DOI:10.32604/csse.2023.023490
| Computer Systems Science & Engineering DOI:10.32604/csse.2023.023490 | |
| Article |
Process Discovery and Refinement of an Enterprise Management System
1COMSATS University Islamabad, Lahore, 54000, Pakistan
2Sunaree University of Technology, Nakhon Ratchasima, 30000, Thailand
*Corresponding Author: Chitapong Wechtaisong. Email: chitapong@g.sut.ac.th
Received: 10 September 2021; Accepted: 20 October 2021
Abstract: The need for the analysis of modern businesses is rapidly increasing as the supporting enterprise systems generate more and more data. This data can be extremely valuable for executing organizations because the data allows constant monitoring, analyzing, and improving the underlying processes, which leads to the reduction of cost and the improvement of the quality. Process mining is a useful technique for analyzing enterprise systems by using an event log that contains behaviours. This research focuses on the process discovery and refinement using real-life event log data collected from a large multinational organization that deals with coatings and paints. By investigating and analyzing their order handling processes, this study aims at learning a model that gives insight inspection of the processes and performance analysis. Furthermore, the animation is also performed for the better inspection, diagnostics, and compliance-related questions to specify the system. The configuration of the system and the conformance checking for further enhancement is also addressed in this research. To achieve the objectives, this research uses process mining techniques, i.e. process discovery in the form of formal Petri nets models with the help of process maps, and process refinement through conformance checking and enhancement. Initially, the identified executed process is reconstructed by using the process discovery techniques. Following the reconstruction, we perform a deep analysis for the underlying process to ensure the process improvement and redesigning. Finally, some recommendations are made to improve the enterprise management system processes.
Keywords: Process mining; enterprise management system; business process management; process discovery; conformance analysis; process enhancement
Mostly, the available data in the digital world is unstructured, and the information systems face many problems due to the huge amount of the unstructured data. The main challenge that today’s organizations face is the extraction of valuable information from such huge amount of data. Nowadays, business processes are becoming increasingly complex in terms of structure and case volume. Due to the digitalization of processes in a rapid way, nowadays, there are terabytes of collected process data available, typically in the form of event logs. This data can be extremely valuable for executing organizations, as it allows constant monitoring, analyzing, and improving the underlying processes along with enabling the reduction of cost and the quality improvement. Process Mining provides the ways to conquer this complexity. It utilizes the event log data information for discovering process models, checking their compliance issues, investigating potential bottlenecks, and proposing improvements.
In [1], the authors point out the process mining as one of the hot topics in business process management. Business process management, referred to as operational business processes, is applied by usinsg the concepts of information technology and management sciences [2]. The analysis of the related disciplines confirms that process mining sits between data science and the process-driven knowledge [3] by stating that process mining is the connection between data sciences and the model-based BPM. It uses and adapts data-science, e.g., by making data mining techniques process-centric, and it builds on new concepts, such as the business process intelligence by extending proven process-science approaches. However, the current theory does not make a clear statement about whether process mining should be considered as a stand-alone research field or as a discipline of BPM or data mining. The process mining taxonomy is illustrated in Fig. 1.
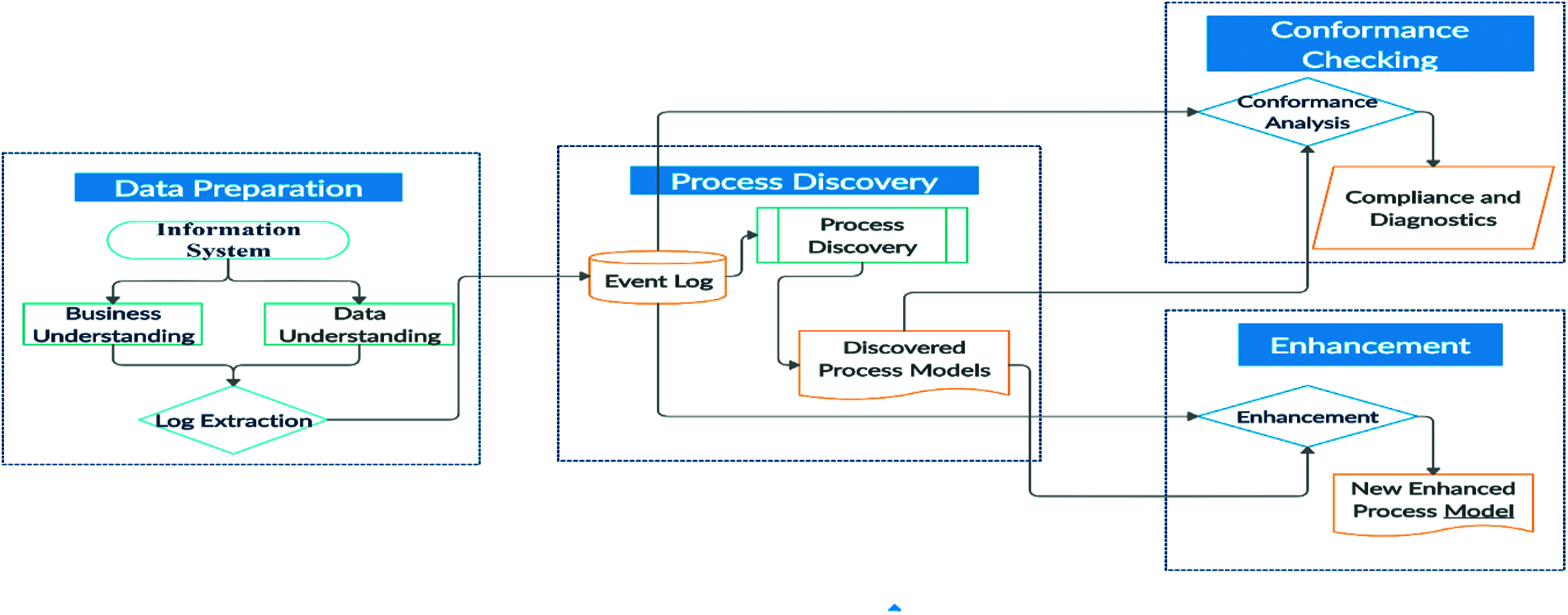
Figure 1: Taxonomy of process mining
1.2 Data Extraction and Preparation
The main objective of process mining is to extract knowledge by focusing on the process of event logs from the existing information systems [4]. Most of the recent information systems are process-aware information systems that record event log data such as enterprise systems and other systems as typical examples of such systems [5]. Following the availability and accessibility of the data, the data is extracted and transformed with the aim of using process mining methods. By considering the importance of event logs for the application of process mining, it is beneficial to know that the following three data elements are required to apply the process mining, i.e., Case ID, Timestamp and Activity.
Process discovery is the first technique of process mining methods [6]. The process mining discovery techniques, such as the α-algorithm [7], allow to automatically generate and learn a process model without a-priori information from the event data [8]. By considering the technical perspectives, the discovery of processes is the most stimulating method of the process mining.
Conformance checking techniques are the second main type of process mining techniques [9]. During this process, we find the quality of the relationship between the event data and the new process model or between the refined model and an existing process model, and it is validated by quantifying the level of conformance [10]. With the help of the validated model, the application of conformance analysis methods are used to find commonalities and deviations among the real process and the determined “tobe” process by running the event log of a process model [11].
Enhancement is a third main process mining technique. The starting point is a validated model resulted from the conformance checking [11]. Process mining enhancement aims to add additional perceptions to achieve a better process of understanding along with building a new integrated process model.
Organizations need adaptive business processes that can be adjusted with the current dynamic environment to achieve competitive advantages. Moreover, companies need to continuously enhance their proficiency and the performance of business processes [12]. The design of business processes affects both the quality and efficiency of service in terms of customer-facing processes. The design and the performance of business processes can act as a competitive differentiator when a company has the better processes compared to the companies that offer similar products or services [13].
Throughout the literature review, the challenges and limitations of process mining are identified which are crucial for the application of process mining. However, it is crucial to have a better understanding of process mining tools because these tools are extremely beneficial for understanding the derived insights during the analysis of process mining in terms of improving the process actions. The understanding of algorithms and techniques as well as the usability of process mining tools are challenging for non-experts. The dense data represented by a graphical representation can negatively impact the understandability. Process mining should not be a black box, infact it should provide insights which can easily be understandable for humans [14,15].
Process mining depends on the event log data. The data extraction and the transformation of event data is the most difficult and effortful task [16]. The continuous organizational changes, especially the increased digitization of business processes, have led to the emergence of complex and legacy information systems [17]. This is typical for information systems in big organizations where it is hard to maintain along with distributing the data among different systems [18]. Consequently, these systems complicate the extraction of meaningful data. Following the collection of data, the next step is the data pre-processing to assess the quality of the data. To derive a filtered event log, we usually require multiple iterations of data extraction, filtering, and mining [19].
Privacy, security, law, and ethics are the key ingredients to protect individuals and organizations from bad data science practices. Since event data contains sensitive data about customers or employee names, data privacy is of great importance. Process mining promises to overcome these limitations by using process-centric event log data and the process-related data mining techniques. In addition, process mining techniques promise to enhance the current laborious analysis techniques.
3 Enterprise Management System
Enterprise Management Systems [20] are getting increasingly related with the operational processes. Moreover, enterprise systems are industry-specific that customize software packages for the integration of information and business processes in organizations [21]. Enterprise management systems are defined as the bulky complex computing systems which handle huge volumes of data and enable organizations to integrate and coordinate their business processes.
The available dataset is the collection of cases from the Purchase-to-Pay process of an enterprise management system. This data is collected from the large organization that deals with coatings and paints. Furthermore, the data is collected to investigate and analyze their enterprise system that contains 1.5 million cases, which are gathered to buy orders of the enterprise management system submitted in 2018. The log has an ample range of numerous categories of goods and services, and a wide range of different kinds of merchants.
The data set is published by 4TU Centre for Research Data, and the contributor is the Eindhoven University of Technology, Department of Mathematics and Computer Science published on 2019-01-31 [22].
The collected dataset contains incorrect timestamps. These cases have the timestamps of 1948, which are out of the scope. In addition, some cases are recorded in the future dates. Although these cases are huge in numbers and most cases show regular behavior, they can impact conformance analysis results. This research uses timestamp filter to neglect these conflicting cases. Futhermore, we have considered cases from 31.12.2018 to 1.1.2019. We kept the cases within the mentioned time interval to get biased and more appropriate conformance analysis. These cases cover 86% of the overall event log and 85% events are covered in the taken time interval.
In the data analysis phase, a detailed introduction of the data set is used and discussed. It is worthy to mention that the stage of data analysis is extremely vital nowadays during the process discovery by considering the fact that the internet data traffic is exponentially increasing with every passing day [23–26]. It assists to understand the in-depth discovery of processes and their analysis. In addition, the analysis of recorded behaviour contained in the event log is briefly explained to identify processes in the event data. Finally, it is concluded by proposing a set of a process models in terms of Petri net modelling and process maps. Process discovery of the event log will help to have a better understanding of the control flow of processes and their sub-processes in a more precise way.
Business Processes that covers purchasing activities such as requesting, purchasing, receiving and paying for goods or services are referred to as purchasing processes. To complete the purchasing processes, numerous inter-related processes are performed. There are 42 activities recorded against different purchase orders performed by 627 users. To understand the processes of purchase order in an enterprise system, the basic step is to understand the process activities from the creation of purchase documents to their invoice clearance. The generalized process flow that contains maximum cases is illustrated in Fig. 2.
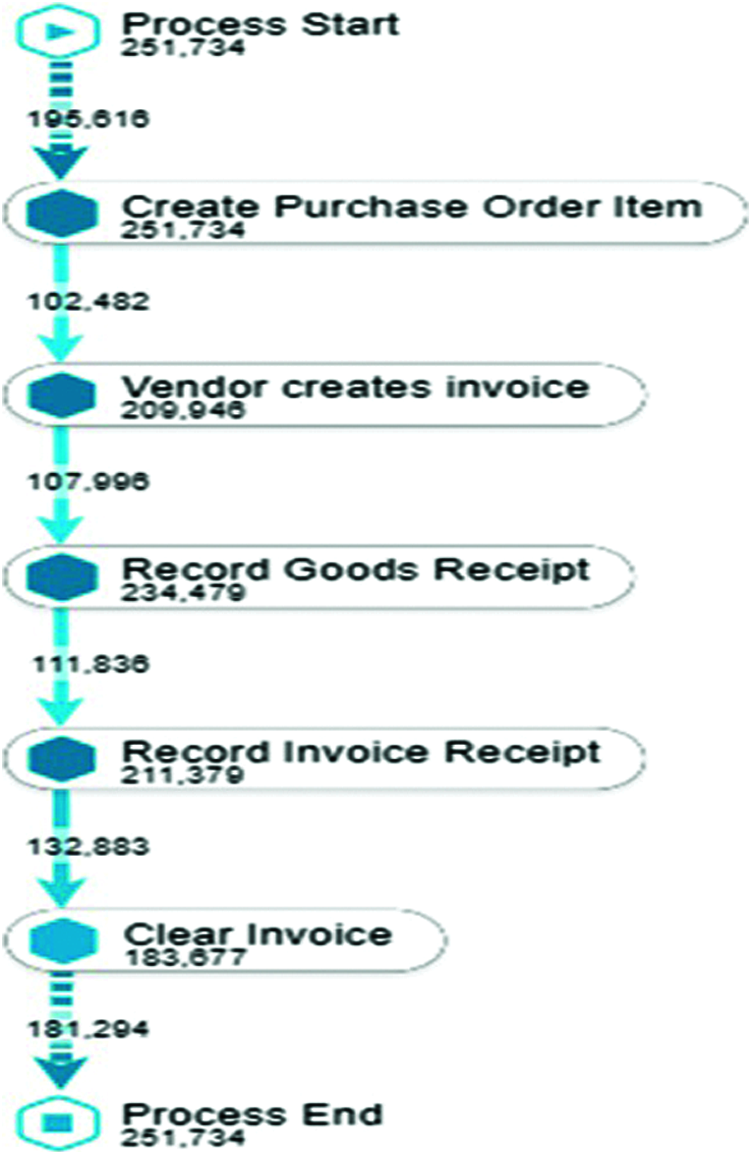
Figure 2: Generalized process flow
The goal of process discovery is to develop a process model that describes the current state of the process in a precise way [27]. Therefore, process models have become a key instrument for the management of business processes. Informal models, such as process maps, have the advantage of being easy to understand. In the context of the formal formulation of the process model, this study used Petri net models that are executabled to provide an unambiguous model of the enterprise management system.
The innovative method of process mining is to create process maps directly from the raw data. In the context of discovering process maps from the event log of the purchasing process of an enterprise management system, this research used a fuzzy miner [28] that creates insightful process maps. Furthermore, this algorithm uses the technique of “map metaphor” for the seamless process simplification and helps to highlight the frequent activities and paths [28]. The most frequent activities of the purchasing process recorded by an enterprise system are described in the Fig. 3. It also contains the frequency of traces of each frequent activity.
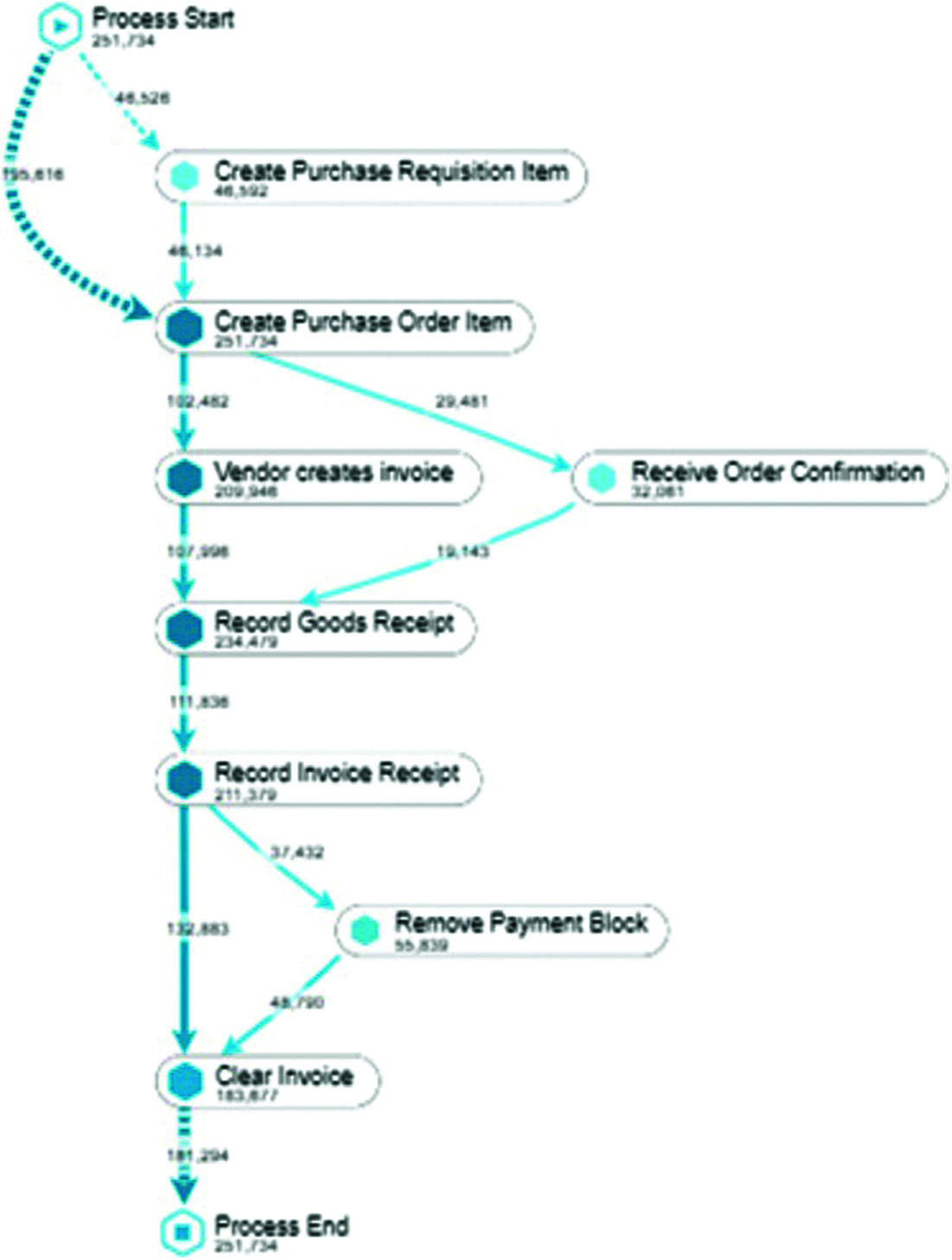
Figure 3: Frequent process activities
4.2 Discovering Petrinet Models
The discovery of process models in terms of Petri net modelling provides an abstract representation of the event log as well as provides assistance to formally describe the behaviour contained in the event log. Petri nets are very useful for modeling distributed systems in a formal way with the help of places and transitions. Alpha algorithm [29] is used to discover the Petri net from the event log of the purchasing process of an enterprise management system. To capture the relevant patterns in the event log, this algorithm used log-based ordering relations. It detects particular patterns by scanning the event log for the casual dependency. This dependency is reflected by connecting places in the corresponding Petri net. In order to form the item category in a two-way match, the formal Petri net model is discussed in Fig. 4, where it can be seen that the process starts with the creation of invoice receipt by the vendors. The purchase order items are then created and invoice receipt is recorded. The process ends up with the clearance of the invoice.
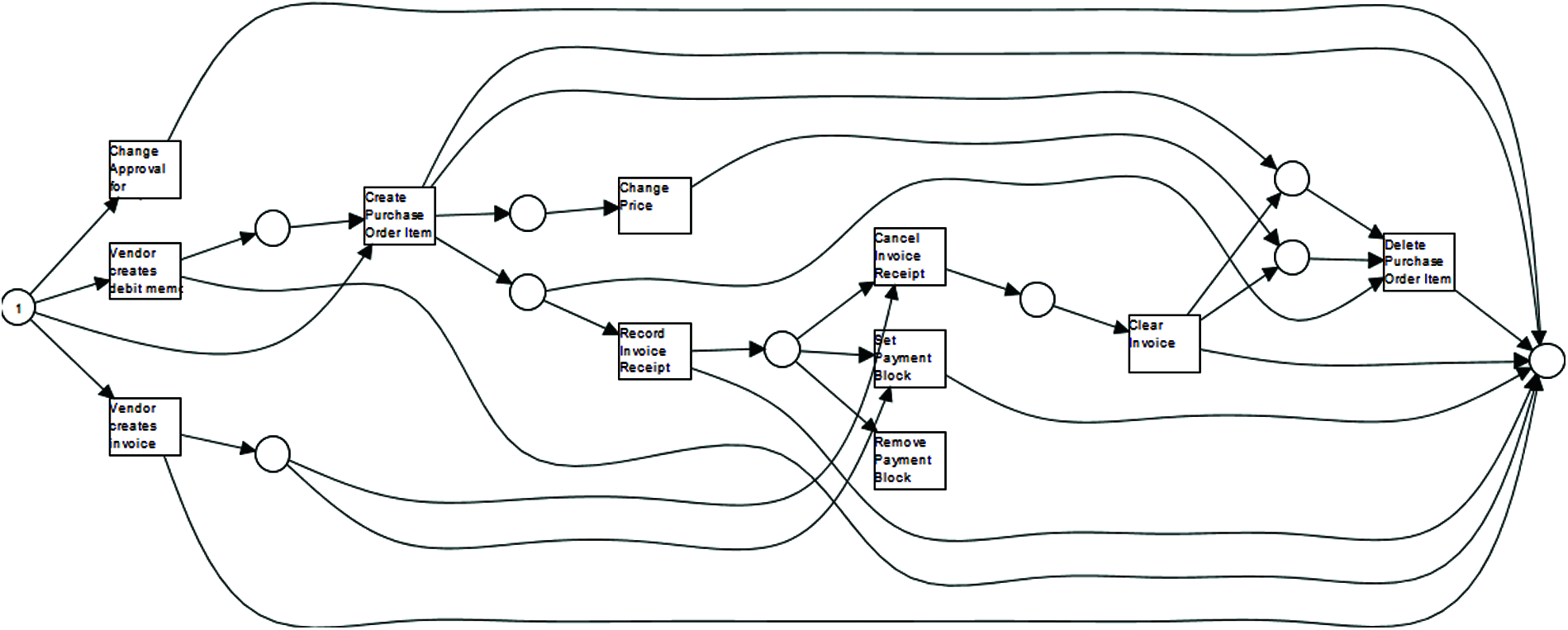
Figure 4: Formal petri net model of item category two-way match
4.3 Process Flows Identification
As the first and the fundamental step of process discovery is to obtain process-related knowledge derived from the event data, understanding the event log and their processes helps in the discovery of process models from the event data. Therefore, process discovery is the method of discovering the process model based on the understanding of behaviour recorded in the event log. Furthermore, the deviation identification will also be defined by the standard behaviour of the generated process model.
4.3.1 Process Discovery in Terms of Document Type
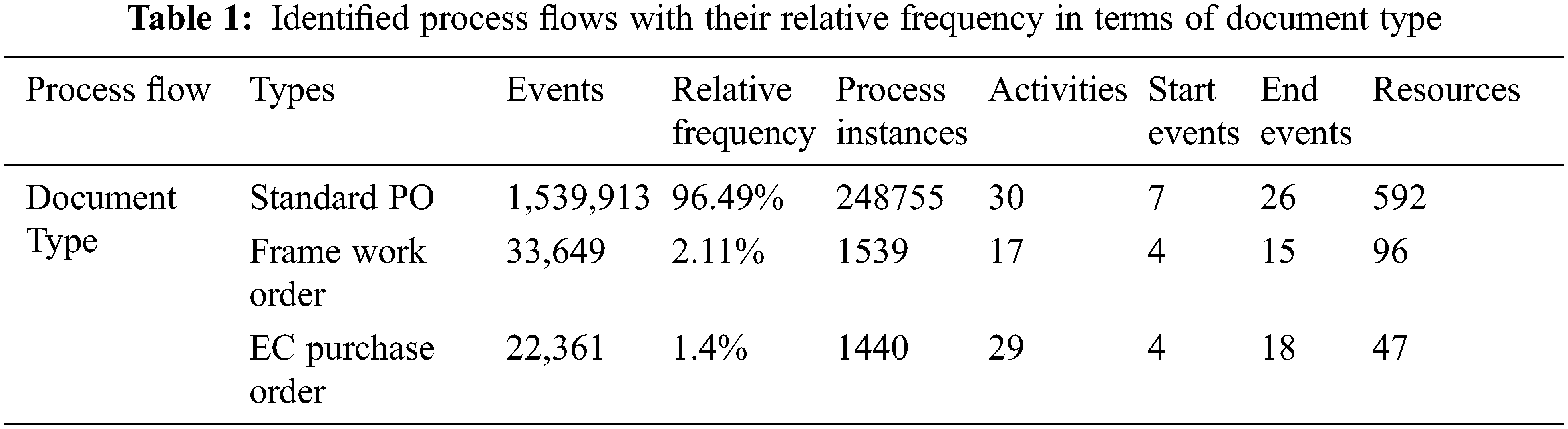
Document types are the groups of buying record categories. However, with the help of customization, we can create and categorize document types. The document type is used to classify items number range, item interval and item categories. There are three types of documents used in the data set. These three types are standard purchase order, framework order, and EC purchase order. The detailed log summary and discovered process factors are shown in Tab. 1.
4.3.2 Process Discovery in Terms of Item Category
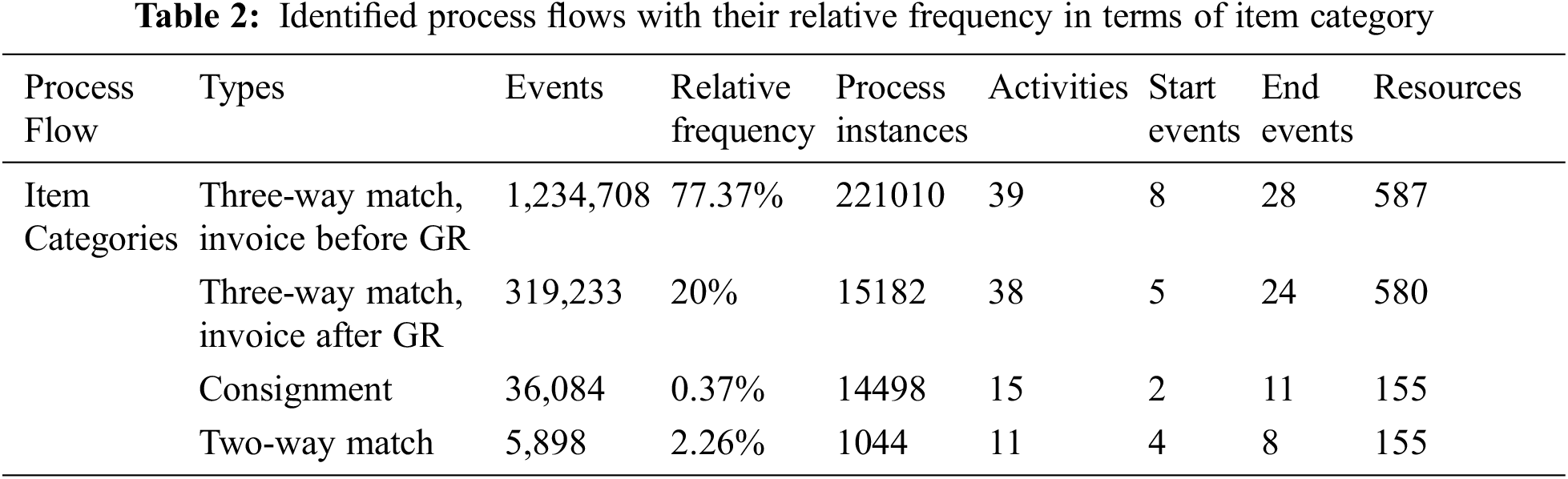
The purchase order document items are divided into four categories that are identified by the item’s category. It is the procedure of matching the purchase invoice document before the payment. Thus, the items are categorized in terms of different flows. The detailed log summary and discovered process factors are shown in Tab. 2.
4.3.3 Process Discovery in Terms of Company Case
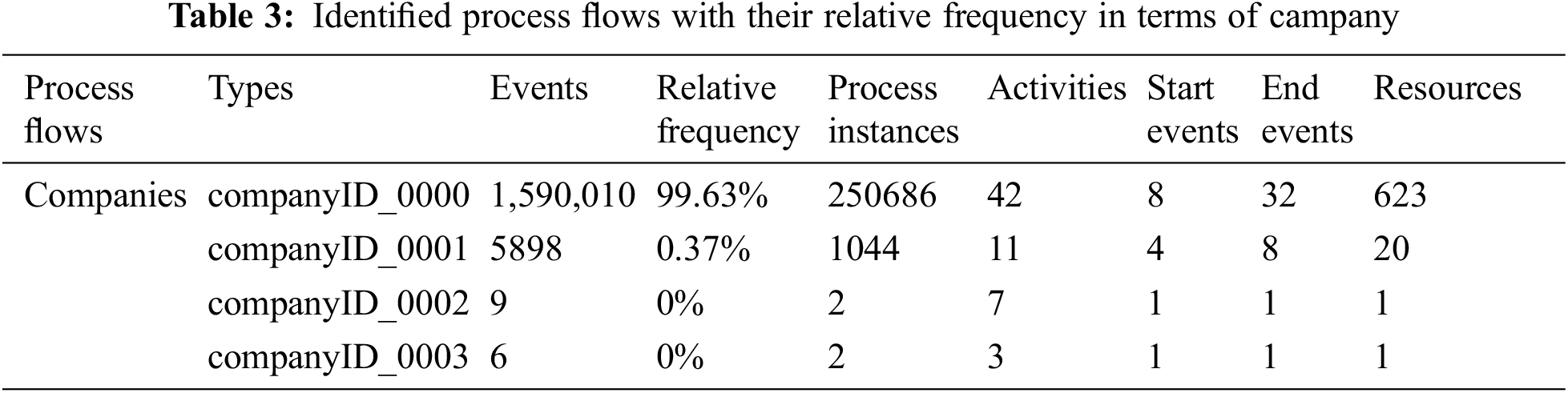
Although four companies are involved in the enterprise, there are anonymized subsidiaries that originate purchase requests. Their anonymized name are companyID_0000 to company companyID_0003. Their detailed log summary and discovered process factors are shown in Tab. 3.
Conformance analysis belongs to the process mining technique for checking compliance and the performance of business processes. This research conducted the conformance analysis on the event data of purchase to pay system recorded by the enterprise system. In the conformance analysis, process model is compared with the event log of the same purchasing process to check the model to define the recorded behaviour correctly. Therefore, this research conducts the conformance analysis to check the actual execution of the business process and identify dominant violations that affect the performance of processes during every process steps. Following are the explanation of each violation along with their causes and impacts:
Incomplete cases are those cases in which the expected end activity clear invoice is not executed. It includes those case which does not end up with the event, i.e., clear invoice which is supposed to be an end activity. There are many reasons for such incomplete cases. However, it is due to the snapshot effect. During the data extraction phase, some cases are still in the process of execution. The process map of incomplete cases is shown in Fig. 5.
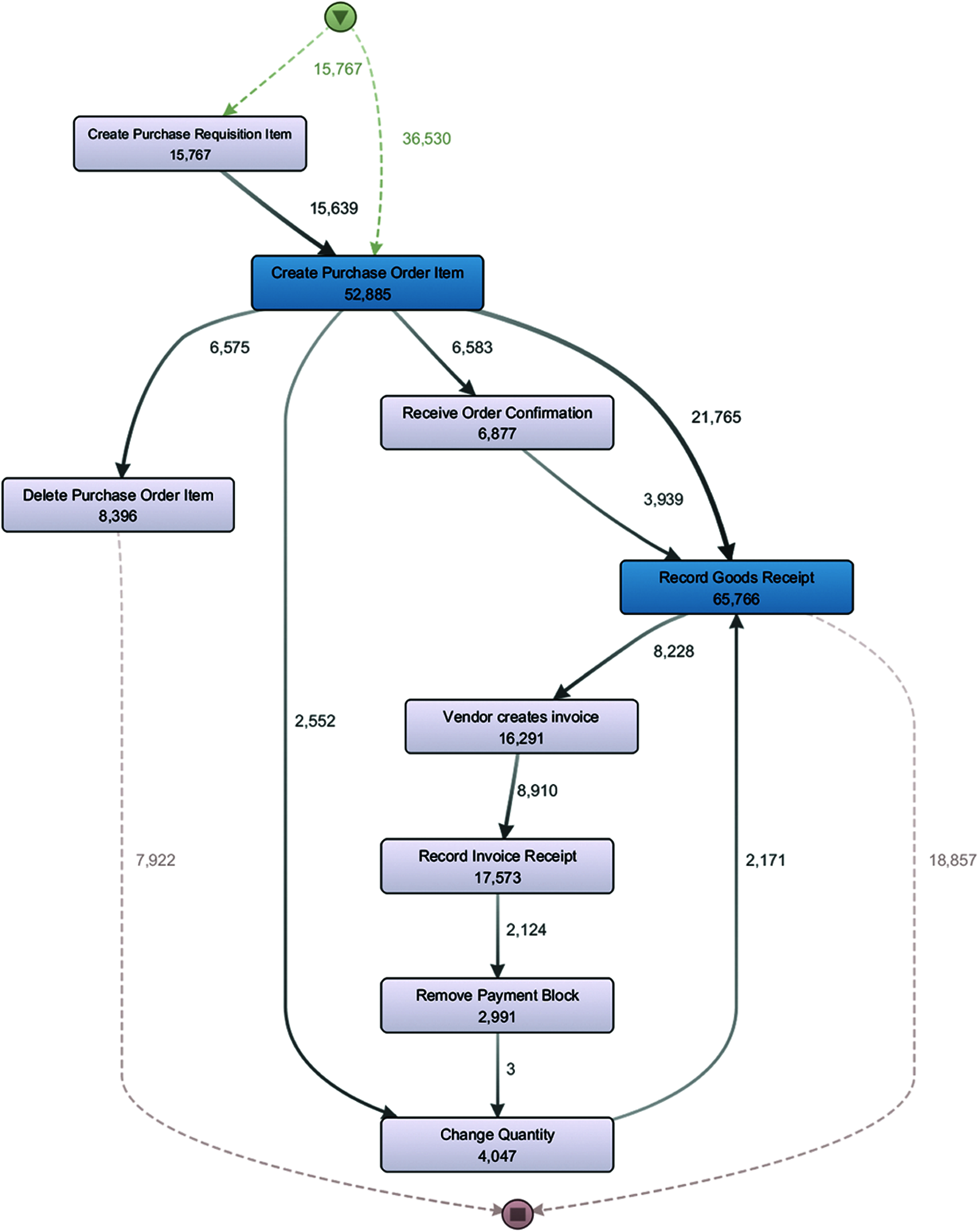
Figure 5: Process map of incomplete cases
Such cases are taken which start with the creation of purchase orders and do not end with the clearance of the invoice as shown in the process map of the incomplete cases. As it can be seen in the process map, the clear invoice activity is missing, and some cases end with the deletion of a purchase order while others end with the recording goods receipt. The overall distribution of cases are classified as complete vs. incomplete. It is discovered that 73% of the cases are complete which means these cases end up with the clearance of invoice and 27% of the cases are incomplete.
Rework means that the same activity is executed more than once in the same case. Such activities cause delays in the process as it slows down the processes and effects the efficiency of business processes. However, these activities contain manual involvement that causes the delay in the throughput time of processes. This research points out the following rework activities to find the root cause of delay analysis. The overall log summary of such rework activities is described in Tab. 4. These activities involve a change in price, quantity, removal of payment block, cancel of invoice receipt, removal of the payment order and deletion of purchase order items. The description of rework activities along with their mean case duration is described in Tab. 4.

The variant is important as it helps in learning paths which are better to deal with constraints. Dataset, which belongs to the large number of cases in the overall data, covers a few variants, as it helps in identifying the most frequent cases as well as specific or customized cases in the dataset. In the context of purchase to pay analysis of the enterprise system, the complete log contains 218,822 cases. As the number of cases is high in numbers, the overall log contains 10224 different variants. As variant analysis helps in finding out the most frequent variant that covers the maximum cases, the variant analysis helps in finding out the most frequent variant which covers the maximum cases. The most frequent variant that holds the maximum cases is Variant 1. It holds 48,751 similar cases concerning events and duration. It contains 22.8% of the overall cases in the dataset. The second most frequent variant that holds the maximum cases is Variant 2. The variant analysis helps to configure incomplete cases as well. Variant 3 contains 11255 similar cases and have only two events, such as the creation of purchase orders and record goods receipts. Such cases in variant three do not complete with the end activity of the purchasing process i.e., clear invoice as shown in Tab. 5.
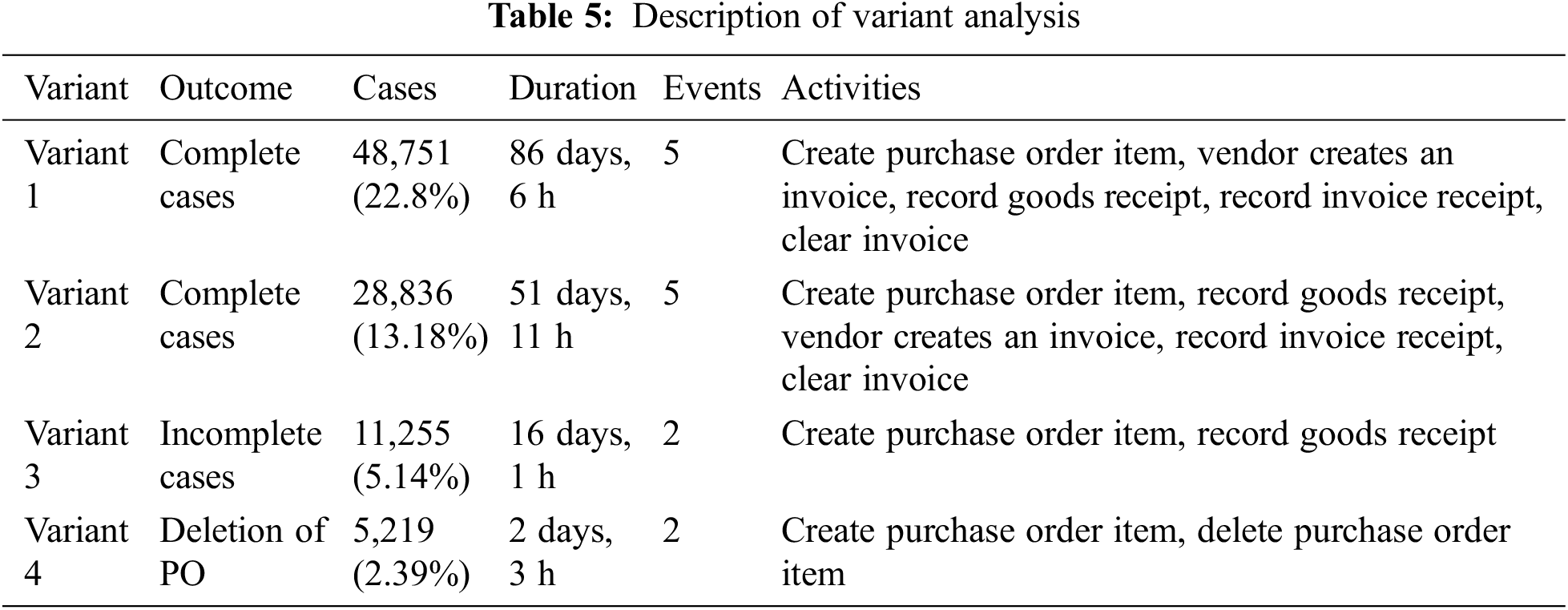
In such cases, purchase orders are deleted after their creation. The deletion of purchase orders occurs due to many reasons. The overall case summary with activities of similar cases is described in Tab. 5.
Throughput time is the amount of time taken to handle single purchase orders by going through the main invoicing process steps, including record goods receipt, record invoice receipt and the clear invoice. In the context of purchasing to pay analysis of an enterprise system, throughput time referred to the amount of time taken to handle a single invoice payment process. Furthermore, the median throughput per case is recorded as 64 days, in which the fastest case takes 0.00 s and the slowest case takes 804 days for their completion. The overall summary of throughput time analysis is described in Tab. 6.

In terms of purchasing to pay analysis of an enterprise system, a bottleneck referred to as the resources that work at the maximum capacity and unable to utilize more workload on it. It is usually the point of the process capacity that handles more applications by considering the constraints as it badly affects the overall performance of the process. Bottleneck identification is important as it helps in finding discrepancies within a process and the cause of delay in processes. The bottleneck can be identified when processing inputs and other resources in later stages are on standby. When the process bottleneck is discovered, it can be visualized through the animation which not only gives statistics and chart of abstract but also visualizes the resources that are on standby. The detailed visualization of the total and median throughput time for the identification of bottleneck is described in Fig. 6.
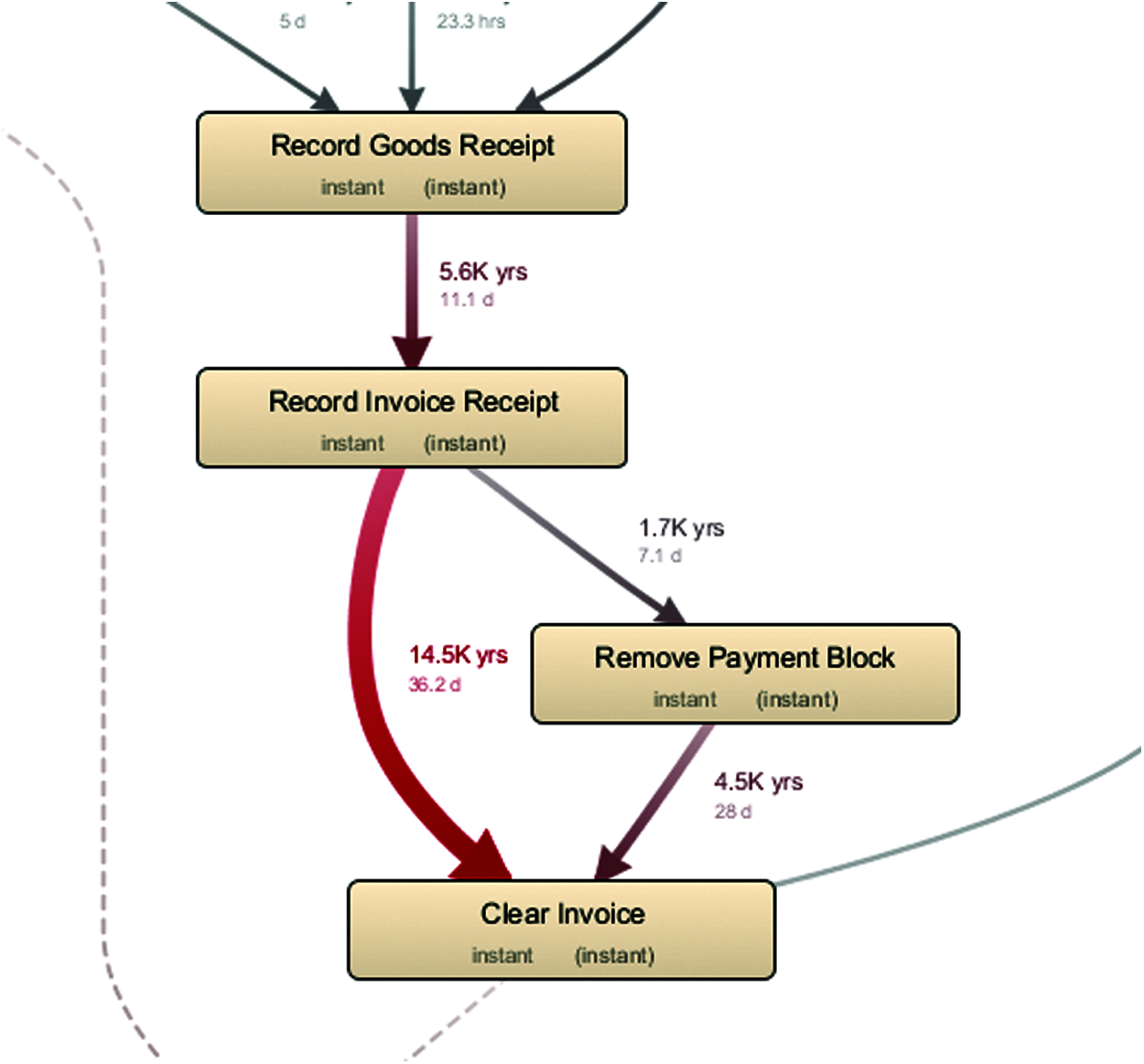
Figure 6: Total and median throughput time for bottleneck analysis
This research conducted bottleneck analysis on the log data of an enterprise and identifed the following bottlenecks unveiled in Fig. 7. The detailed throughput time and its affects on the cases are described in the following Fig. 7.
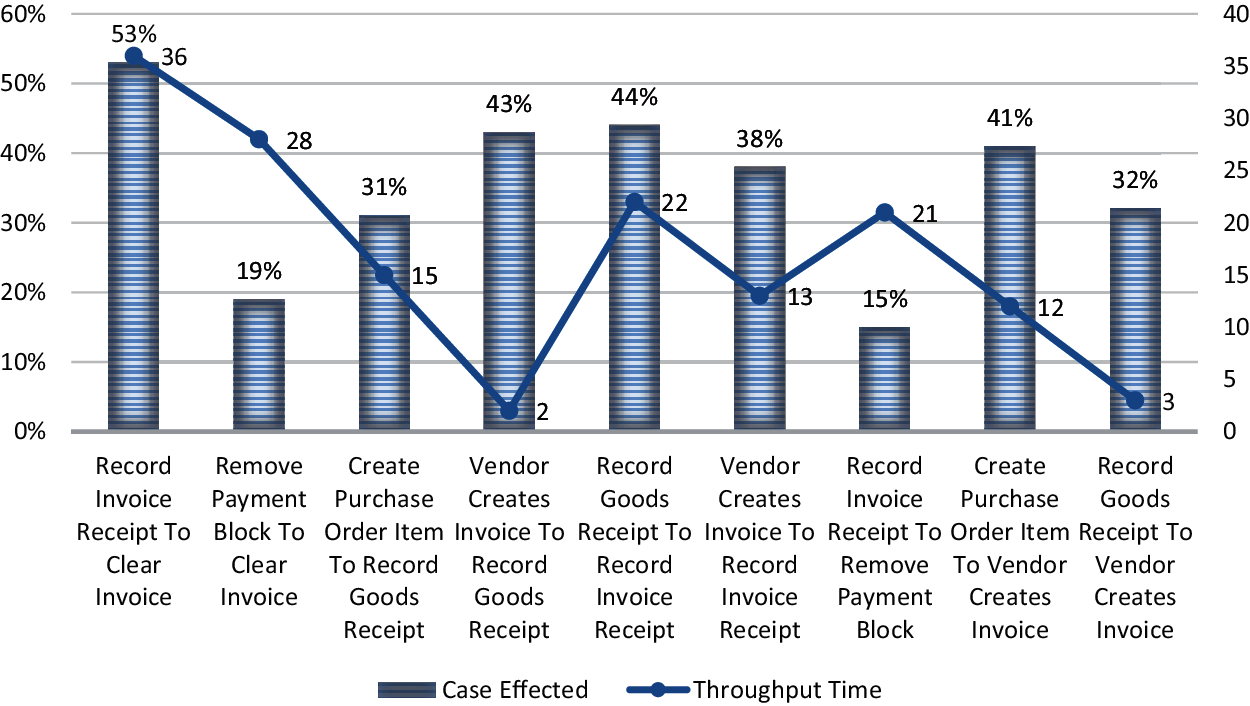
Figure 7: Summary of bottleneck analysis with their throughput time and case affected
This paper analyzed the event log of the purchasing process of an enterprise management system. We conducted the predictive and prescriptive analysis by combining play-in, play-out, and replay techniques, as they assist to construct the overarching process model that explains the process. It is recommended to determine the alternative ways to discover process models through the segregation of the event data. Moreover, we also suggested the investigation for the possibility of more business cases, which are used for further automating the process. The process cost can be significantly reduced by deep-diving into the process models with the aim of scrutinizing the root cause of additional activities without loops. To enable the improvement of business processes, the next levels of process mining methods that combine business intelligence and process intelligence were applied. This allowed the process analyzer to investigate the same dataset with more than one case ID. Based on the detailed rework analysis, it is recommended to put additional resources to rework activities in order to optimize the throughput time of the purchasing processes. For the shipping orders, we recommended that the company should consider changing the process in this way. For this type of order, the value must also be registered (because the inventory is internal to the company) and a connection should be established. We further concluded that the subsequent analysis provides information whether the root cause of the high average return time is simply due to the payment terms or the average throughput is high for other reasons.
Funding Statement: This research was supported by Suranaree University of Technology, Thailand.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. W. V. D. Aalst, “On the representational bias in process mining,” in IEEE 20th Int. Workshops on Enabling Technologies: Infrastructure for Collaborative Enterprises, Paris, France, pp. 2–7, 2011. [Google Scholar]
2. W. V. D. Aalst, “Process mining,” ACM, vol. 55, no. 8, pp. 76–83, 2012. [Google Scholar]
3. V. Huser, “Process mining: Discovery, conformance and enhancement of business processes,” in Discovery, Conformance and Enhancement of Business Processes, 1st ed., Springer, New York, USA, pp. 340–352, 2011. [Google Scholar]
4. A. Pourmasoumi and E. Bagheri, “Business process mining,” Encyclopedia with Semantic Computing and Robotic Intelligence, vol. 1, no. 1, pp. 1630004, 2017. [Google Scholar]
5. W. V. D. Aalst, “Process mining: Overview and opportunities,” ACM Transactions on ManagementInformation Systems (TMIS), vol. 3, no. 2, pp. 1–17, 2012. [Google Scholar]
6. W. V. D. Aalst, “Data science in action,” in Process Mining, 1st ed., Heidelberg, Berlin: Springer, vol. 1. pp. 3–23, 2016. [Google Scholar]
7. A. Rebuge and D. R. Ferreira, “Business process analysis in healthcare environments: A methodology based on process mining,” Information Systems, vol. 37, no. 2, pp. 99–116, 2012. [Google Scholar]
8. A. Rozinat, R. S. Mans, M. Song and W. V. D. Aalst, “Discovering colored petri nets from event logs,” International Journal on Software Tools for Technology Transfer, vol. 10, no. 1, pp. 57–74, 2008. [Google Scholar]
9. E. Rojas, J. Munoz-Gama, M. Sepúlveda and D. Capurro, “Process mining in healthcare: A literature review,” Journal of Biomedical Informatics, vol. 61, pp. 224–236, 2016. [Google Scholar]
10. J. Munoz-Gama, “Conformance checking and diagnosis in process mining,” in Computer Application in Administrative Data Processing, Ist ed., Springer International Publishing AG, New York, USA, vol. 270, pp. 194–202, 2016. [Google Scholar]
11. A. Rozinat and W. V. D. Aalst, “Conformance checking of processes based on monitoring real behavior,” Information Systems, vol. 33, no. 1, pp. 64–95, 2008. [Google Scholar]
12. W. V. D. Aalst, H. A. Reijers, A. J. M. M. Weijter, B. F. V. Dongen, A. K. Alves de Medeiros et al., “Business process mining: An industrial application,” Information Systems, vol. 32, no. 5, pp. 713–732, 2007. [Google Scholar]
13. M. Dumas, M. La Rosa, J. Mendling and H. A. Reijers, “Fundamentals of business process management,” in Computer Appl. in Administrative Data Processing, 2nd ed., Henderson, Berlin: Springer, vol. 1, pp. 506–527, 2018. [Google Scholar]
14. A. A. Kalenkova, W. V. D. Aalst, I. A. Lomazova and V. A. Rubin, “Process mining using BPMN: Relating event logs and process models,” Software & Systems Modeling, vol. 16, no. 4, pp. 1019–1048, 2017. [Google Scholar]
15. D. Fahland and W. V. D. Aalst, “Model repair—Aligning process models to reality,” Information Systems, vol. 47, pp. 220–243, 2015. [Google Scholar]
16. F. Rojos, F. Lucchini, J. M. González, D. Espinoza, J. Lee et al.,“Process mining: research in banking operations,” in 13th Int. Workshop on Business Process Intelligence 2017, Barcelona, Spain, pp. 161–164, 2018. [Google Scholar]
17. M. Bozkaya, J. Gabriels and W. M. van der Werf, “Process diagnostics: a method based on process mining,” in 2009 Int. Conf. on Information, Process, and Knowledge Management, Cancun, Mexico, pp. 22–27, 2009. [Google Scholar]
18. A. Kalenkova, A. Burattin, M. de Leoni, W. M. van der Aalst and A. Sperduti, “Discovering high-level BPMN process models from event data,” Business Process Management Journal, vol. 25, no. 5, pp. 995–1019, 2019. [Google Scholar]
19. W. M. van der Aalst, “Process discovery from event data: Relating models and logs through abstractions,” Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, vol. 8, no. 3, pp. 1244, 2018. [Google Scholar]
20. W. Tan, W. Shen, L. Xu, B. Zhou and L. Li, “A business process intelligence system for enterprise process performance management,” IEEE Transactions on Systems, Man, and Cybernetics, vol. 38, no. 6, pp. 745–756, 2008. [Google Scholar]
21. C. Caserio and S. Trucco, “Enterprise resource planning and business intelligence systems for information quality,” in Enterprise Resource Planning Systems, 1st ed., Springer International Publishing, New York, USA, vol. 1, pp. 13–41, 2018. [Google Scholar]
22. P. Badakhshan, S. Gosling, J. Geyer-Klingeberg, J. Nakladal, J. Schukat et al., “Process mining in the coatings and paints industry: the purchase order handling process,” in Int. Conf. on Process Mining (ICPM), Bolzano, Italy, 2019. [Google Scholar]
23. A. A. Khan, P. Uthansakul, P. Duangmanee and M. Uthansakul, “Energy efficient design of massive MIMO by considering the effects of nonlinear amplifiers,” Energies, vol. 11, pp. 1045, 2018. [Google Scholar]
24. P. Uthansakul and A. A. Khan, “Enhancing the energy efficiency of mmWave massive MIMO by modifying the RF circuit configuration,” Energies, vol. 12, pp. 4356, 2019. [Google Scholar]
25. P. Uthansakul and A. A. Khan, “On the energy efficiency of millimeter wave massive MIMO based on hybrid architecture,” Energies, vol. 12, pp. 2227, 2019. [Google Scholar]
26. A. A. Khan, P. Uthansakul and M. Uthansakul, “Energy efficient design of massive MIMO by incorporating with mutual coupling,” International Journal on Communication Antenna and Propagation, vol. 7, pp. 198–207, 2017. [Google Scholar]
27. F. Bienhaus and A. Haddud, “Procurement 4.0: Factors influencing the digitisation of procurement and supply chains,” Business Process Management Journal, vol. 24, no. 4, pp. 965–984, 2018. [Google Scholar]
28. C. W. Günther and A. Rozinat, “Disco: Discover your processes,” BPM (Demos), vol. 940, pp. 40–44, 2012. [Google Scholar]
29. W. M. Van Der Aalst and B. F. Van Dongen, “Discovering petri nets from event logs,” in Transactions on Petri Nets and other Models of Concurrency, 1st ed., Henderson, Berlin: Springer, vol. 1, pp. 372–422, 2004. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |