| Computers, Materials & Continua DOI:10.32604/cmc.2022.024759 | |
| Article |
Multi Layered Rule-Based Technique for Explicit Aspect Extraction from Online Reviews
1School of Systems and Technology, University of Management and Technology, Lahore, 54770, Pakistan
2Department of Computer Science and It, The University of Lahore, Lahore, 54000, Pakistan
3School of Computer Sciences, Universiti Sains Malaysia (USM), Penang, 11800, Malaysia
4Department of Computer Science, Comsats University Islamabad, Lahore, 54000, Pakistan
5Department of Computer Science, GC Women University Sialkot, Pakistan
6Department of Software Engineering, The Superior University, Lahore, 53700, Pakistan
7Faculty of Computing and It, Albaha University, Albaha, Saudi Arabia
8Department of Computer Science, Majmaah University, Saudi Arabia
*Corresponding Author: M. Usman Ashraf. Email: m.usmanashraf@yahoo.com
Received: 30 October 2021; Accepted: 23 March 2022
Abstract: In the field of sentiment analysis, extracting aspects or opinion targets from user reviews about a product is a key task. Extracting the polarity of an opinion is much more useful if we also know the targeted Aspect or Feature. Rule based approaches, like dependency-based rules, are quite popular and effective for this purpose. However, they are heavily dependent on the authenticity of the employed parts-of-speech (POS) tagger and dependency parser. Another popular rule based approach is to use sequential rules, wherein the rules formulated by learning from the user’s behavior. However, in general, the sequential rule-based approaches have poor generalization capability. Moreover, existing approaches mostly consider an aspect as a noun or noun phrase, so these approaches are unable to extract verb aspects. In this article, we have proposed a multi-layered rule-based (ML-RB) technique using the syntactic dependency parser based rules along with some selective sequential rules in separate layers to extract noun aspects. Additionally, after rigorous analysis, we have also constructed rules for the extraction of verb aspects. These verb rules primarily based on the association between verb and opinion words. The proposed multi-layer technique compensates for the weaknesses of individual layers and yields improved results on two publicly available customer review datasets. The F1 score for both the datasets are 0.90 and 0.88, respectively, which are better than existing approaches. These improved results can be attributed to the application of sequential/syntactic rules in a layered manner as well as the capability to extract both noun and verb aspects.
Keywords: Explicit aspect; aspect extraction; opinion mining; rule-based; verb aspects
With the expansion of the digital market and increase in daily internet usage, people are showing extreme interest in E-commerce and online shopping instead of physically visiting the shops. This online shopping gives comfort and ease to customers as well as beneficial to companies and manufacturers as it becomes a cost effective way to collect feedback about the products through user reviews. This review posting tendency gives a huge lift to the research area of Sentiment analysis (SA) also called opinion mining.
Different levels of SA are: (a) document level (b) sentence level (c) aspect level sentiment analysis [1]. Document level opinion mining extracts words, which reveal some opinion from product reviews, then identifying the divergence of these opinion terms [2]. The system then chooses whether the review contains negative or positive opinion about the matter based on these terms.
Sentence-level classification identifies the sentence as objective or subjective, also known as subjectivity classification [3]. Then considering these subjective sentences as small documents, sentiments expressed by these sentences classified as negative or positive. A more fine-grained model of sentiment analysis is the aspect-level or feature-level sentiment classification that extracts expressed-opinion against different features or aspects of the entity being discussed [4]. This includes extracting the features and views, classifying them, finding divergence of opinions and summarizing them into results. Different levels of classification and associated subtasks of SA are shown in Fig. 1 [1].
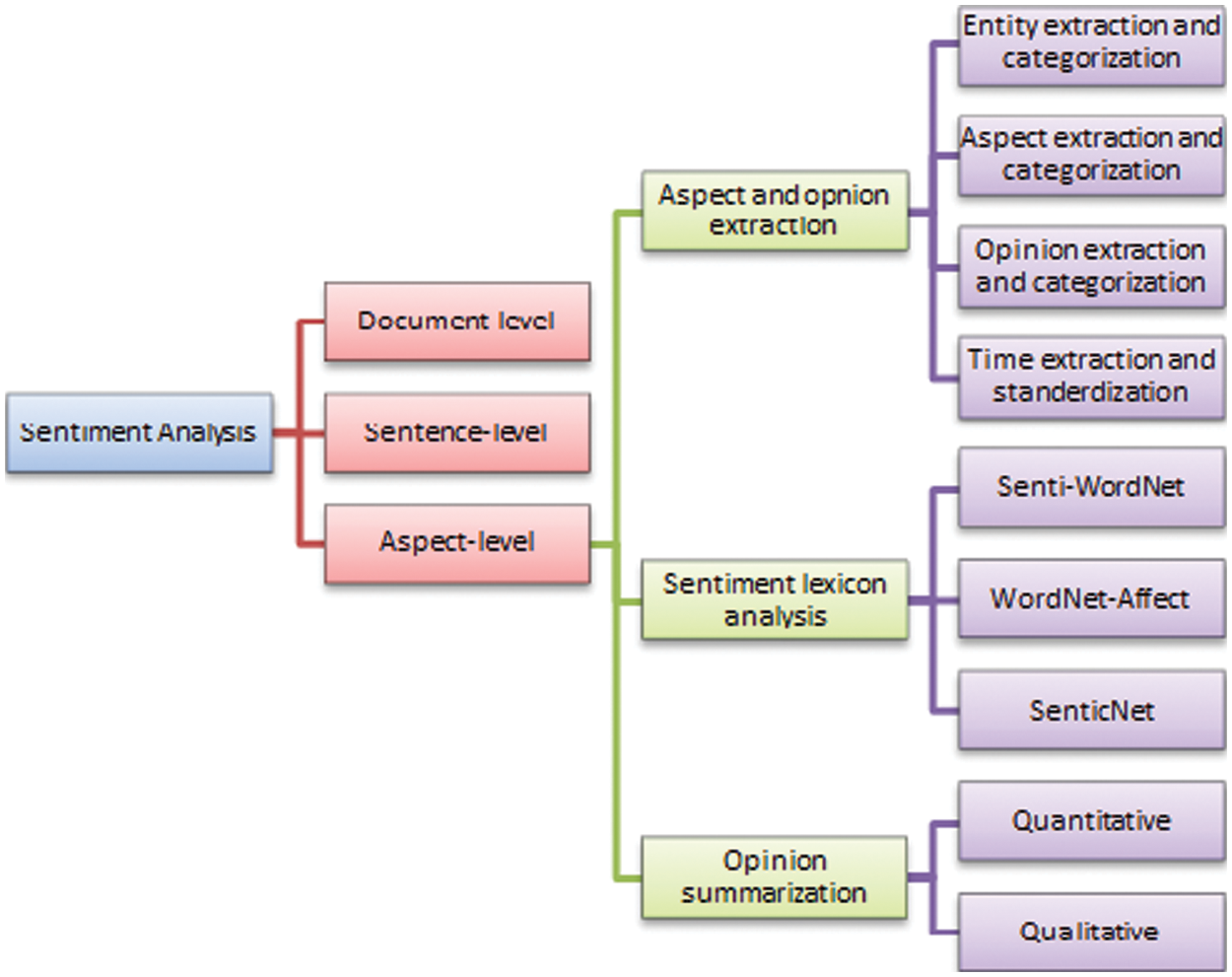
Figure 1: Classification of sentiment analysis
This study is targeted towards aspect-based SA [5] which includes aspects extraction and their relationship with the text polarity. Opinion target, more formally called an aspect, refers to a feature under discussion in a customer review/opinion. For instance, in the sentence, “This phone has an awesome battery and I love its camera”, the author has expressed his likeness towards this phone so the review has a positive polarity. More precisely, the phone’s battery and camera are aspects having opinions ‘awesome’ and ‘love’. Aspect extraction is a process of finding aspects/opinion targets, from some opinionated document or text (i.e. reviews).
Aspect-based SA usually involves two types of aspects: implicit aspects and explicit aspects. The explicit aspects are those, which clearly/directly mentioned in the opinionated text. For example, in the aforementioned example, the aspects ‘battery’ and ‘camera’ are explicit aspects. Implicit aspects refer to the cases, where aspect word represented but not directly mentioned in the document/review. For instance, in the sentence, “This watch is much affordable for me”, a positive opinion expressed about the feature/aspect ‘price’ of this watch but not explicitly mentioned. Contrary to the implicit aspect in this example, the sentence “Love to buy this watch because the price is much affordable” contains “price” as an explicit aspect [6].
Since, the last several years, aspect extraction is becoming a widely studied area. Multiple approaches were used including supervised as well as unsupervised [7]. Several studies showed that the double propagation approach based on syntactic dependency [8] performs well as compared to many supervised learning techniques [9]. This approach focused on an assumption, as every opinion has some target word and there is a clear dependency relation among opinion (e.g., “love”) and aspect (e.g., “camera”). Using these relations, double propagation and some other relevant models [10] use opinion lexicon (consisting mostly of adjectives) for the extraction of aspects as well as different opinion words.
In general, rule-based approaches (e.g., dependency-based rules) perform relatively well, however these approaches are heavily dependent on the authenticity of the employed part of speech (POS) tagger and the dependency parser. Another rule-based approach is based on sequential rules [11,12] wherein the rules are formed by learning from the user’s behavior. However, in general, the sequential rule-based approaches have poor generalization capability. Moreover, existing approaches mostly consider the aspects as noun or noun phrases. Thus, in general, these approaches are unable to extract verb aspects from reviews.
In this article, for overcoming the said problems with the existing approaches, we have proposed a Multi-layered rule-based (ML-RB) technique. The proposed ML-RB technique extracts noun aspects using the syntactic dependency-parser based rules along with some selective sequential rules in separate layers. It also uses some manually crafted rules for extraction of verb aspects after rigorous analysis in the final layer. These verb rules primarily based on the association among the verb and opinion words.
In the proposed approach, following steps performed in each layer. In the first layer, we have used a rule set that consists of double propagation rules [8] based on dependency relations between aspect and opinion words. To implement these rules, we have used Stanford parser instead of Minipar, which is no longer available. In the second layer we have used a sequential rule set, which is a subset of the rule set generated in an earlier study [11]. This selection of rules performed on the bases of performance on those noun aspect words that the first layer is not able to extract. In the third and last layer, a rule set is used which we have crafted for the extraction of verb aspects after careful analysis of the relationship between opinion words and the verb in the sentence.
We have used two publicly available datasets of online customer review. The first one is a benchmark dataset used in various studies [8–9,11,13] of explicit aspect extraction. It contains the reviews of customers on five different electronic products [4]. The second contained customer reviews of three other products and was actually presented in later study [14]. Researchers in many earlier studies also use it.
The rest of the paper is organized as follows. Section 2 refers to some of the prominent existing works in the contemporary literature on aspect extraction. Section 3 discusses the proposed methodology in detail. In Section 4, experimental results are presented and compared with different approaches. Section 5 discusses the conclusion.
For aspect extraction unsupervised approaches have been extensively used by the scholars from online product reviews. Such approaches have been used on different domains and language datasets. Most of them have used the customer review dataset by Hu et al. [4]. Main focus of these datasets was the domain of product reviews. Hu and Liu initially started the study on aspect based opinion mining [4]. They consider extracting all aspects which are frequent and then get the associated opinion words from customer reviews. The aspects towards the user wanting to show their sentiments are frequent aspects. To achieve this, they applied Apriori [15] based CBA (Classification Based Associations) association rule miner [16]. It was perceived that, commonly in a sentence, nouns/noun phrases denote an aspect. Thus, the noun was mined from reviews and then labeled them as frequent aspects if they cross the given threshold. After selecting all frequent aspects, the nearby adjectives were mined as opinions. They have also described that all aspects are not frequent.
Some researchers have also studied the semi-supervised techniques. These approaches need initial seed as well as user input to run the algorithm. Similar to unsupervised approaches, these techniques are also usually focused on online product reviews. In study researchers [17] context-dependency have been used for aspect extraction and also opinions concurrently. To recognize opinion and their targets, they have used a bootstrapping technique that takes opinion lexicon for input to get aspects of the product. Furthermore, they have applied a mutual information model to recognize relation between opinion words and their targets. For identification of uncommon aspects, language rules were used. They have used opinions to recognize implicit aspects. New bootstrapping approaches were introduced likelihood ratio test bootstrapping (LRTBOOT) as well as latent semantic analysis bootstrapping (LSABOOT) latent semantic-analysis [18]. In another study [19] researchers have combined the refinement process and bootstrapping approach which was helpful to automate rule improvement to trim out bad results and change the rules for improving the extraction of opinions and aspects. An idea of phrase dependency parsing to get relations among aspects and their targets was given in a study [10].
For aspect extraction and finding their relation with opinions from blogs [20] researchers proposed an approach which can extract opinion targets as well as find association between product aspects and opinions. The phase of opinion extraction is done by supervised approach and using a dictionary-based method. By using these extracted opinions and syntactic pattern approach the aspects were identified. Now these pairs of opinions and aspects were used to find the relation and co-occurrence between words and aspects, and evaluated by a classifier which was trained on a corpus.
A tree-based technique [21] was used, generalized aspect-sentiment tree, for aspect extraction from online reviews. Four diverse tree kernels were defined to find opinion targets from online reviews. The kernel-based approach evaluates the likeness between two trees rather than extracting every separate aspect from every tree. Project Management Institute (PMI) values were used to find relationships between aspects and opinions. There are some models where they have used Conditional random fields (CRF) to extract the explicit aspects. Initially CRF was applied in a study [22] for extraction of aspects. Moreover, CRF was again implemented in [23] for the same task.
In a study [24], they have combined CRFs with three different types of language features to extract the aspects. These features include, word and POS feature, pulse sentence structure. Another researcher [25] proposed multi-feature embedding, using CRF for extraction of aspects. In a paper [26], they have used Bidirectional Long Short Term Memory (BI-LSTM) CRF model along with three different types of dependency relations for the Chinese language for aspect extraction. Initially, BI-LSTM-CRF was used to extract aspects and associated opinion words. In another work [27], they have used Convolutional Neural Network (CNN) with seven layers to extract the explicit aspects from reviews. Additionally, to improve the performance of aspect extraction they have joined CNN with four rules based on dependency.
Feng [28], one of the most recent studies about aspect extraction. In this method, topic modeling along with synonym recognition was used. Negative Group Delay (NGD) and CNET [29], is also a recent study. In this approach, Natural Language Processing (NLP) features along with NGD pulse ConceptNet are used to extract the aspects. DomSent [30], which is the latest work in the aspect extraction field. In this approach, they assumed nouns as potential aspects and they have used a self-created opinion lexicon. Many techniques have used the association between aspect terms and opinions using NLP dependency parser [10,31] which produces a dependency tree that shows the relationship between different words in a sentence. Syntactic patterns beside the word alignment were used [32] to get association among opinion and their targets in sentence. In a study [12] researchers have mine sequential patterns to get a relation between opinion words and aspects. Initially the idea was proposed in a study [33] to find every possible pattern of opinions and opinion targets for aspect extraction. This study follows the sequential rules produced in a study [12] which just focused on generation of sequential patterns. Similar rules were used to increase the accuracy of aspect extraction [34]. Though a sequential pattern approach was also used in a study [35] but, the rules were manually defined by using labels and the only focus is the objective aspects. Recently researcher has used Whale optimization algorithm (WOA) with new local search algorithm for extraction of explicit aspects [36]. In another study hybrid feature set of lemmas and word dependency relations is used on a SemEval restaurant review dataset for this task [37].
This proposed Multi-layered rule-based (ML-RB) technique consists of three steps to perform explicit aspect extraction from online product reviews. First two steps focused on extracting noun aspects and third to extract verb aspects from reviews. (1) In the first step, we have used a rule set that consists of double propagation rules [8] based on dependency relations between aspect and opinion words. To implement these rules, we have used Stanford parser instead of Minipar which is no longer available. (2) In the second step we have used a sequential rule set, which is a subset of the rules set generated in a study [11]. We have selected this rule set on the basis of performance on those noun aspect words that the first layer is not able to extract. (3) In the third and last step, a rule set is used for aspect extraction, which we have crafted for extraction of verb aspects after rigorous analysis. Then the output of each layer is combined and used for evaluation with the actual aspect annotation as shown in Fig. 2.
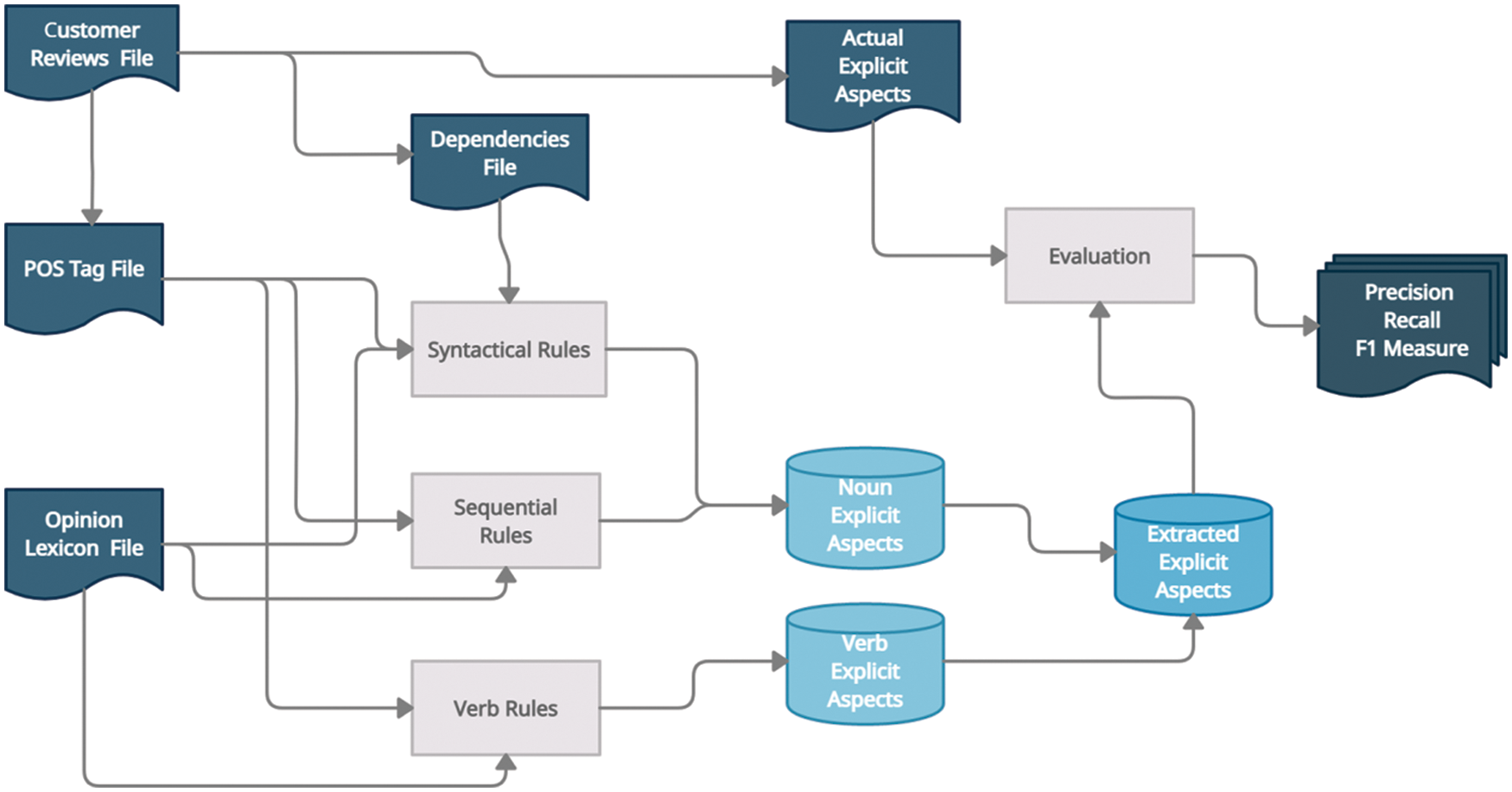
Figure 2: Proposed multi layered rule-based (ML-RB) approach
In the first layer, we have used the rule set based on dependency relations (dependency relations of Stanford parsers1 shown in Tab. 1) among aspect words and opinions, used in a study [14]. These rules were derived from double propagation rules [8] to decrease the incorrect aspects due to propagation. These rules with examples are discussed subsequently.

Rule11: “if any word ‘A’ tagged NN (noun) by POS tagger, is depended by a word ‘O’ which is in opinion lexicon through some dependency, where dependency relation is one of R1 to R7, then word ‘A’ is potential aspect.” also can be denoted as:
In this rule, dependency (Dep, A, O) shows the words ‘A’, ‘O’ are connected with a ‘Dep’ dependency relation and POS-Tag (A, NN) shows the word ‘A’ is tagged as noun by the part of speech tagger, opinionword (O) shows the word ‘O’ is present in opinion lexicon, potential-Aspect (A) means extract the word ‘A’ it cloud be an aspect.
Let’s take an example, as we can see in Fig. 1. 2 the sentence “The phone has a good screen”. By using the above rule, we will get the potential aspect “screen” because there is R1 relation amongst the word “good” and word “screen” since “good” also exists in opinion lexicon, also the word “screen” tagged as noun by the POS tagger.
Rule12: “if a word ‘O’ which is in opinion lexicon and word ‘A’, having POS-Tag NN (noun), both depends on word ‘T’ by some dependency Dep i and Dep j respectively, since Dep i and Dep j are from R1 to R7 then word ‘A’ is potential-aspect” also can be denoted as:
Let’s take an example, “Nokia is the finest cell phone” from this sentence we can get the aspect “Nokia” by using above rule, because there is R1 relationship among words “finest” and “phone” also R3 relation between the words “phone” and “Nokia” given that “finest” is from opinion lexicon, and “Nokia” is tagged as noun by POS Tagger.
Next rule in the double propagation is Rule21: “if any word ‘O’, is tagged JJ (adjective) by POS Tagger, associate with an aspect word ‘A’ via some dependency Dep, from R1to R7 then ‘O’ will be an opinion word.” also can be denoted as:
Let’s take an example, “This mp3 player has a great battery” from this sentence we will get opinion word “great” because there is R1 dependency relation among “great” and “battery” also “battery” is aspect, as well as “great” have Tag JJ (adjective) by POS tagger.
Rule22: “if any word ‘O’, tagged JJ (adjective) by POS Tagger, and any aspect word ‘A’, depends on word ‘T’ via dependency relation Dep i and Dep j respectively, and Dep i and Dep j are form R1 to R7, then word ‘O’ is an opinion.” also can be denoted as:
For instance, from sentence “Nokia is the finest cell phone” we will get the opinion “finest” by using above rule, because there is R1 relation among words “finest” and “phone” also R3 relation among the words “phone” and “Nokia” also “Nokia” is from aspects, and “finest” is tagged as adjective by POS Tagger.
Rule31: “if any word ‘A j’, tagged noun by POS tagger, associates with aspect word ‘A i’ via dependency R8, then word ‘A j’ is also an aspect.” also can be denoted as:
For instance, “Does this player will play my dvd with both audio plus video?” We can get “audio” as a potential aspect from the above sentence because there is a dependency relation R8 among the words “audio” plus “video” also “video” is already known.
Rule32: “if any word ‘A j’ tagged noun by POS tagger, and any aspect ‘A i’, depends on any word ‘T’ via some dependency Dep i and Dep j from R1 to R7, then word ‘A j’ is also a potential aspect.” also can be denoted as:
For instance, “Nokia phone has a good camera” we will get “phone” as an aspect by applying the above rule in the above sentence. Because there is R3 dependency relation among words “has” and “phone” and R6 dependency relation among words “has” and “camera” also “camera” is already extracted.
Rule41: “if any word ‘O j’ is tagged adjective by POS tagger, depending on opinion ‘O i’ via dependency relation R8, then the word ‘O j’ is also opinion word.” also can be denoted as:
Let’s take an example, “The player is beautiful but costly” we can get the word “costly” as opinion by using above rule from this sentence, because there is dependency relation R8 among the words “beautiful” and the word “costly” also “beautiful” is already in opinion lexicon.
Rule42: “if any word ‘O j’, is tagged adjective by POS tagger, and opinion ‘O i’, depend on word ‘T’ via some relation Dep i and Dep j from R1to R8 then ‘O j’ is also opinion word.” also can be denoted as:
For instance, “did you need to purchase sexy, beautiful phone, choose Nokia” we will get “beautiful” as opinion by using above rule form this sentence, as there is dependency relation R1 between the words “sexy” and “phone” and also R8 relation between the words “beautiful” and “phone” also “sexy” is from opinion lexicon.
We are using a subset of sequential rules proposed in a study [11], in the second step of our approach. Rules are selected by analyzing the performance on those noun aspect words which were not extracted by the first step of our approach. Following are rules set we have used in the second step of our proposed approach.
Sequential patterns give us relationships between aspect and opinion. First rule says if there is word ‘A’ with POS tag (NN) noun, and the associated (‘∼’ sign is used to show association) adjective (JJ) or verb (VB) word ‘O’ is in opinion lexicon, then the A is a potential aspect, for instance,
In the sentence “very poor screen”, the adjective word ‘poor’ is associated with the noun word ‘screen’. Thus, the screen will be mined as an aspect. This rule can be denoted by the following:
In linguistics copula words are used to link subject plus predicate. If there is any noun found before copula word i.e. is, are, etc., used as a verb in a sentence, then opinion will be next to copula word, for instance, in sentence “video is brilliant”. ‘Video’ is recognized as an aspect as well as the ‘brilliant’ word as opinion. This rule can be denoted by the following:
In the dataset, the majority of the annotated aspects are nouns, but there are also some verb explicit aspects. The above-mentioned approaches are unable to extract these types of aspects from sentences, as they do not consider verbs as aspects. For example, in the sentence “the phone looks great”, the word ‘looks’ is tagged by the POS tagger as a verb and the aspect “look” is annotated in the dataset. But as the POS tag of ‘look’ is a verb the sequential/syntactical approaches will ignore this aspect.
For specifically these verb aspects we have crafted some rules rigorous analysis on different sentences from different datasets heaving verb aspects. Following are the rules for extraction of verb aspects:
If there is a word ‘V’ whose POS tag is a verb, is directly associated with a word ‘O’ with a tag adjective and also present in opinion lexicon then the base word of ‘V’ is an aspect. This rule can be denoted as following:
For example, in the sentence “phone looks great” we can extract the aspect “look” by using the above rule, as the word “looks” is a verb associated with word “great” which is an opinion word, so the base word of “looks” is extracted which is “look”.
If in a sentence there is a word ‘O’, present in opinion lexicon, is directly associated with a preposition “to” which is again associated with a word ‘V’ which is a verb, then base word of ‘V’ is a potential Aspect.
For example, in a sentence “player is very easy to use” we can extract aspect “use” as aspect, because word “easy” is an opinion and word “use” is tagged as verb by POS tagger and use itself as a base word so extracted as potential aspect.
These are the three types of rule sets we have used in this study as shown in Fig. 3. We implement these separately and combine the results, then evaluate by comparing extracted aspects with actual aspects which are annotated by the author of the dataset.
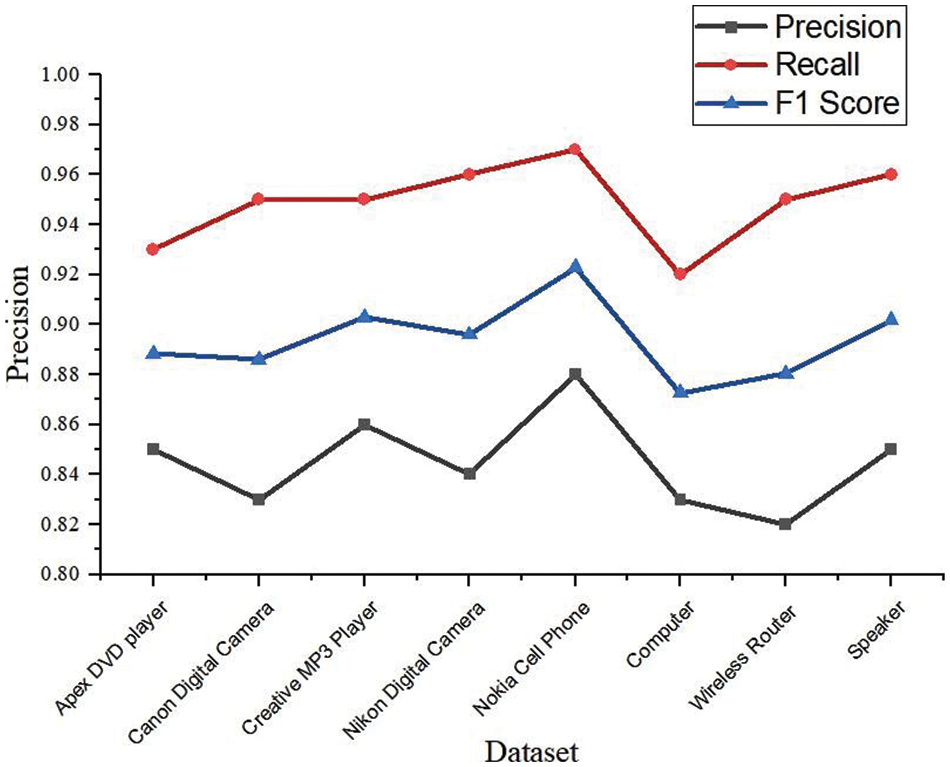
Figure 3: Performance chart
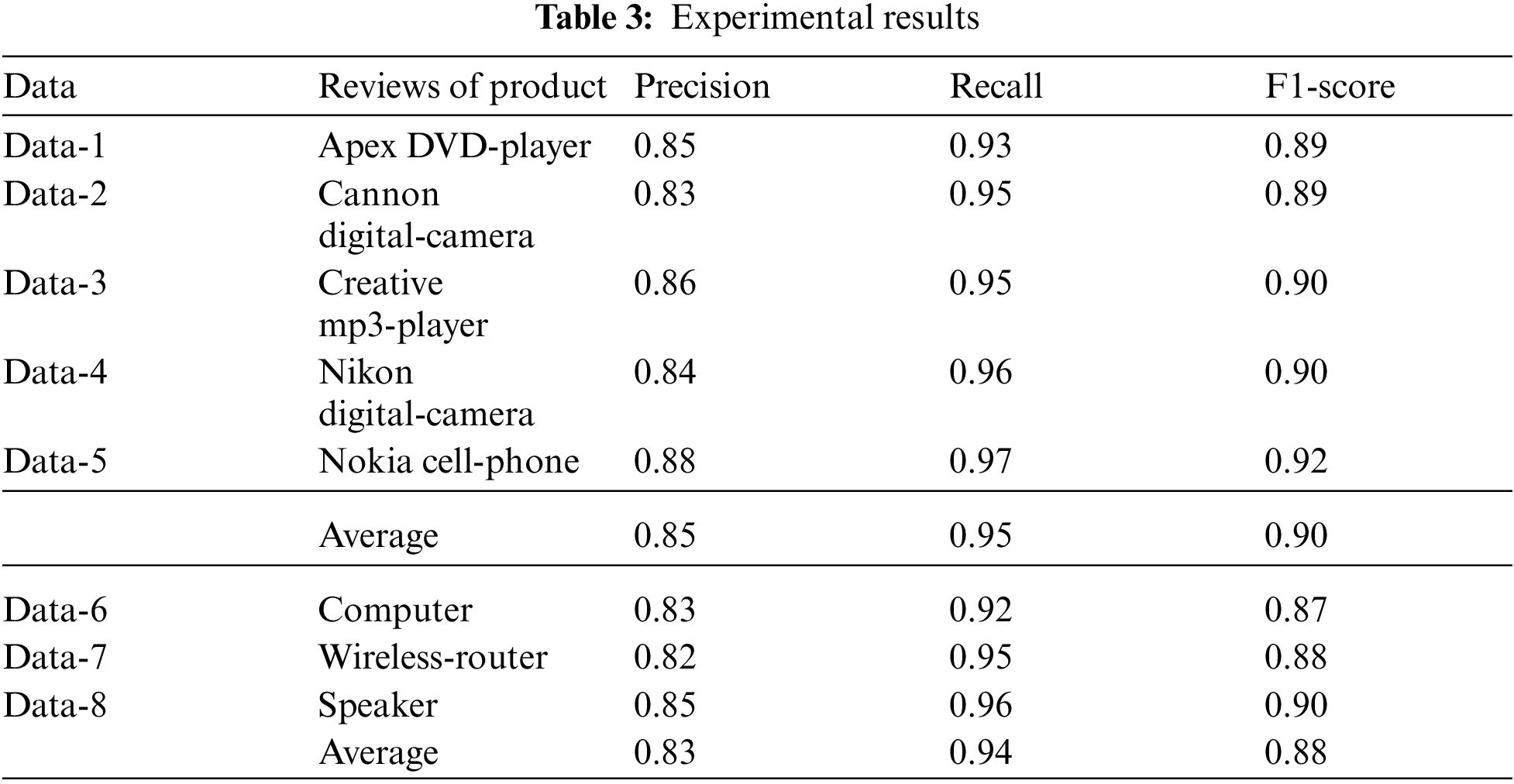
We have used two publically available datasets of online customer review to validate the proposed ML-RB approach. The first one is a benchmark public dataset used in various studies of explicit aspect extraction [8,11,28,38,39]. It contains the reviews of customers on five different electronic products [4]. The second dataset is from the study [14], and has customer reviews of three products. The sentences in both datasets are annotated in terms of number of aspects, type of aspect (explicit or implicit) and polarity of sentence (positive or negative). Tab. 2 summarizes the information on product reviews in both the datasets. For simplicity, the data related to each product is referred to as Data-[M], where M is the product number.
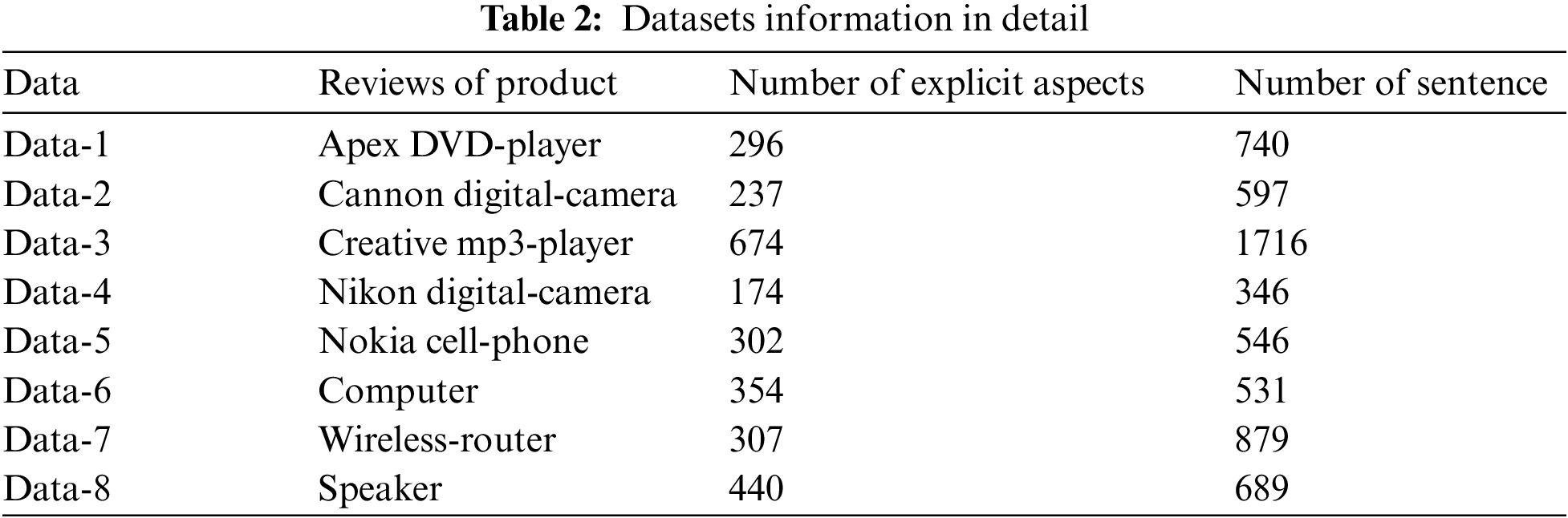
This section first reports the performance of the proposed ML-RB approach on the 8 products data from both datasets in terms of precision, recall and F1-score measures. Then, the performance of the proposed approach is compared with some other contemporary techniques applied to the same datasets.
The proposed (ML-RB) approach in this work has been implemented using the Python programming language with Jupyter Notebook development environment. The command-line interface of Stanford Parser has been used to get POS Tags and dependencies of reviews. For quantitative evaluation of the proposed approach, the measures of precision, recall and F1-score have been used, which are widely used measures for this purpose. The standard formulas for calculating precision, recall and F1 scores are given as follows, where TP, FP and FN represent the true positive, false positive and false negative measures.
4.1 Performance on Customer Reviews Datasets
The performance of the proposed (ML-RB) approach in terms of the said evaluation measures on customer reviews datasets is shown in Tab. 3. It can be seen from average results that recall measure evaluation is much higher compared to precision. This is because the technique has multiple layers; the slight false positive score of each layer collectively makes an effect on precision. A similar trend is also seen for all individual products (Data-1 to Data-8) as well. Nevertheless, the F1 measure, which is a harmonic mean of precision and recall, is promising (0.90 and 0.88) for both the dataset. This emphasizes the efficacy of the proposed approach for automated explicit aspect extraction as elaborated in Fig. 3.
4.2 Comparison with Existing Approaches
In this section, the proposed ML-RB approach is compared with the baseline approaches including some state-of-the-art techniques for aspect extraction. The primary features for each of these techniques are listed below.
● One of the most famous and classical techniques for aspect extraction is Double propagation(DP) [8], wherein 8 rules based on dependency relations were used.
● Feng [28] uses topic modeling along with the synonym recognition to extract explicit aspects.
● RubE [13] extends DP with some novel rules.
● TF-RBM [38] is a two-fold rule-based technique and uses sequential patterns with similaritybased approach.
● RSLS+ [14] also uses extended DP rules with some new rules, but also performs refined rulesselection based on a simulated annealing approach.
● DomSent [32] uses a self-created opinion lexicon and assumes nouns as potential aspects.
● CRF [23,39] is a traditional approach, and is implemented by using a group of featuresfor learning CRF like tokens, POS, dependencies, word and opinion distance.
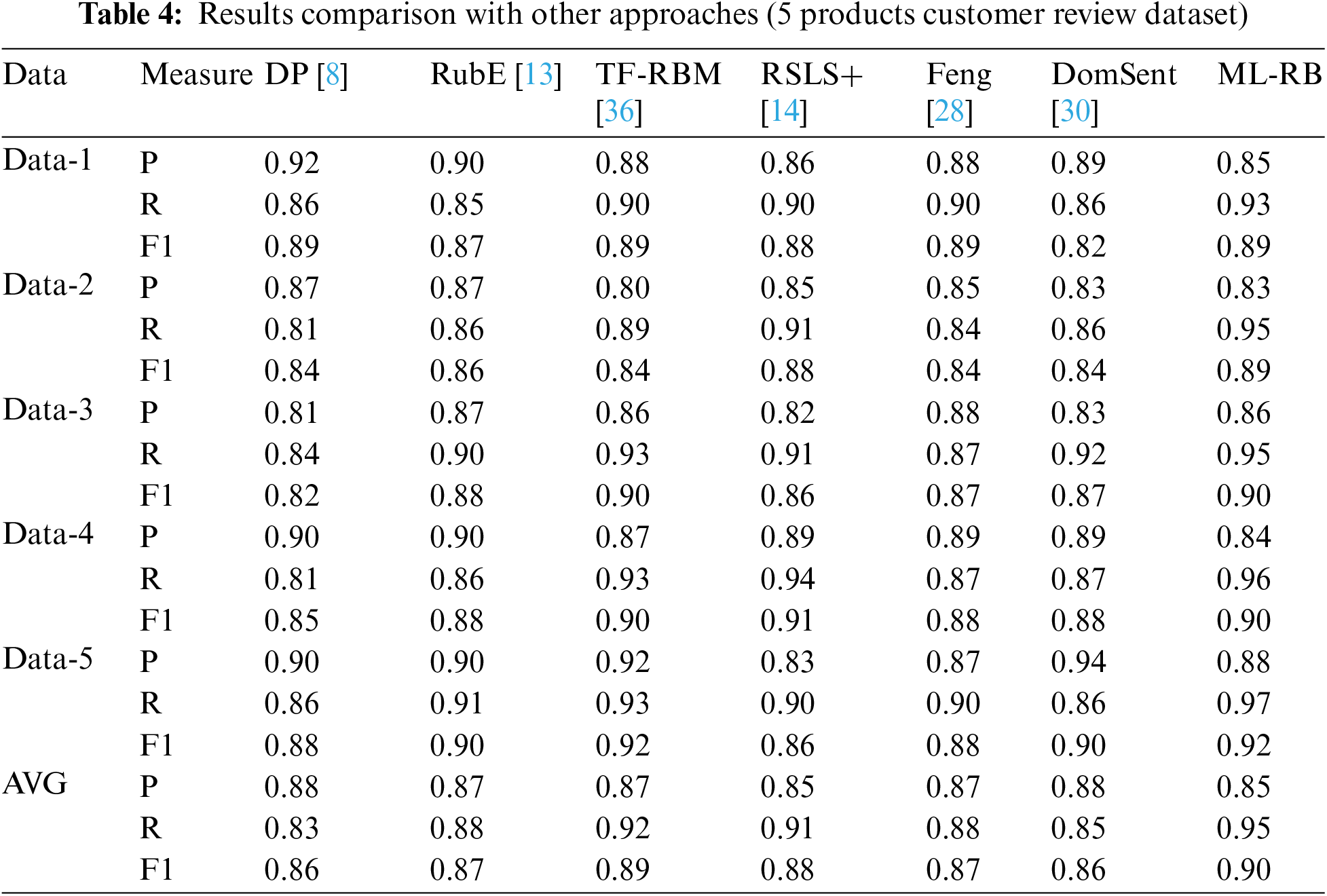
Tab. 4 shows the results in terms of the aforementioned performance measures for the five products customer review dataset. The results for the above given techniques are reported for comparison with the proposed approach. Overall, ML-RB produced higher recall and F1-score compared to all approaches. The recall measure was also better for individual products data in all cases. The precision measure is best for DomSent [30]. However, a higher F1-score implies overall better performance of the proposed approach, as F1-score is a harmonic mean of both precision and recall. Minor drop in precision is because the technique has multiple layers; the slight false positive score of each layer collectively makes an effect on precision. Similar to Tab. 4, the results for the 3 products additional customer review dataset are reported in Tab. 5. The proposed ML-RB approach consistently produced higher performance in terms of all 3 measures. The F1-score was also better for individual products data in all cases.
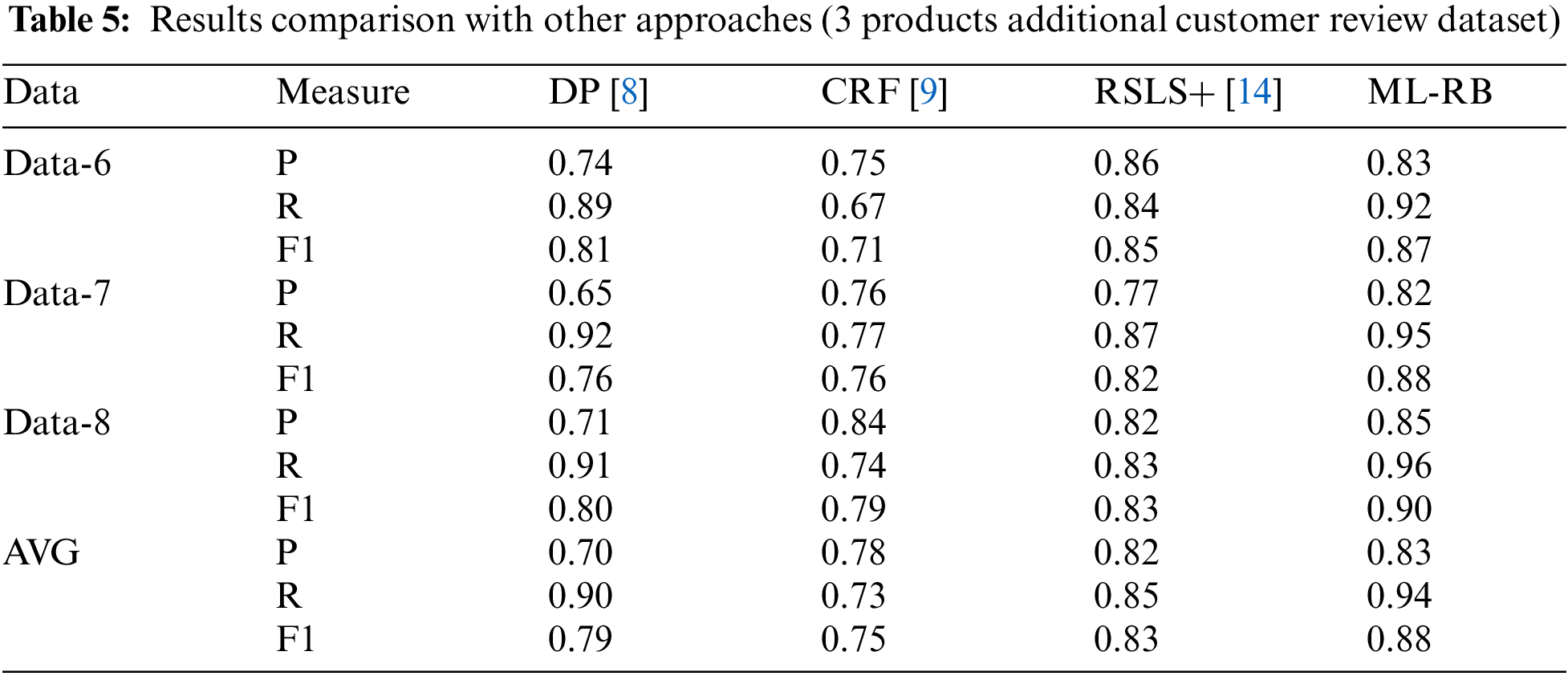
For better visual comparison, these results are also presented in graphical form in Figs. 4 and 5. It should be noted that Tab. 5 and Fig. 5 show results comparison with only 3 existing techniques. This is because the 3 additional products customer reviews dataset was not used in other studies mentioned above.
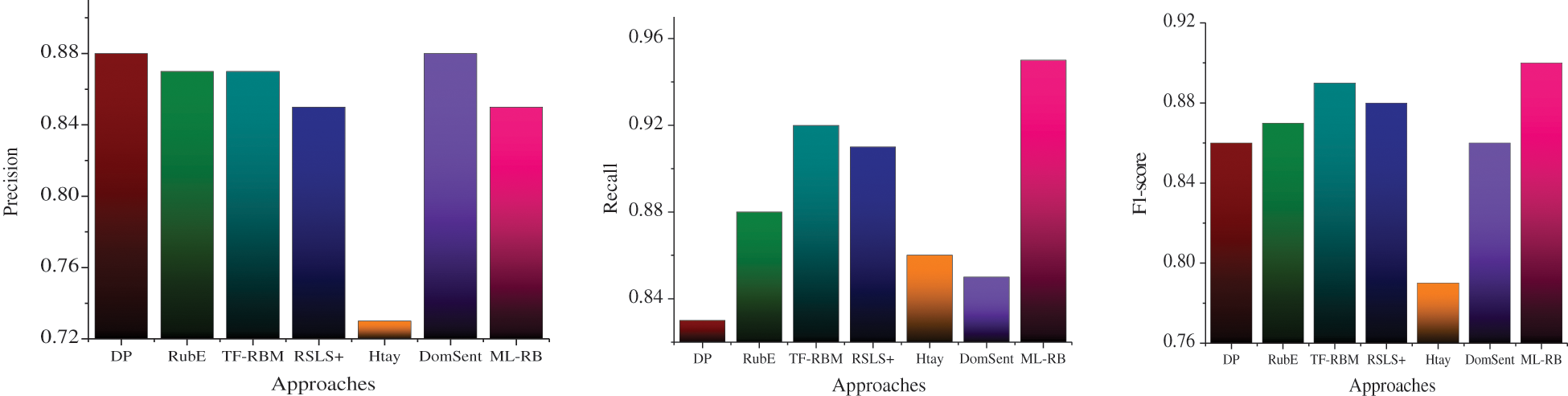
Figure 4: Average precision, recall, F1-score comparison chart on 5 product customer reviews dataset
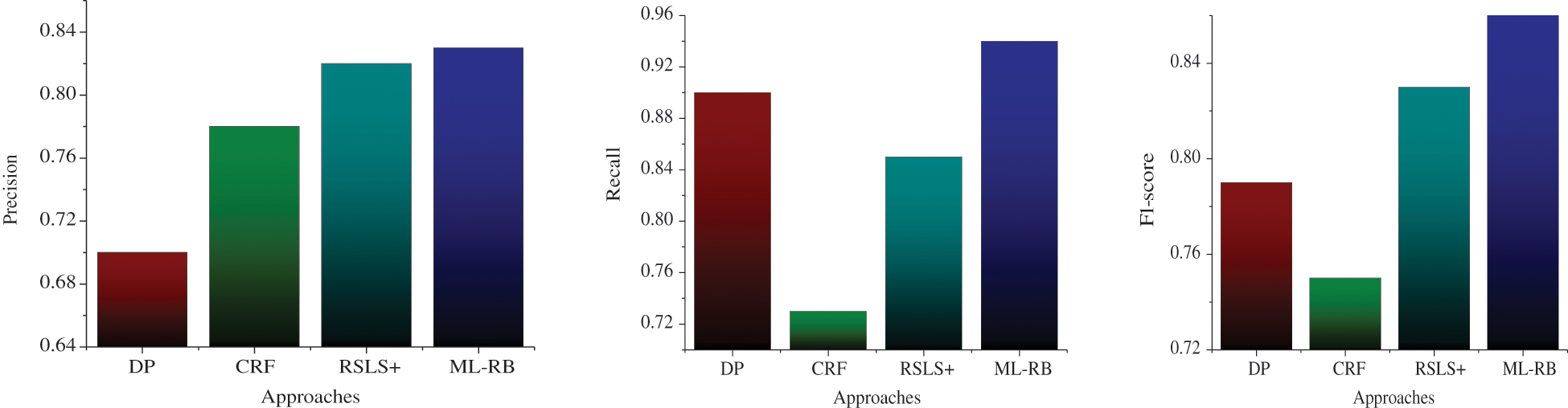
Figure 5: Average precision, recall, F1 comparison chart on 3 product customer reviews dataset
In this study, we have proposed a multi layered rule-based approach for the extraction of explicit aspects from customer reviews. This proposed model can identify the noun as well as verb aspects. The proposed approach is a 3-step process, where each step complements the succeeding one. In the first step, we used DP rules for noun explicit aspect extraction. As the second step, we used the rules based on sequential patterns with opinion lexicon for noun aspects. In the last step, we have manually crafted some rules and implemented verb aspects extraction. The experimental results have shown the significance improvement in the Recall and F1-score of the proposed approach compared to other approaches of this field on two widely used products customer review datasets. In future, this work can be extended by employing domain dependent opinion and extended opinion lexicon.
Acknowledgement: Thanks to our families & colleagues who supported us morally.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1https://nlp.stanford.edu/software/lex-parser.shtml
References
1. B. Liu, “Sentiment analysis and opinion mining,” Synthesis Lectures on Human Language Technologies, vol. 5, no. 1, pp. 1–167, 2012. [Google Scholar]
2. S. V. wawre and S. N. Deshmukh, “Sentiment classification using machine learning techniques,” International Journal of Science and Research (IJSR), vol. 5, no. 4, pp. 1–3, 2016. [Google Scholar]
3. J. M. Wiebe, R. F. Bruce and T. P. O’Hara, “Development and use of a gold-standard data set for subjectivity classifications,” in Proc. of the 37th Annual Meeting of the Association for Computational Linguistics, Maryland, USA, pp. 246–253, 1999. [Google Scholar]
4. M. Hu and B. Liu, “Mining and summarizing customer reviews,” in Proc. of the 10th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, Washington, USA, pp. 168–177, 2004. [Google Scholar]
5. X. Ding, B. Liu and P. S. Yu, “A holistic lexicon-based approach to opinion mining,” in Proc. of the 2008 Int. Conf. on Web Search and Data Mining, California, USA, pp. 231–240, 2008. [Google Scholar]
6. S. Poria, E. Cambria and A. Gelbukh, “Aspect extraction for opinion mining with a deep convolutional neural network,” Knowledge-Based Systems, vol. 108, no. 1, pp. 42–49, 2016. [Google Scholar]
7. M. Makhtar, S. Nafis, M. A. Mohamed, M. K. Awang, M. N. A. Rahman et al., “Churn classification model for local telecommunication company based on rough set theory,” Journal of Fundamental and Applied Sciences, vol. 9, no. 6S, pp. 854–868, 2017. [Google Scholar]
8. G. Qiu, B. Liu, J. Bu and C. Chen, “Opinion word expansion and target extraction through double propagation,” Computational Linguistics, vol. 37, no. 1, pp. 9–27, 2011. [Google Scholar]
9. J. Lafferty, A. McCallum and F. C. N. Pereira, “Conditional random fields: Probabilistic models for segmenting and labeling sequence data,” in Proc. of the 18th Int. Conf. on Machine Learning, Williamstown, MA, USA, pp. 286–289, 2001. [Google Scholar]
10. Y. Wu, Q. Zhang, X. Huang and L. Wu, “Phrase dependency parsing for opinion mining,” in Proc. of the 2009 Conf. on Empirical Methods in Natural Language Processing, Malaysia, Singapore, pp. 1533–1541, 2009. [Google Scholar]
11. T. A. Rana and Y. -N. Cheah, “Sequential patterns-based rules for aspect-based sentiment analysis,” Advanced Science Letters, vol. 24, no. 2, pp. 1370–1374, 2018. [Google Scholar]
12. T. A. Rana and Y. -N. Cheah, “Sequential patterns rule-based approach for opinion target extraction from customer reviews,” Journal of Information Science, vol. 45, no. 5, pp. 643–655, 2018. [Google Scholar]
13. Y. Kang and L. Zhou, “Rube: Rule-based methods for extracting product features from online consumer reviews,” Information & Management, vol. 54, no. 2, pp. 166–176, 2017. [Google Scholar]
14. Q. Liu, Z. Gao, B. Liu and Y. Zhang, “Automated rule selection for aspect extraction in opinion mining,” Knowledge-Based Systems, vol. 104, no. 1, pp. 74–88, 2015. [Google Scholar]
15. R. Agrawal and R. Srikant, “Fast algorithms for mining association rules,” in Proc. of the 20th Int. Conf. Very Large Data Bases, VLDB, Santiago, Chile, vol. 1215, pp. 487–499, 1994. [Google Scholar]
16. B. Liu, W. Hsu and Y. Ma, “Integrating classification and association rule mining,” in Proc. of the 10th Int. Conf. on Knowledge Discovery and Data Mining, Washington, USA, pp. 24–25, 1998. [Google Scholar]
17. A. Amin, T. A. Rana, N. A. Mian, M. W. Iqbal, A. Khalid et al., “Top-rank: A novel unsupervised approach for topic prediction using keyphrase extraction for urdu documents,” IEEE Access, vol. 8, no. 2020, pp. 212675–212686, 2020. [Google Scholar]
18. B. Wang and H. Wang, “Bootstrapping both product features and opinion words from Chinese customer reviews with cross-inducing,” in Proc. of the Third Int. Joint Conf. on Natural Language Processing: Volume-I, Hyderabad, India, 2008. [Google Scholar]
19. Z. Hai, K. Chang and G. Cong, “One seed to find them all: Mining opinion features via association,” in Proc. of the 21st ACM Int. Conf. on Information and Knowledge Management, Maui Hawaii, USA, pp. 255–264, 2012. [Google Scholar]
20. Q. Zhao, H. Wang, P. Lv and C. Zhang, “A bootstrapping based refinement framework for mining opinion words and targets,” in Proc. of the 23rd ACM Int. Conf. on Information and Knowledge Management, Shanghai China, pp. 1995–1998, 2014. [Google Scholar]
21. N. Kobayashi, K. Inui and Y. Matsumoto, “Extracting aspect-evaluation and aspect-of relations in opinion mining,” in Proc. of the 2007 Joint Conf. on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, pp. 1065–1074, 2007. [Google Scholar]
22. P. Jiang, C. Zhang, H. Fu, Z. Niu and Q. Yang, “An approach based on tree kernels for opinion mining of online product reviews,” in 2010 IEEE Int. Conf. on Data Mining, Sydney, Australia, pp. 256–265, 2010. [Google Scholar]
23. F. Li, C. Han, M., Huang, X. Zhu, Y. Xia et al., “Structure-aware review mining and summarization,” in Proc. of the 23rd Int. Conf. on Computational Linguistics (Coling 2010), Bejing, China, pp. 653–661, 2010. [Google Scholar]
24. T. A. Rana, B. Bakht, M. Afzal, N. A. Mian, M. W. Iqbal et al., “Extraction of opinion target using syntactic rules in urdu text,” Intelligent Automation & Soft Computing (IASC), vol. 29, no. 3, pp. 839–853, 2021. [Google Scholar]
25. N. Jakob and I. Gurevych, “Extracting opinion targets in a single and cross-domain setting with conditional random fields,” in Proc. of the 2010 Conf. on Empirical Methods in Natural Language Processing, Massachusetts, USA, pp. 1035–1045, 2010. [Google Scholar]
26. S. Huang, X. Liu, X. Peng and Z. Niu, “Fine-grained product features extraction and categorization in reviews opinion mining,” in 2012 IEEE 12th Int. Conf. on Data Mining Workshops, Brussels, Belgium, pp. 680–686, 2012. [Google Scholar]
27. Y. Xiang, H. He and J. Zheng, “Aspect term extraction based on MFE-cRF,” Information, vol. 9, no. 8, pp. 198–210, 2018. [Google Scholar]
28. H. Xiong, H. Yan, Z. Zeng and B. Wang, “Dependency parsing and bidirectional lSTM-cRF for aspect-level sentiment analysis of Chinese,” in JIST (Workshops & Posters), Awaji, Japan, pp. 90–93, 2018. [Google Scholar]
29. P. Ray and A. Chakrabarti, “A mixed approach of deep learning method and rule-based method to improve aspect level sentiment analysis,” Applied Computing and Informatics, vol. 18, no. 1, pp. 163–178, 2020. [Google Scholar]
30. J. Feng, W. Yang, C. Gong, X. Li and R. Bo, “Product feature extraction via topic model and synonym recognition approach,” in CCF Conf. on Big Data, Wuhan, China, pp. 73–88, 2019. [Google Scholar]
31. A. Nawaz, S. Asghar and S. H. A. Naqvi, “A segregational approach for determining aspect sentiments in social media analysis,” The Journal of Supercomputing, vol. 75, no. 5, pp. 2584–2602, 2019. [Google Scholar]
32. G. S. Chauhan and Y. K. Meena, “Domsent: Domain-specific aspect term extraction in aspect-based sentiment analysis,” in Smart Systems and IoT: Innovations in Computing, vol. 141. Singapore: Springer, pp. 103–109, 2020. [Google Scholar]
33. J. Yu, Z. J. Zha, M. Wang and T. S. Chua, “Aspect ranking: Identifying important product aspects from online consumer reviews,” in Proc. of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland Oregon, pp. 1496–1505, 2011. [Google Scholar]
34. K. Liu, H. L. Xu, Y. Liu and J. Zhao, “Opinion target extraction using partially-supervised word alignment model,” in Proc. of the 23rd Int. Joint Conf. on Artificial Intelligence, Beijing, China, vol. 13, pp. 2134–2140, 2013. [Google Scholar]
35. T. A. Rana and Y. N. Cheah, “Hybrid rule-based approach for aspect extraction and categorization from customer reviews,” in 9th Int. Conf. on IT in Asia (CITA), Kuching, Malaysia, pp. 1–5, 2015. [Google Scholar]
36. T. A. Rana and Y. N. Cheah, “Improving aspect extraction using aspect frequency and semantic similarity-based approach for aspect-based sentiment analysis,” in Int. Conf. on Computing and Information Technology, Singapore, pp. 317–326, 2017. [Google Scholar]
37. T. A. Rana and Y. N. Cheah, “Exploiting sequential patterns to detect objective aspects from online reviews,” in 2016 Int. Conf. on Advanced Informatics: Concepts, Theory and Application (ICAICTA), Penang, Malaysia, pp. 1–5, 2016. [Google Scholar]
38. T. A. Rana and Y. N. Cheah, “A two-fold rule-based model for aspect extraction,” Expert Systems with Applications, vol. 89, no. 1, pp. 273–285, 2017. [Google Scholar]
39. B. R. Bhamare and J. Prabhu, “A supervised scheme for aspect extraction in sentiment analysis using the hybrid feature set of word dependency relations and lemmas,” PeerJ Computer Science, vol. 7, no. 347, pp. 1–22, 2021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |