DOI:10.32604/iasc.2022.023510
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2022.023510 | |
| Article |
On NSGA-II and NSGA-III in Portfolio Management
1Department of Mathematics, Faculty of Science, Mansoura University, Mansoura, 35516, Egypt
2Department of Computational Mathematics, Science, and Engineering (CMSE), Michigan State University, East Lansing, 48824, USA
*Corresponding Author: Mohamed Abouhawwash. Email: abouhaww@msu.edu
Received: 11 September 2021; Accepted: 27 October 2021
Abstract: To solve single and multi-objective optimization problems, evolutionary algorithms have been created. We use the non-dominated sorting genetic algorithm (NSGA-II) to find the Pareto front in a two-objective portfolio query, and its extended variant NSGA-III to find the Pareto front in a three-objective portfolio problem, in this article. Furthermore, in both portfolio problems, we quantify the Karush-Kuhn-Tucker Proximity Measure (KKTPM) for each generation to determine how far we are from the effective front and to provide knowledge about the Pareto optimal solution. In the portfolio problem, looking for the optimal set of stock or assets that maximizes the mean return and minimizes the risk factor. In our numerical results, we used the NSGA-II for the portfolio problem with two objective functions and find the Pareto front. After that, we use Karush-Kuhn-Tucker Proximity Measure and find that the minimum KKT error metric goes to zero with the first few generations, which means at least one solution converges to the efficient front within a few generations. The other portfolio problem consists of three objective functions used NSGA-III to find the Pareto front and we use Karush-Kuhn-Tucker Proximity Measure and find that The minimum KKT error metric goes to zero with the first few generations, which means at least one solution converges to the efficient front within a few generations. Also, the maximum KKTPM metric values don’t show any convergence until the last generation. Finally, NSGA-II is effective only for two objective functions, and NSGA-III is effective only for three objective functions.
Keywords: Genetic algorithm; NSGA-II; NSGA-III; Portfolio problem
Genetic algorithms (GA) have been widely employed as optimization and search methods in a variety of problem domains [1,2], including industry [3], architecture [4], and research, over the past ten years [5,6]. Their strong applicability, global outlook, and ease of usage are the key explanations for their high success rate.
Genetic algorithms are the most common algorithms for solving many real-life applications. These algorithms are inspired by natural selection. Genetic algorithms are population search algorithms, which introduced the idea of survival of the best fitness function. Most of these algorithms incorporate the genetic operation to obtain the new chromosome (solution). The basic genetic operations are selection, crossover, and mutation [7].
In the past, the portfolio optimization problem was designed to find the configuration of assets that generated the maximum expected return which was the main criterion. However, this design changed in 1952, a new variable with the expected return was introduced by Harry Markowitz that called the risk of each portfolio. Thereafter, analysts began to incorporate a risk-return trade-off in their models [8]. Harry Markowitz doesn’t consider the real-world challenges as cardinality constraints, lower and upper bounds, substantial stock size, class constraint, round-lots constraint, computational power and time, pre-assignment constraint, and local-minima avoidance.
In this article, we solve the portfolio problem [9] using two genetic algorithms, NSGA-II and NSGA-III. The competing parameters in the portfolio dilemma are optimizing anticipated return and mitigating risk, also known as the Markowitz, mean-variance model [10].
This study aims to find the Pareto front for portfolio problems with two and three objective functions using the methods NSGA-II and NSGA-III which are simpler and easy to apply. Those methods can address portfolio optimization problems without simplification and with decent results in a fair amount of time, and it has a lot of practical applications. we obtained solutions for the portfolio models using NSGA-II and NSGA-III same as theoretical solutions.
The main contributions of this paper are as follows:
• A genetic algorithm can be used to find the Pareto front for portfolio optimization problems which are the same as those found in other approaches.
• A genetic algorithm can handle the portfolio optimization problems without simplification and with decent results in a fair amount of time.
• The two cases studied were presented to prove the applicability of the genetic algorithm.
• The framework of NSGA-II and NSGA-III are elaborated in algorithms 1 and algorithm 2.
In the following part of the article, we first give a literature review of NSGA-II, NSGA-III, and portfolio optimization problems in the second section. After that, we explain the concept of the NSGA-II method. The NSGA-III is discussed in the fourth section. The Karush-Kuhn-Tucker proximity measure (KKTPM) is analyzed in section five for multi-objective optimization problems [11,12]. In section six, evolutionary algorithms are used to solve a portfolio dilemma. Finally, in section seven, we bring the article to a close.
There are many studies in NSGA-II. Deb et al. [13] have proposed NSGA-II which improves the iterative convergence rate while ensures population diversity by employing the fast non-dominated sorting approach. Kodali et al. [14] used NSGA-II to solve a problem that involves two objectives, four constraints, and ten decision variables of the grinding machining operation. Wang et al. [15] have used improved NSGA-II to solve multi-objective optimization of turbomachinery.
There are some studies in NSGA-III. Deb and Jian [16] have proposed the first algorithm of NSGA-III to solve multi-objective optimization problems. Mkaouer et al. [17] are used NSGA-III to solve many-objective software remodularization. Zhu et al. [18] were studied an improved NSGA-III algorithm for feature selection used in intrusion detection. Yi et al. [19] were studied the behavior of crossover operators in NSGA-III for large-scale optimization problems.
Markowitz [20] was proposed the portfolio problem, that it is looking for the expected mean-return is maximized (profit), and the risk is minimized. The factor in measuring risk is the variance of the portfolio return; the smaller the variance lower will be the risk. Michaud [21] has found that mean-variance theory has some limitations because asset volatility is required for constructing the model, and determining an asset’s future volatility is challenging in practice. Momentum investment is a well-known quantitative investment strategy. Hong and Stein [22] show that this strategy, the momentum effect is used to reveal the price stickiness of stocks over a certain period; this information is then used to predict price trends and make investment decisions.
3 NSGA-II or Elitist Non-Dominated Sorting GA
The NSGA-II protocols [23] is the most used EMO procedure for finding multiple Pareto-optimal solutions in a multi-objective optimization problem, and it has the following features:
It employs three principles: 1. an apparent diversity-preserving mechanism; 2. an elitist principle; and 3. non-dominated alternatives are stressed.
Consider a community of size
Now we demonstrate a crowded tournament collection operator. The crowded comparison operator
Definition: If all of the above assumptions are true, the crowded tournament selection operator [24] compares two solutions (solution
Crowding gap; To find the estimation density of solutions around a given solution
The lowest and highest objective function values are denoted by

4 An Evolutionary Many-objective Optimization Algorithm Using Reference Point Based Non-Dominated Sorting Approach (NSGA-III)
NSGA-III begins [26] with a random population of
The following procedures are carried out at descent

5 Karush-Kuhn-Tucker Proximity Measure (KKTPM) for Multi-Objective Optimization
For a
the Karush-Kuhn-Tucker optimality [29] conditions for Eq. (2) are given as follows:
The
The authentic analysis generated an output scalarization feature (ASF) for a given repeated (solution)
The reference point
Thereafter, the KKTPM calculation process advanced for single-objective optimization problems to the ASF showed previously. So that the ASF formulation produce the objective function not differentiable, a smooth transformation of the ASF (a performance scalarization function) problem was made firstly by inserting slack variables
At this moment, the KKTPM optimization problem for the previous single-objective problem for
The added term in the objective function permits a penalty correlated with the violation of the complementary slackness condition. The restrictions
The optimal objective value
Exact KKTPM
In this section, we will solve a portfolio problem in special cases using NSGA-II in the first model and NSGA-III in the second model. After that, we will show figures for each model. But, one must know the main portfolio problem. The portfolio is a set of assets or securities (
To illustrate the mechanism of the evolutionary algorithms and KKT proximity measure using an evolutionary multi-objective (EMO) algorithm, we thought of three and two-objective Portfolio problems. NSGA-II is used to solve two objective problems, while NSGA-III is used to solve three objective problems. We use the SBX recombination operator [31,32] with
6.1 Model-I for Portfolio Problem
Consider the three-security problems with expected returns vector and covariance matrix [35] given by:
Let
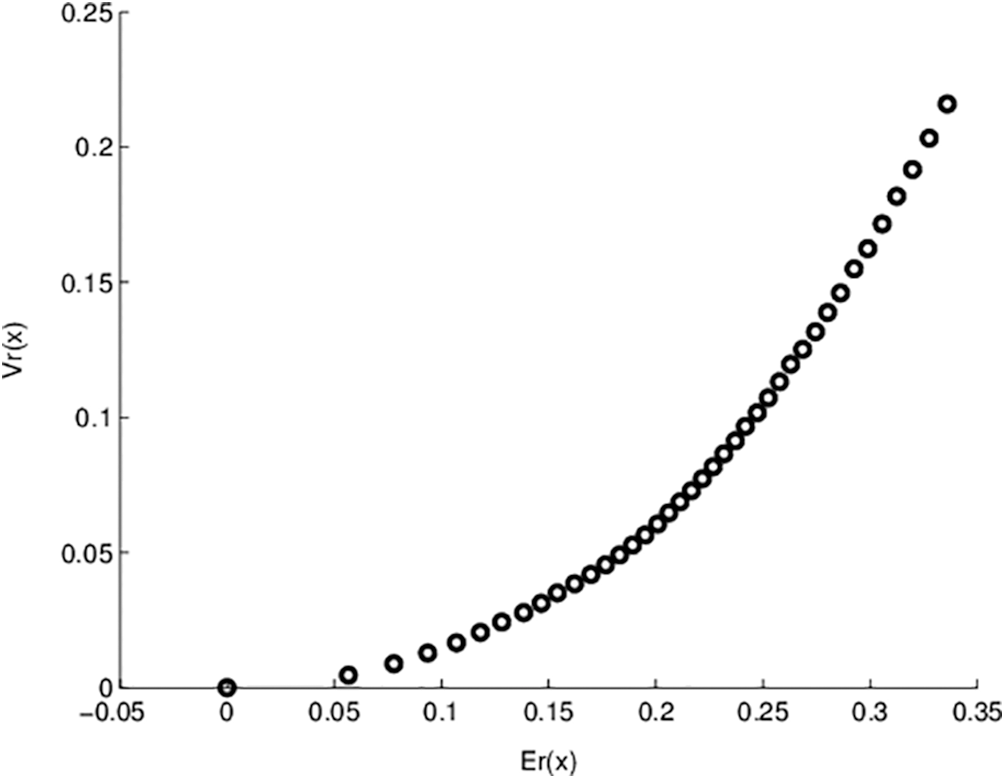
Figure 1: Pareto optimal points for model- I objective functions
Fig. 1 shows the non-dominated points for model-I. In this figure, NSGA-II runs 200 generations with 100 population sizes. The obtained solutions exactly equal the previously exact obtained solutions. One advantage of applying genetic algorithms is that we obtain many solutions in a single run. Also, Fig. 2 represents the relation between generation number and KKT proximity measure. As shown from the figures, the KKT metric reduces with increasing the number of generations.
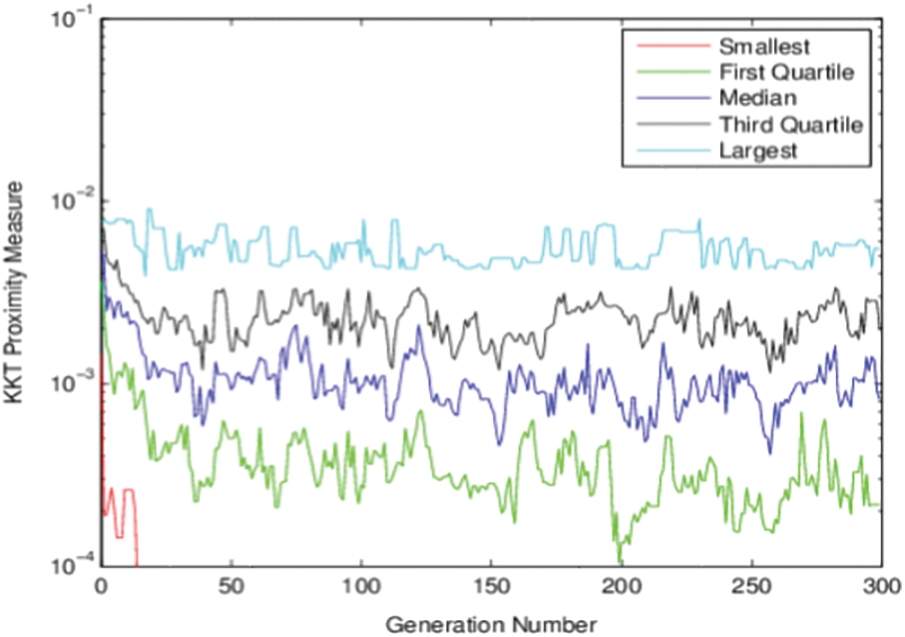
Figure 2: KKT Proximity measure vs. generation number for Model-I using NSGA-II
6.2 Model-Il for Portfolio Problem [31]:
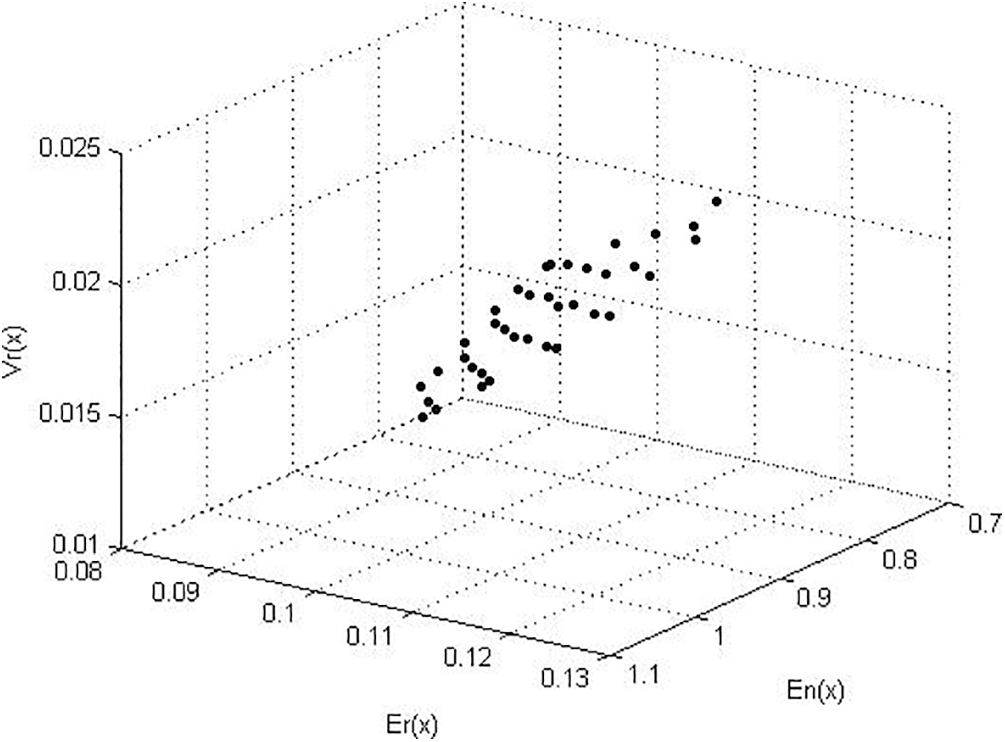
Figure 3: Pareto optimal points for model- II objective functions
Fig. 3 shows the non-dominated points for model-II obtained by the NSGA-III algorithm. In this figure, NSGA-III runs 300 generations with 100 population sizes. The obtained solutions for this model by the proposed algorithm equal previously published results for this model. In Fig. 4, the relation between generation number and the KKT proximity measure is introduced. As shown from the figures, the KKT metric reduces with increasing the number of generations.
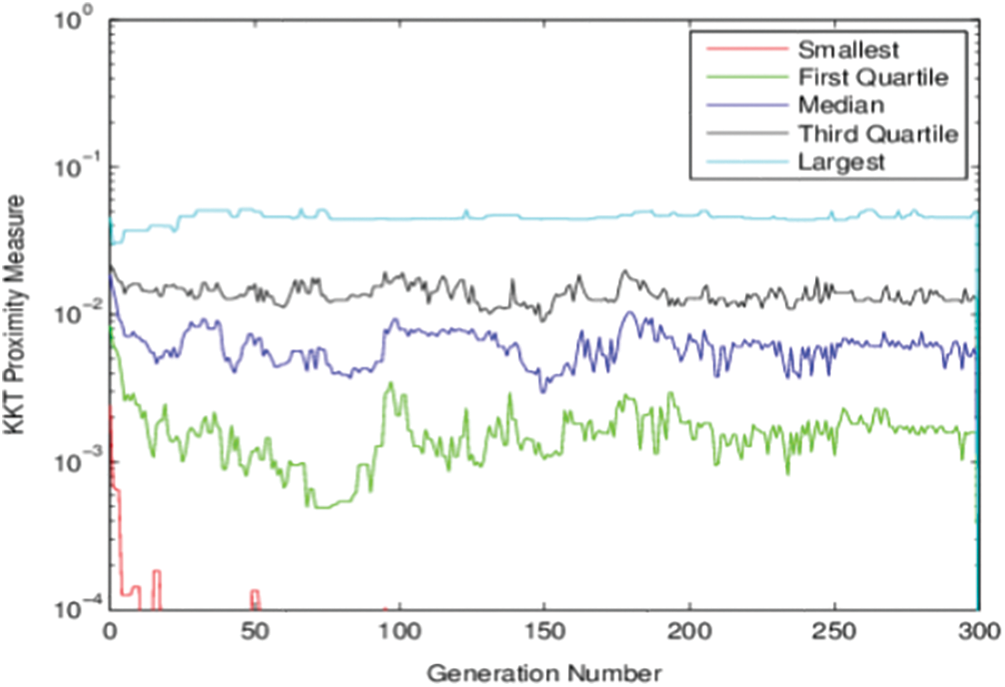
Figure 4: KKT Proximity measure vs. generation number for Model-II using NSGA-III
The minimum KKT error metric goes to zero with the first few generations, which means at least one solution converges to the efficient front within a few generations. Also, the maximum KKTPM metric values don’t show any convergence until the last generation.
The solutions found in genetic algorithms are the same as those found in other approaches, and they are as effective. The genetic algorithm, on the other hand, is simpler and easier to apply. A genetic algorithm can address portfolio optimization problems without simplification and with decent results in a fair amount of time, and it has a lot of practical applications. NSGA-II and NSGA-III are used to address portfolio problems in models I and II. We measure the smallest, first quartile, median, third quartile, and highest KKTPM values as a function of generation, and the figure shows that KKTPM values decrease with generation. The obtained solutions for the portfolio models using the genetic algorithms same as theoretical solutions. NSGA-II is effective only for two objective functions, and NSGA-III is effective only for three objective functions. NSGA-II can be solving real-life optimization problems with two objective functions, and NSGA-III can be solving real-life optimization problems with three objective functions. In the future direction of this work, we will extend the proposed algorithms with more real-life applications with many objective functions.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that no conflicts of interest occurred regarding the publication of the paper.
1. A. T. Khan, X. Cao, S. Li, B. Hu and V. N. Katsikis, “Quantum beetle antennae search: A novel technique for the constrained portfolio optimization problem,” Science China Information Sciences, vol. 64, no. 5, pp. 1–14, 2021. [Google Scholar]
2. D. E. Goldberg, “Genetic algorithms in search, optimization, and machine learning,” Reading: Addison-Wesley vol. 3, no. 2, pp. 25–45, 1989. [Google Scholar]
3. J. Patalas-Maliszewska, I. Pająk and M. Skrzeszewska, “Ai-based decision-making model for the development of a manufacturing company in the context of industry 4.0,” in 2020 IEEE Int. Conf. on Fuzzy Systems (FUZZ-IEEEGlasgow, Scotland, UK, IEEE, pp. 1–7, 2020. [Google Scholar]
4. S. A. Darani, “System architecture optimization using hidden genes genetic algorithms with applications in space trajectory optimization,” Michigan Technological University, vol. 12, no. 2, pp. 5–24, 2018. [Google Scholar]
5. T. Harada and E. Alba, “Parallel genetic algorithms: A useful survey,” ACM Computing Surveys (CSUR), vol. 53, no. 4, pp. 1–39, 2020. [Google Scholar]
6. Z. Drezner and T. D. Drezner, “Biologically inspired parent selection in genetic algorithms,” Annals of Operations Research, vol. 287, no. 1, pp. 161–183, 2020. [Google Scholar]
7. S. Katoch, S. S. Chauhan and V. Kumar, “A review on genetic algorithm: Past, present, and future,” Multimedia Tools and Applications, vol. 80, no. 5, pp. 8091–8126, 2021. [Google Scholar]
8. J. González-Díaz, B. González-Rodríguez, M. Leal and J. Puerto, “Global optimization for bilevel portfolio design: Economic insights from the Dow Jones index,” Omega, vol. 102, no. 5, pp. 102353, 2021. [Google Scholar]
9. A. Goli, H. K. Zare, R. Tavakkoli-Moghaddam and A. Sadeghieh, “Hybrid artificial intelligence and robust optimization for a multi-objective product portfolio problem Case study: The dairy products industry,” Computers & Industrial Engineering, vol. 137, no. 4, pp. 106090, 2019. [Google Scholar]
10. H. Markowitz, “Portfolio selection: Efficient diversification of investments,” Cowles Foundation Monograph, vol. 16, no. 3, pp. 24–45, 1959. [Google Scholar]
11. K. Deb, “Karush-kuhn-tucker proximity measure for convergence of real-parameter single and multi-objective optimization,” Numerical Computations: Theory and Algorithms NUMTA, vol. 27, no. 3, pp. 23–34, 2019. [Google Scholar]
12. M. Abouhawwash, M. Jameel and K. Deb, “A smooth proximity measure for optimality in multi-objective optimization using Benson’s method,” Computers & Operations Research, vol. 117, no. 2, pp. 104900, 2020. [Google Scholar]
13. K. Deb, A. Pratap, S. Agarwal and T. A. M. T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: NSGA-II,” IEEE Transactions on Evolutionary Computation, vol. 6, no. 2, pp. 182–197, 2002. [Google Scholar]
14. S. P. Kodali, R. Kudikala and K. Deb, “Multi-objective optimization of surface grinding process using NSGA II,” in 2008 First Int. Conf. on Emerging Trends in Engineering and Technology (IEEEIEEE, pp. 763–767, 2008. [Google Scholar]
15. X. D. Wang, C. Hirsch, S. Kang and C. Lacor, “Multi-objective optimization of turbomachinery using improved NSGA-II and approximation model,” Computer Methods in Applied Mechanics and Engineering, vol. 200, no. 9–12, pp. 883–895, 2011. [Google Scholar]
16. K. Deb and H. Jain, “An evolutionary many-objective optimization algorithm using reference-point based non-dominated sorting approach, part i: Solving problems with box constraints,” IEEE Transactions on Evolutionary Computation, vol. 18, no. 4, pp. 577–601, 2014. [Google Scholar]
17. W. Mkaouer, M. Kessentini, A. Shaout, P. Koligheu, S. Bechikh et al., “Many-objective software remodularization using NSGA-III,” ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 24, no. 3, pp. 1–45, 2015. [Google Scholar]
18. Y. Zhu, J. Liang, J. Chen and Z. Ming, “An improved NSGA-III algorithm for feature selection used in intrusion detection,” Knowledge-Based Systems, vol. 116, no. 12, pp. 74–85, 2017. [Google Scholar]
19. J. H. Yi, L. N. Xing, G. G. Wang, J. Dong, A. V. Vasilakos et al., “Behavior of crossover operators in NSGA-III for large-scale optimization problems,” Information Sciences, vol. 509, no. 15, pp. 470–487, 2020. [Google Scholar]
20. H. Markowitz, “Portfolio selection,” Journal of Finance, vol. 7, no. 1, pp. 77–91, 1952. [Google Scholar]
21. R. O. Michaud, “The Markowitz optimization enigma: Is 'optimized' optimal,” Financial Analysts Journal, vol. 45, no. 1, pp. 31–42, 2018. [Google Scholar]
22. H. Hong and J. C. Stein, “A unified theory of underreaction, momentum trading, and overreaction in asset markets,” Journal of Finance, vol. 54, no. 6, pp. 2143–2184, 1999. [Google Scholar]
23. K. Deb, “Multi-objective optimization using evolutionary algorithms,” John Wiley & Sons, Vol.16, 2001. [Google Scholar]
24. H. Chen, K. P. Wong, D. H. M. Nguyen and C. Y. Chung, “Analyzing oligopolistic electricity market using coevolutionary computation,” IEEE Transactions on Power Systems, vol. 21, no. 1, pp. 143–152, 2006. [Google Scholar]
25. X. S. Yang, “Nature-inspired optimization algorithms,” Academic Press, vol. 14, no. 3, pp. 1–45, 2020. [Google Scholar]
26. H. Jain and K. Deb, “An evolutionary many-objective optimization algorithm using reference-point based non-dominated sorting approach, part ii: Handling constraints and extending to an adaptive approach,” IEEE Transactions on Evolutionary Computation, vol. 18, no. 4, pp. 602–622, 2014. [Google Scholar]
27. H. Seada and K. Deb, “U-nsga-iii: A unified evolutionary optimization procedure for single, multiple, and many objectives: Proof-of-principle results,” in Int. Conf. on Evolutionary Multi-Criterion Optimization, Cham, Springer, pp. 34–49, 2015. [Google Scholar]
28. T. Huang, Y. J. Gong, S. Kwong, H. Wang and J. Zhang, “A niching memetic algorithm for multi-solution traveling salesman problem,” IEEE Transactions on Evolutionary Computation, vol. 24, no. 3, pp. 508–522, 2019. [Google Scholar]
29. K. Deb, M. Abouhawwash and H. Seada, “A computationally fast convergence measure and implementation for single-, multiple-, and many-objective optimization,” IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 1, no. 4, pp. 280–293, 2017. [Google Scholar]
30. E. Ahmed and A. S. Hegazi, “On different aspects of portfolio optimization,” Applied Mathematics and Computation, vol. 175, no. 1, pp. 590–596, 2006. [Google Scholar]
31. M. Abouhawwash and A. Alessio, “Develop a multi-objective evolutionary algorithm for PET image reconstruction: Concept,” IEEE Transactions on Medical Imaging, vol. 40, no. 8, pp. 2142–2151, 2021. [Google Scholar]
32. M. Abouhawwash and K. Deb, “Reference point based evolutionary multi-objective optimization algorithms with convergence properties using KKTPM and ASF metrics,” Journal of Heuristics, Springer, vol. 27, no. 4, pp. 575–614, 2021. [Google Scholar]
33. K. Deb and M. Abouhawwash, “An optimality theory-based proximity measure for set-based multi-objective optimization,” IEEE Transactions on Evolutionary Computation, vol. 20, no. 4, pp. 515–528, 2016. [Google Scholar]
34. M. Abouhawwash, H. Seada and K. Deb, “Towards faster convergence of evolutionary multi-criterion optimization algorithms using Karush-Kuhn-Tucker optimality based local search,” Computers & Operations Research, vol. 79, no. 3, pp. 331–346, 2017. [Google Scholar]
35. B. Samanta and T. K. Roy, “Multi-objective portfolio optimization model,” Tamsui Oxford Journal of Mathematical Sciences, vol. 21, no. 1, pp. 55, 2005. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |