DOI:10.32604/cmc.2022.020471
| Computers, Materials & Continua DOI:10.32604/cmc.2022.020471 | |
| Article |
A DQN-Based Cache Strategy for Mobile Edge Networks
1School of Electronic Engineering, Beijing University of Posts and Telecommunications, Beijing, 100876, China
2State Key Laboratory of Intelligent Manufacturing System Technology, Beijing Institute of Electronic System Engineering, Beijing, 100854, China
3Ningbo Sunny Intelligent Technology Co., LTD, Yuyao, 315400, China
4Dublin City University, Dublin 9, Ireland
*Corresponding Author: Siyuan Sun. Email: sunsy@bupt.edu.cn
Received: 25 May 2021; Accepted: 11 July 2021
Abstract: The emerging mobile edge networks with content caching capability allows end users to receive information from adjacent edge servers directly instead of a centralized data warehouse, thus the network transmission delay and system throughput can be improved significantly. Since the duplicate content transmissions between edge network and remote cloud can be reduced, the appropriate caching strategy can also improve the system energy efficiency of mobile edge networks to a great extent. This paper focuses on how to improve the network energy efficiency and proposes an intelligent caching strategy according to the cached content distribution model for mobile edge networks based on promising deep reinforcement learning algorithm. The deep neural network (DNN) and Q-learning algorithm are combined to design a deep reinforcement learning framework named as the deep-Q neural network (DQN), in which the DNN is adopted to represent the approximation of action-state value function in the Q-learning solution. The parameters iteration strategies in the proposed DQN algorithm were improved through stochastic gradient descent method, so the DQN algorithm could converge to the optimal solution quickly, and the network performance of the content caching policy can be optimized. The simulation results show that the proposed intelligent DQN-based content cache strategy with enough training steps could improve the energy efficiency of the mobile edge networks significantly.
Keywords: Mobile edge network; edge caching; energy efficiency
With the rapid development of wireless communication networks and the fast growing of smart devices, various mobile Internet applications has been spawned, such as voice recognition, autonomous driving, virtual reality and augmented reality. These emerging services and applications put forward higher requirements for high capacity, low latency and low energy consumption. By deploying edge server at the wireless access network, the end user's computing tasks can be executed near the edge of the network, which could effectively reduce the congestion of the backhaul network, greatly shortens the service delay, and meets the needs of delay-sensitive applications. The mobile edge networks are essentially the subsidence of cloud computing capability, and could provide third-party application at the edge nodes, making it possible for service innovation of mobile edge entry.
With the popularity of video services, the traffic of video content grows explosively. The huge data traffic is mainly caused by the redundant transmission of popular content. Edge nodes also have certain storage capacity for caching, and edge caching is becoming more and more important. Deploying a cache in an edge network can avoid data redundancy caused by many repeated content deliveries. By analyzing the content popularity and proactively caching the popular content from the core network to the mobile edge server, then the request for the repeated content could be transmitted directly from the nearby edge nodes without going back to the remote core network, which greatly reduces the transmission delay and effectively alleviates the pressure on the backhaul link and the core network. Edge cache has been widely studied because it can effectively improve user experience and reduce energy consumption [1]. Enabling caching ability in a mobile edge system is a promising approach to reduce the use of centralized databases [2]. However, due to the edge equipment size, the communicating, computing and caching resources in a mobile edge network are limited. Besides, end users’ mobility makes mobile edge networks, becoming a dynamic system, where the energy consumption may increase because of improper caching strategies. In order to address these problems, we focus on how to improve energy efficiency in a cache-abled mobile edge network through smart caching strategies. In this article, we study a mobile edge network with unknown content popularity, and design a dynamic and smart content cache policy based on online learning algorithm which utilizes deep reinforcement learning (DRL).
The rest of this article is arranged as follows. Firstly, Section 2 elaborated the existing related work and some solutions on the content cache strategy in mobile edge networks. Section 3 introduce a cache-enabled mobile edge network scenario and builds related system models and energy models. Section 4 analyzes the energy efficiency of the system, and formulates the optimization problem in the system according to the deep reinforcement learning models, then the caching content distribution strategy is proposed to solve the energy efficiency optimization problem of mobile edge networks. Finally, we design some numerical simulations and analyze the results, which show that the proposed strategy could greatly improve mobile edge networks energy efficiency without decreasing the system performance.
In this section, we will investigate the existing related work and some solutions on mobile edge networks with caching capability and artificial intelligence (AI) in network resource management.
2.1 Energy-Aware Mobile Edge Networks with Cache Ability
By simultaneously developing computing offloads and smart content caches near the edge of the network, mobile edge network can further improve the efficiency of network content distribution and computing capabilities, and effectively reducing latency and improving service quality and the energy consumption of cellular networks. Thus, adding cache ability at the network edge has become one of the most important approaches [3,4]. Authors in [5] separated the controlling and communicating functions of heterogeneous wireless networks with software defined network (SDN)-based techniques. Under the proposed network architecture, the cache-enabled of macro base stations and relay nodes are overlaid and cooperated in a limited backhaul scenario to meet service quality requirement. Authors in [6] investigated cache policies which aim to improve energy efficiency in information centric networks. Numerous papers [7,8] focus on caching policies based on user demands, e.g., authors in [9] proposed a light-weight cooperating edge storage management strategy thus the utilization of edge caching can be maximized and the bandwidth cost can be decreased. Jiang et al. [10] proposed a caching and delivering policy for femto cellulars where access nodes and user devices are all able to cache local contents, the proposed policy aims at realizing a cooperative allocation strategy for communicating and caching resources in a mobile edge network. A deep-Learning-based content popularity prediction algorithm is developed for software defined networks in [11]. Besides, due to the users’ mobility, how to cache contents properly is challenging in mobile edge network, thus many works [12–15] aimed at addressing mobility-aware caching problems. Sun et al. [16] proposed a mobile edge cloud framework which uses big medical sensor data and aims at predicting diseases.
Those works inspire us to research on how to improve the energy consumption of the mobile edge networks by taking advantage of cache ability. However, cache strategies from the work above are all based on user demands and behavior, which are features that are difficult to extract or forecast. To solve this problem, many researchers work on using the architectures of the network function virtualization or software defined networks. By separating control and communicate planes and virtualizing network device functions, those techniques realized a flexible and intelligent way to manage edge resources in mobile edge networks. Thus, many smart energy efficiency-oriented caching policies are able to be integrated as network applications, which are operated by network managers and run on top of a centralized network controller [17]. Li et al. [18] surveyed Software-Defined Network Function Virtualization. Mobility Prediction as a Service which was proposed in [19] offers an on-demand long-term management by predicting user activities, moreover, the function is virtualized as a network service, which is fully placed on top of the cloud and works as a cloudified service. Authors in [20] designed a network prototype which takes advantage of not only content centric networks but also Mobile Follow-Me Cloud, therefore the performance of cache-aided edge networks are improved. Those works suggested feasible paradigms of mobile edge network virtualization with cache ability. Furthermore, authors in [21] designed a content-centric heterogeneous networks architecture which is able to cache contents and compute local data, in the analyzed network scenario, users associated to various network services but were all allowed to share the communication, computation and storage resources in one cellular. Tan et al. [22] proposed a full duplex-enabled software defined networks framework for mobile edge computing and caching scenario, and the first framework suits network services which are sensitive to data rate, while the second one suits network services which are sensitive to data computing speed.
2.2 Artificial Intelligence in Network Management
In recent years, deploying more intelligence in networks is a promising approach to realize effectively organizing [23,24], managing and optimizing network resources. Xie et al. [25] investigated how to use machine learning (ML) algorithms to add more intelligence to software defined networks. Reinforcement learning (RL) and related algorithms has been adapted for automatic goal-oriented decision-making for ages [26]. Wei et al. [27,28] suggested a joint optimization for edge resource allocating problem, the proposed strategy uses the model-free actor-critic reinforcement learning to solve the joint optimization problems of content caching, wireless resource allocation and computation offloading, thus the overall network delay performance is improved. Qu et al. [29,30] proposed a novel controlled flexible representation and a novel secure and controllable quantum image steganography algorithm for quantum image, this algorithm allows the sender to control all the process stages during a content transmitting phrase, thus a better information-oriented security is obtained. Deploying cache in the edge network can enhance content delivery networks and reducing the data traffic caused by a large number of repeated content requests [31]. There are many related works, mainly focusing on computing offloading and cache decisions and resources allocation [32].
However most of RL algorithms needs lots of computation power. Although the SDN architecture offers an efficient flow-based programmable management approach, the local controllers mostly have limited resources (e.g., storage, CPU.) for data processing. Thus an optimization algorithm with controllable computing time is required for mobile edge networks. Amokrane et al. [33] proposed a computation efficient approach which is based on Ant-Colony optimization to solve the formulated flow-based routing problem, the simulation results showed that the Ant Colony-based approach can substantially decrease computation time comparing with other optimal algorithms.
Various deep reinforcement learning main architectures and algorithms are presented in [34], in which reinforcement learning algorithms are reproduced with deep learning methods. The authors highlighted the impressive performance of deep neural networks (DNN) when solving various management problems (e.g., video gaming). With development of deep learning, reinforcement learning has been successfully combined with DNN [35]. In wireless sensor networks, Toyoshima et al. [36] described a design of a simulation system using DQN.
This paper takes advantages of DQN, which can efficiently obtain a dynamic optimized solution without having a priori knowledge of the dynamic statistics.
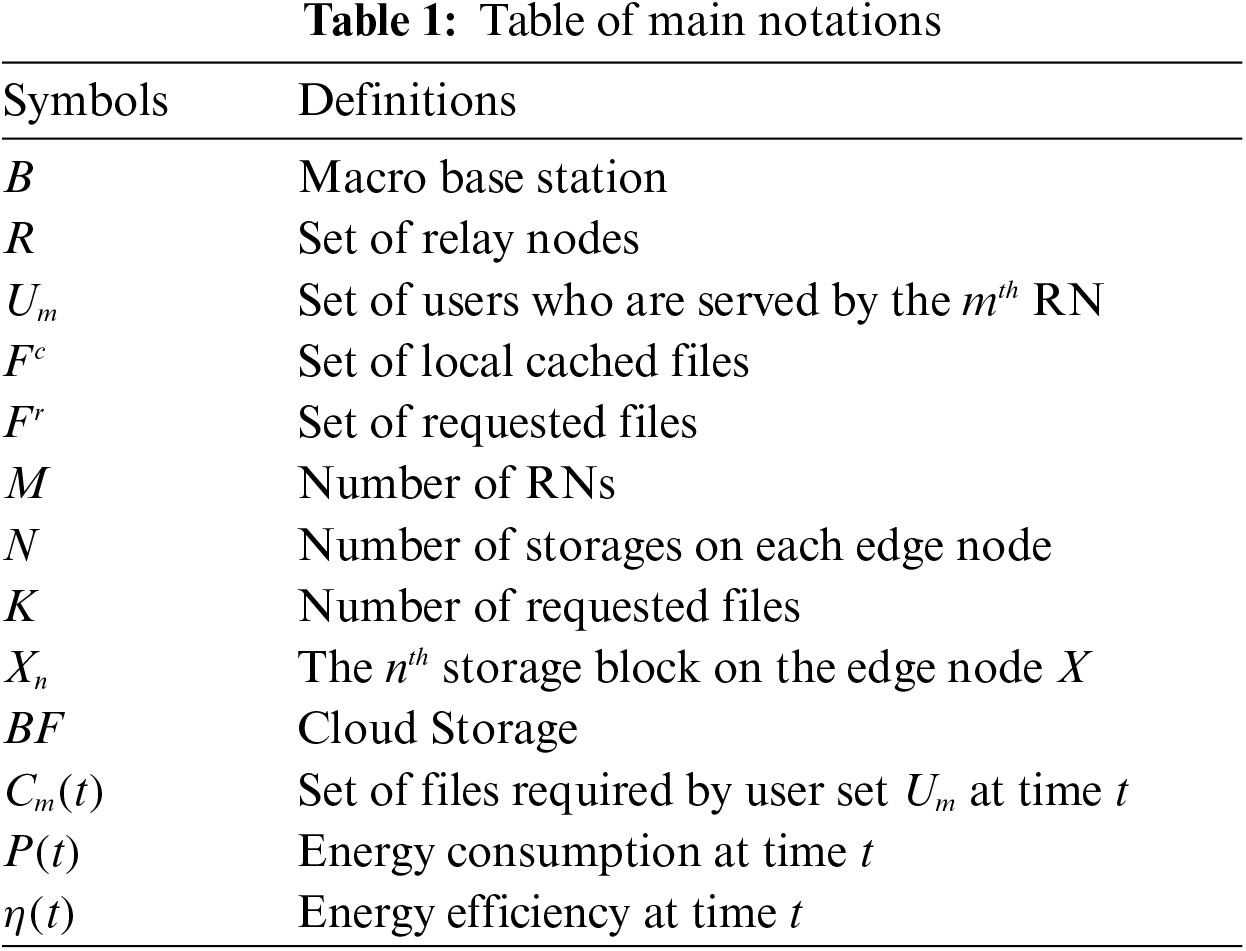
This section analyzes a caching edge network scenario with unknown content popularities, then we build the energy model for the system. The main notations used in the rest of this article are listed in Tab 1.
A typical mobile edge network scenario is shown in Fig. 1, which contains not only communicating but also caching resources. The edge accessing devices include macro base stations (MBSs) and relay nodes (RNs), they all have different communicate and cache abilities, but any of them can connect to end users and cache data from end user or far cloud. We consider a set of relay nodes

Figure 1: Example of an edge cellular network with caching ability
We consider a cellular wireless accesnetwork that consists of an MBS and a set of RNs, the a large number of end users who are served by relay
and
The optimization problem here is how to maximize the system energy efficiency. According to the network architecture which has been analyzed in Section 3.1, the system energy consumption in a mobile edge network can be divided into three components:
1. Basic power
2. Transmitting power in the mobile edge network
3. Transmitting power between the mobile edge network and far cloud
Thus the system total energy consumption can be written as:
The
According to the formula (1) and (2), the system energy consumption can be written as:
where
In a mobile edge network, the propagation model can be represented by a function of radiated power:
where
In order to meet the user QoS, a fixed transmission rate
where W and
Comparing to a traditional mobile edge network, a cache-enabled mobile edge network focuses on delivering contents to end users rather than transmitting data. Thus the EE in the analyzed system is defined as the size of delivered contents during a time slot, instead of transmitted data. The EE can be written as follow:
where L denote content size of each file.
Therefore, the system EE maximization problem can be written as an optimization formulation as follow:
where the first constraint means that the users’ QoS should be satisfied by defining the minimal SINR threshold, the second constraint means that each requested file should be transferred to the edge node which serves the user. We use the optimization variables
In this section we first formulate the energy efficiency-oriented cached content distribution optimization problem, which has been discussed in Section 3, according to reinforcement learning model, then we give the solution of a caching strategy based on DQN algorithm.
4.1 Reinforcement Learning Formulation
There is an agent, an action space and a state space in a general reinforcement learning model, the agent learns which action in the action space should be taken at which state in the state space. For example, we use
The state space is represented as S, where
During a time slot, the caching distribution state changes from an initial state
And the terminal state of time slot t
In our problem, we assume that there is a blank storage block
The executed action serial, which starts from the initial state
The reinforcement learning system obtains an immediate reward after an action is performed. Because reinforcement learning algorithm is using for a model-free optimization problem. The value of the immediate reward is zero until the agent reaches the terminal state. We denote the immediate reward as
where
RL problems can be described as the optimal control decision making problem in MDP. Q-learning is one of effective model-free RL algorithms, which has been analyzed in Section 4.2. The long-term reward, which is learned by Q-learning algorithm, of performing action
where
Based on (15), Q-learning algorithm is effective when solving the problem with small state and action spaces, where a Q-table is able to be stored to represent all the Q values of each state-action pair. However, the process becomes extremely slow in a complex environment where the state and action space dimensions are very high. Deep Q-learning is a method that combines neural network and Q-learning algorithm. Neural network can solve the problem that needs to store and retrieve a large number of Q values.
The agent in our RL model is trained by DQN algorithm in this paper, the DQN algorithm uses two neural networks to realize the convergence of value function. As we have analyzed, due to the complex and high-dimensional network cached content distribution state space, calculating all the optimal Q-values requires significant computations. Thus, we approximate Q-values with a Q-function, which can be trained to the optimal Q value by updating the parameter
where
DQN uses a memory bank to learn the previous experience. At each update, some previous experience is randomly selected for learning, while the target network is updated with two network structures with the same parameters and different network structures, making the neural network update more efficient. When the neural network can't maintain convergence, there will be some problems such as unstable training or difficult training. DQN uses experience playback and target networks to improve on these issues. Experience replay is usually used to store the collected sequence of observations (
where
The process of the proposed DQN-based cache strategy based can be illustrated with pseudocode as shown in Algorithm 1.

This section conducts a number of simulations to evaluate and test the performance of the proposed DQN-based caching strategy in mobile edge networks. The numerical simulations are conducted in the simulation software MatLab 2020a. We firstly test and verify the energy efficiency improvement with the DQN training-based caching policy in a simple cellular, then we evaluate the energy efficiency of the proposed caching policy in a more general complex network scenario.
Firstly, we set a cellular network scenario that consists of an MBS, an RN and 3 end users. The cellular covers an area with radius

As shown in Fig. 2, we evaluate the system energy efficiency with a random caching policy, where the service contents are cached in either the MBS or RN randomly, and compare with the energy efficiency performance of the caching policy with DQN training. The red line with triangles in the figure denotes the system energy efficiency with DQN training, while the blue line with squares denotes the system energy efficiency with random caching policy. We generate user distribution ten times and each of them is used for a certain training step number. As can be seen in the figure, with enough training steps, the energy efficiency of DQN training caching policy can improve the system energy efficiency.
For a better analysis on the performance of proposed policy and its convergency, we simulate the relationship between training steps and system energy cost. It can be seen in Fig. 3 that system energy cost declines with the increasing of training steps, which means that the algorithm trends to converge with 1500 steps.
In order to test the proposed caching policy in complex network scenes, we simulate a mobile edge network with different numbers of RNs. In this part, we set the end user number is 20, the numbers of RNs are M = 2, 3, 4, 5, 6. Consider a polar coordinate situation, the MBS is located at the place [0,0], and the m-th RN is located at the place [500, 2
We evaluate and compare the energy efficiency performance of the networks under three types of mobile edge networks architecture, includes a mobile edge network without caching ability, a mobile network with random caching strategy and a mobile edge network with the proposed DQN-based caching strategy. A mobile edge network without caching ability (as shown in Fig. 4 “non cache”) firstly send the requested contents to the MBS from far cloud, then deliver the contents to corresponding end users through edge nodes. A mobile edge network with random caching strategy caches contents in edge nodes by random, under this caching strategy, a requested content has to be acquired from cloud when it is not stored in an edge node who cannot connect to corresponding end user directly.

Figure 2: Comparison of the random and DQN policies

Figure 3: Cost in each training as function training numbers
The energy efficiency comparison with multi-RNs is showed in Fig. 4. By comparing the mobile edge networks energy efficiency with and without storage function, we can see that adding caching ability to mobile edge networks can significantly increase system energy efficiency. By comparing the energy efficiency of mobile edge networks with DQN-based caching strategy and random caching strategy, we can see that the proposed DQN-based caching strategy shows better energy efficiency improvement than random caching strategy when M > 2. Besides, we can also see the network energy efficiency as a function of RN numbers, the more RNs in a mobile edge network, the better network performance the proposed caching strategy can achieve.

Figure 4: Energy efficiency comparison with multi-RNs
Fig. 5 shows the computation time when algorithm converges for Q-learning and DQN. Due to the enormous computation burden, general Q-learning algorithm usually costs lots of computation time, which is unacceptable in real scenes. The experimental results show that the algorithm convergence speed of the proposed DQN policy is significant faster than general Q-learning method.

Figure 5: Computation time comparison
In this paper, we investigate and focus on the energy efficiency problem in mobile edge networks with caching capability. A cache-enabled mobile edge network architecture is analyzed in a network scenario with unknown content popularity. Then we formulate the energy efficiency optimization problem according the main purpose of a content-based edge network. To address the problem, we put forward a dynamic online caching strategy using the deep reinforcement learning framework named deep-Q learning algorithm. The numerical simulation results indicate the proposed caching policy can be found quickly and it can improve the system energy efficiency performance significantly in both networks with single RN and multi-RNs. Besides, the convergence speed of the proposed DQN algorithms is significant faster than general Q-learning.
Funding Statement: This work was supported by the National Natural Science Foundation of China (61871058, WYF, http://www.nsfc.gov.cn/).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. S. Abolfazli, Z. Sanaei, E. Ahmed, A. Gani and R. Buyya, “Cloud-based augmentation for mobile devices: Motivation, taxonomies, and open challenges,” IEEE Commun. Surveys Tuts, vol. 16, no. 1, pp. 337–368, 2014. [Google Scholar]
2. C. Wang, Y. He, F. Yu, Q. Chen and L. Tang, “Integration of networking, caching, and computing in wireless systems: A survey, some research issues, and challenges,” IEEE Commun. Surveys Tuts, vol. 20, no. 1, pp. 7–38, 2017. [Google Scholar]
3. X. Wang, M. Chen, T. Taleb, A. Ksentini and V. C. M. Leung, “Cache in the air: Exploiting content caching and delivery techniques for 5G systems,” IEEE Communications Magazine, vol. 52, no. 2, pp. 131–139, 2014. [Google Scholar]
4. P. Liu, S. R. Chaudhry, T. Huang, X. Wang and M. Collier, “Multi-factorial energy aware resource management in edge networks,” IEEE Transactions on Green Communications and Networking, vol. 3, no. 1, pp. 45–56, 2019. [Google Scholar]
5. J. Zhang, X. Zhang and W. Wang, “Cache-enabled software defined heterogeneous networks for green and flexible 5G networks,” IEEE Access, vol. 4, pp. 3591–3604, 2016. [Google Scholar]
6. C. Fang, F. R. Yu, T. Huang, J. Liu and Y. Liu, “A survey of energy-efficient caching in information-centric networking,” IEEE Communications Magazine, vol. 52, no. 11, pp. 122–129, 2014. [Google Scholar]
7. A. Ioannou and S. Weber, “A survey of caching policies and forwarding mechanisms in information-centric networking,” IEEE Communications Surveys & Tutorials, vol. 18, no. 4, pp. 2847–2886, 2016. [Google Scholar]
8. A. Sengupta, S. Amuru, R. Tandon, R. M. Buehrer and T. C. Clancy, “Learning distributed caching strategies in small cell networks,” in Proc. 11th Int. Symp. Wireless Commun. Syst. (ISWCSBarcelona, Spain, pp. 917–921, 2014. [Google Scholar]
9. S. Borst, V. Gupta and A. Walid, “Distributed caching algorithms for content distribution networks,” in Proc. IEEE INFOCOM, San Diego, CA, USA, pp. 1–9, 2010. [Google Scholar]
10. W. Jiang, G. Feng and S. Qin, “Optimal cooperative content caching and delivery policy for heterogeneous cellular networks,” IEEE Transactions on Mobile Computing, vol. 16, no. 5, pp. 1382–1393, 2017. [Google Scholar]
11. W. Liu, J. Zhang, Z. Liang, L. Peng and J. Cai, “Content popularity prediction and caching for ICN: A deep learning approach with SDN,” IEEE Access, vol. 6, pp. 5075–5089, 2018. [Google Scholar]
12. R. Wang, X. Peng, J. Zhang and K. B. Letaief, “Mobility-aware caching for content-centric wireless networks: Modeling and methodology,” IEEE Commun. Mag, vol. 54, no. 8, pp. 77–83, 2016. [Google Scholar]
13. Y. Guan, Y. Xiao, H. Feng, C. -C. Shen and L. J. Cimini, “Mobicacher: mobility-aware content caching in small-cell networks,” in Proc. IEEE Global Commun. Conf., Austin, TX, USA, pp. 4537–4542, 2014. [Google Scholar]
14. C. Jarray and A. Giovanidis, “The effects of mobility on the hit performance of cached D2D networks,” in Proc. 14th Int. Symp. Modeling Optim. Mobile, Ad Hoc,Wireless Netw, (WiOptTempe, AZ, USA, pp. 1–8, 2016. [Google Scholar]
15. H. Li and D. Hu, “Mobility prediction based seamless RAN-cache handover in hetNet,” in Proc. IEEE Wireless Commun. Netw. Conf., Doha, Qatar, pp. 1–7, 2016. [Google Scholar]
16. L. Sun, Q. Yu, D. Peng, S. Subramani and X. Wang, “Fogmed: A fog-based framework for disease prognosis based medical sensor data streams,” Computers, Materials & Continua, vol. 66, no. 1, pp. 603–619, 2021. [Google Scholar]
17. C. Liang, F. R. Yu and X. Zhang, “Information-centric network function virtualization over 5 g mobile wireless networks,” IEEE Network, vol. 29, no. 3, pp. 68–74, 2015. [Google Scholar]
18. Y. Li and M. Chen, “Software-defined network function virtualization: A survey,” IEEE Access, vol. 3, pp. 2542–2553, 2015. [Google Scholar]
19. M. Karimzadeh, Z. Zhao, L. Hendriks, R. Schmidt, S. Fleur et al., “Mobility and bandwidth prediction as a service in virtualized LTE systems,” in Proc. IEEE 4th Int. Conf. on Cloud Networking, CloudNet, Niagara Falls, ON, Canada, pp. 132–138, 2015. [Google Scholar]
20. A. S. Gomes, B. Sousa, D. Palma, V. Fonseca, Z. Zhao et al., “Edge caching with mobility prediction in virtualized LTE mobile networks,” Future Generat. Comput. Syst, vol. 70, pp. 148–162, 2017. [Google Scholar]
21. Y. Zhou, F. R. Yu, J. Chen and Y. Kuo, “Resource allocation for information-centric virtualized heterogeneous networks with in-network caching and mobile edge computing,” IEEE Transactions on Vehicular Technology, vol. 66, no. 12, pp. 1339–1351, 2017. [Google Scholar]
22. Z. Tan, F. R. Yu, X. Li, H. Ji and V. C. M. Leung, “Virtual resource allocation for heterogeneous services in full duplex-enabled SCNs with mobile edge computing and caching,” IEEE Transactions on Vehicular Technology, vol. 67, no. 2, pp. 1794–1808, 2018. [Google Scholar]
23. P. Liu, S. R. Chaudhry, X. Wang and M. Collier, “PROGRES: A programmable green router with controlled service rate,” IEEE Access, vol. 7, pp. 3792–3804, 2019. [Google Scholar]
24. A. Ghiasian, P. Liu, X. Wang and M. Collier, “Energy-efficient operation of a network of openFlow switches featuring hardware acceleration and frequency scaling,” Transactions on Emerging Telecommunications Technologies, vol. 30, no. 6, pp. 613–619, 2019. [Google Scholar]
25. J. Xie, F. R. Yu, T. Huang, R. Xie, J. Liu et al., “A survey of machine learning techniques applied to software defined networking (SDNResearch issues and challenges,” IEEE Communications Surveys & Tutorials, vol. 21, no. 1, pp. 393–430, 2019. [Google Scholar]
26. R. S. Sutton and A. G. Barto, In Reinforcement Learning: An Introduction, Cambridge, UK: MIT press, 1998. [Google Scholar]
27. Y. Wei, F. R. Yu, M. Song and Z. Han, “Joint optimization of caching, computing, and radio, resources for fog-enabled IoT using natural actor-critic deep reinforcement learning,” IEEE Internet of Things Journal, vol. 6, no. 2, pp. 2061–2073, 2019. [Google Scholar]
28. Y. Wei, F. R. Yu, M. Song and Z. Han, “User scheduling and resource allocation in hetNets with hybrid energy supply: An actor-critic reinforcement learning approach,” IEEE Transactions on Wireless Communications, vol. 17, no. 1, pp. 680–692, 2018. [Google Scholar]
29. Z. G. Qu, S. Y. Chen and X. J. Wang, “A secure controlled quantum image steganography algorithm,” Quantum Information Processing, vol. 19, no. 380, pp. 1–25, 2020. [Google Scholar]
30. Z. G. Qu, S. Y. Wu, W. J. Liu and X. J. Wang, “Analysis and improvement of steganography protocol based on bell states in noise environment,” Computers, Materials & Continua, vol. 59, no. 2, pp. 607–624, 2019. [Google Scholar]
31. L. Li, Y. Wei, L. Zhang and X. Wang, “Efficient virtual resource allocation in mobile edge networks based on machine learning,” Journal of Cyber Security, vol. 2, no. 3, pp. 141–150, 2020. [Google Scholar]
32. Y. Wei, Z. Wang, D. Guo and F. R. Yu, “Deep q-learning based computation offloading strategy for mobile edge computing,” Computers, Materials & Continua, vol. 59, no. 1, pp. 89–104, 2019. [Google Scholar]
33. A. Amokrane, R. Langar, R. Boutaba and G. Pujolle, “Flow-based management for energy efficient campus networks,” IEEE Transactions on Network and Service Management, vol. 12, no. 4, pp. 565–579, Dec. 2015. [Google Scholar]
34. K. Arulkumaran, M. P. Deisenroth, M. Brundage and A. A. Bharath, “Deep reinforcement learning: A brief survey,” IEEE Signal Process. Mag, vol. 34, no. 6, pp. 26–38, 2017. [Google Scholar]
35. W. G. Hatcher and W. Yu, “A survey of deep learning: Platforms, applications and emerging research trends,” IEEE Access, vol. 6, pp. 411–432, 2018. [Google Scholar]
36. K. Toyoshima, T. Oda, M. Hirota, K. Katayama and L. Barolli L, “A DQN based mobile actor node control in WSAN: Simulation results of different distributions of events considering three-dimensional environment,” Advance in Internet, Data and Web Technologies, vol. 47, pp. 197–209, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |