DOI:10.32604/cmc.2022.023716
| Computers, Materials & Continua DOI:10.32604/cmc.2022.023716 | |
| Article |
Enhancing Task Assignment in Crowdsensing Systems Based on Sensing Intervals and Location
1Faculty of Computers and Information, Mansoura University, Mansoura, 35516, Egypt
2Faculty of Computers and Artificial Intelligence, Benha University, Banha, 13518, Egypt
3Faculty of Computer Science and Engineering, Galala University, Suez, 435611, Egypt
4College of Computer and Information Systems, Umm Al-Qura University, Mecca, 715, Saudi Arabia
*Corresponding Author: Louai Alarabi. Email: lmarabi@uqu.edu.sa
Received: 18 September 2021; Accepted: 23 November 2021
Abstract: The popularity of mobile devices with sensors is captivating the attention of researchers to modern techniques, such as the internet of things (IoT) and mobile crowdsensing (MCS). The core concept behind MCS is to use the power of mobile sensors to accomplish a difficult task collaboratively, with each mobile user completing much simpler micro-tasks. This paper discusses the task assignment problem in mobile crowdsensing, which is dependent on sensing time and path planning with the constraints of participant travel distance budgets and sensing time intervals. The goal is to minimize aggregate sensing time for mobile users, which reduces energy consumption to encourage more participants to engage in sensing activities and maximize total task quality. This paper introduces a two-phase task assignment framework called location time-based algorithm (LTBA). LTBA is a framework that enhances task assignment in MCS, whereas assigning tasks requires overlapping time intervals between tasks and mobile users’ tasks and the location of tasks and mobile users’ paths. The process of assigning the nearest task to the mobile user's current path depends on the ant colony optimization algorithm (ACO) and Euclidean distance. LTBA combines two algorithms: (1) greedy online allocation algorithm and (2) bio-inspired travel-distance-balance-based algorithm (B-DBA). The greedy algorithm was sensing time interval-based and worked on reducing the overall sensing time of the mobile user. B-DBA was location-based and worked on maximizing total task quality. The results demonstrate that the average task quality is 0.8158, 0.7093, and 0.7733 for LTBA, B-DBA, and greedy, respectively. The sensing time was reduced to 644, 1782, and 685 time units for LTBA, B-DBA, and greedy, respectively. Combining the algorithms improves task assignment in MCS for both total task quality and sensing time. The results demonstrate that combining the two algorithms in LTBA is the best performance for total task quality and total sensing time, and the greedy algorithm follows it then B-DBA.
Keywords: Mobile crowdsensing; online task assignment; participatory sensing; path planning; sensing time intervals; ant colony optimization
The popularity of mobile devices that consists of internal sensors (camera, temperature, microphone, GPS, Wi-Fi/3G/4G interfaces, accelerometer, etc.) and external sensors (Google glass, healthcare sensors, wearable sensors, etc.) is captivating the attention of researchers for the internet of things (IoT) [1,2] and mobile crowdsensing (MCS) [3,4] techniques. MCS is a novel paradigm of crowdsourcing that is a methodology in which many people use their mobile sensors for sensing, collecting, sharing data, and extracting information to analyze [5].
Comparing MCS with traditional sensor networks, one of the significant benefits is the active participation of workers in the collection and sharing of sensing data. This is attributed to that MCS is a powerful paradigm because of has extraordinary sensing requirements [5–8]. The sensing requirements, communication capabilities, and computation allow smartphones to execute more complicated tasks. There are many applications examples of MCS include intelligent transportation [9], air quality monitoring [10], road traffic monitoring [11], surface monitoring of road pavements [12], noise level sensing, location-based/mobile/spatial crowdsourcing, smart cities, etc.
Participatory sensing and opportunistic sensing are the two paradigms of MCS. Active engagement of mobile users is not required in opportunistic sensing [13], and mobile users typically walk along predetermined pathways or follow movement patterns driven by their everyday schedules, tastes, or desires. Mobile devices may be designed to capture sensing data when their owners travel automatically. Mobile users are expected to travel to certain task sites to complete those activities in participatory sensing [14]. The motions of such users are planned around delegated sensing tasks, and their participation is voluntary and regulated.
Mobile crowdsensing had many challenges for research, such as maximizing data and tasks quality, minimizing sensing cost, privacy guarantee, the storage and energy limitation of mobile node resources, and task assignment. To overcome these challenges, this work focuses on the tasks assignment considering various constraints, such as spatial coverage travel budget, energy consumption, travel cost, sensing time intervals, and sensing task quality [15]. To maximize the sensed data quality, the scenario allocated sensing tasks to a suitable number of participants in a certain area with minimum sensing time.
MCS process consists of: (1) requesters, who send tasks, (2) workers, who have sensor-rich devices, and (3) platform, which receives sensing tasks from requesters and allocates them to workers then sends data back to requesters. The relationship between workers and tasks is critical to the success of MCS applications. The sensing tasks are an essential part of the sensing process.
Selecting tasks for a mobile user might be difficult because different task assignment schemes have varying assignment criteria. Therefore the online task assignment problem for MCS is described in this work. There are many challenges for allocating tasks for a mobile user:
▪ Challenge 1: There is a large number of sensing tasks for a large number of participants, and a single mobile user may participate in multiple sensing tasks. The sensing tasks need data from various sensors at various times.
▪ Challenge 2: Encourage more people to engage in sensing activities.
▪ Challenge 3: Determine whether the task has the smallest increasing aggregate sensing time assigned to a mobile user.
▪ Challenge 4: Locating the nearest task for the mobile user whose total travel budget is less than the worker's total travel distance.
To address these challenges, there are two mechanisms. First, reducing the total sensing time of mobile users reduces energy consumption to encourage more participants to engage in sensing activities. Second, determining the location of both mobile users and tasks then choosing the nearest task to the mobile user's path. This work presents a framework location time-based algorithm (LTBA). The framework works on reducing total sensing time based on overlapping in sensing time intervals and assigning the nearest task to the path of the mobile user. Reducing total sensing time and increasing task quality incentivizes mobile users to participate in mobile crowdsensing applications.
LTBA enhances performance metrics for total tasks quality and aggregate sensing time. LTBA combines two algorithms: (1) greedy online allocation algorithm [16,17] and (2) bio-inspired travel-distance-balance-based algorithm (B-DBA) [18]. B-DBA was location-based and worked on maximizing total task quality. The greedy algorithm was sensing time interval-based and worked on reducing the overall sensing time of the mobile user. Combining the algorithms improves task assignment in MCS for both total task quality and sensing time of both mobile users and tasks.
The scenario has a sensing task set T and a mobile worker set M that arrive in sequence at the service platform. Their arrival obeys a Poisson distribution without knowing what will happen next. The service platform must reply to each incoming request, and delegate tasks in the tasks set T to users in the users set M. The smartphone's sensing capabilities can be fully utilized. Because of location privacy for mobile users in mobile crowdsensing, the cases focused on where they are anonymous, and no single mobile user's contribution history is tracked.
The main contributions of this paper are summarized as follows:
▪ This work formulates and enhances the problem of sensing tasks assignment in MCS by a tradeoff between maximizing total tasks quality and minimizing aggregate sensing time.
▪ Considering two critical attributes: sensing time of mobile user and location of both tasks and mobile user.
▪ For improving tasks assignment, this work proposes a combination of two algorithms: (1) greedy online allocation algorithm and (2) B-DBA.
▪ Overlapping or covering in the sensing time interval, in this scenario, the service platform divides the available tasks into two task groups based on the complete or partial intersection in time intervals of tasks and mobile user's task pool.
▪ Determining the nearest task. The service platform chooses the nearest task in the available task set to the mobile user's path without exceeding budget constraints for increasing task quality. Selecting tasks depends on the ant colony optimization algorithm (ACO) [19] and Euclidean distance.
▪ Both synthetic and real-world data are used. The synthesis data set is used to generate information on tasks and mobile users. The real data set is for the location of both tasks and mobile users.
The rest of the paper is structured as follows. Section 2 introduces previous work. Section 3 formulates the task assignment problem and designs the system models. Section 4 discusses in detail the combination of two task assignment algorithms. Section 5 discusses the results’ simulation for success assessment. Finally, Section 6 concludes the work and represents the future direction.
In this section, some previous work that studied task assignment problems based on two attributes: sensing time and location of both sensing tasks and mobile users are addressed. MCS employs smartphones to collect data on a much bigger scale than is possible with traditional methods. Selecting tasks for a mobile user might be difficult because different task assignment schemes have varying assignment criteria and objectives. For example, Zhao et al. [16,17] introduced two allocation algorithms, approximation algorithm for offline model and greedy algorithm for the online model. Allocating tasks with mobile users was depended on time overlapping between tasks’ sensing intervals that needed the same sensing services from mobile users. They focused on the energy consumption of smartphones, fairness in assigning tasks, and task arrivals that were dynamic and unexpected. They did not work on heterogeneous sensing tasks or with flexible times’ starting and ending and concentrated on reducing smartphone sensing time, but no energy savings have been reported.
Gong et al. [18,20] designed four algorithms to assign workers based on the location of tasks and the current location of workers to increase task quality. Whereas quality/progress-based algorithm (QPA) chose the work with the highest task quality increment to trip cost ratio, task density-based (TDA) tended to direct users to high task-density regions. At the same time, travel-distance-balance-based (DBA) considered journey distance balance information. Bio-inspired travel-distance-balance-based (B-DBA), the final algorithm, combines the travel-distance-balance-aware measure in DBA with a bio-inspired search to further boost job assignment performance. One type of task was assigned to workers.
Wang et al. [21] used spatiotemporal correlations to address heterogeneous crowdsensing tasks. They involved all sharing the same resources but had different spatiotemporal granularities. They used assignment stages such as intra- and inter-task. To enhance the time efficiency, they developed a decomposition-and-combination framework. They aimed to improve data quality while reducing the total incentive budget.
Xia et al. [22] employed geoindistinguishability to make workers’ location privacy more secure and minimize workers’ travel distance. So, they designed two probability-based distance comparison mechanisms, the worker-based distance comparison mechanism (WDCM) and the task-based distance comparison mechanism (TDCM). Yin et al. [23] introduced task assignment in crowdsourcing platforms by allocating one task to multiple workers using a many-to-one matching approach. They focused on budgetary limits, quality requirements of tasks, and heterogeneity in sensing tasks and workers. Tao et al. [24] worked on the task assignment that depended on the location of both workers and tasks to maximize data quality and increase worker profit. They provided a genetic algorithm (GA) and a detective algorithm (DA).
Miao et al. [25,26] assigned crowdsourcing task allocation dependent on participant position. The aim is to use a quality-aware online task assignment (QAOTA) algorithm to improve overall efficiency for location-based tasks. Gad-ElRab et al. [27] classified tasks based on sensors that required providing interval tree structure in interval tree-based task scheduling method (ITBTS) and determined the overlapping between sensing time instances to minimize the energy consumption and time for the sensing process. Lai et al. [28] focused on the sensitive duration of each task and the capabilities of participants. The objective was to increase the number of tasks that were completed. For allocating tasks to participants, that article used a greedy heuristic algorithm. Xiao et al. [29] studied mobile social networks (MSNs) using MCS to solve the makespan-sensitive task assignment. The goal for different types of sensing tasks was minimizing the average or the largest makespan. Average makespan sensitive online task assignment (AOTA) algorithm and the largest makespan sensitive online task assignment (LOTA) algorithm.
Wu et al. [30] evaluated the extrinsic and intrinsic ability of mobile users for allocating tasks. A modified Thompson sampling worker selection (MTS-WS) algorithm was context-aware that was designed to evaluate a worker's service quality. Huang et al. [31] outlined task assignments based on the performing task time. They illustrated a task assigning technique called the optimized allocation scheme of time-dependent tasks (OPAT) to increase each mobile user's sensing capacity.
The previous studies focused on the sensitive duration of tasks, sending tasks, receiving results, context or location. Tab. 1 summarizes previous literature on task assignment problems in MCS. This paper addresses the task assignment, total sensing time, and path planning problem. The requests of mobile crowdsensing tasks determine the time interval for sensing the required data in specific regions. For the mobile user's tour, he moves from his starting point to his destination. In contrast, this work differs from them in terms of problem definition. It redefines the task assignment problem by working with task sensing time interval and location for both tasks and mobile users’ constraints. Combining the two metrics improves the task assignment process in MCS, increasing the total task quality and reducing the overall aggregate sensing time.
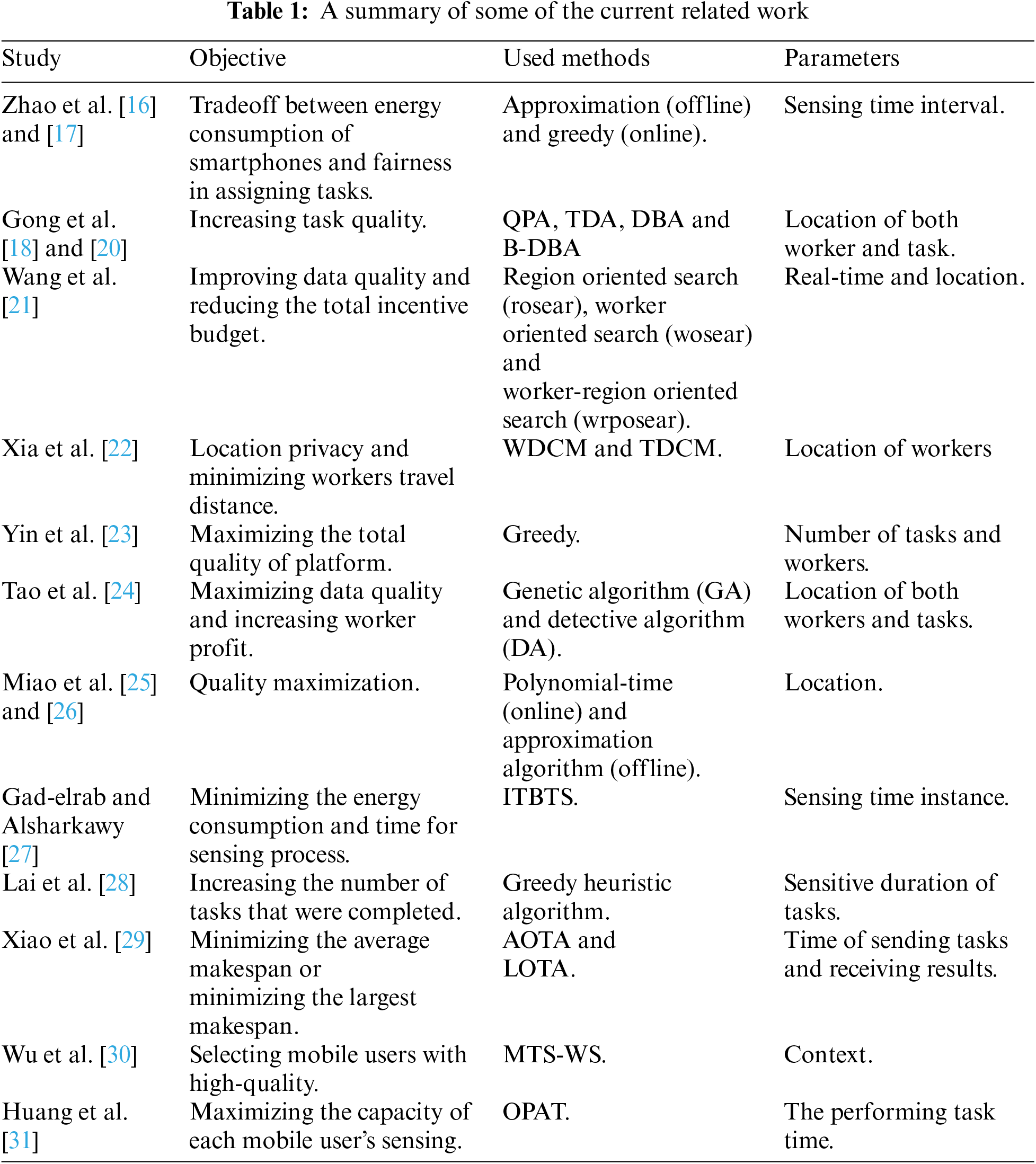
This section discusses the system model and constructs the problem of online task assignment based on two constraints: (1) task sensing time interval and (2) location for both task and mobile user (the starting location and predetermined destination). The next subsections illustrate the system model, task model, mobile user model, and algorithm design. Fig. 1 illustrates the proposed framework. The proposed framework is explained in detail in Subsection 3.4. The proposed framework consists of three phases. First, the preprocessing phase sets available tasks into task set T and mobile users into worker set M. Second, overlapping or covering in time interval phase divides the available tasks into two task groups based on a complete or partial intersection in time intervals of tasks and worker's task pool. Third, determining the nearest task phase chooses the nearest task in the available task set T to mobile user mi path.
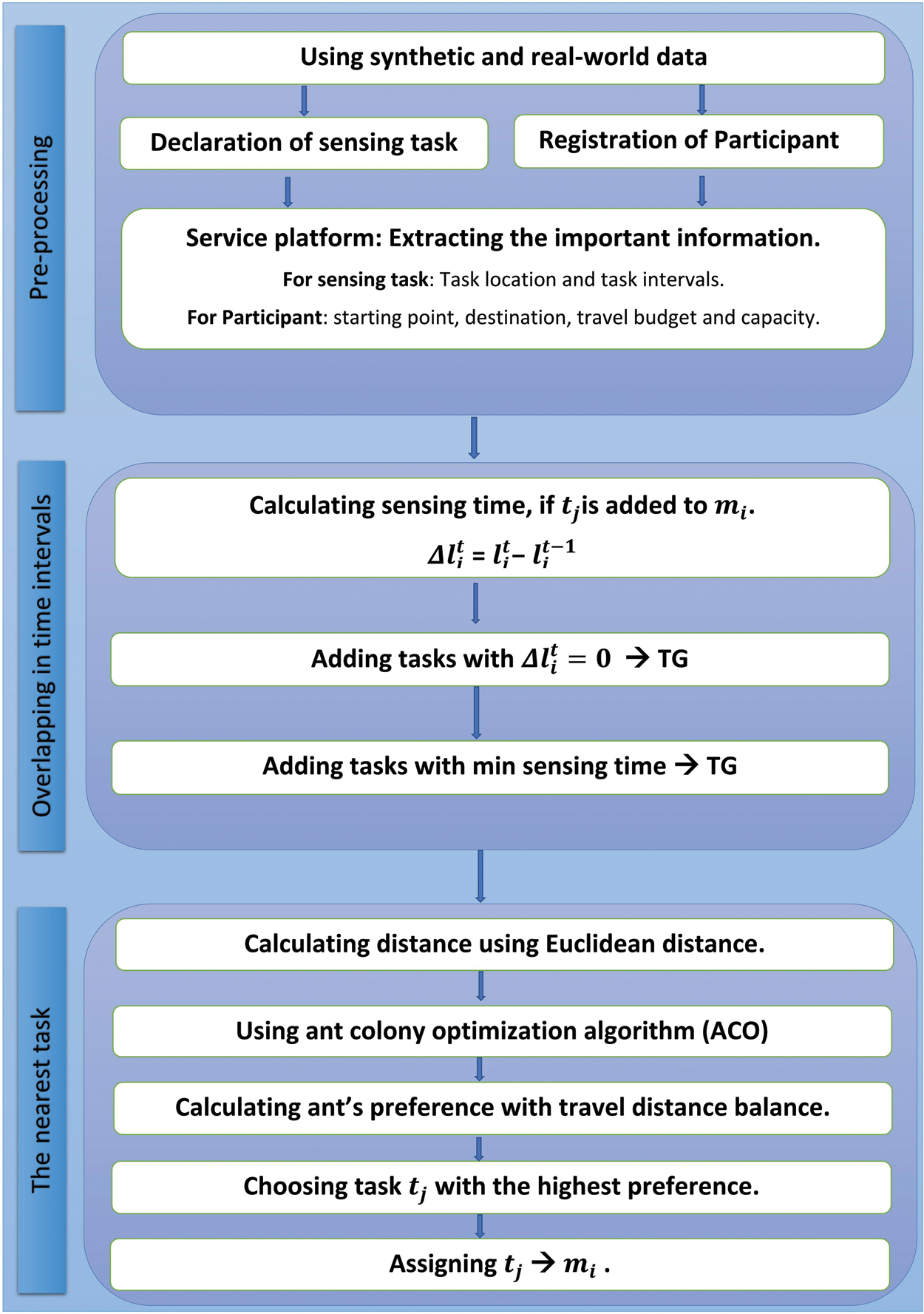
Figure 1: The framework of location time-based algorithm (LTBA)
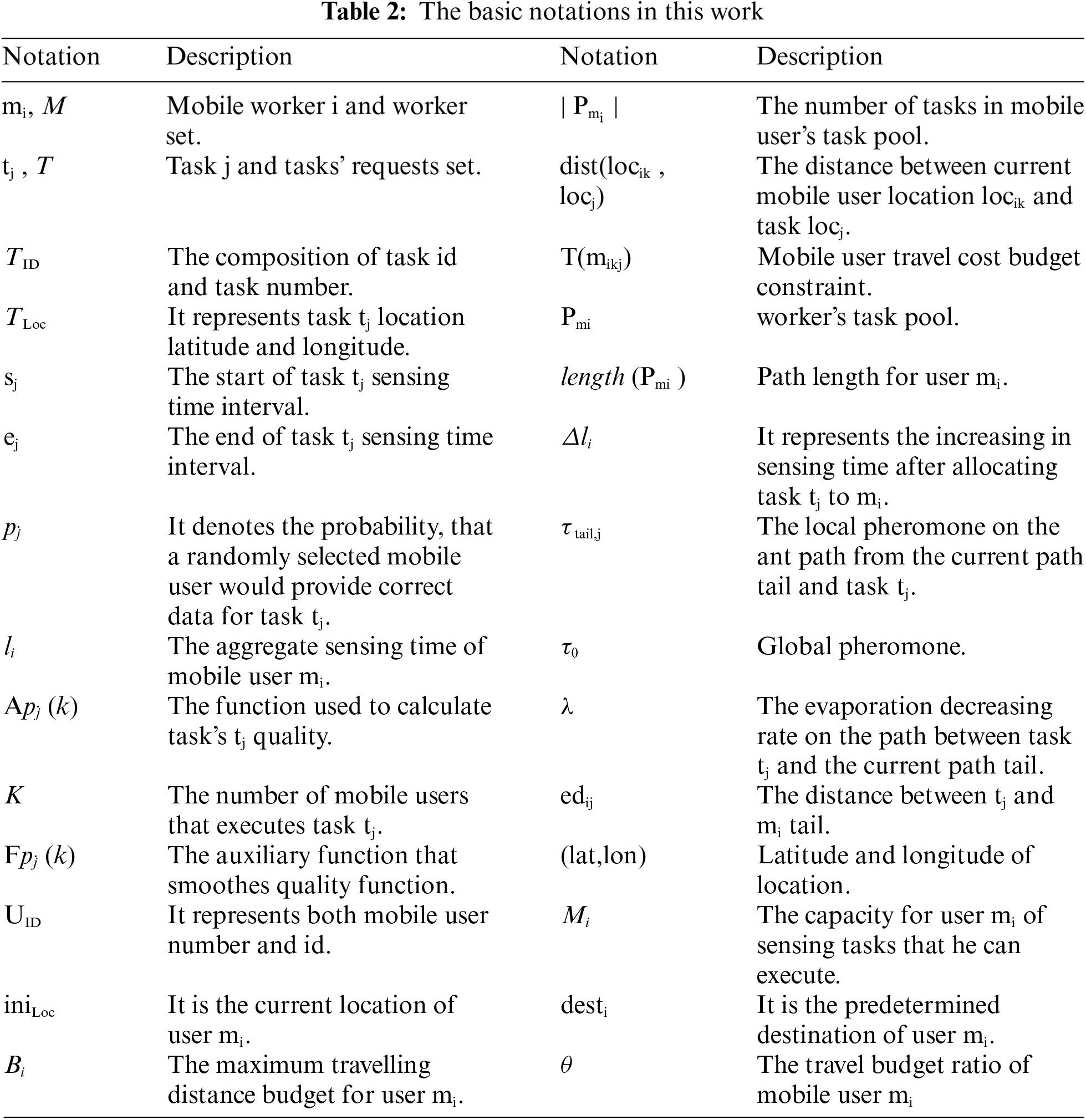
In the MCS sensing process, a mobile user mi has a tour from his starting point to his destination. The requests of mobile crowdsensing tasks determine the time interval for the sensing required data in specific regions. A mobile user mi is allocated with sensing tasks in mi path without exceeding mi travel budget. In a real-time system, requesters’ mobile users and tasks arrive at the service platform online sequentially. The service platform must reply to each incoming request without knowing what will happen next. Because of location privacy for mobile users in MCS, this work focuses on cases where users are anonymous, and no single mobile user's contribution history is tracked. The assignment is dependent on the tasks that are still available on the service platform that have arrived and have not yet expired. The algorithm regards tasks that demand the same sensing service from mobile users to be homogeneous. Tab. 2 shows a list of notations that are used in this work.
Requesters send sensing tasks to the service platform that are published dynamically upon their arrival. The sensing tasks set are denoted T = {t1, t2, ….., tn} every task has attributes such as tj = {TID, TLoc, sj, ej,
where
▪ for odd values of k:
▪ else,
where k is the number of mobile users that perform task tj and a non-negative integer.
▪ for zero and odd values of k:
▪ else
The mobile user intended to travel from his or her current location to a destination. The service platform assigns tasks to mobile users’ tours to perform without exceeding their travel budget. Every mobile user sends his information to the service platform. Mobile users set is denoted as M = {m1, m2, …., mm}. Every user has attributes such as mi = {UID, iniLoc, desti,
▪ Mobile user sensing time constraint:
▪ Mobile user capacity constraint:
▪ Mobile user travel cost budget constraint:
▪
where Δlij = lij−li. li is the sensing time of mobile user mi. lij is the sensing time of mi after assigning task tj. Δlij = 0 means that the sensing interval of task tj is within a task interval in
The sensing tasks and mobile users arrive at the service platform upon arrival rate. At each time instance, the service platform schedules available tasks in task set T and available mobile user in worker set M based on the sensing time interval of each task and location of both tasks and workers. LTBA algorithm consists of three phases:
1) Preprocessing phase: In this phase, the service platform sets available tasks into task set T and mobile users into worker set M. To explain this phase in detail, at each time instance of arrival rate, the service platform adds the arrival tasks to task set T and the arrival mobile user to worker set M, then extracts tasks’ attributes (i.e., location TLoc, start sensing time sj, end sensing time ej and task correctness
2) Overlapping or covering in time interval phase: In this phase, the service platform divides the available tasks into two task groups based on the complete or partial intersection in time intervals of tasks and worker's task pool. To explain this phase in detail, mi in worker set Δlij is determined for each mobile user, representing the increasing sensing time for mi after allocating task tj to him, where Δlij = lij−li.
For example, a mobile user mi has task tj [2,5] in task pool
1. In the case of adding tx to
2. In the case of adding ty is
3. In the case of adding tz to
From the previous example, the delta sensing Δlij and the sensing time lij are smaller in cases 1 and 2. In case1, tx is covered by tj. In case 2, there is an overlapping between tj and ty. So, the chance of choosing these tasks for the next phase is greater. Then dividing available task set into two groups, one has tasks with smaller sensing time and the other with greater sensing time. In this phase, the algorithm uses two rules [16]. “Rule 1: assigning a task to a smartphone if it can be fulfilled by other tasks already assigned to that smartphone. Rule 2: assign a task to the smartphone with the shortest aggregate sensing time if the task were to be assigned.
3) Determining the nearest task phase: In this phase, the service platform chooses the nearest task in the available task set T to mobile user mi path. To explain this phase in detail, use the task group TGi with smaller sensing time from the previous phase to find the nearest mobile user mi that exceeds the mobile user's budget. The algorithm uses B-DBA [18]. Selecting the nearest tasks process depends on the ACO algorithm and Euclidean distance [32].
For ACO, intelligent ants begin their moves to search for food randomly. When an ant finds food, it returns to the colony and leaves a trail of pheromones. Other ants use that route in search of food if they detect the pheromone. The pheromone fades with time, preventing the algorithm from reaching a local optimum solution. The basic idea of B-DBA was dependent on the bio-inspired search and travel distance. B-DBA works as follows: it consists of rounds where (round > 1). Each round has a group of ants that move from the user's current position and all available tasks to the destination. In the first round, the initial global pheromone τ0 is the same for each task location. Then measure preferences of the available tasks using Eq. (10) for each ant to select the next task's location in the user's tour.
Euclidean distance between two locations:
where τtail,tj denotes local pheromone between the current user's location and task tj. ε, γ and α are weighting parameters.
The chance of selecting task tj as the next task depends on its probability and performance value. The highest preference value of task tj gives a high probability to tj to be chosen as the next task. The pheromone on the path between task tj and the current path tail is reduced by evaporation rate λ, when selecting tj as the next task. For updating local pheromone:
After determining all ants’ pathways for one round, select the two highest increments of task quality of two ants. The best two ant's global pheromones of task locations are increased by τ0 for the best ant and τ0/2 for the second-best ant, on the path that they follow, then a new round starts after all local pheromones have been modified to match their global pheromones.
Algorithm 1 illustrates the steps of the LTBA scenario. New tasks from available tasks are assigned to mobile users at every arrival without exceeding the budget and capacity constraints. Line 2 initializes, sensing time, delta, and creates task group TGi set. Lines 3 and 4 calculate sensing time by CalcSensingTime() function at Algorithm 2 and delta sensing time for each task tj, if it is added to the worker's task pool. Lines from 5 to 9 check if task covered by any tasks in worker's pool, then add tj to TGi else add sensing time and delta sensing to subsets Δ, TL. Line 12 checks for overlapping and append those tasks with minimum delta and sensing time to TGi. Line 13 calls TGi to TheClosestTask () function.
CalcSensingTime () at Algorithm 2 checks the length of the worker's pool to determine sensing time then return it. TheClosestTask () function at Algorithm 3 is used to find the nearest task tj in the mobile user mi path. Line 2 determines the global pheromone for the tasks in TGi. Using iteration of rounds to select the nearest task. Line 4 uses a global pheromone as a local pheromone. Line 5 makes iterations for a group of ants to select the best next task. Lines from 6 to 11 calculate preference for each task, and the task with the maximum preference is selected, then update the local pheromone of the chosen task. At the end of ant iterations, choose the best two ants, update the global pheromone of tasks chosen, and start a new round iteration. Line 16 adds the nearest task tj to the worker's pool

In this section, the performance is measured using two metrics: total task quality and aggregate sensing time. This work aims to reduce total sensing time that reduces energy consumption, and increase the quality of tasks metrics to encourage more participants and tasks requesters to engage in sensing activities. The default parameter settings are discussed in the next subsection. The B-DBA and greedy online allocation algorithms are used as the performance comparison baseline with LTBA. The used dataset and simulation settings are illustrated in the next Subsections 4.1 and 4.2.


This paper uses both synthetic and real-world datasets. The synthesis data set is used to generate information on tasks and mobile users. The real data set is for the location of both tasks and mobile users. Gowalla [33] is the real data set, a location-based social networking service where users check in to report their whereabouts. It contains user-id, check-in time, latitude, longitude, and location id. The location of tasks and mobile users is selected spatially uniformly distributed from 5000 data set records.
The algorithms were implemented using MATLAB R2018a and running on a laptop with 16 GB memory and Intel Core i7-8550U CPU. Both synthesis and real datasets are used. Calculating the average of total tasks quality performance by:
where n is the number of tasks, and aggregate sensing time by:
The default parameters for sensing tasks are as follows: the arrival rate, location, the end of sensing task intervals, and the probability of task correctness. Poisson distribution is used to determine the arrival rate for tasks that are spatially uniformly distributed. The task arrival rate is set to 2.0 by default. The task-lasting time intervals follow a normal distribution with default mean and standard deviation values of 100 and 30, respectively. The probability of a task correctness pj follows a normal distribution with 0.8 and 0.15 as the default mean and standard deviation, respectively.
The default parameters for mobile users are as follows: the arrival rate, the current location, the travel budget ratio, and capacity. For the arrival rate, Poisson distribution is used and set to 1.0 by default. The starting location and predetermined destination are spatially uniformly distributed. The shortest trip distance between mobile users’ starting location and destination is denoted as travel budget ratio (≥1) that follows a normal distribution with default 1.5 and 0.6 values for mean and standard deviation, respectively. Capacity is set to 3.
The default setting for LTBA and DBA parameters, γ is 1, weighting parameters ε is 3, evaporation rate λ is 0.9. Furthermore, the round number and the ant population size are set to 30 and 30, respectively. Euclidean distance is used to measure the distance between tasks’ location and the mobile user's current location. The default parameter settings are displayed in Tab. 3.
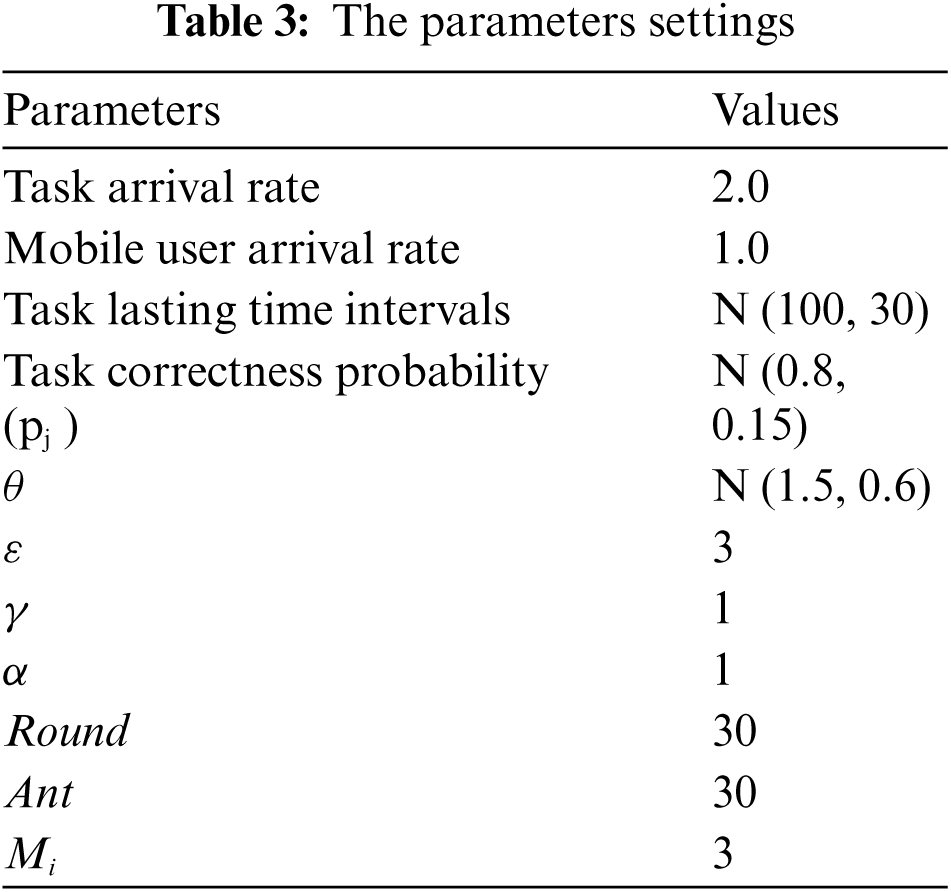
These parameters are determined by trial and error to achieve the best performance for the tradeoff between higher task quality and lower sensing time in LTBA than in B-DBA and greedy. The travel budget of mobile users is computed as Bi = dist(iniLoc, desti)* θ. θ follows N(μθ, σθ) and the probability of a task correctness pj follows N(μpj, σpj) as [18] and [25].
Effects of the ant population size on optimum solution, execution time, and pheromone buildup [34]. The performance of the algorithm is not improved by having a large ant population size. As a result, a limited number is recommended. In general, to restrict the worst-case complexity, the values of round and ant are small. Capacity
There are several scenarios for parameters settings that influence the tasks’ quality and sensing time. The simulation results for parameters of different algorithms are presented. Varying parameter settings, while the default values are used for other parameters.
The impact of γ on tasks’ quality in Fig. 2a and sensing time Fig. 2c. γ is tested in the range [1,5], increasing by 1. The quality of The total task is higher for both LTBA and B-DBA at γ equal 2. However, sensing time is less at γ equal to 1. The tasks’ quality and sensing time are constant in the greedy online allocation algorithm. The expected value of γ is 1 or 2. To determine γ, the difference in values is calculated. The difference in the quality value at γ of 1 and 2 is very small, but the difference in the sensing time at γ 1 and 2 is large. γ is equal to 1 for the optimal value for both task quality and sensing time.
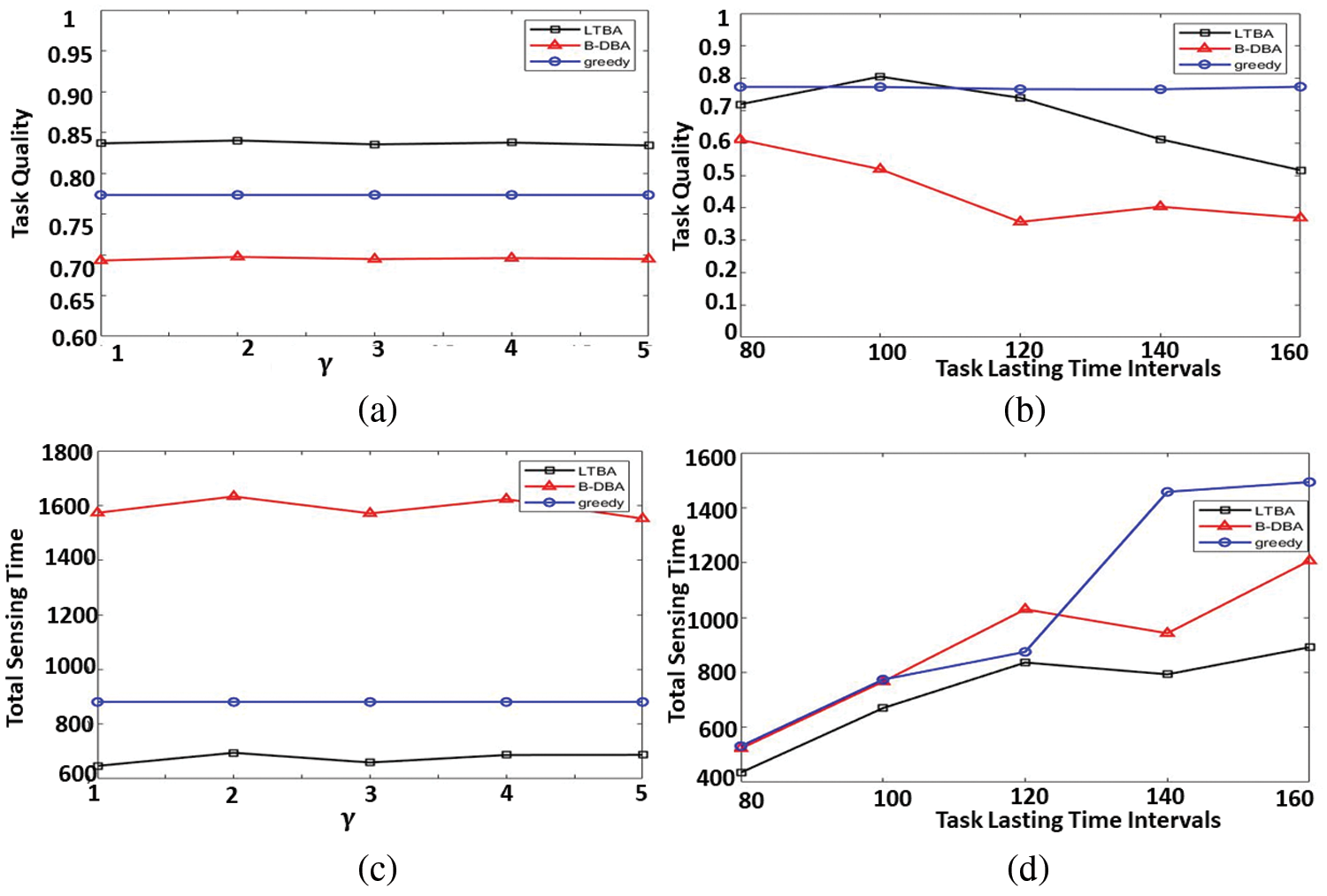
Figure 2: y and task lasting time intervals settings vs. total tasks quality and overall sensing time. (a) The impact of y on tasks' quality. (b) The impact of the task-lasting time interval on tasks' quality. (c) The impact of y on sensing time. (d) The impact of the task-lasting time interval on sensing time
5.2 The Impact of Sensing Time Intervals
In this test, the simulations are to see how the lasting task interval impacts different algorithms. The task-lasting time interval follows a normal distribution with a default mean equals to 30. Figs. 2b and 2d illustrate the average tasks quality and total sensing time vs. standard deviation value that is changed from 80 to 160. The task-lasting time interval is set to be 100 to achieve the best performance for both quality and sensing time for LTBA sensing time.
5.3 The Impact of Task Arrival Rate
In this test, we are varying the task arrival rate from 1.0 to 5.0. Figs. 3a and 3c present the performance of average task quality and overall sensing time under different settings vs. varying task arrival rates. In LTBA, the peak for the average task quality is at an arrival rate of 4.0, and the next is at an arrival rate of 2.0. However, the minimum value of the sensing time is at a task arrival rate of 3.0, and the next is at 2.0. In B-DBA and greedy, the peak is at 2.0. Therefore, the task arrival rate is set to be 2.0 to achieve the optimal solution for increasing the average task quality and decreasing the sensing time for LTBA.
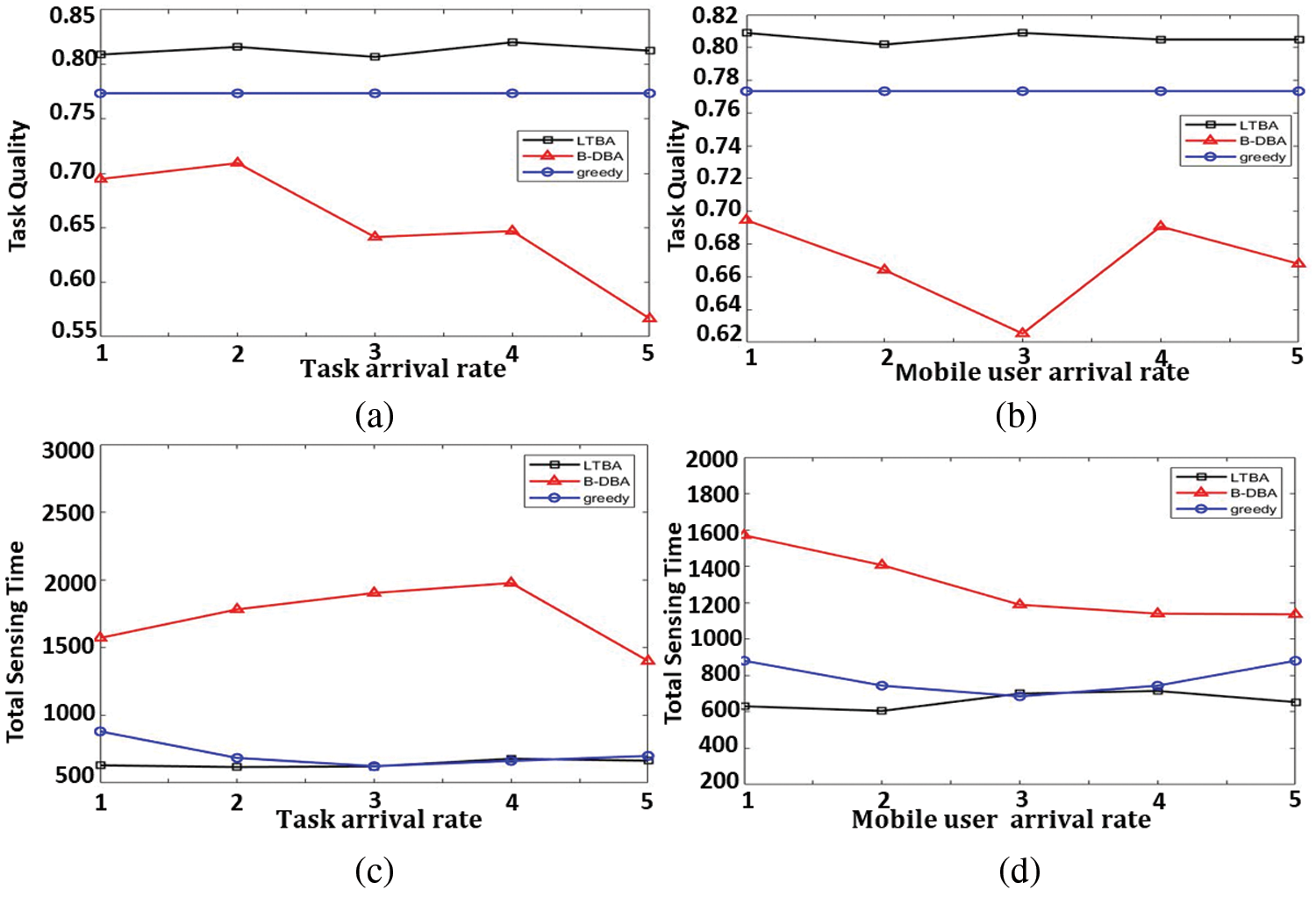
Figure 3: The arrival rate settings for both tasks and mobile users vs. total tasks quality and overall
5.4 The Impact of Mobile User Arrival Rate
In this test, we are varying the mobile user arrival rate from 1.0 to 5.0. Figs. 3b and 3d illustrate the performance of average task quality and overall sensing time under different settings vs. varying mobile user arrival rates. The peak of the average task quality is at the mobile user arrival rate of 1.0 for LTBA, B-DBA, and greedy. The minimum value of the sensing time is at a mobile user arrival rate of 1.0 for LTBA and greedy but for B-DBA is at 5.0. Therefore, the mobile user arrival rate is set to be 1.0 to achieve the optimal solution for increasing the average task quality and decreasing the sensing time for LTBA.
5.5 Different Cases of Tasks and Mobile Users
In Figs. 4a and 3b, different cases of tasks and mobile users are tested. In the case of increasing tasks and mobile users, the total task quality decreases, and the overall sensing time increases. LTBA is the best total task quality and the least sensing time, and the greedy algorithm follows it. The B-DBA algorithm performs the worst if the number of tasks is greater than the number of mobile users. LTBA is better than sensing time but smaller than the greedy algorithm in total task quality.
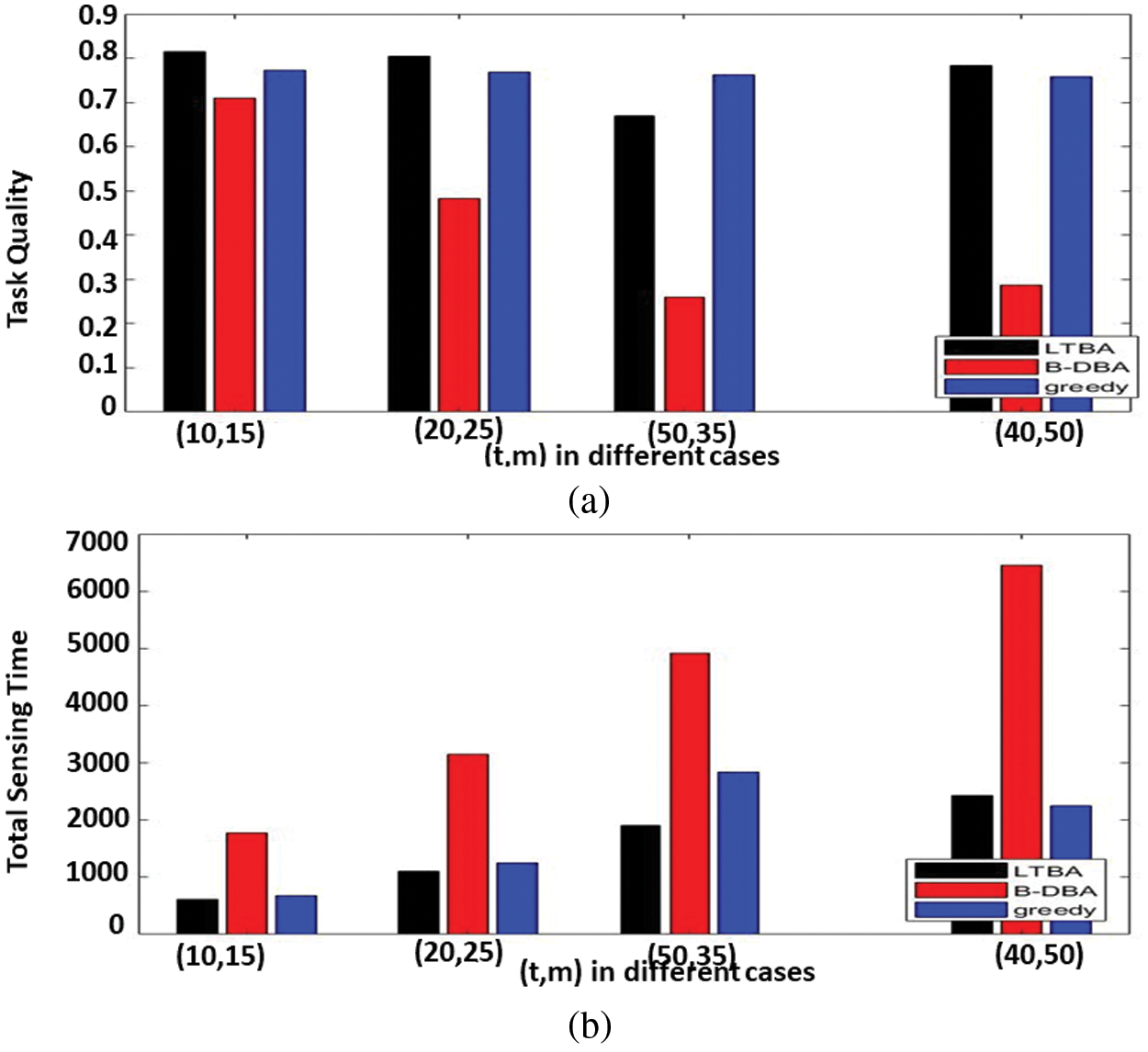
Figure 4: The different cases of tasks and mobile users vs. (a) total tasks quality and (b) overall sensing time
The previous observation motivates us to investigate the problem of assignment sensing tasks for minimizing sensing time while maximizing total task quality based on sensing time and path planning attributes. However, there are still a number of major challenges to be resolved. Striking a good balance between maximizing overall job quality and minimizing sensing time is extremely important.
The requesters determine the time interval for each sensing task to collect the required sensing data and the area of interest. In the proposed method, the covered phase is used because the optimal solution remains optimal after assigning tasks covered by the optimal solution tasks. The optimal aggregate sensing time remains constant.
This work uses the D-BDA, which consists of a bio-inspired search algorithm and a travel-distance-balance-based Algorithm (BDA). ACO is easy to integrate with other methods, and it excels at solving challenging optimization problems. The idea of BDA is based on whether there are two possible tasks to consider: 1 and 2. The work quality increment is the same for both tasks, as is the extra trip distance. The distance between task 1 and the user destination, on the other hand, is substantially greater than the distance between task 2 and the user destination. As a result, if task 1 is chosen, a far larger travel distance budget must be set aside for the user to arrive at his or her destination finally. If task 1 is chosen, the trip distance budget for visiting other task sites will be considerably reduced. We should act based on this observation.
Using the default parameter settings in Tab. 3 to calculate both total task quality and sensing time for LTBA, B-DBA, and greedy. Tab. 4 shows the results. The results demonstrate that combining the two algorithms in LTBA is the best performance for total task quality and total sensing time, and the greedy algorithm follows it then B-DBA. Combining the algorithms improves task assignment in MCS for both total task quality and sensing time.

The computational complexity of function that calculates sensing time for all available sensing tasks is O(n). The function that determines the closest task to the mobile user path has O(r
The performance metric for task assignment is based on task quality. D-BDA was compared with quality-aware online task assignment QAOTA [25], which improved the overall task quality of location-based. QAOTA has the lowest performance and the highest complexity. So, LTBA is the best performance for total task quality and total sensing time, and the greedy algorithm follows it, then B-DBA then QAOTA.
This work presents LTBA that enhances the task assignment in MCS, whereas assigning tasks is restricted by time intervals and location of both tasks and mobile users. LTBA aims to achieve the best performance for the tradeoff between higher task quality and lower sensing time. LTBA combines two algorithms: (1) B-DBA, which was location-based and focused on increasing total task quality, and (2) the greedy online allocation algorithm, which focused on minimizing overall sensing time for mobile users. Minimizing the aggregate sensing time of the mobile user is based on the overlapping between sensing time intervals. The process of assigning the nearest task to the mobile user's current path depends on the ACO algorithm and Euclidean distance. Using a combination of the two algorithms to improve task assignment in MCS enhances task quality and reduces overall sensing time for mobile users. Under various settings, LTBA outperforms the compared algorithms (B-DBA and greedy). The future study will investigate ways to increase the performance of the proposed algorithm as well as investigate their performance in other scenarios, such as discussing the privacy of mobile workers’ locations. The heterogeneous crowdsensing tasks will be the scope of the next work to maximize the quality of the collected data.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. R. J. Hassan, S. R. M. Zeebaree, S. Y. Ameen, S. F. Kak, M. A. M. Sadeeq et al., “State of art survey for IoT effects on smart city technology: Challenges, opportunities, and solutions,” Asian Journal of Research in Computer Science, vol. 8, no. 3, pp. 32–48, 2021. [Google Scholar]
2. A. Zanella, N. Bui, A. Castellani, L. Vangelista and M. Zorzi, “Internet of things for smart cities,” IEEE Internet of Things Journal, vol. 1, no. 1, pp. 22–32, 2014. [Google Scholar]
3. X. Zhang, Z. Yang, W. Sun, Y. Liu, K. Xing et al., “Incentives for mobile crowdsensing: A survey,” IEEE Communications Surveys & Tutorials, vol. 18, no. 1, pp. 54–67, 2015. [Google Scholar]
4. A. Capponi, C. Fiandrino, B. Kantarci, L. Foschini, D. Kliazovich et al., “A survey on mobile crowdsensing systems: Challenges, solutions, and opportunities,” IEEE Communications Surveys and Tutorials, vol. 21, no. 3, pp. 2419–2465, 2019. [Google Scholar]
5. J. Wang, Y. Wang, D. Zhang, Q. Lv and C. Chen, “Crowd-powered sensing and actuation in smart cities: Current issues and future directions,” IEEE Wireless Communications, vol. 26, no. 2, pp. 86–92, 2019. [Google Scholar]
6. B. Guo, Z. Wang, Z. Yu, Y. Wang, N. Y. Yen et al., “Mobile crowdsensing and computing: The review of an emerging human-powered sensing paradigm,” ACM Computing Surveys (CSUR), vol. 48, no. 1, pp. 1–31, 2015. [Google Scholar]
7. J. An, X. Gui, Z. Wang, J. Yang and X. He, “A crowdsourcing assignment model based on mobile crowd sensing in the Internet of Things,” IEEE Internet of Things Journal, vol. 2, no. 5, pp. 358–369, 2015. [Google Scholar]
8. R. K. Ganti, F. Ye and H. Lei, “Mobile crowdsensing: Current state and future challenges,” IEEE Communications Magazine, vol. 49, no. 11, pp. 32–39, 2011. [Google Scholar]
9. K. Ali, D. Al-Yaseen, A. Ejaz, T. Javed and H. S. Hassanein, “Crowdits: Crowdsourcing in intelligent transportation systems,” in 2012 IEEE Wireless Communications and Networking Conf. (WCNC), Paris, France, pp. 3307–3311, 2012. [Google Scholar]
10. Y. Zheng, F. Liu and H. -P. Hsieh, “U-air: When urban air quality inference meets big data,” in Proc. of the 19th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, Chicago, USA, pp. 1436–1444, 2013. [Google Scholar]
11. X. Wang, J. Zhang, X. Tian, X. Gan, Y. Guan et al., “Crowdsensing-based consensus incident report for road traffic acquisition,” IEEE Transactions on Intelligent Transportation Systems, vol. 19, no. 8, pp. 2536–2547, 2017. [Google Scholar]
12. F. Abbondati, S. A. Biancardo, R. Veropalumbo and G. Dell'Acqua, “Surface monitoring of road pavements using mobile crowdsensing technology,” Measurement, vol. 171, pp. 108763, 2021. [Google Scholar]
13. X. Wang, W. Wu and D. Qi, “Mobility-aware participant recruitment for vehicle-based mobile crowdsensing,” IEEE Transactions on Vehicular Technology, vol. 67, no. 5, pp. 4415–4426, 2017. [Google Scholar]
14. T. Hu, M. Xiao, C. Hu, G. Gao and B. Wang, “A QoS-sensitive task assignment algorithm for mobile crowdsensing,” Pervasive and Mobile Computing, vol. 41, pp. 333–342, 2017. [Google Scholar]
15. W. Gong, B. Zhang and C. Li, “Task assignment in mobile crowdsensing: Present and future directions,” IEEE Network, vol. 32, no. 4, pp. 100–107, 2018. [Google Scholar]
16. J. Peng, Y. Zhu, Q. Zhao, H. Zhu, J. Cao et al., “Fair energy-efficient sensing task allocation in participatory sensing with smartphones,” the Computer Journal, vol. 60, no. 6, pp. 850–865, 2017. [Google Scholar]
17. Q. Zhao, Y. Zhu, H. Zhu, J. Cao, G. Xue et al., “Fair energy-efficient sensing task allocation in participatory sensing with smartphones,” in IEEE INFOCOM 2014-IEEE Conf. on Computer Communications, Toronto, Ontario, Canada, pp. 1366–1374, 2014. [Google Scholar]
18. W. Gong, B. Zhang and C. Li, “Location-based online task assignment and path planning for mobile crowdsensing,” IEEE Transactions on Vehicular Technology, vol. 68, no. 2, pp. 1772–1783, 2018. [Google Scholar]
19. S. Konatowski and P. Pawłowski, “Ant colony optimization algorithm for UAV path planning,” in 2018 14th Int. Conf. on Advanced Trends in Radioelecrtronics, Telecommunications and Computer Engineering (TCSET), Lviv-Slavske, Ukraine, pp. 177–182, 2018. [Google Scholar]
20. W. Gong, B. Zhang and C. Li, “Location-based online task scheduling in mobile crowdsensing,” in GLOBECOM 2017–2017 IEEE Global Communications Conf., Singapore, Singapore, Asia, pp. 1–6, 2017. [Google Scholar]
21. L. Wang, Z. Yu, D. Zhang, B. Guo and C. H. Liu, “Heterogeneous multi-task assignment in mobile crowdsensing using spatiotemporal correlation,” IEEE Transactions on Mobile Computing, vol. 18, no. 1, pp. 84–97, 2018. [Google Scholar]
22. Y. Xia, B. Zhao, S. Tang and H. -T. Wu, “Repot: Real-time and privacy-preserving online task assignment for mobile crowdsensing,” Transactions on Emerging Telecommunications Technologies, vol. 32, no. 5, pp. e4035, 2021. [Google Scholar]
23. X. Yin, Y. Chen and B. Li, “Task assignment with guaranteed quality for crowdsourcing platforms,” in 2017 IEEE/ACM 25th Int. Symp on Quality of Service (IWQoS), Vilanova i la Geltrú, Spain, Spain, pp. 1–10, 2017. [Google Scholar]
24. X. Tao and W. Song, “Location-dependent task allocation for mobile crowdsensing with clustering effect,” IEEE Internet of Things Journal, vol. 6, no. 1, pp. 1029–1045, 2018. [Google Scholar]
25. Y. Kang, X. Miao, K. Liu, L. Chen and Y. Liu, “Quality-aware online task assignment in mobile crowdsourcing,” in 2015 IEEE 12th Int. Conf. on Mobile Ad Hoc and Sensor Systems, Dallas, TX, USA, pp. 127–135, 2015. [Google Scholar]
26. X. Miao, Y. Kang, Q. Ma, K. Liu and L. Chen, “Quality-aware online task assignment in mobile crowdsourcing,” ACM Transactions on Sensor Networks (TOSN), vol. 16, no. 3, pp. 1–21, 2020. [Google Scholar]
27. A. A. A. Gad-ElRab and A. S. Alsharkawy, “Interval tree-based task scheduling method for mobile crowd sensing systems,” Journal of Communications Software and Systems, vol. 14, no. 1, pp. 51–59, 2018. [Google Scholar]
28. C. Lai and X. Zhang, “Duration-sensitive task allocation for mobile crowd sensing,” IEEE Systems Journal, vol. 14, no. 3, pp. 4430–4441, 2020. [Google Scholar]
29. M. Xiao, J. Wu, L. Huang, R. Cheng and Y. Wang, “Online task assignment for crowdsensing in predictable mobile social networks,” IEEE Transactions on Mobile Computing, vol. 16, no. 8, pp. 2306–2320, 2017. [Google Scholar]
30. Y. Wu, F. Li, L. Ma, Y. Xie, T. Li et al., “A Context-aware multiarmed bandit incentive mechanism for mobile crowd sensing systems,” IEEE Internet Things Journal, vol. 6, no. 5, pp. 7648–7658, 2019. [Google Scholar]
31. Y. Huang, H. Chen, G. Ma, K. Lin, Z. Ni et al., “OPAT: Optimized allocation of time dependent tasks for mobile crowdsensing,” IEEE Transactions on Industrial Informatics, pp. 1, 2021. [Google Scholar]
32. X. Chen, Y. Kong, X. Fang and Q. Wu, “A fast two-stage ACO algorithm for robotic path planning,” Neural Computing and Applications, vol. 22, no. 2, pp. 313–319, 2013. [Google Scholar]
33. SNAP: Network datasets: Gowalla. 2009. [Online]. Available: https://snap.stanford.edu/data/loc-gowalla.html. [Google Scholar]
34. M. M. Alobaedy, A. A. Khalaf and I. D. Muraina, “Analysis of the number of ants in ant colony system algorithm,” in 2017 5th Int. Conf. on Information and Communication Technology (ICoIC7), Melaka, Malaysia, pp. 1–5, 2017. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |