DOI:10.32604/iasc.2023.027865
| Intelligent Automation & Soft Computing DOI:10.32604/iasc.2023.027865 | |
| Article |
Ensemble Deep Learning with Chimp Optimization Based Medical Data Classification
1Department of Computer Science and Information Systems, College of Applied Sciences, AlMaarefa University, Ad Diriyah, Riyadh, 13713, Kingdom of Saudi Arabia
2Department of Computer Engineering, College of Computers and Information Technology, Taif University, Taif, 21944, Kingdom of Saudi Arabia
3Department of Computing, Arabeast Colleges, Riyadh, 11583, Kingdom of Saudi Arabia
4Department of Basic Medical Sciences, College of Medicine. Almaarefa University, AlMaarefa University, Ad Diriyah, Riyadh, 13713, Kingdom of Saudi Arabia
5Department of Archives and Communication, King Faisal University, Al Ahsa, Hofuf, 31982, Kingdom of Saudi Arabia
*Corresponding Author: Ashit Kumar Dutta. Email: drashitkumar@yahoo.com
Received: 27 January 2022; Accepted: 07 March 2022
Abstract: Eye state classification acts as a vital part of the biomedical sector, for instance, smart home device control, drowsy driving recognition, and so on. The modifications in the cognitive levels can be reflected via transforming the electroencephalogram (EEG) signals. The deep learning (DL) models automated extract the features and often showcased improved outcomes over the conventional classification model in the recognition processes. This paper presents an Ensemble Deep Learning with Chimp Optimization Algorithm for EEG Eye State Classification (EDLCOA-ESC). The proposed EDLCOA-ESC technique involves min-max normalization approach as a pre-processing step. Besides, wavelet packet decomposition (WPD) technique is employed for the extraction of useful features from the EEG signals. In addition, an ensemble of deep sparse autoencoder (DSAE) and kernel ridge regression (KRR) models are employed for EEG Eye State classification. Finally, hyperparameters tuning of the DSAE model takes place using COA and thereby boost the classification results to a maximum extent. An extensive range of simulation analysis on the benchmark dataset is carried out and the results reported the promising performance of the EDLCOA-ESC technique over the recent approaches with maximum accuracy of 98.50%.
Keywords: EEG eye state; data classification; deep learning; medical data analysis; chimp optimization algorithm
At present, the electroencephalography (EEG) eye state category is the most important research field. In several analyses on EEG signal was executed. The outcomes in these analyses are essential and helpful to human cognitive state types that aren't only vital for clinical care along with important to any daily routine task [1]. For instance, EEG eye state type was effectively implemented from the regions of infant sleep-waking state recognition, drive drowsiness recognition, epileptic seizure recognition, type of bipolar mood disorder (BMD) and attention deficit hyperactivity disorder (ADHD) patient, stress feature recognition, human eye blinking recognition, etc. These situations specify the significance of researches on EEG eye state signal study [2]. In a typical cases, the data describe EEG eye state relates to the constant category of time-series data. The amount of machine learning (ML) and statistical methods that are utilized for resolving the classifier issues with this time-series data. In addition, preceding researches have confirmed that EEG eye state signal was effectively examined by any ML or statistical techniques [3].
A major problem with EEG based system is the interruption of artefacts from the signal. Artefacts are maximum frequency signals that deal with non-cerebral sources and is dramatically change the recorded signals [4]. The artefacts are separated as to 2 groups as internal as well as external. The external artefacts were created in the environments or power equipment. The internal artefacts are muscle, eye blink, respiratory artefacts, and eye movement [5]. In the EEG experimentally processes, the issues could not control spontaneous eye movement or blinking [6]. These artefacts are nearly every case is extremely distorted brain activities. So, this occurrence establishes the significance of researches on EEG eye state signal study. In recent times, the area of deep learning (DL) was appealing to widespread concern by creating extraordinary researches from nearly all the aspects of artificial intelligence (AI). Distant from obtaining empirical success from the huge amount of practical applications, it can be offered recent efficiency from natural language processing (NLP), speech detection, object detection, and several other domains [7]. DL has developed most important parts of ML family. It can be dependent upon the group of techniques which try to learn hierarchical, non-linear representation of information.
Zeng et al. [8] present for utilizing deep convolutional neural network (DCNN) and deep reinforcement learning (DRL) for predicting the mental state of driver in EEG signal. Therefore, it can be established 2 mental state classifier techniques named as EEG-Conv and EEG-Conv-R. Testing on intra-and inter-subject, the outcomes depict that combined techniques demonstrate the classical long short term memory (LSTM) and support vector machine (SVM) based techniques. The main outcomes contain (i) Together EEG-Conv and EEG-Conv-R yields great classifier efficiency to mental condition forecast; (ii) EEG-Conv-R has further appropriate to inter-subject mental condition forecast; (iii) EEG-Conv-R converge further faster than EEG-Conv. Zhu et al. [9] examine a content based ensemble method (CBEM) for promoting depression recognition accuracy, combining static as well as dynamic CBEM are explained. During the presented technique, an EEG dataset was separated as to subset with the context of experimental, afterward, the most vote approach has been utilized for determining the subject label. The validation of technique was testified on 2 datasets that contained free observing eye track and resting state EEG, and these 2 datasets contain 36, 34 subjects correspondingly.
In Hu et al. [10], for catching the vital features of EEG signal, 4 kinds of entropies (dependent upon EEG signals of single channel) are estimated as feature sets containing instance entropy, fuzzy entropy, estimated entropy, and spectral entropy. Every feature set was utilized as input of gradient boosting decision tree (GBDT), quick and extremely accurate boosting ensemble technique. The resultant of GBDT defined that drivers from fatigue state or not dependent upon its EEG signal. In 3 recent techniques are k-nearest neighbor (KNN), SVM, and neural network (NN) are also utilized. Durongbhan et al. [11] purposes for exploring a routine for gaining as biomarker utilizing the quantitative analysis of electroencephalography (QEEG). It can present a supervised classifier structure that utilizes EEG signals for classifying healthy controls (HC) and Alzheimer's disease (AD) participants. The structure has KNN, data augmentation, quantitative evaluation, feature extraction, and topographic visualization. The presented structure is efficiently classified HC as well as AD participants with maximum accuracy, in the meantime present identification and localization of important QEEG feature. These vital finding and the presented classifier structure was utilized to the progress of biomarker to the analysis and observing of disease development from AD.
In Woon et al. [12], it is examined the classification of EEG eye state data utilizing statistical and common spatial pattern (CSP) filter approaches. The statistical feature was implemented from EEG signal classification of eye-as well as eye-open situations however the accuracy was stated that lesser than 78%. The CSP filters have famous techniques to classifier of motor imagery EEG from the brain computer interface (BCI) field however if executed to EEG eye state classifier. So, this work purposes for developing technique utilizing statistical-CSP feature to eye state classifier in EEG signals. The benefit on the discriminative feature given by combined approaches, statistical as well as CSP filters that is estimated for increasing the accuracy of eye state classifier technique. In Yasoda et al. [13], a new technique of independent component analysis (WICA) utilizing fuzzy kernel SVM (FKSVM) was presented to eliminate as well as categorize the EEG artefacts automatically. The presented technique is an effectual and robust model for adopting the robotic classifier and artefact calculation in EEG signals without obviously offering the cut-off value. Also, the target artefacts were distant effectively from integrating with WICA as well as FKSVM.
This paper presents an Ensemble Deep Learning with Chimp Optimization Algorithm for EEG Eye State Classification (EDLCOA-ESC). The proposed EDLCOA-ESC technique involves min-max normalization approach as a pre-processing step. Besides, wavelet packet decomposition (WPD) technique is employed for the extraction of useful features from the EEG signals. In addition, an ensemble of deep sparse autoencoder (DSAE) and kernel ridge regression (KRR) models are employed for EEG Eye State classification. Finally, hyperparameters tuning of the DSAE model takes place using COA and thereby boost the classification results to a maximum extent. An extensive range of simulation analyses on the benchmark dataset is carried out.
In this study, a new EDLCOA-ESC technique has been developed for EEG Eye State Classification. The proposed EDLCOA-ESC technique involves min-max normalization based pre-processing step, WPD based feature extraction, ensemble classification, and COA based hyperparameter tuning. Also, an ensemble of DSAE and KRR methods are employed for EEG Eye State classification. At last, hyperparameters tuning of the DSAE model take place using COA and thereby boost the classification results to a maximum extent. Fig. 1 depicts the overall process of EDLCOA-ESC technique.
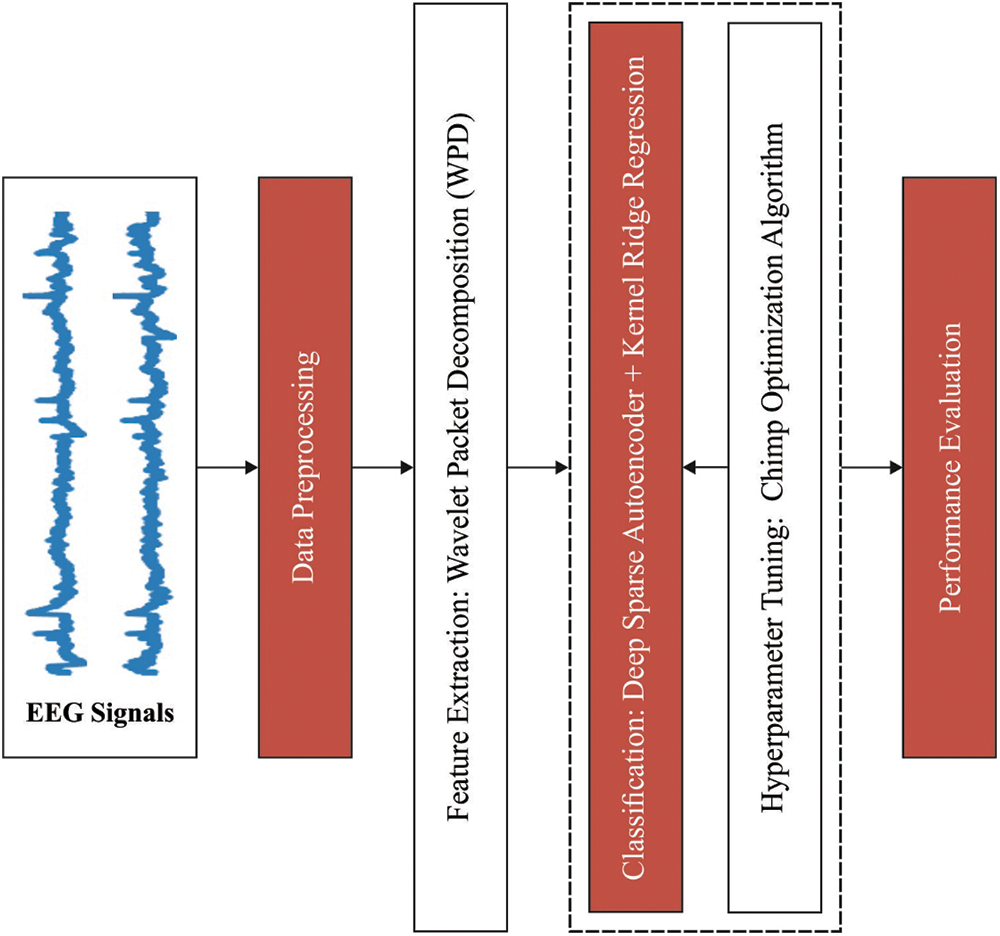
Figure 1: Overall process of EDLCOA-ESC technique
The scaling represents altering data which are various scales for obtaining off biases because of the occurrence of outliers. The most commonly used approach of feature scaling was Mini-Maxi normalized. Mini-Maxi normalized changes the signal values of some range as to zero and one. The common equation of Mini-Maxi normalized was written as:
At this point m and m′ are novel and normalization values correspondingly.
WPD based method was established for extracting features of EEG signal. The co-efficient of WPD and wavelet packet energy of special subbands were obtained as the novel feature. Noticeable during the presented technique defining appropriate wavelet and the amount of decomposition levels are serious. Especially, distinct kinds of wavelets were generally utilized from tests for finding the wavelet with maximal performance to specific applications. The smoothing feature of daubechies 4 (db4) wavelet is further appropriate to detect modifies of EEG signal. Therefore, it can be utilized this approach for computing the wavelet coefficient.
2.3 Ensemble of DL Based Classification
At this stage, an ensemble of DSAE and KRR models are employed for EEG Eye State classification process is carried out. DSAE can resolve the issue of trivial identity maps by implementing sparsity constraints. Autoencoder (AE) execute sparsity regularized constraint to hidden unit is named as DSAEs. The neuron was noticing that when its outcome values are closer to 1 and it can be deemed that inactive when its outcome values are closer to 0. It desires for adding constraints that output is nearby 0 normally. Assume the average activation of hidden layer j as:
It desires to be estimated
is the KL divergence. With adding KL divergence terms its cost function develops as:
where β denotes the weight of sparsity regularized term. With minimized this cost function, it is optimizing parameters
A typical RR [15], the part of hidden state is for mapping the input state neuron to hidden state neuron that is hidden state neuron of RR are mapped data in the data space to any high dimension space, in which all dimensions relates to hidden neurons. Therefore, the efficacy of RR is commonly dependent upon the hidden state neuron and it can be application particular. For avoiding the oversaid hidden neurons selective issue a KRR was utilized for classifying every microarray clinical data set. In KRR, a positive regularize co-efficient C was established for making it further generalization and stability. The resultant weight β is
At this point H refers the hidden state resultant matrix, C signifies the regulation co-efficient and T implies the resultant matrix. The resultant function of KRR develops
At this time, before significant, the hidden state feature map, h(x), their equivalent
So the resultant of kernel ridge regression is expressed as:
where θRR = HHT and
• Radial basis kernel
• Wavelet kernel
KRR is useful in comparison to RR as there is no condition of significant the hidden state feature map and set the amount of hidden state neuron L. It gets optimum generalized, most stable related to RR, and is over SVM.
2.4 COA Based Hyperparameter Optimization
Lastly, the hyperparameters tuning of the DSAE model takes place using COA and thereby boost the classification results to a maximum extent. COA is a mathematical process which is dependent upon intelligent diversity [17]. Drive, chase, block, and attack were accomplished by 4 distinct kinds of chimps that are able by attacker, driver, obstacle, and chaser. The 4 hunting stages were ended in 2 phases. The primary phase was exploration step, and secondary phase was exploitation step. The exploration step contains driving, blocking, and chasing the prey.
During the exploitation step, it has for attacking the prey whereas, the drive and chase were demonstrated in Eqs. (11) and (12).
where Xprey implies the vector of prey place, xchimp refers the vector of chimp place, t signifies the amount of existing iterations,
where f non-linearly decayed in 2.5 to
The chimps are upgraded their places dependent upon the other chimps, and this mathematical process is signified in Eqs. (16) and (18).
The experimental result analysis of the EDLCOA-ESC technique is tested using the benchmark dataset from UCI repository (available at https://archive.ics.uci.edu/ml/datasets/EEG+Eye+State). The dataset holds 14980 instances, with two classes namely eye closed with 6723 instances (class 1) and eye open (class 0) with 8257 instances.
Fig. 2 shows the correlation matrix generated for the benchmark EEG Eye state dataset.
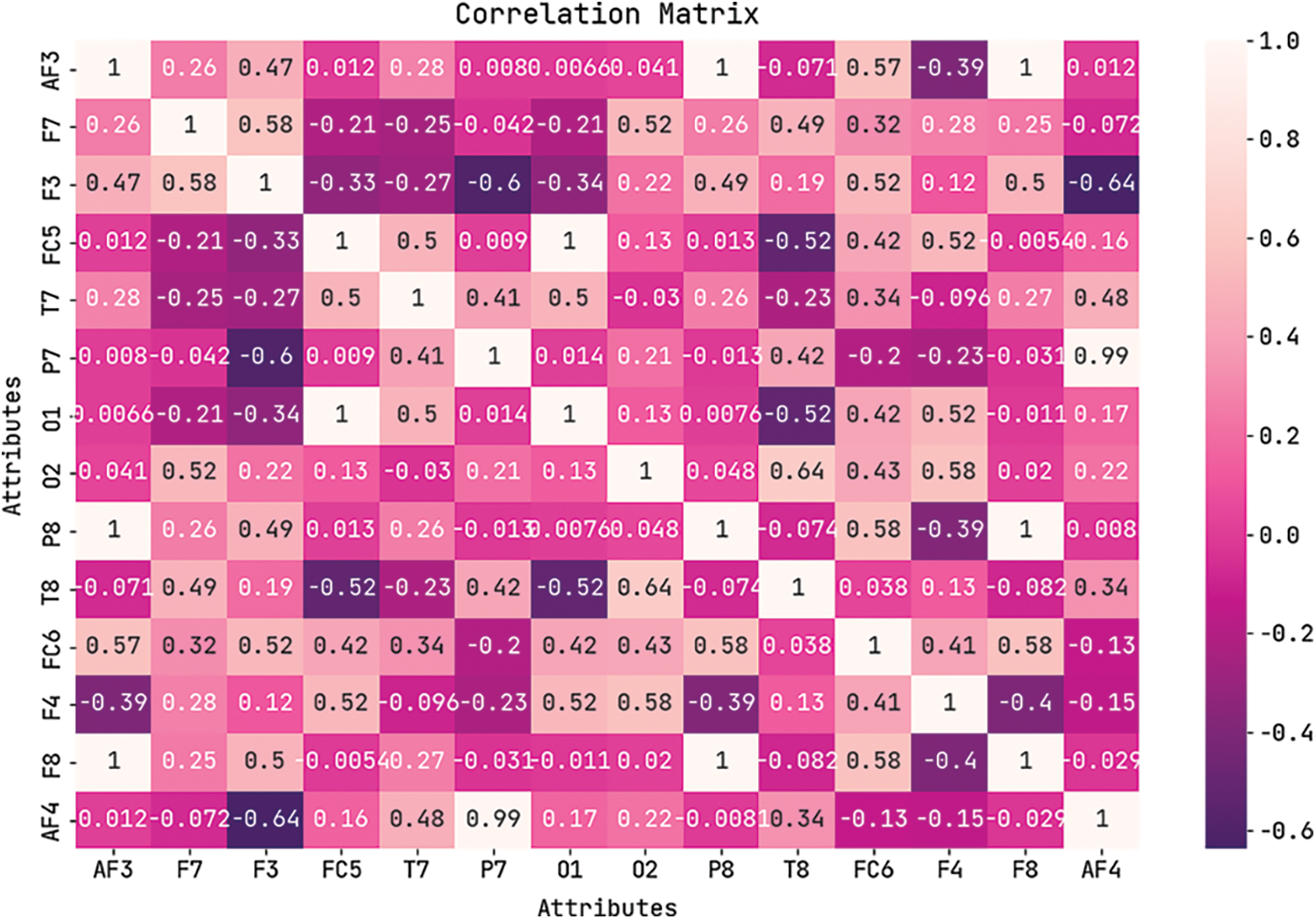
Figure 2: Correlation matrix of EDLCOA-ESC technique
Fig. 3 demonstrates the confusion matrices created by the EDLCOA-ESC technique under ten distinct runs. The results demonstrated that the EDLCOA-ESC technique has effectually identified proper class labels. For instance, with run-1, the EDLCOA-ESC technique has recognized 6624 instances under class 1 and 8143 instances under class 0. Meanwhile, with run-4, the EDLCOA-ESC approach has recognized 6614 instances under class 1 and 8145 instances under class 0. Eventually, with run-6, the EDLCOA-ESC method has recognized 6609 instances under class 1 and 8154 instances under class 0. Concurrently, with run-8, the EDLCOA-ESC approach has recognized 6593 instances under class 1 and 8166 instances under class 0. Simultaneously, with run-10, the EDLCOA-ESC system has recognized 6616 instances under class 1 and 8147 instances under class 0.
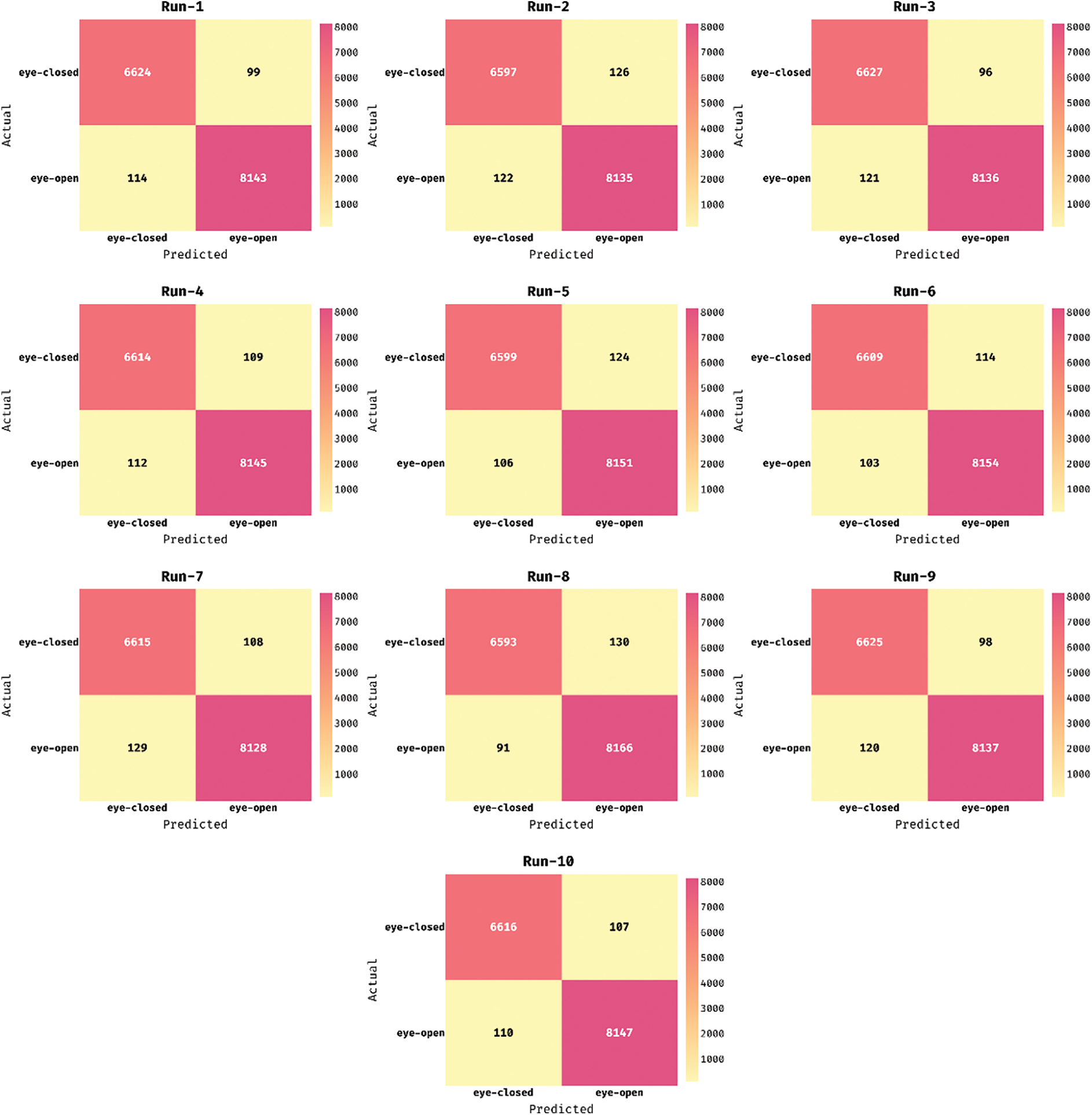
Figure 3: Confusion matrix of EDLCOA-ESC technique under different runs
Tab. 1 and Fig. 4 illustrate the overall classifier results analysis of the EDLCOA-ESC technique under distinct runs. The table values indicated that the EDLCOA-ESC technique has resulted in enhanced classifier results under every run. For instance, with run-1, the EDLCOA-ESC technique has obtained positive predictive value (PPV) of 98.31%, true positive rate (TPR) of 98.53%, accuy of 98.58%, F1score of 98.42%, and kappa coefficient of 98.22%. In addition, with run-4, the EDLCOA-ESC methodology has reached PPV of 98.33%, TPR of 98.38%, accuy of 98.52%, F1score of 98.36%, and kappa coefficient of 98.15%. Also, with run-6, the EDLCOA-ESC approach has gained PPV of 98.47%, TPR of 98.3%, accuy of 98.55%, F1score of 98.38%, and kappa coefficient of 98.19%. Along with that, with run-8, the EDLCOA-ESC system has achieved PPV of 98.64%, TPR of 98.07%, accuy of 98.52%, F1score of 98.35%, and kappa coefficient of 98.16%. Moreover, with run-9, the EDLCOA-ESC approach has attained PPV of 98.22%, TPR of 98.54%, accuy of 98.54%, F1score of 98.38%, and kappa coefficient of 98.18%. Lastly, with run-10, the EDLCOA-ESC methodology has obtained PPV of 98.36%, TPR of 98.41%, accuy of 98.55%, F1score of 98.39%, and kappa coefficient of 98.19%.
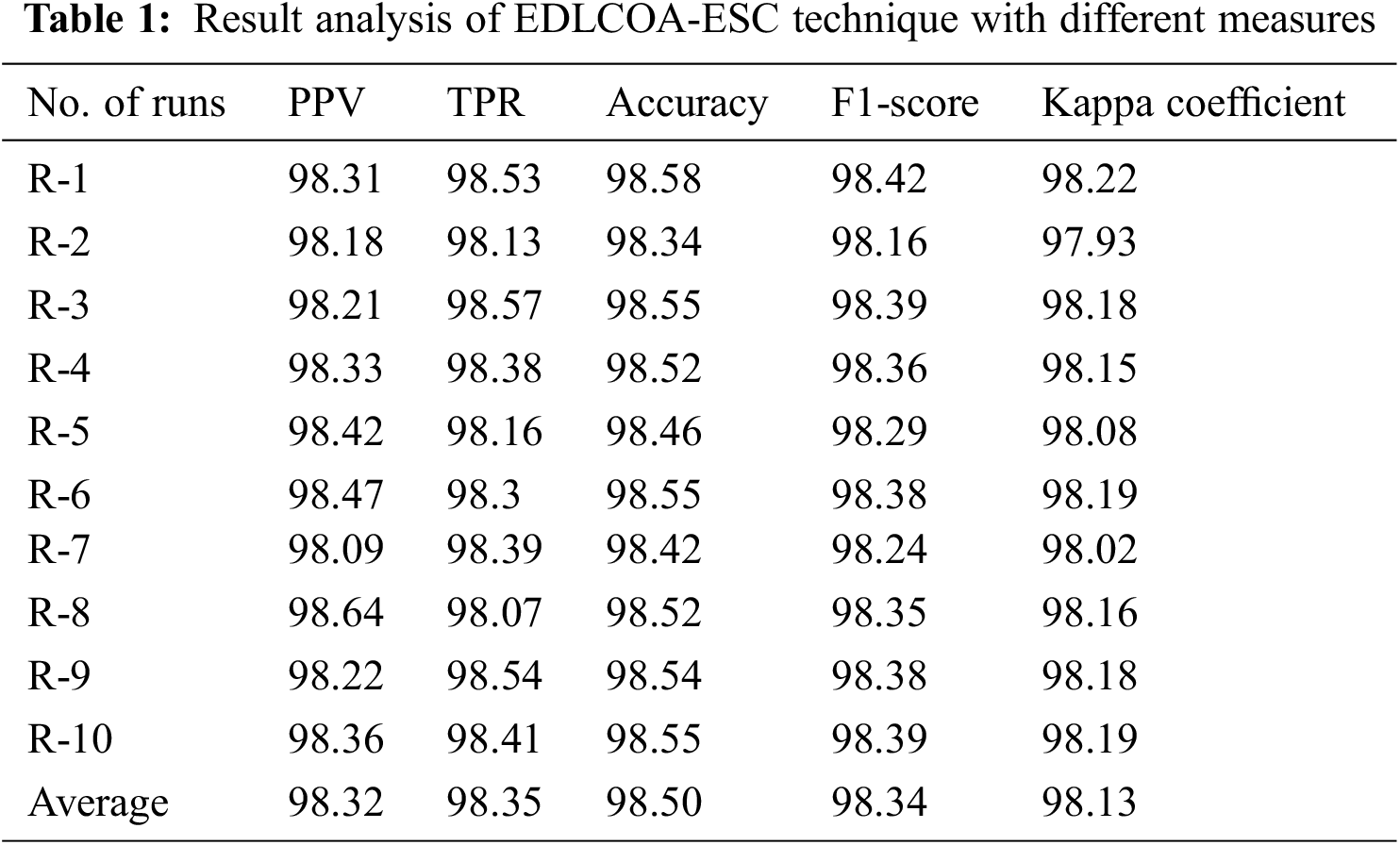
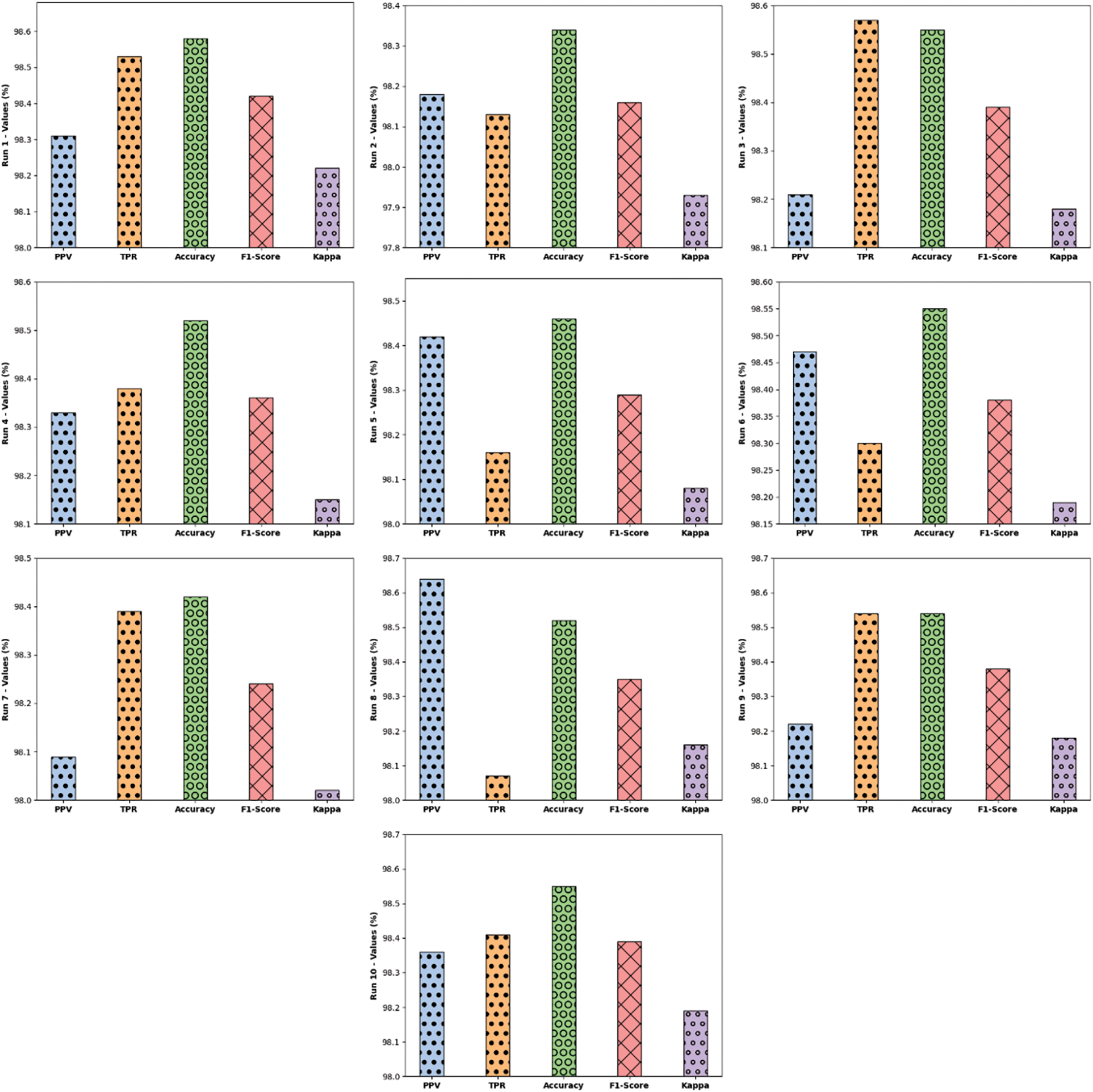
Figure 4: Result analysis of EDLCOA-ESC technique with distinct measures
Fig. 5 illustrates the overall average EEG Eye State classification result analysis of the EDLCOA-ESC technique. The figure reported the enhanced performance of the EDLCOA-ESC technique with the PPV of 98.32%, TPR of 98.35%, accuy of 98.50%, F1score of 98.34%, and kappa coefficient of 98.13%.
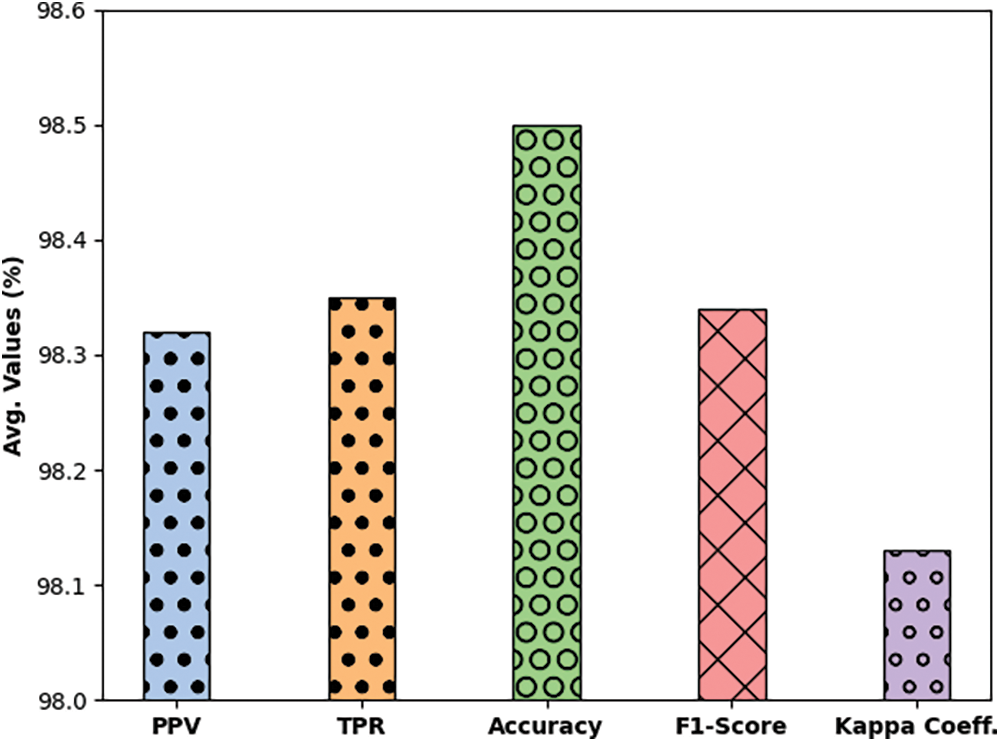
Figure 5: Average analysis of EDLCOA-ESC technique
The accuracy outcome analysis of the EDLCOA-ESC technique on the test data is demonstrated in Fig. 6. The results exhibited that the EDLCOA-ESC system has accomplished enhanced validation accuracy compared to training accuracy. It is also observable that the accuracy values get saturated with the epoch count of 1000.
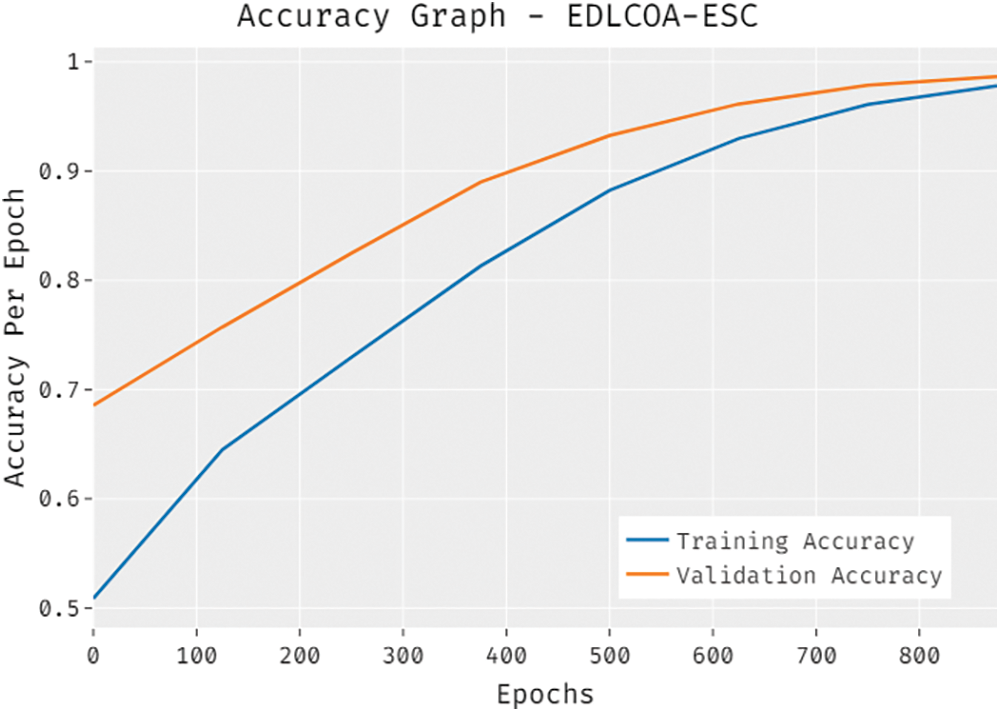
Figure 6: Accuracy graph analysis of EDLCOA-ESC technique
The loss outcome analysis of the EDLCOA-ESC approach on the test data is exhibited in Fig. 7. The figure described that the EDLCOA-ESC method has denoted the lower validation loss over the training loss. It is additionally clear that the loss values get saturated with the epoch count of 1000.
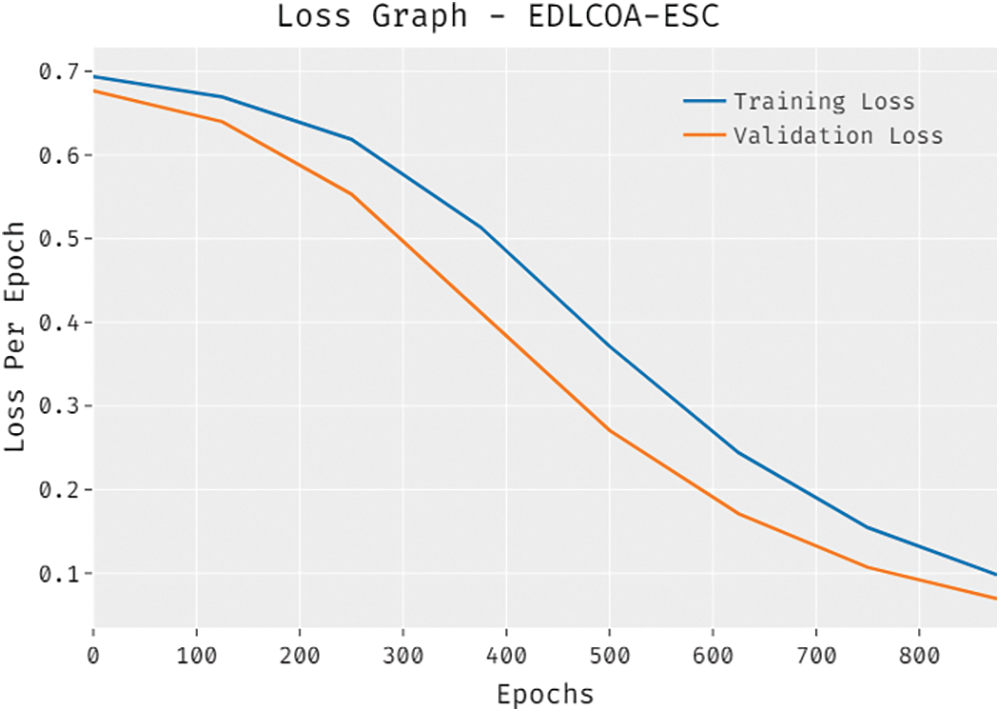
Figure 7: Loss graph analysis of EDLCOA-ESC technique
The comparative result analysis of the EDLCOA-ESC technique with recent methods is provided in Tab. 2 [19].
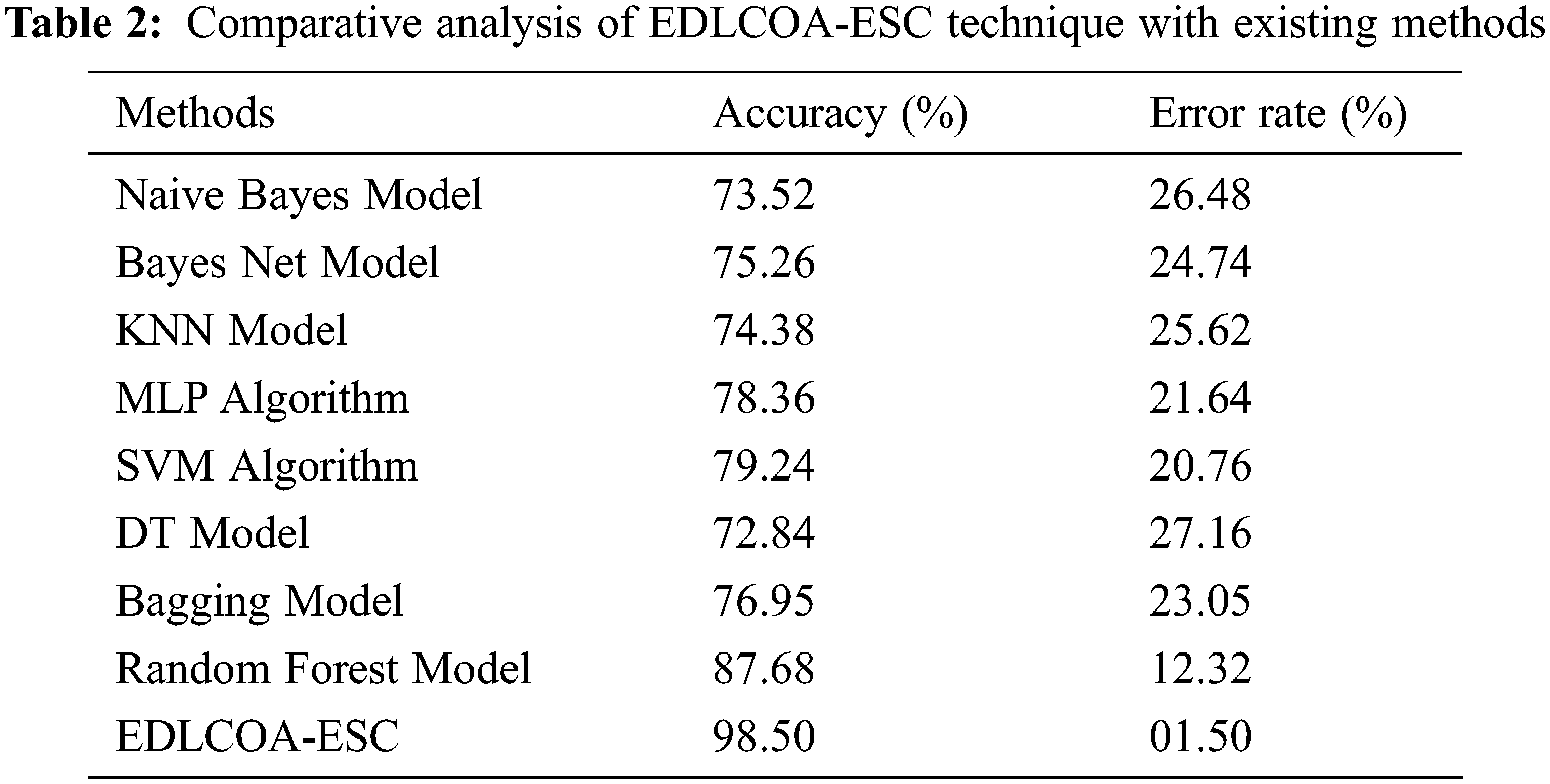
Fig. 8 demonstrates the comparison study of the EDLCOA-ESC technique with existing ones interms of accuy. The results showed that the Naïve Bayes, Bayes Net, KNN, decision tree (DT), and Bagging techniques have attained ineffective outcomes with the accuy of 73.52%, 75.26%, 74.38%, 72.84%, and 76.95% respectively, In line with, the multilayer perceptron (MLP) and SVM models have resulted in moderately improved outcome with the accuy of 78.36% and 79.24% respectively. Though the RF model has attained near optimal outcome with accuy of 87.58%, the proposed EDLCOA-ESC technique has outperformed the other methods with the higher accuy of 98.50%.
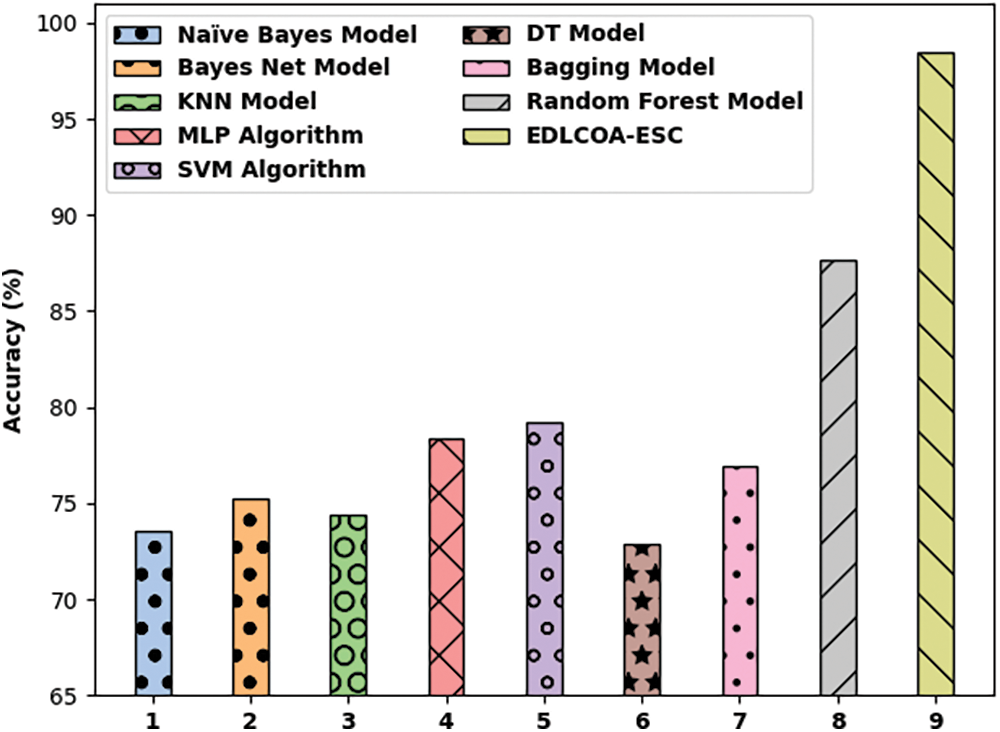
Figure 8: Accuracy analysis of EDLCOA-ESC technique with recent methods
Fig. 9 depicts the comparison study of the EDLCOA-ESC approach with existing ones with respect to error rate (ER). The outcomes demonstrated that the Naïve Bayes, Bayes Net, KNN, DT, and Bagging techniques have attained ineffective outcomes with the ER of 26.48%, 24.74%, 25.62%, 27.16%, and 23.05% correspondingly. Also, the MLP and SVM methodologies have resulted in moderately improved outcomes with the ER of 21.64% and 20.76% correspondingly. Eventually, the RF approach has gained near optimal outcome with ER of 12.32%, the presented EDLCOA-ESC system has demonstrated the other techniques with the lower ER of 1.50%.
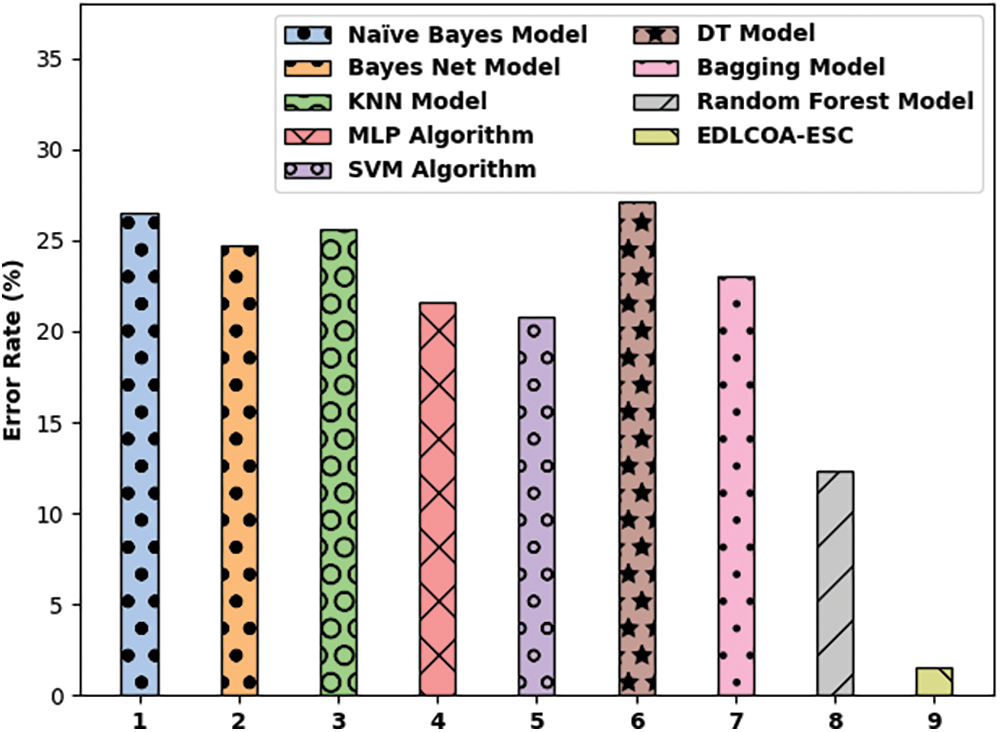
Figure 9: Error rate analysis of EDLCOA-ESC technique with recent methods
By looking into the above mentioned tables and figures, the proposed EDLCOA-ESC technique has accomplished better performance over the other existing techniques.
In this study, a new EDLCOA-ESC technique has been developed for EEG Eye State Classification. The proposed EDLCOA-ESC technique involves min-max normalization based pre-processing step, WPD based feature extraction, ensemble classification, and COA based hyperparameter tuning. In addition, an ensemble of DSAE and KRR models are employed for EEG Eye State classification. At last, hyperparameters tuning of the DSAE model take place using COA and thereby boost the classification results to a maximum extent. An extensive range of simulation analysis on the benchmark dataset is carried out and the results reported the promising performance of the EDLCOA-ESC technique over the recent approaches with the higher accuy of 98.50%. In future, hybrid DL models can be utilized instead of DSAE model to enhance the classification results.
Acknowledgement: The authors deeply acknowledge the Researchers supporting program (TUMA-Project-2021–27) Almaarefa University, Riyadh, Saudi Arabia for supporting steps of this work. The authors deeply acknowledge the Researchers Supporting Program (TUMA-Project-2021–33), Almaarefa University, Riyadh, Saudi Arabia for supporting steps of this work.
Funding Statement: This research was supported by the Researchers Supporting Program (TUMA-Project-2021–27) Almaarefa University, Riyadh, Saudi Arabia. Taif University Researchers Supporting Project Number (TURSP-2020/161), Taif University, Taif, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. T. Wang, S. U. Guan, K. L. Man and T. O. Ting, “EEG eye state identification using incremental attribute learning with time-series classification,” Mathematical Problems in Engineering, vol. 2014, pp. 1–9, 2014. [Google Scholar]
2. C. Hao, W. Li and S. Du, “Classification of EEG in eyes-open and eyes-closed state based on limited penetrable visibility graph,” in 2016 IEEE Int. Conf. on Cyber Technology in Automation, Control, and Intelligent Systems (CYBER), Chengdu, China, pp. 448–451, 2016. [Google Scholar]
3. X. R. Zhang, W. F. Zhang, W. Sun, X. M. Sun and S. K. Jha, “A robust 3-D medical watermarking based on wavelet transform for data protection,” Computer Systems Science & Engineering, vol. 41, no. 3, pp. 1043–1056, 2022. [Google Scholar]
4. X. R. Zhang, X. Sun, X. M. Sun, W. Sun and S. K. Jha, “Robust reversible audio watermarking scheme for telemedicine and privacy protection,” Computers, Materials & Continua, vol. 71, no. 2, pp. 3035–3050, 2022. [Google Scholar]
5. S. Narejo, E. Pasero and F. Kulsoom, “EEG based Eye state classification using deep belief network and stacked AutoEncoder,” International Journal of Electrical and Computer Engineering (IJECE), vol. 6, no. 6, pp. 3131, 2016. [Google Scholar]
6. T. Wang, S. U. Guan, K. L. Man and T. O. Ting, “Time series classification for EEG eye state identification based on incremental attribute learning,” in 2014 Int. Symp. on Computer, Consumer and Control, Taichung, Taiwan, pp. 158–161, 2014. [Google Scholar]
7. L. Ma, J. W. Minett, T. Blu and W. S. Y. Wang, “Resting state EEG-based biometrics for individual identification using convolutional neural networks,” in 2015 37th Annual Int. Conf. of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, pp. 2848–2851, 2015. [Google Scholar]
8. H. Zeng, C. Yang, G. Dai, F. Qin, J. Zhang et al. “EEG classification of driver mental states by deep learning,” Cognitive Neurodynamics, vol. 12, no. 6, pp. 597–606, 2018. [Google Scholar]
9. J. Zhu, Z. Wang, T. Gong, S. Zeng, X. Li et al. “An improved classification model for depression detection using eeg and eye tracking data,” IEEE Transactions on NanoBioscience, vol. 19, no. 3, pp. 527–537, 2020. [Google Scholar]
10. J. Hu and J. Min, “Automated detection of driver fatigue based on EEG signals using gradient boosting decision tree model,” Cognitive Neurodynamics, vol. 12, no. 4, pp. 431–440, 2018. [Google Scholar]
11. P. Durongbhan, Y. Zhao, L. Chen, P. Zis, M. D. Marco et al. “A dementia classification framework using frequency and time-frequency features based on EEG signals,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 27, no. 5, pp. 826–835, 2019. [Google Scholar]
12. W. C. Woon, N. Yahya and N. Badruddin, “EEG eye state identification based on statistical feature and common spatial pattern filter,” in 2019 IEEE Student Conf. on Research and Development (SCOReD), Bandar Seri Iskandar, Malaysia, pp. 225–230, 2019. [Google Scholar]
13. K. Yasoda, R. S. Ponmagal, K. S. Bhuvaneshwari and K. Venkatachalam, “Automatic detection and classification of EEG artifacts using fuzzy kernel SVM and wavelet ICA (WICA),” Soft Computing, vol. 24, no. 21, pp. 16011–16019, 2020. [Google Scholar]
14. B. Abraham and M. Nair, “Computer-aided diagnosis of clinically significant prostate cancer from MRI images using sparse autoencoder and random forest classifier,” Biocybernetics and Biomedical Engineering, vol. 38, no. 3, pp. 733–744, 2018. [Google Scholar]
15. C. Saunders, A. Gammerman and V. Vovk, “Ridge regression learning algorithm in dual variables,” in ICML ‘98: Proc. of the Fifteenth Int. Conf. on Machine Learning, San Francisco, CA, United States, pp. 515–521, 1998. [Google Scholar]
16. P. Mohapatra, S. Chakravarty and P. K. Dash, “Microarray medical data classification using kernel ridge regression and modified cat swarm optimization based gene selection system,” Swarm and Evolutionary Computation, vol. 28, pp. 144–160, 2016. [Google Scholar]
17. M. Khishe and M. Mosavi, “Chimp optimization algorithm,” Expert Systems with Applications, vol. 149, pp. 113338, 2020. [Google Scholar]
18. D. Wu, W. Zhang, H. Jia and X. Leng, “Simultaneous feature selection and support vector machine optimization using an enhanced chimp optimization algorithm,” Algorithms, vol. 14, no. 10, pp. 282, 2021. [Google Scholar]
19. E. Antoniou, P. Bozios, V. Christou, K. D. Tzimourta, K. Kalafatakis et al. “EEG-Based eye movement recognition using brain–computer interface and random forests,” Sensors, vol. 21, no. 7, pp. 2339, 2021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |