DOI:10.32604/iasc.2022.018041
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2022.018041 | |
| Article |
Bayesian Approximation Techniques for the Generalized Inverted Exponential Distribution
Department of Statistics, College of Science, University of Jeddah, Jeddah, Saudi Arabia
*Corresponding Author: Maha A. Aldahlan. Email: maal-dahlan@uj.edu.sa
Received: 22 February 2021; Accepted: 02 May 2021
Abstract: In this article, Bayesian techniques are adopted to estimate the shape parameter of the generalized inverted exponential distribution (GIED) in the case of complete samples. Normal approximation, Lindley’s approximation, and Tierney and Kadane’s approximation are used for deriving Bayesian estimators. Different informative priors are considered, such as Jeffrey’s prior, Quasi prior, modified Jeffrey’s prior, and the extension of Jeffrey’s prior. Non-informative priors are also used, including Gamma prior, Pareto prior, and inverse Levy prior. The Bayesian estimators are derived under the quadratic loss function. Monte Carlo simulations are carried out to make a comparison among estimators based on the mean square error of the estimates. All estimators using normal, Lindley’s, and Tierney and Kadane’s approximation techniques perform consistently since the MSE decreases as the sample size increases. For large samples, estimators based on non-informative priors using normal approximation are usually better than the ones using Lindley’s approximation. Two real data sets in reliability and medicine are applling to the GIED distribution to assess its flexibility. By comparing the estimation results with other generalized models, we prove that estimating this model using Bayesian approximation techniques gives good results for investigating estimation problems. The models compared in this research are generalized inverse Weibull distribution (GIWD), inverse Weibull distribution (IWD), and inverse exponential distribution (IED).
Keywords: Bayesian estimation; generalized inverted exponential distribution; informative and non-informative priors; Lindley’s approximation; Monte Carlo simulation; normal approximation; Tierney and Kadane’s approximation
Lifetime models are widely used in the statistical inference field. These models are very important in many areas such as engineering, medicine, zoology, and forecasting. The generalized inverted exponential distribution (GIED) is one of the important lifetime models. It is first proposed by Bakoban et al. [1]. GIED is a flexible model because it has various shapes of the hazard function.
The probability density function (PDF) of a two-parameter GIED is
and the cumulative distribution function (CDF) is
where
The GIED distribution has attracted the recent attention of statisticians but has not been discussed in detail in the Bayesian approach. Some authors are interested in this distribution or its generalization [2–8].
On the other hand, others study GIED using Bayesian methods. Ahmed [9] obtains the Bayesian estimators of GIED based on Type II progressive censored samples by applying Lindley’s approximation and importance sampling technique. In addition, Oguntunde et al. [10] discuss Bayesian predictors based on progressive Type-II censoring. Further, Hassan et al. [11] derive the Bayesian estimators based on the Markov Chain Monte Carlo method. Abouammoh et al. [12] study the exponentiated generalized inverse exponential distribution. They derive statistical properties and study applications to real-life data as compared with some other generalized models. Moreover, Singh et al. [13] study Bayesian estimators of reliability function based on upper record value and upper record ranked set sample using Lindley’s approximation. Eraikhuemen et al. [14] discuss Bayesian and maximum likelihood estimation of the shape parameter of the exponential inverse exponential distribution. They use a comparative approach. Bayesian estimation is derived with informative and non-informative priors. In Bayesian analysis, it is well known that Bayesian estimators are usually expressed in an implicit form. Therefore, many approximation procedures are used to evaluate Bayesian estimators. Shawky et al. [15], Singh et al. [16], Sultan et al. [17,18], and Fatima et al. [19] discuss some approximation approaches as the Lindley’s, Tierney and Kadane’s (T-K), and normal approximation methods to compute the Bayesian estimators of the exponentiated Gamma, Marshall-Olkin extended exponential, Kumaraswamy, Topp-Leone, and inverse exponential distributions, respectively. So, in this article, we use normal, Lindley’s, and Tierney and Kadane’s approximation methods to derive Bayesian estimators for the shape parameter of GIED in Sections 2 and 3. The rest of the article is organized as follows. Section 4 studies the simulation and presents numerical results. Section 5 applies the model to real data sets. Finally, Sections 6 and 7 discuss the results and present the conclusion of the study.
2 Bayesian Approximation Methods
The Bayesian estimate of any function of
where
When the posterior distribution
where
Lindley [20] gives an approximation to the following integration ratio
where
where
where
2.3 Tierney and Kadane’s (T-K) Approximation
For any arbitrary function
where
In the following section, we derive Bayesian estimators for GIED using these approximation methods with different priors.
In this section, Bayesian approximation techniques are studied for estimating the shape parameter of the generalized inverted exponential distribution based on complete samples. Normal, Lindley’s, and Tierney and Kadane’s approximation methods are used to compute the Bayesian estimators. Also, Bayesian estimators are derived based on squared error loss function for different prior distributions.
Let
where
The posterior distribution is obtained by multiplying Eq. (12) with the prior distribution
In this article, we choose some informative and non-informative priors, as shown in Tab. 1. In the following subsections, the Bayesian estimators are obtained based on the squared error loss function
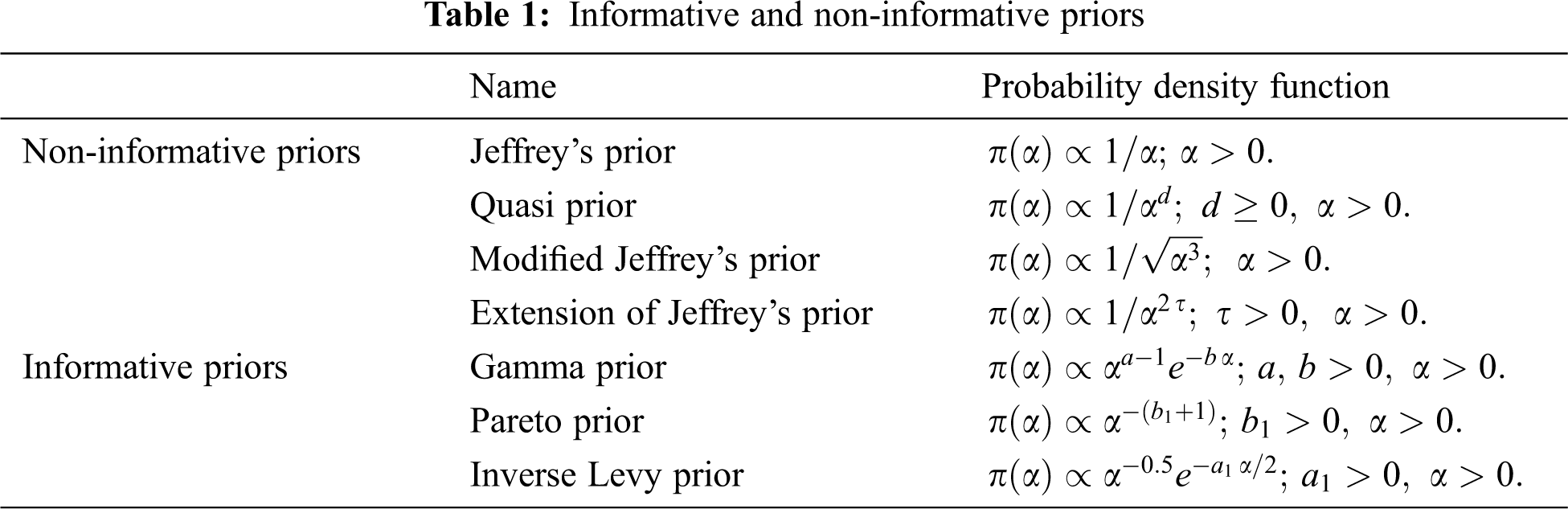
3.1 Bayesian Estimators Using Normal Approximation
In this subsection, we derive Bayesian estimators for GIED using the priors in Tab. 1.
i. Jeffrey’s Prior
According to Eq. (14), the posterior distribution of
By taking the first derivative of Eq. (15) concerning
The posterior distribution can be approximated as Eq. (3). Thus, for GIED, the posterior distribution can be approximated as
ii. Quasi Prior
The posterior distribution of
By taking the first derivative of Eq. (16) concerning
iii. Modified Jeffrey’s Prior
The posterior distribution of
By taking the first derivative of Eq. (17) concerning
The posterior distribution can be approximated as Eq. (3). Thus, for GIED, the posterior distribution can be approximated as
iv. Extension of Jeffrey’s Prior
The posterior distribution of
By taking the first derivative of Eq. (18) concerning
The posterior distribution can be approximated as Eq. (3). Thus, for GIED, the posterior distribution can be approximated as
v. Gamma Prior
The posterior distribution of
By taking the first derivative of Eq. (19) concerning
The posterior distribution can be approximated as Eq. (3). Thus, for GIED, the posterior distribution can be approximated as
vi. Pareto Prior
The posterior distribution of
By taking the first derivative of Eq. (20) concerning
The posterior distribution can be approximated as Eq. (3). Thus, for GIED, the posterior distribution can be approximated as
vii. Inverse Levy Prior
The posterior distribution of
By taking the first derivative of Eq. (21) concerning
The posterior distribution can be approximated as Eq. (3). Thus, for GIED, the posterior distribution can be approximated as
3.2 Bayesian Estimators Using Lindley’s Approximation
With Lindley’s approximation, we can evaluate the posterior mean as Eq. (4). By setting
Using Eq. (12), we obtain
Also,
By substituting Eqs. (23), (24), and (25) into Eq. (22), we can evaluate the posterior mean for GIED under different priors as follows.
i. Jeffrey’s Prior
By taking the logarithm of Jeffrey’s prior, we get
Then by using Eqs. (22)–(25), we obtain the posterior mean for GIED with Jeffrey’s prior as
ii. Quasi Prior
By taking the logarithm of Quasi prior, we get
iii. Modified Jeffrey’s Prior
By taking the logarithm of modified Jeffrey’s prior, we get
iv. Extension of Jeffrey’s Prior
By taking the logarithm of the extension of Jeffrey’s prior, we get
v. Gamma Prior
By taking the logarithm of Gamma prior, we get
vi. Pareto Prior
By taking the logarithm of Pareto prior, we get
vii. Inverse Levy Prior
By taking the logarithm of inverse Levy prior, we get
Then by using Eqs. (22)–(25), we obtain the posterior mean for GIED under inverse Levy prior as
3.3 Bayesian Estimators Using Tierney and Kadane’s Approximation
To obtain the Bayesian estimator for GIED, we evaluate the posterior mean
i. Jeffrey’s Prior
Using Eqs. (9)–(11), we get
ii. Quasi Prior
Using Eqs. (9)–(11), we get
iii. Modified Jeffrey’s Prior
Using Eqs. (9)–(11), we get
iv. Extension of Jeffrey’s Prior
Using Eqs. (9)–(11), we get
v. Gamma Prior
Using Eqs. (9)–(11), we get
vi. Pareto Prior
Using Eqs. (9)–(11), we get
vii. Inverse Levy Prior
Using Eqs. (9)–(11), we get
4 Simulation and Numerical Results
In this section, a simulation study is conducted to assess the performance of the estimators in the previous section. Mathematica V. 11.0 is used to run a Monte Carlo simulation with 10,000 iterations. Samples of sizes n = 20, 50, 100, and 500 are generated from GIED using the quantile formula
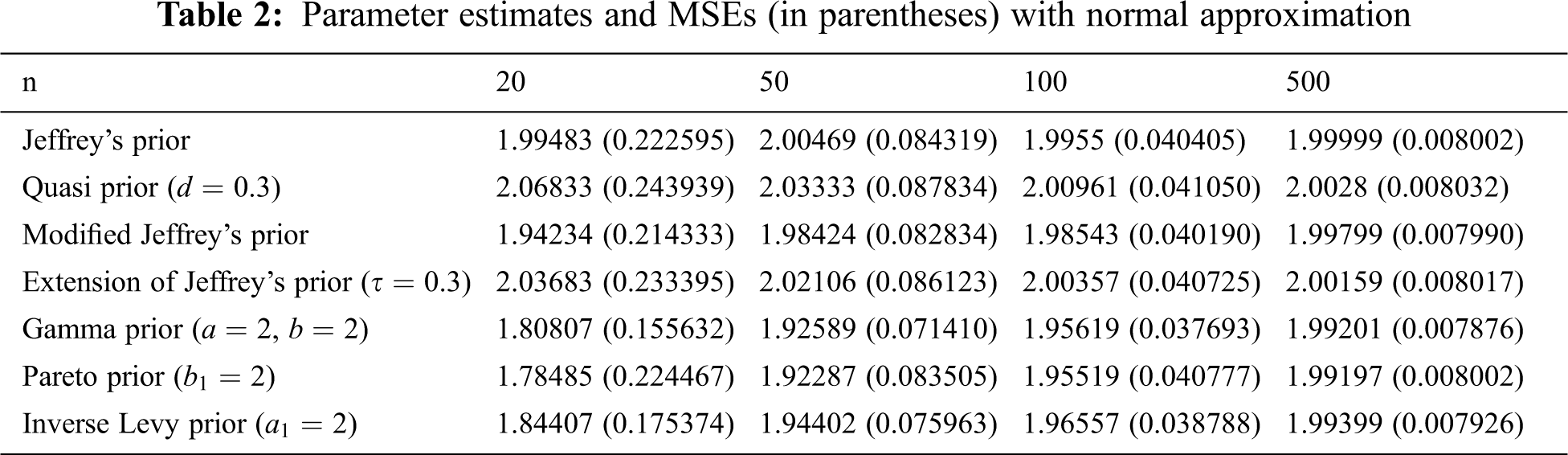
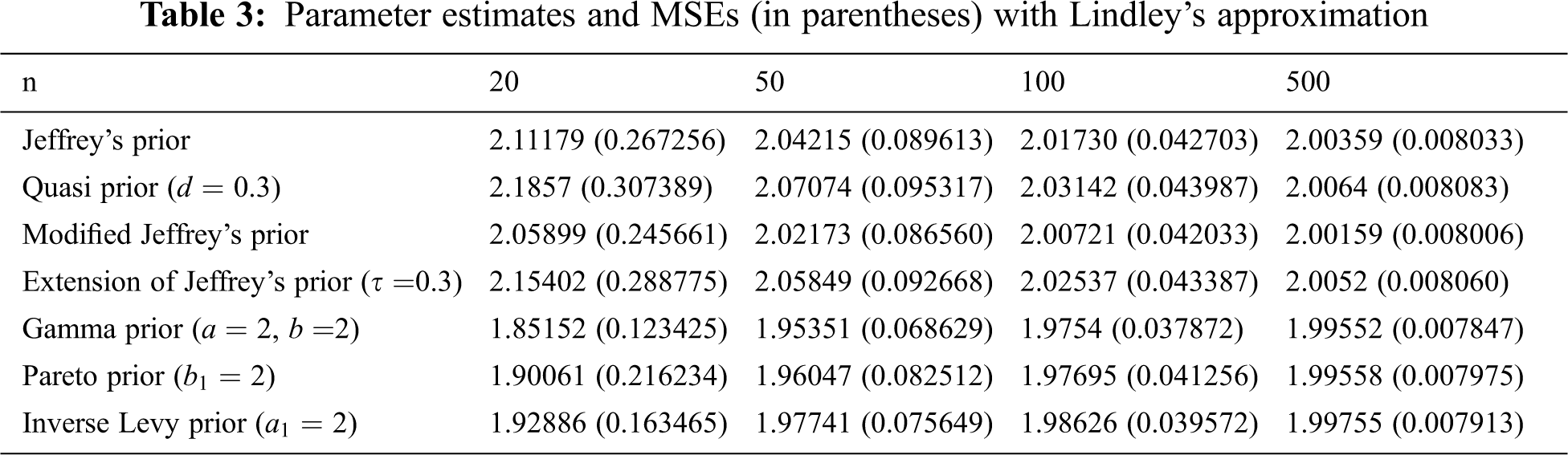
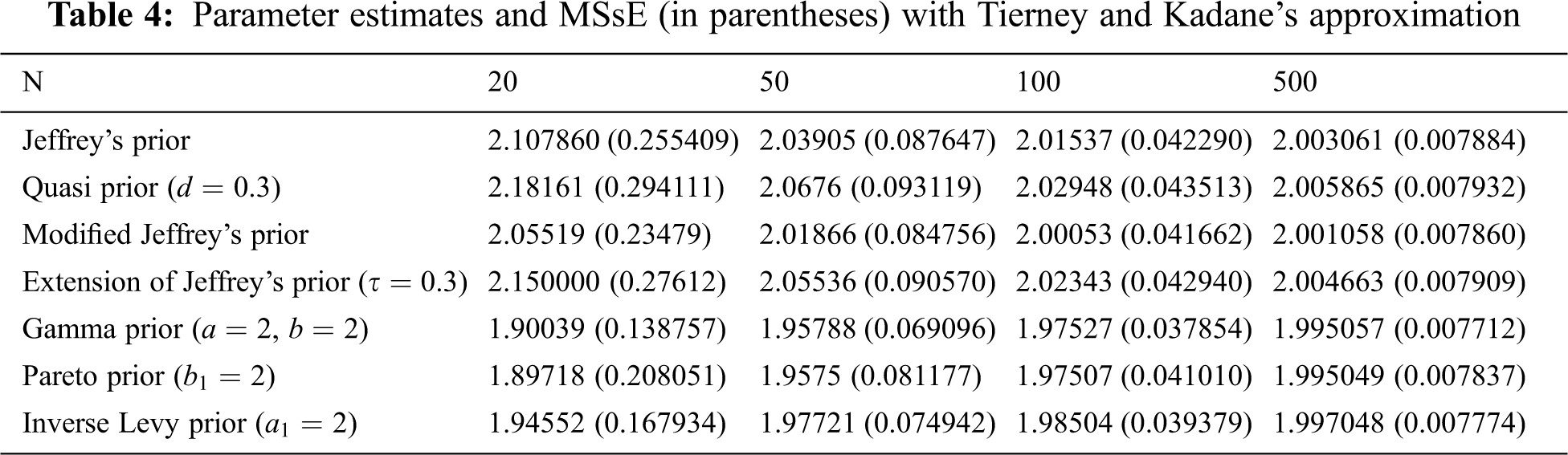
From Tabs. 2–4, we note that all estimators using normal, Lindley’s, and Tierney and Kadane’s approximation techniques perform consistently that the MSE decreases as the sample size increases. In addition, we conclude that the estimator with Gamma prior has the lowest MSE for all techniques. Tierney and Kadane’s technique works more effectively with large samples (n = 100 and 500) than normal and Lindley’s approximations. However, the normal approximation is better than Lindley’s and Tierney and Kadane’s approximations with non-informative priors for n = 20 and 50, and Tierney and Kadane’s approximation is better than Lindley’s approximation in this case. Moreover, estimators under informative priors for n = 20 and 50 using Lindley’s approximation are usually better than normal and Tierney and Kadane’s approximations. For n = 100 and 500, estimators based on non-informative priors using normal approximation are usually better than the ones using Lindley’s approximation. The normal approximation works as well as Lindley’s approximation with informative priors for n = 100, but Lindley’s works better than normal for n = 500 with informative priors.
In this section, the GIED distribution is applied to real-life data sets to assess its flexibility over its baseline distribution and some other generalized models. The baseline models are generalized inverse Weibull distribution [22, GIWD], inverse Weibull distribution [23, IWD], and inverse exponential distribution [24, IED]. The fitting performance is evaluated by Kolmogorov-Smirnov (K-S) statistic and some information criteria. A model is the best if it has the lowest Akaike information criteria (AIC), log-likelihood (LL), Bayesian information criterion (BIC), consistent Akaike information criterion (CAIC), and Hannan-Quinn information criterion (HQIC) [25]. The formulas of these criteria are
where
I. Animal Vaccination Data Set
The first data is the numbers (in thousands) of animals vaccinated against the most widespread epidemic diseases in the 13 regions of Saudi Arabia from 1/1/2020 to 6/30/2020, according to the introduction on the electronic platform (Anaam). This data is downloaded from (https://data.gov.sa/Data/en/dataset/the-numbers-of-animals-vaccinated-against-the-most-widespread-epidemic-diseases).
The statistics of the data set and the performance measures of the models are presented in Tabs. 5 and 6, respectively.

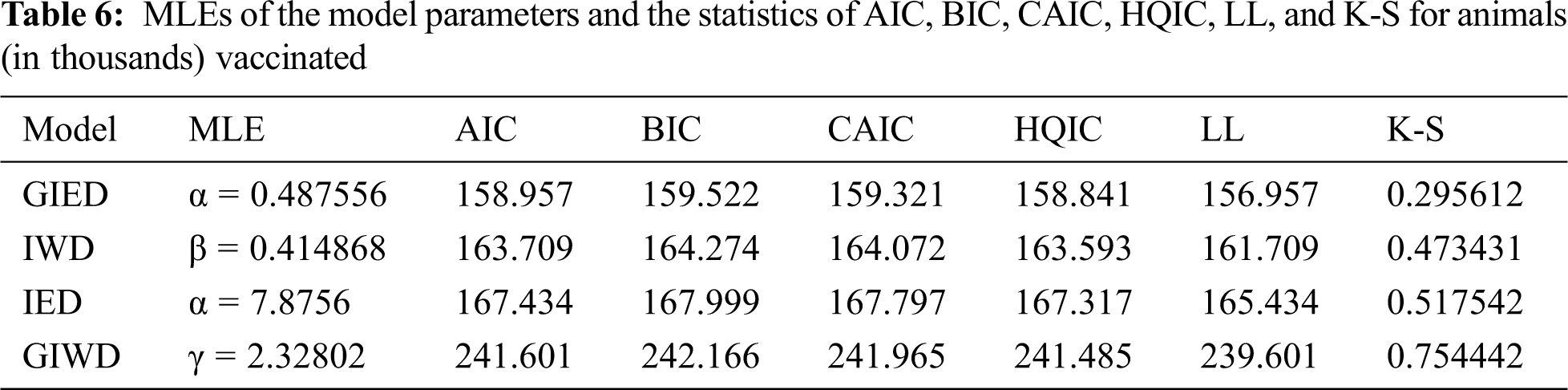
Fig. 1 plots the empirical distribution of the number of animals vaccinated and the estimated CDFs of GIE, IW, IE, and GIW distributions.
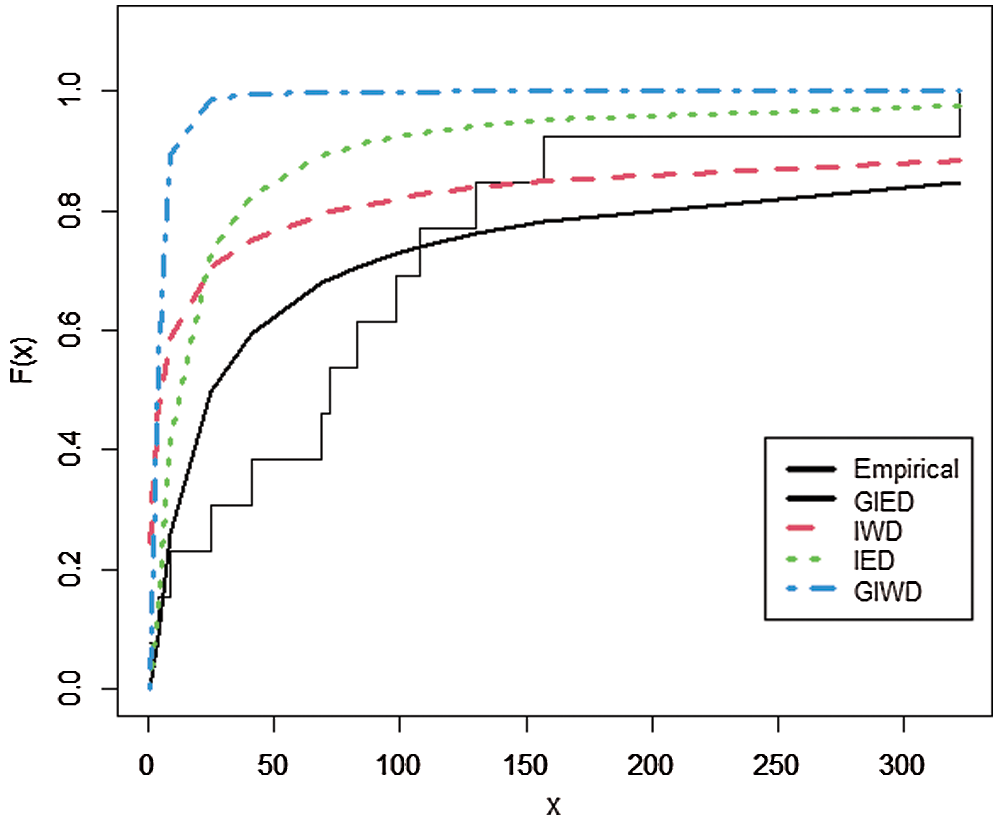
Figure 1: The empirical distribution of the number of animals vaccinated and the estimated CDFs of GIED and other competitive models
II. Medical Data Set
The second data below shows the survival time (in months) of patients with Hodgkin’s disease and heavy therapy (nitrogen mustards) [26].
The statistics of the data set and the performance measures of the models are presented in Tabs. 7 and 8, respectively.

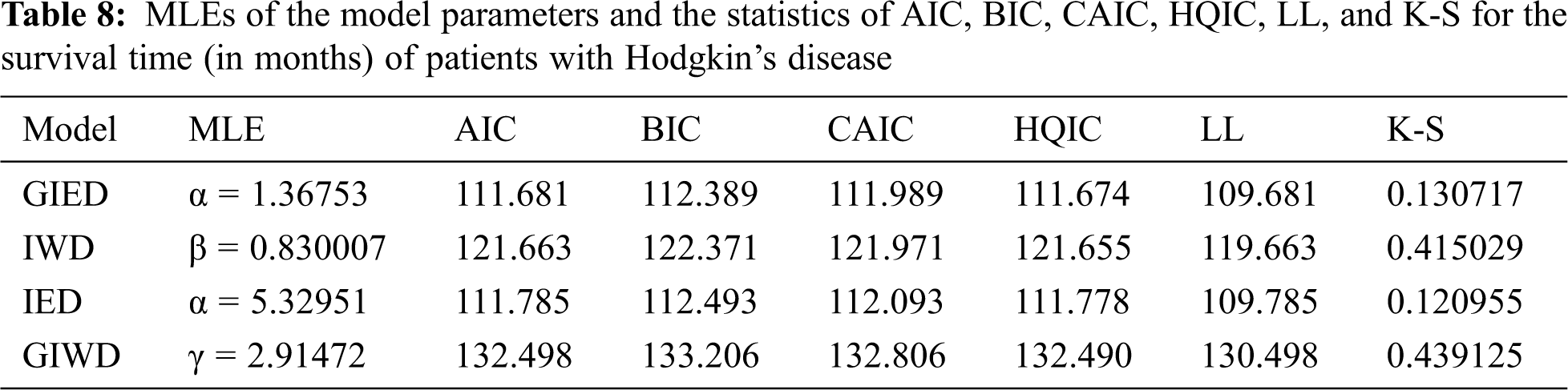
According to the experiments, GIED shows flexibility to real data sets since it has the lowest AIC, BIC, CAIC, HQIC, LL, and K-S as is shown in Tabs. 6 and 8. Our model fits better than the competitive models of IED, IWD, and GIWD. We choose IWD and GIWD as competitive models because GIED is a special case for them. So researchers can use GIED instead of those models. It decreases the amount of computation for estimating and gets better results. On the other hand, GIED shows better fitting performance than its special case IED. Plots in Figs. 1 and 2 show that GIED has the best approximate fitting performance especially for survival time of patients with Hodgkin’s disease.
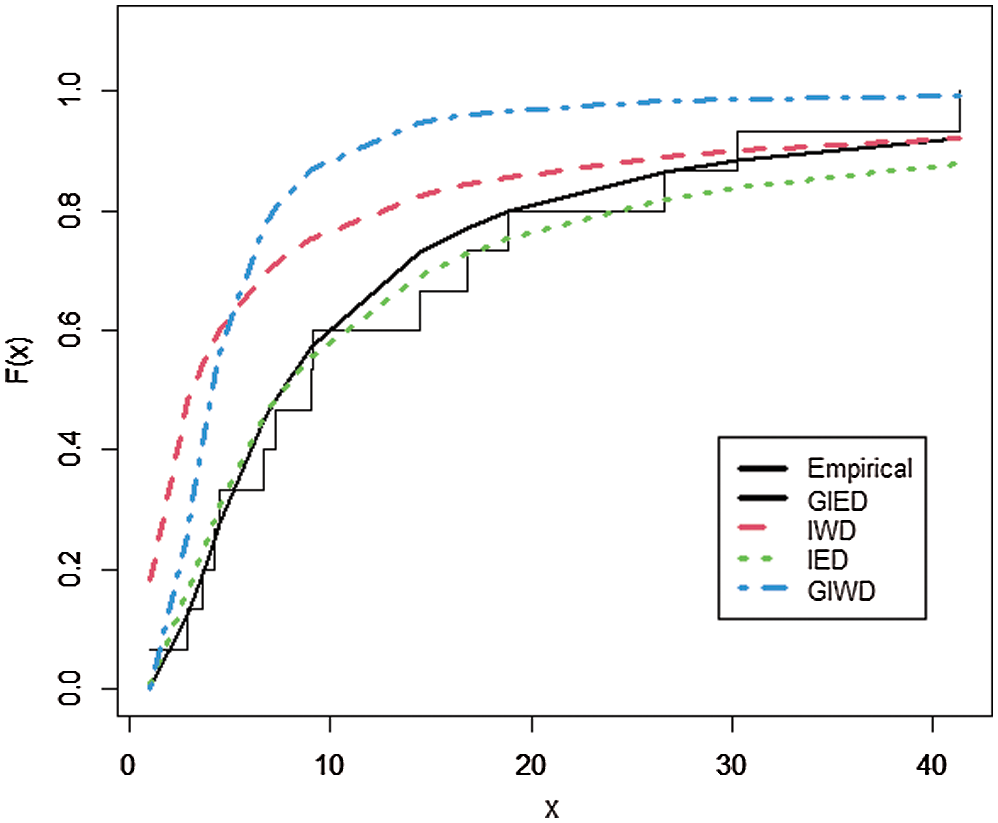
Figure 2: The empirical distribution of survival time of patients and the estimated CDFs of GIED and other competitive models
It is well known that the Bayesian estimators usually have explicit forms, which is hard for a researcher to code, program, and compute the estimates. Therefore, it is very important to study and compare Bayesian approximation techniques using different priors in statistical inference and especially in Bayesian analysis. These approximations are useful for computing non-closed form estimators, which are very important for reliability analysis. This article presents a comparison among normal, Lindley’s, and Tierney and Kadane’s approximations for Bayesian estimators using seven informative and non-informative priors.
Singh et al. [16] compare Lindley’s, Tierney and Kadane’s, and Markov Chain Monte Carlo (MCMC) methods for Marshall-Olkin extended exponential distribution. Their results show that for n = 20 and 50 with informative priors, Lindley’s works better than Tierney and Kadane’s and MCMC. However, with non-informative priors (Gamma prior), Tierney and Kadane’s has the best estimators.
Fatima et al. [19] compare two techniques: normal and Tierney and Kadane’s for IED. Their results show that normal approximation with the extension of Jeffrey’s prior performs better.
Our results on simulated data show that estimators under informative priors for n = 20 and 50 using Lindley’s approximation are usually better than normal and Tierney and Kadane’s approximations. But with non-informative priors for n = 20 and 50, Tierney and Kadane’s approximation is better than Lindley’s approximation, which agrees with the results of Singh et al. [16].
Moreover, our results in the simulation study show that normal approximation is better than Tierney and Kadane’s approximation with non-informative priors for n = 20 and 50, which agrees with the results of Fatima et al. [19].
Furthermore, in this article, a flexible model, generalized inverted exponential distribution, is used as a lifetime model and applied to two data sets of reliability and medicine. So estimating this model using Bayesian approximation techniques gives good results for investigating estimation problems.
In this article, we estimate the shape parameter of GIED using three Bayesian approximation techniques, which are the normal, Lindley’s, and Tierney and Kadane’s approximations. Tierney and Kadane’s works better than the rest of the other methods for large samples. Estimates with informative priors are better than those with non-informative priors. Estimates with Gamma prior are the best among all estimators with the three techniques. This work is a generalization of the inverted exponential distribution studied by Fatima et al. [19].
Acknowledgement: We would like to thank all four reviewers and the academic editor for their interesting comments on the article, greatly improving it in this regard. This work was funded by the University of Jeddah, Saudi Arabia, under grant No (UJ-02-087-DR). The authors, therefore, acknowledge with thanks the University’s technical and financial support. We appreciate the linguistic assistance provided by TopEdit (www.topeditsci.com) during the preparation of this manuscript.
Funding Statement: This work was funded by the University of Jeddah, Saudi Arabia, under grant No (UJ-02-087-DR).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. R. A. Bakoban and H. Abu-Zinadah, “The beta generalized inverted exponential distribution with real data applications,” REVSTAT-Statistical Journal, vol. 15, no. 1, pp. 65–88, 2017. [Google Scholar]
2. H. Panahi, “Exact confidence interval for the generalized inverted exponential distribution with progressively censored data,” Malaysian Journal of Mathematical Sciences, vol. 11, no. 3, pp. 331–345, 2017. [Google Scholar]
3. W. H. Gui and L. Guo, “Different estimation methods and joint confidence regions for the parameters of a generalized inverted family of distributions,” Hacettepe Journal of Mathematics and Statistics, vol. 47, no. 1, pp. 203–221, 2018. [Google Scholar]
4. Y. Z. Tian, A. J. Yang, E. Q. Li and M. Z. Tian, “Parameters estimation for mixed generalized inverted exponential distributions with type-II progressive hybrid censoring,” Hacettepe Journal of Mathematics and Statistics, vol. 47, no. 4, pp. 1023–1039, 2018. [Google Scholar]
5. R. A. Bakoban, M. A. Aldahlan and L. S. Alzahrani, “New statistical properties for beta inverted exponential distribution and application on Covid-19 cases in Saudi Arabia,” International Journal of Mathematics and its Applications, vol. 8, no. 3, pp. 233–254, 2020. [Google Scholar]
6. Z. A. Al-saiary and R. A. Bakoban, “The Topp-Leone generalized inverted exponential distribution with real data applications,” Entropy, vol. 22, no. 10, pp. 1–16, 2020. [Google Scholar]
7. S. Dey and T. Dey, “On progressively censored generalized inverted exponential distribution,” Journal of Applied Statistics, vol. 41, no. 12, pp. 2557–2576, 2014. [Google Scholar]
8. S. Dey, S. Singh, Y. M. Tripathi and A. Asgharzadeh, “Estimation and prediction for a progressively censored generalized inverted exponential distribution,” Statistical Methodology, vol. 32, pp. 185–202, 2016. [Google Scholar]
9. E. A. Ahmed, “Estimation and prediction for the generalized inverted exponential distribution based on progressively first-failure-censored data with application,” Journal of Applied Statistics, vol. 44, no. 9, pp. 1576–1608, 2017. [Google Scholar]
10. P. E. Oguntunde, A. O. Adejumo and E. A. Owoloko, “On the exponentiated generalized inverse exponential distribution,” in Proc. of the World Congress on Engineering, London, UK, pp. 1–4, 2017. [Google Scholar]
11. A. S. Hassan, M. Abd-Allah and H. F. Nagy, “Estimation of P(Y < X) using record values from the generalized inverted exponential distribution,” Pakistan Journal of Statistics and Operation Research, vol. 14, no. 3, pp. 645–660, 2018. [Google Scholar]
12. A. M. Abouammoh and A. M. Alshingiti, “Reliability estimation of generalized inverted exponential distribution,” Journal of Statistical Computation and Simulation, vol. 79, no. 11, pp. 1301–1315, 2009. [Google Scholar]
13. R. K. Singh, S. K. Singh and U. Singh, “Maximum product spacings method for the estimation of parameters of generalized inverted exponential distribution under Progressive Type II Censoring,” Journal of Statistics and Management Systems, vol. 19, pp. 219–245, 2016. [Google Scholar]
14. I. B. Eraikhuemen, F. B. Mohammed and A. A. Sule, “Bayesian and maximum likelihood estimation of the shape parameter of exponential inverse exponential distribution: A comparative approach,” Asian Journal of Probability and Statistics, vol. 7, no. 2, pp. 28–43, 2020. [Google Scholar]
15. A. I. Shawky and R. A. Bakoban, “On finite mixture of two-component exponentiated gamma distribution,” Journal of Applied Sciences Research, vol. 5, no. 10, pp. 1351–1369, 2009. [Google Scholar]
16. S. K. Singh, U. Singh and A. S. Yadav, “Bayesian estimation of Marshall-Olkin extended exponential parameters under various approximation techniques,” Hacettepe Journal of Mathematics and Statistics, vol. 43, no. 2, pp. 341–354, 2014. [Google Scholar]
17. H. Sultan and S. P. Ahmad, “Bayesian approximation techniques for Kumaraswamy distribution,” Mathematical Theory and Modeling, vol. 5, no. 5, pp. 49–60, 2015a. [Google Scholar]
18. H. Sultan and S. P. Ahmad, “Bayesian approximation techniques of Topp-Leone distribution,” International Journal of Statistics and Mathematics, vol. 2, no. 2, pp. 66–72, 2015b. [Google Scholar]
19. K. Fatima and S. P. Ahmad, “Bayesian approximation techniques of inverse exponential distribution with applications in engineering,” International Journal of Mathematical Sciences and Computing, vol. 4, no. 2, pp. 49–62, 2018. [Google Scholar]
20. D. V. Lindley, “Approximate Bayesian method,” Trabajos de Estadistica, vol. 31, pp. 223–237, 1980. [Google Scholar]
21. L. Tierney and J. Kadane, “Accurate approximations for posterior moments and marginal densities,” Journal of the American Statistical Association, vol. 81, pp. 82–86, 1986. [Google Scholar]
22. F. R. Gusmão, E. M. Ortega and G. M. Cordeiro, “The generalized inverse Weibull distribution,” Statistical Papers, vol. 52, pp. 591–619, 2011. [Google Scholar]
23. A. Z. Keller and A. R. Kamath, “Alternate reliability models for mechanical systems,” in Proc. of the 3rd Int. Conf. on Reliability and Maintainability, pp. 411–415, 1982. [Google Scholar]
24. C. Lin, B. Duran and T. Lewis, “Inverted gamma as a life distribution,” Microelectronics Reliability, vol. 29, no. 4, pp. 619–626, 1989. [Google Scholar]
25. Z. A. Al-saiary, R. A. Bakoban and A. A. Al-zahrani, “Characterizations of the beta Kumaraswamy exponential distribution,” Mathematics, vol. 8, no. 23, pp. 1–12, 2020. [Google Scholar]
26. R. A. Bakoban and M. I. Abubaker, “On the estimation of the generalized inverted Rayleigh distribution with real data applications,” International Journal of Electronics Communication and Computer Engineering, vol. 6, no. 4, pp. 502–508, 2015. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |