| Computers, Materials & Continua DOI:10.32604/cmc.2022.031096 | |
| Article |
Hyperparameter Tuned Deep Learning Enabled Cyberbullying Classification in Social Media
1Department of Computer Science, College of Sciences and Humanities-Aflaj, Prince Sattam bin Abdulaziz University, Saudi Arabia
2Department of Electrical Engineering, College of Engineering, Princess Nourah Bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3Department of Information Systems, College of Computing and Information System, Umm Al-Qura University, Saudi Arabia
4Department of Computer Science, College of Science & Art at Mahayil, King Khalid University, Muhayel Aseer, Saudi Arabia
5Faculty of Computers and Information, Computer Science Department, Menoufia University, Egypt
6Research Centre, Future University in Egypt, New Cairo, 11845, Egypt
7Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, Al-Kharj, Saudi Arabia
8Department of Information System, College of Computer Engineering and Sciences, Prince Sattam bin Abdulaziz University, Al Kharj, Saudi Arabia
*Corresponding Author: Mesfer Al Duhayyim. Email: m.alduhayyim@psau.edu.sa
Received: 10 April 2022; Accepted: 20 May 2022
Abstract: Cyberbullying (CB) is a challenging issue in social media and it becomes important to effectively identify the occurrence of CB. The recently developed deep learning (DL) models pave the way to design CB classifier models with maximum performance. At the same time, optimal hyperparameter tuning process plays a vital role to enhance overall results. This study introduces a Teacher Learning Genetic Optimization with Deep Learning Enabled Cyberbullying Classification (TLGODL-CBC) model in Social Media. The proposed TLGODL-CBC model intends to identify the existence and non-existence of CB in social media context. Initially, the input data is cleaned and pre-processed to make it compatible for further processing. Followed by, independent recurrent autoencoder (IRAE) model is utilized for the recognition and classification of CBs. Finally, the TLGO algorithm is used to optimally adjust the parameters related to the IRAE model and shows the novelty of the work. To assuring the improved outcomes of the TLGODL-CBC approach, a wide range of simulations are executed and the outcomes are investigated under several aspects. The simulation outcomes make sure the improvements of the TLGODL-CBC model over recent approaches.
Keywords: Social media; deep learning; cyberbullying; cybersecurity; hyperparameter optimization
With the rising number of users on social media results in a new method of bullying. The latter term is termed as aggressive or intentional move that is performed by individuals or groups of persons by recurrently transmitting messages over time toward a sufferer who is not in a state to defend him or herself [1]. Bullying has become a portion of the community forever. With the emergence of the internet, it has been only a matter of time unless bullies discover their way on to this opportunistic and new medium. According to National Crime Prevention Council Cyberbullying (CB) is termed as the usage of mobile phones, Internet, or another device for sharing or posting messages or pictures that intentionally hurts or embarrasses any other individual. Several researchers state that amongst 10%–40% of internet consumers are considered the sufferer of CB [2,3]. Effects of CB have serious effects which may range from impermanent anxiety to suicide.
Identification of CB in mass communication is regarded as difficult job. Definition of what represents CB is completely subjective [4]. For instance, according to common people, recurrent usage of swear texts or messages may be regarded as bullying. But, teen-related mass media platforms namely Form spring are not considered bullying [5]. CBs attack victims on distinct subjects namely religion gender, and race. Based on the subjects of CB, glossary and perceived meaning of words change remarkably. CB awareness is raised in most countries because of the consequences described in this work. Correspondingly, most of the authors submitted their works by machine learning (ML) methods for identifying CB in an automatic way [6,7]. However, many studies in this domain have been carried out for the English language. Moreover, the study which is carried out usually utilizes text mining methods which are equivalent to the sentiment analysis study [8]. The reality is mass media post are context-dependent and interactive; therefore, it is not regarded as a standalone message. A lot of research work was conducted on explicit speech identification [9]. Still, more volume of studies becomes necessary for solving the implicit language which makes identifying cyber-bullying in mass communication a difficult task [10]. Nonetheless, advancement was made in the identification of cyber-bullying by methods of deep learning (DL) and ML. But many recent studies have to be advanced for offering an appropriate method which includes clear and indirect elements.
The authors in [11] presented XP-CB, a new cross-platform structure dependent upon Transformer and adversarial learning. The XP-CB is to improve a Transformer leveraging unlabelled data in the source and target platforms for appearing with a general representation but preventing platform-specific trained. The authors in [12] relate the performance of several words embedded approaches in fundamental word embedded approaches for present advanced language techniques for CB recognition. It can be utilized LightGBM and Logistic regression (LR) techniques for the classifier of bullying and non-bullying tweets. Murshed et al. [13] examine the hybrid DL technique named deep autoencoder with recurrent neural network (DEA-RNN), for detecting CB on Twitter social media networks. The presented DEA-RNN technique integrates Elman form RNN with an optimizing Dolphin Echolocation Algorithm (DEA) to fine-tune the Elman RNN parameter and decrease training time.
Dewani et al. [14] executed wide pre-processing on Roman Urdu micro-text. This classically includes development of Roman Urdu slang- phrase dictionary and mapping slang then tokenization. The unstructured data are more managed for handling encoder text format and metadata or non-linguistic feature. Also, it can be implemented wide experimental by applying convolution neural network (CNN), RNN-long short term memory (LSTM), and RNN-bidirectional LSTM (BiLSTM) techniques. Ahmed et al. [15] presented binary and multi-class classifier methods utilizing hybrid neural network (NN) for bully expression recognition in Bengali language. It can be utilized 44,001 users comment on popular public Facebook pages that fall as to 5 classes Religious, Sexual, Non-bully, Threat, and Troll.
This study introduces a Teacher Learning Genetic Optimization with Deep Learning Enabled Cyberbullying Classification (TLGODL-CBC) model in Social Media. The proposed TLGODL-CBC model intends to identify the existence and non-existence of CB in social media context. Initially, the input data is cleaned and pre-processed to make it compatible for further processing. Followed by, independent recurrent autoencoder (IRAE) model is utilized for the recognition and classification of CBs. Finally, the TLGO algorithm is used to optimally adjust the parameters related to the IRAE model. To assuring the improved outcomes of the TLGODL-CBC method, a wide range of simulations are executed and the outcomes are investigated in several aspects.
In this study, a new TLGODL-CBC model was established for identifying the existence and non-existence of CB in social media context. At the primary stage, the input data is cleaned and pre-processed to make it compatible for further processing. Then, the pre-processed data is fed into the IRAE method for the recognition and classification of CBs. Finally, the TLGO algorithm is used to optimally adjust the parameters related to the IRAE model and thus results in enhanced classification performance. Fig. 1 depicts the overall block diagram of TLGODL-CBC technique.
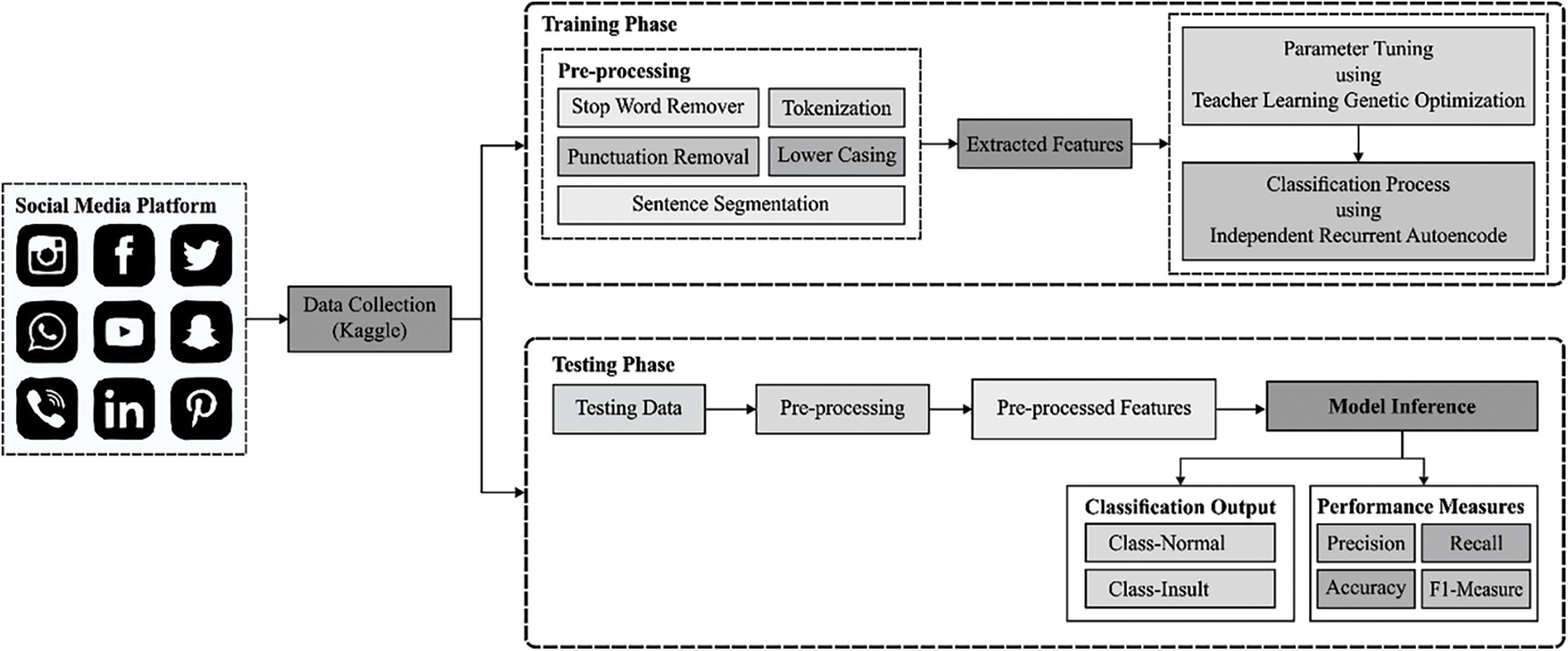
Figure 1: Overall block diagram of TLGODL-CBC technique
Primarily, the data was analyzed to a maximum degree of refinement by executing and subsequent the step stipulated under punctuation removal, Stop word remover, sentence segmentation, tokenization, and lower casing. These are the stages which are obtained to have data decreased to size, and so, it can be also eliminated unwanted data which is established from the data. During this method, it can be generated a generic pre-processed which resulted from the elimination of punctuation and is some non-letter character in every document. At last, the letter case of all the documents is lowered. The outcome of this method provided us with a sliced document text dependent upon n length with n-gram word-based tokenizer. The next stage then it had gone with the tokenization model is for transforming the token as to another normal format. Similar to stemming, the resolve of lemmatization is for minimizing inflectional procedures for a particular base procedure. Preposition and conjunction, Article, and some pronouns, i.e., are assumed to stop words.
At this stage, the pre-processed data is fed into the IRAE technique for the recognition and classification of CBs. The standard RNNs are inclined to gradient vanishing and explosion in the training because of the repeating multiplication of weighted matrix. IRNN is a novel recurrent network which efficiently resolves the gradient problem by altering the time-based gradient back propagation [16–20]. Also, IRNN is employ unsaturated function (i.e., rectified linear unit (ReLU)) as an activation function and retains higher robustness and then training. The IRNN network is formulated as:
In which the input weighted W is a matrix, the recurrent weighted u is a vector, and
whereas
In which
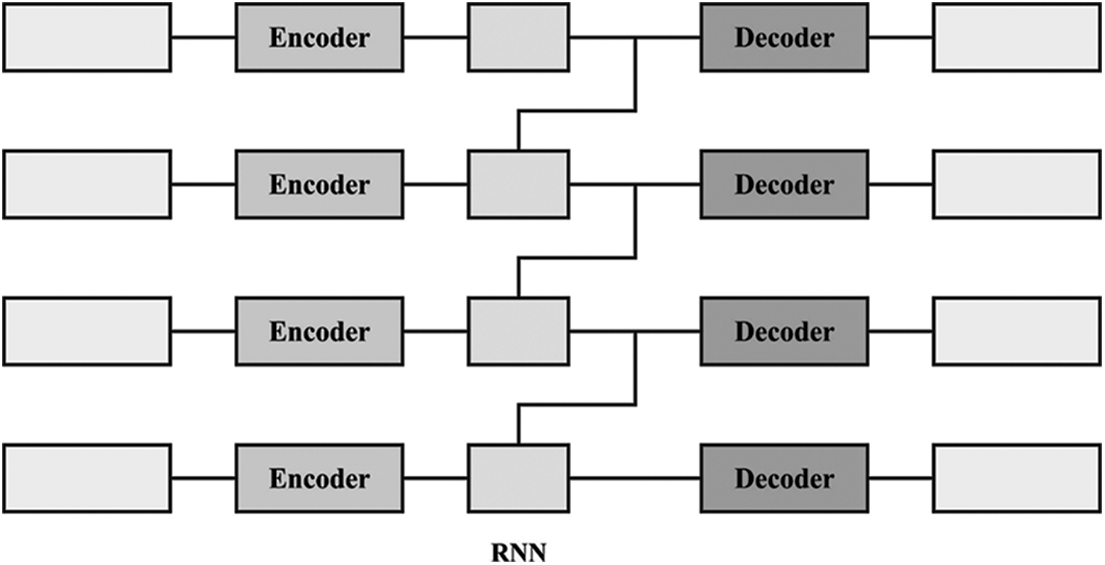
Figure 2: Structure of recurrent autoencoder
2.3 TLGO Based Parameter Optimization
Lastly, the TLGO algorithm is used to optimally adjust the parameters related to the IRAE model and thus results in enhanced classification performance. We have projected TLGO approach by integrating the feature of genetic algorithm (GA) with teaching learning based optimization (TLBO) [21]. Here, exploration and exploitation are 2 major features that should be considered. To accomplish superior outcome, there needs to be a balance among global and local searching agents. TLBO is well performed in exploitation phase, that is, finding the optimal solution in local searching space, and poorly performed in exploration phase. To resolve the imbalance between exploitation and exploration stage, we developed TLGO method by adding the mutation and crossover operators of GA into TLBO algorithm. GA performed well in exploration phase and has better convergence rate. At first, TLGO approach has similar step as TLBO step. The first two stages of TLBO approach that is., teacher and learner phases are added to TLGO method without making any changes. In learner stage, each learner interacts with others for improving their knowledge. For every learner
The TLGO method uses exploration as well as exploitation phases and maintains a balance in local and global searching agents by using mutation and crossover operators of GA to TLBO technique. The presented method has good convergence rate with lesser computation effort, interms of finding an optimum solution. Algorithm 1 illustrates the working process of the presented TLGO approach.

The experimental validation of the TLGODL-CBC model is tested using a benchmark dataset from Kaggle repository [22]. The dataset holds images under two class labels (Insult-1049/Normal-2898). Tab. 1 illustrates the dataset details.
The confusion matrices generated by the TLGODL-CBC model on distinct sizes of training (TR) and testing (TS) data are illustrated in Fig. 3. With 80% of TR data, the TLGODL-CBC model has recognized 743 samples into insult and 2212 samples into normal. Moreover, with 20% of TS data, the TLGODL-CBC approach has recognized 187 samples into insult and 548 samples into normal. Furthermore, with 70% of TR data, the TLGODL-CBC system has recognized 667 samples into insult and 1903 samples into normal. At last, with 30% of TS data, the TLGODL-CBC algorithm has recognized 282 samples into insult and 832 samples into normal.
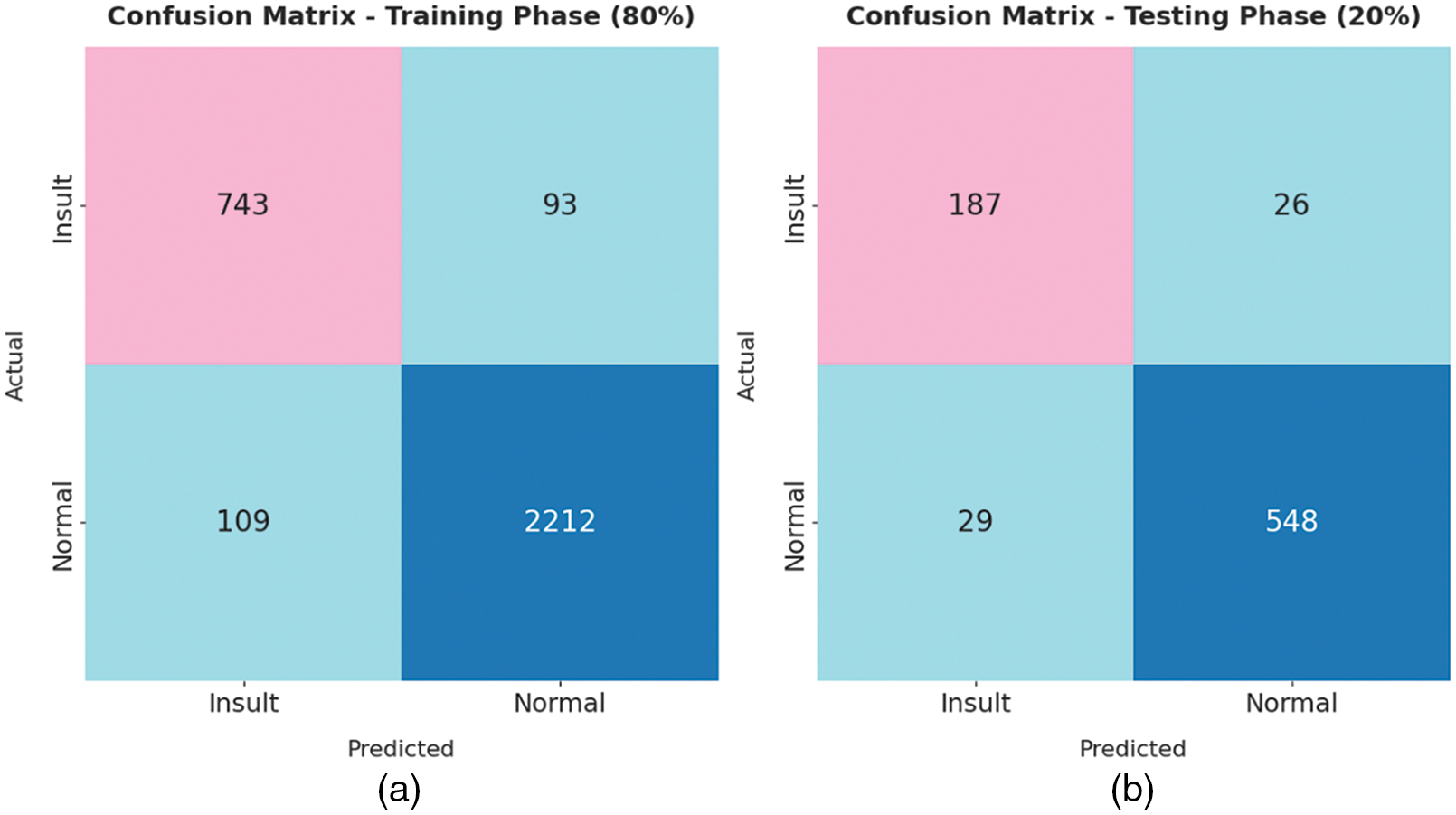
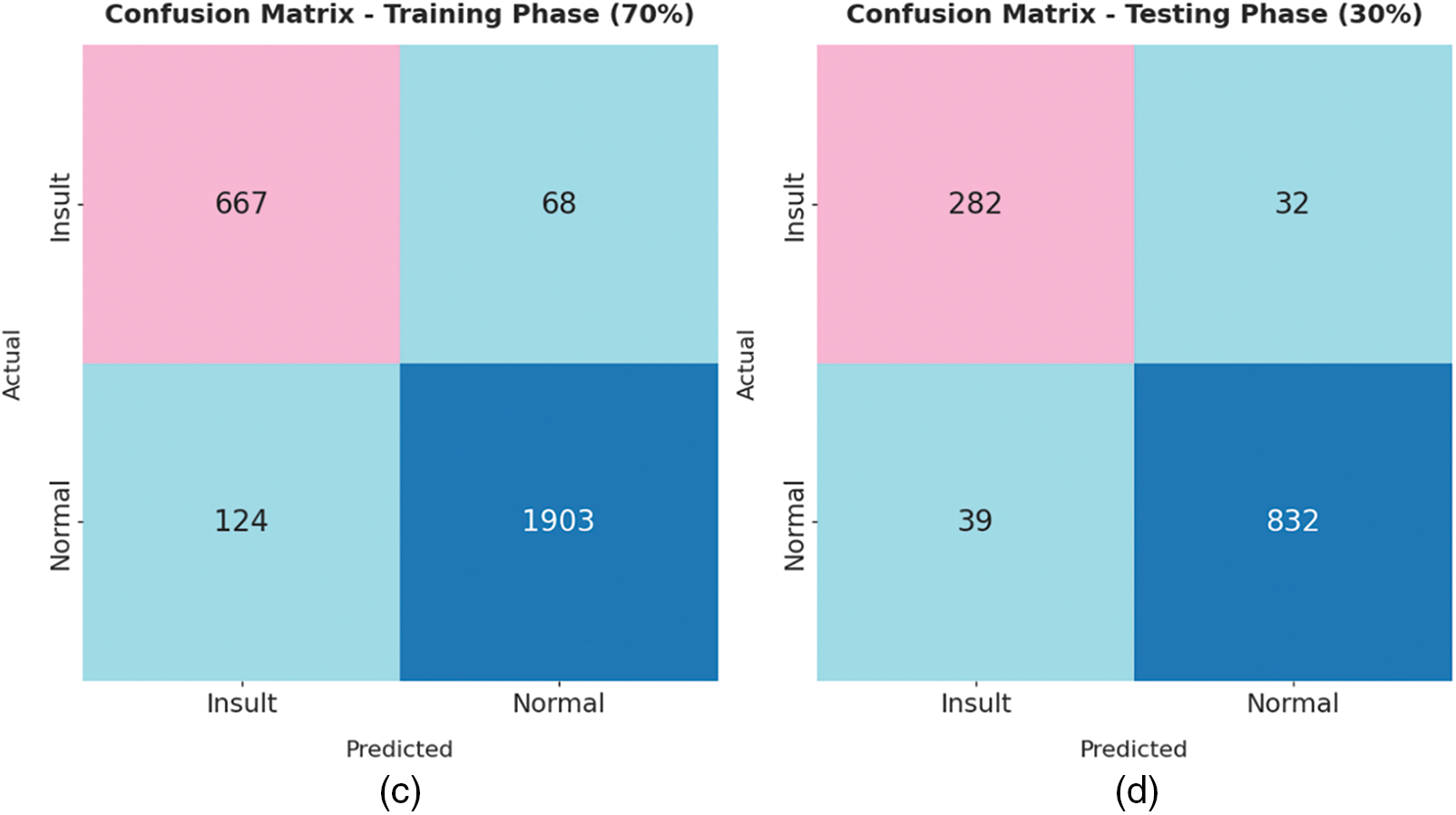
Figure 3: Confusion matrix of TLGODL-CBC technique: a) 80% of TR, b) 80% of TS, c) 70% of TR, and d) 30% of TS
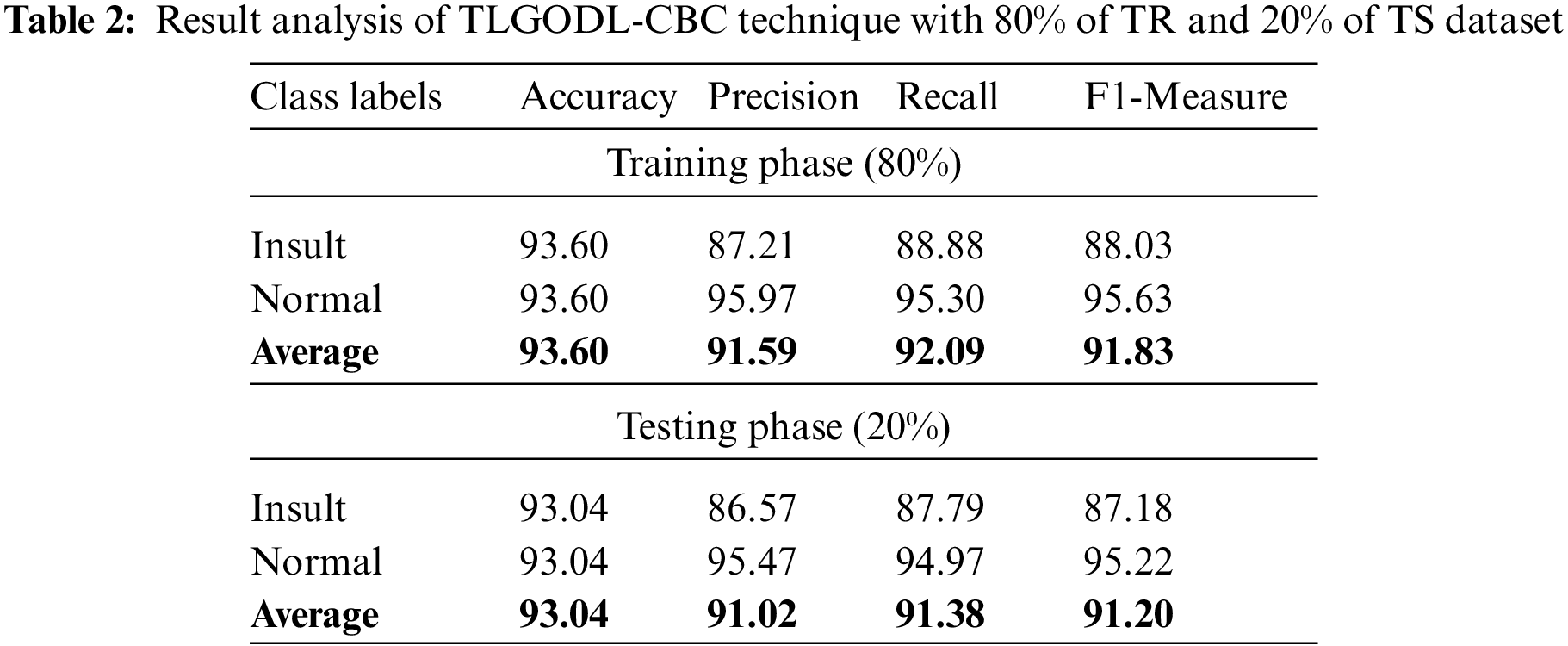
Tab. 2 reports a brief classifier result of the TLGODL-CBC model with 80% of TR data and 20% of TS data. The experimental results indicated that the TLGODL-CBC model has reached effectual outcomes in both cases. For instance, with 80% of TR data, the TLGODL-CBC model has offered average
Tab. 3 defines a detailed classifier result of the TLGODL-CBC model with 70% of TR data and 30% of TS data. The experimental outcomes outperformed that the TLGODL-CBC approach has reached effectual outcomes in both cases. For instance, with 70% of TR data, the TLGODL-CBC approach has accessible average
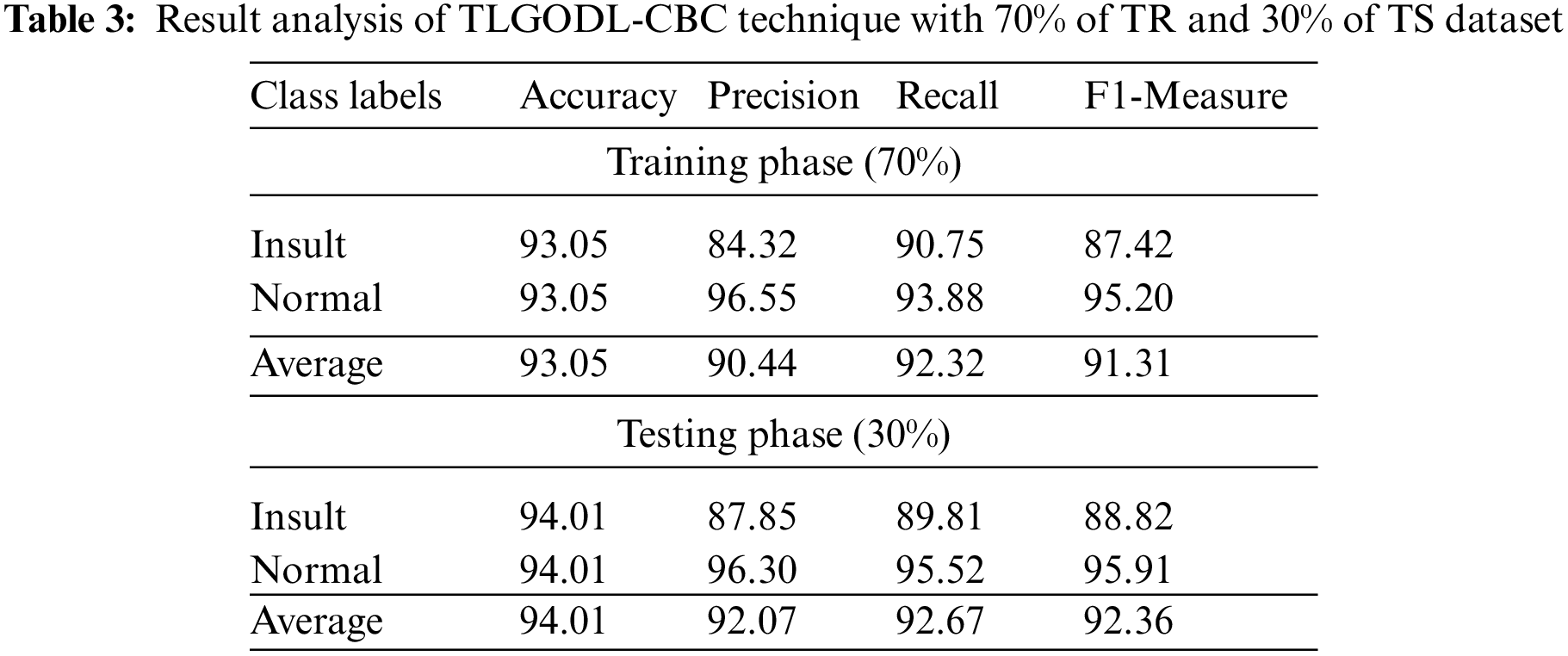
Fig. 4 provides an average result analysis of the TLGODL-CBC model with varying TR/TS data. The figure reported that the TLGODL-CBC model has accomplished effectual outcomes under distinct sizes of TR/TS data.
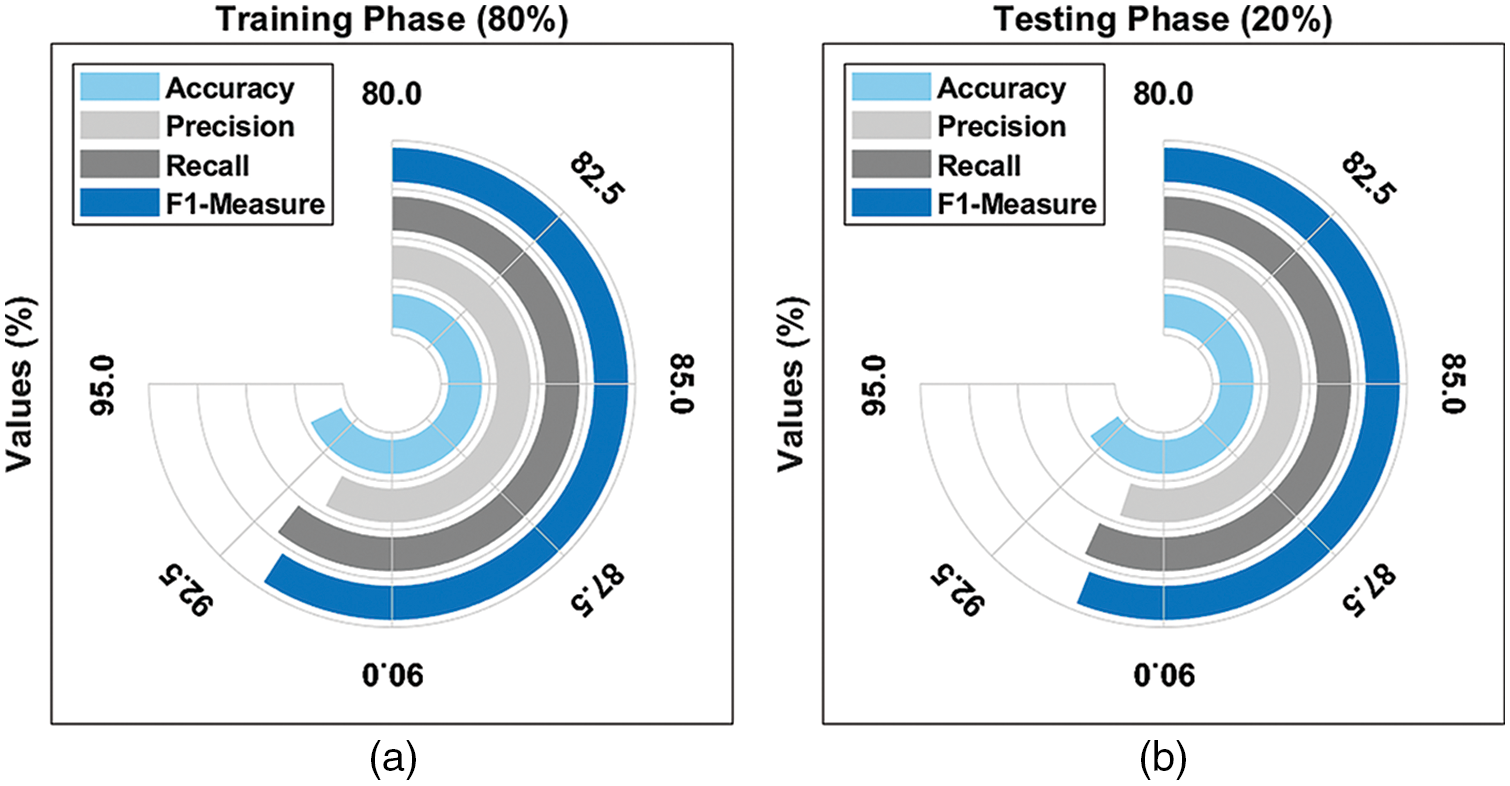
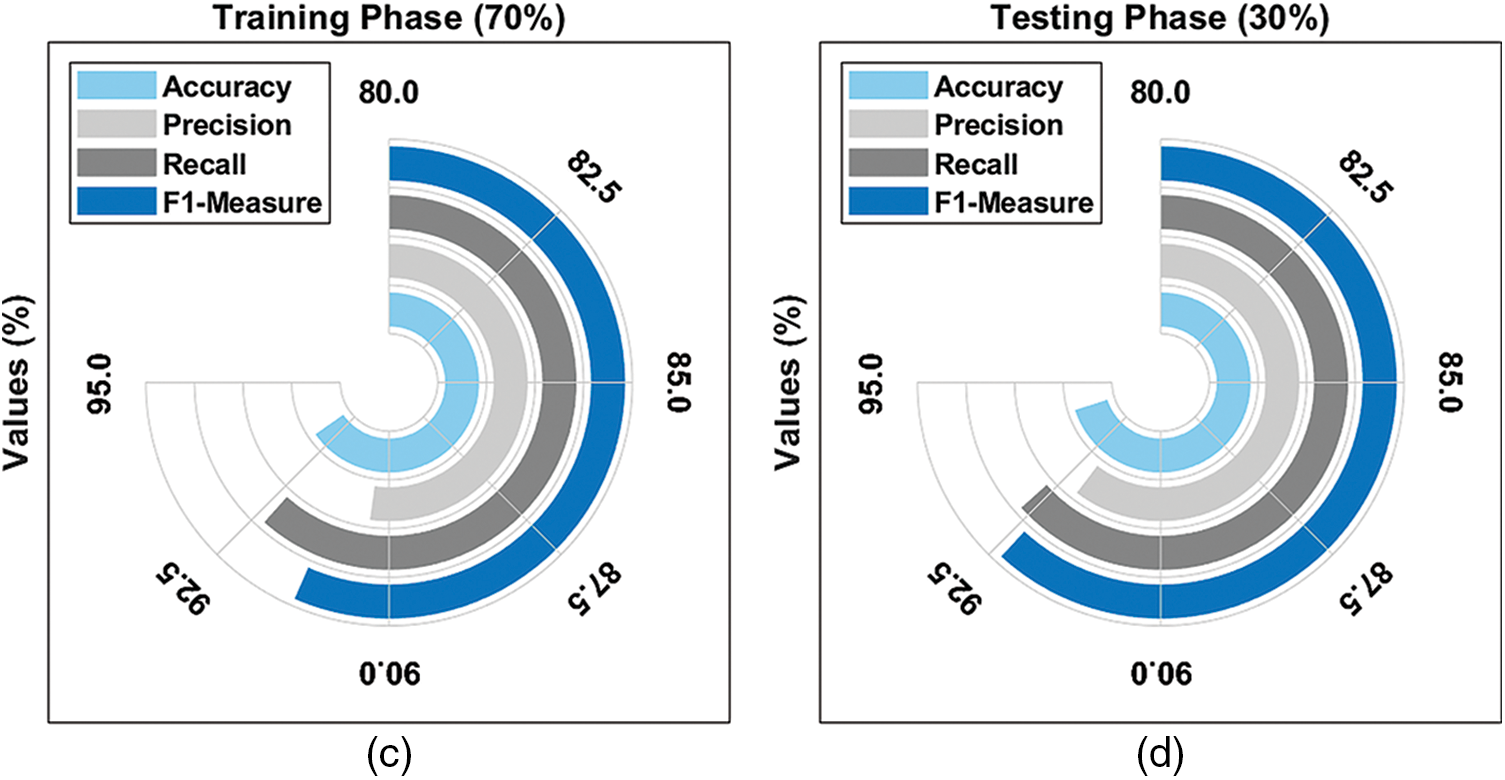
Figure 4: Average analysis of TLGODL-CBC technique: a) 80% of TR, b) 80% of TS, c) 70% of TR, and d) 30% of TS
Fig. 5 offers the accuracy and loss graph analysis of the TLGODL-CBC method on distinct TR/TS datasets. The results exhibited that the accuracy value inclines to improve and loss value inclines to reduce with a higher epoch count. It can be also exposed that the training loss is lower and validation accuracy is higher on the test dataset.
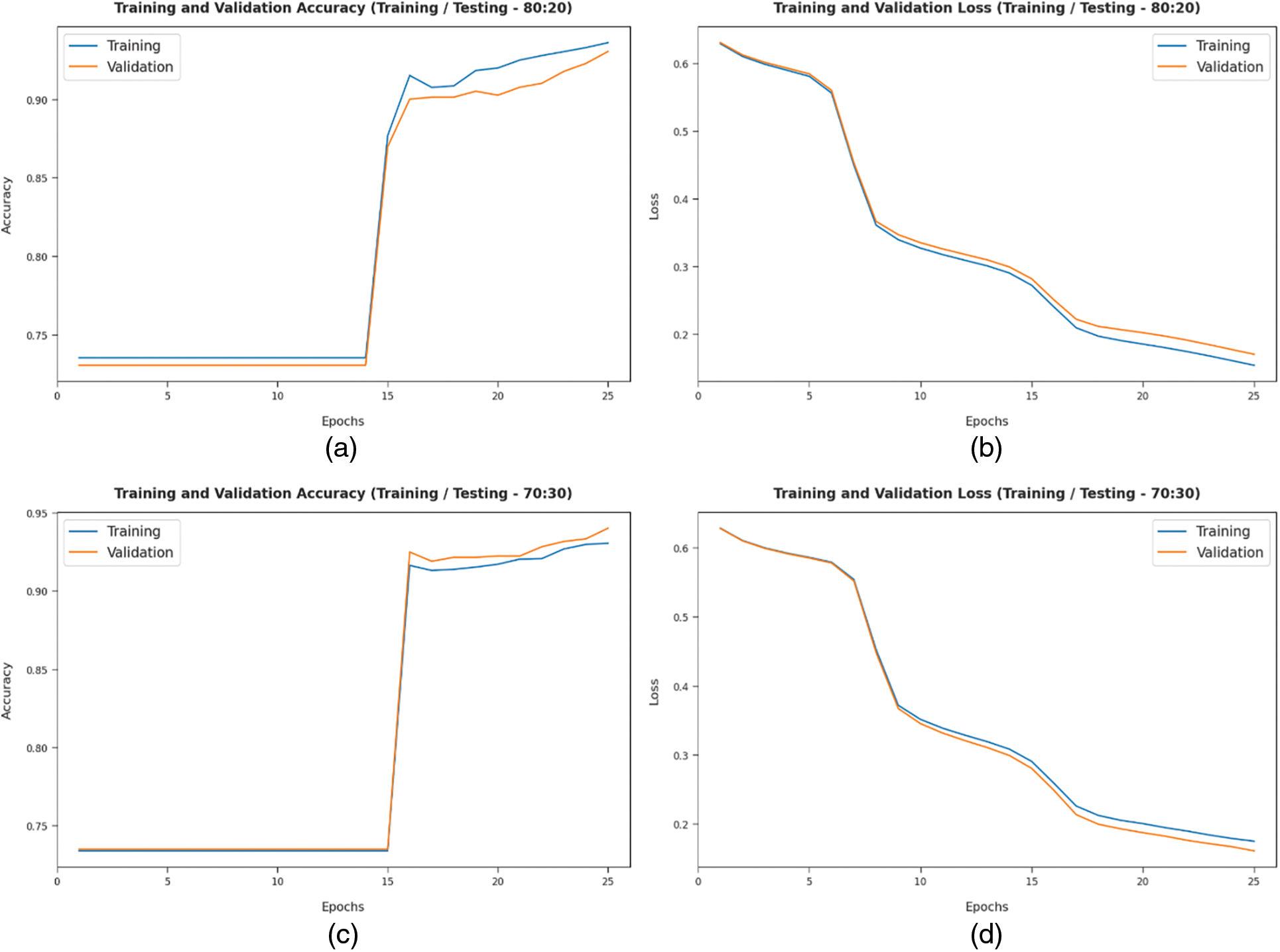
Figure 5: Accuracy and loss analysis of TLGODL-CBC technique: a) 80:20 of TR/TS accuracy, b) 80:20 of TR/TS loss, c) 70:30 of TR/TS accuracy, and d) 70:30 of TR/TS loss
To assuring the enhanced performance of the TLGODL-CBC model, a comparison study is made with recent models in Tab. 4 [23]. Fig. 6 provides a comprehensive comparative
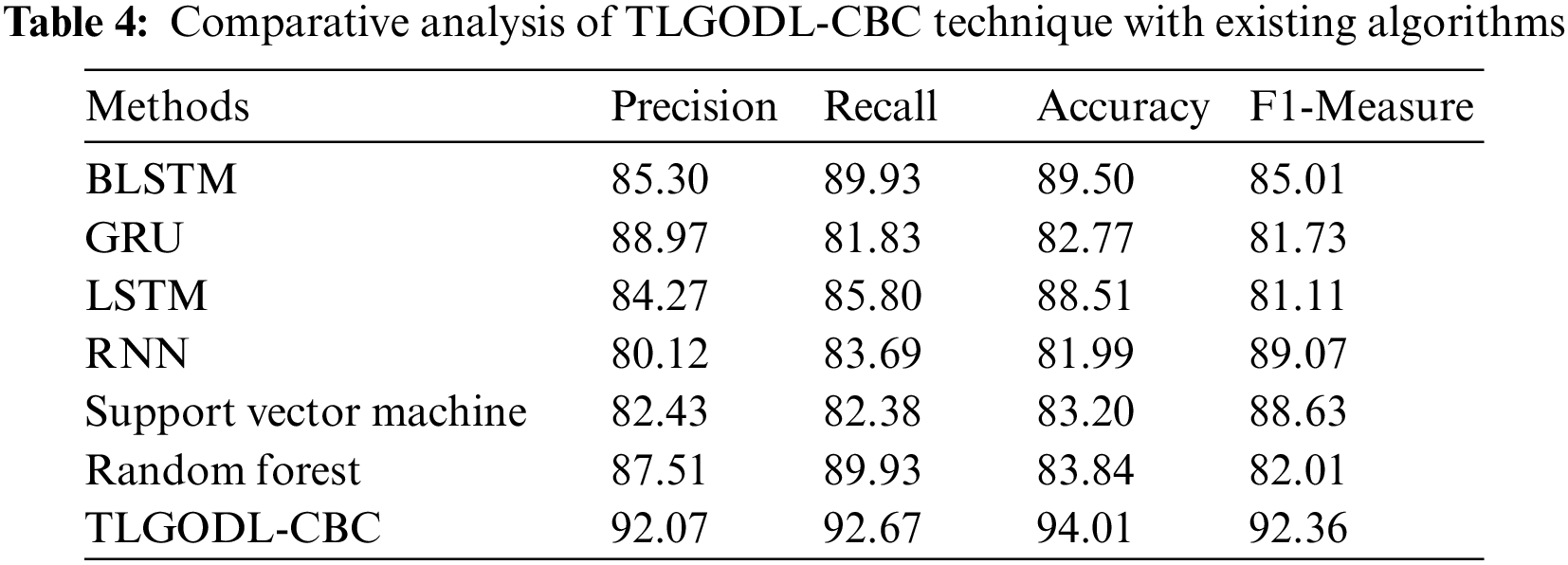

Figure 6:
Fig. 7 offers a detailed comparative
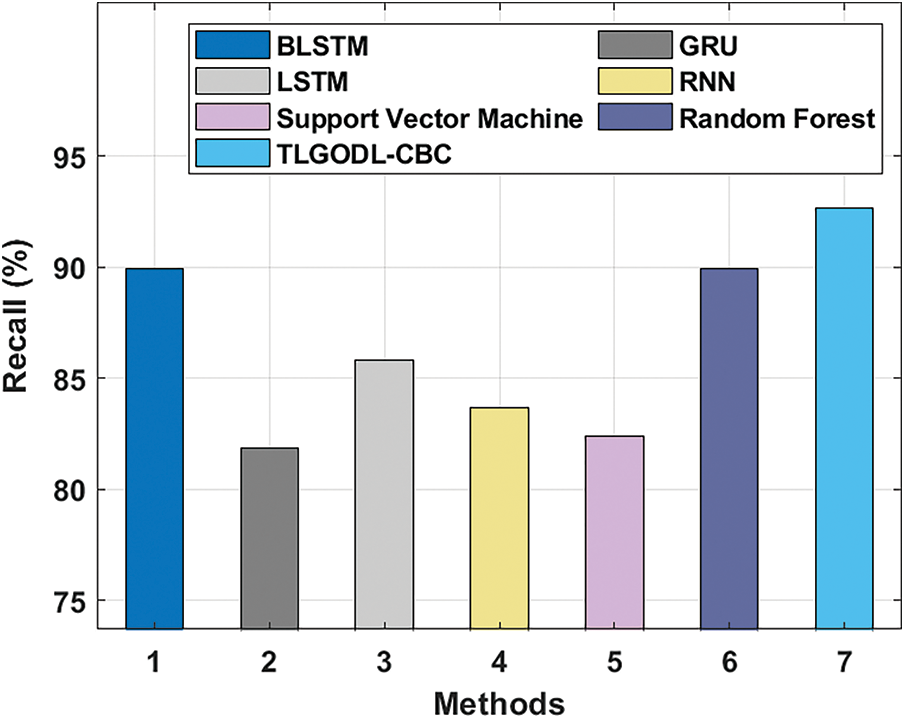
Figure 7:
Fig. 8 illustrates a brief comparative

Figure 8:
Fig. 9 demonstrates a comprehensive comparative

Figure 9:
In this study, a novel TLGODL-CBC model was established for identifying the existence and non-existence of CB in social media context. At the primary stage, the input data is cleaned and pre-processed for making it compatible for further processing. Then, the pre-processed data is fed into the IRAE technique for the recognition and classification of CBs. Finally, the TLGO algorithm is used to optimally adjust the parameters related to the IRAE model and thus results in enhanced classification performance. To assuring the enhanced outcomes of the TLGODL-CBC technique, a wide range of simulations was carried out and the outcomes are investigated in several aspects. The simulation outcomes ensured the improvements of the TLGODL-CBC model over recent approaches. Thus, the TLGODL-CBC model has exhibited reasonable performance over other methods. In future, hybrid DL classification models can be included to boost the overall classification performance.
Funding Statement: The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work under Grant Number (RGP 2/46/43). Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R140), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4210118DSR12).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. V. Balakrishnan, S. Khan and H. R. Arabnia, “Improving cyberbullying detection using twitter users’ psychological features and machine learning,” Computers & Security, vol. 90, pp. 101710, 2020. [Google Scholar]
2. A. Muneer and S. M. Fati, “A comparative analysis of machine learning techniques for cyberbullying detection on twitter,” Future Internet, vol. 12, no. 11, pp. 187, 2020. [Google Scholar]
3. Z. L. Chia, M. Ptaszynski, F. Masui, G. Leliwa and M. Wroczynski, “Machine learning and feature engineering-based study into sarcasm and irony classification with application to cyberbullying detection,” Information Processing & Management, vol. 58, no. 4, pp. 102600, 2021. [Google Scholar]
4. A. Ali and A. M. Syed, “Cyberbullying detection using machine learning,” Pakistan Journal of Engineering and Technology, vol. 3, no. 2, pp. 45–50, 2020. [Google Scholar]
5. M. Arif, “A systematic review of machine learning algorithms in cyberbullying detection: Future directions and challenges,” Journal of Information Security and Cybercrimes Research, vol. 4, no. 1, pp. 1–26, 2021. [Google Scholar]
6. A. Bozyiğit, S. Utku and E. Nasibov, “Cyberbullying detection: Utilizing social media features,” Expert Systems with Applications, vol. 179, pp. 115001, 2021. [Google Scholar]
7. T. Alsubait and D. Alfageh, “Comparison of machine learning techniques for cyberbullying detection on youtube arabic comments,” International Journal of Computer Science & Network Security, vol. 21, no. 1, pp. 1–5, 2021. [Google Scholar]
8. A. Kumar and N. Sachdeva, “Multimodal cyberbullying detection using capsule network with dynamic routing and deep convolutional neural network,” Multimedia Systems, 2021, https://doi.org/10.1007/s00530-020-00747-5. [Google Scholar]
9. M. Alotaibi, B. Alotaibi and A. Razaque, “A multichannel deep learning framework for cyberbullying detection on social media,” Electronics, vol. 10, no. 21, pp. 2664, 2021. [Google Scholar]
10. Y. Fang, S. Yang, B. Zhao and C. Huang, “Cyberbullying detection in social networks using bi-gru with self-attention mechanism,” Information, vol. 12, no. 4, pp. 171, 2021. [Google Scholar]
11. P. Yi and A. Zubiaga, “Cyberbullying detection across social media platforms via platform-aware adversarial encoding,” arXiv:2204.00334 [cs], 2022, Accessed: Apr. 09, 2022. [Online]. Available: http://arxiv.org/abs/2204.00334. [Google Scholar]
12. S. Pericherla and E. Ilavarasan, “Performance analysis of word embeddings for cyberbullying detection,” IOP Conference Series: Materials Science and Engineering, vol. 1085, no. 1, pp. 012008, 2021. [Google Scholar]
13. B. A. H. Murshed, J. Abawajy, S. Mallappa, M. A. N. Saif and H. D. E. A. Ariki, “DEA-RNN: A hybrid deep learning approach for cyberbullying detection in twitter social media platform,” IEEE Access, vol. 10, pp. 25857–25871, 2022. [Google Scholar]
14. A. Dewani, M. A. Memon and S. Bhatti, “Cyberbullying detection: Advanced preprocessing techniques & deep learning architecture for roman urdu data,” Journal of Big Data, vol. 8, no. 1, pp. 160, 2021. [Google Scholar]
15. M. F. Ahmed, Z. Mahmud, Z. T. Biash, A. A. N. Ryen, A. Hossain et al., “Cyberbullying detection using deep neural network from social media comments in bangla language,” arXiv:2106.04506 [cs], 2021, Accessed: Apr. 09, 2022. [Online]. Available: http://arxiv.org/abs/2106.04506. [Google Scholar]
16. L. Wang, R. Tao, H. Hu and Y. R. Zeng, “Effective wind power prediction using novel deep learning network: Stacked independently recurrent autoencoder,” Renewable Energy, vol. 164, pp. 642–655, 2021. [Google Scholar]
17. A. Muthumari, J. Banumathi, S. Rajasekaran, P. Vijayakarthik, K. Shankar et al., “High security for de-duplicated big data using optimal simon cipher,” Computers, Materials & Continua, vol. 67, no. 2, pp. 1863–1879, 2021. [Google Scholar]
18. R. Gopi, P. Muthusamy, P. Suresh, C. G. G. S. Kumar, I. V. Pustokhina et al., “Optimal confidential mechanisms in smart city healthcare,” Computers, Materials & Continua, vol. 70, no. 3, pp. 4883–4896, 2022. [Google Scholar]
19. D. A. Pustokhin, I. V. Pustokhin, P. Rani, V. Kansal, M. Elhoseny et al., “Optimal deep learning approaches and healthcare big data analytics for mobile networks toward 5G,” Computers & Electrical Engineering, vol. 95, pp. 107376, 2021. [Google Scholar]
20. J. A. Alzubi, O. A. Alzubi, M. Beseiso, A. K. Budati and K. Shankar, “Optimal multiple key-based homomorphic encryption with deep neural networks to secure medical data transmission and diagnosis,” Expert Systems, vol. 39, no. 4, pp. e12879, 2022. [Google Scholar]
21. A. Manzoor, N. Javaid, I. Ullah, W. Abdul, A. Almogren et al., “An intelligent hybrid heuristic scheme for smart metering based demand side management in smart homes,” Energies, vol. 10, no. 9, pp. 1258, 2017. [Google Scholar]
22. Dataset: https://www.kaggle.com/competitions/detecting-insults-in-socialcommentary/data?select=test.csv. [Google Scholar]
23. C. Iwendi, G. Srivastava, S. Khan and P. K. R. Maddikunta, “Cyberbullying detection solutions based on deep learning architectures,” Multimedia Systems, 2020, https://doi.org/10.1007/s00530-020-00701-5. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |