DOI:10.32604/csse.2023.024868
| Computer Systems Science & Engineering DOI:10.32604/csse.2023.024868 | |
| Article |
Optimal and Effective Resource Management in Edge Computing
1Department of Information Science and Engineering, New Horizon College of Engineering Research Centre, Visvesvaraya Technological University (VTU), Bangalore, India
2Department of CSE, Nagarjuna College of Engineering and Technology, Bangalore, India
*Corresponding Author: Darpan Majumder. Email: darpanmajumder21@gmail.com
Received: 02 November 2021; Accepted: 27 December 2021
Abstract: Edge computing is a cloud computing extension where physical computers are installed closer to the device to minimize latency. The task of edge data centers is to include a growing abundance of applications with a small capability in comparison to conventional data centers. Under this framework, Federated Learning was suggested to offer distributed data training strategies by the coordination of many mobile devices for the training of a popular Artificial Intelligence (AI) model without actually revealing the underlying data, which is significantly enhanced in terms of privacy. Federated learning (FL) is a recently developed decentralized profound learning methodology, where customers train their localized neural network models independently using private data, and then combine a global model on the core server together. The models on the edge server use very little time since the edge server is highly calculated. But the amount of time it takes to download data from smartphone users on the edge server has a significant impact on the time it takes to complete a single cycle of FL operations. A machine learning strategic planning system that uses FL in conjunction to minimise model training time and total time utilisation, while recognising mobile appliance energy restrictions, is the focus of this study. To further speed up integration and reduce the amount of data, it implements an optimization agent for the establishment of optimal aggregation policy and asylum architecture with several employees’ shared learners. The main solutions and lessons learnt along with the prospects are discussed. Experiments show that our method is superior in terms of the effective and elastic use of resources.
Keywords: Federated learning; machine learning; edge computing; resource management
Private data centers have been popularized and fast-paced by cloud computing companies. To manage their workload, many companies and government agencies and research centers rely on external clouds [1]. Cloud data centers, though, are normally far from the end consumer and may not be up to par for perceived latency. Over recent decades, the model of cloud computing has enhanced its capacity through closeness of end-users to computing services and services. Facing a massive rise in application requests particularly emerging through Internet-of-Things (IoT) technologies, such as independent cars generating data from their different cameras, radar or accelerometers, the edge computer platform is expected to produce consistent output. In federated learning, many parties can work together to build a model without having to share training data. Because of legal, technological, ethical, or safety concerns, exchanging data in some industries like medical and banking might be difficult, but this system allows for collaboration without losing accuracy. There is a single point of failure in centralised federated learning since there is only one central server. Federated learning that is decentralised does not require updates to be made to a single central server.
Effective resource utilization of their edge data centers and limited calculation and computing capacities are the latest issue for edge service providers [2]. Providers would particularly seek automated solutions, which can be adapted to different demands and workloads. Recently, the novel distributed model of profound learning has become federated learning [3]. Clients prepare their localized deep neural network frameworks independently from their own private data in federated learning. The updates of the local model are submitted to the central server while the customer's private details are held. This centralized server is responsible for adding a new global model, which is to be distributed to customers when the next round of model training, after receiving all local updates [4]. This distributed iteration of testing is repeated till the model parameter converges to a satisfactory test precision.
The personal information of customers can be efficiently maintained using federated learning since no personal data is exchanged between customers and the central server [5]. The rapidly expanding needs for deep learning applications and AI need an effective computer design to enable deployment of the framework. Federated learning in user-facing computing, which involves local model programming for mobile customers, provides a future distributed platform to deploy profound learning apps [6]. But the difficulty is that federated education consumes mobile edge computing rather than resources. In the one hand the teaching of a profound learning paradigm generally calls for vast computing resources which are a major burden for mobile customers.
By assigning parameters for particular criteria such as an expiry date or time to live, the parameter policies allows to manage an ever-expanding number of parameters. The use of parameter rules allows changing or removing passwords and other parameters of the stored data. Fig. 1 shows the overview of edge computing model.

Figure 1: Overview of edge computing model
In the other hand, federated learning often occupies a large bandwidth resource as a distributed learning paradigm, and can require up to 100 rounds of coordination between the central server and clients for model iterations [7]. Federated learning deployments of mobile computing have to address the challenges of mobile customers using their intense tools. Effective resource control in mobile computing is the key to federated learning. The management of resources for federated learning in mobile technology requires the mutual optimization process of many types of resources, including computation, bandwidth, energy and data. There are attempts in the literature to address the issue, but far from sufficient [8]. In this study, we explore the state of the art approaches for resource management in mobile edge computing for federal learning.
Our strategy for identifying the components that have the most impact on the energy consumption of smartphones and identifying the states of each influential device served as the foundation for creating the energy consumption models. In addition, we devised an approach for evaluating the model's correctness and a way for demonstrating the robustness of models generated using faulty hardware. The methods used in current work are generally divided into two groups from the point of view of resource optimization: the black box and the white box approaches based on the extent to which optimization takes into account the internal design of the deep learning models. Federated Learning (FL) is creating a mathematical model to allow mobile users to train their local models on mobile data sets [9]. The users only share the learned parameters of the local model to a central server for model aggregation. These works are inspired by an approach of distributing model teaching, for example FL, by using current cellular networks in order to give users learning. However, most work [10] underlines the implications of optimization of wireless resources, convergence analysis and a minimization of the training time when conducting distributed model education over complex wireless environments.
In addition, several other outstanding obstacles and open issues exist for the direct deployment of FL across wireless networks. On the one hand, the efficiency of the model training is determined considerably by the local datasets and computer tools used for the training. In the other hand, in any model training round the subset of mobile devices chosen affects the appropriate time to achieve the target global model precision standard [11]. When there are complex wireless situations, this situation gets worse. By allowing FL Multi-access Edge Computing (MEC), the compromise between model efficiency, energy and time usage can be resolved [12]. MEC takes the high calculation servers closer to Smartphone users so they're able to discharge the latency and computer-intensive activities to their edge servers, with low processing and energy capacity.
MEC offers application developers and content providers cloud-computing capabilities and an IT service environment at the edge of the network. Most importantly, edge computing may improve network performance by decreasing latency. As opposed to typical cloud architecture, the data collected by IoT edge computing devices can be processed locally or at adjacent edge data centers. In addition to the significant upfront expenses and continuous upkeep, there is also the issue of what the future holds. Using traditional private facilities restricts expansion by tying organisations into projections of their future computing requirements. Insufficient computer capabilities may prevent companies from taking advantage of growth prospects if it is more than expected.
Mobile users will then download to the edge server a select section of local data collection, where the edge server concurrently trains a mathematical model and handles multiple mobile devices [13] while FL is designed as a data protection programme, for further computation a portion of local data sets not sensitive to privacy can be offloaded to the MEC. The MEC server is then able to conduct model training concurrently on all of the data sets of the mobile users and to average the parameters of the local model and model collected to create a new global model. In addition, users can identify the data samples offloaded based on the crispness of the data gathered [14]. This way, the customer will determine the sort of data those who want to exchange and boost the model efficiency even more. This solution is also more realistic.
A huge number of advanced mobile applications, such as real-time location tracking, online interactive contests, virtual reality, and augmented reality, have emerged in recent years as a result of the rapid growth of smart devices such as smart cameras; smart glasses; smart bracelets; and smart phones; These mobile apps necessitate mobile devices with a large amount of processing power and battery life. Because of their small size, smartphones and other mobile devices tend to be resource-constrained. As a result, implementing mobile apps is hampered by the tension between the rising resource demands of these applications and the constrained resource capabilities of mobile devices.
In addition, variability in computer resources of the mobile system for learning the local model strongly influences the efficiency of the global model in FL. In addition, the consumer could use fewer local data and computational resources for model training because of the energy constraint of mobile devices, which will lead to lower model efficiency. Therefore, the trade-off between mobile device energy use and training model efficiency needs to be discussed by FL. In this respect, the edge device is a versatile computer device; the model training on the edge server thus consumes little time and resources [15]. It is therefore intuitive, during the model training phase, to use the MEC infrastructure in order to share the computing burden of mobile devices with restricted resource.
The efficiency of the model based can be maintained thus reducing the energy usage of mobile devices by encouraging mobile users to load part of their local datasets onto the edge server. In this post, we suggest a FL model with machine learning capabilities to deal with the interaction between the output, total time and energy use of mobile devices in the training model. Because of the links between the offloading decision and resource management, the common learning model and resort management dilemma are difficult [16]. The energy deficiency of mobile users is taken into account in local computing resource utilization, where mobile users have a modest computing capability and rational privacy issues.
We suggest a resource management approach based on the neural structural knowledge that enables mobile customers to be allocated various sub-networks of the global model based on their local position. Our solution provides an elastic educational platform for emergent apps like edge technologies and internet of Things, with customers having minimal computation, space, power and data services. So, this article highlights the main contributions as follows:
1) We give an outline of the basics of FL and edge computing and suggest a new model for edge networks. 2) The technological problems within the suggested solution, including costs of communication, distribution of resources, opportunity learning, security and preservation of privacy, are identified and discussed. 3) We introduced a proximal optimization strategy, an asynchronous architecture and the best aggregation strategy for multiple employee-to-work learners that allows for faster integration, even with an abridged result.
Recently, edge computing has gained more recognition. The discharge of such requests into separate edge data centers is a typical case scenario. The issue of task planning is discussed in [17] which suggest a Reinforcement Learning (RL) based plan and successfully downloaded tasks to other datacenters. Also, Distributed RL (DRL) based Virtual Machine (VM) de-loading solutions are discussed. However, computational downloads can lead to unbalanced problems, since some edge data centers may be overwhelmed in the field, while some other ones are idle. Unbalanced data centers result in loss of efficiency and waste. One solution is to extend the load evenly between the data centers with differing edges [18].
A bread-first-search solution is discussed in [19] to maintain a distribution of the residential applications equally. Edge data centers are therefore distinguished by limited capacity relative to conventional servers and the amount of programmes available for use is not maximized by a load balancing strategy. The end-user as well as the service provider has conflicting goals. The end user expects assured application efficiency, while the supplier wishes to increase its income by increasing the amount of applications serviced [15]. It is fair to characterize the ultimate goal as a consolidation challenge in order to satisfy the expectations of both end user and supplier: to place as many demands as possible, often subject to resource limitations using the minimal resources.
In order to do that, some scholars have concentrated on carrying out activities in edge data centers. Zhu et al. succeeded in implementing two approach algorithms to minimize energy consumption and to reduce the total task implementation delay [20]. The co-allocation of many applications on a same physical server will benefit from using virtual machines. A collection of proposed device positioning options in edge data centers is discussed in [21]. The optimization range from nonlinear to mixed linear programming is achieved through particle swarm optimization. However, the ability to optimally position the VM in edge data centers, which aims to minimize resource losses, seems to be lacking in solutions.
Many alternatives to federated learning for resource optimization are discussed in [22]. They aim to organize network entities and machine tools as per the evaluation of the external properties of deep learning models concerned, following the theory of conventional networking optimization. In comparison, the methods in the white box aim to explain the internal configuration and module capabilities of the deep learning models at least partly [23]. For optimum use, the engineered network entities and machine tools with the neural structure adaptation are employed. Training neural structures are an efficient way to increase the federated learning efficiency.
Training hyperparameters such as descent methods, the load scale, epochs, the rate of learning and the rate of decay are empirically tailored to minimize the number of contact rounds [24]. Furthermore, a data increase approach is often used to improve the precision of the inference. The findings show that the contact rounds of five separate model architectures and four datasets are reduced substantially by one to two orders of magnitude with these training tricks [25]. By including the federated learning hierarchical network topology, model aggregation can be performed in a multi-step client-edge cloud process, i.e., by one or two stage of local aggregations on edge servers and then a global aggregation on the central server.
Several incremental edge servers are installed well before global aggregate on the central node to conduct various local aggregations. The justification for this multi-phased consolidation is that the earlier generation aggregations on the network edge are less expensive to communicate and can effectively mitigates the unsafe model changes due to the unpredictability of local data [26]. The convergence of the global aggregation would be very fast once the central server has perfected model updates. The key concept for information distillation is the finding that an external regulator to “teach” a new algorithm could be used for a portion of the active activations, for example, the soft probability distribution based on the softmax performance and a well-trained deep learning model [27]. In reality, distillation of information is a very effective method of transfer of knowledge.
The Softmax's performance contains rich model knowledge information [28]. Inspired by this theory, decentralized learning based on information distillation shares class scores among customers and aggregates them to reach consensus on model updates. Test accuracy for all participants increases by 20%, as announced. But this strategy is sadly based heavily on an unusually large public dataset. FL has become an interested subject in wireless resource management. The latency of communications on wireless networks are examined in [29] for decentralized learning, where each node would communicate with its own neighbours.
The optimization template proposed in [30] for FL via wireless networks, where power allocation, local computer resource and model accuracy is jointly optimized for the energy and time usage. FL across wireless networks is being examined where the authors addressed mutual optimization of model testing and the distribution of wireless resources. In the case of cooperative planning and distribution of resource blocks in order to reduce the lack of FL precision, chain incertitude is assumed [31]. By choosing smartphone users who participate in FL, costs and learning losses are collectively reduced. The data sample used for model training can be determined by the chosen users [32]. There is a two-step FL aggregation in which an intermediary model aggregation will take place on the edge server with the overall statistical accumulation on the cloud server.
In previous works, the popular optimization of radio and computer resource management in MEC was carefully studied. A two-stage algorithm is introduced in [33] for the distribution of radio and computer resources which optimizes the overall processing time. A multi-cell MEC [34] is considered where the radio and computer services are jointly optimized to save mobile users’ energy usage where the mission offloading latency is taken into account. In order to meet the reliability of the queues in tasks of offloading and resource allocation, the queueing pattern for resource allocation is analyzed. Generalized Nash Equilibrium Protocol (GNEP) is a fruitful technique to address the strong combination of optimization problem in allocation of resources problems, where players are relying on one another both on goal and strategy sets.
The attributes, existence, and solution algorithms of the general Nash equilibrium are examined. GNEP proposes the multi-cloud system model between many service providers for service provisioning problem [35]. The offloading decision proposes the GNEP for the MEC job download, which minimizes the overall time usage. The popular management of the radio and the computational resources of MEC have been formulated by the authors, as a GNEP, to identify a Generalized Nash Equilibrium (GNE) dependent resource algorithm based on penalties. Blockchain has the special properties that enhance the FL safety of edge networks. In particular, the decentralized blockchain allow the removal of the need for a FL training central server [36]. Rather, a shared, immutable booklet is used to add the global model and deliver global updates to customers for direct computation.
The decentralization of model amplification not only alleviates the possibility of single-point failure for better training efficiency but also lowers the burden of global model aggregation on the central server, particularly as edge networks have multiple customers. The learning changes are added to unchangeable blocks during the preparation, which ensure high protection for training against external threats [37]. The duplication of blocks across the network also helps all customers to check and monitor the success of the training so that the FL chain mechanism can have high confidence and accountability [38]. In addition, removing a central server for the aggregation of the FL chain model would theoretically ease connectivity costs and draw more smartphone users in their data training based on the clustered topology of their network.
In this paper, a Single Cell Edge Computing (SCEC) framework is designed where an edge processor is deployed simultaneously with mobile devices on an access point for training a statistical model. Through downloading part of the datasets to the network edge for training purposes, the energy demand for model training on the smartphone users can be reduced. The computer resources used for local training are controlled to reduce the lack of work outcomes and the time spent on the model training depending on the energy level of the smartphone users. The cell users decide the data loading and computing resources allotted, while the edge server manages the management of the radio resources for the loading and weight transmitting of the datasets.
In addition, this article takes into account the synchronous FL upgrade model. Mobile devices in FL practice the learning algorithm with mobile data sets and send the model weights to the network edge on the standard FL method. Mobile devices concurrently discharge a portion of their data sets to the edge server in our proposed MEC enabled FL platform and train the rest of their local model. After the edge server receives all the unloaded data sets, the edge implementation is carried out. After the edge training and weight transfer of all cell devices the model aggregation is carried out. In this section, we suggest a module-based approach that divides the global model into many training subs models.
Multiple customers may work out an identical sub models together or train different sub models separately with local resources with a model partition. This new federated learning architecture has simultaneously combined two parallel data parallelism computation patterns and model parallelism in terms of distributed training. The services of mobile customers could then be effectively coordinated to complete the sub model instruction. The balancing of the use of local storage in customers during model training is important. The main server can swap filter blocks annually between sub-models so that all filters in the global model are trained similarly by all customers. This sub model interchange should be carried out in order to use local data equally, while preserving the cross-cutting relationships of sub models. The proposed SCEC framework is shown in Fig. 2.

Figure 2: Proposed SCEC framework
The central server can reassemble all the sub-models and rebuild the global architecture for model aggregation. Notice that many versions of the model based can be separated and trained simultaneously. The global model copies can be separated and conditioned by various customers in many ways. The number of global model copies defines multiplexing component. When the global model is aggregated, the central server reconstructs first all versions of the global model and then aggregates gradients within copies. The aggregation of model gradients is commensurate with the dimensions of the local data sets, as is the norm in standard, federated education. Clients can report gradients to the centralized computer in every round of the iteration of federated learning. The more precise the gradients registered, the better the efficiency of learning.
We suggest the idea of aggregate gradient knowledge to show the learning efficiency of a particular neural system model. From an information-theoretical point of view, we regard federated learning training as a method to reduce the ambiguity about the optimum model parameters progressively. We are looking to determine the optimum X^* weight with the lowest loss function value. The model gradient may be used as a test of the variance of the optimum X^* in any round of iteration. The bigger the absolute value of the gradient, the greater the incertitude.
In general, the absolute value of the gradient decreases about and finally reaches zero at X^*. The greater the power of the neural network, the greater the gradient and the more knowledge it holds. It is defined in Eq. (1).
This also represents the precision of the gradient during the model training for the parameter change. For a particular learning challenge like federated health analytics on edge networks, a group of servers are initialized with its related computers. Each server devotes its resources as a learning client to blockchain consensus or mining, and mobile devices enter the FL process to run training algorithms. Each training node uses its own data to create a local model and then transfers the local model via blockchain to its associated server. The servers gather transactions from their customers and then save them in a certain time frame in accordance with a given data structure in Eq. (2) like a Merkle tree.
A special hash value, a time stamp and a sequence number are used to identify each block to avoid unwanted recreations of the block. The servers then engage in the refining process to check the latest block and reach a consensus between all servers. A server can be selected to function as a mining manager in its own time slot. Notice that computers often participate as complete or partial nodes for additional gains in mining blocks. After mining, the blockchain will be completed and sent via server node communications to all local computers. Now, modifications of the local model are safely saved on the blockchain. The block containing all local updates from other devices is loaded by local devices. This allows individual devices, based on an existing model consisted rule such as a weighted total rule, and an error-based regression rule, to calculate the Global Model directly on the local instrument. Fig. 3 shows the data mapping model.

Figure 3: Data mapping model
In other words, rather than in a central server, as in the conventional FL architecture, the global model is calculated locally. The teaching is iterated up to the global weight vector or to obtain the optimal precision. The teaching scenarios can't be entirely deterministic during the training. For instance, customers may provide different image data sets of different pixel resolution in federated on line image classification tasks that can also be continuously modified across sensor environments. Whereas the selling price of a payment must be exclusive to the material, transaction stored in blockchain includes exact content. Because of this, it is a crucial question how to achieve synchronisation between training and blockchain storage. A potential approach is to build adaptive frameworks in the formulation of data block hash, which will help to achieve a robust and efficient blockchain storage and function, for different training example, in the model exchange of continuous reconfiguration of its running hash specifications. A multiplexer is a device that takes multiple analog signals and forwards the selected input into a single line. These devices are used to increase the amount of data that can be transmitted over a network.
The best strategy can be learned through diverse ways. The political algorithms learn the strategy without an intermediate function explicitly, as the name implies. The policy α-function
where Δ is an episode, this means a series of states and actions, i.e., a predefined order of requests and their corresponding position in the edge data centre; It is the strong level of variance which prevents convergence into an optimal strategy. Role of advantage in the φ used in the feature gradient tends to reduce this variation. The benefit feature measures how well an action is relative to an ordinary action within a particular state without getting through the particulars in depth.
The agent specializes in edge data centers which use virtual machinery to position applications as an abstraction layer. It uses policy gradient enhancement to understand and respond to various arrival models of VM requests and complex use of resources. By combining this with the asynchronous design, the optimum positioning guidelines can be easily found, which squeeze the greatest output out of lower edge data centre ability. The first move was to devise the Edge computing environment for an RL-based agent. Any or more boundary cloud services consisting of n physical servers are scenarios. Any physical server has a certain resource capability, n. The agent must learn the α best strategy, represented as a VM form with unique resource needs, which fits each incoming request with the best available physical server. The general objective is to increase the number of applications that can be completed in view of the existing capabilities. In this respect, the issue of resource management at edge data centers can be described in Eq. (5) as a Markov Decision Process.
The main purpose of the edge data centre is to increase the number of requests with the bandwidth available. With this aim in mind, the reward function
For data transfer, i.e., for data downloading and weight transmission, we consider the Manifold Admittance extraneous frequency division. Contingent on their channel state and energy level, the size of the unpacked data set is same for all mobile devices. The size of the unpacked weight vectors is the same. Thus, the uplink radio resource control is carried out twice for download and uploading of weight. The two signals are not conducted at the same time. For data set downloading, the bandwidth fraction
The global model's performance depends on not just the local data collection, but also on the computer tools used during local training. A local user j model is formed by upgrading the weight in several iterations based on stochastic gradient approach. By stopping the training after several hours, Uj could save his energy consumption. Users will unload a portion of their data set from the edge server in order to maintain efficiency of the final global model and energy usage. The final product aggregation takes place after the model training is finished on the edge server and the weight transmission from the smartphone users is completed. This segment presents the energy-conscious resource management dilemma for the proposed FL, whereby the lack of preparation and time in one contact is reduced in conjunction with the energy level.
Edge computing transactions can be coordinated by generating and verifying fine-grained timestamp values across distributed computing devices inside an edge computing system. Transaction data, a timestamp, and a timestamp signature for a transaction are all obtained by an edge computing device in an edge computing system, with the timestamp generated from a secure timestamp procedure that is coordinated with another entity, including via a network-coordinated timestamp synchronisation. Using the timestamp signature and the transaction data, the device verifies this timestamp, and the transaction is either completed at the device or elsewhere in the system, depending on the outcome of this validation process. The coordinated timestamp may also be used for additional purposes and verifications of timestamp values, such as multi-version concurrency control transactions and Blockchain transaction verification.
The likelihood of a random sample is governed by user preferences for material. The chance that the user uses content can be defined in Eqs. (8) and (9),
In this section, the FL is devised as energy-conscious resource management challenge, where the lack of training and time usage is jointly reduced when taking into account the amount of energy available from mobile devices. In the proposed SCEC framework, it is essential to minimize the time required for a round of contact because the time needed to offload the dataset affect the overall time consumption considerably higher than the standard FL model. The entire time required for a contact round is described as follows, because both the edge server and the mobile user j is involved in model training for the efficient FL model in Eq. (10):
Due to nonconvexity and close connection between decision variables, the formulated energy-aware resource management dilemma is difficult to resolve. Therefore, we first disentangle the formulated problem from user j into the problem of data loading and computation management. Then, for edge server uplink management and the user j downloading data package, the proposed SCEC framework model is devised to explore the coupling in its goal feature and strategy setting. The energy-aware control algorithm for the resource management is presented in which model training and resource management issues are alternatively disconnected on edge servers and smartphone devices. The edge server radio resource management issue with the aim of minimizing overall time usage, while ensuring that the energy limit of mobile devices is set as follows in Eq. (11):
Therefore, the optimum distribution of the computational resources by the j customer depends not just on their energy level but also on the volume of data set used in the uplink transmissions for local training and energy usage. If the residual energy of the mobile consumer j, is small or the overall power usage of unlinking transmissions is high, the computer resources employed in the local model training xj would be less. In addition, less computational power can be used for model training to ensure the energy cap of mobile device j, if the volume of data set used for model training is high. In neural network training, the learning rate is an adjustable hyper-parameter with a modest positive value, usually between 0.0 and 1.0. Changing the learning rate affects how quickly a model is adjusted to a new situation.
Mobile users are supposed to satisfy their energy limitations by managing mobile apps’ computing resources. Therefore, from the download and connection resource management issue, we eradicate the energy restriction constraints of mobile devices. The energy limitations of mobile devices indicated by the simulation results may, however, be satisfied by our proposed SCEC framework. For the joint learning, data set, download, computation and uplink resource management of the proposed SCEC framework, the energy-aware resource management algorithm is proposed. Firstly, you choose the average state for the distribution of Lagrange multipliers, data collection, and computer system and resource uplink. The Lagrange multipliers, the downloading, computing and uplink assignment of resources will then be modified. The edge server and users also conduct the training model and upgrade weights. As the best solution approach is implemented by both smartphone users and the edge server, the proposed SCEC framework converges on the stations. Also, we have estimated the loss function using Eq. (12):
The above Eq. (12) estimates the model loss function of this approach for training using the energy efficient edge approach with the sample dataset E. It is common for DL jobs to be computationally expensive and need substantial amounts of memory. Despite this, large-scale DL models cannot be supported in the edge due to lack of resources. It is possible to save resources by adjusting the weights of DL models and optimizing their parameters. The most pressing issue is how to ensure that the model's accuracy is not significantly reduced following optimization. An effective optimization strategy is one that transforms and adapts data layer models to fit on edge devices with the least amount of model performance degradation. To keep track of the times of a gradient coordinate participating in gradient synchronization, hidden weights are kept. Gradient coordinates with a big hidden weight value are regarded important gradients and are more likely to be picked for the next round of training in subsequent rounds.
A possible study area for 5G networks; edge cloud computing aims to improve network efficiency by utilizing the power of cloud computing and mobile devices in the user's immediate vicinity. For future generations of mobile devices, Edge cloud computing will have a profound impact on network performance and migration overheads, so a comprehensive review of the current Edge Cloud Computing frameworks and approaches is presented, with a detailed comparison of its classifications through various QoS metrics (relevant to network performance and migration overheads). The study gives a complete review of the state-of-the-art and future research prospects for multi-access mobile edge computing, taking into account the information acquired, techniques assessed and theories addressed.
In the study, the federated learning scenario for image recognition tasks on an MNIST data set [39] is considered with 64 mobile customers. 60,000 of them were used in preparation and other processing for the 70,000 specimens in the MNIST dataset. Customers are assigned the training data in two different ways. We mix and randomly split the data for the Independently and Identically Distributed (IID) environment for all customers with 937 specimens. We process the data by labeling for non-IID configurations; divide them into 320 screens with 5 screens for each client. The global convolution neural network model in the experiment has the arrangement with partitioning factors respectively for the coevolutionary layers.
A virtual world of the edge data centre consists of several uniform physical servers. The Processor, storage, network and disc specifications of each physical and VM request are specified. The specified resource is normalized to 0–1 for the input of the model. In specific, 15 VM forms allocated to a computer with an id 0 are rooted in real-world records from Microsoft Azure data centre. Both algorithms are implemented by Tensorflow v2.5.0 and the models are conditioned on a GPU. The experimental hardware includes an Intel core i5, 16 GB RAM computer, NVIDIA GeForce MX330. For model training and aggregation, we consider a single-cell macrobase station used with an edge node. Fig. 4a shows the learning rate and Fig. 4b shows the performance of learning model.

Figure 4: (a) Learning rate (b) Performance of learning model
For model testing where logistical regression is carried out on 50 smartphone users, the MINIST dataset is used. The data samples in the entire data set are randomly mixed and distributed among users with around 4000 data samples for each user. The cell users’ energy cap is regarded as a uniform allocation. We equate the conventional FL and proposed MEC-controlled FL where the edge testing dataset is not permitted to be downloaded in the conventional FL, which uses all sequence data in the training dataset. In the statistics the loss value is the loss test on the measurement result. Fig. 5a shows the training accuracy. The preliminary points for the offloading and computational resource allotment of the datasets are selected arbitrarily for the planned energy-aware resource management algorithm while the even allocation is done on uplink bandwidth resources. The uniform distribution is used for uplink bandwidth resource control in order to equate conventional and proposed SCEC framework with respect to the size of the unloaded dataset and processing resource. Fig. 5b shows a comparison of the standard and proposed SCEC framework with the scale of the offloaded data set with the failure and overall period. Since the data set cannot be discharged in the standard FL, the loss and overall time consumption is unchanged over the whole scale of the discharged data set.

Figure 5: (a) Training accuracy (b) Learning model comparison
By downloading part of the local dataset in which the edge server carries out model training on all local data sets downloaded from the user, the proposed SCEC framework would achieve the best model results. When the fragment of the downloaded data is zero, the suggested FL is the same as the standard FL, which ensures that smartphone users have any dataset for their local training. If the percentage becomes 1, the proposed SCEC framework is identical to a core model testing, where all local data sets are used for edge server model training.
The overall time usage of the proposed model exceeds standard FL, since the users must upload the local datasets to the edge server; however, the decent management of resources will reduce it. With more computer tools for the preparation of the local model, losses and time usage are reduced. However, with the redistribution of computer resources, the energy demand of the mobile device would increase. With respect to the volume of the offloaded data set, the loss and energy decrease with the scale of the offloaded data set increasing as model training energy usage is significantly higher than the energy consumption of transmissions. But owing to the time required to download the dataset, the overall time usage is raised in respect of the downloaded data collection. The cell-centre user takes much less time than cell-edge user. The time needed is far less. The cell-edge consumer has a high effect on the overall time usage as the synchronous updating is used for the model aggregation. Time required for the cell-center and cell edge users to train locally and edge. Fig. 6a shows the learning curve of proposed SCEC framework and Fig. 6b shows the loss function comparison.

Figure 6: (a) Learning curve of proposed SCEC framework (b) Loss function comparison
During the offloaded data scale, the time for local training is lower than for the edge training. Because of the bad state of the channel the user of the cellular edge takes more time to load the data set than the user of the cell core. The decent use of resources is also necessary to reduce the overall time use. The TLF in both high and low power modes is observed in our MFL. MFL has between 43% and 30% energy savings on IID as well as non-IID data to achieve test accuracy of 96% in low power mode relative to TFL. In high voltage, MFL's power saving benefits for both IID as well as non-IID data amount to approximately 37% and 22%. Meanwhile, MFL takes far less time than TFL to achieve the test exactness of 96% as a result of convergence times. We suggest wireless communication virtualization to serve a variety of IoT-enabled devices with varying needs and robustness by creating a variety of mobile virtual network operators (MVN). To maximise RF spectrum use, improve coverage, boost network capacity, promote energy efficiency and offer security wireless virtualization is an emerging paradigm. We've presented a Blockchain based strategy to deliver quality-of-service to consumers in order to avoid double-spending by allocating the same frequency to various wireless resource network providers. IoT is predicted to create a tremendous quantity of data, thus we consider edge computing to process large amounts of data when individual devices possess limited computational and storage capabilities Fig. 7a shows the training accuracy and Fig. 7b shows energy consumption comparison.

Figure 7: (a) Training accuracy (b) Energy consumption comparison
For IID and non-IID in low power modes, the convergence period for MFL is 33% and 18% lower than for TFL and for IID as well as non-IID data in high power mode, respectively, is approximately 33% and 17%. The findings of the experiment are seen in a decaying channel state. In this scenario, the customers are expected to fail to recover the gradients in each round with a 20% chance. We see that MFL continues to work satisfactorily. This shows that MFL is effective in wireless complex communications settings. The round robin algorithm is implicit in this and attempts to distribute the load over multiple nodes. This inevitably leads to fragmentation of resources which restricts the level of resources which can be put in a data centre. RL-based agents, on the other hand, learn easily a strategy to optimize the use of the resources. In comparison to the heuristic agent, 89% and 91% are achieved by state-of-the-art baseline processes, namely PPO and PG. With its parallel architecture, 94% of the 2000 VM demands in the same edge data centre will explore further scenarios in a short time and thus train the policies to get the best placement rate. Fig. 8a shows the accuracy comparison and Fig. 8b shows the parameter ratio comparison.
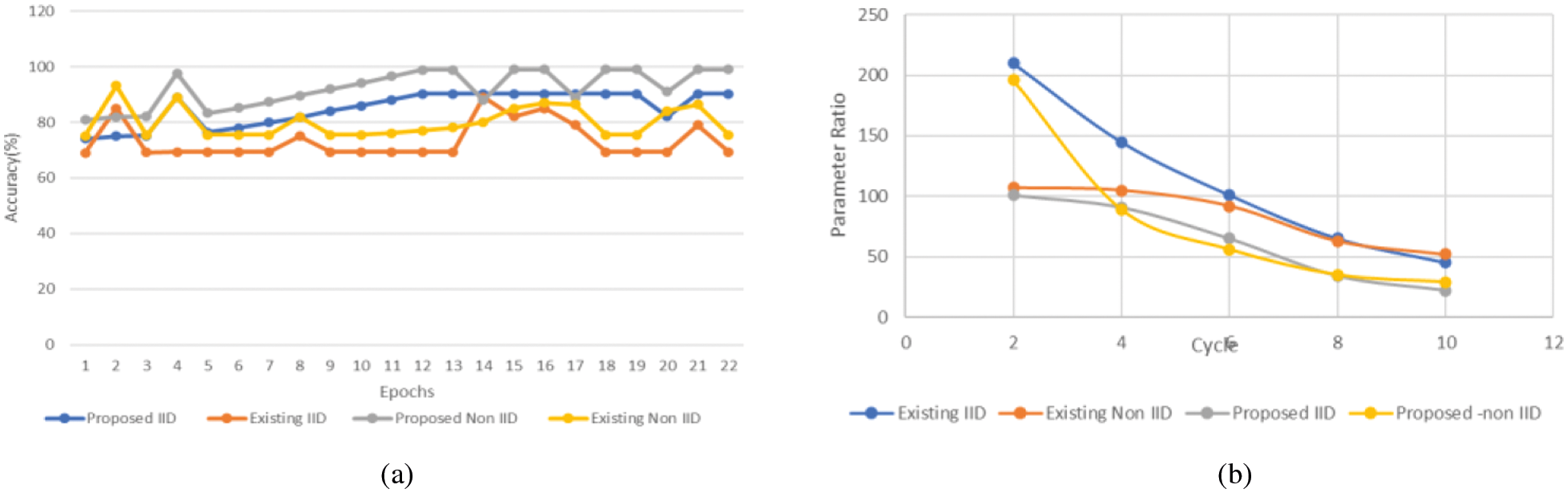
Figure 8: (a) Accuracy comparison (b) Parameters ratio comparison
Because of the cell-edge user's bad channel conditions, fewer local dataset becomes outsourced to the edge server and more uplink is needed to download the dataset than the mobile phone user so that overall time usage is reduced. Such as the uplink resource allotment for the data collection of offloading, for weight transfer the cell-edge user has a greater uplink bandwidth to cut the overall time usage than the cell-center user. Since the cellular consumer discharges a tiny subset of its specific datasets into the edge server, more computer resources than those of the mobile phone user are needed for local training. The bigger the R-ranking, the greater the energy consumption of communication and computing; this is because the model parameter size grows with the R-ranking. It is also evident that the energy usage is substantially bigger for communication than for computing. Thanks to its great compression efficiency, our Model can also achieve lower transmission energy consumption than previous tensor decomposition techniques. Meanwhile, the method that is suggested uses computer energy, which shows that our technique can minimize power consumption without creating new computer complexity, is similar to that of the other ways. This phenomenon is that, rather than regular communication with other edge nodes, the edge node may learn by itself the characteristic of the complete dataset when it is distributed equally and randomly at each edge node. The proposed SCEC framework is not focusing on data dimensionality reduction that increases the response time of the algorithm. This can be improved in the future.
In this paper, we suggest optimal control of resources for machine-based FL learning in edge computing framework. In particular, smartphone users will download part of their local dataset to the cloud, thus dealing with the volumes of information used for local training seen between learning model's output and the energy usage on the user's computer. In this regard, an energy-sensitive challenge in resource management is conceived in order to minimize the lack of preparation and time usage when meeting the energy restrictions of the device. Due to the connection between the decision variables, the problem formulated is disconnected into many subproblems. Therefore, the approach for the maintenance of computer resources is extracted from ensuring smartphone users’ energy budget. In theory we endorse the model division in terms of distance, depth and kernel size in our learning environment. In the future research the approach to resources management of systems of sub-models, both modular in width, depth and kernel size will be of interest to be explored further. Deep learning should be used to find the best configuration of resources adaptively.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. N. Abbas, Y. Zhang, A. Taherkordi and T. Skeie, “Mobile edge computing: A survey,” IEEE Internet of Things Journal, vol. 5, no. 1, pp. 450–465, 2017. [Google Scholar]
2. A. Abeshu and N. Chilamkurti, “Deep learning: The frontier for distributed attack detection in fog-to-things computing,” IEEE Communications Magazine, vol. 56, no. 2, pp. 169–175, 2017. [Google Scholar]
3. M. Chen and Y. Hao, “Label-less learning for emotion cognition,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 7, pp. 1–11, 2019. [Google Scholar]
4. Y. Chen, X. Sun and Y. Jin, “Communication-efficient federated deep learning with layerwise asynchronous model update and temporally weighted aggregation,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 10, pp. 4229–4238, 2019. [Google Scholar]
5. M. Chen, H. V. Poor, W. Saad and S. Cui, “Convergence time optimization for federated learning over wireless networks,” IEEE Transactions on Wireless Communications, vol. 20, no. 4, pp. 2457–2471, 2020. [Google Scholar]
6. C. Chen, H. Xiang, T. Qiu, C. Wang, Y. Zhou et al., “A rear-end collision prediction scheme based on deep learning in the internet of vehicles,” Journal of Parallel and Distributed Computing, vol. 117, pp. 192–204, 2018. [Google Scholar]
7. C. Feng, Y. Wang, Z. Zhao, T. Q. Quek, M. Peng et al., “Joint optimization of data sampling and user selection for federated learning in the mobile edge computing systems,” in IEEE Int. Conf. on Communications Workshops, Dublin, Ireland, pp. 1–6, 2020. [Google Scholar]
8. T. Fu, P. Liu, K. Liu and P. Li, “Privacy-preserving vehicle assignment in the parking space sharing system,” Wireless Communications and Mobile Computing, vol. 2020, pp. 1–13, 2020. [Google Scholar]
9. A. Hard, K. Rao, R. Mathews, S. Ramaswamy, F. Beaufays et al., “Federated learning for mobile keyboard prediction,” arXiv preprint arXiv:1811.03604, pp. 1–7, 2018. [Google Scholar]
10. G. Hou, S. Feng, S. Qin and W. Jiang, “Proactive content caching by exploiting transfer learning for mobile edge computing,” International Journal of Communication Systems, vol. 31, no. 11, pp. 1–13, 2018. [Google Scholar]
11. E. Jeong, S. Oh, J. Park, H. Kim, M. Bennis et al., “Multi-hop federated private data augmentation with sample compression,” arXiv preprint arXiv:1907.06426, pp. 1–8, 2019. [Google Scholar]
12. M. Jindal, J. Gupta and B. Bhushan, “Machine learning methods for IoT and their future applications,” in Int. Conf. on Computing, Communication, and Intelligent Systems, Greater Noida, India, pp. 430–434, 2019. [Google Scholar]
13. J. Konečný, H. B. McMahan, F. X. Yu, P. Richtárik, A. T. Suresh et al., “Federated learning: Strategies for improving communication efficiency,” arXiv preprint arXiv:1610.05492, pp. 1–10, 2016. [Google Scholar]
14. P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis et al., “Advances and open problems in federated learning,” arXiv preprint arXiv:1912.04977, pp. 1–121, 2019. [Google Scholar]
15. W. Y. Lim, N. C. Luong, D. T. Hoang, Y. Jiao, Y. C. Liang et al., “Federated learning in mobile edge networks: A comprehensive survey,” IEEE Communications Surveys & Tutorials, vol. 22, no. 3, pp. 2031–2063, 2020. [Google Scholar]
16. D. Li and J. Wang, “Fedmd: Heterogenous federated learning via model distillation,” arXiv preprint arXiv:1910.03581, pp. 1–8, 2019. [Google Scholar]
17. L. Liu, J. Zhang, S. H. Song and K. B. Letaief, “Client-edge-cloud hierarchical federated learning,” in IEEE Int. Conf. on Communications, Dublin, Ireland, pp. 1–6, 2020. [Google Scholar]
18. T. Li, A. K. Sahu, A. Talwalkar and V. Smith, “Federated learning: Challenges, methods, and future directions,” IEEE Signal Processing Magazine, vol. 37, no. 3, pp. 50–60, 2020. [Google Scholar]
19. Q. Li, X. Wang and D. Wang, “Optimal D2D cooperative caching system in SDN based wireless network,” in Annual Int. Symp. on Personal, Indoor and Mobile Radio Communications, Istanbul, Turkey, pp. 1–7, 2019. [Google Scholar]
20. P. Mach and Z. Becvar, “Mobile edge computing: A survey on architecture and computation offloading,” IEEE Communications Surveys & Tutorials, vol. 19, no. 3, pp. 1628–1656, 2017. [Google Scholar]
21. M. M. Wadu, S. Samarakoon and M. Bennis, “Federated learning under channel uncertainty: Joint client scheduling and resource allocation,” in IEEE Wireless Communications and Networking Conf., Seoul, South Korea, pp. 1–6, 2020. [Google Scholar]
22. S. Mehrizi, S. Chatterjee, S. Chatzinotas and B. Ottersten, “Online spatiotemporal popularity learning via variational bayes for cooperative caching,” IEEE Transactions on Communications, vol. 68, no. 11, pp. 7068–7082, 2020. [Google Scholar]
23. S. Niknam, H. S. Dhillon and J. H. Reed, “Federated learning for wireless communications: Motivation, opportunities, and challenges,” IEEE Communications Magazine, vol. 58, no. 6, pp. 46–51, 2020. [Google Scholar]
24. T. Nishio and R. Yonetani, “Client selection for federated learning with heterogeneous resources in mobile edge,” in IEEE Int. Conf. on Communications, Shanghai, China, pp. 1–7, 2019. [Google Scholar]
25. N. Naderializadeh, “On the communication latency of wireless decentralized learning,” arXiv preprint arXiv:2002.04069, pp. 1–7, 2020. [Google Scholar]
26. S. R. Pandey, N. H. Tran, M. Bennis, Y. K. Tun, A. Manzoor et al., “A crowdsourcing framework for on-device federated learning,” IEEE Transactions on Wireless Communications, vol. 19, no. 5, pp. 3241–3256, 2020. [Google Scholar]
27. S. Murugan, T. R. Ganesh Babu and C. Srinivasan, “Underwater object recognition using KNN classifier,” International Journal of MC Square Scientific Research, vol. 9, no. 3, pp. 48–52, 2017. [Google Scholar]
28. G. Prakash, V. Bhaskar and K. Venkata Reddy, “Secure & efficient audit service outsourcing for data integrity in clouds,” International Journal of MC Square Scientific Research, vol. 6, no. 1, pp. 5–60, 2014. [Google Scholar]
29. Y. E. Sagduyu, Y. Shi and T. Erpek, “IoT network security from the perspective of adversarial deep learning,” in 16th Annual IEEE Int. Conf. on Sensing, Communication, and Networking, Boston, MA, USA, pp. 1–9, 2019. [Google Scholar]
30. M. Salimitari, M. Joneidi and M. Chatterjee, “Ai-enabled blockchain: An outlier-aware consensus protocol for blockchain-based IoT networks,” in IEEE Global Communications Conf., Waikoloa, HI, USA, pp. 1–6, 2019. [Google Scholar]
31. S. Samarakoon, M. Bennis, W. Saad and M. Debbah, “Federated learning for ultra-reliable low-latency V2V communications,” in IEEE Global Communications Conf., Abu Dhabi, United Arab Emirates, pp. 1–7, 2018. [Google Scholar]
32. A. S. Sohal, R. Sandhu, S. K. Sood and V. Chang, “A cyber security framework to identify malicious edge device in fog computing and cloud-of-things environments,” Computers & Security, vol. 74, pp. 340–54, 2018. [Google Scholar]
33. T. Taleb, K. Samdanis, B. Mada, H. Flinck, S. Dutta et al., “On multi-access edge computing: A survey of the emerging 5G network edge cloud architecture and orchestration,” IEEE Communications Surveys & Tutorials, vol. 19, no. 3, pp. 1657–1681, 2017. [Google Scholar]
34. N. H. Tran, W. Bao, A. Zomaya, M. N. Nguyen, C. S. Hong et al., “Federated learning over wireless networks: optimization model design and analysis,” in IEEE Conf. on Computer Communications, Paris, France, pp. 1387–1395, 2019. [Google Scholar]
35. Z. Yang, M. Chen, W. Saad, C. S. Hong, M. Shikh-Bahaei et al., “Energy efficient federated learning over wireless communication networks,” IEEE Transactions on Wireless Communications, vol. 20, no. 3, pp. 1935–1949, 2020. [Google Scholar]
36. X. Yao, T. Huang, C. Wu, R. Zhang, L. Sun et al., “Towards faster and better federated learning: a feature fusion approach,” in IEEE Int. Conf. on Image Processing, Taipei, Taiwan, pp. 175–179, 2019. [Google Scholar]
37. S. Yang, S. Fan, G. Deng and H. Tian, “Local content cloud based cooperative caching placement for edge caching,” in IEEE 30th Annual Int. Symp. on Personal, Indoor and Mobile Radio Communications, Istanbul, Turkey, pp. 1–6, 2019. [Google Scholar]
38. N. Yoshida, T. Nishio, M. Morikura, K. Yamamoto, R. Yonetani et al., “Hybrid-FL for wireless networks: cooperative learning mechanism using non-IID data,” in IEEE Int. Conf. on Communications, Dublin, Ireland, pp. 1–7, 2020. [Google Scholar]
39. MNIST Database: https://www.tensorflow.org/datasets/catalog/mnist. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |