DOI:10.32604/cmc.2022.029438
| Computers, Materials & Continua DOI:10.32604/cmc.2022.029438 | |
| Article |
Sign Language Recognition and Classification Model to Enhance Quality of Disabled People
1Department of Computer Sciences, College of Computer and Information Sciences, Princess Nourah Bint Abdulrahman University, Riyadh, 11671, Saudi Arabia
2Department of Information Systems, College of Computing and Information System, Umm Al-Qura University, Saudi Arabia
3Department of Computer Science, College of Science & Art at Mahayil, King Khalid University, Saudi Arabia
4University of Tunis EL Manar, Higher Institute of Computer, Research Team on Intelligent Systems in Imaging and Artificial Vision (Siiva)–Lab Limtic, Aryanah, 2036, Tunisia
5Department of Information Systems, College of Computer and Information Sciences, Princess Nourah Bint Abdulrahman University, Riyadh, 11671, Saudi Arabia
6Research Centre, Future University in Egypt, New Cairo, 11745, Egypt
7Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, Alkharj, Saudi Arabia
*Corresponding Author: Anwer Mustafa Hilal. Email: a.hilal@psau.edu.sa
Received: 04 March 2022; Accepted: 08 May 2022
Abstract: Sign language recognition can be considered as an effective solution for disabled people to communicate with others. It helps them in conveying the intended information using sign languages without any challenges. Recent advancements in computer vision and image processing techniques can be leveraged to detect and classify the signs used by disabled people in an effective manner. Metaheuristic optimization algorithms can be designed in a manner such that it fine tunes the hyper parameters, used in Deep Learning (DL) models as the latter considerably impacts the classification results. With this motivation, the current study designs the Optimal Deep Transfer Learning Driven Sign Language Recognition and Classification (ODTL-SLRC) model for disabled people. The aim of the proposed ODTL-SLRC technique is to recognize and classify sign languages used by disabled people. The proposed ODTL-SLRC technique derives EfficientNet model to generate a collection of useful feature vectors. In addition, the hyper parameters involved in EfficientNet model are fine-tuned with the help of HGSO algorithm. Moreover, Bidirectional Long Short Term Memory (BiLSTM) technique is employed for sign language classification. The proposed ODTL-SLRC technique was experimentally validated using benchmark dataset and the results were inspected under several measures. The comparative analysis results established the superior performance of the proposed ODTL-SLRC technique over recent approaches in terms of efficiency.
Keywords: Sign language; image processing; computer vision; disabled people; deep learning; parameter tuning
Machine Learning (ML) technique [1] has transformed the societal perceptions and human-device interaction with one another. In recent years, a multi-dimensional evolution has been observed across a wide range of applications [2,3], assisted by ML techniques. ML technique includes three formats such as reinforcement, supervised learning, and unsupervised learning to obtain the outcomes in a novel manner. These outcomes affect the lives of people and provide business owners, a new shape to their businesses. Amongst different applications of ML, Computer Vision (CV) technique is an attractive field among researchers since it exploits the best of technical possibilities [4]. With the developments made in the area of CV technology, it is possible to fulfil the inherent need that exists among disabled persons, across the globe, who utilize sign language for day-to-day communication.
Sign language is a CV-based complicate language that engrosses signs formed by hand movements and facial expressions [5]. Sign language is utilized by hearing-impaired people for interaction with others in the form of distinct hand signs that correspond to words, sentences, or letters [6]. This kind of interaction allows the hearing-impaired persons to communicate with others which in turn reduces the transmission gap between hearing-impaired persons and other individuals [7]. Automated detection of human signs is a complicated multi-disciplinary issue that has not been fully resolved yet. Recently, several methods have been developed that include the usage of ML approach for sign language detection. There have been many attempts to identify human signs through technology, thanks to the advancement of DL approaches [8]. A network that depends upon DL algorithms handles the architecture while the learning algorithm is inspired biologically along with traditional networks [9,10].
Tamiru et al. [11] introduced the growth of automated Amharic sign language translators who translate Amharic alphabet signs into respective text using ML algorithm and digital image processing. A total of 34 features was extracted from color, shape, and motion hand gestures to characterize the base and derive the class of Amharic sign character. The classification model was constructed using multi-class SVM and ANN. In literature [12], optimization was conducted at feature level, while the aim of the optimization is to offer complete characteristics and features of the designed sign language. During the procedure, the layout of sensors, add-on feature, and combine feature data from other sensors were also executed. The optimized feature was tested on dual LMC sensor which increased the detection performance of Indonesian sign language. Alon et al. [13] presented a hand sign language or hand gesture detection method, trained through YOLOv3 approach that focuses on detection of hand sign language or hand gesture that can detect its corresponding letter alphabet. The research tool i.e., LabelImg, to annotate the dataset, categorized all the images of hand gestures, according to the correspondent letter alphabet.
Azizan et al. [14] focused on the growth of sign language translator devices for speech-impaired individuals. By capturing real-time gesture movements and sign language through high-resolution camera, the scheme processes the signal and translates the information into visualized data. The device was planned to identify distinct digits and alphabets in line with the guidelines for Malaysian Sign Language (MSL). In literature [15], a smart human-computer communication scheme was proposed to resolve the transmission inconvenience among non-disabled people and people who have hearing constraints. The scheme integrates AI with wearable devices and categorizes the gestures using BPNN. Thus, it efficiently solves the transmission issue between non-disabled people and those people who have hearing constraints.
The current study designs the Optimal Deep Transfer Learning Driven Sign Language Recognition and Classification (ODTL-SLRC) model for disabled people. The aim of the proposed ODTL-SLRC technique is to recognize and classify sign language for disabled people. ODTL-SLRC technique derives the EfficientNet model to generate a collection of useful feature vectors. In addition, the hyper parameters involved in EfficientNet model are adjusted with the help of HGSO algorithm. Moreover, Bidirectional Long Short Term Memory (BiLSTM) technique is also employed for sign language classification. The experimental validation of the proposed ODTL-SLRC technique was executed using benchmark dataset and the results were inspected under several measures.
Rest of the paper is organized as follows. Section 2 discusses about the proposed model, Section 3 validates the performance of the proposed model while Section 4 draws the conclusion for the study.
In this study, a new ODTL-SLRC technique has been developed to recognize and classify sign language for disabled people. The proposed ODTL-SLRC model involves three major stages. At first, EfficientNet model generates a collection of feature vectors. Secondly, the hyper parameters involved in EfficientNet model are fine-tuned using HGSO algorithm. Thirdly, sign classification process is carried out by BiLSTM model. Fig. 1 depicts the overall process of ODTL-SLRC technique.
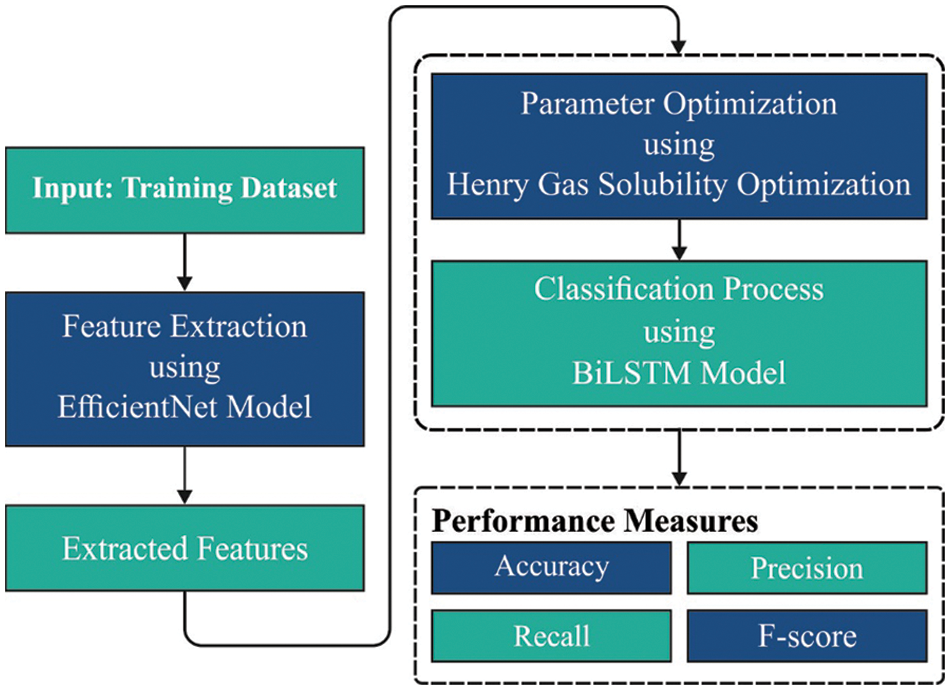
Figure 1: Overall process of ODTL-SLRC technique
2.1 Efficientnet Feature Extractor
Initially, EfficientNet method is executed to derive the set of useful feature vectors from sign images [16]. EfficientNet group has a total of eight models in the range of B0 to B7. As the model number produces, the count of computed parameters does not enhance much. However, the accuracy gets enhanced distinctly. The purpose of DL infrastructure is to reveal a better performance technique with less number of models. EfficientNet, unlike other approaches, attains better performance outcomes with uniform scaling resolution, depth, and width. However, it scales down the method’s outcome. In compound scaling approach, the primary phase is search a grid to determine the connection between distinct scaling dimensions of the baseline network in resource constraint setting. During this approach, an appropriate scaling factor is defined for dimensions such as resolution, depth, and width. Then, the co-efficient is executed for scaling the baseline network towards the chosen target network. Inverted bottleneck MBConv is an essential structure block for EfficientNet which is initially presented in MobileNetV2. However, due to the enhanced FLOPS (Floating Point Operations Per Second) budget, it can be utilized somewhat higher than MobileNetV2. In MBConv, the blocks contain layers that get primarily expanded and compress the channel. Therefore, a direct connection is utilized amongst the bottlenecks which connect with much smaller channels than the expansion layer. This in-depth separable convolutional infrastructure decreases the computation by nearly k2 factor, related to typical layers whereas k refers to kernel size that implies the width and height of 2D convolutional window: depth: d = αψ, width: w = βψ, resolution: r = γψ, α ≥ 1, β ≥ 1, γ ≥ 1.
Here, α, β, γ α, β and γ are constants and are defined as grid search. φ stands for user-defined co-efficient which controls that several resources are accessible to model scaling. However, α, β, γ α, β and γ define that more resources are allocated to network resolution, width, and depth correspondingly. During regular convolutional procedure, FLOPS is proportional to d, w2 and r2.
2.2 HGSO-Based Hyperparameter Optimization
During hyperparameter tuning process, HGSO algorithm is employed for optimal tuning of EfficientNet model parameters such as learning rate, batch size, and epoch count. HGSO algorithm depends upon solubility, while it precisely defines the maximal solute quantity dissolved in the provided count of solvents at specific pressure and temperature [17]. HGSO depends upon the performance of gases as per Henry’s law. It is feasible to apply Henry’s law for establishing that low solubility gases are soluble in particular liquids. The solubility is also powerfully controlled by temperature and pressure. If the temperatures are maximum, then the solubility of the solids gets enhanced though it decays in case of gases. In case of increasing pressure, the solubility of the gases too increases. This analysis is concerned about gas and its solubility. Accordingly, Hashim et al. (2019) presented the HGSO technique and simulated it. Following is the list of formulae used for computation rule of HGSO technique Eqs. (1)–(11).
whereas, t defines the entire number of iterations and refers to iteration time correspondingly.
The current study analysis utilizes the subsequent parameters:
2.3 Bilstm Based Classification Model
In this final stage, BiLSTM model is employed for detection and classification of sign languages. LSTM achieves good outcomes than DNN system in terms of signal classification and sound classes and it is a component of RNN [18]. Special memory block and recurrent connection in recurrent hidden state make them stronger for modelling the sequential data, in comparison with classical RNN and FFNN. Additionally, the multiplication unit called ‘gates’ offers the data flow to memory cell (input gate) and from one cell to another unit (output gate). Also, forget gate is applied for scaling the interior cell state prior to the addition of input to the cell as self-recurrence, whereas forgetting or resetting the cell memory is done as and when required. LSTM consists of ‘peephole’ connections to know the precise timing of the output. Fig. 2 demonstrates the framework of BiLSTM.
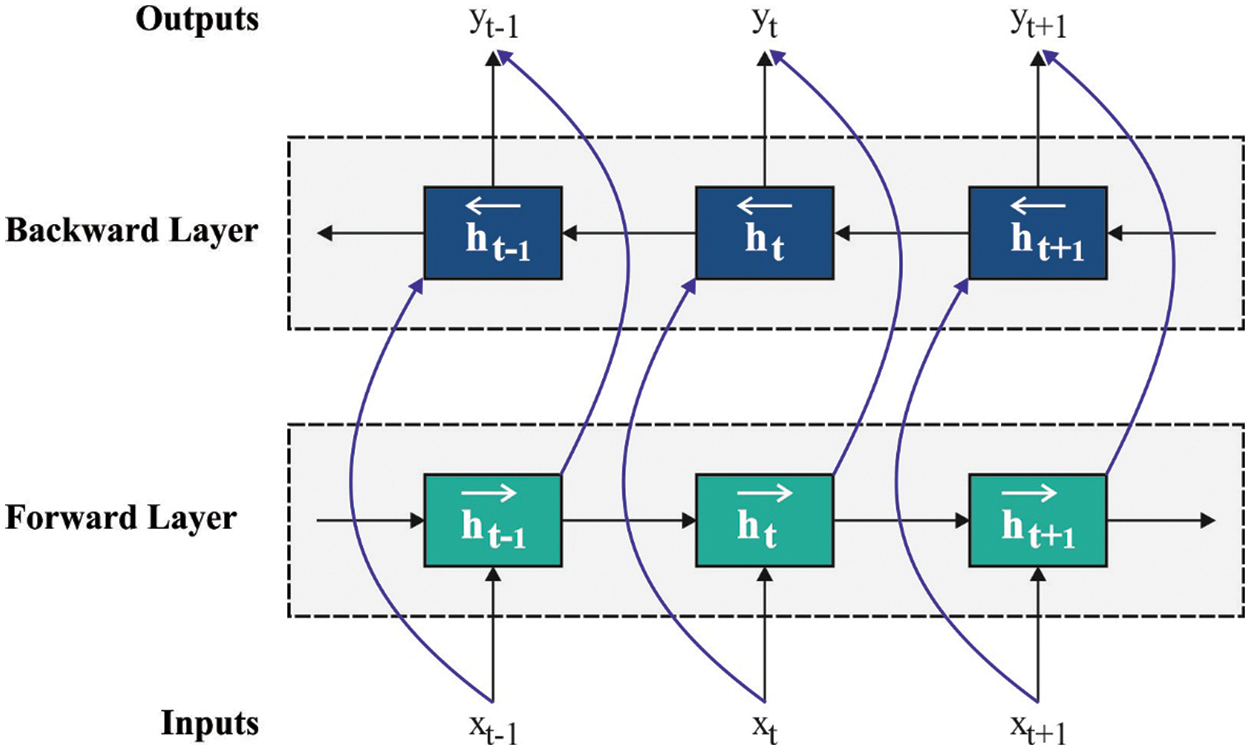
Figure 2: BiLSTM structure
The weighted peephole connection from cell to gate is exposed in dashed lines. Here,
Here, W denotes the weight matrices. For instance,
Even though RNN has the benefit of coding the dependencies among inputs, it creates a state of vanishing and exploding against the gradient for lengthier data sequence. Since RNN and LSTM take data from the preceding context, further enhancement is made by utilizing Bi-RNN. Bi-RNN deals with two data sources and integrated with LSTM to create Bi-LSTM. Besides, Bi-LSTM have the benefit of using feedback from LSTM for the next layers and it also handles the information with dependence on a lengthy range.
In this section, the sign classification outcomes of the proposed ODTL-SLRC model were investigated using a benchmark dataset from Kaggle repository [19]. The training dataset comprises of 87,000 images sized at 200 × 200 pixels. Out of 29 classes, 26 are for letters A-Z and 3 for SPACE, DELETE, and NOTHING. Some of the sample images are demonstrated in Fig. 3.

Figure 3: Sample images
Tab. 1 provides the comprehensive analysis results accomplished by ODTL-SLRC system. The outcomes indicate that the proposed ODTL-SLRC methodology improved the performance in all classes. For instance, ODTL-SLRC technique classified A signs with
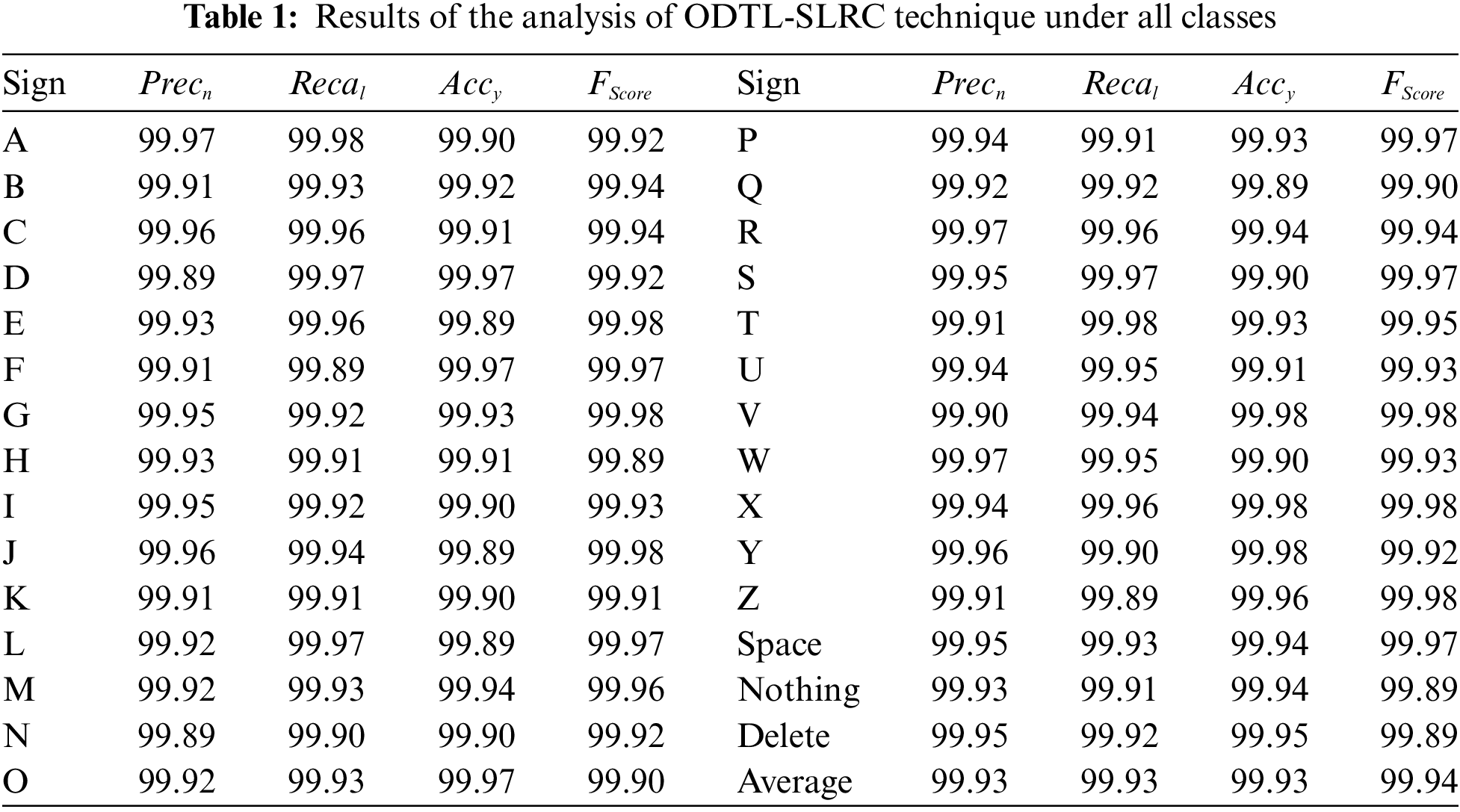
Fig. 4 portrays the overall average sign detection and classification performance results achieved by ODTL-SLRC approach. The figure portrays that the proposed ODTL-SLRC model proficiently classified the sign languages with average
Tab. 2 provides a brief overview on the classification outcomes of ODTL-SLRC model under different optimizers. The experimental values highlight that the proposed ODTL-SLRC model produced effectual outcomes in all the optimizers.
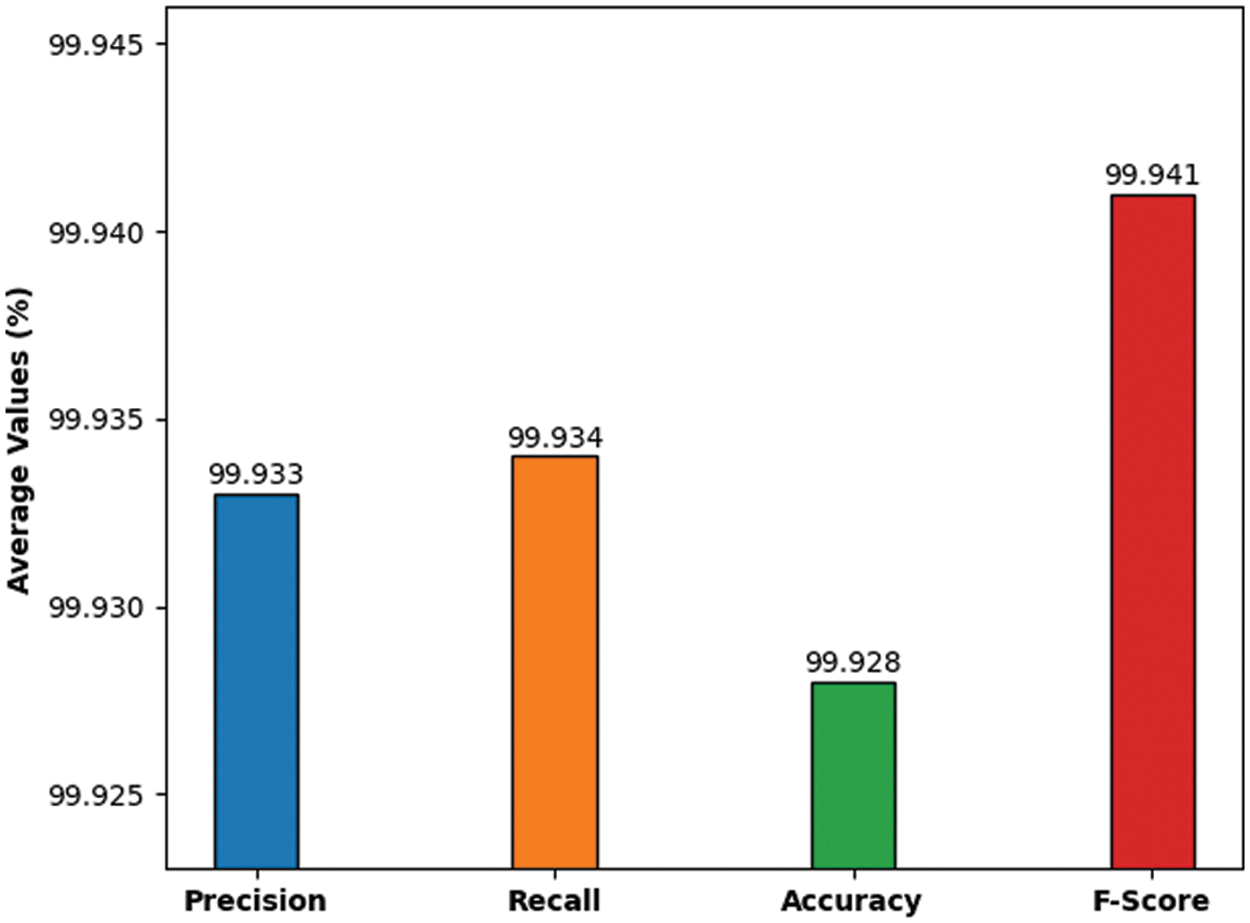
Figure 4: Average analysis of ODTL-SLRC technique with different measures
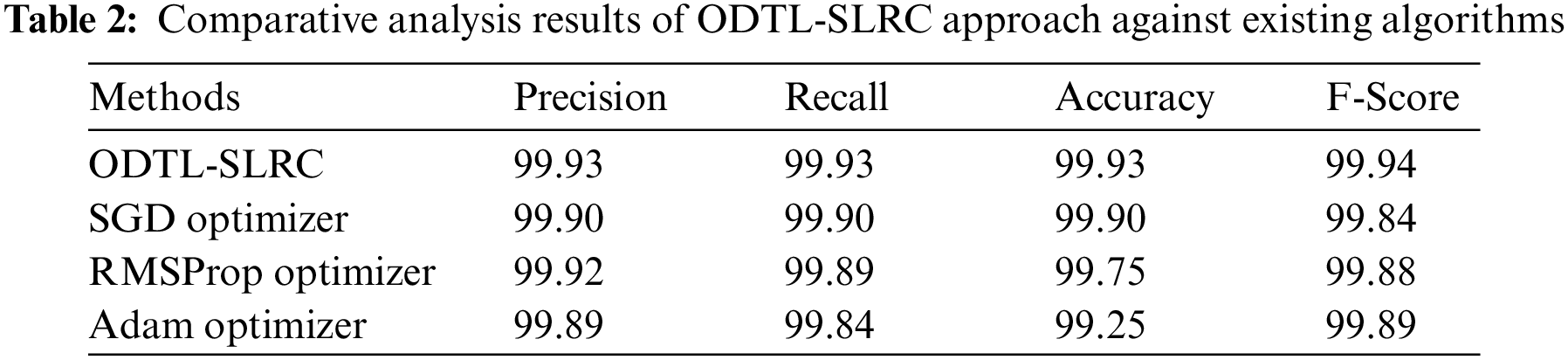
Fig. 5 examines
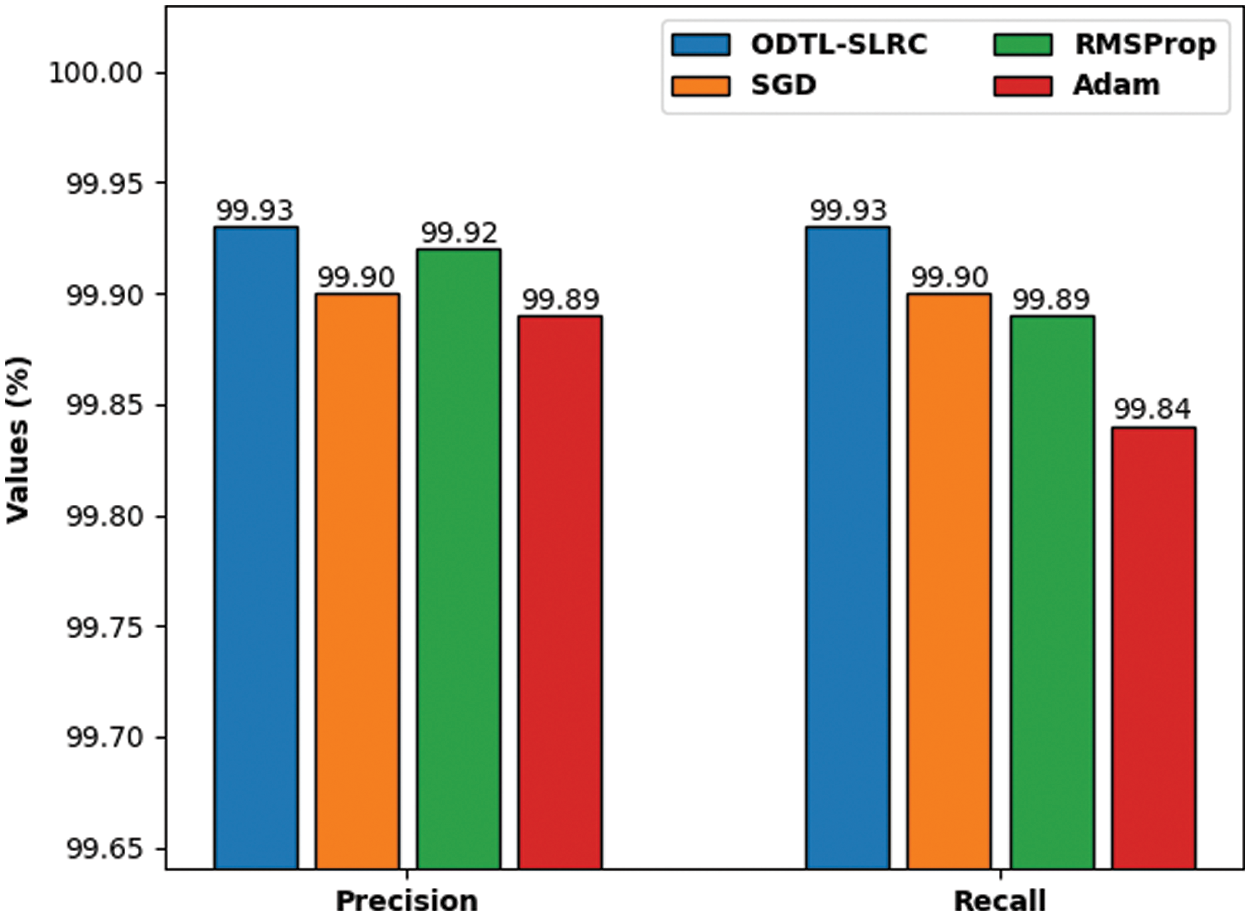
Figure 5:
Fig. 6 examines the
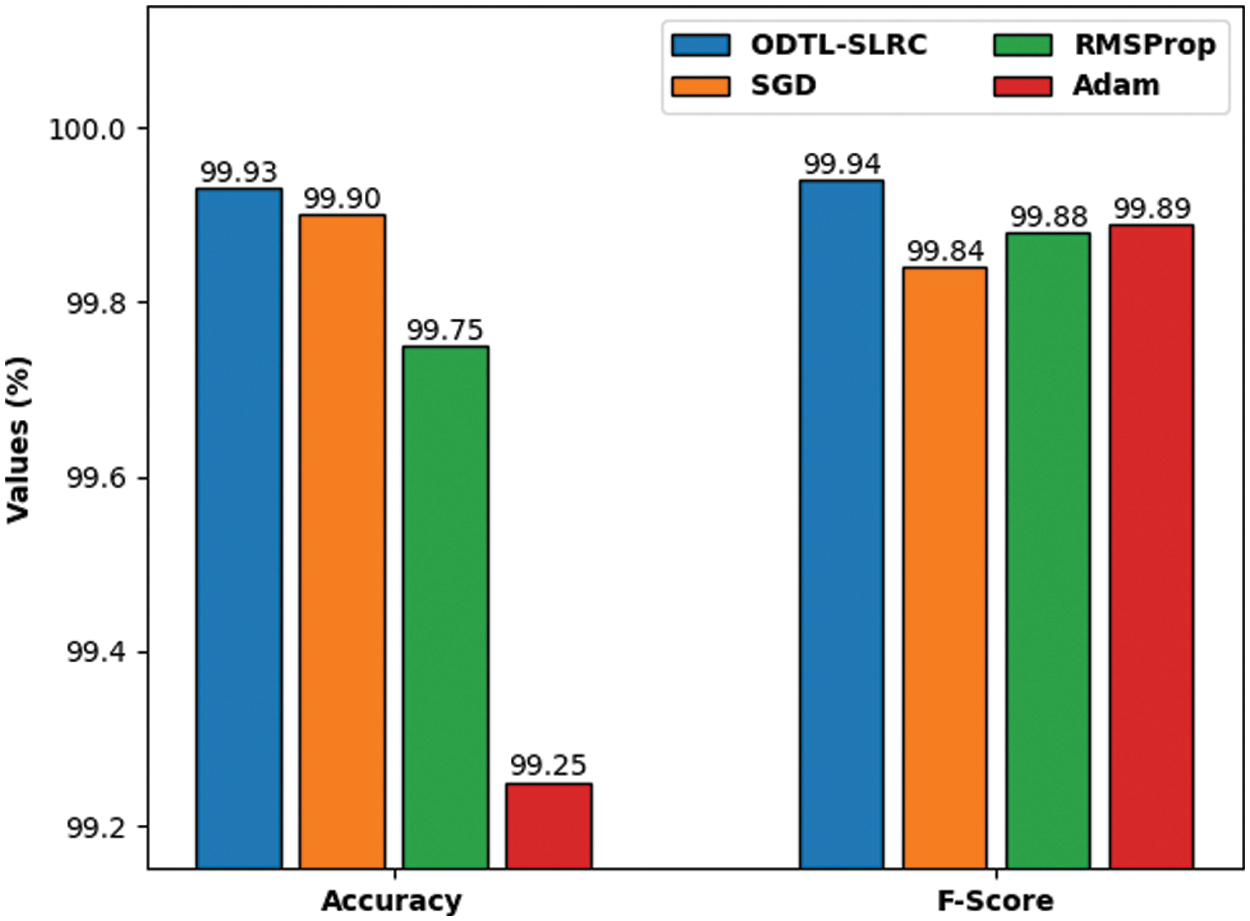
Figure 6:
Fig. 7 provides the accuracy and loss graph analyses results, achieved by the proposed ODBN-IDS model against recent methods. The outcomes show that the accuracy value got increased and the loss value decreased with an increase in epoch count. Further, the training loss was low and validation accuracy was high in existing algorithms.
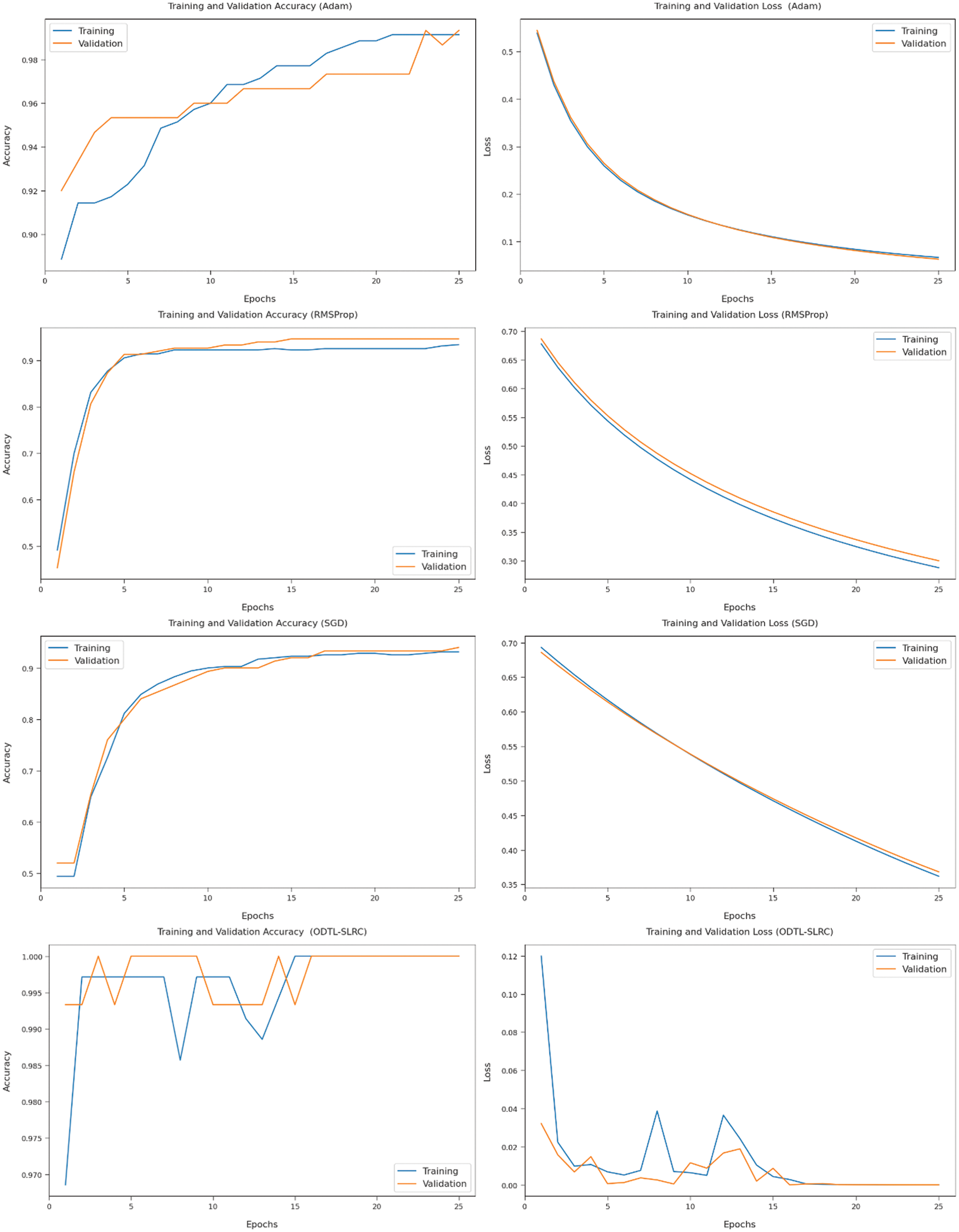
Figure 7: Accuracy and loss analyses results of ODTL-SLRC technique with existing approaches
Tab. 3 reports the overall sign language classification performance of ODTL-SLRC technique against existing techniques [20].
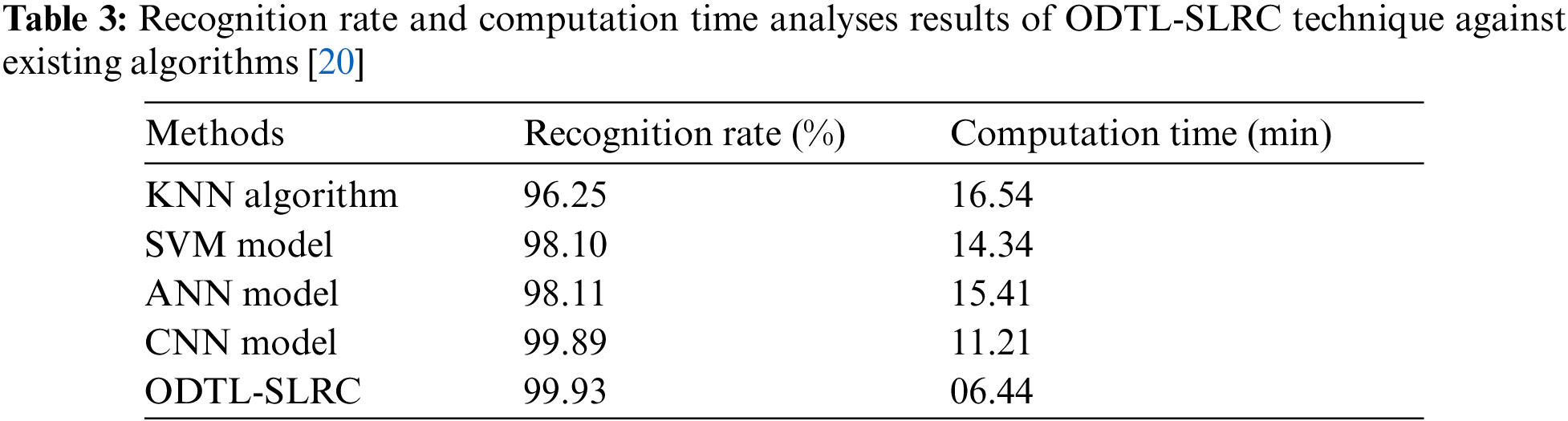
Fig. 8 demonstrates the results of detailed Recognition Rate (RR) analysis, accomplished by ODTL-SLRC model, against existing approaches. The experimental outcomes indicate that KNN technique produced the least performance with an RR of 96.25%. At the same time, SVM model obtained a slightly enhanced performance with an RR of 98.10%. Furthermore, ANN approach resulted in even more improved outcome i.e., RR of 98.11%. Moreover, CNN methodology achieved a near optimal outcome with an RR of 99.89%. However, the proposed ODTL-SLRC model accomplished the best performance over other methods with an RR of 99.93%.
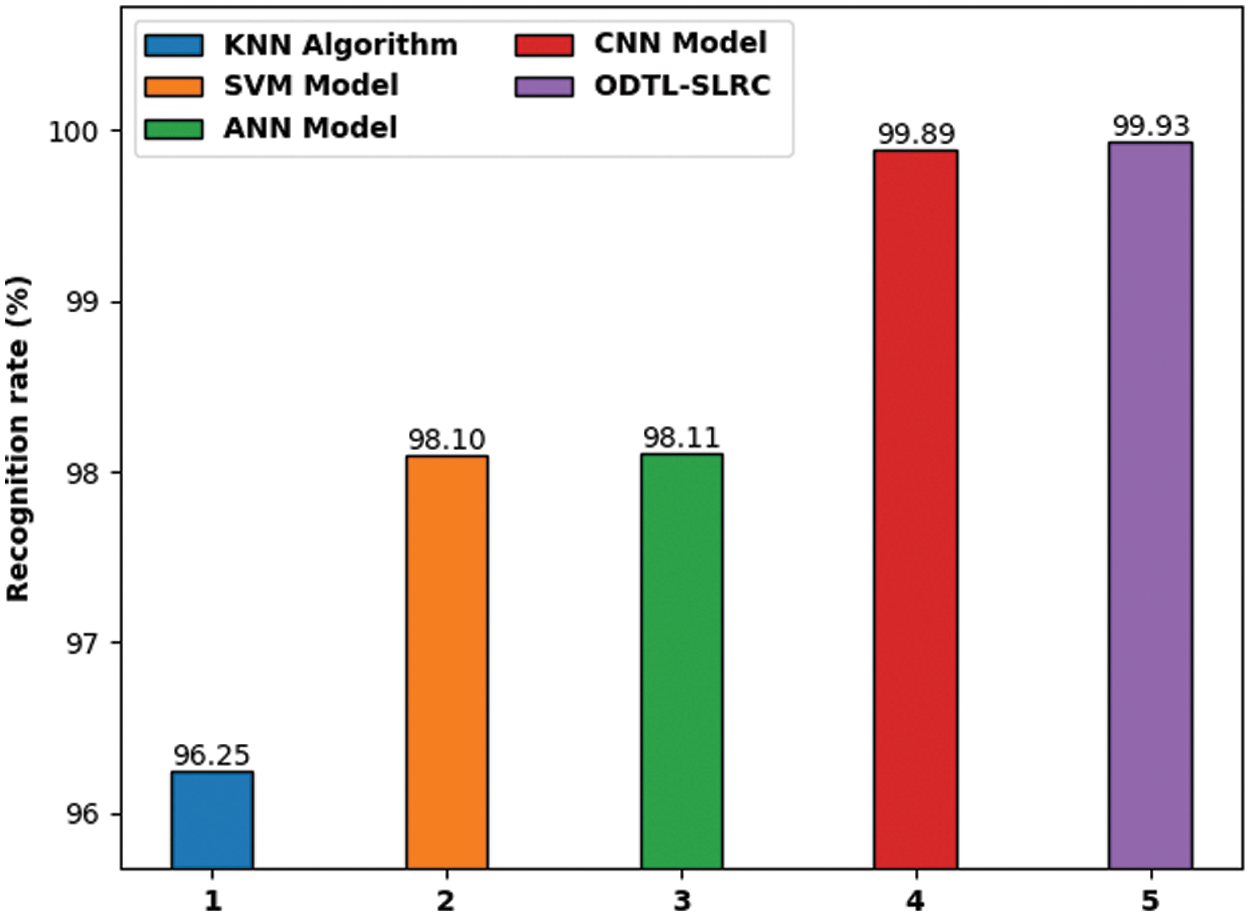
Figure 8: RR analysis results of ODTL-SLRC technique against existing algorithms
Fig. 9 demonstrates the results achieved from detailed Computation Time (CT) analysis between ODTL-SLRC model and existing methods. The experimental outcomes indicate that KNN method produced the least performance with a CT of 16.54 min. Simultaneously, SVM model obtained a slightly enhanced performance with a CT of 14.34 min. ANN model attained an even more improved outcome with a CT of 15.41min. Besides, CNN approach gained a near optimal outcome with a CT of 11.21 min. At last, the proposed ODTL-SLRC methodology accomplished the best performance than other methods with a CT of 6.44 min. From the above mentioned tables and discussion, it is obvious that the proposed ODTL-SLRC model accomplished the maximum performance on the applied dataset.
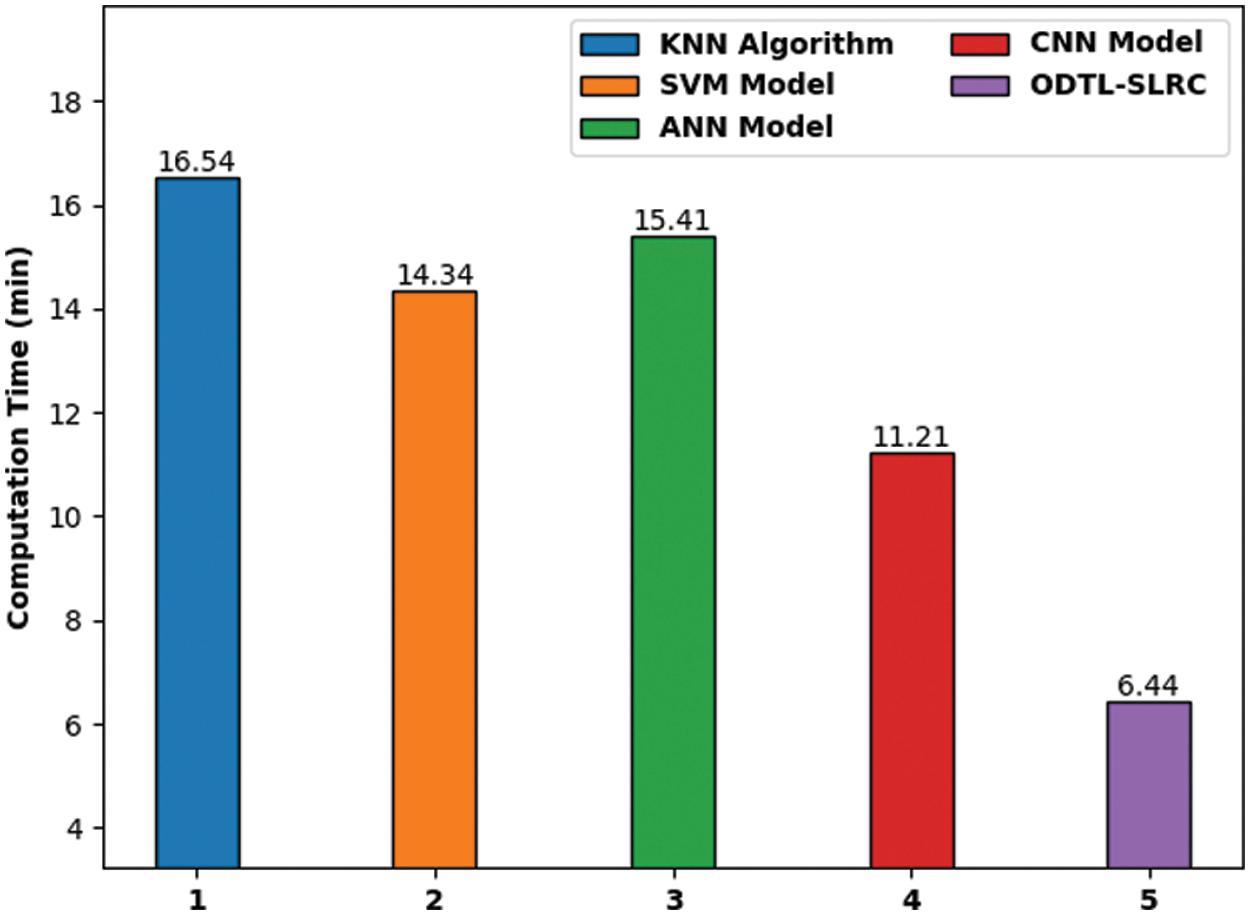
Figure 9: CT analysis results of ODTL-SLRC technique against existing algorithms
In current study, a new ODTL-SLRC technique has been developed to recognize and classify sign language for disabled people. The proposed ODTL-SLRC model involves three major stages. Firstly, EfficientNet model generates a collection of feature vectors. Secondly, the hyper parameters involved in EfficientNet technique are fine-tuned using HGSO algorithm. Thirdly, sign classification process is carried out using BiLSTM model. The experimental validation of the proposed ODTL-SLRC technique was executed using benchmark dataset and the results were inspected under different measures. The comparison study outcomes established the enhanced efficiency of ODTL-SLRC technique than the existing algorithms. In future, hybrid DL models can be designed to improve classification performance.
Funding Statement: The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work under grant number (RGP 1/322/42). Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R77), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4210118DSR02).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. F. Beser, M. A. Kizrak, B. Bolat and T. Yildirim, “Recognition of sign language using capsule networks,” in 2018 26th Signal Processing and Communications Applications Conf. (SIU), Izmir, Turkey, pp. 1–4, 2018. [Google Scholar]
2. M. A. Ahmed, B. B. Zaidan, A. A. Zaidan, M. M. Salih and M. M. b. Lakulu, “A review on systems-based sensory gloves for sign language recognition state of the art between 2007 and 2017,” Sensors, vol. 18, no. 7, pp. 2208, 2018. [Google Scholar]
3. M. P. Kumar, M. Thilagaraj, S. Sakthivel, C. Maduraiveeran, M. P. Rajasekaran et al., “Sign language translator using LabVIEW enabled with internet of things,” in Smart Intelligent Computing and Applications, Smart Innovation, Systems and Technologies Book Series, Springer, Singapore, vol. 104, pp. 603–612, 2019. [Google Scholar]
4. X. R. Zhang, J. Zhou, W. Sun and S. K. Jha, “A lightweight CNN based on transfer learning for COVID-19 diagnosis,” Computers, Materials & Continua, vol. 72, no. 1, pp. 1123–1137, 2022. [Google Scholar]
5. Y. Dai and Z. Luo, “Review of unsupervised person re-identification,” Journal of New Media, vol. 3, no. 4, pp. 129–136, 2021. [Google Scholar]
6. K. Snoddon, “Sign language planning and policy in ontario teacher education,” Lang Policy, vol. 20, no. 4, pp. 577–598, 2021. [Google Scholar]
7. H. M. Mohammdi and D. M. Elbourhamy, “An intelligent system to help deaf students learn arabic sign language,” Interactive Learning Environments, pp. 1–16, 2021, https://doi.org/10.1080/10494820.2021.1920431. [Google Scholar]
8. A. Kumar and R. Kumar, “A novel approach for iSL alphabet recognition using extreme learning machine,” International Journal of Information Technology, vol. 13, no. 1, pp. 349–357, 2021. [Google Scholar]
9. N. Basnin, L. Nahar and M. S. Hossain, “An integrated CNN-lSTM model for bangla lexical sign language recognition,” in Proc. of Int. Conf. on Trends in Computational and Cognitive Engineering, Advances in Intelligent Systems and Computing Book Series, Springer, Singapore, vol. 1309, pp. 695–707, 2020. [Google Scholar]
10. C. U. Bharathi, G. Ragavi and K. Karthika, “Signtalk: Sign language to text and speech conversion,” in 2021 Int. Conf. on Advancements in Electrical, Electronics, Communication, Computing and Automation (ICAECA), Coimbatore, India, pp. 1–4, 2021. [Google Scholar]
11. N. K. Tamiru, M. Tekeba and A. O. Salau, “Recognition of amharic sign language with amharic alphabet signs using ANN and SVM,” The Visual Computer, 2021, https://doi.org/10.1007/s00371-021-02099-1. [Google Scholar]
12. S. N. Rachmat, T. Istanto and A. Prayitno, “Feature optimization on dual leap motion controller for Indonesian sign language,” E3S Web of Conf., vol. 328, pp. 03006, 2021. [Google Scholar]
13. H. D. Alon, M. A. D. Ligayo, M. P. Melegrito, C. F. Cunanan and E. E. U. II, “Deep-hand: A deep inference vision approach of recognizing a hand sign language using American alphabet,” in 2021 Int. Conf. on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, pp. 373–377, 2021. [Google Scholar]
14. M. A. Azizan, I. Zulkiflee and N. Norhashim, “Development of sign language translator for speech impairment person,” in Human-centered Technology for a Better Tomorrow, Lecture Notes in Mechanical Engineering Book Series, Springer, Singapore, pp. 115–131, 2022. [Google Scholar]
15. Q. Fu, J. Fu, S. Zhang, X. Li, J. Guo et al., “Design of intelligent human-computer interaction system for hard of hearing and non-disabled people,” IEEE Sensors Journal, vol. 21, no. 20, pp. 23471–23479, 2021. [Google Scholar]
16. Ü. Atila, M. Uçar, K. Akyol and E. Uçar, “Plant leaf disease classification using efficientNet deep learning model,” Ecological Informatics, vol. 61, pp. 101182, 2021. [Google Scholar]
17. F. Hashim, E. Houssein, M. Mabrouk, W. A. Atabany and S. Mirjalili, “Henry gas solubility optimization: A novel physics-based algorithm,” Future Generation Computer Systems, vol. 101, pp. 646–667, 2019. [Google Scholar]
18. W. Cai, B. Liu, Z. Wei, M. Li and J. Kan, “Tardb-net: Triple-attention guided residual dense and BiLSTM networks for hyperspectral image classification,” Multimedia Tools and Applications, vol. 80, no. 7, pp. 11291–11312, 2021. [Google Scholar]
19. https://www.kaggle.com/grassknoted/asl-alphabet?select=asl_alphabet_test. [Google Scholar]
20. A. Wadhawan and P. Kumar, “Deep learning-based sign language recognition system for static signs,” Neural Computing and Applications, vol. 32, no. 12, pp. 7957–7968, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |