DOI:10.32604/csse.2022.020504
| Computer Systems Science & Engineering DOI:10.32604/csse.2022.020504 | |
| Article |
Hybrid Feature Extractions and CNN for Enhanced Periocular Identification During Covid-19
1College of Computing and Informatics, Saudi Electronic University, Riyadh, 11673, Saudi Arabia
2The School of Information Technology, Sebha University, Sebha, 71, Libya
*Corresponding Author: Rami Ahmed. Email: r_a_sh2001@yahoo.com
Received: 26 May 2021; Accepted: 27 June 2021
Abstract: The global pandemic of novel coronavirus that started in 2019 has seriously affected daily lives and placed everyone in a panic condition. Widespread coronavirus led to the adoption of social distancing and people avoiding unnecessary physical contact with each other. The present situation advocates the requirement of a contactless biometric system that could be used in future authentication systems which makes fingerprint-based person identification ineffective. Periocular biometric is the solution because it does not require physical contact and is able to identify people wearing face masks. However, the periocular biometric region is a small area, and extraction of the required feature is the point of concern. This paper has proposed adopted multiple features and emphasis on the periocular region. In the proposed approach, combination of local binary pattern (LBP), color histogram and features in frequency domain have been used with deep learning algorithms for classification. Hence, we extract three types of features for the classification of periocular regions for biometric. The LBP represents the textual features of the iris while the color histogram represents the frequencies of pixel values in the RGB channel. In order to extract the frequency domain features, the wavelet transformation is obtained. By learning from these features, a convolutional neural network (CNN) becomes able to discriminate the features and can provide better recognition results. The proposed approach achieved the highest accuracy rates with the lowest false person identification.
Keywords: Person identification; convolutional neural network; local binary pattern; periocular region; Covid-19
At present, the whole world is suffering from a global pandemic of Covid-19 as it affects all dimensions of human life. It is impossible to predict when the pandemic will be over, and human lives will get back to normal. Considering the long-term effects, it is important to combat the situation with the help of modern technologies and adopt contactless methods to prevent widespread use of the virus [1–3]. Biometric authentication is an important tool for the security departments of the country and under the Covid-19 crisis, almost all the organizations stopped using fingerprint-based biometric systems. Fingerprint-based biometric systems could be a reason to spread the virus and it is not a safe method of authentication. Other options for biometric authentication include face or Iris recognition but they also have certain limitations [4,5]. With the recommended use of face masks, it is impossible to adopt face recognition and iris recognition needs high user cooperation that is also impossible to implement [6]. The only suitable option under this condition is the use of the periocular region for biometric authentication. The periocular region includes the eyes, eyebrow, and pre-eye orbital region and these biometric traits work well even with a face mask or veil covering the face as shown Fig. 1.
The periocular biometric for e-ID technique is well suited to be applied to access control and provides strong person identification services [7,8]. With the introduction of periocular biometrics, many sectors benefit to identify people faster even with masked face for a situation like Covid’19 where the people need to cover their mouth and nose for public health and can recognize Muslim women with hijab and niqab. For example, customs and immigration enterprises such as INS Passenger Accelerated Service System (INSPASS), which authorizes quicker handling of travelers at immigration checkpoints based on periocular geometry, will significantly enhance the functioning effectiveness [9,10]. Moreover, a successful practice of access to the e-services is associated with the ability for every citizen eligible for identification to gain easy, quick, and reliable access to their personal pages.

Figure 1: Examples of masked face
Ocular biometrics has made rapid strides over the past few years primarily due to the considerable progress that has been made in iris recognition [11,12]. The iris is the annular colored structure in the eye surrounding the pupil and its role is to regulate the size of the pupil thereby controlling the amount of light incident on the retina [12]. Both technological and operational tests conducted under largely constrained conditions have demonstrated the uniqueness of the iris texture to an individual and its potential as a biometric in large-scale systems enrolling millions of individuals [13]. Despite the tremendous progress made in ocular biometrics, there are significant challenges encountered by these systems. Localizing the iris in eye images obtained at a distance in unconstrained environments can be difficult and appropriate invisible lighting is required to illuminate it before image acquisition [14]. Face images acquired with low-resolution sensors or large distances offer very little or no information about iris texture. Retinal vasculature cannot be easily imaged unless the subject is cooperative, and the imaging device must be near the eye [15–17]. While conjunctival vasculature can be imaged at a distance, the curvature of the sclera, the specular reflections in the image, and the fineness of the vascular patterns can confound the feature extraction and matching modules of the biometric system [18].
To overcome Iris concerns, a small region around the eye i.e., the periocular region was considered as an additional biometric [2,19]. In images where the iris cannot be reliably obtained (or used), the surrounding skin region may be used to either confirm or refute an identity [9]. The periocular biometric can be useful over a wide range of distances such as when portions of the face on the mouth and nose are occluded, the periocular region may be used to determine the identity. Another benefit includes that the design of a newer sensor is not necessary as both periocular and face regions can be obtained using a single sensor. Hence, the periocular region has been proven to be a better ocular biometric than the iris.
However, periocular biometric is a new area of research, therefore, requires a comprehensive study to withstand the stability of traits. Some of the issues in periocular biometric that need to be addressed are as follow:
1) Periocular region needs to be well defined. Should this region comprise the iris, sclera, and eyebrows or it excludes certain portions?
2) Feature Extraction to identify the most suitable features that can represent this region? What are the reliable approaches to extract these features?
3) Classification to identify the approaches that can be employed to classify these extracted features.
In this study, we have addressed some of the above-mentioned issues. The experimentation on the periocular matching has examined different techniques including region of interest, feature extractions, and person identification. Experiments are based on the images captured in the visible spectrum. This allows us to combine the iris texture and periocular region for improved recognition performance. Convolutional Neural Network (CNN) based recognition model is proposed with a sequence of operations including RoI extraction, feature extraction, and feature matching.
The proposed architecture has adopted multiple features and emphasis on the semantical regions including eyes and eyebrows in the periocular region. By learning from these features, CNN becomes able to discriminate between the features and can provide better recognition results. In the proposed approach, combination of local binary pattern (LBP), color histogram and features in frequency domain have been used with deep learning algorithms for classification. Hence, we extract three types of features for the classification of periocular regions for biometric. The LBP represents the textual features of the iris while the color histogram represents the frequencies of pixel values in the RGB channel. In order to extract the frequency domain features, the wavelet transformation is obtained. The statistical analysis (mean, standard deviation and moments) of the wavelet transformed in all bands and combined together. All the features are extracted and processed with a deep learning algorithm for classifications.
This paper looks at an approach of periocular biometrics identification and its applicability for person identification. It highlights the importance of periocular biometrics recognition as the most cost-effective way that ensures an incessant security of users in many security services [12]. The paper attempts to prove that with the application of periocular biometrics a universal identity management solution as it provides high accuracy, precision, recall and F1 score. The rest of this paper design as follows: Section 2 provides literature review of the related studies. Then, Section 3 describes the proposed model. Next, Section 4 provides experimental analysis and outcomes and finally Section 5 presents the conclusion.
Park et al. (2009) proposed a new direction to use periocular region-based biometric authentication for personal identification as a standalone modality [20]. The authors extended their study to examine the non-ideal scenarios of periocular region biometric systems such as masking of critical eye components, pose variation, and inclusion of eyebrows [21]. The results of the experiments demonstrate strong support for the development of a periocular region-based biometric verification system. According to continuous research [22–24], the periocular region is identified as a strong biometric trait. During early research, researchers used handcrafted features for periocular image matching that is broadly divided into two groups i.e., (1) global feature descriptors and (2) local feature descriptors. The global feature descriptor considers the image as a whole and creates a single feature vector for the whole image whereas the local feature descriptor divides the image into patches (a group of pixels), creates feature vectors for every patch, and finally combines them to create a single feature vector.
A handcrafted and non-handcrafted feature fusion approach was proposed by Tiong et al. (2019) [25]. They fed a combination of OCLBP feature and RGB data to each stream of CNN for periocular biometric recognition. The drawback of this approach is that it does not apply to the subject wearing glasses. A score fusion and rotation invariant LBP approach are implemented by Raffei et al. (2019) to extract color moments and textural features for color feature extraction [26]. They developed two different matching scores and fused them to obtain the final matching accuracy. The limitation of this approach is related to the use of Color Moment, the input images are converted to HSV from RGB that may affect the removal of micro-features of the image and lower the performance of the system. Local Binary Pattern is a well-known handcrafted feature used by Kumar et al. (2019) to match periocular images of the same subject at different ages [27]. The self-enhancement quotient technique is implemented with a discrete wavelet transform to improve the performance of the system. The proposed method looks simple and provides good results, but the study lacks discussion about the complexity of DWT that requires more process cycles and memory and increases the cost of the overall system.
A feature reduction approach is implemented by Bakshi et al. (2018) to extract Phase Intensive Local Patterns (PILP) [28]. The study is based on a Nearest Neighbor classifier that obtains significant recognition accuracy with less time taken for computation. This approach performs very well but feature reduction is technical and needs intensive care. If wrong features are removed, it will result in high-performance degradation in terms of accuracy.
The periocular region is used by many researchers to identify the gender of the subject [29], race or ethnicity [30] etc. a novel idea of using semantic information in recognition was proposed by Zhao et al. (2016) [30], they added CNN branch trained with gender recognition. This model obtains significant accuracy of almost 92%. Later, the authors created a novel deep learning architecture to emphasize the important components of the periocular region like the shape of the eye and eyebrow [30]. Their model performed better and acquired improved recognition accuracy as compared to other works in literature.
The non-ideal conditions of the previous research resulting degradation of accuracy and the common use of handcrafted, non-handcrafted, and semantic data for biometric authentication lead to the basis of proposed research that evaluates feature extraction approach; a combination of three information approaches including local binary pattern (LBP), color histogram and features in frequency domain have been used with deep learning algorithm for classification. Hence, we extract three types of features for the classification of periocular regions for biometric. The LBP represents the textual features of the iris while the color histogram represents the frequencies of pixel values in the RGB channel. In order to extract the frequency domain features, the wavelet transformation is obtained. The statistical analysis (mean, standard deviation and moments) of the wavelet transformed in all bands and combined together. By learning from these features, CNN becomes able to discriminate between the features and can provide better recognition results. The following section will describe how the proposed method works in order to improve the recognition performance.
Periocular recognition has been emerging as an effective biometric identification approach especially under less constrained environments where face and/or iris recognition is not applicable. This paper proposes a new deep learning-based architecture for robust and more accurate periocular recognition which incorporates attention models to emphasize important regions in the periocular images. The new architecture adopts a multi-glance mechanism, in which part of the intermediate components are configured to incorporate emphasis on important semantic regions, i.e., eyebrow and eye, within a periocular image. By focusing on these regions, the deep CNN is able to learn additional discriminative features which in turn improves the recognition capability of the whole model [31]. The proposed method involves image preprocessing, feature extraction, and development of the classification model. The proposed method described the three categories of features extractions for the classification and evaluation of the peculiar region using the dataset.
The region of interest in the proposed method is the periocular region. Research has proven that there is no standard procedure for ROI extraction, the extraction of ROI depends on the image input. To isolate the ROIs on the proposed method, we initially standardize rotation by arranging each face upright with concern to the eyes as shown in Fig. 2 [32]. The objective of this pre-handling stage is making the pictures strong against rotation in faces. The estimation of the vital rotation to standardize each face direction was acquired utilizing seven key ideas. These manually labelled or named points relate directly with the landmarks on the face. The points 1 through 4 are put at the four extremities at the edges of the eyes; the points that are left relate to tip of the nose, the focal point of the upper lip, and the jawline, appeared in Fig. 3. The essential angle of rotation can then be figured by the eye centroids, utilizing the initial four facial landmarks. In addition, corresponding with the invariance of rotation, the focal length of the countenances was likewise standardized by fixing the level separation from one eye to another, utilizing the external extrema (points 1 and 4). This consequently makes up for any varieties in separation from the camera or zooming impacts, a vital part to performance while considering the periocular area.
Following standardization, the pictures from the database were separated into the training and test sets with a proportion of 3:1 yielding 702 pictures in training and 234 in the test. In the wake of splitting that data, each picture was resized and trimmed from its unique to a particular ROI. Each image was edited to four regions utilizing the seven key facial landmark spots. These ROIs, alluded to as “Full” and “Regions 13,” are portrayed in Fig. 3. In this work, we assign region 3 as the periocular region.
Every ROI is characterized by utilizing four limits: right, left, upper and lower. For consistency, we fix the right and left limits of every ROI. These limits were set at the right and left edge of the face individually, with slight consideration of the ear. The upper and lower limits for the Full edited image were obtained from the vertical distance from eye-to-chin, that is, from the chin landmark to the eyeline (point 7). In Region 1, the upper side is differentiated by utilizing the vertical eye-to-nose distance from the eye line to eliminate data in the head or hair area. At that point, we eliminate the mandible in Region 2 by moving the base bound to the nose landmark (point 5). In the periocular Region 3, the ROI is diminished to a box that is revolved around the eye line with fifty percent of the vertical eye-to-nose distance above and underneath the eye line bringing about a tight periocular region.
After the refinement of the region, each harvest was resized to a similar resolution for each separate area. All pictures were resized utilizing bilinear interjection with no anti-aliasing of associating or any kind of pre-filtering. The goal of applying these techniques for scaling is in the computational ease and proof of the performance, in any event, when utilizing bad quality pictures.

Figure 2: Face normalization [31]

Figure 3: Face landmarks [31]
Image captured for iris detection are always affected by noise. The preprocessing techniques are required to enhance the efficiency of the detection process by improving the image quality. Though there are several operations available to improve the image quality, the operations used for the peculiar region recognition include grayscale conversion, noise removal, and histogram enhancement. Noise is reduced or removed from image using noise filtering technique. In this methodology, the logarithmic homomorphic filtering will be adopted for image denoising.
Feature extraction is the process of obtaining the most relevant properties of the image for the classification of the peculiar region. The feature extracted is classified into three which are the texture-based feature, color-based feature and the frequency-based feature.
Textual based features are patterns that define the appearance of the object, this category of feature is aimed at extracting pixel arrangement, density, and proportions within the image. The local binary pattern (LBP) is used as the textual based feature.
The local binary pattern (LBP) extracts the pixels’ pattern by labeling it with a decimal number, called LBPs [33,34]. LBP method is achieved by thresholding the neighborhood of each pixel with a binary number [35]. To perform LBP, the image is converted to grayscale and LPB value is calculated by selecting the image block and using the pixel at the center as the reference point. LBP operator is performed on neighborhoods and across the image. The local neighborhood is a small subblock with a centered point. Example of LBP operator is described in Fig. 4 for 3 × 3 neighborhood small blocks. Fig. 5 shows the application of LBP a sample image in the UBIRIS database.

Figure 4: Example of basic LBP operation [36]

Figure 5: The extraction of local binary pattern (LBP)
3.3.2 Color Based Feature Extraction
The color-based feature is the extraction of properties that defines the color distribution of the image as defined by the light emitted on the object [37]. Digital images are defined in RGB which is attributed to the primary color of nature.
Color Histogram The color histogram is the measure of frequency of the pixel value in the three channels of the image. The color histogram is computed by defining a color range in the three image channels (red, green and blue). The frequency of pixels value in the range of [0 255] is used to compute the color histogram. Color histogram is one of the effective color-based feature extraction for image recognition [37,38]. Color histogram for the three channels was combined together to form a 3-dimensional feature that is used for the peculiar region recognition. Hence, a total feature size of (3,256) is extracted for the peculiar region classification. The extraction of the color histogram of a sample image in the UBIRIS database is described in Fig. 6.

Figure 6: Extraction of color histogram as feature from the image
3.3.3 Frequency Based Feature Extraction
High relevant features are extracted in frequency due to the distribution of signal energy in the object [39]. They are several techniques that have been applied to the extraction of frequency domain features. These techniques include Fast Fourier Transform (FFT), Discrete Cousin Transform (DCT) and the Continuous Wavelet Transform (CWT). In this methodology, CWT is used for the frequency-based feature extraction.
3.3.4 Continuous Wavelet Transform (CWT)
The continuous wavelet transform is used to decompose the image into wavelets. The filters in CWT store highly relevant data that can be extracted for the recognition of images [40]. The CWT is applied to decompose the images into four filters based on the signal energy level, then statistical analysis was computed on each of the filters. The image is split into three channels (red, green and blue) and filters are extracted for each at each of the energy levels. The four filters extracted refer to approximation, the horizontal detail, vertical detail and the diagonal details [41]. The statistical analysis is computed for each of the filter banks: mean, standard deviation, skewness and kurtosis.
Since four features are extracted from each of the filters and for the three image channels. The total number of features extracted is 4 × 4 × 3 = 48 features. Fig. 7 shows the filters extracted for each of the frequency domain features for an image channel for a sample image in the UBIRIS database.

Figure 7: The CWT filters for a sample image in the UBIRIS database
In the proposed approach, combination of local binary pattern (LBP), color histogram and features in frequency domain have been used with deep learning algorithms for classification. Hence, we extract three types of features for the classification of periocular regions for biometric. The LBP represents the textual features of the iris while the color histogram represents the frequencies of pixel values in the RGB channel. In order to extract the frequency domain features, the wavelet transformation is obtained. The statistical analysis (mean, standard deviation and moments) of the wavelet transformed in all bands and combined together. By learning from these features, Convolutional Neural Network (CNN) becomes able to discriminate between the features and can provide better recognition results. CNN’s feature classification and feature extraction are combined into a single learning body. CNN can optimize the features directly by taking them from raw input. The CNN neurons are sparsely connected compared to the conventional multilayer connected perceptron’s network that is fully connected. The sparsely connected neurons can process huge raw data with great efficiency. CNN’s are flexible and different input sizes can be adopted.
The conventional MLP has scaler weight on each hidden neuron; the neuron contains 2-D axes for weight, and the input and output are called feature maps [42]. The basic conventional block of 24 × 24-pixel images into two categories. The network consists of two pooling and convolutional layers. The last pooling layer is a single fully connected layer followed by the classification output layer. The weighting filters are feeding convolutional layers that have a kernel size of (Kx. Ky). The dimensions of the feature map are reduced to (Kx – 1, Ky-1); as the convolution takes place within the boundaries of the image. The subsampling sets are developed in advance at the pooling layer; it is to notice that these values are deliberately taken, and the last pooling layers are scalars. The output layers are connected with the two neurons corresponding to the class in which the image is categorized. The following are the propagation steps for each CNN sample.
• The first convolution neurons perform linear convolution to corresponding images that generate the input feature map.
• The input feature map is further passed to activation that generates an output convolution map.
• The pooling layer process involves each neuron feature map that is created by the convolution of the previous feature map of output.
• The scalar output layer is formed by the fully connected output layer that presents the classification of the input image.
By employing the stochastic gradient descent method used to train the CNN’s that is also called backpropagation algorithm. The iteration of each BP, the network parameters like weight, gradient magnitude, and connected layers are computed. The CNN is updated to the sensitive parameters, to optimize the input and output results. The algorithms of the most popular ancestor CNN “LeNet”, and deep learning CNN “AlexNet” are the important models to study [43,44]. The difference between deep learning CNN’s and conventional MLP’s are the weight sharing and limited connection that is not present in conventional MLP’s [45]. Otherwise, both models follow the homogeneous linear neural network.
The proposed method used the following datasets for the testings and training:
The images used for validation of the proposed method were obtained from the UBIRIS database and the UTIRIS database [46,47]. UBIRIS database is considered to be Noisy visible wavelength iris image database that is divided into two versions depending on the image size.
UBIRIS version 1 (UBIRIS.v1) database is made up of 1877 images that are collected from 241 persons [47]. The images were captured in two different sessions. The first version was made-up of low noise and with moderate properties such as luminosity, reflection and contrast. The image was collected from a focal length of 71 mm.
UBIRIS version 2 (UBIRIS.v2) [48] images were designed to evaluate biometric detection with the effect of far imaging condition. The image was collected from a focal length of 400 mm.
UBRIS datasets are prepared for 200 by 150 image size and UBIRIS 800 by 600 image size. The images were collected in the folders and sub folders. With a sub folder containing images for a particular person. The dataset was divided into the Training set and the testing set by excluding a person image from each of the sub folders. The excluded image is prepared for the testing set while the other image is used for the training set. The images are prepared in two different versions: Infrared and the RGB version [26].
4.1.2 IMM Frontal Face Database
The IMM Frontal face database was selected for eye recognition and periocular detection [49]. Unlike the aforementioned database, this database is made up of high quality frontal images with different facial expressiones collected from 12 persons (all male).
The image classification process is carried out using the local binary pattern (LBP) which is texture based feature, color histogram which is color based feature, continuous wavelet transform which is the frequency based features and the combination of the three features. The feature extracted is subjected to the convolutional neural network for the classification and evaluation of the peculiar region detection.
Proposed method evaluation can be cultivated by carrying out the normal regular execution strategies: accuracy (Acc), Recall (DR), false alarm rate (FAR), Mcc, Precision, F1 score, CPU period to execute a technique (TBM), and CPU period to look at the model (TT). Accuracy or precision shows the all-out effectiveness of a methodology [50]. Recall, states to the measure of imitation attacks apparently separated by the entire measure of imitation events in the assessment dataset. Accuracy is the aggregate sum of artificial attacks apparent among the entire measure of events ordered as an attack. The F1 score tallies the symphonious maliciousness of exactness and the recall. Bogus alert rate is the measure of an attack isolated by the entire measure of customary events in the test dataset, while False Negative Rate (FNR) shows the measure of attack events that can’t be taken note of. Mcc implies the affiliation coefficient between the observed and test information [51]. Normally, the goal is to achieve an unprecedented Acc, DR, exactness, Mcc, and F1 score and, simultaneously, keep up low FAR TBM, and TT. Equations related to performance measures are generally distinguishable and known to all in terms of accuracy, recall, precision, FAR, FNR, and F1; Where true positive (TP) is the measure of intrusions appropriately named an attack, true negative (TN) is the measure of standard events acceptably delegated a compassionate parcel, the false negative (FN) is the number of interruptions inaccurately named a compassionate bundle or packet, and the false positive (FP) is the measure of normal events wrongly classified as an attack. The performance of the test of intrusion can likewise be estimated graphically with a disarray framework or a confusion matrix. This confusion matrix or the disarray network shows the TP, TN, FP, and FN for the problem of classification.
The periocular detection was demonstrated on the dataset using four different approaches: LBP feature extraction, color histogram feature extraction, frequency based domain feature extraction and the combination of the features. The extracted features were trained using the convolutional neural network (CNN) for periocular region detection using the datasets.
Tab. 1 shows the results of the accuracy, precision, recall and f1-score for the proposed method. The table analyzes the method for each feature extraction and then the last row shows the results of the combination of the three feature extractions used on the method. The performance of combining the three features surpasses the performance of the single feature extraction which indicates the efficiency of using the three feature extractions. Tab. 2 shows the performance comparison of the proposed method and other benchmark methods based on UBIRISv2. The proposed method outweighs the accuracy, precision, recall and f1score of other benchmarks.
Tabs. 3 and 4 describe the training and validation accuracy respectively. Moreover, Tab. 5 shows the accuracy of iris detection for different datasets. The highest accuracy obtained by UIRIS.V2 Session 2 (600 × 800) with by joining the three features together. Therefore, by combining the three features together have proven to improve the accuracy of the detection.



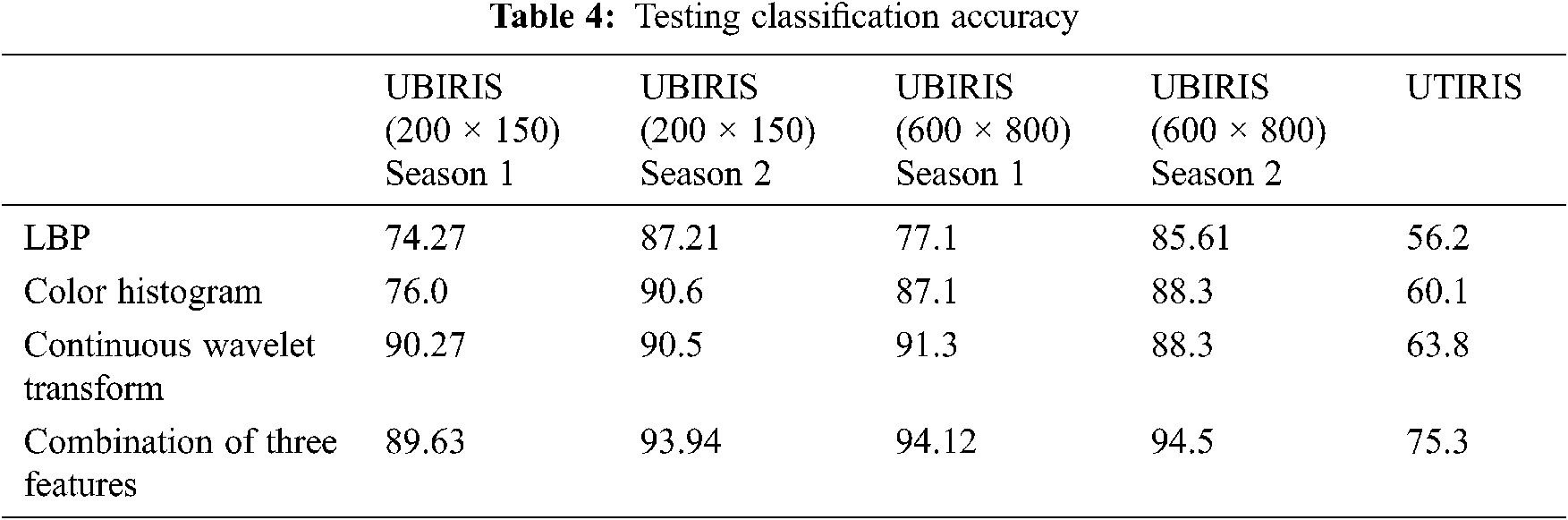

4.4 Evaluation of Periocular Detection
The IMM Frontal Face detection is used for evaluating the eye detection method [49], a sample image is selected for each person as shown in Fig. 8. Moreover, Fig. 9 shows the face and eyes of the sample images are perfectly extracted for iris detection. The proposed method has correctly identified the eye region and recognized the name of the person.

Figure 8: Sample images for eye detection

Figure 9: Eye detection for each of the sample images
In this study, periocular biometric identification and its utilization are analyzed. The study has highlighted the importance of periocular biometric verification as the most cost-effective and highly reliable security approach. With the advancing technology and increased utilization of information databases, intelligent personal identification has become an important research topic. Traditional security parameters being used by the many systems such as PIN code, fingerprint or facial recognition are suffering from the security risks and threats. Therefore, reliable methods to distinguish various individuals are required. The proposed architecture has adopted multiple features and emphasis on the semantical regions including eyes and eyebrows in the periocular region. By learning from these features, Convolutional Neural Network (CNN) becomes able to discriminate between the features and can provide better recognition results. In the proposed approach, combination of local binary pattern (LBP), color histogram and features in frequency domain have been used with deep learning algorithms for classification. Hence, we extract three types of features for the classification of periocular regions for biometric. The LBP represents the textual features of the iris while the color histogram represents the frequencies of pixel values in the RGB channel. In order to extract the frequency domain features, the wavelet transformation is obtained. The statistical analysis (mean, standard deviation and moments) of the wavelet transformed in all bands and combined together. All the features are extracted and processed with a deep learning algorithm for classifications. We attempted to optimize the accuracy of this method in subsequent studies to decrease the false person recognition. The study was evaluated and compared with other recent models based on the UBIRIS.v1, UBIRIS.v2 and IMM Frontal Face databases. The performance of the three selected features was superior to that of feature extraction by one, indicating the effective use of the three feature extraction. In addition to the superiority of the proposed model in performance compared to other methods in terms of different metrics such as accuracy, precision, recall and f1-score.
In future works, the study can be further expanded to analyze the fusion of periocular and iris recognition for systems with high user security. Furthermore, the proposed work can be extended to include a lightweight module for self-attention [56].
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. S. M. Lee and D. Lee, “Opportunities and challenges for contactless healthcare services in the post-covid-19 era,” Technological Forecasting and Social Change, vol. 167, no. 6, pp. 1–11, 2021. [Google Scholar]
2. W. Shishah and S. Alhelaly, “User experience of utilising contactless payment technology in Saudi Arabia during the covid-19 pandemic,” Journal of Decision Systems, vol. 30, no. 1, pp. 1–18, 2021. [Google Scholar]
3. A. S. Manolis, A. A. Manolis, T. A. Manolis, E. J. Apostolopoulos, D. Papatheou et al., “Covid-19 infection and cardiac arrhythmias,” Trends in Cardiovascular Medicine, vol. 30, no. 8, pp. 451–460, 2020. [Google Scholar]
4. Z. Rui and Z. Yan, “A survey on biometric authentication: Toward secure and privacy preserving identification,” IEEE Access, vol. 7, no. 12, pp. 5994–6009, 2018. [Google Scholar]
5. M. Kumar, K. S. Raju, D. Kumar, N. Goyal, S. Verma et al., “An efficient framework using visual recognition for IoT based smart city surveillance,” Multimedia Tools and Applications, vol. 80, no. 1, pp. 1–19, 2021. [Google Scholar]
6. S. Ilankumaran and C. Deisy, “Multi-biometric authentication system using finger vein and iris in cloud computing,” Cluster Computing, vol. 22, no. 1, pp. 103–117, 2019. [Google Scholar]
7. M. Wang, H. El-Fiqi, J. Hu and H. A. Abbass, “Convolutional neural networks using dynamic functional connectivity for EEG-based person identification in diverse human states,” IEEE Transactions on Information Forensics and Security, vol. 14, no. 12, pp. 3259–3272, 2019. [Google Scholar]
8. F. Alonso and J. Bigun, “A survey on periocular biometrics research,” Pattern Recognition Letters, vol. 82, no. 2, pp. 92–105, 2016. [Google Scholar]
9. S. Dargan and M. Kumar, “A comprehensive survey on the biometric recognition systems based on physiological and behavioral modalities,” Expert Systems with Applications, vol. 143, no. c, pp. 113114, 2020. [Google Scholar]
10. P. Drozdowski, C. Rathgeb, A. Dantcheva, N. Damer and C. Busch, “Demographic bias in biometrics: A survey on an emerging challenge,” IEEE Transactions on Technology and Society, vol. 1, no. 2, pp. 89–103, 2020. [Google Scholar]
11. F. Alonso-Fernandez, R. A. Farrugia, J. Bigun, J. Fierrez and E. Gonzalez-Sosa, “A survey of super-resolution in iris biometrics with evaluation of dictionary-learning,” IEEE Access, vol. 7, no. 5, pp. 6519–6544, 2019. [Google Scholar]
12. A. Czajka and K. W. Bowyer, “Presentation attack detection for iris recognition: An assessment of the state-of-the-art,” ACM Computing Surveys (CSUR), vol. 51, no. 4, pp. 1–35, 2018. [Google Scholar]
13. J. Sun and W. Rong, “Eye shape classification of curve similarity,” Journal of Frontiers of Computer Science and Technology, vol. 11, pp. 8, 2017. [Google Scholar]
14. F. Wang, J. Feng, Y. Zhao, X. Zhang, S. Zhang et al., “Joint activity recognition and indoor localization with wifi fingerprints,” IEEE Access, vol. 7, pp. 80058–80068, 2019. [Google Scholar]
15. N. Khalil, O. Gnawali, D. Benhaddou and J. Subhlok, “Sonicdoor: A person identification system based on modeling of shape, behavior, and walking patterns,” ACM Transactions on Sensor Networks (TOSN), vol. 14, no. 3–4, pp. 1–21, 2018. [Google Scholar]
16. B. Korany, C. R. Karanam, H. Cai and Y. Mostofi, “Xmodal-id: Using Wi-Fi for through wall person identification from candidate video footage,” in 25th Annual Int. Conf. on Mobile Computing and Networking, Los Cabos, Mexico, pp. 1–15, 2019. [Google Scholar]
17. M. M. M¨, T. Rumyantseva, V. T. M¨ucke, K. Schwarzkopf, S. Joshi et al., “Bacterial infection-triggered acute-on-chronic liver failure is associated with increased mortality,” Liver International, vol. 38, no. 4, pp. 645–653, 2018. [Google Scholar]
18. R. Popli, I. Kansal, A. Garg, N. Goyal and K. Garg, “Intelligent method for detection of coronary artery disease with ensemble approach,” in Advances in Communication and Computational Technology. Singapore: Springer, pp. 1033–1042, 2020. [Google Scholar]
19. W. Puriwat and S. Tripopsakul, “Explaining an adoption and continuance intention to use contactless payment technologies: During the covid-19 pandemic,” Emerging Science Journal, vol. 5, no. 1, pp. 85–95, 2021. [Google Scholar]
20. U. Park, A. Ross and A. K. Jain, “Periocular biometrics in the visible spectrum: A feasibility study,” in 2009 IEEE 3rd Int. Conf. on Biometrics: Theory, Applications, and Systems, Washington: IEEE, pp. 1–6, 2009. [Google Scholar]
21. U. Park, R. R. Jillela, A. Ross and A. K. Jain, “Periocular biometrics in the visible spectrum,” IEEE Transactions on Information Forensics and Security, vol. 6, no. 1, pp. 96–106, 2011. [Google Scholar]
22. F. Alonso-Fernandez and J. Bigun, “Eye detection by complex filtering for periocular recognition,” in 2nd Int. Workshop on Biometrics and Forensics. Valletta, Malta: IEEE, pp. 1–6, 2014. [Google Scholar]
23. P. Kumari and K. Seeja, “Periocular biometrics: A survey,” Journal of King Saud University-Computer and Information Sciences, vol. 91, no. 7, pp. 11, 2019. [Google Scholar]
24. I. Nigam, M. Vatsa and R. Singh, “Ocular biometrics: A survey of modalities and fusion approaches,” Information Fusion, vol. 26, no. 3, pp. 1–35, 2015. [Google Scholar]
25. L. C. O. Tiong, A. B. J. Teoh and Y. Lee, “Periocular recognition in the wild with orthogonal combination of local binary coded pattern in dual-stream convolutional neural network,” in 2019 Int. Conf. on Biometrics (ICBCrete, Greece: IEEE, pp. 1–6, 2019. [Google Scholar]
26. A. F. M. Raffei, T. Sutikno, H. Asmuni, R. Hassan, R. M. Othman et al., “Fusion iris and periocular recognitions in non-cooperative environment,” Indonesian Journal of Electrical Engineering and Informatics, vol. 7, no. 3, pp. 543–554, 2019. [Google Scholar]
27. K. K. Kumar and M. Pavani, “Periocular region-based age-invariant face recognition using local binary pattern,” in Microelectronics, Electromagnetics and Telecommunications, Andhra Pradesh, India: Springer, pp. 713–720, 2019. [Google Scholar]
28. S. Bakshi, P. K. Sa, H. Wang, S. S. Barpanda and B. Majhi, “Fast periocular authentication in handheld devices with reduced phase intensive local pattern,” Multimedia Tools and Applications, vol. 77, no. 14, pp. 17595–17623, 2018. [Google Scholar]
29. M. Castrillon-Santana, J. Lorenzo-Navarro and E. Ramon-Balmaseda, “On using periocular biometric for gender classification in the wild,” Pattern Recognition Letters, vol. 82, no. 12, pp. 181–189, 2016. [Google Scholar]
30. Z. Zhao and A. Kumar, “Accurate periocular recognition under less constrained environment using semantics-assisted convolutional neural network,” IEEE Transactions on Information Forensics and Security, vol. 12, no. 5, pp. 1017–1030, 2017. [Google Scholar]
31. Mustaqeem and S. Kwon, “A CNN-assisted enhanced audio signal processing for speech emotion recognition,” Sensors, vol. 20, no. 1, pp. 183, 2020. [Google Scholar]
32. J. Merkow, B. Jou and M. Savvides, “An exploration of gender identification using only the periocular region,” in 2010 Fourth IEEE Int. Conf. on Biometrics: Theory, Applications and Systems, Washington: IEEE, pp. 1–5, 2010. [Google Scholar]
33. C. Chahla, H. Snoussi, F. Abdallah and F. Dornaika, “Discriminant quaternion local binary pattern embedding for person re-identification through prototype formation and color categorization,” Engineering Applications of Artificial Intelligence, vol. 58, no. 4, pp. 27–33, 2017. [Google Scholar]
34. Q. Zhou, H. Fan, H. Yang, H. Su, S. Zheng et al., “Robust and efficient graph correspondence transfer for person re-identification,” IEEE Transactions on Image Processing, vol. 30, no. 10, pp. 1623–1638, 2021. [Google Scholar]
35. Y. Yoo and J. G. Baek, “A novel image feature for the remaining useful lifetime prediction of bearings based on continuous wavelet transform and convolutional neural network,” Applied Sciences, vol. 8, no. 7, pp. 1102, 2018. [Google Scholar]
36. X. Tan and B. Triggs, “Fusing gabor and lbp feature sets for kernel-based face recognition,” in Int. Workshop on Analysis and Modeling of Faces and Gestures, Janeiro, Brazil: Springer, pp. 235–249, 2007. [Google Scholar]
37. H. R. Koushkaki, M. R. Salehi and E. Abiri, “Color-based feature extraction with application to facial recognition using tensor-matrix and tensor-tensor analysis,” Multimedia Tools and Applications, vol. 79, no. 9–10, pp. 5829–5858, 2020. [Google Scholar]
38. M. Li and X. Yuan, “Adaptive segmentation-based feature extraction and S-STDM watermarking method for color image,” Neural Computing and Applications, vol. 32, no. 1, pp. 1–20, 2019. [Google Scholar]
39. M. S. Akter, M. R. Islam, Y. Iimura, H. Sugano, K. Fukumori et al., “Multiband entropy-based feature-extraction method for automatic identification of epileptic focus based on high-frequency components in interictal ieeg,” Scientific Reports, vol. 10, no. 1, pp. 1–17, 2020. [Google Scholar]
40. D. Huang, C. Shan, M. Ardabilian, Y. Wang and L. Chen, “Local binary patterns and its application to facial image analysis: A survey,” IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 41, no. 6, pp. 765–781, 2011. [Google Scholar]
41. J. E. Koh, U. R. Acharya, Y. Hagiwara, U. Raghavendra, J. H. Tan et al., “Diagnosis of retinal health in digital fundus images using continuous wavelet transform (cwt) and entropies,” Computers in Biology and Medicine, vol. 84, no. 3, pp. 89–97, 2017. [Google Scholar]
42. S. Kiranyaz, O. Avci, O. Abdeljaber, T. Ince, M. Gabbouj et al., “1d convolutional neural networks and applications: A survey,” Mechanical Systems and Signal Processing, vol. 151, pp. 107398, 2021. [Google Scholar]
43. Y. LeCun, L. Bottou, Y. Bengio and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998. [Google Scholar]
44. A. Krizhevsky, I. Sutskever and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in Neural Information Processing Systems, vol. 25, no. 1, pp. 1097–1105, 2012. [Google Scholar]
45. A. S. Shamsaldin, P. Fattah, T. A. Rashid and N. K. Al-Salihi, “A study of the applications of convolutional neural networks,” Journal of Science and Engineering, vol. 3, no. 2, pp. 31–39, 2019. [Google Scholar]
46. M. S. Hosseini, B. N. Araabi and H. Soltanian-Zadeh, “Pigment melanin: Pattern for iris recognition,” IEEE Transactions on Instrumentation and Measurement, vol. 59, no. 4, pp. 792–804, 2010. [Google Scholar]
47. H. Proença, S. Filipe, R. Santos, J. Oliveira and L. A. Alexandre, “The UBIRIS.v2: A database of visible wavelength iris images captured on-the-move and at-a-distance,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 8, pp. 1529–1535, 2010. [Google Scholar]
48. H. Proenca, S. Filipe, R. Santos, J. Oliveira and L. A. Alexandre, “The ubiris. v2: A database of visible wavelength iris images captured on-the-move and at-a-distance,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 8, pp. 1529–1535, 2009. [Google Scholar]
49. M. M. Nordstrom, M. Larsen, J. Sierakowski and M. B. Stegmann, “The IMM face database,” Environment, vol. 22, no. 10, pp. 1319–1331, 2003. [Google Scholar]
50. H. HaddadPajouh, A. Dehghantanha, R. Khayami and K. K. R. Choo, “A deep recurrent neural network-based approach for internet of things malware threat hunting,” Future Generation Computer Systems, vol. 85, no. 4, pp. 88–96, 2018. [Google Scholar]
51. M. Conti, A. Dehghantanha, K. Franke and S. Watson, “Internet of things security and forensics: Challenges and opportunities,” Future Generation Computer System, vol. 78, no. 2, pp. 544–546, 2018. [Google Scholar]
52. C.-W. Tan and A. Kumar, “Towards online iris and periocular recognition under relaxed imaging constraints,” IEEE Transactions on Image Processing, vol. 22, no. 10, pp. 3751–3765, 2013. [Google Scholar]
53. A. Jain, P. Mittal, G. Goswami, M. Vatsa and R. Singh, “Person identification at a distance via ocular biometrics,” in IEEE Int. Conf. on Identity, Security and Behavior Analysis (ISBA 2015Hyderabad, India: IEEE, pp. 1–6, 2015. [Google Scholar]
54. A. Gangwar, A. Joshi, R. Sharma and Z. Saquib, “Person identification based on fusion of left and right periocular region,” in Int. Conf. on Signal, Image and Video Processing (ICSIVP 2012Daejeon, Korea, pp. 13–15, 2012. [Google Scholar]
55. H. Proenca and J. C. Neves, “A reminiscence of “mastermind”: Iris/periocular biometrics by “in-set” cnn iterative analysis,” IEEE Transactions on Information Forensics and Security, vol. 14, no. 7, pp. 1702–1712, 2018. [Google Scholar]
56. S. Kwon, “Att-Net: Enhanced emotion recognition system using lightweight self-attention module,” Applied Sciences, vol. 11, no. 9, pp. 107101, 2021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |