DOI:10.32604/iasc.2022.020435
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2022.020435 | |
| Article |
Robustness Convergence for Iterative Learning Tracking Control Applied to Repetitfs Systems
Laboratory of Analysis, Conception and Control of Systems (LACCS), University of Tunis El Manar, Tunis, 1002, Tunisia
*Corresponding Author: Ben Attia Selma. Email: benattiaselma@gmail.com
Received: 24 May 2021; Accepted: 22 July 2021
Abstract: This study addressed sufficient conditions for the robust monotonic convergence of repetitive discrete-time linear parameter varying systems, with the parameter variation rate bound. The learning law under consideration is an anticipatory iterative learning control. Of particular interest in this study is that the iterations can eliminate the influence of disturbances. Based on a simple quadratic performance function, a sufficient condition for the proposed learning algorithm is presented in terms of linear matrix inequality (LMI) by imposing a polytopic structure on the Lyapunov matrix. The set of LMIs to be determined considers the bounds on the rate of variation of the scheduling parameter. The control law designs polynomial ILC by constructing a sequence of control inputs to a discrete-time R-LPV system, producing an iterative dynamic for the R-LPV system with respect to the polytopic structure for uncertain parameters. Numerical simulations were performed to demonstrate the benefits of the proposed technique.
Keywords: ILC control; quadratic approach; LMI; repetitive LPV systems; output disturbance; robust control
Repetitive linear parameter varying processes (R-LPVs) are a distinct class of 2D systems [1,2] (i.e., information propagation in two independent directions) of both system theoretic and application interest whose unique characteristic is a series of sweeps, termed “passes,” through a set of dynamics defined over a fixed finite duration known as the “pass length,” and many articles have been published [3,4]. On each pass, an output, called the “parameter varying pass profile,” is produced, which acts as a forcing function on, and, hence, contributes to, the dynamics of the next pass profile [5,6].
Physical examples of these processes include long-wall coal-cutting and metal-rolling operations [7]. In recent years, applications have arisen, where adopting a repetitive parameter varying process setting for analysis has distinct advantages over alternatives. An example of these algorithmic applications is iterative algorithms for solving nonlinear dynamic optimal stabilization problems based on the maximum principle [8], where the use of the repetitive process setting provides the basis for the development of extremely reliable and efficient iterative solution algorithms [9–11].
In particular, iterative learning control schemes provide one approach for controlling systems operating in a repetitive parameter varying (or pass-to-pass) mode with the requirement that a reference trajectory yk (t) defined over a finite interval 0 ≤ t ≤ T be followed with high precision [12,13]. In this case, a repetitive process setting for analysis provides a stability theory that, unlike many alternatives, enables the design to meet pass-to-pass error convergence and control of the along-the-pass dynamics.
The problem considered in this study is similar to robust iterative learning control (ILC) for linear discrete-time R-LPV systems [14,15] with a prescribed bound on the rate of parameter variation [16–20]. In this regard, ILC has attracted attention for the past two decades. A 2D system theory view of ILC has been considered, and the tracking problems generally treated under the ILC framework must have some 2D properties. With the help of a delay operator in the time domain (standard Z-transformation), the dynamics of linear discrete-time systems are converted into a dynamic process in the iteration domain. This extension can be applied to time R-LPV systems, input variables, output variables, and errors. Based on this idea, the tracking problem and the stabilization problem of R-LPV systems is a topic that has been studied extensively, to the best of the authors’ knowledge. However, basic control problems, such as stability and stabilization, can be relatively easily extended to involve robustness analysis and more control performance specifications using H∞ norms. Therefore, robust monotonic convergence (RMC) is formulated in terms of a set of linear matrix inequalities (LMIs), while the learning gains can be determined directly by solving the LMIs. The stability analysis shows that the output error l2 norm has RMC as the learning process proceeds from one trial to the next.
The remainder of this paper is organized as follows. Section 2 provides a brief description of the problem formulation and a discussion of the control objective. In Section 3, the idea that the convergence conditions for the polynomial control law design ILC based on the bounded real lemma (BRL) approach produce a monotonic convergence error at iteration for an LPV repetitive system with varying bounded parameters is described. In Section 4, the stability analysis of the system and sufficient conditions for the existence of a stabilizing polynomial ILC controller are derived in terms of a set of matrix inequalities. In Section 5, a new approach for a system to achieve optimal noise attenuation using the ILC control problem for R-LPV systems with output disturbance is discussed. In Section 6, numerical examples are presented to illustrate the feasibility and effectiveness of the design algorithms in this study. Finally, the conclusions of this study are presented in Section 7.
Throughout this work, the null matrix and the identity matrix with appropriate dimensions are denoted by 0 and I, respectively. In large matrix expressions, the symbol * replaces the terms that are induced by symmetry, ‖ ‖ denotes the induced operator norm, and Z is a z transform. The expression sym(M) represents a symmetric matrix M + MT, and diag{x, y} denotes the diagonal matrix obtained from vectors or matrices x, y.
The following discrete linear repetitive parameter varying system is considered over
where k is the iteration number, which denotes the kth repetitive operation of the system, and xk+1(t) ∈ ℝn, and yk+1(t) ∈ ℝl are the state, input, and output variables, respectively. Moreover, x0 is the initial condition for each iteration. It is assumed that the dynamic matrices A(θ(t)), B(θ(t)), C(θ(t)) are dependent on the parameters θi(t), i.e.,
where Ai, Bi, Ci, Di are a constant matrix i = (1, …, N).
The time-varying parameter θ(t) varies in a polytope given by θ(t) ∈ ΛN, where
where N is the number of vertices of the polytope.
If a control law of the following form exists over t ∈ [0, T] and k ∈ ℤ+,
where
By applying the control law in Eq. (4) to the system in Eq. (1), the following state space is obtained.
where Acl(θ(t)) = A(θ(t)) + B(θ(t)) L(θ(t))
For all t ≥ 0, the rate of variation of the parameters is defined by:
Is assumed to be limited by an a priori known bound b such that: − b ≤ Δθi(t) ≤ b i = 1, …, N In this work, a specific case of polytopic discrete-time R-LPV systems with known bounds on the rate of variation of the parameters Δθi(t) is proposed that is well defined at all times and satisfies the Lemma 1.
Lemma 1. If the uncertain parameter Δθi(t) belongs to the set given by Eq. (6) and satisfies previous Equation, then its time derivative can be written as:
where
The following assumption is considered for the R-LPV system in Eq. (1).
A1. The desired output yd(t), t = 1, …, T is given a priori over the same time duration, and it is assumed that the initial resetting condition is satisfied, i.e., yk(0) = yd(0).
It follows from Eq. (5) that the Z-transform of the output is of the form
Xk+1(z) = (zI − Acl (θ)) −1B(θ) Uk+1(z) when
where G(z) = C(θ) (zI − Acl (θ)) −1B(θ)
A2. The initial state remains the same at each iteration, i.e.,
For any given assumptions A1 and A2, one desirable objective in ILC is that yk(t) converges monotonically to yd (t) when k tends to infinity for all t within the time interval [0, T]. This can guarantee reasonable transients during the learning process. In the sense of the ℓ2,[0,T] norm, this objective can be transformed by considering the index.
where γ > 0 is the prescribed scalar, and ek(t)is the tracking error at the kth iteration, expressed as
The norm error ‖ek(t)‖2[0,T] can be guaranteed to converge monotonically along the iteration axis k if J(γ) < 0 holds for any γ ∈ ]0, 1[. With this fact, the objective can be given as follows.
The objective of this study is to present LMI conditions to ensure the monotonic convergence of ILC by considering the performance index J(γ, k) of Eq. (16) and applying the BRL from the robust H∞ control theory.
To achieve this objective, it should be noted that, for a prescribed scalar, γ, J(γ) can be transformed as the performance index defined for the system.
where Ek(z) = Z[ek(t)], and H(z) is a transfer function matrix to be determined.
Once the system in Eq. (18) is established, ‖G‖∞ < γ can be used to guarantee that J(γ) < 0.
Moreover, there exist matrices Acl(θ), Bcl(θ), Ccl(θ), Dcl(θ) such that H(z) is expressed in the form
Hence, it can be derived that, if ‖H(z)‖∞ < γ, γ ∈ [0, 1) holds, then
3 Design for ILC-Tracking Control
Now, the polynomial ILC law is as follows.
where:
In which the Z-transform Ek(z) = Z[ek(t)], Km,r is a polynomial learning varying gain matrix to be designed, and r is the degree of K(θ, z).
According to the developments in Section 2.2, it is straightforward to derive an H∞ condition for the monotonic convergence of the ILC system in Eqs. (5) and (17). When Ek is subtracted from Ek+1 and Eqs. (10) and (17) are inserted, one obtains
which leads to:
Comparing Eq. (19) with Eq. (13) yields:
Lemma 2. Consider the ILC system in Eqs. (1) and (17). If K(θ, z) is designed such that ‖I − G(z) K(θ, z)‖ < γ, γ ∈ (0, 1] is satisfied, then the tracking error ek(t) converges monotonically to zero when k tends to infinity in the sense of the l2,[0,T] norm. According to the previous developments, it is straightforward to derive a condition for the monotonic convergence of ILC–R-LPV system in Eqs. (1) and (17).
From Eq. (20), one obtains:
The relative degree of the polynomial regulator r = 1, and, based on Eq. (21), one obtains this result:
Using the fact that:
and respecting Eq. (23),
In this section, the LMI conditions are presented to ensure the monotonic convergence of the ILC–R-LPV system by considering the performance index J(γ) and applying the BRL from the robust H∞ control theory.
Theorem 1. If one considers the R-LPV system in Eq. (1) and the ILC law with r = 1, then the tracking error robustly converges monotonically to zero when k tends to infinity in the sense of the l2,[0,T] norm if there exist scalars γ > 0 and N symmetric positive matrices Pi > 0 and the appropriate matrices
In addition,
Proof 2: Applying the BRL [18] to Eq. (24), it follows that a sufficient condition for ‖H(z)‖∞ < γ is the existence of a positive definite solution P(θ(t)) > 0 to the following inequality:
Subsequently, the so-called “relaxation method” discussed in a previous report [21] is introduced to decouple the Lyapunov variable from the system matrices to provide more design freedom. The LMI in Eq. (24) can be written as:
The parameter-dependent LMI conditions in Eq. (27) must be evaluated for all θ(t) in the unit simplex ΛN, which leads to an infinite-dimensional problem. By imposing an affine parameter-dependent structure on the Lyapunov matrix P(θ(t)), such that:
and Δθi(t) given by Eq. (6) replaces Eq. (6) into Eq. (28), one obtains
Using Eqs. (8) and (29), it can be shown that
where
Then, assuming that
Using the change of variable
5 Robust Control of R-LPV Systems with Output Disturbances
This section starts with a problem of gain-scheduled H∞control formulation. The associated robust stability condition with a tracking error of zero is developed. The class of R-LPV discrete-time linear systems with output disturbance is considered.
where (Acl(θ(t)), B(θ(t)), C(θ(t)), Bw(θ(t)), Dw(θ(t))) are the matrices describing the system in the state space, wk+1(t) ∈ ℝl×1 represents any repeating disturbance written as an equivalent output disturbance, and zk+1(t) is the measured output. The fundamental aim is to make yk+1(t) converge to yd(t) for all k tending to infinity and to guarantee that the design of a control law continuously monitors the performance of the studied system and changes the commands as necessary to stay on track.
It follows from Eq. (33) that the Z-transform of the output is of the form
where d denotes the disturbance vectors and describes the contribution from external sources in the current trial. From Eqs. (17) and (33),
This leads to
Using Eq. (36) and respecting Eq. (20),
It is easy to verify that parameter uncertainty in a linear setting can often be modeled as Fig. 1.
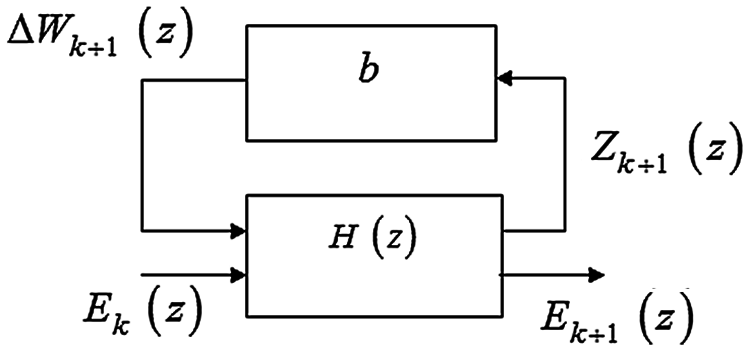
Figure 1: Uncertain model
Introducing ηk+1(t) as the state vector, which is related to the previous system in Eq. (37), the following state space representation is obtained:
For a prescribed scalar, γ, J(γ) can be transformed as the performance index defined for the system.
and
Then, from Eqs. (39) and (40), given this repetitive single-input multi-output model,
This 1D equivalent model was developed in previous research [22,23], and here it is only necessary to give the final construction. Here,
Theorem 2. The R-LPV system in Eq. (1) and the ILC law with r = 1 are considered. The tracking error robustly converges monotonically to zero when k tends to infinity in the sense of the l2,[0,T] norm if there exist scalars γ > 0 and N symmetric positive matrices Pi > 0, and the appropriate matrices
In addition,
Proof 3. Applying the BRL [18] to Eq. (38), it follows immediately that a sufficient condition for ‖H(z)‖∞ < γ is the existence of a positive definite solution P(θ(t)) > 0 to the following inequality:
in much the same way, leading to
which is transformed using the projection lemma used in a previous study and the Schur complement technique. It follows that
The LMI in Eq. (45) gives polytopic structures that come directly from Section 4, so that the proof will be almost omitted. Given P(θ(t)) = X−1(θ(t)), one obtains Eq. (43).
6.1 Application to Printing Systems
The effectiveness of the proposed method was demonstrated by simulation. MATLAB software was used for the simulation. The wide-format printer and paper positioning are shown in Figs. 2 and 3. The aim of this system was to correct quickly the angular offset paper sheets that pass through the unit at high speeds. During this motion, the inertia of the sheets changes the motors, which are modeled with LPV dynamics.
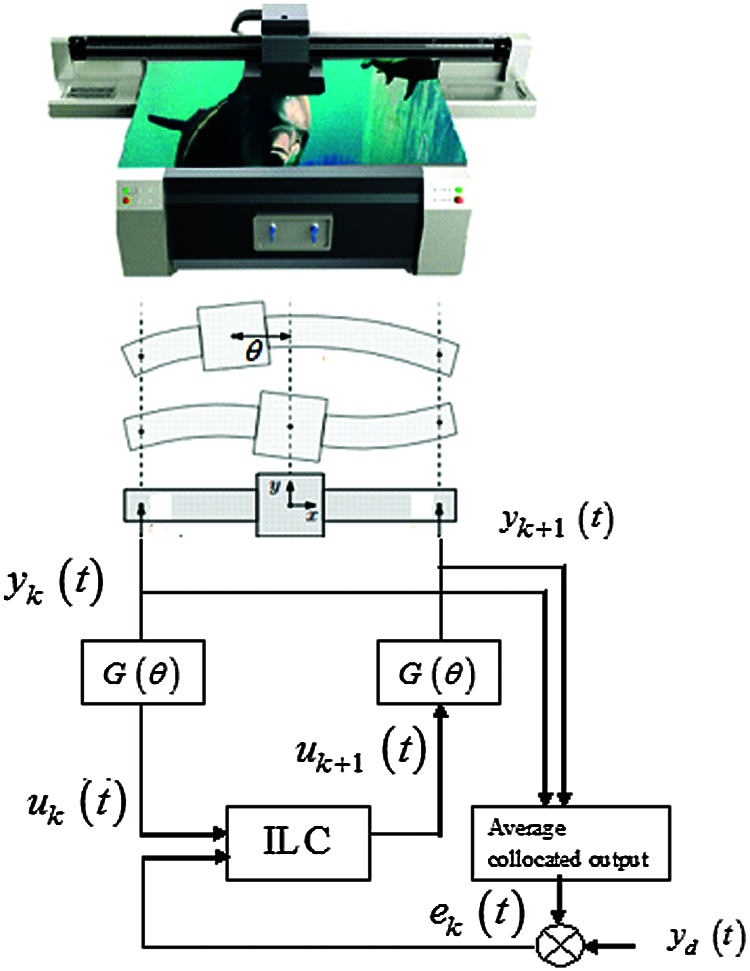
Figure 2: Dynamics of an industrial flat-bed printer dependent on its configuration
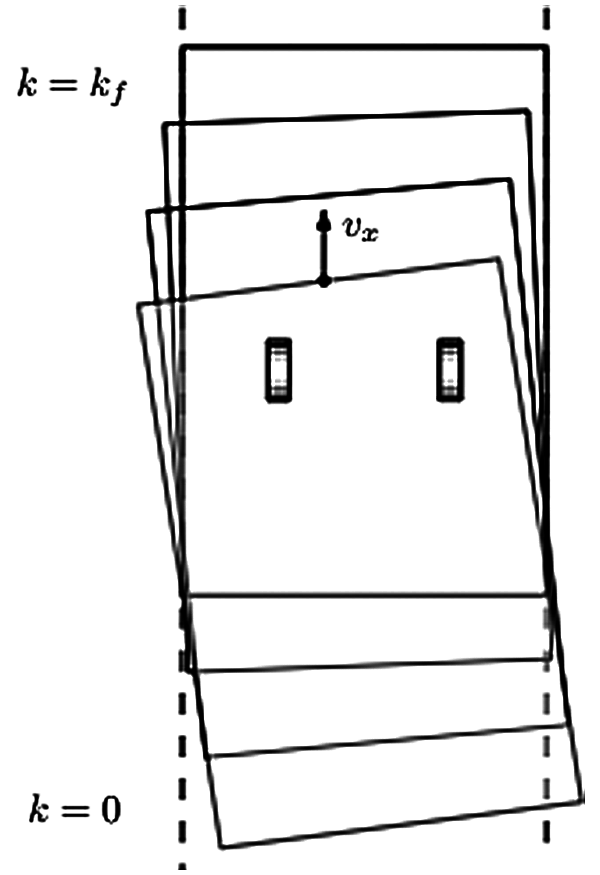
Figure 3: Inertia of the sheet: the pinches change, which is modeled as LPV dynamics
The accurate positioning of the carriage in the y-direction is hampered by a resonance mode that varies as a function of its x-position, as schematically shown in Figs. 2 and 3. A symmetric force is applied to uk(t), and the output is the average of the collocated memory output
A simplified polytopic LPV model is given by
where δ ∈ ℝ+ is a given nonnegative scalar. These system matrices were borrowed from a prior report [24,25].
The problem considered here is the design of an iterative learning controller that stabilizes the R-LPV system. The result obtained using Theorem 1 is compared with the three methods developed in previous studies and summarized in Tab. 1. The R-LPV system is characterized by the number of vertices of the polytope (N), system order (n), number of inputs (m), and number of outputs (l). For fixed values of (N, n, m, l), 100 R-LPV systems of the form in Eq. (1) were generated. Therefore, the purpose was to design an ILC controller using four methods in the form of Eq. (22) such that the closed system is robust and stable, and the output system converges to the desired trajectory.
(i)Method 1 uses switching ILC control in Theorem 2.
(ii)Method 2 uses the method developed in a previous study [1].
(iii)Method 3 uses the method developed in another study [6].
(iv)Method 4 uses a method developed previously [8].
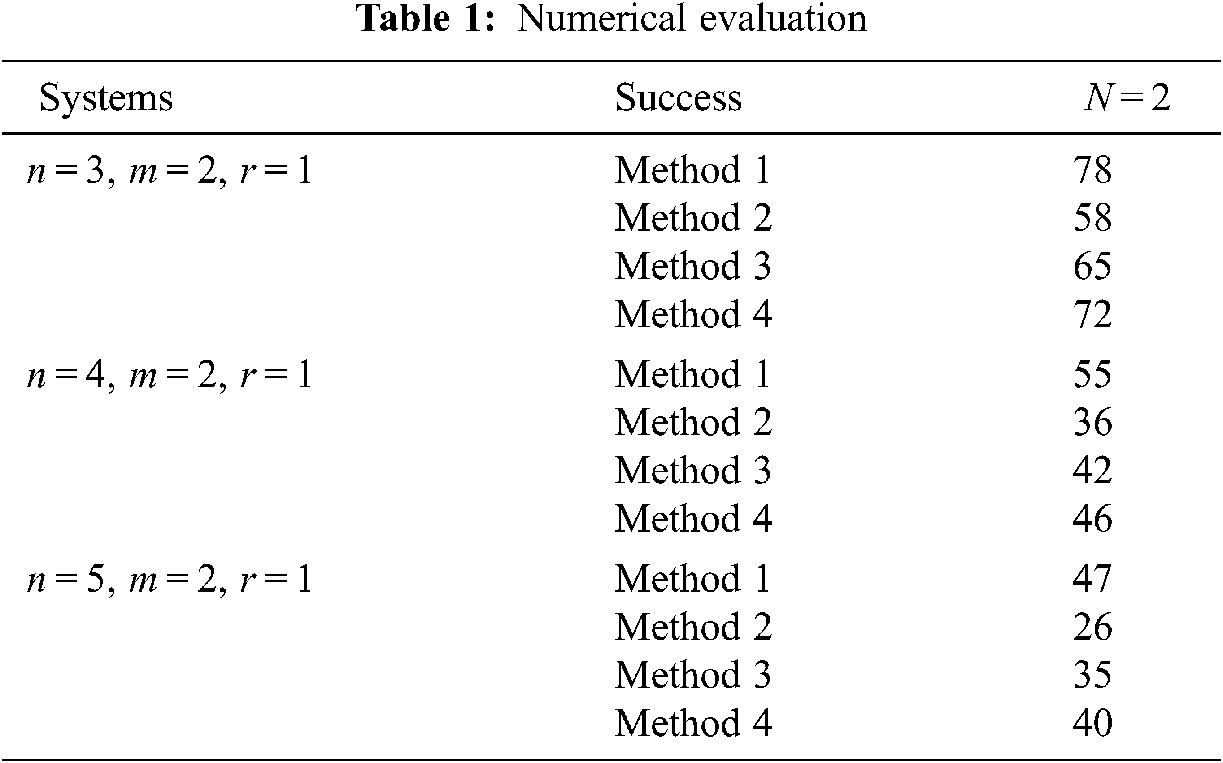
By using the MATLAB LMI Control Toolbox to check the feasibility of the LMI conditions, a counter (Success Method 1, Success Method 2, Success Method 3, and Success Method 4) was introduced, which is increased if the corresponding method succeeds in providing an ILC-tracking control.
The contribution of this study is the combination of a specific case of polytopic discrete-time R-LPV systems with known bounds on the rate of variation parameters Δθi(t) with robust stability by applying ILC control.
The aim was to determine the maximum limits of stability in the plane (δ, b) from one side (based on Theorem 1) such that the system is robust and monotonically stabilized by varying learning gains — the LMIs in Eq. (30) are feasible — and to guarantee the upper bound of the real parameter γ. The result obtained using Theorem 1 was compared with the method developed in other research and is summarized in Tab. 2.

The computational results show that the condition in Theorem 1 is less conservative than the results given in the other methods.
Fig. 4 shows the resulting maximum allowed bound bmax on the rate of variation for the different control designs as a function of the scalar stabilizability regions by the maximum variation of the parameter. The gain parameters obtained by Theorem 1 (optimization problem) are as follows:
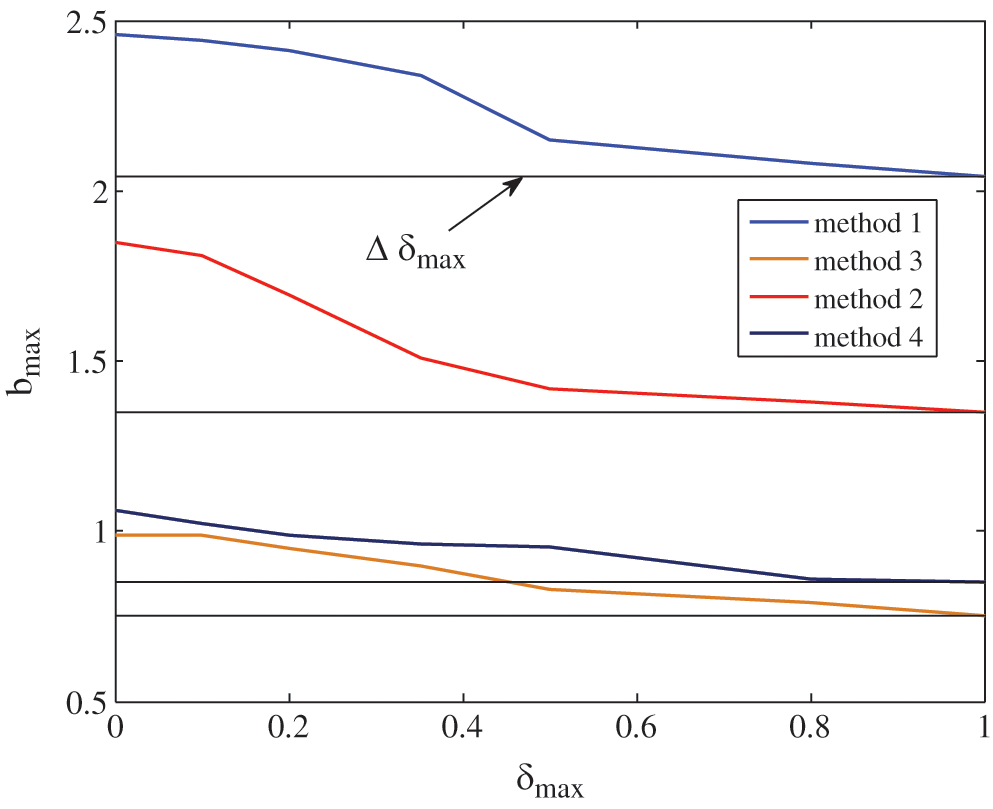
Figure 4: Stabilizability regions as a function of the plane (δ, b)
To check the performance achieved using the new design procedure, b is fixed to b = 1. Fig. 5 shows the achieved upper bound γmax = 0.998 of the closed-loop system in Eq. (29) as a function of the allowed bound on the rate of variation.
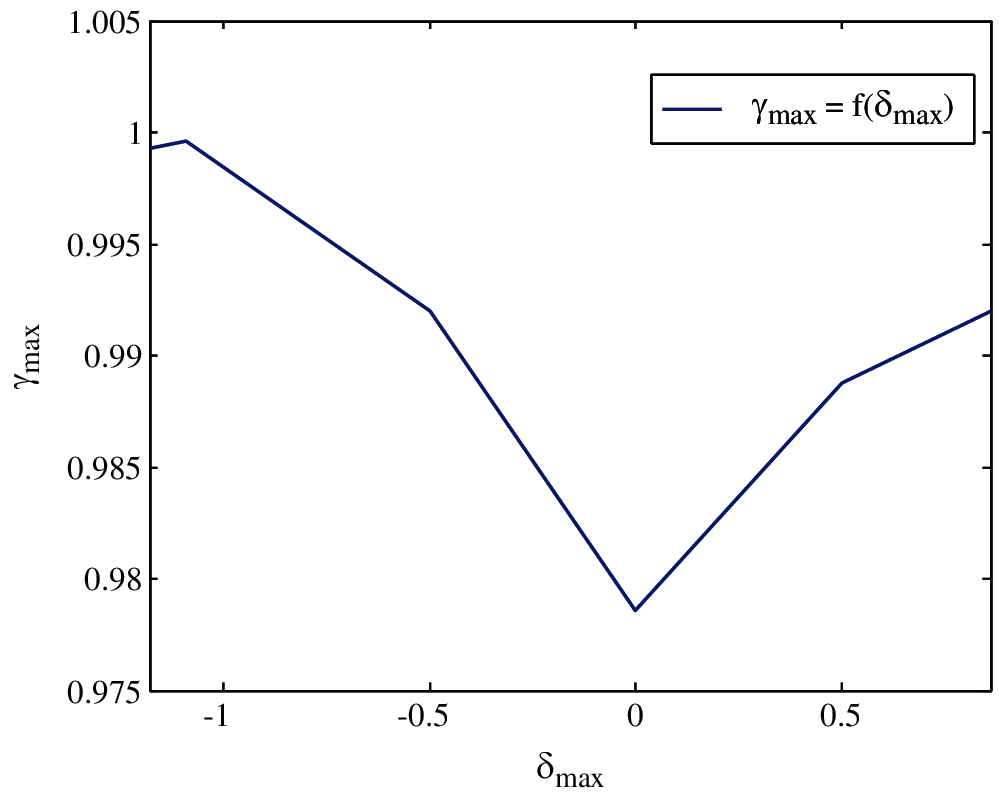
Figure 5: Guaranteed upper bounded γ as a function of uncertain parameter δ
In this study, the linear system in Eq. (16) was considered. The desired trajectory was set as
First, the resulting ILC process can be guaranteed with its tracking error converging to zero along the iteration and time. Figs. 6 and 7 show the time evolution of the output error ek(t) and the output system profiles yk(t) successively at the maximum value of δmax = 0.86, b = 1.
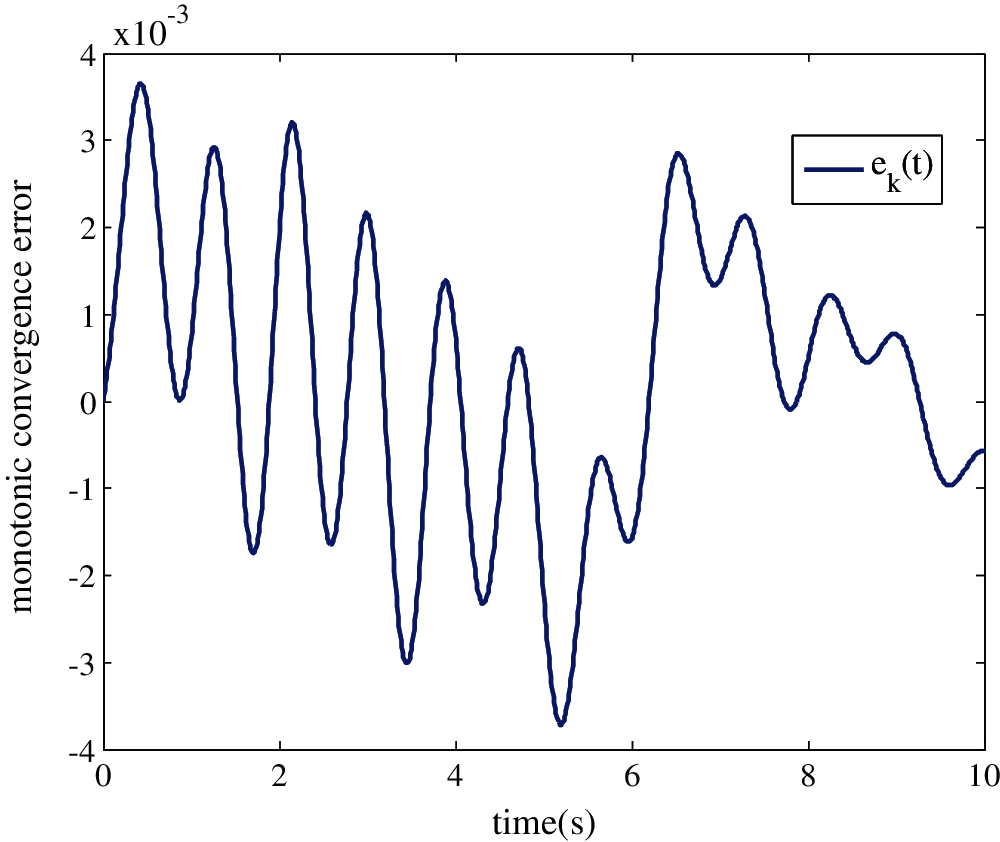
Figure 6: Evolution of the error ek(t) to zero for the maximum value of δmax after 10 iterations
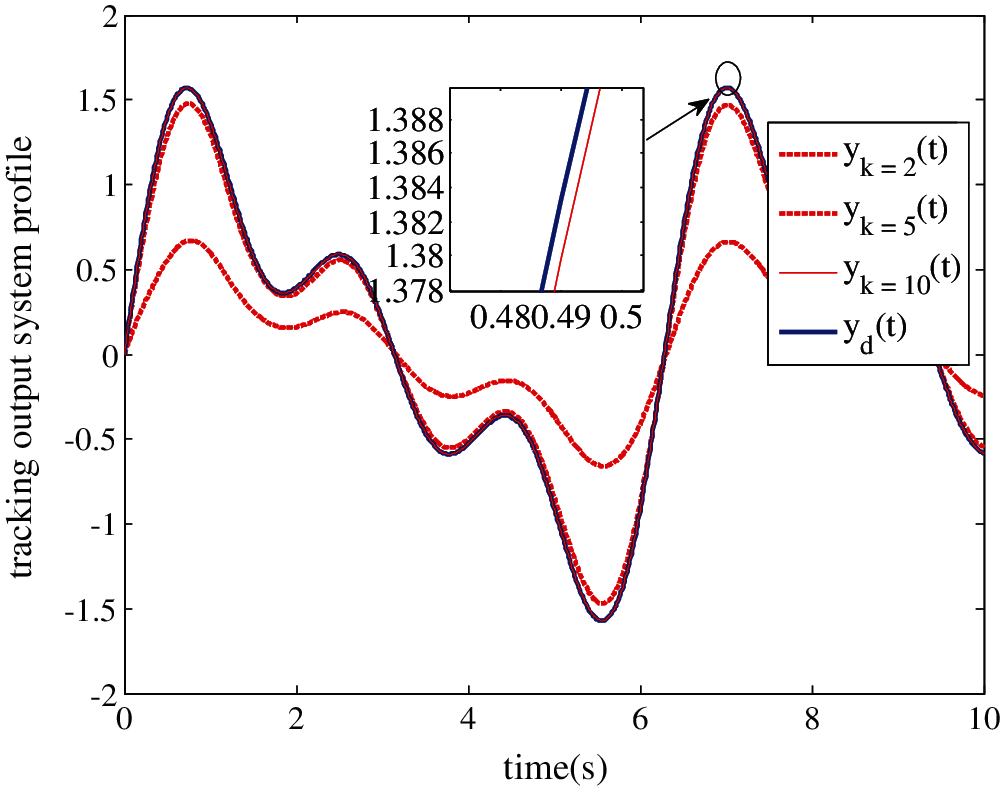
Figure 7: Evolution of the output trajectory yk(t) to desired trajectory yd(t). for the maximum value of δmax after 10 iterations
Remark. The feasibility of the studied problem with a maximum value of (δmax, bmax) requires a certain number of iterations to converge on the desired output. However, the influence of the two parameters (δ, b) on the rapidity of the monotonic convergence of the ILC controller.
First, b is fixed to be bmax = 1 and for different values of the uncertain varying parameter δ to check the influence of δ on the convergence of error at five iterations.
Fig. 8 shows that using the maximum value of δmax = 0.55 found in a previous report [6], one can guarantee the monotonic convergence of error at the minimum number of iterations and guarantee a very important tracking between yk(t), yd(t)—hence, the efficiency of the algorithm shown in Theorem 1.
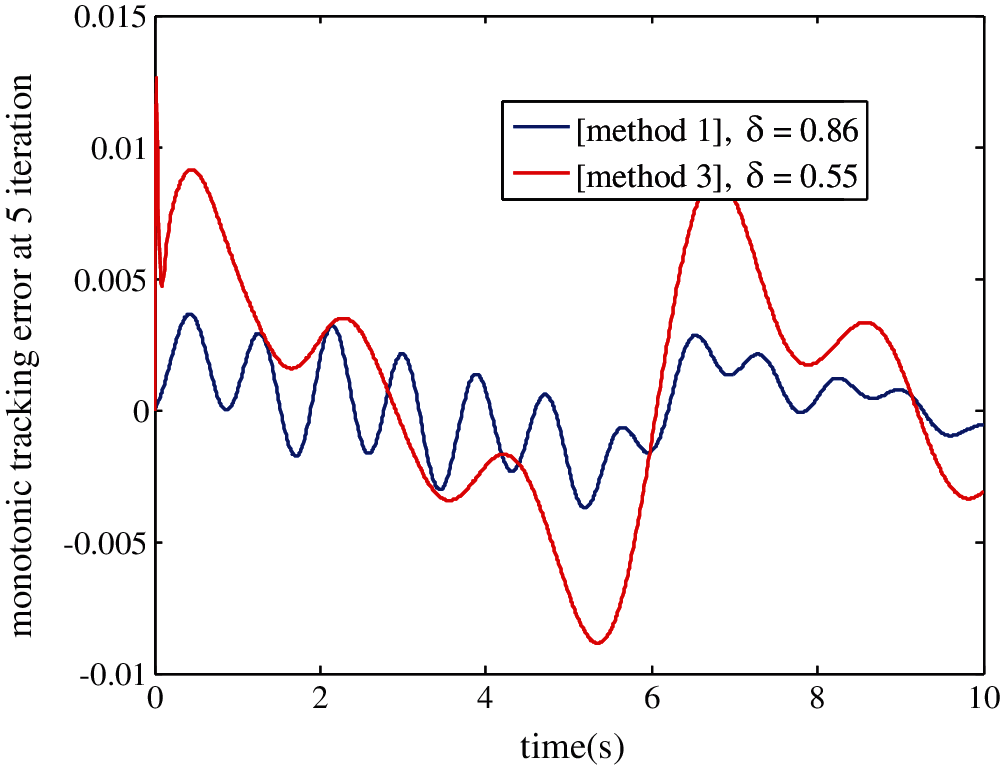
Figure 8: Output error convergence at five iterations as a function of the uncertain varying parameter δ, b = 1
However, Fig. 9 shows evolution of the tracking error with respect to the allowed bound b. Now, δ is fixed to be δmax = 0.86. To check the influence of the bound b on the limited iteration number, different cases are considered: b = {0.25, 0.8, 1}. Thus, the resulting ILC process can be tested with its tracking error converging to zero over five iterations.
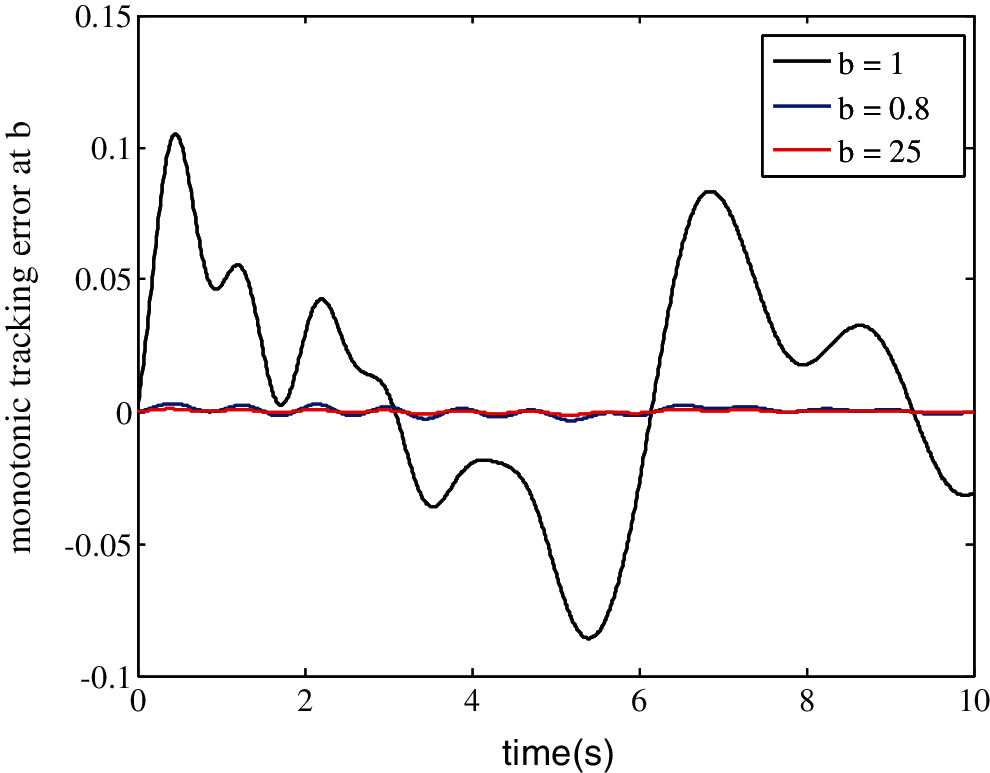
Figure 9: Output error convergence at five iterations as a function of the allowed bound b, δmax = 0.86
The control effort required for this study is shown in Fig. 9, where, as the speed of varying uncertain parameter b increases, the output error between iterations increases. Thus, from the upper bound of bmax, the system requires more iterations, so the error converges to zero.
In this study, the problem of polynomial ILC-tracking control induced by the BRL was discussed for a class of linear R-LPV systems with a prescribed bound on the rate of parameter variation. The control law designs polynomial ILC by constructing a sequence of control inputs to a discrete-time R-LPV system, producing an iterative dynamic for the R-LPV system with respect to the polytopic structure for uncertain parameters. This can guarantee the monotonic convergence error of the closed-loop R-LPV system. The ILC algorithm should be studied when there are disturbances in the system, and it was shown that the choice in the ILC algorithm depends highly on the type of disturbance. Sufficient conditions for the existence of such a controller were formulated in terms of a set of LMIs. A numerical example was provided to illustrate the effectiveness of the proposed method.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. L. Y. Hui, L. S. Shan and H. Zhao, “Dynamic output feedback control for discrete LPV repetitive processes,” Journal of Control and Decision, vol. 28, no. 11, pp. 1745–1750, 2013. [Google Scholar]
2. S. Boyd, L. E. Ghaoui, E. Feron and V. Balakrishnan, “Linear matrix inequality in systems and control theory,” in SIAM Frontier Series, Philadelphia, PA: SIAM, 1994. [Google Scholar]
3. R. W. Longman, “Iterative learning control and repetitive control for engineering practice,” International Journal of Control, vol. 73, pp. 930–954, 2000. [Google Scholar]
4. W. Paszke, P. Rapisarda, E. Rogers and M. Steinbuc, “Dissipative stability theory for linear repetitive processes with application in iterative learning control,” in Proc. SLC IEEE CDC, Shanghai, China, 2009. [Google Scholar]
5. W. Paszke, E. Rogers and K. Galkowski, “Design of robust iterative learning control schemes in a finite frequency range,” in Proc. IWM (nD) Systems, Poitiers, France, pp. 1–6, 2011. [Google Scholar]
6. Q. Ji and L. Y. Hui, “Control of time-delayed LPV repetitive processes,” Journal of Control and Decision, vol. 27, no. 1, pp. 920–1001, 2012. [Google Scholar]
7. N. Aouani, S. Salhi, G. Garcia and M. Ksouri “New robust stability and stabilizability conditions for linear parameter time varying poly-topic systems,” in Proc. ICSCS, Medenine, Tunisia, pp. 1–6, 2009. [Google Scholar]
8. L. Yanhui and F. Z. Fan, “Robust L2-L∞ filtering for LPV systems with distributed delays,” in Proc IOP Conference Series: Materials Science and Engineering, vol. 631, pp. 483–492, 2019. [Google Scholar]
9. E. Rogers, K. Galkowski and D. H. Owens, “Control systems theory and applications for linear repetitive processes,” LNCIS, Springer, vol. 349, pp. 470–488, 2007. [Google Scholar]
10. W. Xie, “Gain scheduled state feedback for LPV system with new LMI formulation,” in Proc. CTA, Kitami, Japan, vol. 152, no. 6, 2005. [Google Scholar]
11. L. Rodriguez, F. Camino and J. P. De Caigny, “Gain-scheduled control of discrete-time polytopic time-varying systems,” in Proc. ABCM Symposium Series in Mechatronics, vol. 4, pp. 208–217, 2010. [Google Scholar]
12. J. C. Geromel and P. Colaneri, “Robust stability of time varying polytopic systems,” Systems and Control Letters, vol. 55, pp. 81–85, 2006. [Google Scholar]
13. H. Ouerfelli, J. Dridi, S. Ben Attia and S. Salhi, “Robust iterative learning control for discrete time switched system,” advances in computational intelligence and robotics,” IGI Global Book Series, vol. 1, pp. 563–586, 2014. [Google Scholar]
14. H Ouerfelli, J. Dridi, S. Ben Attia and S. Salhi, “Iterative learning tracking control for discrete time switched system,” International Journal of Scientific Research & Engineering Technology, vol. 3, no. 3, pp. 43–46, 2015. [Google Scholar]
15. L. Zhifu, P. Yuan, H. Yueming, G. Qiwei and M. Ge, “LMI approach to robust monotonically convergent iterative learning control for uncertain linear discrete-time systems,” in Proc. Chinese Control Conf., Hefei, China, no. 20, pp. 670–821, 2012. [Google Scholar]
16. F. Wu and K. M. Grigoriadis, “LPV systems with parameter-varying time delays: Analysis and control,” Automatica, vol. 37, no. 2, pp. 221–229, 2001. [Google Scholar]
17. F. Wu, X. H. Yang and G. Becker, “Induced I2 norm control for LPV systems with bounded parameter variation rates,” International Journal of Robust and Nonlinear Control, vol. 6, pp. 983–998, 1996. [Google Scholar]
18. M. Deyuan, J. Yingmin, D. Junping and Y. Fashan, “Monotonically convergent ILC systems designed using bounded real lemma,” International Journal of Systems Science, vol. 43, no. 11, pp. 2062–2071, 2012. [Google Scholar]
19. N. Aouani, S. Salhi, G. Garcia and M. Ksouri, “Robust control analysis and synthesis for LPV systems under affine uncertainty structure,” Transactions on Systems, Signals and Devices,” TSSD, vol. 10, pp. 1041–1046, 2010. [Google Scholar]
20. J. D. Caigny, J. Camino, R. C. L. F. Oliveira, P. Peres and J. Swevers, “Gain-scheduled H∞-control of discrete-time polytopic time-varying systems,” in Proc. of the 47th IEEE Conf. on Decision and Control, Haifa, Israel, pp. 3872–3877, 2008. [Google Scholar]
21. N. Aouani, S. Salhi, G. Garcia and M. Ksouri, “Analysis for LPV systems by parameter-dependent lyapunov functions,” IMA Journal of Mathematical Control and Information, vol. 28, no. 8, pp. 63–78, 2011. [Google Scholar]
22. D. Jiuxiang and Y. Hong, “Robust static output feedback control for linear discrete-time systems with time varying uncertainties,” Systems & Control Letters, vol. 57, pp. 123–131, 2008. [Google Scholar]
23. Y. Li and Y. Liang, “Gain-scheduled L-one control for linear parameter-varying systems with parameter-dependent delays,” Journal of Control Theory Applied, vol. 9, no. 4, pp. 617–623, 2011. [Google Scholar]
24. J. De Caigny, J. F. Camino, R. C. L. F. Oliviera, P. L. D. Peres and J. Swevers, “Gain-scheduled and control of discrete-time polytopic time-varying systems,” IET Control Theory and Applications, vol. 4, pp. 362–380, 2008. [Google Scholar]
25. R. De Rozario, T. A. E. Oomen and M. Steinbuch, “Iterative learning control and feedforward for LPV systems: applied to a position-dependent motion system,” in Proc. IEEE American Control Conf., Seattle, Washington, pp. 3518–3523, 2017. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |