DOI:10.32604/cmc.2022.021833
| Computers, Materials & Continua DOI:10.32604/cmc.2022.021833 | |
| Article |
Design of Automated Opinion Mining Model Using Optimized Fuzzy Neural Network
1Department of Cybersecurity, College of Computer Science and Engineering, University of Jeddah, Jeddah, Saudi Arabia
2Department of Computer Engineering, College of Computers and Information Technology, Taif University, Taif, 21944, Saudi Arabia
3Department of Mathematics, Faculty of Sciences, Taif University, Taif, 21944, Saudi Arabia
4Centre for Artificial Intelligence in Precision Medicine, King Abdulaziz University, Jeddah, 21589, Saudi Arabia
5Department of Mathematics, Faculty of Science, New Valley University, El-Kharga, 72511, Egypt
*Corresponding Author: Romany F. Mansour. Email: romanyf@sci.nvu.edu.eg
Received: 16 July 2021; Accepted: 27 August 2021
Abstract: Sentiment analysis or Opinion Mining (OM) has gained significant interest among research communities and entrepreneurs in the recent years. Likewise, Machine Learning (ML) approaches is one of the interesting research domains that are highly helpful and are increasingly applied in several business domains. In this background, the current research paper focuses on the design of automated opinion mining model using Deer Hunting Optimization Algorithm (DHOA) with Fuzzy Neural Network (FNN) abbreviated as DHOA-FNN model. The proposed DHOA-FNN technique involves four different stages namely, preprocessing, feature extraction, classification, and parameter tuning. In addition to the above, the proposed DHOA-FNN model has two stages of feature extraction namely, Glove and N-gram approach. Moreover, FNN model is utilized as a classification model whereas GTOA is used for the optimization of parameters. The novelty of current work is that the GTOA is designed to tune the parameters of FNN model. An extensive range of simulations was carried out on the benchmark dataset and the results were examined under diverse measures. The experimental results highlighted the promising performance of DHOA-FNN model over recent state-of-the-art techniques with a maximum accuracy of 0.9928.
Keywords: Opinion mining; sentiment analysis; fuzzy neural network; metaheuristics; feature extraction; classification
Information Technology (IT) has evolved with several new innovations, new programming languages and Data Mining (DM) approaches to benefit the user and the community. Sentiment Analysis (SA) has resulted in rapid growth and development of corporate sectors. This is because the business sectors include an IT team who keep an eye on Opinion Mining (OM) methods so as to uplift their corporate and move forward [1]. OM or SA is a domain in IT that investigate about a person’s mind-set. Opinion Mining or Sentiment Analysis is conducted based on perception, opinion, attitude, and information. It assists the stakeholders to understand the product ordered in the market for sale. Earlier, the opinion analysis is conducted either through online/manual responses or else they could state their opinions through point-based method. However, it was observed that the input toward the product and the business are not genuine and the data cannot be relied upon since it does not provide any connections with real-world statistics [2]. Hence it becomes inevitable to understand the state of a user who is willing to provide feedback regarding the product. The feedback of users changes when their sentiment changes for similar products. This provides a novel challenge for the businesses, regarding their product since the same product is demeaned as well as appreciated by users under different scenarios.
OM is a field of study, which handles knowledge detection and information retrieval, from the text [3,4] with the help of NLP and DM approaches. DM is a procedure which utilizes data analyses tools to find and uncover the relationships and patterns amongst data that might lead to extraction of novel information from huge databases [5]. The aim of OM is to study about thoughts and opinions, identify the developing social polarities that depend on sentiments, views, expectations, moods, and attitudes of majority of the people/beneficiary groups [6]. Generally, the aim is to identify a user’s attitudes through content analysis which they send to the community. The attitudes are categorized based on their polarities such as negative, positive, and neutral. Automated support from the analytical procedure is highly significant since the information available is huge in volume and such kinds of support remain the major challenge. OM could be considered as an automated knowledge detection process which is aimed at detecting unobserved patterns in tweets, ideas, and blogs. Recently, several investigations have been conducted in different areas of OM in social media. By studying the methods projected in these areas, it is determined that the key challenges are high training cost due to lack of enriched lexicons, memory/time utilized, ambiguity in negative/positive detection of few sentences, and high feature space dimension.
Multiclass Sentiment Classification (SC) and Binary Sentiment Classification (SC) are the most utilized methods of Sentiment Classification. Every feedback/document review of the dataset is categorized under two major kinds, i.e., negative and positive sentiments in binary SC [7]. While, in case of multiclass SC, every document is categorized under several classes and the degree of sentiment can be positive, solid positive, solid negative, neutral and negative [8]. SA is classified as Document Level (DL), feature/Aspect Level (AL), and Sentence Level (SL). Among these, AL indicates the sentiment i.e., exposed on several aspects/features of an entity. In SL, the major concern is the choice i.e., either to infer all the sentences as neutral and positive or else a negative opinion [9].
The current research paper focuses on the design of automated opinion mining model using Deer Hunting Optimization Algorithm (DHOA) with Fuzzy Neural Network (FNN), called DHOA-FNN model. In the proposed DHOA-FNN model, preprocessing is the first stage to remove the unwanted data and improve the quality of data. Besides, Glove and N-gram based feature extraction techniques are designed to derive a set of useful features. Moreover, FNN model is utilized as a classification model and parameter optimization process takes place with the help of GTOA. DHOA is applied to adjust the variables of FNN model which results in maximum classification outcome. The design of DHOA-ENN technique for OM shows the novelty of current work. A wide range of experimental analyses was conducted on benchmark datasets and the results were explored under different metrics.
Rest of the paper is organized as follows. Section 2 offers a review of literature and Section 3 details about the proposed model. Then, Section 4 discusses the performance validation and Section 5 concludes the paper.
Sidorov et al. [10] investigated the ways in which the classifier works, when performing OM on Spanish Twitter data. The researchers examined how various settings (corpus size, n-gram size, various domains, balanced vs. unbalanced corpus and amount of sentiment classes) affect the accuracy of ML method. Further, the study also investigated and compared NB, DT, and SVM approaches. This study focused on language specific preprocessing for Spanish language tweets. Gamal et al. [11] examined several ML methods used in sentiment analysis and review mining in various databases. Generally, SC tasks consist of two stages in which the initial stage handles FE. This study employed three distinct FE methods. The next stage covers the classification of review through several ML approaches. Alfrjani et al. [12] presented a Hybrid Semantic Knowledgebase ML method for OM at domain feature level and categorized the entire set of opinions using a multipoint scale. The retrieved semantic data remains a useful resource for ML classification model in order to predict the mathematical rating of every review.
In Keyvanpour et al. [13], a useful technique was proposed based on lexicon and ML named OMLML with the help of social media networks. The major advantage of the presented technique, compared to another approach, is that the presented approach can simultaneously tackle the challenge. In the presented approach, the polarity of the opinion, towards a target word, is initially defined by a technique based on textual and lexicon features of sentences and words. Then, based on the mapped feature space to 3-dimension vector, opinions are classified. Then the opinions are analyzed using a novel ML technique. Dubey et al. [14] proved the efficiency of an ML method as either negative or positive sentiment on twitter. Twitter’s API (Application Programming Interface) service can perform the collection of tweets and process them by filtrating an optimally-authorized IPL hashtag. The authors analyzed the efficiency of RF against the present supervised ML method.
Tavoschi et al. [15] presented the results of OM analyses about vaccination executed on twitter from Italy. Vaccine-related tweets were manually categorized as different elements such as neutral, against and in favour of the vaccination topics using supervised ML methods. At that time, they established growing trends on that topic. Zvarevashe et al. [16] designed an architecture for sentiment analyses using OM for hotel customer pointers. The most accessible databases of hotel analyses remain unlabeled and are presented in various studies for researcher as far as text data preprocessing task is considered. Furthermore, sentiment database is highly a domain-sensitive one and is difficult to develop, since the sentiments like opinions, attitudes, emotions, and feelings are common with onomatopoeias, idioms, phonemes, homophones, acronyms, and alliterations. Jeong et al. [17] suggested a method to support decision making in stock investment via OM and ML analyses. Within the architecture of support decision making, this study (1) Made predictions depending upon critical signal detection, (2) Filtered fake data for precise prediction, and (3) assessed credit risk. Initially, financial data involving news, SNS and financial statement are gathered whereas fake data such as rumours and fake news are sophisticated by study analyses and rule-based method. Next, the credit risk is calculated using SA and OM for social news and data through sentiment scores and trends of documents for every stock. Then, a risk signal in stock investment is identified according to the credit risk acquired from financial risk and OM is detected using the financial database. Estrada et al. [18] developed two corpora of expression to the programming languages’ domain which reflects the mood of scholars based on exams, teachers, academic projects, homework, etc. In DL, the fundamental concern is the classification of either entire opinion in a document as either negative or positive sentiment. Both SL and DL analyses are inadequate to monitor what people reject and accept accurately. So, the current study emphasizes the document level of SA.
The workflow of the proposed DHOA-FNN technique is demonstrated in Fig. 1. DHOA-FNN model involves various sub-processes namely, preprocessing, feature extraction (Glove and N-gram), FNN-based classification, and DHOA-based parameter tuning. A comprehensive description about the functioning of these sub-processes is offered in subsequent sections.
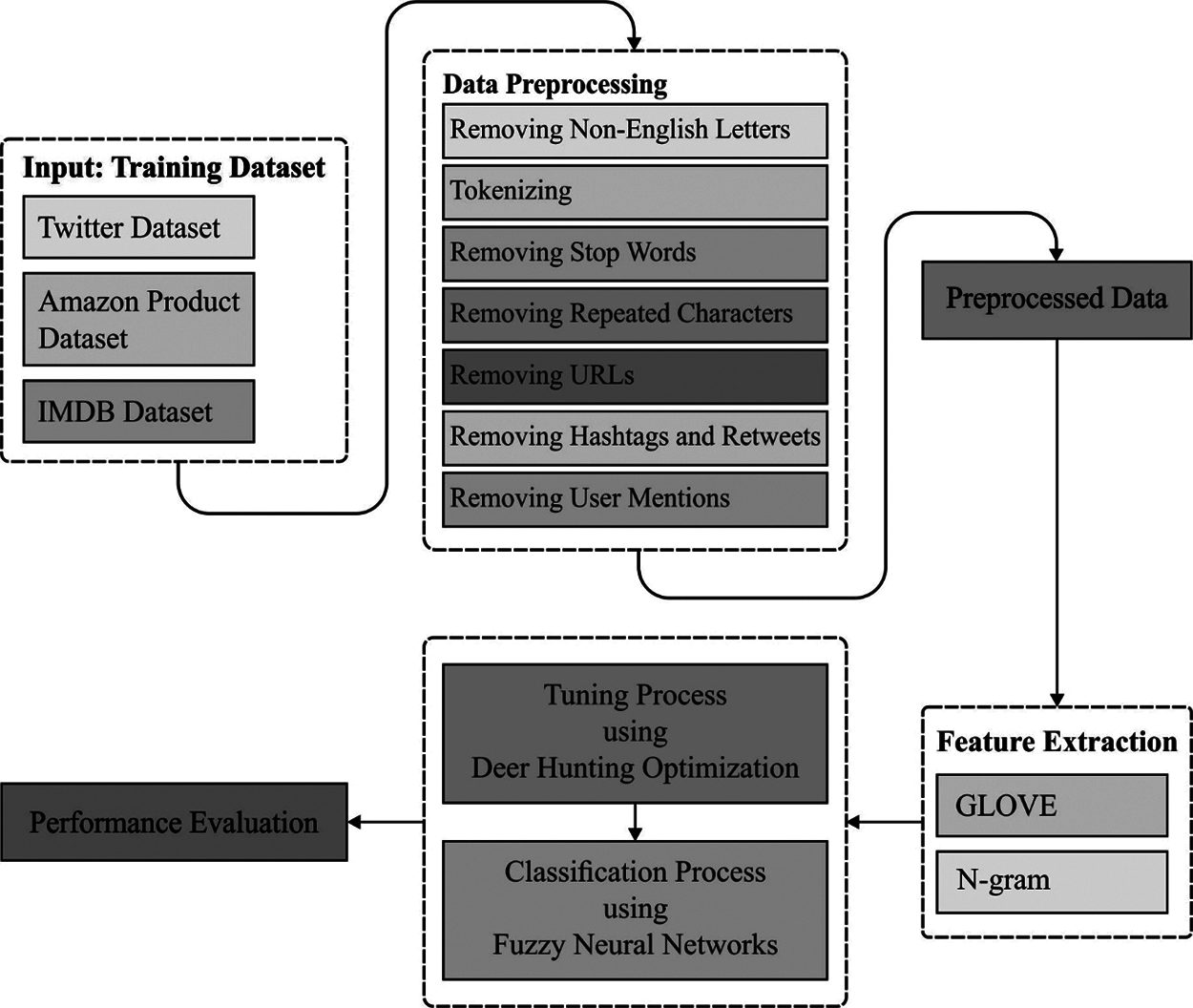
Figure 1: Overall process of DHOA-FNN model
The input dataset comprises of some of the feedbacks and opinions written by client. The dataset employed is previously classified with negative as well as positive polarities. The actual data, containing polarity, is particularly susceptible to discrepancy, irregularities, and redundancies. The framework of data controls the outcomes. To enhance the quality and efficiency of classifier procedure, the actual data requires to be pre-processed. The pre-processing task manages the research procedure which extracts the repetitive word, non-English characters, and punctuation. It improves the ability and proficiency of data. It gets rid of non-English letters, tokenization, stop words, repetitive characters, URL and user mentions, hashtag and retweets for twitter datasets, and managing emoticons.
In order to apply ML techniques in SA dataset, it is important to extract the important features which results in maximum classification outcome. The actual text data is defined as an element of Feature Set (FS), FS = (feature 1, feature 2, … feature n). During this investigation, two FE techniques are implemented such as Glove and N-gram. The GloVe technique controls the production of vector demonstration of words in the application of similarity amongst words as invariant. It utilizes two different methods such as Skip-gram and CBOW. The problems experienced in classic methods are as follows, maximal processing time, minimal accuracy, etc. An important goal of Glove is to integrate two approaches so that the optimum accuracy is confirmed. Before the creation of GloVe technique, the vector illustration of words is determined. These techniques are implemented to generate a vector with fixed dimension (say d) to all the words. This approach executes similarity between two words as invariant, where the word in similar content is regarded and demonstrates identical meaning. N-gram is used to capture the textual context to few scopes and is mostly utilized in NLP tasks. It is debated already whether the execution of a superior order of n-gram is valuable or not. Several researchers approximated that unigram is superior to bigram in categorizing the movie analyses by sentiment polarities. But different analysts and investigators establish that several analyses include dataset, bigram, and trigram demonstrate unigram.
3.3 Data Classification using FNN Technique
Once the feature vectors are generated, the next stage is data classification process which is done by FNN model. As illustrated, the connections between input and the HL are completely connected. The outcome of every hidden neuron or FSH is defined using a fuzzy membership function. The partial connections exist between hidden and outcome layers as the FSH is generated at the time of clustering. In this process, the class is interconnected with class nodes. It is witnessed that class one contains
Step 1: FSH is generated in HL of FNN by carrying out fuzzy clustering with maximal amount. In this procedure, a pattern is selected as the centroid since it can cluster the maximal pattern count of the individual class with the help of fuzzy membership function [19]. After the clustering procedure gets completed, Pruning approach is executed to reduce individual pattern cluster. The fuzzy membership function is expressed as follows.
whereas
Step 2: The outcome layer is created by constructing the class nodes interconnected with related FSH from HL, i.e., generated at the time of clustering for that class.
Clustering procedure is performed in two stages as briefed herewith. Firstly, the potential number of clusters are created and then, pruning approach is utilized to optimize the number of clusters by decreasing the individual pattern cluster. During clustering procedure, FSH/clusters are created for all the classes by taking into account, single class pattern and other class patterns.
Step 1: Here
Step 2: For every pattern, consider the maximal number of patterns it can cluster
Step 3: The patterns that cluster the maximal number of patterns gets selected as centroid and the distance between centroid and the furthest patterns in the clustered pattern is considered as the radius.
Step 4: The above mentioned step is continued till each pattern of these classes gets clustered
Step 5: Steps 1 to 4 are continued for every class
The projected method eliminates one pattern cluster, when this cluster is camouflaged by its individual class cluster. Here,
Let
Step 1. The membership value of
Step 2. When membership value for is denoted by
Step 3. Continue steps 1 & 2 for each class viz.
When the last cluster viz., FSH is generated by FCMCPA approach, the connections between the outcome and HLs are performed, as described in the previous section.
3.4 Parameter Tuning Using DHOA Technique
The efficiency of FNN model can be optimally adjusted using DHOA technique, thereby the classification performance can also be boosted.
The major goal of the presented technique is to detect the optimum location for person to hunt a deer and it is essential to examine the nature of deer. It includes particular features that create difficulty in hunting the predators. An individual feature represents visual power which is five times more than human beings. But, they exhibit challenges in viewing green and red colors. This segment discusses the mathematical modelling of DHOA with these steps.
The main step of the method is the initiation of hunter populations and is given as follows.
where
Next, the significant variables such as population initiation, deer location, and wind angles that define the optimum hunter location are initialized.
Since the searching area is assumed as a circle, the wind angle follows the circumference of a circle.
where
where
Since the location of optimum space is initially unidentified, the method considers the candidate solution near optimal position, defined by fitness function (FF), as the optimum result [20]. Now, it assumes two results i.e., leader location,
(i) Propagation via leader location: After determining the optimal location for every individual in the population, attempts are made to attain the optimum location. So, the procedure of upgrading the location also starts. Consequently, the encircling nature is demonstrated as follows.
where
where
(ii) Propagation via angle location: To improve the searching area, the idea gets expanded by assuming the location of angle in the upgraded rules. Angle estimation is necessary to define the location of hunter, thus the prey is inattentive of the attack. Henceforth, the hunting procedure gets efficient. The visualization angle of preys/deer can be calculated herewith.
According to the variance between visual and wind angles of the deer, a variable is calculated which assists the upgradation of angle location.
where
By considering the angle location, the location gets upgraded and is implemented as follows.
where
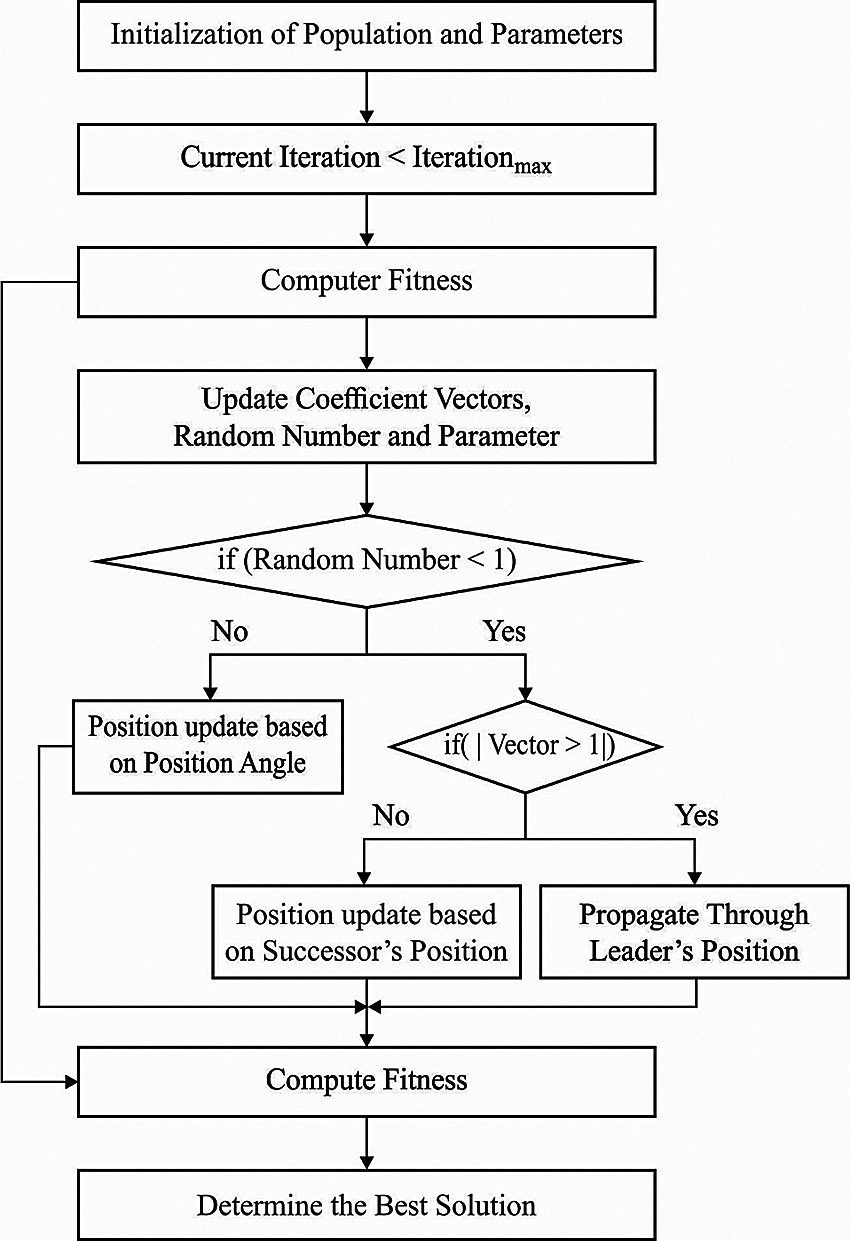
Figure 2: Flowchart of DHOA
(iii) Propagation via successor location: During exploration stage, a similar concept is adjusted in encircling nature by adopting the vector, L. At first, it considers an arbitrary searching while the value of vector L is assumed less than one. Thus, the upgrade location depends upon the location of successor instead of attaining the initial optimum solution. This permits a global searching and is given by the equation below.
where,
The presented DHOA-FNN technique was experimentally tested for its efficiency against three datasets namely IMDB, Amazon, and Twitter. The IMDB dataset has 25000 instances, the Amazon dataset has 1000 instances, and finally, the Twitter dataset has 150000 instances. All three datasets possess two class labels and the instances are equally divided. \
The results were examined under varying feature extraction techniques. Tab. 1 and Fig. 3 shows the classifier results achieved by DHOA-FNN technique on the applied IMDB dataset under four distinct feature extraction techniques. The table values point out that the proposed DHOA-FNN technique accomplished better performance under all the feature extraction techniques applied. When using unigram feature extraction technique, the proposed DHOA-FNN technique offered a high accuracy of 0.9931, whereas AdaBoost, SGD, SVM, LR, and RR techniques accomplished least accuracy values such as 0.8036, 0.8616, 0.8576, 0.8746, and 0.9916 respectively. Besides, when utilizing bigram feature extraction approach, the projected DHOA-FNN method offered a superior accuracy of 0.9995, whereas AdaBoost, SGD, SVM, LR, and RR techniques accomplished the least accuracy values such as 0.6526, 0.8496, 0.8526, 0.8526, and 0.9986 correspondingly. Similarly, when employing trigram feature extraction technique, the presented DHOA-FNN approach offered a superior accuracy of 0.9991, whereas AdaBoost, SGD, SVM, LR, and RR algorithms accomplished less accuracy values such as 0.5796, 0.7426, 0.7336, 0.7216, and 0.9986 correspondingly. At last, when using GLOVE feature extraction technique, the proposed DHOA-FNN technique accomplished high accuracy of 0.9925, while AdaBoost, SGD, SVM, LR, and RR methodologies accomplished minimal accuracy values such as 0.8169, 0.8725, 0.8726, 0.8839, and 0.9929 correspondingly.
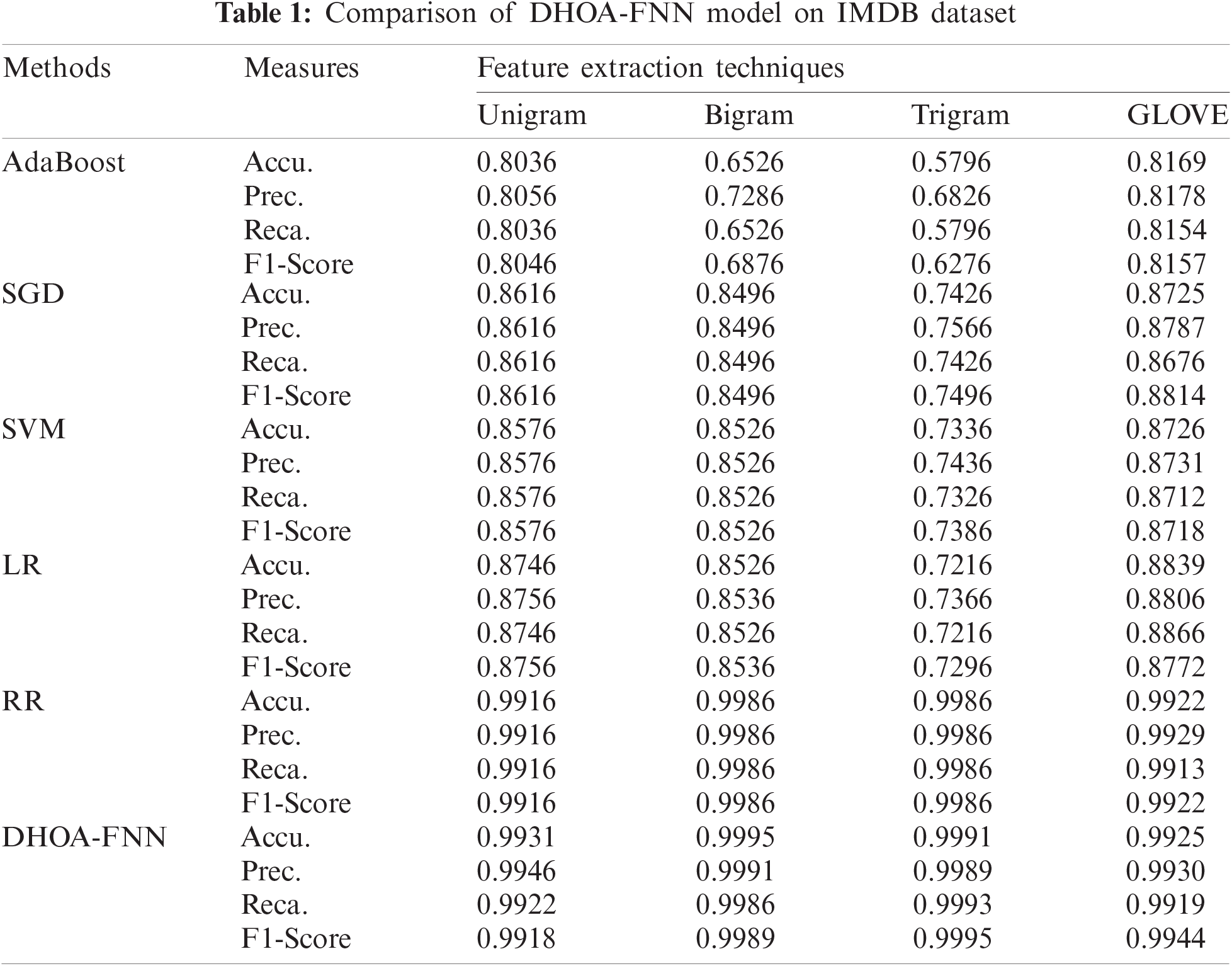
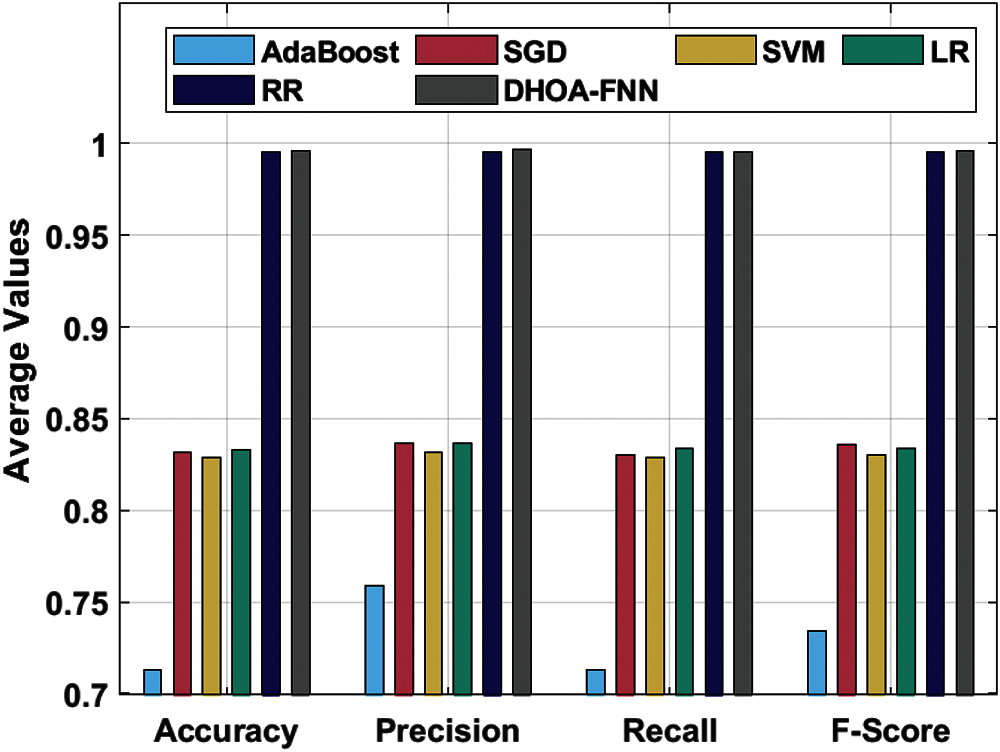
Figure 3: Result analysis of DHOA-FNN model on IMDB dataset
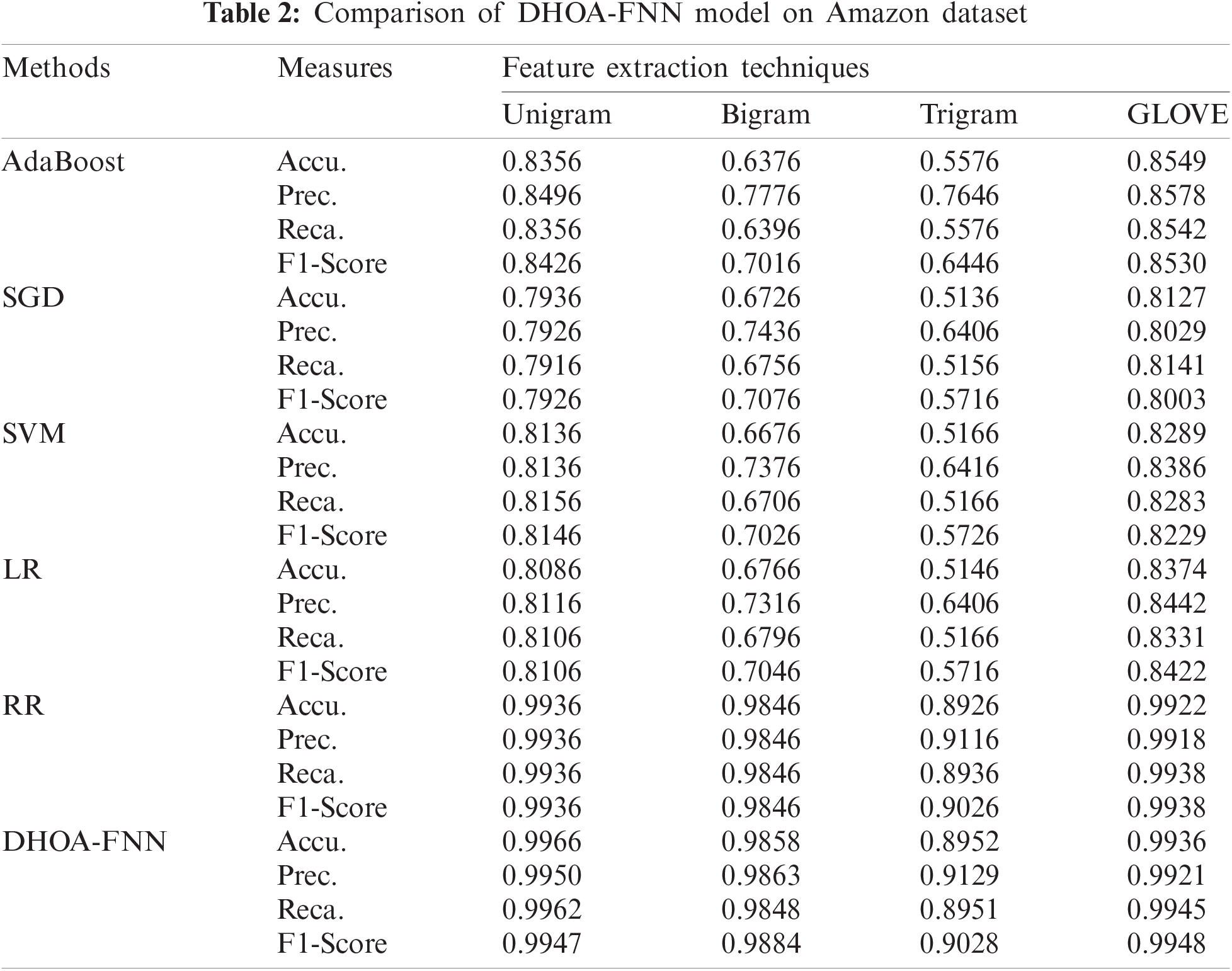
Tab. 2 and Fig. 4 shows the results of classifier outcomes achieved by DHOA-FNN approach on the applied Amazon dataset under four different feature extraction approaches. The table values point out that the proposed DHOA-FNN method accomplished better efficiency under all the feature extraction approaches applied. When utilizing unigram feature extraction approach, the projected DHOA-FNN method accomplished a maximum accuracy of 0.9966, whereas AdaBoost, SGD, SVM, LR, and RR methods accomplished the least accuracy values such as 0.8356, 0.7936, 0.8136, 0.8086, and 0.9936 correspondingly. Along with these, when using bigram feature extraction technique, the proposed DHOA-FNN technique offered a high accuracy of 0.9858, whereas AdaBoost, SGD, SVM, LR, and RR techniques accomplished the least accuracy values such as 0.6376, 0.6726, 0.6676, 0.9846, and 0.9858 respectively. Also, when using trigram feature extraction technique, the proposed DHOA-FNN technique offered an improved accuracy of 0.8952, whereas AdaBoost, SGD, SVM, LR, and RR methodologies accomplished the least accuracy values such as 0.5576, 0.5136, 0.5166, 0.5146, and 0.8926 respectively. Finally, when employing GLOVE feature extraction method, the proposed DHOA-FNN technique accomplished a superior accuracy of 0.9936, whereas the AdaBoost, SGD, SVM, LR, and RR algorithms accomplished the least accuracy values such as 0.8549, 0.8127, 0.8289, 0.8374, and 0.9922 correspondingly.
Tab. 3 and Fig. 5 shows the classification outcomes attained by the proposed DHOA-FNN algorithm on the applied twitter dataset under four different feature extraction methods. The simulation outcomes infer that DHOA-FNN technique accomplished an optimum efficiency under all the feature extraction techniques applied. When employing unigram feature extraction algorithm, the presented DHOA-FNN approach achieved an increased accuracy of 0.9374, whereas AdaBoost, SGD, SVM, LR, and RR approaches accomplished least accuracy values such as 0.6446, 0.7496, 0.7366, 0.7556, and 0.9346 correspondingly. At the same time, when using bigram feature extraction method, the projected DHOA-FNN method achieved a maximum accuracy of 0.9928, whereas AdaBoost, SGD, SVM, LR, and RR algorithms accomplished the least accuracy values such as 0.5276, 0.6566, 0.6486, 0.6586, and 0.9916 respectively. In addition, when using trigram feature extraction technique, the presented DHOA-FNN technique offered a maximum accuracy of 0.9720, whereas AdaBoost, SGD, SVM, LR, and RR methods accomplished minimal accuracy values such as 0.5116, 0.5296, 0.5386, 0.5396, and 0.9686 correspondingly. Eventually, when utilizing GLOVE feature extraction method, the projected DHOA-FNN method achieved a superior accuracy of 0.9243, whereas the AdaBoost, SGD, SVM, LR, and RR methods accomplished minimal accuracy values such as 0.6819, 0.7489, 0.7284, 0.7573, and 0.9195 correspondingly.
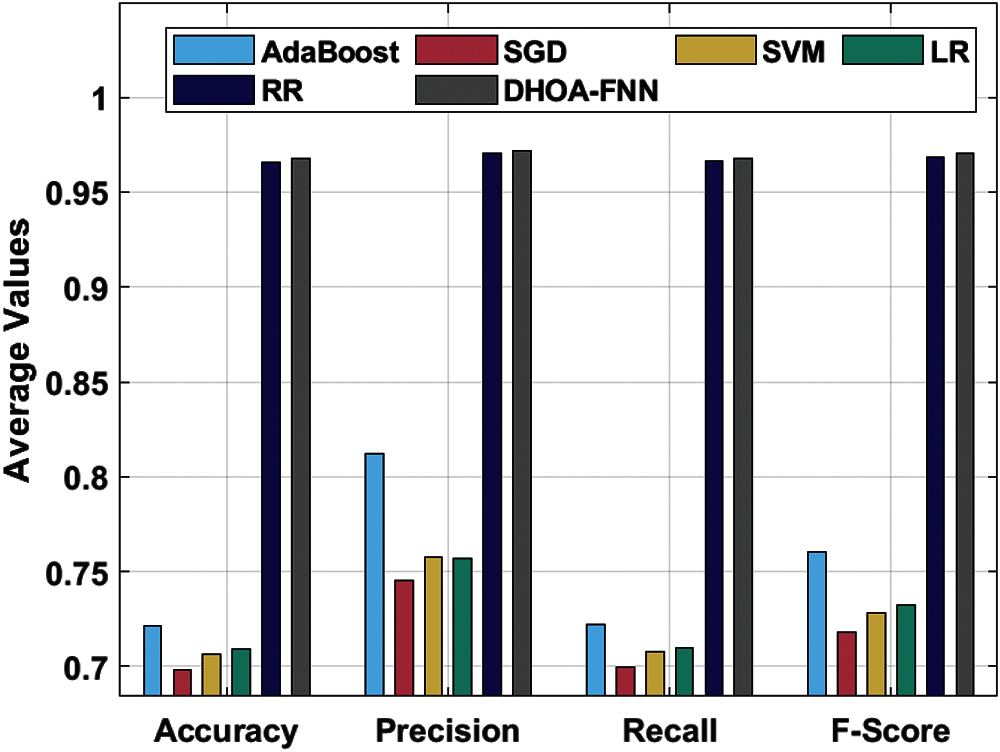
Figure 4: Results of the analysis of DHOA-FNN model on Amazon dataset
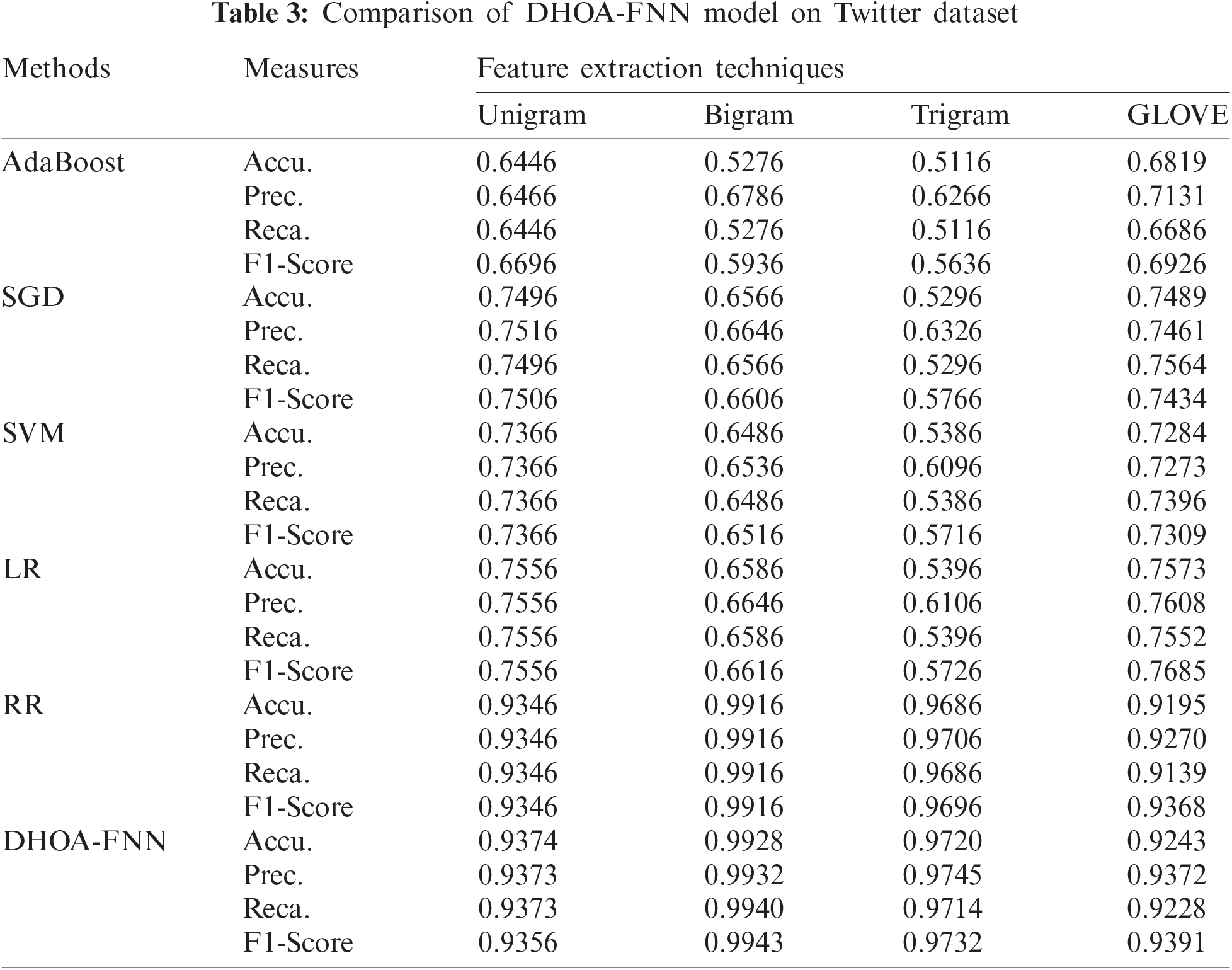
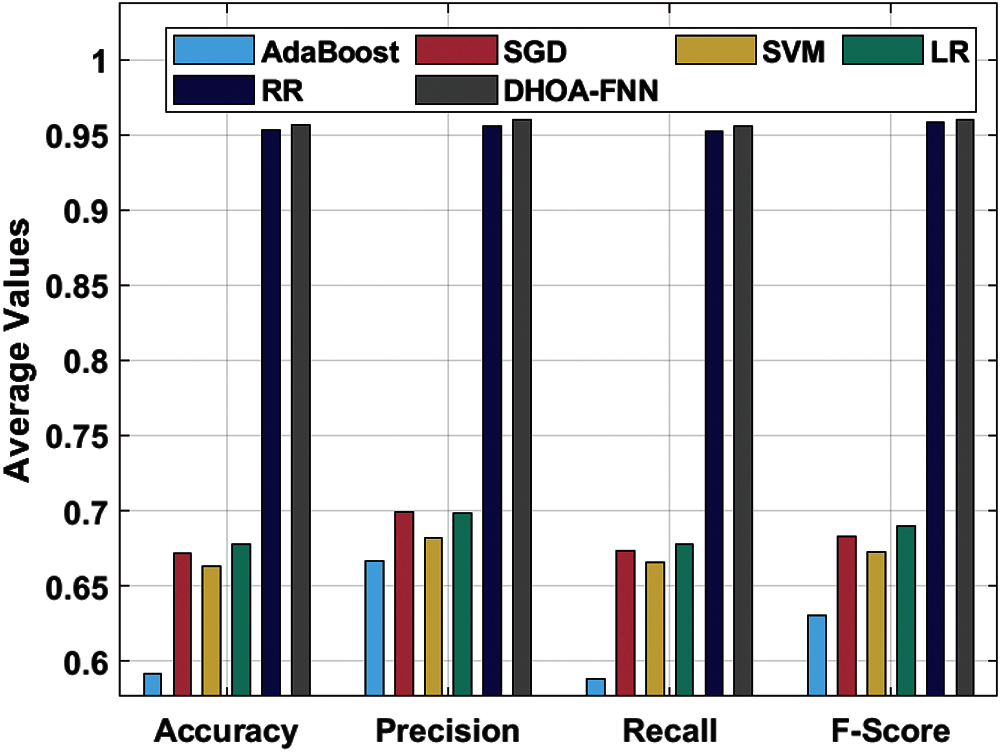
Figure 5: Results of the analysis of DHOA-FNN model on Twitter dataset
The current research paper presented a DHOA-FNN technique to mine opinions and identify the sentiments. The proposed DHOA-FNN technique involves preprocessing, feature extraction, classification, and parameter tuning processes. In addition, Glove and N-gram techniques are also employed as feature extractors which are then fed into FNN model to identify the sentiments. To enhance the efficacy of FNN technique, the parameters are optimally adjusted using DHOA. The application of DHOA, to adjust FNN variables, results in maximum classification outcome. A wide range of experimental analyses was performed on benchmark datasets and the results were inspected under different metrics. The simulation outcome highlighted the promising performance of DHOA-FNN technique over recent state-of-the-art techniques under several aspects. In future, the proposed DHOA-FNN model can be enhanced by using advanced deep learning architectures.
Funding Statement: Taif University Researchers Supporting Project Number (TURSP-2020/216), Taif University, Taif, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. W. Y. Kim, J. S. Ryu, K. I. Kim and U. M. Kim, “A method for opinion mining of product reviews using association rules,” in Proc. of the 2nd Int. Conf. on Interaction Sciences Information Technology, Culture and Human-ICIS “09, Seoul, Korea, pp. 270–274, 2009. [Google Scholar]
2. J. Uthayakumar, N. Metawa, K. Shankar and S. K. Lakshmanaprabu, “Intelligent hybrid model for financial crisis prediction using machine learning techniques,” Information Systems and e-Business Management, vol. 18, no. 4, pp. 617–645, 2020. [Google Scholar]
3. M. M. S. Missen, M. Boughanem and G. Cabanac, “Opinion mining: Reviewed from word to document level,” Social Network Analysis and Mining, vol. 3, no. 1, pp. 107–125, 2013. [Google Scholar]
4. S. K. Lakshmanaprabu, K. Shankar, D. Gupta, A. Khanna, J. J. P. C. Rodrigues et al., “Ranking analysis for online customer reviews of products using opinion mining with clustering,” Complexity, vol. 2018, pp. 1–9, 2018. [Google Scholar]
5. Z. K. Zandian and M. Keyvanpour, “Systematic identification and analysis of different fraud detection approaches based on the strategy ahead,” International Journal of Knowledge-Based and Intelligent Engineering Systems, vol. 21, no. 2, pp. 123–134, 2017. [Google Scholar]
6. S. Sankhwar, D. Gupta, K. C. Ramya, S. Sheeba Rani, K. Shankar et al., “Improved grey wolf optimization-based feature subset selection with fuzzy neural classifier for financial crisis prediction,” Soft Computing, vol. 24, no. 1, pp. 101–110, 2020. [Google Scholar]
7. P. Barnaghi, P. Ghaffari and J. G. Breslin, “Opinion mining and sentiment polarity on twitter and correlation between events and sentiment,” in 2016 IEEE Second Int. Conf. on Big Data Computing Service and Applications (BigDataServiceOxford, United Kingdom, pp. 52–57, 2016. [Google Scholar]
8. D. N. Le, V. S. Parvathy, D. Gupta, A. Khanna, J. J. P. C. Rodrigues et al., “IoT enabled depthwise separable convolution neural network with deep support vector machine for COVID-19 diagnosis and classification,” International Journal of Machine Learning and Cybernetics, pp. 1–14, 2021. https://doi.org/10.1007/s13042-020-01248-7. [Google Scholar]
9. A. Rajagopal, A. Ramachandran, K. Shankar, M. Khari, S. Jha et al., “Optimal routing strategy based on extreme learning machine with beetle antennae searching algorithm for low earth orbit satellite communication networks,” International Journal of Satellite Communications and Networking, vol. 39, no. 3, pp. 305–317, 2021. [Google Scholar]
10. G. Sidorov, S. M. Jiménez, F. V. Jiménez, A. Gelbukh, N. C. Sánchez et al., “Empirical study of machine learning based approach for opinion mining in tweets,” in Mexican Int. Conf. on Artificial Intelligence, San Luis Potosí, Mexico, pp. 1–14, 2012. [Google Scholar]
11. D. Gamal, M. Alfonse, E. S. M. El-Horbaty and A. B. M. Salem, “Analysis of machine learning algorithms for opinion mining in different domains,” Machine Learning and Knowledge Extraction, vol. 1, no. 1, pp. 224–234, 2018. [Google Scholar]
12. R. Alfrjani, T. Osman and G. Cosma, “A hybrid semantic knowledgebase-machine learning approach for opinion mining,” Data & Knowledge Engineering, vol. 121, no. 7, pp. 88–108, 2019. [Google Scholar]
13. M. Keyvanpour, Z. K. Zandian and M. Heidarypanah, “OMLML: A helpful opinion mining method based on lexicon and machine learning in social networks,” Social Network Analysis and Mining, vol. 10, no. 1, pp. 10, 2020. [Google Scholar]
14. A. K. P. Dubey and S. Agrawal, “An opinion mining for indian premier league using machine learning techniques,” in 2019 4th Int. Conf. on Internet of Things: Smart Innovation and Usages (IoT-SIUGhaziabad, India, pp. 1–4, 2019. [Google Scholar]
15. L. Tavoschi, F. Quattrone, E. D’Andrea, P. Ducange, M. Vabanesi et al., “Twitter as a sentinel tool to monitor public opinion on vaccination: An opinion mining analysis from September 2016 to August 2017 in Italy,” Human Vaccines & Immunotherapeutics, vol. 16, no. 5, pp. 1062–1069, 2020. [Google Scholar]
16. K. Zvarevashe and O. O. Olugbara, “A framework for sentiment analysis with opinion mining of hotel reviews,” in 2018 Conf. on Information Communications Technology and Society (ICTASDurban, South Africa, pp. 1–4, 2018. [Google Scholar]
17. Y. Jeong, S. Kim and B. Yoon, “An algorithm for supporting decision making in stock investment through opinion mining and machine learning,” in 2018 Portland Int. Conf. on Management of Engineering and Technology (PICMETHonolulu, HI, pp. 1–10, 2018. [Google Scholar]
18. M. L. B. Estrada, R. Z. Cabada, R. O. Bustillos and M. Graff, “Opinion mining and emotion recognition applied to learning environments,” Expert Systems with Applications, vol. 150, pp. 113265, 2020. [Google Scholar]
19. A. Kulkarni and N. kulkarni, “Fuzzy neural network for pattern classification,” Procedia Computer Science, vol. 167, pp. 2606–2616, 2020. [Google Scholar]
20. G. Brammya, S. Praveena, N. N. Preetha, R. Ramya, B. Rajakumar et al., “Deer hunting optimization algorithm: A new nature-inspired meta-heuristic paradigm,” The Computer Journal, 2019. https://doi.org/10.1093/comjnl/bxy133. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |