DOI:10.32604/iasc.2021.018983
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2021.018983 | |
| Article |
Modelling Supply Chain Information Collaboration Empowered with Machine Learning Technique
1School of Business Administration, National College of Business Administration and Economics, Lahore, 54000, Pakistan
2Department of Management Sciences, Lahore Garrison University, Lahore, 54000, Pakistan
3Center for Cyber Security, Faculty of Information Science and Technology, Universiti Kebansaan Malaysia (UKM), Bangi, 43600, Malaysia
4School of Information Technology, Skyline University College, University City Sharjah, 1797, Sharjah, UAE
5School of Computer Science, National College of Business Administration and Economics, Lahore, 54000, Pakistan
6Riphah School of Computing and Innovation, Faculty of Computing, Riphah International University Lahore Campus, Lahore 54000, Pakistan
7Pattern Recognition and Machine Learning Lab, Department of Software Engineering, Gachon University, Seongnam, 13120, Republic of Korea
8School of Business, Skyline University College, University City Sharjah, Sharjah, 1797, UAE
*Corresponding Author: Naeem Ali. Email: naeemali@ncbae.edu.pk
Received: 28 March 2021; Accepted: 30 April 2021
Abstract: Information Collaboration of the supply chain is the domination and control of product flow information from the producer to the customer. The data information flow is correlated with demand fill-up, a role delivering service, and feedback. The collaboration of supply chain information is a complex contrivance that impeccably manages the efficiency flow and focuses on its vulnerable area. As there is always room for growth in the current century, major companies have shown a growing tendency to improve their supply chain’s productivity and sustainability to increase customer consumption in complying with environmental regulations. Therefore, in supply chain collaboration, it is a precarious problem to find the best approaches to achieving business intentions, and most organizations prefer to partner with reputable and viable firms. In this respect, machine learning methodology such as Support Vector Machine is used to jeopardize the supply chain information collaboration. More specific efficiency is obtained from the more productive device model. Simulation results show that by adopting the proposed model and applying the Support Vector Algorithm, 98.99 percent accuracy is obtained by training, 98.91 percent by testing, and 98.92 percent from validation. It is clinched that this model will revolutionize the supply chain information collaboration patterns and will provide a significant competitive edge for business sustainability.
Keywords: Supply chain; simulation; supply chain information collaboration; machine learning; support vector machine; intelligent model; supply chain performance
Supply Chain Information Collaboration (SCIC) has been an essential part of all organizations that are in any way involved in the development and distribution of a commodity. This enormous scope of SCIC makes it possible to understand various operations, from procurement and manufacturing to delivery. The most successful and fast way to respond to the current fierce global rivalry is supply chain information cooperation. A process-based integrated partnership model is the essence of supply chain information collaboration. The implementation of integrated thinking in the supply chain of commodities and the introduction of integrated information sharing through the use of information technology have become the key to breaking through the bottleneck of growth and creating new markets and the ultimate destination for enhancing supply chain information collaboration of commodities in today’s society. From a single internal horizontal agglomeration, the product supply chain has grown to an internal vertical integration that will extend to the point of multiple complex supply chain alliances. It is possible to scientifically develop an integrated and efficient operational performance measurement framework using the study and analysis of applicable theoretical information appropriate for the product supply chain. A corresponding performance assessment model can then be created to make the whole supply chain collaboration an optimized sated. At the same time, it respects consumers’ rights and interests to the most significant degree and offers a more systematic and analytical optimization method to boost results. SCIM has two primary objectives in general [1]. These are; (1) dealing with the complexities observed on the supply and demand side and (2) globally achieving optimization. Participants in the supply chain need to collaborate on crucial market practices to reach these objectives [2]. This task is referred to as the collaboration of the Supply Chain.
In such networks, operations such as the manufacture and transport of raw materials occur, with each company’s ultimate objective meeting its customers’ orders at a minimal cost while enhancing their competitiveness. In other words, the effective management of the receipt of raw materials and the prompt scheduling of supplies at the right time, location, and quantity. The supply chain is an operation in which original raw materials, manufactured materials, semi-finished materials, and some parts are similarly turned into goods. The transformation of inputs into outputs is, in other words, achieved. The processes are carried out in close coordination in supply chain information collaboration, representing an orderly set of resources whose purpose is to transform inputs into desired outputs [3]. Part of a studied system emphasizing only one computer or workplace can be captured. Still, it is difficult to analyze the system as a larger whole by analytical optimization, if not impossible. Some parts of production need to be maximized, and others minimized. In other instances, parameters that are neither minimized nor maximized, such as the right color, the right size, the suitable form, etc., are taken into account.
In such networks, operations such as the manufacture and transport of raw materials occur, with each company’s ultimate objective meeting its customers’ orders at a minimal cost while enhancing their competitiveness. In other words, the effective management of the receipt of raw materials and the prompt scheduling of supplies at the right time, location, and quantity. The supply chain is an operation in which original raw materials, manufactured materials, semi-finished materials, and some parts are similarly turned into goods. The transformation of inputs into outputs is, in other words, achieved. The processes are carried out in close coordination in supply chain information collaboration, representing an orderly set of resources whose purpose is to transform inputs into desired outputs [3]. Part of a studied system emphasizing only one computer or workplace can be captured. Still, it is difficult to analyze the system as a larger whole by analytical optimization, if not impossible. Some parts of production need to be maximized, and others minimized. In other instances, parameters that are neither minimized nor maximized, such as the right color, the right size, the suitable form, etc., are taken into account.
Business process modeling and business process simulation help to encourage process thinking [4]. Adopting a strategy of supply chain management requires applying a company model. In a collaborative atmosphere and a logistical network, more industrial nodes operate together, following mutual interests and continuously sharing information while maintaining each unit’s operational autonomy. A business vision is applied to various manufacturing processes, such as procurement, logistics, marketing, etc. Multiple policies, such as continuous replenishment, co-marketing, etc., are implemented with solution methodologies such as heuristics, statistics, modeling, and simulation [5]. Furthermore, in many decisions, Supply Chain Information Collaboration (SCIC) often suffers from uncertainty or data asymmetry, defined as the upstream intensification chosen for demand heterogeneity. Precise preparation for each person is often challenging to accomplish.
Companies must adjust the way they do business, as there will be a shift from human operators to sensor-activated machines and robots. It is good to note that the trend in global industrial operations driven by machine learning is growing exponentially, suggesting that machine learning has already been or has become a priority for many businesses worldwide.
In projection and forecasting, machine learning is used effectively. Organizations are also keen on balancing both supply and demand. A better forecast is thus expected for its supply chain and manufacturing. Because machine learning can store, analyze, and, more importantly, forecast data (automatically, It provides accurate and reliable forecasting specifications that enable businesses to optimize their procurement in terms of purchasing and order processing. Besides, it describes trends and patterns that help to establish better retailing and production strategies. Cooperation in the supply chain has become more information-intensive than the current business scene’s volatility and dynamism. Professionals and scholars have now found ways to properly manage the data and use it to make more robust decisions [5].
For the last two decades, computers have managed enormous input data to make reasonable and correct decisions. Some machines could also find hidden patterns and complex relationships, particularly for disruptive and discontinuous information. The literature showed that machines could generate more reliable results than human beings in many decision-making areas and, in particular, supply chain information collaboration [6].
The simulation systems’ design depends on the quality of the data available and the comprehensive system analysis. Sufficient information on the product segments, weaknesses, and risks is needed to model the production systems. The simulation itself does not offer an instant solution to the issue; it explains its behavior. It is possible to carry out changes and successful measures in the system when the action is identified. Those will be checked by the simulation afterward, assuming that the natural System will react similarly to the simulated one. The entire system’s compliance with the simulated one depends on the simulated system’s consistency and accuracy. The efficacy of the measures in the virtual environment predetermines this compliance [7]. A large-scale production system’s most common characteristics are long cycle time, low total throughput, and limited buffer space [8]. They are used in medical research, for example, and in investment decisions. They are data-driven systems in which a relationship based on IF-THEN rules is formed between the input variables and the output variables.
The supply chain information collaboration [9] seeks to achieve this objective. Another stream of research focused on the importance of performance indicators and goals in measuring the supply chain. Individual performance was defined as the collaboration in the production of performance systems. As the core concern of cooperation, the performance system approach seeks to design and integrate performance indicators [10].
The supply chain collaboration shows that two or more chain members work together to perform the tasks [9]. Simulation tools are becoming more complicated to capture the relationship between operation and future revenue generation. Higher demand provides the opportunity for cost reductions, which generates future incentives for higher demand since substantial economies of scale in logistics. The automotive industry is one of the fields where this hierarchical approach leads [11]. Unlike consumers, among other items, have different specifications concerning interior, color, and safety features. These additional components are bought from various contract suppliers. These requirements can be fulfilled only by a robust logistics information chain to ensure that production flows effectively and without high costs.
It uses the expertise of developers of simulation models and advanced simulation tools to capture these large-scale structures. They begin to establish a common strategic goal and, with the strategic intent, commit to their interface processes and maintain consistency. This mechanism ensures that from the interchange of a partnership, the strategic objective can be achieved.
As the supply chain dataset has been taken from [12], consisting of the following factors the Category Name, Customer Country, Order Country, Order Item Discount, Order Item Product Price, Order Item Quantity, Shipping Mode, Order Status, Delivery Status, and Feedback.
The research aims at evaluating and recognizing the potential of the proposed simulation model using the Support Vector Machine using machine learning techniques to improve the effectiveness of the supply chain collaboration model.
2.2 Supply Chain Information Collaboration and Support Vector Machine (SVM)
Notwithstanding forecasting the demand with Support Vector Machines (SVM) algorithms, this research proposes a simulation model for supply chain information collaboration. In raw data, two crucial machine-based learning techniques are helpful, especially the support vector machine.
• The ability to learn an arbitrary function;
• The capacity to track the process of learning itself.
Support Vector Machine algorithms are also used to predict real-time and memorized data. A chaotic time series is called the manufacturer’s demand, which helps the machines to learn patterns over time at an arbitrary depth. SVM, a more recent learning algorithm derived from statistical learning theory, has a fundamental mathematical basis and has previously been used to analyze time series [13]. It is a dynamic and multi-faceted model of information collaboration systems for the supply chain, with various factors coming into play. The information collaboration supply chain is a system of continuous transportation, processing, and information processing that ensures customers and business’s functioning.
2.3 Proposed Model for Supply Chain Information Collaboration Using Support Vector Machine
A systematic technique to explain a system’s complex behavior is an intelligent system based on machine learning approaches. Large-scale structures, such as nonlinearities, time delays, and uncertainties have traditionally been described as large numbers of variables, the configuration of interconnected subsystems, and other characteristics that confuse control models. It is difficult and multi-faceted to develop production processes, with a range of factors coming into play. Manufacturing is an operation Where initial raw materials, processed materials, semi-finished materials, and some components are similarly converted into products. It completes, in other words, the transformation of inputs into outputs. In production systems, production processes are carried out, representing an orderly set of resources whose purpose is to turn information into desired outcomes [14]. It is necessary to use the most detailed possible model to ensure critical production objectives, namely benefit, throughout their life cycle, productivity, performance, production, adaptability, responsiveness, quality, and continuous improvement of products and services. The larger the system is created, the greater the variables, options, restrictions, and hazards. Decomposing large-scale structures into smaller, more manageable subsystems enables efficient decentralization and collaboration to be introduced [15].

Figure 1: Proposed model for supply chain information collaboration empowered with machine learning technique
The proposed intelligent system Proposed for Supply Chain Information Collaboration using the machine learning approach of Support Vector Machine (SVM) as depicted in Fig. 1. In this proposed model, there are two phases,
1. Training phase
2. Validation phase
In the training process, the data acquisition layer receives customer requests by following the suggested model. This process requires four layers, the data acquisition layer, preprocessing layer, prediction layer, and output layer. The data acquisition layer consists of the category, customer country, order country, and the customer input are obtained at the end. The data moves as raw data from the data acquisition layer through the Internet of Things to the database, and this raw data is transferred to the preprocessing layer, where three steps are performed.
Support Vector Machine (SVM) For non-linearly separable datasets, the algorithm does not work optimally. First, in contemplating optimizing the margin between two classes, it translates characteristics into a high-dimensional room. SVM is a regular classifier with linearly separable image datasets that works optimally.
The problem with higher dimensional feature space is that translating the datasets into higher dimensional space is computationally costly. Using “Kernel Trick,” a method that returns the dot product of the parameters in the feature space, will reduce this problem so that each data point is mapped using unique transformation techniques into a higher dimensional vector.
Classification utilizes a polynomial kernel SVM strategy, allowing a multi-class classifier against all approaches in which the model generates a hyperplane between multi-class or other techniques. It can be adapted to define decision functions using various kernel tricks [16]. It is also effective and efficient in memory when converting high-dimensional space image classification. It has a higher accuracy-recall ratio and allows it to be used for a wide variety of functions in the image dataset. They are also commonly used in the fields of predictions of the urban environment, processing pattern recognition images, security monitoring, empowerment of transport systems, etc.
3.1 Simulation Results and Discussions
Support Vector Machine Mathematical Model is described as:
Therefore, if the line slope and b are some constant, we get the above equation form.
Notation Vector of the Eq. (1) published as, possibly:
Let
The Eq. (1) Vector Form is given by:
The magnitude of the w and x vectors is given by:
The norm gives the Cartesian form of the vector of magnitude.
The cosine of the angle between 2 is returned by the inner product, unit length vectors, as known.
From Eq. (3), we have
We know that l (
From the above equation, we may get:
Putting the value of cos (
For n-dimensional vectors, let the fitness function of slop be determined by:
The minimum classification value is either 0 or 1; there are only two possibilities., i.e.,
To train a dataset, we have to compute (multiple inputs, labels) to train the entire dataset d, so that it is given:
To determine the optimal data, set operating margin (f), the Lagrangian Multiplier Method is evaluated for weight optimization. Our goal is to find an ideal hyperplane that, after optimizing the weight vector
By extending the last w.r.t.
where
After substituting the Langrangian Function
Thus
Subject to
The complementary state of KKT outcomes is as below. Because of the constraints, we have inequalities that can get rid of the dependency on β and
However, at the optimum point
Several equations (11) by ‘γ’ on both sides it is obtained as:
It is known as a support vector, the closest point given by Eq. (14) to the hyperplane. The hypothesis function is provided by
Class +1 (blank space discovered) will be classified as the hyperplane point above, and the hyperplane point is labeled below as –1. (no available space). The SVM algorithm aims to find a hyperplane, also referred to as the optimal hyperplane, that can correctly isolate the data and find the best result. This function can be used if we give non-zero alpha values corresponding to the support vectors, i.e., setting the margin’s overall width to those that make everything alpha positive. Let’s only take two cases:
Case 1. If two lj, li features are entirely different in the subject dataset vectors, their vector product is 0, and they do not contribute to support-vector maximization.
Case 2. If two features, lj, li are entirely identical, their dot product is 0 too. But there are two subcases; Subcase 1: if both lj and li classify the same output value γj (either +1 or –1). Then γjljγi is always 1, and the value of αjαiγjγiljli will be helpful. So, the algorithm lowers similar term vectors that make precise detection. It will, however, decrease the value of
3.2 Simulation Results Simulation of the Proposed Model using Support Vector Machine
Support Vector Machine algorithm is more effective in measuring the output of high dimensional spaces. It is reasonably memory-efficient. Therefore, its efficiency is analyzed as accuracy, miss-rate, sensitivity, Specificity, true positive rate, true negative rate, and false-positive value. After evaluating the standard attributes, the data is transferred to the cloud if the required learning criteria are met. Suppose the necessary learning is not achieved. The information is retrained in the prediction layer. The performance is reassessed, and so on. When accuracy of learning is gained, and the response in the case of YES is achieved, the results are transferred to the cloud, and If the data is not trained and the desired results cannot be obtained, the data is returned to the prediction layer.
The simulation results obtained by using the proposed model and the Support Vector Machine algorithm are as follows
The dataset attributes are 180519, which was divided into three portions. The training was taken as 70% (126363), and the Testing and Validation were carried as 15%, 15% (27078), (27078), respectively. The Medium Gaussian SVM algorithm of machine learning was applied and the results obtained are shown in the tabular form and justified by graphical representation.
In this proposed model the 0 is denoted by Satisfactory, 1 is denoted by Good, 2 is taken as Average, and Bad renders 3. The proposed Modeling and Simulation to access the model’s performance for Supply Chain Information Collaboration using the Machine Learning Technique of Medium gaussian SVM.
Firstly, the training of the data is done, and the Testing and Validation is followed by it.

The data for training is shown as 0,1,2,3, as demonstrated in Tab. 1 and Fig. 2. The Medium gaussian SVM algorithm is applied, and the Reddish line shows the 0(Satisfactory), The green line shows the 1(Good), The black line indicates the 2(Average). The yellow line shows the 3(Bad) feedback of the customers regarding Supply chain information collaboration.

Figure 2: ROC Curve for proposed model of SCIC (Training)
The graphical representation in Fig. 2 provides the Training Accuracy of supply chain information collaboration performance as 98.99%, so its miss rate is 1.01. The sensitivity for training is 98.99%. Specificity is 98.66%, True positive Rate is 98.99%, True negative Rate is 99.66%, False Positive Value is 1.003, and the False Negative Rate for Training of data for Supply Chain information collaboration is 1.01.

The data for testing is shown as 0,1,2,3, as demonstrated in Tab. 2 and Fig. 3. The Medium Gaussian SVM algorithm is applied, and the Reddish line shows the 0(Satisfactory), The green line shows the 1(Good), The black line indicates the 2(Average). The yellow line shows the 3(Bad) responses of the Supply chain information collaboration.

Figure 3: ROC Curve for proposed Model of SCIC(Testing)
The graphical representation in Fig. 3 provides the Testing Accuracy of the supply chain information collaboration model’s performance as 98.91%, so its miss rate is 1.09. The sensitivity for testing is 98.96%. Specificity is 99.65%, True positive Rate is 98.95%, True negative Rate is 99.65%, False Positive Value is 1.003, and the False Negative Rate for Training of data for Supply Chain information collaboration is 1.01.

The data for validation is shown as 0,1,2,3, as demonstrated in Tab. 3 and Fig. 4. The Medium gaussian SVM algorithm is applied, and the Reddish line shows the 0(Satisfactory), The green line shows the 1(Good), The black line indicates the 2(Average). The yellow line shows the 3(Bad) response of the Supply chain information collaboration.
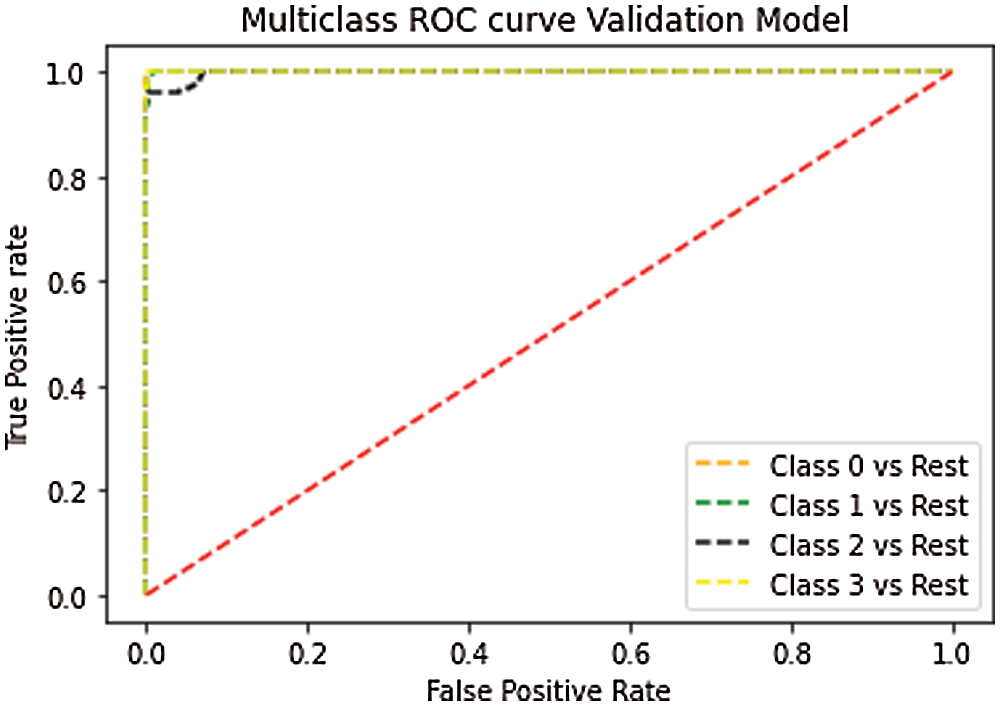
Figure 4: ROC Curve for proposed Model of SCIC(Validation)
The graphical representation in Fig. 4 provides the Validation Accuracy of the supply chain information collaboration model’s performance as 98.92%, so its miss rate is 1.08. The sensitivity for validation is 98.92%. Specificity is 99.16%, True positive Rate is 98.92%, True negative Rate is 99.64%, False Positive Value is 1.01, and False Negative Rate for Validation of data for Supply Chain information collaboration is 1.01.
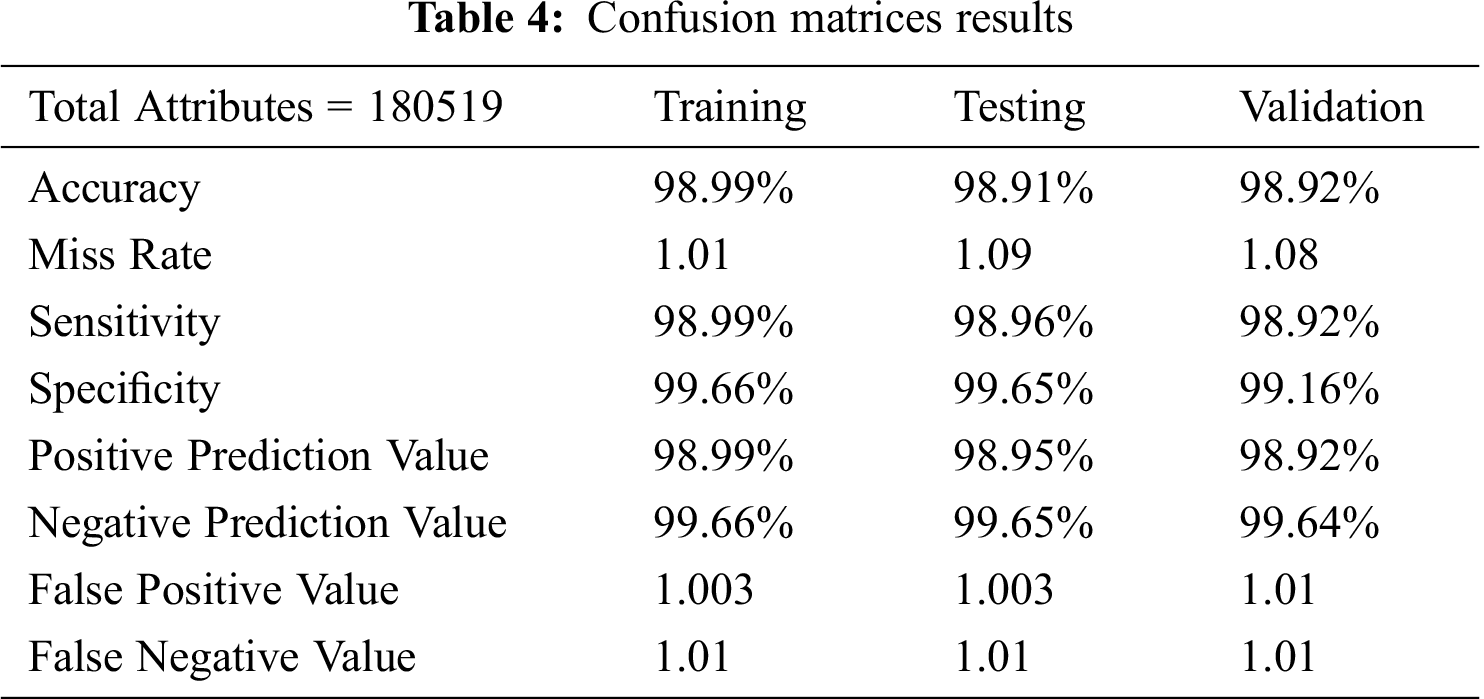
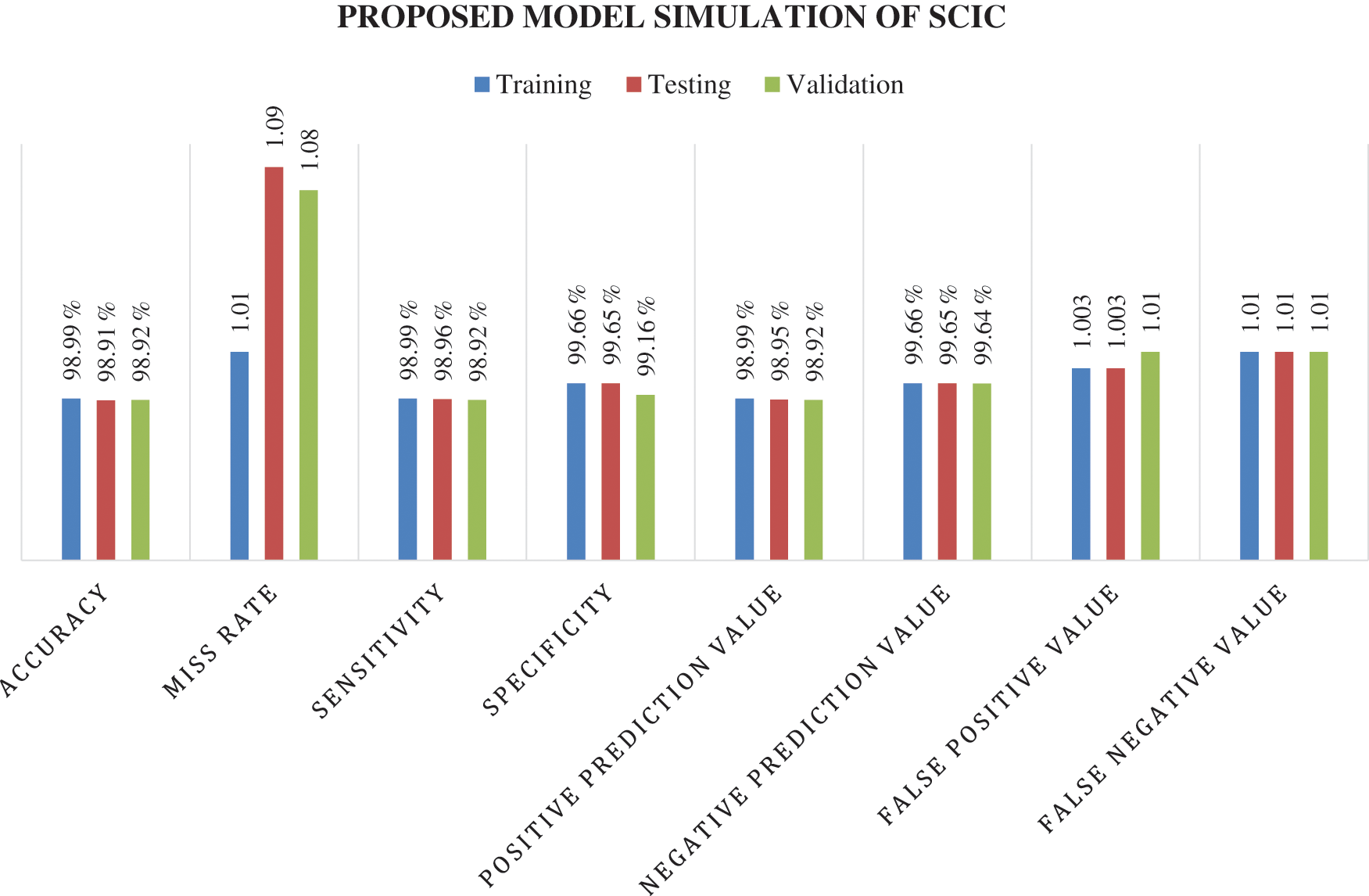
Figure 5: Graphical elaboration of simulation results of the proposed model of supply chain information collaboration support vector machine algorithm
In Tab. 4, the Accuracy, Miss Rate, Sensitivity, Specificity, Positive Prediction Value, Negative Prediction Value, False Positive Value, False Negative Value are calculated by the formulas mentioned above. The Accuracy, Precision, and Specificity of Training, Testing, and Validation Data are calculated individually and explained graphically in Fig. 5.
The input demand is taken by the data acquisition layer, where the data is collected as input from the customers. This stage consists of 3 layers. The data acquisition layer, preprocessing layer, then the cloud data is imported for prediction purpose and. Data consists of the category (supply chain), customer country, order country, and the customer’s feedback are collected at the end in the data acquisition layer. The data moves as raw data from the data acquisition layer via the Internet of Things to the database, and this raw data is transferred to the Preprocessing layer, where three steps are carried out
i) Handling categorized attributes
ii) Handling Missing Value
iii) Handling Outlier
The information is then transferred from the preprocessing layer, and for prediction purposes, the help vector machine is called from the cloud. Then the shipment’s status is reviewed. There are four attributes at this stage, Fine, Good, Satisfactory and Poor would be the shipment status. The feedback will be stored on the cloud as commemorated data for the future in the case of Nice, Average and Acceptable, and the appropriate steps will be taken in the case of poor feedback. The supply chain plan will be modified so that such cases do not happen again.

In Tab. 5 and [17], the Support Vector Machine algorithm was used by applying the decision tree technique, and the accuracy rate obtained is 94 percent, which reduced operational costs. In comparison, by adopting the proposed model and applying the Support Vector Algorithm, 98.99 percent accuracy is obtained by training, 98.91 percent by testing, and 98.92 percent from validation. This pattern will not only reduce the supply chain shipment time and help deliver the shipment in reduced time and, most of all, bring revolution in the domain of supply chain information collaboration.
To achieve good results, MATLAB R2020b is used for the simulation of the dataset. By applying the Support Vector Algorithm, 98.99 percent accuracy is obtained by training, 98.91 percent by testing, and 98.92 percent from validation of the supply chain information collaboration data taken from [12]. In the simulation, the output is the customers’ feedback on whether they are getting satisfactory, good, average, or bad results. The proposed model considers each attribute’s results over time and integrates collaboration attributes for the supply chain information with customer performance and feedback. Besides, this work’s other innovation is the adaptation and using this technique to derive managerial insights for supply chain decision-making processes. This suggested supply chain information collaboration model makes our forecasts more accurate in pattern shifts and seasonality practices. The proposed strategy fits very well into the big data sets with the support vector machine algorithm’s help. The best approaches to achieving companies’ goals are vital in the collaboration of supply chain information, and most organizations tend to collaborate with reliable and profitable businesses. The collaboration of supply chain information with machine learning techniques has suggested the authenticity and usefulness of supply chain information’s entire collaboration process. Compared to previously published methods used for supply chain information collaboration, more detailed and improved results are obtained via this suggested model.
Through extracting information from other sources, such as economic studies, buying habits, as a potential goal, we plan to enrich the set of features in social media, social events, and location-based store demographic data. Another analysis can be carried out by applying the fusion over the less performing machine learning techniques to improve the data’s accuracy and validation.
Acknowledgement: Thanks to the families, colleagues for their moral support.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. H. Golpîra and R. Khan, “A multi-objective risk-based robust optimization approach to energy management in smart residential buildings under combined demand and supply uncertainty,” Energy, vol. 170, no. 1, pp. 1113–1129, 2019. [Google Scholar]
2. N. Kshetri, “Blockchain’s roles in meeting key supply chain management objectives,” International Journal of Information Management, vol. 39, no. 1, pp. 80–89, 2018. [Google Scholar]
3. J. Y. Zhao, Y. J. Wang, X. Xi and G. D. Wu, “Simulation of steel production logistics system based on multi-agents,” International Journal of Simulation Modelling, vol. 16, no. 1, pp. 167–175, 2017. [Google Scholar]
4. K. D. Barber, F. W. Dewhurst, R. L. D. H. Burns and J. B. B. Rogers, “Business-process modeling and simulation for manufacturing management,” Business Process Management Journal, vol. 9, no. 1, pp. 527–542, 2003. [Google Scholar]
5. S. Terzi and S. Cavalieri, “Simulation in the supply chain context: A survey,” Computers in Industry, vol. 53, no. 1, pp. 3–16, 2004. [Google Scholar]
6. B. Marr, Key Business Analytics: The 60+ business analysis tools every manager needs to know. Pearson UK, UK, 2016. [Google Scholar]
7. M. Straka, M. Malindzakova, P. A.Rosova, M. Pekarcikova and M. Fill, “Application of extendsim for improvement of production logistics’ efficiency,” International Journal of Simulation Modelling, vol. 16, no. 3, pp. 422–434, 2017. [Google Scholar]
8. S. G. García and M. G. García, “Industry 4.0 implications in production and maintenance management: An overview,” Procedia Manufacturing, vol. 41, no. 1, pp. 415–422, 2019. [Google Scholar]
9. T. M. Simatupang, A. Schwab and D. Lantau, “Introduction: Building sustainable entrepreneurship ecosystems,” International Journal of Entrepreneurship and Small Business, vol. 26, no. 4, pp. 389–398, 2015. [Google Scholar]
10. K. Kasemsap, “Fostering supply chain management in global business,” in Handbook of Research on Global Supply Chain Management, IGI Global, USA, pp. 45–71,2016. [Google Scholar]
11. M. Straka, R. Lenort, S. Khouri and J. Feliks, “Design of large-scale logistics systems using computer simulation hierarchic structure,” International Journal of Simulation Modelling, vol. 17, no. 1, pp. 105–118, 2018. [Google Scholar]
12. F. Constante, F. Silva and A. Pereira, “Data co smart supply chain for big data analysis,” Mendeley Data, New Orleans, LA 70118, United States, pp. 1–13, 2019. [Google Scholar]
13. A. Lal and B. Datta, “Multiple objective management strategies for coastal aquifers utilising new surrogate models,” International Journal of GEOMATE, vol. 15, no. 48, pp. 79–85, 2018. [Google Scholar]
14. J. Y. Zhao, L. Liang, X. Gu, Z. Li, S. Wu et al., “DNA methyltransferase DNMT3a contributes to neuropathic pain by repressing Kcna2 in primary afferent neurons,” Nature Communications, vol. 8, no. 1, pp. 1–15, 2017. [Google Scholar]
15. R. J. Laracy, “A systems-theoretic security model for large scale, complex systems applied to the US air transportation system,” International Journal of Communications, Network and System Sciences, vol. 10, no. 5, pp. 75–105, 2017. [Google Scholar]
16. J. Abukhait, A. M. Mansour and M. Obeidat, “Classification based on Gaussian-kernel support vector machine with adaptive fuzzy inference system,” Margin, vol. 7, no. 8, pp. 14–22, 2018. [Google Scholar]
17. P. Priore, B. Ponte, R. Rosillo and D. L. Fuente, “Applying machine learning to the dynamic selection of replenishment policies in fast-changing supply chain environments,” International Journal of Production Research, vol. 57, no. 11, pp. 3663–3677, 2019. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |