DOI:10.32604/csse.2022.021459
| Computer Systems Science & Engineering DOI:10.32604/csse.2022.021459 | |
| Article |
An Efficient Deep Learning-based Content-based Image Retrieval Framework
1Department of CSE, Sri Krishna College of Engineering and Technology, Anna University, Coimbatore, Tamil Nadu, 641008, India
2Department of CSE, M. Kumarasamy College of Engineering, Anna University, Karur, Tamil Nadu, 639113, India
*Corresponding Author: M. Sivakumar. Email: siva.recursion@gmail.com
Received: 03 July 2021; Accepted: 22 November 2021
Abstract: The use of massive image databases has increased drastically over the few years due to evolution of multimedia technology. Image retrieval has become one of the vital tools in image processing applications. Content-Based Image Retrieval (CBIR) has been widely used in varied applications. But, the results produced by the usage of a single image feature are not satisfactory. So, multiple image features are used very often for attaining better results. But, fast and effective searching for relevant images from a database becomes a challenging task. In the previous existing system, the CBIR has used the combined feature extraction technique using color auto-correlogram, Rotation-Invariant Uniform Local Binary Patterns (RULBP) and local energy. However, the existing system does not provide significant results in terms of recall and precision. Also, the computational complexity is higher for the existing CBIR systems. In order to handle the above mentioned issues, the Gray Level Co-occurrence Matrix (GLCM) with Deep Learning based Enhanced Convolution Neural Network (DLECNN) is proposed in this work. The proposed system framework includes noise reduction using histogram equalization, feature extraction using GLCM, similarity matching computation using Hierarchal and Fuzzy c- Means (HFCM) algorithm and the image retrieval using DLECNN algorithm. The histogram equalization has been used for computing the image enhancement. This enhanced image has a uniform histogram. Then, the GLCM method has been used to extract the features such as shape, texture, colour, annotations and keywords. The HFCM similarity measure is used for computing the query image vector's similarity index with every database images. For enhancing the performance of this image retrieval approach, the DLECNN algorithm is proposed to retrieve more accurate features of the image. The proposed GLCM+DLECNN algorithm provides better results associated with high accuracy, precision, recall, f-measure and lesser complexity. From the experimental results, it is clearly observed that the proposed system provides efficient image retrieval for the given query image.
Keywords: Content based image retrieval (CBIR); improved gray level co-occurrence matrix (GLCM); hierarchal and fuzzy C-means (HFCM) algorithm; deep learning based enhanced convolution neural network (DLECNN)
The fast and exceptional growth in digital technology has resulted in a significant increase in the image storage produced by the scientific, educational, medical, industrial, and other applications. From an image database, similar images are searched using a retrieval technique called CBIR. Image features such as texture, shape and color are automatically extracted by the CBIR approach [1,2]. CBIR has been widely used in various applications such as art collections, education, training, crime prevention, military, architectural and engineering design. A CBIR system computes the similarity among every image in an image database, and lastly, ranks the images in collection according to its relevance degree to user's query. Even after designing several compact and efficient feature vectors to index each image, still there remains a wide gap between the actual human perceptions model with that of the feature based model used for the CBIR [3]. This is mainly due to the fact that the design of feature vector is solely based on the low level visual information like color, texture, shape etc., without taking into account the semantic information like spatial organization, context, events etc. At the region level, the local features are extracted by splitting the image into various regions and at the image level, the global features are extracted [4]. Images with high similarity in the query image based on its visual contents are indexed at the top. Relevancy of the retrieved images is arranged in the decreasing order. Pattern recognition, statistics processing, signal processing and computer vision are the various domains that contribute in the image retrieval process. These fields contribute to the feature extraction process [5]. Fig. 1 shows the general block diagram of the CBIR system.

Figure 1: General block diagram of CBIR system
In the relevancy evaluation, the similarity measure plays a vital role between the query image and the stored image database [6]. The evaluation measures like Canberra, Bhattacharyya, Mahantam, Euclidean and Chi square are used for computing similarity. Every time, the comparison evaluation is computed between the target images and the query images for generating the score value. The high relevancy of the Target image is defined using the lower similarity score. Firstly, the indexing of images with high relevancy is carried out. In general, the retrieval performance is affected by the similarity measure selection. The feature extraction techniques are used to define the significance of the retrieval system. The distance between the target and source image features are computed using the similarity measure [7].
Image classification has become one of the important tasks in the field of image processing. Classification is a process of classifying the data into a number of known categories or classes. The input image elements are used for predicting its class in the process of image categorization. Support Vector Machine (SVM) [8], Artificial Neural Network (ANN), K-Nearest Neighbour (KNN) techniques are widely used in image classification [9,10]. The principle of CBIR is associated with various real-world applications such as medical applications, remote sensing image retrieval, natural image retrieval, forensic applications, security applications, business applications and miscellaneous applications.
This research work mainly focuses on developing an efficient CBIR framework. There are various CBIR approaches available in the literature, but, the previous CBIR models have their own limitations. Especially, the existing CBIR techniques consume more time and produces inaccurate retrieval results. In order to handle the above mentioned problems, this work proposes a Gray Level Co-occurrence Matrix (GLCM) integrated with Deep Learning based Enhanced Convolution Neural Network (DLECNN) framework to enhance the overall retrieval performance. The proposed work includes three steps such as noise reduction, GLCM based feature extraction and DLECNN based classification. In this proposed work, the optimal weight and the parameter updation of DLECNN results in better efficiency when compared to the traditional CNN methodology. This GLCM integrated DLECNN proposed method is used to provide accurate results for a specified CBIR dataset. The article is organized as follows: Section 2 provides brief review about the literature works in noise reduction, feature extraction, and image retrieval and classification methods on CBIR system. In Section 3, the proposed GLCM+DLECNN methodology is explained. Section 4 elaborates about the experimental results and performance is analyzed. At last, Section 5 concludes the findings of the research methodology.
Lotfi et al. [11] discussed about a technique to estimate the noiseless histogram from a Gaussian noise image. Azevedo-Marques and Rangayyan (2013) examined about the pre-processing, segmentation, land marking, feature extraction, mammograms indexing for the CBIR system. Pre-processing is carried out through the anisotropic diffusion and the Wiener Filter (WF) for noise elimination and enrichment. This work provides better results compared to the previous approaches [12].
Shijin Kumar et al. [13] described about the GLCM based texture feature extraction and connected regions for extracting the shape features. These evaluated features are then given to the classifier. Bhatti et al. [14] presented a CBIR system that consists of an image database and extracting the visual features from the images for attaining the efficient CBIR results. In this work, colour histogram technique and Euclidian distance are used. Then, the performance analysis and validation are carried out for the given database.
Ergen et al. [15] explored the spatial techniques such as Gray Level Run Length Matrix (GLRLM), GLCM and Gabor wavelet algorithms. These techniques are analyzed thoroughly with their advantages and limitations. Ban et al. [16] introduced the steps to get the superior threshold such that the fuzzy partition can be realized, and then the fuzzy c-means algorithm is utilized to perform image classification process. Then, the authors calculated the subjection degree of one picture in the respective class. The mathematical framework of the approach is defined clearly.
Malliga et al. [17] presented the Modified Fuzzy C Means clustering technique based Content Based Medical Image Retrieval (CBMIR) system. In this system, initially, the Haralick and Texture spectrum features are extracted from medical image database. Thus, the extracted features from the training database images are clustered using FCM clustering technique. The performance of this work is evaluated and validated. Fu et al. [18] explored the actual deep features generated using a Convolutional Neural Network (CNN) for the CBIR system and trained a hyperplane that can distinguish the related and different image pairs using a linear SVM. The pair features generated by a pair of images, including the query image and every test image present in the image dataset are fed into the SVM for generating the output results. Liu et al. [19] proposed an image retrieval framework that combines the high-level features obtained from a CNN model with low-level features attained from the Dot Diffused Block Truncation Coding (DDBTC). Sharif et al. [20] suggested an approach based on the fusion of the visual words and achieved effective results on the Corel-1 K, Corel-1.5 K, Corel-5 K, and Caltech-256 image repositories as equated to the feature fusion of both descriptors and latest CBIR approaches with the surplus assistances of scalability and fast indexing.
Yousuf et al. [21] introduced an effective technique to improve the performance of CBIR on the basis of visual words fusion of the Scale Invariant Feature Transform (SIFT) and the Local Intensity Order Pattern (LIOP) descriptors. The performance analysis was evaluated and the results are validated. Mehmood et al. [22] presented an adapted triangular area-based technique to compute the LIOP features, weighted soft codebooks, and triangular histograms from the four triangular areas of each image. All the above mentioned existing CBIR research techniques had their own advantages and limitations. Especially, the existing research techniques had not handled the images with noise. Moreover, the computational complexity of the existing CBIR research techniques is higher. These issues are to be handled in the proposed research methodology.
In this proposed research work, the Gray Level Co-occurrence Matrix (GLCM) with Deep Learning based Enhanced Convolution Neural Network (DLECNN) is proposed for the efficient image retrieval. The proposed work involves the noise reduction, feature extraction, similarity measure and image retrieval results. Fig. 2 illustrates the overall block diagram of the proposed system.

Figure 2: Overall block diagram of the proposed system
3.1 Noise Reduction Using Histogram Equalization
In this work, the noise reduction process is done by using the histogram equalization method which is used to increase the image quality. The normalized cumulative histogram is used as a grey scale mapping function for achieving better image quality. Noise reduction and averaging are concentrated in the image histogram equalization via adding some other noisy images. Contrast intensities which are not having proper distribution are produced by images during histogram representation. Then, fewer adjustments are done in this step for producing better contrast image. Effective distribution of intensity values are done in histogram equalization.
In general, image's intensity level is taken and total pixel's counts at every pixel intensity level are computed in histogram equalization [23]. For filling the entire available intensities space, the image intensity levels are spread over and the image's contrast is increased. In these pixels, every intensity level is allocated with a percentage range that matches the total pixels percentage in an image. In an equalized image, the total intensity range's 20% is occupied. In the same order, the pixels will remain to all the darker and lighter pixels in the original image. They will just be shifted and or stretched in terms of where and how much of intensity range they occupied.
3.2 Feature Extraction Using GLCM Method
In this work, GLCM algorithm is used for performing the feature extraction operation. From specified dataset, highly informative features are extracted using this GLCM algorithm. An important characteristic feature for image analysis is the texture feature. Texture feature of an image could provide valuable region of interests. GLCM has been widely used in various texture analysis applications and is an important technique used for extracting the features. For retrieval and indexing, the image's visual contents are captured using GLCM. This GLM information is used to solve the computational tasks in various applications. A CBIR system should have an efficient feature extraction method and valuable features including the visual features like shape, texture, colour and text based features like annotation and keywords should be extracted. In texture feature, the homogeneity properties having no relationship with intensity presence or single colour's visual patterns are indicated using the texture. Effective recognition of the important image features is carried out using colour feature. In CBIR, a visual feature is colour, simple and robust processing is moderated. In GLCM image matrix, gray levels count G, defines columns and rows count in that matrix. Relative frequency is defined using the matrix element P (i, j | Δx, Δy) with which two pixels, isolated using pixel distance (Δx, Δy), are found within a specified neighborhood, one having intensity ′i′ and the other with ′j′. At a specific angle (ө) and at a particular displacement distance d, for variations between gray levels ′i′ and ′j’, second order statistical probability values are there in matrix element P (i, j | d, θ). Storing huge amount of temporary data is implied using large intensity values G i.e., a G × G matrix for every fusion of (Δx, Δy) or (d, θ). Texture sample's size on which it is estimated is having high influence on GLCM because of its high dimensionality [24]. Thus, there will be a minimization in gray levels count. Between neighbour pixel (j) and reference pixel (i) relationship is represented using GLCM.
From images, GLCM is a well-established statistical tool to extract the second order texture information. Every part (i, j) in GLCM denotes quantity of times picture element with worth i appears horizontally neighbouring to a picture element with worth j. Typically, the image with gray-level (gray-scale potency) worth i happens horizontally neighbour to a picture element along with the worth j. GLCM contents are used in texture feature computations. At interested pixel location, intensity variations are measured. Typically, according to two parameters namely, relative orientation and relative distance between pixel pair d measured in pixel number, it computes co-occurrence matrix. In general, they are quantized in four directions (0°, 45 °, 90 ° and 135 °). It is possible to quantize them in some other directions. There are fourteen features in GLCM. In that, highly useful features include, correlation's information measure, sum entropy, inverse difference moment, correlation, contrast, angular second moment (ASM). These features are promising thoroughly.
Co-occurrence matrices Normalized probability density
where x, y = 0, 1,…N−1 refer to the co-ordinates of the pixel
i, j = 0, 1, ….L − 1 are the gray levels
S indicates the set of pixel pairs having specific association in the image
#S is the number of elements in S.
where, in GLCM, gray-level co-occurrence matrices count is represented as p.
Entropy: Randomness's statistical measure is given by this. Input image's texture is characterized using this entropy value.
Contrast: In GLCM, local variations are measured using this. For entire image, between a pixel and its neighbor pixel, intensity contrast is computed using this. For a constant image, contrast value is 0.
where, pixel at location (i, j) is expressed as p(i, j).
Correlation: Specified pixel pair's joint probability occurrence is measured using this.
Homogeneity: In GLCM to GLCM diagonal, element distribution's closeness is measured using this.
In Eq. (7), the first element shows the vertical coordinate and second element shows horizontal coordinate.

For distinguishing the various image types, high discriminative power is given by all these features. In this work, the statistical texture features are extracted using second order texture GLCM. The six second order features namely contrast, dissimilarity, homogeneity, correlation, entropy and energy are computed. Image smoothness is measured using energy value. Local level variations are measured using contrast value and for high contrast image, high value is given and for low contrast image, low value is given. In GLCM, the element distribution's closeness is measured using homogeneity. The value lies between 0 and 1. For a diagonal GLCM, the homogeneity value will be 1. Randomness measure is given by entropy. Dissimilarity gives the difference between two image features effectively and it provides a further insight into cancer type or cancers class which they are likely to fall into actual class. Thus, the GLCM method is used to provide more informative features using energy, homogeneity, entropy, correlation, dissimilarity and contrast texture features on given weed database.
3.3 Hierarchal and Fuzzy C-Means (HFCM) Algorithm for Similarity Measure
In this work, the similarity measure is done by the clustering algorithm. The clustering algorithm used in this work is Hierarchal and Fuzzy c- Means (HFCM) algorithm. HFCM is nothing but it is a combined process of hierarchal and FCM algorithm. The query image is also passed through the image descriptor to extract its feature vector. Similarity calculation is done between the query image and all the images in database. For evaluating the similarity, the obtained gray levels are normalized. Then, the gray level of the query image and that of all the images present in the training set obtained from color filter evaluations are matched. A score ranging from 0 to 1 is assigned for each comparison, the lowest score having the maximum relevance. To classify and retrieve the images along with texture and color feature extraction, similarity measure is utilized in CBIR. Similarity measure defines the distance between every database image feature and query image feature vector query image feature vector in feature space. According to this measure, indexing is performed and according to image indices measure, retrieved image set is sorted. FCM algorithm is a typical clustering algorithm. Between the data points and prototypes, for measuring the similarity, the squared-norm is employed. In spherical clusters clustering, it shows high effectiveness. For general dataset clustering, various algorithms are derived from FCM. The images are retrieved using a measure called dissimilarity/similarity [25]. The FCM algorithm obtains the image retrieval results by measuring the similarity between the input and query images. Clustering performs grouping of set of objects with similar attributes among different groups. Fig. 3 shows the HFCM process for similarity measurement.

Figure 3: HFCM process for similarity measurement
Hierarchical clustering involves a cluster in hierarchy. All cluster holds contains child cluster node where the sibling clusters partition points wrapped using their common parent. Hence, exploiting data on different levels of granularity are performed. The clustering is performed using all data point's single cluster iteratively until reaching the stopping criterion (frequently, requested clusters number k) is targeted [26]. All clusters contains child cluster node where sibling clusters focuses on wrapping by their parent. Henceforth, exploiting data on various granularity levels are performed. Hierarchical clustering is improved by FCM clustering. A single part of the data is allowed to be in more than two clusters in HFCM. Fuzzy model is used for studying about HFCM's objective function with its generalization. There exists an infinite possible fuzzy partitions range. So, for searching the optimum partition based on the selected objective function, there is a need to devise an objective function or optimization model. An iterative local optimum technique termed as HFCM algorithm is used by various researchers for solving the optimization problem. Between a specified prototype and data point, the distance is weighted based on the corresponding membership degree between these two in HFCM objective function. Thus, the high membership values are assigned with small weights and low memberships values are assigned with high weights in partitioning for function minimization. Following, the objective function minimization is formulated.
where, a real number with a value greater than 1 is represented as m, in cluster j, xi's membership degree is represented as uij, d-dimensional measured data is represented as xi, cluster center's D-dimension is represented as, and cluster centers cj by
Where, termination criterion is represented as ɛ and its value lies between 0 to 1 and iteration steps are represented as k. To a saddle point of jm or local minimum, this procedure converges.
3.4 DLECNN Classifier Algorithm for Image Retrieval
For enhancing the retrieval accuracy of specified query image, this work proposes a DLECNN algorithm. In the image retrieval process, the features like contrast, shape, texture and color are used. Query image is provided as input. From the database, the images that are highly similar to query image are retrieved and they are shown as output. For retrieving similar images in database, techniques are selected to identify correctly as well integrate effectively for a specified image. In this work, DLECNN is proposed to provide the more accurate results of image retrieval for the given database. In this proposed work, DLECNN is introduced to classify the test data into yes (or) no classes. The proposed deep learning method attains higher accuracy. There exist an output, input and multiple hidden layers in basic CNN. Fully connected, pooling and convolutional layers are there in CNN's hidden layer. Input is applied with convolution operation in convolutional layers and to next layer, results are transferred. Individual neuron's response is emulated as visual stimuli using convolution operation. The architecture diagram of DLECNN is shown in Fig. 4.

Figure 4: Architecture diagram of DLECNN
Global or local pooling layers are included in convolutional networks. In one layer, neuron cluster's outputs are combined as a single neuron in next layer. In the previous layer, every neuron cluster's average value is used by mean pooling. In one layer, every neuron is connected to every neuron in next layer using fully connected layers. Principle of traditional multi-layer perceptron neural network is similar to CNN [27,28]. Classification, sub-sampling, convolutional and input layers are there in proposed DLECNN. In high-dimensional data analysis, this proposed technique shows its effectiveness. Parameter sharing scheme is employed in this approach. Parameters count is minimized as well as controlled using these convolutional layers. From the training samples, the query images called features are given to input layer and data is transformed as a unified form for delivering it to next layer properly. Initial parameters like various filters, local receptive field's scale value are defined in this layer. Input data is processed in Convolution layer (Cx) using convolution algorithm and various layers called feature maps are produced. Convolution computation results of previous layers are present. Key features are extracted and network's computational complexity is minimized by this technique. After each convolutional layer, an activation function is employed. Outputs are mapped into a set of inputs using activation function. This mapping makes a non-linear network structure. For entire specified feature values, initial connection weights are set. Then, a new input pattern is applied and the output is expressed as,
where, iteration index is expressed as n
Update of connection weights are performed as,
where, gain factor is represented as η
Then standard deviation is applied
The proposed DLECNN network is given with these weighted image dataset features and highly accurate classification results are obtained. On the same dataset, the major analysis findings are confirmed using polynomial distribution. In this layer, the sub-sampling of each feature map of the earlier convolution layer is performed. As indicated in Fig. 3, the informative features are summed using Sx + 1. Also, in order to select the highest accuracy image feature values, the genetic algorithm is combined with this DLECNN algorithm for improving the overall CBIR system performance. In this work, DLECNN is used to classify the similarity and dissimilarity image features through the selection of important features via genetic fitness value. The genetic algorithm is applied for choosing the accurate features from the DLCNN architecture through the best fitness values. Hence, the DLCNN is enhanced by polynomial distribution and genetic fitness values hence it named as DLECNN. Two parents need to be selected for performing the genetic crossover operation. From a population, two parents are selected by defining a selection operator. Ideally, for the next chromosomes generation, this would be like ‘breed’ favorable qualities. In general, they exist in chromosomes with better fitness scores. A selection operator is defined, where population members are selected randomly using this operator with every chromosome ci’s population probability P(ci), n population size and it is defined as,
During selection, chromosomes with high fitness score are selected. Availability of favorable qualities in children are created using crossover operation.

The more accurate similarity image retrieval results are computed by learning the numerous feature indications. For the GA, the maximal generation count and population size are initialized first and the image classification dataset is given. The DLECNN architecture is formulated using a series of evolutionary processes for classifying the specified image database. On a specified image database, DLECNN’s specific architecture is encoded using by every individual’s fitness in evolution process. Then, according to the fitness value, the parent individuals are selected. The genetic operators like mutation and crossover operators are used for generating the new offspring in the next stage. At last, the count value is increased by one and until count value exceeding predefined maximum generation value, evolution is continued.
The VisTex_MD, Corel_MD, VisTex_MR, Corel_MR, VisTex [29], and Corel (Corel stock photo library 1994) databases are used in testing and they have color RGB images as illustrated in Fig. 5. In Corel DB, there will be an interested object in every image. There are 11 groups and 90 images in every group. So, there exist an overall of 990 images. Homogeneous pattern images are included in VisTex DB. There exist 75 groups and 16 images are there 16 images in every group. So, there exist a total of 1200 images. The H.-H. Bu et al.1 images are there in Corel_MR DB with a size 96 × 64, 144 × 96 and 192 × 128. VisTex_MR DB has images of 80 × 80, 96 × 96, 112 × 112 and 128 × 128 size. The 45° rotated images are there in VisTex_MD and Corel_MDDBs. The rotation angle may vary from 0 to 315 degrees.


Figure 5: Original image samples of (a) Corel DB, (b) Corel_MR DB, (c) Corel_MD DB, (d) VisTex DB, (e) VisTex_MR DB, and (f) VisTex_MD DB
Precision
Precision value is computed as:
Quality or accuracy measurement corresponds to precision and quantity or fullness measure corresponds to recall. Algorithms ability in returning substantially high relevant results is indicated using high precision value. For a classification process, precision value is given as a ratio between true positives count to total elements count labelled as positive class.
Precision performance metric comparison between available and proposed technique is shown in above Fig. 6. Different techniques are plotted along the X-axis of above mentioned figure and precision values are plotted in y-axis. Existing methods like GLCM and RULBP algorithms provides low precision whereas proposed GLCM+DLECNN algorithm provides high precision for a specified Corel image database. HFCM algorithm is used to retrieve the higher similarity image features from the Corel database effectively. Thus, result concludes that proposed GLCM+DLECNN increase image retrieval precision through more informative features.

Figure 6: Precision
Recall
Recall value is measured as:
The proportion between relevant documents count retrieved by a search to the overall available relevant documents count specifies the recall value and the proportion between relevant documents count retrieved by a search to the overall retrieved documents count specifies precision value.
The Recall performance metric comparison between the existing and proposed technique is shown in above Fig. 7. The techniques are plotted along the X-axis of above mentioned figure and recall values are plotted in y-axis. The existing methods like GLCM and RULBP algorithms provides lower recall whereas the proposed GLCM+DLECNN algorithm provides higher recall for a specified image database. HFCM algorithm is used to retrieve the higher similarity image features from the Corel database effectively. Thus, result concludes that proposed GLCM+DLECNN increases the image retrieval recall value through the more informative features.

Figure 7: Recall
F-Measure
F1-score is defined as:
The performance metric comparison in terms of F-measure between the existing and the proposed technique is illustrated in above Fig. 8. The methods involved in this work are represented in X-axis of above mentioned figure and F-measure values are plotted in y-axis. The existing methods like GLCM and RULBP algorithms provides lower F-measure whereas the proposed GLCM+DLECNN algorithm provides higher F-measure for a specified Corel image database. The similarity calculation is done by using the HFCM algorithm which is used to retrieve the better query image outcomes. It is concluded from the result that the proposed GLCM+DLECNN increases the image retrieval f-measure value through more informative features.

Figure 8: F-measure
Accuracy
Accuracy is defined by the overall correctness of the model and the overall original classification parameters (Tp + Tn) are segregated from classification parameters (Tp + Tn + Fp + Fn) sum for computing this. It is defined as,
The accuracy performance metric comparison between the existing and proposed technique is shown in above Fig. 9. The techniques are plotted along the X-axis of above mentioned figure and accuracy values are plotted in y-axis. The existing methods like GLCM and RULBP algorithms provide lower accuracy whereas the proposed GLCM+DLECNN algorithm provides higher accuracy for a specified Corel image database. The HFCM algorithm is used to retrieve the higher similarity image features from the Corel database effectively. Thus, the result concludes that the proposed GLCM+DLECNN increase the image retrieval accuracy through more informative features.

Figure 9: Accuracy
Error Rate
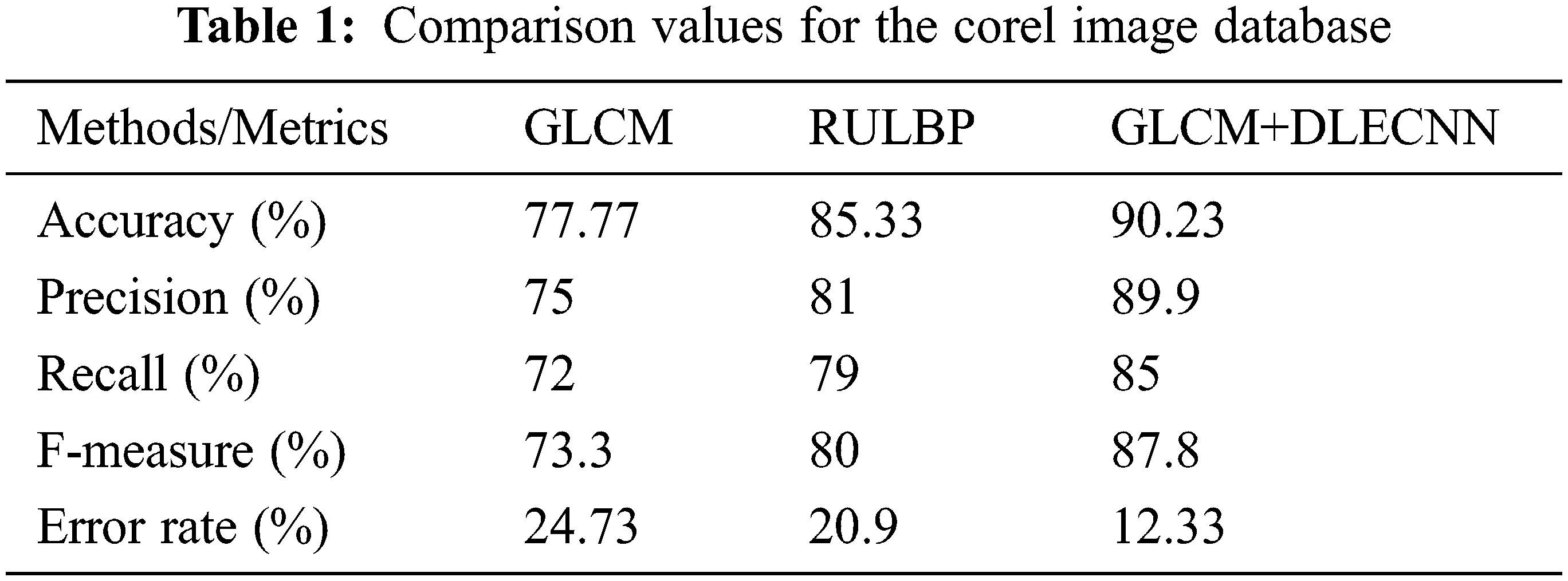
The error rate performance metric comparison is shown in the above Fig. 10. The existing techniques such as the GLCM and RULBP algorithms provide higher error rate whereas the proposed GLCM+DLECNN algorithm provides lower error rate for the given Corel image database. Thus, it can be concluded from the result that the proposed GLCM+DLECNN algorithm increases the accuracy of CBIR system significantly. The Tab. 1 shows the comparison values between the existing and proposed methods for the above mentioned performance metrics for the given Corel image database.

Figure 10: Error rate comparison
In this research work, GLCM based DLECNN algorithm is proposed for improving the CBIR system accuracy. In this work, the noise reduction process is focused to remove the irrelevant features from the given Corel database. It is done by using the histogram equalization technique. Then, the feature extraction is performed through the GLCM algorithm. The significant features are extracted that are used to increase the image retrieval results. Then, the similarity measurement is done by using the HFCM algorithm which is used to compute best similarity images for the given query image. The DLECNN algorithm is used to increase the image retrieval accuracy through the relevant and similarity features. The experimental result clearly shows that the proposed GLCM based DLECNN algorithm is superior with respect to higher precision, recall, accuracy, f-measure and lower error rate than the existing GLCM and RULBP methods. In future work, the optimization based feature selection algorithm can be developed for improving the CBIR results considerably.
Acknowledgement: We show gratitude to anonymous referees for their useful ideas.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. M. K. Alsmadi, “Content-based image retrieval using color, shape and texture descriptors and features,” Arabian Journal for Science and Engineering, vol. 45, no. 4, pp. 3317–3330, 2020. [Google Scholar]
2. M. Garg and G. Dhiman, “A novel content-based image retrieval approach for classification using GLCM features and texture fused LBP variants,” Neural Computing and Applications, vol. 33, pp. 1311–1328, 2021. [Google Scholar]
3. J. Lee and J. Nang, “Content-based image retrieval method using the relative location of multiple ROIs,” Advances in Electrical and Computer Engineering, vol. 11, no. 3, pp. 85–90, 2011. [Google Scholar]
4. T. Sutojo, P. S. Tirajani, C. A. Sari and E. H. Rachmawanto, “CBIR for classification of cow types using GLCM and color features extraction,” in IEEE Int. Conf. on Information Technology, Information Systems and Electrical Engineering (ICITISEE), Yogyakarta, Indonesia, pp. 182–187, 2017. [Google Scholar]
5. Z. Mehmood, F. Abbas, T. Mahmood, M. A. Javid, A. Rehman et al., “Content-based image retrieval based on visual words fusion versus features fusion of local and global features,” Arabian Journal for Science & Engineering (Springer Science & Business Media BV), vol. 43, no. 12, pp. 7265–7284, 2018. [Google Scholar]
6. G. Blanco, M. V. Bedo, M. T. Cazzolato, L. F. Santos, A. E. S. Jorge et al., “A Label-scaled similarity measure for content-based image retrieval,” in IEEE Int. Symposium on Multimedia (ISM), San Jose, CA, USA, pp. 20–25, 2016. [Google Scholar]
7. R. Z. Liang, L. Shi, H. Wang, J. Meng, J. J. Y. Wang et al., “Optimizing top precision performance measure of content-based image retrieval by learning similarity function,” in IEEE Int. Conf. on Pattern Recognition (ICPR), Cancun, Mexico, pp. 2954–2958, 2016. [Google Scholar]
8. A. Sarwar, Z. Mehmood, T. Saba, K. A. Qazi, A. Adnan et al., “A novel method for content-based image retrieval to improve the effectiveness of the bag-of-words model using a support vector machine,” Journal of Information Science, vol. 45, no. 1, pp. 117–135, 2019. [Google Scholar]
9. N. Kaur, S. Jindal and B. Kaur, “Relevance feedback based CBIR system using SVM and BAYES classifier,” in IEEE Second Int. Conf. on Computational Intelligence & Communication Technology (CICT), Ghaziabad, India, pp. 214–218, 2016. [Google Scholar]
10. V. Garcia, E. Debreuve, F. Nielsen and M. Barlaud, “K-Nearest neighbor search: fast GPU-based implementations and application to high-dimensional feature matching,” in IEEE Int. Conf. on Image Processing, Hong Kong, China, pp. 3757–3760, 2010. [Google Scholar]
11. E. Lotfi, “An adaptive fuzzy filter for Gaussian noise reduction using image histogram estimation,” Advances in Digital Multimedia, vol. 1, no. 4, pp. 190–193, 2013. [Google Scholar]
12. P. M. D. Azevedo-Marques and R. M. Rangayyan, “Content-based retrieval of medical images: Land marking, indexing, and relevance feedback,” Synthesis Lectures on Biomedical Engineering, vol. 8, no. 1, pp. 1–143, 2013. [Google Scholar]
13. P. S. Shijin Kumar and V. S. Dharun, “Extraction of texture features using GLCM and shape features using connected regions,” International Journal of Engineering and Technology, vol. 8, no. 6, pp. 2926–2930, 2016. [Google Scholar]
14. A. Bhatti, S. M. Butt and M. M. Butt, “Visual feature extraction for content-based image retrieval,” Science International, vol. 26, no. 1, pp. 1–5, 2014. [Google Scholar]
15. B. Ergen and M. Baykara, “Texture based feature extraction methods for content based medical image retrieval systems,” Bio-Medical Materials and Engineering, vol. 24, no. 6, pp. 3055–3062, 2014. [Google Scholar]
16. X. Ban, X. Lv and J. Chen, “Color image retrieval and classification using fuzzy similarity measure and fuzzy clustering method,” in Proc. of the 48th IEEE Conf. on Decision and Control (CDC) Held Jointly with 2009 28th Chinese Control Conf., Shanghai, China, pp. 7777–7782, 2009. [Google Scholar]
17. L. Malliga and K. B. Raja, “A novel content based medical image retrieval technique with aid of modified fuzzy c-means clustering (CBMIR-MFCM),” Journal of Medical Imaging and Health Informatics, vol. 6, no. 3, pp. 700–709, 2016. [Google Scholar]
18. R. Fu, B. Li, Y. Gao and P. Wang, “Content-based image retrieval based on CNN and SVM,” in 2nd IEEE Int. Conf. on Computer and Communications (ICCC), Chengdu, China, pp. 638–642, 2016. [Google Scholar]
19. P. Liu, J. M. Guo, C. Y. Wu and D. Cai, “Fusion of deep learning and compressed domain features for content-based image retrieval,” IEEE Transactions on Image Processing, vol. 26, no. 12, pp. 5706–5717, 2017. [Google Scholar]
20. U. Sharif, Z. Mehmood, T. Mahmood, M. A. Javid, A. Rehman et al., “Scene analysis and search using local features and support vector machine for effective content-based image retrieval,” Artificial Intelligence Review, vol. 52, no. 2, pp. 901–925, 2019. [Google Scholar]
21. M. Yousuf, Z. Mehmood, H. A. Habib, T. Mahmood, T. Saba et al., “A novel technique based on visual words fusion analysis of sparse features for effective content-based image retrieval,” Mathematical Problems in Engineering, vol. 2018, no. 3, pp. 1–13, 2018. [Google Scholar]
22. Z. Mehmood, N. Gul, M. Altaf, T. Mahmood, T. Saba et al., “Scene search based on the adapted triangular regions and soft clustering to improve the effectiveness of the visual-bag-of-words model,” EURASIP Journal on Image and Video Processing, vol. 2018, no. 1, pp. 1–16, 2018. [Google Scholar]
23. A. Ziaei, H. Yeganeh, K. Faez and S. Sargolzaei, “A novel approach for contrast enhancement in biomedical images based on histogram equalization,” in IEEE Int. Conf. on BioMedical Engineering and Informatics, Sanya, China, pp. 855–858, 2008. [Google Scholar]
24. M. Benčo and R. Hudec, “Novel method for color textures features extraction based on GLCM,” Radio Engineering, vol. 16, no. 4, pp. 64–67, 2007. [Google Scholar]
25. J. Samraj and M. Nazreen Bee, “Content based medical image retrieval using fuzzy c-means clustering with RF,” International Journal of Innovative Science,” Engineering & Technology, vol. 2, no. 1, pp. 512–518, 2015. [Google Scholar]
26. D. Cai, X. He, Z. Li, W. Y. Ma and J. R. Wen, “Hierarchical clustering of www image search results using visual, textual and link information,” in Proc. of the 12thAnnual ACM Int. Conf. on Multimedia, New York, USA, pp. 952–959, 2004. [Google Scholar]
27. M. Suganuma, S. Shirakawa and T. Nagao, “A genetic programming approach to designing convolutional neural network architectures,” in Proc. of the Genetic and Evolutionary Computation Conf., Berlin, Germany, pp. 497–504, 2017. [Google Scholar]
28. H. Li, N. A. Parikh and L. He, “A novel transfer learning approach to enhance deep neural network classification of brain functional connectomes,” Frontiers in Neuroscience, vol. 12, no. 7, pp. 01–12, 2018. [Google Scholar]
29. R. Aravindhan and R. Shanmugalakshmi, “Visual analytics for semantic based image retrieval (SBRSemantic tool,” International Journal of Latest Trend in Engineering and Technology, vol. 7, no. 2, pp. 300–312, 2016. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |