DOI:10.32604/cmc.2022.030016
| Computers, Materials & Continua DOI:10.32604/cmc.2022.030016 | |
| Article |
Methods and Means for Small Dynamic Objects Recognition and Tracking
Department of Computer Engineering, Lviv Polytechnic National University, Lviv, 79013, Ukraine
*Corresponding Author: Dmytro Kushnir. Email: dmytro.o.kushnir@lpnu.ua
Received: 16 March 2022; Accepted: 12 May 2022
Abstract: A literature analysis has shown that object search, recognition, and tracking systems are becoming increasingly popular. However, such systems do not achieve high practical results in analyzing small moving living objects ranging from 8 to 14 mm. This article examines methods and tools for recognizing and tracking the class of small moving objects, such as ants. To fulfill those aims, a customized You Only Look Once Ants Recognition (YOLO_AR) Convolutional Neural Network (CNN) has been trained to recognize Messor Structor ants in the laboratory using the LabelImg object marker tool. The proposed model is an extension of the You Only Look Once v4 (Yolov4) 512 × 512 model with an additional Self Regularized Non–Monotonic (Mish) activation function. Additionally, the scalable solution for continuous object recognizing and tracking was implemented. This solution is based on the OpenDatacam system, with extended Object Tracking modules that allow for tracking and counting objects that have crossed the custom boundary line. During the study, the methods of the alignment algorithm for finding the trajectory of moving objects were modified. I discovered that the Hungarian algorithm showed better results in tracking small objects than the K–D dimensional tree (k-d tree) matching algorithm used in OpenDataCam. Remarkably, such an algorithm showed better results with the implemented YOLO_AR model due to the lack of False Positives (FP). Therefore, I provided a new tracker module with a Hungarian matching algorithm verified on the Multiple Object Tracking (MOT) benchmark. Furthermore, additional customization parameters for object recognition and tracking results parsing and filtering were added, like boundary angle threshold (BAT) and past frames trajectory prediction (PFTP). Experimental tests confirmed the results of the study on a mobile device. During the experiment, parameters such as the quality of recognition and tracking of moving objects, the PFTP and BAT, and the configuration parameters of the neural network and boundary line model were analyzed. The results showed an increased tracking accuracy with the proposed methods by 50%. The study results confirmed the relevance of the topic and the effectiveness of the implemented methods and tools.
Keywords: Object detection; artificial intelligence; object tracking; object counting; small movable objects; ants tracking; ants recognition; YOLO_AR; Yolov4; Hungarian algorithm; k-d tree algorithm; MOT benchmark; image labeling; movement prediction
The increased need for autonomous systems for object finding, tracking, and monitoring [1–4] pushes for the development and applying new Machine Learning techniques. The most applicable task such systems may be applied to is car traffic monitoring [2–6]. However, at the same time, such tasks open doors for analyzing specific small objects, like ants [7,8]. Such systems analyze ants’ movement in specific isolated environments, but they do not provide a scalable solution for counting and analyzing ants’ movement patterns. Moreover, recognizing small movable objects requires great recognition and tracking algorithms since such objects occupy small space on the screen and may not move in strict, predictable directions.
Therefore, the development of methods and means that would allow to continuously train and process custom CNN models with specific classes such as ants species, and analysis of the advantages and disadvantages of using the developed methods for specific conditions, is an actual scientific task.
In this study, the proposed system aims to continuously train and process custom CNN models, like a model for recognizing ant species. Afterward, I perform recognition and tracking for small movable objects in real-time. Finally, I propose the set of filters and modified tracking algorithm to enchant output results.
1.2 Contributions of the Study
The main contribution consists of the following:
• the current study designs a new CNN YOLO_AR model with Mish activation function and 516 × 516 dimensions;
• The ant’s dataset in the indoor environment, which was used for labeling and training the CNN model;
• the scalable docker environment is employed as a storage for all system modules, like training, processing, and tracking nodes;
• the OpenDataCam object tracker module was enchanted with the usage of the Hungarian algorithm instead of the K-d tree algorithm, which showed a 50% accuracy increase for tracking small objects;
• the additional tracker filters were used to smooth the trajectory prediction like BAT and PFTP;
• finally, all modules were combined in the OpenDataCam system [1], which serves as an analytics tool for showing the results of the predictions and tracking. A wide range of simulations was carried out to highlight the YOLO_AR CNN model and modified tracking algorithm accuracy increase.
This paper consists of several sections. Section 2 briefs the recently-developed models for object Recognition and Tracking and scalable systems for showing output results related to the study domain. Section 3 introduces the proposed system architecture. Section 4 showed the training labeling and training process using the proposed dataset. Also, it introduces a set of filters for Object Recognition output. In Section 5, a new tracking algorithm with matching and smoothing parameters is proposed to obtain better accuracy during small object counting. Section 6 showed the test execution process. Afterward, Section 7 showed the test results calculation and obtained data interpretation. Lastly, Section 8 draws the conclusion.
There are plenty of means for continuous monitoring and tracking of objects embedded on mobile devices. The most popular systems are Opendatacam [1,2] and DeepStream Software Development Kit (SDK) [3].
Opendatacam is an open-source system for continuously monitoring objects using a custom Machine Learning model. The system can be integrated on mobile devices like Jetson Nano, Raspberry Pi, or Android operating system or executed on Linux-based machines via a web server. It reads data from the camera or through the Camera Serial Interface (CSI) bus.
DeepStream SDK allows executing programs directly on Nvidia mobile devices, like Jetson Nano or Jetson Xavier NX. In addition, it provides more quick data transfer between the visual sensor (Camera) via the CSI bus. However, it does not support many customization options for the Machine Learning model and Tracking parameters.
The Opendatacam system was chosen for further investigation as it provides better scalability and can be easily customized.
There are several approaches to formalizing the task of detecting small movable objects [5,6].
In particular, the Re-Identification (Re–ID) model [5] is based on optimized DenseNet121 with joint loss. This model applies the Squeeze–and–Excitation (SE) block to automatically obtain the importance of each channel feature and assign the corresponding weight to it. Features are transferred to the deep layer by adjusting the corresponding weights, which reduces the transmission of redundant information in the process of feature reuse in DenseNet121. The proposed model leverages the complementary expression advantages of the middle features of the CNN to enhance the feature expression ability [5].
At the same time, Real–the time Small Object Detection Algorithm (RSOD) [6] algorithm improves the small object detection accuracy by
– using feature maps of a shallower layer containing more fine-grained information for location prediction;
– fusing local and global features of shallow and deep feature maps in Feature Pyramid Network (FPN) to enhance the ability to extract more representative features;
– assigning weights to output features of FPN and fusing them adaptively;
– improving the excitation layer in the Squeeze–and–Excitation (SE) attention mechanism to adjust the feature responses of each channel more precisely [6].
Such approaches may be considered a good start for implementing our Tracking algorithm methods and means. However, such systems were applied only for the car–traffic tasks, where objects usually move in strict patterns. Therefore, I may consider ants tracking systems [7,8]. For example, in [7], the authors present their detection framework for ant’s movement tracking. They propose:
– adopting a two-stage object detection framework using (Residual Network with 50 Layers) ResNet–50 as the backbone and coding the position of regions of interest to locate ants accurately;
– using the ResNet–50 model to develop the appearance descriptors of ants;
– constructing long–term appearance sequences and combining them with motion information to achieve online tracking.
At the same time, the following article [8] proposes an online MOT framework to track ant individuals. This framework combines both motion and appearance matching, effectively preventing trajectory fragments and ID (True Positive Id’s) switches from long–term occlusion caused by frequent interactions of ants, achieving efficient and high–precision tracking [8].
Assuming the results of the authors, the MOT benchmark could be used to test the Tracker performance. However, the ResNet–50 model looks not so efficient for ant’s recognition. Therefore, finding the most effective model for small movable object recognition is valuable.
Currently, many families of neural network models provide the ability to search and recognize objects. It is vital to highlight the family of You Only Look Once (Yolo) models, which use the division of the input video stream into cells and calculate the recognition probabilities for each of them [9].
In general, the following models of the Yolo family can be distinguished:
• You Only Look Once v3 (Yolov3) [10]—based on previous Yolo models with objectivity assessment of the regions. As a backbone, it uses the Darknet–53 framework instead of ResNet–152 as in previous versions. Additionally, Rectified Linear Activation Unit (Relu) [11] is used as an activation function. A three-level probability estimate has also been added to the model to improve the recognition rate of small objects.
• Yolov4 [12]—An updated version of Yolo [10], which shows an improvement of 10% mean Average Precision (mAP) compared to the previous model. As a backbone uses a modified version of Darknet CSPDarknet53. Mish [13] is used as an activation function. The SPP (Spatial Pyramid Pooling) unit is also used to increase the efficiency of the receptive field. At the same time, the PAN (Path Aggregation Network) unit is used for more efficient aggregation of parameters between different levels of the backbone. Additionally, Yolov4 offers Mosaic data augmentation methods and Self–Adversarial Training (SAT) to improve recognition.
• You Only Look Once v4 Scaled (Yolov4 Scaled) [14]—a modified version of yolov4 [12]. It has additional backbone layers: ResNet and ResNeXt and the main CSPDarknet53. The authors also added some functionality to scale the power of the model.
• You Only Look Once v5 (Yolov5) [15]—A completely new Yolo [10] model implementation on the PyTorch framework. However, identical architecture with Yolov4 [12] significantly reduces image recognition speed and quality.
• You Only Learn One Representation (YoloR) [16]—Continuation of research to improve the effectiveness of the yolov4 model [11]. The idea is to add to the learning mechanism conscious cognition (prepared data for learning) and unconscious cognition (by analogy with the human subconscious).
The Yolov4 algorithm was chosen for further research because it showed the highest efficiency among all models of neural networks for tracking small objects. Furthermore, the chosen model was modified with minimizing and smoothing filters [9] to increase recognition output.
For image labeling purposes in Yolov4 format, the LabelImg [17] tool was chosen, as it is free, open-source, and can spread object labeled rectangles to the next frame. Therefore, it is useful when there is a need to annotate the video stream, where objects are not moving much compared to the next frame.
The tracking algorithms may provide different results with different output parameters [18,19]. The MOT (Multiple Object Tracking Benchmark) [20,21] evaluation tool may be used to standardize observation results. It provides several measures, from recall to precision to running time.
The matching algorithms can be applied for multiple tasks, but the most efficient object trajectory tracking methods are Hungarian [22] k-d tree [23] algorithms.
The Docker system [24] was used to increase the reliability and scalability of the recognition and tracking model. Docker tasks manager proved to be the most efficient for this class. The system does not require large capacities and calculations but configures the environment and performs the necessary operations.
In conclusion, the reviewed tracking systems do not provide efficient ways to analyze small movable objects, as they are usually applied to car traffic tasks. Therefore, it is advisable to develop and research methods and tools to recognize and track small movable objects in real-time.
3 Means for Objects Recognizing and Tracking
According to the results of literary works research, I propose a system for small movable objects recognition and tracking. Furthermore, the system is fully scalable, which means any custom objects may be trained via the proposed train service and applied to the system.
The proposed system consists of an OpenDataCam tool extension with extra integrated modules for achieving the research goal. The schematic diagram of the recognition and tracking system is shown in Fig. 1.
The system is fully dockerized, which means it can be deployed on an external cyber-physical system based on Jetson Nano or Raspberry PI. The current implementation was handled on an Ubuntu machine with Ray Tracing Texel eXtreme (RTX) 2070 graphics card.
The system consists of the following components:
– Model train service. The extended service for the autonomous deployment of new weights of the model to the Neural Network Execution Environment;
– Neural Network Execution Environment (NNEE). This docker image stores the YOLO_AR pre-trained object recognition model based on the YOLOv4 Darknet CNN model. A Compute Unified Device Architecture (CUDA) processor processes all parallel operations. Additionally, this container listens to the input video stream from the camera. It bypasses the data via the Open Source Computer Vision Library (OpenCV) module to the Node Js application backend service.
– Node Js Application.
It consists of two server apps: OpenDataCam Server and Hypertext Transfer Protocol (HTTP) Proxy.
• OpenDataCam HTTP Proxy. This app is the starting point that receives model configurations and executes the process of execution of the NNEE docker image. In addition, this component starts web UI and passes input data by Motion Joint Photographic Experts Group (MJPEG) stream via port 8090 to the Frontend Application.
• OpenDataCam Server. Backend Service continuously receives recognition data from NNEE JsonStream via exposed port 8070. This object recognition data is processed and stored in MongoDB Database via port 27017. In the next step, the obtained video frames with recognition results are bypassed to the Tracker Module to track and count recognized objects. This data will be stored and remain in the database volume memory even if the system is offline. After each frame execution, the processed data is sent to the Frontend Application via public port 8080.
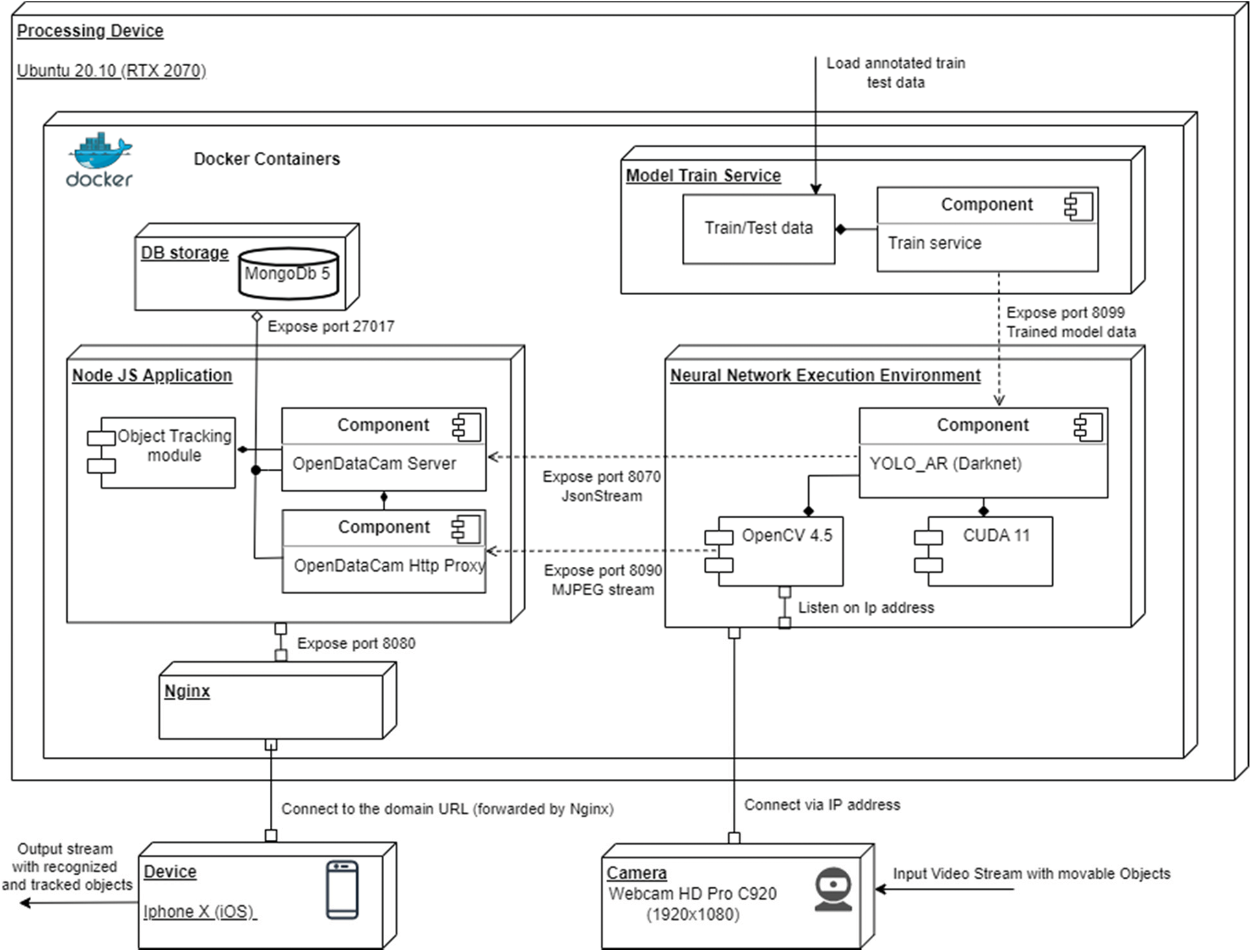
Figure 1: The schematic diagram of the proposed system for continuously recognizing and tracking movable objects
• Database storage. Storage for user history of tracking information per some recognized classes.
• Engine–X (Nginx). Container for forwarding Application Stream to the Frontend App. Uses reverse–proxy technique to direct requests to a particular client domain.
• Device. User device to see and manipulate Application results.
• Camera. Sensor for recording Object Recognition and Tracking stream.
4 Training and Evaluating the Proposed Model Based on the Ants Dataset
For study purposes, I choose the YoloV4 model architecture. The resulted YOLO_AR consists of 3 layers with dimensions of 512 × 512 pixels. The additional Mish layer was added to increase the model recognition accuracy. Such YOLO architecture overview with image processing techniques as described in the previous paper [9]. The resulted model was adjusted with smoothing and minimization filters.
4.1 Preparing the Dataset for the Model and Marking Process
The target object is ants ranging in size from 8 to 14 mm. I created the corresponding image dataset [25] to fulfill research goals.
The dataset was created using Fast Forward MPEG (FFmpeg) Linux tool by obtaining an image sequence from the video stream. I have used two types of videos: big and small size of ants. Each frame from the dataset has 2160 × 3840 dimensions.
The dataset consists of 500 hundred images that capture ant movements in the indoor environment. The important thing here is that ants should be located on the visible surface. Otherwise, the recognition results will not be enough as objects may merge with the surrounding landscape or nest surface. For test evaluation, Camera HD Pro C920 was used. For labeling output image results, the LabelImg tool was used. The labelimg process is depicted in Fig. 2.
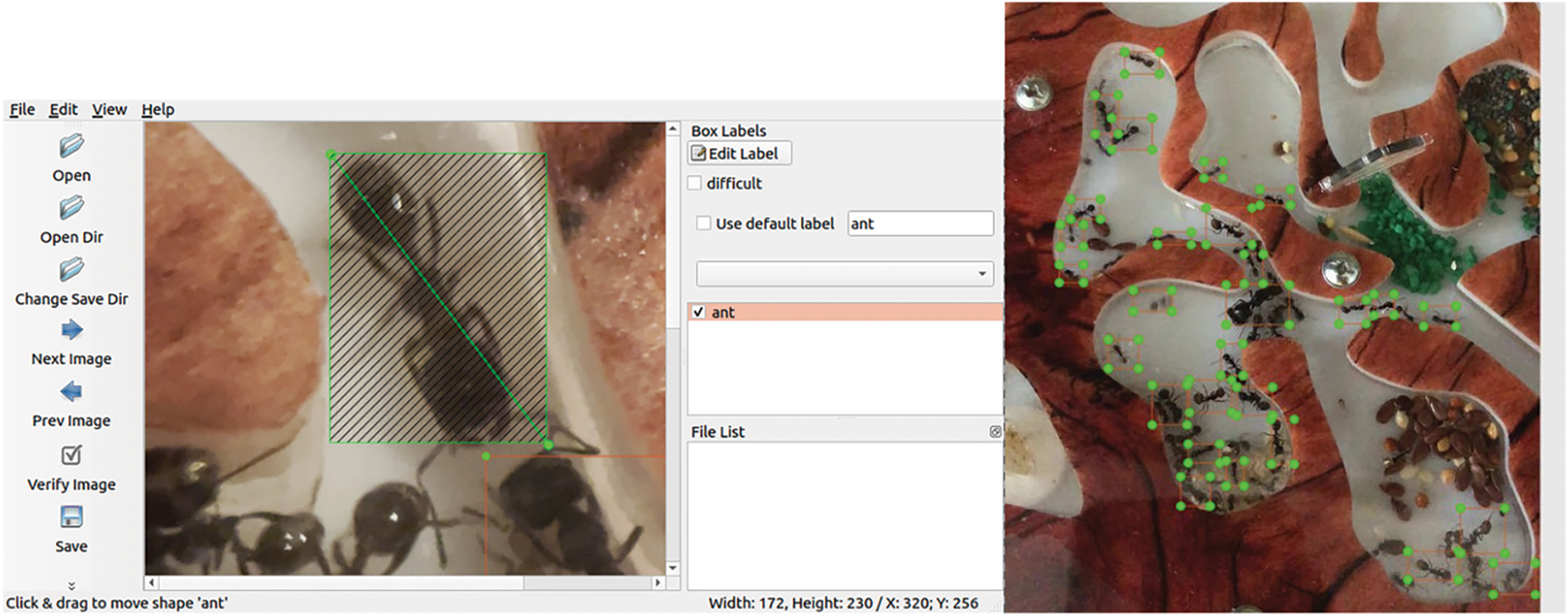
Figure 2: Labeling process of marking messor structor ants with different objects size. the boundary limit for ants is set to 14 mm
4.2 Training the YOLO_AR Model
We used a darknet framework [13] to train the YOLO_AR model on GeForce RTX 2070 with CUDA 11. The results are the follows (Fig. 3).
The blue curve indicates how many errors occur when learning and demonstrates whether the network is learning (graph is down) or degrading (graph is up). The y–axis represents the value of the loss ratio, while the x–axis represents the number of performed iterations. Also, the red graphic shows mAP (mean over precision) per iteration. The training was finished at 4000 iterations as it was noticed that model was not improved much after that point. After the training, the resulting model weights and configuration were loaded to the NNEE docker image module, from where it was accessed by the recognition and tracker modules.
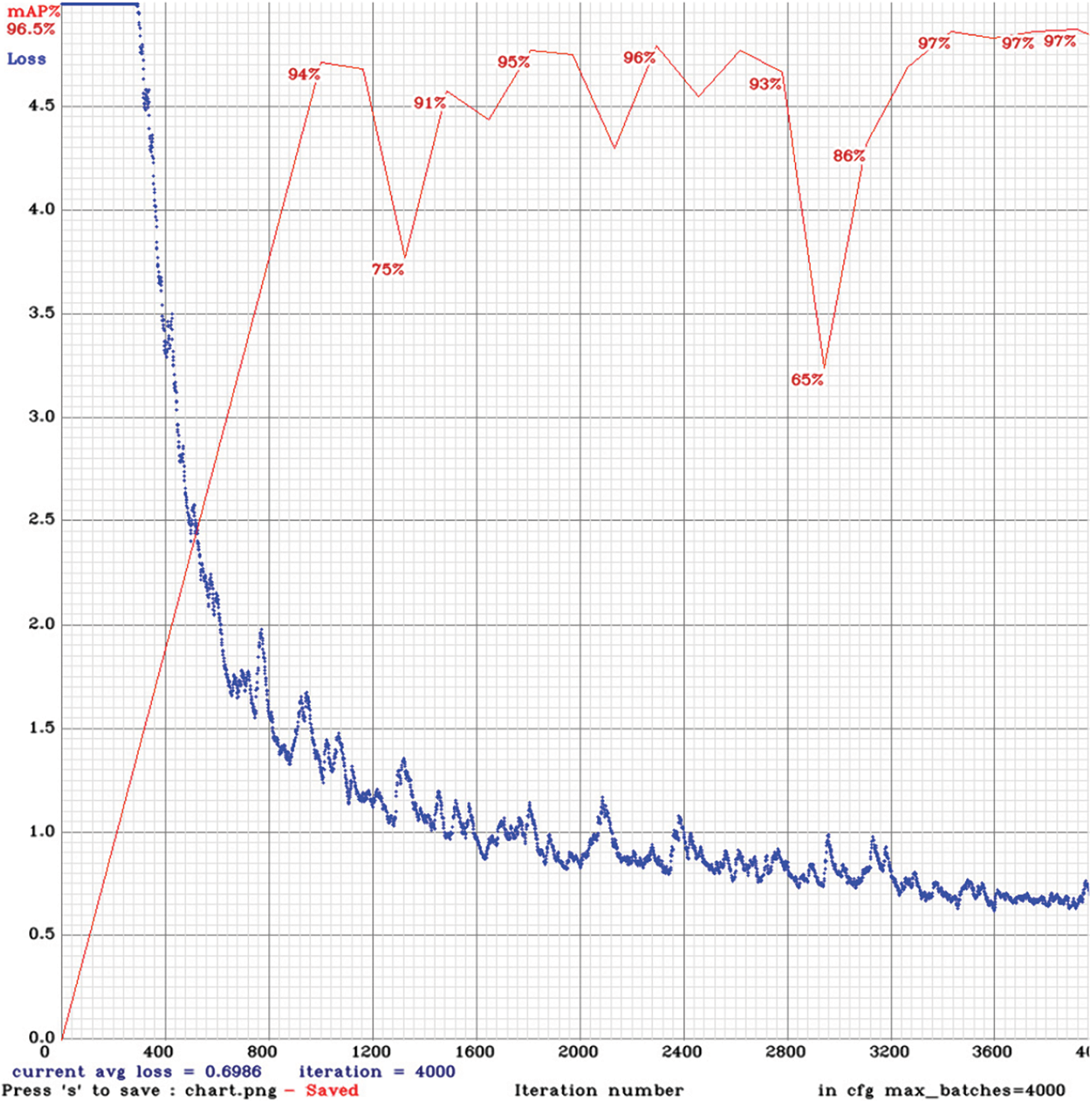
Figure 3: The training process of the proposed YOLO_AR neural network
4.3 Model Output Results Dynamic Customization
We applied an additional set of filters to increase Object Recognition accuracy and remove objects overlapping. Such filters are crucial for YOLO models since such architecture divides the frame into regions with a probability of recognition. Afterward, the regions may overlap each other. The following set of filters should help omit such collisions:
– recognized frame size filter (RFSF): Filters out objects whose area is higher than a certain percentage of the total frame area calculated by the following formula:
Where:
detectionwh—input frame resolution (height and width) of the recognized bounding box;
framewh—input frame resolution (height and width) from the optical sensor;
area_koef—recognized frame size coefficient determines how many recognized objects should be skipped.
– confidence threshold minimizing filter (CTMF): minimization filter for removing the recognized object with the confidence value more minor than in the provided filter value;
– IOU smoothing filter limit: filter checks the border values of input object recognition IOU results per frame. I expect less overlapping with the small value of this filter.
5 Methods for Object Tracking and Counting
5.1 Applying Tracker Algorithm based on V–IOU
Based on Visual Intersection over Union (V–IOU) [18], the algorithm compares the overlapping areas between two recognized objects. This method allows checking if the object is the same during recognition. Under the hood, it computes the IOU (Intersection over Union) value by following the formula.
Where Si means interception area and Su means union area.
The graphical representation of this formula is the follows (Fig. 4).
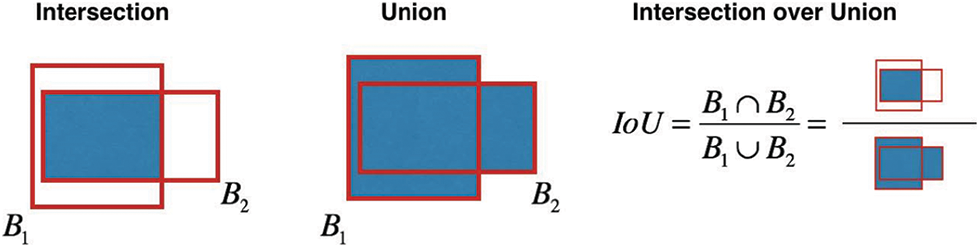
Figure 4: The graphical representation of the IOU formula
If gaps are in the prediction array, the algorithm skips those predictions and restores them after the wrong path is restored. The schematic diagram of the Tracking algorithm can be seen in Fig. 5.
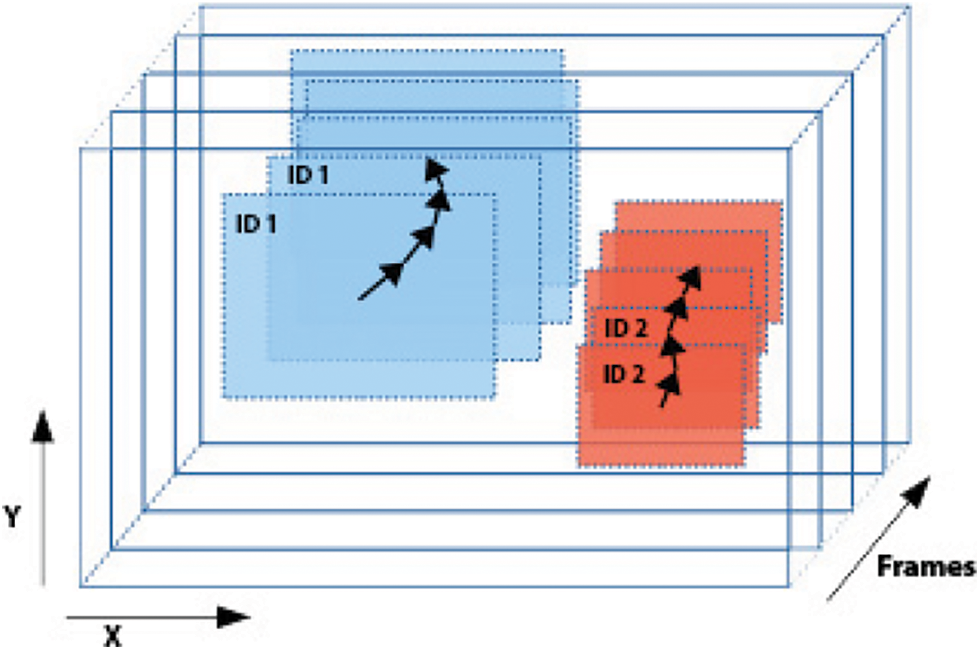
Figure 5: The YOLO objects tracker algorithm. It assigns a unique identifier for each object and tracks it over the frame’s stream
Additionally, the tracking algorithm matches predictions for the next frame based on the velocity and acceleration vector to avoid ID (True Positive Id) reassignment when the object is missed only for a few frames. The existent OpenDataCam matching algorithm is based on the k-d tree algorithm.
5.2 Customization Options for Tracking Results Enchantment
We added several sets of parameters to adjust tracking results. The primary enchantments are the follows:
– frame pending limit (FPL): the number of the frame to keep predicting the object trajectory if the next frame does not match it. Setting this higher will cause fewer ID switches but more potential false positives with an ID going to another object.
– boundary angle threshold (BAT): Count items crossing the counting line only if the angle between their trajectory and the counting line is superior to this angle (in degree). Ninety degrees would count only perfectly perpendicular objects, whereas 0 degrees will count every recognized object. The graphic representation of such a method is depicted in Fig. 6.
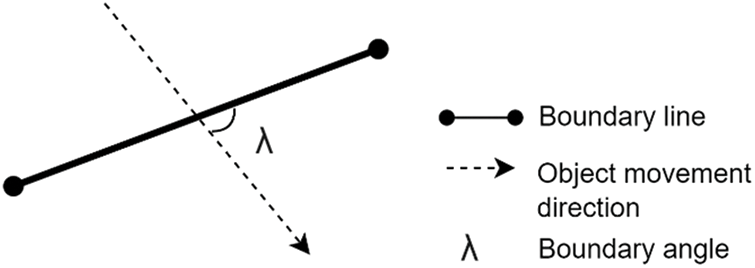
Figure 6: The boundary angle threshold parameter for changing objects’ accessibility to the boundary line
– past frames trajectory prediction (PFTP): parameter computes the trajectory to determine if an object crosses the line based on this number of the past frames. In most cases, the trajectory of the center of the bounding box given by YOLO_AR changes per frame, so the smoothing filtering will help verify object line crossing time and the angle of crossing. For example, if the object ID were lost during tracking, the algorithm would choose the last frame assigned to the ID from memory (Fig. 7).
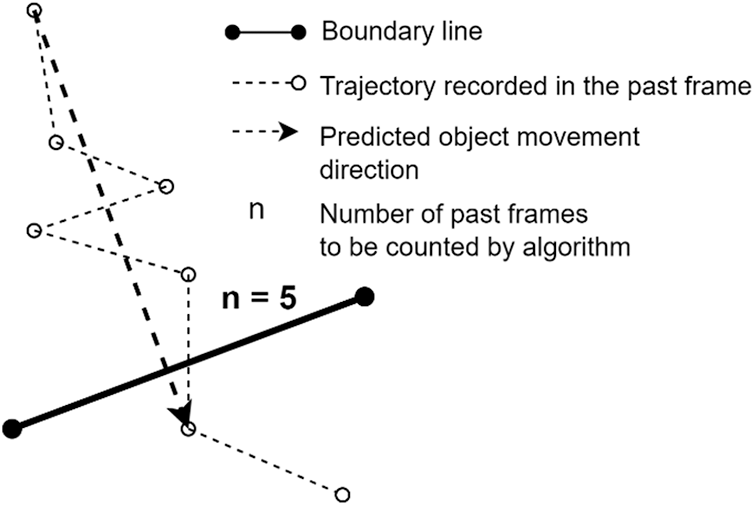
Figure 7: The past frames trajectory prediction parameter normalizes the object trajectory to the boundary line
5.3 Hungarian Algorithm Integration in Comparison to K-D Tree Algorithm
I discovered that an alternative matching algorithm using the Hungarian algorithm (also called the Munkres assignment algorithm) instead of the existing k-d tree algorithm used in OpenDataCam could improve efficiency with YOLO models, especially for small tracked objects. Furthermore, that algorithm should show better accuracy because it finds the minimum cost matching while the k-d tree algorithm only approximates a positive solution.
The tests were executed on the MOT17 benchmark by applying Tracker logic with the k-d tree matching algorithm and the proposed Hungarian algorithm. The results are the follows (Figs. 8 and 9).
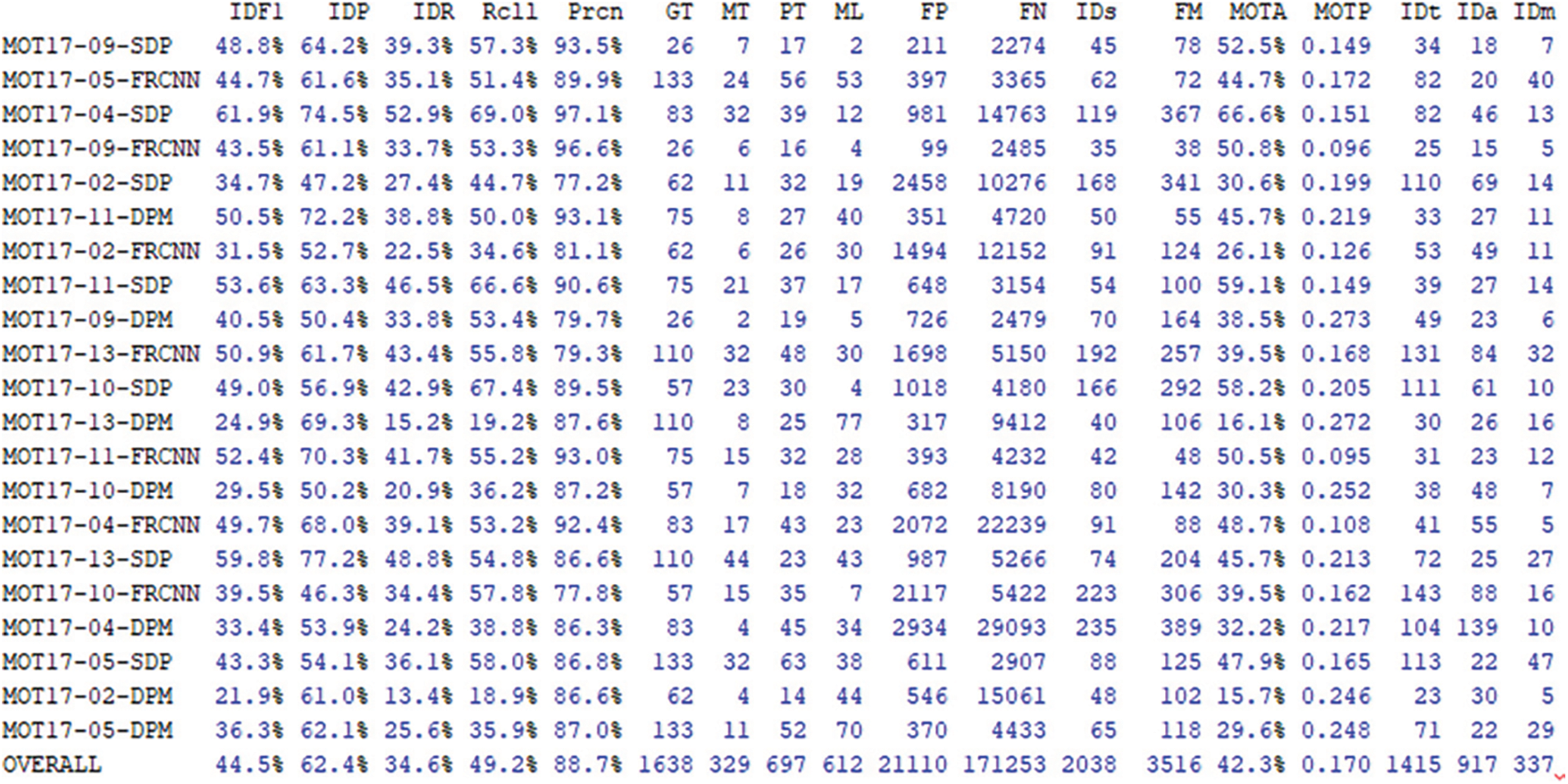
Figure 8: The k-d tree matching algorithm tests results with mocked data on the MOT17 benchmark
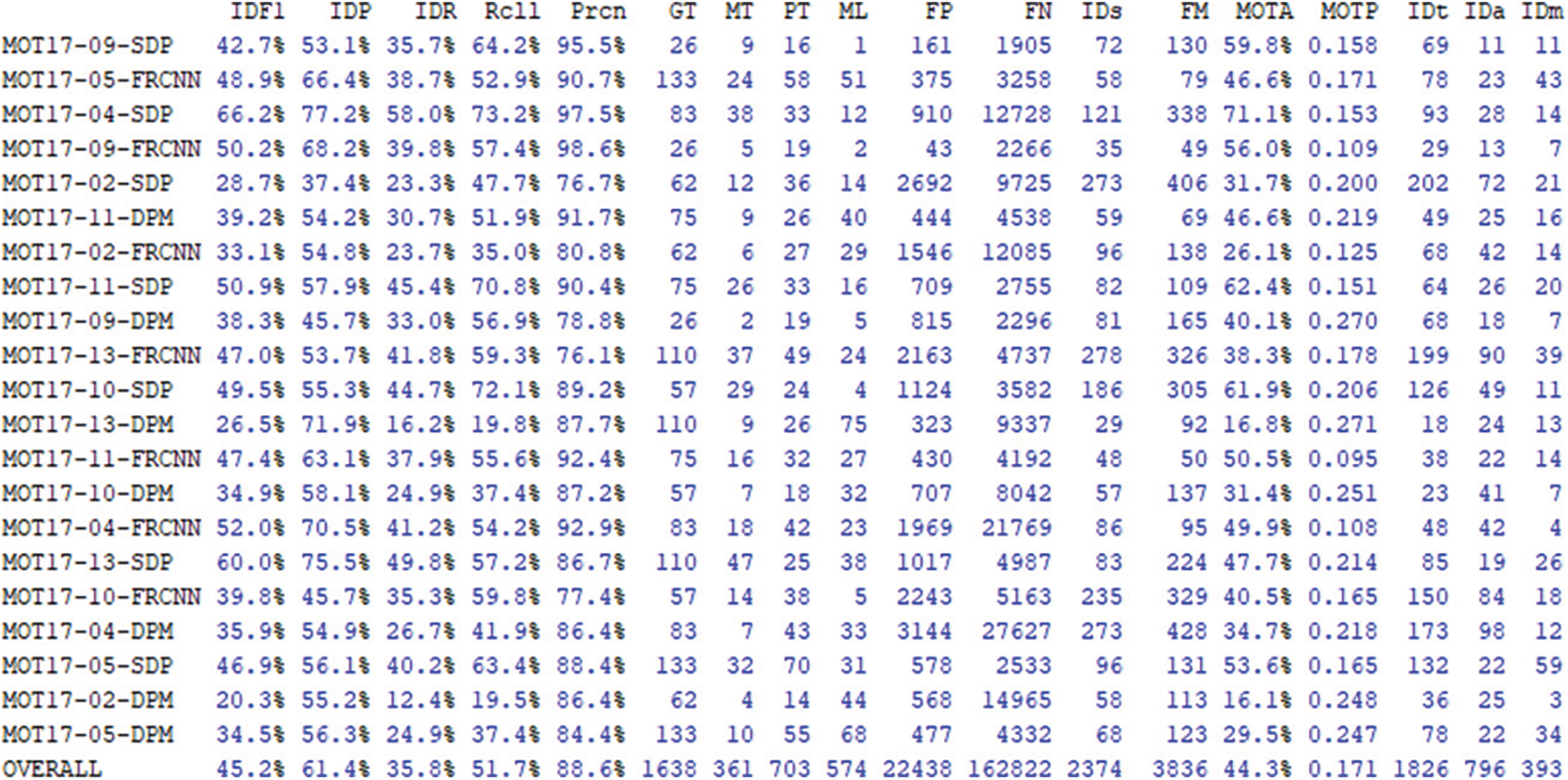
Figure 9: The Hungarian(munkers) matching algorithm tests results with mocked data on the MOT17 benchmark
Where:
– IDF1: The ratio of correctly identified detections over the average number of ground-truth and computed detections;
– IDP: global min–cost precision;
– IDR: global min–cost recall;
– GT: number of ground–truth objects;
– RCLL: Ratio of correct detections to the total number of GT boxes;
– PRCN: Ratio of TP/(TP+FP). Where TP–True Positive, FP–False Positive;
– MT: number of mostly tracked trajectories. I.e., the target has the same label for at least 80% of its life span;
– PT: partially tracked ground–truth trajectory;
– ML: number of mostly lost trajectories. i.e., the target is not tracked for at least 20% of its life span;
– FP: number of false detections;
– FN: number of missed detections;
– IDs: number of times an ID switches to a different previously tracked object;
– Frag: number of fragmentations where a track is interrupted by miss detection;
– FM: the number of track fragmentations. Counts how many times a ground–truth trajectory is interrupted;
– MOTA: Multi–object tracking accuracy. Summarize three errors sources (FN, FP, IDS) with a single performance measure (GT);
– MOTP: Multi–object tracking precision. The average dissimilarity between all true positives and their corresponding ground–truth targets;
– iDt, iDa, iDm: True positive ids.
Since the proposed tracking algorithm finds optimal matching, the Hungarian algorithm shows better results in object tracking, with more false positives (FP) and fewer false negatives (FN). Additionally, the Mostly tracked parameter (MT) is higher (361 vs. 329).
In general, the tracker using the Hungarian algorithm performs slightly worse when the detector has a lot of false positives and slightly better when the detector does not have that many false positives. However, the Hungarian algorithm should be slightly better when using YOLOv4 detections, as the number of false positives tends to be relatively small.
Additionally, the IOU smoothing filter limit was decreased from default 0.05 to 0.2 to increase the overlap and decrease the number of double detections.
6 Results for Ants Trail Recognition and Tracking
The set of tests was executed on the iOS mobile device. The tests include: ants tracking and unique identifier assignment; Ants object path creation; Ant’s entities custom boundary lines crossing. The results are the follows (Figs. 10–14).

Figure 10: The Recognition and Tracking results of ants in formicarium and unique object assignment

Figure 11: The Recognition and Pathfinding for each ant. On the left–with Hungarian matching algorithm, on the right–with k-d tree matching algorithm

Figure 12: The Recognition and Counting ant in different nest directions. On the left is applying the Hungarian matching algorithm, and on the right is applying the k-d tree matching algorithm. The BAT parameter is set to 45 for both scenarios

Figure 13: The recognition and counting ant in different nest directions. On the left is applying the Hungarian matching algorithm, and on the right is applying the k-d tree matching algorithm. The BAT parameter is set to 0 for both scenarios
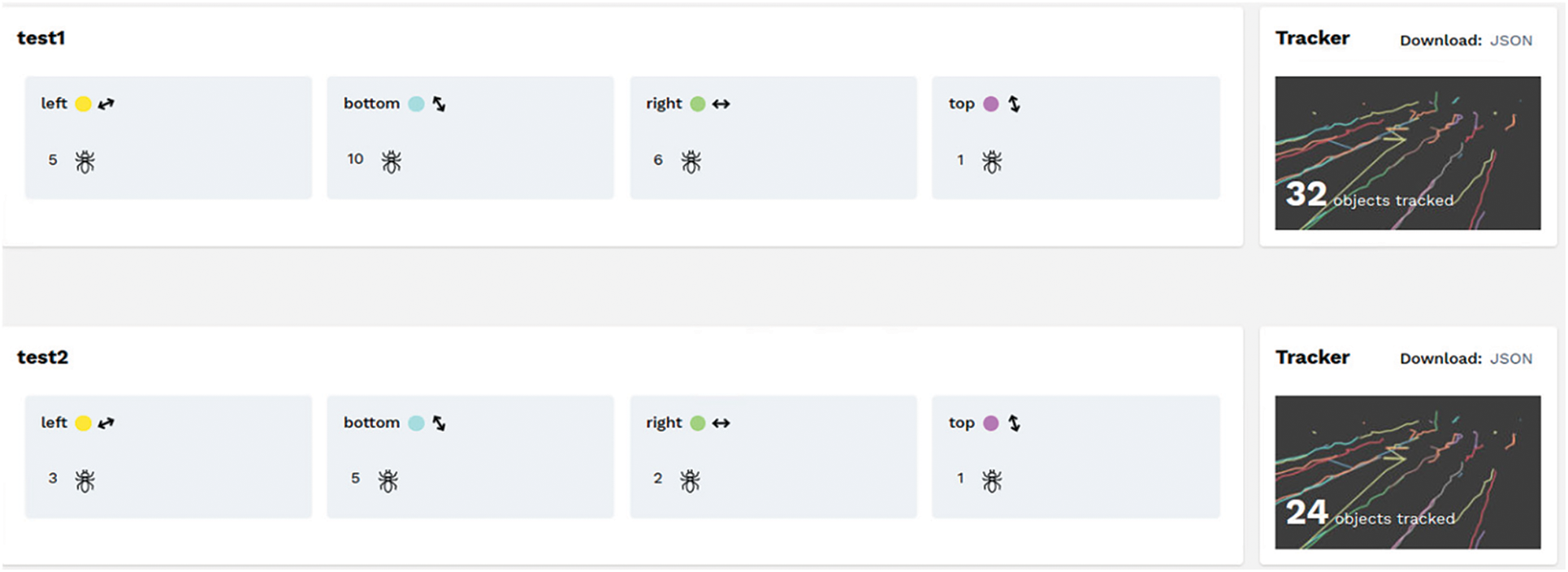
Figure 14: The results are stored in the database for each test for each boundary line
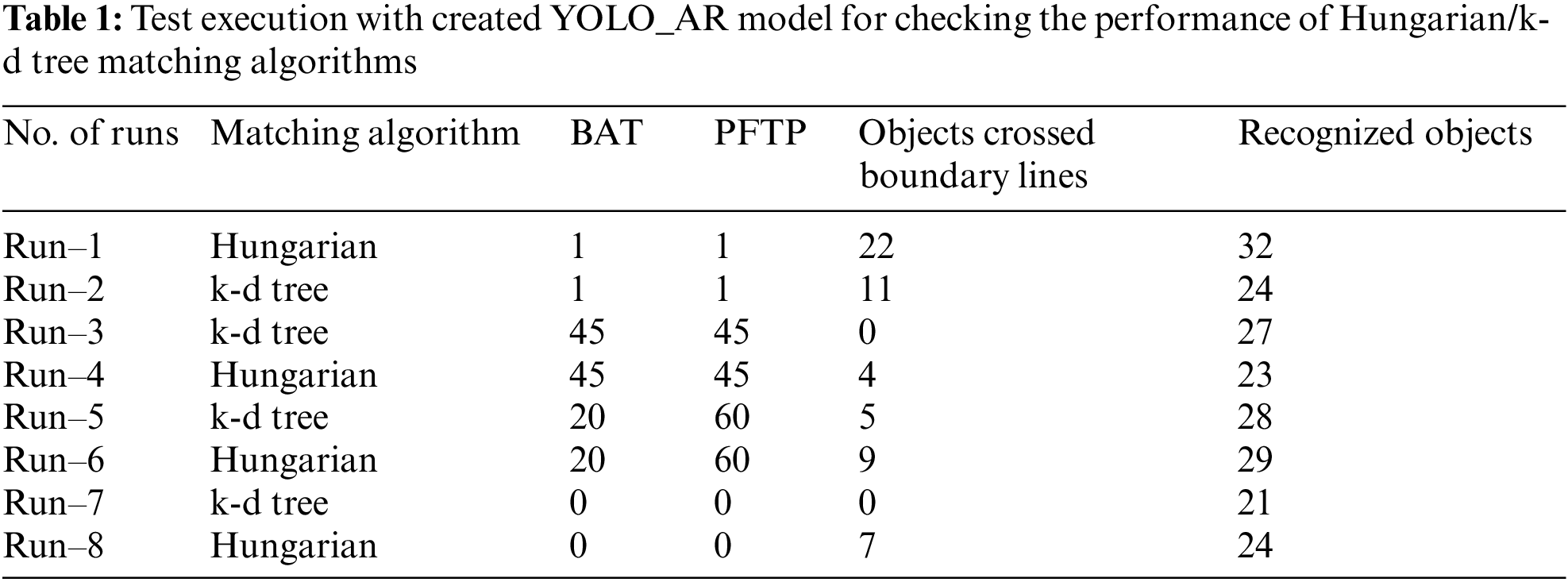
The results of the test execution are provided in Tab. 1.
Some parameters were stable during the test:
– Model name: YOLO_AR 512x512;
– Test duration: 1 min. The video fragment is the same for each test;
– Approximate FPS (Frames Per Second): 12–16. FPL was set to 18 to keep high number of True Positives (TP);
– Ant’s average size: 8mm;
– IOU smoothing filter: 0.1;
– RFSF: such formula was applied for input screen resolution 2532 × 1170;
– CTMF: 90.
The tests were executed on one video recording where ants with an average size equal to 8 mm move through the nest. The overall recognized objects count is the total number of unique IDs assigned to the ants. Some ids were reassigned during the test since the ant trajectory was lost when it did not move on the white surface. The results also show a more extensive trajectory loss (this can be observed in Fig. 11) in the case of the K–d tree algorithm. In addition, the count of tracked ants that crossed the boundary line is also lower compared to Hungarian matching algorithm integration. The tracking results for the Hungarian algorithm shown on Tab. 1 depict an accuracy increase of 50%. If BAT and PFTP filters are disabled, the trajectory loss will increase by 40%. This is observable in the case of high FPS; however, the negative results may be adjusted by the FPL filter. The ant’s recognition results are worse in case the ant is located on the nest wall. Also, ants can hardly be recognized if they are not on a white surface. Such results are expected, as the current train data contain only ants filmed in the laboratory environment. Overall, real-time tests showed promising results in recognizing, tracking, and counting ants with the size up to 14 mm. The proposed CNN model YOLO_AR showed efficient results in recognizing such ant species.
The paper introduced a scalable system for recognizing and tracking small movable objects in sizes from 8 to 14 mm.
Analyzing the results of the research, I can say that:
– The Hungarian algorithm is overcoming k-d tree algorithm in matching small movable objects with the YOLO_AR model because of the lack of false positive values. The actual results were confirmed on MOT benchmark mock data. The obtained results on the real environment showed a 50% accuracy increase comparting to the existing method;
– The implemented BAT and PFTP filters showed an increase in tracking accuracy in real-time, mainly when the video–stream contains high FPS. Without the implemented filters, the loss for tracked paths is higher by 40%;
– The OpenDataCam system can be easily extended to fulfill research needs. Also, additional system modules may be added or enchanted. For example, I modified the Tracker module in our particular case and added an autonomous Model Train Service.
– The proposed system can be used for ants in sizes from 8 to 14 mm behavioral investigation. In addition, it can be scaled to recognize other classes of ant species or breeds.
The additional results of the research are the follows:
– The Messor Structor ant’s dataset was created from 2 video streams via the FFmpeg tool. Afterward, the LabelImg image framework was used to annotate the obtained dataset. Finally, the received data was used to train the YOLO_AR 512 × 512 model with the Mish activation function;
– Additional smoothing and minimization filters were used to remove image overlapping and increase object recognition results;
– The train service was created to train the CNN model autonomously and forward the training output to the subsequent system nodes.
The obtained results can be used to design and implement scalable systems for continuously recognizing, tracking, and counting custom counts of object classes.
9 Prospects for Future Research
The key results of the research could be extended in two main directions. The first is a complete iOS mobile platform integration without using an external server. To achieve this Core Machine Learning (CoreML) framework [26] may be used to recognize and track a small movable object. The second one is to adjust the Neural Network model to recognize different ant species castes. So, the system may track and count different types of ants of different sizes and behaviors. The sizes of ants now will be crucial. For example, the size of solder is up to 10mm, the size of workers is from 4 to 9.5 mm, and the size of the queen is up to 14 mm.
Funding Statement: The author received no specific funding for this study.
Conflicts of Interest: The author declares that they have has no conflicts of interest to report regarding the present study.
1. B. Groß, M. Kreutzer and T. Durand, “OpenDataCam 3.0.2: An open source tool to quantify the world,” Move Lab, 2021, https://www.move-lab.com/project/opendatacam. [Google Scholar]
2. S. Valladares, M. Toscano, R. Tufiño, P. Morillo and D. Vallejo-Huanga, “Performance evaluation of the Nvidia Jetson Nano through a real-time machine learning application,” in Advances in Intelligent Systems and Computing, Palermo, Italy, pp. 343–349, 2021. [Google Scholar]
3. H. N. Abdulghafoor and H. N. Abdullah, “Real-time moving objects detection and tracking using Deep-Stream technology,” Journal of Engineering Science and Technology, vol. 16, no. 1, pp. 533–545, 2021. [Google Scholar]
4. N. Pavych and V. Zahurskii, “Software architecture for analyzing the impact of news on the stock market,” in 2021 11th Int. Conf. on Advanced Computer Information Technologies (ACIT), Ternopil, Ukraine, pp. 613–617, 2021. [Google Scholar]
5. X. R. Zhang, X. Chen, W. Sun and X. Z. He, “Vehicle re-identification model based on optimized DenseNet121 with joint loss,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3933–3948, 2021. [Google Scholar]
6. W. Sun, L. Dai, X. R. Zhang, P. S. Chang and X. Z. He, “Real-time small object detection algorithm in UAV-based traffic monitoring,” Applied Intelligence, vol. 92, no. 6, pp. 1–16, 2021. [Google Scholar]
7. M. Wu, X. Cao and S. Guo, “Accurate detection and tracking of ants in indoor and outdoor environments,” BioRxiv, vol. 2, no. 1, pp. 1–26, 2020. [Google Scholar]
8. X. Cao, S. Guo, J. Lin, W. Zhang and M. Liao, “Online tracking of ants based on deep association metrics: Method, dataset and evaluation,” Pattern Recognition, vol. 103, no. 11, pp. 1–25, 2020. [Google Scholar]
9. D. Kushnir and Y. Paramud, “Model for real-time object searching and recognizing on mobile platform,” in 2020 IEEE 15th Int. Conf. on Advanced Trends in Radioelectronics, Telecommunications and Computer Engineering (TCSET), Slavsk, Ukraine, pp. 127–130, 2020. [Google Scholar]
10. J. Redmon and A. Farhadi, “YOLOv3: An incremental improvement,” ArXiv, 2018, https://arxiv.org/abs/1804.02767. [Google Scholar]
11. C. Banerjee, T. Mukherjee and E. Pasiliao, “The multi-phase ReLU activation function,” in Proc. of the 2020 ACM Southeast Conf. (ACM SE ‘20), New York, NY, USA, Association for Computing Machinery, pp. 239–242, 2020. [Google Scholar]
12. D. Misra, “Mish: A self-regularized non-monotonic activation function,” ArXiv, 2019, https://arxiv.org/abs/1908.08681. [Google Scholar]
13. A. Bochkovskiy, J. Redmon, S. Sinigardi, T. Hager, J. JaledMC et al., “AlexeyAB/darknet:YOLOv4 (version yolov4),” Zenodo, 2021, https://doi.org/10.5281/zenodo.562267. [Google Scholar]
14. W. Kin-Yiu, “Implementation of Scaled-YOLOv4 using PyTorch framework (v1.0.0),” Zenodo, 2021, https://doi.org/10.5281/zenodo.5534091. [Google Scholar]
15. G. Jocher, A. Stoken, A. Chaurasia, J. Borovec, T. Xie et al., “Ultralytics/YOLOv5:v6.0–YOLOv5n ‘Nano’ models, Roboflow integration, TensorFlow export, OpenCV DNN support (v6.0),” Zenodo, 2021, https://doi.org/10.5281/zenodo.5563715. [Google Scholar]
16. C. Wang, I. Yeh and H. M. Liao, “You only learn one representation: Unified network for multiple tasks,” ArXiv, 2021, https://arxiv.org/abs/2105.04206. [Google Scholar]
17. D. T. Zutalin, “LabelImg,” GitHub, 2021, https://github.com/tzutalin/labelImg. [Google Scholar]
18. E. Bochinski, T. Senst and T. Sikora, “Extending IOU based multi-object tracking by visual information,” in 2018 15th IEEE Int. Conf. on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, pp. 1–6, 2018. [Google Scholar]
19. A. Bewley, Z. Ge, L. Ott, F. Ramos and B. Upcroft, “Simple online and real-time tracking,” in 2016 IEEE Int. Conf. on Image Processing (ICIP), Phoenix, Arizona, pp. 3464–3468, 2016. [Google Scholar]
20. A. Milan, L. Leal-Taixe, I. Reid, S. Roth and K. Schindler, “MOT16: A benchmark for multi-object tracking,” ArXiv, 2016, https://arxiv.org/abs/1603.00831. [Google Scholar]
21. P. Dendorfer, A. Ošep and A. Milan, “MOTChallenge: A benchmark for single-camera multiple target tracking,” International Journal of Computer Vision, vol. 129, no. 4, pp. 845–881, 2021. [Google Scholar]
22. H. Kuhn, “The hungarian method for the assignment problem,” 50 Years of Integer Programming, 2010, https://www.semanticscholar.org/paper/The-Hungarian-Method-for-the-Assignment-Problem-Kuhn/b6a0f30260302a2001da9999096cfdd89bc1f7fb. [Google Scholar]
23. M. Skrodzki, “The k-d tree data structure and a proof for neighborhood computation in expected logarithmic time,” ArXiv, 2019, https://arxiv.org/abs/1603.00831. [Google Scholar]
24. D. Merkel, “Docker: Lightweight Linux containers for consistent development and deployment,” Linux Journal, no. 239, pp. 1–2, 2015, https://www.linuxjournal.com/content/docker-lightweight-linux-containers-consistent-development-and-deployment. [Google Scholar]
25. D. Kushnir, “Ants dataset (indoor/outdoor Messor Structor) + trained YOLOv4 weights,” Mendeley Data, 2022, https://doi.org/10.17632/zprk7wkf9j.1. [Google Scholar]
26. A. Mishra, Machine learning for iOS developers. New York, NY, USA: John Wiley & Sons, 2020. [Online]. Available: https://www.wiley.com/en-ie/Machine+Learning+for+iOS+Developers-p-9781119602903. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |