DOI:10.32604/cmc.2022.026145
| Computers, Materials & Continua DOI:10.32604/cmc.2022.026145 | |
| Article |
Automatic Eyewitness Identification During Disasters by Forming a Feature-Word Dictionary
1Department of Computer Science, National Textile University, Faisalabad, Pakistan
2Computer Sciences Department, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University (PNU), P.O. Box 84428, Riyadh 11671, Saudi Arabia
3Department of Software Engineering and Computer Science, Al Ain University, Abu Dhabi, United Arab Emirates
4Department of Data Science, University of the Punjab, Pakistan
*Corresponding Author: Muhammad Asif. Email: asif@ntu.edu.pk
Received: 16 December 2021; Accepted: 08 March 2022
Abstract: Social media provide digitally interactional technologies to facilitate information sharing and exchanging individuals. Precisely, in case of disasters, a massive corpus is placed on platforms such as Twitter. Eyewitness accounts can benefit humanitarian organizations and agencies, but identifying the eyewitness Tweets related to the disaster from millions of Tweets is difficult. Different approaches have been developed to address this kind of problem. The recent state-of-the-art system was based on a manually created dictionary and this approach was further refined by introducing linguistic rules. However, these approaches suffer from limitations as they are dataset-dependent and not scalable. In this paper, we proposed a method to identify eyewitnesses from Twitter. To experiment, we utilized 13 features discovered by the pioneer of this domain and can classify the tweets to determine the eyewitness. Considering each feature, a dictionary of words was created with the Word Dictionary Maker algorithm, which is the crucial contribution of this research. This algorithm inputs some terms relevant to a specific feature for its initialization and then creates the words dictionary. Further, keyword matching for each feature in tweets is performed. If a feature exists in a tweet, it is termed as 1; otherwise, 0. Similarly, for 13 features, we created a file that reflects features in each tweet. To classify the tweets based on features, Naïve Bayes, Random Forest, and Neural Network were utilized. The approach was implemented on different disasters like earthquakes, floods, hurricanes, and Forest fires. The results were compared with the state-of-the-art linguistic rule-based system with 0.81 F-measure values. At the same time, the proposed approach gained a 0.88 value of F-measure. The results were comparable as the proposed approach is not dataset-dependent. Therefore, it can be used for the identification of eyewitness accounts.
Keywords: Word dictionary; social media; eyewitness identification; disasters
Social media is enriched with many individuals [1]. For example, Twitter has 1.3 billion accounts and 330 million active users among social media applications. Twitter contains 23% population of the Internet, and 83% of leaders of the world are using this social media application. Twitter handles 6000 Tweets per second, 500 million Tweets per day and 200 billion Tweets per year [2].
Twitter provides a platform where users share their opinions, ideas, news [3], and sentiments with others. The extreme usage of Twitter has turned the focus of researchers to extract beneficial information from it [4]. Researchers have explored Twitter for recommendations [5], alerts [6], advertisements [7], journalism [8], etc. Specifically, at the time of any disaster [9], people share the information that disaster management can utilize. Twitter provides the platform to users. They can break the news of any happenings around them before any television channel, such as the news of an airplane crash in New York, was broken by an eyewitness on Twitter. A News agency detected a Tweet by the plane passenger, whose engine was failed, and it made an emergency landing on a remote Island. An eyewitness of the attack on Westgate shopping mall posted the information of the incident on Twitter about thirty-three minutes earlier than the news channels [10]. Similarly, the news of the Bombing attack of Boston Well [11] was initially broken on Twitter by an eyewitness.
Researchers have adopted different location-based, linguistic-based, content-based, etc.Researchers in [12] proposed a hybrid approach based on linguistic and meta-features to identify eyewitnesses during disastrous events. [13] utilized grammatical rules and natural language techniques to find out the eyewitness from Twitter. The research was conducted by [14] to identify the eyewitness of natural disasters on Twitter. The author performed an analysis on Tweets and identified thirteen different features. The author claimed that eyewitness tweets contain the prescribed features. Similar features were utilized by [15], the author proposed linguistic rules for eyewitness identification. The state-of-the-art techniques are still not fully automatic, and some are dataset-dependent. Therefore, the need of the hour is to find an automated solution for eyewitness identification.
This paper proposed an approach to identify the eyewitness of any natural disaster from Twitter. The proposed method is based on word dictionary formation related to features. To conduct the experiment, the dataset collected by [14] was utilized, which was consisted of 8000 Tweets. Further, thirteen different features were deemed for the classification of Tweets. The state-of-the-art approaches stated that these 13 features could potentially classify the eyewitness accounts on Twitter. A word dictionary was created for each feature by an algorithm that inputs a random list of words for each feature, reflecting the sense of the corresponding feature.
The algorithm considers the list of words and mines the synonyms for each list word. Further, a new list of original words and their synonyms is formed. In the next module, we utilize Wiktionary to extract the pre-derived and post-derived words and embed them into the list. In the last module, all the original words, synonyms and derived words are searched on Google while adding “and” after each word. For each heading on google, the word after “and” is extracted while forming a dictionary of words for features. The developed algorithm provided the dictionary for features and further, we performed keyword matching. If the words in Tweets matched with any word in the feature dictionary, it was termed as 1 otherwise, the feature value was kept as 0. We utilized 11 features, and the classification of feature values produced F-measure as 0.886, comparable with state-of-the-art techniques.
The rest of the article is organized as Related Work, Research Aim and Objective, Methodology, Results, Discussions and Conclusion.
Social media, specifically Twitter, has become an emerging platform where users express their emotions opinions and share different happenings in the world. Twitter is a microblog and the posts on Twitter are termed as Tweets. It was founded in 2006 by the United States. According to Pear Analytics, Twitter contains news 3.6%, Spam 3.8%, Conversation 37.6%, self-promotion 5.9%, pointless 40.1% and pass-along value 8.7%. The posts on Twitter are public and are easily accessible by anyone. The users can also retweet the post and have the facility to follow the other users. Twitter handles on average 1.6 billion queries per day.
The individuals usually search for different events that have occurred or will happen. When it comes to some natural disaster, people use Twitter to inform others about the current situation nearby them or share their views and concerns. [16] argued that Twitter is also used for news and headlines and not only as social media. The authors claimed that more than 85% of highlighted topics are news. On Twitter, a massive corpus exists and therefore, it has become challenging to extract valuable information. Researchers in [17] explored the usage of Twitter during disasters. The author stated that users Tweet about disasters. They include both original Tweets and Retweets. [18] researched while exploiting the disaster of Forest fire. The author utilized Twitter data set to detect this disaster. Imranet al. [19] investigated the Tweets if they belonged to the information category with the help of volunteers. Kumar et al. [20] developed a crawler to crawl the Tweets.
The researcher in [21] proposed an approach to identify eyewitness accounts of some events. The authors identified the accounts from where the Tweets about the Bush fire of 2013 were mentioned. The authors achieved a 77% score, but the eyewitness was not cleared in their Tweets because of distance. Their model utilized the location of the Tweet and Network for eyewitness identification. A filter-based approach was proposed by [22] to identify eyewitnesses. The author used five features based on linguistic factors. First, predefined keywords were considered to determine the eyewitness from their posts. The proposed approach achieved an average accuracy of 62%, but this approach also suffers from limitations as it requires the Tweet’s location and considers events, not the eyewitness.
Diakopolous et al. [23] proposed an approach to identify eyewitnesses for journalism. For automatic identification of eyewitnesses, a technique was introduced by scientists. The author defined linguistics features and labeled the events. OpenCalais was utilized for this purpose. Linguistic inquiry and word count (LIWC) dictionary was used to find out the keywords related to the events. The list of terms was created manually, and the model requires language information and location to identify the eyewitness. The author produced the average F-measure as 89.7%. To identify different events [24] utilized natural language algorithms. The author identified the events from news articles. The author produced a Precision value of 42 and Recall as 66. An approach for understanding the eyewitness reports was conducted by [25]. Later, they used thirteen different features to identify eyewitnesses of disasters. The dataset was collected from Twitter. The domain experts classified the Tweets. The author achieved a score of F-measure of 0.917. The proposed approach of the author was not suitable for a large number of Tweets. This technique was manually implemented and proposed linguistic rules to identify eyewitnesses. The author utilized 13 characteristics that were proposed in the literature. Using the characteristics, the author developed linguistic rules. This approach was dataset dependent as rules were created utilizing the specific dataset and after that, the approach was tested on the same dataset.
The key objective of this research is to identify eyewitnesses in disastrous situations, as the information of direct eyewitnesses can be helpful to the disaster management department and non-governmental organizations. For this purpose, the literature supports 13 different features that can highlight the eyewitness Tweets. We used the Twitter dataset having disastrous information and developed an algorithm that creates a dictionary of words for each feature; further, the algorithm matches feature dictionary words with tweet tokens. If a feature exists in a tweet, the feature value is marked as 1; otherwise, 0. After that, the obtained feature values for all tweets are classified with potential classifiers and the eyewitness accounts on Twitter are identified.
This section presents the adopted approach for identifying eyewitnesses from the Twitter platform. The first task was the Feature Identification from the benchmark dataset. After that, we formed the word list. Further, each word’s synonyms were identified and added to the original word list. After that, we extracted the derived words from Wiktionary for each word and its synonym. After that, related words from Google were parsed considering the list formed with original words, synonyms, and derived words. Finally, the overall Methodology diagram of the approach is presented in Fig. 1.

Figure 1: Methodology diagram
To implement the proposed approach, the dataset was collected by Zahra in 2020. This dataset was collected from Twitter using Twitter streaming application programming interface. The author considered specific keywords reflecting disaster situations such as earthquake, flood, heavy rain, hurricane, forest fire, wildfire, etc. Four categories were selected for further manipulation 1) Earthquake, 2) Flood, 3) Wildfire and 4) Hurricane. The span for dataset collection was from July 2016 to May 2018. This span was chosen as many natural disasters occurred during this period. The Tweets were classified into three categories such as 1) eyewitness, 2) non-eyewitness and 3) vulnerable, as presented in Tab. 1.
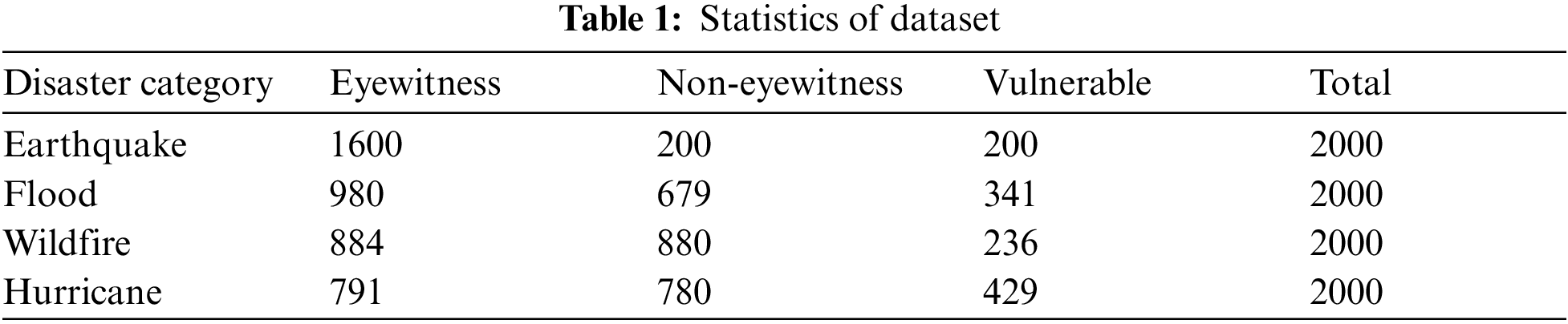
An eyewitness is an individual that has first-hand knowledge and experience about the event. The information contained by the eyewitness can be helpful in different local departments. While the non-eyewitness shares the information received from an eyewitness. Several Tweets went undecided; therefore, such Tweets were categorized as vulnerable. For annotation of the dataset, crowdsourcing was utilized.
Zahra specified thirteen features to perform the experiment, which was utilized after performing manual text analysis on Tweets. These features include surrounding details, words reflecting the impact of a disaster, expletives, first-person pronouns, the length of Tweet, words indicating location, etc. The classification of Tweets is based on these features, as the presence of these features in Tweets can indicate the eyewitness. The detail of the features and their examples are given in the following Tab. 2.

Considering each feature, a word dictionary is formed that consists of all the words which belong to that specific feature. Then, an algorithm is developed to form the word dictionary for features that takes a list of feature-related words as input. The algorithm needs a few words to start. After that, it further extracts all related terms.
This algorithm is composed of three modules, as described in Fig. 2. Initially, the algorithm extracts all synonyms from wordnet and merges them with the input list for each word. In the second module, the algorithm considers the list of original words and their synonyms. Further, each word is searched on Wiktionary and the derived words are extracted. The derived words are again merged with the actual words and synonyms list. Finally, the words of the updated list are searched on Google while concatenating with the “and” keyword. On the result page of Google, the words that came after the “and” keyword were extracted. The steps for word dictionary formation are explained in the following.

Figure 2: Word dictionary formation for features
Word Dictionary Maker (WDM)
Input: List of words
Output: Dictionary of Words
list ← list of words
newlist_1 ← []
For each word ∈ list
newlist.append() ← word.synonyms()
End For
list = list + newlist_1
newlist_2 ← []
For each word ∈ list
page← parse(“https://en.wiktionary.org/wiki/” + word)
newlist_2.append() ← page.find_all(derived_words)
End For
list = list + newlist2
newlist_3 ← []
For each word ∈ list
page← parse(“https://www.google.com/search?q=”+word+“and”)
text ← page.extract_all(heading)
token ← tokenize (text)
newlist_3.append() ← token.extract(index(‘and’) + 1)
End For
list = list + newlist_3
Return list
To initialize the WDM algorithm, a list of feature-related words is required. The list should contain 4 to 5 keywords, as it will reduce the time consumption by the algorithm and fewer irrelevant words would be part of the word dictionary. Therefore, for all features except Feature 7, Feature 8, and Feature 11, we considered a list of words that contained the sense of that specific feature and created a word dictionary. The word lists for features are presented in the following Tab. 3.

For making the word lists, specific words were considered that reflect the respective feature’s characteristics. These word lists were further fed to WDM, a word dictionary-making algorithm. For Feature 7, we used the question mark and the exclamation mark. For Feature 8, the expletives were manually added, while for Feature 11, we checked the length of the Tweets.
For synonym extraction, we used Natural Language Tool Kit [26]. For each word in the list, the algorithm extracts all the synonyms of the respective word. Further, the synonyms and the original words were combined in the list. After merging the synonyms and words, we removed repeating words as there was a possible duplication of synonyms.
4.3.3 Wiktionary Words Extraction
Wiktionary is a web-based project that provides a dictionary of words, phrases, linguistic reconstructions, proverbs, etc. it can be accessed in 171 languages. To extract the derived words from Wiktionary [27], we searched the word automatically by placing the word at the end of the Wiktionary link and then parsed the whole page. The class tag containing derived words was considered and all the derived words were extracted. The extraction rules are given in the following.
• google_search = parse page (“https://en.wiktionary.org/wiki/” + word)
• derived_words = extract word (‘div’, { “class” : “derivedterms term-list ul-column-count”})
The extracted derived words were merged with the original words and their synonyms. Before moving to the next phase, we apply the distinction function on word list to remove the repeating words.
Google is a search engine that provides billions of web links against input queries [28]. We used the google search capability for mining the related words. All the words in the list were searched on Google with the keyword “and” automatically and the whole page was parsed. All the headings were extracted and then tokenized. The word next to the keyword “and” was extracted. The search was based on the concept that when a word is searched on Google with the “and” keyword, the word after “and” would be more relevant in headings. For this module, we developed the following rules:
• google_search = parse page (“https://www.google.com/search?q = ” + word + “and”)
• search_result = extract headings (‘h3’)
• google_words = extract words after “and”
After extracting words from google, a word dictionary was created consisting of input list words, synonyms, Wiktionary words and google words. For each feature, a word list was given to the algorithm WDM. The algorithm returns the word dictionary for that specific input list.
Tokenization is splitting text corpus into smaller units such as phrases or words [29]. These smaller units are termed as tokens. We performed the tokenization and converted the Tweets into tokens in this step. For each Tweet, a list of separated words was generated.
To inspect if the Tweets contain feature keywords, we performed keyword matching. After making a word dictionary of features and performing Tokenization of Tweets, we matched the tokens with feature keywords. If any keyword of a feature is matched with the token, the value of the feature is considered as 1 and if no match occurs, the value of the feature is termed as 0.
In the first column of Tab. 4, Category value 1 indicates the Tweet is from an eyewitness, while 2 presents that the Tweet is from a non-eyewitness. For feature values, 1 indicates that the feature keyword is found in Tweet and 0 indicates no keyword is found.

Feature reduction eliminates the feature from the dataset without losing essential information [30]. It is also termed Dimensionality Reduction. Eradicating the features from the dataset reduces the number of computations. We used cfsSubsetEval as attribute evaluator and Best First as searching method. Feature reduction was performed for all the datasets such as earthquakes, Flood, Hurricane and Forest Fire.
We used the performance metrics F-measure, Precision and Recall [31] for evaluation. Precision is used for measuring the quality of classification. If the Precision is high, it would be meant that the algorithm has returned more relevant results and less irrelevant ones.
On the other hand, Recall is used to express completeness. Eqs. (1)–(3) represents Precision, Recall and f-measure. High Recall means that the algorithm has returned most of the relevant ones. Precision is calculated as retrieved relevant articles divided by total articles. At the same time, Recall is calculated as retrieved relevant articles divided by total relevant articles. These measures are based on (1) True Positive, (2) False Positive, (3) False Negative and (4) True Negative.
The manual analysis of massive corpus to identify eyewitnesses is problematic for humans in disastrous situations. Therefore, we have proposed an approach based on a word dictionary. In this section, we present the proposed approach results and the discussions based on results.
To form the word dictionary [32], we developed an algorithm that inputs a list of words and extracts all the related words. The algorithm first extracts all synonyms from wordnet, further it combines the original list words and synonyms to find the associated words from Wiktionary. After combining original words, synonyms and Wiktionary words, the new list searches for linked words on Google. This algorithm was executed for all the features except 7,8 and 11. A specific list of words was given to the algorithm related to the feature and the algorithm returned the words reflecting that feature. For Feature 8, the expletives were collected from Wiktionary and web. While Feature 7 consisted of only two symbols and Feature 11 was related to the length of the Tweets. All the feature dictionaries are presented in the following Fig. 3.

Figure 3: Feature words
After collecting the related words, we performed text processing by removing 1) non-English words 2) blank symbols. This task was considered as during scraping, some non-English words and some blank symbols were extracted. The total number of words are presented in the following Tab. 5:

The maximum words were extracted for Feature 3, and minimum cells were occupied by Feature 7. For Feature 3, the extracted words were 783, while for Feature 7, only two symbols were considered. The total number of words extracted for all features except Feature 11, were 3,267. For feature 11, we only consider the length of Tweets. Therefore, no word was extracted for this feature.
To identify the eyewitness from Twitter, A technique by Zahra was proposed having 13 different features and these thirteen features were utilized by Sajjad. In this phase, we performed feature reduction to reduce the number of computations. For this purpose, Correlation Feature Selection was utilized with the Greedy Stepwise searching method. The results showed that Feature 1 and Feature 13 provided minor information in the eyewitness identification task. Feature 1 provides little surrounding details, while Feature 13 describes the location. Considering the Feature Reduction results, we removed Feature 1 and Feature 13. The experiment was performed on 11 features.
To classify the Tweets, we used three classifiers Neural Network, Random Forest and Naïve Bayes [33]. The three algorithms were implemented on dataset of Earthquake, Hurricane, Flood and Forest-fire, to identify the eyewitness. For testing and training purpose, 10-Fold technique was used and for evaluation of we utilized performance measures such as Precision, Recall and F-measure. The results for earthquake are presented in Fig. 4.

Figure 4: Results of earthquake
The maximum precision value for earthquake [34] eyewitness identification, was produced by Random Forest, while the maximum Recall value was generated by Neural Network and similarly Neural Network gained maximum F-measure value 0.886. The Neural Network showed better overall performance than other algorithms. In Tweets related to flood disasters, the maximum Precision for eyewitness was observed by Naïve Bayes 0.554. The maximum Recall value was produced by Neural Network 0.34 and highest F-measure was generated by Random Forest 0.405. Therefore, the overall performance in identification of eyewitness was disclosed by Random Forest algorithm. The Flood results are given in Fig. 5.

Figure 5: Results of flood
As shown in Fig. 6, the better precision value was presented by Neural Network 0.598 and the highest values of Recall and F-measure were introduced by Naïve Bayes. Therefore, Naïve Bayes performed slightly better than Neural Network and Random Forest. For Forest Fire, Neural Network produced maximum Precision of 0.391 while Neural Network produced the value of Recall was minimum. Naïve Bayes produced the maximum value of F-measure. The results of Forest Fire are presented in Fig. 7.

Figure 6: Results of hurricane

Figure 7: Forest fire results
The implementation of the complete algorithm, feature dataset and all results have been uploaded on GitHub1 site and are publicly available now.
The proposed approach was implemented for disasters such as earthquakes, hurricanes, Flood and Forest fires. All the features were evaluated and compared with state-of-the-art approaches. Zahra proposed 13 features and the author manually created the static dictionary. The results were in the form of Precision, Recall and F-measure. This research work was enhanced by Sajjad. Linguistic rules were introduced by the author for each feature. These rules were created keeping in view the specific dataset. Therefore, these rules may not be valid for varying datasets. The comparison of F-measure values is presented in Fig. 8.

Figure 8: Comparison of results
For flood, the proposed approach produced lower results, while for other disasters, the proposed approach outperformed the state-of-the-art approach. We further investigated the results and computed the features in each dataset. The following Tab. 6 explores the statistics of results.

It can be observed that for 5 features such as F_4, F_5, F_6, F_9 and F_12 the matches were found maximum in Flood dataset. The feature words were observed with overlapping which caused the slightly low results for Flood dataset. On the other hand, the proposed approach is not dataset dependent and automatically builds word dictionary. The core of the approach is WDM algorithm which is scalable and need only a few related words to initialize the extraction. Sajjad implemented their approach with 13 features while the proposed approach considered only 11 features. The overall performance of the proposed approach is better than Sajjad’s approach. The proposed methodology can be exploited for eyewitness identification in disastrous situations.
6 Conclusion and Research Implications
In today’s era, social media such as Twitter, Facebook, Instagram, etc., are widely used to share opinions, information, and ideas. During any disaster, the credible information shared by an eyewitness can be helpful for agencies and organizations. The research community has introduced approaches to identify eyewitnesses. Zahra performed feature engineering to identify 13 features pointing out eyewitness Tweets. The author manually built a static word dictionary and classified the Tweets. This approach was dataset-dependent and not scalable. To update the static dictionary, domain experts are again needed. Sajjad improved the research work and introduced linguistic rules for all 13 features defined by Zahra. The rules were created based on the Tweets in the dataset. Therefore, this approach was also dataset dependent, and the rules may not outperform with a different dataset. This research paper introduces an approach to identify eyewitness accounts. We utilized 11 features instead of 13, and the core of the proposed approach is WDM. This algorithm inputs very few words for each feature and extracts all the related terms. Further, we performed the preprocessing and tokenized the Tweets. The tokens of Tweets were matched with keywords of each feature. If the feature word is found in Tweet, it was termed as 1; otherwise, 0. The Tweets were classified using feature values. We used Naïve Bayes, Random Forest and Neural Network to classify Tweets. The proposed approach produced 0.886 value of F-measure while [15] approach gained 0.81. The proposed approach can outperform in varying datasets while the state-of-the-art approaches are dataset-dependent. This research can assist the Government disaster management departments and different NGOs in identifying the direct eyewitness individuals to gather and transmit authentic information about the disasters and eliminate the fake news reports. The information from eyewitnesses can also help make alerts.
Funding Statement: This research is funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R54), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Conflict of Interest: The authors have no conflict of interest to report regarding the present study.
1https://github.com/Shahzad-Nazir/EyewitnessIdentification.
1. D. Miller, J. Sinanan, X. Wang, T. McDonald, N. Haynes et al., How the world changed social media. London, UCL press, 2016. [Google Scholar]
2. W. Online, “Twitter usage statistics,” 2021. [Online]. Available: https://www.internetlivestats.com/twitter-statistics/. [Google Scholar]
3. H. Jo, S. Park, D. Shin, J. Shin and C. Lee, “Estimating cost of fighting against fake news during catastrophic situations,” Telematics and Informatics, vol. 66, pp. 101734, 2021. [Google Scholar]
4. S. Chen, J. Mao, G. Li, C. Ma and Y. Cao, “Uncovering sentiment and retweet patterns of disaster-related tweets from a spatiotemporal perspective-a case study of hurricane harvey,” Telematics and Informatics, vol. 47, no. 3, pp. 101326, 2020. [Google Scholar]
5. L. P. Forbes, “Does social media influence consumer buying behavior? An investigation of recommendations and purchases,” Journal of Business & Economics Research, vol. 11, no. 2, pp. 107–112, 2013. [Google Scholar]
6. J. Brynielsson, M. Granåsen, S. Lindquist, M. Narganes Quijano, S. Nilsson et al., “Informing crisis alerts using social media: Best practices and proof of concept,” Journal of Contingencies and Crisis Management, vol. 26, no. 1, pp. 28–40, 2018. [Google Scholar]
7. B. Pikas and G. Sorrentino, “The effectiveness of online advertising: Consumer’s perceptions of ads on Facebook, Twitter and YouTube,” Journal of Applied Business and Economics, vol. 16, pp. 70–81, 2014. [Google Scholar]
8. D. L. Lasorsa, S. C. Lewis and A. E. Holton, “Normalizing twitter: Journalism practice in an emerging communication space,” Journalism Studies, vol. 13, no. 1, pp. 19–36, 2012. [Google Scholar]
9. N. Kankanamge, T. Yigitcanlar and A. Goonetilleke, “Public perceptions on artificial intelligence driven disaster management: Evidence from Sydney, Melbourne and Brisbane,” Telematics and Informatics, vol. 65, no. 5, pp. 101729, 2021. [Google Scholar]
10. Wikipedia, “Westgate shopping mall attack,” 2013. [Online]. Available: https://en.wikipedia.org/wiki/Westgate_shopping_mall_attack. [Google Scholar]
11. Wikipedia, “Boston marathon bombing,” 2013. [Online]. Available: https://en.wikipedia.org/wiki/Boston_Marathon_bombing. [Google Scholar]
12. A. N. R. Fang, X. Liu, S. Shah and Q. Li, “Witness identification in twitter,” in Proc. of the 4th Int. Workshop on Natural Language Processing for Social Media, Austin, TX, USA, pp. 65–73, 2016. [Google Scholar]
13. H. Tanev, V. Zavarella and J. Steinberger, “Monitoring disaster impact: Detecting micro-events and eyewitness reports in mainstream and social media,” Proc. of the 14th ISCRAM Conf., Albi, France, 2017. [Google Scholar]
14. K. Zahra, M. Imran and F. O. Ostermann, “Automatic identification of eyewitness messages on twitter during disasters,” Information Processing & Management, vol. 57, no. 1, pp. 102107, 2020. [Google Scholar]
15. S. Haider and M. T. Afzal, “Autonomous eyewitness identification by employing linguistic rules for disaster events,” Computers Materials & Continua, vol. 66, no. 1, pp. 481–498, 2021. [Google Scholar]
16. H. Kwak, C. Lee, H. Park and S. Moon, “What is twitter, a social network or a news media?,” in presented at the Proc. of the 19th Int. Conf. on World Wide Web, Raleigh, North Carolina, USA, pp. 591–600, 2010. [Google Scholar]
17. O. Oh, M. Agrawal and H. R. Rao, “Community intelligence and social media services: A rumor theoretic analysis of tweets during social crises,” Management Information Systems, Quarterly, vol. 37, no. 2, pp. 407–426, 2013. [Google Scholar]
18. O. Frank and S. Laura, “Context analysis of volunteered geographic information from social media networks to support disaster management: A case study on forest fires,” International Journal of Information Systems for Crisis Response and Management, vol. 4, pp. 16–37, 2012. [Google Scholar]
19. M. Imran, C. Castillo, F. Diaz and S. Vieweg, “Processing social media messages in mass emergency: A survey,” Association for Computing Machinery, Computing. Survey, vol. 47, no. 4, pp. 1–38, 2015. [Google Scholar]
20. S. Kumar, G. Barbier, M. A. Abbasi and H. Liu, “Tweettracker: An analysis tool for humanitarian and disaster relief,” in Fifth Int. AAAI Conf. on Weblogs and Social Media, New York, NY, United States, vol. 5, pp. 661–662, 2011. [Google Scholar]
21. M. Truelove, M. Vasardani and S. Winter, “Testing a model of witness accounts in social media,” in Proc. of the 8th Workshop on Geographic Information Retrieval, Barcelona, Catalonia, Spain, pp. 1–8, 2014. [Google Scholar]
22. E. Doggett, “Identifying eyewitness news-worthy events on twitter,” in Proc. of The Fourth Int. Workshop on Natural Language Processing for Social Media, Austin, TX, USA, pp. 7–13, 2016. [Google Scholar]
23. N. Diakopoulos, M. D. Choudhury and M. Naaman, “Finding and assessing social media information sources in the context of journalism,” in Proc. of the Special Interest Group on Computer-Human Interaction Conf. on Human Factors in Computing Systems, Austin, Texas, USA, pp. 2451–2460, 2012. [Google Scholar]
24. J. Teevan, D. Ramage and M. R. Morris, “#TwitterSearch: A comparison of microblog search and web search,” in Proc. of the Fourth Association for Computing Machinery Int. Conf. on Web Search and Data Mining, Hong Kong, China, pp. 35–44, 2011. [Google Scholar]
25. K. Zahra, M. Imran, F. O. Ostermann, K. Boersma and B. Tomaszewski, Proc. of the 15th ISCRAM Conf., Rochester, NY, USA, pp. 687–695, 2018. [Google Scholar]
26. E. Loper and S. Bird, “Nltk: The natural language toolkit,” 2002. [Online]. Available: https://arxiv.org/abs/cs/0205028. [Google Scholar]
27. E. Navarro, F. Sajous, B. Gaume, L. Prévot, H. ShuKai et al., “Wiktionary and NLP: Improving synonymy networks,” in Association for Computational Linguistics Workshop on The People’s Web Meets NLP: Collaboratively Constructed Semantic Resources, Singapore, pp. 19–27, 2009. [Google Scholar]
28. J. Jarvis and J. Jarvis, What would google do?. Vol. 48. New York: Collins business, 2009. [Google Scholar]
29. J. J. Webster and C. Kit, “Tokenization as the initial phase in NLP,” in COLING 1992: The 14th Int. Conf. on Computational Linguistics, vol. 4, pp. 1106–1110, 1992. [Google Scholar]
30. B. Mwangi, T. S. Tian and J. C. Soares, “A review of feature reduction techniques in neuroimaging,” Neuroinformatics, vol. 12, no. 2, pp. 229–244, 2014. [Google Scholar]
31. D. M. Powers, “Evaluation: From precision, recall and f-measure to roc, informedness, markedness and correlation,” 2010. [Online]. Available: https://arxiv.org/abs/2010.16061. [Google Scholar]
32. S. L. Nist and S. Olejnik, “The role of context and dictionary definitions on varying levels of word knowledge,” Reading Research Quarterly, vol. 30, no. 2, pp. 172–193, 1995. [Google Scholar]
33. G. S. Sajja, M. Mustafa, R. Ponnusamy and S. Abdufattokhov, “Machine learning algorithms in intrusion detection and classification,” Annals of the Romanian Society for Cell Biology, vol. 25, pp. 12211–12219, 2021. [Google Scholar]
34. J. W. Cheng, H. Mitomo, T. Otsuka and S. Y. Jeon, “Cultivation effects of mass and social media on perceptions and behavioural intentions in post-disaster recovery-the case of the 2011 great east Japan earthquake,” Telematics and Informatics, vol. 33, no. 3, pp. 753–772, 2016. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |