DOI:10.32604/cmc.2022.019450
| Computers, Materials & Continua DOI:10.32604/cmc.2022.019450 | |
| Article |
Deep Learning-Based Approach for Arabic Visual Speech Recognition
1Computer Science Department, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, 21589, Saudi Arabia
2Electrical Engineering Department, Faculty of Engineering at Shoubra, Benha University, Cairo, 11629, Egypt
*Corresponding Author: Nadia H. Alsulami. Email: nadiaalsulami@yahoo.com
Received: 14 April 2021; Accepted: 03 June 2021
Abstract: Lip-reading technologies are rapidly progressing following the breakthrough of deep learning. It plays a vital role in its many applications, such as: human-machine communication practices or security applications. In this paper, we propose to develop an effective lip-reading recognition model for Arabic visual speech recognition by implementing deep learning algorithms. The Arabic visual datasets that have been collected contains 2400 records of Arabic digits and 960 records of Arabic phrases from 24 native speakers. The primary purpose is to provide a high-performance model in terms of enhancing the preprocessing phase. Firstly, we extract keyframes from our dataset. Secondly, we produce a Concatenated Frame Images (CFIs) that represent the utterance sequence in one single image. Finally, the VGG-19 is employed for visual features extraction in our proposed model. We have examined different keyframes: 10, 15, and 20 for comparing two types of approaches in the proposed model: (1) the VGG-19 base model and (2) VGG-19 base model with batch normalization. The results show that the second approach achieves greater accuracy: 94% for digit recognition, 97% for phrase recognition, and 93% for digits and phrases recognition in the test dataset. Therefore, our proposed model is superior to models based on CFIs input.
Keywords: Convolutional neural network; deep learning; lip reading; transfer learning; visual speech recognition
Lip-reading recognition system which is also known as Visual Speech Recognition (VSR), plays an essential role in human language communication and visual knowledge. It refers to the ability to learn or recognize visual speech without the need to hear the audio, and it works only with visual data (such as movements of the lips and face). Lip-reading technology is an appealing area of study for researchers because, by recognizing visual information without the need of audio, it introduces a new tool in visual speech recognition for situations in which audio is not available or must be secured professionally. Recognizing spoken words from the speaker’s lip movement is called visual lip-reading, and it is an efficacious communication form in many situations. People with hearing disabilities, for example, can be served by this useful hearing aid [1]. The automatic recognition of visual speech greatly improves human communication by helping handicapped persons via interaction with the machine through the visual information from the speaker's lip, enhancing human speech perception by extracting the visual features. This technology includes the following necessary processes: face detection, lip localization, feature extraction, training the classifier, and recognition of the word [2], as demonstrated in Fig.1.

Figure 1: Visual speech recognition main processes
Lip visual feature extraction is considered the most critical phase in preparing the extracted visual data for the automatic lip-reading model. The existing feature extraction approaches can be classified into two main categories: handcrafted features-based models and deep learning features-based models. In the handcrafted features-based models the geometrical, model-based, appearance-based, image-transformed, and motion-based features are applied to manually extract features as demonstrated in [3]. This approach uses a set of rules and algorithms, including the shape of the lip, contour, mouth height or width, etc. As reviewed by [4], dimensionality reduction techniques have been utilized in handcrafted approaches as in the transformed approaches where images are transformed into a space of feature such as Discrete Cosine Transform (DCT), and the Principal Component Analysis (PCA). Recognition of the spoken words is the next step in which the extracted features have usually been supplied to the classifiers, such as the Hidden Markov Model (HMM) [5]. Recently, deep learning had meaningful artificial progress in the computer vision field. Accordingly, researchers have been encouraged to alter their research direction to focus on lip-reading approaches that are forwarded to deep learning models rather than the traditional manual feature extraction [6]. Recently, researchers have been focused on Convolutional Neural Networks (CNN) to concentrate on: region of interest, classification, and the purpose of image detection. Due to the continuous changes in lip-reading visual data, some researchers intend to apply the Long Short-Term Memory (LSTM) network as will be discussed in the reviewed studies. Indeed, the handcrafted process requires extra knowledge, tedious work by hand, and input data knowledge, which needs more time. In contrast, deep learning-based models avoid these processes, and their basic property is automatic learning for a series of nonlinear features that enhance the performance of many tasks in computer vision [7].
Nowadays, researchers intended to replace any spoken word with CFI, as input representation in the CNN model, where each video converts into one single image. Some researchers employed the concept of stretching the sequence with the nearest image to a specific length to normalize the speaking speed, and others have produced the CFI with a fixed number of frames [8].
The importance of this research is due to the limited studies for developing a lip-reading technology in the Arab region particularly in the deep learning area. Therefore, this paper aims to develop a lip-reading model for the Arabic word recognition, to classify the lip images extracted from the video database by applying a high-performance features extraction method, and by utilizing CNN to achieve a high accuracy recognition of Arabic words.
The key contributions of this research are:
1) Building an Arabic visual dataset to evaluate and test the proposed model, the videos were collected from different native speakers, taking into consideration all the suitable environments.
2) Applying the concept of the concatenated stretched image to produce CFIs for the input of videos after applying the keyframes selection technique for the first time in the Arabic visual dataset to the best of our knowledge.
3) Investigating transfer learning different models of deep learning, Visual Geometry Group (VGG19), and VGG19 combined with Batch Normalization (BN).
The paper is structured as follows: Section 2 summarizes the related works, while Section 3 presents the existing visual speech datasets. Section 4 outlines the proposed Arabic visual speech recognition model and its stages and the collected dataset in detail, and Section 5 presents the experiments and results discussion. Finally, the conclusion and feature work are presented in Section 6.
In this section, we summarize recent research conducted in lip-reading recognition techniques. Much research has been done in the field for English, French, and Chinese, as well as several other languages. In contrast, few works have attended to develop a lip-reading model for the Arabic language, and there is no public Arabic visual dataset for lip reading. Most of the reviewed lip-reading models are composed of three primary steps: pre-processing, feature extraction, and visual speech recognition. The reviewed studies are divided into two main categories: handcrafted features-based models and deep learning features-based models.
2.1 Handcrafted Features Based Models
Reda et al. [9] have created a hybrid voting model for automatic Arabic digits recognition, they have been applying three techniques for visual feature detection: Speeded-Up Robust Features (SURF), a Histogram of Oriented Gradient (HoG), and Haar feature extractor. The features are passed individually into HMM to recognize the corresponding digit. The SURF, HoG, and Haar techniques are also applied for feature extraction in [10] to build the Silent password recognition framework. The model has five layers to provide Arabic digit prediction for the password matching process, and then each feature separately is fed into the HMM. The model has achieved a high detection rate and accuracy while maintaining a low False Positive Rate (FPR).
The DCT technique is used for extracting visual features as proposed by Elrefaei et al. [11], the results show that the average Word Recognition Rate (WRR) is 70.09%, by applying the SVM for classification. Also, Catalán in [12] has utilized the DCT coefficients, HMM, Gaussian Mixture Models (GMM), to build the visual password model for user authentication, by using the GRID dataset [13] to measure the performance of the models. The results show the model performed well when recognizing users, with an equal error rate of 4.23%. This approach can be considered a method for user identification rather than word recognition because it does not achieve lip-reading recognition; the word recognition errors were too high.
The multi-view audiovisual dataset has been produced for mouth motion analysis by the authors in [14]. They concentrate on building a more flexible VSR that supports a multi-view dataset called OuluVS2. In the feature extraction stage, they use 2D DCT, and PCA for feature reduction. The results show that a 60° angle provides an average of 47% as the highest recognition rate.
Liang et al. [15] have defined the automatic lip-reading model. Firstly, they have used an XM2VTS dataset. They localize the mouth by applying the Support Vector Machine (SVM), and the extraction of visual features from lip movements is executed using hybrid PCA and Linear Discriminative Analysis (LDA). All the extracted features and acoustic sequences are combined using a coupled HMM. The result of the WRR is 55%.
Komai et al. [16] have presented a model to extract the lip movement’s features from various face directions, by transforming the sideways view of the lip into a frontal view. They have applied the Active Appearance Models (AAM), followed by the HMM for the recognition. The model has achieved 77% and 80.7% in average accuracy for visual recognition rates with and without normalization of the face direction, respectively. The dataset is 216 words in the Japanese language.
Luettin et al. [17] have utilized a statistical model called an Active Shape Model (ASM) for modeling the mouth shape, which is then applied to perform the localization, parameterization, and tracking of the lip movements. They have presented two types of lip models: the first one for the outer lip contour and the second for the representation of both inner and outer lip contour. The recognition phase was done by applying HMM. The experiments were performed by utilizing the Tulips1 dataset [18], which was the first datasets used in this field. The experiments proved that the accuracy of a single contour model is 80.21 % and 80.42% for the double contour model.
Yavuz et al. [19] have implemented a lip-reading model where the features extracted by applying the PCA. They extracted the features of inner width, outer width, height between outer lips, height between inner lips, and distance between the lip, and peaks of lips. They have applied dynamic thresholding to locate the lip. A manifold representation performs the visual lip movement recognition by presenting a generic framework to recognize the words. They have tested the proposed model using 56 different videos, including Turkish vowels, and the results prove the accuracy to be 60%.
Hazen et al. [20] have extracted the features by applying PCA from visual lip measurements. For recognition, they have applied a segment constrained HMM. The collected AV-TIMIT dataset consists of 450 English sentences. The results clarify that there is a reduction in phonetic error rate with 2.5%.
Shaikh et al. [21] have presented a model to classify discrete utterances. They have calculated the optical flow (statistical properties) vectors, and the SVM then performed the classification. They have achieved an accuracy of 95.9%.
Ibrahim et al. [22] have presented a geometrical-based automatic lip-reading. The geometric feature-based approach, called a Multi Dimension Dynamic Time Warping (MDTW) uses a skin color filter, a border following method, and the calculation of convex hulls, to provide recognition of the digit. The model achieved 71% in word recognition accuracy for the CUAVE dataset [23].
Sharma et al. [24] have investigated audio-visual speech recognition for the Hindi language by utilizing the Mel Frequency Cepstral Coefficient (MFCC) for audio features. For visual features, they have used the Optical Flow (OF) and conventional lip localization approach, and then it is followed by a HMM for recognition. The dataset is 10 numeral digits from Hindi, prepared by recording videos of 24 speakers in which each speaker pronounces each digit 10 times. The 240 samples were divided for training and testing into 200, and 40 samples. The WRR is 93.76%.
The system proposed by Sagheer et al. [25] applies the hyper column neural network model combined with HMM to extract the relevant features. The system is considered the first to be applied to VSR in the Arabic language. The experiments used a dataset of nine Arabic sentences. They compared Arabic language recognition results with those of the Japanese language, with the performance for the Arabic dataset recorded as 79.5% and 83.8% for Japanese.
2.2 Deep Learning Features Based Models
Lu et al. [26] have proposed lip-reading architecture that combines CNN with a Recurrent Neural Network (RNN) with an attention mechanism. They applied the LSTM network for retrieving hidden information in a time series. CNN was enhanced by using the VGG19 model, achieving 88.2% of accuracy.
Zhang et al. [27] have implemented an architecture model for visual-Chinese lip-reading called LipCH-Net. They applied concepts from deep neural networks model: CNN with LSTM and Gated Recurrent Unit (GRU) to recognize lip movement. The architecture combines the two models because the Chinese language needs to achieve recognition for Picture to-Pinyin (mouth motion pictures to pronunciations) and Pinyin-to-Hanzi (pronunciations to texts). They gathered daily news from Chinese Central Television (CCTV). The proposed model has accelerated training and overcome ambiguity in the Chinese language. LipCH-Net accomplishes 50.2% and 58.7% accuracy in sentence-level and Pinyin-level tasks respectively.
The main contributions of the proposed model in [28] are building concatenated stretched lip images for the input video in order to execute a deep-learning model for lip reading, by applying a 12-layer CNN with two layers of batch normalization. The validation of the performance was on MIRACLE-VC1 dataset [29]. The results show 96% in training accuracy and 52.9% in validation accuracy.
Wen et al. [30] have stated that a model with few parameters will decrease performance complexity. They have applied LSTM for extracting the sequence information between keyframes. The collected dataset represents the pronunciation of 10 English digit words (from 0 to 9). The accuracy of the model is 86.5%, which indicates that the model saves computing resources and memory space.
Faisal et al. [31] intended to combine both models to enhance speech recognition in load environments; however, they were unable to merge both networks to confirm the results of audio-visual recognition. They have applied two different deep-learning models for lip-reading spatiotemporal convolution neural network and Connectionist Temporal Classification Loss (CTC), and for audio, they have used the MFCC features in a layer of LSTM cells and output the sequence for the Urdu language.
Petridis et al. [32] have presented an end-to-end visual speech recognition model by applying LSTM networks. The model has two streams: one for features extraction from the pixel values of the lip region, and the other is called a different image by computing the difference between two sequential frames. The second streams utilized a Bidirectional LSTM (Bi-LSTM) with a pre-trained model of Restricted Boltzmann Machines (RBMs), after which the softmax produces the predicted result. The OuluVS2 [14] and CUAVE datasets [23] were used for testing and validating with a classification accuracy of 84.5% and 78.6%, respectively.
According to [33], with the variety of models and methods that have been proposed, an overall lip-reading model is produced by applying six type of models: a CNN with LSTM baseline model, a deep layered CNN with LSTM model, an ImageNet pre-trained VGG-16 features with LSTM model, and a fine- tuned VGG-16 with LSTM model. For expanding the number of training sequences of the MIRACL-V1 dataset size, they have appended horizontally flipped and pixel-jittered versions of each image. The best accuracy of 79% was achieved with the fine- tuned VGG with LSTM.
Assael et al. [34] have applied a spatiotemporal CNN with Bi-LSTM and CTC. It is the first application to work in the end-to-end model for sentence-level. The spatiotemporal convolutions with GRUs were applied, and CTC loss function was used for training. The GRID dataset [13] was employed for evaluating, which indicated the highest accuracy to be 95.2%. A more profound architecture is used by Stafylakis et al. [35], they have proposed a model consisting of the following components: the front-end, which is the spatiotemporal convolution to the frame sequence, a Residual Network (ResNet), and the backend two-layer of Bi-LSTM. The softmax layer then provides word recognition from the LRW dataset (BBC TV broadcasts), attaining 83% accuracy.
Chung et al. [36] have trained the ConvNet to identify the visual features which passed as an input to LSTM for 10 phrases from the OuluVS2 [14] dataset (frontal view). The proposed work concentrated on combining the sound and mouth images as a synchronization, as well as a non-lip-reading problem statement. The achieved high accuracy in the LSTM based model with the SyncNet pre-trained model.
Garg et al. [37] have used images of celebrities from Google Images and IMDB for training the pre-trained VGGNet model. For extracting the features, they applied two approaches: the LSTMs for a sequence of frames, and the CFI for each video. The dataset used is MIRACL-VC1 [29]. The model achieved best accuracy in CFIs of 76%.
Mesbah et al. [38] have focused on the application of this technology to the medical field, particularly for people who suffer from laryngectomies. The model consists of the Hahn Convolutional Neural Network (HCNN). The first layer of Hahn moments eliminates the video image dimensionality and provides the extracted features to CNN. The training was executed using different datasets: AVLetters, OuluVS2, and BBC LRW.
Wang et al. [39] have sought the solution for sign language word classification, to provide a bidirectional communication system for sign language and visual speech recognition. For the feature extraction phase in their VSR, they applied the ConvNet unit (DenseNet) and Bi- LSTM as well as CTC loss to identify the recognized sentence. The dataset utilized was the public data LRW for the Chinese language, 49000 videos were used for training and 500 videos for testing. They have reached an average recognition rate of 35%.
Bi et al. [40] have developed a DenseNet network structure, the 3D convolution neural network with LSTM (E3DLSTM), which handles the time modeling for features extraction. The CTC layer is then utilized as a cascading time classification. The results show a high recognition rate compared with traditional methods for the Chinese language. The proposed model achieves the following accuracy results according to a length of letters corresponding to pinyin: 38.96% for easy, 38.49% in medium and 37.92% in hard.
Saitoh et al. [41] have built a model that depends on the concept of CFI for the required pre-processing of video frames with two types of dataset augmentation, with CNN applied for features extraction. For classification, the softmax layer with cross-entropy loss has been utilized. They have employed the OuluVS2 dataset (frontal view) to evaluate the method using different pre- trained models. The accuracy is 61.7% with the NiN model and 89.4% with the GoogLeNet model.
Tab. 1 summarizes the existing studies whose three main stages we have discussed: preprocessing, features extraction, classification, and finally the results are presented.

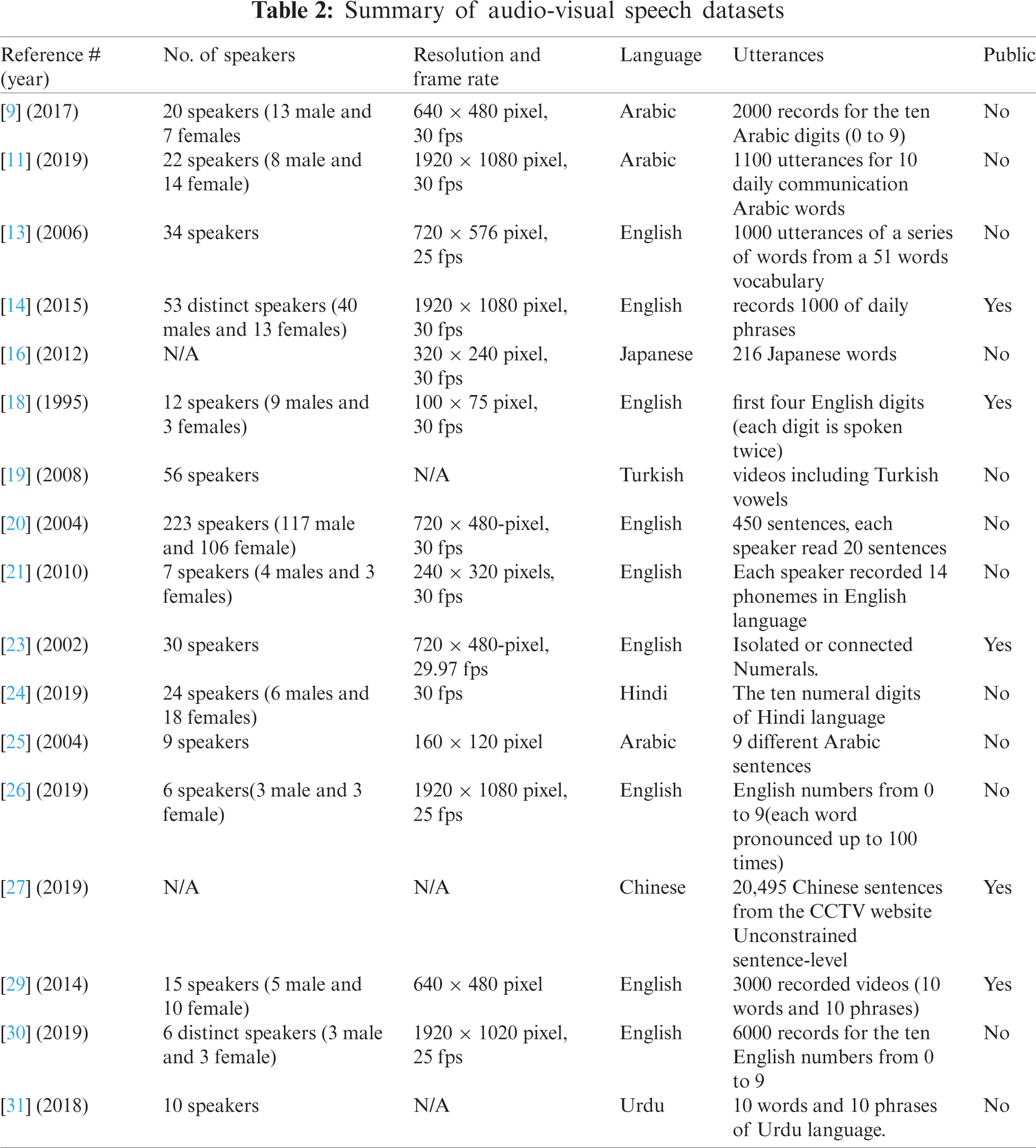
The visual speech datasets vary in terms of language, acquisition device, number of speakers, resolution, number of frames, size, speed of speech, and many other characteristics [11]. Several public visual datasets are available to visual speech recognition researchers for the purpose of development in languages other than the Arabic language, such as GRID [13], OuluVS2 [14], CUAVE [23], and MIRACL-VC1 [29]. Since there are no public Arabic datasets, we have collected our dataset as will be explained in section 4.1. Tab. 2 summarizes the existing datasets that have been collected by researchers in the field.
4 Proposed Arabic Visual Speech Recognition Model
In this section we define four major stages of our proposed VSR model: data collection, data preprocessing, feature extraction, and classification as presented in Fig. 2. For any uttered word, there is a different accent. Therefore, we extract a series of images that represent the lip movement. All this temporal information will be produced into one single spatial image, as we will discuss in the next sections.

Figure 2: The proposed model architecture
The public visual datasets are available to researchers in languages other than Arabic. Since no public Arabic datasets are available, we decided to collect the required data by considering all possible difficulties such as background, speed of speech, speaker posture, and the lighting. The collected experimental dataset for the proposed model is based on 10 independent Arabic digit utterances (from 0 to 9) and 4 selected Arabic phrases. The resolution of each frame is 1920 × 1080 and approximately 25 fps, using a smartphone camera with a ring light stand. The number of speakers is 24 native speakers (14 males and 10 females). Each speaker pronounces 10 Arabic numerical words and 4 phrases, and each number and phrase repeated 10 times, resulting in 2400 records for digits and 960 records for phrases. Data acquisition was done among one month and produced with white backgrounds, and there were male speakers with and without a mustache or beard. The dataset used is shown in Tabs. 3 and 4. To accurately determine the start and end of each recorded video, we have tracked the audio to separate each spoken word. The recorded video is approximately 1 second for each digit and 2 seconds for each phrase. After preparing each video and performing frame extraction, we produced a concatenated image of 224 × 224 pixels, which contains a sequence of the uttered number or phrase as standard inputs of the CNN model.


The preprocessing stage consists of three main steps: face detection and lip localization, keyframe selection from lip frames, and finally the producing CFIs. As discussed in the following points.
• Face Detection and Lip Localization: The OpenCV library has been employed for loading the images and transforming them into a 3-dimensional matrix [21]. Then the facial landmark detection is employed from the Dlib toolkit, by using the face images as inputs for the method, in order to return the 68 landmarks of the face structure in these images. Then to crop the region of the mouth, we used the landmarks to locate the key points of the mouth region (landmarks between 48 and 68), to decrease the complexity of repetitive information and computational processing [26].
• Keyframe Selection: After localizing the lips and producing cropped frames of the lip region, we applied a keyframes selection technique to remove redundant information from the extracted lip frames sequence. The many factors that vary in the recorded videos, such as the length, make the process more difficult for the model to extract hidden features through all sequences. The applied keyframes extraction technique depends on calculating the average pixel intensity of the two consecutive frames [42]. As illustrated in Algorithm 1, the absolute difference between two consecutive frames is computed. Then we get the average inter-frame difference intensity by dividing the sum of the absolute difference by 64 × 64 pixels, which is the size of each lip frame. In the end, we select the frames with the largest average inter-frame difference as keyframes. We performed our experiments to select the appropriate keyframes by testing different numbers of frames: 10, 15, and 20 for Arabic digits and phrases.
• Concatenated Frame Images: In this step, we stretch the keyframes' sequence to produce concatenated lip image by duplicate some frames' sequence to fit a length of L = 25 as shown in Fig. 3, similar to the method in [37]. The speaking speed differed from one speaker to another. Consequently, the speed was normalized by applying Eq. (1) where i indicates the index of the frame in the CFI structure (from i = 0 to L − 1), orig_images are the selected lip frames. Fig. 4 clarifies the overview structure of CFI with keyframe = 20, as highlighted five frames out of 20 have been duplicated to normalize the speaking speed. For each row and column with the image size 320 × 320 pixels, five lip images were concatenated, and each image has a size of w′ × h′ [pixels], where w′ = 64 and h′ = 64. In the end, a total of 25 lip images were represented in one single image, which was resized to the fixed dimension of 224 × 224 pixels, as standard input to VGG19 in our architecture.


Figure 3: Concatenated Sample Dataset Images (key frames = 20)

Figure 4: Overview Structure of Concatenated Frame Images (keyframes = 20)
Deep learning algorithms are adopted to extract deep features to learn long-term dependency information. We have utilized the concept of convolutional neural networks with different techniques: transfer learning and batch normalization as presented in next sections.
• Transfer Learning: The efficient and active way for researchers to develop and solve a problem is employing transfer learning by employing the pre-trained networks and utilizing a similar problem that the network has been trained on ImageNet [43]. The most commonly used pre-trained model is VGG, and we chose to use the technique of transfer learning by applying a VGG-19 network which is pre-trained on ImageNet to improve the part of CNN. Fig.5 define the architecture of VGG-19. In our model, the VGG-19 does not include the last two fully connected layers, and we continued training the model based on the pre-training parameters of a grey-scale image with the input size of 224 × 244 pixel.
• The Batch Normalization (BN) technique is usually applied in a deep neural network to perform the network’s training more efficiently, by stabilizing the training process, avoiding overfitting problem, and improve the performance of the model [44], it added after a convolutional layer in the model.
• The following points describe the proposed approaches in our architecture:
Approach 1: We examined the VGG-19 base model as shown in Fig.5, without any additional layers, we just replace the last fully connected layer with a new one with the number of our classes in the dataset.
Approach 2: We removed the top classification layers of the VGG19 model with unfreezing all layers, and the 2D convolution layer added with the Relu activation function. We then added the batch normalization layer followed by two Fully Connected Layers (FCs) with Relu: FC (512) + ReLu + FC (256) + ReLu, we have examined different features size in FC layers as demonstrated in [45], and the best results were with sizes of 512 and 256 as will be shown in section 5. Finally, the SoftMax layer was added for classification. Fig. 6 illustrates the concept.

Figure 5: VGG19 network structure
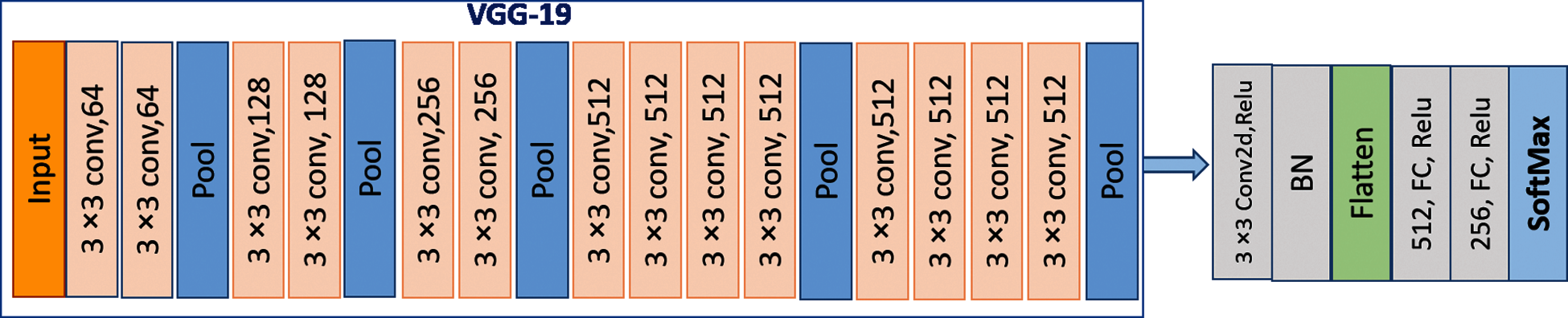
Figure 6: Approach two of fine-tuning VGG19 with batch normalization
Deep learning has made a vital rule in terms of classification accuracy. After the phase of learning the sequence of features which interprets the input video with the mouth area of a speaker saying one specific word, this sequence is employed to provide the target prediction of classification among several possible words in order to produce distribution on the class labels. Hence, the 3D representation (width × height × depth) is transformed into a vector, and finally, the vector is treated as the input to the fully connected layers and softmax convert the prediction results into probability. In our experiment, we applied the softmax with the categorical-cross-entropy to perform the classification among classes to predict the results, and the gradient descent with Adam optimizer was used to update the weights for optimization. The SoftMax function is defined in Eq. (2), where n is the number of classes, and the exponential function was applied to the input vector
5 Experiments and Results Discussion
In this section, we describe the hardware and software tools, and we discuss the performance results of our model. We also compared our model with the existing approaches.
5.1 Hardware and Software Tools
The building and development of the model was conducted using an ASUS laptop with a Core i7-10750H 2.60 GHz CPU and 16 GB RAM. The Keras 2.4.3 open library with a TensorFlow 2.3.1 backend in Python 3.8.6 was used to build the deep learning model. OpenCV 4.4.0 library was employed to prepare the collected dataset, and the scikit-learn 0.23 was used to measure the performance of the model.
The dataset is composed of 2400 videos for Arabic digits and 960 videos for Arabic phrases, totaling 3360 videos. The dataset was split into 3 sets: 75% for the training set, 15% for validation, and 10% for testing. We trained our model on the training set and evaluating the accuracy of the unseen data. We applied checkpoints in the training process to monitor the loss metrics by applying the callback function during the training. By monitoring the minimum loss value, the model weights were saved automatically based on the quantity being monitored. The speed of speech is different from one speaker to another, so there were a different number of frames for each recorded video. We computed the average number of frames for each class as depicted in Fig. 7. The average number of frames for digits is 33 and for phrases, it is 56. According to the variations, the production of CFIs was executed with different numbers of keyframes: 10, 15, and 20. In the experiments, we examined all discussed approaches for: digit recognition and phrases recognition, and we ultimately mixed the digits and phrases datasets.

Figure 7: The average number of frame’s length for each class in the dataset
Our proposed model for Arabic digit and phrase recognition has achieved the best model accuracy in the second approach with the keyframes number of 20, where the batch normalization was utilized in VGG19 architecture. The loss has decreased and hence we can say that the digit and phrases recognition model is improving with the test accuracy of 94% for digit recognition, 97% for phrase recognition, and 93% in the experiments of digits and phrase recognition. The results are represented in Tab.5.

Fig. 8 gives the confusion matrices for the best model of the digit and phrase recognition experiment evaluated on test data. The matrices depicted for us the errors made, showing which digits and phrases are most often confused for one another. For example, the number 3, ‘Thlatha,’ is confused with number 2 ‘Ethnan.’ This is because the speaker’s mouth movements at the beginning of the utterances are the same, in order to pronounce the letter ‘th.’ Additionally, number 6, ‘Setta,’ and number 7, ‘Sabaa,’ are confused with number 9, ‘Tessa,’ as they share the same viseme sequences. The phrase ‘Call the Ambulance,’ or ‘Atasil Bialaiseaf,’ is confused with 3 digits: number 5, ‘Khamsa,’ number 6, ‘Setta,’ and number 7 ‘Sabaa.’

Figure 8: Confusion matrix of mixed digits and phrases model
As shown in Fig. 9, in the precision and recall for digits from 0 to 9 and the 4 selected phrases, the highest precision was 100% for the number 4, which is ‘Arbaa,’ and ‘Call the Ambulance,’ which is ‘Atasil Bialaiseaf.’ For recall, the highest record was 100% for number 1, which is ‘Wahed,’ number 3 ‘Thlatha,’ number 7, ‘Sabaa,’ and the phrase peace be upon you, which is ‘Assalam Ealaykum.’ The lowest precision appeared in number 6, ‘Setta,’ and number 7, ‘Sabaa’, and lowest recall was found in number 4 ‘Arbaa.’ The precision and recall are calculated using Eqs. (3) and (4), where TP is True Positive predicted value, FP is False Positive where the prediction of positive value was incorrect, and FN is False Negative.
As presented in Fig. 9, the highest F1 measure as defined in Eq. (5), recorded 92% for the phrase call the police ‘Atasil Bishurta,’ while the lowest F1 measure recorded 88% for the number 6 ‘Setta.’

Figure 9: Precision recall and f1 score for the speech recognition model of Arabic Digits and phrases

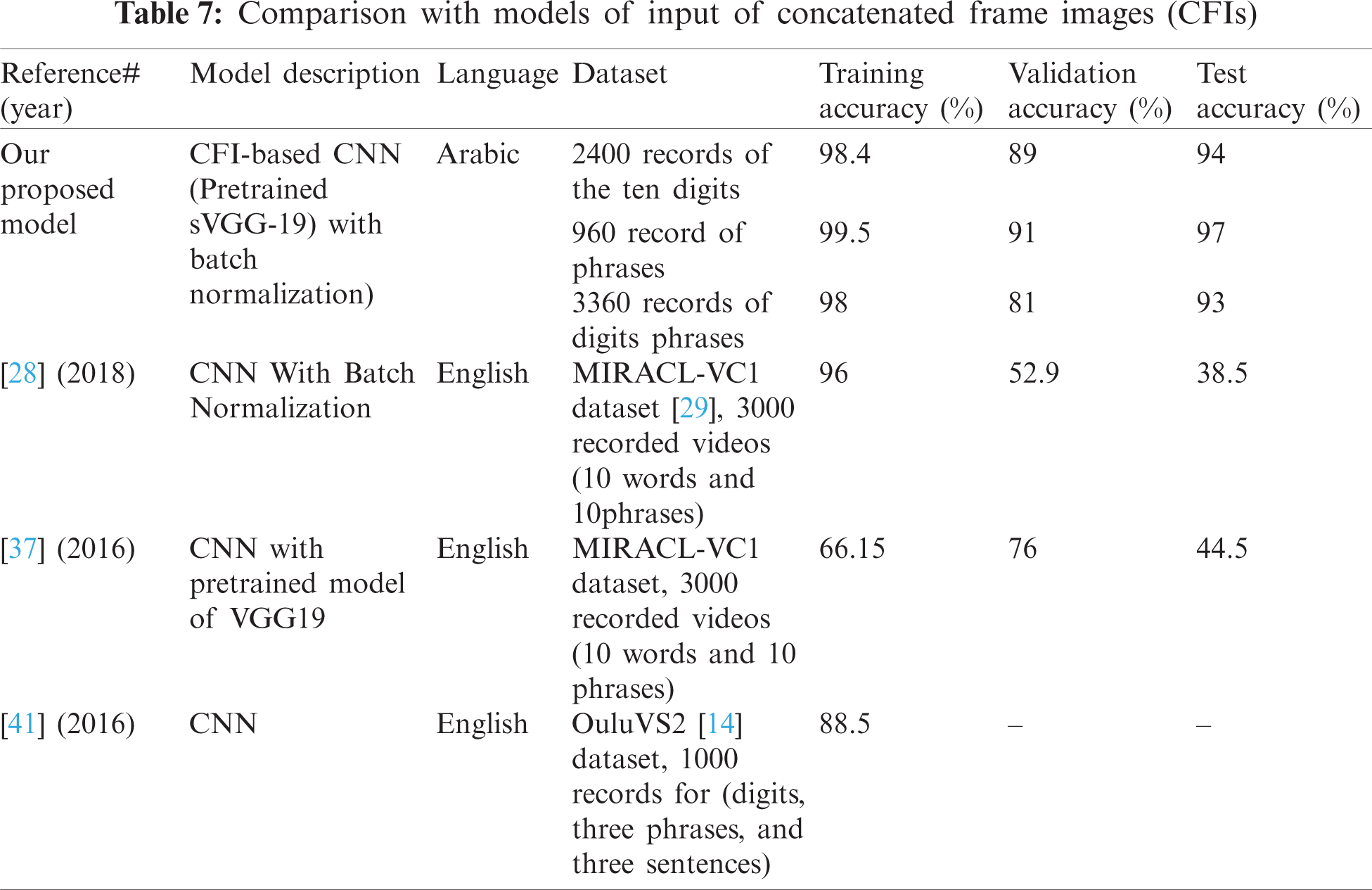
The experimental results show that compared with the existing models of Arabic visual speech recognition, our proposed architecture can effectively predict digits and phrases on our collected dataset: the accuracies of the proposed model are 94% for the test accuracy of digit recognition, 97% for phrase recognition, and 93% in the experiments of digit and phrase recognition. In Tab. 6, we compare our proposed model with the existing Arabic recognition model, as shown in the case of digit recognition. The model in [9] has provided an accuracy of 96.2%, and we have attained 94%. That is due to the fact that the nature of the dataset is different in terms of number of speakers according to gender, as well as the recorded video time, as the majority of their speakers were males, and the average time of the recorded videos were 30 seconds. In contrast, our collected dataset has 14 males and 11 females, and the recorded video time is one second for each digit. Furthermore, we have compared our model with state-of-the-art methods where the input of the model is concatenated frame images to the corresponding digit or phrase, as proposed in our work. As presented in Tab. 7, our model can effectively predict the digits and phrases with the highest recognition accuracy compared to models based on CFIs input, all of which are tested with the English language.
The proposed Arabic visual speech recognition model is capable of classifying digits and phrases in the Arabic language by examining our collected visual datasets. The keyframe extraction technique and CFIs were utilized to perform the concatenated stretch image, which represents the sequence of the input video. Different approaches were used in the experiments, and the performance has been validated on our collected dataset. The results show that the CNN network with VGG19 networks to extract the bottleneck features by employing the batch normalization provides a high accuracy by stabilizing the training process, as compared to state-of-the-art methods where the input of the models is concatenated frame images. The performance of our model has yielded the best test accuracy of 94% for digit recognition, 97% for phrase recognition, and 93% in the experiments of digit and phrase recognition. Furthermore, we intend to focus on examining the model by working with different locations of the lip landmark localization by increasing the dataset to provide more accurate results in the field of visual speech recognition.
Acknowledgement: We would like to extend our thanks and appreciation to all volunteers for their participation in the dataset collecting process.
Funding Statement : The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |