DOI:10.32604/cmc.2022.024438
| Computers, Materials & Continua DOI:10.32604/cmc.2022.024438 | |
| Article |
Sammon Quadratic Recurrent Multilayer Deep Classifier for Legal Document Analytics
School of Engineering, Cochin University of Science and Technology, Kerala, India
*Corresponding Author: Divya Mohan. Email: divyamohancusat@yahoo.com
Received: 17 October 2021; Accepted: 11 February 2022
Abstract: In recent years, machine learning algorithms and in particular deep learning has shown promising results when used in the field of legal domain. The legal field is strongly affected by the problem of information overload, due to the large amount of legal material stored in textual form. Legal text processing is essential in the legal domain to analyze the texts of the court events to automatically predict smart decisions. With an increasing number of digitally available documents, legal text processing is essential to analyze documents which helps to automate various legal domain tasks. Legal document classification is a valuable tool in legal services for enhancing the quality and efficiency of legal document review. In this paper, we propose Sammon Keyword Mapping-based Quadratic Discriminant Recurrent Multilayer Perceptive Deep Neural Classifier (SKM-QDRMPDNC), a system that applies deep neural methods to the problem of legal document classification. The SKM-QDRMPDNC technique consists of many layers to perform the keyword extraction and classification. First, the set of legal documents are collected from the dataset. Then the keyword extraction is performed using Sammon Mapping technique based on the distance measure. With the extracted features, Quadratic Discriminant analysis is applied to perform the document classification based on the likelihood ratio test. Finally, the classified legal documents are obtained at the output layer. This process is repeated until minimum error is attained. The experimental assessment is carried out using various performance metrics such as accuracy, precision, recall, F-measure, and computational time based on several legal documents collected from the dataset. The observed results validated that the proposed SKM-QDRMPDNC technique provides improved performance in terms of achieving higher accuracy, precision, recall, and F-measure with minimum computation time when compared to existing methods.
Keywords: Legal document data analytics; recurrent multilayer perceptive; deep neural network; sammon mapping; quadratic discriminant analysis; likelihood ratio test
In common law legal systems, judges make decisions for issues between parties by reference to previous decisions that consider similar factual situations. A new decision frequently cites previous relevant decisions and such decisions (citations) may form rich citation networks. Such labeling of cases is important to the process of determining whether a case is proper law. These citations help lawyers and students to easily look up case files and documents they are searching in a pile of other documents. These labels serve as a matter of convenience in citation indices enabling lawyers to prioritize decisions to examine and to understand the current state of the law. These also helps in predicting the results of legal cases and hence in making the legal decision-making process faster. Legal text mining aims to automatically evaluate the texts in the legal domain. Efficient document classification techniques are applied for Legal text mining. However, the conventional machine learning-based classification techniques are often inefficient for achieving higher accuracy.
In recent years deep learning techniques has shown promising results in the field of legal domain. Neural networks such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have been used for various legal domain tasks such as information retrieval, document classification, document summarization, etc.
A Joint Bidirectional Label Attention Conditional Network (JBLACN) model was introduced in [1] to classify the court record documents based on the extracted evidence information with higher precision and recall. But the accuracy of the court record documents classification was not improved while considering the more documents. A novel hierarchically nested attention structure model was introduced in [2] for predicting the classification of judgment documents. But, the designed method failed to use the more complex legal judgment cases for accurate document classification.
An active learning method was developed in [3] for document classification. But the deep learning-based classification was not performed to further increase the overall accuracy. In [4], data mining techniques were introduced for smart legal systems but the automatic keyword extraction from legal data was not performed. A controversial issues classification algorithm was designed in [5] to improve the accuracy. But the time consumption of the classification was not reduced.
A long–short-term memory (LSTM) based recurrent neural networks were introduced in [6] for document classification. However, the model failed to use the efficient classification approach for the capability of training the model. A bidirectional Recurrent Neural Network was introduced in [7] to improve the text classification accuracy. But the performance of time consumption was not minimized.
A Graph LSTM (Long Short-Term Memory) was introduced in [8] based on domain knowledge extraction for Chinese legal document categorization. Though the model reduces the time complexity, the classification was not performed through semantic analysis. The machine learning techniques were developed in [9] for categorizing the text documents to predict the ideological way of judgment from the associated text. However, the performance of accuracy and precision of different methods was not analyzed.
An ontology-driven knowledge block summarization method was introduced in [10] for categorizing the judgment documents based on the similarity. However, it failed to explore the novel techniques to investigate for the most similar case judgments.
A local convolutional feature aggregation technique was introduced in [11] to execute document categorization. The designed technique failed to get better parameters to improve the performance. A semi-supervised approach was presented in [12] to improve the accuracy and precision of the document categorization. But the time consumption of the designed approach was not minimized.
A Multichannel Attentive Neural Network (MANN) was introduced in [13] for judgment documents classification. But the designed network failed to provide better performance. A neural network language modeling (NNLM) approach was designed in [14] to analyze and recognize the judgment documents. However, the quantitative evaluations of the system, incorporating legal expert evaluation were not performed. In [15], different machine learning classification algorithms were developed. But it is difficult to automatically extract the features from the text of judgment while enabling the collection of a large number of structured documents.
A deep learning-based robust reconstruction model was introduced in [16] to facilitate faster strip-shredded documents classification. However, the designed deep learning model failed to extract text information from the reconstructed documents. A target center-based LSTM model was introduced in [17] for performing the task of keywords extraction. But, it failed to focus on finding the semantic relations between different words.
A Topical Position Rank model was introduced in [18] for keyphrase extraction and key phrase classification. But the deep learning model was not implemented to enhance the accuracy of classification. An improved TextRank model was introduced in [19] for increasing accuracy and minimizing the complexity of document classification. However, the model failed to combine more heterogeneous information for keywords rank value estimation. A Maximum Entropy Partitioning (MEP) method was introduced in [20] for extracting the keywords to perform document analysis. But the method was not efficient to decrease the time complexity.
A deep learning architecture was proposed in [21] that adopts domain-specific pre-training and a label-attention mechanism for multi-label document classification. A deep neural network model was proposed in [22] for coreference resolution in court record documents. An efficient and appropriate safety testing tool was introduced in [23] to identify the source of printed documents is an important task in the meantime.
The neural model with the Simulated Annealing (SA) a classic global optimization algorithm with low computational complexity was developed in [24] to reduce the daily training time, providing a more friendly graphic visualization of documents in high dimensions, supporting the judicial decision process. An exhaustive and unified repository of judgments documents, called ECHR-OD was presented in [25] based on the European Court of Human Rights.

The major contribution of the proposed SKM-QDRMPDNC on the contrary to the conventional method is summarized as given below,
• To increase the accuracy of legal document classification, a novel SKM-QDRMPDNC technique is introduced based on two different processes namely keyword extraction, and classification.
• To extract keywords from the documents based on the frequency score, novelty of Sammon Mapping technique is applied in SKM-QDRMPDNC technique. Then distance measure is performed among frequency score and threshold value. Depending on the distance measures machine learning technique transforms keywords from high-dimensional space into lower dimensionality. This helps to decrease computational time.
• To perform the document classification based on the likelihood ratio test, SKM-QDRMPDNC technique uses novelty of Quadratic Discriminant analysis in second hidden layer of deep learning. The likelihood ratio is used to classify the documents with higher accuracy.
• Finally, experimental evaluation is performed to estimate the quantitative analysis of the proposed SKM-QDRMPDNC technique with the existing algorithms and different performance metrics like accuracy, precision, recall and F-score have been used for this purpose.
The remainder of this paper is organized into different sections. In Section 2, the proposed SKM-QDRMPDNC technique is described in detail. Section 3 shows the experimental analysis. Quantitative discussion of the proposed technique and existing methods are presented in Section 4. Finally, the conclusion is presented in Section 5.
2 Sammon Keyword Mapping Based Quadratic Discriminant Recurrent Multilayer Perceptive Deep Neural Classification
A novel SKM-QDRMPDNC technique is introduced for improving the legal document analysis. For large number of legal texts, significant keywords extraction is a challenging task. Therefore, the proposed SKM-QDRMPDNC technique uses a dimensionality reduction technique to extract the significant keywords from the legal documents to minimize the time complexity of document classification.
Fig. 1 demonstrates the structural design of the proposed SKM-QDRMPDNC technique consisting of two major processes for improving accuracy. Initially, the set of legal documents are gathered from the dataset. After that, the important keywords are extracted for accurate classification with minimum time. Secondly, the classification is done with the help of a correlation coefficient. The proposed SKM-QDRMPDNC technique uses the recurrent multilayer perceptive deep neural classification where the structure uses many layers of nodes to obtain high-level functions from input information.
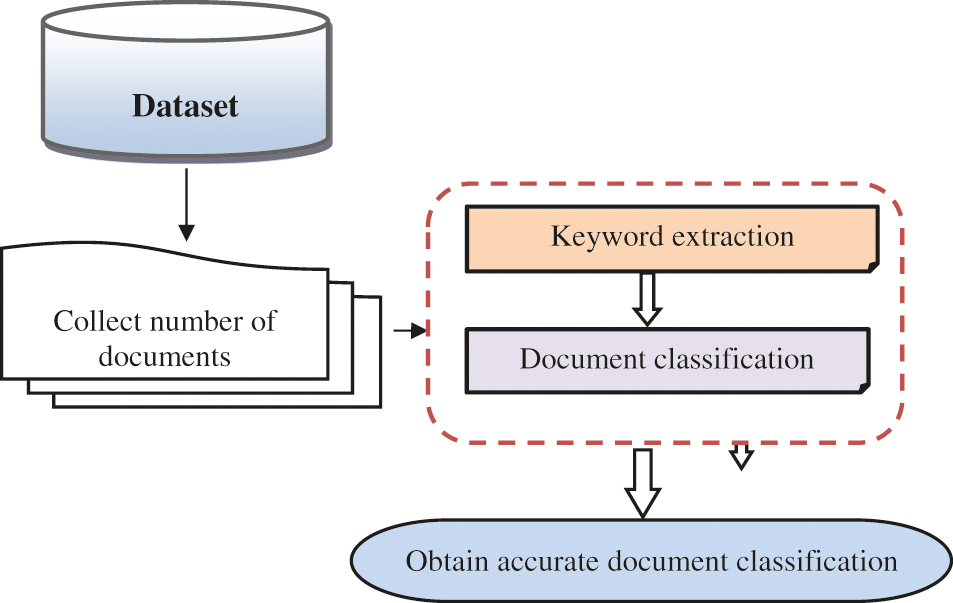
Figure 1: Architecture of the SKM-QDRMPDNC technique
SKM-QDRMPDNC technique helps a model to increase accuracy. It also allows a model to take a set of inputs and provide an output. Each of these layers is feed-forward except for the last layer (i.e., output), which has feedback connections to the hidden layer.
Fig. 2 illustrates the structural design of recurrent multilayer perceptive deep neural classification. A recurrent deep neural classification is an artificial neural learning network that consists of three layers of nodes - an input layer, a hidden layer, and an output layer. The input layer receives the number of legal documents
where,
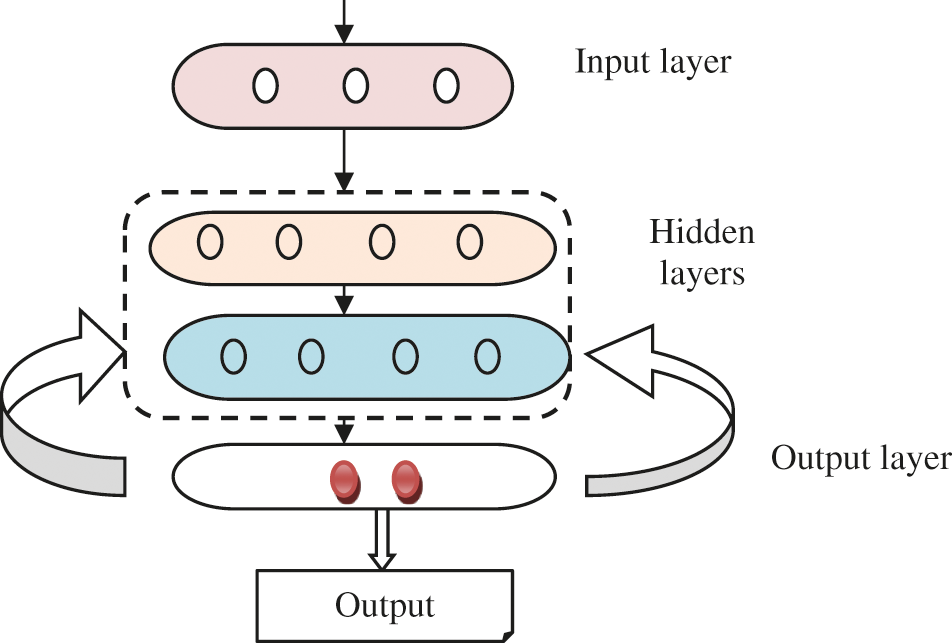
Figure 2: Structural design of recurrent multilayer perceptive deep neural classification
From (2),
After performing the keyword extraction, classification is performed using Quadratic discriminant analysis. The Quadratic discriminant analysis is a classifier that helps to separate the input into two or more classes based on the likelihood ratio test. The likelihood ratio test is performed between the legal documents and the mean of their respective class. The likelihood is estimated as given below,
From (3),
where ‘

The above algorithm provides the step-by-step process of legal document classification based on keyword extraction and classification. Initially, the number of legal documents is collected from the dataset. Then the keyword extraction is performed using Sammon mapping based on the distance measure. The frequency score relevant to the threshold is selected as a significant keyword for classifying the documents. After the feature extraction, the classification is done at the second hidden layer. Depending on distance measures machine learning technique applies machine keywords from high-dimensional space into lower dimensionality. The Quadratic Discriminant classifier is applied for measuring the likelihood between the documents and the mean of the classes. Based on the likelihood measure, the legal documents are correctly classified at the output layer with higher accuracy. Likelihood function classifies the documents into different classes. The document which is closer to the mean of a particular class is classified. The process is repeated until the proposed SKM-QDRMPDNC technique finds the minimum training error in the document classification. The classification result with minimum training error is considered as final result.
In this section, experimental assessment of the proposed SKM-QDRMPDNC technique and existing methods namely JBLACN [1] and hierarchical nested attention structure model [2] are implemented using Legal Case Reports Data Set taken from the UCI machine learning repository https://archive.ics.uci.edu/ml/datasets/Legal+Case+Reports. This dataset contains Australian legal cases collected from the Federal Court of Australia (FCA). This includes all cases from the years 2006, 2007, 2008, and 2009. The dataset which consists of the court report documents have been used to perform automatic legal citation classification. For each document in the dataset, catchphrases, citations sentences, citation catchphrases, and citation classes are collected. Citation classes are indicated in the document, and denote the type of treatment given to the cases cited by the present case.
For each case, a list of labeled citations are provided. A case may be cited differently in different citing cases or even within the same citing case. This is due to the fact that different aspects of the cited case may be of interest.
The distribution among the citation classes [26] for the years 2006–2009 from 3890 FCA documents containing 18715 labelled citations is shown in Tab. 1.

The dataset consists of around 3890 documents. Among the 3890 documents, the number of documents taken for experimental analysis are in groups of 300, 600, 900…3000. The proposed technique is applied on the input set of documents and results in classifying documents based on the citation classes listed. This task of classifying documents is vital to law professionals to know whether the decision has received positive, negative, cautionary or neutral treatment in subsequent judgements.
The performance evaluation of the SKM-QDRMPDNC technique and existing methods namely JBLACN [1] and hierarchical nested attention structure model [2] are done with certain parameters such as accuracy, precision, recall, F-measure, and computational time. The performance results of proposed and existing techniques are discussed as given below,
Accuracy is measured as the ratio of numbers of legal documents that are correctly categorized into various classes to the total number of documents. The accuracy of the three methods are estimated as follows,
From (5),
Tab. 2 provides the experimental outcome of the accuracy of three methods namely the SKM-QDRMPDNC technique and existing methods namely JBLACN [1] and hierarchical nested attention structure model [2] vs. several legal documents taken in the ranges from 300 to 3000. The accuracy is measured based on the number of legal documents correctly identified. The comparative analysis indicates that the SKM-QDRMPDNC technique offers improved performance in terms of achieving higher accuracy of legal documents classification. As shown in Tab. 2, ‘

It is measured as the ratio of relevant documents that are correctly classified to the total number of documents. The precision of different algorithms is expressed as given below,
From (6),
Fig. 3 demonstrates the precision for different numbers of legal documents in the range of 300 to 3000. From the graphical design, the precision is notably increased using the SKM-QDRMPDNC technique than the conventional methods. The precision of the SKM-QDRMPDNC technique is
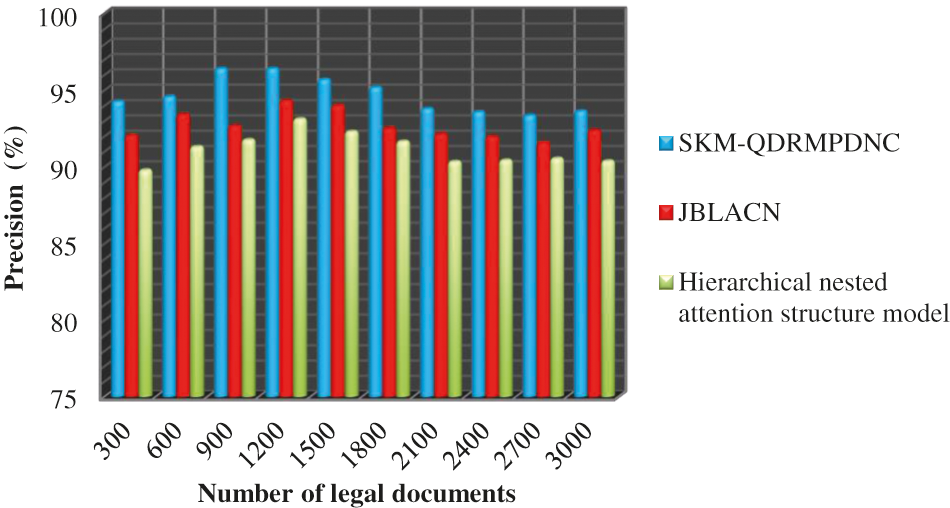
Figure 3: Performance analysis of precision
It is defined as the ratio of relevant documents that are correctly classified to the total number of relevant documents. Therefore, the overall recall rate is measured as given below,
From (7) ‘
Tab. 3 explains the performance results of recall rate vs. several legal documents collected from the dataset. The numbers of legal documents are taken as an input in the ranges 300 to 3000 for calculating the recall. The recall rate is measured based on the true positive and false negatives. As shown in Tab. 3, the SKM-QDRMPDNC technique minimizes the recall rate of document classification when compared to existing techniques. For instance, with 300 legal documents, the true positive and false negative of the SKM-QDRMPDNC technique are 248 and 12. Whereas the true positive and false negative of existing JBLACN [1] are 232 and 18 and true positive and false negative of existing hierarchical nested attention structure model [2] are 220 and 20. Therefore, the overall recall rate was found to be ‘

It is measured based on the mean of precision as well as recall. It is formulated as given below,
From (8),
Fig. 4 illustrates the performance results of the F-measure to the number of legal documents. The F-measure is estimated based on precision and recall. The tabulated results reveal that the proposed SKM-QDRMPDNC technique outperforms well in terms of achieving higher F-measure. Let us consider ‘
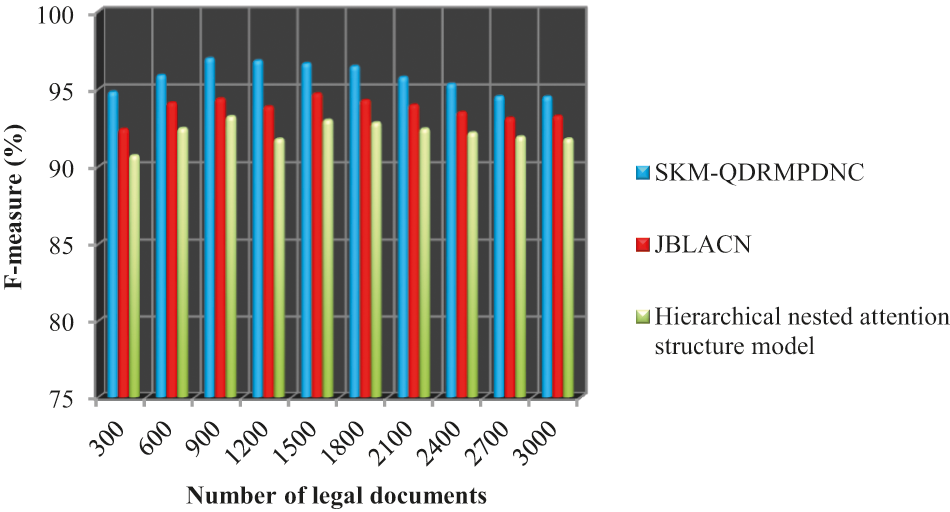
Figure 4: Performance analysis of F-measure
4.5 Impact of Computational Time
It is formulated as the amount of time consumed by the algorithm for categorizing the documents into different classes. As a result, the overall consumption of the time is measured as given below,
From (9),
Tab. 4 indicates the performance results of computational time for finding the document's classification time. From the observed results, the SKM-QDRMPDNC technique decreases the computational time when compared to existing classification techniques. For example, with 300 legal documents, the computational time of a single document is ‘
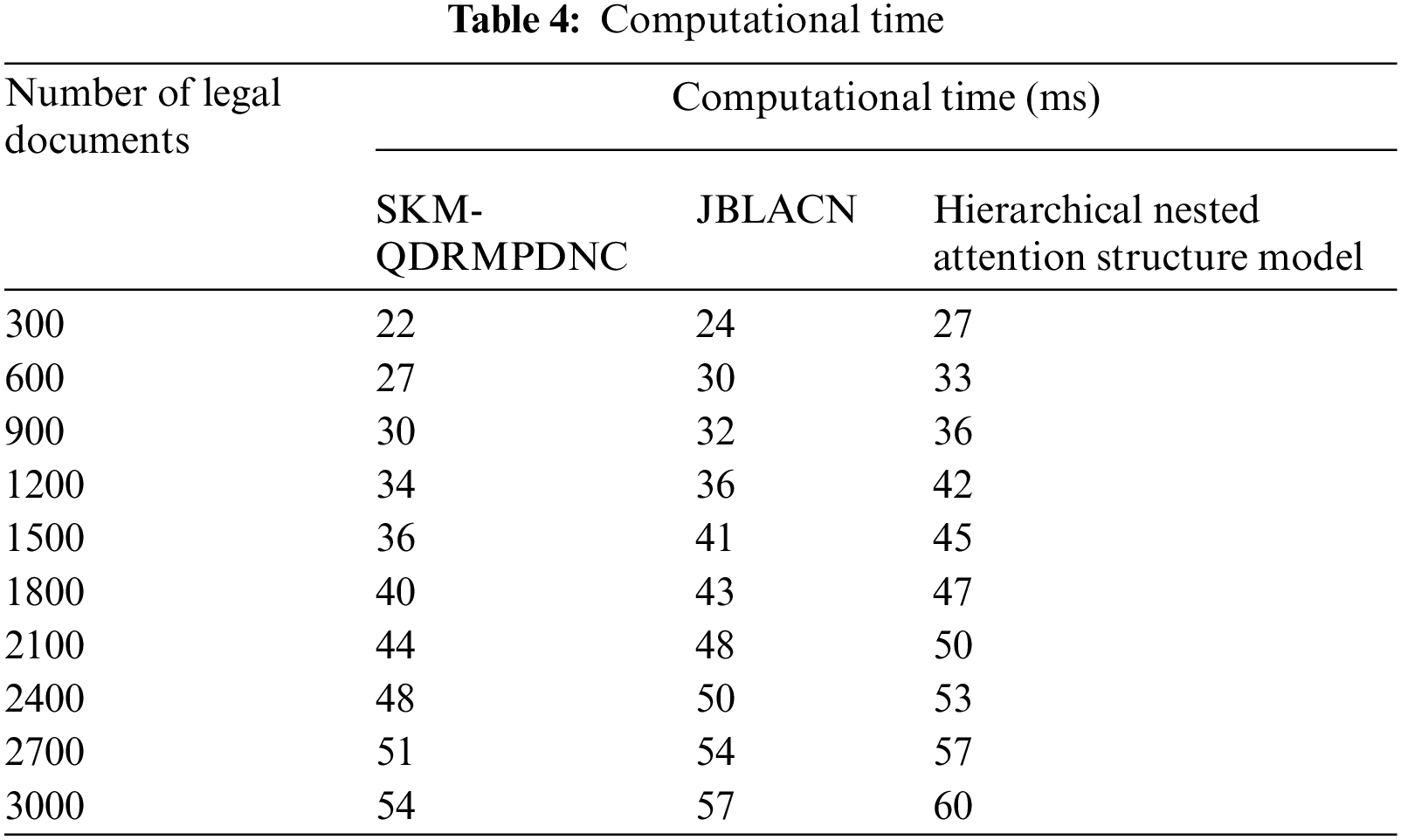
The average of ten comparative results exposes that the SKM-QDRMPDNC technique decreased the document classification time by 7% when compared to [1] and 15% when compared to [2].
In this paper, a novel deep learning technique called SKM-QDRMPDNC is proposed for learning the textual legal document representations for automatic legal citation classification. This task characterizes the relation between the present case and the cited ones, which is a novel application in itself helping law professionals in better understanding of court decisions. The proposed technique receives input legal documents and keyword extraction process is performed by Sammon keyword mapping technique. Depending on distance measure, machine learning technique maps the keywords from high-dimensional space into lower dimensionality. After keyword extraction, Quadratic Discriminant analysis is applied into a hidden layer of recurrent multilayer perceptive deep neural network to perform the legal document classification based on likelihood measure. Lastly, classification results are obtained with higher accuracy. The classification result with minimum frequency error is considered as final class result. Experimental result is performed with various parameters namely accuracy, precision, recall, F-measure, and computational time vs. several legal documents collected from the dataset. The proposed technique performs legal document classification, however time complexity involved in the legal document data analytics could be further reduced. In future work, SKM-QDRMPDNC technique is extended for learning the textual legal document representations by using optimization based deep learning methods.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. D. Ji, P. Tao, H. Fei and Y. Ren, “An end-to-end joint model for evidence information extraction from court record document,” Information Processing & Management, Elsevier, vol. 57, no. 6, pp. 1–14, 2020. [Google Scholar]
2. K. Zhu, B. Ma, T. Huang, Z. Li, H. Ma et al., “Sequence generation network based on hierarchical attention for multi-charge prediction,” IEEE Access, vol. 8, pp. 109315–109324, 2020. [Google Scholar]
3. M. Sharma and M. Bilgic, “Learning with rationales for document classification,” Machine Learning, Springer, vol. 107, no. 5, pp. 797–824, 2018. [Google Scholar]
4. S. Sharafat, Z. Nasar and S. W. Jaffry, “Data mining for smart legal systems,” Computers & Electrical Engineering, Elsevier, vol. 78, no. December(6), pp. 328–342, 2019. [Google Scholar]
5. Y. Fang, X. Tian, H. Wu, S. Gu, Z. Wang et al., “Few-shot learning for chinese legal controversial issues classification,” IEEE Access, vol. 8, pp. 75022–75034, 2020. [Google Scholar]
6. W. Zhang, Y. Li and S. Wang, “Learning document representation via topic-enhanced LSTM model,” Knowledge-Based Systems, Elsevier, vol. 174, pp. 194–204, 2019. [Google Scholar]
7. C. Du and L. Huang, “Text classification research with attention-based recurrent neural networks,” International Journal of Computers Communications & Control, vol. 13, no. 1, pp. 50–61, 2018. [Google Scholar]
8. G. Li, Z. Wang and Y. Ma, “Combining domain knowledge extraction with graph long short-term memory for learning classification of chinese legal documents,” IEEE Access, vol. 7, pp. 139616–139627, 2019. [Google Scholar]
9. C. I. Hausladena, M. H. Schubert and E. Ash, “Text classification of ideological direction in judicial opinions,” International Review of Law and Economics, Elsevier, vol. 62, no. 10, pp. 1–19, 2020. [Google Scholar]
10. Y. Ma, P. Zhang and J. Ma, “An ontology driven knowledge block summarization approach for chinese judgment document classification,” IEEE Access, vol. 6, pp. 71327–71338, 2018. [Google Scholar]
11. L. Liu, K. Liu, Z. Cong, J. Zhao, Y. Ji et al., “Long length document classification by local convolutional feature aggregation,” Algorithms, vol. 11, no. 8, pp. 1–12, 2018. [Google Scholar]
12. I. S. Bajwa, F. Karim, M. A. Naeem and R. U. Amin, “A semi supervised approach for catchphrase classification in legal text documents,” Journal of Computers, vol. 12, pp. 451–461, 2017. [Google Scholar]
13. S. Li, H. Zhang, L. Ye, X. Guo and B. Fang, “MANN: A multichannel attentive neural network for legal judgment prediction,” IEEE Access, vol. 7, pp. 151144–151155, 2019. [Google Scholar]
14. C. V. Trappey, A. J. C. Trappey and B. H. Liu, “Identify trademark legal case precedents - Using machine learning to enable semantic analysis of judgments,” World Patent Information, Elsevier, vol. 62, no. 1, pp. 1–10, 2020. [Google Scholar]
15. R. A. Shaikha, T. P. Sahua and V. Anand, “Predicting outcomes of legal cases based on legal factors using classifiers,” Procedia Computer Science, Elsevier, vol. 167, pp. 2393–2402, 2020. [Google Scholar]
16. T. M. Paixao, R. F. Berriel, M. C. S. Boeres, A. L. Koerich, C. Badue et al., “Self-supervised deep reconstruction of mixed strip-shredded text documents,” Pattern Recognition, Elsevier, vol. 107, no. 7, pp. 1–37, 2020. [Google Scholar]
17. Y. Zhang, M. Tuo, Q. Yin, L. Qi, X. Wang et al., “Keywords extraction with deep neural network model,” Neurocomputing Elsevier, vol. 383, no. 2, pp. 113–121, 2020. [Google Scholar]
18. M. N. Awan and M. O. Beg, “TOP-Rank: A topical postion rank for extraction and classification of keyphrases in text,” Computer Speech & Language, Elsevier, vol. 65, pp. 1–29, 2021. [Google Scholar]
19. Z. Huang and Z. Xie, “A patent keywords extraction method using Text Rank model with prior public knowledge,” Complex & Intelligent Systems, Springer, vol. 7, pp. 1–12, 2021. [Google Scholar]
20. S. Susan and J. Keshari, “Finding significant keywords for document databases by two-phase maximum entropy partitioning,” Pattern Recognition Letters, Elsevier, vol. 125, pp. 195–205, 2019. [Google Scholar]
21. D. Song, A. Vold, K. Madan and F. Schilder, “Multi-label legal document classification: A deep learning-based approach with label-attention and domain-specific pre-training,” Information Systems, vol. 106, pp. 101718, 2021. [Google Scholar]
22. D. Ji, J. Gao, H. Fei, C. Teng, Y. Ren et al., “A deep neural network model for speakers coreference resolution in legal texts,” Information Processing & Management, vol. 57, no. 6, pp. 102365, 2020. [Google Scholar]
23. M. J. Tsai, Y. H. Tao and I. Yuadi, “Deep learning for printed document source identification,” Signal Processing: Image Communication, vol. 70, pp. 184–198, 2019. [Google Scholar]
24. L. R. C. de Mendonça and G. da. C. Júnior, “Deep neural annealing model for the semantic representation of documents,” Engineering Applications of Artificial Intelligence, vol. 96, no. 6, pp. 103982, 2020. [Google Scholar]
25. A. Quemy and R. Wrembel, “ECHR-OD: On building an integrated open repository of legal documents for machine learning applications,” Information Systems, vol. 106, pp. 1–20, 2021. [Google Scholar]
26. F. Galgani and A. Hoffmann, “Lexa: Towards automatic legal citation classification,” in AI 2010: Advances in Artificial Intelligence, J. Li (eds.Vol. 6464, pp. 445–454, 2010. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |