DOI:10.32604/csse.2023.024945
| Computer Systems Science & Engineering DOI:10.32604/csse.2023.024945 | |
| Article |
Homogeneous Batch Memory Deduplication Using Clustering of Virtual Machines
1Department of CSE, Thanthai Periyar Government Institute of Technology, Vellore, 632002, India
2Department of IT, Sona College of Technology, Salem, 636005, India
*Corresponding Author: N. Jagadeeswari. Email: jagadeeswarinj@gmail.com
Received: 05 November 2021; Accepted: 24 January 2022
Abstract: Virtualization is the backbone of cloud computing, which is a developing and widely used paradigm. By finding and merging identical memory pages, memory deduplication improves memory efficiency in virtualized systems. Kernel Same Page Merging (KSM) is a Linux service for memory pages sharing in virtualized environments. Memory deduplication is vulnerable to a memory disclosure attack, which uses covert channel establishment to reveal the contents of other colocated virtual machines. To avoid a memory disclosure attack, sharing of identical pages within a single user’s virtual machine is permitted, but sharing of contents between different users is forbidden. In our proposed approach, virtual machines with similar operating systems of active domains in a node are recognised and organised into a homogenous batch, with memory deduplication performed inside that batch, to improve the memory pages sharing efficiency. When compared to memory deduplication applied to the entire host, implementation details demonstrate a significant increase in the number of pages shared when memory deduplication applied batch-wise and CPU (Central processing unit) consumption also increased.
Keywords: Kernel same page merging; memory deduplication; virtual machine sharing; content-based sharing
Cloud computing is becoming increasingly popular in a variety of sectors. Virtual machines (VMs) have resurfaced, presenting a huge opportunity for cluster, parallel, cloud, grid, and distributed computing. Virtualization technology serves the majority of IT (Information Technology) and computer-related sectors by allowing users to share expensive hardware resources by executing VMs on the same set of server hosts. Virtualization is a computer architecture concept that allows the execution of many virtual machines (VMs) on the same host machine. The concept of virtual reality dates back to the 1960s. The goal of a virtual machine (VM) is to facilitate resource sharing among multiple users while also increasing computer efficiency and performance in terms of resource consumption and application flexibility. In various layers of cloud architecture, hardware resources such as Central Processing Unit, memory, and Input -Output devices, as well as software resources such as operating systems and software libraries, can be virtualized. Cloud computing is increasingly based on a virtualized architecture, in which massive programmes run inside virtual servers that are assigned to each physical server. Virtual machines are installed on top of virtual machine monitors, which are in charge of allocating physical resources such as CPU, memory, and other resources to each virtual machine separately. The number of pages shared is high if the guest operating system of virtual machines contains similar applications of data. If these sharing options are appropriately exploited, the virtual machine monitor can supply significantly more memory to the virtual machines, resulting in a higher level of server consolidation [1].
Memory deduplication was established primarily in Disco [2] using the transparent page sharing methodology, which involved recognising identical copies of memory pages, merging them, and mapping them to the same physical page in order to decrease the memory footprint of redundant data. However, this para-virtualization paradigm necessitates some changes to both the guest and the host. Due to their licence agreements and source code changes, it is impossible to modify guests. The VMware ESX (Elastic Sky X) server employs content-based page sharing, which determines whether a page is available in many virtual machines by calculating the hash value. According to research, this method can help to reclaim 10% to 20% of system RAM [3]. The Xen virtual machine monitor now enables page compression and page patching, in addition to memory deduplication [4]. However, in all circumstances, the time to merge, or the time it takes to merge identical copies of memory, is often long. The scan rate is set to slow, but it may be tweaked.
Despite the fact that memory deduplication reduces memory footprints, existing techniques lack isolation and trustworthiness in addition to their efficiency [5]. Some tenants may be reluctant to share sensitive or confidential information with others. Covert Channel [6] is a system that uses CPU loads to provide a illegal channel for transmitting confidential information between virtual machines. Furthermore, the virtual machine monitor placed on the host performs a global memory deduplication procedure. It is not possible to set the appropriate sharing rate based on the virtual machine’s workload [7].
The rest of the paper is organized as below. In Section 2, background and motivation of this research is presented and Section 3 contains Literature review, In Section 4, the approach and implementation has been illustrated. Experimental results are discussed in Section 5. The paper is concluded in Section 6.
The background and motivation of this research is given below.
2.1 Types of Sharing of Memory Pages
Intra-virtual machine sharing, inter-virtual machine sharing, homogeneous sharing, and heterogeneous sharing are the several types of memory page sharing. Intra-Virtual machine sharing refers to the sharing of identical memory pages within the same virtual machine. Inter-Virtual machine sharing refers to the sharing of identical pages between multiple distinct virtual machines. Homogeneous virtual machine sharing refers to the sharing of memory pages across identical operating systems. Heterogeneous sharing refers to the sharing of virtual machines across multiple operating system platforms [8]. Kernel Same Page (KSM) merging shared pages on Windows VMs is more effective than on Linux VMs.
Kernel Same Page Merging is a memory deduplication implementation that originally appeared in the Linux Kernel version 2.6.32. Kernel daemon, ksmd, searches the user memory for pages that can be shared among users. It scans only the prospective candidates and develops signatures for them, rather than scanning the full region of memory, which is time consuming and CPU intensive. These signatures are kept in the deduplication table. When two or more pages are verified to determine if they are in the same signatures, KSM scans at a 20 millisecond interval and at a rate of 25% of possible memory pages at a time. KSM looks at three different sorts of memory pages. 1. Volatile pages, or pages that change frequently and are therefore unsuitable for memory sharing, 2. Unshared pages, also known as deduplication candidate pages, are the locations where madvise() instructs ksmd to merge., 3. Pages shared by processes or users that have been deduplicated (shared pages) [9].
For candidate pages of deduplication, KSM uses two Red-Black trees: a stable tree and an unstable tree. The RB (Red Black) tree’s efficiency is O(log n) per tree, and its height is never greater than 2log(n+1), where n is the number of nodes. In a round robin technique, KSM searches each memory location one by one. If the page is accessed, KSM first looks at the stable RB tree and merges with it if, it is identical. Otherwise, it checks the unstable tree for a match, and if one is found, it removes the page from the unstable tree and adds it to the stable tree [10].
Before starting memory sharing, allocated memory must be registered as being potentially shared by KSM. The stable tree comprises all of KSM’s shared and write-protected pages. Unstable trees are those that have the potential to be shared and whose contents haven’t changed in a long time. The contents of memory pages are used to index the nodes of both trees. Nodes in the stable tree point to memory pages that are shared, whereas nodes in the unstable tree indicate pages that are ideal candidates for sharing but are not shared. Both trees are initially empty. Scanned pages are examined for matches in the unstable tree as long as the shared tree is empty. A page is added to the unstable tree if there is no match in the unstable tree [11].
KVM (Kernel Virtual Machine) is a complete virtualization framework that enables hardware virtualization on x86 CPUs (Intel VT or AMD-V). It is made up of two primary parts: A group of kernel modules (kvm.ko, kvm-intel.ko, and kvm-amd.ko) that offer the underlying fundamental virtualization framework and processor specific drivers, as well as a userspace programme (qemu-kvm) that provides virtual device emulation and management mechanisms (virtual machines). The word KVM refers to the virtualization functionality at the kernel level, but it is more generally used to refer to the userspace component. Libvirt-based and QEMU-based tools could be used to manage VM Guests (virtual machines), virtual storage, and networks. libvirt is a library that provides an API (Application programming interface) for maintaining VM Guests utilising various virtualization solutions, including KVM and Xen. It has a graphical user interface and a command line program also. The QEMU (Quick Emulator) tools are specific to KVM/QEMU and are only available through the use of the command line [12].
QEMU is a cross-platform, fast Open - sourced machine emulation approach that can simulate a broad range of hardware architectures. QEMU allows users to run a fully functional operating system (VM Guest) on top of the current system (VM Host Server). QEMU is composed of several components: a processor emulator, emulated devices, generic devices for communicating the emulated devices to the related host devices, debugger, and a user interface for interacting with the emulator. QEMU can be used in conjunction with the KVM kernel module to provide a virtualization solution. QEMU can take use of KVM acceleration if indeed the VM Guest hardware architecture is the same as the VM Host Server’s architecture. Tools based on libvirt, such as virt-manager and vm-install, provide simple interfaces for creating and managing virtual machines [13].
Libvirt is a virtualization platform management toolkit that is accessible from C, Python, Perl, and GO, among many other languages, and is licenced under many standard open sources. It supports KVM, QEMU (Quick EMUlator), Virtuozzo, VMware ESX (Elastic Sky X), LXC (Linux Containers), BHyve (BSD hypervisor), and other virtualization technologies. It is destined for use with Linux, FreeBSD, Windows, and MacOS. Virsh is a shell wrapper in Libvirt that includes access to libvirt functionality on platforms that support virtualization. Virsh is a command-line and batch scriptable tool for managing all libvirt-managed domains, networks, and storage. This is included with the libvirt core distribution. libvirt-host is a libvirt module that provides several APIs. It has several macros for getting and setting various memory parameters of the virtual machine, such as virNodeGetInfo, virNodeGetMemoryParameters, virNodeGetMemoryStats, and virNodeSetMemoryParameters [14].
2.6 Attacks Based on Covert Channels Using Deduplication of Memory
A single physical server can collocate several virtual machines being used by many users in a cloud computing environment where multi-tenants are used. The public cloud environment uses sharing of identical memory pages among different users to maximise resource utilisation, which can lead to a memory disclosure attack. On deduplicated pages that are re-created by Copy-on-write, malicious users can take advantage of the time difference. Because of the Copy-on-write method, more time is spent accessing the page than if it were accessed normally. To protect against memory disclosure attacks, sharing can be enabled within single-user virtual machines but disabled for other users.
2.7 Hierarchical Agglomerative Clustering
For data clustering, hierarchical clustering is a widely used unsupervised machine learning technique. Agglomerative clustering and divisive clustering were the two broad classifications. The following are the steps involved: 1. Each data point in the dataset was treated as a separate cluster at first. 2. To create a cluster, connect the data points that are closest to each other. 3. Connect nearby clusters to form new clusters. 4. Dendrograms are used to split a large cluster into several smaller ones. The following are unique features: 1. the number of clusters does not need to be specified. 2. Dendrograms make it easy to understand how data has been grouped.
Gu et al. [15] discussed virtual machine guest OS finger printing. The upgraded OS-Sommelier+, a multiaspect, memory-exclusive methodology, reduced the virtual machine’s physical memory utilisation while maintaining precision and usability. This study encourages us to conduct a thorough review of code hashing and data signature. Guest OS administration, kernel dump analysis, memory forensics, penetration testing, and virtual memory introspection are all aided by this approach.
Jia et al. [16], developed Loc-K, a new memory deduplication algorithm that uses logical addresses of separate pages to provide greater continuity, resulting in improved spatial locality. This approach enhances the prediction ratio by predicting k probable duplication places for page scanning. The prediction opportunity increased to 97.8%, with a 96.5 percent prediction hit ratio.
Wang et al. [17], implemented and evaluated Covert Inpector, a virtual machine monitor based approach to identify and eliminate covert timing channels to build on memory being shared. The test finds and throttles a covert timing channel based on shared memory. This test finds and eliminates covert channels that have a significant impact on the performance of the guest virtual machine.
Elghamrawy et al. [18], investigated the wide discrepancy between existing prediction mechanisms and actual behaviour was investigated by. They investigated memory page behaviour using page flags provided through the Linux kernel’s proc file system and used the framework to anticipate memory pages that are expected to be generally stable, as well as memory deduplication and virtual machine live migration.
Garoa et al. [19], studied the impact of ASLR (Address Space Layout Randomization) over memory deduplication. They looked at how memory deduplication affects kernel randomization. When kernel ASLR is enabled, the memory cost of running approximately 24 kernels rise by 534 percent (from 613 MiB to 3.9 GiB).
Patel et al. [20], used a machine learning approach to classify virtual machines into labelled clusters for server consolidation. To group similar virtual machines, they adopted neural networks, which come under the category of supervised learning. In terms of the number of virtual samples properly identified, their work outperforms. This study motivates us to classify virtual machines according to their guest Operating Systems installed inside it.
Zhu et al. [21], proposed a new memory deduplication method called Page Correlation Aggregation (PCA). It almost effectively reduces the number of covert channel operations. Since pages with comparable features have a higher possibility of sharing, this strategy entails separating the virtual machine’s pages into several sets. Pages are then classified into several classes based on their access permissions within each category. As a result, for sharing purposes, page comparisons are limited to the same classifications. PCA seems to be a strategy to minimise copy-on-write latency while using a covert channel.
Lindermann et al. [22], suggested a timing side channel attack to detect software versions operating in co-located virtual machines, and executed an intrusion to assess whether pages are unique to a certain software version in co-located virtual machines. The tests are carried out in a fair amount of time, and viable countermeasures against the described side channel attack are also examined.
Lindermann et al. [23], devised a memory deduplication side-channel intrusion to reveal applications of other virtual machines that were co-located. This entails verifying memory page availability in co-located virtual machines that are unique across all versions of the software.
You et al. [24], investigated lightweight memory deduplication. This work involves individual memory pages being divided into various segments, and the joined strings of the hash values of these segments are used as indexed keys in trie data structures, reducing the time required to search for identical twin pages and the number of memory page comparisons. As a result, CPU consumption will be reduced by 44.9 percent, and memory bandwidth usage will be reduced by 31.6 percent.
Shiba [25], discussed how the cost of finding mergeable pages is considerably high, and how pages are distributed in address spaces. MashitoShiba, classifies pages by the state of consecutive memory pages, measures the ratio of pages in each state, and shows the measuring distribution that can be used to evaluate the likelihood of merging.
The Cgroups mechanism was used by Goa et al. [26], to enable operating system containerization. Cgroups mechanisms separate processes into hierarchical groups and controllers in order to keep system resources like the CPU, memory, and I/O (Input/Outout) in check. For the establishment of resource control, newly generated child processes immediately copy Cgroups attributes from their parent processes. But the inherited Cgroups incarceration via process formation does not assure a steady and good accounting of resources. By separating processes from their original process groups, they establish a set of exploitation techniques for producing out-of-band workloads. They examined five case studies using Docker containers to see how they may overcome Cgroup’s resource dominance in real-world circumstances. An adversarial container can substantially increase the amount of consumed resources in a multitenant environment by exploiting Cgroups, which appears to slow down other containers on the same host and gives it unfair benefits in the system. This study motivated us to allocate resources to various processes.
Garcia et al. [27], developed a novel kernel randomization technique adaptive with memory deduplication that detects and mitigates threats at the kernel level, as well as the memory pages shared by each area. They introduced KASLR-M+ (Kernel Address Space Layout Randomization), the first efficient and practical Kernel ASLR memory security that maximises memory deduplication savings without losing security, based on their findings.
Garcia et al. [28], investigated the impact of function granular Kernel Randomization on memory deduplication and why it is incapable of providing the utmost memory protection and sharability in their research. They proposed a method that forces guest kernels belonging to the same tenant to use the same random memory layout of memory regions, which has a significant influence on deduplication.
This approach provides a mechanism that supports multiple deduplication threads, each of which is dedicated to a batch that has a set of similar operating systems. The grouping of each batch is based on similar OS. When the Kernel Virtual Machine (KVM) instantiates a new virtual machine, it registers the memory region of each virtual machine to the memory regions of KSM. Once KSM gets started, a global ksmd daemon process automatically starts and performs memory deduplication. In this approach, the global ksmd daemon is split into similar threads, each performing memory deduplication of each homogeneous batch. Cgroups, of Linux, is utilised to allocate CPU/memory resources of each user process. Overview architecture of homogeneous batch memory deduplication using clustering of virtual machines is shown in Fig. 1.
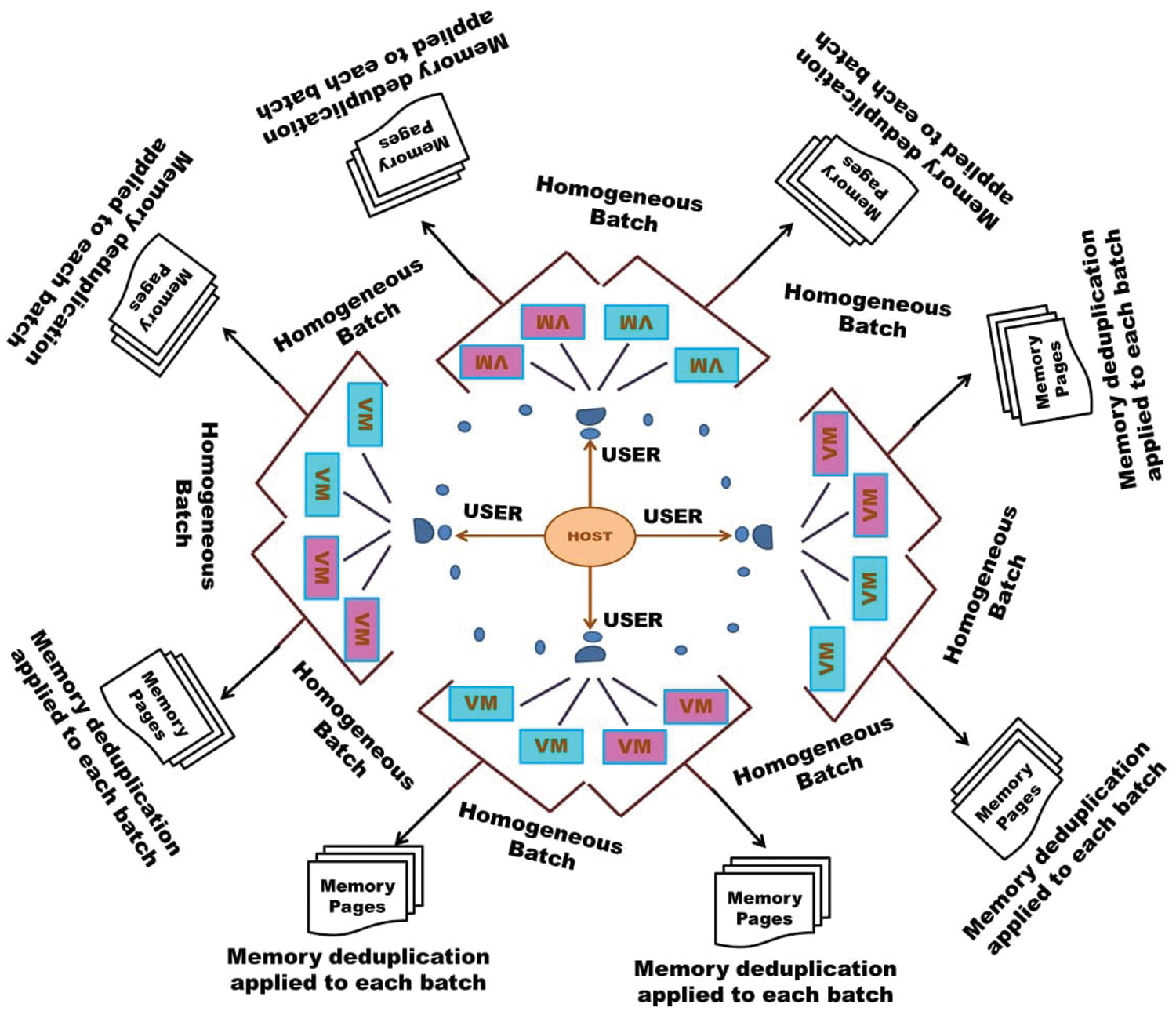
Figure 1: Overview architecture of homogeneous batch memory deduplication using clustering of virtual machines
Implementation: The aforementioned work was divided into two components for implementation.
Module1: Using Hierarchical Agglomerative Clustering, virtual machines are clustered depending on the guest operating system.
Module 2: Memory Deduplication is applied separately to each homogeneous batch.
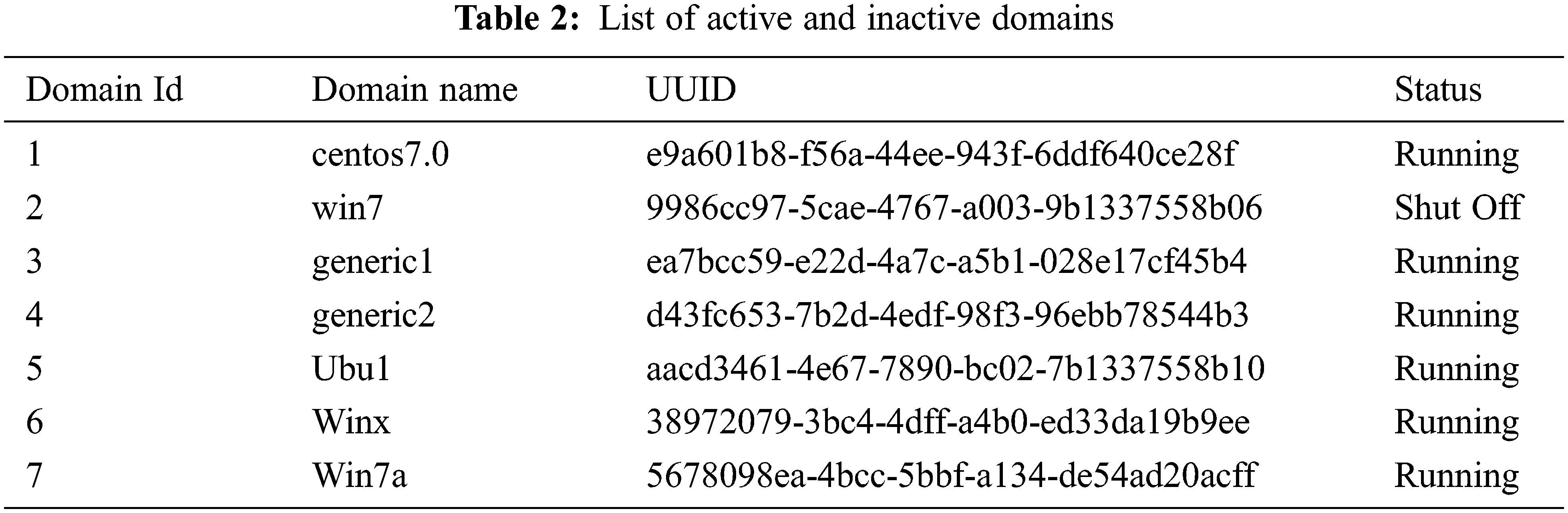
Module 1 entails clustering virtual machines based on the guest operating system deployed, which entails the actions below. Tab. 1 shows the information log of virtual machines created. Information about the virtual machine, such as its domain name, Universal Unique Identifier (UUID), (Operating System) OS type, OS variant, and user of the virtual machine, is entered into the information repository as soon as it is formed. When a new virtual machine is generated, the information log is updated, and the related record is deleted when a virtual machine is removed from the host. A Python code is executed to identify the list of active and inactive domains on the host, tabulated in Tab. 2. Information of all active and inactive domains with their domain id, domain name, UUID of that domain and the current status of domains either running or shutoff, listed in Tab. 2. Based on the output, another Python program is run, which uses Hierarchical Agglomerative Clustering to group only the active domains into different clusters based on their guest operating systems. The virtual machines with Domain ID 2 (Identifier) and 5 clustered on Windows, whereas virtual machines with Domain ID 3 and 4 clustered on Linux, and all four virtual machines are running domains, as shown in Fig. 2.

Once the active domains are classified a dendrogram, shown as snapshot, representing the clusters of various active domains. In Fig. 2, domains with id’s 1 and 5 are clustered into a batch of User1, domains with id’s 3 and 4 are clustered into a batch of User2 and domains with id’s of 6 and 7 are clustered in another batch of User3 and all are currently active at the moment.
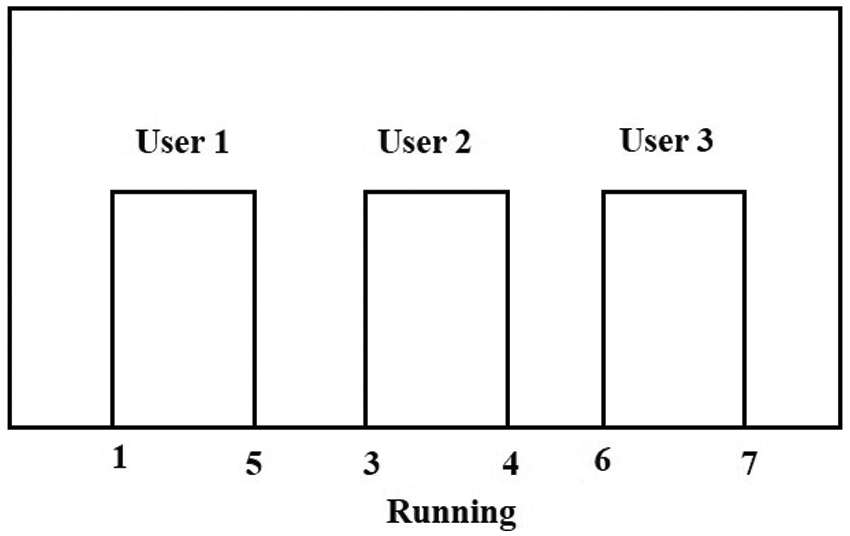
Figure 2: Snapshot generated after clustering of active domains
After clustering of the active domains, it’s time to move on to the next phase. Deduplication threads are applied to each batch, and memory deduplication activities are performed inside the memory given to the batch. Various scan rates are assigned to each batch. The scan rate of a batch with CPU-intensive activities, such as games, can be set as low. Each batch has a KSM daemon thread, seperate “Stable tree” and “unstable tree” are two data structures used by KSM. In a batch, scan a new page, KSM checks the new page against the stable tree and merges it with the page if a match is found. If no match was detected, a search of the unstable tree was conducted. If a match was found in the unstable tree, the page was moved from the unstable tree to the Stable tree. If no match was found, a new page entry was generated in the unstable tree, and a new page was searched for. Flow chart of homogeneous batch memory deduplication was shown in Fig. 3. The details of information log created and information of active and inactive domains are also shown by the side of the first two steps of flowchart. Next to that, step by step implementation of homogeneous batch memory deduplication was given.
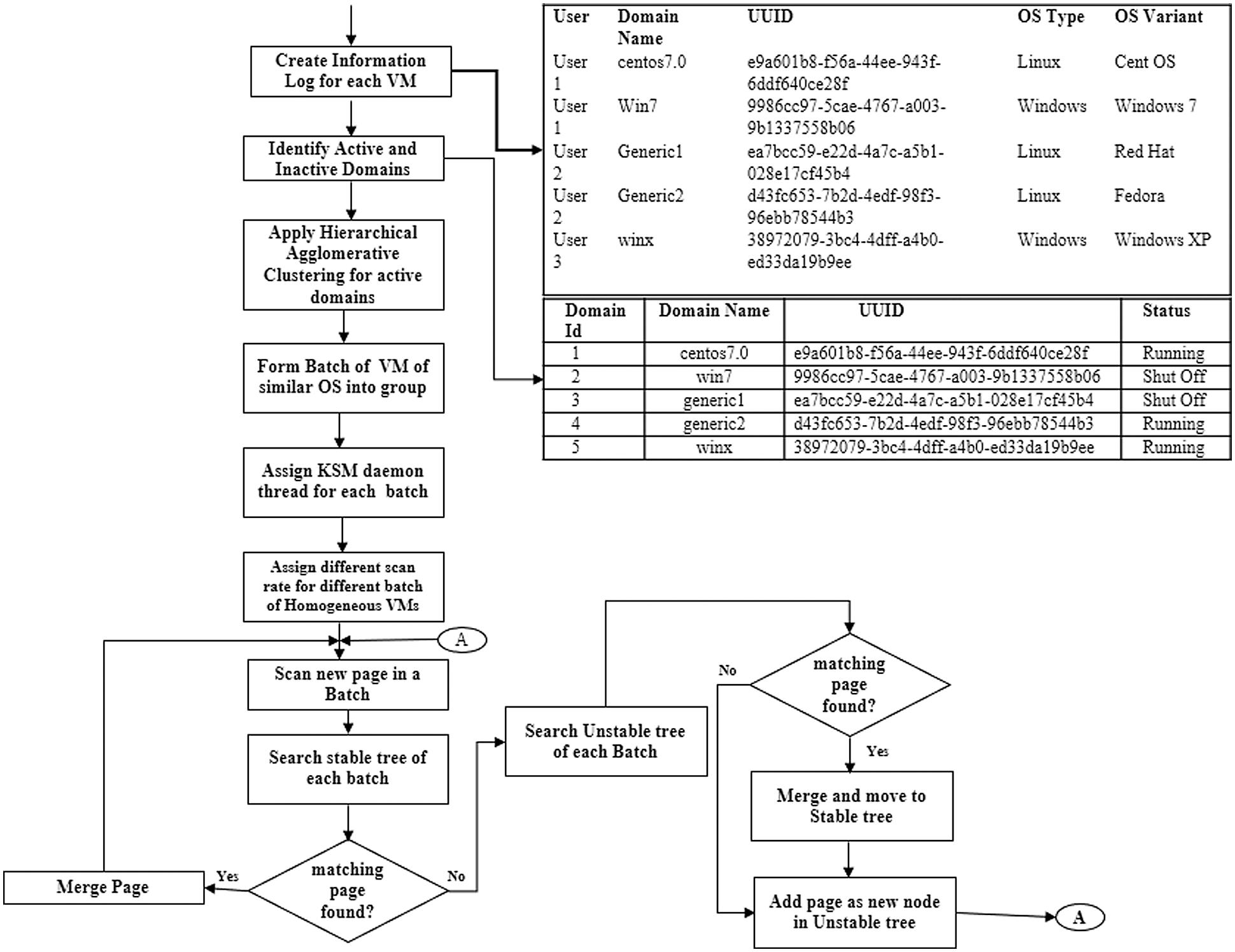
Figure 3: Flow chart of homogeneous batch memory deduplication
The experimental results are shown below:
The following Tab. 3 shows experimental setup:
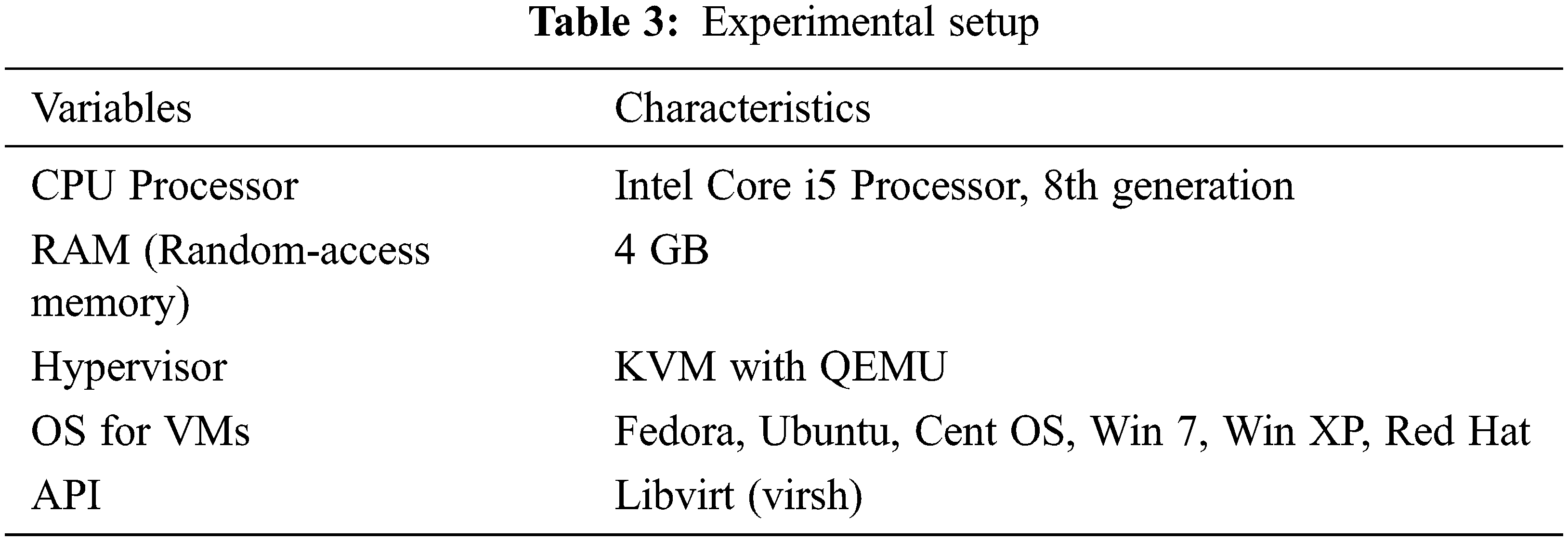
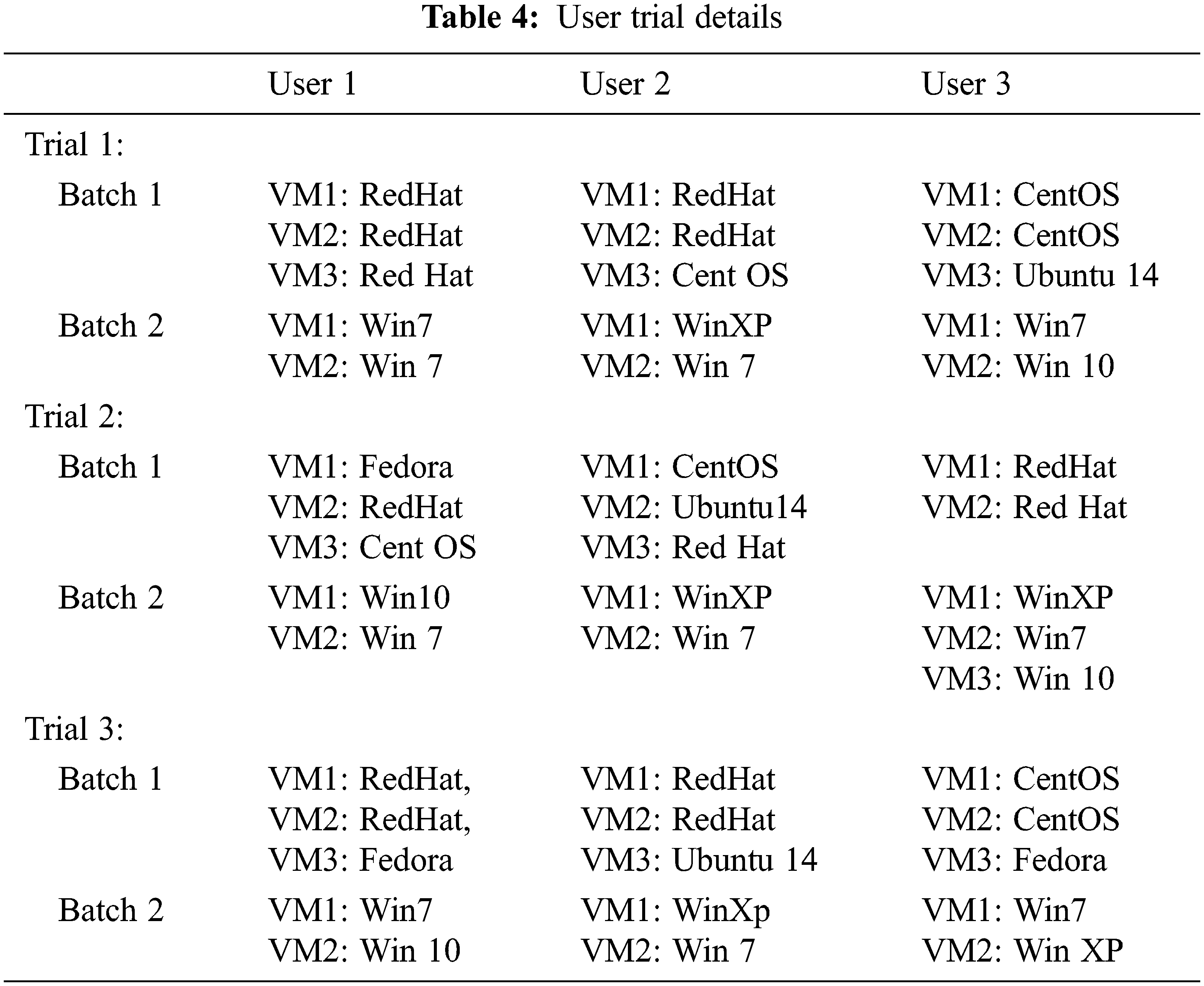
Three trial versions for three users are performed and the following Tab. 4 shows virtual machine set up assigned for each user. In each trial, minimum of 5 virtual machines executed for each user and virtual machines of Linux guest operating system are grouped in Batch I and Windows virtual machines are grouped in Batch II.
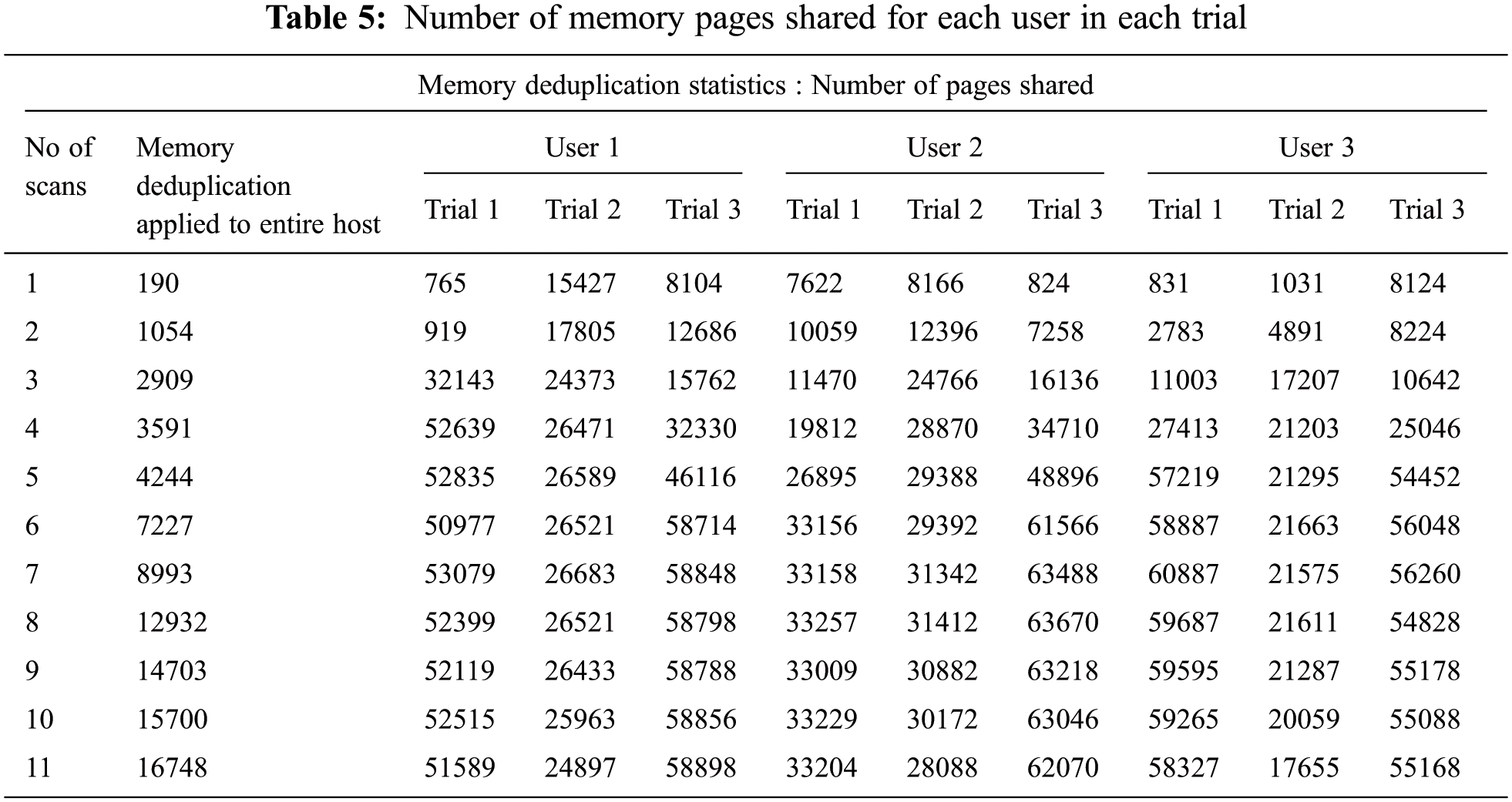
In Fig. 4, the first part of the figure show the memory deduplication applied to the entire host. The next lane shows memory pages shared for each trial of each users for each number of scans. In Fig. 5, the merge rate is comparatively high, when merging performed in various trials of users than deduplication applied to the entire host. Fig. 6 shows the memory saving rate, which is calculated from total number of pages shared per user, for each scan of three different users. is found that it is increasing rapidly at the initial stage and gradually afterwards. Fig. 7, shows the percentage of Memory Pages shared for each scan. The utilization of CPU is high when compared with memory deduplication applied to the whole host, shown in Fig. 8. Fig. 9 shows the Statistics of Memory Deduplication in which the following information are noted: No. of Pages sharing- indicates how many pages that virtual machines create, No. of Pages shared- indicates how many pages actually in use and being shared, No. of Pages unshared - indicates number of pages that are unshared, No. of Pages volatile - indicates pages that change often and too fast be inserted in RB tree, No. of scans - how many times all merge able areas have been scanned. From the information, it is found that the ratio of pages sharing to pages shared is high, which infers good sharing opportunities and the number of memory pages shared for each user in each trial is tabled in Tab. 5.
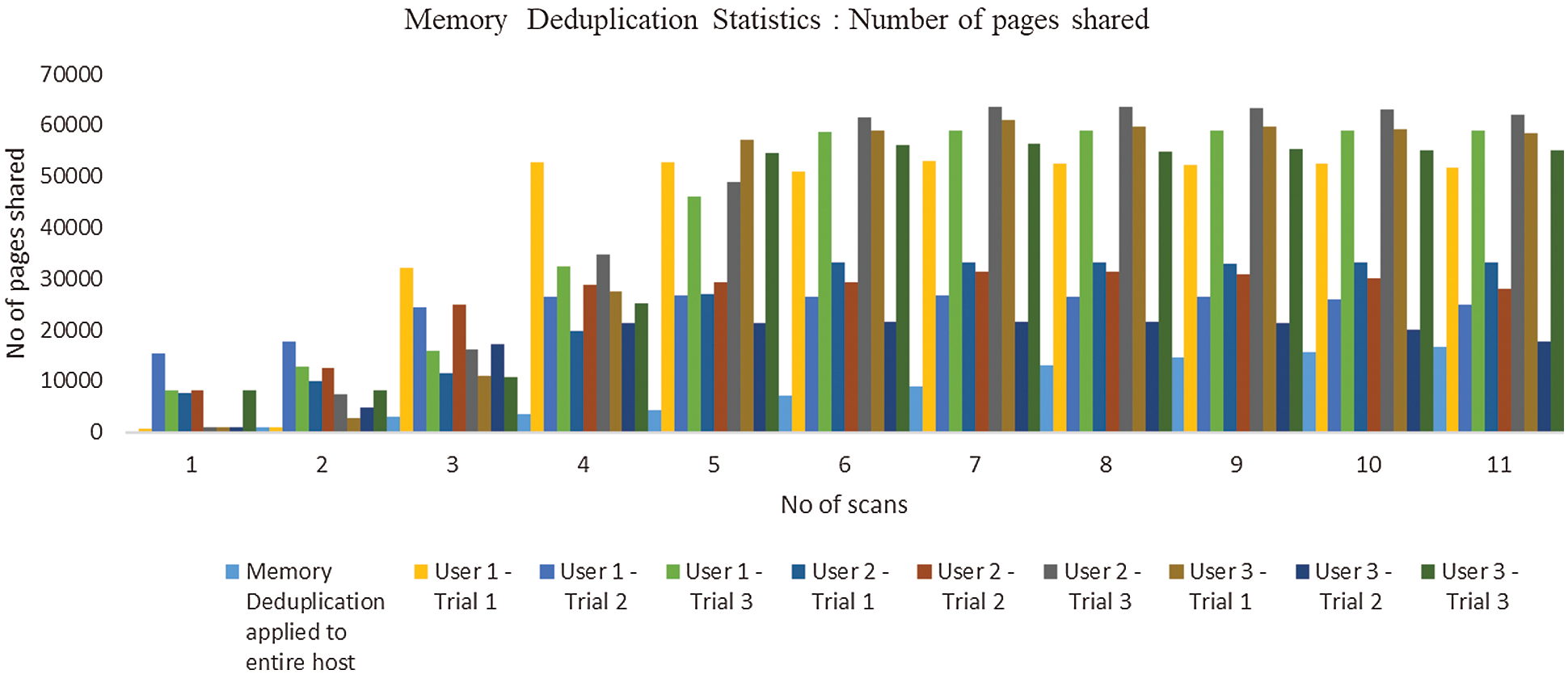
Figure 4: Statistics of homogeneous memory deduplication and KSM
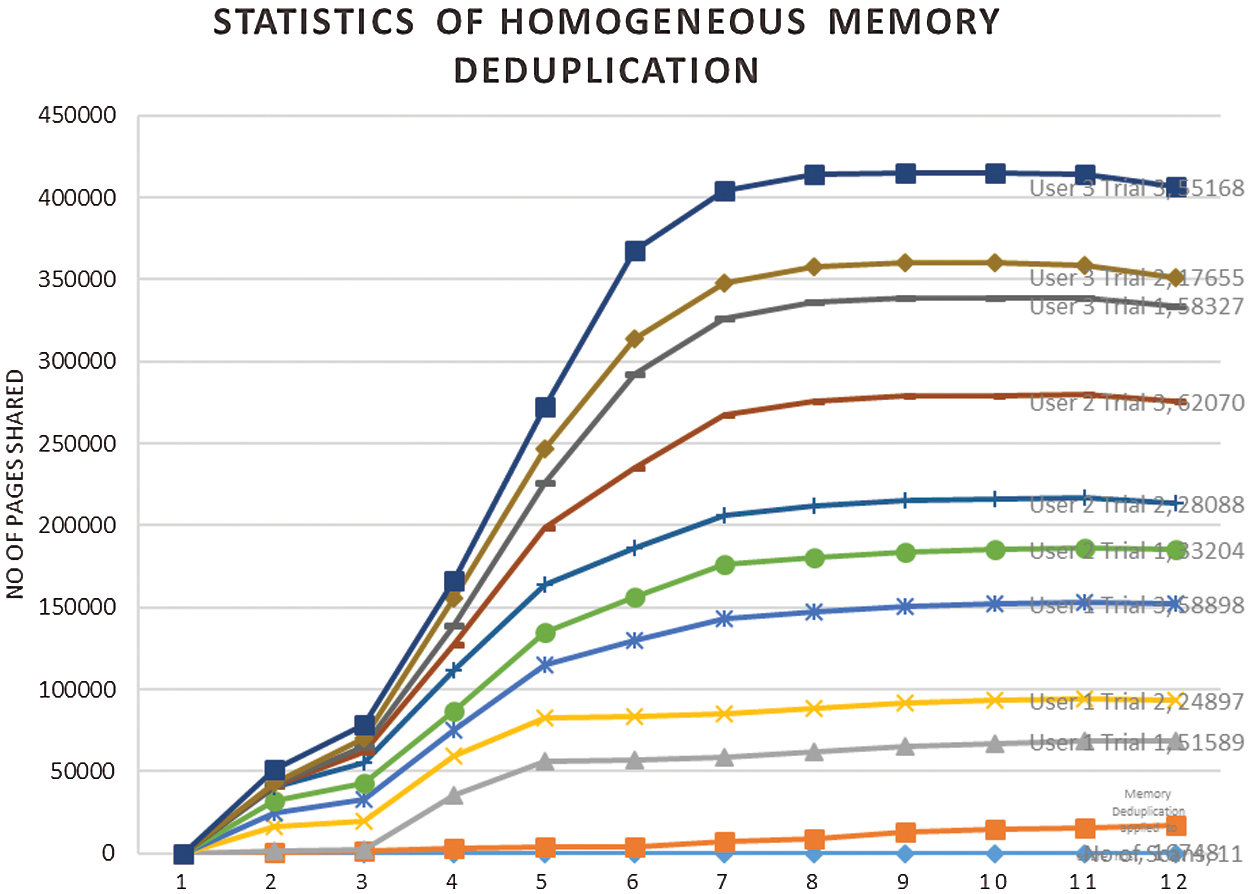
Figure 5: Number of pages shared in each trial of user
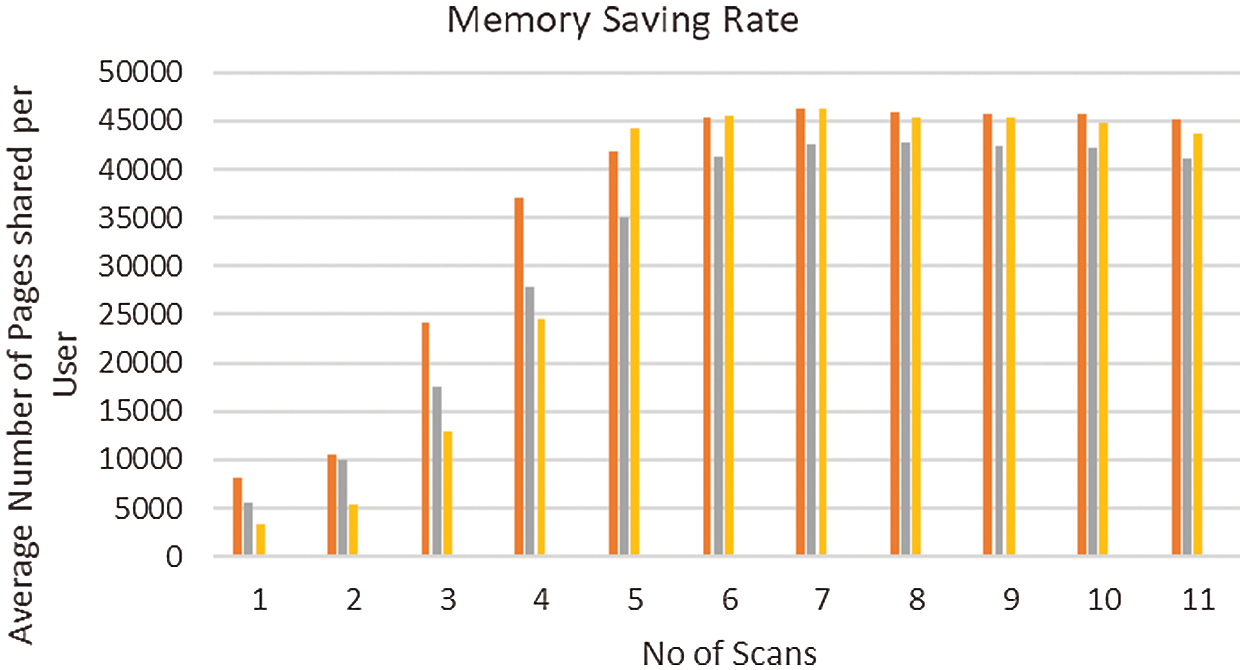
Figure 6: Memory saving rate
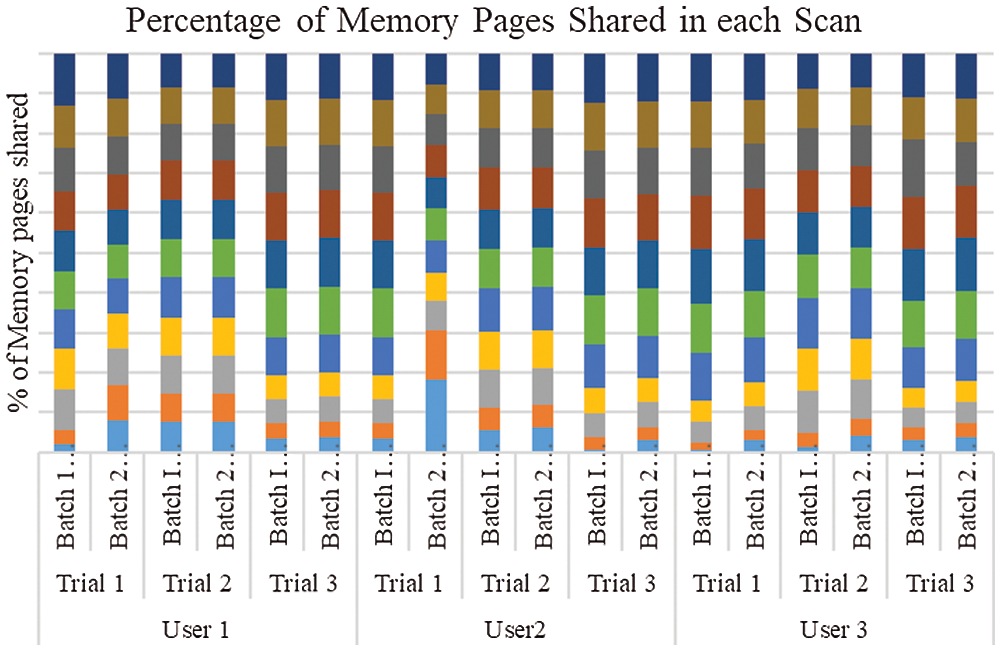
Figure 7: Percentage of memory pages shared for each scan
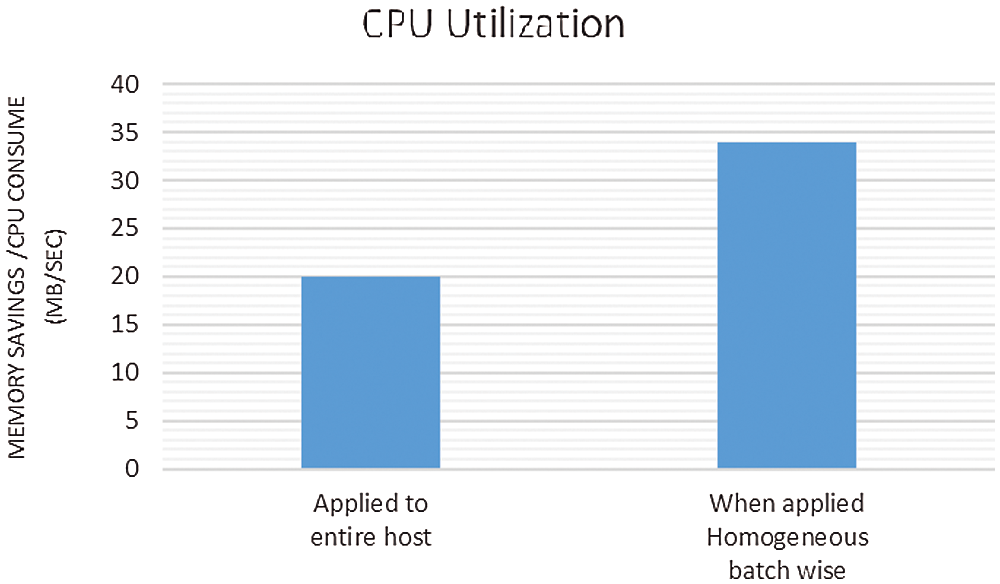
Figure 8: CPU utilization
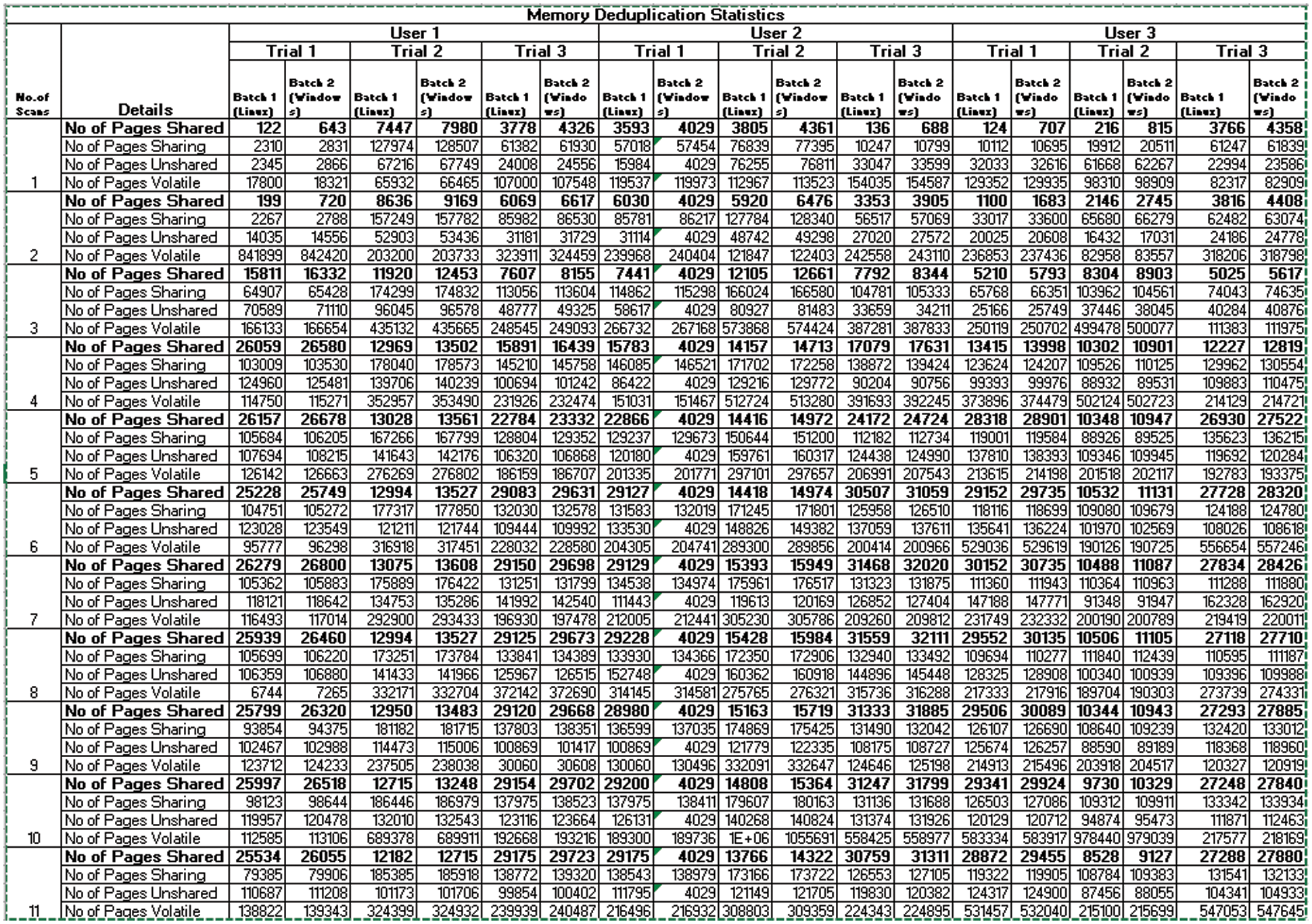
Figure 9: Amount of pages shared in each user’s trial, memory deduplication statistics for user’s trial
Memory deduplication is particularly vulnerable to memory disclosure attacks. Memory deduplication can be used on virtual machines belonging to a single user group to prevent this attack. When compared to memory deduplication applied to the entire host, user virtual machines are grouped suitably and memory deduplication is performed to homogenous batch wise and the proportion of sharing of memory pages is increased and CPU utilization is high. In future work, the identical applications running in virtual machines of homogeneous batch are categorized further and memory deduplication to be performed.
Acknowledgement: The author with a deep sense of gratitude would thank the supervisor for his guidance and constant support rendered during this research.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. K. Hwang, J. Dongarra and G. C. Fox, Distributed and Cloud Computing: From Parallel Processing to the Internet of Things, Waltham, MA, USA, China Machine Press, 2013. [online]. Available:https://books.google.com/books. [Google Scholar]
2. E. Bugnion, S. Devine, K. Govil and M. Rosenblum, “DISCO: Running commodity operating systems onscalable multiprocessors,” ACM Transactions on Computer Systems (TOCS), vol. 15, no. 4, pp. 412–447, 1997. [Google Scholar]
3. C. A. Waldspurger, “Memory resource management in VMware ESX server,” in Proc. Sym. on Operating Systems Design and Implementation, New York, NY, USA, pp. 181–194, 2002. [Google Scholar]
4. D. Gupta, S. Lee, M. Vrable, S. Savage, A. C. Snoeren et al., “Difference engine: Harnessing memory redundancy in virtual machines,” Communications of the ACM, vol. 53, no. 10, pp. 85–93, 2008. [Google Scholar]
5. K. Suzaki, K. Iijima, T. Yagi and C. Artho, “Memory deduplication as a threat to the guest OS,” in Proc. European Workshop on System Security, Salzburg, Austria, pp. 1–3, 2011. [Google Scholar]
6. K. Okamura and Y. Oyama, “Load-based covert channels between Xen virtual machines,” in Proc. ACM Sym. on Applied Computing, Sierre, Switzerland, pp. 173–180, 2010. [Google Scholar]
7. Y. Deng, C. Hu, T. Wo, B. Li and L. Cui, “A memory deduplication approach based on in virtualized environments state key laboratory of software development environment,” in Proc. IEEE Seventh Int. Sym. on Service-Oriented System Engineering, San Francisco, CA, USA, pp. 367–372, 2012. [Google Scholar]
8. S. Barker, T. Wood, P. Shenoy and R. Sitaraman, “An empirical study of memory sharing in virtual machines,” in Proc. Annual Technical Conf., Boston, MA, pp. 273–284, 2012. [Google Scholar]
9. W. C. Lin, C. H. Tu, C. W. Yeh and S. H. Hung, “GPU acceleration for kernel samepage merging,” in Proc. Int. Conf. on Embedded and Real-Time Computing Systems and Applications (RTCSAIEEE, Busan, Korea, pp. 1–6, 2017. [Google Scholar]
10. A. Arcangeli, I. Eidus and C. Wright, “Increasing memory density by using KSM,” in Proc. Linux Sym., USA, pp. 19–28, 2009. [Google Scholar]
11. K. V. M. Contributors, Kernel Samepage Merging KSM, Canada, KVM, Red Hat Open Shift, 2015. [online]. Available:https://www.linux-kvm.org/page/KSM. [Google Scholar]
12. K. Ivanov, KVM Virtualization Cookbook - Learn how to effectively use KVM in production, Mumbai, India, Packt Publishing, 2017. [online]. Available:https://books.google.com/books. [Google Scholar]
13. H. D. Chirammal, P. Mukhedkar and A. Vettathu, “Mastering KVM Virtualization” in Packt Publishing,1st ed., vol. 1. New York, Kindle Edition, pp. 468,2004. [Google Scholar]
14. K. Suzaki, K. Iijima, T. Yagi and C. Artho, “Implementation of a memory disclosure attack on memory deduplication of virtual machines,” IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, vol. 96, no. 1, pp. 215–224, 2013. [Google Scholar]
15. Y. Gu, Y. Fu, A. Prakash, Z. Lin and H. Yin, “OS-sommelier: Memory-only operating system fingerprinting in the cloud,” in Proc. Third ACM Sym. on Cloud Computing, New York, USA, pp. 1–13, 2012. [Google Scholar]
16. S. Jia, C. Wu and J. Li, “Loc-K: A spatial locality-based memory deduplication scheme with prediction on k-step locations,” in Proc. IEEE 23rd Int. Conf. on Parallel and Distributed Systems (ICPADS), Shenzhen, China, pp. 310–317, 2017. [Google Scholar]
17. S. Wang, W. Qiang, H. Jin and J. Yuan, “Covert Inspector: Identification of shared memory covert timingchannel in multi-tenanted cloud,” International Journal of Parallel Programming, vol. 45, no. 1, pp. 142–156, 2017. [Google Scholar]
18. K. Elghamrawy, D. Franklin and F. T. Chong, “Predicting memory page stability and its application to memory deduplication and live migration,” in Proc. 2017 IEEE Int. Sym. on Performance Analysis of Systems and Software (ISPASS), Santa Rosa, CA, USA, pp. 125–126, 2017. [Google Scholar]
19. F. V. Garcia and H. M. Gisbert, “How kernel randomization is canceling memory deduplication in cloud computing systems,” in Proc. 2018 IEEE 17th Int. Sym. on Network Computing and Applications (NCA), Cambridge, MA, USA, pp. 1–4, 2018. [Google Scholar]
20. E. Patel, A. Mohan and D. S. Kushwaha, “Neural network based classification of virtual machines in IaaS,” in Proc. 5th IEEE Uttar Pradesh Section Int. Conf. on Electrical, Electronics and Computer Engineering (UPCON), Gorakhpur, India, pp. 1–8, 2018. [Google Scholar]
21. M. Zhu, K. Zhang and B. Tu, “PCA: Page correlation aggregation for memory deduplication in virtualized environments,” in Proc. Int. Conf. on Information and Communications Security, Lille, France, pp. 566–583, 2018. [Google Scholar]
22. J. Lindeman and M. Fischer, “Efficient identification of applications in co-resident vms via a memory side-channel,” in Proc. IFIP Int. Conf. on ICT Systems Security and Privacy Protection, Poznan, Poland, pp. 245–259, 2018. [Google Scholar]
23. J. Lindemann and M. Fischer, “On the detection of applications in co-resident virtual machines via a memorydeduplication side-channel,” ACM SIGAPP Applied Computing Review, vol. 18, no. 4, pp. 31–46, 2019. [Google Scholar]
24. L. You, Y. Li, F. Guo, Y. Xu, J. Chen et al., “Leveraging array mapped tries in ksm for lightweight memory deduplication,” in Proc. IEEE Int. Conf. on Networking, Architecture and Storage (NAS), EnShi, China, pp. 1–8, 2019. [Google Scholar]
25. M. Shiba, “An examination method of mergeable memory page distribution for memory deduplication,” in Proc. 2019 IEEE 8th Global Conf. on Consumer Electronics (GCCE), Osaka, Japan, pp. 1027–1031, 2019. [Google Scholar]
26. X. Gao, Z. Gu, Z. Li, H. Jamjoom and C. Wang, “Houdini’s escape: Breaking the resource rein of linux control groups,” in Proc. ACM SIGSAC Conf. on Computer and Communications Security, London, United Kingdom, pp. 1073–1086, 2019. [Google Scholar]
27. F. V. Garcia and H. M. Gisbert, “KASLR-MT: Kernel address space layout randomization for multi-tenant cloud systems,” Journal of Parallel and Distributed Computing, vol. 137, pp. 77–90, 2020. [Google Scholar]
28. F. V. Garcia and H. M. Gisbert, “An info-leak resistant kernel randomization for virtualized systems,” IEEE Access, vol. 8, pp. 161612–161629, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |