DOI:10.32604/cmc.2022.025059
| Computers, Materials & Continua DOI:10.32604/cmc.2022.025059 | |
| Article |
Fault Tolerance in the Joint EDF-RMS Algorithm: A Comparative Simulation Study
1University of Petroleum & Energy Studies (UPES), School of Computer Science, Energy Acres Building, Bidholi, Dehradun, 248007, Uttarakhand, India
2Department of Electrical Engineering and Computer Science, College of Engineering and Applied Science, University of Cincinnati, 2600 Clifton Ave, Cincinnati, OH 45221, United States
3College of Computer and Information Sciences (CCIS), Majmaah University, Majmaah, 11952, Kingdom of Saudi Arabia
*Corresponding Author: Deepak Dahiya. Email: d.dahiya@mu.edu.sa
Received: 10 November 2021; Accepted: 21 February 2022
Abstract: Failure is a systemic error that affects overall system performance and may eventually crash across the entire configuration. In Real-Time Systems (RTS), deadline is the key to successful completion of the program. If tasks effectively meet the deadline, it means the system is working in pristine order. However, missing the deadline means a systemic fault due to which the system can crash (hard RTS) or degrade inclusive performance (soft RTS). To fine-tune the RTS, tolerance is the critical issue and must be handled with extreme care. This article explains the context of fault tolerance with improvised Joint EDF-RMS algorithm in RTS. The backup method has been derived to prevent the system from being recursively migrating the same task. If any task migrates three times, this migrated task will get shifted to the backup queue. This backup queue assigns the task to a backup processor and is destined for final execution. For performance evaluation purposes, a relative graph between fault and failure rates, failure and total processor utilization along with other averages have been evaluated. Furthermore, these archived results are compared with fault-tolerant Earliest Deadline First (EDF) and Rate Monotonic Scheduling (RMS) algorithms independently in relatively similar conditions. These comparisons show better performance against overloading conditions.
Keywords: Fault tolerance; joint edf-rms algorithm; real-time systems (RTS); distributed systems; migration
RTS is a system where task execution is not dependent only on correct logic, but on-time execution (deadline) is equally important [1–3]. Based on deadline RTS is of two types: Hard and Soft [1–3]. In soft RTS, missing deadlines degrade the performance of the system, but hard RTS give catastrophic result along. Video game is a good example of soft RTS where the target timing of the game is scheduled. If a player is unable to achieve the mentioned time then only the player performance affect. Whereas, in hard RTS, if an aircraft is unable to execute some operations on time, then catastrophic results like loss of life can happen. The above-mentioned catastrophe or performance deprivation may occur due to the occurrence of a fault in the system and the mechanism used to handle such problems called fault tolerance [4].
In RTS, priority-based scheduling algorithms employee to schedule the tasks, with criteria to decide the priority of tasks. If a task is unable to match the criteria, then that task is non-schedulable. In RTS, meeting the deadline means successful task execution and missing a deadline means failure of a task. The occurrence of a fault in scheduling algorithms is one of the reasons for missing a deadline. Many researchers have discussed the fault tolerance techniques in EDF and RMS [5–7]. Here, fault tolerance technique is embed in joint EDF-RMS real-time scheduling algorithm [8] to reduce the permanent fault along with intermittent. The organization of remaining paper is as follows: Next section will explain the fault tolerance mechanisms in Real-Time and Distributed Systems (both), along with the scheduling algorithms of RTS. Further Section 3 explains the fault tolerance in the Joint EDF-RMS algorithm. Simulation studies and results explain in Section 4 and 5. Conclusion and future work will depict at the end.
2 Background and Preliminaries
In today’s era, features of RTS have been merged with many technologies i.e., cloud computing, distributed systems, mixed-criticality systems, big data and many more. In all stated systems, fault tolerance is the main concern of all algorithms. In [9], hybrid of traditional fault tolerance methods discuss for mobile distributed systems. Dependently fast library uses in [10] to implement the interface to prevent unexpected fail-slow tolerant distributed systems. A scheduling algorithm for cloud computing is proposed in [11] to minimize the response time of tasks present in backup after multiple failures of tasks. The stopwatch automata network model use to make real-time computer system (RTCS) fault tolerant [12]. Additionally, to provide reliability against transient faults high power-based backup processor use to execute selective backup tasks [12]. In [13] author has proposed two scheduling algorithms FEED-O and FEED-OD to handle the overloading of backup tasks in overlapping time intervals. In [14], Fault-tolerant multi-core mixed criticality systems use to cope with high power and temperature for dependent dual-criticality tasks. In [15], with server CAN (one of the types of storage), a fault tolerance mechanism has been used. In [16] also the fault-tolerance concept implements in big data. Based on aforementioned work, it is clear that fault tolerance is not important in RTS only, but in every domain [9–17].
The focus of this paper is on fault tolerance scheduling algorithms in Real-Time Distributed systems (RTDS). RTDS is a distributed system with temporal and dynamic behaviour, as it changes with time. Temporal activity/behaviour includes arrival time, waiting time, execution and completion time of a task. The completion time of any task affects the performance of dependent and enqueuer tasks. Therefore, timely execution of tasks is the uppermost priority of any RTS scheduling algorithms. Presence of fault in a system may affect its performance by continuous missing of tasks deadline. The system failure can happen due to many improperly handled faults, like preemption of lower priority tasks or lack of resources. This missing deadline is bearable in soft RTS, but not in hard [18,19]. The further section will explain the detailed information about failure, faults and their relationship with each other.
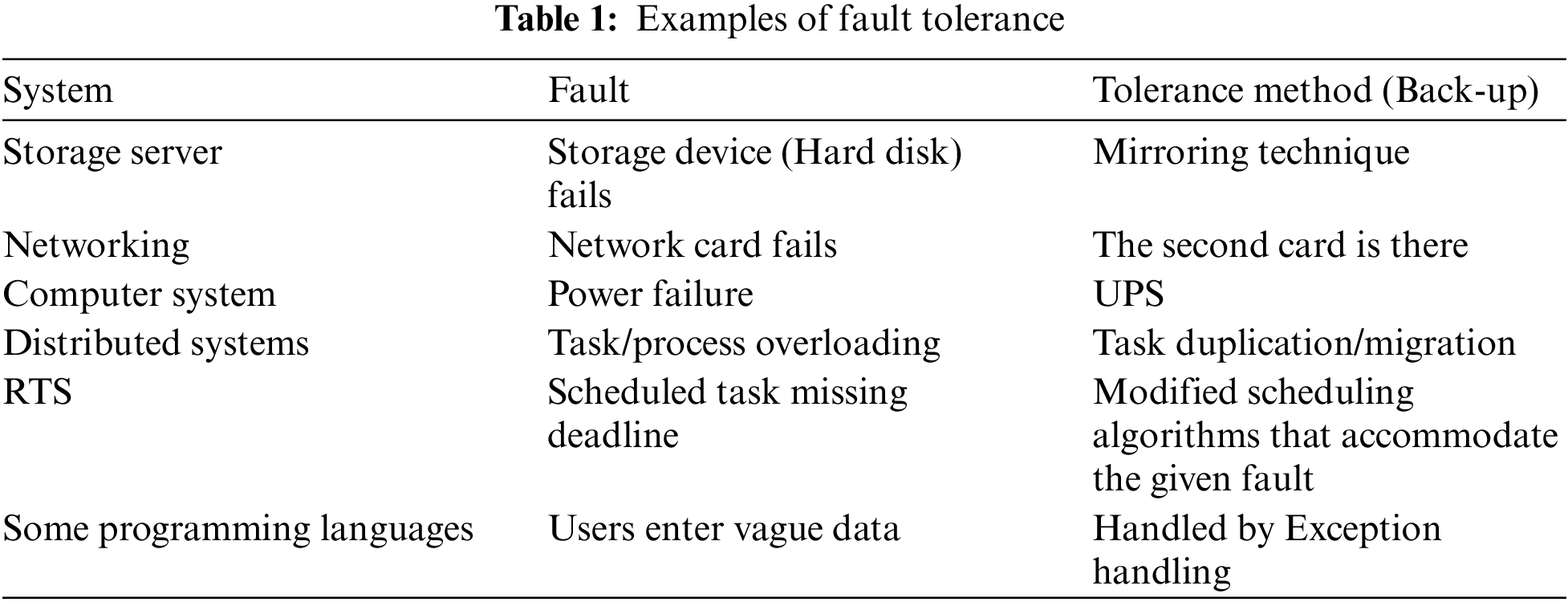
When we talk about fault tolerance, the scenario comes to our mind that there is a situation where an irregular, unusual, erroneous function is being played. It degrades the performance or sometimes fails the entire system. Now tolerance channels our system in such a way that these faults are bypassed, thus, maintaining the near normal functioning of the system. Sometimes multiple modules in a redundant fashion, mirror images of the existing system and some kinds of remedial measures are proposed inline. Tolerance methods are necessary for the successful running of any system because critical faults strike without warning. Following (Tab. 1) are few examples where tolerance methods for faults present:
Real-Time tasks schedule on distributed systems where faults of distributed systems affect respective real-time tasks or vice versa. Following Tab. 2 summaries, some common types of faults in both systems [20,21] and Fig. 1 displaying the visualizations of respective fault types:
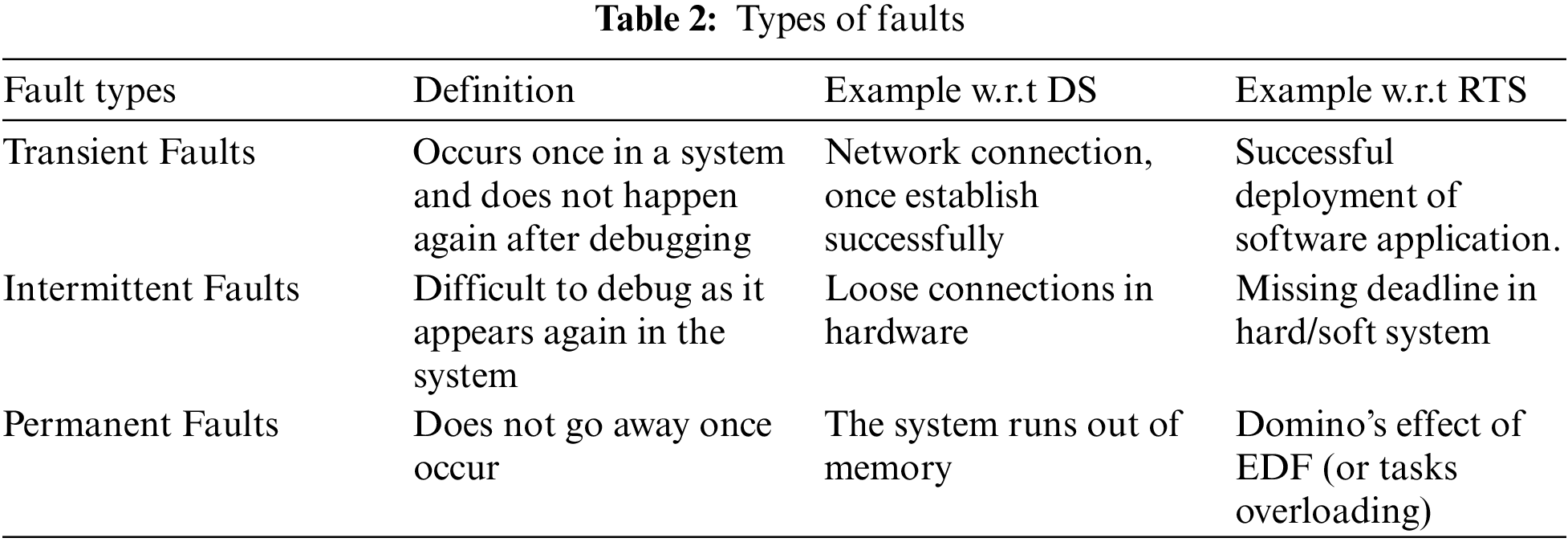
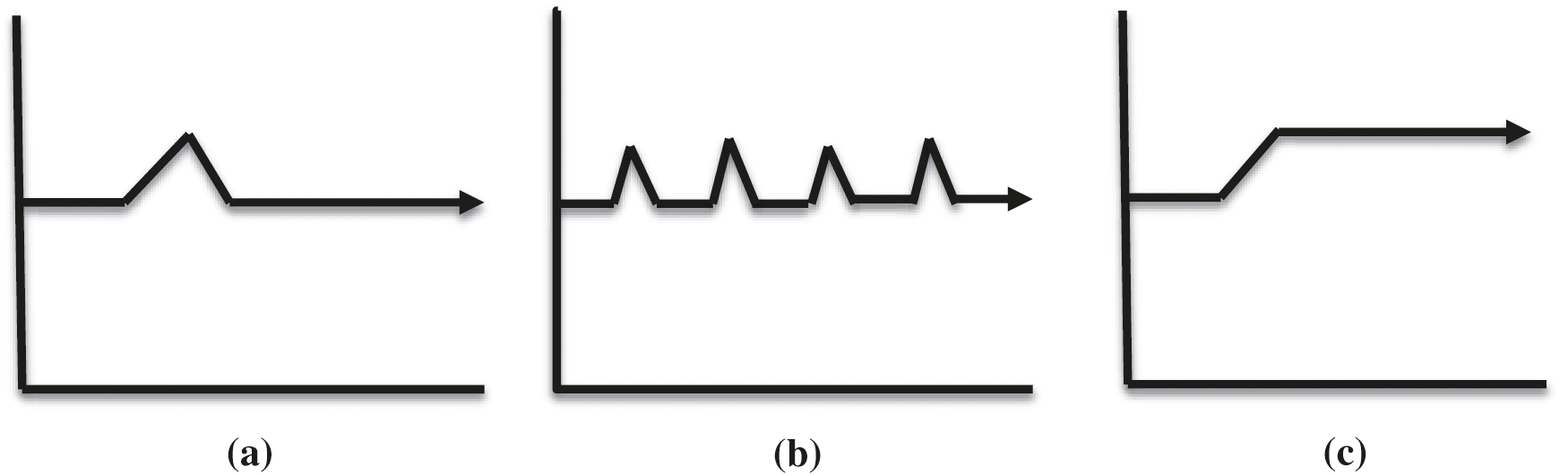
Figure 1: Visualization of (a) Transient fault (b) Intermittent fault and (c) Permanent fault
2.3 Fault Tolerance Techniques
The fault is an unintended behaviour of a system that either reduces the performance or fails the system. To protect the system, fault tolerance strategies are required. However, fault-masking and system reconfiguration are a few techniques for fault tolerance but commonly, redundancy in hardware, software, information or time is used [22–24]. In following Tab. 3 detailed discussions on redundancy techniques have explained:
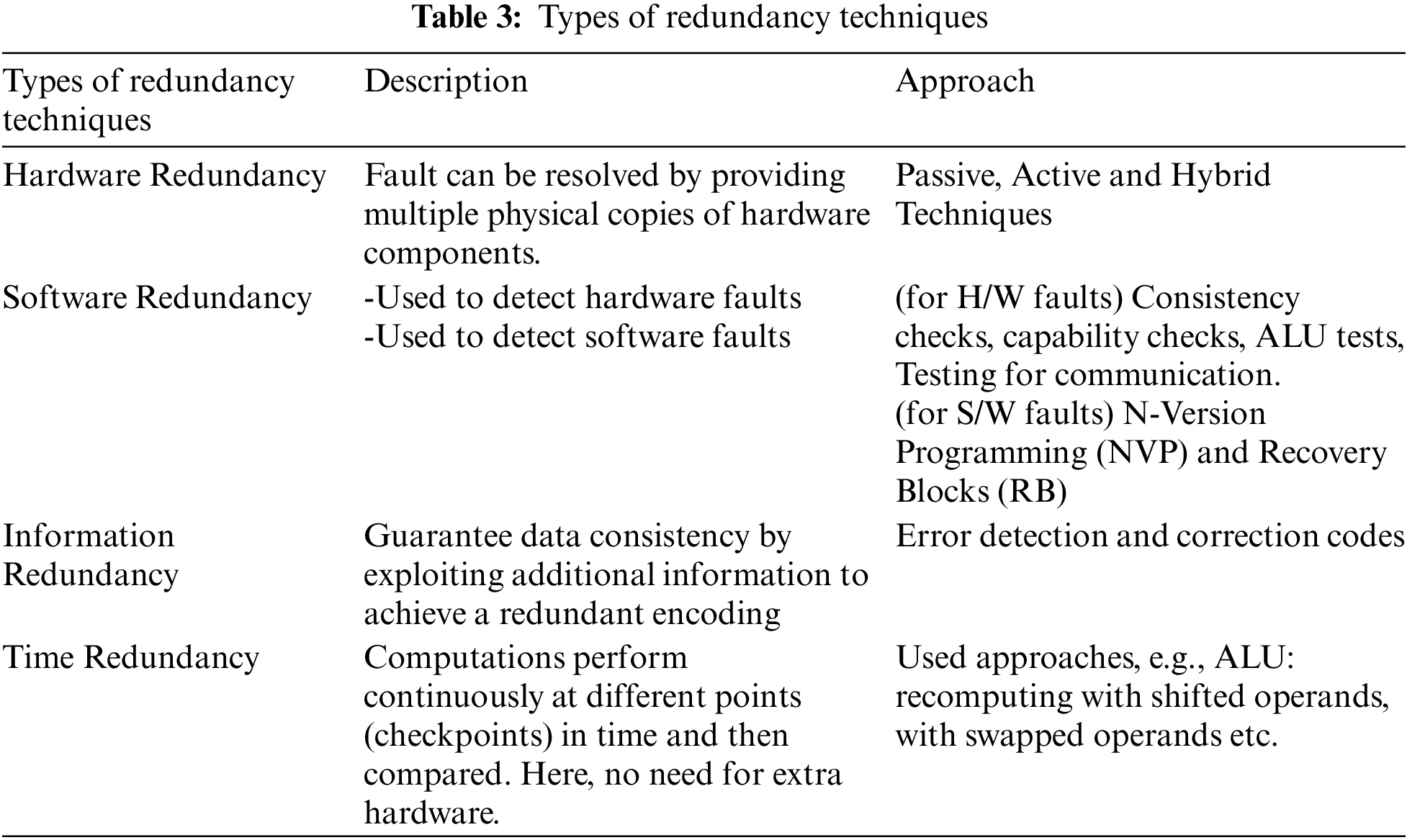
Further section explains fault tolerance scheduling algorithms.
2.4 Fault Tolerance Scheduling Algorithms in RTS
While designing any scheduling algorithms for RTS, following criteria should be considered:
• Each task should execute once in a system i.e., parallelism between the same task should not be there
• All tasks should meet the deadline
• Number of processors failure should be tolerated i.e., failure of one processor should not affect the progress of the entire system (hence, always schedule a backup of tasks on separate processors)
• Preemption of tasks helps to improve the efficiency of the system.
Following are scheduling algorithms employed for the fault tolerance and avoidance as well[2,25–28]:
• First come first serve (FCFS)
• Shortest Job First (SJF)
• Preemptive
• Non- preemptive
• Round Robin Techniques
For all scheduling algorithms following terminologies are common:
Input: Arrival of Periodic tasks
Output: Task meeting
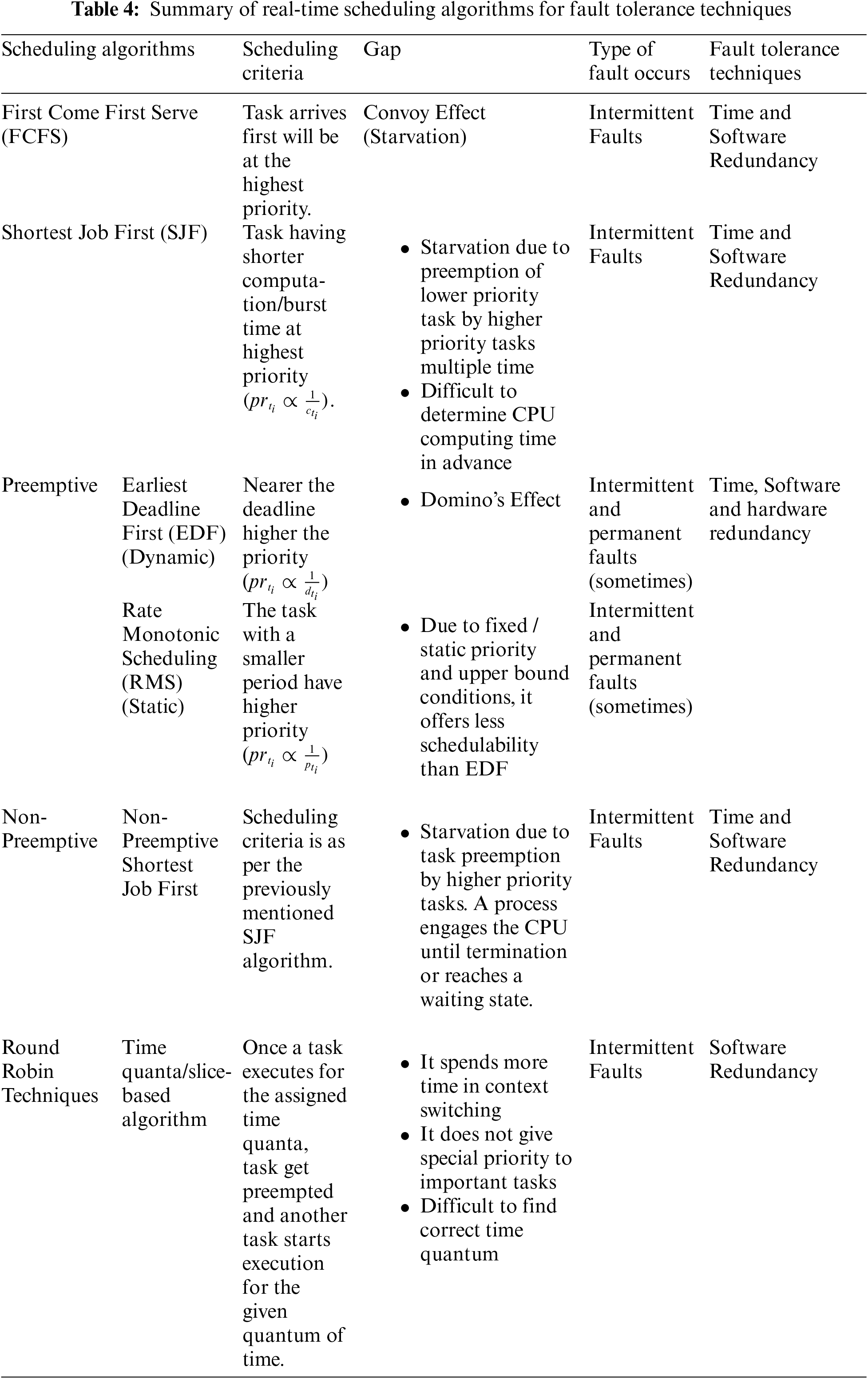
The above-mentioned Tab. 4 is the summary of a few scheduling algorithms to tolerate the occurrence of faults. Most algorithms use for intermittent faults because missing deadlines are difficult to predict Hence, to endure such faults, many time-based scheduling algorithms exist that come under software and time redundancy technology. Out of the above-mentioned categories, this paper deals with preemptive scheduling algorithm class where EDF and RMS both algorithms are used for fault tolerance purposes. The next section will describe the working of the joint EDF-RMS algorithm in a faulty environment.
3 Fault Tolerance in Joint EDF-RMS Algorithm
In RTS, failure of single task may affect the system performance and destroy it as well (catastrophe result). Hence, fault management is required in RTS. Many researchers actively participate and implement/simulate the fault-tolerant system with the help of some scheduling algorithms. Therefore, the performance of Joint EDF-RMS algorithm improvises by embedding the feature of fault tolerance in it. Following Fig. 2 is the pictorial representation of mentioned algorithm with fault tolerance management.
There are four blocks A, B, C and D. Block ‘A’ represents a global queue where tasks will assign to randomly selected processors. According to RMS, the task having highest priority will assign first to a chosen processor of block ‘B’ and similar trend will follow for remaining tasks. To avoid overloading in a queue, RMS criteria has been used i.e.,
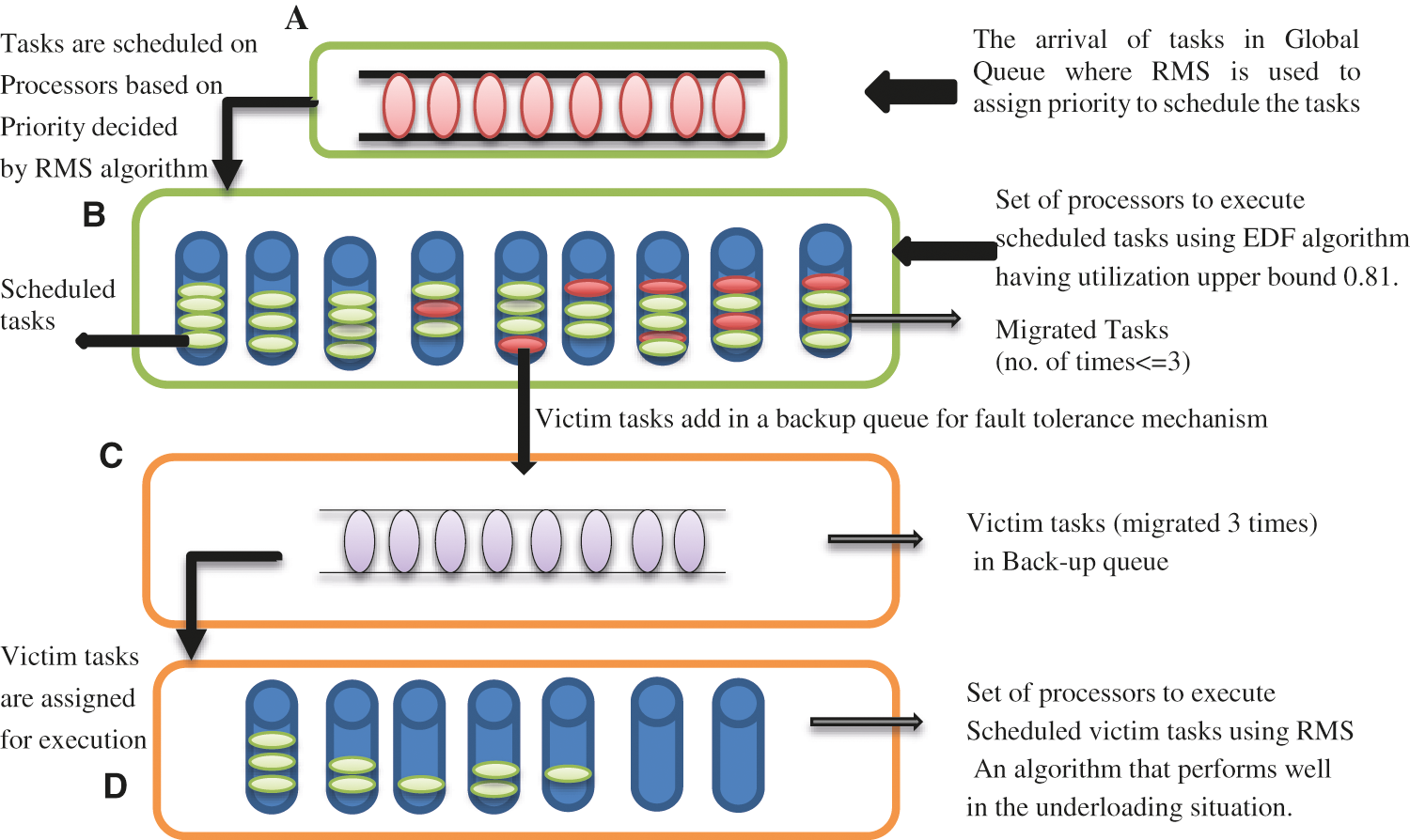
Figure 2: Working of joint EDF-RMS algorithm with fault tolerance technique
Following is the algorithm for the proposed work:
Fault-Tolerant Joint EDF-RMS Algorithm

• Experimental Set-up
For simulation purposes, the Eclipse Oxygen.3a version use for the java programming language. The concept of thread uses here to create, wait and execution of tasks. Maximum 2100 and minimum 300 tasks are used in distributed systems of six (3 for backup) processors. The implementation of all three algorithms EDF, RMS and joint EDF-RMS done on same tasks in synchrony to provide the same simulation parametrization. Following parameters use to evaluate the performance of the above-mentioned algorithms:
1. Fault rate: In RTS, if the task has less chance to meet the deadline as per utilization calculations and
2.Failure rate: Tasks fail to meet the deadline due to fault done by scheduling algorithms by allowing tasks to execute. Following equation calculate failure rate:
3. Processor utilization threshold: The reason behind task migration is utilization of CPU. If any task crosses the threshold limit of CPU utilization then, that task will migrate. Hence, migration point in RMS is
Before the discussion on the results, the following lemma explains the dependency of task execution on the aforementioned parameters:
• Lemma 5.1 Failure of task is dependent on victim tasks, migration and CPU utilization.
Proof
Considering the arrival of

Now, here the arrival of tasks
I. The system is occupied in the execution of tasks
Initially tasks fulfill the condition
II. In the above case, Tab. 5 migration was not in the picture. Here, Tab. 6 if more than one processor is there in the system
Suppose three processors are there in a system

Hence, we can say that CPU utilization, victim tasks and migration of tasks affect the successful execution of upcoming tasks.
EDF, RMS and Joint EDF-RMS algorithms implement and test up to 2100 tasks. These tasks divide into the transaction of 300, 600, 900, 1200, 1500, 1800 and 2100 tasks. As fault tolerance is the main point of concern here, the relation of fault with task failure, CPU utilization and migration of victim tasks are under consideration.
-Fault rate vs. Failure rate
Fig. 3 demonstrates the number of victim tasks out of total tasks in a given transaction. In EDF, tasks exceed the CPU utilization of more than 1, in RMS
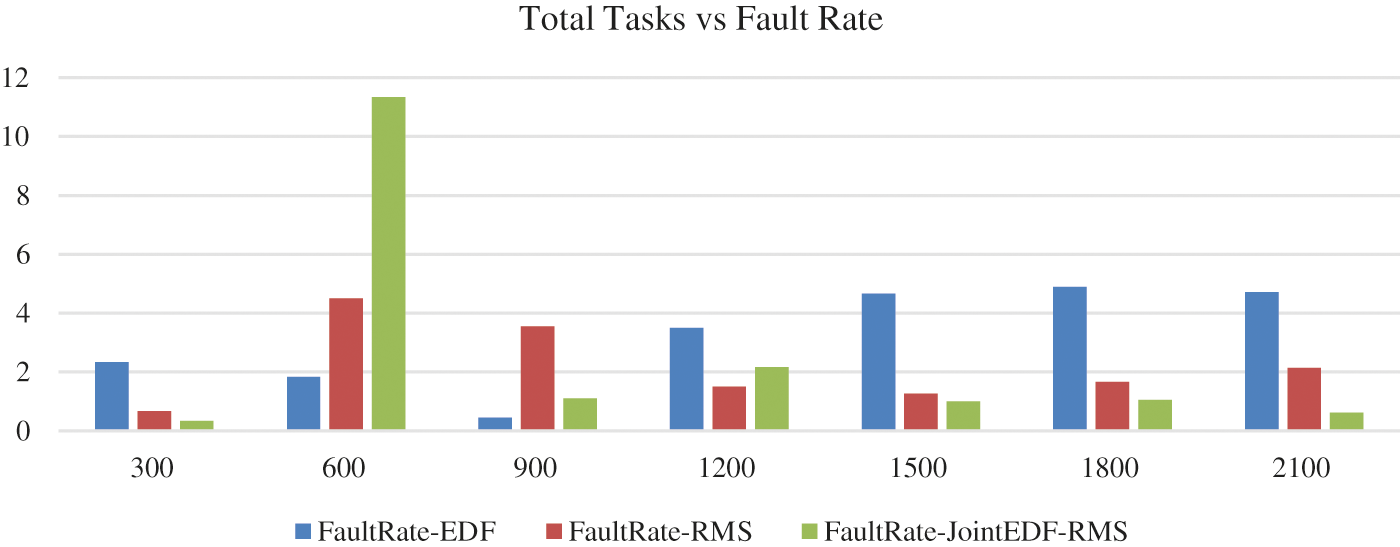
Figure 3: Arrived tasks vs. fault rate calculations based on EDF, RMS and Joint EDF-RMS algorithm
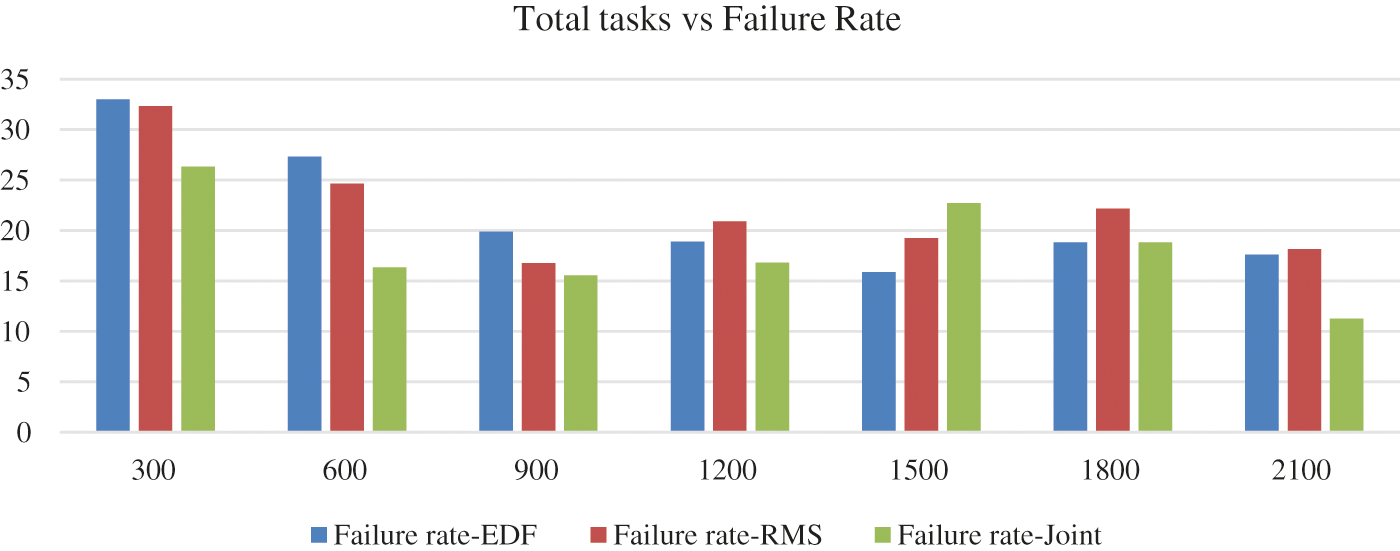
Figure 4: Arrived tasks vs. failure rate of tasks calculations based on EDF, RMS and Joint EDF-RMS algorithm
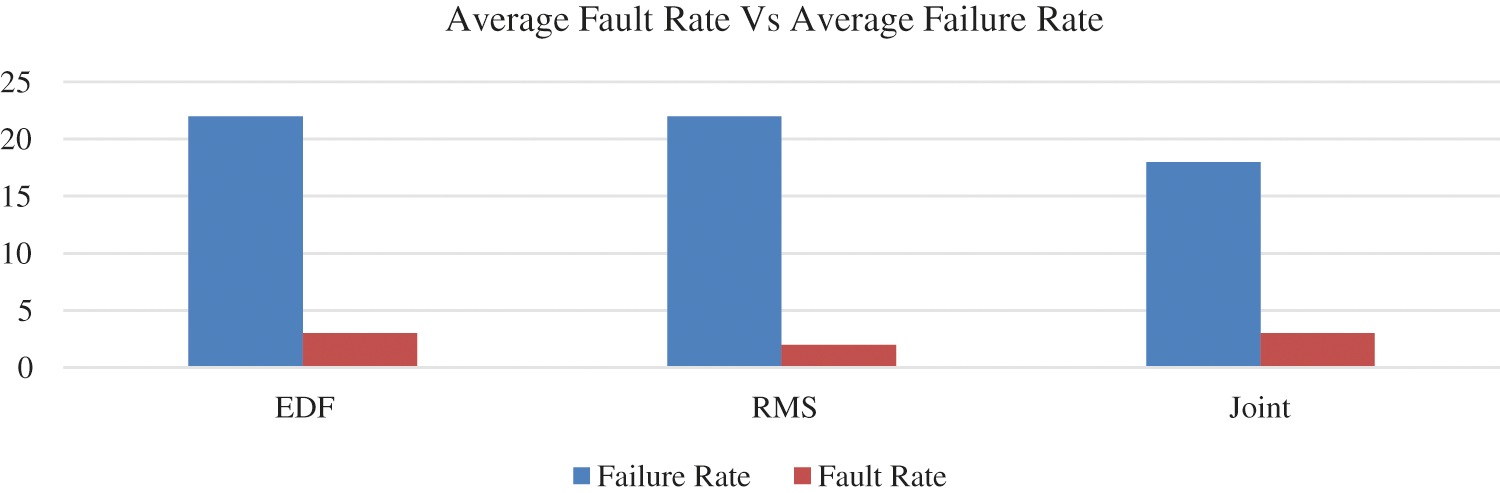
Figure 5: Average Impact of fault rate on failure rate in EDF, RMS and Joint EDF-RMS algorithm
--Processor utilization vs. failure rate
Up to three processors use in this simulation. The Fig. 6, demonstrates the effect of total CPU utilization on the failure of tasks. As the participation of processors in the system increases, the total CPU utilization escalates accordingly. The behaviour of system while using the EDF algorithm illustrates in the Fig. 6. When it increases the limit by more than 3 (
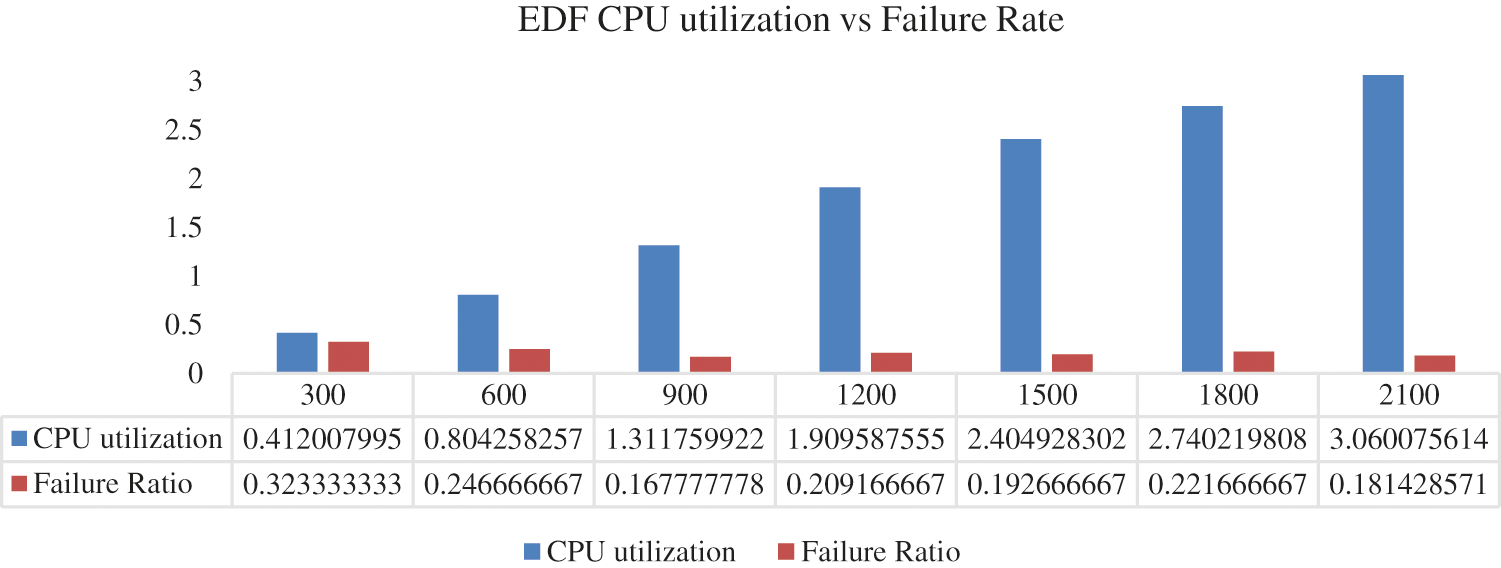
Figure 6: CPU utilization vs. failure rate based on EDF scheduling algorithm
Fig. 7 explains the total CPU utilization effect on failure task when the RMS algorithm is in use. In Joint EDF-RMS, RMS algorithm uses to handle arrival of tasks in global queue and EDF algorithm use with threshold limit 0.81 in every processor. Hence, in Fig. 8 the failure ratio is less as compared to others due to the threshold limit of EDF algorithms and usage of RMS for priority assignment.
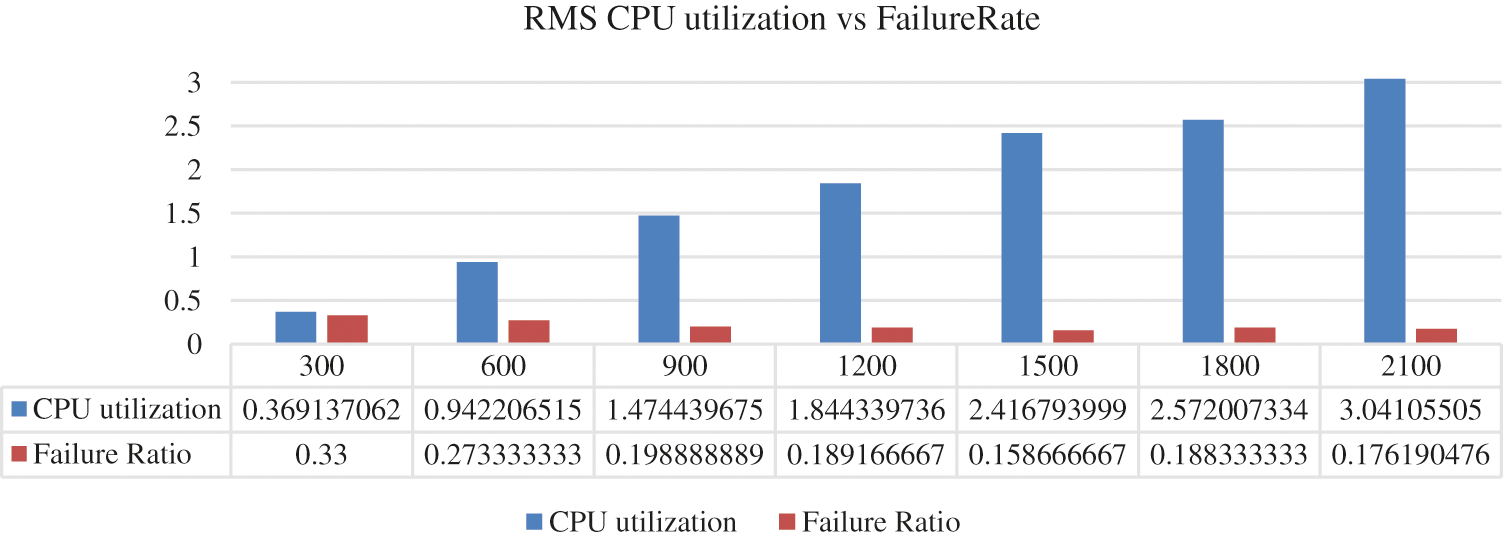
Figure 7: CPU utilization vs. failure rate based on RMS algorithm

Figure 8: CPU utilization vs. failure rate based on Joint EDF-RMS algorithm
CPU utilization is the main parameter due to which victim tasks can recognize and migrate to other processors, that helps in failure tasks reduction. Fig. 9 are showing the complete result of all three scheduling algorithms. On average for every 1200 tasks the failure percentage of Joint EDF-RMS is less i.e., 17% as compared to the remaining two scheduling algorithms. Similarly, due to the application of migration technique on 0.81% threshold, the victim tasks percentage is also very less i.e., only 2% in Joint EDF-RMS algorithm, whereas in EDF and RMS victim tasks percentage is greater or equal i.e., 4% and 2%, respectively.
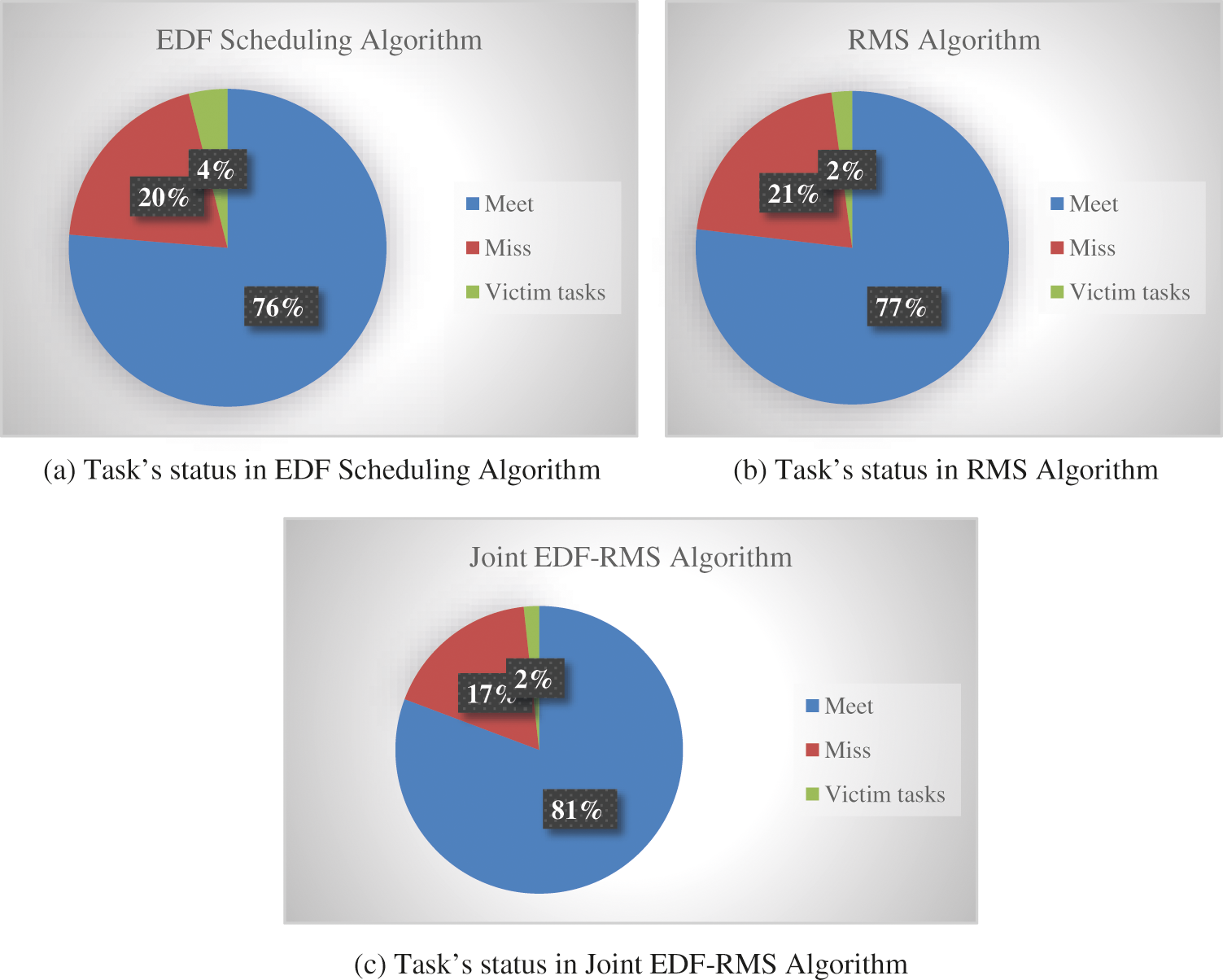
Figure 9: Task’s status in all three scheduling algorithms based on average number of tasks
The fault tolerance mechanisms in RTS with the help of migration techniques in distributed systems successfully simulated. Basic scheduling algorithms (EDF and RMS) select to evaluate the performance of hybrid scheduling algorithm (Joint EDF-RMS) with fault tolerance mechanism. The vital role of fault tolerance algorithms in various applications discuss in previous sections. Here, fault tolerance implant in new hybrid algorithm (Joint EDF-RMS) and simulate in Real Time Distributed Systems. How overloaded (victim) task affect the execution of upcoming or enqueuer tasks have been explained with the help of lemma (with or without migration) and simulation. Overall, the behaviour of EDF, RMS and Joint EDF-RMS algorithm evaluates in faulty environment of RTDS. The Joint EDF-RMS algorithm handle faults efficiently due to the presence of both EDF and RMS algorithms that overcome limitations of each other. Additionally, usage of RMS algorithm in Backup processors improve the performance because this algorithm is good to handle overloading conditions due to its schedulability criteria.
This fault tolerance concept will implement in information-theoretic entropy based work [30–32]. The simulation of information theoretic entropy based EDF scheduling algorithm is already done and in future, its behaviour in faulty environment will check by using fault tolerance mechanism use in this paper.
Funding Statement: Deepak Dahiya would like to thank Deanship of Scientific Research at Majmaah University for supporting this work under Project No. R-2022-56.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. P. A. Laplante, Real-time Systems Design and Analysis, 3rd ed., New York: Wiley, IEEE press, 2004. [Google Scholar]
2. J. W. S. Liu, Real-Time Systems, Upper Saddle River, New Jersey: Prentice Hall, 2000. [Google Scholar]
3. R. Alur and D. Dill, “Automata for modeling real-time systems,” in Int. colloquium on automata, languages and programming. Berlin, Heidelberg: Springer, 1990. [Google Scholar]
4. H. Aysanüseyin, “Fault-tolerance strategies and probabilistic guarantees for real-time systems,” Ph.D. dissertation. Mälardalen University, Sweden, 2012. [Google Scholar]
5. L. I. U. Huai and F. E. I. Shu-Min, “A fault-tolerant scheduling algorithm based on EDF for distributed control systems,” Journal of Software, vol. 14, no. 8, pp. 1371–1378, 2003. [Google Scholar]
6. Y. Guo, D. Zhu and H. Aydin, “Generalized standby-sparing techniques for energy-efficient fault tolerance in multiprocessor real-time systems,” in Proc. 19th Int. Conf. on Embedded and Real-Time Computing Systems and Applications, Taipei, Taiwan, IEEE, pp. 62–71, 2013. [Google Scholar]
7. S. Ghosh, R. Melhem, D. Mossé and J. S. Sarma, “Fault-tolerant rate-monotonic scheduling,” Real-Time Systems, vol. 15, no. 2, pp. 149–181, 1998. [Google Scholar]
8. R. Sharma, N. Nitin, M. A. R. AlShehri and D. Dahiya, “Priority-based joint edf-rm scheduling algorithm for individual real-time task on distributed systems,” Journal of Supercomputing, vol. 77, no. 1, pp. 890–908, 2021. [Google Scholar]
9. Y. Wu, D. Liu, X. Chen, J. Ren, R. Liu et al., “MobileRE: A replicas prioritized hybrid fault tolerance strategy for mobile distributed system,” Journal of Systems Architecture, vol. 118, no. 10–11, pp. 102217, 2021. [Google Scholar]
10. A. Yoo, Y. Wang, R. Sinha, S. Mu and T. Xu, “Fail-slow fault tolerance needs programming support,” in 2021 the Workshop on Hot Topics in Operating Systems, Ann Arbor, Michigan, pp. 228–235, 2021. [Google Scholar]
11. P. Gupta, P. K. Sahoo and B. Veeravalli, “Dynamic fault tolerant scheduling with response time minimization for multiple failures in cloud,” Journal of Parallel and Distributed Computing, vol. 158, no. 1, pp. 80–93, 2021. [Google Scholar]
12. A. Glonina and V. Balashov, “A stopwatch automata-based approach to schedulability analysis of real-time systems with support for fault tolerance techniques,” in Proc. 2021 Int. Conf. on Dependability and Complex Systems, Cham, Springer, pp. 116–125, 2021. [Google Scholar]
13. S. Saha, A. Adetomi, X. Zhai, S. Kasap, S. Ehsan et al., “EnSuRe: Energy & accuracy aware fault-tolerant scheduling on real-time heterogeneous systems,” in Proc. 27th Int. Sym. on On-Line Testing and Robust System Design (IOLTS), Italy, IEEE, pp. 1–4, 2021. [Google Scholar]
14. B. Ranjbar, A. Hosseinghorban, M. Salehi, A. Ejlali and A. Kumar, “Toward the design of fault-tolerance-and peak-power-aware multi-core mixed-criticality systems,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, pp. 1, 2021. DOI 10.1109/TCAD.2021.3082495. [Google Scholar] [CrossRef]
15. T. Nolte, G. Rodríguez-Navas, J. Proenza, S. Punnekkat and H. Hansson, “Towards analyzing the fault-tolerant operation of server-CAN,” in Proc. Int. Conf. on Emerging Technologies and Factory Automation, Catania, Italy, IEEE, vol.1, pp. 4, 2005. [Google Scholar]
16. M. Saadoon, S. H. A. Hamid, H. Sofian, H. H. Altarturi, Z. H. Azizul et al., “Fault tolerance in big data storage and processing systems: A review on challenges and solutions,” Ain Shams Engineering Journal, vol. 13, no. 2, pp. 101538, 2021. [Google Scholar]
17. S. Bansal, R. K. Bansal and K. Arora, “Energy efficient backup overloading schemes for fault tolerant scheduling of real-time tasks,” Journal of Systems Architecture, vol. 113, pp. 101901, 2021. [Google Scholar]
18. A. Burns, A. Welling, K. Ramamritham, J. Hooman, S. Schneider et al., “Real time systems: Specification, verification and analysis,” M. Joseph (Ed.vol. 62. New York, NY, USA: Prentice Hall, 1996. [Google Scholar]
19. K. Berns, A. Köpper and B. Schürmann, Real time systems in technical foundations of embedded systems, In Lecture Notes in Electrical Engineering, vol. 732, Cham: Springer, pp. 339–361, 2021. [Google Scholar]
20. E. Ertugrul and O. K. Sahingoz, “Fault tolerance in real time systems: A review,” in Proc. Int. Conf. on Intelligent Systems Design and Applications, Cham, Springer, pp. 283–293, 2017. [Google Scholar]
21. A. C. Persya and T. R. G. Nair, “Fault tolerant real time systems,” in Proc. 2008 Int. Conf. on Managing Next Generation Software Application (MNGSA-08), Coimbatore, India, pp. 177–180, 2008. [Google Scholar]
22. J. C. Laprie, “Dependable computing and fault tolerance: Concepts and terminology,” in Proc. 15th Int. Sym. on Fault-Tolerant Computing (FTSC-15), Ann Arbor, Michigan, IEEE, vol.III, pp. 2–11, 1985. [Google Scholar]
23. J. Kaur and S. Kinger, “Analysis of different techniques used for fault tolerance,” International Journal of Computer Science and Information Technologies (IJCSIT), vol. 5, no. 3, pp. 4086–4090, 2014. [Google Scholar]
24. A. Avizienis, “Fault-tolerant systems,” IEEE Transactions on Computers, vol. 25, no. 12, pp. 1304–1312, 1976. [Google Scholar]
25. A. A. Bertossi and L. V. Mancini, “Scheduling algorithms for fault-tolerance in hard-real-time systems,” Real-Time Systems, vol. 7, no. 3, pp. 229–245, 1994. [Google Scholar]
26. N. Audsley, A. Burns, R. Davis, K. Tindell and A. Wellings, Real time system scheduling. in Predictably Dependable Computing Systems, Berlin, Heidelberg: ESPRIT Basic Research Series, Springer, pp. 41–52, 1995. [Google Scholar]
27. R. Mehta and M. Upasna, “Real time system fault tolerance scheduling algorithm,” International Journal of Computer Science and Mobile Computing, vol. 3, no. 9, pp. 297–306, 2014. [Google Scholar]
28. A. Silberschatz, G. Gagne and P. B. Galvin, Operating System Concepts, United States, 8th ed., John Wiley & Sons, 2008. [Google Scholar]
29. R. Sharma and Nitin, “Performance evaluation of new joint EDF-RM scheduling algorithm for real time distributed system,” Journal of Engineering, Hindawi publishers, vol. 2014, no. 1, pp. 1–13, 2014. [Google Scholar]
30. R. Sharma and Nitin, “Entropy, a new dynamics governing parameter in real time distributed system: A simulation study,” International Journal of Parallel, Emergent and Distributed Systems, vol. 29, no. 6, pp. 562–586, 2014. [Google Scholar]
31. R. Sharma and Nitin, “Visualization of information theoretic maximum entropy model in real time distributed system,” in Proc. 3rd Int. Conf. on Advances in Computing and Communications, Cochin, IEEE, pp. 282–286, 2013. [Google Scholar]
32. R. Sharma and Nitin, “Evaluation and comparison of load balancing in RTDS using Information theoretic entropy,” in Proc. Int. Advance Computing Conf. (IACC), Gurgaon, India, IEEE, pp. 674–679, 2014. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |