DOI:10.32604/iasc.2021.016981
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2021.016981 | |
| Article |
Adaptive Multi-Layer Selective Ensemble Least Square Support Vector Machines with Applications
1State Key Laboratory of Process Automation in Mining & Metallurgy, Beijing, 102600, China
2Faculty of Information Technology, Beijing University of Technology, Beijing, 100024, China
3School of Computer and Software, Nanjing University of Information Science & Technology, 210044, China
4Beijing Key Laboratory of Process Automation in Mining & Metallurgy, Beijing, 102600, China
5BGRIMM Technology Group Co., Ltd., Beijing, 102600, China
6Department of Computer and Information Science, The University of Mississippi, Mississippi, MS 38655, USA
*Corresponding Author: Jian Tang. Email: freeflytang@bjut.edu.cn
Received: 17 January 2021; Accepted: 01 March 2021
Abstract: Kernel learning based on structure risk minimum can be employed to build a soft measuring model for analyzing small samples. However, it is difficult to select learning parameters, such as kernel parameter (KP) and regularization parameter (RP). In this paper, a soft measuring method is investigated to select learning parameters, which is based on adaptive multi-layer selective ensemble (AMLSEN) and least-square support vector machine (LSSVM). First, candidate kernels and RPs with K and R numbers are preset based on prior knowledge, and candidate sub-sub-models with K*R numbers are constructed through utilizing LSSVM. Second, the candidate sub-sub-models with same KPs and different RPs are selectively fused by using the branch and bound SEN (BBSEN) to obtain K SEN-sub-models. Third, these SEN-sub-models are selectively combined through using BBSEN again to obtain SEN models with different ensemble sizes, and then a new metric index is defined to determine the final AMLSEN-LSSVM-based soft measuring model. Finally, the learning parameters and ensemble sizes of different SEN layers are obtained adaptively. Simulation results based on the UCI benchmark and practical DXN datasets are conducted to validate the effectiveness of the proposed approach.
Keywords: Multi-layer selective ensemble learning; least square support vector machine; soft measuring model; municipal solid waste incineration; dioxins emission
Data-driven soft measuring techniques can be used for online estimation of offline assay process parameters and experts’ estimation quantity variables [1,2]. Especially, soft measuring models are used in many fields according to their inferential estimation capability [3], and the two most common ones include artificial neural networks (ANN) and support vector machines (SVM). Although ANN is used to model DXN emission concentration [4], it has several shortcomings, such as easily falling into local minimum, over fitting, and unstable generalization performance in terms of small samples. For SVM, it is more suitable to build a prediction model for DXN emission, however, its prediction performance heavily depends on kernel and RPs [5]. Furthermore, SVM has to suffer from the quadratic program (QP) problem, which can be solved by least square-support vector machines (LSSVMs) including a set of linear equations. Due to the data dependence of kernel learning methods [6], some optimization methods are employed to address this problem through using single- or multi-objective optimization in terms of learning parameters [7,8]. However, such methods are time-consumed and prone to obtain a sub-optimum solution [9]. In addition, as the KP determines the geometry of the feature space, it can be optimally selected through class reparability [10,11]. Thus, this parameter is also calculated by using Fisher discrimination of classification problems [12]. For regression problems, a stable generalization performance can only be found within a certain range. However, the evaluation process must be dynamic and the searching results are unstable for small samples. Therefore, a fast and definitive method for KP selection should be developed in future researches. The RP of kernel learning method has no intuitive meaning in terms of geometry and is normally determined through cross-validation or optimization search methods [13]. In Wang et al. [14], a KP selection approach is proposed for small high-dimensional mechanical frequency spectral samples, which only selects a single kernel. Moreover, multiple kernel learning algorithms exhibit high efficiency and effectiveness in both classification and regression tasks [14]. And one of them named multiple kernel ensemble learning approach has been applied into hyper-spectral remote sensing image classification [15,16]. However, the optimized selection of learning parameters is not addressed jointly. Therefore, a new adaptive method for selecting learning parameters should be developed to model small samples with complex characteristics.
Selective ensemble (SEN) modeling can selectively fuse multiple sub-models in a linear or nonlinear method and achieve better prediction performances than single modeling. However, SEN modeling still exerts several limitations. One of them is ensemble construction, which creates a set of candidate sub-models for the same training dataset. The ensemble construction method based on the resample of training samples validates the ensemble method, and many available sub-models can obtain better performances than the ensemble of all the sub-models [17]. However, the selection problem of learning parameters remains unsolved in this scenario. Consequently, based on the above ensemble construction strategy, double-layer GA-based SEN latent structure modeling is proposed for collinear and nonlinear data [18]. However, this method has disadvantages of long searching time and randomized prediction results. Another ensemble construction method named manipulation of input features is used to model multi-source multi-scale high-dimensional frequency spectral data [13,19,20], and it can construct a soft measuring model by using the interesting mechanical sub-signals and their spectral feature subsets, which focuses on the selective fusion of different multi-source feature sub-sets from the perspective of selective information fusion. As a result, this method is thus suitable for modeling frequency spectral data with multi-source and high dimension, especially for small samples.
In this paper, the SEN kernel leaning algorithm for small data-driven samples is adopted to softly measure the DXN emission. Although several SEN-LSSVMs such as fuzzy C-means cluster-based SEN-LSSVM [21] and evolutionary programming (EP)-based multi-level LSSVM [22] have been proposed, they do not address the selection problem of learning parameters and are unsuitable for small samples. As multiple KPs can clearly describe the complex characteristics of small sample data (e.g., DXN), a soft measuring model for the SEN-LSSVM-based DXN emission concentration can be built through using multiple candidate KPs and the ensemble construction strategy. Meanwhile, the RP of the kernel learning algorithm is also data-dependent. Therefore, the algorithm can also be used and selected with the same idea like KPs.
Motivated by the above problems, this paper proposes a new adaptive multi-layer SEN-LSSVM (AMLSEN-LSSVM) method for modeling small samples with complex characteristics. Compared to the existing literatures, the distinctive contributions of this study are listed as follows. (1) A new SEN-LSSVM modeling framework is proposed to model small samples according to the candidate learning parameters at the first time; (2) The proposed method can adaptively select the kernel and RPs simultaneously. Moreover, the ensemble sizes of different SEN layers are also adaptively determined in implicit pattern; (3) A new metric index is defined for selecting the final AMLSEN-LSSVM soft measuring model to achieve tradeoff between model complexity and prediction performance.
The remainder of this paper is organized as follows. Section 2 describes the proposed modeling strategy. In Section 3, a detailed realization of the proposed approach is demonstrated. Section 4 presents the experimental results on two UCI benchmarks and practical DXN datasets for references. Finally, Section 5 concludes this paper.
2 Modeling Strategy Description
Based on the above analysis, an adaptive multi-layer SEN-LSSVM (AMLSEN-LSSVM) soft measuring strategy is proposed, which consists of candidate sub-sub-models, candidate SEN-sub-models, SEN-models, and decision selection modules. The process is shown in Fig. 1.
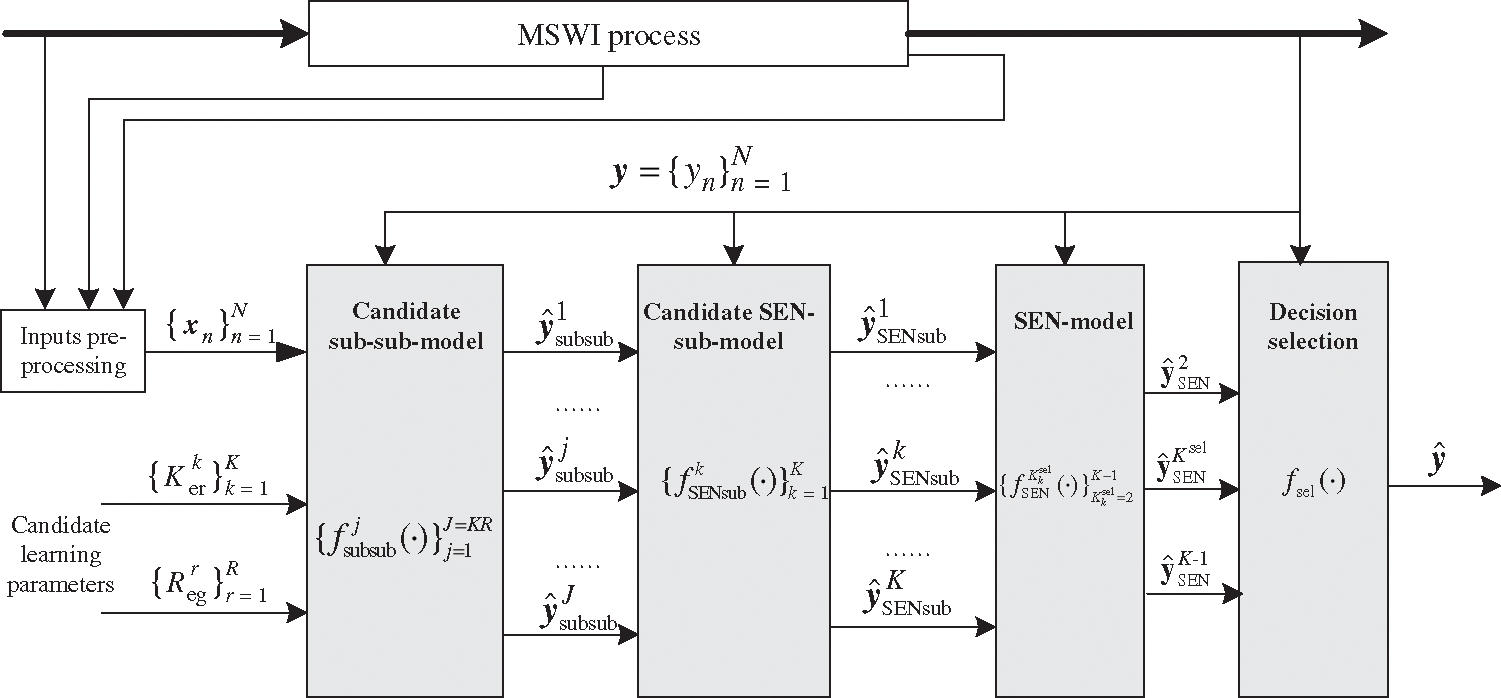
Figure 1: SEN-LSSVM-based soft measuring strategy
In Fig. 1,
The functions of the different modules are illustrated as follows:
(1) Candidate sub-sub-model module: Construct the
(2) Candidate SEN-sub-model module: Construct the K SEN-sub-models by using the prediction outputs of
(3) SEN-model module: Construct the SEN-models with an ensemble size from 2 to (
(4) Decision selection module: Select the final soft measuring model from SEN-models with the different ensemble sizes by defining a new metric index and making a trade-off between prediction accuracy and model complexity.
3.1 Candidate Sub-Sub-Model Module
As the candidate kernels and RPs of the LSSVM model are respectively denoted as
where
Taken the
where
where
where
Accordingly, the above problem becomes a linear equation system:
By solving the above system,
For a concise expression, (7) can also be expressed as
Therefore, all these candidate sub-sub-models are denoted as
3.2 Candidate SEN-Sub-Model Module
The prediction outputs of these candidate sub-sub-models can be rewritten as
where
In (9), the
The candidate SEN-sub-models are built for each row of (10) by selecting and combining the candidate sub-sub-models based on different
where
where
where the root mean square error (RMSE) is used to evaluate the generalization performance of the SEN-sub-model with ensemble size
In order to solve the above problem, the optimized ensemble sub-sub-models and their weighted coefficients are obtained through repeating the BBSEN optimization algorithm
where
For simplification, all the RPs of the
Based on the above sub-sections, the SEN-sub-models with the same KPs and different RPs are obtained. Then, Equation (10) can be transformed into the following form.
In this context, BBSEN is further employed to obtain the prediction output
where
where
where
Accordingly, the SEN model
In Eq. (19), the SEN-model
Supposed that
where
According to the above metric index, the SEN-model with the lowest RMSE is selected as the final DXN soft measuring model. Thus, the final prediction output is obtained by
where
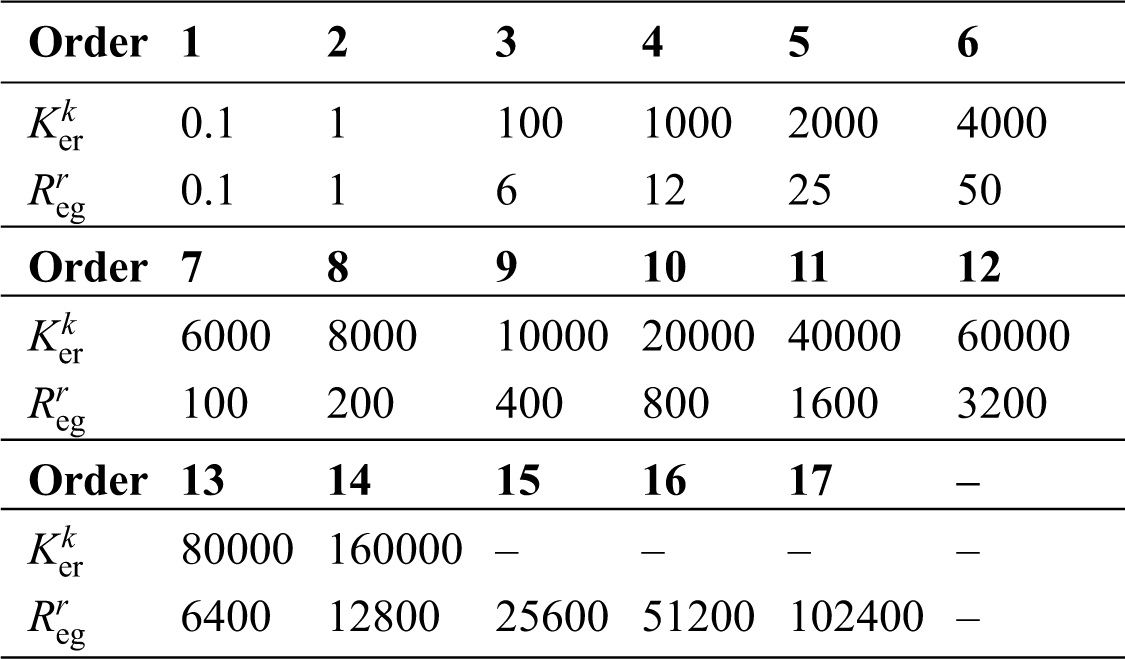
In this section, two UCI benchmarks and a practical DXN datasets are exploited to validate the proposed methods. Primarily, each dataset is divided into two parts: training data and testing data. Then radius basis function (RBF) is used for the kernel type of the LSSVM. Finally, the candidate kernel and RP datasets are selected as Can_1{0.1, 1, 100, 1000, 2000, 4000, 6000, 8000, 10000, 20000, 40000, 60000, 80000, 160000} and Can_2{0.1, 1, 6, 12, 25, 50, 100, 200, 400, 800, 1600, 3200, 6400, 12800, 25600, 51200, 102400}, respectively. Seen from the samples, Can_1 and Can_2 illustrate that the candidate learning parameters have a wide range. The order number and their values are shown in Tab. 1.
Table 1: Order number and learning parameters value
In order to present preliminary results, two UCI benchmark datasets, Boston housing and concrete compressive strength, are used to validate the proposed method, which are listed as follows.
For Boston housing data, the inputs include: (1) the per capita crime rate of the town (CRIM);(2) the proportion of residential land zoned over 25,000 sq. ft. (ZN); (3) the proportion of non-retail business acres per town (INDUS); (4) the Charles River dummy variables (CHAS); (5) the nitric oxide concentrations (NOX); (6) the average number of rooms per dwelling (RM); (7) the proportion of owner-occupied units built before 1940 (AGE); (8) the weighted distances to five employment centers of Boston (DIS); (9) the index of radial highway accessibility (RAD); (10) the full property tax rate per $10,000 (TAX); (11) the pupil–teacher ratio of the town (B); (12) the lower status of the population (LSTAT); and (13) the median value of owner-occupied homes per $1000 (MEDV). The output is the housing values of the suburbs of Boston with data size 506.
For concrete compressive strength data, the inputs include: (1) cement; (2) blast furnace slag; (3) fly ash; (4) water; (5) superplasticizer; (6) coarse aggregate; (7) fine aggregate of the various ingredients of concrete placement per cubic meter; and (8) conserved days. The output is concrete compressive strength with data size 1030.
According to the candidate learning parameters, 14 × 17 = 238 sub-sub-models based on the LSSVM are constructed. Correspondingly, the BBSEN method is employed to build 14 SEN-sub-models. The statistical results are shown in Tab. 2.
Table 2: Statistical results of different SEN-sub-models for benchmark datasets
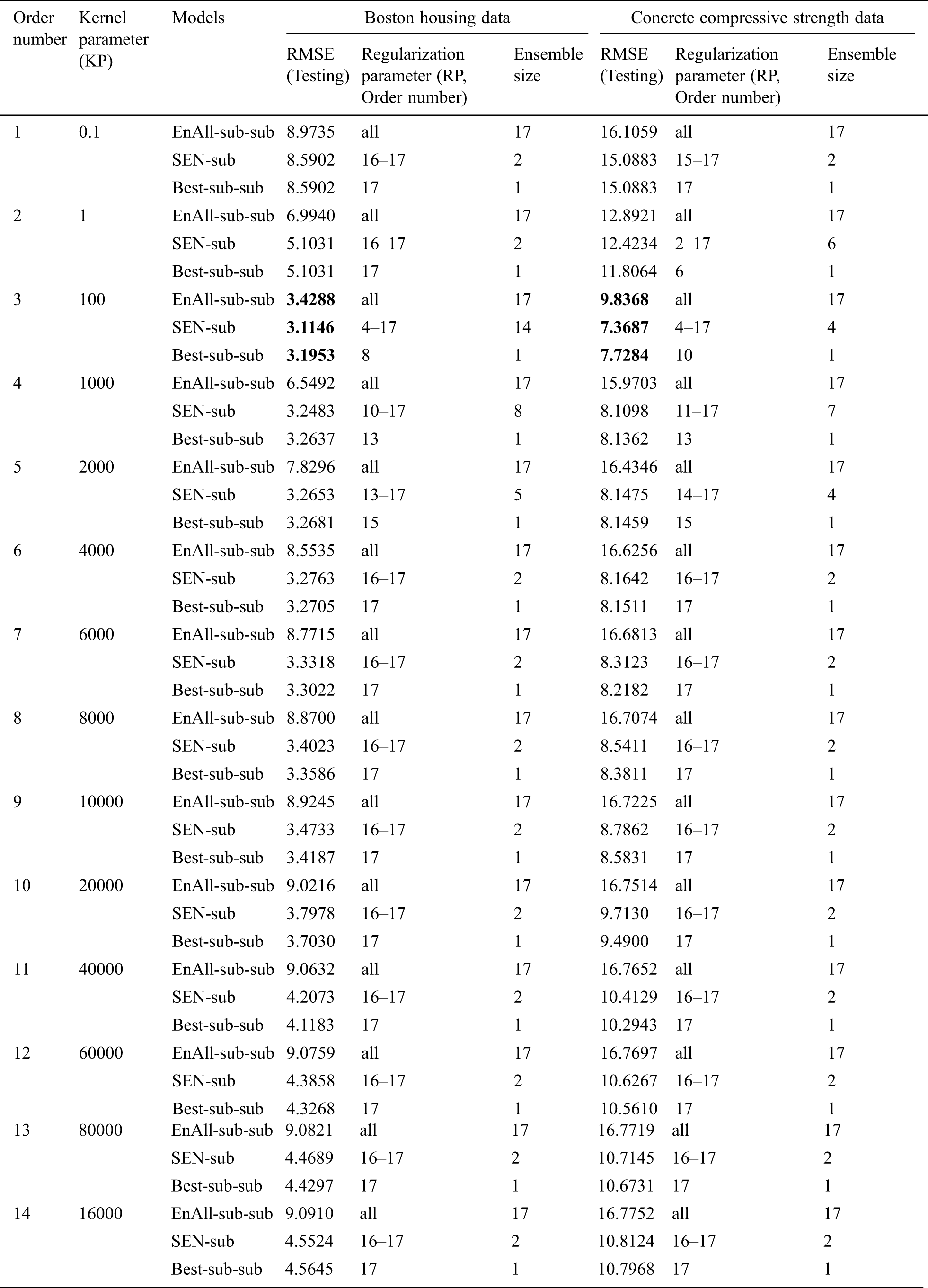
Tab. 2 illustrates that: (1) the best SEN-sub-model of Boston housing dataset has KP 100 and RPs {25, 50, 100, 200, 400, 800, 1600, 3200, 6400, 12800, 25600, 51200, 102400} with RMSE 3.1146 and an ensemble size 14. The best sub-sub-model picks up KP 100 and RP 200 with RMSE 3.1953, and the best EnAll-sub-sub-model possesses the same KP with RMSE 3.4288;(2) the best SEN-sub-model of concrete compressive strength data has the KP 100 and RPs {25, 50, 100, 200, 400, 800, 1600, 3200, 6400, 12800, 25600, 51200, 102400} with RMSE 7.368 and an ensemble size 14. The best sub-sub-model picks up KP 100 and RP 800 with RMSE 7.7284, and the best EnAll-sub-sub-model possesses the same KP with RMSE 9.8368;(3) different KPs have different effects on the prediction performance of the SEN-sub-models, so that parts of the best sub-sub-models have lower RMSEs than those of the SEN-sub-models. Thus, setting a suitable RP is very important to demonstrate the relationship among RMSEs, ensemble sizes, and different types of models with the single KP, which are shown in Figs. 2 and 3.
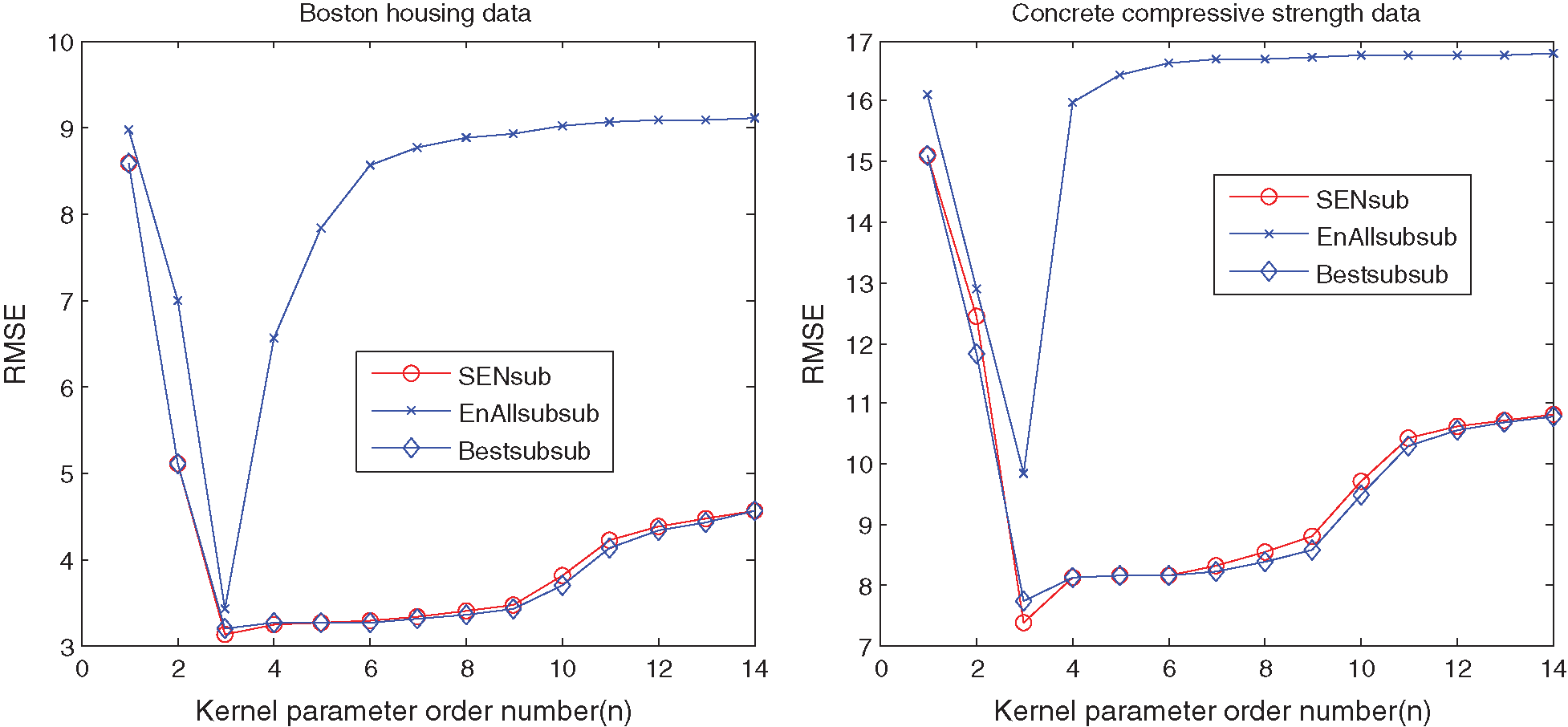
Figure 2: Relationship between RMSEs and different types of models based on the single KP for the UCI benchmark datasets
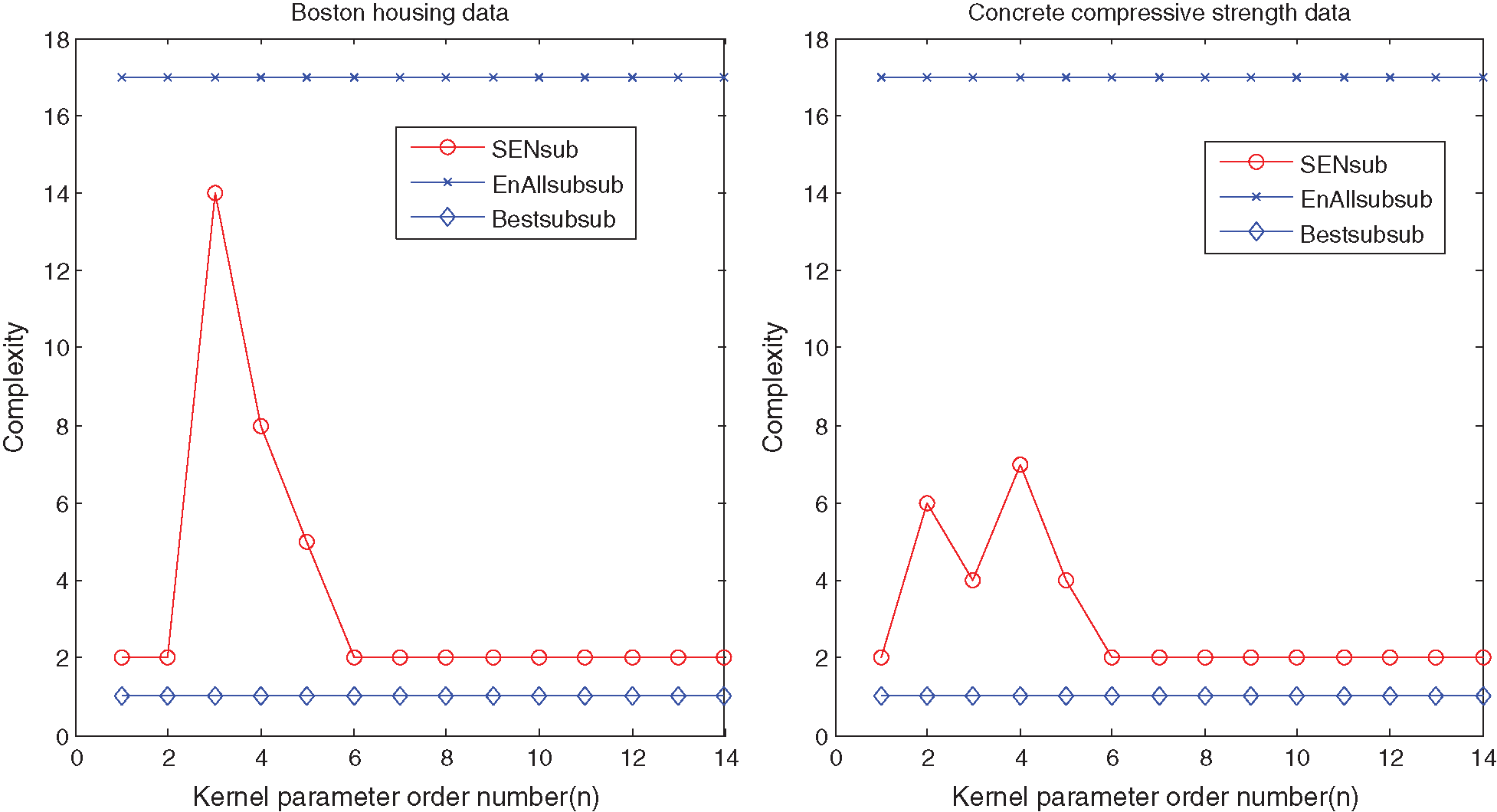
Figure 3: Relationships between ensemble sizes and different models based on the single KP for the UCI benchmark datasets
Figs. 2 and 3 show that suitable learning parameters are crucial. From this perspective, the ensemble size with the best prediction performance of the Housing and Concrete data are 14 and 6 in terms of the same KP 100, respectively. However, the ensemble size of the SEN-sub-model does not increase with the KPs after 4000.
For the 14 SEN-sub-models, the BBSEN method is used again to obtain the SEN-model with a different ensemble size, and the detailed statistical results of the SEN-models are illustrated in Tab. 3.
Table 3a: Statistical results of all SEN-models for the Boston housing dataset
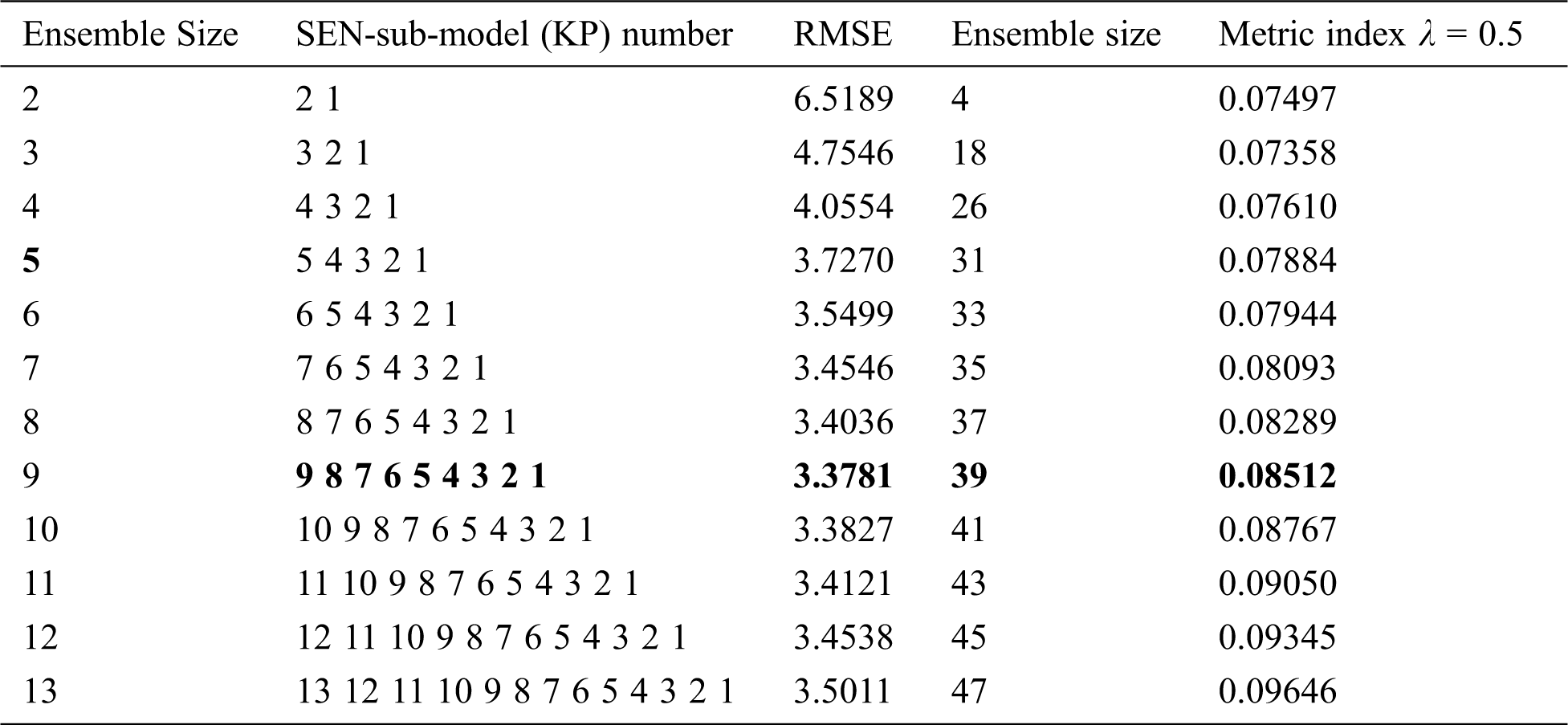
Table 3b: Statistical results of all SEN-models for the concrete compressive strength dataset
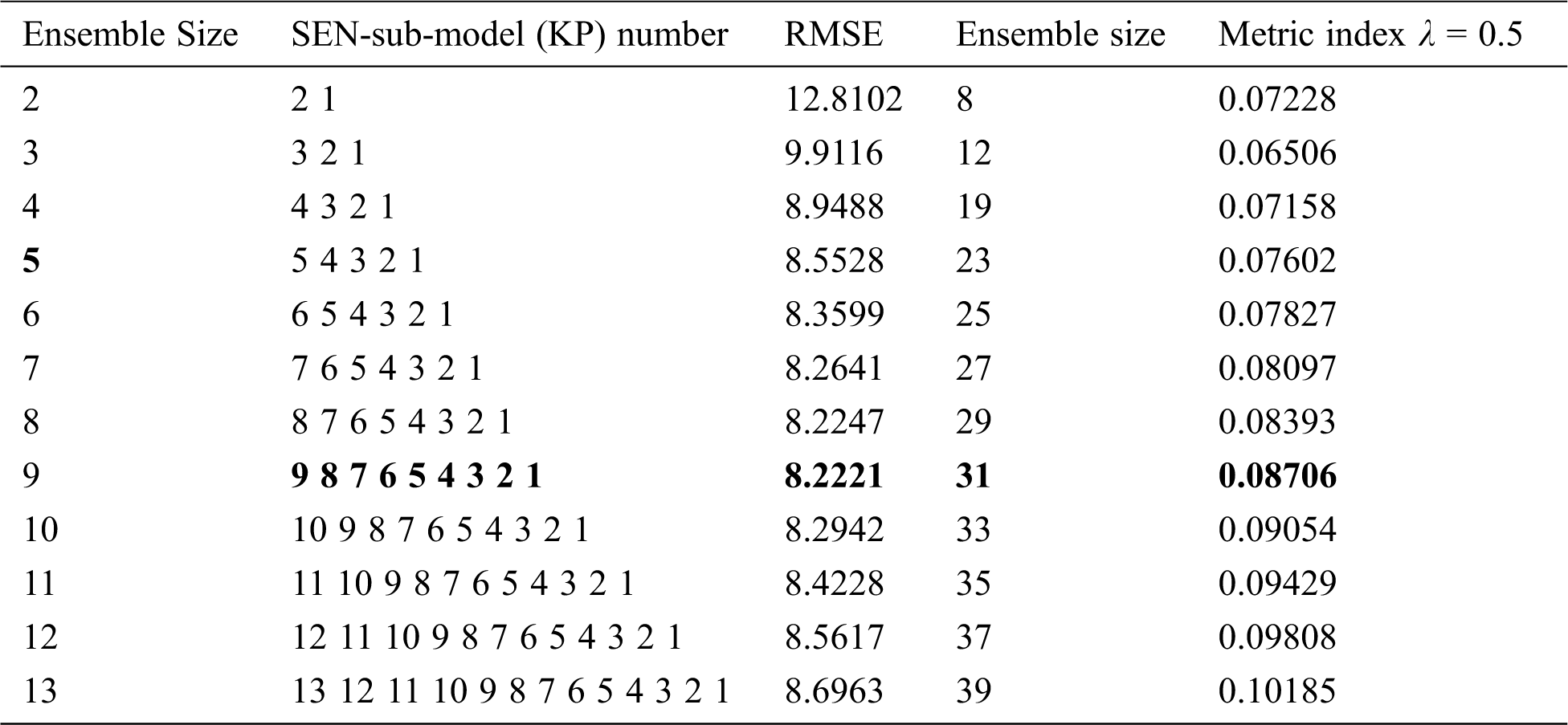
Tab. 3 shows that:(1) in the Boston housing dataset, the SEN-model with an ensemble size 9, KPs {0.1, 1, 100, 1000, 2000, 4000, 6000, 8000, 10000}, has the best prediction performance (RMSE 3.3781) among all the SEN-models, which is higher than that of the best SEN-sub-mode, but lower than that of the EnAll-SEN-sub-model;(2) in the concrete compressive strength dataset, the SEN-model with an ensemble size 9, KPs {0.1, 1, 100, 1000, 2000, 4000, 6000, 8000, 10000}, has the best prediction performance (RMSE 8.2221) among all the SEN-models. However, it is larger than that of the best SEN-sub-mode, but lower than that of the EnAll-SEN-sub-model; (3) the best SEN-sub-models in the above datasets has the best prediction performance. Moreover, the prediction performance of different SEN-models is not further improved with the increase of the ensemble size. The relationship between RMSEs and the ensemble sizes of SEN models is shown in Figs. 4 and 5.
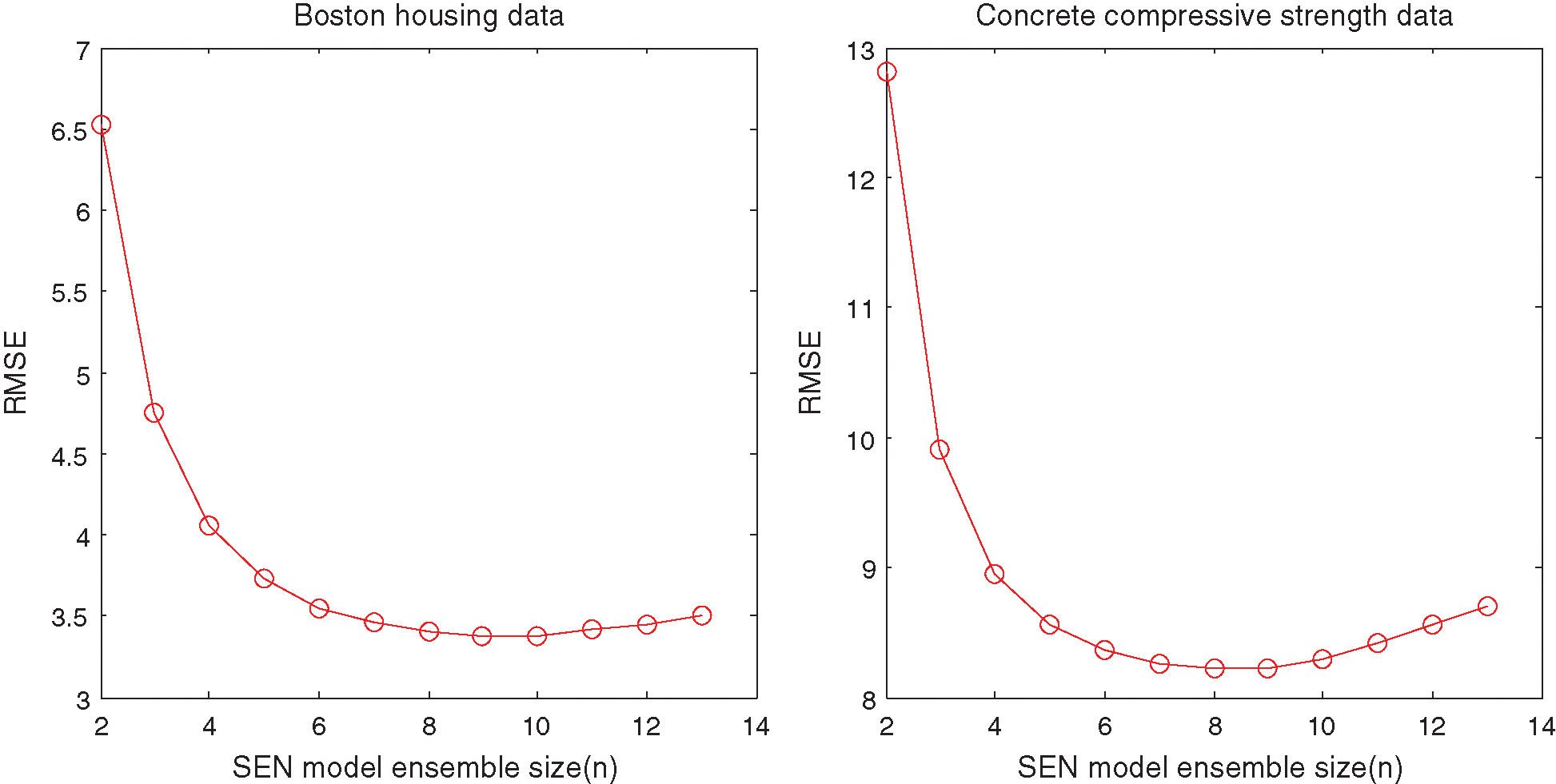
Figure 4: RMSE of SEN model with different ensemble sizes for the UCI benchmark datasets
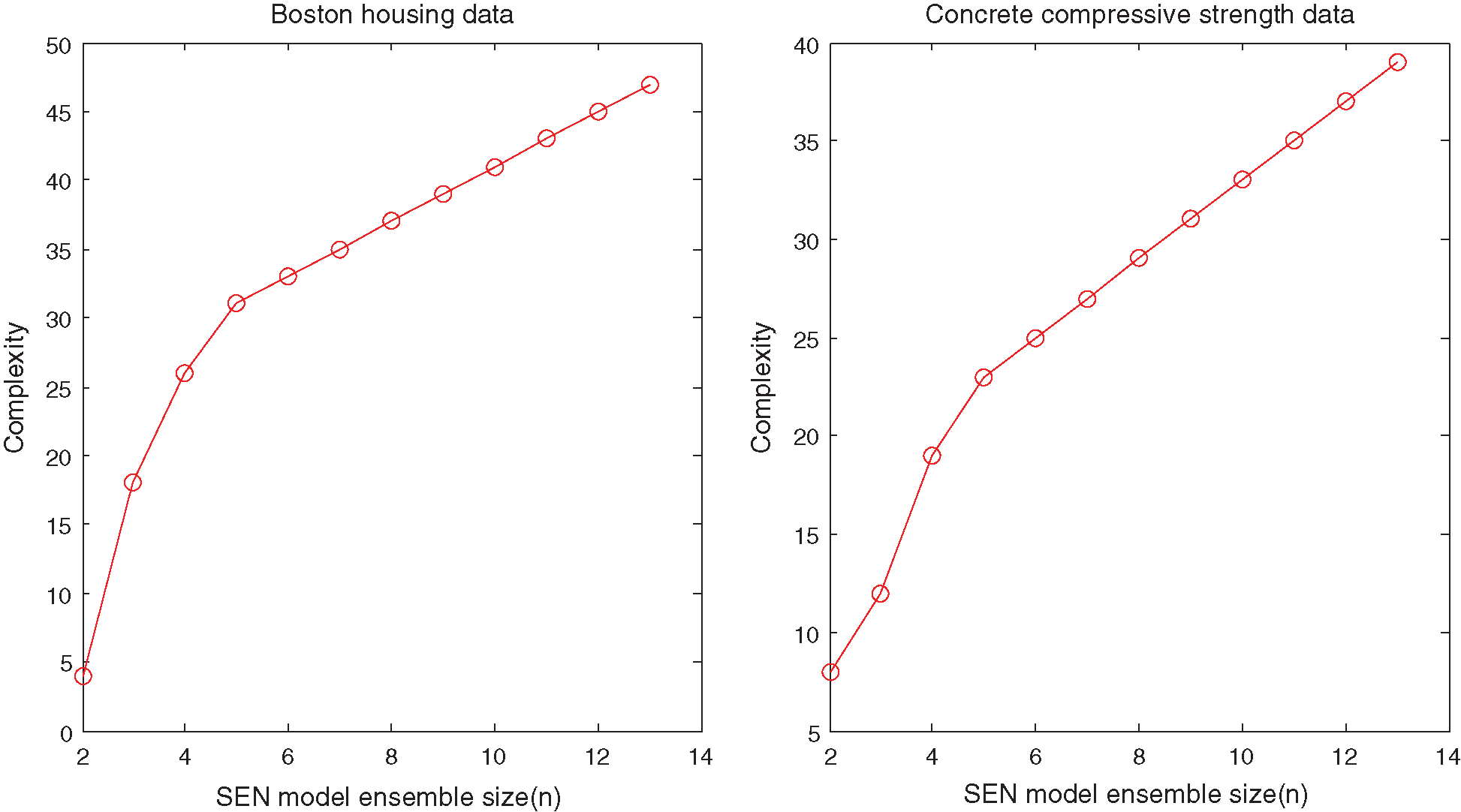
Figure 5: Ensemble size of SEN model with different ensemble sizes for the UCI benchmark datasets
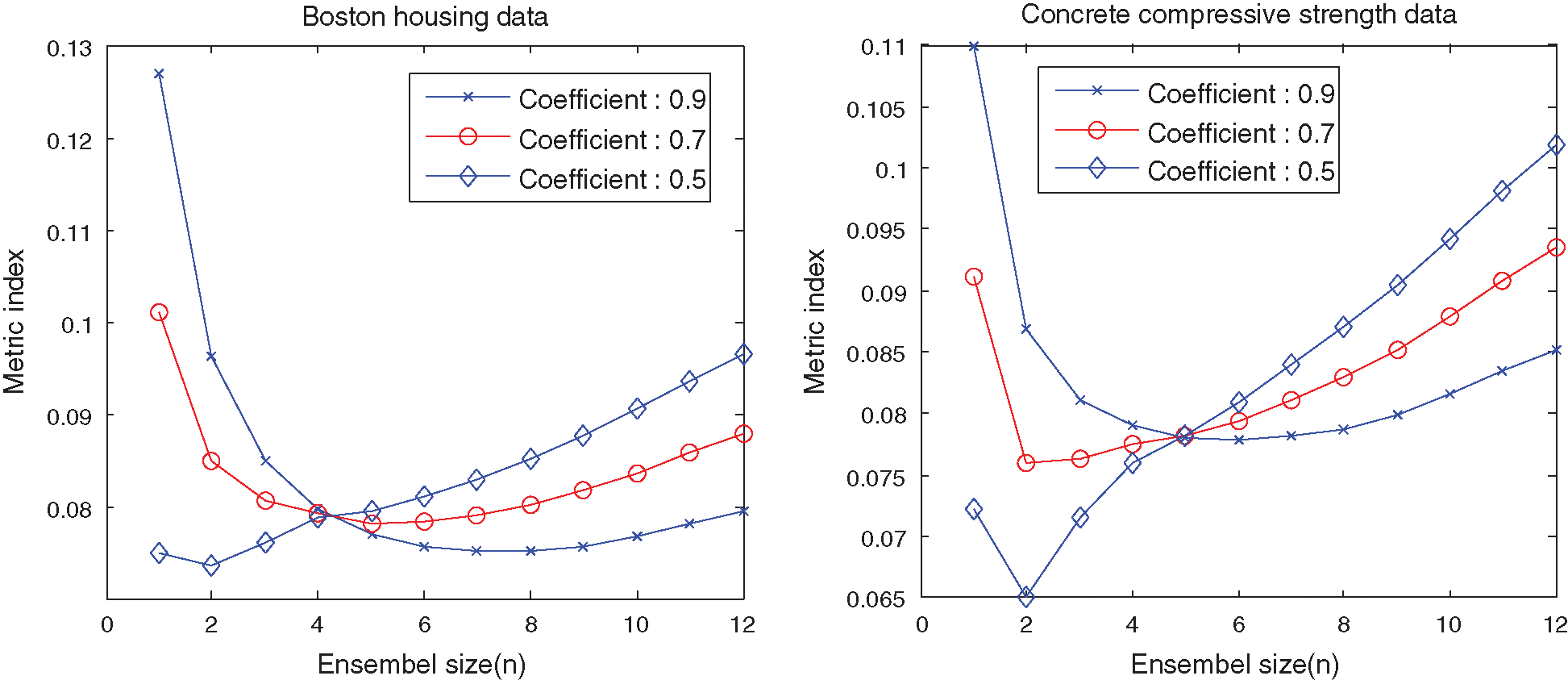
Figure 6: Metric index curves of the SEN-models with different
The above results show that it is essential to make a tradeoff between prediction performance and model complexity. The proposed indices of different SEN-models with
Seen form Fig. 6, the optimal value of the metric index shifts to the left with increasing coefficient (
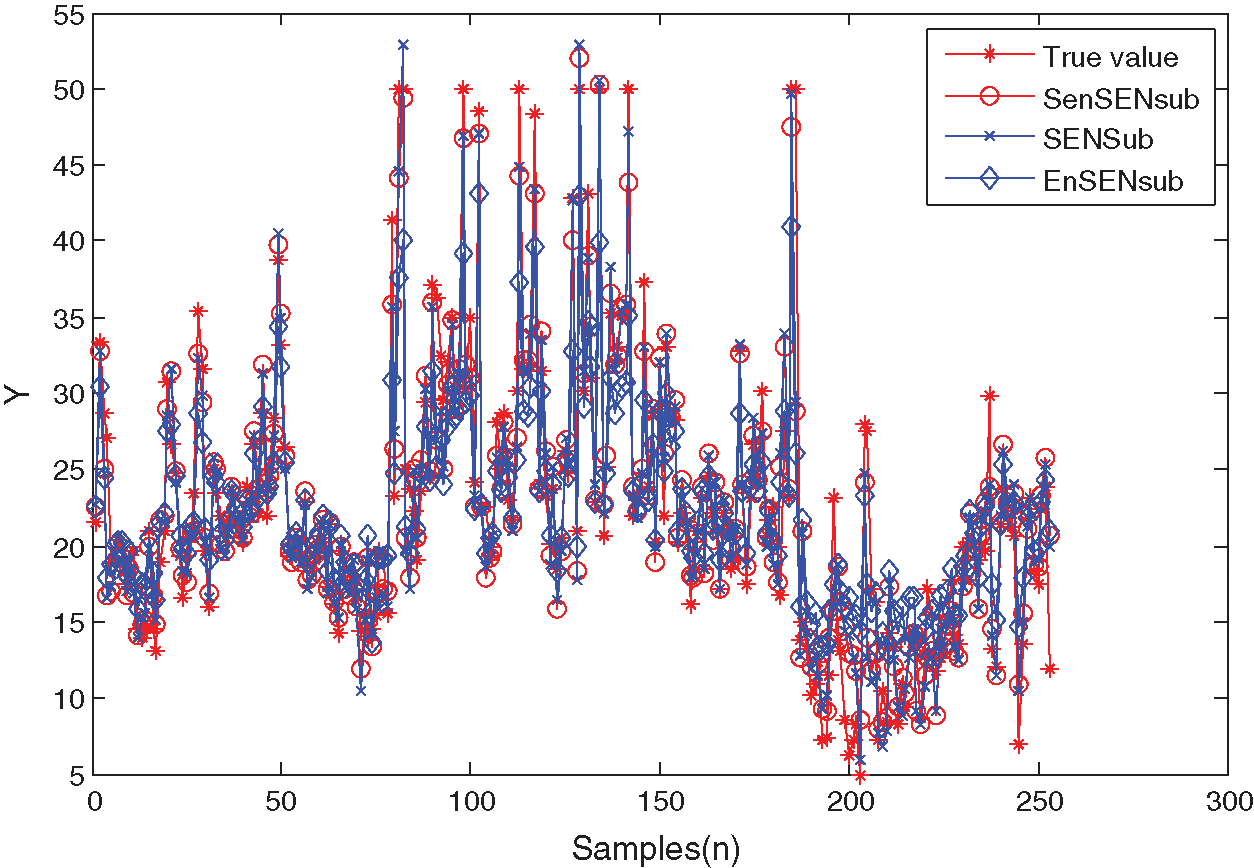
Figure 7: Prediction curves of the Boston housing data
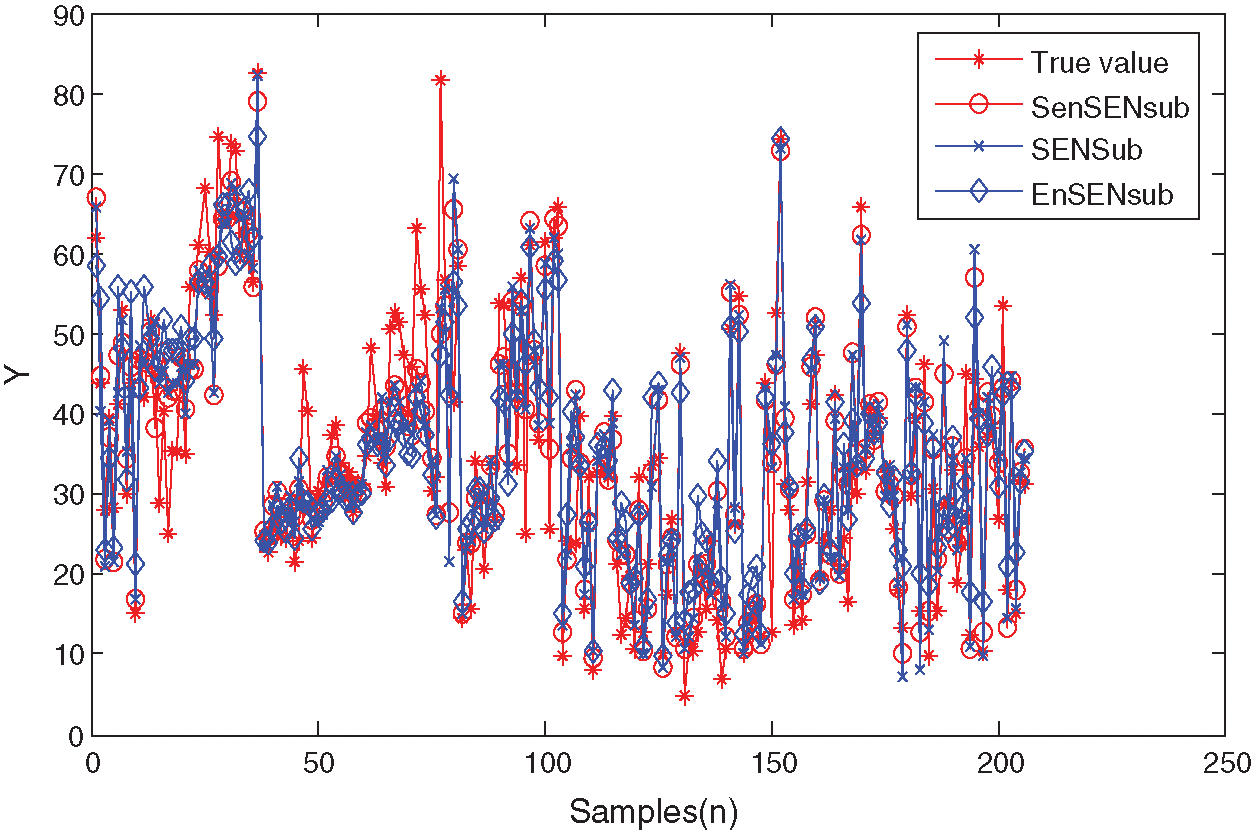
Figure 8: Prediction curves of the concrete compressive strength data
The above results show that the proposed method can model the two UCI benchmark datasets effectively, which can make an adaptive selection of the learning parameters.
The proposed method is compared with the PLS, KPLS, GASEN-BPNN, and GASEN-LSSVM approaches. Concretely, the number of latent variables (LVs) and kernel LVs (KLVs) are decided by the leave-one-out cross-validation, and the number of hidden nodes of the GASEN-BPNN is set to two times plus one of the original inputs’ number. Thus, the structure of BPNN is 13-27-1 for the housing data, and 8-16-1 for concrete data. Meanwhile, the learning parameters of GASEN-LSSVM are used as ones of the best sub-sub-model in the proposed method. For GASEN-BPNN and GASEN-LSSVM, the modelling process is repeated 10 times to overcome their randomness.
Table 4: Statistical results of comparative methods
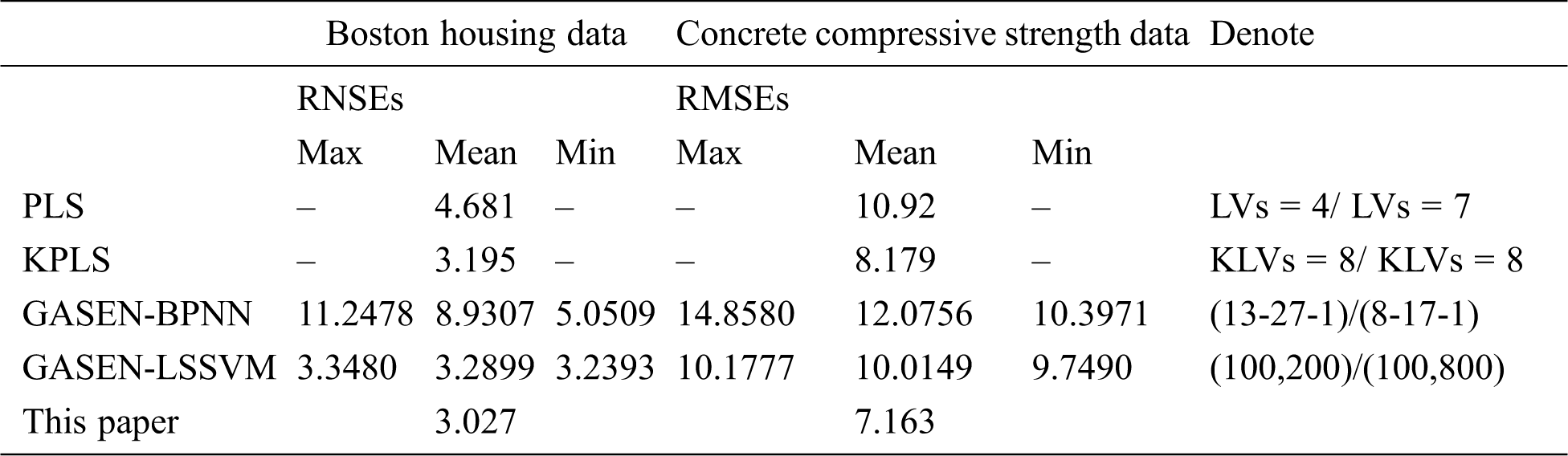
Tab. 4 shows that the proposed method has the best prediction performance without any disturbance.
Although the GASEN-based prediction results are disturbed within a certain range due to the random initialization of the input weights and the bias of BPNN and population GA, the PLS/KPLS methods can activate the extracted latent variables to construct a linear or nonlinear model with a single KP for stabilization.
KP determines the geometry of the feature space, which can be calculated by using the Fisher discrimination for classification problem. Actually, due to the deficiency of the range obtained for the regression problem, the candidate KP set in our proposed method serves as the key factor to obtain an effective soft sensor model. In addition, a wide range of KPs must be used for very small sample data with complex characteristics, such as DXN.
4.4.2 Regularization Parameter
RP is always decided by the cross validation or other optimization methods. In terms of results, a small number of modeling samples require more RPs, that is, the ensemble size increases with decrease of the number of samples. Moreover, a large KP requires a small number of RPs. As a result, the reasonable range should also be optimized in the future studies.
Selecting a suitable number of ensemble sub-models from candidates in the SEN-modeled process means that more ensemble sub-models leads to the more complex method, which implies sub-sub-models can measure the complexity of the proposed AMLSEN method. In practice, the ensemble size of the SEN-model in the proposed method is selected to make a trade-off between prediction accuracy and model complexity. Additionally, the ensemble size of the SEN-sub-model is implicitly determined by using the BBSEN algorithm in terms of prediction performance. Thus, the proposed method has a flexible structure to demonstrate the conclusion that the ensemble size increases with the decrease of the number of training samples.
A new soft measuring method is proposed based on the AMLSEN-LSSVM algorithm, and many sub-sub-models based on the different candidate learning parameters are constructed by using the LSSVM. According to the same KP, these candidate sub-sub-models are selectively fused to obtain SEN-sub-models by using the BBSEN, which are selectively combined by using the BBSEN again for building SEN models with different ensemble sizes. Ultimately, the final soft measuring model is determined based on a newly defined metric index. The simulation results based on the benchmark datasets show the effectiveness of the proposed method, which demonstrate that not only the proposed method can be used for softly measuring other difficult-to-measure process parameters in different industrial processes, but also a more common adaptive multi-layer SEN modeling framework can be explored.
Funding Statement: This research is supported by the State Key Laboratory of Process Automation in Mining & Metallurgy and Beijing Key Laboratory of Process Automation in Mining & Metallurgy under the Grant No. BGRIMM-KZSKL-2020-02, and National Key Research and Development Project under the Grant No. 2020YFE0201100 and 2019YFE0105000. The authors Jian Zhang and Jian Tang received the grants, respectively, and the URLs of sponsor’s website is https://www.bgrimm.com/.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. W. Wang, T. Y. Chai and W. Yu, “Modelling component concentrations of sodium aluminate solution via hammerstein recurrent neural networks,” IEEE Transactions on Control Systems Technology, vol. 20, no. 4, pp. 971–982, 2012. [Google Scholar]
2. J. Tang, T. Y. Chai, W. Yu and L. J. Zhao, “Modeling load parameters of ball mill in grinding process based on selective ensemble multisensor information,” IEEE Transactions on Automation Science and Engineering, vol. 10, no. 3, pp. 726–740, 2013. [Google Scholar]
3. M. Kano and K. Fujiwara, “Virtual sensing technology in process industries: trends & challenges revealed by recent industrial applications,” Journal of Chemical Engineering of Japan, vol. 46, pp. 1–17, 2013. [Google Scholar]
4. S. Bunsan, W. Y. Chen, H. W. Chen, Y. H. Chuang and N. Grisdanurak, “Modeling the dioxin emission of a municipal solid waste incinerator using neural networks,” Chemosphere, vol. 92, no. 3, pp. 258–264, 2013. [Google Scholar]
5. T. A. F. Gomes, R. B. C. Prudêncio, C. Soares, A. L. D. Rossi and A. Carvalho, “Combining meta-learning and search techniques to select parameters for support vector machines,” Neurocomputing, vol. 75, no. 1, pp. 3–13, 2012. [Google Scholar]
6. J. Tang, Z. Liu, J. Zhang, Z. W. Wu, T. Y. Chai et al., “Kernel latent features adaptive extraction and selection method for multi-component non-stationary signal of industrial mechanical device,” Neurocomputing, vol. 216, no. Suppl. 1–4, pp. 296–309, 2016. [Google Scholar]
7. A. Bemani, A. Baghban, S. Shamshirband, A. Mosavi, P. Csiba et al., “Applying ANN, ANFIS, and LSSVM models for estimation of acid solvent solubility in supercritical co2,” Computers, Materials & Continua, vol. 63, no. 3, pp. 1175–1204, 2020. [Google Scholar]
8. C. Soares, “A hybrid meta-learning architecture for multi-objective optimization of SVM parameters,” Neurocomputing, vol. 143, no. 1–3, pp. 27–43, 2014. [Google Scholar]
9. S. Yin and J. Yin, “Tuning kernel parameters for SVM based on expected square distance ratio,” Information Sciences, vol. 370–371, no. 12, pp. 92–102, 2016. [Google Scholar]
10. J. Sun, C. Zheng, X. Li and Y. Zhou, “Analysis of the distance between two classes for tuning svm hyperparameters,” Neural Netw. IEEE Trans, vol. 21, no. 2, pp. 305–318, 2010. [Google Scholar]
11. K. P. Wu and S. D. Wang, “Choosing the kernel parameters for support vector machines by the inter-cluster distance in the feature space,” Pattern Recognition, vol. 42, no. 5, pp. 710–717, 2009. [Google Scholar]
12. W. Wang, Z. Xu, W. Lu and X. Zhang, “Determination of the spread parameter in the Gaussian kernel for classification and regression,” Neurocomputing, vol. 55, no. 3-4, pp. 643–663, 2003. [Google Scholar]
13. J. Tang, T. Y. Chai, Q. M. Cong, B. C. Yuan, L. J. Zhao et al., “Soft sensor approach for modeling mill load parameters based on EMD and selective ensemble learning algorithm,” Acta Automatica Sinica, vol. 40, no. 9, pp. 1853–1866, 2014. [Google Scholar]
14. Y. Wang, X. Liu, Y. Dou, Q. Lv and Y. Lu, “Multiple kernel learning with hybrid kernel alignment maximization,” Pattern Recognition, vol. 70, no. 1, pp. 104–111, 2017. [Google Scholar]
15. C. Qi, Z. Zhou, Y. Sun, H. Song, L. Hu et al., “Feature selection and multiple kernel boosting framework based on PSO with mutation mechanism for hyperspectral classification,” Neurocomputing, vol. 220, no. 10, pp. 181–190, 2017. [Google Scholar]
16. U. Suleymanov, B. K. Kalejahi, E. Amrahov and R. Badirkhanli, “Text classification for azerbaijani language using machine learning,” Computer Systems Science and Engineering, vol. 35, no. 6, pp. 467–475, 2020. [Google Scholar]
17. Z. H. Zhou, J. Wu and W. Tang, “Ensembling neural networks: Many could be better than all,” Artificial Intelligence, vol. 137, no. 1–2, pp. 239–263, 2002. [Google Scholar]
18. J. Tang, J. Zhang, Z. Wu, Z. Liu, T. Chai et al., “Modeling collinear data using double-layer GA-based selective ensemble kernel partial least squares algorithm,” Neurocomputing, vol. 219, no. 4, pp. 248–262, 2017. [Google Scholar]
19. J. Tang, T. Y. Chai, Q. M. Cong, L. J. Zhao, Z. Liu et al., “Modeling mill load parameters based on selective fusion of multi-scale shell vibration frequency spectrum,” Control Theory & Application, vol. 32, no. 12, pp. 1582, 2015. [Google Scholar]
20. J. Tang, W. Yu, T. Y. Chai, Z. Liu and X. J. Zhou, “Selective ensemble modeling load parameters of ball mill based on multi-scale frequency spectral features and sphere criterion,” Mechanical Systems and Signal Processing, vol. 66–67, pp. 485–504, 2016. [Google Scholar]
21. Y. Lv, J. Liu and T. Yang, “A novel least squares support vector machine ensemble model for NOx, emission prediction of a coal-fired boiler,” Energy, vol. 55, no. 1, pp. 319–329, 2013. [Google Scholar]
22. L. Yu, “An evolutionary programming based asymmetric weighted least squares support vector machine ensemble learning methodology for software repository mining,” Information Sciences, vol. 191, no. 8, pp. 31–46, 2012. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |