DOI:10.32604/iasc.2021.014419
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2021.014419 | |
| Article |
An Enhanced Convolutional Neural Network for COVID-19 Detection
1College of Islamic Sciences, University of Anbar, Ramadi, Iraq
2College of Computer Science and Information Technology, University of Anbar, Ramadi, Iraq
3eVIDA Lab, University of Deusto, Avda/Universidades 24, 48007, Bilbao, Spain
*Corresponding Author: Belal Al-Khateeb. Email: belal-alkhateeb@uoanbar.edu.iq
Received: 19 September 2020; Accepted: 23 January 2021
Abstract: The recent novel coronavirus (COVID-19, as the World Health Organization has called it) has proven to be a source of risk for global public health. The virus, which causes an acute respiratory disease in persons, spreads rapidly and is now threatening more than 150 countries around the world. One of the essential procedures that patients with COVID-19 need is an accurate and rapid screening process. In this research, utilizing the features of deep learning methods, we present a method for detecting COVID-19 and a screening model that uses pulmonary computed tomography images to differentiate COVID-19 pneumonia from healthy cases. In this study, 256 cases (128 COVID-19, 128 normal) are used to detect COVID-19 early. Real cases of 51 external COVID-19 images are also taken from Iraqi hospitals and used to validate the proposed method. Segmentations of the lung and infection fields are retrieved from the images during preprocessing. The total accuracy obtained from the results is 98.70%, indicating the success of the designed model.
Keywords: COVID-19; deep learning; convolution neural network; X-ray
Coronaviruses envelop positive-sense non-segmented RNA viruses that belong to the orders of Corona Miridae and Nidovirales and are common in humans and other mammals [1]. Although the majority of coronavirus infections in humans are minor, two beta-corona virus epidemics, including the acute severe respiratory syndrome coronavirus in December 2019 in Wuhan, Hubei province, became the center of a pneumonia outbreak of an unknown cause, thus raising massive attention in China and the world [1]. Health authorities in China conducted an immediate investigation to characterize and control this disease, including isolating people suspected of having the disease, close contact monitoring, collecting clinical and epidemiological data from patients, and developing diagnostic and treatment procedures. Researchers also communicated directly with the patients and/or their families to ascertain the epidemiological and symptom data. The results from the patients admitted to intensive care units and the ones who were not were compared [2]. While extreme precautionary measures taken in South Korea, China, and Hong Kong successfully contained the virus, the rising number of cases in the Western world is alarming. A clear picture of the space–time dependence of the virus’s propagation may be obtained from China’s data, for which numbers are considerably large [3]. The present research utilized 307 computed tomography (CT) images to classify COVID-19. Before the classification, images and samples of the datasets were labeled as either normal or COVID-19. The analysis of image contents has become one of the important subjects in modern life. To recognize the images in an efficient way, several techniques have been proposed and periodically enhanced by developers. Image retrieval (IR) has become one of the main problems the computer society is facing inside such technological revolution.
To increase the effectiveness of computing similarities among images, many programmers have focused on hashing approaches that convert images to strings of float numbers hash code. In the past few years, deep learning (DL) has been considered the backbone of image analysis using a convolutional neural network (CNN). DL approaches are used for feature extraction and the classification of coronavirus images, and IR techniques have become widespread in the detection of the image category among several categories. In this work, the CT scan image is the input to the classifier system and the output is either the person who has COVID-19 or does not. CNN is a neural network type that is very efficient in extracting image features and building classifier models that can be trained and tested on the features [4,5]. A decision matrix integrating a combination of 10 assessment parameters and 12 diagnostic models for COVID-19 was devised in another work. The multi-criteria decision-making approach was used to test and benchmark the various COVID-19 diagnostic models with respect to the assessment criteria [6]. A lightweight DL model was also proposed to accurately screen COVID-19. A lightweight model is important because it can be distributed without considering the memory storage space of different devices, including cell phones, tablets, and computers. [7]. Moreover, identifying a suitable CNN model through an initial comparative study of several popular CNN models was proposed to supervise the case of the patient for several days [8]. The findings showed that the proposed method can be used as an assistant system to diagnose COVID-19 [2].
Wang et al. altered the typical network of Inception and fine-tuned the model of modified Inception with pre-trained weight values. The architecture consisted of three necessary procedures: a) random ROI selection, b) training the CNN model for feature extraction, and c) training the classification model of a fully connected network and predicting multiple classifiers. CT images were obtained retrospectively from 99 patients, including 55 typical viral pneumonia cases and 44 cases from 3 separate hospitals that had confirmed SARS-COV2 nucleic acid testing. The rest of the images were utilized afterward for external validations. The training model was iterated 15,000 times with a 0.01 step size, and the algorithm of the DL was given a 0.9 (95% CI, 0.86–0.94) AUC on internal validations and 0.78 (95% CI, 0.71–0.84) on external validations. With the use of maximized Youden index threshold probability, the internal and external datasets reached the following parameters: 80.50% and 67.10% sensitivity, 84.20% and 76.40% specificity, 82.90% and 73.10% accuracy, 0.88 and 0.81 negative prediction values, 0.69 and 0.44 Youden index, and 0.77 and 0.64 F1 score, respectively. The datasets constructed a migration of the Inception neuro network, which reached an accuracy of 82.90%. In addition, the high efficiency of the developed DL model in this research was tested using external samples with 73% accuracy [9].
Xu et al. measured the minimal distance from the mask to the patch’s center. The minimum circumscribed pulmonary image diagonal rectangle and relative distance to the distance from the edge reached were obtained from the previous step. The present research evaluated two CNN 3D models of classification: the first model is a relatively conventional ResNet-23-based network, and the second model is designed on the basis of the first network structure through the concatenation of the location attention mechanism in the full-connection layer to improve the general efficiency. The classic ResNet18 network structure was utilized to extract image features. For data dimension reduction, pooling operations were used to avoid overfitting and strengthen the issue of generalization. The output of the convolution layer was flattened to a 256-dimension feature vector and then transformed using a completely connected network to a 16-dimensional feature vector. The relative distance-from-the-edge value was originally standardized to the same order of magnitude for location-attention networks and eventually concatenated into this fully connected network structure. Next, in accordance with the trust ranking, three completely linked layers were pursued to achieve the final classification result. Experimental results of the benchmark dataset showed that the general accuracy was 86.70% from the CT case viewpoint as a whole. The Noisy-or Bayesian function was utilized to identify the dominant types of infections. Three types of exported results were derived: no infection found, COVID-19, and Influenza A viral pneumonia. Since items unrelated to infection (previous step) would be overlooked and not counted by the Bayes function, the researchers only compared the average F1-score for the second two items, which were 0.806 and 0.843, respectively, showing a 4.70% promotion. In addition, the general accuracy of classification for all three groups was 86.70% [10].
Narin, Kaya, and Pamuk presented an automatic COVID-19 prediction method using deep CNN-based pre-trained transfer models and images of chest X-rays. The researchers utilized the ResNet-50, Inception-V3, and Inception-ResNet-V2 pre-trained models to obtain a higher level of prediction accuracy for the small X-ray dataset. The model of residual neural networks (ResNet) is an enhanced CNN version. By adding shortcuts between layers to solve an issue, it can prevent distortions occurring as the network’s deepness and complexity increase. Bottleneck blocks have also been utilized to make the training faster in the ResNet model. ResNet-50 is a network with 50 layers that have been trained on the ImageNet dataset. This dataset has over 14 million images belonging to over 20,000 classes produced for image identification competitions. Inception-V3 is a type of CNN model consisting of several convolutions and maximum pooling steps. In the final stage, it includes a full-connection neural network. Concerning the model of the ResNet-50, the network has been trained using the ImageNet dataset. The model includes a deep CNN using the Inception ResNet-V2 model, which has been trained on the ImageNet2012 dataset. Taking under consideration the obtained performance results, the pre-trained ResNet-50 model provided maximum classification efficiency with an accuracy equal to 98% among the other two suggested models (87% accuracy for Inception-ResNet-V2 and 97% accuracy for Inception-V3) [11].
Wang and Wong constructed an initial design prototype of a network based on human-driven design principles and optimal practices. In particular, the design principles of residual architectures were leveraged in their research because these continuously enabled reliable NN architectures, which are easier to train, exhibit better performance, and enable success in building deeper architectures. In their work, the authors constructed the initial prototype of the network design to make one of the following four predictions: i) no infections (i.e., normal), ii) bacterial infections, iii) non-COVID viral infections, and iv) viral infection of COVID-19. These four possibilities were selected because they can help clinicians more efficiently reach a decision on who needs to be prioritized for PCR testing to confirm a COVID-19 case as well as which treatment strategy should be employed according to the infection cause, given that each infection type requires a different treatment strategy. The collaborative design of “human–machine” strategy has been utilized to create the suggested COVID-Net. It is a stage of machine-driven design exploration where the prototype of the initial network design, the data, and the requirements of human-specific design serve as guides toward a strategy of design exploration for learning and identifying the optimum macro architecture and the microarchitecture designs with which to construct the ultimate tailor-made architecture of the deep NN. In this research, leveraging generative synthesis is a strategy of machine-driven design exploration to generate the ultimate COVID-Net network model that can satisfy the human-specified design requirements below the (a) accuracy of the test ≥ 80% and the (b) computational complexity of the network ≤ 2.5 billion multiply-accumulate (MAC) operations [12].
Shan et al. proposed a system called VB-Net that trained with 249 COVID-19 patients, and the validation was carried out using 300 new patients with COVID-19. A human-in-the-loop (HITL) technique was introduced to help radiologists optimize the automated annotation of each case and speed up the preparation of the manual CT images for delineation. For the sake of evaluating the DL-based system performance, the coefficient of the Dice similarity, volume differences, and percentage of infection (POI) between the effects of automated and manual segmentation on the validation collection were determined. Training samples were required for the proposed VB-Net with comprehensive delineations of each infected area. However, this is labor-intensive work for radiologists because they need to annotate hundreds of CT scans of COVID-19. This is why the HITL strategy was adopted for the iterative updating of the DL model. In particular, training data were segmented into several batches. Initially, CT data in the minimal batch were contoured manually by the radiologists. Afterward, the segmentation network was trained using the minimal batch as an initial model, which was implemented to segment the infection areas in the next batch. The radiologists then performed manual correction of the segmentation results provided by the segmentation network. These corrected results of the segmentation were fed afterward as the new training data, making it possible to update the model with an increased training dataset. This way, the training dataset was iteratively increased, and the ultimate VB-Net was built. In the testing stage, the trained segments of the segmentation network of infected areas on a new CT scan through a forward pass of the NN and the HITL interaction provided potential interventions and human–machine interactions for the radiologists in the clinical applications. The training strategy of the HITL converged following three to four iterations. The suggested system resulted in a Dice similarity coefficient of 91.60% ± 10% between the automatic and manual segmentations and an average 0.30% POI estimation error for the entire lung on the validation dataset. Compared to the fully manual delineation cases that usually take one to five hours, the suggested HITL strategy was capable of dramatically reducing the time of the delineation to four minutes after three updates of model iterations [13].
Barstugan, Ozkaya, and Ozturk performed a two-stage coronavirus classification. The classification process was implemented on four separate sub-sets with no feature extraction processes in the first stage. The sub-sets were transformed into a vector and classified through SVM. In the second stage, five feature extraction methods, namely, local directional patterns, gray level co-occurrence matrix (GLCM), gray level size zone matrix (GLSZM), gray level run length matrix, and discrete wavelet transform (DWT), extracted the features, which were then classified with the use of the SVMs. The 2-fold, 5-fold, and 10-fold cross-validation methods were used in the classification process. Average classification findings were obtained after the cross-validation procedure. The dataset of this study was formed manually and achieved 99.68% classification accuracy, which showed that the best performance was obtained by extracting the features of the patches. In the 10-fold cross-validation, the GLCM, GLSZM, and DWT methods still achieved over 90% classification accuracy. The best classification efficiency was obtained by using the GLSZM approach with 5-fold cross-validation. Accordingly, another coronavirus CT image dataset should be tested using the proposed method [14].
Al-Waisy et al. accurately diagnosed COVID-19 virus in chest X-ray images by developing a fast and hybrid DL framework called COVID-CheXNet system. The researchers enhanced the contrast of the X-ray image and reduced the noise level by using contrast-limited adaptive histogram equalization and Butterworth bandpass filter, respectively. These were accompanied by the fusion of the findings obtained from two separate pre-trained DL models based on the integration of a ResNet34 model and a large-scale dataset-trained high-resolution network model. The researchers used the parallel architecture to differentiate between healthy and COVID-19-compromised individuals and provide radiologists with a high degree of trust. With the use of the score-level weighted sum rule, the proposed COVID-CheXNet system managed to correctly and reliably diagnose patients with COVID-19, achieving 99.99% identification accuracy rate, 99.98% sensitivity, 100% precision, 100% accuracy, 99.99% F1 score, 0.011% MSE, and 0.012% RMSE. The utility and efficacy of the proposed COVID-CheXNet method were developed along with the possibility of using the method as a supplement for rapid diagnosis and treatment in real clinical centers, requiring just less than two seconds per image to obtain the predictive outcome [15].
CNNs are variants of a multi-layer perceptron. Usually, multi-layer perceptron refers to completely connected networks, where each neuron in one layer is connected to all neurons in the next layer. The “full connection” of these networks makes them vulnerable to data overfitting. Typical methods of regularization include applying to the loss function some form of magnitude calculation of weights. CNNs have a particular approach to regularization: using smaller and simplified patterns, they take advantage of the structured pattern of data and assemble more complicated patterns. Therefore, CNNs are on the lower extremity of the connectedness and complexity scale. Completely linked layers link every neuron in one layer to a neuron in another layer [16]. It is, in theory, the same as the conventional multi-layer perceptron neural network. To distinguish the images, the flattened matrix goes through a fully connected layer. Each neuron in a neural network calculates an output value by applying a particular feature to input values from the receptive area of the previous layer. A vector of weights and a bias (typically real numbers) determine the function applied to the input values. Learning occurs in a neural network by making iterative changes to these biases and weights [17]. A recurrent neural network (RNN) is a class of artificial neural networks where connections between nodes form a directed graph along a temporal sequence. This allows it to exhibit temporal dynamic behavior. RNNs, originating from feedforward neural networks, can process variable-length sequences of inputs using their internal state (memory). This capability makes them applicable to assignments such as unsegmented, associated recognition of handwriting or recognition of expression. Basic RNNs are a neuron-like network of nodes arranged into successive layers [18]. Each node in each layer is connected to every other node in the next successive layer with a guided (one-way) connection [19]. Each node (neuron) has a time-varying real-valued activation, and each connection (synapse) has a modifiable real-valued weight. Nodes are either input nodes (that collect data from outside the network), output nodes (that deliver results), or hidden nodes (that alter the input-to-output data route) [20].
DL is a research area in machine learning that is based upon a specific learning mechanism type. It has been identified by efforts toward creating a learning model at a number of levels, where the deepest levels take outputs of the previous levels as inputs and transform them, always abstracting more. Such knowledge on learning levels was inspired by how the brain learns and processes information and responds to external effects. In the present research, an automatic COVID-19 prediction was suggested using a deep CNN based upon pre-trained transfer models and chest X-rays images. CNN architectures have shown exceptional efficiency in numerous machine learning and computer vision tasks. The CNN performs training and prediction in abstract levels. Such a CNN mdel has been widely utilized in modern applications of machine learning due to its record-breaking effectiveness. Linear algebra is the base for the way those CNN models operate. The multiplication of the matrix-vector is at the core of representing the data and the weights. Every layer includes a different group of properties and a set of images.
In this section, the design method behind the suggested COVID-19 classification system is discussed.
In this study, the dataset was utilized for training and evaluating the suggested COVID-19 and was referred to as COVID-19. The dataset contains 256 images divided into two categories (128 images for normal cases and 128 images for COVID-19 cases) for building and training models. The dataset can be downloaded from the link below:
https://www.dropbox.com/sh/ior4ij1wp0z8s71/AABYnuU-3VQlStWdHBcWbwr0a?dl=0.
Figs. 1 and 2 show samples of normal and COVID-19 X-ray images, respectively.
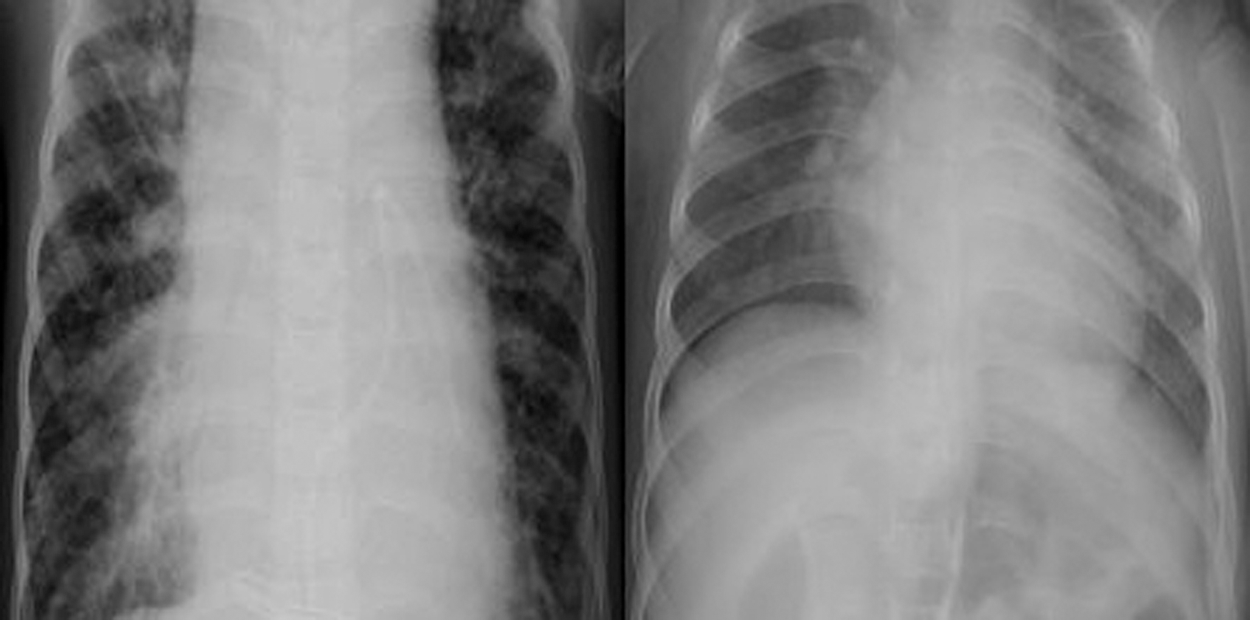
Figure 1: Two normal X-ray images
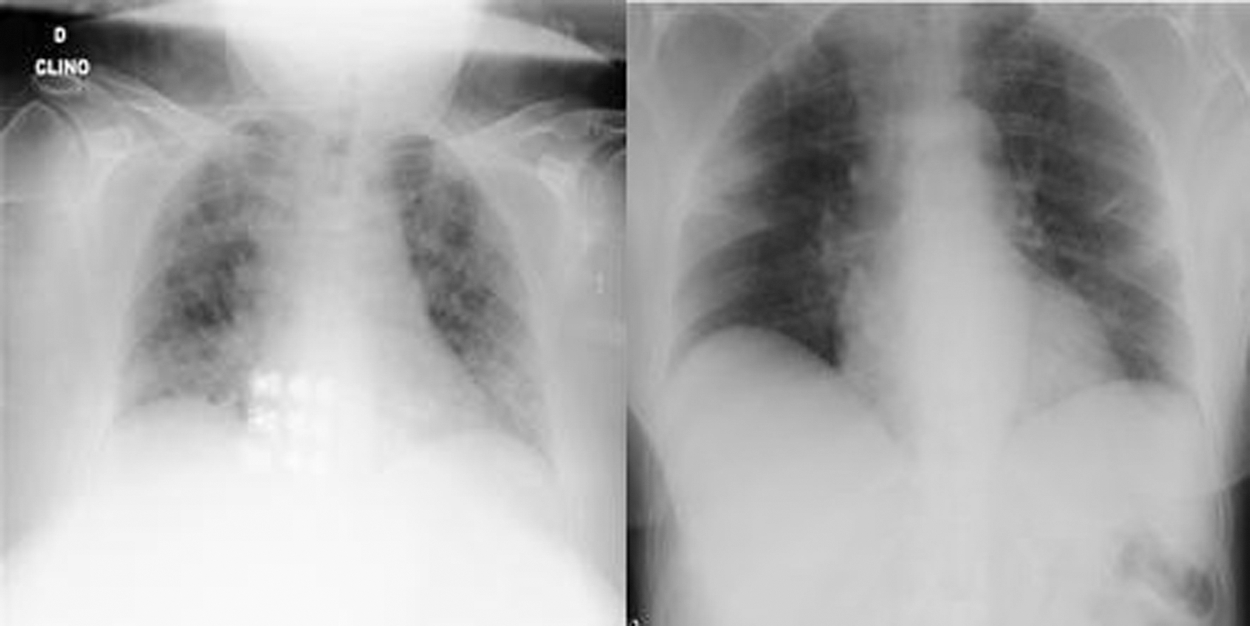
Figure 2: Two COVID-19 X-ray images
The transfer values (TRVs) of the dataset were extracted using the GoogleNet Inception model (V3). These (TRVs) were used to train the classifier model. However, after the classifier model was built, they were used to classify the status of the person if he/she was normal or has COVID-19 with the use of the chest X-ray images, as shown below:
Algorithm 1: Generating TRVs of dataset

Algorithm 2: Building classifier model

Algorithm 3: Diagnosing operation

The parameters used in this approach are shown below.
The GoogleNet Inception model has 21 convolution layers with three types of convolutions: 5*5, 3*3, and 1*1. These layers work as filters for extracting the TRVs of the dataset. Then between the layers there are max pooling layers that are responsible for value reduction from layer to layer. The result is the TRVs of images, which is a matrix consisting of two dimensions: number of images and 2048 values (TRVs) for each image. Finally, these values are the input of the RNN classifier model that consists of two fully connected layers: the first one consists of 64 nodes and the second one has 32 nodes. The output of these layers represents the category that the image belongs to.
In this research, chest X-ray images were utilized to predict patients with COVID-19. The classifier part’s selected architecture was an RNN with two hidden layers, in which the number of nodes in the first layer is 64 and the number of nodes in the second layer is 32. The selected RNN architecture was based on an intrusion detection system designed by [16].
The results of training the classifier model for 10 training rounds are shown in Tab. 1; each round has 100 epochs and then the accuracy and loss for each round are considered. Afterward, the average accuracy and loss for all rounds were calculated.
Table 1: Results of training the classifier model
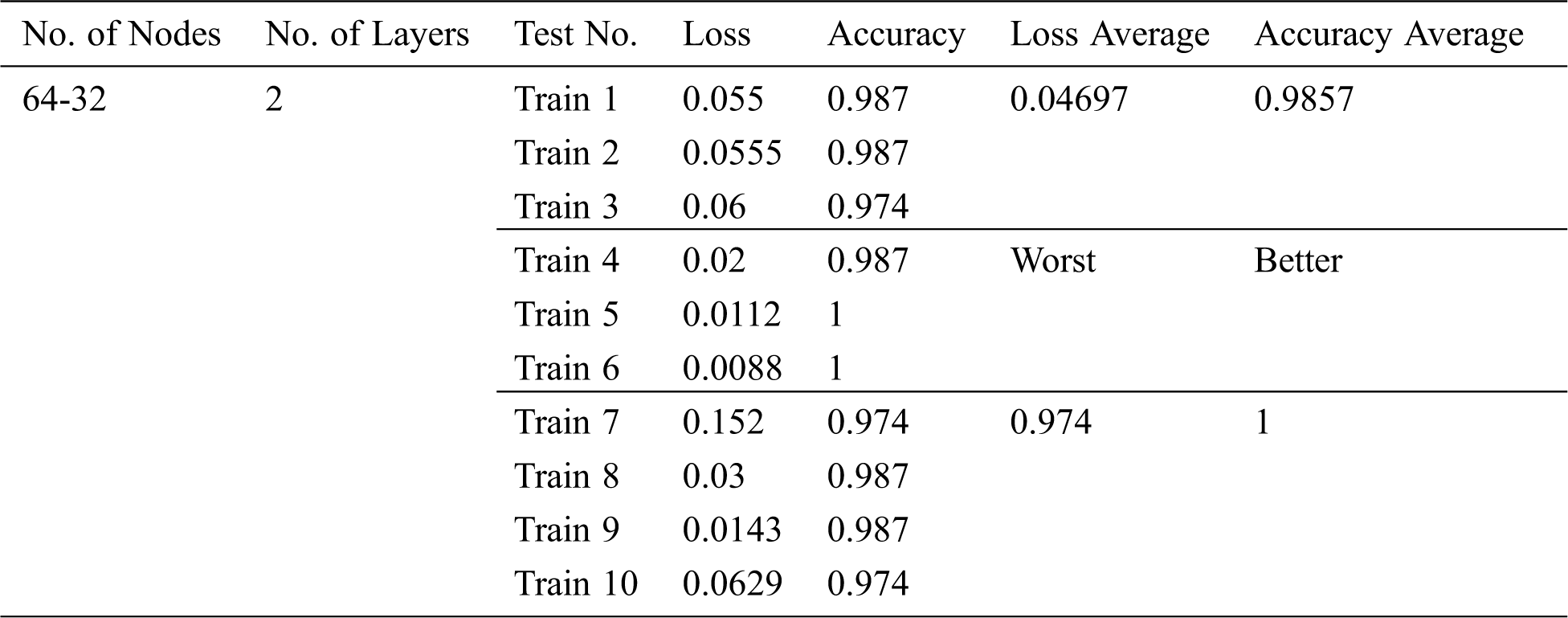
The results in Tab. 1 show the stability of the classifier because the obtained accuracies are close. The confusion matrix and loss value are shown respectively in Figs. 3 and 4 below.
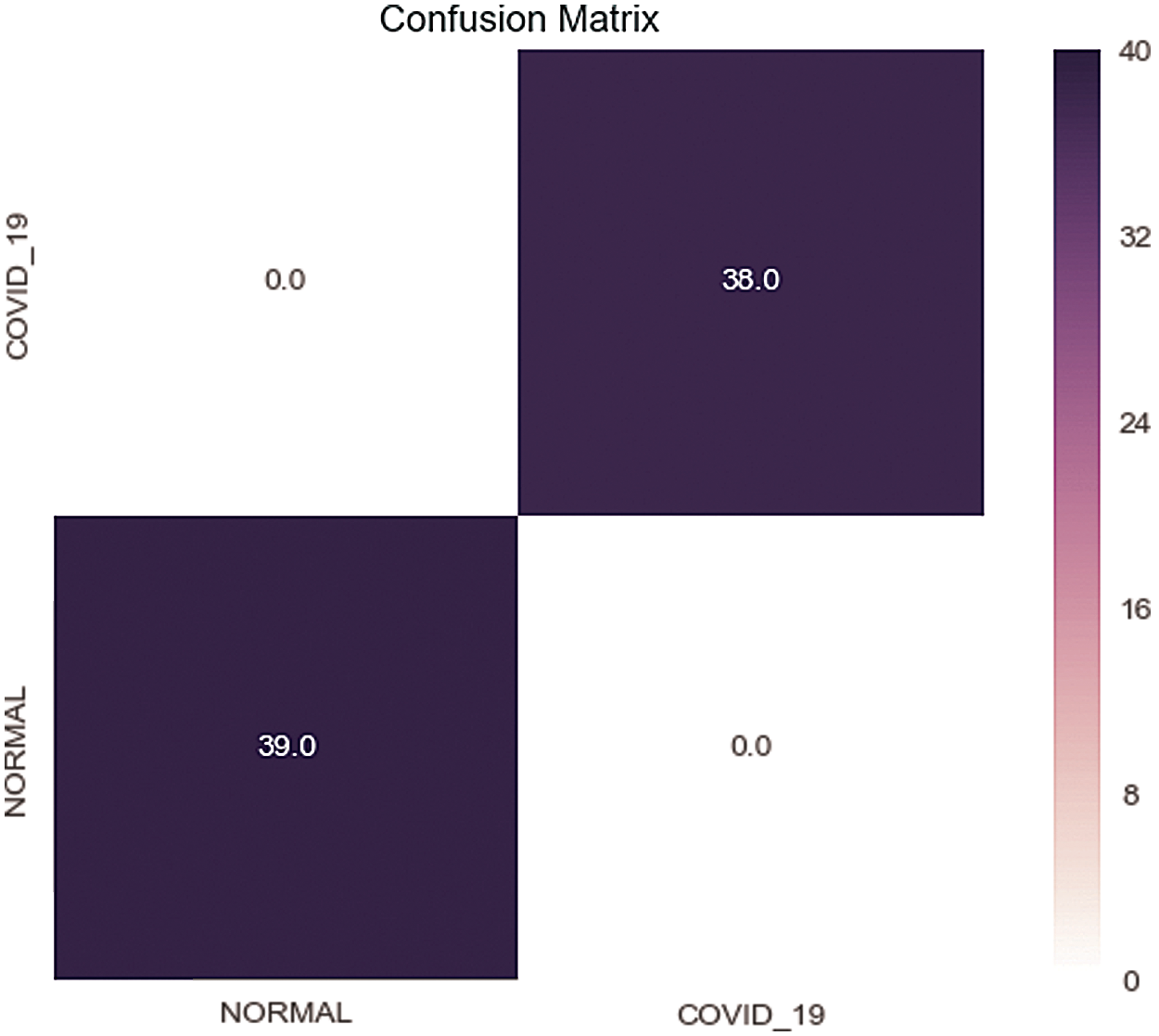
Figure 3: Confusion matrix of the test set
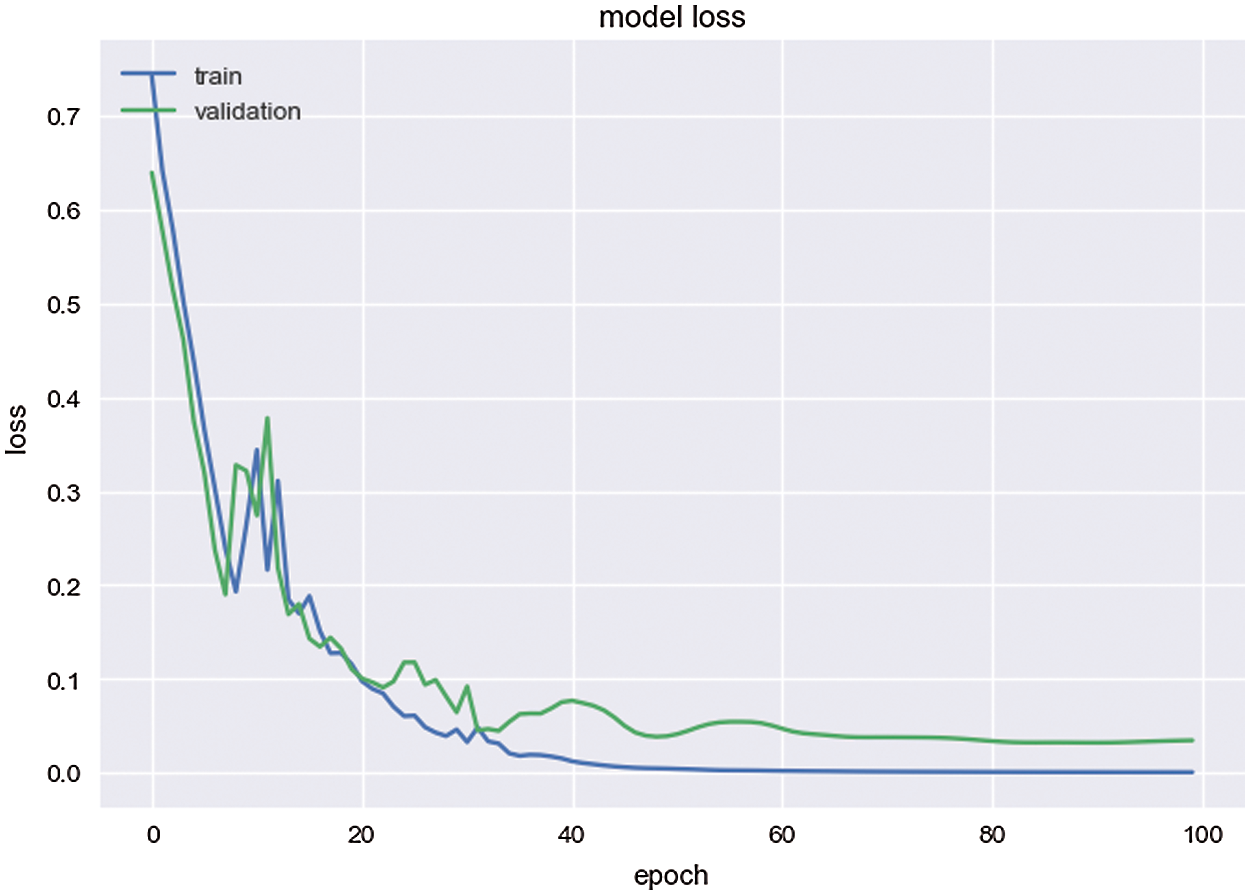
Figure 4: Loss value of the model
The confusion matrix of the test set in Fig. 3 shows that the model succeeds in predicting all images correctly. In Fig. 4, the loss value is close to zero while training reflects that the model prediction of the images is very near to the correct categories of these images.
Tab. 2 shows the results of classifying images. These images are made up of 307 images, of which 256 images represent the original dataset with two categories (used in the training and testing phases). Other images are taken from external resources, and some of them are real test cases (obtained from Iraqi hospitals).
Table 2: Results of image classification
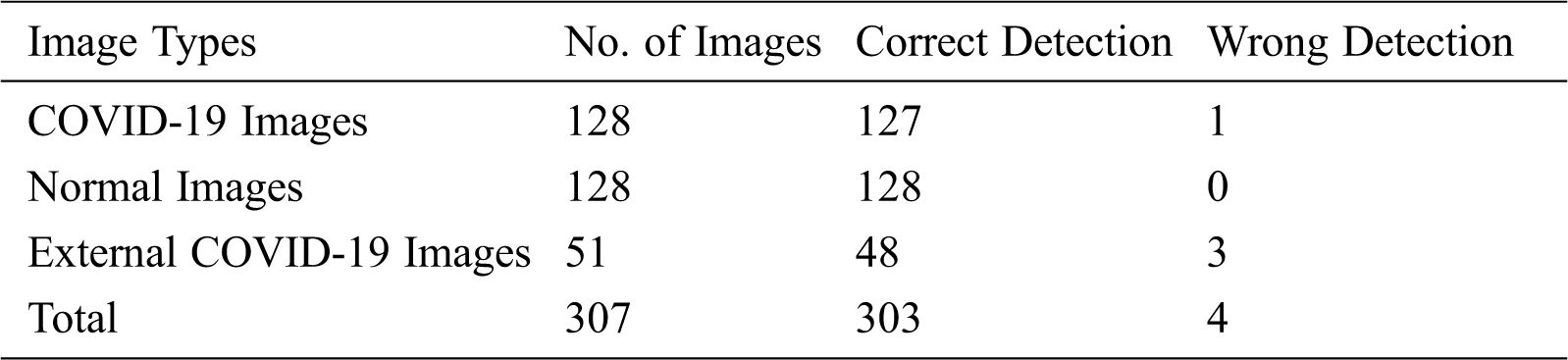
Tab. 2 shows 303 true predicted cases out of 307, indicating outstanding efficiency of the classifier model, where the accuracy is 98.70%. The misclassified cases result from the fact that the images are too similar to the normal cases, and their resolution is not clear.
Tab. 3 below shows a comparison with a lightweight DL model for COVID-19 detection proposed in [7].
Table 3: Results of comparing the proposed approach with a lightweight deep learning model for COVID 19 detection

In Tab. 3, the proposed approach has higher accuracy than the lightweight DL model for COVID-19 detection, thereby reflecting a success for our approach. The reason behind this is because the proposed method uses an efficient transfer learning for extracting TRVs.
DL models that were established in this research were efficient for the early screening of patients with COVID-19 and proved themselves as potential additional approaches in the diagnostics for front-line clinical doctors. CT images have become a sufficient tool to screen patients with COVID-19 and assess the severity of the disease. However, radiologists lack a computerized tool for the accurate quantification of COVID-19 severity. To detect COVID-19 at the early stages, this study presented information about utilizing deep transfer learning methods that may be utilized. In the following research, the classification performances of various CNN models may be tested by increasing the number of images in the dataset. In this work, the GoogleNet Inception model is a pre-trained model that has high performance to extract the TRVs of the image dataset and make these values suitable for building and training the RNN classifier models. The model has 21 convolution layers trained on the ImageNet dataset using a supercomputer. The dataset has 1.2 million images divided into 1000 categories, making this model very efficient in transfer learning technique (i.e., extracting important TRVs from images).
The RNN classifier model was trained using these TRVs to classify new X-ray images and determine whether the person is normal or has COVID-19.
The limitation of this approach is that it is used as a binary classifier for two categories only. Therefore, if there are more than two categories, such as bacteria and virus, then the model will predict the image according to the nearest category (e.g., bacteria image predicted as COVID-19 image).
In future work, a multi-classifier model can be used to classify X-ray images that have more than two categories, such as normal, COVID-19, bacteria, and Virus. In addition, algorithms that can extract the lungs only from the X-ray image can be used to obtain more accuracy.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. K. Biswas and P. Sen. (2020). “Space-time dependence of coronavirus (COVID-19) outbreak,” arXiv: Physics and Society, arXiv: 2003.03149. [Google Scholar]
2. C. Huang, Y. Wang, X. Li, L. Ren, J. Zhao et al. (2020). , “Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China,” TheLancet, vol. 395, no. 10223, pp. 497–506. [Google Scholar]
3. K. Biswas, A. Khaleque and P. Sen. (2020). “Covid-19 spread: Reproduction of data and prediction using a SIR model on euclidean network,” arXiv: Physics and Society, arXiv:2003.07063. [Google Scholar]
4. G. Vargas-Solar, J. A. Espinosa-Oviedo and J. L. Zechinelli-Martini. (2016). “Big continuous data: Dealing with velocity by composing event streams,” in Big Data Concepts, Theories, and Applications, S. Yu and S. Guo (eds.Cham: Springer. [Google Scholar]
5. P. Tino, L. Benuskova and A. Sperduti. (2015). “Artificial Neural Network Models,” in SPRINGER HANDBOOK OF COMPUTATIONAL INTELLIGENCE, J. Kacprzyk, W. Pedrycz (eds.Dordrecht / Heidelberg: Springer, pp. 455–472, , 978-3-662-43504-5. [Google Scholar]
6. M. A. Mohammed, K. H. Abdulkareem, A. S. Al-Waisy, S. A. Mostafa, S. Al-Fahdawi et al. (2020). , “Benchmarking methodology for selection of optimal COVID-19 diagnostic model based on entropy and TOPSIS methods,” IEEE Access, vol. 8, pp. 99115–99131. [Google Scholar]
7. Zulkifley and N. Hani Zulkifley. (2020). “A Lightweight Deep Learning Model for COVID-19 Detection,” in IEEE Sym. on Industrial Electronics & Applications (ISIEATBD, Malaysia: IEEE. [Google Scholar]
8. M. J. Horry, S. Chakraborty, M. Paul, A. Ulhaq, B. Pradhan et al. (2020). , “COVID-19 Detection Through Transfer Learning Using Multimodal Imaging Data,” IEEE Access, vol. 8, pp. 149808–149824. [Google Scholar]
9. S. Wang, B. Kang, J. Ma, X. Zeng, M. Xiao et al. (2020). , “A deep learning algorithm using CT images to screen for coronavirus disease (COVID-19),” medRxiv. [Google Scholar]
10. X. Xu, X. Jiang, C. Ma, P. Du, X. Li et al. (2020). , “Deep learning system to screen coronavirus disease 2019 pneumonia,” Engineering, vol. 6, no. 10, pp. 1122–1129. [Google Scholar]
11. A. Narin, K. Ceren and P. Ziynet. (2020). “Automatic detection of coronavirus disease (COVID-19) using x-ray images and deep convolutional neural networks,” arXiv: eess. IV, arXiv:2003.10849. [Google Scholar]
12. L. Wang and A. Wong. (2020). “COVID-Net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest radiography images,” arXiv: eess. IV, arXiv:2003.09871. [Google Scholar]
13. F. Shan, Y. Gao, J. Wang, W. Shi, N. Shi et al. (2020). , “Lung infection quantification of COVID-19 in CT images with deep learning,” arXiv: cs.CV, arXiv:2003.04655. [Google Scholar]
14. M. Barstugan, U. Ozkaya and S. Ozturk. (2020). “Coronavirus (COVID-19) classification using CT images by machine learning methods,” arXiv: cs.CV, arXiv:2003.09424. [Google Scholar]
15. A. S. Al-Waisy, S. Al-Fahdawi, M. A. Mohammed, K. H. Abdulkareem and S. A. Mostafa. (2020). “COVID-CheXNet: Hybrid deep learning framework for identifying COVID-19 virus in chest X-rays images,” Soft Computing, pp. 1–16. [Google Scholar]
16. A. A. Abdul Lateef. (2019). “Intrusion detection system based on deep learning,” M.S. thesis, Computer science, University of Anbar, Ramadi, Anbar, Iraq. [Google Scholar]
17. J. E. Sklan, A. J. Plassard, D. Fabbri and B. A. Landman. (2015). “Toward content based image retrieval with deep convolutional neural networks,” Proc. SPIE Int. Soc. Opt. Eng., vol. 9417, 94172C. [Google Scholar]
18. F. Shan, Y. Gao, J. Wang, W. Shi, N. Shi et al. (2018). , “Detection and diagnosis of dental caries using a deep learning-based convolutional neural network algorithm,” Journal of dentistry, no. 77, pp. 106–111. [Google Scholar]
19. J. Zhou, Y. Cao, X. Wang, P. Li and W. Xu. (2016). “Deep recurrent models with fast-forward connections for neural machine translation,” Transactions of the Association for Computational Linguistics, vol. 4, no. 2, pp. 371–383. [Google Scholar]
20. R. J. Williams and D. Zipser. (1989). “A learning algorithm for continually running fully recurrent neural networks,” Neural Computation, vol. 1, no. 2, pp. 270–280. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |