DOI:10.32604/cmc.2022.023101
| Computers, Materials & Continua DOI:10.32604/cmc.2022.023101 | |
| Article |
Signet Ring Cell Detection from Histological Images Using Deep Learning
1Department of Computer Science, UET, Taxila, 47050, Pakistan
2Department of Computer Science, HITEC University Taxila, Taxila, Pakistan
3Faculty of Applied Computing and Technology, Noroff University College, Kristiansand, Norway
4Department of Civil Engineering, Imperial College London, London SW7 2AZ, UK
5College of Arts, Media, and Technology, Chiang Mai University, Chiang Mai 50200, Thailand
*Corresponding Author: Orawit Thinnukool. Email: orawit.t@cmu.ac.th
Received: 27 August 2021; Accepted: 29 November 2021
Abstract: Signet Ring Cell (SRC) Carcinoma is among the dangerous types of cancers, and has a major contribution towards the death ratio caused by cancerous diseases. Detection and diagnosis of SRC carcinoma at earlier stages is a challenging, laborious, and costly task. Automatic detection of SRCs in a patient's body through medical imaging by incorporating computing technologies is a hot topic of research. In the presented framework, we propose a novel approach that performs the identification and segmentation of SRCs in the histological images by using a deep learning (DL) technique named Mask Region-based Convolutional Neural Network (Mask-RCNN). In the first step, the input image is fed to Resnet-101 for feature extraction. The extracted feature maps are conveyed to Region Proposal Network (RPN) for the generation of the region of interest (RoI) proposals as well as they are directly conveyed to RoiAlign. Secondly, RoIAlign combines the feature maps with RoI proposals and generates segmentation masks by using a fully connected (FC) network and performs classification along with Bounding Box (bb) generation by using FC layers. The annotations are developed from ground truth (GT) images to perform experimentation on our developed dataset. Our introduced approach achieves accurate SRC detection with the precision and recall values of 0.901 and 0.897 respectively which can be utilized in clinical trials. We aim to release the employed database soon to assist the improvement in the SRC recognition research area.
Keywords: Mask RCNN; deep learning; SRC; segmentation
Humanity is facing many health care challenges which put a demand on health professionals to be prepared to cope with harmful diseases with care and control them timely. Cancer is one of the deadliest diseases due to which 16% of victims die every day [1,2]. As per Global Cancer Incidence, Mortality and Prevalence (GLOBOCAN) statistics, in 2018, about 18.1 million new cancer cases were emanated and become the second prominent cause of death with an estimated 9.6 million deaths [3]. Moreover, in 2020 this number arises to 19.3 million cases with 10 million deaths [4].
Cells are the basic units that make up the human body which grows and divide to make new cells based on the requirements of the body [5]. Cancer is the immoderate expansion of new cells and aberrant gene variations that can be induced from any part of the body and keep spreading [6]. Abnormal growth of cells results in a mass called a tumor. The tumor cells are of regenerative natures which grow so rapidly in the entire human body. During this procedure, the tumor cells expand and may result in a different tumor and this process is named metastasis. In the human body, the lymph nodes are the most sensitive part in which often cancer cells grow. Lymph nodes are small organs, bean-shaped cells that assist the human body to fight against infection. These organs are found as groups in the different parts of the body i.e., beneath the arms, neck, and groin parts. The tumor cells can expand via the bloodstream to the various body portion and cause severe pain. Some of the deadliest cancers are the brain, skin, bones, lungs, and liver cancers which have the highest mortality rate. Usually, the tumor is named after the body part from where it originates like if breast cancer develops in the lungs, it is named metastatic breast cancer [7].
Cancer is a combination of more than 277 varying diseases that can be found anywhere in the human body. Cancer can be categorized into four different types based on its origination point as sarcoma starts in the cells that support and join the body. Whereas leukemia is a type of blood cancer that occurs when normal blood tissues expand abnormally and are found in the lymphatic system. Similarly, carcinoma begins in the skin tissue that surrounds the surface of internal organs and glands. Carcinomas normally develop solid cancers and are among the fatal forms of cancer [8].
Carcinoma cancer [9] is formed by epithelial cells that cover the interior and exterior sides of the skin as well as the tissue lining organs. Based on epithelial cell types, carcinoma has different distinct names like Adenocarcinoma, Basal cell carcinoma, etc. SRC carcinoma is adenocarcinoma with a high risk of cancer metastasis [8]. SRC Carcinoma is most likely to be found in the stomach and could also be disseminated to the lungs, breast, ovaries, and other organs. The survival rate of patients could be ameliorated by the embodiment of SRCC. Pathologists usually employ the microscope or immune histochemistry (IHC) to visualize the SRCs [10]. The sample images of SRCs are shown in Fig. 1. SRCs are illustrated by a main optically clear, globoid droplet of cytoplasmic mucin with a bizarrely placed nucleus that made their appearance peculiar from other types of cells.
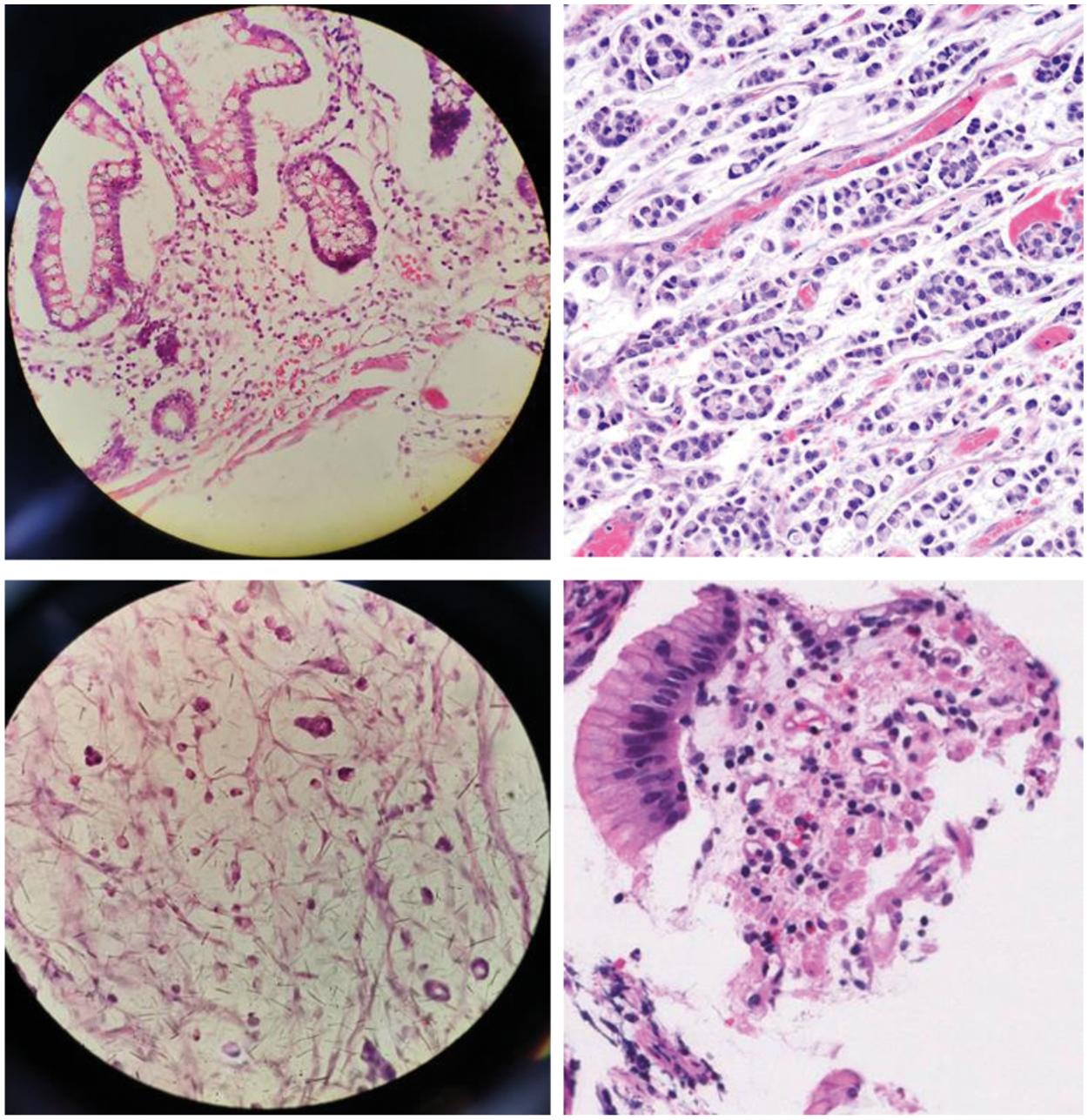
Figure 1: Sample images of SRCs
Although, the research community has started to propose systems for the recognition of SRCs, however, the accurate recognition of these dangerous diseases is still a challenging job. The varying properties of SRCs like their shape, size, and color make it complex to be identified at its earliest stage. Although, the ability of machine learning (ML) methods to resolve challenging real-world problems is remarkable over human brain intelligence. However, the major issues of ML-based techniques are their less efficacy and high processing time as these frameworks produce lengthy codes that increase the computational complexity. To deal with the issue of long codes, DL-based methods have been emerged, however, at the cost of enhanced code complexity. Moreover, existing methods are not well generalized to real-world scenarios. So, there is room for performance improvement both in terms of SRCs detection accuracy and time complexity.
In the presented framework, we have tried to overcome the limitations of the existing approaches by proposing a DL-based framework namely Mask-RCNN with ResNet-101 as base network. More specifically, we have applied the ResNet-101 approach as a feature extractor to compute the deep features from the suspected samples which are later localized and segmented by the Mask-RCNN framework. Moreover, we have developed a custom dataset that is challenging in terms of size, color, and shapes of SRCs and contains several image distortions like image blurring, noise, and intensity variations. Our work has the following main contributions:
• We have presented an efficient and effective model namely Mask-RCNN that achieved good performance under different conditions i.e., noise, blur light variations and size, etc.
• We have generated an SRCs dataset having 200 images and then generate the annotated samples as well to identify the RoIs which are essential to perform transfer learning.
• Our method is capable of recognizing the SRCs and has no issue in learning to identify the images of a healthy patient.
• The proposed method is robust to SRCs segmentation due to the accurate feature computation power of the ResNet-101 framework.
• The presented framework is robust to image post-processing attacks due to the ability of the Mask-RCNN framework to deal with the overfitted training data.
The rest of the paper follows the following structure: Section 2 shows the related work, while Section 3 explains the proposed method. The obtained results are elaborated in Section 4 while Section 5 contains the conclusion and future work.
In this section, we have reviewed the existing work performed in the field of SRCs detection and segmentation. The quick growth rate of various cancers has focused the attention of researchers to propose automated solutions, as the manual systems are highly dependent on the availability of human experts which in turn delays the identification process. The power of ML and DL-based methods have exhibited better recognition accuracy in the area of medical image analysis [11–16].
The detection of SRCs is a complex job because of the challenging structure of these cells which makes it quite different from other cell categories [17]. In [18–22], analysis on natural images using various computer vision methods has been proposed and verified by supervised and semi-supervised learning techniques however, these approaches exhibit low performance. Li et al. in [23] presented an approach for the automated detection of signet cells by proposing a semi-supervised learning technique. Initially, a self-training framework was introduced to tackle the problem of incomplete annotations. Then the cooperative-training approach was presented to identify the unlabeled areas. The approach in [23] exhibits better SRC detection performance by combining both methods which assist it to employ both labeled and unlabeled data effectively. However, the approach in [23] is suffering from high computational costs. Ying et al. in [24] proposed a deep convolutional model to identify false positives in suspected sample areas and locate SRCs under the presence of partial annotations. Precisely, a DL-based approach namely the RetinaNet was trained to accurately categorize sample labels and accurately identify the SRCs. To enhance the detection accuracy of the proposed framework, the work [24] introduced a self-training approach to produce pseudo bbs based on test time augmentation and modified non-maximum suppression to re-train the detector. Then, the employed framework namely the RetinaNet was retrained from scratch using the annotated bb.
Wang et al. [25] introduced a technique to automatically detect the SRCs by introducing the classification reinforcement detection network (CRDet). The CRDet framework comprised a Cascade RCNN model along with a dedicated devised Classification Reinforcement Branch (CRB). The main objective of CRDet was to compute the more discriminative set of features from the input samples which enabled it to locate the cells of small sizes. It is concluded in [25] that the CRDet model works well than CNN-based techniques. Sun et al. in [26] presented a CNN-based approach to automatically locate the SRCs from the input samples. The work [26] employed the region proposal framework by introducing an embedding layer that allowed similarity learning for network training. The work in [26] is robust to SRC detection, however, performance needs further improvements. Lin et al. in [27] proposed Decoupled Gradient Harmonizing Mechanism (DGHM) and inserted it into classification loss. Moreover, positive SRCs and negative samples further uncoupled noisy samples from clean examples and match the corresponding gradient distributions in classification, respectively.
The proposed method aims to automatically locate and segment the SRCs using a DL-based method namely Mask RCNN [28]. Initially, annotations are made which are passed to the Mask RCNN for training. Then, the ResNet-101 is employed as the base network of the Mask RCNN for the features extraction from the images. The computed keypoints are later used by the Mask RCNN to localize and segment the SRCs. Finally, the model is evaluated using test images to demonstrate the robustness of the proposed framework. The architecture of the presented technique is shown in Fig. 2.
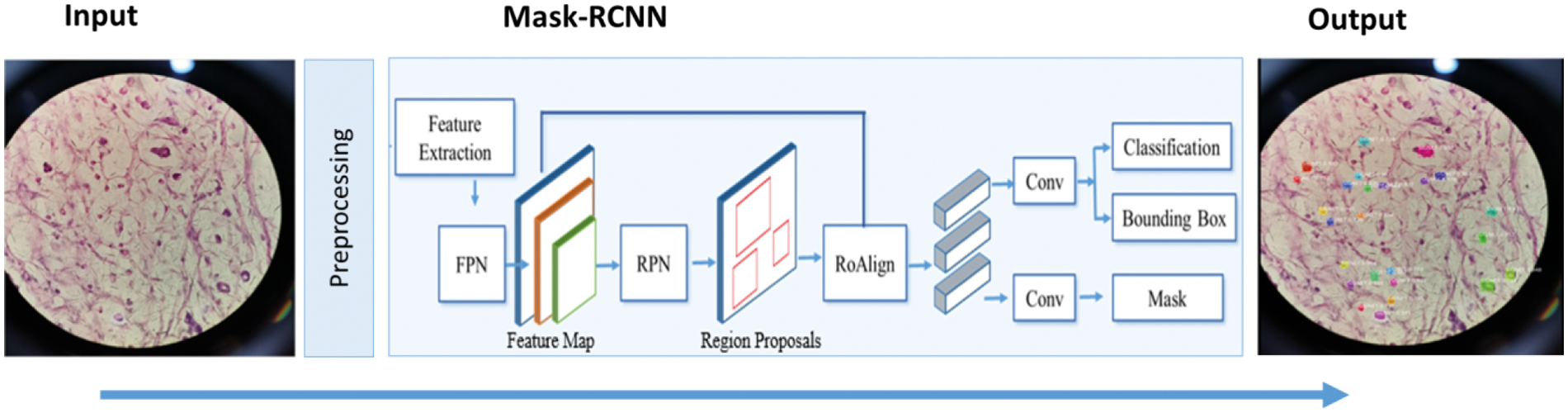
Figure 2: Proposed framework of SRCs detection
The existence of unwanted information like noise in images can influence the recognition performance of the model. To solve this problem, we employed the level set technique for bias field correction and median filter to reduce the noise to get the enhanced image.
3.2 SRCs Localization and Segmentation
In the proposed work, a DL technique namely the Mask RCNN is used to obtain the features from the input samples. Mask RCNN is the extension of Faster RCNN [29] and is employed for both detection and segmentation of regions. Our goal is to accurately locate and segment all the SRCs present in the image. The proposed methodology is described in Algorithm 1. The Mask RCNN framework consists of four steps and a comprehensive explanation of every phase is given in the subsequent sections.
For the extraction of robust features from the input images, a backbone network namely ResNet-101 is used. The ResNet-101 along with a Feature Pyramid Network (FPN) is found effective for the detailed features extraction which gives a gain in both processing time and detection accuracy. The architecture of Resnet-101 is shown in Fig. 3. In the employed keypoints extractor, the low-level features i.e., corners and edges are extracted at initial layers whereas the high-level complex features i.e., texture and color are extracted on deep layers. For better results, the consequence feature map is further enhanced using FPN which extracts detailed features to pass on to RPN.

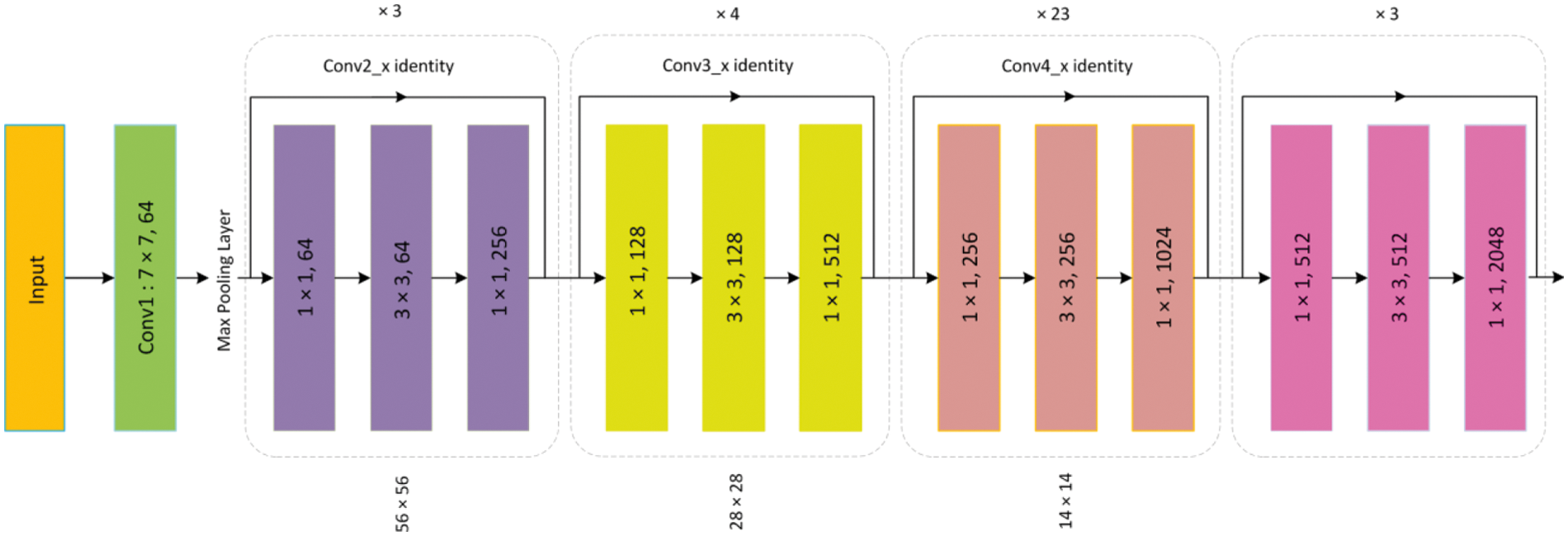
Figure 3: Architecture of ResNet-101
To detect SRCs, RoI's are generated by giving previous computed feature maps as input to the RPN network. Image is scanned in a sliding window approach using a Convolutional layer of 3 × 3, applied to generate anchors that represent bb of different sizes distributed over the entire image. More specifically, the image is covered with 20k anchors that correspond with each other and are distinct in size. Binary classification is applied to determine whether the anchor contains the SRCs or background (FG/BG). Finally, the bbs are generated to bound the SRCs with the bb regressor according to the set Intersection-over-Union (IoU) value. Particularly, if the IoU value of an anchor corresponding to each GT box is greater than 0.7, then it is categorized as a positive anchor, otherwise, it is marked negative. The RPN generates extensive regions, therefore, a non-maximum suppression technique is applied to maintain the RoIs with significant overlaps while the remaining are discarded. Finally, the consequent RoIs (region proposals) containing SRCs are passed to the next stage.
This module accepts the RoIs and feature maps as input which are later categorized to a specific class as Signet/non-signet rings. Furthermore, the size of the bb is improved in this step as well. To encapsulate the SRCs, the size and location of the bb are refined by the bb regressor. Generally, the edges of RoI do not overlap with the hardness of the feature map which is compensated by using the RoIAlign. Lately, each RoI is pooled by RoIAlign to a fixed-sized feature map.
Apart from classification and regression, the Mask RCNN works differently and gives a segmentation mask for RoIs as well. In comparison to binary masks, the obtained segmentation mask of 28 × 28 resolution contains more information and is represented by floating numbers. To compute loss, the GT masks are scaled down during the training process, whereas, in the prediction step, the estimated mask is scaled up to the output mask.
The Mask RCNN model uses a function of multi-task loss L which achieves an end-to-end training of the deep neural network. During training, a model tries to minimize the value of L, and the most suitable model obtained through the minimization of L on the training data is later used as a trained model. The L is defined as:
where
where
Where
where
where
The proposed approach is implemented in Keras and TensorFlow libraries with ResNet-101 along with FPN for keypoints computation. We adjusted the method employing pre-trained weights acquired from the COCO database and then fine-tune (shown in Tab. 1) the technique on SRCs datasets for detection and segmentation. Our proposed approach is implemented using Python on an intel Core I-5 machine with 16-GB ram.

We have generated our SRCs dataset having a total of 200 images. In which 23 Hematoxylin and Eosin (H&E) stained histology images are acquired from Allied General Hospital, Faisalabad, and 19 images from the Punjab Medical College, Faisalabad. We also attained 68 more images for our research under the supervision of the above-mentioned institutes along with some images obtained from the internet.
We have employed various evaluation matrices like Precision, Recall, Accuracy, IoU, and mean average precision (mAP) for performance evaluation which are expressed in the following equations:
Fig. 4 shows the geometrical representation of the Precision, recall and IoU metrics.

Figure 4: Evaluation metrics (a) Precision, (b) Recall and (c) IoU
The precise localization of SRCs is essential for creating an automated Signet recognition method. Therefore, we intended an experiment to evaluate the localization efficiency of the proposed model. For this study, we utilized all the test images from the dataset and presented a few visual results, as shown in Fig. 5. From the reported results we can see that that the proposed approach is capable to locate SRCs of differing sizes, shapes, and colors. To quantitatively measure the localization efficiency, we have computed the mAP and IoU.
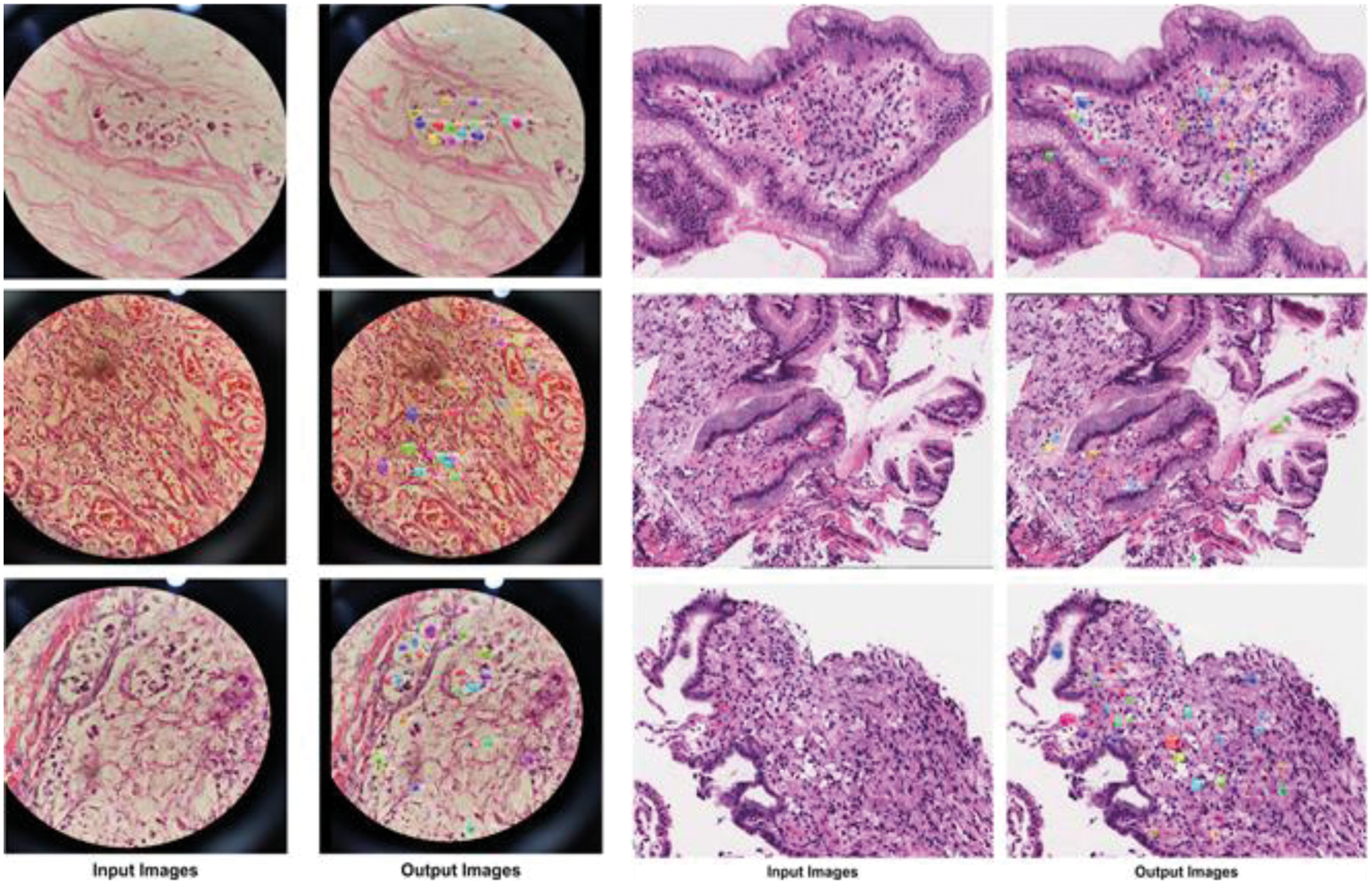
Figure 5: Localization of SRCs
More precisely, we attained the mAP and mean IoU of 0.903 and 0.920 respectively. We can conclude from these qualitative and quantitative analyses that the presented technique can effectively detect and precisely localize the SRCs. The proposed approach segmentation results are demonstrated in the bar graph (Fig. 6). The method attained an accuracy of 91.8%, precision of 0.901. and recall of 0.897.
4.4 Performance Comparison with Other Object Detection Techniques
We have compared the performance of our approach with other object detection methods. An accurate SRCs localization is important because a noisy background can mislead the model when the target region is not salient and the presence of multiple SRCs in a sample image requires respective detection. We have considered different techniques i.e., Fast-RCNN [30], Faster-RCNN [29] for comparison.
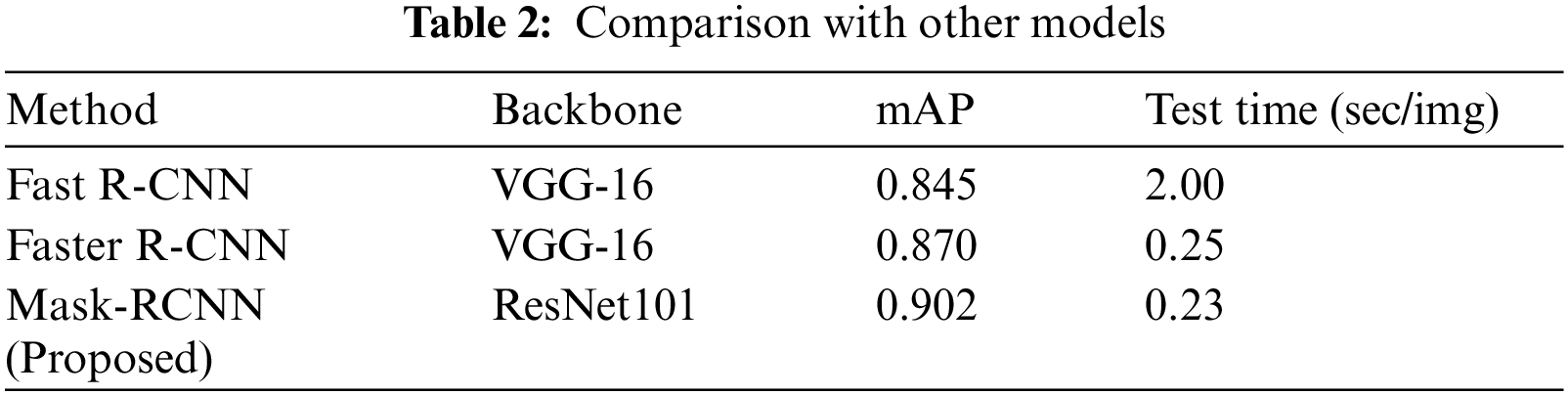
To conduct the performance analysis, we have computed the mAP measure, and test time of all models to measure their computational complexity. Tab. 2 shows the SRCs detection performance comparison of different object detection approaches. It is cleared from Tab. 2, that our approach outperforms the comparison approaches both in terms of mAP and test time. In the case of mAP, the Fast R-CNN and Faster R-CNN obtain the mAP values of 0.845 and 0.870, while the Mask-RCNN obtains the mAP value of 0.902 and gives the performance gain of 0.044. Moreover, in the case of test time complexity, the Fast RCNN is computationally expensive and takes 2 s to perform the image testing as it randomly generates region proposals and employs the selective search technique. The Faster RCNN automatically calculates the region proposals by utilizing the RPN module and shares the convolutional layer among the class and bb network to minimize the processing cost and takes 0.25 s for processing the suspected sample. While in comparison, the Mask-RCNN gives an extended advantage over Faster-RCNN by producing a computerized segmentation mask as well and takes only 0.23 s which is less than all the comparative approaches. Therefore, the conducted analysis is clearly showing that the presented Mask-RCNN is more robust in comparison to other methods both in terms of model evaluation and processing time.
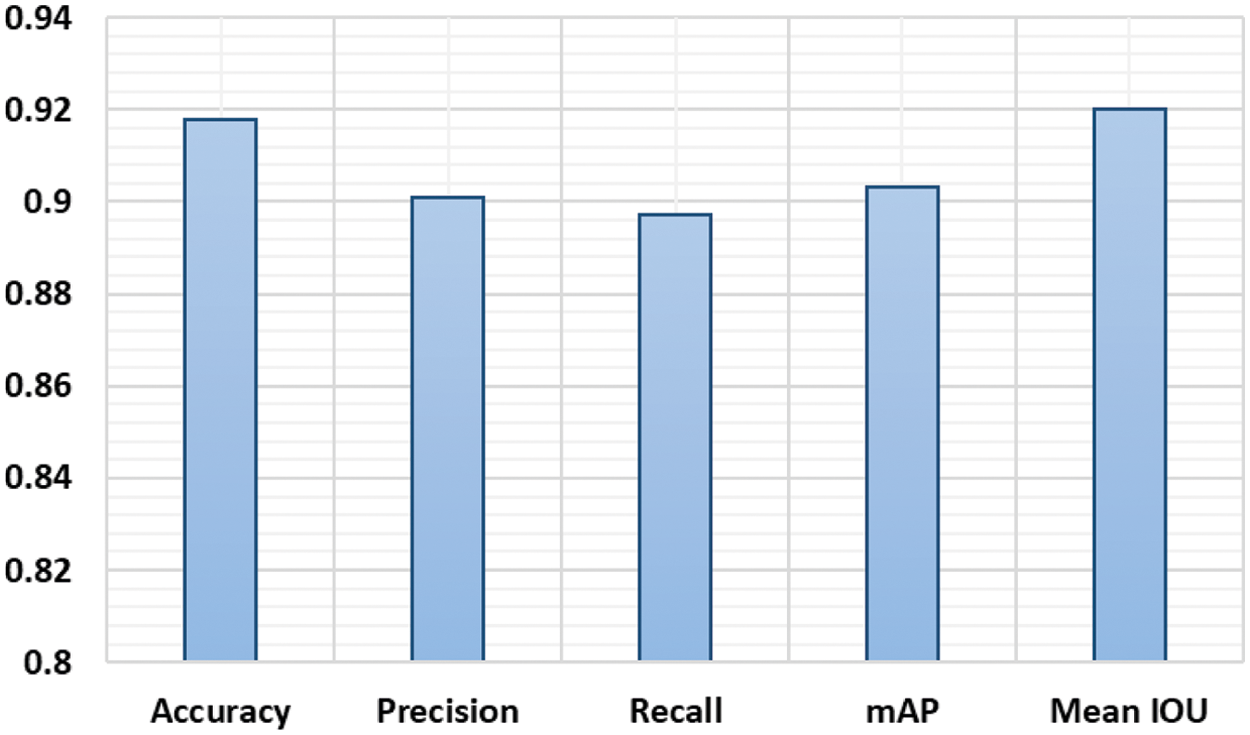
Figure 6: Proposed approach performance
4.5 Performance Comparison with Other Methods
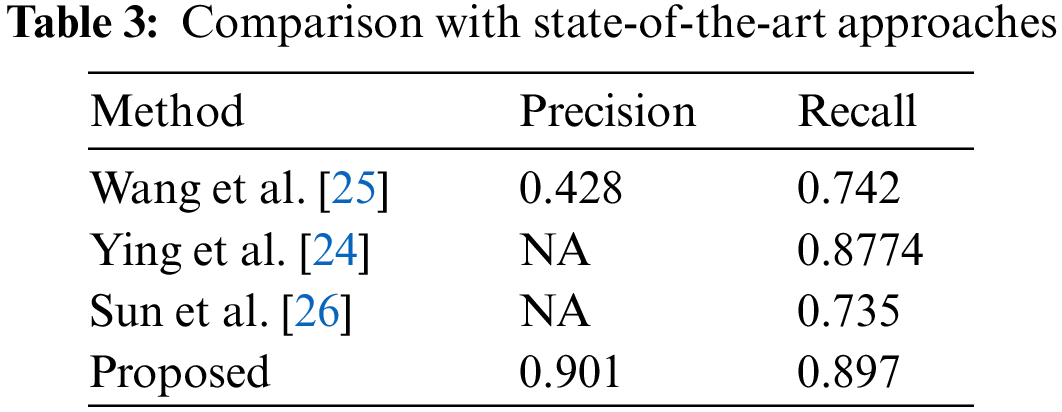
In this section, we have performed an experiment to compare the performance of our framework with the latest approaches, and performance results are reported in Tab. 3. It can be witnessed, that our approach outperforms the other approaches. More specifically, in the case of Precision, we have obtained an average value of .901 while the other approaches show an average precision value of 0.428, which is showing an average performance gain of 0.473. Similarly, in the case of a recall, our method obtains the average value of 0.897, while the comparative methods show an average recall value of 0.7848, so we acquire the performance gain of 0.1122 which is showing the robustness of our technique. The reason for the effective performance of our approach is due to the employment of the ResNet-101 framework which results in a more robust set of image features and assists in better recognizing the cancerous cells.
SRCC is the variant of adenocarcinoma and is defined by the presence of cancerous SRCs with prominent intracytoplasmic mucin, typically with displacement and molding of the nucleus. Detection of SRCs at earlier stages can avoid expensive and dangerous treatments such as chemotherapy and radiotherapy in most cases, but it is an exhaustive way of diagnosis. We have presented a DL model to recognize and segment the SRCs. A CNN model namely ResNet-101 is utilized at the key points computation level of Mask-RCNN. The presented CNN model can calculate the more representative set of features which helps in precisely locating the SRCs. The proposed model can also accurately segment the SRCs under the presence of complex background and various challenging conditions such as size, location, and shapes of cells, however, performance may be degraded over the images with intense color variations. Moreover, the model is computationally efficient as the ResNet-101 employs skip connections which gives the compact feature representation. From the reported results, we confirm that our method is robust both in terms of SRCs recognition and time complexity as compared to other latest approaches. In the future, we aim to enhance this research work by applying it to other cancer diseases and evaluating our model on other challenging datasets.
Funding Statement: This research work was partially supported by Chiang Mai University.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. M. Lodge, “The role of the commonwealth in the wider cancer control agenda,” The Lancet Oncology, vol. 21, no. 7, pp. 879–881, 2020. [Google Scholar]
2. K. D. Miller, L. Nogueira, A. B. Mariotto, J. H. Rowland, K. R. Yabroff et al., “Cancer treatment and survivorship statistics, 2019,” CA: A Cancer Journal for Clinicians, vol. 69, no. 5, pp. 363–385, 2019. [Google Scholar]
3. F. Bray, J. Ferlay, I. Soerjomataram, R. L. Siegel, L. A. Torre et al., “Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries,” CA: A Cancer Journal for Clinicians, vol. 68, no. 6, pp. 394–424, 2018. [Google Scholar]
4. A. Mandal, P. Singh, A. Samaddar, D. Singh, M. Verma et al., “Vaccination of cancer patients against COVID-19: Towards the end of a dilemma,” Medical Oncology, vol. 38, no. 8, pp. 1–8, 2021. [Google Scholar]
5. E. Bianconi, A. Piovesan, F. Facchin, A. Beraudi, R. Casadei et al., “An estimation of the number of cells in the human body,” Annals of Human Biology, vol. 40, no. 6, pp. 463–471, 2013. [Google Scholar]
6. I. D. Nagtegaal, R. D. Odze, D. Klimstra, V. Paradis, M. Rugge et al., “The 2019 WHO classification of tumours of the digestive system,” Histopathology, vol. 76, no. 2, pp. 182, 2020. [Google Scholar]
7. G. Powis, D. Mustacichi, and A. Coon, “The role of the redox protein thioredoxin in cell growth cancer,” Free Radic Biol Med, vol. 29, pp. 312–322, 2000. [Google Scholar]
8. T. Fehm, E. Solomayer, S. Meng, T. Tucker, N. Lane et al., “Methods for isolating circulating epithelial cells and criteria for their classification as carcinoma cells,” Cytotherapy, vol. 7, no. 2, pp. 171–185, 2005. [Google Scholar]
9. C. L. Collins, J. Malvar, A. S. Hamilton, D. M. Deapen and D. R. Freyer, “Case-linked analysis of clinical trial enrollment among adolescents and young adults at a National Cancer Institute-designated comprehensive cancer center,” Cancer, vol. 121, no. 24, pp. 4398–4406, 2015. [Google Scholar]
10. Q. Duan, G. Wang, R. Wang, C. Fu, X. Li et al., “SenseCare: A research platform for medical image informatics and interactive 3D visualization,” Cytotherapy, vol. 7, no. 2, pp. 1–18, 2020. [Google Scholar]
11. T. Nazir, M. Nawaz, J. Rashid, R. Mahum, M. Masood et al., “Detection of diabetic eye disease from retinal images using a deep learning based centerNet model,” Sensors, vol. 21, no. 16, pp. 5283, 2021. [Google Scholar]
12. A. Mehmood, M. Iqbal, Z. Mehmood, A. Irtaza, M. Nawaz et al., “Prediction of heart disease using deep convolutional neural networks,” Arabian Journal for Science Engineering, vol. 46, no. 4, pp. 3409–3422, 2021. [Google Scholar]
13. M. Masood, T. Nazir, M. Nawaz, A. Mehmood, J. Rashid et al., “A novel deep learning method for recognition and classification of brain tumors from MRI images,” Diagnostics, vol. 11, no. 5, pp. 744, 2021. [Google Scholar]
14. M. Nawaz, M. Masood, A. Javed, J. Iqbal, T. Nazir et al., “Melanoma localization and classification through faster region-based convolutional neural network and SVM,” Multimedia Tools Applications, vol. 80, pp. 28953–28974, 2021. [Google Scholar]
15. T. Nazir, A. Irtaza, A. Javed, H. Malik, D. Hussain et al., “Retinal image analysis for diabetes-based eye disease detection using deep learning,” Applied Sciences, vol. 10, no. 18, pp. 6185, 2020. [Google Scholar]
16. S. Albahli, T. Nazir, A. Irtaza and A. Javed, “Recognition and detection of diabetic retinopathy using Densenet-65 based faster-rcnn,” Computers, Material, and Continua, vol. 67, pp. 1333–1351, 2021. [Google Scholar]
17. F. T. Bosman, F. Carneiro, R. H. Hruban and N. D. Theise, “WHO classification of tumours of the digestive system.” World Health Organization, vol. 10, no. 5, No. Ed. 4, ISBN: 9789283224327, 2017. [Google Scholar]
18. R. Hu, P. Dollár, K. He, T. Darrell and R. Girshick, “Learning to segment every thing,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, Channai, India, pp. 4233–4241, 2018. [Google Scholar]
19. P. Luo, G. Wang, L. Lin and X. Wang, “Deep dual learning for semantic image segmentation,” in Proc. of the IEEE Int. Conf. on Computer Vision, NY, USA, pp. 2718–2726, 2017. [Google Scholar]
20. M. Rajchl, M. C. Lee, O. Oktay, K. Kamnitsas, J. Passerat-Palmbach et al., “Deepcut: Object segmentation from bounding box annotations using convolutional neural networks,” IEEE Transactions on Medical Imaging, vol. 36, no. 2, pp. 674–683, 2016. [Google Scholar]
21. X. Zhang, F. Xing, H. Su, L. Yang and S. Zhang, “High-throughput histopathological image analysis via robust cell segmentation and hashing,” Medical Image Analysis, vol. 26, no. 1, pp. 306–315, 2015. [Google Scholar]
22. G. Litjens, T. Kooi, B. E. Bejnordi, A. A. A. Setio, F. Ciompi et al., “A survey on deep learning in medical image analysis,” Medical Image Analysis, vol. 42, no. 6, pp. 60–88, 2017. [Google Scholar]
23. J. Li, S. Yang, X. Huang, Q. Da, X. Yang et al., “Signet ring cell detection with a semi-supervised learning framework,” in Int. Conf. on Information Processing in Medical Imaging, Cham, Springer, pp. 842–854, 2019. [Google Scholar]
24. H. Ying, Q. Song, J. Chen, T. Liang, J. Gu et al., “A Semi-supervised deep convolutional framework for signet ring cell detection,” Neurocomputing, vol. 453, pp. 347–356, 2021. [Google Scholar]
25. S. Wang, C. Jia, Z. Chen and X. Gao, “Signet ring cell detection with classification reinforcement detection network,” in Int. Symposium on Bioinformatics Research and Applications, Cham, Springer, pp. 13–25, 2020. [Google Scholar]
26. Y. Sun, X. Huang, E. G. L. Molina, L. Dong and Q. Zhang, “Signet ring cells detection in histology images with similarity learning,” in 2020 IEEE 17th Int. Symposium on Biomedical Imaging (ISBI), NY, USA, pp. 490–494, 2020. [Google Scholar]
27. T. Lin, Y. Guo, C. Yang, J. Yang and Y. Xu, “Decoupled gradient harmonized detector for partial annotation: Application to signet ring cell detection,” Neurocomputing, vol 453, pp. 337–346, 2021. [Google Scholar]
28. K. He, G. Gkioxari, P. Dollár and R. Girshick, “Mask r-cnn,” in Proc. of the IEEE Int. Conf. on Computer Vision, Venice, Italy, pp. 2961–2969, 2017. [Google Scholar]
29. S. Ren, K. He, R. Girshick and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” Advances in Neural Information Processing Systems, vol. 28, pp. 91–99, 2015. [Google Scholar]
30. R. Girshick, “Fast r-cnn,” in Proc. of the IEEE Int. Conf. on Computer Vision, NW Washington, DC United States, pp. 1440–1448, 2015. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |