this, our proposed Obscure attack may have little more computational complexity compared to other standard shilling attacks. However, this should not be a serious issue because the attacker's profiles are usually generated offline.
In future, two possible solutions to improve the detection of unknown attacks can be thought of. The first is to train the classifier with the ratings of the trustworthy users, which can be obtained by applying different attack features on the rating dataset. A user profile will be considered malicious if it does not belong to the class of trustworthy users. The second is to use rated item correlation as a feature in attack detection. In this case, a user may be considered as the attacker if its rated item correlation is different from the real users.
Funding Statement: Funding is provided by Taif University Researchers Supporting Project number (TURSP-2020/10), Taif University, Taif, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. K. Chen, P. P. Chan, F. Zhang and Q. Li, “Shilling attack based on item popularity and rated item correlation against collaborative filtering,” International Journal of Machine Learning and Cybernetics, vol. 10, no. 7, pp. 1833–1845, 2019. [Google Scholar]
2. P. Cremonesi, Y. Koren and R. Turrin, “Performance of recommender algorithms on top-n recommendation tasks,” in Proc. Fourth ACM Conf. on Recommender Systems (RecSys ‘10Barcelona, Spain, 2010. [Google Scholar]
3. G. Karypis, “Evaluation of item-based top-n recommendation algorithms,” in Proc. 10th Int. Conf. on Information and Knowledge Management (CIKM ‘01Atlanta, Georgia, USA, 2001. [Google Scholar]
4. E. Christakopoulou and G. Karypis, “Local item-item models for top-n recommendation,” in Proc. 10th ACM Conf. on Recommender Systems (RecSys ‘16Boston, USA, 2016. [Google Scholar]
5. P. K. Singh, P. K. D. Pramanik and P. Choudhury, “A comparative study of different similarity metrics in highly sparse rating dataset,” in Proc. 2nd Int. Conf. on Data Management, Analytics and Innovation (ICDMAI 2018). Advances in Intelligent Systems and Computing, vol. 839, Springer, Singapore, pp. 45–60, 2019. [Google Scholar]
6. M. Deshpande and G. Karypis, “Item-based top-n recommendation algorithms,” ACM Transactions on Information Systems, vol. 22, no. 1, pp. 143–177, 2004. [Google Scholar]
7. R. A. Zayed, L. F. Ibrahim, H. A. Hefny and H. A. Salman, “Shilling attacks detection in collaborative recommender system: Challenges and promise,” in Web, Artificial Intelligence and Network Applications (WAINA 2020). Advances in Intelligent Systems and Computing, vol. 1150, L. Barolli, F. Amato, F. Moscato, T. Enokido and M. Takizawa, (Eds.Springer, Cham, pp. 429–439, 2020. [Google Scholar]
8. C. Williams, B. Mobasher, R. Burke, J. Sandvig and R. Bhaumik, “Detection of obfuscated attacks in collaborative recommender systems,” in Proc. ECAI'06 Workshop on Recommender Systems (17th European Conf. on Artificial Intelligence (ECAI'06)Riva del Garda, Italy, 2006. [Google Scholar]
9. P. K. Singh, P. K. D. Pramanik and P. Choudhury, “Collaborative filtering in recommender systems: Technicalities, challenges, applications, and research trends,” in New Age Analytics: Transforming the Internet Through Machine Learning, IoT, and Trust Modeling, G. Shrivastava, S. L. Peng, H. Bansal, K. Sharma and M. Sharma, (Eds.Apple Academic Press, Burlington, Canada, pp. 183–215, 2020. [Google Scholar]
10. M. P. O'Mahony, N. J. Hurley and G. C. Silvestre, “Recommender systems: Attack types and strategies,” in Proc. 12th National Conf. on Artificial Intelligence and the Seventeenth Innovative Applications of Artificial Intelligence Conf., Pittsburgh, USA, 2005. [Google Scholar]
11. Z. Zhang and S. R. Kulkarni, “Graph-based detection of shilling attacks in recommender systems,” in Proc. IEEE Int. Workshop on Machine Learning for Signal Processing, Southampton, UK, 2013. [Google Scholar]
12. B. Mobasher, R. Burke, R. Bhaumik and J. J. Sandvig, “Attacks and remedies in collaborative recommendation,” IEEE Intelligent Systems, vol. 22, no. 3, pp. 56–63, 2007. [Google Scholar]
13. B. Mobasher, R. Burke, R. Bhaumik and C. Williams, “Effective attack models for shilling item-based collaborative filtering systems,” in Proc. WebKDD Workshop, Chicago, USA, 2005. [Google Scholar]
14. B. Mobasher, R. Burke, R. Bhaumik and C. Williams, “Toward trustworthy recommender systems: An analysis of attack models and algorithm robustness,” ACM Transactions on Internet Technology, vol. 7, no. 4, pp. 23:1–23:38, 2007. [Google Scholar]
15. P. Kaur and S. Goel, “Shilling attack models in recommender system,” in Proc. Int. Conf. on Inventive Computation Technologies, Coimbatore, India, 2016. [Google Scholar]
16. S. K. Lam and J. Riedl, “Shilling recommender systems for fun and profit,” in Proc. 13th Int. Conf. on World Wide Web (WWW ‘04New York, USA, 2004. [Google Scholar]
17. R. Burke, B. Mobasher, R. Bhaumik and C. Williams, “Segment-based injection attacks against collaborative filtering recommender systems,” in Proc. 5th IEEE Int. Conf. on Data Mining, Houston, USA, 2005. [Google Scholar]
18. R. Burke, B. Mobasher, C. Williams and R. Bhaumik, “Classification features for attack detection in collaborative recommender systems,” in Proc. 12th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, Philadelphia, USA, 2006. [Google Scholar]
19. W. Bhebe and O. P. Kogeda, “Shilling attack detection in collaborative recommender systems using a meta learning strategy,” in Proc. Int. Conf. on Emerging Trends in Networks and Computer Communications, Windhoek, Namibia, 2015. [Google Scholar]
20. Z. Zhang and S. R. Kulkarni, “Detection of shilling attacks in recommender systems via spectral clustering,” in Proc. 17th Int. Conf. on Information Fusion, Salamanca, Spain, 2014. [Google Scholar]
21. P. A. Chirita, W. Nejdl and C. Zamfir, “Preventing shilling attacks in online recommender systems,” in Proc. 7th Annual ACM Int. Workshop on Web Information and Data Management, Bremen, Germany, 2005. [Google Scholar]
22. W. Zhou, J. Wen, Q. Qu, J. Zeng and T. Cheng, “Shilling attack detection for recommender systems based on credibility of group users and rating time series,” PLOS One, vol. 13, no. 5, pp. e0196533, 2018. [Google Scholar]
23. D. Shriver, S. Elbaum, M. B. Dwyer and D. S. Rosenblum, “Evaluating recommender system stability with influence-guided fuzzing,” Proc. AAAI Conf. on Artificial Intelligence, vol. 33, no. 1, pp. 4934–4942, 2019. [Google Scholar]
24. S. Bansal and N. Baliyan, “Evaluation of collaborative filtering based recommender systems against segment-based shilling attacks,” in Proc. Int. Conf. on Computing, Power and Communication Technologies (GUCONNew Delhi, India, 2019. [Google Scholar]
25. P. K. Singh, S. Setta, P. K. D. Pramanik and P. Choudhury, “Improving the accuracy of collaborative filtering-based recommendations by considering the temporal variance of top-n neighbors,” in Proc. Int. Conf. on Innovative Computing and Communication (ICICC-2019). Advances in Intelligent Systems and Computing, vol. 1087, Springer, Singapore, pp. 1–10, 2020. [Google Scholar]
26. P. K. Singh, P. K. D. Pramanik, N. C. Debnath and P. Choudhury, “A novel neighborhood calculation method by assessing users’ varying preferences in collaborative filtering,” in Proc. 34th Int. Conf. on Computers and Their Applications, Honolulu, Hawaii, 2019. [Google Scholar]
27. P. K. Singh, M. Sinha, S. Das and P. Choudhury, “Enhancing recommendation accuracy of item-based collaborative filtering using bhattacharyya coefficient and most similar item,” Applied Intelligence, vol. 50, no. 12, pp. 4708–4731, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |