DOI:10.32604/iasc.2022.022021
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2022.022021 | |
| Article |
End-to-End Speech Recognition of Tamil Language
1Department of Electronics and Communication Engineering, C.Abdul Hakeem College of Engineering & Technology, Melvisharam, 632509, India
2Department of Information Technology, Sri Sivasubramaniya Nadar College of Engineering, Kalavakkam, 603110, India
3School of Computer Science and Engineering, Vellore Institute of Technology, Chennai, 600127, India
*Corresponding Author: Mohamed Hashim Changrampadi. Email: hashim@alumni.chalmers.se
Received: 25 July 2021; Accepted: 22 September 2021
Abstract: Research in speech recognition is progressing with numerous state-of-the-art results in recent times. However, relatively fewer research is being carried out in Automatic Speech Recognition (ASR) for languages with low resources. We present a method to develop speech recognition model with minimal resources using Mozilla DeepSpeech architecture. We have utilized freely available online computational resources for training, enabling similar approaches to be carried out for research in a low-resourced languages in a financially constrained environments. We also present novel ways to build an efficient language model from publicly available web resources to improve accuracy in ASR. The proposed ASR model gives the best result of 24.7% Word Error Rate (WER), compared to 55% WER by Google speech-to-text. We have also demonstrated a semi-supervised development of speech corpus using our trained ASR model, indicating a cost effective approach of building large vocabulary corpus for low resource language. The trained Tamil ASR model and the training sets are released in public domain and are available on GitHub.
Keywords: End to end speech recognition; deep learning; under-resourced language; semi-supervised speech corpus development
The recent advancement in Automatic Speech Recognition (ASR) in the past couple of years is commendable, surpassing even human perception. However, most of these achievements are limited to languages with massive digital resources. Low resource languages always have challenges in adopting similar methodology due to limitations or unavailability of enormous training data, pronunciation dictionaries, language model, etc. In addition, low resource languages have their own challenges like code-switching, less fluent native speakers for data collection, and too many dialects. In this paper, we investigate the use of open-source speech recognition toolkits to build a speech recognition model for the Tamil language. This developed pre-trained model will provide an out-of-the-box support for transfer learning for keyword spotting, isolated word recognition, etc.
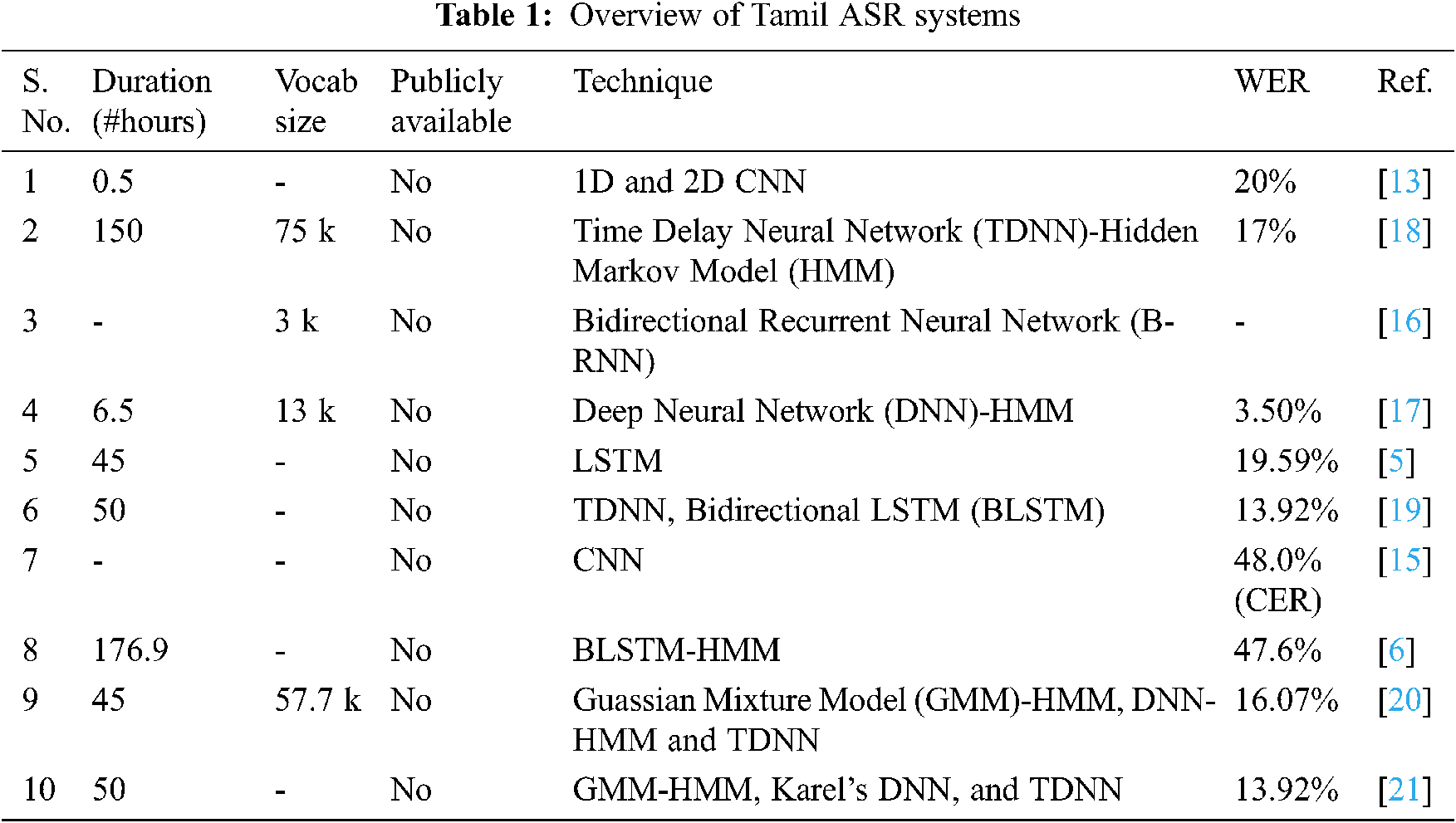
In the English language, speech recognition research has witnessed massive speech corpora and state-of-the-art ASR systems. Some of the common speech corpora in the English language include Switchboard (300 h), LibriSpeech (960 h), TedLium-3 (450 h), Common Voice (1400 h) and SPGISpeech (5000 h) [1]. Apart from Switchboard, all other stated English corpora are available for free download and use for research and non-commercial purposes. The speech recognition accuracy in terms of Word Error Rate (WER) for English has improved significantly in recent years. The WER on LibriSpeech test-clean [2] dataset has improved from 5.33 [3] to 1.4 [4]. However, low-resourced Indian languages lack similar massive speech corpus for ASR research. Recently, Microsoft [5] released a dataset for speech recognition challenge for low resource Indian languages. The dataset consists of 50 h of transcribed speech in three Indian languages-Tamil, Telugu, and Gujarati, amounting to a total of 150 h of data, with 40 h of training data and 5 h of test data for each language. Several attempts were also made to develop massive speech corpus for under-resourced languages using augmentation [6]. Tab. 1, summarizes the corpus and recent works in Tamil ASR, stating that almost all the corpus used are not available in public domain. Therefore, there is a tremendous need to develop a massive Tamil language speech corpus or a pretrained model to assist in transfer learning, semi-supervised corpus development, etc.
In this paper, we present a novel approach to build a pre-trained model using low resources and substantially assist in developing a massive speech corpus using semi-supervised learning. To our knowledge, this is the first attempt to use the Common Voice dataset and release a pre-trained ASR model for Tamil language.
The major contributions of this paper are documented below:
• Open-source ASR Model: Although pre-trained ASR models are available for most languages, they are seldom available for under-resourced languages. Use of a pre-trained model will ease transfer learning approach and lessen the complexity of training the speech model from scratch. In this paper, we have developed Tamil ASR and released the trained model for transfer learning. We have demonstrated isolated digit recognition using transfer learning from our trained Tamil ASR model.
• Semi-Supervised Speech Corpus Development: Large vocabulary corpus is essential for development of generic speech recognition systems. The process is time consuming and costly. However, in our paper, we have validated the invalidated set of Common Voice Tamil dataset using our trained ASR model. The validation of speech dataset using semi-supervised assistance has reduced time by 75% compared to manual validation. Such a semi-supervised approach could escalate the process of building a large vocabulary corpus.
• Cost-effective Approach: Solving any machine learning problem requires massive amount of data and extensive training of data. Training any speech recognition model depends on computational and financial resources. Since these resources are not available in a financially constrained environment, an alternative approach to achieve state-of-the-art results is necessary. In this paper, we have fully trained our ASR model using open-source toolkits, open dataset, and free computing resources like Google Colab. We have demonstrated that using available resources on the internet, design and development of ASR for under-resourced languages could be performed in a cost-effective manner.
The outline of the paper is as follows: Section 2 reviews related works done in Tamil ASR and challenges of Tamil language. Section 3 describes the processes in the proposed ASR system; development of speech corpus, ASR architecture and language modelling. Section 4 explains the training setup with experimentation results and demonstrated isolated digit recognition using transfer learning. Finally, Section 5 presents our conclusion.
Automatic Speech Recognition (ASR) has progressed extensively in recent years with state-of-the-art results in the English language. End-to-End speech recognition systems [3] have eliminated the need for preprocessing of audio data, without compromising recognition accuracy. The sequence-to-sequence model with attention approach [7] has also produced promising results. Similar attention-based approach in Speech Emotion Recognition (SER) [8] has shown impressive performance. Convolutional Long Short Term Memory (ConvLSTM) Network [9] originally proposed for forecasting rainfall, works well for speech recognition and SER systems [10]. Convolutional Neural Network (CNN) based deep learning models have achieved promising results in ASR and SER systems [11,12]. However, most of the ASR systems developed for the English language have used massive corpus for training, which makes it difficult for under-resourced languages to replicate such techniques for developing ASR systems.
Speech recognition systems for Tamil language are seldom built using single clean large corpus or as a baseline monolingual end-to-end system. Often, transfer learning [13,14], data augmentation [6], language adaptation [15] or limited vocabulary [13,16,17] is opted. Transfer learning based Tamil ASR [14] produced better WER of 46.2%, than the baseline ASR with WER of 49.9%. Due to unavailability of large Tamil corpus, a monolingual Tamil ASR developed by massive augmentation of Tamil speech corpus using speed and volume perturbation, SpecAugment and addition of noise, gave an average of 47.6 WER [6]. Language adaptation is the process of pre-training in a source language and then training in a target language. Pretrained models of Bengali, Tagalog and Zulu were used to perform language adaptation for Tamil monolingual ASR that resulted in Character Error Rate (CER) of 48.0 [15].
Majority of these works are not close enough for real-world applications because of high WER/CER, and hence there is need for exhaustive research to develop a state-of-the art Tamil ASR. One major step towards this is to develop a massive Tamil speech corpus. Tamil language is considered as one of the oldest languages, yet focus on ASR research is minimal due to many challenges and complexity of the language.
2.1 Is Tamil a Low Resource Language?
Under-resourced or low-resource language [22] are those languages which may have a few or all of the following aspects; lack of linguistic expertise, less web resources, lack of transcribed speech data, lack of digital phonetical dictionaries, etc. Indeed, Tamil language has lack of linguistic expertise with technological exposure, lack of digital pronunciation dictionaries, extremely limited transcribed speech data, and lack of statistical language models. Tamil language also possess other challenges like many dialects in different regions, code-switching (interchangeably using Tamil and English during conversation), and many non-native/non-fluent speakers.
CoVoST 2 [23], a large-scale multilingual speech-to-text translation (ST) corpus covering translations from 21 languages into English and from English into 15 languages, has used Tamil speech data of only 4 h. A few Tamil speech recognition systems developed recently have utilized very minimal data; 0.5 h [13], 6.5 h [17] and 3 K sentences [16].
2.2 Structure of Tamil Language and Its Challenges
Tamil is the official language of Tamil Nadu (Indian State), Sri Lanka and Singapore, with more than 66 million speakers worldwide. There are numerous recognized geographical dialects and community slangs. Within a single state of India, Tamil Nadu, there are dialects based on different region; Chennai (ெமட்ராஸ் பாைஷ), Coimbatore (ேகாைவ தமிழ்), Trichy (மத்திய தமிழ்), Madurai (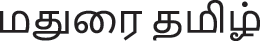 ), Tirunelveli (தி௫ெநல்ேவலி தமிழ்), Kanniyakumari (
), Tirunelveli (தி௫ெநல்ேவலி தமிழ்), Kanniyakumari (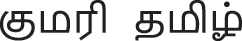 ). Consider an example sentence “Friend! When are you coming?”, it is spoken in Tirunelveli dialect as “மக்கா! நீ எப்ப வ௫த?”, in Chennai dialect as “நண்பா! நீ எப்ேபா வர?” and in literary Tamil as “
). Consider an example sentence “Friend! When are you coming?”, it is spoken in Tirunelveli dialect as “மக்கா! நீ எப்ப வ௫த?”, in Chennai dialect as “நண்பா! நீ எப்ேபா வர?” and in literary Tamil as “ ?”. It is observed from these examples, that each dialect has their own vocabulary for the same sentence. Hence, it is necessary to create a speech corpus comprising the vocabulary of all dialects to develop a dialect independent ASR. However, addressing this problem is beyond the scope of this paper and we leave this problem open for future researchers.
?”. It is observed from these examples, that each dialect has their own vocabulary for the same sentence. Hence, it is necessary to create a speech corpus comprising the vocabulary of all dialects to develop a dialect independent ASR. However, addressing this problem is beyond the scope of this paper and we leave this problem open for future researchers.
In Tamil language, Diglossia situation exists in the community [24]. The language has two different versions: Literary and Spoken with significant differences in their structure (sounds) (Fig. 1). For example, in the literary version of words 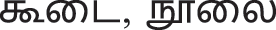 , கைட the sound ‘ை’ is removed in the spoken version of words
, கைட the sound ‘ை’ is removed in the spoken version of words 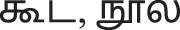 , கட. Tamil language is considered as an intonation language with syllable-based rhythm. The speech features like pitch, loudness, duration, pause, tempo, and rhythm form the intonation system of Tamil language. Tamil graphemic system is generally syllabic in nature and there are a greater number of graphemes than the phonemes. There are instances of a single grapheme used to denote two or more sounds of a single phoneme. The phoneme/k/ has a grapheme <க> which represents [k] in the initial position of a word, as in கண் (eye), [x] in the medial position of a word, as in நகம் (nail) and [g] after homorganic voiced velar nasal [n] as in மாங்காய் (mango) [24]. Tamil language is embodied with such complex structure, semantics, and syntax [25]. Such complexity challenges the development of corpus based on letter-to-sound transcriptions, text to speech engine or other simplistic ways to populate the corpus. Therefore, an end-to-end recognition system is preferable in such a case of low-resourced complex languages. The proposed Tamil ASR is developed using open datasets, web resources to train language model and free computing resources; to demonstrate the cost-effective approach for under-resourced language in a financially constrained environment. We also propose an optimal, cost-effective method to develop a semi-supervised speech corpus using our trained ASR model.
, கட. Tamil language is considered as an intonation language with syllable-based rhythm. The speech features like pitch, loudness, duration, pause, tempo, and rhythm form the intonation system of Tamil language. Tamil graphemic system is generally syllabic in nature and there are a greater number of graphemes than the phonemes. There are instances of a single grapheme used to denote two or more sounds of a single phoneme. The phoneme/k/ has a grapheme <க> which represents [k] in the initial position of a word, as in கண் (eye), [x] in the medial position of a word, as in நகம் (nail) and [g] after homorganic voiced velar nasal [n] as in மாங்காய் (mango) [24]. Tamil language is embodied with such complex structure, semantics, and syntax [25]. Such complexity challenges the development of corpus based on letter-to-sound transcriptions, text to speech engine or other simplistic ways to populate the corpus. Therefore, an end-to-end recognition system is preferable in such a case of low-resourced complex languages. The proposed Tamil ASR is developed using open datasets, web resources to train language model and free computing resources; to demonstrate the cost-effective approach for under-resourced language in a financially constrained environment. We also propose an optimal, cost-effective method to develop a semi-supervised speech corpus using our trained ASR model.
3 Tamil ASR System Architecture
The general pipeline of modelling a speech recognition system is collecting audio utterances, transcribing audio files, mapping letter to sound to form phoneme dictionary, phonetic transcription, acoustic modelling or language modelling, extracting speech features [25] and a learning algorithm with loss minimization. However, the end-to-end speech recognition model does not require phonetic transcription or synchronized audio samples with letter-to-phonemes mapping. Instead, raw audio file is fed into the ASR system, which extracts some audio features, maps the segments of audio to characters, giving recognized characters with its probabilities. In the case of DeepSpeech, the Mel-Frequency Cepstral Coefficient (MFCC) features are extracted from the audio files and fed into a 6-layer deep neural network, obtaining probabilities of entire alphabets. The language model is then used to convert these probabilities into meaningful words and sentences. Connectionist Temporal Classification or CTC is used to minimize loss by ranking the correct transcriptions with higher probabilities. As in Fig. 2, the CTC removes any abnormalities and merges repeated letters, combining a sequence of letters into a valid word.
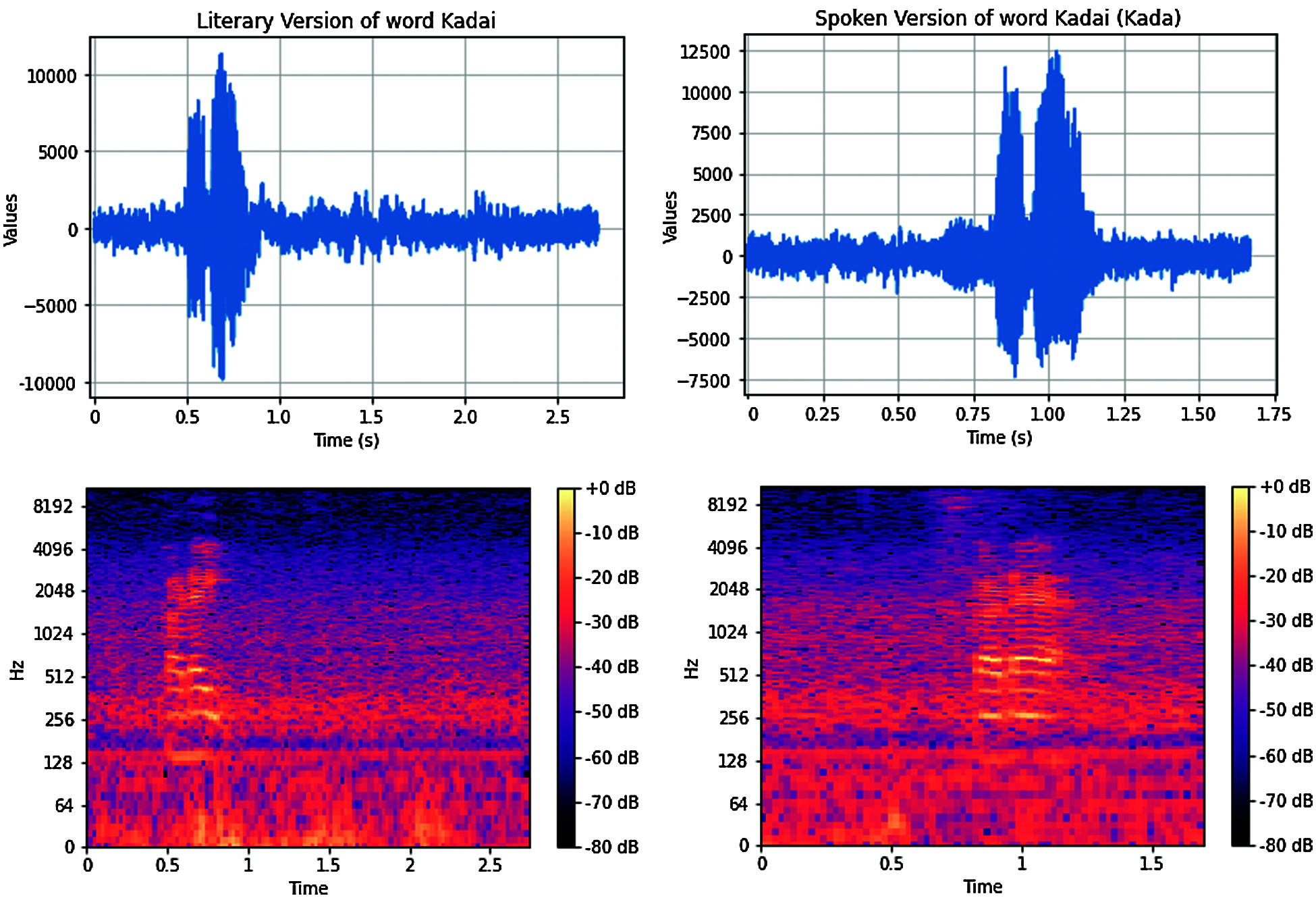
Figure 1: Audio waveforms and corresponding spectrogram of (a) literary and (b) spoken version of word கைட (Kadai)
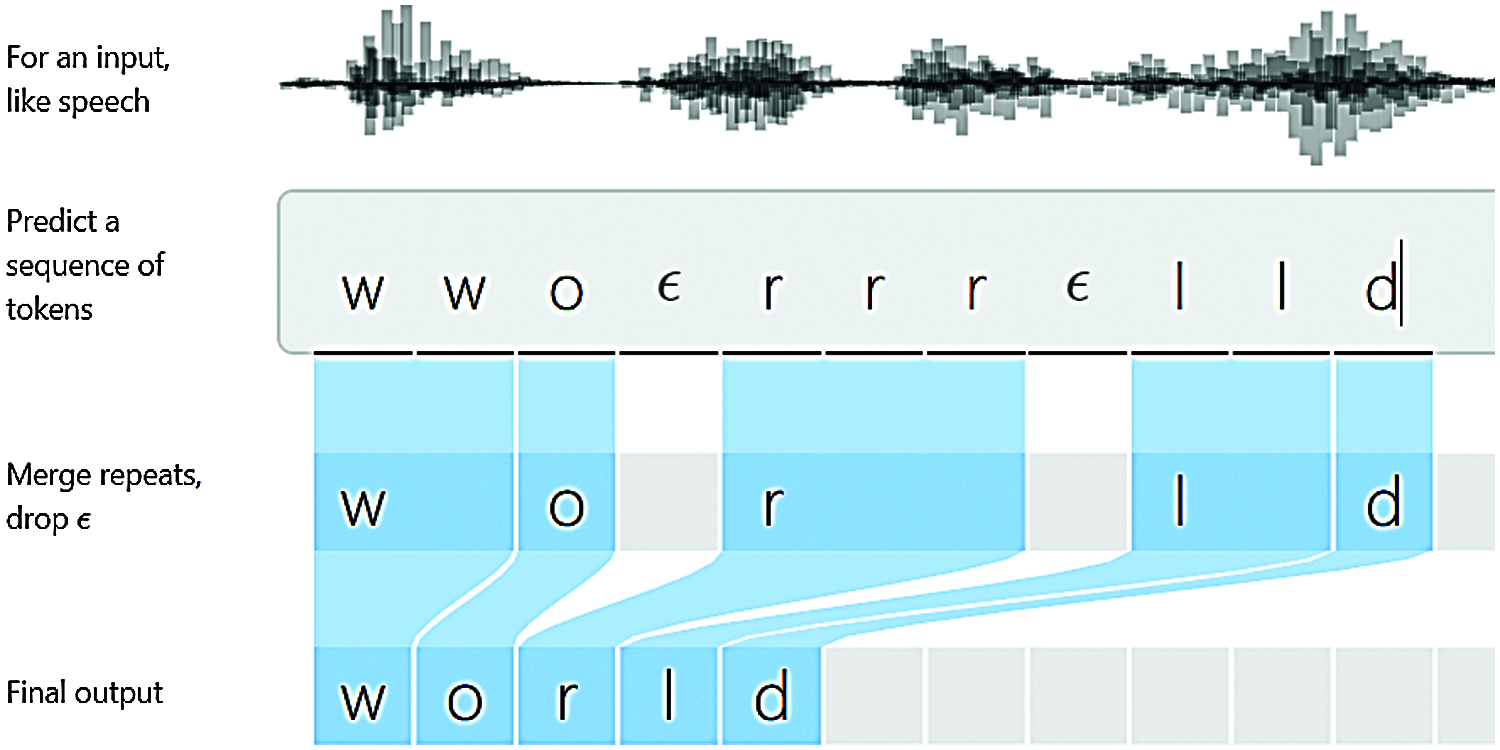
Figure 2: Working of connectionist temporal classification (CTC) [26]. CTC converts the predicted sequence of tokens to valid words with higher probability. In the predicted sequence ‘wwo rrr ll d’, the pause and the repeated tokens are dropped, giving the final output as ‘world’ with highest probability
Data collection and processing is the first major task in speech recognition. The speech corpus used for training comprises audio utterances and its corresponding transcriptions. Speech corpus can be of read, conversational or spontaneous speech. To build a read speech corpus, the following minimal steps are to be executed. 1) Prepare large text data (sentences) covering most of the vocabulary of the target language. 2) Record those sentences uttered by a variety of speakers (native, fluent, different age and gender) in different environments (noise, clean, outdoor/indoor). Conversational speech corpus can be built by recording the normal conversation of a speaker on any topic, and then transcribing each of them. Usually, these raw recordings are termed as uncleaned dataset, as post processing must be done to prepare a clean dataset. Post processing steps include preparing the transcriptions of audio utterances, cleaning audio samples (removing too noisy, repeated words, etc.) and synchronization of audio and text transcriptions. The whole process is time consuming and financially expensive (recording setup, incentives to speakers, hosting of data, etc.). The researchers with resource and financial constraints must depend only on publicly available corpus or some innovative crowdsourcing [27].
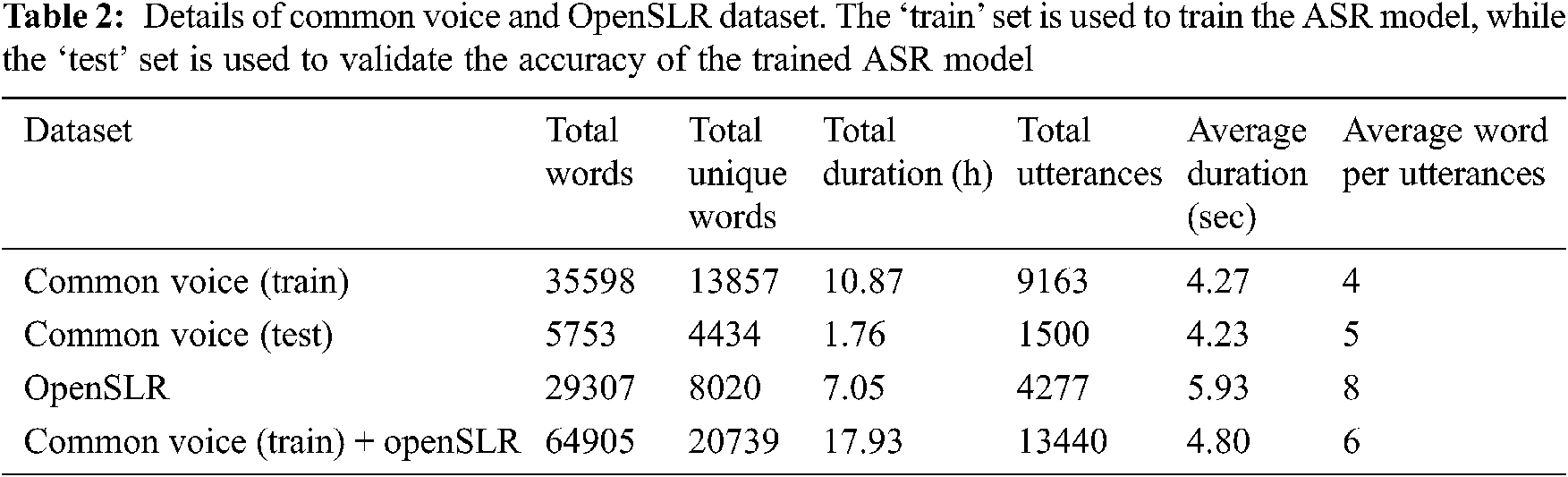
However, a good open-source initiative to create free speech corpus by Mozilla [28], the Common Voice Corpus 6.1, has recorded speech data of 7300 h covering 60 languages. Common Voice Corpus 6.1 has over 2000 h of recorded speech for English language, while it has only 24 h for Tamil language out of which only 14 h is validated. A generic large vocabulary Tamil speech corpus is yet to be developed and made available to the public. In our paper, we utilize Common Voice and OpenSLR [29] speech corpus for training Tamil ASR. The summary of both the corpora, total words, unique words, total duration, total utterances, average duration of each utterance and average word per utterance is listed in Tab. 2.
The DeepSpeech (v0.7.4) is a modified version of the original TensorFlow implementation of Baidu’s End-to-End ASR system [24]. The original version used a bi-directional Recurrent Neural Network (RNN), making it difficult for real-time ASR. In bi-directional RNN, an entire input is fed to get the entire output. However, in the recent v0.7.4, bi-directional layer is replaced with unidirectional layer. This enables the model to process the segments of input data to get partial output, and then pass the same as the initial state for the next segment of input data. The core of the DeepSpeech architecture is a Recurrent Neural Network which is trained on the MFCC extracted from the audio data.
The model consists of six layers. The MFCC is extracted from the raw audio and fed into the input layer which is connected to three fully connected dense layers. Further, it is connected to an unidirectional RNN layer, then to a fully connected dense layer, and finally to an output layer giving estimated probabilities of all the alphabets. Clipped Rectified-Linear unit (ReLu) is used as the activation function. Once the predicted character probabilities for each time segment and characters in the alphabet set are computed, the CTC loss is used to measure the error in prediction. The ASR architecture used in our experiments is illustrated in Fig. 3.
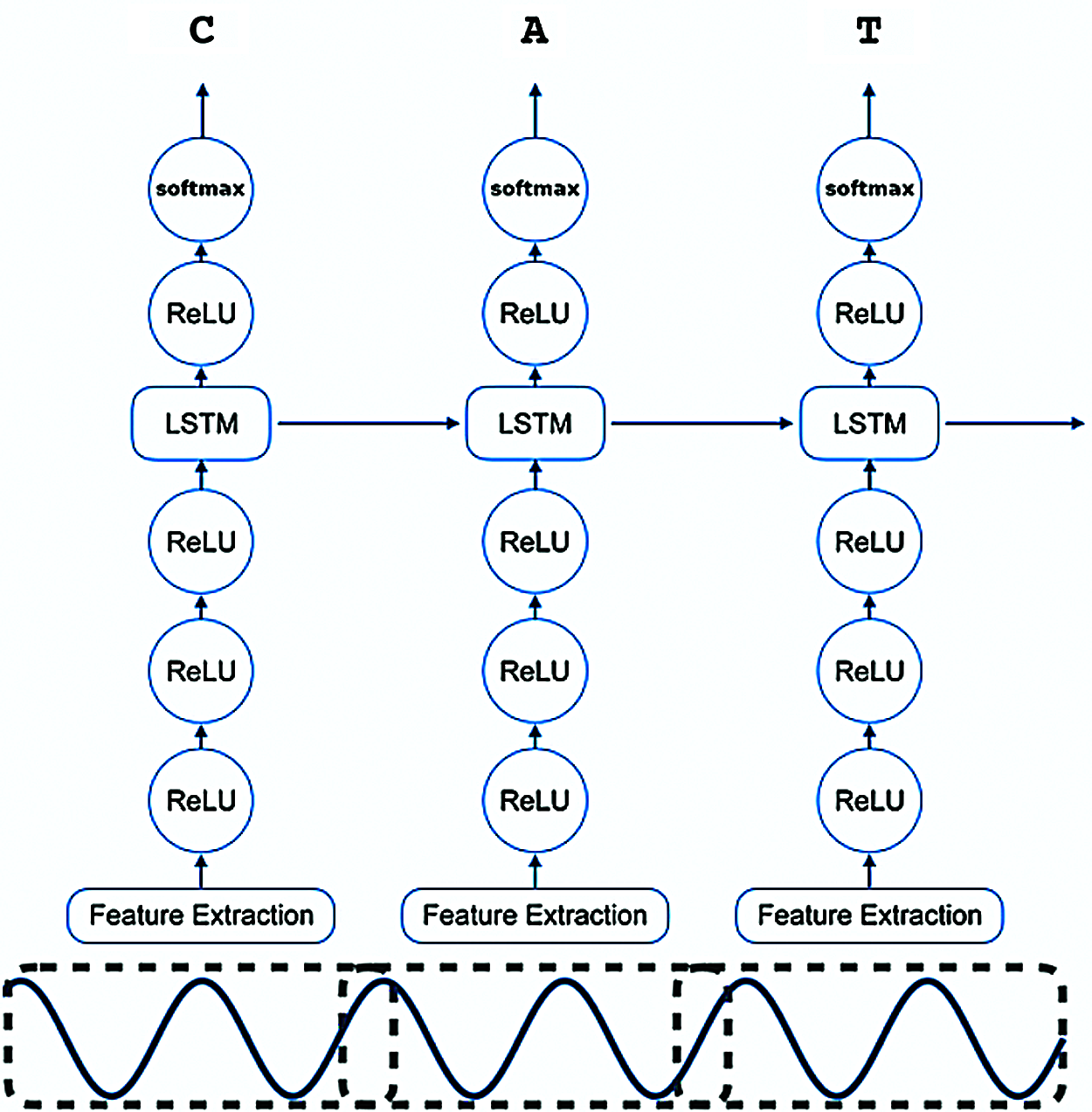
Figure 3: Six-layer DeepSpeech ASR architecture [30]

Figure 4: Training loss of train and dev set for two different datasets (a) commonVoice (train) and (b) commonVoice (train) + OpenSLR. The former dataset is small compared to the latter dataset; hence the convergence takes more steps for larger dataset

Figure 5: Confusion matrix of different speaker for isolated digit recognition
DeepSpeech outputs an acoustic model, mapping acoustic features to probabilities of alphabets. These probabilities are converted into a sequence of meaningful words using the language model. The language model is trained over a large text corpus of Tamil language, which then assigns probabilities to valid Tamil words and phrases. Once a language model is learnt from the training data, the trained language model assigns higher probability to the valid sentence, than the invalid sentences. Consider an example of sentence with homophone, நான் ெவல்லம் சாப்பிட்ேடன் (I ate jaggery) and நான் ெவள்ளம் சாப்பிட்ேடன் (I ate flood). The model will assign higher probability to the former (valid) sentence than the latter (invalid) one, because the word ‘ate’ is most likely to be followed by the word ெவல்லம் (jaggery) than the word ெவள்ளம் (flood) in the training text corpus, even though both the words are phonetically similar.
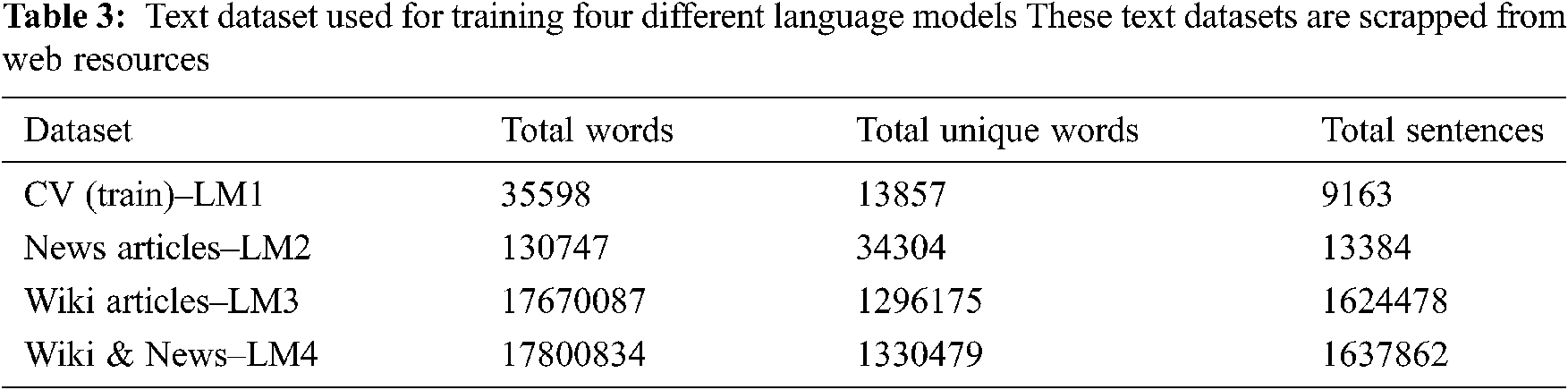
A 3-gram language model is trained using kenLM [31], and the training data is a corpus of text data listed in Tab. 3. Four language models are trained using different text data of minimal vocabulary to large vocabulary; to test the speech recognition accuracy using different language models. Language model (LM2) is trained over text data of approximately 6500 news articles [32] and language model (LM3) is trained over 127k Tamil wikipedia articles. The larger language model (LM4) is trained over both news and wikipedia articles. The KenLM scorer built using text data and the account model trained using speech data work together to provide better overall accuracy.
DeepSpeech (v0.7.4) is used in the experimentation, both for training and testing. The whole experiment is intended to utilize minimal financial resources, hence publicly available free dataset is used as training corpus. CommonVoice Tamil dataset comprising both training set and test set are used for the experimentation. Google Colaboratory (GC) is used as computational resource for training our model. DeepSpeech architecture needs Graphics Processing Unit (GPU) resources to run the training in minimal time, hence GPU is selected as the hardware accelerator in GC. Even though GC has usage time limits while using GPU, checkpoints are saved at regular intervals, which are continued after the time limit is revoked. The specification of GPU in GC is Tesla K80 with 2496 CUDA cores, 12GB VRAM. Typical runtime for training a model takes almost 8 h.
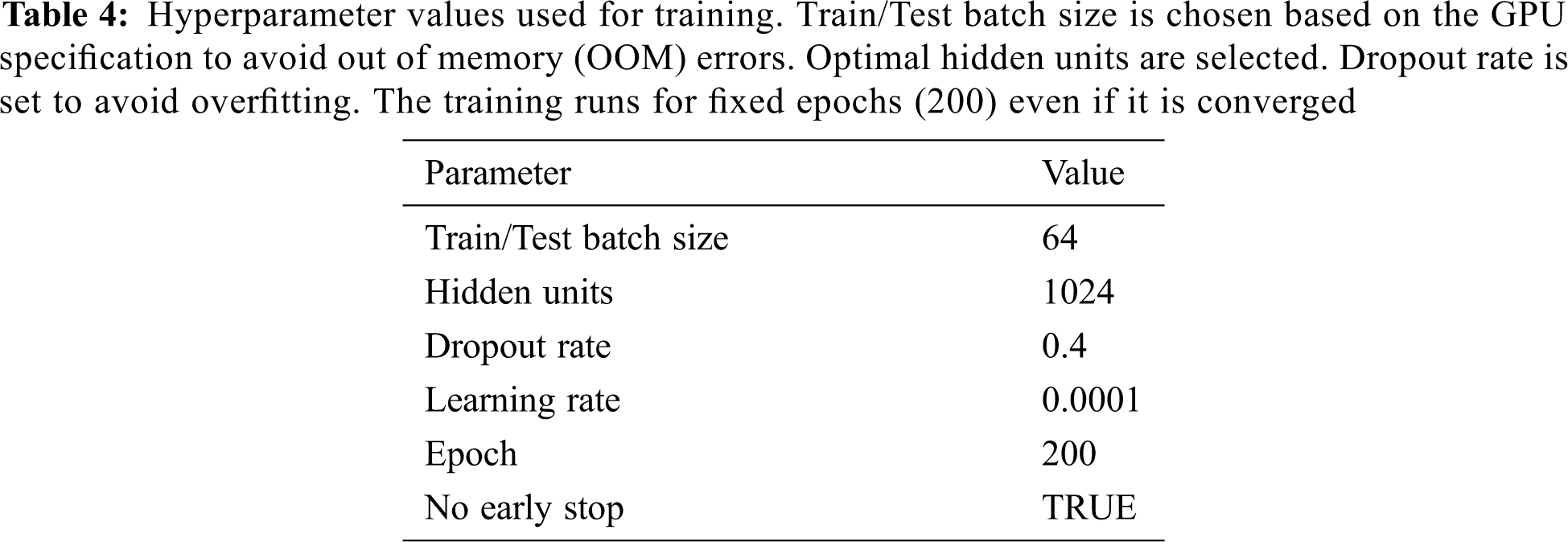
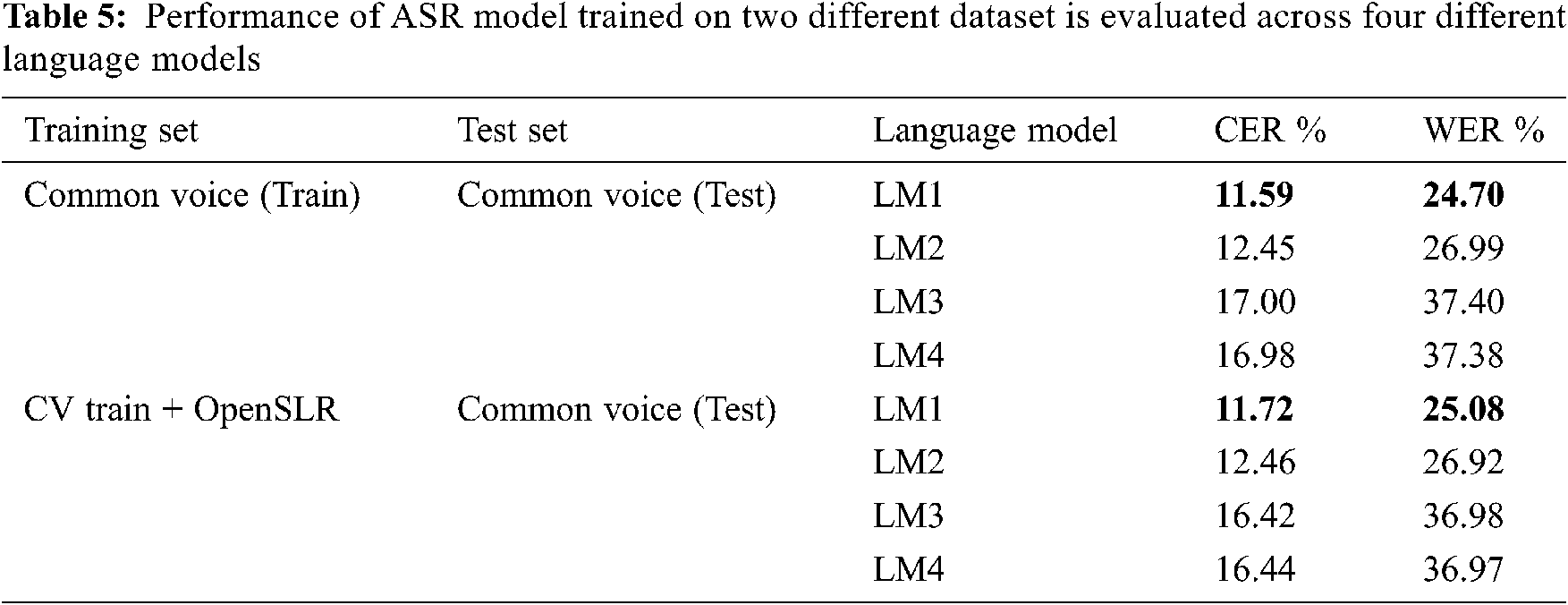
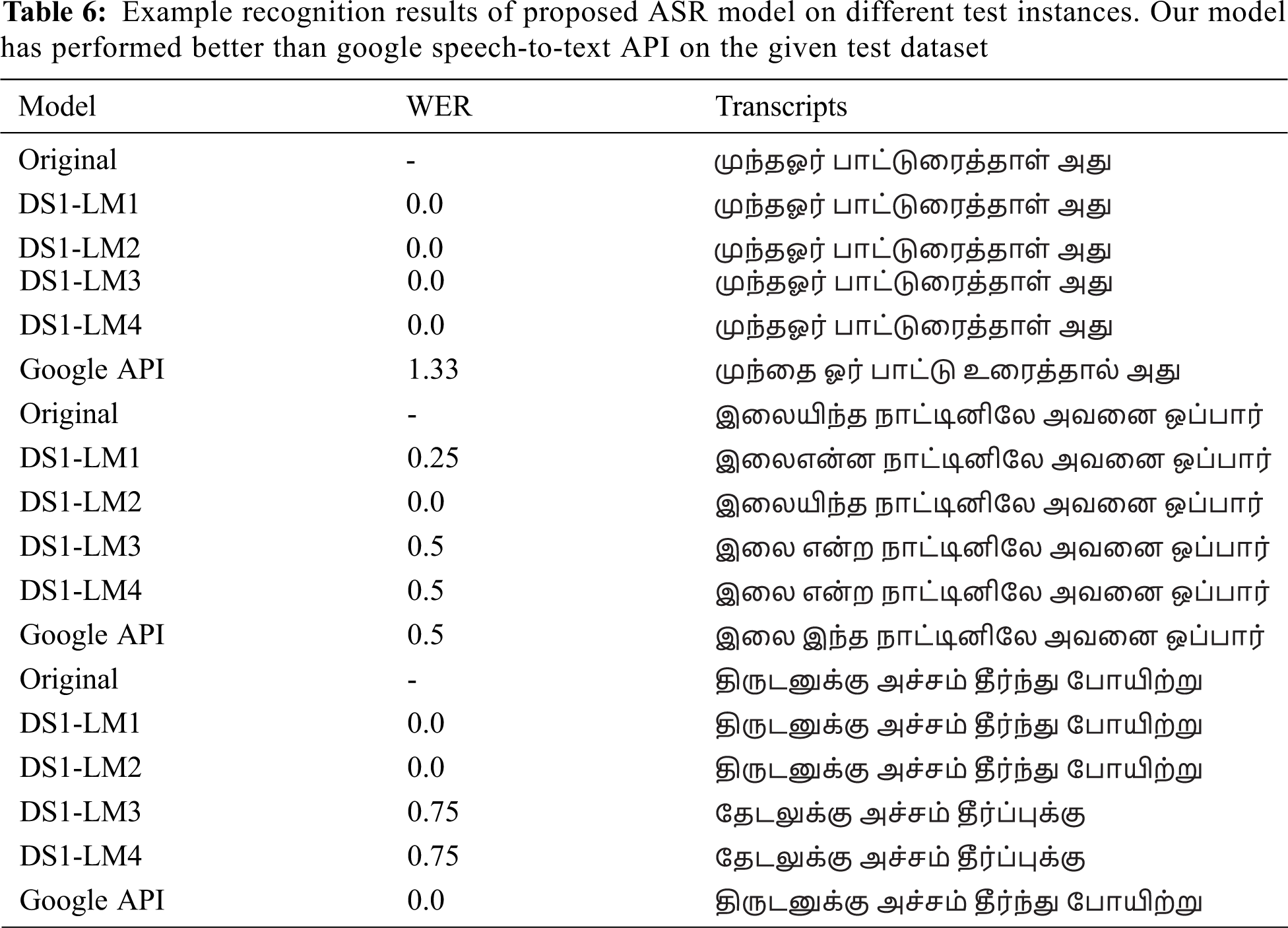
In DeepSpeech, hyperparameters that are to be chosen and configured during training the model are listed in Tab. 4. The optimal train and test batch size are chosen based on the memory allocation of the GPU, to avoid out-of-memory issues. To utilize deep neural network, 1024 hidden units are configured. Overfitting is avoided by setting the dropout rate at 0.4. Training is performed over two datasets; Common Voice (train) [DS1] and OpenSLR merged with Common Voice (train) [DS2]. A single test set, Common Voice (test), is used for validation of trained models. Character Error Rate (CER) and Word Error Rate (WER) are used as a measure to obtain the efficiency of the trained model. The testing of both the trained models is done using all the four language models, and their results are stated in Tab. 5. To compare the accuracy of proposed models, the test set is also validated using Google’s speech-to-text. The Google Speech API processed the whole Common Voice (Test) audio files, with an average WER of 55%, while our proposed model performed better with a best WER of 24.7%. Sample test instances with predicted transcriptions by our proposed model and Google speech-to-text are listed in Tab. 6.

The training of the ASR model is performed by splitting the Common Voice (Train) dataset into 80% as train set and 20% as dev set. The model’s parameters are tuned to minimize the negative log-likelihood
4.2 Transfer Learning for Isolated Tamil Digit Recognition
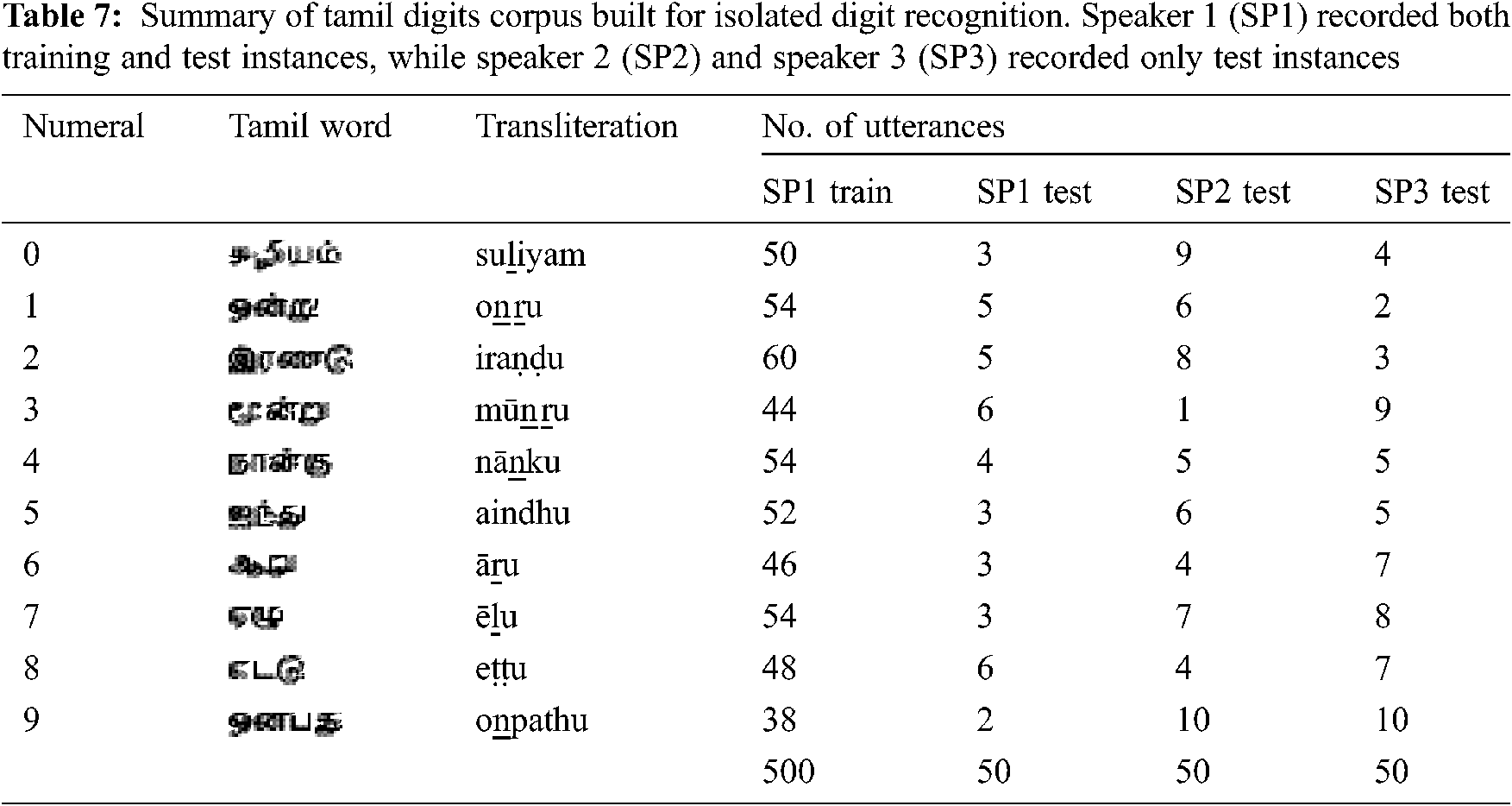
SpeechStew [33] is an English speech recognition model trained on a massive dataset; combination of seven publicly available datasets totaling to approx. 5140 h. Transfer learning of SpeechStew on CHiME-6, a low resource noisy dataset, produced an improved WER of 38.9 from the official CHiME-6 HMM baseline result of 51.3 WER on dev sets. Such transfer learning on a low resource dataset of 40 H noisy microphone conversational speech recognition is possible only when a massive or numerous publicly available dataset is present. However, for Tamil Language, neither massive dataset nor many public datasets are available, hindering the ASR research. Hence, we have built a pre-trained model using open-source toolkits & open-source dataset and investigated transfer learning approach for limited vocabulary speech recognition. Tamil digits from 0 to 9 are uttered by a single speaker and recorded as a training set (Tab. 7). The digits are displayed randomly one after the other for recording, to avoid sequential utterance of digits. Test set of 50 utterances of digits is recorded by the same speaker and two other speakers. Speakers 1 and 3 are fluent in Tamil language, whereas speaker 2 is non-native. Transfer learning applies a pre-trained model to continue training on a different dataset for a specific use case. CV-LM1 Tamil ASR trained model is used for transfer learning on small digits dataset for isolated Tamil digits recognition. In the pre-trained model, only the last layer is dropped, retaining all the other layers and their weights for transfer learning. The results in Tab. 8 show that the WER obtained in digit recognition is better, while noting that limited dataset is used. Also, the transfer-learned model gives better WER for speaker-independent recognition. The confusion matrix for each speaker is shown in Fig. 5.
4.3 Semi-Supervised Development of Speech Corpus
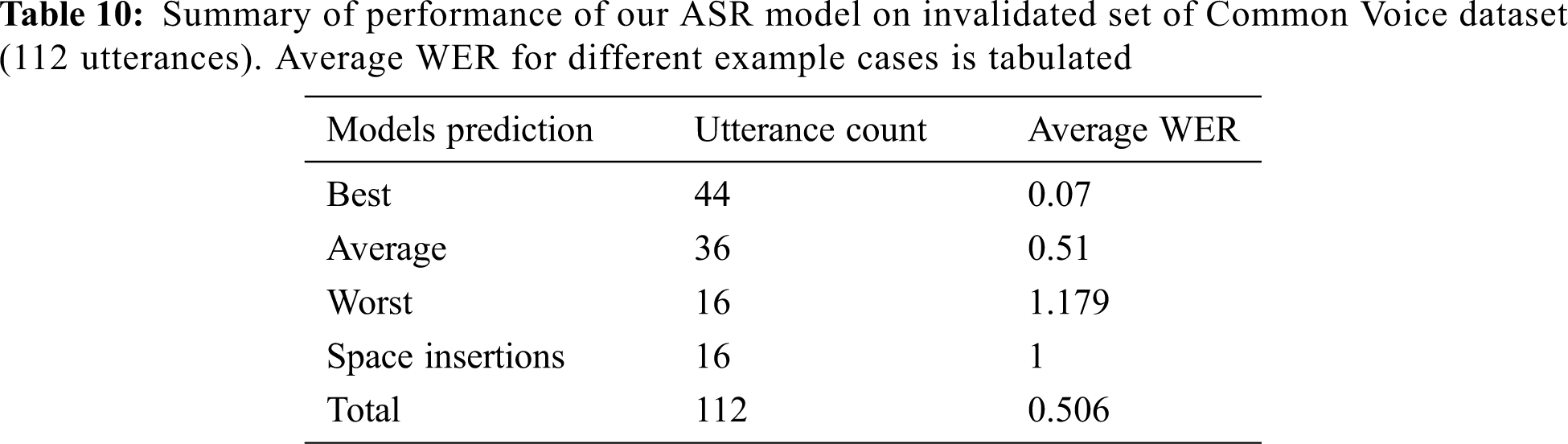
Large vocabulary corpus is essential to develop a generic speech recognition system. Building such a corpus is time consuming and financially costly. We propose that our pre-trained ASR model could be utilized to create unclean transcription of publicly available audio data of Tamil language. Further manual validation of such transcription could be executed in minimal time, instead of transcribing the audio data from scratch. To demonstrate this, we feed the invalidated Common Voice Tamil dataset to our trained Tamil ASR model and obtain unclean transcriptions. These transcriptions were manually corrected and validated. However, the time taken to validate the unclean transcriptions is 75% lesser than transcribing the audio data from scratch. The results are explained in Tabs. 9 and 10.

In this paper, we investigated the end-to-end speech recognition system for the low resource language, Tamil and presented the first results of developing a Tamil model using DeepSpeech. Different challenges of low-resourced and semantically complex languages are discussed. We discussed the challenges of developing a corpus for under-resourced languages and presented a novel approach to utilize open source toolkits and datasets. Actively taking part in Mozilla’s Common Voice project could lead to development of large corpus with minimal incentivization to volunteers. Our Tamil ASR trained model gave the best result of 24.7% WER, compared to 55% WER by Google speech-to-text. However, our model was evaluated with a limited vocabulary language model. The accuracy of our ASR model depends on the trained language model. This could be improved by building a larger vocabulary language model, assisted by language experts. The proposed model is trained using 14 h of speech corpus, hence the trained ASR model is only suitable for limited vocabulary speech recognition. However, the proposed ASR model could be helpful for the transfer learning approach, which has been demonstrated with simple isolated Tamil digits recognition. Similar approaches could be taken with our trained model for keyword-spotting, isolated word recognition, etc. Use of larger speech corpus (approx. 100 h) to train ASR model will assist in development of generic ASR model. Semi-supervised development of speech corpus using our pre-trained ASR model has demonstrated that large vocabulary corpus could be built with minimal manual assistance. This could further be used to transcribe publicly available audio data and build a large vocabulary corpus. Speech corpus comprising regional dialects needs to be addressed, which could help in the development of a dialect-independent Tamil ASR. The proposed approach can be easily replicated for any other datasets, by utilizing our publicly available Google Colab notebook.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. P. K. O’Neill, V. Lavrukhin, S. Majumdar, V. Noroozi, Y. Zhang et al., “SPGISpeech: 5,000 h of transcribed financial audio for fully formattedend-to-end speech recognition,” submitted to INTERSPEECH, 2021. [Google Scholar]
2. V. Panayotov, G. Chen, D. Povey and S. Khudanpur. “Librispeech: An ASR corpus based on public domain audio books,” in IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSPQueensland, Australia, pp. 5206–5210, 2015. [Google Scholar]
3. D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Battenberg et al., “Deep speech 2: End-to-end speech recognition in English and mandarin,” in Int. Conf. on Machine Learning, NY, USA, vol. 48, pp. 173–182, 2016. [Google Scholar]
4. Y. Zhang, J. Qin, D. S. Park, W. Han, C. C. Chiu et al., “Pushing the limits of semi-supervised learning for automatic speech recognition,” arXiv preprint arXiv: 2010.10504, 2020. [Online]. Available: http://arxiv.org/abs/2010.10504. [Google Scholar]
5. J. Billa, “ISI ASR system for the Low resource speech recognition challenge for Indian languages,” INTERSPEECH, Hyderabad, India, pp. 3207–3211, 2018. [Google Scholar]
6. C. Liu, Q. Zhang, X. Zhang, K. Singh, Y. Saraf et al., “Multilingual graphemic hybrid ASR with massive data augmentation,” in Proc. of the 1st Joint Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU) and Collaboration and Computing for Under-Resourced Languages (CCURLMarseille, France, pp. 46–52, 2020. [Google Scholar]
7. D. Bahdanau, J. Chorowski, D. Serdyuk, P. Brakel and Y. Bengio, “End-to-end attention-based large vocabulary speech recognition,” in IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSPShanghai, China, pp. 4945–4949, 2016. [Google Scholar]
8. Mustaqeem and S. Kwon, “Att-net: Enhanced emotion recognition system using lightweight self-attention module,” Applied Soft Computing, vol. 102, pp. 107101, 2021. [Google Scholar]
9. X. Shi, Z. Chen, H. Wang, D. Yeung, W. Wong et al., “Convolutional LSTM network: A machine learning approach for precipitation nowcasting,” Advances in Neural Information Processing Systems, vol. 28, pp. 802–810, 2015. [Google Scholar]
10. Mustaqeem and S. Kwon, “CLSTM: Deep feature-based speech emotion recognition using the hierarchical ConvLSTM network,” Mathematics, vol. 8, no. 12, pp. 2133, 2020. [Google Scholar]
11. Mustaqeem and S. Kwon, “1D-Cnn: Speech emotion recognition system using a stacked network with dilated cnn features,” Computers, Materials & Continua, vol. 67, no. 3, pp. 4039–4059, 2021. [Google Scholar]
12. Mustaqeem and S. Kwon, “A CNN-assisted enhanced audio signal processing for speech emotion recognition,” Sensors, vol. 20, no. 1, pp. 183, 2020. [Google Scholar]
13. Y. Karunanayake, U. Thayasivam and S. Ranathunga, “Sinhala and tamil speech intent identification from English phoneme based ASR,” in Int. Conf. on Asian Language Processing (IALPShanghai, China, pp. 234–239, 2019. [Google Scholar]
14. H. Inaguma, J. Cho, M. K. Baskar, T. Kawahara and S. Watanabe, “Transfer learning of language-independent end-to-end ASR with language model fusion,” in Int. Conf. on Acoustics, Speech and Signal Processing (ICASSPBrighton, UK, pp. 6096–6100, 2019. [Google Scholar]
15. Y. Chen, J. Y. Hsu, C. K. Lee and H. Y. Lee, “DARTS-Asr: Differentiable architecture search for multilingual speech recognition and adaptation,” INTERSPEECH, Shanghai, China, pp. 1803–1807, 2020. [Google Scholar]
16. S. Lokesh, P. M. Kumar, M. R. Devi, P. Parthasarathy and C. Gokulnath, “An automatic tamil speech recognition system by using bidirectional recurrent neural network with self-organizing map,” Neural Computing and Applications, vol. 31, no. 5, pp. 1521–1531, 2019. [Google Scholar]
17. A. Madhavaraj and A. G. Ramakrishnan, “Design and development of a large vocabulary, continuous speech recognition system for tamil,” in IEEE India Council Int. Conf. (INDICON), Uttarakhand, India, pp. 1–5, 2017. [Google Scholar]
18. A. Madhavaraj, H. R. S. Kumar and A. G. Rarnakrishnan, “Online speech translation system for tamil,” INTERSPEECH, Hyderabad, India, pp. 1966–1967, 2018. [Google Scholar]
19. B. Pulugundla, M. K. Baskar, S. Kesiraju, E. Egorova, M. Karafiát et al., “BUT system for Low resource Indian language ASR,” INTERSPEECH, Hyderabad, India, pp. 3182–3186, 2018. [Google Scholar]
20. N. Fathima, T. Patel, C. Mahima and A. Iyengar. “TDNN-Based multilingual speech recognition system for Low resource Indian languages,” INTERSPEECH, Hyderabad, India, pp. 3197–3201, 2018. [Google Scholar]
21. B. M. L. Srivastava, S. Sitaram, R. K. Mehta, K. D. Mohan, P. Matani et al., “Interspeech 2018 Low resource automatic speech recognition challenge for Indian languages,” in 6th Int. Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU-2018Gurugram, India, pp. 11–14, 2018. [Google Scholar]
22. L. Besacier, E. Barnard, A. Karpov and T. Schultz. “Automatic speech recognition for under-resourced languages: A survey,” Speech Communication, vol. 56, pp. 85–100, 2014. [Google Scholar]
23. C. Wang, A. Wu and J. Pino, “Covost 2: A massively multilingual speech-to-text translation corpus,” arXiv preprint 2007.10310, 2020. [Google Scholar]
24. “Tamil language variations,” Central Institute of Indian Languages, 2021. [Online]. Available: http://lisindia.ciil.org/Tamil/Tamil_vari.html. [Google Scholar]
25. S. A. Mahar, M. H. Mahar, J. A. Mahar, M. Masud, M. Ahmad et al., “Superposition of functional contours based prosodic feature extraction,” Intelligent Automation and Soft Computing, vol. 29, no. 1, pp. 183–197, 2021. [Google Scholar]
26. A. Hannun, “Sequence modelling with CTC,” in Distill, Distill Working Group, San Francisco CA, USA, 2017. [Google Scholar]
27. A. A. Raza, A. Athar, S. Randhawa, Z. Tariq, M. B. Saleem et al., “Rapid collection of spontaneous speech corpora using telephonic community forums,” INTERSPEECH, Hyderabad, India, pp. 1021–1025, 2018. [Google Scholar]
28. R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler et al., “Common voice: A massively-multilingual speech corpus,” arXiv preprint arXiv: 1912.06670, 2019. [Google Scholar]
29. F. He, S. H. C. Chu, O. Kjartansson, C. Rivera, A. Katanova et al., “Open-source multi-speaker speech corpora for building gujarati, kannada, malayalam, marathi, tamil and telugu speech synthesis systems,” in The 12th Language Resources and Evaluation Conf., Palais du Pharo, Marseille, pp. 6494–6503, 2020. [Google Scholar]
30. A. Hannun, C. Case, J. Casper, B. Catanzaro, G. Diamos et al., “Deep speech: Scaling up end-to-end speech recognition,” arXiv preprint arXiv: 1412.5567, 2014. [Google Scholar]
31. K. Heafield, “KenLM: Faster and smaller language model queries,” in Proc. of the Sixth Workshop on Statistical Machine Translation, Edinburgh, UK, pp. 187–197, 2011. [Google Scholar]
32. G. Arora, “iNLTK: Natural language toolkit for indic languages,” in Proc. of Second Workshop for NLP Open Source Software (NLPOSSpp. 66–71, 2020. [Google Scholar]
33. W. Chan, D. Park, C. Lee, Y. Zhang, Q. Le et al., “Speechstew: Simply mix all available speech recognition data to train one large neural network,” Workshop on Machine Learning in Speech and Language Processing (Online), Brno, Czechia, 2021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |