DOI:10.32604/cmc.2022.021990
| Computers, Materials & Continua DOI:10.32604/cmc.2022.021990 | |
| Article |
Sign Language to Sentence Formation: A Real Time Solution for Deaf People
1Bahauddin Zakariya University, Department of Computer Science, Multan, 60,000, Pakistan
2Air University, Department of Computer Science, Multan, 60,000, Pakistan
3Air University, Department of Computer Science, Islamabad, 44,000, Pakistan
4Centre for Research in Data Science, Department of Computer and Information Sciences, Universiti Teknologi PETRONAS, Seri Iskandar, 32610, Perak, Malaysia
5Department of Intelligent Mechatronics Engineering, Sejong University, Seoul, 05006, Korea
*Corresponding Author: Muhammad Sanaullah. Email: drsanaullah@bzu.edu.pk
Received: 23 July 2021; Accepted: 29 September 2021
Abstract: Communication is a basic need of every human being to exchange thoughts and interact with the society. Acute peoples usually confab through different spoken languages, whereas deaf people cannot do so. Therefore, the Sign Language (SL) is the communication medium of such people for their conversation and interaction with the society. The SL is expressed in terms of specific gesture for every word and a gesture is consisted in a sequence of performed signs. The acute people normally observe these signs to understand the difference between single and multiple gestures for singular and plural words respectively. The signs for singular words such as I, eat, drink, home are unalike the plural words as school, cars, players. A special training is required to gain the sufficient knowledge and practice so that people can differentiate and understand every gesture/sign appropriately. Innumerable researches have been performed to articulate the computer-based solution to understand the single gesture with the help of a single hand enumeration. The complete understanding of such communications are possible only with the help of this differentiation of gestures in computer-based solution of SL to cope with the real world environment. Hence, there is still a demand for specific environment to automate such a communication solution to interact with such type of special people. This research focuses on facilitating the deaf community by capturing the gestures in video format and then mapping and differentiating as single or multiple gestures used in words. Finally, these are converted into the respective words/sentences within a reasonable time. This provide a real time solution for the deaf people to communicate and interact with the society.
Keywords: Sign language; machine learning; conventional neural network; image processing; deaf community
Communication is the primary source of sharing and transferring any knowledge in any society. Generally, human do this task through speaking/talking whereas deaf people cannot hear and talk. Therefore, the medium of communication for such kind of persons is the Sign Language (SL) to interact and participate into a society. The statistics of such people is very alarming according to the World Health Organization (WHO) which is around 466 million people in the world [1,2] and0.6 million people only from United States [3]. The SL is based on hand gestures to transfer and share their ideas with the society. Although, the understanding of common used gestures such as hungry, drink, go and study are easy but for the formal or professional talks, there must be a proper knowledge of SL is required. These talks contain on such kind of sentences as what is your name? How old are you? What is the specification of this mobile phone?
Hence, the deaf people face many difficulties in sharing their thoughts in their professional career and as a result, they feel lonely and go in isolation. A technical solution is demanded to overcome the information transferring barrier which must provide the answer of the following concerns.
In SL the movements of the hand gestures can be divided into two categories, “Single Sign” (e.g., I, eat, drink) which contains the sign of a single gesture and “Multiple Sign” (e.g., she, hot, outside, etc.) which accommodates the multiple gestures for a single concept. This categorization is further divided into “Single Hand” and “Both Hand” gestures on the basis of hand movement. For example, the gestures of “I”, “You”, “go”, “drink” etc. are performed by a single hand and have a single sign. On the same site, the gestures of “she”, “hot”, “outside” etc. are performed by a single hand and have multiple signs. Whereas some gestures are performed by both hands and have single signs e.g., “home”, “love” etc. and both hands with multiple signs for e.g., play, football, car, drive, etc.
According to the categorization and grouping mentioned above, a summary of the found literature is shown in Tab. 1. Most of the literature is about “single sign by single hand”. Unfortunately, no literature is found on “multiple signs with both hands”. The capturing and recognition of hand movement and rotation add complexities in the computed solutions design; therefore, the existing research mainly focuses on the primary category.
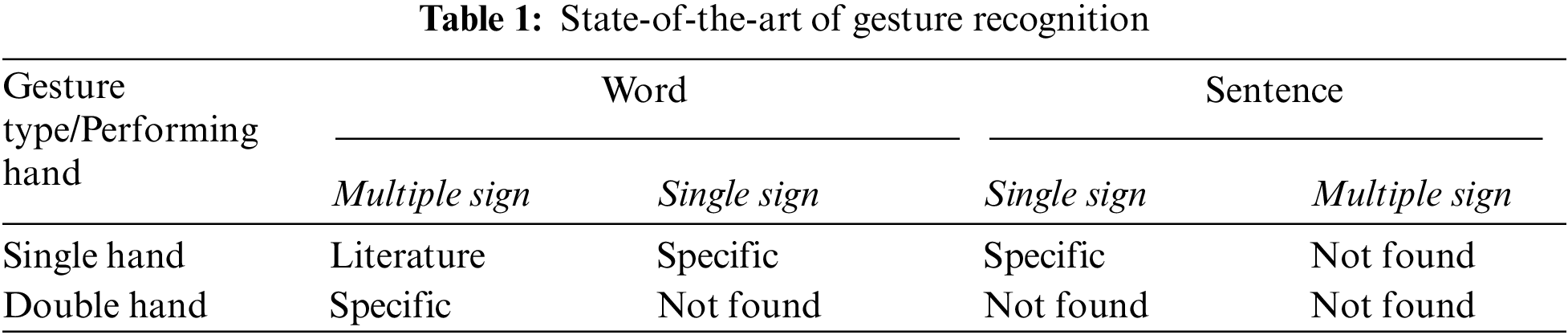
Fig. 1 the left side gesture is from Britain Sign Language (BSL), which shows that the right hand with the first finger in up-word direction is used to perform “What”. The middle gesture is from American Sign Language(ASL), which shows that both hands with open palms are used to perform “What” and the right side gesture is from Pakistan Sign Language (PSL), which shows that the right hand with first two out-word pointing fingers is used to perform “What”. Hence, a holistic solution for all cultural societies is not possible and each country has to design and develop its own solution according to its society gestures.

Figure 1: Sign of “What” in different sing languages
Moreover, in the current proposed solutions the following concern are also addressed:
• Mobility Issue: Most of the researchers use Kinect 3D camera, which can easily detect hands movements. But in a real world, it is difficult to carry out such hardware to every place where ever the special person move (e.g., market, school and hospital). There is another solution in form of a sensory glove with Flex sensor, in which contact sensor and accelerometer is used to detect hand movement and rotation. However, this solution also required to carry out the extra hardware at every-time. The proposed methodology is offering a solution without any extra hardware for mobility and movement of such special persons.
• Sign Capturing Issue: In a real environment, the person can wear any color and type ofshirt/t-shirt and the detection of hand and their movement is not an easy task (skin segmentation of face, arms and hand). Therefore, most researchers assume to use colored gloves or different color strips attached to white color gloves. To wear these gloves at everywhere and every time which is a difficult job. This issue is resolved in the proposed solution using the video capturing for signs identifications.
• Special Environment Issue: For the recognition of a person, researchers design a special environment in which some specific colored dress with a specific color background is required. They used the black dress with black background (easy detection of skin), but in a real environment, it is quite challenging to maintain such an environment everywhere. Hence, there must be a solution for real time world in which the person and sign detection is much easier.
• Sign Recognition Issue: Most researchers work on recognizing words with “Single sign” gesture, but in real life, we speak complete sentences. The SL sentences consist of a sequence of gestures, recognizing each words from a single sign is also a difficult task.
• Human Experimental Issues: Experimental issues are also found in literature where solutions are validated with a limited number of persons and a recorded dataset of videos.
Thanks to Conventional Neural Network (CNN) and advanced Image Processing techniques to facilitate us for providing a solution to translate the SL without any special environment and fixed specific hardware. It also facilitates us in recognition of the gestures of sentences involving both hands with multiple signs. The validation of the proposed solution is confirmed with ten different males and females in a different real environment. After resolving all the mentioned issues, 94.66% accuracy is achieved.
In the rest of the paper, Section 2 present the literature review, Section 3 explains the proposed solution and the results are presented in Section 4. The discussions on results are presented inSection 5. The conclusion and future work is given in Section 6.
In this section, a literature review of the existing research work is presented, due to the space limitation only the paper which are mostly cited are presented. The literature is evaluated on the basis of the following parameters: their research assumptions, considered gestures, used hardware, numbers of verified signs, number of participants, learning and testing techniques and the accuracy. A summary in the form tabular view, of the evaluation, is presented in Tabs. 2 and 3.
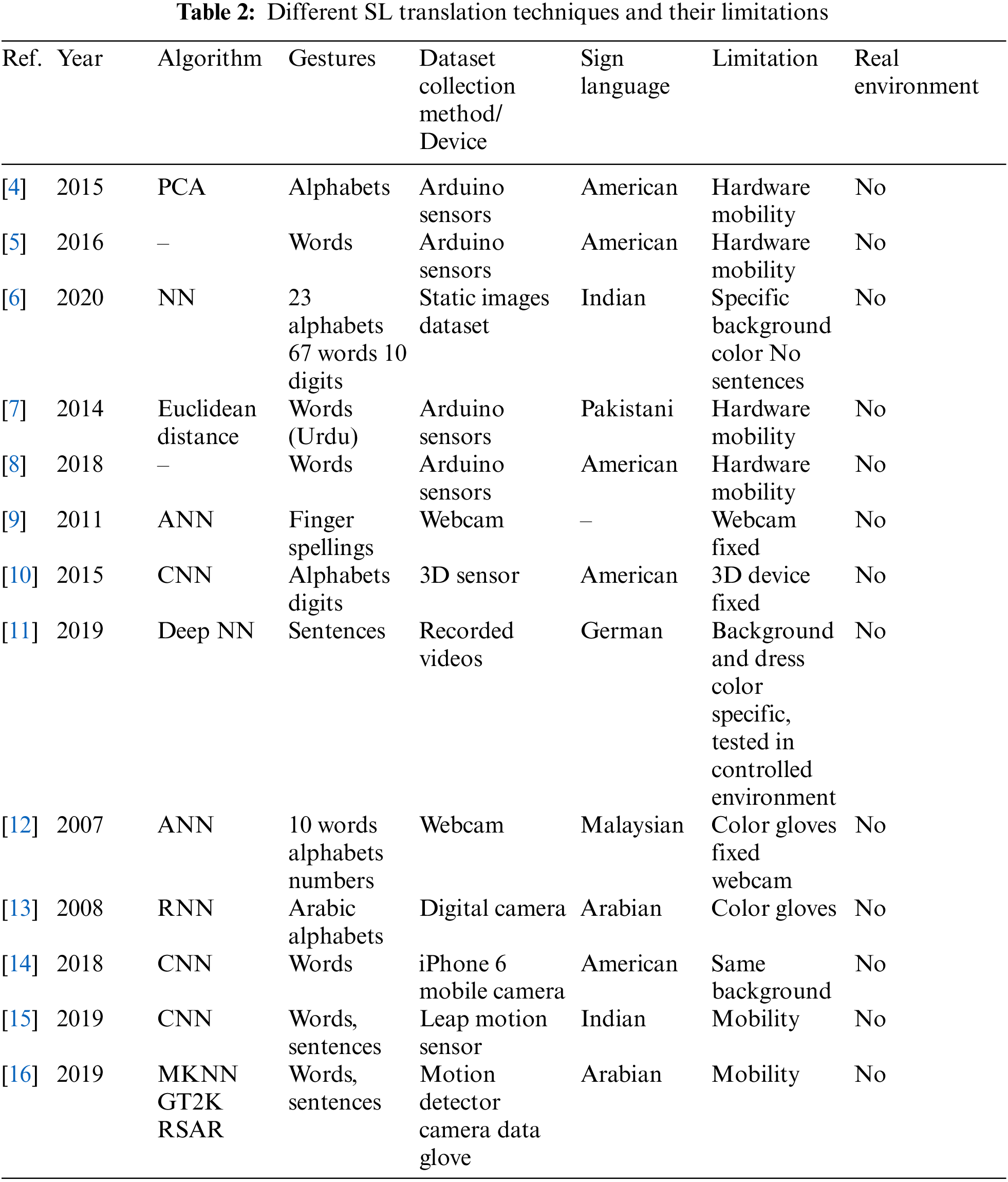
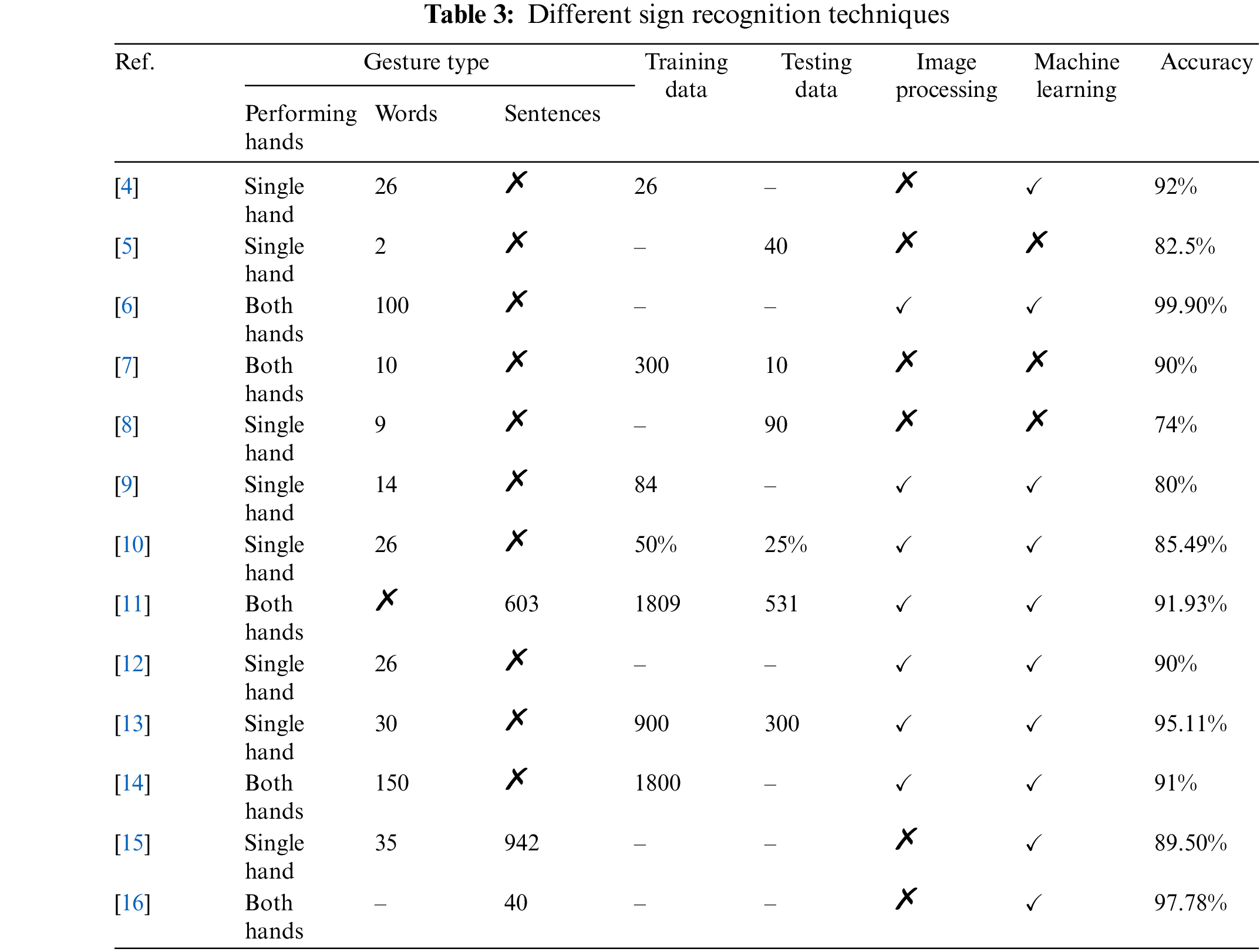
Bukhari et al. [4] designed a sensory glove having flex sensors for capturing the movement of fingers, accelerometer for capturing the rotation of hands and contact sensors for bending of palm. They used 26 gestures for recognition. Each sign is recorded 20 times. They got 92% accuracy for the recognition of gestures. This work has issues of mobility, sign recognition and Human Experimental.
Helderman et al. [5] designed a sensory glove for the translation of SL. They used flex sensor, contact sensor and gyroscope for capturing the contact between fingers and rotation of hand. They used Arduino for controlling sensors. Blue-tooth module was used to transmit signal from Arduino to smart phone. They recognized only two signs from ASL. The first sign was “apple” and second was “party”. They test each sign 20 times. Their glove recognized “apple” 19 times and 14 times “party” sign. Their glove shows 95% accuracy for “apple” and 70% accuracy for “party” sign. This work has issues of mobility, sign recognition and Human Experimental.
Wadhawan et al. [6] proposed a deep learning based SL recognition system. They used 100 static words for the recognition and they achieved 99.90% accuracy. Their system has the limitation of mobility and real environment.
Kanwal et al. [7] designed a sensory glove for the translation of Pakistani SL. They tested ten signs of PSL and their glove recognized only nine signs accurately. The accuracy of their sensory glove is 90%. This work has issues of mobility, sign recognition issues and Human Experimental issues.
Ambar et al. [8] designed a sensory glove to recognize the words of American SL. They got an accuracy of 74% for translating SL. They used the sensor for capturing the movement of fingers and hands. This work has issues of mobility, sign recognition issues and Human Experimental issues.
Lungociu [9] proposed a neural network approach for the recognition of SL. They used 14 finger spellings for the recognition. Their accuracy was 80%. They used webcam for data acquisition and only captured the hand shapes. This work has issues of mobility, sign recognition, Human Experimental, Sign capturing and special environment.
Kang et al. [10] used CNN for the recognition of SL. They recognized alphabets and digits taken from ASL. They used 3D sensor for the capturing of sign. They got 85.49% accuracy. This work has issues of mobility, sign recognition, Human Experimental, Sign capturing and special environment.
Cui et al. [11] proposed a framework for SL recognition. They recognized 603 recorded sentences of German SL. They got 91.93% accuracy for using Deep NN. This work has human experimental issues.
Akmeliawati et al. [12] translated the Malaysian SL using image processing technique. A webcam is used for data capturing and color gloves are used to capture the sign. In this approach, the author translated A–Z alphabets, 0–9 numbers and ten words. Their approach gained 90% accuracy for recognition. This work has mobility issues, sign recognition issues, human experimental issues, Sign capturing and special environment issues.
Maraqa et al. [13] proposed a system for Arabic SL recognition. They used the Digital camera for capturing images and captured 900 images of 30 signs training data-set. Three hundred more images are captured for testing data. They used the white color glove with different color patches on the fingertips and a wrist color band. They gained an accuracy of 95% for sign recognition. This work has mobility issues, sign recognition issues, human experimental issues, Sign capturing and special environment issues.
Bantupalli et al. [14] American SL using RNN and CNN. They recorded videos using iPhone 6 with same background. They tested 150 signs and achieved accuracy of 91%. Their work has specific background issue.
Mittal et al. [15] used Leap Motion sensor to capture Indian SL CNN was used to recognize it. They tested words and sentences. CNN was trained using 35 isolated words and model is tested using 942 sentences. Average accuracy for words 89.50% and for sentences 72.30%. This work has mobility issues.
Hassan et al. [16] produced three data sets of Arabian SL. They also used different techniques of recognition. Data sets have words and sentences. Two data sets are produced using motion detector and camera and one data set is produced using sensory glove. Tools used for classification of SL are MKNN, RASR and GT2K.
Ullah et al. [17] used Wi See technology that can detects the gestures using multiple antennas. They used the gesture to control the movement of a car. This work has mobility issues, sign recognition issues, human experimental issues, Sign capturing and special environment issues.
The proposed solution is divided in three components: Image Processing--in which video signs are captured and Key Frames are extracted–Classification–of gestures with the use of CNN–and Sentence Formation–where the words are arranged in a semantic form with the use of Natural Language Processing (NLP). The framework of the proposed solution is presented in Fig. 2 and explanation of each component is given in the following subsections:

Figure 2: Framework of the proposed solution
The work performed in this component is to identify those frames in which some gestures are performed from the real time recording then frames are extracted. Further key frames are filtered from extracted frames. The key frames contain useful information of gesture sign. So that instead of working on all extracted frames, only filtered key frames are considered for further processing. This component consists of the following subcomponents.
Real Time signs are captured in a video format using any digital camera. The real time video is accessed frame by frame and parsed to detect focused person movement by comparing these frames. In detecting any movement in a focused person, this component stores the frame identity and continues its working to detect the frame in which the movement stops. A set of these frames, from starting to end the movement detected frames, is sent to the “Skin Segmentation” component for further processing.
The skin Segmentation process works to identify the hands of the focused person. For this purpose, Otsu threshold method, which iterates through all the possible threshold values, calculates the spread for the pixels that fall in foreground or background. LAB color space is selected because it is an effective color space in Otsu thresholding. The activities performed for this purpose is sequenced in Algorithm 1. In which, the set of frames, extracted in the previous section and are in RGB format, are work as input and also shown in Fig. 3 part (A).


Figure 3: Image of signer showing hand and face detection
A set of these binary images consists of many frames. Most of the frames represent the sequence of moving hands and do not contain any factual information, which is required for the recognition of gestures. The inclusion of these frames increases time and space complexity along with the increase of error rate. We need to exclude these frames. The rest of the frames are considered as key frames, which have some specific information. The step performed for key frames identification is presented in Algorithm 2.
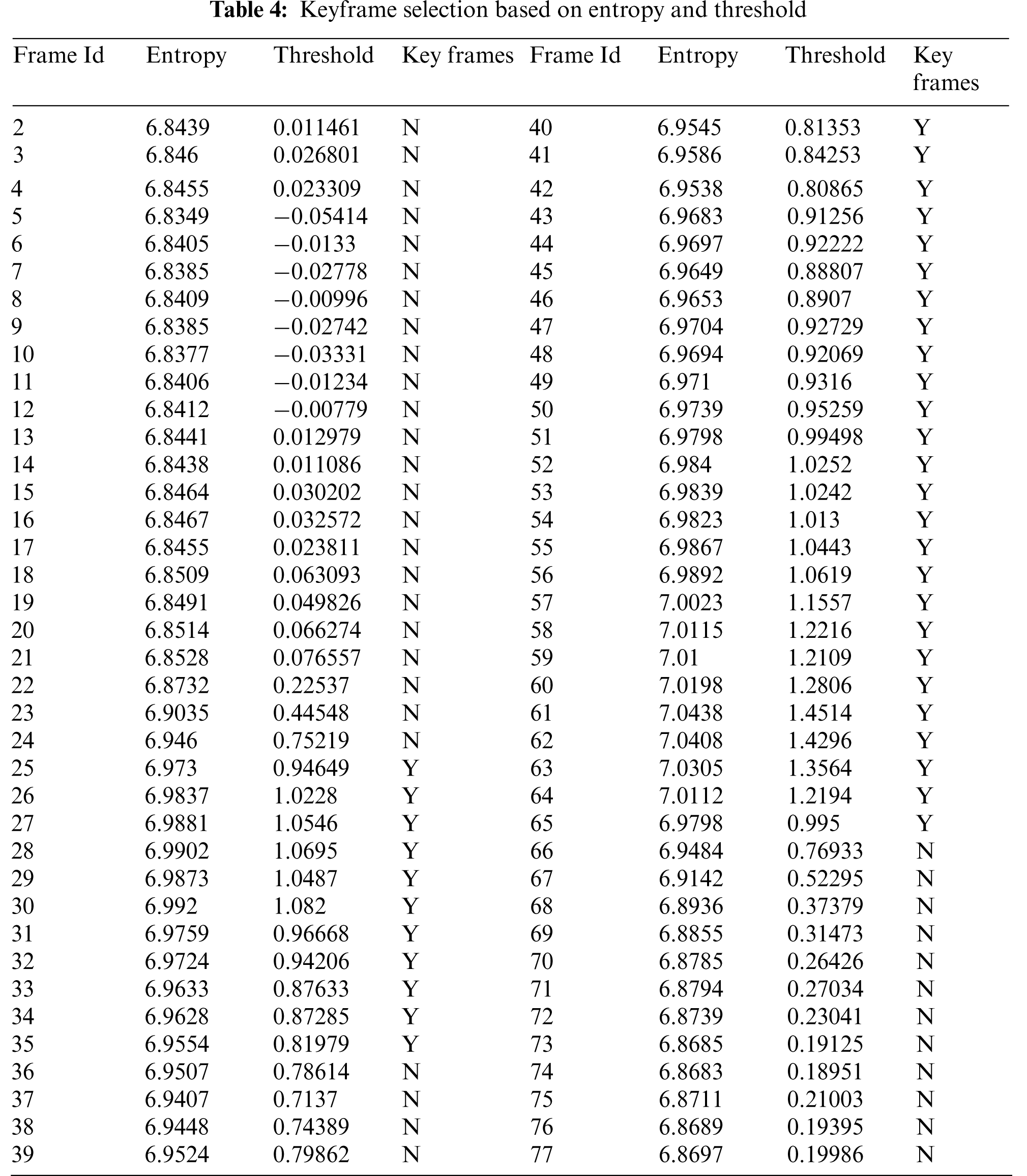
Firstly, it calculates the entropy of the considering frame based on the frames histogram values and then compares these values. The base value from which the comparison is made is the base frames entropy in which hands are in the rest position. This comparison is performed based on Eq. (1) in which, α represents the entropy of the first frame, βj represents the entropy of other frames and μ represents the threshold value.
From a lot of experiments, it is observed that the frames having threshold value less than 0.8 are just containing hands movements and therefore can be excluded. Hence, the frames having threshold value greater than 0.8 are considered as key frames of this sign. Let consider the sign “I”, as shown in Fig. 3 the entropy and threshold values against each fame is presented in Tab. 4. In which the entropy of the first/base frame is 6.8423 which will remain same in the whole process. This “I” sign consist of 77 frames and after the key frame identification process only 38 frames are considered as key frames, rest of the frames are excluded, these 38 frames are passed to the classification component for further processing.

The classification component takes the key frames as input and predicts the label of gesture that belongs to that key frames. The overall working of the classification component is explained in the following subsections.
PSL case study is used to implement the developed methodology. A repository of PSL signs is created using pre-recorded gestures performed by different people at different places of different age and gender groups. Some of the videos from the official PSL website [18] are also included in the repository. Firstly, a database of 300 daily life sentences are created, in which it is found that some words are repeatedly used, among which 21 high-frequency words are selected and shown in Tab. 5 with their occurrence frequencies. These words gesture is recorded three times by three different people and their videos are stored in a signed repository. Moreover, 15 gestures videos are downloaded from the PSL website and also stored in the signed repository. Hence, the total recorded videos are 204. The total number of Key frames that are extracted from 204 videos is 1882. The key frames of each gesture are labeled with the appropriate name (e.g., we, Today, Drive, etc.).

PSL case study is used to implement the developed methodology. A repository of PSL signs is created using pre-recorded gestures performed by different people at different places of different age and gender groups. Some of the videos from the official PSL website [18] are also included in the repository. Firstly, a database of 300 daily life sentences are created, in which it is found that some words are repeatedly used, among which 21 high-frequency words are selected and shown in Tab. 5 with their occurrence frequencies. These words gesture is recorded three times by three different people and their videos are stored in a signed repository. Moreover, 15 gestures videos are downloaded from the PSL website and also stored in the signed repository. Hence, the total recorded videos are 204. The total number of Key frames that are extracted from 204 videos is 1882. The key frames of each gesture are labeled with the appropriate name (e.g., we, Today, Drive, etc.).
3.2.2 Training and Testing with CNN Model
CNN is a type of Deep Learning algorithm which belongs to machine learning. CNN is best for recognition because it implicitly calculates the features, whereas, in other techniques, the features are required to be calculated explicitly. The input image layer is 200 × 200 pixels in size, we have 1882 images in over sign repository. Convolution filters are applied to the inputted image using a 2-D convolution layer. This layer convolves the image vertically and horizontally by moving the filters and computes the dot product of CNN weights to the inputted image. Moreover, the convolutional layer has 20 filters of size 5 × 5 and has a ReLU layer, which automatically works for rectifying the error. The max-pooling layer is created, which performs down-sampling on the input and dividing into rectangular regions by computing the maximum value for every region. The layer has pool size 2 × 2 and a stride of 2, followed by the Fully Connected Layers. The architecture of the Designed neural network is shown in Fig. 4. From the signed repository, 75% data is used for training purposes and 25% data is used for testing purposes.

Figure 4: CNN architecture
After training and testing, recognition is done through CNN. Extracted Key frames of a gesture are given to the Recognizer component, which works with the trained CNN model, discussed inSection 3.2.2. The recognizer identifies the total number of gestures in the given set of key frames and returns the gestures labels. In the case of gesture “I” 38 frames are passed to the recognizer. It takes 4 s to recognize and label it. In the case of “She” and “beautiful”, it takes 13 s to recognize and label it.
The identified labels are sent to this component. Firstly, the nature of labels are identified like subject, verb or object using NLP and a dictionary in which most terms are classified with their nature. The frequency in which these terms are used that their labels are arranged in Subject–verb–object format. Although it is not fully satisfied the English grammar rules but some extent it is able to convey the meaning of the sentence. For example when a person perform gestures as shown in Fig. 5 after all the processing the sentence formation component returns “I go Home”.

Figure 5: Frames from the sentence “I go to home”
To measure the validity of the proposed solution, a set of 300 daily used sentences is considered. A “bag of words” file is generated from these sentences, which contains the different words with their occurrence frequencies, as 21 high-frequency words are shown in Tab. 5. The dataset for training and testing purposes is created by using these 21 gestures. Each gesture is performed three times by three different males and females of different age groups at different locations. Moreover, 15 videos or SL expert from the Pakistan Sign Language website [18] is also added to the repository. Overall, we have 204 videos, these videos are processed for the key frame extraction component and in-result 1882 frames were generated. The CNN considers 75% for training and takes approx. 4 min(3 min and 37 s) for this purpose.
Real Time Sign Capturing identifies the focused person body movement and parses it for the key frame extraction. These key frames are further passed to the recognizer component, which performs recognition of the gesture(s) based on the trained module and returns the label(s) of the gesture(s).
The time required of key frame identification from real time video to movement identification, frame by frame parsing and then key frame extraction is given in Tab. 8 under Capturing time parameter and the recognition time shows the time taken for the recognition and labeling of the gestures and the accuracy is the values provided by CNN model against each sentence. Overall, the achieved accuracy is 94.66%.
Tab. 7, shows the time spend in the case of single words, in which, Gesture capturing time is that time which is required for the Key frames extraction from a video of a gesture and the recognition time is the time which recognizer takes to recognize a gesture.
Precision, recall, false-negative rate, false discovery rate and f-score are the measure used to measure a classification algorithms performance. For this, the standard formulas are given below. In which, True Positive (TP): Actual value is positive and predicted is also positive value, False Negative (FN): Actual value is positive but predicted is a negative value, True Negative (TN): Actual value is negative and predicted is also negative value and False Positive (FP): Actual value is negative, but the predicted value is positive.
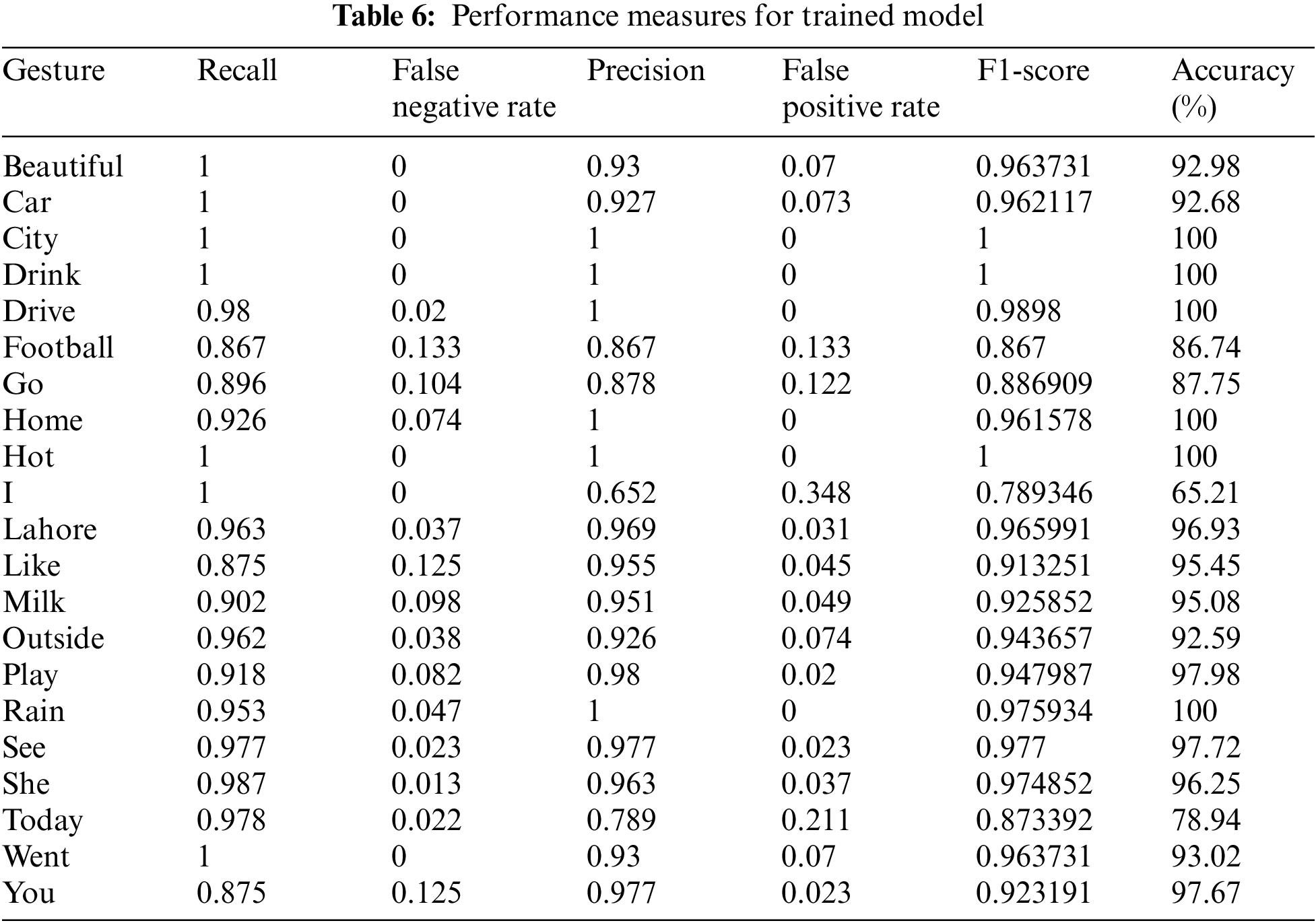
These formulas are used to calculate the binary classification results. Our dataset has multi-class labels and results are calculated using confusion matrix which is given in Fig. 6. The following Tab. 6 is playing the calculated values for precision, recall, false positive rate, false negative rate, F1-score and accuracy of the above mentioned gestures.
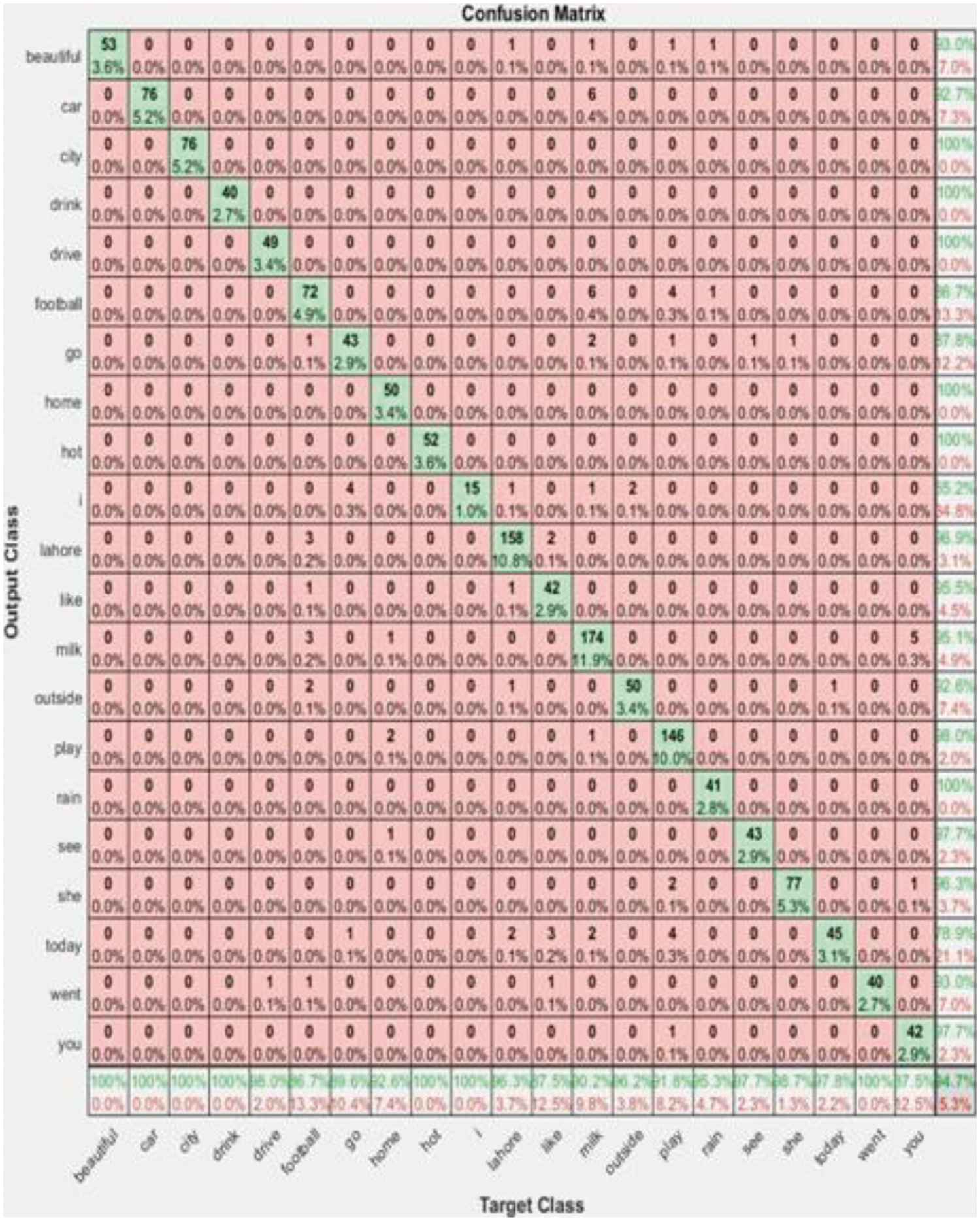
Figure 6: Confusion matrix
The rows presents the predicted class and the columns presents to the actual class. The diagonal cells presents to observations that are correctly classified. The off-diagonal cells presents incorrectly classified observations. Both the number of observations and the percentage of the total number of observations are shown in each cell. The last column shows the percentages of all the examples predicted to belong to each class that are correctly and incorrectly classified. These metrics are often called the precision and false discovery rate, respectively. The row at the bottom shows the percentages of all the examples belonging to each class that are correctly and incorrectly classified. These metrics are often called the recall and false negative rate, respectively. The cell in the bottom right of the plot shows the overall accuracy.
Tab. 7 the first column displays the Gesture label and the second column displays gesture capturing time. The “Real Time Sign Capturing” component takes gesture capturing time. The “Real Time Sign Capturing” component has three sub-components. The total time of three sub-components is given in that column. This time is depending on the number of key frames in a gesture or gesture performing time. As gesture performing time increases, the number of key frames also increases, so capturing time increases. One more observation is that which gesture consists of multiples signs also has a large capturing time. The gesture, which consists of a single gesture, has the lowest capturing time. As shown in table “Lahore” gesture has the highest capturing time, 171 s, because it consists of multiple gestures and has a greater performing time. Similarly, a gesture “I” has the lowest capturing time because it consists of a single sign, has the lowest number of key frames and has the lowest-performing time. This time can be reduced if we can build a method that finds the minimum number of key frames from a gesture.
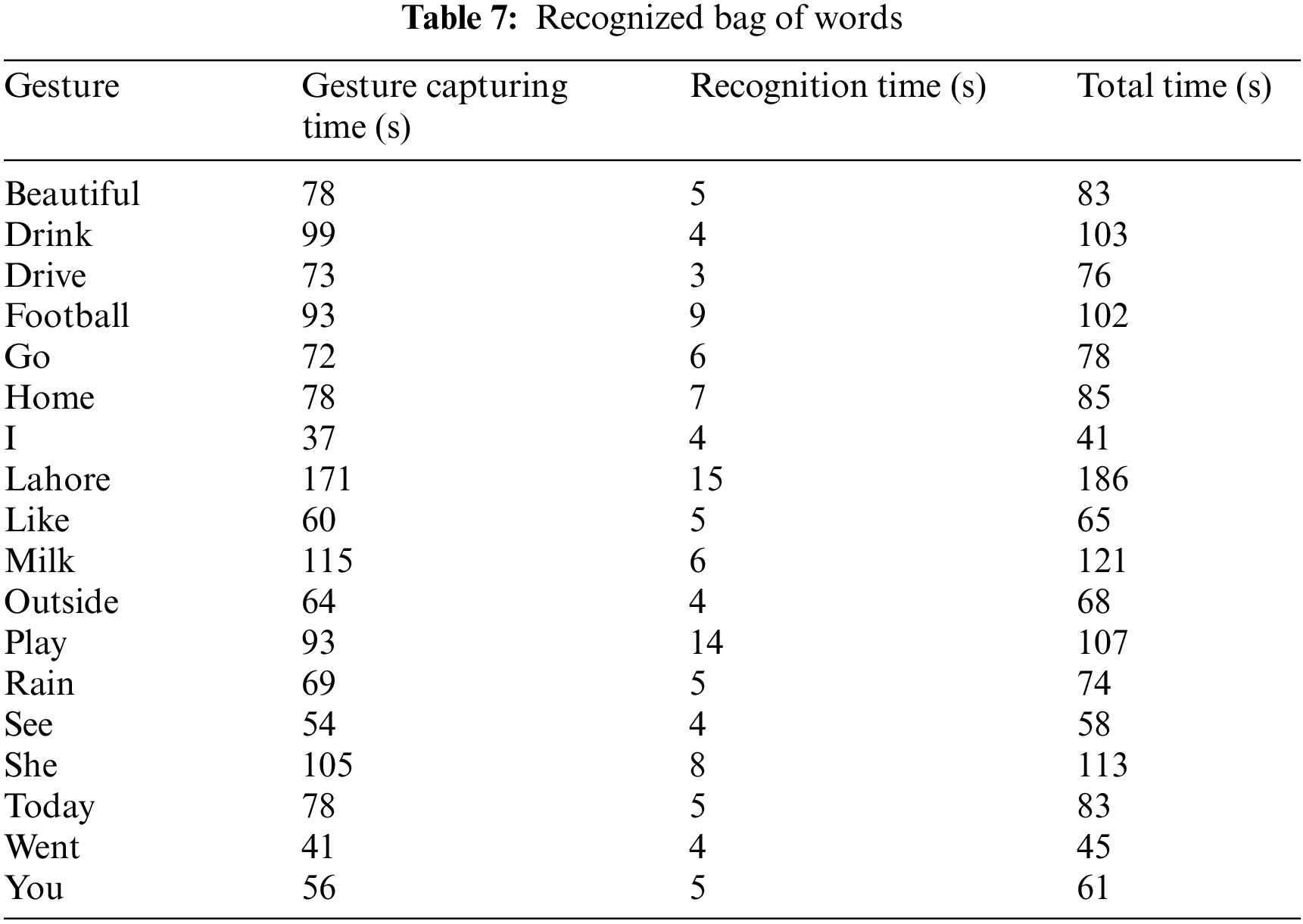
The third column in Tab. 7 is displaying the gesture recognition time. A trained model recognizes a frame in milliseconds, but our recognizer takes some seconds to recognize a gesture because it recognizes the whole number of key frames extracted from a gesture. So recognition time is depending on the number of key frames that are given to the recognizer. As shown in the table “I” gesture takes 4 s, which is the lowest recognition time in our case because gesture “I” has the lowest number of extracted key frames. Similarly, the gesture “Lahore” has the highest recognition time, which 15 s in our case. This time is highest due to the highest number of key frames. After the recognition of key frames, the highest frequency label is considered as a final label of gesture. The highest frequency label approach is adopted due to similar key frames in gesture. It is observed that many of the gesture has similar key frames e.g., (Drink and Milk, Drive and Car, etc.). Similarly, Tab. 8 shows the capturing and recognition time of the sentence gestures.

Deaf people are part of society and have the right to live in society and participate in every aspects of life. They need communication way to transfer and interact with other people participating in society. In this research, an automated gestures/signs recognition system is designed and developed. The computer-based Sign Language (SL) recognition solution is efficiently implemented to help the deaf people of Pakistan. We tried to remove mobility and gestures limitations of single vs. multiple signs by creating a special environment for SL translation in proposed computer-based solution. The proposed solution is even applicable for the signer to communicate through multiple gestures with the deaf people. For this purpose, he does not need to wear any extra hardware such as special gloves for SL translation. The multiple signs/gestures of individual words as well as the complete sentences can be recognized in the proposed solution as it works on the basis of sign videos captured from real environment and translate it into text. The results are verified by adding 204 videos which consist on 1882 key frames with an accuracy of 94.66%. In the future, the computational optimization for smart phone is recommended. On the other hand, computation power of mobile technology can be enhanced to enable the processing of the complex image processing and machine learning tasks.
Acknowledgement: The work presented in this paper is part of an ongoing research funded by Yayasan Universiti Teknologi PETRONAS Grant (015LC0-311 and 015LC0-029).
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. World Health Organization, https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss. Accessed: 2020-02-02. [Google Scholar]
2. World Health Organization, https://www.yesprograms.org/stories/sign-language-accessibility-for-the-deaf-in-pakistan. Accessed: 2020-02-02. [Google Scholar]
3. U.S deaf population, https://www.gallaudet.edu/office-of-international-affairs/demographics/deafemployment-reports. Accessed: 2020-10-07. [Google Scholar]
4. J. Bukhari, M. Rehman, S. I. Malik, A. M. Kamboh and A. Salman, “American sign language translation through sensory glove,” International Journal of u- and eService, Science and Technology, vol. 8, no. 1, pp. 131–142, 2015. [Google Scholar]
5. A. M. Helderman, P. M. Cloutier and R. Mehilli, “Sign language glov,” in BS Project, US: Worcester Polytechnic Institute, 2016. [Google Scholar]
6. A. Wadhawan and P. Kumar, “Deep learning-based sign language recognition system for static signs,” Neural Computing and Applications, vol. 32, no. 12, pp. 7957–7968, 2020. [Google Scholar]
7. K. Kanwal, S. Abdullah, Y. B. Ahmed, Y. Saher and A. R. Jafri, “Assistive glove for Pakistani sign language translation,” in Proc. 17th IEEE Int. Multi Topic Conf., Karachi, Pakistan, pp. 173–176, 2014. [Google Scholar]
8. R. Ambar, C. K. Fai1, M. H. A. Wahab, M. M. A. Jamil and A. A. Ma'radzi, “Development of a wearable device for sign language recognition,” Journal of Physics: Conference Series, vol. 1019, no. 1, pp. 012017, 2018. [Google Scholar]
9. C. Lungociu, “Real time sign language recognition using artificial neural networks,” INFORMATICA, vol. 56, no. 4, pp. 75–84, 2011. [Google Scholar]
10. B. Kang, S. Tripathi and T. Q. Nguyen, “Real-time sign language finger spelling recognition using convolutional neural networks from depth map,” in Proc. 3rd IAPR Asian Conf. on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, pp. 136–140, 2015. [Google Scholar]
11. R. Cui, H. Liu and C. Zhang, “A deep neural framework for continuous sign language recognition by iterative training”, IEEE Transactions on Multimedia, vol. 21, no. 7, pp. 1880–1891, 2019. [Google Scholar]
12. R. Akmeliawati, M. P. L. Ooi and Y. C. Kuang, “Real-time Malaysian sign language translation using colour segmentation and neural network,” in Proc. IEEE Instrumentation & Measurement Technology Conf., Warsaw, Poland, pp. 1–6, 2007. [Google Scholar]
13. M. Maraqa and R. Abu-Zaiter, “Recognition of arabic sign language (arsl) using recurrent neural networks,” in Proc. First Int. Conf. on the Applications of Digital Information and Web Technologies, Ostrava, Czech Republic, pp. 478–781, 2008. [Google Scholar]
14. K. Bantupalli and Y. Xie, “American sign language recognition using deep learning and computer vision,” in Proc. IEEE Int. Conf. on Big Data, Seattle, WA, USA, pp. 4896–4899, 2018. [Google Scholar]
15. A. Mittal, P. Kumar, P. P. Roy, R. Balasubramanian and B. B. Chaudhuri, “A modified lstm model for continuous sign language recognition using leap motion,” IEEE Sensors Journal, vol. 19, no. 16, pp. 7056–7063, 2019. [Google Scholar]
16. M. Hassan, K. Assaleh and T. Shanableh, “Multiple proposals for continuous arabic sign language recognition,” Sensing and Imaging, vol. 20, no. 1, pp. 1–23, 2019. [Google Scholar]
17. S. Ullah, Z. Mumtaz, S. Liu, M. Abubaqr, A. Mahboobet et al., “An automated robot-car control system with hand-gestures and mobile application using arduino,” Sensing and Image, preprint, 2019. [Google Scholar]
18. Pakistan sign language. https://www.psl.org.pk/signs. Accessed: 2020-02-02. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |