DOI:10.32604/iasc.2021.018111
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2021.018111 | |
| Article |
Inference on Generalized Inverse-Pareto Distribution under Complete and Censored Samples
1Department of Basic Sciences, College of Science and Theoretical Studies, Saudi Electronic University, Riyadh, 11673, Saudi Arabia
2Department of Mathematical Statistics, Faculty of Graduate Studies for Statistical Research, Cairo University, Giza, 12631, Egypt
3Department of Mathematics, College of Science and Arts, Qassim University, Ar Rass, 51921, Saudi Arabia
4Department of Statistics, Mathematics and Insurance, Benha University, Benha, 13511, Egypt
*Correspondence: Ahmed Z. Afify. Email: ahmed.afify@fcom.bu.edu.eg
Received: 21 February 2021; Accepted: 25 March 2021
Abstract: In this paper, the estimation of the parameters of extended Marshall-Olkin inverse-Pareto (EMOIP) distribution is studied under complete and censored samples. Five classical methods of estimation are adopted to estimate the parameters of the EMOIP distribution from complete samples. These classical estimators include the percentiles estimators, maximum likelihood estimators, least squares estimators, maximum product spacing estimators, and weighted least-squares estimators. The likelihood estimators of the parameters under type-I and type-II censoring schemes are discussed. Simulation results were conducted, for various parameter combinations and different sample sizes, to compare the performance of the EMOIP estimation methods under complete and censored samples. Further, the mean square errors, asymptotic confidence interval, average interval length, and coverage percentage are calculated under the two censored schemes. The simulation results illustrate that the coverage probabilities of the confidence intervals increase to the nominal levels when the sample size increases. A real data set from the insurance field is analyzed for illustrative purposes. The data represent monthly metrics on unemployment insurance from July 2008 to April 2013 and contain 21 variables and particularly we study the variable number 11 in the data. The EMOIP model provides a better fit as compared with the inverse-Pareto distribution under complete and censored schemes. We hope that the EMOIP distribution will attract wider applications in the insurance field which contains several heavy-tailed real data.
Keywords: Inverse-Pareto distribution; censored samples; insurance data; percentile estimators; Marshall-Olkin family; simulation
In statistical literature, many standard distributions are used when studying real data in different applied fields, but the known standard distributions are limited comparing with various real data. There is increased interest of finding new distributions by extending the existing ability of studying the unlimited range of the real data. Marshall et al. [1] introduced an important method of adding an extra parameter to well-known existing distributions, which gives more flexibility to model various types of data. The resulting distribution includes the baseline distribution as a special case when the new added parameter equals one. Their method is called the Marshall-Olkin (MO) family.
In this paper, the estimation of the extended Marshall-Olkin inverse-Pareto (EMOIP) parameters is conducted using five classical estimators, including the maximum likelihood estimators (MLEs), least squares estimators (LSEs), weighted least-squares estimators (WLSEs), percentiles estimators (PCEs), and maximum product spacing estimators (MPSEs). The behavior of these estimators is addressed using extensive simulation results for small and large samples. Furthermore, we address the estimation of the EMOIP parameters under censoring schemes, including type I censoring and type II censoring schemes. We have also conducted a Monte Carlo simulation study to calculate the MLEs for the unknown parameters under type I and type II censoring schemes. Finally, we analyze real data from the insurance field for illustrative purposes.
The EMOIP model was introduced by Gharib et al. [2] to model data with unimodal hazard rate function (HRF). They derived some basic distributional properties, including the quantile function, ordinary moments, incomplete moments, negative moments, moments of residual life and reversed residual life, and order statistics.
Gharib et al. [2] extended the Inverse-Pareto (IP) distribution, as a baseline distribution, to obtain their new distribution, which is called the Extended Marshall-Olkin Inverse-Pareto (EMOIP). The EMOIP model is obtained by applying the MO transformation, which is defined by the following survival function (SF)
Or the cumulative distribution function (CDF)
If
The MO family is one of the most common generators in the literature and has been used extensively to extend several classical distributions as well as several other families of distributions. The most notable recent works include the MO extended-Weibull [3], MO generalized Burr-XII [4], MO exponentiated Burr-XII [5], MO additive-Weibull [6], Marshall-Olkin power Lomax [7], and MO power generalized-Weibull [8] distributions, among many others, including the MO alpha-power family [9], MO Burr-R class [10], and MO Burr-III family [11].
The two-parameter IP distribution [12, P. 707, Sec. A.2.3.2] is specified by the following CDF
in which
The probability density function (PDF) of the IP distribution has the form
The CDF of the EMOIP distribution with three parameters,
in which
The PDF of the EMOIP distribution reduces to
Clearly, for
The HRF of the EMOIP model is given as
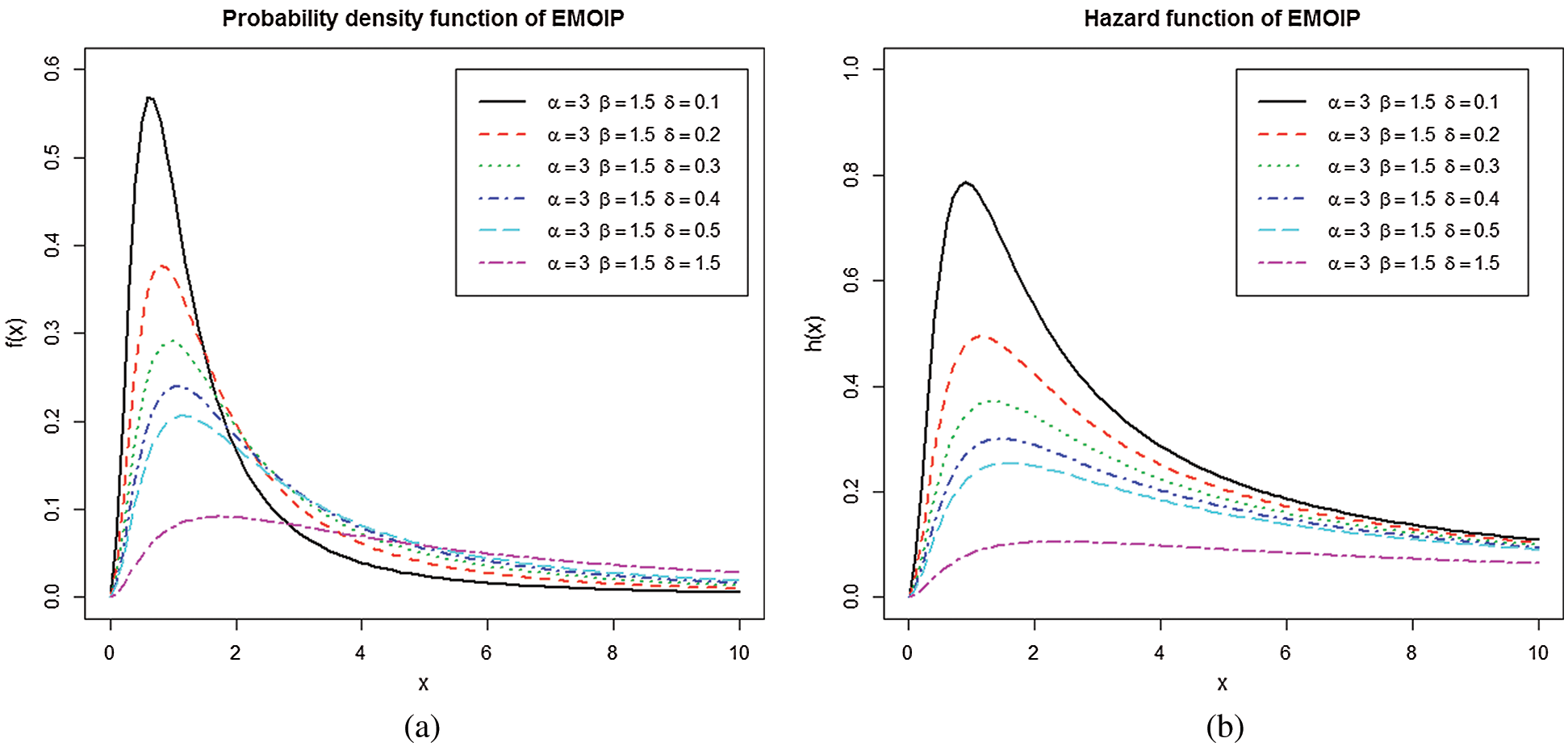
Figure 1: (a) Some plots of the PDF of the EMOIP model; (b) Some plots of the HRF of the EMOIP model
The rest of the article is organized in four sections. Section 2 describes five classical estimation methods for estimating the EMOIP parameters and examines the proposed estimators numerically via Monte Carlo simulations. Section 3 discusses the estimation under censored samples as well as provides a detailed simulation study. A real data set from the insurance science is analyzed in Section 4 for illustrative purposes. Finally, Section 5 is devoted to the conclusion.
2 Estimation Under Complete Samples with Simulations
This section is devoted to estimating the parameters
2.1 Maximum Likelihood Estimation
Let
The MLEs of the EMOIP parameters
and
in which
The MLEs of
The percentiles estimation method is introduced by Kao et al. [21,22]. The PCEs of the parameters
with respect to
where
and
2.3 Least Squares and Weighted Least Squares Estimation
The LSEs and WLSEs are adopted to estimate the beta parameters [23]. The LSEs of the parameters
These estimates can also be obtained by solving the following nonlinear equations:
where
and
The WLSEs of the EMOIP parameters
Further, the WLSEs are obtained by solving the following equations:
in which
2.4 Maximum Product of Spacings Estimation
The maximum product of spacings (MPS) method is proposed by Cheng et al. [24,25] to estimate the model parameters instead of the maximum likelihood.
The MPSEs of the EMOIP parameters
where
Alternatively, these estimates can be obtained by solving the following equations:
in which
In this section, a Monte Carlo simulation study is conducted to compare the performance of the different estimators of the unknown parameters of the EMOIP distribution. The numerical results are obtained using the Mathcad program, version 14.0, to compare the performances of different estimators with respect to their mean squared errors (MSEs). We generate 2000 samples of the EMOIP distribution for
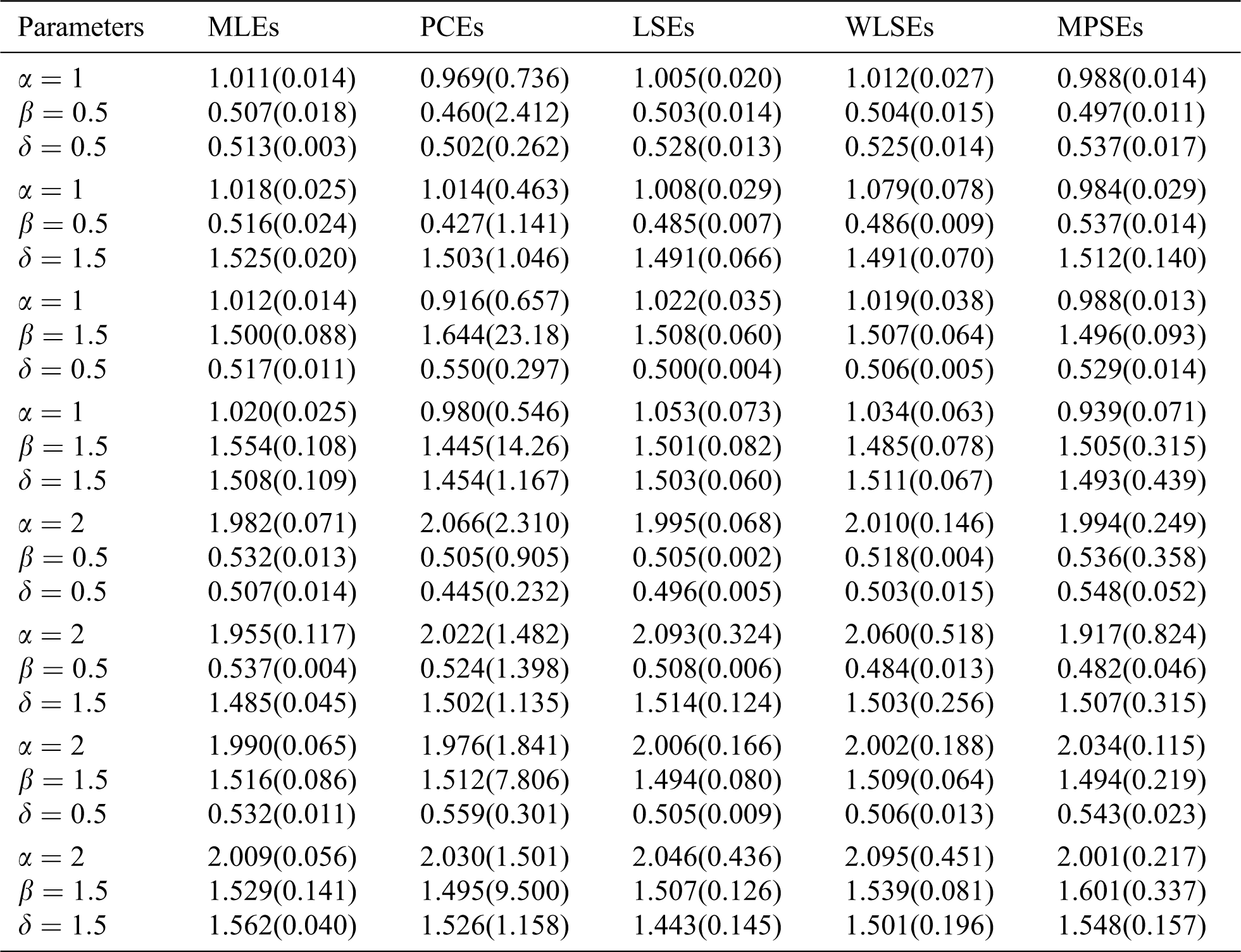
The average values of estimates (AVEs) and MSEs of MLEs, LSEs, WLSEs, PCEs, and MPSEs are displayed in Tabs. 1–4. From Tabs. 1–4, the MSEs decrease as sample size increases. Comparing the different methods of estimation, the results show that the MLE produces the best results for estimating the parameters
3 Estimation Under Censored Samples
In this section, we address the MLEs of the EMOIP parameters under type-I and type-II censored samples. We derive the approximate confidence intervals of the unknown parameters from the Fisher information matrix under type-I and type-II censored samples. Finally, we perform a simulation study to explore the behavior of the estimates. Several authors have been studied the estimation of the model parameters under different censoring schemas, such as Tomazella et al. [26] and Alshenawy et al. [27].
3.1 Maximum Likelihood under Type-I Censored Sample
In censoring of type-I, the unit
Table 1: The AVEs and their corresponding MSEs (in parentheses) for
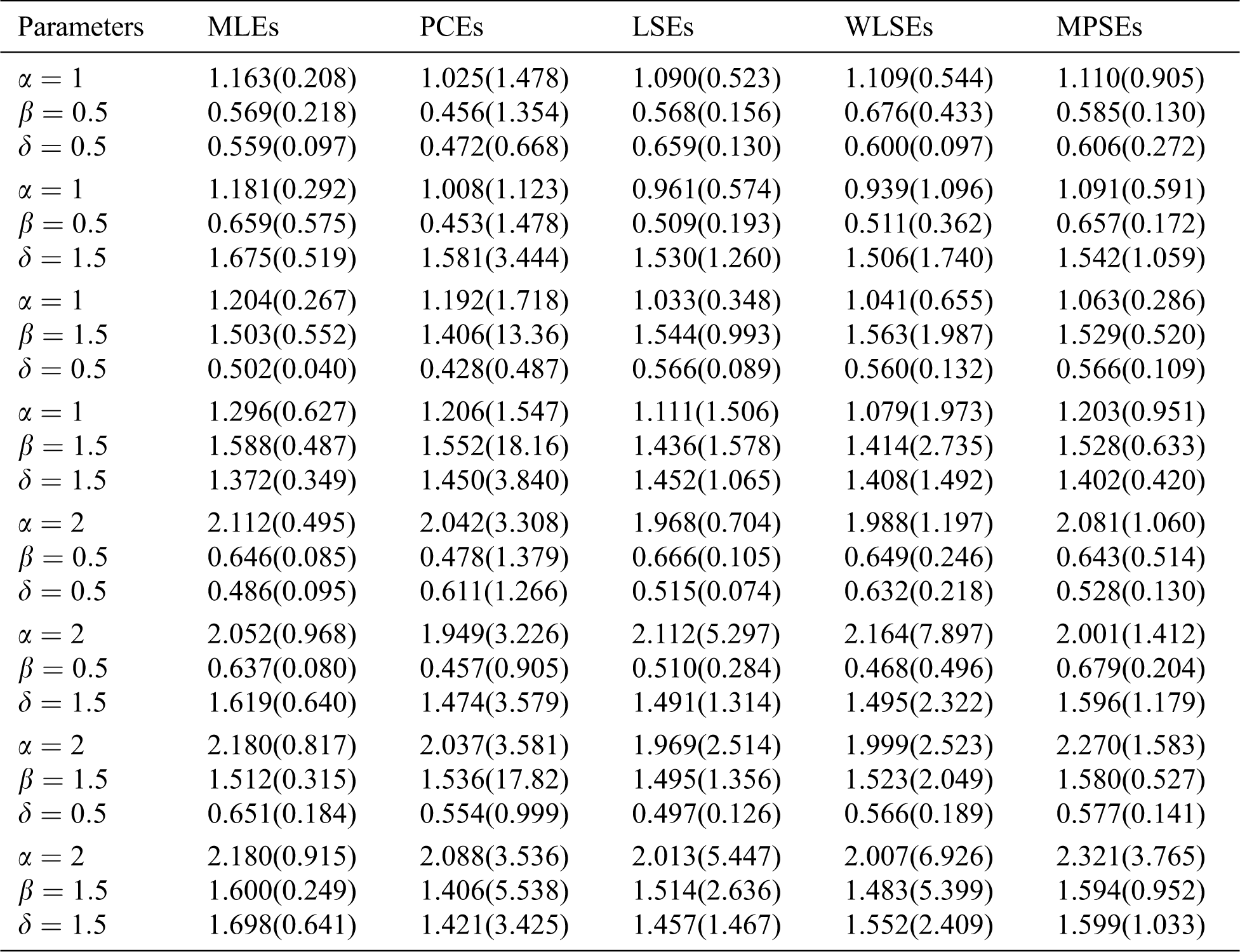
Table 2: The AVEs and their corresponding MSEs (in parentheses) for
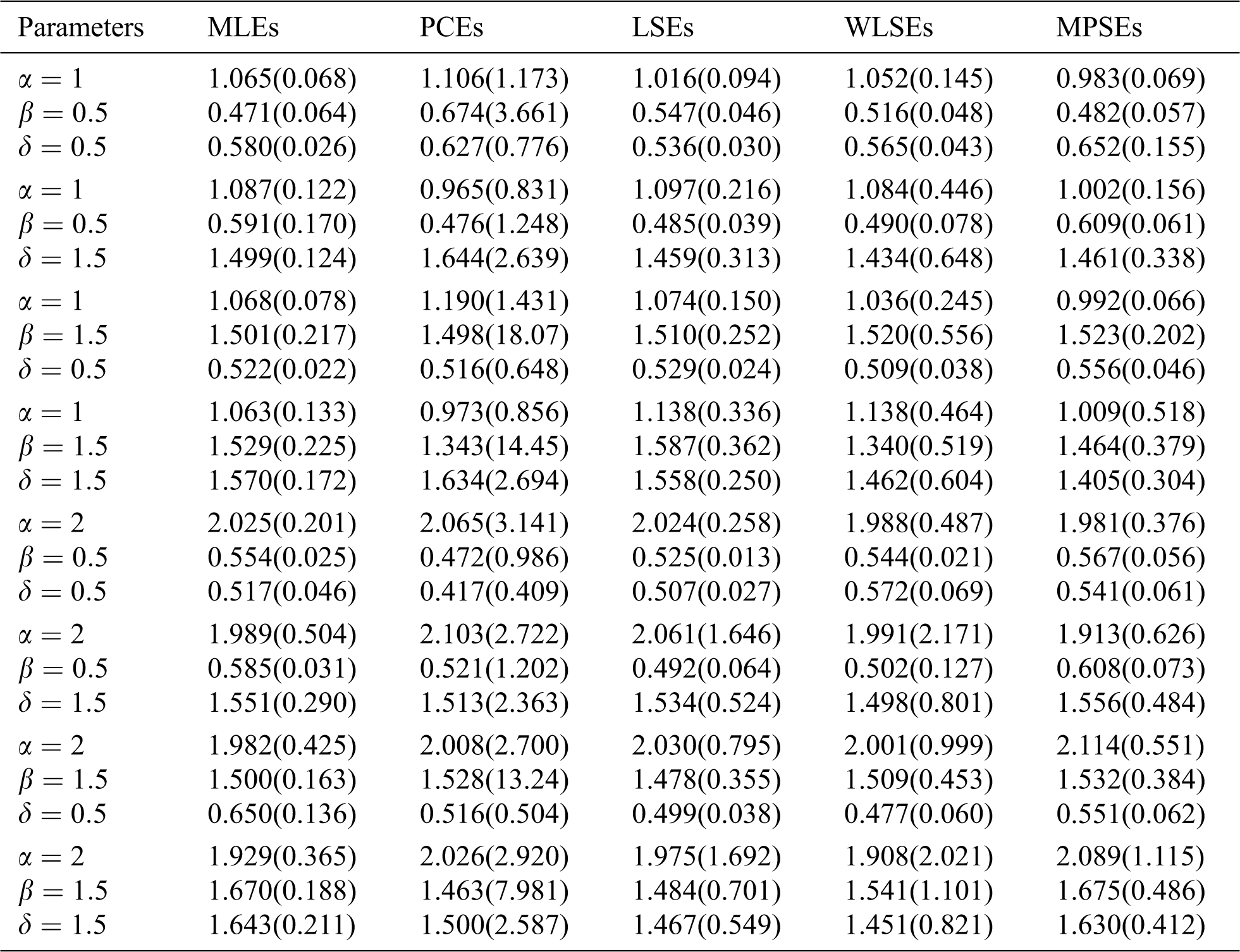
Table 3: The AVEs and their corresponding MSEs (in parentheses) for
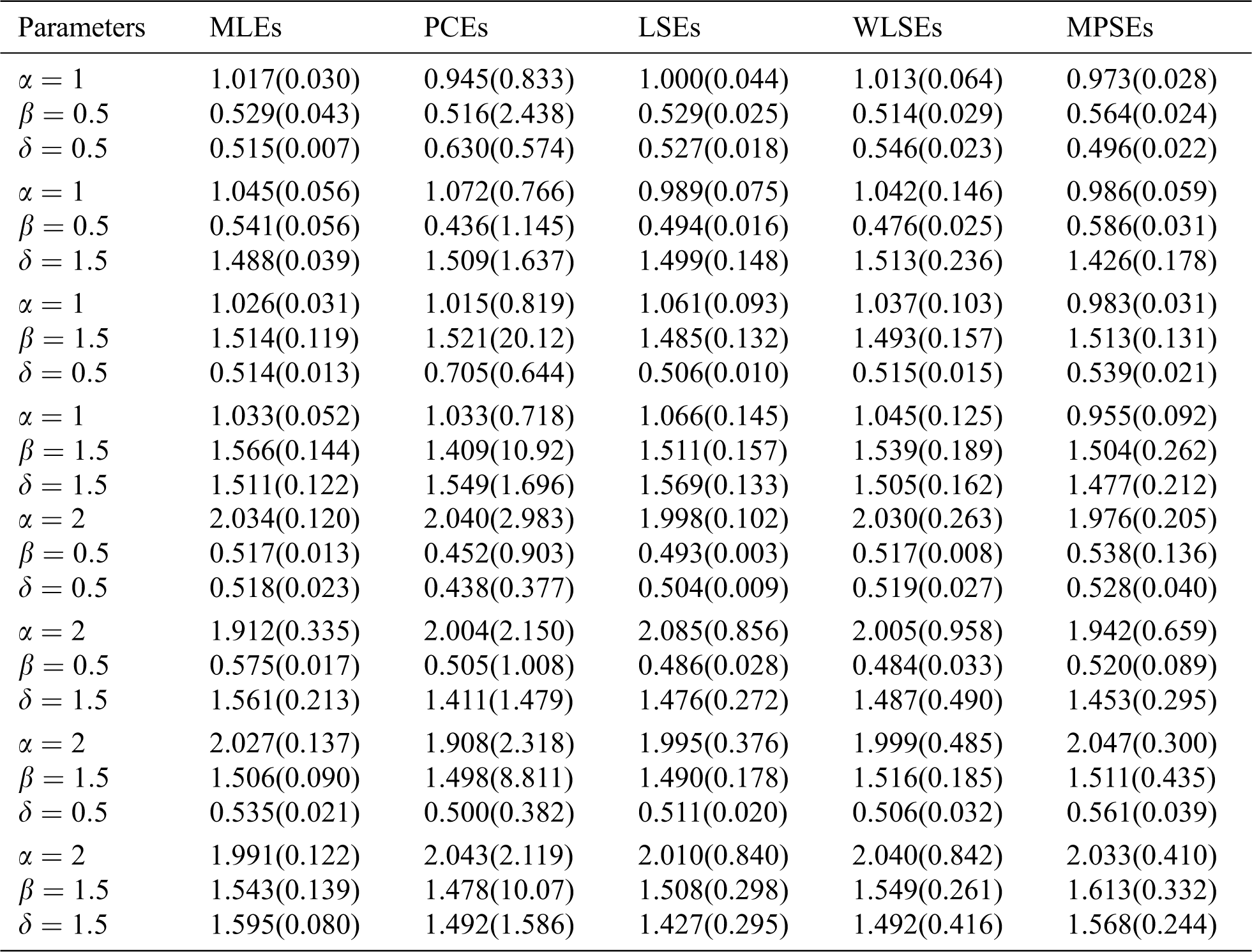
Table 4: The AVEs and their corresponding MSEs (in parentheses) for
in which
Therefore,
Suppose that the fixed observation times for all units are equal to
If
The MLEs of
and
By solving the following equations simultaneously
3.2 Maximum Likelihood under Type-II Censored Sample
Let
For simplicity of notation, we use
The MLEs of
and
The above three equations cannot be solved explicitly, so the numerical techniques can be employed to obtain the MLEs of the parameters, i.e.,
In this section, we conduct a simulation study to explore the performance of the MLEs of the EMOIP parameters in terms of their MSEs, asymptotic confidence interval (ACI), average interval length (AIL), and coverage percentage (CP) under type-I and type-II censored samples. We consider the values 20, 50, 100 and 200 for
All simulation results are carried out using the R software, where we generate
The simulation results, including the AVEs, MSEs, ACI, AIL, and CP, are displayed in Tabs. 5–12. From Tabs. 5–12, we observe that the MSEs decrease as the sample size increases in all the cases under type-I and type-II censored samples. Furthermore, the AVEs tend to the true parameter values as
Table 5: The AVEs, MSEs, ACI, AILs and CPs of the EMOIP distribution under type-I censoring with
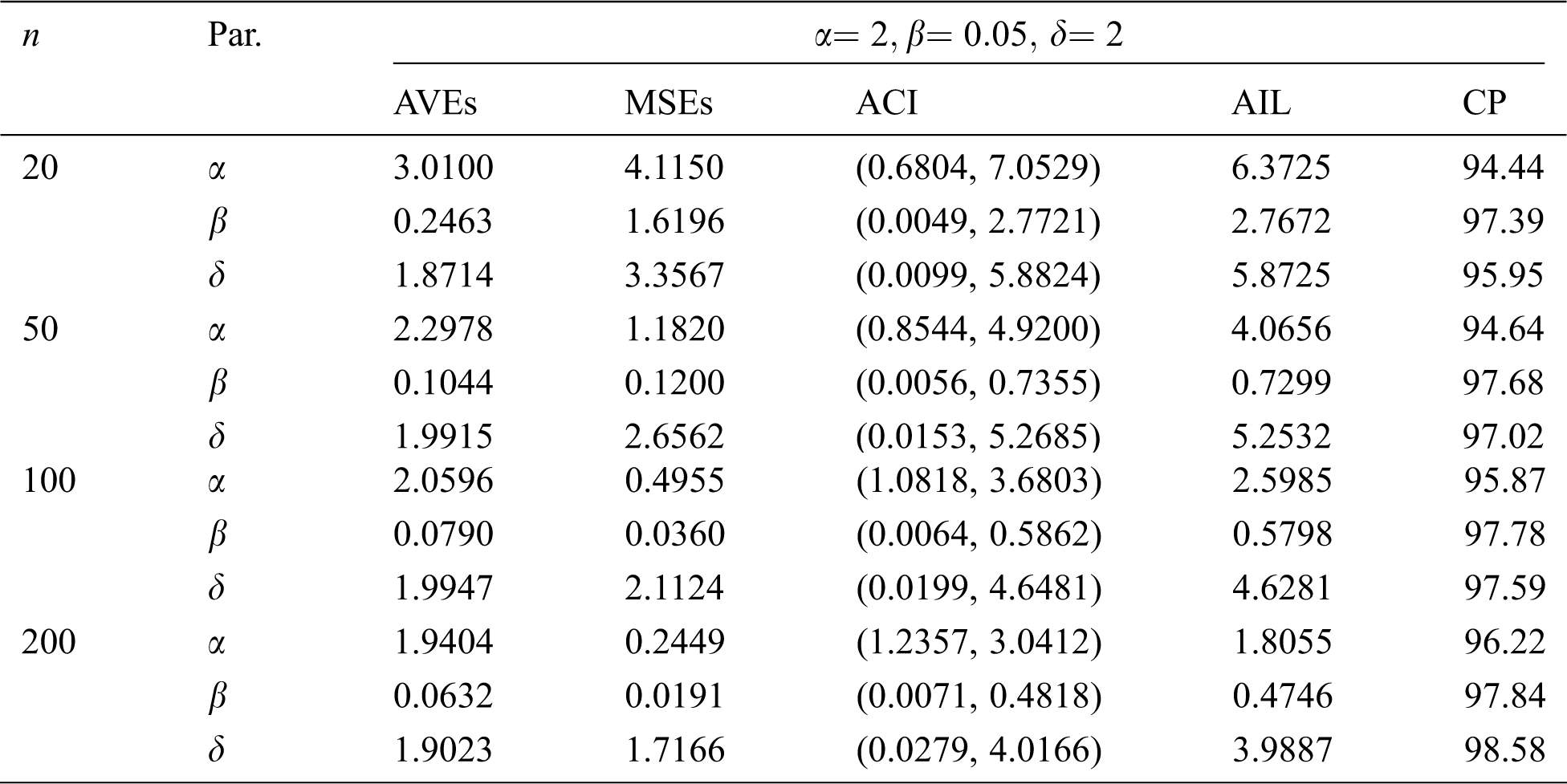
Table 6: MLE estimated, interval estimates, MSEs, AILs and CPs (in %) of EMOIP distribution under type-I censoring with
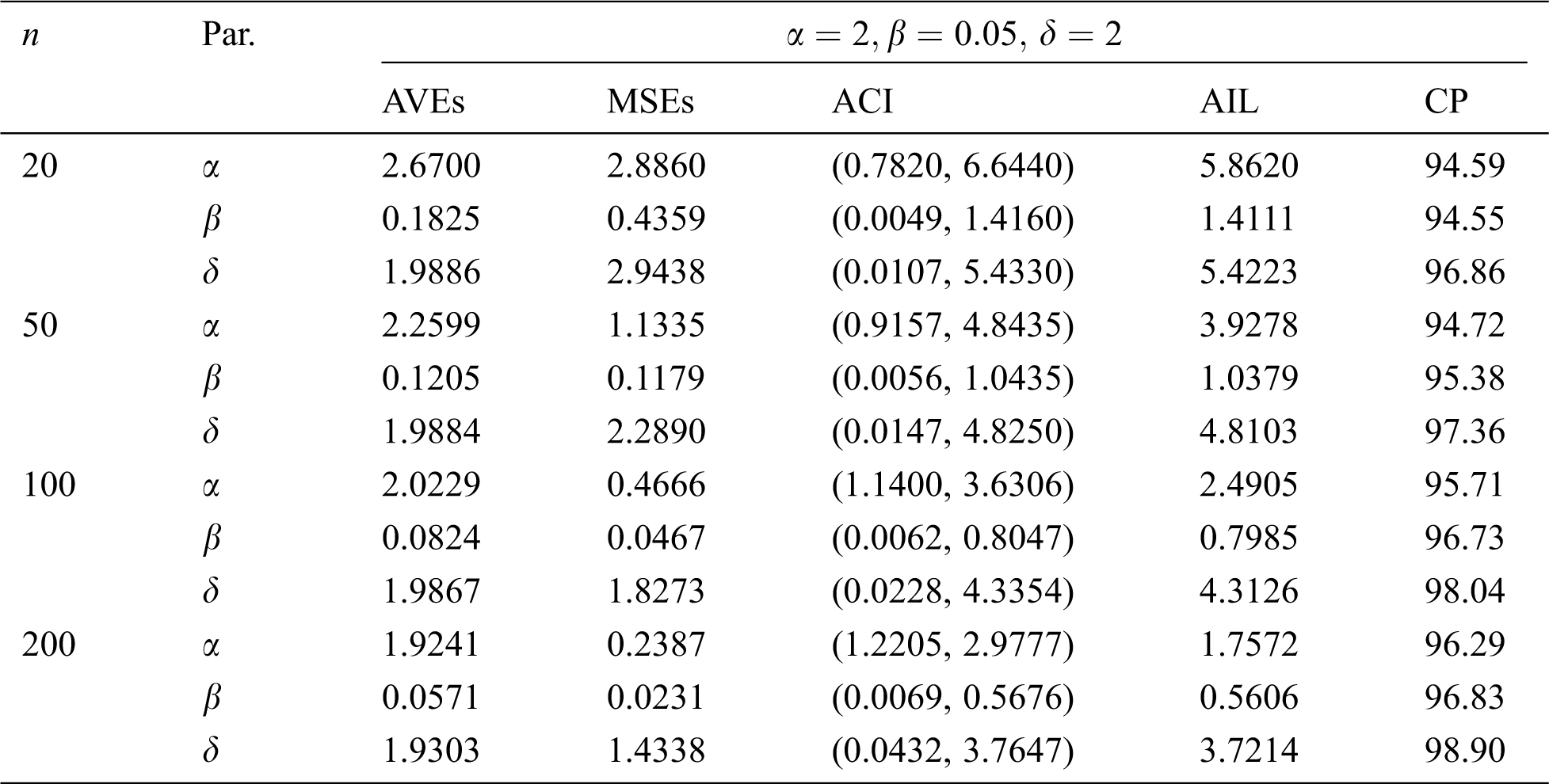
Table 7: MLE estimated, interval estimates, MSEs, AILs and CPs (in %) of EMOIP distribution under type-I censoring with
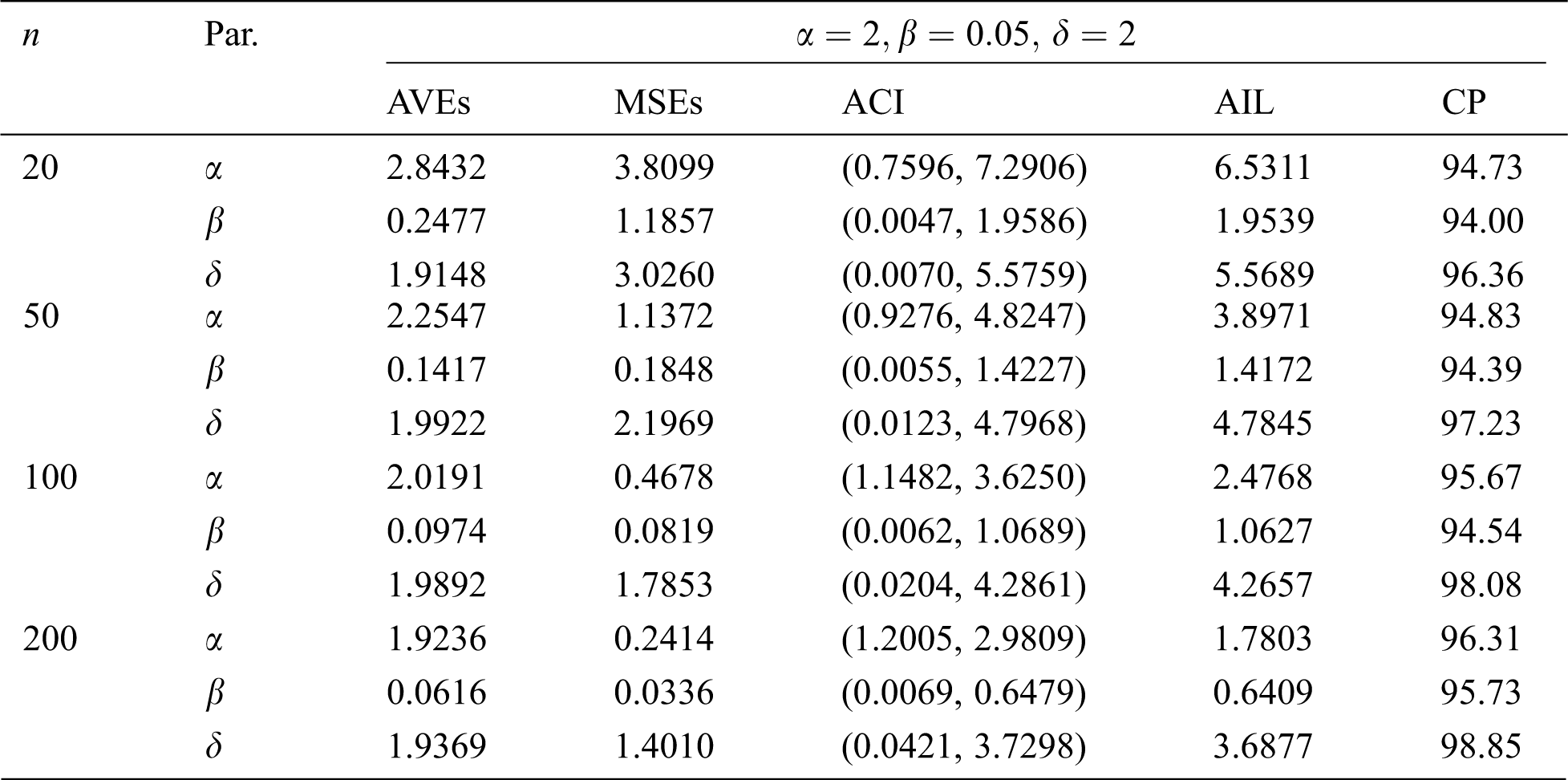
Table 8: MLE estimated, interval estimates, MSEs, AILs and CPs (in %) of EMOIP distribution under type-I censoring with
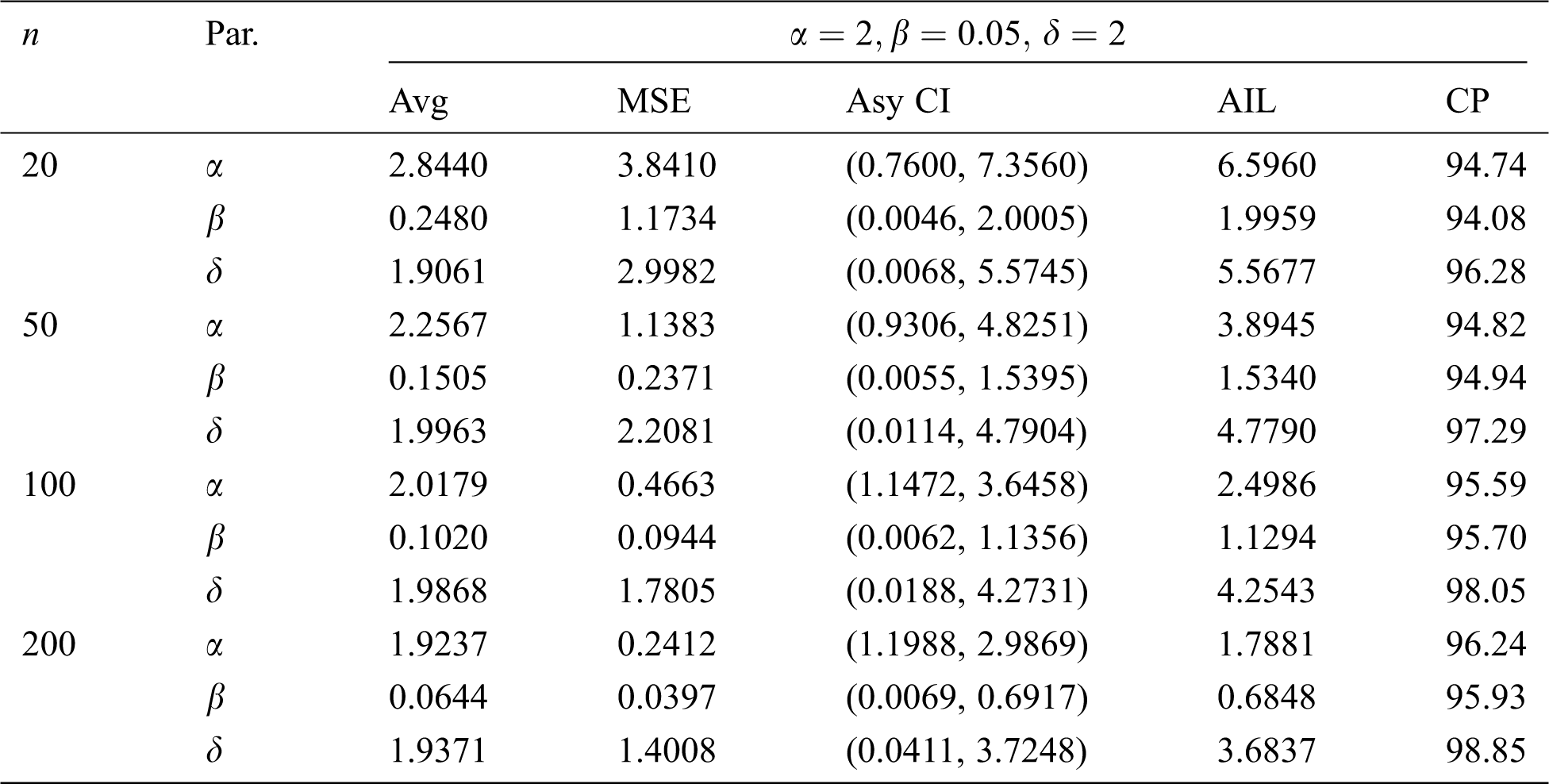
Table 9: MLE estimated, interval estimates, MSEs, AILs and CPs (in %) of EMOIP distribution under type-II censoring with
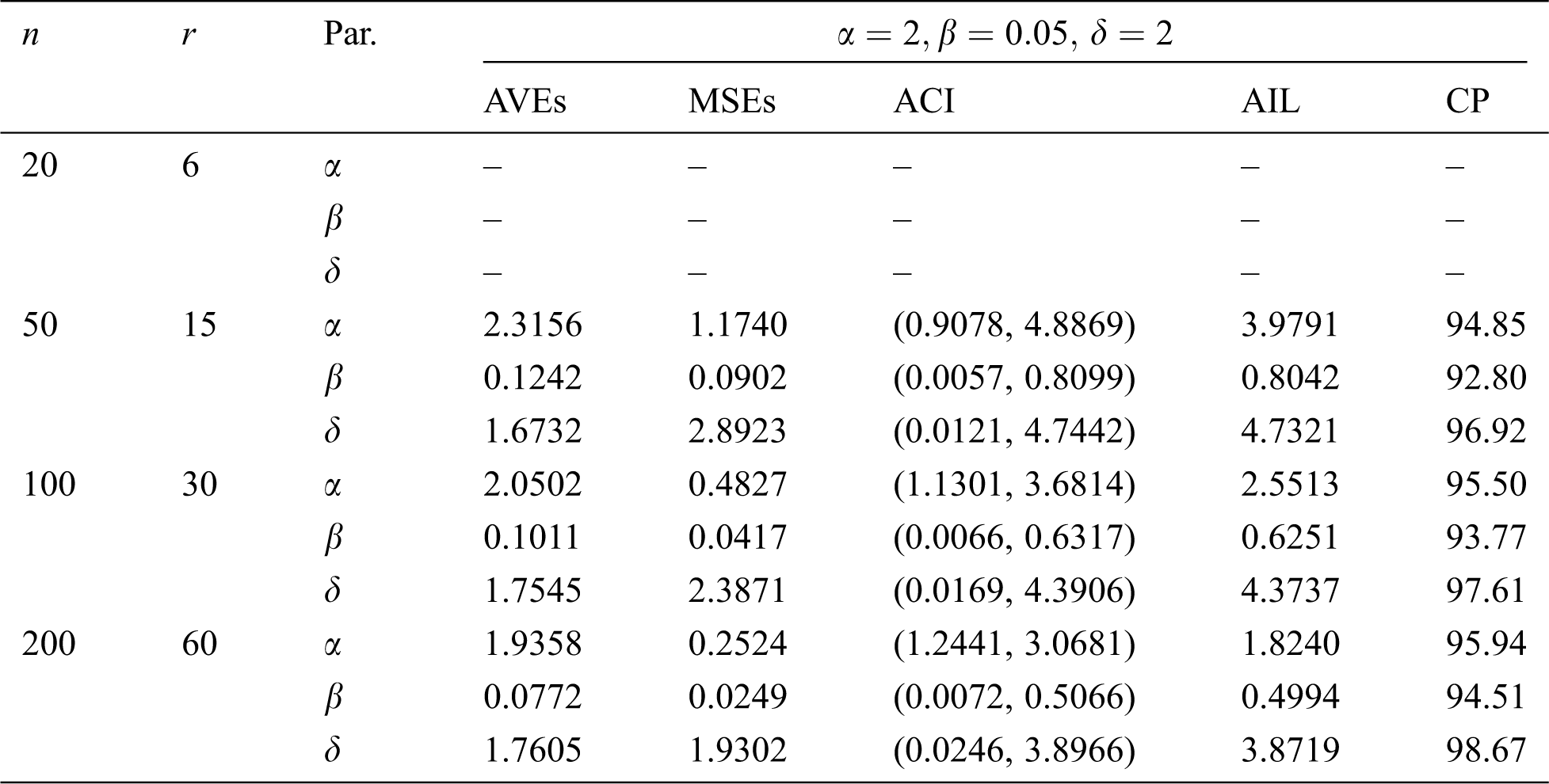
Table 10: MLE estimated, interval estimates, MSEs, AILs and CPs (in %) of EMOIP distribution under type-II censoring with
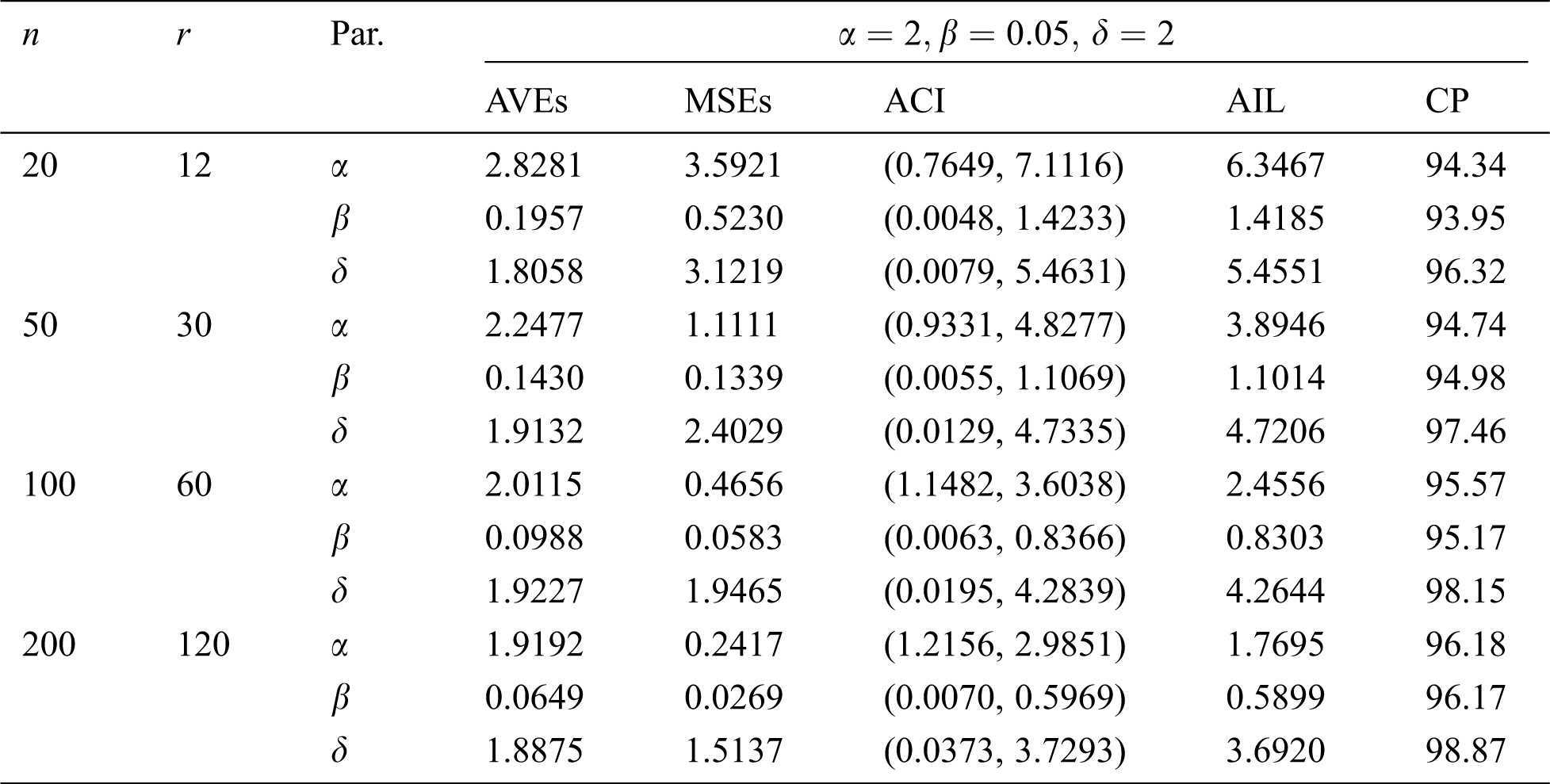
Table 11: MLE estimated, interval estimates, MSEs, AILs and CPs (in %) of EMOIP distribution under type-II censoring with
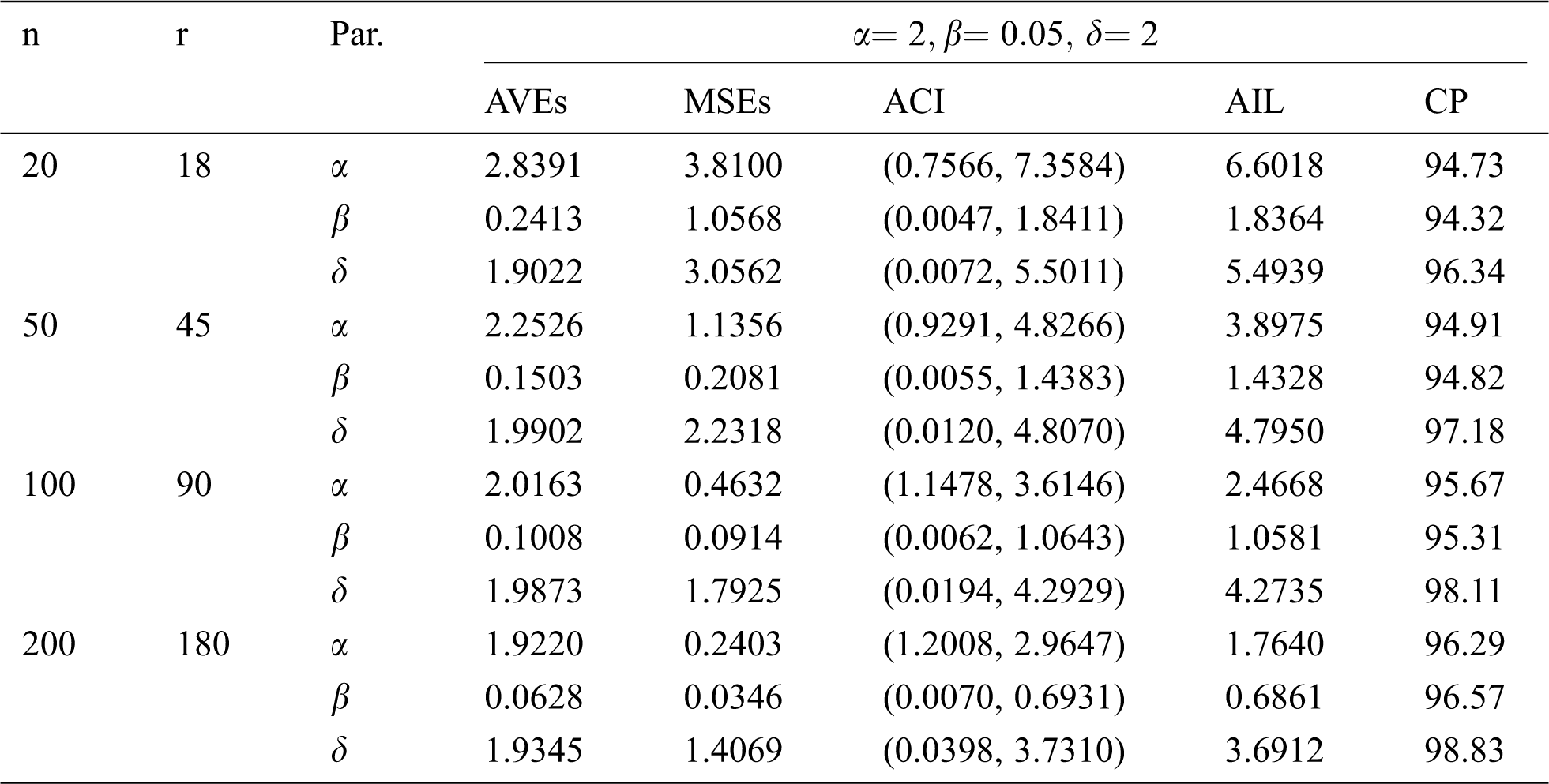
Table 12: MLE estimated, interval estimates, MSEs, AILs and CPs (in %) of EMOIP distribution under type-II censoring with
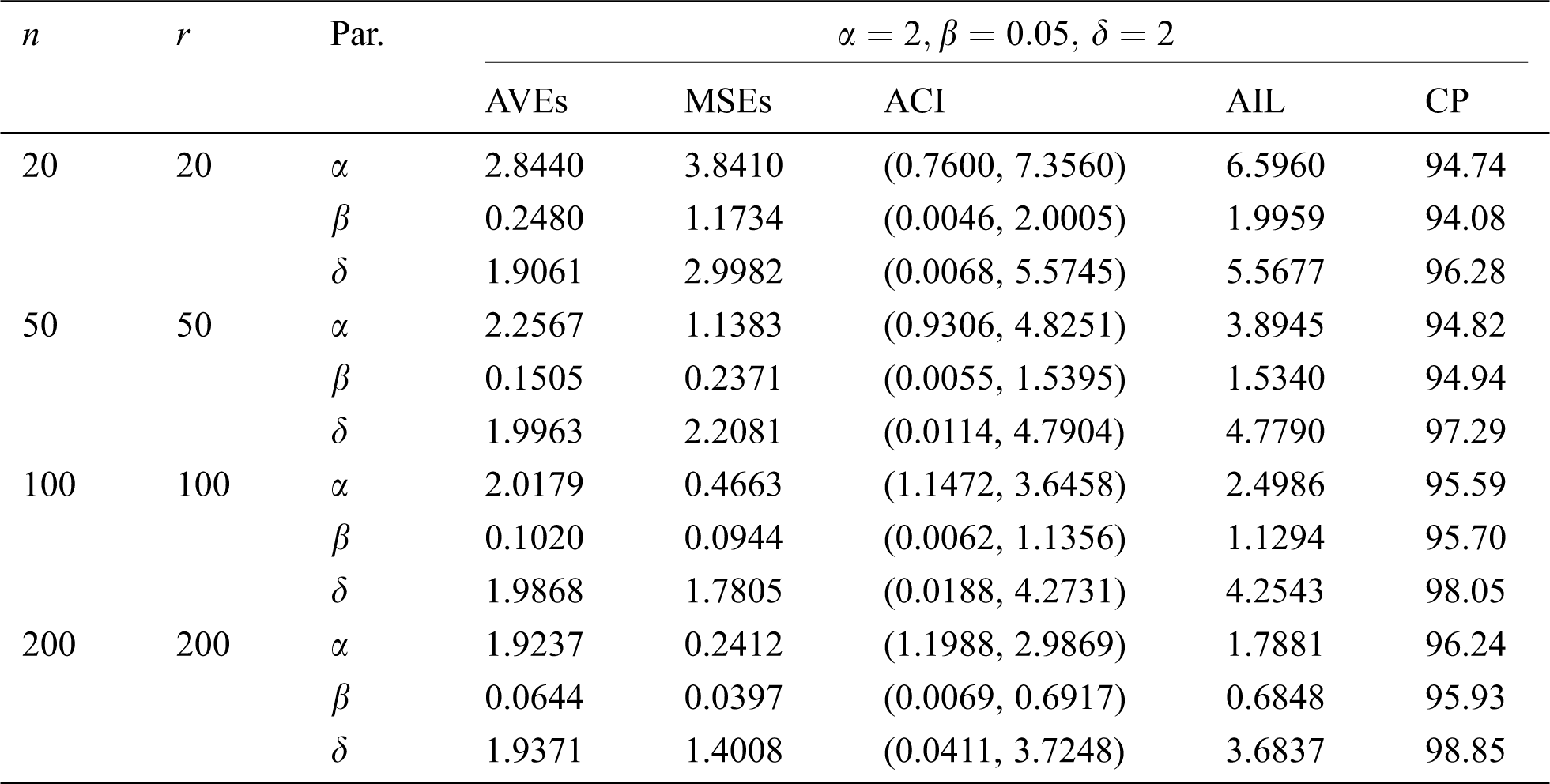
The results show that the MLEs of the EMOIP parameters under type-I and type-II schemes are asymptotically unbiased and consistent. As expected, the performance of the estimates under complete samples is better than those under type-I and type-II censored samples in terms of the MSEs. Furthermore, the AIL decreases as
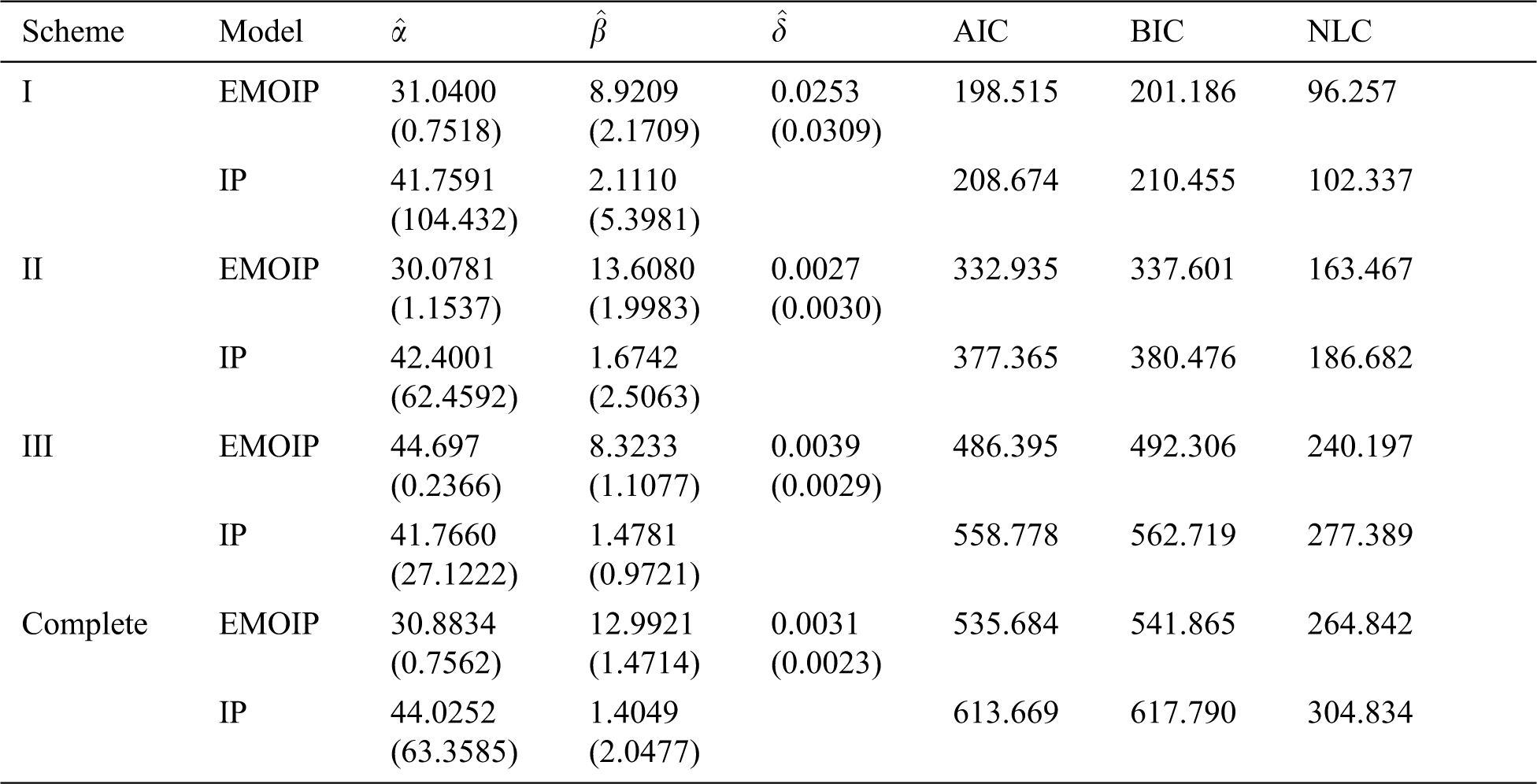
In this section, we analyze a real data set for illustrative purpose. The following data set represents monthly metrics on unemployment insurance from July 2008 to April 2013 as reported by the department of Labor, Licensing and Regulation, State of Maryland, USA. The data set contains 21-variable and here we consider the variable number 11 in the data file which is available at: https://catalog.data.gov/dataset/unemployment-insurance-data-july-2008-to-april-2013. The data contain 58 observations: 29, 32, 33, 36, 39, 41, 44, 50, 50, 50, 52, 52, 52, 52, 53, 54, 56, 57, 57, 57, 58, 59, 60, 60, 60, 61, 61, 61, 63, 64, 64, 64, 65, 66, 66, 68, 68, 69, 69, 70, 72, 73, 74, 75, 80, 80, 80, 83, 90, 90, 95, 100, 109, 114, 133, 137, 170, 222. The EMOIP parameters are estimated using the maximum likelihood (ML) method under the following schemes for type-I and type-II censoring as follows:

These methods will be compared using the Akaike’s information criterion (AIC), (BIC) Bayesian information criterion (BIC), and Negative log-likelihood criterion (NLC). The EMOIP and IP distributions are fitted to the given data set under the considered schemes.
The ML estimates of the parameters of the EMOIP and IP distributions along with their standard errors (SEs), AIC, BIC, and NLC were reported in Tabs. 13 and 14 for type-I and type-II censoring schemes, respectively. It is shown that the EMOIP provides a closer fit under the two types of censoring for all considered setups than the IP model.
Table 13: ML estimates, SEs, AIC, BIC and NLC of the EMOIP and IP distributions under type-I censored insurance data
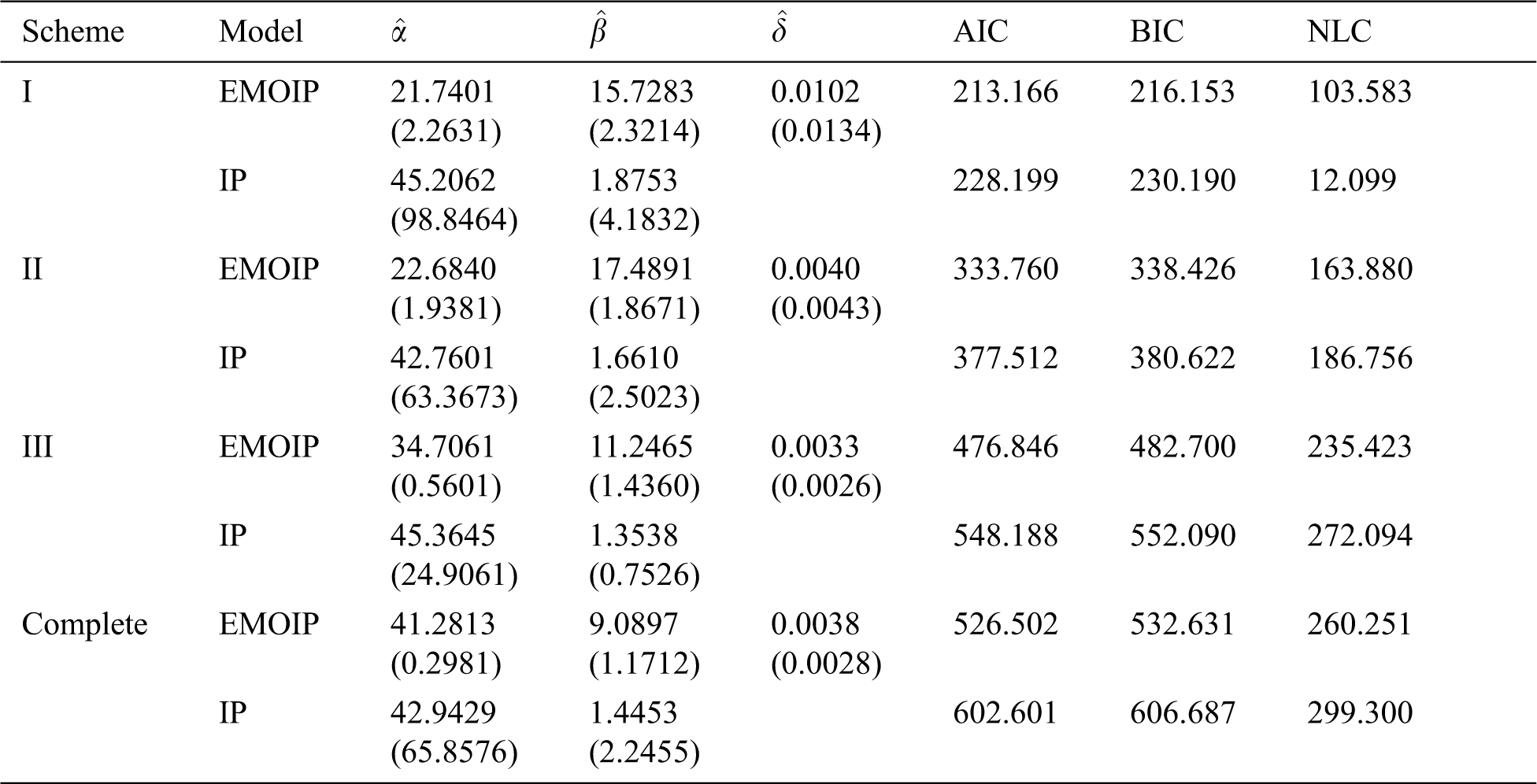
Table 14: ML estimates, SEs, AIC, BIC and NLC of the EMOIP and IP distributions under type-II censored insurance data
In this paper, the Extended Marshall-Olkin Inverse Pareto (EMOIP) parameters are estimated using five classical estimation methods from complete samples, including the maximum likelihood, percentiles, least squares, maximum product spacings, and weighted least-squares. Furthermore, the EMOIP parameters are also estimated using the maximum likelihood estimation under type-I and type-II censored samples. Monte Carlo simulations are conducted to compare and explore the performance of the different estimators of the EMOIP parameters under complete and censored samples. Based on our study, the maximum likelihood is the best performing method in terms of its mean squared errors. We conduct another Monte Carlo simulation study to calculate the maximum likelihood estimators for the model parameters under type-I and type-II censoring schemes. Finally, we analyze a real data set to validate our results.
Availability of Data and Materials: The data sets used in this paper are provided within the main body of the manuscript.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. A. W. Marshall and I. Olkin, “A new method for adding a parameter to a family of distributions with applications to the exponential and Weibull families,” Biometrika, vol. 84, no. 3, pp. 641–652, 1997. [Google Scholar]
2. M. Gharib, B. I. Mohammed and W. E. R. Aghel, “Marshall-Olkin extended inverse Pareto distribution and its application,” International Journal of Statistics and Probability, vol. 6, no. 6, pp. 71–84, 2017. [Google Scholar]
3. M. E. Ghitany, E. K. Al-Hussaini and R. A. Al-Jarallah, “Marshall-Olkin extended Weibull distribution and its application to censored data,” Journal of Applied Statistics, vol. 32, no. 10, pp. 1025–1034, 2005. [Google Scholar]
4. A. Z. Afify and A. Abdellatif, “The extended Burr XII distribution: Properties and applications,” Journal of Nonlinear Sciences and Applications, vol. 13, no. 3, pp. 133–146, 2020. [Google Scholar]
5. G. Cordeiro, M. Mead, A. Z. Afify, A. Suzuki and A.Abd El-Gaied, “An extended Burr XII distribution: Properties, inference and applications,” Pakistan Journal of Statistics and Operation Research, vol. 13, no. 4, pp. 809–828, 2017. [Google Scholar]
6. A. Z. Afify, G. M. Cordeiro, H. M. Yousof, A. Saboor and E. M. M. Ortega, “The Marshall-Olkin additive Weibull distribution with variable shapes for the hazard rate,” Hacettepe Journal of Mathematics and Statistics, vol. 47, pp. 365–381, 2018. [Google Scholar]
7. M. A. Haq, G. G. Hamedani, M. Elgarhy and P. L. Ramos, “Marshall-Olkin Power Lomax distribution: Properties and estimation based on complete and censored samples,” International Journal of Statistics and Probability, vol. 9, no. 1, pp. 48–62, 2020. [Google Scholar]
8. A. Z. Afify, D. Kumar and I. Elbatal, “Marshall-Olkin power generalized Weibull distribution with applications in engineering and medicine,” Journal of Statistical Theory and Applications, vol. 19, no. 2, pp. 223–237, 2020. [Google Scholar]
9. M. Nassar, D. Kumar, S. Dey, G. M. Cordeiro and A. Z. Afify, “The Marshall-Olkin alpha power family of distributions with applications,” Journal of Computational and Applied Mathematics, vol. 351, pp. 41–53, 2019. [Google Scholar]
10. A. A. Al-Babtain, R. A. K. Sherwani, A. Z. Afify, K. Aidi, M. A. Nasir et al., “The extended Burr-R class: Properties, applications and modified test for censored data,” AIMS Mathematics, vol. 6, no. 3, pp. 2912–2931, 2021. [Google Scholar]
11. A. Z. Afify, G. M. Cordeiro, N. A. Ibrahim, F. Jamal, M. Elgarhy et al., “The Marshall-Olkin odd Burr III-G family: Theory, estimation, and engineering applications,” IEEE Access, vol. 9, pp. 4376–4387, 2021. [Google Scholar]
12. S. A. Klugman, H. H. Panjer and G. E. Willmot, Loss models: From data to decisions. Hoboken: John Wiley & Sons, 2012. [Google Scholar]
13. M. Nassar, A. Z. Afify, S. Dey and D. Kumar, “A new extension of Weibull distribution: Properties and different methods of estimation,” Journal of Computational and Applied Mathematics, vol. 336, no. 1, pp. 439–457, 2018. [Google Scholar]
14. S. Sen, A. Z. Afify, H. Al-Mofleh and M. Ahsanullah, “The quasi xgamma-geometric distribution with application in medicine,” Filomat, vol. 33, no. 16, pp. 5291–5330, 2019. [Google Scholar]
15. M. Nassar, A. Z. Afify, M. K. Shakhatreh and S. Dey, “On a new extension of Weibull distribution: Properties, estimation, and applications to one and two causes of failures,” Quality and Reliability Engineering International, vol. 36, no. 6, pp. 2019–2043, 2020. [Google Scholar]
16. A. Z. Afify, M. Nassar, G. M. Cordeiro and D. Kumar, “The Weibull Marshall-Olkin Lindley distribution: Properties and estimation,” Journal of Taibah University for Science, vol. 14, no. 1, pp. 192–204, 2020. [Google Scholar]
17. H. Al-Mofleh, A. Z. Afify and N. A. Ibrahim, “A new extended two-parameter distribution: Properties, estimation methods, and applications in medicine and geology,” Mathematics, vol. 8, no. 9, pp. 1578, 2020. [Google Scholar]
18. P. L. Ramos, F. Louzada, E. Ramos and S. Dey, “The Fréchet distribution: Estimation and application—An overview,” Journal of Statistics and Management Systems, vol. 23, no. 3, pp. 549–578, 2020. [Google Scholar]
19. A. Z. Afify, A. M. Gemeay and N. A. Ibrahim, “The heavy-tailed exponential distribution: Risk measures, estimation, and application to actuarial data,” Mathematics, vol. 8, no. 8, pp. 1276, 2020. [Google Scholar]
20. P. L. Ramos, F. Louzada, T. K. Shimizu and A. O. Luiz, “The inverse weighted Lindley distribution: Properties, estimation, and an application on a failure time data,” Communications in Statistics-Theory and Methods, vol. 48, no. 10, pp. 2372–2389, 2019. [Google Scholar]
21. J. H. K. Kao, “Computer methods for estimating Weibull parameters in reliability studies,” IRE Transactions on Reliability and Quality Control, vol. 13, pp. 15–22, 1958. [Google Scholar]
22. J. H. K. Kao, “A graphical estimation of mixed Weibull parameters in life testing electron tube,” Technometrics, vol. 1, no. 4, pp. 389–407, 1959. [Google Scholar]
23. J. Swain, S. Venkatraman and J. Wilson, “Least squares estimation of distribution function in Johnsons translation system,” Journal of Statistical Computation and Simulation, vol. 29, no. 3, pp. 271–297, 1988. [Google Scholar]
24. R. C. H. Cheng and N. A. K. Amin, “Maximum product-of-spacings estimation with applications to the lognormal distribution, UWIST.” Cardiff: Department of Mathematics, Math Report 791, 1979. [Google Scholar]
25. R. C. H. Cheng and N. A. K. Amin, “Estimating parameters in continuous univariate distributions with a shifted origin,” Journal of the Royal Statistical Society Series B (Methodological), vol. 45, no. 3, pp. 394–403, 1983. [Google Scholar]
26. V. L. Tomazella, P. L. Ramos, P. H. Ferreira, A. L. Mota and F. Louzada, “The Lehmann type II inverse Weibull distribution in the presence of censored data,” in Communications in Statistics-Simulation and Computation, pp. 1–17, 2020. [Google Scholar]
27. R. Alshenawy, A. Al-Alwan, E. M. Almetwally, A. Z. Afify and H. M. Almongy, “Progressive type-II censoring schemes of extended odd Weibull exponential distribution with applications in medicine and engineering,” Mathematics, vol. 8, no. 10, pp. 1679, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |