DOI:10.32604/iasc.2020.012532
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2020.012532 | |
| Article |
Task-Oriented Battlefield Situation Information Hybrid Recommendation Model
PLA Strategic Support Force Information Engineering University, Zhengzhou, 450000, China
*Corresponding Author: Zhou Chun Hua. Email: zchgjb@126.com
Received: 03 July 2020; Accepted: 02 August 2020
Abstract: In the process of interaction between users and battlefield situation information, combat tasks are the key factors that affect users’ information selection. In order to solve the problems of battlefield situation information recommendation (BSIR) for combat tasks, we propose a task-oriented battlefield situation information hybrid recommendation model (TBSI-HRM) based on tensor factorization and deep learning. In the model, in order to achieve high-precision personalized recommendations, we use Tensor Factorization (TF) to extract correlation relations and features from historical interaction data, and use Deep Neural Network (DNN) to learn hidden feature vectors of users, battlefield situation information and combat tasks from auxiliary information. The results are predicted through logistic regression. To solve the multi-source heterogeneity of battlefield situation information, we design a hybrid learning and presentation model that integrates multiple deep learning models such as Doc2Vec, fully connected network and convolutional neural network (CNN), to integrate the rich and diverse data information in situational awareness system effectively. We perform experiments with the maneuvers dataset to test and evaluate the model through scenario simulation.
Keywords: Battlefield situation information recommendation; recommendation system; combat task; deep learning; tensor factorization
With the rapid development of battlefield situation awareness technologies, and the fast growth of situation information resources, the amount of battlefield situation data increases explosively. Using massive data and information effectively to improve operational efficiency has become a research hotspot in the military science and technology domain. However, massive battlefield data, while increasing the amount of available information and enhancing situational awareness, also leads to “information overload” [1]. Therefore, users face the dilemma of “abundant information” but “lack of useful information.”
Nowadays, the primary way for users to get battlefield situation information is situation information distribution. Information distribution mainly adopts classified subscriptions and topic subscriptions. The situation information is classified and cataloged by the manager in a unified way. Users can subscribe by type according to the information catalog, or combine multiple types into topics to subscribe [2]. Wang et al. [3] and Zhong et al. [4] designed information distribution models based on Agent and Multi-Agent and introduced feedback mechanisms and information priority mechanisms into the models to improve the quality and real-time performance of information distribution. Yu et al. [5] and Zhou et al. [6] constructed a hierarchical user interest vector space model and implemented the on-demand distribution of battlefield situation information using the Naive Bayesian classification algorithm and TF-IDF classification method respectively. Dong et al. [7] proposed a real-time and efficient information distribution method for battlefield situations based on semantic publish-subscribe systems and used ontology to describe the conceptual model of battlefield situations. The task-oriented information distribution technology is proposed to realize accurate and practical information distribution [8,9].
Information distribution, like information retrieval, is a pull information service. Although it can meet users’ needs to obtain battlefield information to a certain extent, it cannot actively provide personalized information services to users, but usually requires users to provide clear precipitation needs. It can be said that the way of information acquisition can no longer adequately meet the information needs of users to carry out combat tasks dynamically. Its main manifestations are as follows: (1) The accuracy of information distribution is not accurate enough, and only the directional acquisition of information can be realized from the category of coarse-grained, so users will still face a large amount of redundant information; (2) The timeliness of distribution is inadequate. The traditional information distribution method requires manual screening and subscription from the information catalog, which results in the timeliness not being able to match the rapid changes of battlefield situations; (3) Information is not sufficient to support the users’ combat tasks. Users select situation only from the perspective of classification of information itself and cannot reflect the needs of information generated by the users to complete the tasks during the warfare process.
However, in many cases, users do not know what information they need, or the information that users have subscribed is not sufficient to support users to make decisions. Even for some unexpected events or tasks, while facing vast amounts of data and information, users will often be at a loss and have no way to start, and the application of recommendation technologies can effectively alleviate the above problems. As an effective method to solve information overload, the recommendation system has become a hotspot in academia and industry and plays a vital role in many fields. Especially with the successful application of deep learning in speech recognition, image processing, natural language processing, and other fields, deep learning technology has also become an important research direction in the field of recommendation. It provides practical solutions for data sparsity challenges, cold startup, interest drift, scalability, and cross-domain recommendation of recommendation systems. Researchers have successively proposed many DNN-based recommendation models, such as deep structured semantic models [10], wide & deep learning models [11], neural collaborative filtering model [12] and deep factorization-machine model [13], etc., laying a foundation for the research in this field.
Yu et al. [14] proposed a coupling matrix and tensor decomposition model based on CNN, which is used for the aesthetic based clothing recommendation system. CNN is used to learn image features and aesthetic features. Lei et al. [15] introduced a deep learning model for image recommendation, which consists of two CNNS for image representation learning and one MLP for user preference modeling. ConTagNet [16] is a context-aware tag recommendation system. CNN learns the image features, and the context representation is processed by a two-layer, fully connected feed-forward neural network. The two neural networks’ outputs are connected and input to a Softmax function to predict the probability of candidate tags. A session-based parallel recommendation architecture is proposed in [17], which learns the representations of one-hot vectors, image feature vectors, and text feature vectors, respectively, and then inputs them into a nonlinear activation function to predict the next item in the session. Konstantina et al. [18] designed an interactive recommendation model based on RNN to solve two key tasks in interactive recommendation: question and answer. RNN predicts the questions that the user may ask and predicts the response based on the user’s recent behavior. Trapit et al. [19] used GRU to encode the text sequence into the latent factor model, which solved the problem of hot and cold start. Besides, to prevent overfitting and reduce the sparsity of the training data, a multi-task regularization is used. The model can realize the prediction of item metadata (such as label, type) while completing the score prediction. Huang et al. [20] proposed knowledge-enhanced memory networks to enhance the feature capturing ability and interpretability of the recommendation system, and solve the problems that the sequential recommendation system is not interpretable and the fine-grained features of users cannot be obtained. In order to solve the dynamic changes of news content and user preferences and the diversity of recommendations, a news recommendation system based on reinforcement learning is proposed in [21]. For the successive Point-of-Interest (POI) recommendation problem, Doan et al. [22] proposed a deep LSTM recurrent neural network model with a memory/attention mechanism that captures both the sequential and temporal/spatial characteristics into its learned representations. Rahmani et al. [23] proposed a POI recommendation method based on a Local Geographical Model, which considers the user’s main region of activity and the relevance of each location within that region. The proposed local geographical model is fused into the Logistic Matrix Factorization to improve the accuracy of POI recommendation. Recommendation technologies have also been tried in the field of battlefield situation information recommendation. Gu et al. [24] used personalized recommendation technologies of content similarity to screen intelligence information. Shen et al. [25] tried to alleviate the problem of sparse data combined with the users’ historical behavior and extracted the content features of situation information using Doc2Vec on the basis of the neural network recommendation algorithm.
In the process of interaction between users and battlefield situation information, combat tasks are the key factors that affect users’ information selection. Therefore, in the paper, we combine recommendation algorithms, tensor factorization and deep learning technology to design TBSI-HRM to predict the correlation degree among users, combat tasks and battlefield situation information, and recommend highly correlated situation information to users according to the ranking of correlation degree. The model consists of TF component and DNN component. TF component is used to extract implicit features of users, situation information and combat tasks and their potential semantic associations; And DNN component is used to learn the potential feature vectors of user and situation information from auxiliary information. Finally, the two parts’ predicted values are fused by logistic regression to obtain the final correlation prediction value.
TBSI-HRM integrates the latent features of users, situation information and combat tasks, and the features of auxiliary information. It also can provide personalized, intelligent and dynamic situation information more accurately for users to complete situation information sharing, thus ensuring the consistency of situation information among all levels of command systems, which is helpful to realize the self-coordination of combat organization and command and military actions based on the unified combat situation.
The main contributions of this paper are as follows:
(1) We design TBSI-HRM based on TF and DNN. TF is used to extract correltion relations and features from historical interaction data among users, battlefield situation information and combat tasks, and then hidden feature vectors of users, battlefield situation information and combat tasks are learned from auxiliary information through DNN. Combining the two results to predict the correlation degree can achieve high-precision personalized recommendation.
(2) A hybrid learning and presentation model is designed based on the multi-source heterogeneity of battlefield situation information, using the field-based feature representation method, which is combined with Doc2Vec, fully connected network, CNN and other deep neural networks models, to integrate the rich and diverse data information in situational awareness system effectively.
(3) We use the data from the situation management of the actual combat military confrontation training information system as the experimental dataset and verify the model’s performance by comparing several groups of evaluation indexes in the scenario simulation.
BSIR is related to the feature of users and closely related to the combat tasks undertaken by specific users. Users’ demand for battlefield situation information is closely related to the combat tasks they usually undertake, so the demand for situation information will vary greatly with the different combat objectives and actions in the combat tasks. Furthermore, with the advancement of the battle process and the continuous changes of the battlefield environment, the battle tasks’ content and state will also change and adjust, which means that the corresponding information requirements will also show dynamic changes. Therefore, in order to meet the changing information needs of users in planning and executing combat tasks, situation information should be recommended accurately for combat tasks.
Task-oriented BSIR refers to that artificial intelligence exploits the correlation among users, situation information and tasks according to the specific operational tasks undertaken by users, searches, analyses and processes situation information data in advance, filters out and sorts out important situation information, and finally presents it to users in the form of pictures and texts. Its purpose is to help users quickly acquire high-value battlefield situation information. Moreover, the users here can be commanders, operational command organizations, operational units and operational systems, etc.
Let U be the set of users registered in the system; Let I be the set of situation information registered in the system for command and decision-making; Let T be the set of all combat tasks registered in the system. Tensor model can be used to describe the historical interaction record of user-combat task-situation information. In Fig. 1, three dimensions of tensor 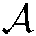 respectively describe users, tasks and situation information. The value of element
respectively describe users, tasks and situation information. The value of element 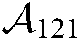 is 3, which indicates that user u1, situation information i2 and task t1 have interacted three times.
is 3, which indicates that user u1, situation information i2 and task t1 have interacted three times.
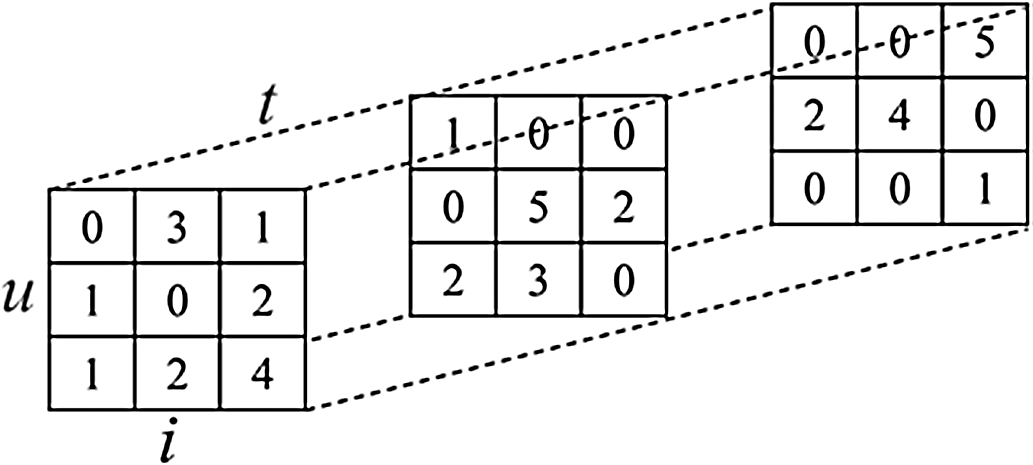
Figure 1: The structure of tensor 
The utility function f is defined as:

where Correlation is a totally ordered set, e.g., non-negative integers or real numbers within a certain range which represents the degree of correlation among users, combat tasks and battlefield situation information. f is used to calculate the degree of association between specific user 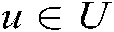 and situation information i
and situation information i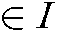 during the execution of combat task
during the execution of combat task 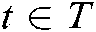 . Therefore, the task-oriented situation information recommendation problem is to find the situation information
. Therefore, the task-oriented situation information recommendation problem is to find the situation information 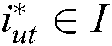 in an unknown state around the target task
in an unknown state around the target task 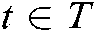 undertaken by the user
undertaken by the user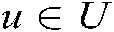 , so as to maximize the utility function f, that is:
, so as to maximize the utility function f, that is:

Therefore, the task of BSIR is how to build a model f that can predict the degree of correlation according to the historical interaction records and auxiliary information, and recommend the situation information with high correlation to users. Each user in U can be defined by their attribute sets, which are registered according to different users’ categories. Generally speaking, for commanders, the registered attributes are as follows: name, gender, age, educational background, military ranks, military services, arms, subordinate troops and other characteristics, and interests. Each element in T can also be defined by their attribute sets, such as type, nature, start time, end time, task goal, etc. Battlefield situation information mainly consists of three types of elements: entity, environment and capability [26,27]. The entity’s situation information includes the unique identification of the entity, the state attribute, the behavior attribute, etc.
3.1 Field-Based Feature Representation
In order to solve the problems of too many training parameters and too low computational efficiency caused by data sparseness and high feature dimension, DNN based recommendation systems at present usually used field-based feature representation, i.e., clustering data features into several fields, and then compressing each field into a low-dimensional, dense real-value embedding vector through a feature embedding layer [28–30]. In this way, even fields with arbitrary length and sparse discretization will become a dense and fixed-length continuous numerical vector after passing through the embedding layer. This paper uses field-based feature representation to extract potential content features of users and battlefield situation information, and designs a hybrid model based on multi-source heterogeneous data.
Assume that the original features of user or situation information are:

where m is the number of fields; fdi can be of continuous numerical type, discrete type or categorical type; It can be text data or multimedia data such as pictures, audio and video. Assuming that the embedding vector of the field fdi after passing through the embedding layer is 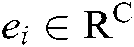 and C is the length of
and C is the length of 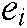 , then the output of the embedding layer can be expressed as:
, then the output of the embedding layer can be expressed as:
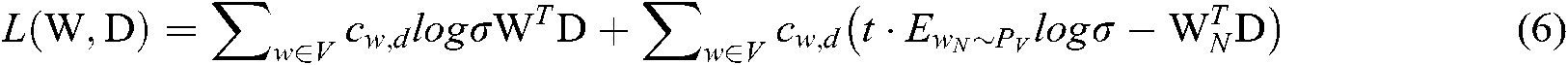
The length of e is  . The categorical or discrete features can be normalized by one-hot coding. For example, the original feature value of a commander is [id = c04, gender = male, age = 35, diploma = bachelor, service = army], so the commander’s one-hot code is:
. The categorical or discrete features can be normalized by one-hot coding. For example, the original feature value of a commander is [id = c04, gender = male, age = 35, diploma = bachelor, service = army], so the commander’s one-hot code is:
Then, each field is converted into an embedded feature vector with a fixed length of C, here C is 5, as shown in Fig. 2.
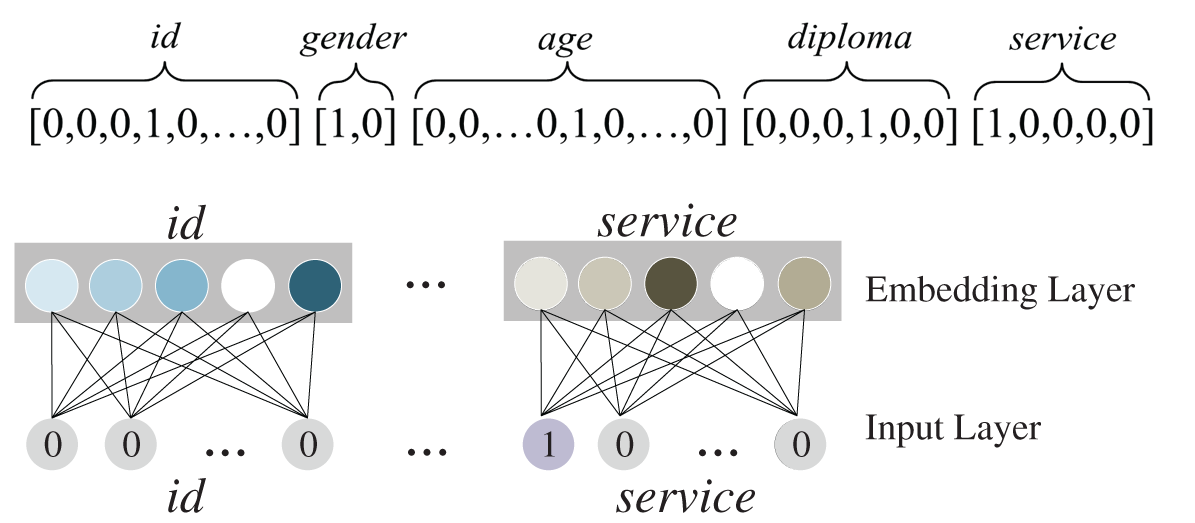
Figure 2: Field-based feature representation. Here C = 5
In recommendation system, when extracting features from users or items through DNN, if the input data is text data, the bag-of-words model is generally adopted to convert the text into dense vectors of fixed-length low-dimensional space, to facilitate learning potentially complex content features in the text and avoid the limitations of traditional manual feature selection [31]. However, the traditional bag-of-words model ignores the order and semantics of words, which will affect the effect of conversion.
Doc2Vec, also known as Paragraph2Vec, is a word embedding model proposed by Google based on Word2Vec [32], aiming at transforming variable-length text segments (such as sentences, paragraphs and documents) into fixed-length feature vector representations [33]. The process of Doc2Vec is divided into two stages: training and inference. Its basic idea is to use the training method under completely unsupervised conditions to obtain softmax() parameters, word vectors and paragraph vectors from the original data through random gradient descent and back propagation, and to train and infer new paragraph vectors through known word vectors and softmax() parameters.
Doc2Vec includes two models: Distributed Memory Model of Paragraph Vectors (PV-DM) and Distributed Bag of Words Version of Paragraph Vector (PV-DBOW). PV-DBOW is a method that uses a paragraph vector to predict words in a paragraph, where words in a paragraph are obtained by randomly sampling in the paragraph. Each word is considered to exist independently in a paragraph and the order of words does not affect the learning result of the paragraph vector. PV-DM model adds paragraph vectors to the training process of word vectors, trains sentence vectors and word vectors at the same time, and saves sentence vectors and word vector matrix. Compared with PV-DBOW model, PV-DM needs to save additional word vector model, so it will slow down the training speed. Because this research only needs to obtain the comment text data or the feature representation of some text descriptive attributes, in order to speed up the training model, PV-DBOW model is chosen in our research.
Let d denote the text data in the data set and the words in the text are w. Let V represent the word dictionary. Let D be the feature vector of the paragraph, and let W be the word vector. According to the hypothesis of the word bag model, the probability of each word w appearing in the document is calculated using softmax(), as shown in Eq. (5):

In order to reduce the cost of calculation, a negative sampling strategy is adopted. Among the words that do not appear, some words are sampled according to a predefined noise distribution and used as negative samples for approximate calculation. The objective function of PV-DBOW is defined as:

where, 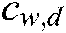 is the number of occurrences of the word w in the document d, t is the number of negative samples, and
is the number of occurrences of the word w in the document d, t is the number of negative samples, and 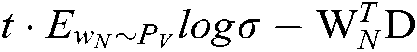 denotes the expectation of
denotes the expectation of 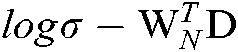 in the noise distribution PV.
in the noise distribution PV.
Tensor is a multidimensional extension of vector, which is an organizational form of high-dimensional data [34,35], represented by 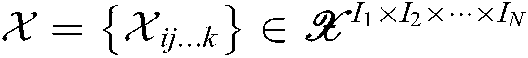 . Where, N is the order of the vector. Similar to matrix factorization, tensor factorization also represents a high-order tensor data through multilinear operations on latent factors. Therefore, it is inspired for the efficient application of matrix factorization in two-dimensional recommendation systems, tensor factorization is used to multidimensional recommendation problems of users, items and context scenarios in [36,37], and extract implicit features from high-order users evaluation tensors. TBSI-HRM only considers the three dimensions of users, combat tasks and situation information, and uses the three-dimensional tensor
. Where, N is the order of the vector. Similar to matrix factorization, tensor factorization also represents a high-order tensor data through multilinear operations on latent factors. Therefore, it is inspired for the efficient application of matrix factorization in two-dimensional recommendation systems, tensor factorization is used to multidimensional recommendation problems of users, items and context scenarios in [36,37], and extract implicit features from high-order users evaluation tensors. TBSI-HRM only considers the three dimensions of users, combat tasks and situation information, and uses the three-dimensional tensor 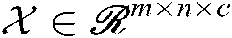 to represent the interaction among them, where m is the number of users, n is the number of combat tasks, and c is the number of situation information.
to represent the interaction among them, where m is the number of users, n is the number of combat tasks, and c is the number of situation information.
CP decomposition [38] and Tucker decomposition [39] are two classical algorithms of tensor decomposition. Most of tensor decomposition algorithms after this are extensions of these two methods, such as higher order singular value decomposition (HOSVD) [40], Nonnegative tucker decomposition (NTD) [41] and hierarchical alternative least squares (HALS) [42], etc. In this paper, HOSVD is used to decompose tensor. HOSVD is an extension of singular value decomposition (SVD) in tensors. Its core idea is to factorize a tensor into three matrices and a core tensor, and then approximate the tensors by solving the approximate low rank matrices of the expansion matrix and the core matrix respectively. HOSVD of three-dimensional tensor  is shown in Fig. 3. HOSVD can be defined as follows [37]:
is shown in Fig. 3. HOSVD can be defined as follows [37]:
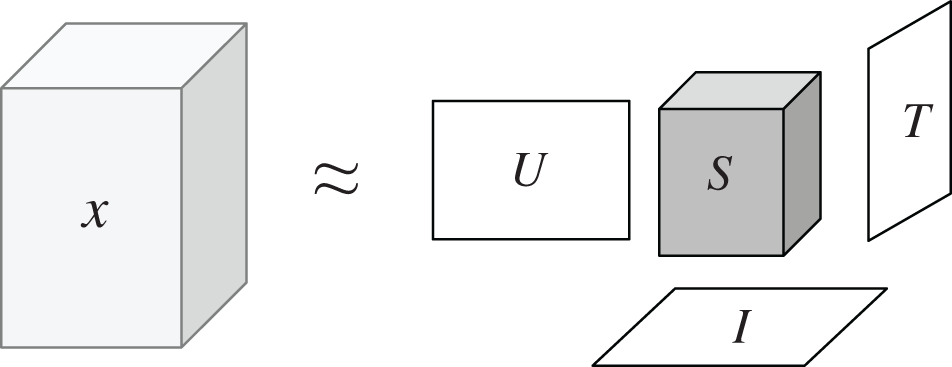
Figure 3: HOSVD of three-dimensional tensor 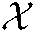

In this case, the decision function for a single user i, situation information j, combat task k, combination becomes:

where 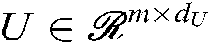 ,
,  ,
, 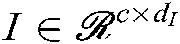 , and the core vector
, and the core vector 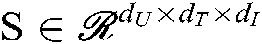 . We can fully control over the dimensionality of the factors extracted for the users, situation information and tasks by adjusting dU, dT and dI parameters.
. We can fully control over the dimensionality of the factors extracted for the users, situation information and tasks by adjusting dU, dT and dI parameters.
TBSI-HRM consists of TF component and DNN component, as shown in Fig. 4. TF module mainly uses the situation information recommendation algorithm based on HOSVD to obtain the prediction value  of correlation degree among users, situation information and tasks; DNN component is used to learn feature vectors of various data to fuse potential features of users and situation information, thus calculating correlation prediction value
of correlation degree among users, situation information and tasks; DNN component is used to learn feature vectors of various data to fuse potential features of users and situation information, thus calculating correlation prediction value 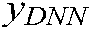 . Finally, the final correlation degree prediction
. Finally, the final correlation degree prediction 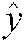 is obtained by integrating the two prediction values through logical regression, that is:
is obtained by integrating the two prediction values through logical regression, that is:
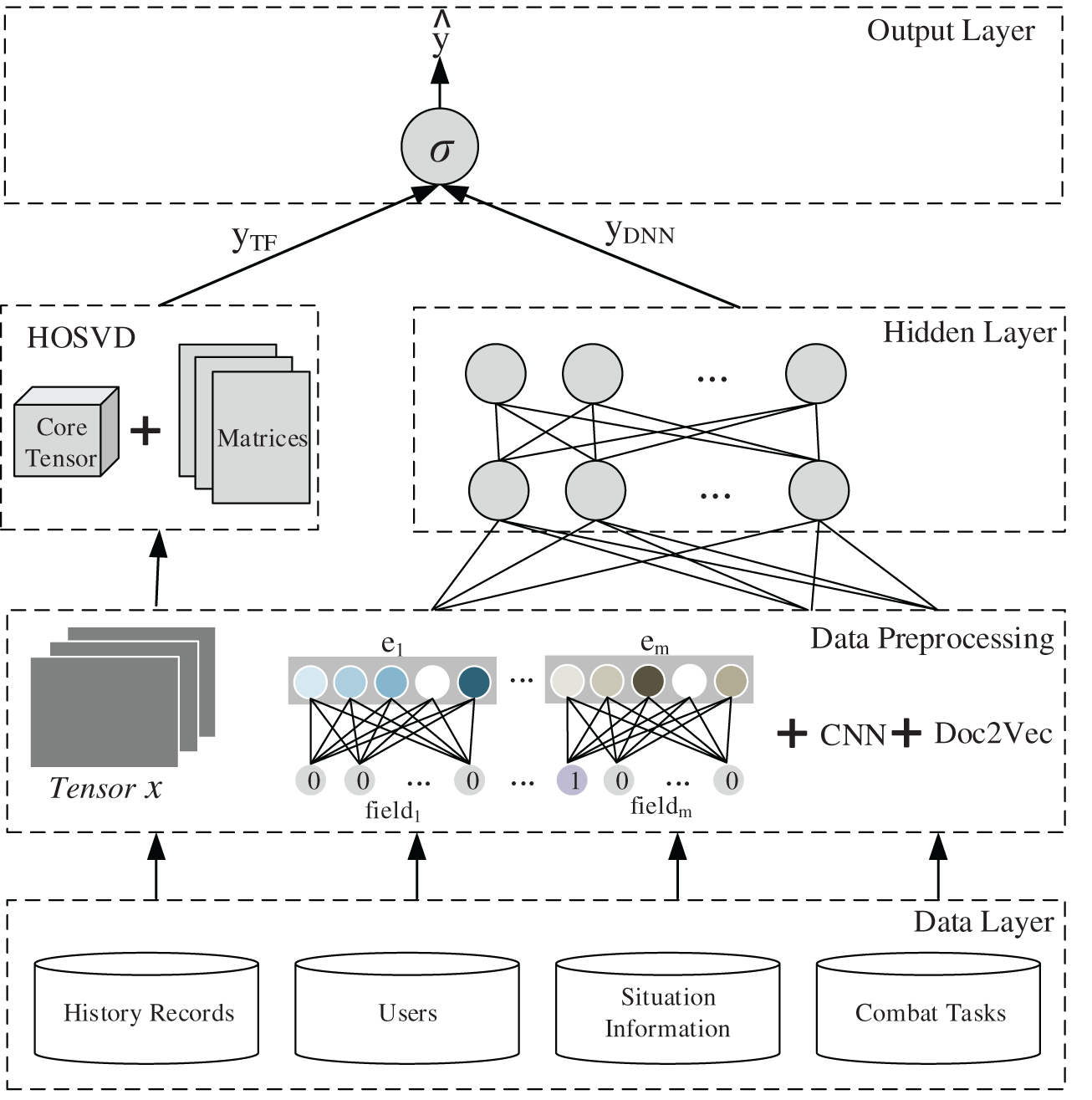
Figure 4: The architecture of TBSI-HRM
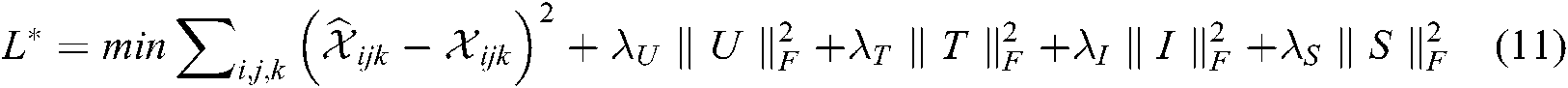
Recommend the situation information with the largest correlation value to the users.
4.2 HOSVD-Based BSIR Algorithm
TBSI-HRM uses three-dimensional tensor 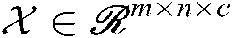 to represent historical interaction data among users, combat tasks and situation information. However, the BSIR algorithm based on HOSVD applies the algorithm idea of HOSVD, iteratively calculates the low-rank approximate matrices of U, T, I and the approximate tensor of core tensor S by gradient descent method, and calculates the predicted value of correlation degree at the same time, thus obtaining the approximate tensor
to represent historical interaction data among users, combat tasks and situation information. However, the BSIR algorithm based on HOSVD applies the algorithm idea of HOSVD, iteratively calculates the low-rank approximate matrices of U, T, I and the approximate tensor of core tensor S by gradient descent method, and calculates the predicted value of correlation degree at the same time, thus obtaining the approximate tensor 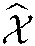 of tensor
of tensor 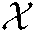 .
.
The loss function of tensor factorization is calculated by the square error between the original value and the approximate value:

When the score matrix of user-situation information is very sparse, overfitting will occur. Usually, the method is to add a regularization term based on the l2 norm of these factors. This norm is also known as the F norm. If F norm is added here, the objective function becomes:

Where, λU, λT, λI and λS are the weights of the regular terms respectively. For the optimization of the objective function, the stochastic gradient descent (SGD) method is adopted, and 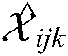 is calculated simultaneously in the iterative process [37]. In order to calculate the update of SGD algorithm, it is necessary to calculate the gradient of loss function, which can be calculated from Eq. (7):
is calculated simultaneously in the iterative process [37]. In order to calculate the update of SGD algorithm, it is necessary to calculate the gradient of loss function, which can be calculated from Eq. (7):




Thus, the iterative updating formula of each factor matrix is obtained as follows:




where η is the step size, i.e., the learning rate, which is a super parameter and can be determined by adjusting parameter. The algorithm is shown in Tab. 1.
Algorithm 1: HOSVD-based BSIR algorithm

Deep component mainly uses a variety of neural networks to preprocess multi-source heterogeneous data to extract embedded feature representations of various data, and then carries out correlation degree prediction. Its structure is shown in Fig. 5.
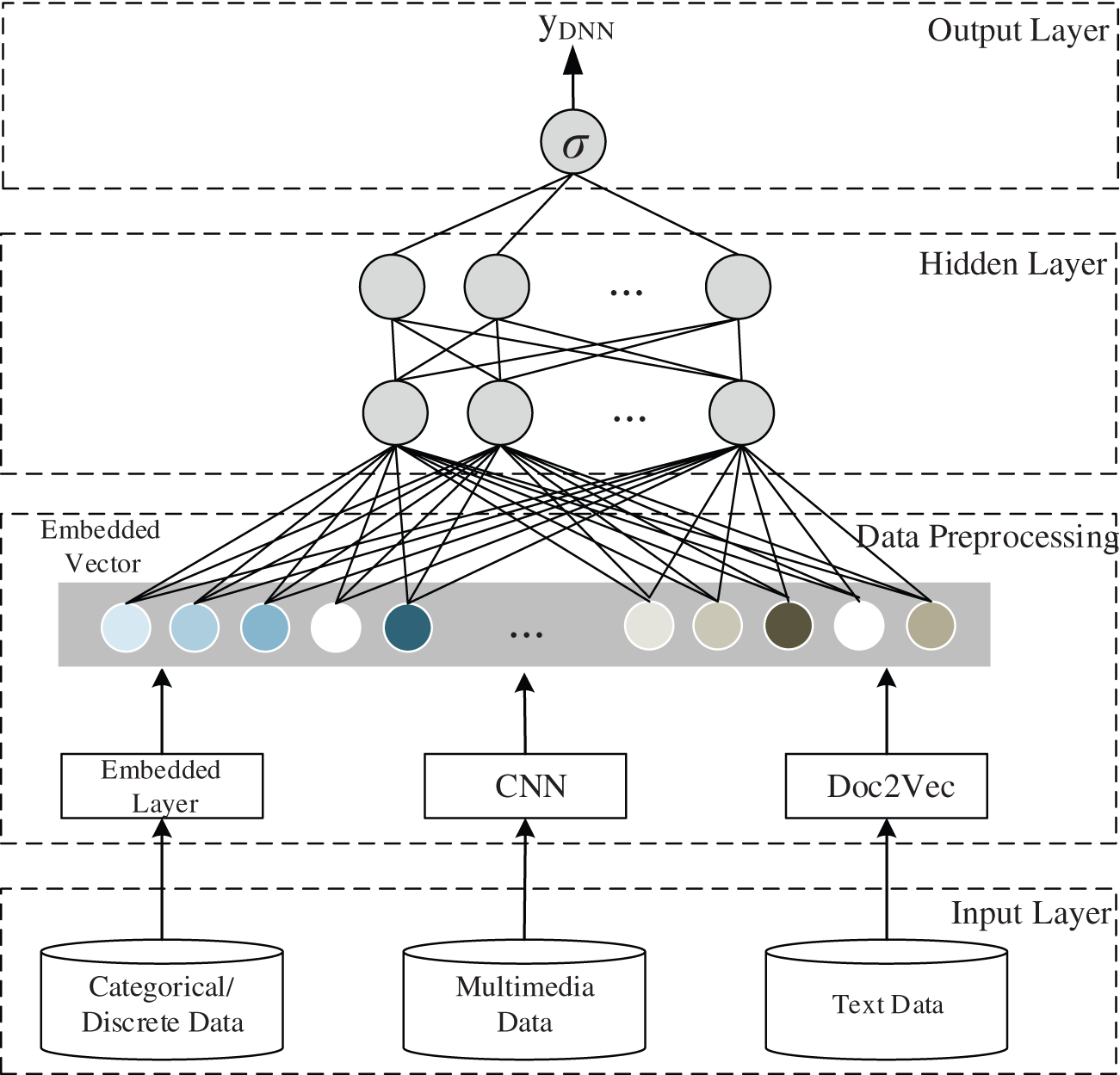
Figure 5: The architecture of the deep component
In recommendation systems, multi-source heterogeneous data usually includes structured, semi-structured, and unstructured data [43]. In BSIR, structured data includes scoring matrix converted by explicit feedback or implicit feedback of users. The semi-structured data include the users’ attribute information (such as age, gender, education background, ranks, military services, etc.), and the attribute information of situation information (identification, category, label, etc.); Unstructured data includes user’s comments, text related to situation information, images, videos, etc. For these heterogeneous data sets with various data forms, it is challenging to express different data forms with vectors of the same dimension.
In many recommendation systems based on DNN, in order to learn hidden feature representations of complex content dta or the interaction between features, a multi-layer fully connected network structure is usually adopted. However, unlike the application of deep neural networks in the field of computer vision, the input data are usually pictures, and the content of these data is dense. In the powerful situation awareness system, the input data are usually highly sparse, super high-dimensional, categorical-continuous-mixed. The amount of calculation increases exponentially, and even “dimension disaster” may occur. If fully connected neural network is directly used to process input data, it will result in extremely many network parameters and extremely low computational efficiency. In order to solve the above problems, this paper uses field-based feature representation and designs a hybrid model based on multi-source heterogeneous data, as shown in Fig. 5.
For semi-structured data, we can transform semi-structured data into structured data by discretization or 0–1. For unstructured data, it can be transformed into structured data through information retrieval technology or machine learning methods. As shown in the model, this paper directly uses the embedding layer to transform the embedded features of the structured information in the users’ information and situation information, and uses the convolution neural network to extract the features of the picture. Furthermore, deep text learning algorithm Doc2Vec is used to extract embedded feature representations of text data, and all data are uniformly mapped to a potential low-dimensional feature space.
The output of the feature embedding layer is a horizontal splicing wide vector with length of  :
:

Where, 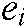 represents the embedding vector of the ith field, D is the dimension of the embedding vector, and m is the number of fields. Then the embedding vector
represents the embedding vector of the ith field, D is the dimension of the embedding vector, and m is the number of fields. Then the embedding vector 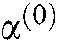 is fed into the DNN, and the calculation update of the hidden layer is performed according to the Eq. (21):
is fed into the DNN, and the calculation update of the hidden layer is performed according to the Eq. (21):

Where, l is the number of hidden layers, σ is sigmod() activation function, that is 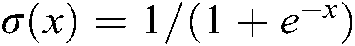 .
.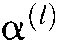 is the input of the hidden layer of the lth level, and
is the input of the hidden layer of the lth level, and 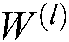 and
and  are the model parameters and offsets of the lth level respectively.
are the model parameters and offsets of the lth level respectively.
Assume the number of hidden layers is L, the prediction value of the correlation degree of the output layer is:

Accuracy is a very important index for evaluating the recommendation system. The purpose of BSIR is also to recommend the situation information that the commander needs, so the accuracy of the situation information recommendation is very important. We selected Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) as the evaluation indexes of our algorithm to evaluate the recommendations effectiveness.
In the experiment, the data from the situation management of an actual combat military confrontation training information system has been used as the experimental dataset. A total of 18 complete exercises were collected. There are about 3–6 tanks in each exercise, of which each has 3 units and each unit has 10 tanks. In the 18 exercises, 362 effective tasks have been received by tank troops, and all units have received 5973 effective tasks. The first 15 exercises’ data are taken as sample sets, and the data of the last 3 exercises are taken as test sets.
This paper mainly tests the algorithm performance through scenario simulation. Firstly, a simulation system consisting of a battle support center, a battle-level command post and two tactical-level command posts with different attributes is constructed. Each command post includes two main decision-making commanders. Among them, the two tactical command posts’ superiors are all operational command posts, and the responsibility areas do not intersect. Each commander and command post customizes the operational situation to the situation service center according to the area of responsibility, and the operational support center is responsible for recommending situation information to the commander and command post. The simulation we have was result in 30 combat tasks and 60000 pieces of various situation information, which will randomly assign combat tasks to command posts and commanders.
The neural network can be trained efficiently by preprocessing all kinds of situation information. Unify picture data by data enhancement, adjusting picture size and converting picture format; for text situation information, the text should be cleaned by eliminating useless punctuation information, text segmentation, synonym merging, eliminating stop words and other operations. For classified and continuous features, the situation information is normalized by field-based feature representation. Then all kinds of situation information data are input into the data feature hybrid learning model for training and learning so as to realize more accurate feature vector representation.
5.1 Compare TBSI-HRM with Publish/Subscribe Situation Distribution Mechanism
The accuracy index φ is used to evaluate and compare the performance of TBSI-HRM, topic-based publish/subscribe method [2] and content-based publish/subscribe method [44]. Accuracy φ is defined as follows:

Where, n is the total number of situation information pushed to users, and m is the number of situation information that has been pushed to the users and users are interested in.
The comparison of the accuracy rates of the three methods are shown in Tab. 2.
Table 2: The comparison of the accuracy rates
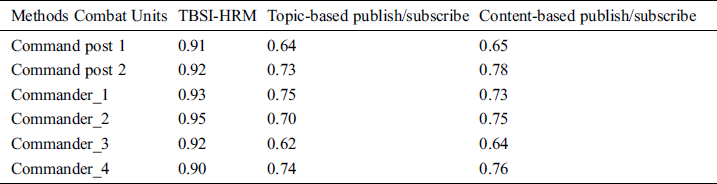
As we can see from Tab. 2, the accuracy rate of situation information of TBSI-HRM can reach more than 90%, and it is hardly affected by changes in combat tasks. Subscribe/publish-based methods suffer from low accuracy because of subscription content will affect the matching of combat tasks. Especially when sudden tasks occur or the assigned tasks do not match the subscribed situation content completely, it will seriously affect the accuracy of situation push. For example, command post 1 and commander 3 in the table both receive combat tasks that do not match the information they subscribe to, resulting in users receiving the useless subscribed situation information.
5.2 Compare TBSI-HRM with Independent Models
We use Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), recall rate (Recall) and precision rate (Precision) to compare the TBSI-HRM with two independent models of DNN and TF. The experimental results of MAE and RMSE are shown in Tab. 3.
Table 3: The comparison of MAE and RMSE
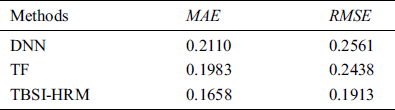
As we can see from Tab. 3, TBSI-HRM has lower error and more accurate recommended results than the two independent models.
The contrast of Recall and Precision is shown in Fig. 6.
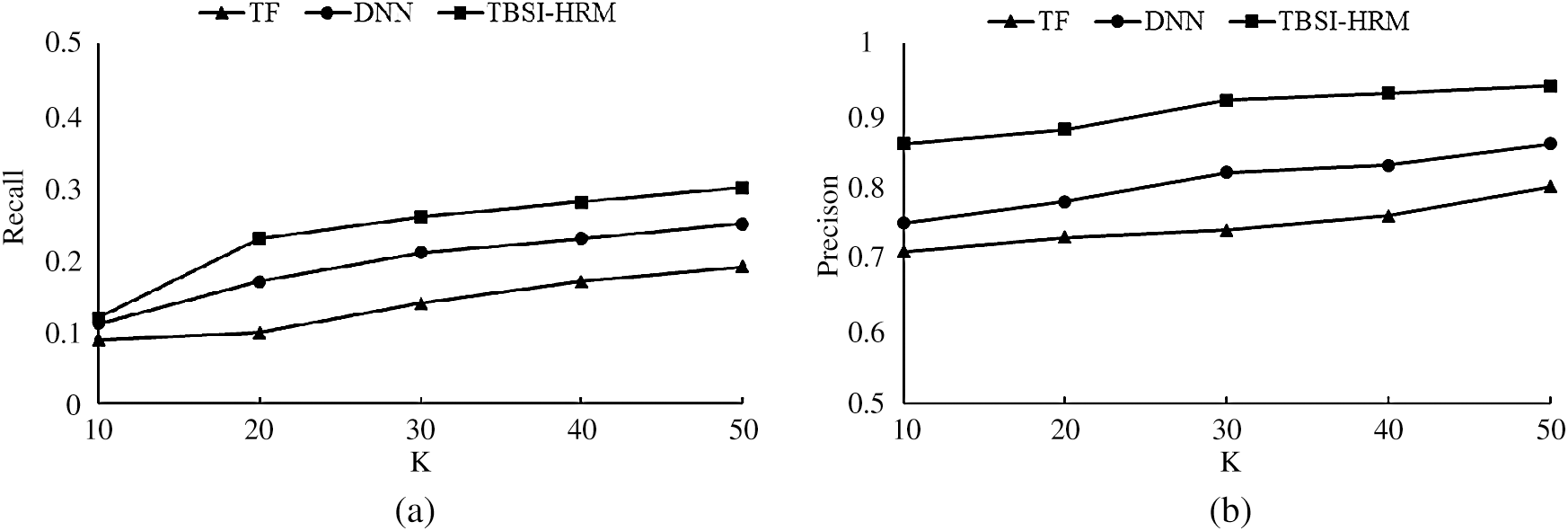
Figure 6: The comparison of recall and precision
As we can see from Fig. 6, TBSI-HRM is obviously more accurate than the other two independent models. This is because TBSI-HRM combines the two models, which can make up for the defect of incomplete data sources extracted by a single model and can learn more effective information, thus improving the accuracy of recommendation results. TBSI-HRM combines TF and DNN learning users’ behavior preference, which has high intelligence, high accuracy and high robustness. Thus, it can be effectively applied in actual combat, reducing the workload of users and improving decision-making efficiency.
In order to meet the needs of users for dynamic battlefield situation information in the process of carrying out combat tasks and realize personalized situation information recommendation, this paper designs a Task-Oriented Battlefield Situation Information Hybrid Recommendation Model (TBSI-HRM). TBSI-HRM combines TF and DNN, taking into account the hidden features of users, battlefield situation information and combat tasks in users score and the features of auxiliary information, expecting to mine more feature information of situations, making the users’ demand modeling more accurate, thus improving the accuracy of recommendation. The performance of TBSI-HRM, independent models and classical recommendation algorithms are compared through experiments, and also the excellent performance of the model in situation information recommendation has been verified.
Acknowledgement: We gratefully acknowledge the financial supports by the National Natural Science Fund of China under Grant numbers 61773399, as well as the National Social Science Fund of China under Grant numbers 14gj003–073.
Funding Statement: The National Natural Science Fund of China (No.61773399) and the National Social Science Fund of China (No. 14gj003–073) supported our work with RMB 200,000 and RMB 100,000 respectively.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. P. Guan and Y. F. Wang. (2016). Identifying optimal topic numbers from Sci-Tech information with LDA model, vol. 32. Modern Library Information Technology, 42–50. [Google Scholar]
2. D. X. Xie and Y. S. Ji. (2014). “Military information distribution based on publish/subscribe techniques,” Command Information System and Technology, vol. 5, no. 1, pp. 17–2l. [Google Scholar]
3. H. Wang, G. P. Shao and G. C. Sun. (2012). “Battlefield situation information dissemination model based on agent,” Journal of Information Engineering University, vol. 13, no. 6, pp. 753–757. [Google Scholar]
4. Z. W. Qiu and Y. Z. Zhang. (2013). “Battlefield information distributed strategy based on multi-agent,” Fire Control & Command Control, vol. 38, no. 12, pp. 52–55+60. [Google Scholar]
5. M. Yu, R. J. Yang, H. B. Cheng and J. Luo. (2014). “Radar information distribution technology based on Naive Bayes algorithm,” Modern Radar, vol. 36, no. 7, pp. 46–50+53. [Google Scholar]
6. H. W. Zhou and H. Y. Zhou. (2015). “Information distribution mechanism of situation intelligence based on user interest vector space model,” Command Information System and Technology, vol. 6, no. 6, pp. 90–95. [Google Scholar]
7. L. M. Dong, T. C. Gao, R. B. Qiu and L. M. Ma. (2017). “Battlefield situation real- time distribution technology based on semantic publish/subscribe system,” Fire Control & Command Control, vol. 42, no. 4, pp. 110–113. [Google Scholar]
8. X. J. Liang and Y. Liang. (2016). “Information distribution technology for mission planning,” Ship Electronic Engineering, vol. 36, no. 7, pp. 14–17+171. [Google Scholar]
9. S. W. Wang, H. D. Cheng and G. B. Liu. (2016). “Task-oriented unified combat situation data distribution,” Command Information System and Technology, vol. 7, no. 1, pp. 32–36. [Google Scholar]
10. P. Huang, X. D. He, J. F. Gao, D. Li, A. Alex,. (2013). et al., “Learning deep structured semantic models for web search using click through data,” in Proc. CIKM, pp. 2333–2338. [Google Scholar]
11. H. T. Cheng, L. Koc and J. Harmsen. (2016). “Wide & deep learning for recommender systems,” in Proc. the 1st Workshop on Deep Learning for Recommender Systems, ACM, pp. 7–10. [Google Scholar]
12. X. N. He, L. Z. Liao, H. W. Zhang, L. Q. Nie, X. Hu. (2017). et al., “Neural collaborative filtering,” in Proc. the 26th International Conference on World Wide Web, pp. 173–182. [Google Scholar]
13. H. F. Guo, R. M. Tang, Y. M. Ye, Z. G. Li and X. Q. He. (2017). “DeepFM: A factorization-machine based neural network for ctr prediction,” in Proc. the 26th International Joint Conference on Artificial Intelligence, [S.l.]: AAAI Press, pp. 1725–1731. [Google Scholar]
14. W. H. Yu, H. D. Zhang, X. G. He, X. Chen, L. Xiong. (2018). et al., “Aesthetic-based clothing recommendation,” in Proc. the 2018 World Wide Web Conf., pp. 649–658. [Google Scholar]
15. C. Y. Lei, D. Liu, W. P. Li, Z. J. Zha and H. Q. Li. (2016). “Comparative deep learning of hybrid representations for image recommendations,” in Proc. the IEEE Conf. on Computer Vision and Pattern Recognition, pp. 2545–2553, . [Google Scholar]
16. S. R. Yogesh and S. K. Mohan. (2016). “ConTagNet: Exploiting user context for image tag recommendation,” in Proc. the 2016 ACM on Multimedia Conf., pp. 1102–1106. [Google Scholar]
17. H. Bal´azs, A. Massimo, K. Alexandros and T. Domonkos. (2016). “Parallel recurrent neural network architectures for feature-rich session-based recommendations,” in Proc. Recsys, pp. 241–248. [Google Scholar]
18. C. Konstantina, B. Alex, R. Li, J. Sagar and E. H. Chi. (2018). “Q&R: A two-stage approach toward interactive recommendation,” in Proc. SIGKDD, pp. 139–148. [Google Scholar]
19. B. Trapit, B. David and M. Andrew. (2016). “Ask the gru: multi-task learning for deep text recommendations,” in Proc. the 10th ACM Conf. on Recommender Systems, pp. 107–114. [Google Scholar]
20. J. Huang, W. X. Zhao, H. Dou and J. R. Wen. (2018). “Improving sequential recommendation with knowledge-enhanced memory networks,” in Proc. the 41st Int. ACM SIGIR Conf. on Research & Development in Information Retrieval, pp. 505–514. [Google Scholar]
21. G. J. Zheng, F. Z. Zhang, Z. H. Zheng, Y. Xiang and N. J. Yuan,. (2018). et al., “ DRN: A deep reinforcement learning framework for news recommendation,” in Proc. WWW, pp. 167–176. [Google Scholar]
22. K. D. Doan, G. Yang and C. K. Reddy. (2019). “ An attentive spatio-temporal neural model for successive point of interest recommendation,” in Proc. PAKDD 2019, LNAI 11441, Macau, China, pp. 346–358. [Google Scholar]
23. H. A. Rahmani, M. Aliannejadi, S. Ahmadian, M. Baratchi, M. Afsharchi et al. 2019. , “LGLMF: Local geographical based logistic matrix factorization model for poi recommendation. arXiv: 1909.06667 [cs.IR]. [Google Scholar]
24. Q. Y. Gu, R. J. Yang and M. R. Huang. (2017). “Radar information screening technology based on content similarity,” Journal of Air Force Early Warning Academy, vol. 31, no. 3, pp. 190–193. [Google Scholar]
25. Y. Ran, Z. L. Huang, B. Hu and S. Z. Wang. (2020). “Research on battlefield situation intelligent push based on Doc2Vec and deep neural network,” Intelligent Computer and Applications, vol. 10, no. 1, pp. 50–55. [Google Scholar]
26. H. F. Liu, D. S. Yang, Z. Liu and W. M. Zhang. (2006). “Tactical situation conception model based on task,” Armament Automation, vol. 05, pp. 21–22+25. [Google Scholar]
27. H. F. Liu, D. S. Yang, Z. Liu and W. M. Zhang. (2006). “Description and organization of object in ttsp,” Armament Automation, vol. 04, pp. 13–14+19. [Google Scholar]
28. J. X. Lian. (2018). Personalized Recommender Systems with Diversified Data. China: University of Science and Technology of China. [Google Scholar]
29. W. Zhang, T. Du and J. Wang. (2016). “Deep learning over multi-field categorical data,” in Proc. European Conf. on Information Retrieval, [S.l.]: Springer, pp. 45–57. [Google Scholar]
30. Y. Qu, H. Cai, K. Ren, W. N. Zhang , Y. Yu. (2016). et al., “Product-based neural networks for user response prediction,” in Proc. Data Mining (ICDMIEEE 16th International Conf. on, [S.l.]: IEEE, pp. 1149–1154. [Google Scholar]
31. N. Passalis and A. Tefas. (2018). “Learning bag-of-embedded-words representations for textual information retrieval,” Pattern Recognition, vol. 81, pp. 254–267, . DOI 10.1016/j.patcog.2018.04.008. [Google Scholar]
32. T. Mikolov, K. Chen, G. Corrado and J. Dean. (2013). “Efficient estimation of word representations in vector space. 2013a.arXiv preprintarXiv: 1301.3781[cs.CL]. [Google Scholar]
33. Q. V. Le and T. Mikolov. (2014). “ Distributed representations of sentences and documents,” in Proc. the 31st Int. Conf. on Machine Learning (ICMLBeijing: Springer, pp. 1188–1196. [Google Scholar]
34. T. G. Kolda and B. W. Bader. (2009). “Tensor decompositions and applications,” SIAM Review, vol. 51, no. 3, pp. 455–500, . DOI 10.1137/07070111X. [Google Scholar]
35. C. Chen. (2017). The Application of Matrix and Tensor Decomposition in Classification. Xiamen University. [Google Scholar]
36. L. Yang, S. H. Wang and B. Zhu. (2020). “Ranking based hybrid deep tensor factorization model for group recommendation,” Application Research of Computers, vol. 37, no. 5, pp. 1311–1316. [Google Scholar]
37. K. Alexandros. (2010). “Multiverse recommendation: n-dimensional tensor factorization for context-aware collaborative filtering,” in Proc. RecSys2010, Barcelona, Spain, pp. 26–30. [Google Scholar]
38. J. D. Carroll and J. Chang. (1970). “Analysis of individual differences in multidimensional scaling via an N-way of ‘Eckart Young’ decomposition,” Psychometrika, vol. 35, no. 3, pp. 283–319, . DOI 10.1007/BF02310791. [Google Scholar]
39. L. R. Tucker. (1963). “Implications of factor analysis of three way matrices for measurement of change,” Problems in Measuring Change, 122–137. [Google Scholar]
40. L. D. Lathauwer, B. D. Moor and J. Vandewalle. (2000). “A multilinear singular value decomposition,” SIAM Journal of Matrix Analysis and Applications, vol. 21, no. 4, pp. 1253–1278, . DOI 10.1137/S0895479896305696. [Google Scholar]
41. Y. D. Kim and S. Choi. (2007). “Nonnegative tucker decomposition,” in Proc. Computer Vision and Pattern Recognition 2007, IEEE Conf., pp. 1–8, . [Google Scholar]
42. A. H. Phan and A. Cichocki. (2011). “HALS algorithm for nonnegative Tucker decomposition and its applications for multiway analysis and classification,” Neurocomputing, vol. 74, no. 11, pp. 1956–1969, . DOI 10.1016/j.neucom.2010.06.031. [Google Scholar]
43. B. Wu, Z. Z. Lou and Y. D. Ye. (2019). “A collaborative filtering recommendation algorithm for multi-source heterogeneous data,” Journal of Computer Research and Development, vol. 56, no. 6, pp. 1034–1047. [Google Scholar]
44. Y. L. Zhang, Y. Xu, J. Ma and Y. B. Wang. (2009). “A method of intelligence distribution by combining neural network with match algorithm,” Journal of Air Force Radar Academy, vol. 23, no. 1, pp. 22–25. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |