DOI:10.32604/csse.2022.023568
| Computer Systems Science & Engineering DOI:10.32604/csse.2022.023568 | |
| Article |
Assessment of Sentiment Analysis Using Information Gain Based Feature Selection Approach
1Department of Computer Science and Engineering, Sri Ramakrishna Engineering College, Coimbatore, India
2Government College of Technology, Coimbatore, India
*Corresponding Author: R. Madhumathi. Email: madhumathi.r@srec.ac.in
Received: 13 September 2021; Accepted: 14 October 2021
Abstract: Sentiment analysis is the process of determining the intention or emotion behind an article. The subjective information from the context is analyzed by the sentimental analysis of the people’s opinion. The data that is analyzed quantifies the reactions or sentiments and reveals the information’s contextual polarity. In social behavior, sentiment can be thought of as a latent variable. Measuring and comprehending this behavior could help us to better understand the social issues. Because sentiments are domain specific, sentimental analysis in a specific context is critical in any real-world scenario. Textual sentiment analysis is done in sentence, document level and feature levels. This work introduces a new Information Gain based Feature Selection (IGbFS) algorithm for selecting highly correlated features eliminating irrelevant and redundant ones. Extensive textual sentiment analysis on sentence, document and feature levels are performed by exploiting the proposed Information Gain based Feature Selection algorithm. The analysis is done based on the datasets from Cornell and Kaggle repositories. When compared to existing baseline classifiers, the suggested Information Gain based classifier resulted in an increased accuracy of 96% for document, 97.4% for sentence and 98.5% for feature levels respectively. Also, the proposed method is tested with IMDB, Yelp 2013 and Yelp 2014 datasets. Experimental results for these high dimensional datasets give increased accuracy of 95%, 96% and 98% for the proposed Information Gain based classifier for document, sentence and feature levels respectively compared to existing baseline classifiers.
Keywords: Sentiment analysis; sentence level; document level; feature level; information gain
With the influence of social networks, people across the globe build social relationships and feel free to express their opinions. Social media generates huge volumes of opinion-based data, which is formulated as blogs, reviews, status updates, tweets, etc. The volume of content produced is enormous for a novice user to interpret, describe and analyze data. Sentimental analysis is an effective tool to identify, extract, measure and study subjective information. It is a widely used text classification process that evaluates the opinions and concludes if the sentiment attitude is neutral, positive or negative. Sentiment analysis has wide range of applications including health care, business, consumer products, financial services and social events [1,2]. Document level sentiment analysis estimates the opinion of the entire document assuming that each individual document will generate opinion about a single entity. The complete document will then be classified based on the opinions as positive or negative [3]. For instance, if a product is reviewed by users, a prediction model is generated and the overall opinion is determined by the system. Clusters may be formed at document level analysis due to which the comparison of multiple entities are not probable [4]. Sentiment analysis assumes every sentence as an individual component and every sentence is considered to have only one opinion. Two main tasks for sentence level analysis are to estimate whether the sentence is having an opinion or not and to evaluate the polarity of that opinion. Feature level sentiment analysis accomplishes more fine-grained scrutiny. It helps to look at opinion as an alternative to language constructs. Feature level analysis is done in three stages namely identification and extraction of object features, determination of polarity of opinions and estimation of sentiments. Feature level sentiment analysis will provide more fine-grained analysis on opinion targets and its major application areas include e-commerce [5]. Sentiment analysis uses opinion targets to analyze and explore entities and their aspects [6]. This paper proposes a simple IGbFS algorithm that selects highly correlated features among the training input set and performs sentiment analysis at three levels.
The remaining paper is organized as follows: Section 2 explains the research gaps towards textual based sentiment analysis. Section 3 elucidates the proposed IGbFS technique. In section 4, the results of IGbFS technique are discussed and the paper is concluded along with its future scope in the last section.
A method was proposed by the authors in [7] which uses Naive Bayes and Support Vector Machine(SVM) for systematic analysis of features and feature weights. Rhetorical Structure Theory (RST) parsers [8] shows significant improvement in document-level sentiment analysis. An enhanced lexicon-based sentiment analysis and recursive neural network algorithm are presented and evaluated. The authors in [9] demonstrated sentiment analysis for movie reviews. They used Machine Learning (ML) algorithms like Random Forest with Gini Index and Support Vector Machine for exploring unigram frequency values and their experiment proved that Random Forest with Gini Index classifier gave high accuracy. The authors in [10] proposed a semi supervised model for estimating semantic term–document information and analyzing rich sentiment contents. Sentiment and non-sentiment information are leveraged and discriminated. The authors in [11] proposed a novel technique which uses text-categorization in estimating minimum cuts in graphs and cross-sentence contextual constraints.
A text classification process is proposed in [12] using machine learning techniques for extracting the information. An opinion question answering system was proposed in [13] using Bayesian classifier for differentiating news stories from editorials for document and sentence levels. Unsupervised statistical methods for predicting opinions are also proposed. The authors in [14] proposed a technique in which sentiment analysis is done by exploiting the underlying semantics. The authors in [15] performed sentence level analysis by designing a deep convolutional neural network using the Stanford Sentiment Treebank (SSTb) and Stanford Twitter Sentiment corpus (STS). The authors in [16] proposed a technique for classifying tweets as positive, negative or neutral. The authors in [17] proposed an approach for sentiment analysis in which the utility of linguistic features are explored for social media messages.
The authors in [18] extracted the sentiments in a phrase or sentence using an approach and also measured the influence of WordNet over General Inquirer (GI). An innovative approach was proposed in [19] using phrase dependency parsing for mining opinions from product reviews. A classifier was used by the authors in [20] in which polarity of subjective phrases are predicted. It uses Dictionary of Affect in Language (DAL) for lexical scoring with WordNet and the words are scored without manual labelling. The authors in [21] detected attitudes, opinions and feelings expressed in the text using automated tools. The authors in [22] proposed phrase-level sentiment analysis where an expression is determined positive, negative or neutral by calculating its polarities. Latent Factor Models (LFM) [23] which is based on Collaborative Filtering (CF) gives good accuracy.
This paper proposes an IGbFS technique that selects highly correlated feature vectors and enables more accurate sentiment classification at document, sentence and feature levels. This algorithm selects the features that has highest relevance and highest occurrence to the output class. It reduces most of the irrelevant features and achieves best application performance. The feature selection algorithm computes mutual information between each feature and the class label thus finding the features with the highest correlations. The relevance between the attributes are measured using Information Gain (I). For any two random variables A and B where A={a1, a2, a3….aN} and B={b1, b2, b3….bM}, the entropy of A is denoted as H(A) as represented in Eqs. (1) and (2).
The conditional entropy is defined in Eq. (3) as
The joint entropy of A and B is denoted as H(B,A) as given in Eq. (4) and is defined as the uncertainty that occur simultaneously with two variables.
The mutual information between variable B and variable A is denoted as I(B ; A) as shown in Eqs. (5) and (6) and it is formulated as
With respect to a class Class and attribute Attr, the Information Gain I is calculated according to Eq. (7).
where H(Class | Attr) is the conditional entropy of the class Class given any attribute Attr. Various proved methods suffer from overfitting even using the existing Document Frequency (DF) thresholding technique [7,11] for selecting the features that appear maximum in the training set.

The algorithm begins by computing information gain between the initial features and the class labels. The first feature is selected and until all correlated features are obtained as a subset, the algorithm computes information gain for all pairs of features and class labels. The final subset of selected features is classified to predict the sentiments.
3.1 Sentence Level Sentiment Analysis
The primary objective of sentence level analysis is to identify polarity, expression strength and its relationship to the subject. The sentences are Part-Of-Speech (POS) tagged and a dependency tree is created using the Stanford Lex parser [24]. Default Polarity Calculation (DPC) with WordNet is used to identify the phrases with sentiments and to calculate polarity of individual phrases. The algorithm outputs overall sentiment of the sentence analyzing the phrases with sentiments. The Default Polarity Calculation method starts by finding the words as positive and negative using the General Inquirer [25]. If a particular word is not present in the GI list, the WordNet dictionary searches for synonyms with semantic orientations with respect to the GI list.
Input: Sentence S
Output: Polarity of the sentence
Procedure:
1. Begin
2. For list of sentences
3. Perform POS tagging
4. Create a dependency tree
5. Identify phrases containing sentiments
6. Calculate polarity of phrases using Default Polarity Calculation
7. End for
8. For every feature do
9. Calculate TF-IDF
10. if frequency >=0.2 then
11. Feature set ←feature set + feature
12. End if
13. End for
14. for every feature in feature set perform
15. Estimate I(Class|Attr)
16. End for
17. for every IG score in I(Class|Attr) perform
18. if I(Class|Attr)==0.5 then
19. vocab ←vocab + Attr
20. if P(Attr)== P(Attr|Class )+ Attr
21. feature setpositive ←feature setpositive + Attr
22. else
23. feature setnegative← feature setnegative + Attr
24. End if
25. End if
26. End for
27. End
The Term Frequency-Inverse document Frequency (TF-IDF) is used to calculate the frequency of the phrases. For every feature in the feature set, the algorithm finds the Information Gain and discriminates positive and negative sentiments.
3.2 Document Level Sentiment Analysis
The entire document consisting of opinioned text is treated as a single entity and classified based on the opinions as positive or negative eliminating irrelevant sentences. Initially the collected documents are aggregated and preprocessed. Combination of unigram, bigram and trigram are considered for evaluating the sentiment of the document. The value of the N-gram feature is calculated using TF-IDF weighting scheme for the document D as represented in Eq. (8).
where tfid is the occurrence frequency of the ith feature in D, {D} is the no. of documents in the corpus, dfi denotes no. of documents having ith feature.
Input : Document D
Output : Sentiment of document
Input: Sentence S
Output: Overall polarity S
Procedure:
1. Begin
2. For any document D perform
3. Apply POS tagger and extract opinion words
4. Prepare seed list
5. Identify candidate words using N-gram
6. End for
7. For every feature in document perform
8. Calculate TF-IDF
9. If frequency >=0.2 then
10. feature set ←feature set + feature
11. End if
12. End for
13. for every feature in feature set perform
14. Estimate I(Class|Attr)
15. End for
16. for every IG score in I(Class|Attr) perform
17. if I(Class|Attr)==0.5 then
18. vocab ←vocab + Attr
19. if P(Attr)== P(Attr|Class )+ Attr
20. feature setpositive ←feature setpositive + Attr
21. else
22. feature setnegative← feature setnegative + Attr
23. End if
24. End if
25. End for
26. End
The algorithm begins by applying POS tagging for extracting opinion words from the document. A seed list is prepared and is searched for candidate words using N-gram. For all set of features in the document, TF-IDF is estimated. If the frequency of the feature is greater than or equal to 0.2, the feature is added to the feature set. For all features in the feature set, Information Gain is calculated. If the Information Gain is equal to 0.5 (which is the threshold fixed), the attribute is added to the vocabulary. The positive and negative feature sets are discriminated and obtained.
3.3 Feature Level Sentiment Analysis
The TF-IDF is used for feature selection in feature level analysis. The feature is selected based on the relevance to one class and the frequency is calculated only when the value is greater than 0.2. Proven techniques in literature use Document Frequency (DF) thresholding technique [14,18] to find feature which appear maximum in the training set. The proposed algorithm results in a seamless reduction of irrelevant and redundant features.
Input : Attributes Attr and class Class
Output : Positive feature set and negative feature set
1. Begin
2. For every feature do
3. Calculate TF-IDF
4. if frequency >=0.2 then
5. feature set ←feature set + feature
6. End if
7. End for
8. for every feature in feature set perform
9. Estimate I(Class|Attr)
10. End for
11. for every IG score in I(Class|Attr) perform
12. if I(Class|Attr)==0.5 then
13. vocab ←vocab + Attr
14. if P(Attr)== P(Attr|Class )+ Attr
15. feature setpositive ←feature setpositive + Attr
16. else
17. feature setnegative← feature setnegative + Attr
18. End if
19. End if
20. End for
21. End
The following supervised classification algorithm depicts the procedure for classifying positive (pos) and negative (neg) sentiments at various levels.

The Cornell repository provided the datasets for document level sentiment analysis, which included 2000 documents and 10,662 sentences. The reviews for Hitcher (1986), Radio Days (1987) from the Indian Movie Archive and Aankhen (2002), Men in Black II (2002) from Rotten Tomatoes are used. The datasets are drawn from the Kaggle repository, which has 76,479 features.

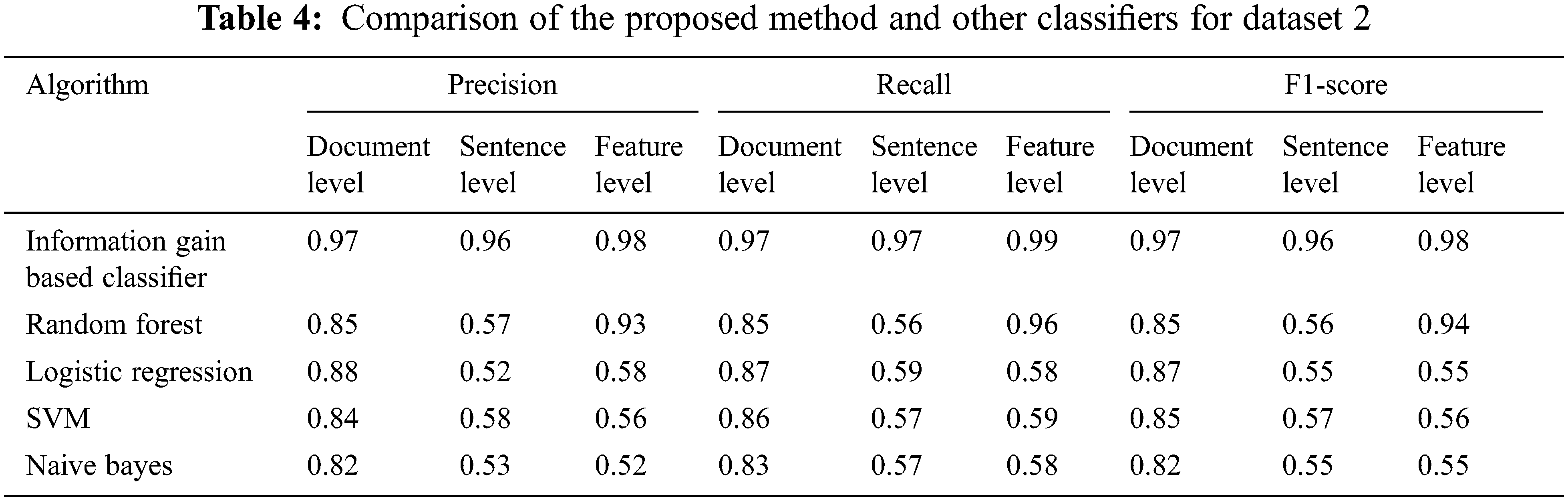
The suggested method presented in sections 3.1, 3.2, and 3.3 are used to perform sentence, document, and feature level sentiment analysis for the above datasets and the classification is done using algorithm 3.4. The efficiency of the IG algorithm is estimated using the metrics like precision, recall, F1-Score, andaccuracy. Experiments showed that the suggested algorithm surpassed all existing algorithms in terms of accuracy throughout all three levels.
Tab. 1 illustrates the precision, recall and F1- score of different classifiers calculated using Eqs. (9)–(11). The proposed IGbFS resulted in highest precision, recall and F1-score at all three levels when compared to the other classifiers namely Random Forest, Logistic Regression, SVM and Naïve Bayes.
The accuracy is calculated using the Eq. (12). Figs. 1–3 compare the accuracy of the proposed algorithm with other baseline classifiers. Information Gain based Feature Selection approach gives higher accuracy when compared to other classifiers. Confusion matrix for each classifier is depicted in Tab. 2.

Figure 1: Document level sentiment analysis

Figure 2: Sentence level sentiment analysis

Figure 3: Feature level analysis

The proposed IGbFS algorithm on sentence level, document level and feature level for high dimensional datasets are analyzed and in order to compare the performance, different datasets namely IMDB, Yelp 2014 and 2013 datasets are used. The statistical information of the dataset is tabulated in Tab. 3.
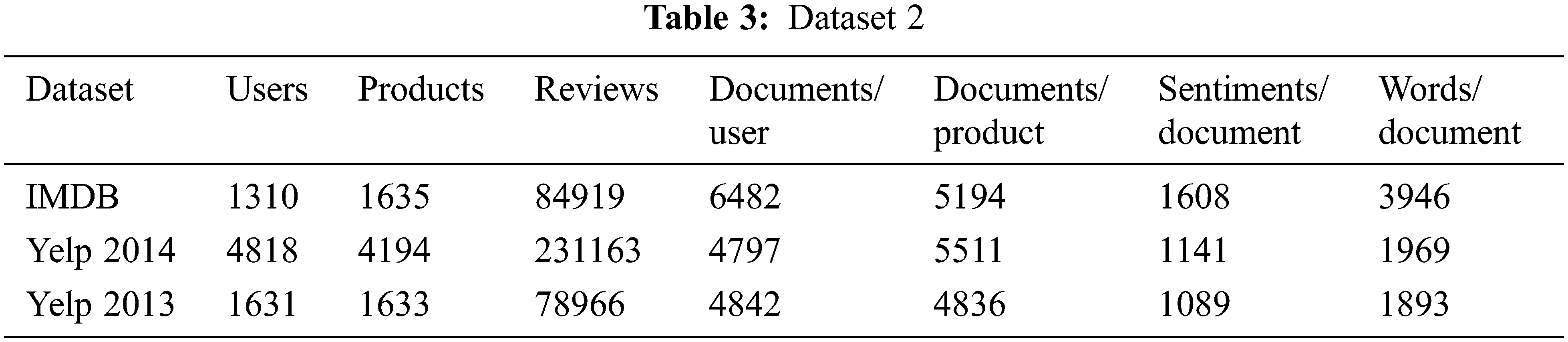
Tab. 4 displays the values of precision, recall and F1-score of the proposed and the existing classifiers for high dimensional datasets. Fig. 4 compares the proposed Information Gain based Classifier and the existing classifiers in terms of accuracy. The proposed methods work better and outperforms the other existing baseline classifiers at all three levels.

Figure 4: Comparison of accuracy scores for dataset 2
Sentiment analysis is a text categorization technology that assess the sentiment and categorizes it as either negative or positive. This work proposes an algorithm using IGbFS approach for sentiment analysis at three levels. The suggested technique selects the feature with highest occurrence that has the greatest Information Gain. Experiments reveal that this Information Gain model has the maximum accuracy of 96% for document, 97.4% for sentence and 98.5% for feature level respectively. Testing the proposed method with IMDB, Yelp 2013 and Yelp 2014 datasets resulted in high accuracy. Enhancing the feature selection process by experimenting with high dimensional dataset is the next challenging process. Effective selection of features at three levels in different dimensional datasets ensure the real time use of proposed application.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. A. M. Kowshalya, R. Madhumathi and N. Gopika, “Correlation based feature selection algorithms for varying datasets of different dimensionality,” Wireless Personal Communications, vol. 108, no. 5, pp. 1977–1993, 2019. [Google Scholar]
2. A. M. Kowshalya and M. L. Valarmathi, “Evaluating Twitter data to discover user’s perception about social Internet of Things,” Wireless Personal Communications, vol. 101, no. 2, pp. 649–659, 2018. [Google Scholar]
3. S. Behdenna, F. Barigou and G. Belalem, “Document level sentiment analysis: A survey,” EAI Endorsed Transactions on Context-Aware Systems and Applications, vol. 4, no. 13, pp. 1–8, 2018. [Google Scholar]
4. M. Hoffman, D. Steinley, K. M. Gates, M. J. Prinstein and M. J. Brusco, “Detecting clusters/communities in social networks,” Multivariate Behavioral Research, vol. 53, no. 1, pp. 57–73, 2018. [Google Scholar]
5. C. Quan and F. Ren, “Feature-level sentiment analysis by using comparative domain corpora,” Enterprise Information Systems, vol. 10, no. 5, pp. 505–522, 2016. [Google Scholar]
6. A. I. Pratiwi and K. Adiwijaya “On the feature selection and classification based on information gain for document sentiment analysis,” Applied Computational Intelligence and Soft Computing, vol. 2018, no. 8, pp. 1–5, 2018. [Google Scholar]
7. T. OKeefe and I. Koprinska, “Feature selection and weighting methods in sentiment analysis,” in Proc. 14th Australasian Document Computing Symposium, Sydney, Australia, pp. 67–74, 2009. [Google Scholar]
8. P. Bhatia, Y. Ji and J. Eisenstein, “Better document-level sentiment analysis from RST discourse parsing,” in Proc. Conf. on Empirical Methods in Natural Language Processing, Lisbon, Portugal, pp. 2212–2218, 2015. [Google Scholar]
9. R. Kaur and P. Verma, “Sentiment analysis of movie reviews: A study of machine learning algorithms with various feature selection methods,” International Journal of Computer Sciences and Engineering, vol. 5, no. 9, pp. 113–121, 2017. [Google Scholar]
10. A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y. Ng et al., “Learning word vectors for sentiment analysis,” in Proc. 49th Annual Meeting of the Association for Computational Linguistics, Human Language Technologies, Stroudsburg, USA, vol.1, pp. 142–150, 2011. [Google Scholar]
11. B. Pang and L. Lee, “A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts,” in Proc. 42nd Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics, Barcelona, Spain, pp. 271–275, 2004. [Google Scholar]
12. M. Ikonomakis, S. Kotsiantis and V. Tampakas, “Text classification using machine learning techniques,” SEAS Transactions on Computers, vol. 4, no. 8, pp. 966–974, 2005. [Google Scholar]
13. H. Yu and V. Hatzivassiloglou, “Towards answering opinion questions: Separating facts from opinions and dentifying the polarity of opinion sentences,” in Proc. Conf. on Empirical Methods in Natural Language Processing, Stroudsburg, USA, pp. 129–136, 2003. [Google Scholar]
14. H. Saif, Y. He and H. Alani, “Semantic sentiment analysis of twitter,” in Proc. 11th Int. Conference on the Semantic Web, Boston, USA, vol. 1, pp. 508–524, 2012. [Google Scholar]
15. C. N. dos Santos and M. Gatti, “Deep convolutional neural networks for sentiment analysis of short texts,” in Proc. 25th Int. Conf. on Computational Linguistics: Technical Papers, Coling, pp. 69–78, 2014. [Google Scholar]
16. S. A. El Rahman, F. A. Al Otaibi and W. A. AlShehri, “Sentiment analysis of twitter data,” in Int. Conf. on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, pp. 1–4, 2019. [Google Scholar]
17. Z. Drus and H. Khalid, “Sentiment analysis in social media and its application: Systematic literature review,” Procedia Computer Science, vol. 161, pp. 707–714, 2019. [Google Scholar]
18. A. Meena and T. V. Prabhakar, “Sentence level sentiment analysis in the presence of conjuncts using linguistic analysis,” in Proc. European Conf. on Information Retrieval, Berlin, Heidelberg, pp. 573–580, 2007. [Google Scholar]
19. Y. Wu, Q. Zhang, X. Huang andL. Wu, “Phrase dependency parsing for opinion mining,” in Proc. Conf. on Empirical Methods in Natural Language Processing, Singapore, pp. 1533–1541, 2009. [Google Scholar]
20. A. Agarwal, F. Biadsy and K. R. Mckeown, “Contextual phrase-level polarity analysis using lexical affect scoring and syntactic N-grams,” in Proc. 12th Conf. of the European Chapter of the ACL, Athens, Greece, pp. 24–32, Mar, 2009. [Google Scholar]
21. C. Lin and Y. He, “Joint sentiment/topic model for sentiment analysis,” in Proc. 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, pp. 375–384, Nov, 2009. [Google Scholar]
22. T. Wilson, J. Wiebe and P. Hoffmann, “Recognizing contextual polarity: An exploration of features for phrase level sentiment analysis,” Computational Linguistics, vol. 35, no. 3, pp. 399–433, 2009. [Google Scholar]
23. Y. Zhang, G. Lai, M. Zhang, Y. Zhang, Y. Liu et al., “Explicit factor models for explainable recommendation based on phrase-level sentiment analysis,” in Proc. 37th Int. ACM SIGIR Conference on Research & Development in Information Retrieval, New York, USA, pp. 83–92, Jul, 2014. [Google Scholar]
24. M. C. Marneffe and C. D. Manning, “The Standford typed dependencies representation,” in Proc. of the workshop on Cross-Framework and Cross-Domain Parser Evaluation, Manchester, pp. 1–8, Aug, 2008. [Google Scholar]
25. T. Karadeniz and E. Dogdu, “Improvement of general inquirer features with quantity analysis,” in Proc. of the IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, pp. 2228–2231, 2018. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |