DOI:10.32604/iasc.2022.028352
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2022.028352 | |
| Article |
Attention Weight is Indispensable in Joint Entity and Relation Extraction
1Key Laboratory of Intelligen Computing and Information Processing, Ministry of Education, Computer science College of Xiangtan University, Xiangtan, 411100, China
2Department of Computer Science, University of Georgia, Athens, USA
*Corresponding Author: Jianquan Ouyang. Email: oyjq@xtu.edu.cn
Received: 08 February 2022; Accepted: 11 April 2022
Abstract: Joint entity and relation extraction (JERE) is an important foundation for unstructured knowledge extraction in natural language processing (NLP). Thus, designing efficient algorithms for it has become a vital task. Although existing methods can efficiently extract entities and relations, their performance should be improved. In this paper, we propose a novel model called Attention and Span-based Entity and Relation Transformer (ASpERT) for JERE. First, differing from the traditional approach that only considers the last hidden layer as the feature embedding, ASpERT concatenates the attention head information of each layer with the information of the last hidden layer by using an attentional contribution degree algorithm, so as to remain the key information of the original sentence in a deep transferring of the pre-trained model. Second, considering the unstable performance of the linear span classification and width embedding structure of the SpERT, ASpERT uses a multilayer perceptron (MLP) and softmax-based span classification structure. Ablation experiments on the feature embedding and span classification structures both show better performances than SpERT’s. Moreover, the proposed model achieved desired results on three widely-used domain datasets (SciERC, CoNLL04, and ADE) and outperforms the current state-of-the-art model on SciERC. Specifically, the F1 score on SciERC is 52.30%, that on CoNLL04 is 71.66%, and that on ADE is 82.76%.
Keywords: Attentional contribution degree; joint entity and relation extraction; BERT; span
Entity and relation extraction (ERE) has received much attention as a fundamental task in NLP, especially in specific domains (e.g., science, journalism, and medicine). The purpose of ERE is to extract structured triplets automatically from unstructured or semistructured natural language texts. A triplet consists of two entities and the relationship between them, and a sentence may contain multiple triplets. Owing to nested entities and overlapping relations, the extracted triplets may have similar or identical entities, and a triplet itself may contain two identical entities (with different relationships).
ERE is divided into pipeline ERE [1] and joint ERE (JERE) [2–5]. Their difference is the execution sequence of two subtasks, named entity recognition (NER) [6–9] and relation extraction (RE) [10]. Specifically, pipeline ERE first extracts entities from the text and then extracts relations between every two entities. In this serial execution, the success of RE most likely depends on the results of NER, and the lack of information interaction between NER and RE can cause errors to accumulate. Compared with the pipeline method, the joint method uses a parameter sharing or joint decoding mechanism between NER and RE. Such a mechanism enhances the information interaction between NER and RE, reduces the high dependence of RE on NER results, and improves the accuracy of ERE. JERE includes three directions: tagging [11], table filling [12], and sequence to sequence (Seq2Seq) [13]. Studies are considerably inclined to methods based on BIO/BILOU labels, and some complex algorithms may cause unbearable computational costs. Unlike BIO/BILOU labels, span-based methods [14] can efficiently identify nested entities, such as “phenytoin” within “phenytoin toxicity.”
Known as state-of-the-art span-based JERE, Span-based Entity and Relation Transformer (SpERT) [15] uses a sufficient number of strong negative samples and localized context to construct lightweight inference of BERT [16] embeddings, but this model still has two main flaws. First, SpERT focuses on learning span representation and lacks clear boundary supervision of entities. That is, the model relies on a width embedding layer to train the span length and directly classifies the sampled span through a fully connected layer. Second, many BERT-based JERE models (including SpERT) do not fully exploit domain-specific information. The semantic learning of sentences by using these models mainly comes from the coding information of the last hidden layer obtained through fine-tuning the BERT model, which limits the model’s performance.
To solve the problems mentioned above, we propose Attention and Span-based Entity and Relation Transformer (ASpERT), which is a JERE model based on the attentional contribution degree and MLP-softmax span classification structure. In ASpERT, a more complex MLP is added to enhance the entity boundary detection. In addition, in JERE’s studies on Transformer [17,18], the multihead self-attention is used to capture interactions among tokens, but only the last hidden layer is considered as the feature embedding for downstream tasks. In this paper, we develop a novel attentional contribution degree algorithm, which concatenates the softmax score of the attention head and the hidden layer feature embedding. View as a training strategy, this algorithm remains the strong attention between words by backpropagating to learn query vectors and key vectors in the pre-trained model. Finally, weighted joint optimization of the multitask loss function is conducted in the training process.
ASpERT is compared with state-of-the-art methods on three datasets, SciERC, CoNLL04 and ADE (public dataset repository address: http://lavis.cs.hs-rm.de/storage/spert/public/datasets/). Specifically, our model shows a significant performance improvement with a 1.39% increase in F1 score comparing to the baseline model (SpERT). Our model outperforms the current state-of-the-art model on the SciERC dataset and achieves desired results on CoNLL04 and ADE. In addition, we also investigate how to set contribution thresholds and different fusion methods more efficiently. And in the ablation experiments, we demonstrate the effectiveness of the novel span classification structure and attentional contribution degree algorithm.
The contributions of our work can be summarized as follows:
a) We analyze the reasons for the inaccurate boundary recognition of SpERT and propose a simple and effective span classification structure to alleviate this problem.
b) We propose an attentional contribution degree algorithm to enhance the model with strong attention between words by backpropagation.
c) Experiments show that our model achieves outstanding performance on domain-specific datasets (SciERC, CoNLL04, and ADE) in science, news, and medicine. Especially, it is better than the current state of the art on SciERC.
Acting as an implementation of ERE, the pipeline method [19,20] executes NER and RE in series. Herein, NER methods [21] can be categorized into rule, dictionary, and machine learning-based methods [22–24]. ER methods can be divided into handcrafted feature-based methods [25] and neural network-based methods [26–28]. Although the pipeline method has been successfully applied in some fields, the sequential execution of NER and RE makes it ignore the correlation between the two tasks, which limits the further development of these methods.
To alleviate the above limitations, researchers proposed JERE, including feature-based methods [29,30] and neural network-based methods [31–35]. Limited by the expression capability of the model, later studies are mainly based on the neural network method. Research on JERE includes three main directions: tagging, table filling, and Seq2Seq. Zheng et al. [36] proposed a novel tagging scheme, which assigns a tag to each word (including word position, relation type, and relation role) for classification. The table filling [37] is usually to construct a two-dimensional table; thus, the solutions of NER and RE become the problems of labeling diagonal and nondiagonal elements in the table, respectively. These methods allow a single model to execute NER and RE simultaneously but cannot fully use the table structure. Wang et al. [38] proposed to learn two separate encoders (a table encoder and a sequence encoder), which effectively alleviates this problem. The Seq2Seq method [39] first retains sentence features and then extracts triplets in sequence. CopyRE [40], the most typical method, is based on the copy mechanism and Seq2Seq structure, but only extracts individual word. In response to this problem, Zeng et al. [41] proposed a multitask learning method based on BIO labeling.
Methods aforementioned are all based on the BIO/BILOU scheme, and they face a common problem—nested entities. To solve the problem, Takanobu et al. [42] adopted a hierarchical reinforcement learning framework. In this framework, entities and relations are divided into different levels, and the semantic information detected by high-level relations is used in extracting low-level entities. The two levels alternate back and forth to achieve JERE. Dai et al. [43] proposed a position-attention mechanism to solve this problem. It uses tag sequences that have the same length as the sentence to annotate each word. Although these methods alleviate the nested entity problem, the immense computational burden is inevitable.
An alternative to the BIO/BILOU scheme is the span-based method [44], which performs a detailed search on all spans to prevent the interference of nested entities on JERE results. This method enhances the interaction among tasks by refining the span representation, allowing the model to learn useful information from a broader context. The methods include the bi-LSTM-based span-level model proposed by Dixit et al. [45] and the dynamic span graph approach through soft coreference and relation links proposed by Luan et al. [46]. To improve the performance of the span method further, Wadden et al. [47] replaced the BiLSTM encoder with Transformers and combined it with BERT encodings and graph propagation to capture context relevance. Recently, Eberts and Ulges’ SpERT [15] found localized context representation and strong negative sampling to be of vital importance. Although SpERT is the state-of-the-art model for span-based JERE, it suffers from underutilization of BERT encoding information and inaccurate identification of span boundaries.
In this section, we introduce the baseline model, SpERT. It uses pretrained BERT as the core, tokenizes the input sentence, and applies span classification, span filtering, and relation classification. Specifically, it classifies each span into entity types, filters nonentities, and categorizes all candidate entity pairs. To train the classifier efficiently, SpERT uses negative samples at the model training stage.
Negative sampling is performed on each sentence
The span classifier of SpERT consists of a fully connected layer and a softmax layer, and regards any candidate span
where
The entity classes include predefined entity types (Tab. 2) and
The relation classifier consists of a fully connected layer and sigmoid. The input of the classifier is any candidate entity pair
where
As mentioned in the Introduction, we determine that SpERT has two problems. First, SpERT’s classifier lacks clear boundary supervision on the span. Width embedding is the only constraint mechanisin span width. Considering that the span is long or short, spans composed of different numbers of words will have distinct characteristics. SpERT specifically learns a width embedding matrix through backpropagation; hence, it should play a key role in entity boundary supervision. To evaluate the effectiveness of width embedding, we test two different training models on three datasets:
• SpERT: It uses the default structure settings, which provide the width embeddings that need to be learned by backpropagation (Eq. (1)).
• ERT’: The variant model of SpERT that removes the width embedding in the span and relational classifiers, while keeping the other default structure settings of the model.
As shown in Tab. 1, the addition of width embedding is unreliable in improving the performance of the span classifier. Especially on the SciERC dataset, the F1 score of the SpERT model with width embedding decreases by 0.75% in terms of NER. Three reasons are considered for our analysis. First, the model lacks boundary supervision when facing a complex dataset. The SciERC dataset is more complicated than the two other datasets. It is more significant than CoNLL04 in the dataset size, and it is 3 times that of ADE in the entity class. Second, the width embedding of SpERT only learns the span width and cannot essentially solve the problem of inaccurate boundary recognition. Consequently, performance degradation is expected. Third, because the span classifier of SpERT is only a fully connected layer, the model is overly dependent on BERT encoding. For example, when the extraction target is the “geometric estimation problem,” the model extracts the correct span while also extracting the semantically similar wrong span “selection of geometric estimation problems,” which leads to a decrease in model performance.

In addition, many experiments have shown that the BERT model effectively extracts text information. If the text data are domain-specific (e.g., science, news, and medicine), we may need to consider creating our domain-specific language model. Relevant models have been created by training the BERT architecture on a domain-specific corpus rather than the general English text corpus used to train the original BERT model. Because pretraining BERT requires a large corpus, and we cannot use this method to improve the model’s extraction of text in a specific field. Therefore, we need to change the method to mine the unexploited information in the Transformers pretrained model under the existing conditions. At present, the input for downstream tasks of many mainstream models (including SpERT) often comes from the last hidden layer embedding of BERT while ignoring the interactive information among words carried by the BERT attention head itself. To this aim, we provide a novel attentional contribution degree algorithm, which combines the softmax attention head score with hidden layer feature embedding to improve the model’s extraction of entities and relationships.
In this section, we choose SpERT as the baseline model, analyze SpERT’s problems of inaccurate span recognition and insufficient information mining in specific fields, and propose a novel ASpERT model (Fig. 1). Then, we introduce a novel attentional contribution degree algorithm and a multitask training method that combines span and relation classifiers.
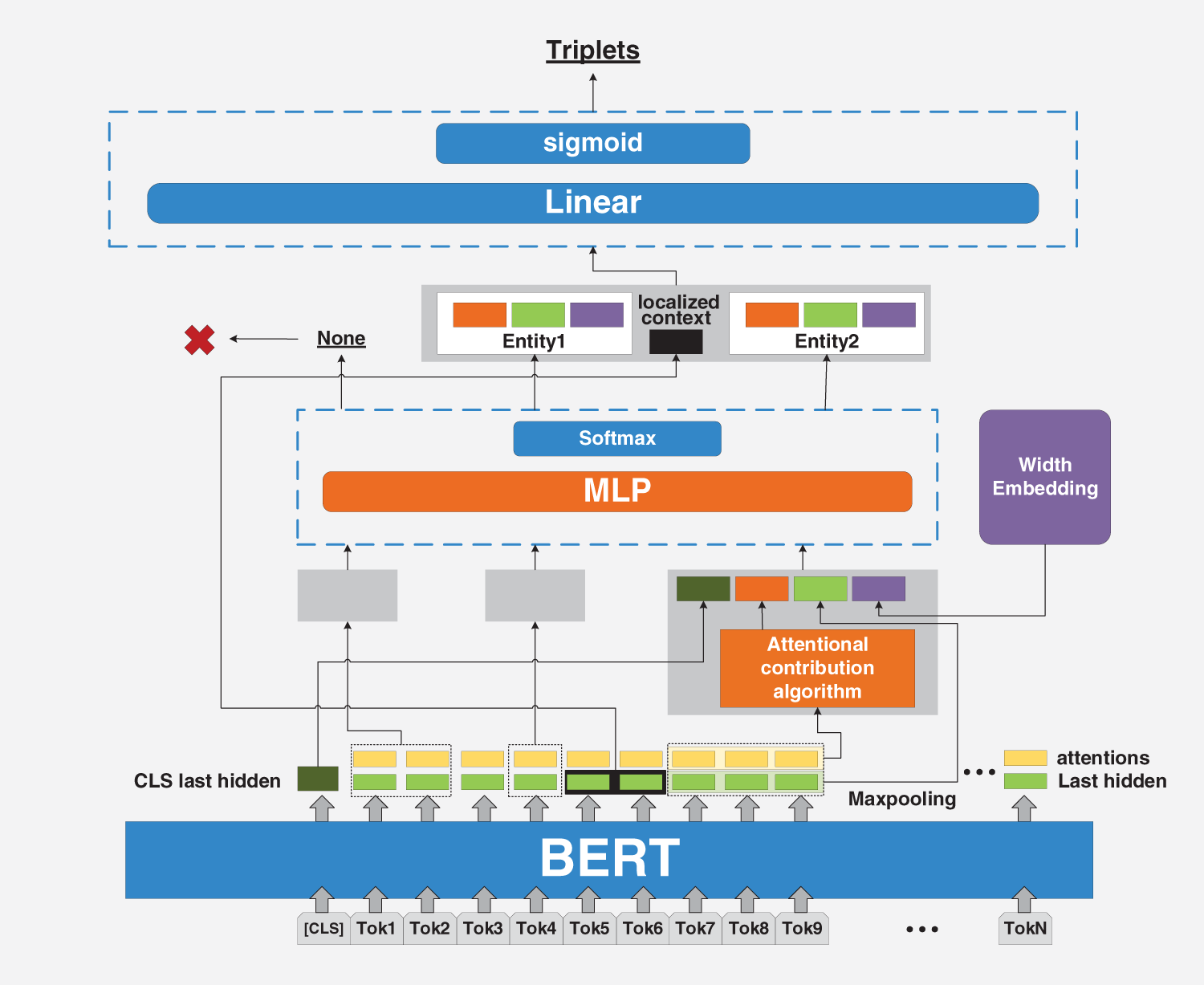
Figure 1: Overview of the ASpERT model for JERE and the orange part is our contribution
4.1 Novel Structure for the Span Classifier
We consider that the span classifier is different from the traditional classifier, such as fully connected layer and softmax layer. In addition to classifying the span, it also needs to predict which words belong to the entity boundary. Thus, we propose a span classification structure that considers these two functions.
The BERT embedding of candidate span
where
JERE tasks are usually converted into one or more classification tasks at the end. Therefore, the classifier’s quality is related to whether the high-dimensional data information can be accurately mapped to a given category. SpERT’s span classifier is a linear fully connected layer. Few data strictly adhere to the linear distribution when noise is introduced, such that a simple linear structure cannot accurately predict the span class. Recently, MLP has been repositioned in visual classification [48]. For migration learning, we use MLP for span classification, hoping to increase the number of parameters to improve the potential representation capability of the classifier. The improvements to Eq. (3) are as follows:
where
4.2 Attentional Contribution Degree Algorithm
In this subsection, we describe the attentional contribution degree algorithm in detail. Attentional contribution degree is a novel attention weight, which concatenates the calculated attentional contribution degree with hidden layer features to obtain a weighted feature encoding. This encoding helps the model understand the contextual information of the span and strengthens the model’s extraction of entities and relations.

The attentional contribution degree is derived from the attention paid to interword information by each attention head in each layer of the pretrained model. Among them, pretrained model comes from the BERT variant of the Transformers library. The large model and corpus symbolize many GPU resources, such that we only fine-tune the pretrained model (such as BERT base (cased) [16], SciBERT (cased) [49], and BioBERT (cased) [50]) in a specific field. This condition does not mean that we are bound by the pretrained model. On the contrary, we fully utilize the attention header information of Transformers. We train and use the intermediate product of the model—self-attention head. For example, BERT base has 12 layers, and each layer has 12 attention heads. Then we can make use of the information of these 144 attention heads.
Specifically, first we extract all the attention heads, which contain information about the relationship among words in a sentence. Second, we concatenate multiple attention heads in the num head dimension. As shown in Algorithm 1, we mask irrelevant words and only retain the relationship information between the candidate span and the words in the full text. Immediately after, considering that each attention layer provides multiple “representation subspaces,” the multihead attention mechanism expands the model’s ability to represent different positions. We provide the contribution threshold

Our training is supervised, providing the model with labeled sentences (including candidate span, entity class, candidate entity pair, and relation class). We learn width embedding
where
We evaluate the model on three datasets from different domains, CoNLL04 [51], SciERC [14], and ADE [52]. As shown in Tab. 2, the CoNLL04 dataset is derived from news articles and includes four entity types and five relationship types. The dataset is divided into a training set of 911 sentences, a validation set of 231 sentences, and a test set of 288 sentences. The SciERC (scientific information extractor) dataset is derived from abstracts of artificial intelligence papers and includes six scientific entity types and seven relationship types. This dataset is divided into a training set of 1861 sentences, a validation set of 275 sentences, and a test set of 551 sentences. The ADE (adverse drug effect) dataset is derived from medical reports describing the adverse effects of drug use and contains two entity types and one relationship type. The dataset is divided into a training set of 3843 sentences and a validation set of 429 sentences.

We evaluated ASpERT on entity extraction and RE. An entity prediction is considered correct if the span and entity type of the entity prediction match the ground truth. A relation prediction is considered correct if the relation type and the two related entities (span and type) match the ground truth. In particular, to be consistent with the evaluation criteria of the comparative model, we only consider the prediction of relationship and entity span (ignoring the accuracy of entity type) on the SciERC dataset. Hyperparameters used for final training are listed in Tab. 3.

5.2 Comparison with the State of the Art
First, to evaluate the effectiveness of ASpERT’s improvement based on SpERT, we train both models on the same device and unify the pretrained model and training parameters. We report an average of over five runs for each dataset. In particular, the ADE dataset uses 10-fold cross validation. As shown in Tab. 4, the performance of ASpERT is significantly better than that of the baseline model (SpERT) on different datasets. For entity extraction, the micro-F1 scores are increased by 0.45% (CoNLL04), 0.20% (SciERC), and 0.52% (ADE), and the macro-F1 scores are increased by 0.71% (CoNLL04), 0.33% (SciERC), and 0.50% (ADE). For RE, the micro-F1 scores are increased by 1.25% (CoNLL04), 1.39% (SciERC), and 1.31% (ADE), and the macro-F1 scores are increased by 1.25% (CoNLL04), 1.29% (SciERC), and 1.31% (ADE).
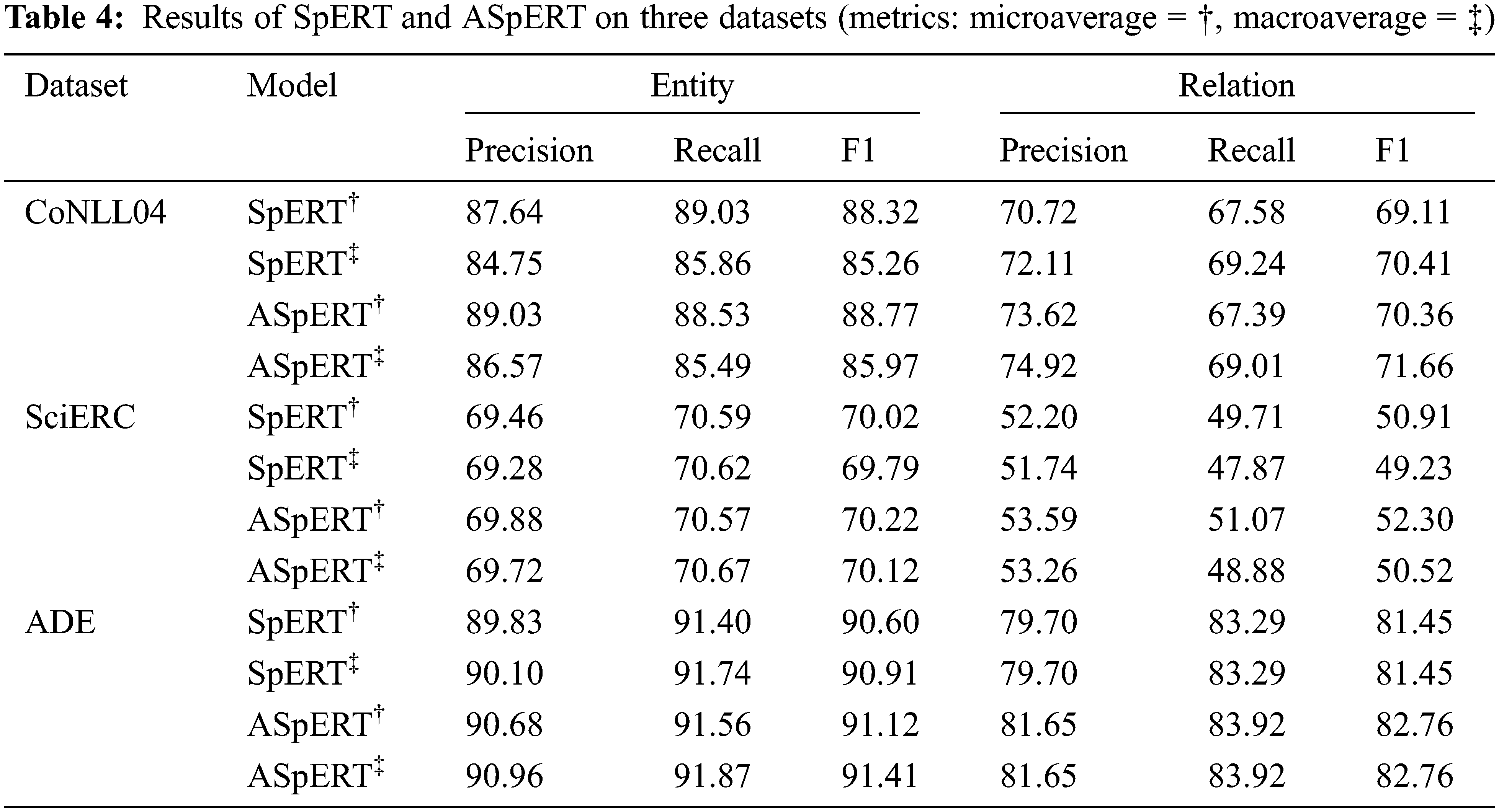
Subsequently, we compared the proposed model with the most advanced models currently. As shown in Tab. 5, these models are the top four models (except for SpERT) of the three datasets in the Papers With Code ranking list. We sorted ASpERT and these models in descending order in accordance with the F1 score of RE. The experimental results show that ASpERT has higher extraction performance in entities and relations. Even in the challenging and domain-specific SciERC dataset, ASpERT’s F1 score RE is 0.30% higher than that of the top-ranked PL-Marker.
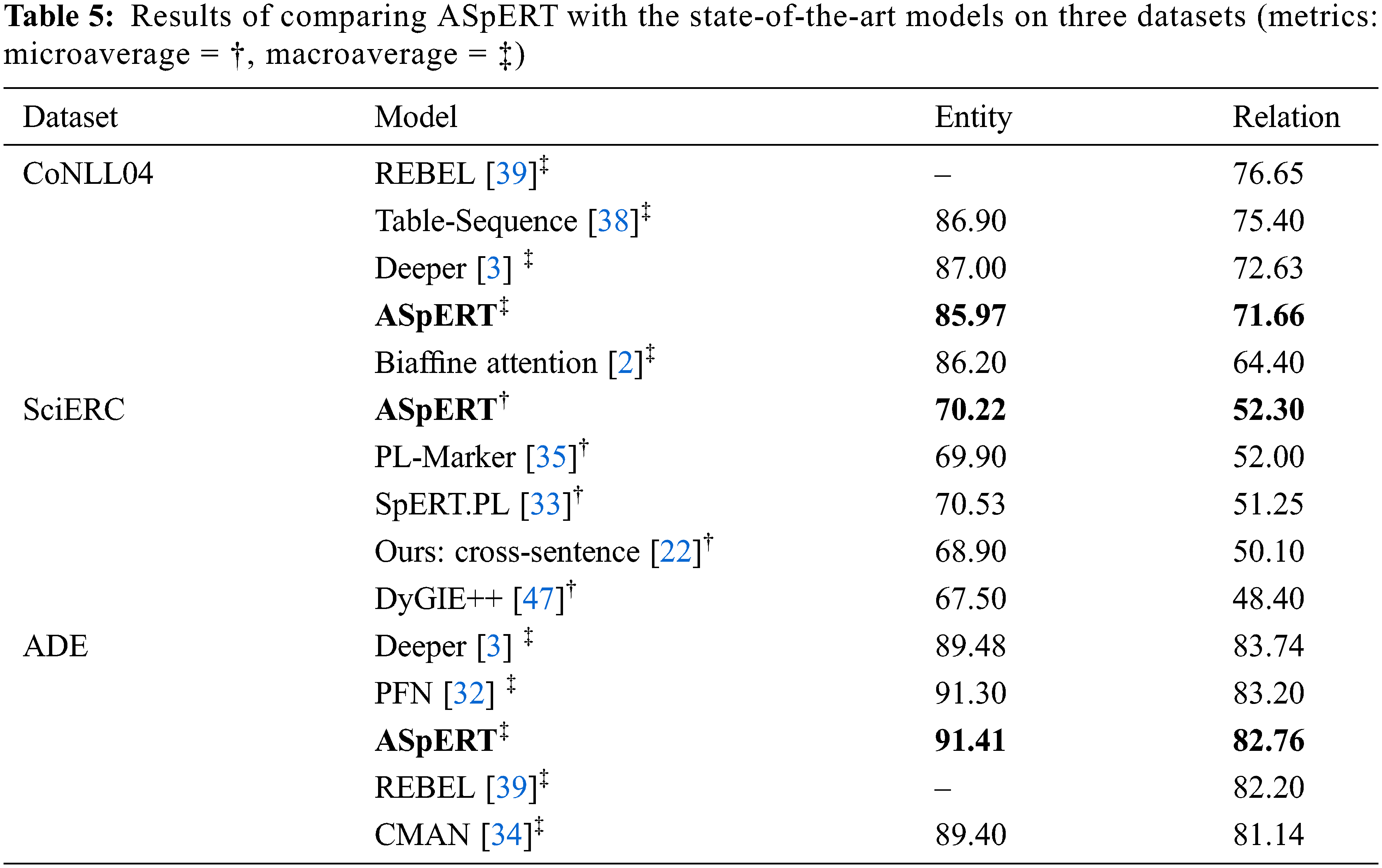
5.3 Effects of Attentional Contribution Degree
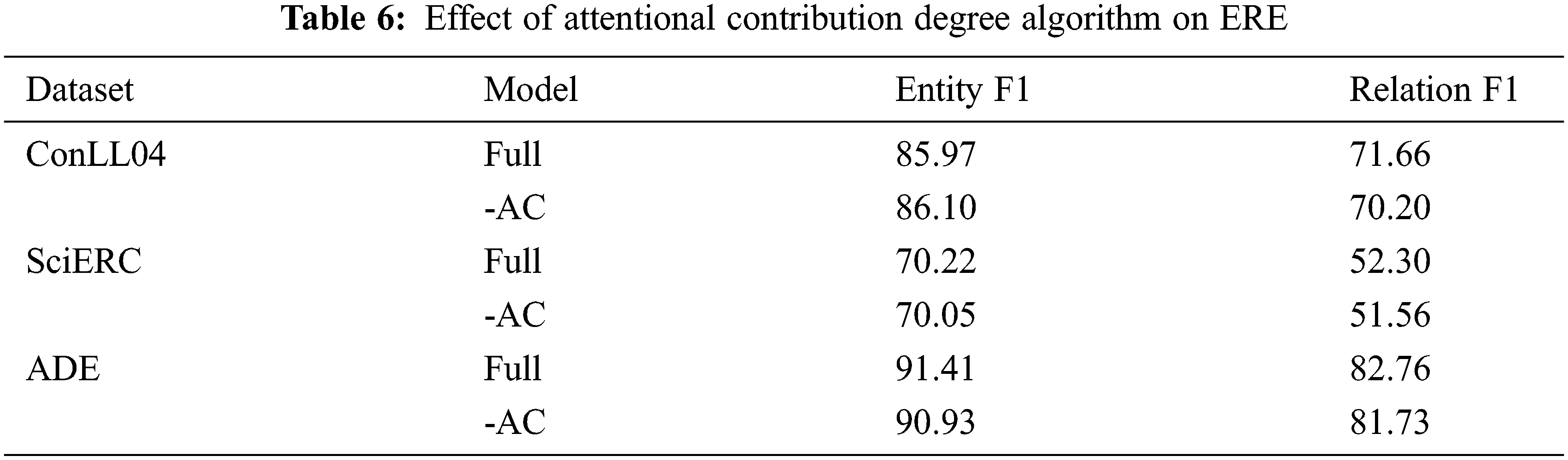
In Tab. 4, although the performance of ASpERT is better than that of SpERT, it is still not clear which part of ASpERT plays a key role. To demonstrate the advantage of the attentional contribution algorithm in JERE, we test two models:
• Full: We use the complete ASpERT model structure.
• -AC: We retain most of the ASpERT model structure but remove the attentional contribution degree algorithm.
We ran these two models more than 5 times on three datasets and average them (the ADE dataset uses 10-fold cross validation). As shown in Tab. 6, the performance of the variant model without the attentional contribution degree algorithm is significantly decreased. In terms of entity extraction, F1 scores decreased by 0.48%. In RE, the F1 score decreased by 1.46%. These experimental results show that the attentional contribution degree algorithm can capture word-to-word relationships adequately, which helps in efficient relation classification and is the main contribution of the new model architecture.
Then, we investigated the effect of setting different contribution thresholds on the model’s ability to capture word-to-word relationships on SciERC and CoNLL04. Fig. 2 shows the F1 scores (RE) with different contribution thresholds. When the threshold is 0.5, the model performance is optimal.
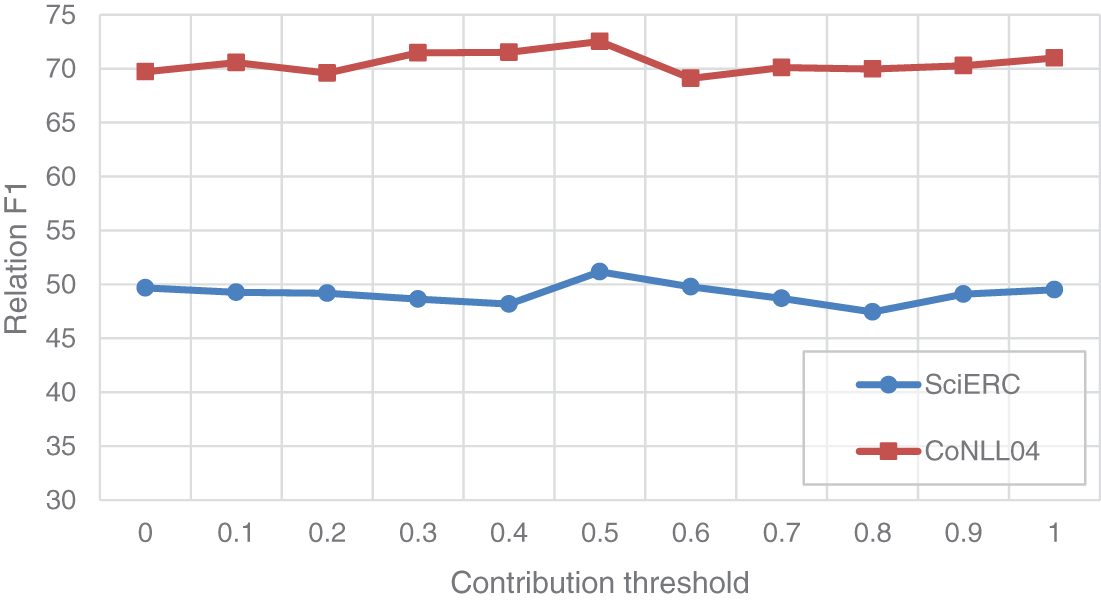
Figure 2: Effect of different contribution thresholds on the relation F1 score
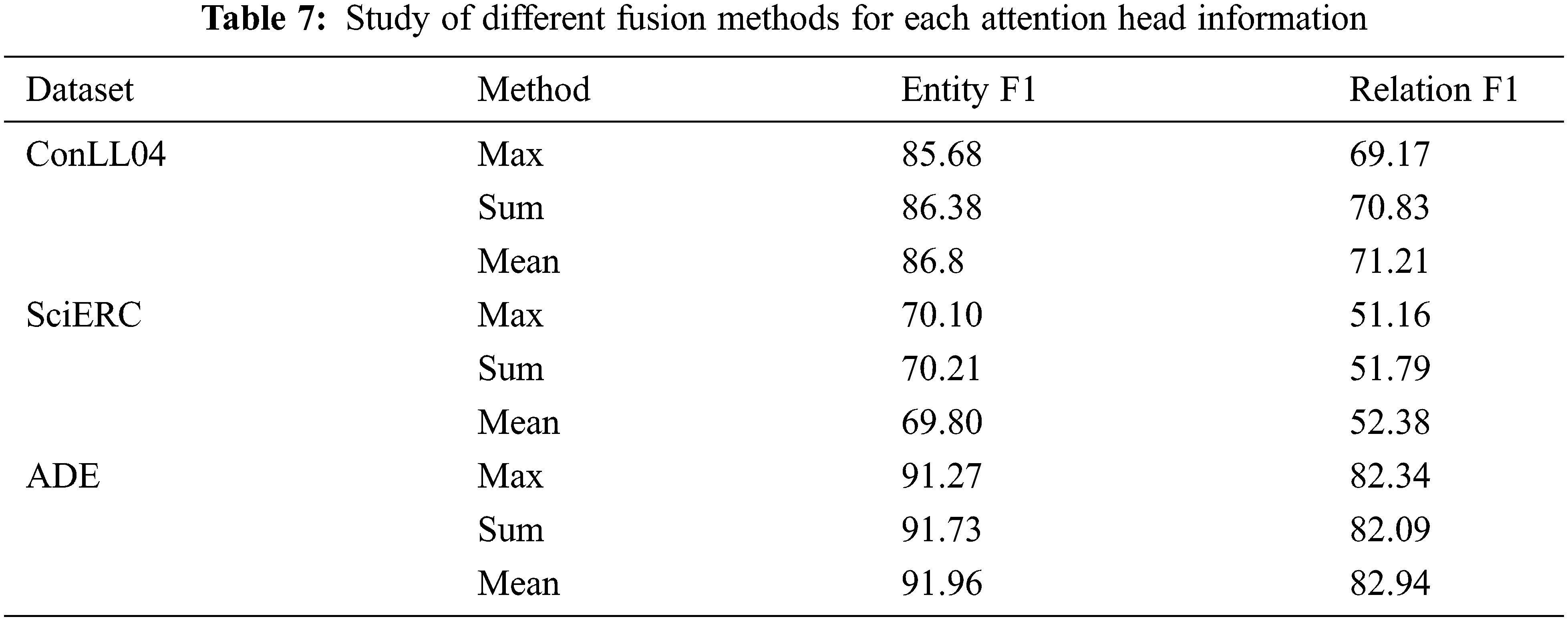
Lastly, we also investigate the different fusion methods of each attention head information, namely, the maximum pooling, sum pooling, and mean pooling. Tab. 7 shows the F1 scores by using different fusion methods on three datasets. We determined that the mean pooling is more advantageous for JERE.
5.4 Effects of the Novel Span Classifier
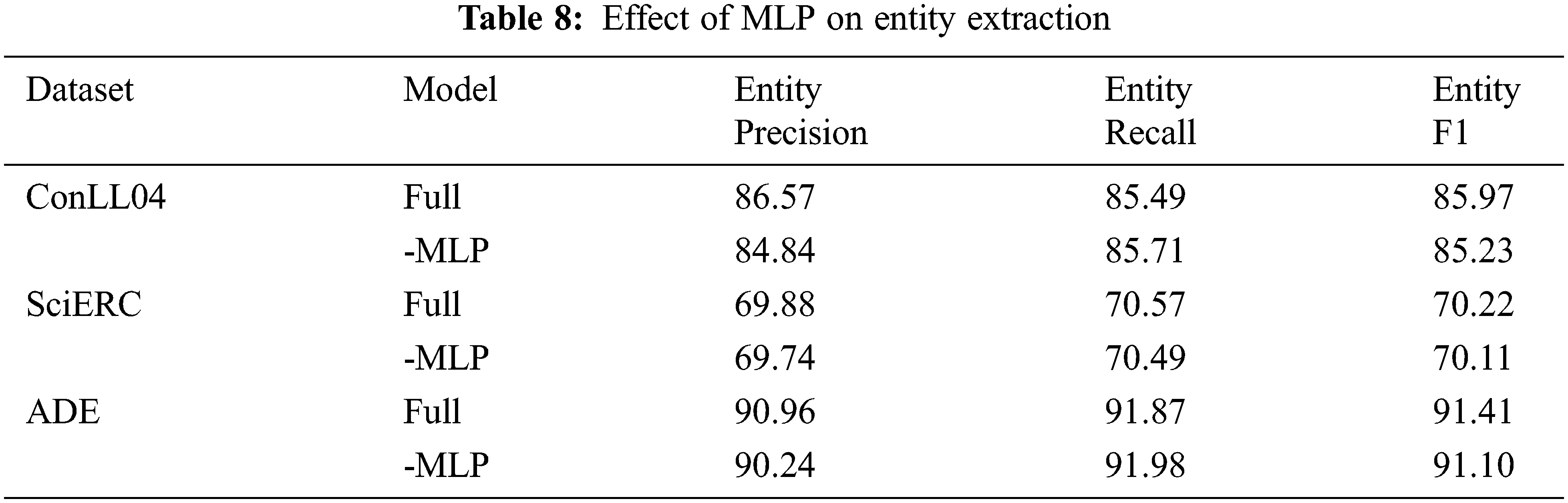
To evaluate the effectiveness of the novel span classifier, we further test two models on the SciERC dataset:
• Full: We use the complete ASpERT model structure.
• -MLP: We retain most of the ASpERT model structure but replace the MLP structure with a fully connected layer in span classification.
As shown in Tab. 8, removing the MLP structure weakened the classifier’s ability to learn information about span boundaries, leading to a decrease in the recall and accuracy of entity extraction and thus a decrease in the F1 score by nearly 0.74%.
In this paper, we have proposed a novel model termed ASpERT for JERE. This model fuses the overlooked attention header information in downstream tasks with the feature embedding of the hidden layer via a new attentional contribution degree algorithm. Specifically, the attentional contribution incorporates word-to-word attention and the residual connectivity of the span classifier with each attentional head. This allows the model to maintain the raw information as depth increases and thus enhance the model’s ability to capture contextual information, thus being adapted to domain-specific JERE. Moreover, the MLP-softmax structure of the span classifier and the attentional contributions is used to determine the boundary supervision and to improve the span classification. Without these ideas, researchers who are limited by hardware conditions may have to fine-tune parameters for information extraction tasks. The use of pre-trained models is not limited to the encoding of implicit layer information.
Considering that the attentional head is the base unit of Transformer pre-training models, in future work, we will further demonstrate the influence of the attentional contribution degree algorithm on other Transformer pre-training models. Notably, Asian languages, however, require more words to express the same meaning as English, which is not friendly to the random sampling method, hence we will focus on spanwise sampling of complex language structures.
Acknowledgement: We thank the open-source authors of the dataset. We also thank all members from Xiangtan University 504 Lab for their strong support for my research.
Funding Statement: This work was supported by Key Projects of the Ministry of Science and Technology of the People’s Republic of China (2020YFC0832401) and National College Students Innovation and Entrepreneurship Training Program (No. 202110530001).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. M. R. Gormley, M. Yu and M. Dredze, “Improved relation extraction with feature-rich compositional embedding models,” 2015. [Online]. Available: https://arxiv.org/abs/1505.02419. [Google Scholar]
2. D. Q. Nguyen and K. Verspoor, “End-to-end neural relation extraction using deep biaffine attention,” in European Conf. on Information Retrieval, Cologne, Germany, pp. 729–738, 2019. [Google Scholar]
3. P. Crone, “Deeper task-specificity improves joint entity and relation extraction,” 2002. [Online]. Available: https://arxiv.org/abs/2002.06424. [Google Scholar]
4. C. Chen and F. Kong, “Enhancing entity boundary detection for better chinese named entity recognition,” in Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Language Processing, vol. 2, pp. 20–25, 2021. [Google Scholar]
5. S. Zhao, M. Hu, Z. Cai and F. Liu, “Dynamic modeling cross-modal interactions in two-phase prediction for entity-relation extraction,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–10, 2021. [Google Scholar]
6. G. Luo, X. Huang, C.-Y. Lin and Z. Nie, “Joint entity recognition and disambiguation,” in Proc. of the 2015 Conf. on Empirical Methods in Natural Language Processing, Lisbon, Portugal, pp. 879–888, 2015. [Google Scholar]
7. Z. Liu and X. Chen, “Research on relation extraction of named entity on social media in smart cities,” Soft Computing, vol. 24, no. 15, pp. 11135–11147, 2020. [Google Scholar]
8. C. Tan, W. Qiu, M. Chen, R. Wang and F. Huang, “Boundary enhanced neural span classification for nested named entity recognition,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 5, pp. 9016–9902, 2020. [Google Scholar]
9. J. Cheng, J. Liu, X. Xu, D. Xia, L. Liu et al., “A review of chinese named entity recognition,” KSII Transactions on Internet and Information Systems, vol. 15, no. 6, pp. 2012–2030, 2021. [Google Scholar]
10. G. Zhou, J. Su, J. Zhang and M. Zhang, “Exploring various knowledge in relation extraction,” in Proc. of the 43rd Annual Meeting of the Association for Computational Linguistics, Ann Arbor, Michigan, USA, pp. 427–443, 2005. [Google Scholar]
11. Y. Wang, B. Yu, Y. Zhang, T. Liu, H. Zhu et al., “Tplinker: Single-stage joint extraction of entities and relations through token pair linking,” 2010. [Online]. Available: https://arxiv.org/abs/2010.13415. [Google Scholar]
12. M. Zhang, Y. Zhang and G. Fu, “End-to-end neural relation extraction with global optimization,” in Proc. of the 2017 Conf. on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, pp. 1730–1740, 2017. [Google Scholar]
13. T. Nayak and H. T. Ng, “Effective modeling of encoder-decoder architecture for joint entity and relation extraction,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 05, pp. 8528–8535, 2020. [Google Scholar]
14. Y. Luan, L. He, M. Ostendorf and H. Hajishirzi, “Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction,” 2018. [Online]. Available: https://arxiv.org/abs/1808.09602. [Google Scholar]
15. M. Eberts and A. Ulges, “Span-based joint entity and relation extraction with transformer pre-training,” 2019. [Online]. Available: https://arxiv.org/abs/1909.07755. [Google Scholar]
16. J. Devlin, M.-W. Chang, K. Lee and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” 2018. [Online]. Available: https://arxiv.org/abs/1810.04805. [Google Scholar]
17. Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma et al., “Albert: A lite bert for self-supervised learning of language representations,” 2019. [Online]. Available: https://arxiv.org/abs/1909.11942. [Google Scholar]
18. Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi et al., “Roberta: A robustly optimized bert pretraining approach,” 2019. [Online]. Available: https://arxiv.org/abs/1907.11692. [Google Scholar]
19. M. Mintz, S. Bills, R. Snow and D. Jurafsky, “Distant supervision for relation extraction without labeled data,” in Proc. of the Joint Conf. of the 47th Annual Meeting of the ACL and the 4th Int. Joint Conf. on Natural Language Processing of the AFNLP, Suntec, Singapore, pp. 1003–1011, 2009. [Google Scholar]
20. Y. S. Chan and D. Roth, “Exploiting syntactico-semantic structures for relation extraction,” in Proc. of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, Oregon, pp. 551–560, 2011. [Google Scholar]
21. D. Nadeau and S. Sekine, “A survey of named entity recognition and classification,” Lingvisticae Investigationes, vol. 30, no. 1, pp. 3–26, 2007. [Google Scholar]
22. Z. Zhong and D. Chen, “A frustratingly easy approach for entity and relation extraction,” 2020. [Online]. Available: https://arxiv.org/abs/2010.12812. [Google Scholar]
23. P. Chen, H. Ding, J. Araki and R. Huang, “Explicitly capturing relations between entity mentions via graph neural networks for domain-specific named entity recognition,” in Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Language Processing, Bangkok, Thailand, vol. 2, pp. 735–742, 2021. [Google Scholar]
24. N. Alsaaran and M. Alrabiah, “Arabic named entity recognition: A bert-bgru approach,” Computers Materials & Continua, vol. 68, no. 1, pp. 471–485, 2021. [Google Scholar]
25. B. Rink and S. Harabagiu, “Utd: Classifying semantic relations by combining lexical and semantic resources,” in Proc. of the 5th Int. Workshop on Semantic Evaluation, Uppsala, Sweden, pp. 256–259, 2010. [Google Scholar]
26. Y. Xu, L. Mou, G. Li, Y. Chen, H. Peng et al., “Classifying relations via long short term memory networks along shortest dependency paths,” in Proc. of the 2015 Conf. on Empirical Methods in Natural Language Processing, Lisbon, Portugal, pp. 1785–1794, 2015. [Google Scholar]
27. S. Zheng, J. Xu, P. Zhou, H. Bao, Z. Qi et al., “A neural network framework for relation extraction: Learning entity semantic and relation pattern,” Knowledge-Based Systems, vol. 114, no. 8, pp. 12–23, 2016. [Google Scholar]
28. Q. Yue, X. Li and D. Li, “Chinese relation extraction on forestry knowledge graph construction,” Computer Systems Science and Engineering, vol. 37, no. 3, pp. 423–442, 2021. [Google Scholar]
29. X. Yu and W. Lam, “Jointly identifying entities and extracting relations in encyclopedia text via a graphical model approach,” in Coling 2010: Posters, Beijing, China: Coling 2010 Organizing Committee, pp. 1399–1407, 2010. [Google Scholar]
30. M. Miwa and Y. Sasaki, “Modeling joint entity and relation extraction with table representation,” in Proc. of the 2014 Conf. on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, pp. 1858–1869, 2014. [Google Scholar]
31. M. Miwa and M. Bansal, “End-to-end relation extraction using lstms on sequences and tree structures,” 2016. [Online]. Available: https://arxiv.org/abs/1601.00770. [Google Scholar]
32. Z. Yan, C. Zhang, J. Fu, Q. Zhang and Z. Wei, “A partition filter network for joint entity and relation extraction,” 2021. [Online]. Available: https://arxiv.org/abs/2108.12202. [Google Scholar]
33. T. Santosh, P. Chakraborty, S. Dutta, D. K. Sanyal and P. P. Das, “Joint entity and relation extraction from scientific documents: Role of linguistic information and entity types,” in Proc. of the 2nd Workshop on Extraction and Evaluation of Knowledge Entities from Scientific Documents (EEKE2021), Virtual Event, 2021. [Google Scholar]
34. S. Zhao, M. Hu, Z. Cai and F. Liu, “Modeling dense cross-modal interactions for joint entity-relation extraction,” in Proc. of the Twenty-Ninth Int. Conf. on International Joint Conf. on Artificial Intelligence, Montreal-themed virtual reality, pp. 4032–4038, 2021. [Google Scholar]
35. D. Ye, Y. Lin and M. Sun, “Pack together: Entity and relation extraction with levitated marker,” 2021. [Online]. Available: https://arxiv.org/abs/2109.06067. [Google Scholar]
36. S. Zheng, F. Wang, H. Bao, Y. Hao, P. Zhou et al., “Joint extraction of entities and relations based on a novel tagging scheme,” 2017. [Online]. Available: https://arxiv.org/abs/1706.05075. [Google Scholar]
37. P. Gupta, H. Schütze and B. Andrassy, “Table filling multi-task recurrent neural network for joint entity and relation extraction,” in Proc. of COLING 2016, the 26th Int. Conf. on Computational Linguistics: Technical Papers, Osaka, Japan, pp. 2537–2547, 2016. [Google Scholar]
38. J. Wang and W. Lu, “Two are better than one: Joint entity and relation extraction with table-sequence encoders,” 2020. [Online]. Available: https://arxiv.org/abs/2010.03851. [Google Scholar]
39. P.-L. H. Cabot and R. Navigli, “Rebel: Relation extraction by end-to-end language generation,” in Findings of the Association for Computational Linguistics: EMNLP 2021, Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, pp. 2370–2381, 2021. [Google Scholar]
40. X. Zeng, D. Zeng, S. He, K. Liu and J. Zhao, “Extracting relational facts by an end-to-end neural model with copy mechanism,” in Proc. of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, vol. 1, pp. 506–514, 2018. [Google Scholar]
41. D. Zeng, H. Zhang and Q. Liu, “Copymtl: Copy mechanism for joint extraction of entities and relations with multi-task learning,” Proceedings of the AAAI Conference on Artificial Intelligence, Hilton New York Midtown, New York, New York, USA, pp. 9507–9514, 2020. [Google Scholar]
42. R. Takanobu, T. Zhang, J. Liu and M. Huang, “A hierarchical framework for relation extraction with reinforcement learning,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 7072–7079, 2019. [Google Scholar]
43. D. Dai, X. Xiao, Y. Lyu, S. Dou, Q. She et al., “Joint extraction of entities and overlapping relations using position-attentive sequence labeling,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 6300–6308, 2019. [Google Scholar]
44. K. Ding, S. Liu, Y. Zhang, H. Zhang, X. Zhang et al., “A knowledge-enriched and span-based network for joint entity and relation extraction,” Computers Materials & Continua, vol. 68, no. 1, pp. 377–389, 2021. [Google Scholar]
45. K. Dixit and Y. Al-Onaizan, “Span-level model for relation extraction,” in Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, pp. 5308–5314, 2019. [Google Scholar]
46. Y. Luan, D. Wadden, L. He, A. Shah, M. Ostendorf et al., “A general framework for information extraction using dynamic span graphs,” 2019. [Online]. Available: https://arxiv.org/abs/1904.03296. [Google Scholar]
47. D. Wadden, U. Wennberg, Y. Luan and H. Hajishirzi, “Entity, relation, and event extraction with contextualized span representations,” 2019. [Online]. Available: https://arxiv.org/abs/1909.03546. [Google Scholar]
48. I. O. Tolstikhin, N. Houlsby, A. Kolesnikov, L. Beyer, X. Zhai et al., Mlp-mixer: An all-mlp architecture for vision. In: Advances in Neural Information Processing Systems. Virtual, Vol. 34, 2021. [Google Scholar]
49. I. Beltagy, K. Lo and A. Cohan, “Scibert: A pretrained language model for scientific text,” in Proc. of the 2019 Conf. on Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 2019. [Google Scholar]
50. J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim et al., “Biobert: A pre-trained biomedical language representation model for biomedical text mining,” Bioinformatics, vol. 36, no. 4, pp. 1234–1240, 2020. [Google Scholar]
51. D. Roth and W.-t Yih, “A linear programming formulation for global inference in natural language tasks,” Illinois Univ at Urbana-Champaign Dept of Computer Science, 2004. [Google Scholar]
52. H. Gurulingappa, A. M. Rajput, A. Roberts, J. Fluck, M. Hofmann-Apitius et al., “Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports,” Journal of Biomedical Informatics, vol. 45, no. 5, pp. 885–892, 2012. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |