| Computers, Materials & Continua DOI:10.32604/cmc.2022.031541 | |
| Article |
Intelligent Slime Mould Optimization with Deep Learning Enabled Traffic Prediction in Smart Cities
1Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
2Department of Information Systems, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3Department of Industrial Engineering, College of Engineering at Alqunfudah, Umm Al-Qura University, Saudi Arabia
4Department of Information Systems, College of Science & Art at Mahayil, King Khalid University, Saudi Arabia
5Department of Computer Science and Bioinformatics, Singhania University, Pacheri Bari, District Jhnujhunu, Rajasthan, India
6Department of Architectural Engineering, Faculty of Engineering and Technology, Future University in Egypt, New Cairo, 11835, Egypt
*Corresponding Author: Manar Ahmed Hamza. Email: Ma.hamza@psau.edu.sa
Received: 20 April 2022; Accepted: 09 June 2022
Abstract: Intelligent Transportation System (ITS) is one of the revolutionary technologies in smart cities that helps in reducing traffic congestion and enhancing traffic quality. With the help of big data and communication technologies, ITS offers real-time investigation and highly-effective traffic management. Traffic Flow Prediction (TFP) is a vital element in smart city management and is used to forecast the upcoming traffic conditions on transportation network based on past data. Neural Network (NN) and Machine Learning (ML) models are widely utilized in resolving real-time issues since these methods are capable of dealing with adaptive data over a period of time. Deep Learning (DL) is a kind of ML technique which yields effective performance on data classification and prediction tasks. With this motivation, the current study introduces a novel Slime Mould Optimization (SMO) model with Bidirectional Gated Recurrent Unit (BiGRU) model for Traffic Prediction (SMOBGRU-TP) in smart cities. Initially, data preprocessing is performed to normalize the input data in the range of [0, 1] using min-max normalization approach. Besides, BiGRU model is employed for effective forecasting of traffic in smart cities. Moreover, the novelty of the work lies in using SMO algorithm to effectively adjust the hyperparameters of BiGRU method. The proposed SMOBGRU-TP model was experimentally validated and the simulation results established the model’s superior performance in terms of prediction compared to existing techniques.
Keywords: Smart cities; traffic flow prediction; slime mould optimization algorithm; deep learning; intelligent models
The tremendous growth experienced in the total number of automobiles in recent years, without any additional supporting means of transportation architecture, is one of the major issues in smart city development [1]. Due to countless number of cars on road, urban regions are overcrowded which in turn causes multiple effects such as increased air and noise pollution, reduced fuel proficiency and increased velocity of traffic. This scenario stimulates the intersection traffic by major alterations in pace control structures of metropolitan cities and towns [2]. Since these systems further disturb traffic signal control mechanisms and pollution control strategies, logistics and traffic management have become major issues to deal with. In earlier times, traffic signal controlling tools were used in traffic administration system whereas such tools are used for traffic management these days in smart cities. It plays a major role in ensuring the safety of people who experience traffic [3]. Traffic data accumulations act as a significant input in both management and understanding of the traffic. Traffic counting process is commonly executed these days while conventional city or state governments have certain ways to track the count of traffic such as microwave sensors, cameras, radar weapons, and speed guns [4]. Fig. 1 illustrates the structure of ITS.
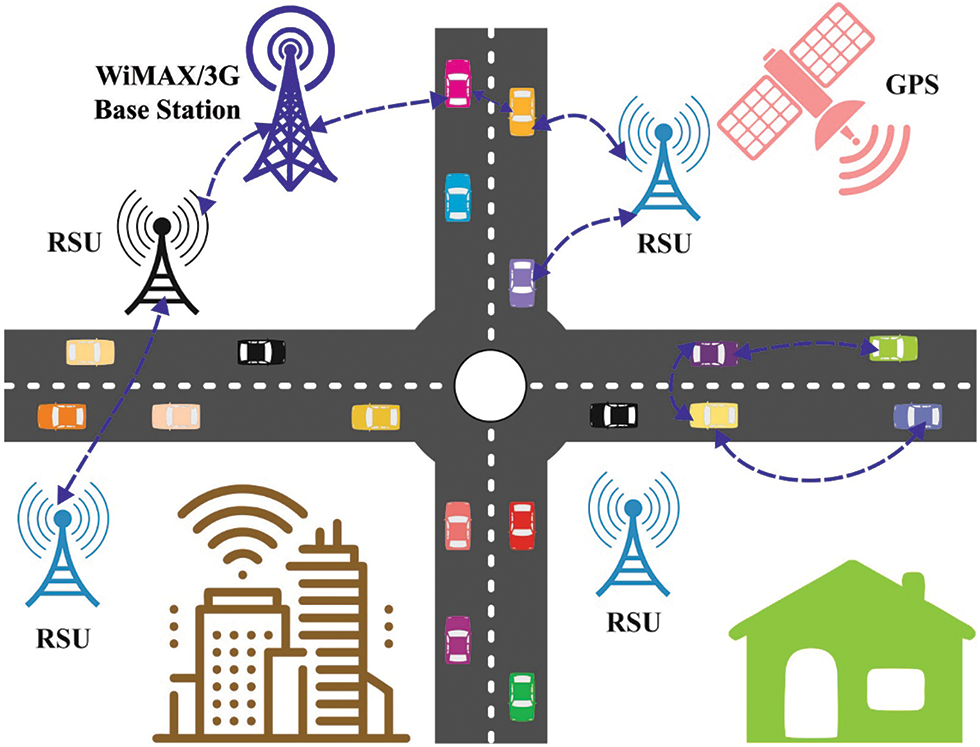
Figure 1: Structure of intelligent transportation systems
For a known period of time, researchers are working on automobile traffic prediction and proposed few models to achieve it. In specialized publications, various solutions have been proposed [5] which function in a fair and accurate manner under regular circumstances i.e., no unplanned incidents on road network. But, on many occasions, these methodologies are unprepared to find out the convoluted congestion propagation patterns. This lack of preparation results in erroneous predictions under severe conditions, although exact predictions are required during these important times [6,7]. Such serious conditions occur through multiple factors such as events, traffic threats, extreme weather conditions, and so on. Even though it is not easy to get rid of the suspicious element entirely from traffic estimation, it is possible to reduce the adverse effect of the blockage by considering exogenous data resources [8–10].
The advancements made in technology and unique ideas for smart cities have encouraged great deals of development in smart cities. The application areas of Artificial Intelligence (AI) such as big data, Deep Learning (DL), Machine Learning (ML), and Internet of Things (IoT) [11], have gained importance in assisting technological evolution of smart cities. Amongst them, ML approaches have endowed numerous applications in different fields such as air pollution monitoring and estimation, city planning, energy demand, consumption estimation, mobility management and monitoring of food supply and production estimation, resource distribution, etc. [12,13].
The current article introduces a novel Slime Mould Optimization (SMO) with Bidirectional Gated Recurrent Unit (BiGRU) model for Traffic Prediction (SMOBGRU-TP) in smart cities. Initially, the data is pre-processed to normalize the input data within a range of [0,1] using min-max normalization approach. Besides, BiGRU model is employed for effective forecasting of traffic in smart cities. Further, SMO algorithm is utilized for fine tuning the hypervariables involved in BiGRU design. In order to validate the superior prediction performance of the proposed SMOBGRU-TP model, numerous analyses were conducted and the results established the supremacy of the proposed model.
Vijayalakshmi et al. [14] projected an attention-based multi-stage predictive method named Convolution Neural Network(CNN)-Long Short Term Memory (LSTM). The suggested system used spatial and time-based traffic information extracted with the help of CNN and LSTM systems in order to enhance the accuracy of the model. Attention-based method assists in identifying the nearby traffic information, since the speed is an important parameter to forecast the upcoming values of the flow. In literature [15], the authors presented ML and optimization methods to empower an intelligent ecosystem. For validation purpose, a computation was executed in this study with multi-layer perceptron and Particle Swarm Optimization (PSO) approach.
Wang et al. [16] introduced a multi-task DL approach named ‘Multitask Recurrent Graph Convolution Network (MRGCN)’ which precisely forecasts the traffic data in smart cities. Especially, this study presented a multitasking architecture that consists of four major elements such as a task-specific decoder to forecast the traffic flow, a region flow encoding unit to model region flow dynamics, a transition flow encoding unit to explore transition flow correlation, and a context modelling module for contextual combination of two kinds of traffic flow. Khan et al. [17] aimed at developing a data fusion-related traffic congestion control scheme in smart city using DL method. A hybrid mechanism was utilized in this study based on CNN and LSTM frameworks for region-related traffic flow prediction in smart cities. CNN was employed here for spatial dataset categorization, whereas LSTM was applied for temporal dataset classification.
Kuang et al. [18] presented a traffic signal control method based on reinforcement learning using state reduction. At first, a reinforcement learning method was determined according to the previous traffic flow dataset. In addition to this, the study also presented a dual-objective reward operation that might improve the matching and degree decrease vehicle delay. Neelakandan et al. [19] developed a powerful IoT-based traffic predictive model with OWENN approach and traffic signal control scheme using Intel 80,286 microprocessor for smart cities. The presented technique comprised of five stages such as traffic signal control system, categorization, optimization of traffic IoT values, feature extraction and IoT data collection. At first, IoT traffic dataset is gathered from the information. Next, weather, direction, and traffic dataset are extracted. Followed by, the extracted feature is fed as input to the classification model that classifies the location as either heavy traffic or not.
In current study, a new SMOBGRU-TP model has been proposed to forecast the flow of traffic in smart city environment. The presented SMOBGRU-TP model comprises of data pre-processing initially, during when the input data is normalized within a range of [0,1] using min-max normalization approach. Further, SMO-BiGRU model is employed for effective forecasting of traffic in smart cities.
At this preliminary level, the presented SMOBGRU-TP model comprises of data pre-processing which is performed to normalize the input data within a range of [0,1] through min-max normalization approach from scikit library. In these experiments, the preceding traffic flow of an hour i.e., a time series of 12 data points, is considered. It is used in the prediction of traffic flow that approaches from the following five minutes. Here, the list is generally grouped into 13 readings and the lists are utilized for training and testing purposes.
3.2 Design of BiGRU Based Predictive Model
After data pre-processing, BiGRU model is employed for effective forecasting of traffic in smart cities. The benefit of utilizing DL approaches is its capability to learn abstract features under several hidden layers. Gated Recurrent Unit (GRU) method is different from LSTM since it combines forget as well as input gates to a single upgrade gate. Further, it also integrates the cell as well as hidden states [16]. Thus, the latest GRU technique is simple and fast compared to typical LSTM technique, particularly when training big data. It is stored for several times with small performance variance compared to typical LSTM method. Both GRU and LSTM maintain essential characteristics with several gates so as to make sure that these characteristics are not lost from long-term broadcast. Fig. 2 illustrates the structure of GRU technique.
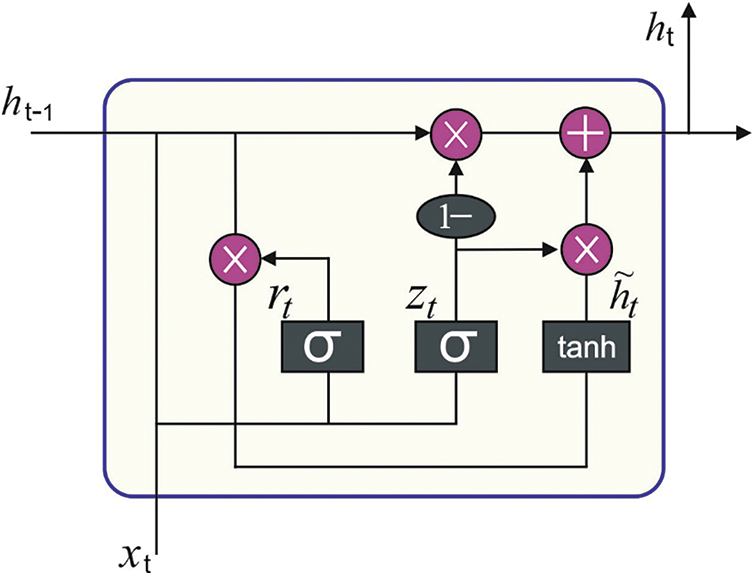
Figure 2: Structure of GRU
Whereas
This is to compute a linear interpolation between the earlier state
Here,
Here,
In case of several sequence modelling tasks, it is useful to gain access to upcoming and past contexts. But typical GRU network procedures perform sequence modelling in temporal manner and it disregards the future context altogether. Bi-directional GRU network expands the unidirectional GRU network by presenting an additional layer whereas the hidden-to-hidden associates flow from the opposite temporal sequence. This technique is capable of exploiting data from both past and the future. Similarly, GRUs provide a disappearing gradient issue by utilizing two gates such as update and reset gates. Essentially, these are two vectors that choose the dissemination of data to the output gate and these vectors are trained to retain the data even earlier. This permits it to pass the the applicable data down a chain of events so as to achieve optimum forecasts.
3.3 SMO Based Hyperparameter Optimization
In this final stage, SMO algorithm is utilized for fine tuning the hyper-variables of BiGRU model [20–23]. Benabbou et al. [24] proposed SMO algorithm which is inspired from natural simulation as per the foraging and diffusion characteristics of slime mould. In current study, ‘slime mould’ (SM) represents Physarum polycephalum which is the major player in nutritious phase of SM. Here, the organic material in SM is accountable for travelling near the food, finding and digesting. The arithmetical model for the abovementioned stages is given below.
The individual objective optimization method is shown herewith.
Here,
SM can approach the food based on the odor in air as given below.
Here,
Now,
Here,
In this equation, the condition indicates the initial half of the population while
This phase mimics the contraction of venous tissues of the SM to search food. It alters the searching pattern based on the quality of food [26]. It is arithmetically formulated in the following equation,
Now, rand and
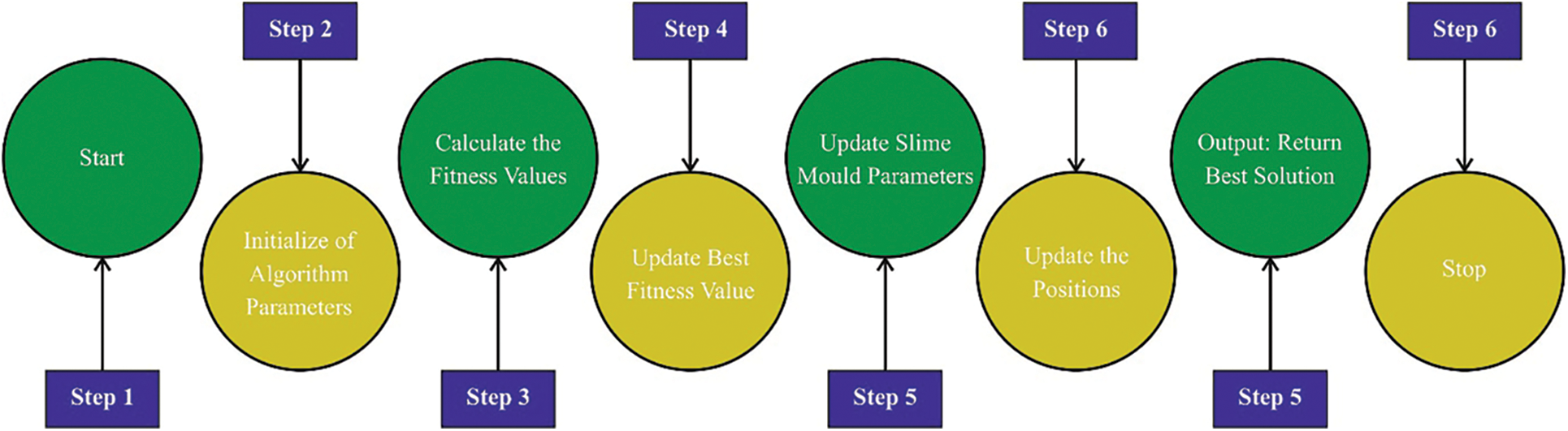
Figure 3: Steps in SMO
In this work, SMO algorithm is applied to appropriately fine-tune the hyperparameters involved in BiGRU model so as to minimize MSE. MSE is calculated as follows.
Here,
In this section, the TFP outcomes of the proposed SMOBGRU-TP model were analyzed under several aspects. Tab. 1 and Figs. 4 and 5 provide a detailed overview on TFP performance outcomes achieved by the proposed SMOBGRU-TP model and other existing models under different measures. The experimental results indicate that Radial Basis Function (RBF)+Principal Component Analysis (PCA)+PIM and RBF+PCC+PCA+PIM models reached ineffectual outcomes compared to other methods. At the same time, RBF+PIM and RBF+PCC models accomplished slightly enhanced results. Though AT-TFP model reached a Mean Absolute Percentage Error (MAPE) of 21.364%, Mean Square Error (MSE) of 299.636, and Root Mean Square Error (RMSE) of 17.310, the proposed SMOBGRU-TP model attained the least MAPE of 18.560%, MSE of 256.350%, and RMSE of 16.011.
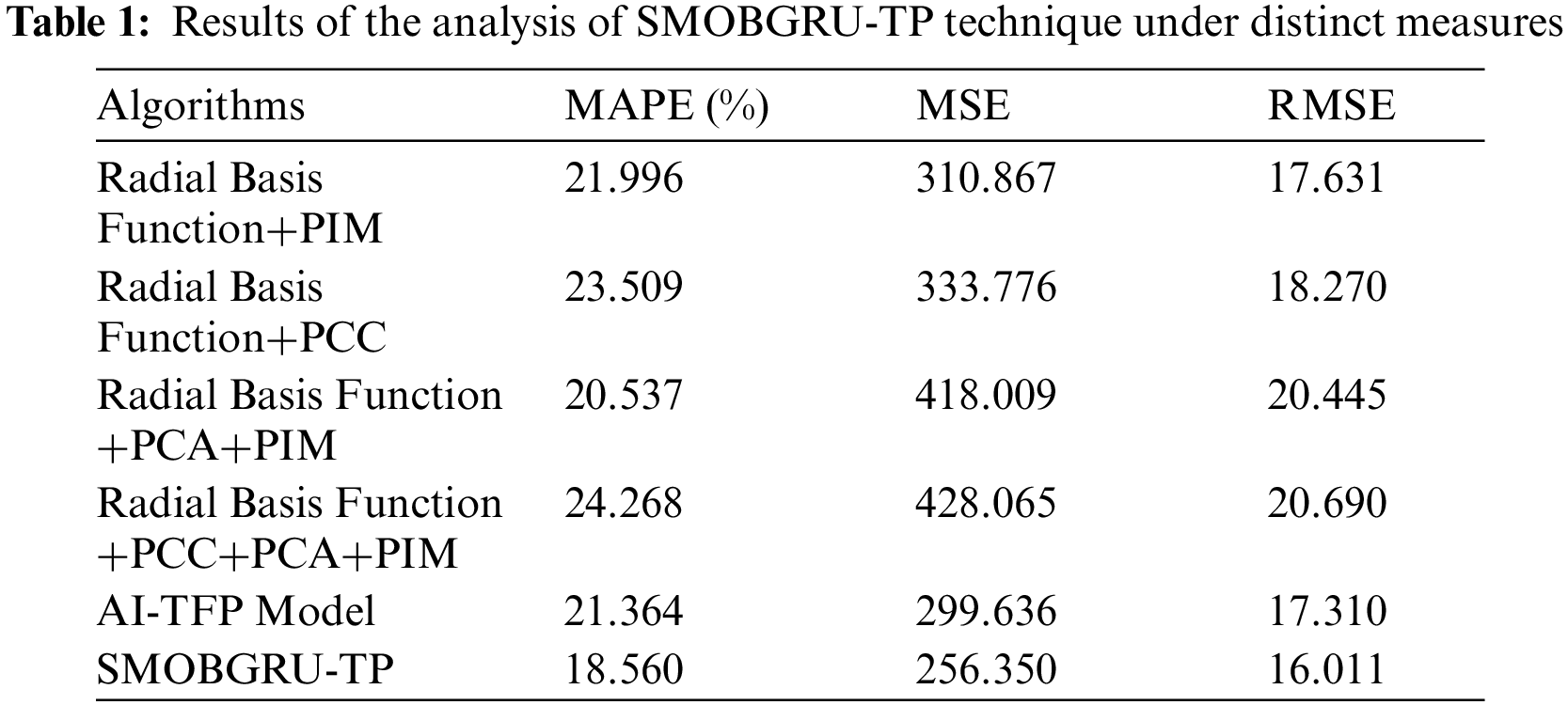
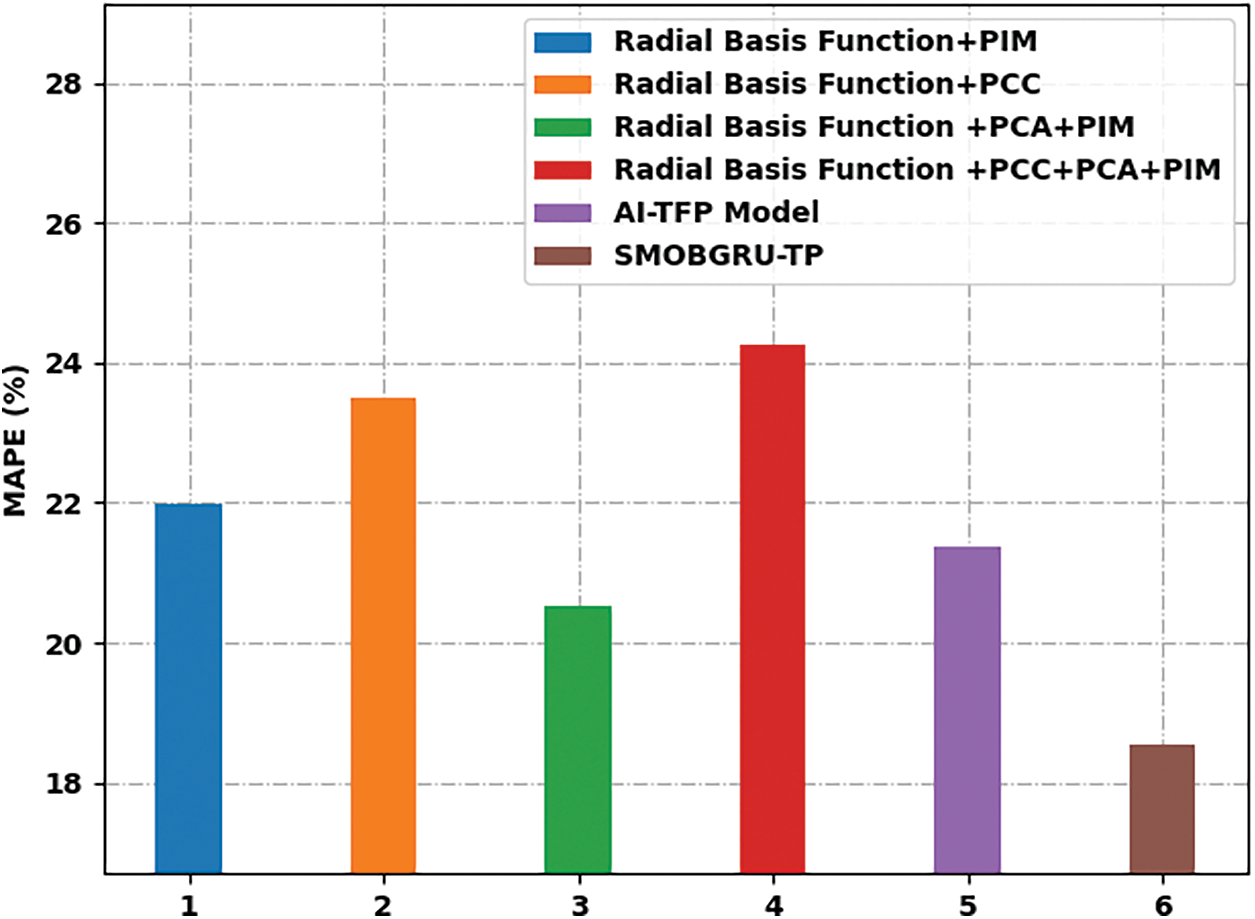
Figure 4: Results of the analysis of SMOBGRU-TP technique in terms of MAPE
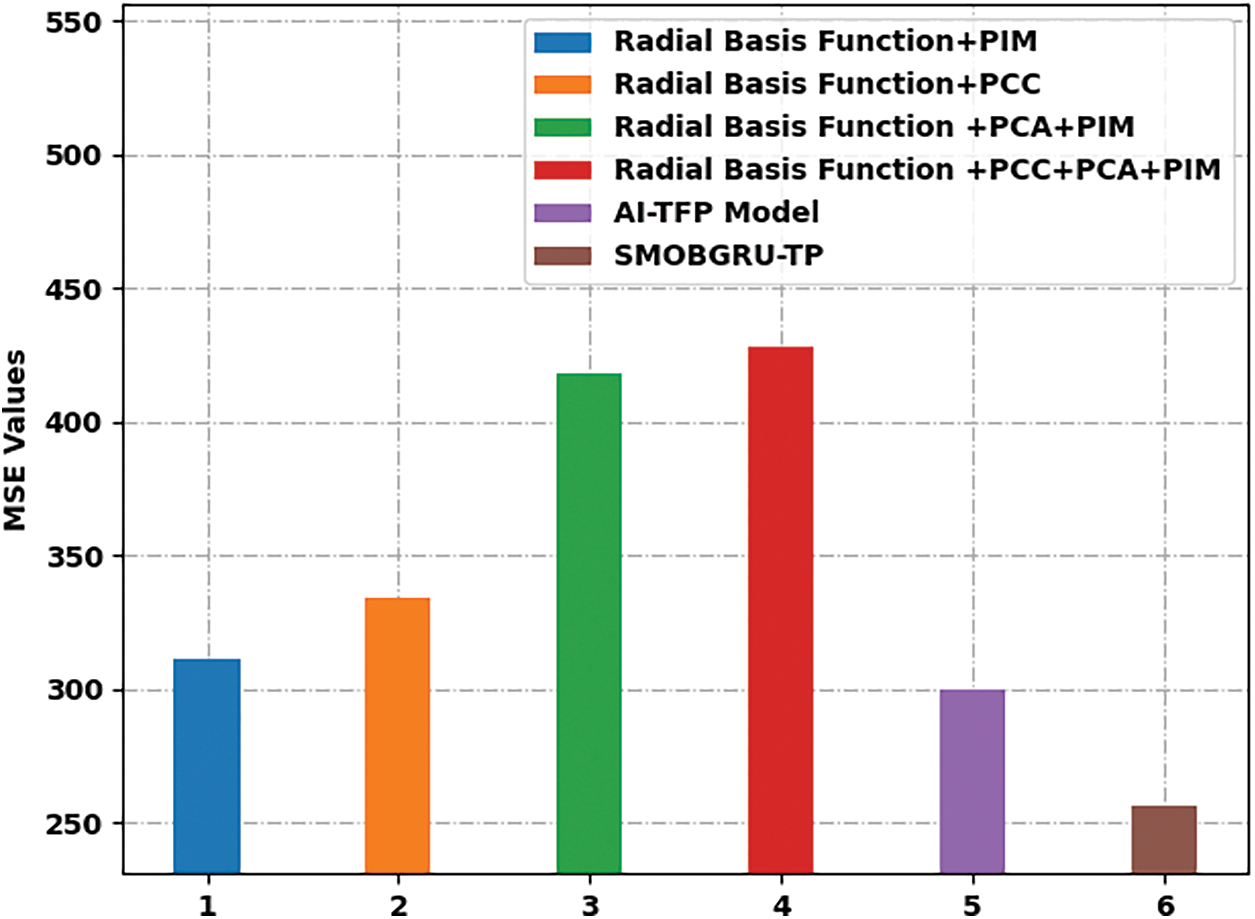
Figure 5: Results of the analysis of SMOBGRU-TP technique in terms of MSE
Tab. 2 and Figs. 6 and 7 provide a detailed overview on predictive outcomes accomplished by the proposed SMOBGRU-TP model and other recent models. The experimental outcomes infer that RNN-LSTM and RNN-GRU models reached ineffectual outcomes with maximal error values. Followed by, the cascaded LSTM, cascaded GRU, and autoencoder methodologies produced slightly lesser error values. Though NN, AE-RBF, and AI-TFP models accomplished reasonable error values, the proposed SMOBGRU-TP model attained an effectual performance with a minimal MAPE of 9.523%, MSE of 142.265, and RMSE of 11.927.
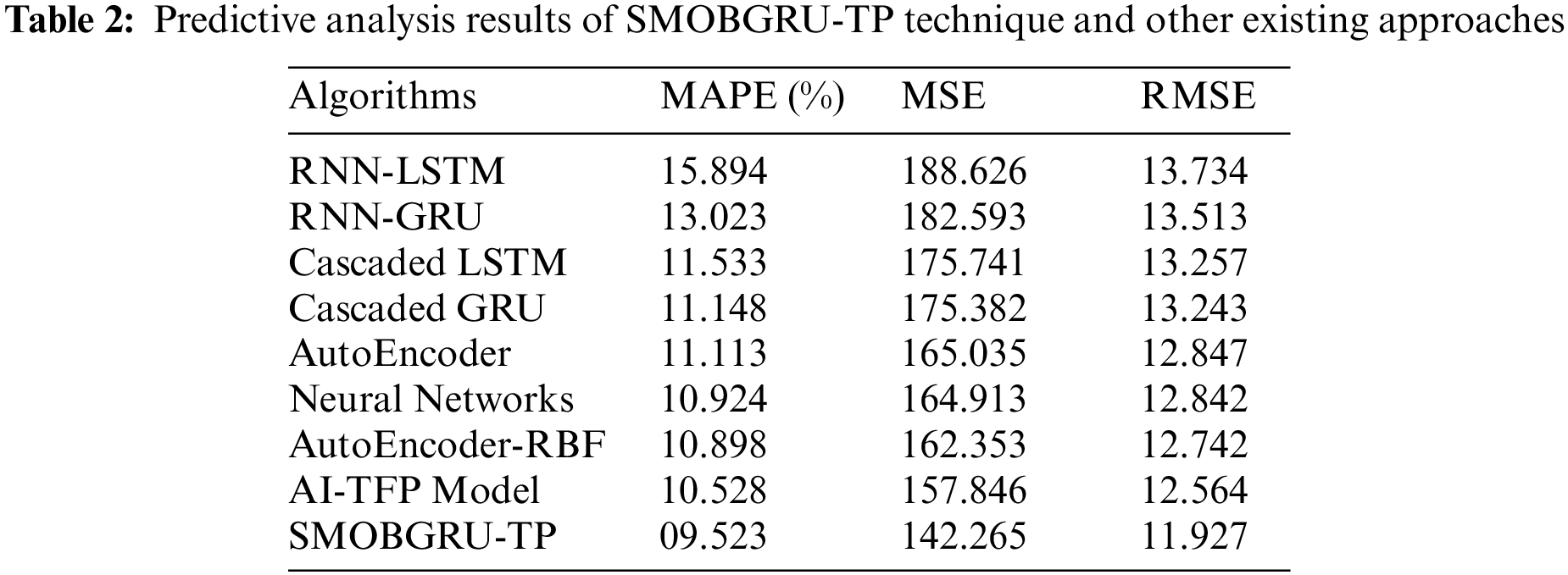
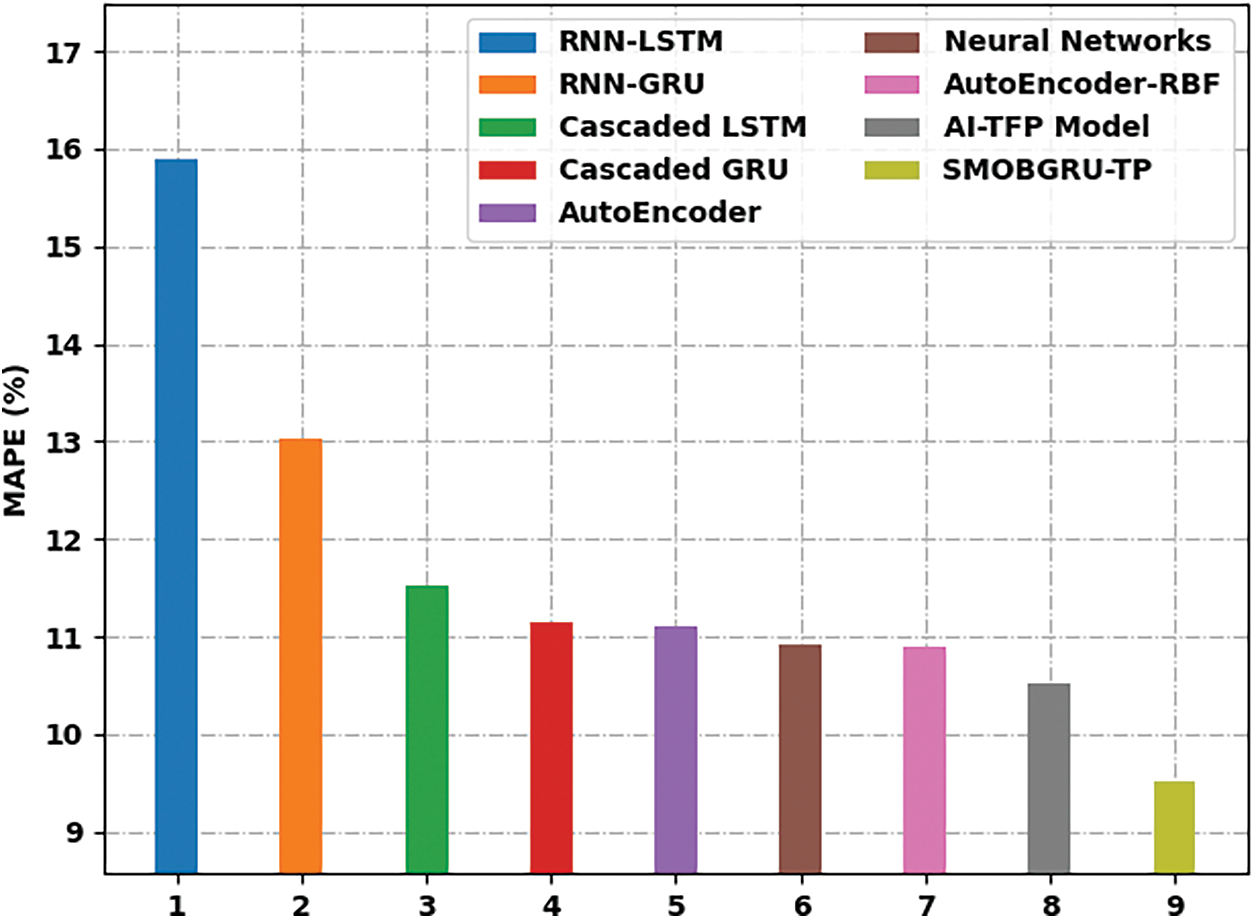
Figure 6: MAPE analysis results of SMOBGRU-TP technique and other existing approaches
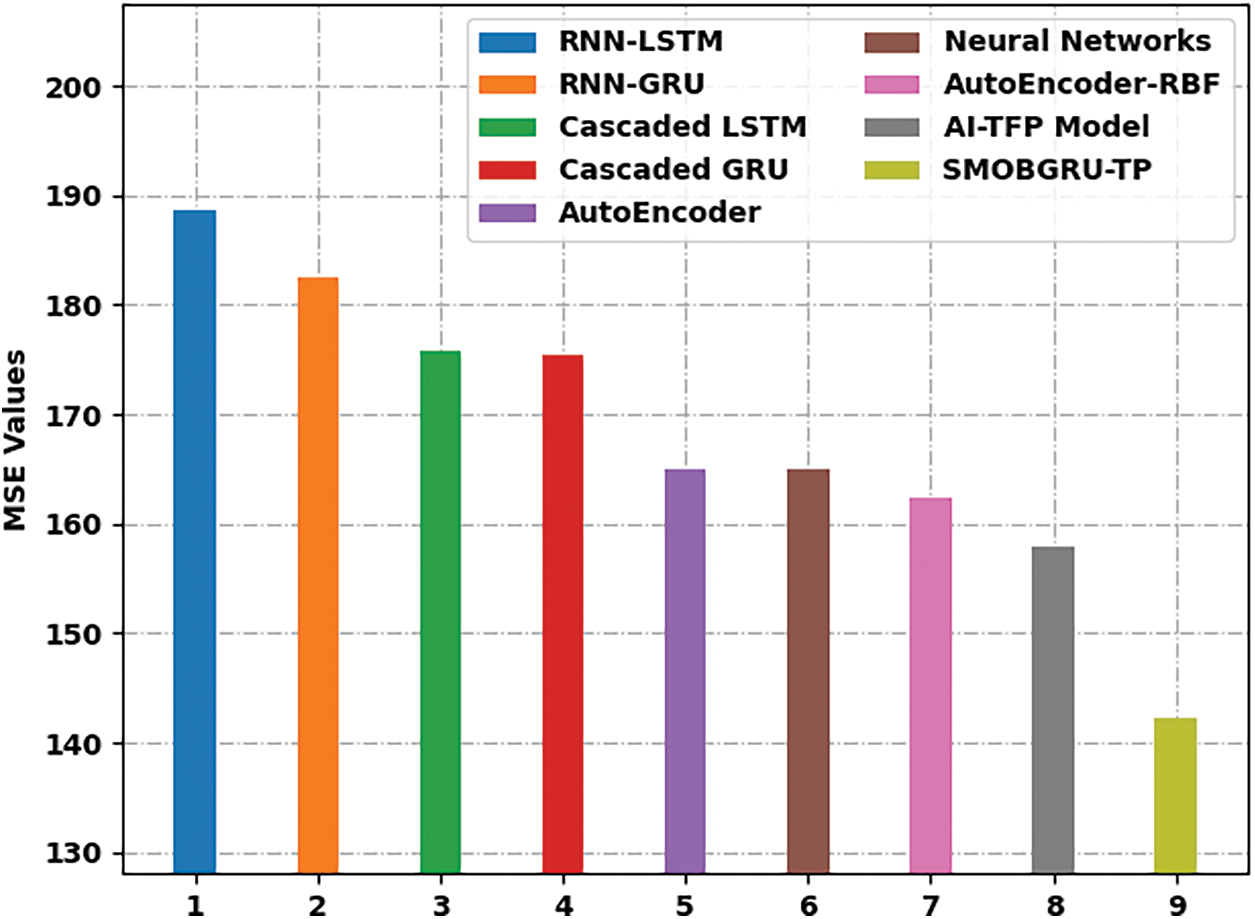
Figure 7: MSE analysis results of SMOBGRU-TP technique and other existing approaches
Tab. 3 and Fig. 8 shows the predictive results achieved by SMOBGRU-TP model and other recent models under distinct time durations [27–29]. The experimental results exhibit that the proposed SMOBGRU-TP model accomplished the least MAPE under all-time durations. For example, with a time duration of 5 mins, SMOBGRU-TP model provided the least MAPE of 15.894%, whereas RNN-LSTM, RNN-GRU, cascaded LSTM, cascaded GRU, AE, NN, AE-RBF, and AI-TFP models reached high MAPE values such as 15.894%, 13.023%, 11.533%, 11.148%, 11.113%, 10.924%, 10.898%, and 10.528% respectively. Along with that, with a time duration of 30 mins, the proposed SMOBGRU-TP method provided a low MAPE of 17.820%, whereas RNN-LSTM, RNN-GRU, cascaded LSTM, cascaded GRU, AE, NN, AE-RBF, and AI-TFP techniques reached high MAPE values such as 25.073%, 24.995%, 22.787%, 22.174%, 21.761%, 21.656%, 20.957%, and 17.820% correspondingly.
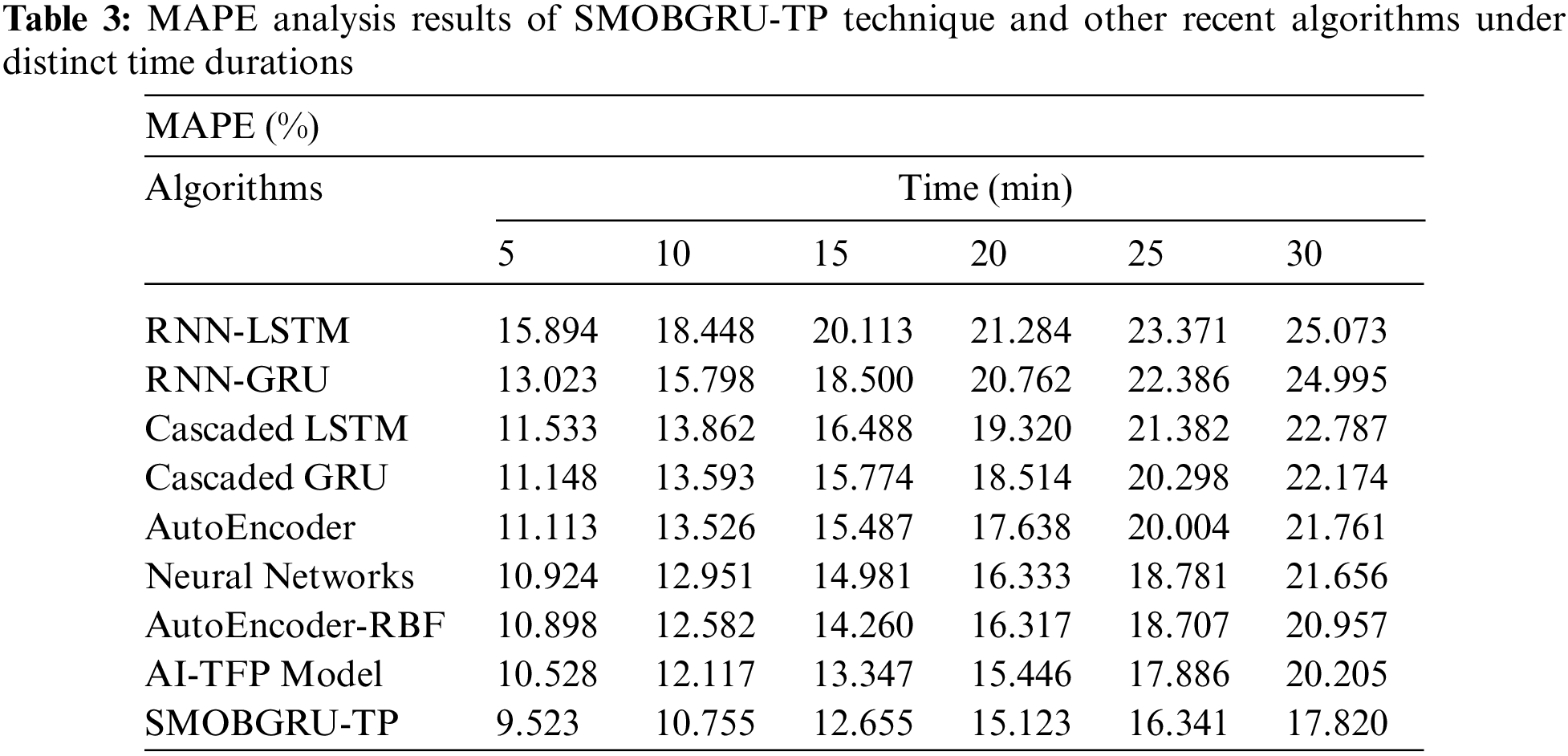
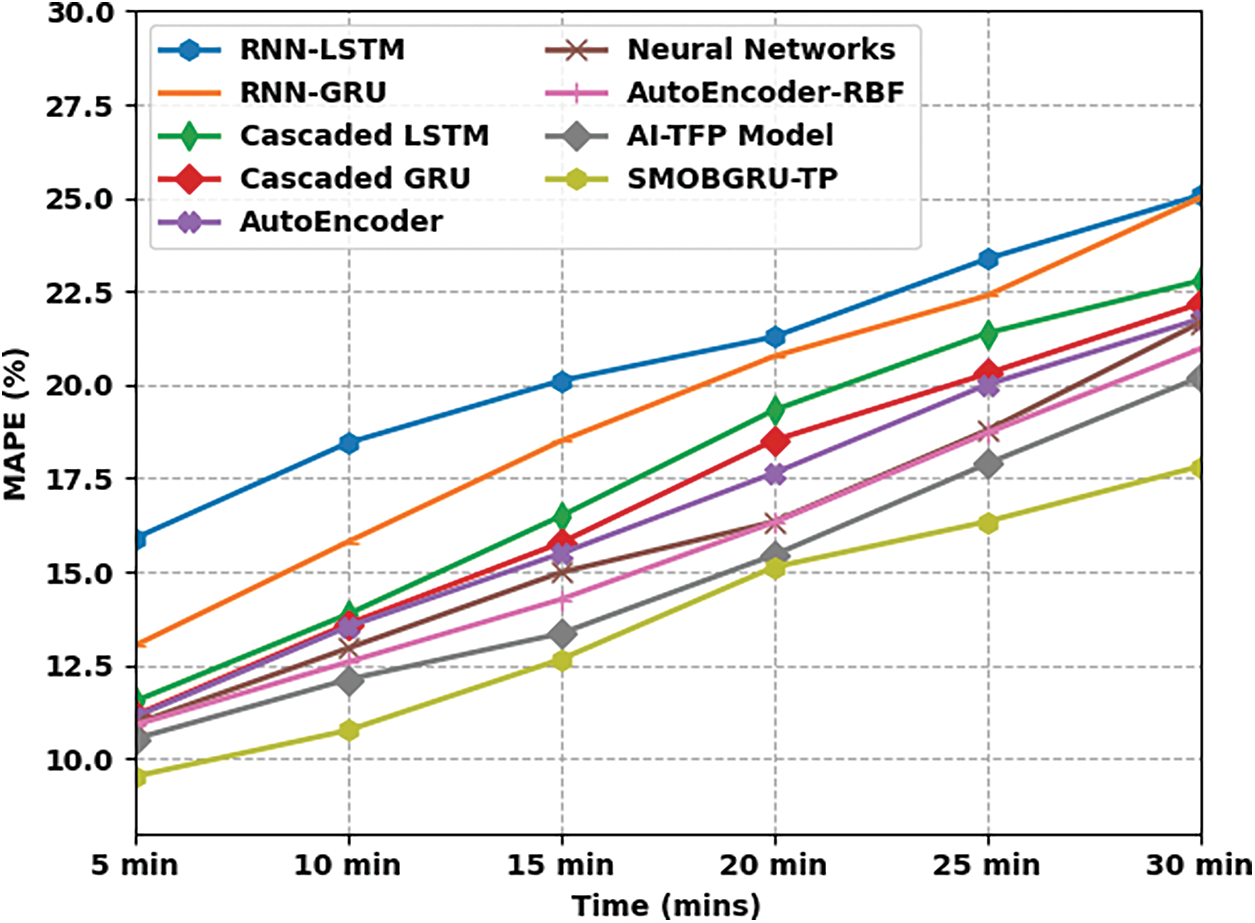
Figure 8: MAPE analysis results of SMOBGRU-TP technique under distinct time durations
Tab. 4 and Fig. 9 portrays the predictive output produced by SMOBGRU-TP model and other recent models under distinct time durations. The experimental results exhibit that the proposed SMOBGRU-TP model accomplished a minimal MSE under all-time durations. For instance, with a time duration of 5 mins, the proposed SMOBGRU-TP model provided a low MSE of 142.265, while RNN-LSTM, RNN-GRU, cascaded LSTM, cascaded GRU, AE, NN, AE-RBF, and AI-TFP methodologies reached high MSE values such as 188.626, 182.593, 175.741, 175.382, 165.035, 164.913, 162.353, and 157.846 respectively. Likewise, at 30 mins duration, SMOBGRU-TP system provided the least MSE of 235.966, but RNN-LSTM, RNN-GRU, cascaded LSTM, cascaded GRU, AE, NN, AE-RBF, and AI-TFP techniques reached high MSE values such as 452.353, 449.797, 441.446, 428.327, 414.809, 398.998, 372.006, and 289.229 correspondingly.
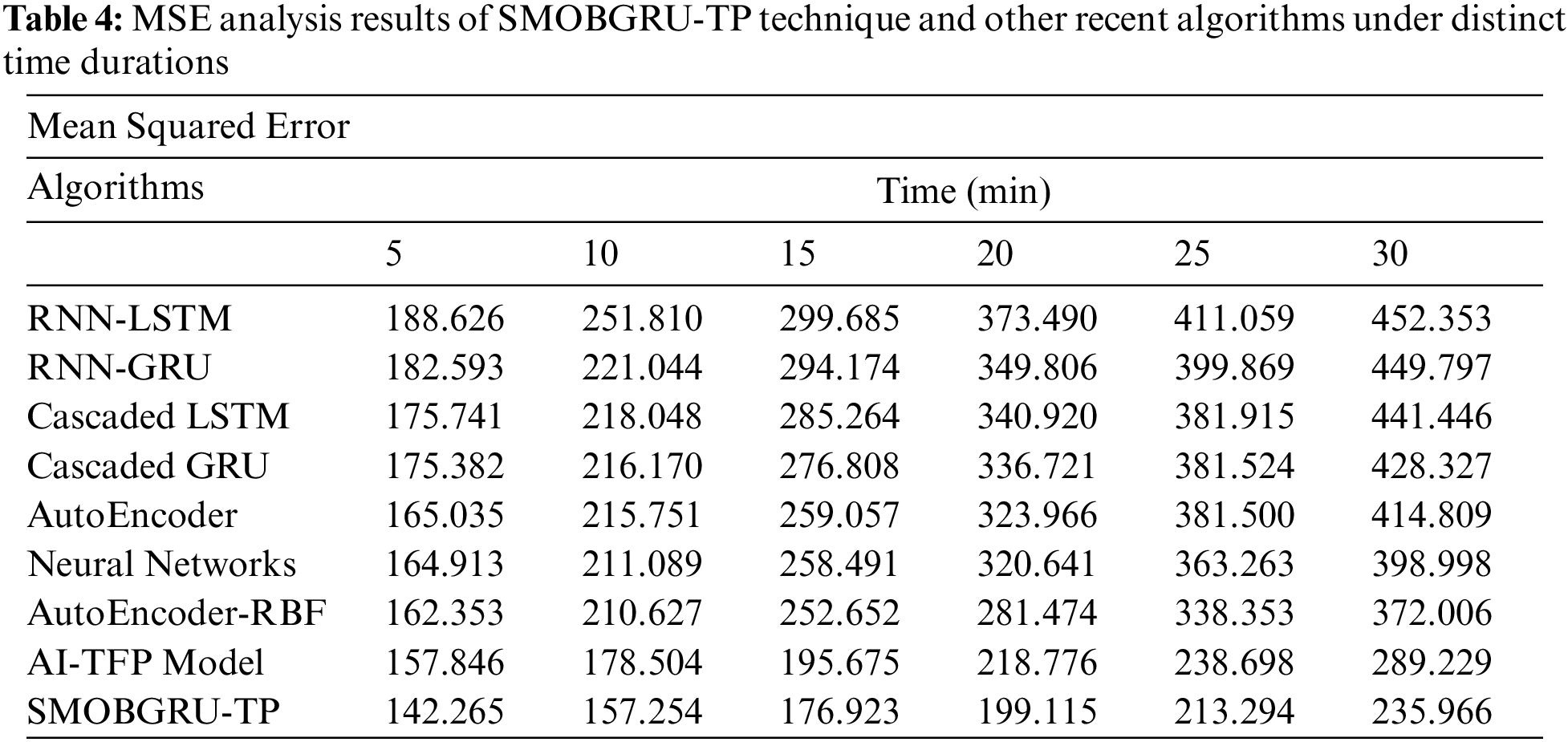
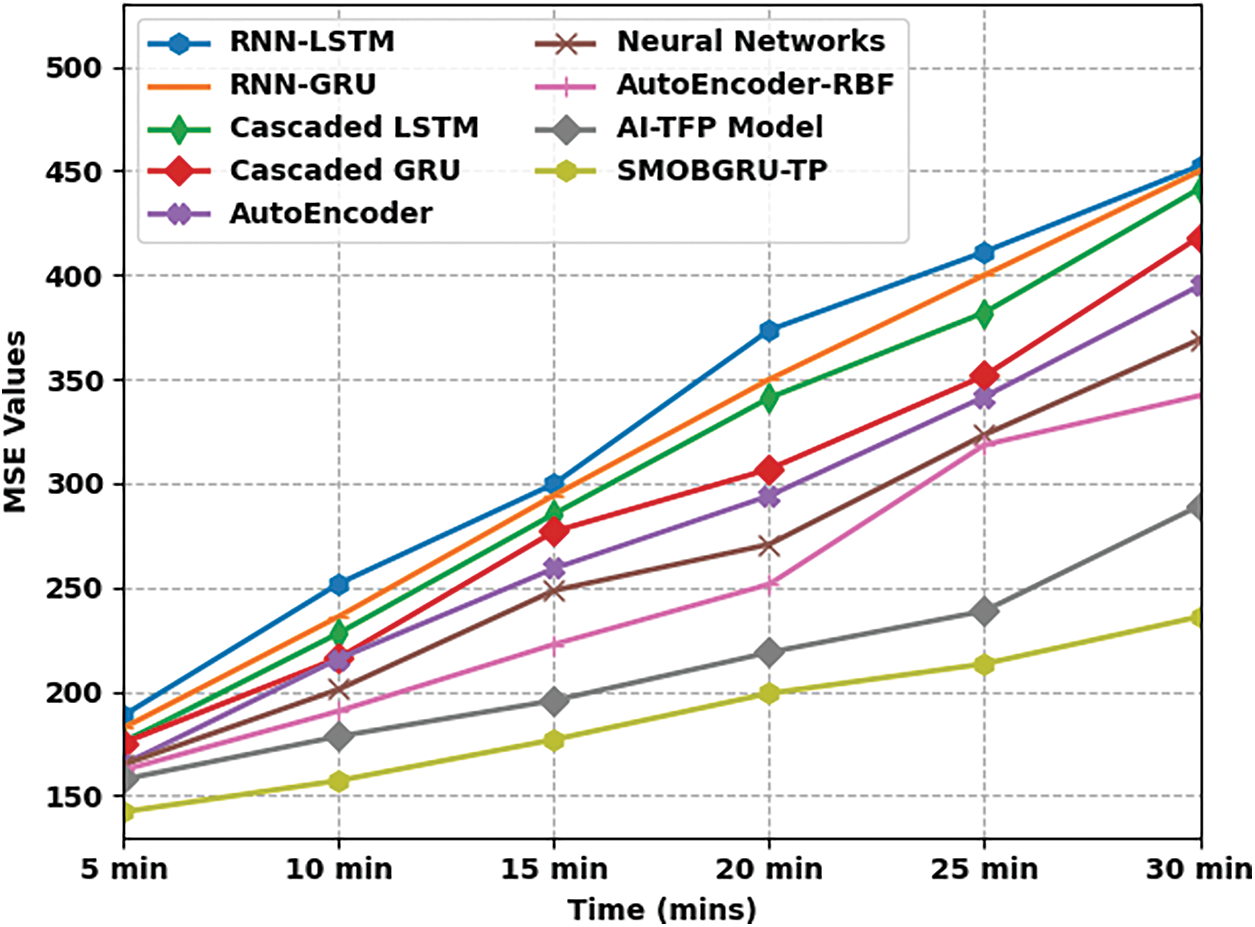
Figure 9: MSE analysis results of SMOBGRU-TP technique under distinct time durations
Tab. 5 and Fig. 10 showcases the predictive results attained by the proposed SMOBGRU-TP model and other recent models under distinct time durations. The experimental results demonstrate that the proposed SMOBGRU-TP model accomplished the least RMSE at all-time durations. For example, for 5 mins time duration, SMOBGRU-TP system provided the least RMSE of 11.927, while RNN-LSTM, RNN-GRU, cascaded LSTM, cascaded GRU, AE, NN, AE-RBF, and AI-TFP techniques reached high RMSE values such as 13.734, 13.513, 13.257, 13.243, 12.847, 12.842, 12.742, and 12.564 correspondingly. In addition, with a time duration of 30 mins, the proposed SMOBGRU-TP approach reached a low RMSE of 15.361, whereas RNN-LSTM, RNN-GRU, cascaded LSTM, cascaded GRU, AE, NN, AE-RBF, and AI-TFP techniques reached high RMSE values such as 21.269, 21.208, 21.011, 20.453, 19.870, 19.209, 18.493, and 17.007 correspondingly. Based on the comprehensive comparative analyses and the simulation results, the proposed SMOBGRU-TP model proved its superiority to other models, in terms of performance.
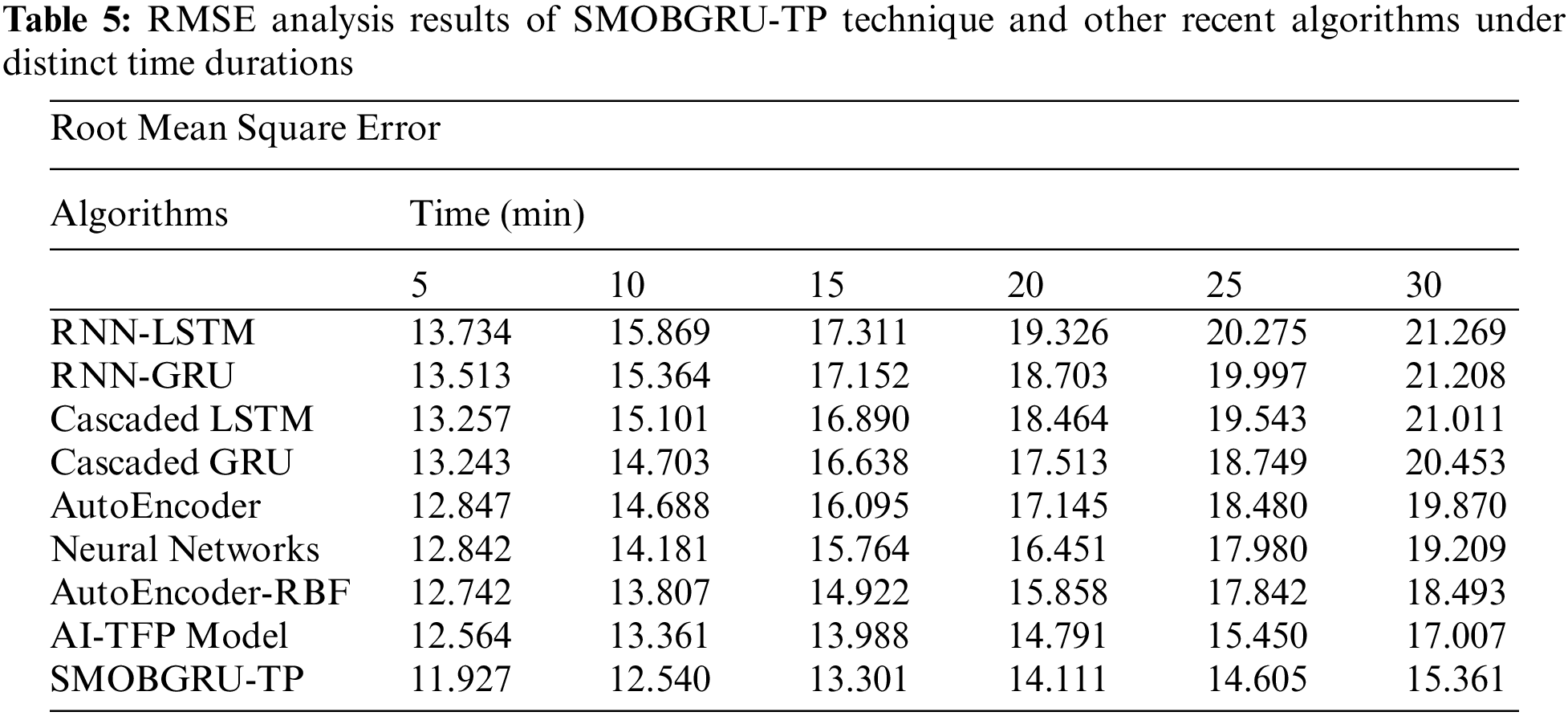
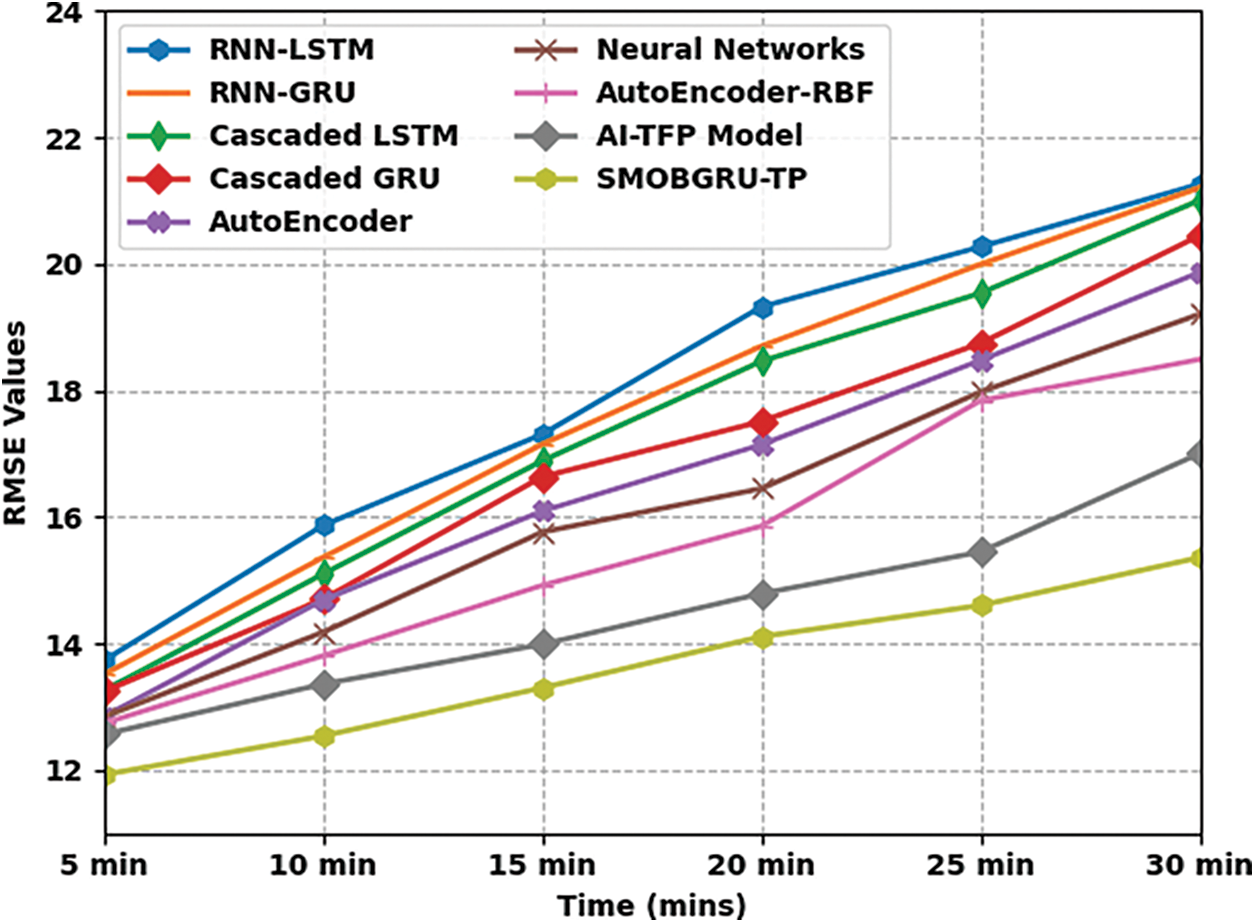
Figure 10: RMSE analysis results of SMOBGRU-TP technique under distinct time durations
In current study, a new SMOBGRU-TP model has been proposed to forecast the flow of traffic in smart city environment. In the initial stage of SMOBGRU-TP model, data pre-processing is performed to normalize the input data within a range of [0,1] using min-max normalization approach. BiGRU model is employed for effective forecasting of the traffic in smart cities. At last, SMO algorithm is utilized to fine tune the hyperparameters involved in BiGRU approach. In order to experimentally validate the superiority of the proposed SMOBGRU-TP models in terms of prediction performance, different analyses were conducted. The simulation outcome confirmed the superior results achieved by SMOBGRU-TP model than the existing techniques. In future, the efficiency of SMOBGRU-TP methodology can be improved with the help of hybrid DL models.
Funding Statement: The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through Large Groups Project under grant number (180/43). Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R303), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: 22UQU4340237DSR21.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. X. Xu, Z. Fang, J. Zhang, Q. He, D. Yu et al., “Edge content caching with deep spatiotemporal residual network for iov in smart city,” ACM Transactions on Sensor Networks, vol. 17, no. 3, pp. 1–33, 2021. [Google Scholar]
2. A. M. Nagy and V. Simon, “Survey on traffic prediction in smart cities,” Pervasive and Mobile Computing, vol. 50, no. 4, pp. 148–163, 2018. [Google Scholar]
3. X. Chen and R. Chen, “A review on traffic prediction methods for intelligent transportation system in smart cities,” in 2019 12th Int. Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Suzhou, China, pp. 1–5, 2019. [Google Scholar]
4. N. Shahid, M. A. Shah, A. Khan, C. Maple and G. Jeon, “Towards greener smart cities and road traffic forecasting using air pollution data,” Sustainable Cities and Society, vol. 72, no. 4, pp. 103062, 2021. [Google Scholar]
5. G. Kothai, E. Poovammal, G. Dhiman, K. Ramana, A. Sharma et al., “A new hybrid deep learning algorithm for prediction of wide traffic congestion in smart cities,” Wireless Communications and Mobile Computing, vol. 2021, no. 8, pp. 1–13, 2021. [Google Scholar]
6. A. M. Nagy and V. Simon, “Improving traffic prediction using congestion propagation patterns in smart cities,” Advanced Engineering Informatics, vol. 50, no. 1, pp. 101343, 2021. [Google Scholar]
7. F. N. Al-Wesabi, M. Obayya, M. Hamza, J. S. Alzahrani, D. Gupta et al., “Energy aware resource optimization using unified metaheuristic optimization algorithm allocation for cloud computing environment,” Sustainable Computing: Informatics and Systems, vol. 35, no. 17, pp. 100686, 2022. [Google Scholar]
8. M. Bai, Y. Lin, M. Ma, P. Wang and L. Duan, “PrePCT: Traffic congestion prediction in smart cities with relative position congestion tensor,” Neurocomputing, vol. 444, no. 1, pp. 147–157, 2021. [Google Scholar]
9. A. M. Hilal, B. S. Alfurhood, F. N. A. Wesabi, M. A. Hamza, M. A. Duhayyim et al., “Artificial intelligence based sentiment analysis for health crisis management in smart cities,” Computers, Materials & Continua, vol. 71, no. 1, pp. 143–157, 2022. [Google Scholar]
10. P. Sirohi, F. N. A. Wesabi, H. M. Alshahrani, P. Maheshwari, A. Agarwal et al., “Energy-efficient cloud service selection and recommendation based on QoS for sustainable smart cities,” Applied Sciences, vol. 11, no. 20, pp. 1–17, 2021. [Google Scholar]
11. A. Nasser and V. Simon, “A novel method for analyzing weather effect on smart city traffic,” in 2021 IEEE 22nd Int. Symp. on a World of Wireless, Mobile and Multimedia Networks (WoWMoM), Pisa, Italy, pp. 335–340, 2021. [Google Scholar]
12. H. Varshney, R. A. Khan, U. Khan and R. Verma, “Approaches of artificial intelligence and machine learning in smart cities: Critical review,” IOP Conference Series: Materials Science and Engineering, vol. 1022, no. 1, pp. 012019, 2021. [Google Scholar]
13. A. Khan, S. Aslam, K. Aurangzeb, M. Alhussein and N. Javaid, “Multiscale modeling in smart cities: A survey on applications, current trends, and challenges,” Sustainable Cities and Society, vol. 78, no. 2, pp. 103517, 2022. [Google Scholar]
14. B. Vijayalakshmi, K. Ramar, N. Z. Jhanjhi, S. Verma, M. Kaliappan et al., “An attention-based deep learning model for traffic flow prediction using spatiotemporal features towards sustainable smart city,” International Journal of Communication Systems, vol. 34, no. 3, pp. 1–14, 2021. [Google Scholar]
15. L. R. Frank, Y. M. Ferreira, E. P. Julio, F. H. C. Ferreira, B. J. Dembogurski et al., “Multilayer perceptron and particle swarm optimization applied to traffic flow prediction on smart cities,” in Int. Conf. on Computational Science and its Applications, Cham, Lecture Notes in Computer Science book series, Springer, 11622, pp. 35–47, 2019. [Google Scholar]
16. F. Wang, J. Xu, C. Liu, R. Zhou and P. Zhao, “On prediction of traffic flows in smart cities: A multitask deep learning based approach,” World Wide Web-internet and Web Information Systems, vol. 24, no. 3, pp. 805–823, 2021. [Google Scholar]
17. S. Khan, S. Nazir, I. G. Magariño and A. Hussain, “Deep learning-based urban big data fusion in smart cities: Towards traffic monitoring and flow-preserving fusion,” Computers & Electrical Engineering, vol. 89, pp. 106906, 2021. [Google Scholar]
18. L. Kuang, J. Zheng, K. Li and H. Gao, “Intelligent traffic signal control based on reinforcement learning with state reduction for smart cities,” ACM Transactions on Internet Technology, vol. 21, no. 4, pp. 1–24, 2021. [Google Scholar]
19. S. Neelakandan, M. A. Berlin, S. Tripathi, V. B. Devi, I. Bhardwaj et al., “IoT-based traffic prediction and traffic signal control system for smart city,” Soft Computing, vol. 25, no. 18, pp. 12241–12248, 2021. [Google Scholar]
20. S. Manne, E. L. Lydia, I. V. Pustokhina, D. A. Pustokhin, V. S. Parvathy et al., “An intelligent energy management and traffic predictive model for autonomous vehicle systems,” Soft Computing, vol. 25, no. 18, pp. 11941–11953, 2021. [Google Scholar]
21. S. K. Lakshmanaprabu, K. Shankar, S. S. Rani, E. Abdulhay, N. Arunkumar et al., “An effect of big data technology with ant colony optimization based routing in vehicular ad hoc networks: Towards smart cities,” Journal of Cleaner Production, vol. 217, no. 3, pp. 584–593, 2019. [Google Scholar]
22. K. Shankar, E. Perumal, M. Elhoseny, F. Taher, B. B. Gupta et al., “Synergic deep learning for smart health diagnosis of covid-19 for connected living and smart cities,” ACM Transactions on Internet Technology, vol. 22, no. 3, pp. 1–14, 2022. [Google Scholar]
23. D. Gupta, A. Khanna, S. K. Lakshmanaprabu, K. Shankar, V. Furtado et al., “Efficient artificial fish swarm based clustering approach on mobility aware energy-efficient for MANET,” Transactions on Emerging Telecommunications Technologies, vol. 30, no. 9, pp. e3524, 2019. [Google Scholar]
24. F. Benabbou, H. Boukhouima and N. Sael, “Fake accounts detection system based on bidirectional gated recurrent unit neural network,” International Journal of Electrical and Computer Engineering, vol. 12, no. 3, pp. 3129, 2022. [Google Scholar]
25. S. Li, H. Chen, M. Wang, A. A. Heidari and S. Mirjalili, “Slime mould algorithm: A new method for stochastic optimization,” Future Generation Computer Systems, vol. 111, pp. 300–323, 2020. [Google Scholar]
26. K. Yu, L. Liu and Z. Chen, “An improved slime mould algorithm for demand estimation of urban water resources,” Mathematics, vol. 9, no. 12, pp. 1316, 2021. [Google Scholar]
27. Y. Hou, Z. Deng and H. Cui, “Short-term traffic flow prediction with weather conditions: Based on deep learning algorithms and data fusion,” Complexity, vol. 2021, pp. 1–14, 2021. [Google Scholar]
28. M. Al Duhayyim, A. A. Albraikan, F. N. A. Wesabi, H. M. Burbur, M. Alamgeer et al., “Modeling of artificial intelligence based traffic flow prediction with weather conditions,” Computers, Materials & Continua, vol. 71, no. 2, pp. 3953–3968, 2022. [Google Scholar]
29. A. N. Espinoza, O. R. L. Bonilla, E. E. G. Guerrero, E. T. Cuautle, D. L. Mancilla et al., “Traffic flow prediction for smart traffic lights using machine learning algorithms,” Technologies, vol. 10, no. 1, pp. 5, 2022. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |