DOI:10.32604/cmc.2022.028560
| Computers, Materials & Continua DOI:10.32604/cmc.2022.028560 | |
| Article |
Optimal IoT Based Improved Deep Learning Model for Medical Image Classification
1Department of Computer Science, King Khalid University, Saudi Arabia
2School of Electrical Engineering, Vellore Institute of Technology, India
3Department of Computer Science, Jazan University, Saudi Arabia
4College of Computer Engineering and Science, Prince Sattam bin Abdulaziz University, Saudi Arabia
*Corresponding Author: Prasanalakshmi Balaji. Email: prengaraj@kku.edu.sa
Received: 12 February 2022; Accepted: 28 March 2022
Abstract: Recently medical image classification plays a vital role in medical image retrieval and computer-aided diagnosis system. Despite deep learning has proved to be superior to previous approaches that depend on handcrafted features; it remains difficult to implement because of the high intra-class variance and inter-class similarity generated by the wide range of imaging modalities and clinical diseases. The Internet of Things (IoT) in healthcare systems is quickly becoming a viable alternative for delivering high-quality medical treatment in today’s e-healthcare systems. In recent years, the Internet of Things (IoT) has been identified as one of the most interesting research subjects in the field of health care, notably in the field of medical image processing. For medical picture analysis, researchers used a combination of machine and deep learning techniques as well as artificial intelligence. These newly discovered approaches are employed to determine diseases, which may aid medical specialists in disease diagnosis at an earlier stage, giving precise, reliable, efficient, and timely results, and lowering death rates. Based on this insight, a novel optimal IoT-based improved deep learning model named optimization-driven deep belief neural network (ODBNN) is proposed in this article. In context, primarily image quality enhancement procedures like noise removal and contrast normalization are employed. Then the pre-processed image is subjected to feature extraction techniques in which intensity histogram, an average pixel of RGB channels, first-order statistics, Grey Level Co-Occurrence Matrix, Discrete Wavelet Transform, and Local Binary Pattern measures are extracted. After extracting these sets of features, the May Fly optimization technique is adopted to select the most relevant features. The selected features are fed into the proposed classification algorithm in terms of classifying similar input images into similar classes. The proposed model is evaluated in terms of accuracy, precision, recall, and f-measure. The investigation evident the performance of incorporating optimization techniques for medical image classification is better than conventional techniques.
Keywords: Deep belief neural network; mayfly optimization; gaussian filter; contrast normalization; grey level variance; local binary pattern; discrete wavelet transform
Owing to the proliferation of digital medical images in the modern healthcare sector has resulted in medical image analysis playing an increasingly important part in clinical practice [1]. In modernized hospitals, IoT devices collect a wide range of imaging data for diagnosis, therapy planning, and monitoring treatment response. The enormous image archives combined with other image sources (clinical manuals) open up new avenues for developing automated tools for image-based diagnosis, training, and biomedical research [2–4]. For such activities, classification and identification of healthcare data is essential to perform corresponding clinical practices [5]. The role of classification is to extract relevant features from the image dataset. Hence in a medical analysis system, medical image classification is an essential part to discriminate medical images based on certain criteria [6,7]. A consistent medical image classification system can help physicians to evaluate medical images quickly and accurately. With modern computer tools, new imaging modalities, and new interpretation challenges, research in Computer-Aided Diagnosis (CAD) [8–12] is quickly explored in such kinds of medical applications.
In medical imaging, a decision-support tool is a crucial one for computer-assisted assessment and diagnosis. In context, CAD aids clinicians to utilize the results of an automated analysis of medical images for determining disease extent with perfect accuracy score by reducing the incidence of false alarms [13–15]. The general approach to CAD is to locate the lesions and evaluate the disease’s likelihood. Typically, CAD systems architecture encompasses training samples selection, image pre-processing, region(s) of interest definition, feature extraction and selection, classification, and segmentation [16]. The descriptiveness and discriminative strength of features retrieved are fundamental in medical image classification challenges to obtain high classification performance. Intensity histograms, filter-based features, and the increasingly popular scale-invariant feature transform (SIFT) and local binary patterns are examples of feature extraction techniques extensively employed in medical imaging [17]. To acquire the image label, the feature vectors are utilized to train a classification model, such as the Machine Learning approaches. Nevertheless, these approaches have the unfortunate consequence: their performance falls well short of what is required in practice, and their development has been modest in recent years.
Furthermore, feature extraction and selection take time and fluctuate depending on the item [18]. The majority of existing medical image classification methods rely on handmade features. Despite the effectiveness of these approaches, designing handmade features that are appropriate for a given classification assignment is frequently challenging. In this case, Deep learning approaches have made considerable advances in medical image classification in recent years [19–21]. These algorithms, while more accurate than handmade feature-based approaches have not held the same success with medical image classification. As a result, it can be concluded that Deep Learning has shown to be quite effective in handling picture classification challenges [22]. Deep learning-based research considerably increased the top performance for a variety of image datasets. The existing studies such as Synergic Deep Learning Model (SDL) [23], Ensemble Learning model (ELM) [24], Deep convolutional neural network(DCNN) [25], Optimal Deep learning model (ODLM) [26] are considered used for IoT enabled medical image classification. It specializes in identifying local and global structures in visual data. Thus, researchers were able to effectively solve these issues by using a correctly designed network topology and methods such as extensive dropout and input distortion to reduce the over-fitting problem [27–29]. Based on this insight, a novel deep learning technique named optimization-driven deep belief neural network is proposed by integrating pre-processing, feature extraction, and feature selection techniques.
The manuscript is organized as follows, Section 2 elaborates the literature review, and Section 3 elucidates the research gap. The next Section 4 illustrates the proposed methodology. Furthermore, Sections 5 and 6 discuss the experimental outcome and conclusion respectively.
Recently several publications are focusing on medical image classification problems. Some of the recent articles are surveyed to identify the research gap in this field, which are discussed as follows,
Azar et al. [23] have introduced a synergic deep learning model for medical image classification problems. The introduced models learn features simultaneously by encompassing multiple convolution layers to learn the features mutually. In the synergic network model, each layer has its image representation that is concatenated as the input whereas the fully connected layer accepts the input to classify output images. Thus the presented model can identify whether the images belong to the same class or not. The model updating process neither is effectively attained due to multiple layers and so the synergic error is not reduced for each pair of layers.
Kumar et al. [24] have exhibited an ensemble learning model for obtaining an optimal set of image features. The main theme of the presented ensemble learning model is that the framework learns dissimilar levels of semantic representation of images so that higher quality of features is extracted. Thus the new set of features is learned with a larger dataset by developing the fine-tuned model. The anticipated fine-tuning CNN architecture leverages the generic number of medical image features from different modality images. With those set of features, a multi-class medical image classification problem is performed on the publically available Image CLEF 2016 medical image dataset.
Wang et al. [25] have utilized the fundamental deep convolutional neural network for an image classification problem. The utilization of the deep learning model in this medical image classification is that the deep learning techniques are proven to act as both feature extraction and classification model. Hence deep learning techniques perform better rather than machine learning approaches. The presented approach lacks in taking annotated training samples so this model suits only for small training samples.
Lai et al. [30] have examined a coding network integrated with multi-layer perceptron for solving a medical image classification problem. On the combination of these models, a deep learning concept is developed to extract discriminative feature sets. For training the network model deep learning approach along with the coding network is hybrid in a supervised manner. The resultant of this network architecture is the raw pixel of the medical image and it acts as a feature vector for the medical image classification problem. Based on this set of feature groups are extracted and produce the relevant outcome.
Raj et al. [26] have developed an optimal deep learning model for three disease classification problems. The optimal selection of features is done to enhance the performance of the presented deep learning algorithm. The three different diseases considered are brain disease, lung cancer, and Alzheimer’s disease. Several steps like pre-processing, feature selection, and classification are incorporated to attain the specific goal. Opposition crow search optimization algorithm is integrated for selecting an optimal set of features as well as for tuning optimal parameters in the network model.
Research into intelligent computer programming for medical applications is a prominent and exciting field. Typically, the physician collects his or her information based on the symptoms of the patient and the basics of the detailed process of diagnosis. Likewise, the prognostic relevance of knowledge in the direction of definite diseases and the diagnostic precision of a patient are extremely demanded by a physician’s experience. As medical and therapeutic knowledge increases rapidly, e.g., the manifestation of new diseases and the availability of new medicines challenge doctors to keep up to date with all the latest information and advances in medical practice. With the advent of computer technology, it is now easier to retrieve and store large amounts of data, e.g., on dedicated domains of electronic patient records. Therefore, the deployment of computerized medical decision-making systems becomes an effective way to help physicians diagnose patients quickly. However, many issues need to be addressed before a comprehensive medical decision-making process can be developed and implemented, including decision-making where there is uncertainty and ambiguity.
• While the knowledge and experience of medical professionals are significant, advances in machine learning techniques, from diagnosing a patient’s condition to diagnosing it, have opened the way for clinicians to use intelligent computer programs to support decisions in their work, e.g., Surgical image and X-ray images.
• When treating a patient, the doctor first needs to use his knowledge and experience to reduce the alleged underlying disease (excluding a list of possible causes), and then confirm the diagnosis with further tests.
• At the same time, computerized intelligent practices can be valuable in helping the doctor to make informative decisions hastily, e.g., predict the diagnosis by learning from related past cases in a vast database of electronic patient records and for the current patient with proper medical analysis.
• A key feature of this is due to the characteristics of the medical data with a combination of information. With the vast amount of information obtainable to a surgeon from modern medical equipment, it is recommended to merges a group of imperfect, indecisive, and conflicting data but this kind of uncertain information makes the conflict in diagnostic problems.
• The chief challenges occurring in medical diagnostic problems are because of a lack of relevant knowledge about the problem area and is also due to uncertainties occurring while providing crisp information to physicians. In addition, the healthcare support structure or clinical decision-making medium has become the first significant tool of medical science to assist clinical surgeons to make decisions, especially when medical diagnosis determines which diseases are on the list of patients’ symptoms and analyzes the majority diagnosis between them. Uncertainty, therefore, occurs as an important factor in diagnostic problems. In this case, the classification of medical information is considered a major aspect in the field of medical information.
However, many mechanisms have been reported in the literature, and there is still a lot of extent since there are some features in the medical data that make their analysis extremely difficult. The compensation utilizing intelligent systems takes account of an increase in the accuracy of the diagnosis and equivalently, it achieves a reduction in the cost and time related to patient treatment. Deep learning models have been deployed in this case to bear various functions of medical decision-making. Based on this insight, the main contributions of the proposed method are listed below;
• A novel optimization-driven deep belief neural network is introduced to classify the collected dissimilar IoT-based medical images.
• To enhance the performance of the classifier, an appropriate feature extraction technique is chosen to extract the statistical measures from an input image.
• Pre-processing procedures are incorporated to improve the quality of an image and are further processed to feature extraction techniques.
• A novel May Fly optimization-based feature selection approach is introduced to ultimately select the relevant features from the extracted feature in an image.
The novelty of this study is to provide a novel optimal IoT-based improved deep learning model named optimization-driven deep belief neural network (ODBNN) for medical image classification.
The research work initiates with pre-processing the medical scanned image using Gaussian filtering and contrast enhancement, which adjusts the image intensity value 0 to 1 for enhancing the performance of feature extraction. Afterward, the geometric and statistical sets of features are extracted and those features are subjected to proposed mayfly optimization [31] driven Deep Belief Neural Network model to select optimal features and to process the classification task. Here the optimization strategy is empowered in the classification model to enhance the performance of model training by performing an optimal selection of designing parameters. Fig. 1. shows the block diagram of the proposed methodology.
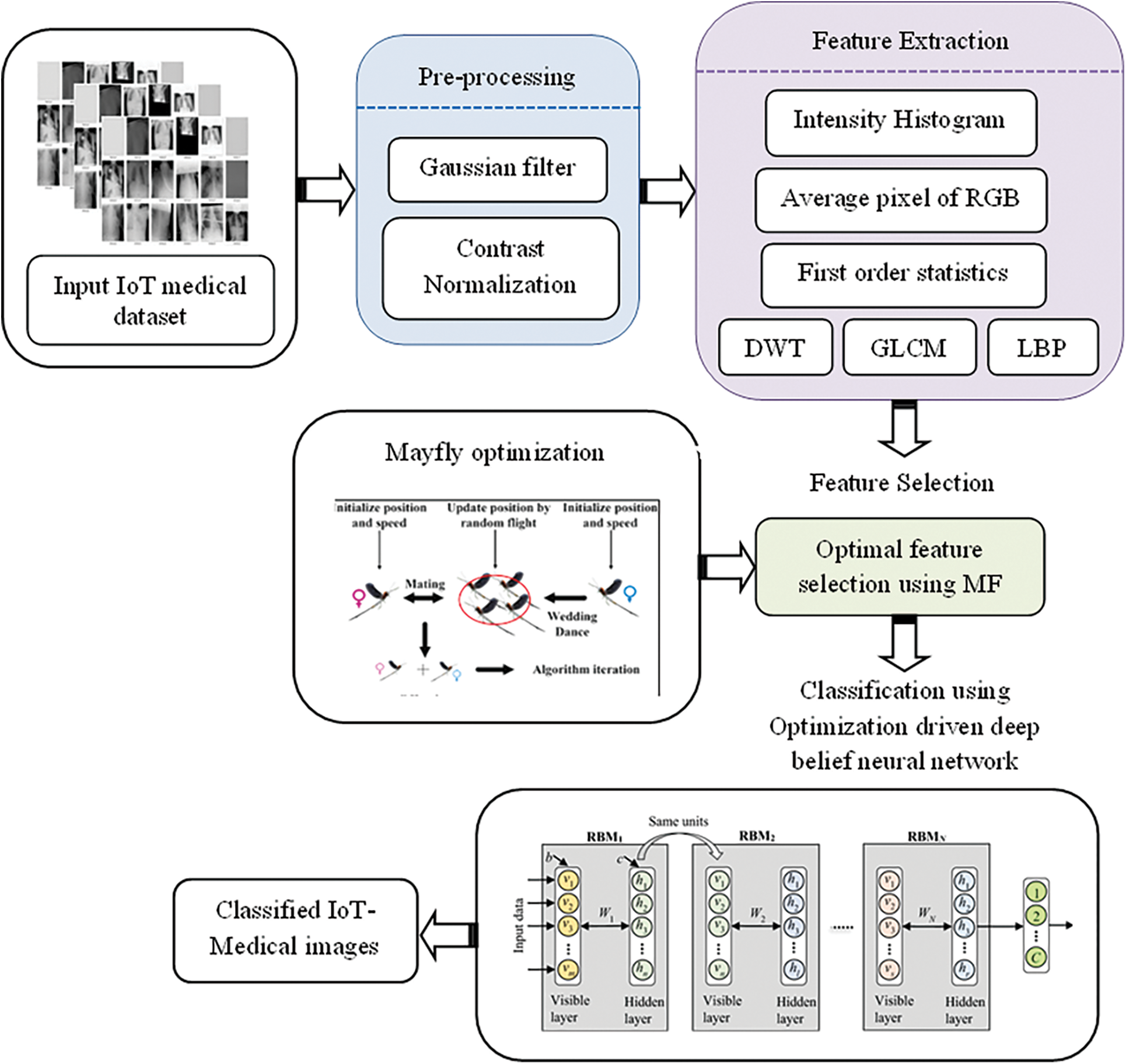
Figure 1: Layout of the proposed model
4.1 Medical Imaging Modalities
The input IoT-based medical imaging modalities are collected from an open-source library for the medical image classification model. Consider the database as J with m number of images and is represented as follows,
4.1.1 Noise Destruction Using Gaussian Filter
Typically, input IoT-based medical images are extremely corrupted with noisy information and so, noise destruction procedure is obligatory for the improvement of image quality. Thus, input IoT image
The sigma value defines the width of the Gaussian function and is considered a 2-dimensional factor. While performing this filter, the objects contained in the image get sharpened. Whereas,
4.1.2 Contrast Normalization for Filtered Image
In the context of IoT-based medical data classification, images are taken under different scanners and their brightness may vary. This leads to images with different intensities and contrast that prevent ease of operation and learning ability. To overcome this challenge Contrast Normalization (CN) is used to avoid the contrast of the image distortion. Currently, the filtered image is in the form of an RGB image and is targeted at the CN section in a channel-wise manner. For each data, the mean and standard deviations are calculated at three channels in the CN segment. After calculating both, the specified value is removed from the three filtered image channels and separated by a standard deviation. The CN class is assessed by the following mathematical expression.
where
The feature Extraction procedure is carried out to measure the relevant features like color, shape, and texture of pre-processed images. To discriminate various classes of medical images accurately, the feature extraction procedure is essential in the proposed research model.
The primary idea behind such a discrete histogram function is to link the number of pixels towards the intensity measure. Before getting the intensity histogram feature, the pre-processed image is converted to a greyscale image and it is assumed that N represents the highest intensity measures. Here the intensity level histogram
The pixel count is denoted as
4.2.2 Average Pixel of RGB Channel
The average measure of the pixel is an essential intensity aspect of images since it indicates the data’s centralized trend. The average pixel value of each color space in an image is stated as
Here the term
4.2.3 Discrete Wavelet Transform
The transformation of the same group image is identified by the use of DWT examination. In the form of a numerical manner, the global features of an input medical image are extracted. Hence the energy of the input image is calculated by applying well-suited wavelet features. By the filter series, the DWT is acquired for the input medical image v. The low pass and high pass filter of an image are symbolized as l and h respectively. These are the series of two filters by having detailed and approximation coefficient while passing discrete model
4.2.4 Grey Level Co-Occurrence Matrix
One of the suitable texture-based image features is extracted by the use of the GLCM technique. It studies the character of the spatial correlation of an image. In the proposed research model, a set of 22 relevant GLCM features are extracted they are correlation, homogeneity, sum average, cluster shade, variance, autocorrelation, information measure of correlation, sum entropy, cluster probability, energy, inverse difference moment, entropy, sum entropy, contrast, dissimilarity, the sum of squares, maximum probability, sum average, inverse difference.
The foremost first-order statistical measures like average contrast, energy value, mean, entropy are calculated in the proposed feature extraction technique. Its mathematical formulation is described as follows,
Here
LBP is an effective texture descriptor by taking threshold and applying it to the neighborhood of every pixel across the center measure of an image. Thus, the LBP operator tends to take categorize the image pixel value along with the threshold output as a binary value. Here the local texture features are extracted and it has the most important benefit such as its focus on gray level variance and rotation. The location of the pixel is recorded as 1 if the value of the neighboring pixel is larger than or equal to the value of the centre pixel, otherwise, it is 0.
Here input image at pixel rate is denoted as
4.3 Optimal Feature Selection Using MF Algorithm
In this section, the optimization strategy used in the proposed is elaborated to understand the background of the study conducted. Formally, Mayfly optimization can be inspired by the social characteristics of mayflies. Especially, it is related to the mating procedure. In this optimization algorithm, the assumption is hatching from the eggs; it contains adults as well as fittest mayflies presented which have the characteristics of long life. In the algorithm, the position of each mayfly in the search space is considered as a potential solution related to the problem. The mayfly algorithm process is presented as follows. In the mayfly algorithm, the initial step is the random population of two sets of mayflies such as female and male mayfly. In the proposed model, the random weights are considered in the initial mayfly population. Every mayfly is placed randomly in the search space which is named as candidate solution which contains with
And, the mayfly velocity can be described as position variation and is denoted as follows,
The dimensional vector is computed based on the objective function.
Every mayfly has the dynamic interaction of both social and individual flying characteristics. In the algorithm, every mayfly changes its trajectory through its current best position so far, as well as the best position can be attained by mayfly characteristics. The mayfly algorithm [31] is adopted for optimization purposes in selecting the best feature
4.4 Proposed Mayfly Optimization is Driven Deep Belief Neural Network
To design a multi-class learning model a novel classification system is developed which is constructed with numerous hidden layers. The proposed learning algorithm requires an enormous number of training samples because of its deeper learning parameters. But subjecting those large training samples leads the network to overfitting issues. Henceforth, before the training process gets started, the feature extraction stage is accompanied to overcome the overfitting issues. In this manuscript, a mayfly optimization-driven DBNN is proposed for the classification procedure. Deeper structures are faster and more efficient than shallow ones. The infrastructure of DBNs is supported by several layers, which are stacked on top of each other so that building a network can capture the basic rules and variations directly from the basic source data. Each RBM, within a given layer, receives the inputs of the previous layer and feeds them to the next layer, allowing the network as a whole to extract and refine the prominent information. The DBN system is given in Fig. 2.
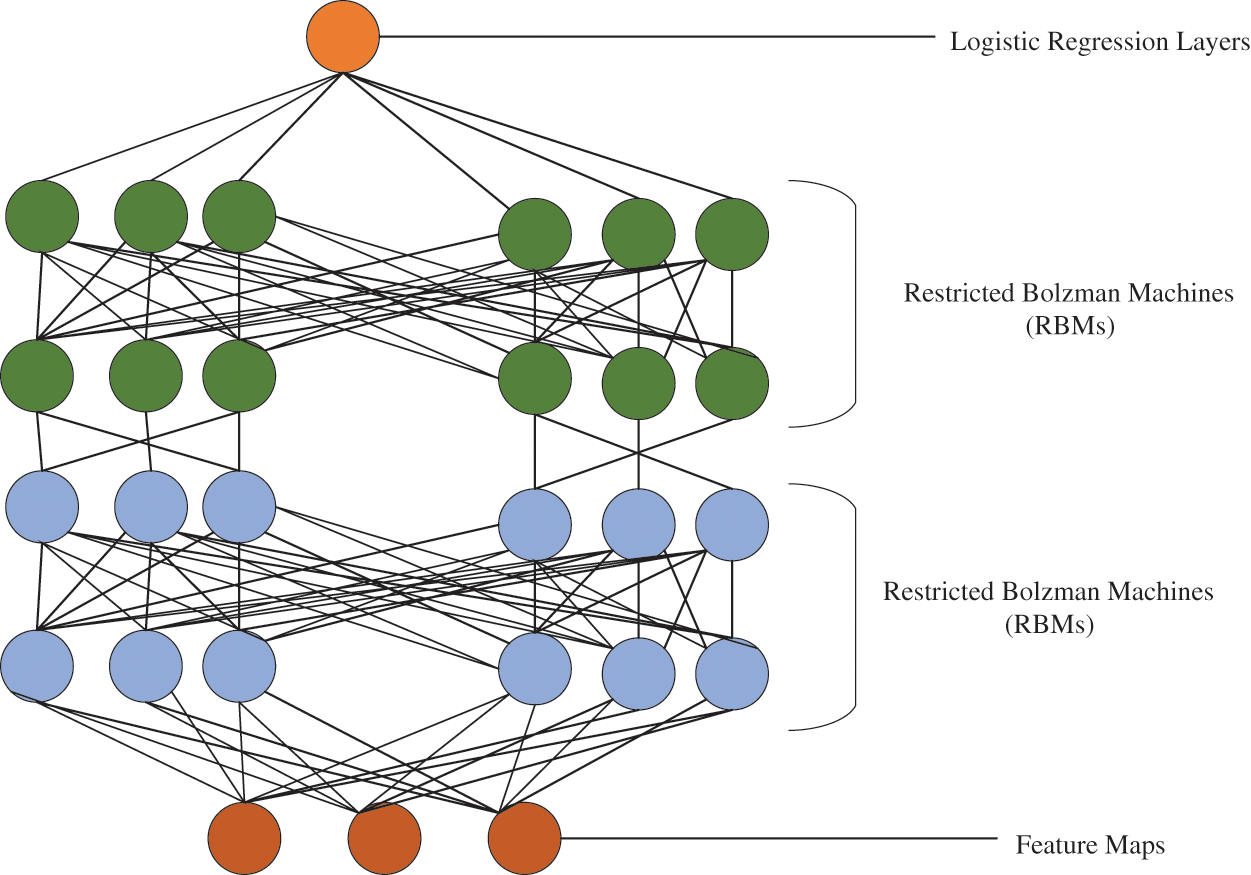
Figure 2: Structure of deep belief neural network
An RBM is an energy-based generative model that consists of a layer of I binary visible units (observed variables), v
Here
Here Z is a normalization constant called partition function by analogy with physical systems, which is obtained by summing up the energy of all possible
Since there are no connections between any two units within the same layer, given a particular random input configuration v, all the hidden units are independent of each other and the probability of h given v becomes,
For implementation purposes,
To reconstruct the input vector, it is vital to force the hidden states to be binary. The actual probabilities violate the information bottleneck, which acts as a strong regularizer and is imposed by forcing the hidden units to convey at most one bit of information. The marginal probability assigned to a visible vector, v, is given by,
Hence, given a specific training vector v, its probability can be raised by adjusting the weights and the biases of the network to lower the energy ofa particular vector while raising the energy of all the others. In context, the optimal selection of bais and weight function retrieve an efficient classification accuracy. Henceforth, mayfly optimization-driven DBNN is proposed and is detailed in the subsequent section. The output of the network model is enumerated from the differences among the predicted and actual probability values. It is calculated on the measure of mean square error. The learning rate is restored for accomplishing the exact output until the error gets minimized. The objective function of the system is specified as follows,
Here, the estimated output is indicated as
In the DBNN, the learning rate is optimally selected with the help of the mayfly algorithm. A detailed description of the mayfly algorithm is presented in this section. The mayfly algorithm is similar to PSO but it contains advantages of GA as well as PSO. So, the mayfly algorithm is also named a hybrid algorithmic structure based on the characteristics of mayflies.
In the proposed methodology, the mayfly algorithm is used to select the optimal learning rate of DBNN by minimizing the error function. The objective function is mathematically specified as follows,
The distance of the mayfly’s calculation is necessary to identify the best position to afford the mating process. The distance of mayflies is computed based on the Cartesian distance which is presented follows,
where,
where R can be described as random value and D can be described as nuptial dance coefficient. The DBNN operation with the mayfly algorithm is used to enhance the error classification rate.
The main purpose of this study is to present an effective optimal IoT-based medical image classification system to suggest ways for classifying different kinds of medical scanned images. The whole process is tested with metrics like accuracy, recall, precision, and F-measure. The performance of the proposed model is compared with the existing algorithms to show the effectiveness of the proposed model. The experimental study was undergone for four classification types taken from the Kaggle dataset. The experimental process is performed on python software. Furthermore, the whole process is conducted on the system configuration of 12GB RAM with an intel i3 processor 9th generation.
To analyze the performance of the proposed prediction model, some of the evaluation metrics are validated and tested. The evaluation taken for analysis includes accuracy as a standard to describe the amount of classification class made correctly, precision as a means to define how accurately the proposed model predicts positive class values. The measure recall or sensitivity defines the classification data to be able to classify correctly. F measure as a way to compute mean value using precision and recall measure provides F-measure or F1-Score. It ranges from 0 (worst performance) to 1 (highest performance). A loss function is one of the quality metrics and helps to define the performance of the classification model. It is calculated based on the error function of the classifier obtained. The total time consumed for the entire classification rate is included as classification time. For each standard statistical measure, the overall performance of proposed and existing techniques is computed and offered in the subsequent section.
5.2 Performance of the Proposed Methodology
Optimal IoT-based medical image classification is proposed based on an optimization-driven deep learning approach. For analyzing the proposed medical image classification system, primarily confusion matrix is generated for the taken dataset based on statistical measures. To show the clarity of the proposed training model-based classification system, its obtained accuracy and loss function of the training process for the taken dataset is graphically displayed in Fig. 3.
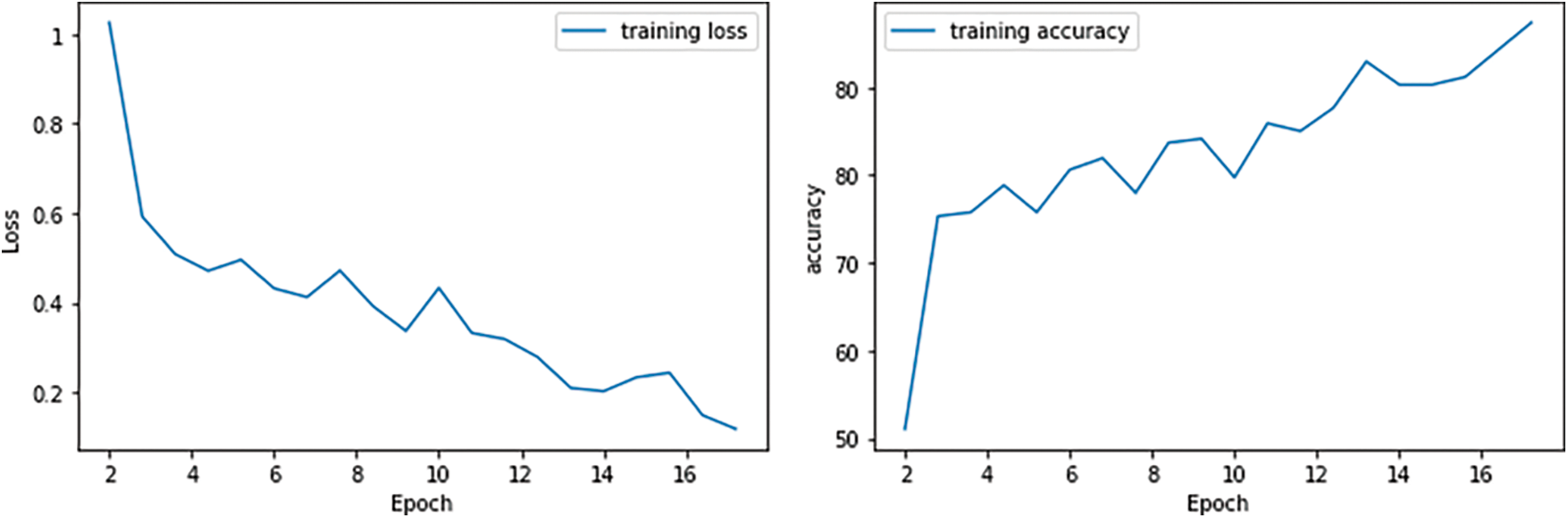
Figure 3: Performance metrics
From the analysis, it can be clearly stated that the proposed process reaches a good level of classification. There is a good precision as the number of iterations increases, the accuracy also increases gradually. The loss function obtained by the DBNN model finds a small predictive. Here, when the iteration is increased, the classification error of the proposed solution is reduced. It is therefore determined that the proposed system achieves effectiveness in terms of accuracy and performance of the error. With the clarity of the proposed method, it is compared with existing methods as in other planning metrics.
5.3 Comparative Analysis of Proposed and Existing Approaches
The performance metrics of the proposed and existing techniques are considering the performance metrics accuracy, precision, recall, F-Measure, and Loss. Furthermore, SDL [16], ELM [17], DCNN [18], and ODLM [20] are the existing methods considered to make a comparative analysis. Fig. 4. illustrates the performance comparison of the performance metrics of the proposed and existing techniques.
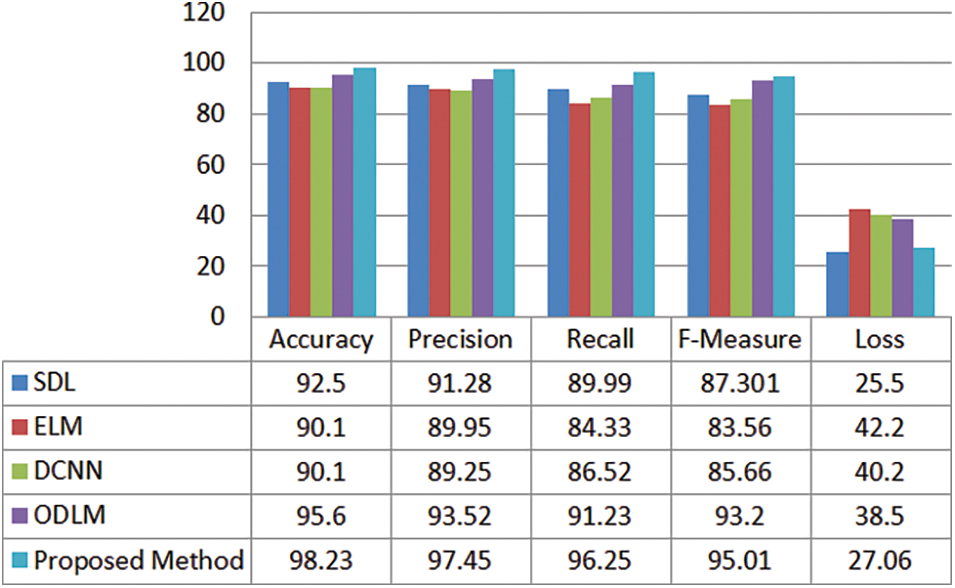
Figure 4: Performance comparison of the proposed and existing methods
The proposed method attains an accuracy of 0.9823, 0.9745 as the precision value, 0.9625 as recall, 0.9501 as F-Measure, and 0.2706 is the loss obtained. It seems to be comparatively a good performance when compared to other existing methods.
From the analysis, it can be stated that the proposed technique achieves a good classification rate. The Fig. 4. furnishes the good accuracy for optimal IoT-based medical image classification utilizing DBNN based mayfly optimization approach. For instance, when the number of iterations gets increases, accuracy also gradually increases. Fig. 4. demonstrates the comparison of the accuracy of the proposed and existing such as SDL, ELM, and DCNN. For the proposed technique, 98.23 is the accuracy value is better than the other existing techniques. For SDL the accuracy is 92.5, ELM with an accuracy of 90.1, DCNN and ODLM with an accuracy of 90.1 and 95.6 respectively. From the analysis, the proposed method is more accurate than the other techniques.
Furthermore, 0.9745 is the precision value of the proposed method that stands good when compared to 91.28 that of SDL, 89.95 of ELM, 89.25 of DCNN, and 93.54 of ODLM. The recall value for the proposed method is 0.9625, 0.9023, 0.8692 and 0.8456 and 0.8264 are recall values of the existing approaches. The recall of the proposed is greater than the other techniques.
Even with the F-Measure metrics, the proposed methods excel with that of existing methods. The proposed has a high F-measure value which is 0.9501. The loss achieved by the proposed model attains minimum prediction error. Here, when the iteration is raised, the prediction error of the proposed solution decreases. Hence it is determined that the proposed system achieves betterment in terms of accuracy and error function. Fig. 5. demonstrates the processing time of the proposed and existing methods. The processing time of the proposed method is 8.13 s, in addition, for the existing methods, 9.2 s for Hyperparameter optimization (Talos), 12.32 s for NB, 15.2 for LR, and 18.2 for SVM.
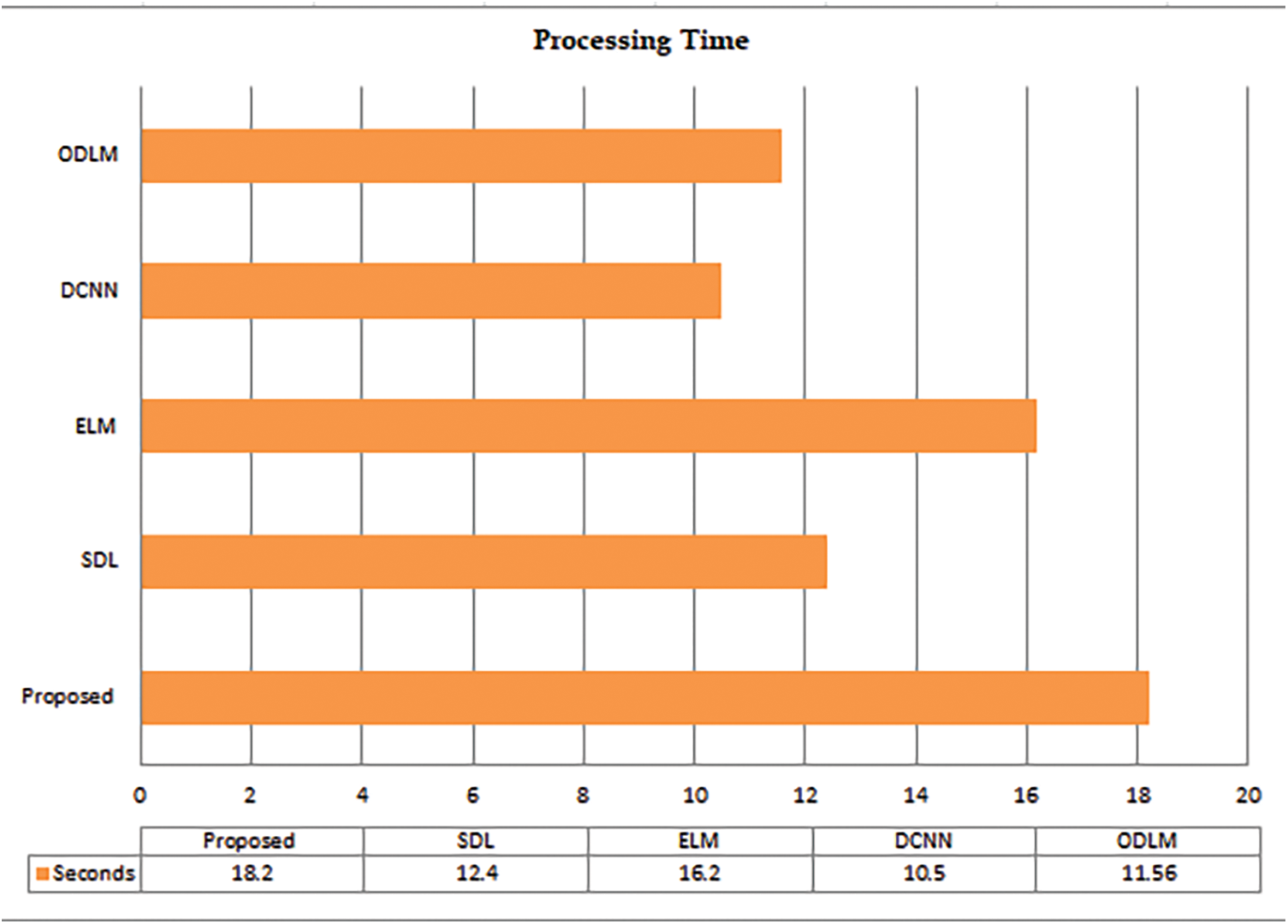
Figure 5: The processing time of the proposed and existing techniques
It is well-known fact that when the loss acquired is lesser, then automatically the system performance will get improves. By satisfying the above fact, the proposed system outperforms well by attaining a minimum loss value. Thus, from the analysis, it is concluded that overall performance is improved enough for the classification of optimal IoT-based medical images. From the overall analysis, it is concluded that the proposed attains a better solution for the classification system due to the incorporation of an optimization procedure. From the achievable outcome, it is proven that the proposed model is most appropriate in the classification of medical images.
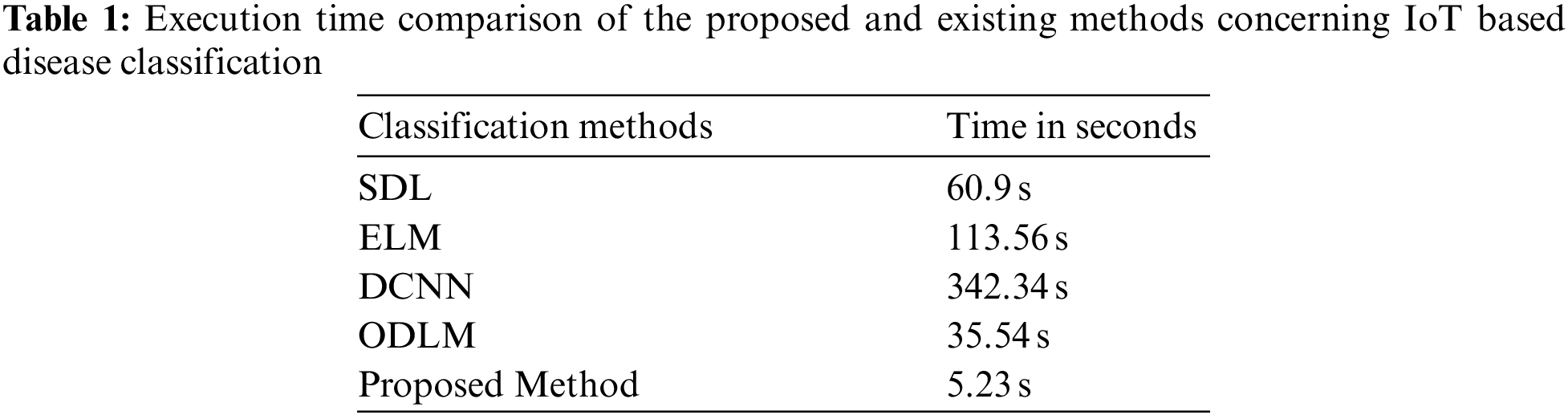
The computational execution time of the proposed and existing techniques concerning IoT-based disease classification is discussed in Tab. 1. Furthermore, SDL [23], ELM [24], DCNN [25], and ODLM [26] are considered the existing methods thereby evaluating the computational time of the proposed work. Tab. 1. illustrates the performance comparison of the execution time of the proposed and existing techniques.
In this paper, we propose an optimal deep learning model named Optimization driven Deep Belief Neural Network integrated with Mayfly Optimization algorithm. An effort has been made to design an optimal IoT-based medical image diagnostic system that can improve classification accuracy. High-performance DBNN with optimized designing parameter selection-based medical image classification system is proposed in this study to assist the physician with automatic generation of classification outcomes. Test analysis yields promising results in the field of medical image classification performance. The performance has been further enhanced by the techniques of feature selection. From the experimental results, it can be concluded that the proposed system can help physicians to make the accurate decision in classifying medical images. In the future, it is recommended to utilize reinforcement learning for automatically selecting the layers in the network structure.
Acknowledgement: The authors would like to express her gratitude to King Khalid University, Saudi Arabia for providing administrative and technical support.
Funding Statement: This research is financially supported by the Deanship of Scientific Research at King Khalid University under research grant number (RGP.2/202/43).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. E. Miranda, M. Aryuni and E. Irwansyah, “A survey of medical image classification techniques,” in Int. Conf. on Information Management and Technology, Indonesia, pp. 56–61, 2016, https://doi.org/10.1109/ICIMTech.2016.7930302. [Google Scholar]
2. R. J. Ramteke and K. Y. Monali, “Automatic medical image classification and abnormality detection using k-nearest neighbour,” International Journal of Advanced Computer Research, vol. 2, no. 4, pp. 190–196, 2012. [Google Scholar]
3. L. Faes, S. K. Wagner, D. J. Fu, X. Liu, E. Korot et al., “Automated deep learning design for medical image classification by health-care professionals with no coding experience: A feasibility study,” The Lancet Digital Health, vol. 1, no. 5, pp. e232–e242. 2019. [Google Scholar]
4. S. S. Yadav and S. M. Jadhav, “Deep convolutional neural network based medical image classification for disease diagnosis,” Journal of Big Data, vol. 6, no. 1, pp. 1–18, 2019. [Google Scholar]
5. Q. Liu, L. Yu, L. Luo, Q. Dou and P. A. Heng, “Semi-supervised medical image classification with relation-driven self-ensembling model,” IEEE Transactions on Medical Imaging, vol. 39, no. 11, pp. 3429–3440, 2020. [Google Scholar]
6. P. Manikandan, “Medical big data classification using a combination of random forest classifier and k-means clustering,” International Journal of Intelligent Systems and Applications, vol. 11, pp. 11–19, 2018. [Google Scholar]
7. S. K. Lakshmanaprabu, K. Shankar, M. Ilayaraja, A. W. Nasir, V. Vijayakumar et al., “Random forest for big data classification in the internet of things using optimal features,” International Journal of Machine Learning and Cybernetics, vol. 10, no. 10, pp. 2609–2618, 2019. [Google Scholar]
8. R. Zhang, J. Shen, F. Wei, X. Li and A. K. Sangaiah, “Medical image classification based on multi-scale non-negative sparse coding,” Artificial Intelligence in Medicine, vol. 83, pp. 44–51, 2017. [Google Scholar]
9. Y. Song, W. Cai, H. Huang, Y. Zhou, D. D. Feng et al., “Large margin local estimate with applications to medical image classification,” IEEE Transactions on Medical Imaging, vol. 34, no. 6, pp. 1362–1377, 2015. [Google Scholar]
10. P. R. Jeyaraj and E. R. S. Nadar, “Computer-assisted medical image classification for early diagnosis of oral cancer employing deep learning algorithm,” Journal of Cancer Research and Clinical Oncology, vol. 145, no. 4, pp. 829–837, 2019. [Google Scholar]
11. M. S. Hosseini and M. Zekri, “Review of medical image classification using the adaptive neuro-fuzzy inference system,” Journal of Medical Signals and Sensors, vol. 2, no. 1, pp. 49–60, 2012. [Google Scholar]
12. Y. Dai, Y. Gao and F. Liu, “TransMed: Transformers advance multi-modal medical image classification,” Diagnostics, vol. 11, no. 8, pp. 1–15, 2021. [Google Scholar]
13. Y. Zhang, B. Zhang, F. Coenen, J. Xiao and W. Lu, “One-class kernel subspace ensemble for medical image classification,” EURASIP Journal on Advances in Signal Processing, vol. 2014, no. 1, pp. 1–13, 2014. [Google Scholar]
14. R. Neelapu, G. L. Devi and K. S. Rao, “Deep learning based conventional neural network architecture for medical image classification,” Traitement du Signal, vol. 35, no. 2, pp. 169–182, 2018. [Google Scholar]
15. Z. Lai and H. Deng, “Medical image classification based on deep features extracted by deep model and statistic feature fusion with multilayer perceptron,” Computational Intelligence and Neuroscience, vol. 2018, pp. 1–13, 2018. [Google Scholar]
16. S. Dutta, B. C. S. Manideep, S. Rai and V. Vijayarajan, “A comparative study of deep learning models for medical image classification,” IOP Conference Series: Materials Science and Engineering, vol. 263, no. 4, pp. 1–9, 2017. [Google Scholar]
17. M. Abedini, N. C. F. Codella, J. H. Connell, R. Garnavi, M. Merler et al., “A generalized framework for medical image classification and recognition,” IBM Journal of Research and Development, vol. 59, no. 2/3, pp. 1–18, 2015. https://doi.org/10.1147/JRD.2015.2390017. [Google Scholar]
18. E. M. Hassib, A. I. El-Desouky, L. M. Labib and E. S. M. El-kenawy, “WOA + BRNN: An imbalanced big data classification framework using whale optimization and deep neural network,” Soft Computing, vol. 24, no. 8, pp. 5573–5592, 2020. [Google Scholar]
19. C. Jaya Sudha and Y. S. Sneha, “Classification of medical images using deep learning to Aid in adaptive Big data crowdsourcing platforms,” in ICT with Intelligent Applications, Singapore, pp. 69–77, 2022. [Google Scholar]
20. N. P. Karlekar and N. Gomathi, “OW-SVM: Ontology and whale optimization-based support vector machine for privacy-preserved medical data classification in cloud,” International Journal of Communication Systems, vol. 31, no. 12, pp. 1–18, 2018. [Google Scholar]
21. W. Xing and Y. Bei, “Medical health big data classification based on KNN classification algorithm,” IEEE Access, vol. 8, pp. 28808–28819, 2019. [Google Scholar]
22. A. T. Azar and A. E. Hassanien, “Dimensionality reduction of medical big data using neural-fuzzy classifier,” Soft Computing, vol. 19, no. 4, pp. 1115–1127, 2015. [Google Scholar]
23. J. Zhang, Y. Xie, Q. Wu and Y. Xia, “Medical image classification using synergic deep learning,” Medical Image Analysis, vol. 54, pp. 10–19, 2019. [Google Scholar]
24. A. Kumar, J. Kim, D. Lyndon, M. Fulham and D. Feng, “An ensemble of fine-tuned convolutional neural networks for medical image classification,” IEEE Journal of Biomedical and Health Informatics, vol. 21, no. 1, pp. 31–40, 2016. [Google Scholar]
25. W. Wang, D. Liang, Q. Chen, Y. Iwamoto, X. H. Han et al., “Medical image classification using deep learning,” in Deep Learning in Healthcare, vol. 171, pp. 33–51. Springer, 2020. https://doi.org/10.1007/978-3-030-32606-7_3. [Google Scholar]
26. R. J. S. Raj, S. J. Shobana, I. V. Pustokhina, D. A. Pustokhin, D. Gupta et al., “Optimal feature selection-based medical image classification using deep learning model in internet of medical things,” IEEE Access, vol. 8, pp. 58006–58017, 2020. [Google Scholar]
27. C. Jiang and Y. Li, “Health big data classification using improved radial basis function neural network and nearest neighbor propagation algorithm,” IEEE Access, vol. 7, pp. 176782–176789, 2019. [Google Scholar]
28. M. M. Rathore, A. Ahmad, A. Paul, J. Wan and D. Zhang, “Real-time medical emergency response system: Exploiting IoT and big data for public health,” Journal of Medical Systems, vol. 40, no. 12, pp. 1–10, 2016. [Google Scholar]
29. P. K. Sahoo, S. K. Mohapatra and S. L. Wu, “Analyzing healthcare big data with prediction for future health condition,” IEEE Access, vol. 4, pp. 9786–9799, 2016. [Google Scholar]
30. Z. Lai and H. Deng, “Medical image classification based on deep features extracted by deep model and statistic feature fusion with multilayer perceptron,” Computational Intelligence and Neuroscience, vol. 2018, pp. 1–13, 2018. [Google Scholar]
31. K. Zervoudakis and S. Tsafarakis, “A mayfly optimization algorithm,” Computers & Industrial Engineering, vol. 145, pp. 106559, 2020. https://doi.org/10.1016/j.cie.2020.106559. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |