
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
REVIEW

Exploring the Latest Applications of OpenAI and ChatGPT: An In-Depth Survey
1 School of Electrical Information Engineering, Jiangsu University of Technology, Changzhou, 213001, China
2 Department of Electrical and Computer Engineering, University of Nevada, Las Vegas, 89154, USA
* Corresponding Author: Hong Zhang. Email:
Computer Modeling in Engineering & Sciences 2024, 138(3), 2061-2102. https://doi.org/10.32604/cmes.2023.030649
Received 18 April 2023; Accepted 26 July 2023; Issue published 15 December 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
OpenAI and ChatGPT, as state-of-the-art language models driven by cutting-edge artificial intelligence technology, have gained widespread adoption across diverse industries. In the realm of computer vision, these models have been employed for intricate tasks including object recognition, image generation, and image processing, leveraging their advanced capabilities to fuel transformative breakthroughs. Within the gaming industry, they have found utility in crafting virtual characters and generating plots and dialogues, thereby enabling immersive and interactive player experiences. Furthermore, these models have been harnessed in the realm of medical diagnosis, providing invaluable insights and support to healthcare professionals in the realm of disease detection. The principal objective of this paper is to offer a comprehensive overview of OpenAI, OpenAI Gym, ChatGPT, DALL E, stable diffusion, the pre-trained clip model, and other pertinent models in various domains, encompassing CLIP Text-to-Image, education, medical imaging, computer vision, social influence, natural language processing, software development, coding assistance, and Chatbot, among others. Particular emphasis will be placed on comparative analysis and examination of popular text-to-image and text-to-video models under diverse stimuli, shedding light on the current research landscape, emerging trends, and existing challenges within the domains of OpenAI and ChatGPT. Through a rigorous literature review, this paper aims to deliver a professional and insightful overview of the advancements, potentials, and limitations of these pioneering language models.Graphic Abstract
Keywords
OpenAI and ChatGPT possess tremendous potential to enhance the accuracy and speed of computational applications, thereby enabling engineers to design more efficient and reliable systems. In the domain of computational mechanics, for instance, these cutting-edge technologies can revolutionize the simulations of dynamic system dynamics by improving their precision and speed. Furthermore, in the realm of computational mathematics, these state-of-the-art innovations can expedite symbolic computation tasks, such as solving algebraic equations and computing derivatives, with unparalleled efficiency. In addition, OpenAI and ChatGPT can accelerate the development of highly effective optimization algorithms and improve the precision of optimization solutions, thereby enhancing their efficacy. In the field of physics research, these technologies can effectively analyze massive datasets generated by experiments and simulations, thereby revealing previously concealed patterns and relationships. Moreover, OpenAI and ChatGPT can accurately predict the behavior of complex fluid mechanics systems and the properties of substances at varying temperatures and pressures. In addition, in the field of image and signal processing, these technologies can seamlessly process and analyze data generated by physical experiments and simulations, facilitating the extraction of insightful information. Through the utilization of OpenAI and ChatGPT’s capabilities, applications for machine learning in mathematics, such as predictive analysis and analysis of large datasets, can be significantly advanced.
ChatGPT is an advanced language model developed by OpenAI, utilizing the cutting-edge Generative Pretrained Transformer (GPT) architecture. This model showcases exceptional natural language processing capabilities, achieved through extensive pre-training based on the GPT framework. ChatGPT excels in engaging in conversations with users, addressing inquiries, providing informative responses, and executing user instructions, among other functionalities. The primary objective of this paper is to offer a comprehensive introduction to several significant components, including OpenAI, OpenAI Gym, ChatGPT, DALL E, stable diffusion, the pre-trained clip model, and other models encompassing CLIP Text-to-Image, education, medical imaging, computer vision, social influence, natural language processing, software development, coding assistance, and Chatbot domains, among others. Notably, both OpenAI and ChatGPT, as natural language processing models, encounter limitations in directly processing the original state of the environment within OpenAI Gym, such as images or continuous action spaces. This limitation impedes their ability to effectively model and control intricate environments and precludes direct interaction with said environments. Consequently, an intermediary agent must facilitate communication with the environment, thereby increasing the difficulty level of interaction and limiting their potential for industrial applications. Additionally, the performance of reinforcement learning in complex environments is hampered by a lack of comprehension of domain-specific techniques, including model predictive control and value function estimation.
While OpenAI and ChatGPT excel in analyzing natural scenery to discern target meanings, their capacity to analyze abstract semantics remains inadequate, particularly in incorporating regional characteristics, human-specific terms, and remarkable illusions. Furthermore, OpenAI and ChatGPT demonstrate a limited understanding of subject domain expertise, which may result in incorrect or inaccurate responses. Moreover, adapting to students’ unique needs and learning styles poses a significant challenge, as they lack personalized teaching support and long-term behavior analysis. Similarly, their ability to interpret and analyze clinical data is limited, potentially leading to erroneous diagnosis outcomes. They struggle to effectively comprehend the distinctive circumstances of each patient, consider pertinent medical history, symptoms, and related medical assistance, as well as legal, ethical, and privacy considerations. OpenAI and ChatGPT face challenges related to data deviation, sample imbalance, and training accuracy instability when encountering new data. The interpretability of these models is also limited, hindering the understanding and explanation of prediction and decision-making processes. Furthermore, their efficacy in adapting to complex scenarios and diverse computer vision tasks is suboptimal, potentially resulting in security risks, such as data leakage. This may lead to flawed semantic comprehension and generation, particularly in the analysis of multi-environment, multi-language, multilingual, diverse text data, emotions, and cultural factors. Insufficient considerations in these areas can introduce cultural biases and emotional inaccuracies. Moreover, the deployment of OpenAI and ChatGPT in engineering applications necessitates substantial computing and storage resources, potentially encountering performance bottlenecks in resource-constrained environments. Consequently, meeting the real-time requirements of certain application scenarios becomes challenging. Furthermore, the analysis of complex business processes and interaction logic remains inadequate, often requiring additional customization and adjustments to fulfill the demands of practical applications.
The rest of this paper is organized as follows, perspective applications, text-to-image/video applications, education assistance applications, clinical diagnosis applications, machine learning applications, natural language processing applications, and hybrid engineering applications, are introduced in Sections 2–8, respectively.
2 Perspective Application Based on OpenAI Gym
OpenAI Gym developed by OpenAI, stands as an indispensable toolkit fostering the construction and comparative assessment of reinforcement learning algorithms. Its purpose revolves around furnishing a standardized repertoire of environments, which aids researchers and developers in the meticulous scrutiny and evaluation of such algorithms. OpenAI, an autonomous research laboratory and corporation, endeavors to propel the advancement of artificial intelligence for the collective benefit of humanity. This pursuit necessitates employing a diverse array of tools and frameworks within their research and engineering endeavors, with OpenAI Gym serving as a pivotal constituent facilitating the realization of reinforcement learning algorithms. OpenAI Gym confers researchers and developers with an encompassing environment amenable to a diverse array of reinforcement learning tasks, encompassing domains such as gaming and control problems. These environments furnish a unified interface, fostering the simplification and facilitation of algorithm implementation and evaluation, thereby heightening reproducibility. Moreover, OpenAI Gym provides practical functionalities, including visualization tools and benchmarks, engendering deeper comprehension and amplification of algorithmic prowess. By virtue of its multifaceted utility, OpenAI Gym functions as a comprehensive toolkit developed by OpenAI to foster the seamless creation and assessment of reinforcement learning algorithms, thus constituting an indispensable component within the OpenAI ecosystem dedicated to driving research and development in the realm of artificial intelligence. Brockman et al. [1] described OpenAI Gym as an open-source Python toolkit designed to provide a uniform API and a variety of environments for the development and evaluation of reinforcement learning algorithms. The probability distribution of GPT 3 is given by Eq. (1).
where
where
The OpenAI Gym is an exploratory device for reinforcement learning, encompassing a comprehensive set of standard benchmark challenges and a platform for users to publish their findings and contrast algorithm efficiency. Brockman et al. [1] elucidated the OpenAI Gym software’s ingredients and the choices taken throughout its design. Some applications based on OpenAI Gym are provided in Table 1.
Zamora et al. [2] extend the OpenAI Gym for robotics by utilizing the Robot Operating System (ROS) and the Gazebo simulator. The text examines the proposed software architecture and the outcomes generated by two reinforcement learning techniques: Q-Learning and Sarsa. In conclusion, they present a robot benchmarking system that enables the comparison of various methodologies and algorithms in identical virtual environments. The purpose of Akhtar’s [3] book is to improve the reader’s machine learning abilities by introducing reinforcement learning algorithms and techniques. It also discusses the fundamentals of the practical implementation of case studies and current research activities in order to aid researchers in their advancement with RL. OpenAI Gym’s simulation was used by Cullen et al. [4] to show how active inference models of game play may be used to look at the molecular and algorithmic characteristics of psychiatric illnesses. By contrasting the gaming behaviors of younger (18 to 35 years old) and older (57 years or older) adult players, the first study investigates how aging impacts cognition. The second reduces reward sensitivity to approximate anhedonia. This advance sustainable how active deduction can be used to look at changes in neurobiology and beliefs in psychiatric populations. The creation of intricate game environments by simulated people is aided by active inference employing epistemic and value-based motives. Kozlowski et al. [5] talked about how to connect ACS2 to OpenAI Gym, which is a common way to compare reinforcement learning problems. The new Python library and LCS-derived environments are introduced. Common use scenarios allow speedy evaluation of research challenges. In order for an RL control agent to learn the appropriate policies, it must interact with its environment frequently. The ns3-gym was presented by Gawlowicz et al. [7] as the first framework for RL networking research. It represents an NS3 simulation as an environment within the Gym framework and makes entity state and control settings available for agent learning. A cognitive radio wireless node learns the channel access pattern of a periodic interferer in order to avoid collisions. Industry 4.0 systems had to be optimized in order to reduce costs, boost productivity, or ensure that actuators operated in tandem to complete or accelerate product production. These obstacles make industrial settings optimal for the application of all contemporary reinforcement learning (RL) techniques. The primary issue is a deficiency in manufacturing environments. Zielinski et al. [9] created a tool for converting any systematic framework represented as an FSM to the open-source Gym wrapper and optimizing any task using RL techniques. In the first tool evaluation, traditional and deep Q-learning approaches are evaluated in two basic scenarios. Effective retail supply chain management (SCM) significantly relies on forecasting, which optimizes performance and reduces costs. To accomplish this, merchants acquire and analyze data using AI and machine learning (ML) models for cognitive demand forecasting, product end-of-life forecasting, and demand-connected product flow. Early research centered on traditional techniques to enhance network traffic and graphs, but recent disruptions have prompted a renewed emphasis on constructing more resilient supply chains. Demand-supply coordination is the most difficult. SCM is utilizing RL to improve prediction accuracy, address supply chain optimization problems, and train systems to respond to unforeseen circumstances [10]. UPS and Amazon employ RL algorithms to develop AI strategies and meet rising consumer delivery demands. The OpenAI Gym toolbox is becoming the most popular method for developing RL algorithms for supply chain use cases due to its potent event-driven simulation architecture. The developing history of the OpenAI is shown in Fig. 1.
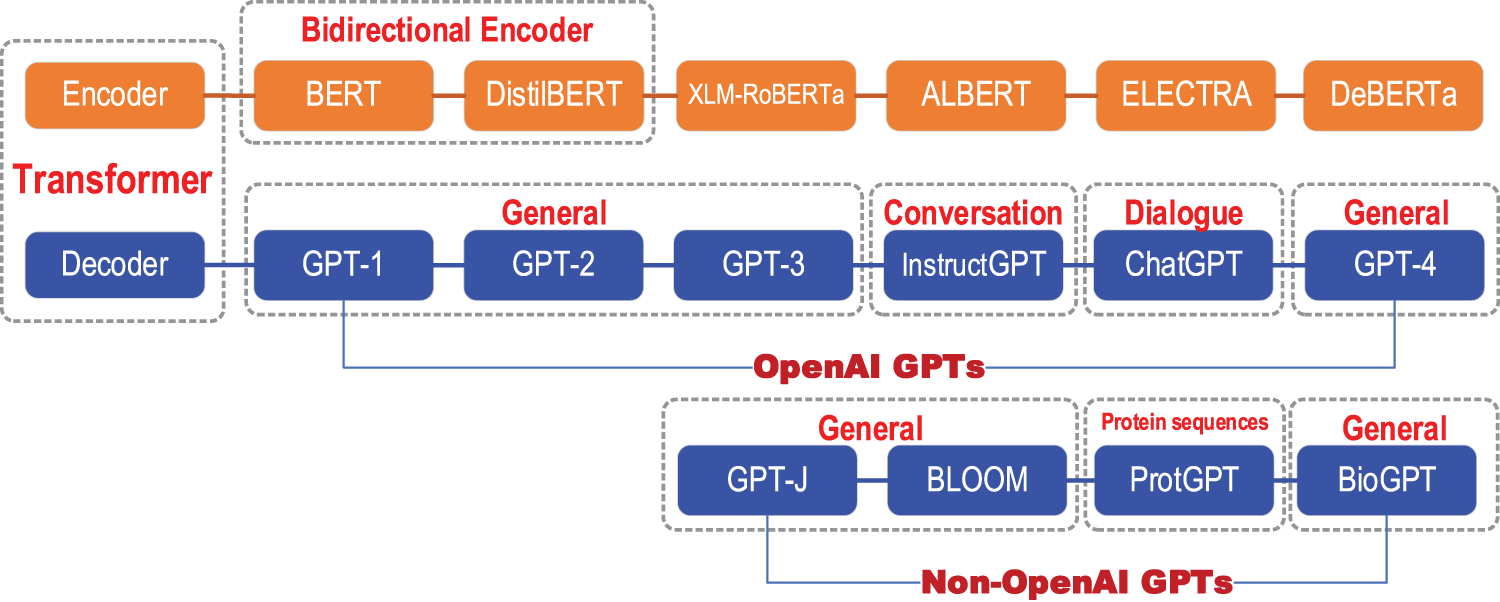
Figure 1: The developing history of the OpenAI
Researchers in reinforcement learning (RL) use simulations to train and evaluate RL algorithms for self-adaptive agents. To increase code reuse in model and simulation-related code across all RL investigations, however, methodological and tool support is required. The workflow and tool proposed by Schuderer et al. [11] enable the decoupled development and maintenance of multi-purpose agent-based models and derived single-purpose reinforcement learning (RL) environments, facilitating the exchange of environments with different perspectives or reward models while maintaining a separate domain model. Quantum reinforcement learning is a relatively new and expanding field, in contrast to quantum neural networks for supervised learning, which are widely employed. Nagy et al. [12] combined photonic variational quantum agents with proximal policy optimization to solve a classical continuous control problem while investigating the effects of data re-uploading. Using Strawberry Fields, a photonic simulator with a Fock backend, and a hybrid training framework that interfaces to an OpenAI Gym environment and TensorFlow, the technique’s effectiveness was evaluated empirically. Gross et al. [14] introduced COOL-MC, a tool that integrates reinforcement learning (RL) and advanced prediction. The tool is specifically derived from Storm, a probabilistic model analyzer, and OpenAI Gym. Hsiao et al. [15] demonstrated that quantum reinforcement learning (RL) obtains faster convergence than classical RL, while requiring at least an order of magnitude fewer trainable parameters for comparable performance. In RL benchmarking environments such as CartPole and Acrobot, they observed that a quantum RL agent utilizing a single-qubit variational quantum circuit without entangling gates and a classical neural network post-processing measurement output outperformed conventional fully connected networks. Using IBM quantum processors, these experiments were conducted. ChatGPT and other AI/NLP tools may facilitate a better understanding of climate change and more precise climate projections. In climate research, ChatGPT is utilized to assist with model parameterization, data analysis and interpretation, scenario creation, and model evaluation. Biswas [16] questioned ChatGPT regarding climate change research. This technology enables scientists and decision-makers to make more accurate climate projections by creating and analyzing climate scenarios based on a variety of data inputs. OpenAI and ChatGPT, as natural language processing models, are unable to directly process the original state of the environment in OpenAI Gym, such as images or continuous action spaces, which limits their ability to model and control complex environments and prevents them from interacting directly with the environment. Agent must serve as an intermediary, which increases the difficulty of communication with the environment and limits its industrial application potential. In addition, the performance of reinforcement learning in complex environments is hindered by a lack of understanding of domain-specific techniques, such as model predictive control and value function estimation.
3 Text-2-Image/Video Based on Diffusion/CLIP Models
Wang et al. [17] proposed a novel method for leveraging language-image priors from a pre-trained CLIP model, known as the self-supervised CLIP-GEN approach. The CLIP (Contrastive Language-Image Pre-Training) neural network is trained on diverse (image, text) pairs and is capable of generating images from text. To train an autoregressive transformer, this method primarily necessitates unlabeled images and extracts image embeddings in a joint language-vision space. Notably, the proposed approach achieves performance levels that are comparable to those of supervised models, such as CogView [18] and Dall-E [19], while outperforming optimization-based text-to-image techniques.The applications based on diffusion/CLIP models is provided in Table 2.

Vidyadhar et al. [25] proposed an intelligent self-learning route selection method that can adapt to the network’s requirements and conditions. Q-routing with Net-AI-Gym optimizes path exploration to provide multi-QoS-aware services in networking applications. Using the CLIP image encoder, Radford et al. [26] analyzed the image encoding in the combined language-vision embedding space. The focus was on the broader implications of prompt engineering beyond text-to-image generation and AI-generated art, with a particular emphasis on Human-AI Interaction (HAI) and future applications. Schaldenbrand et al. [27] detailed a method for producing videos from descriptions written in natural language that employs an iterative process to optimize the video frames in accordance with the CLIP image-text encoder’s recommendations. In order to accomplish real-time processing, the presented method computes the CLIP loss directly at the pixel level as opposed to using a computationally expensive image generator model. This technique can produce films with a frame rate of 1–2 frames per second, a resolution of up to 720p, and varying frame rates and aspect ratios. Karras et al. [28] proposed a simplified design space for diffusion-based generative models, leading to significant improvements in sampling efficiency and image quality. Their modifications achieve new state-of-the-art FID scores, including faster sampling and enhancing the performance of pre-trained score networks, demonstrating the versatility and effectiveness of their approach. Borji [29] measured the capacity of three well-known systems, Stable Diffusion, Midjourney, and DALL-E 2, to generate photorealistic faces in the real world. On the basis of the FID score, he determined that stable diffusion generates faces that are superior to those produced by the other procedures. In addition, the GFW dataset of 15,076 created features from the real world was displayed. Kapelyukh et al. [30] published the first investigation into robot web-scale diffusion models. DALL-E-Bot enables robots to rearrange objects by presuming a detailed description of the scene’s objects, creating an image of a natural, human-like arrangement, and then physically rearranging the objects. DALL-zero-shot is extraordinary, as is E’s lack of training and data collection. Real-world human investigations yield encouraging results for web-scale robot learning. They also provided instructions for the text-to-image community on how to create robotic models. Oppenlaender [31] discussed the use of prompt modifiers in “prompt engineering” and the possibility of Human-Computer Interaction (HCI) research. Latent diffusion models (LDMs) were proposed by Rombach et al. [32] for denoising autoencoders and diffusion models to achieve state-of-the-art synthesis results on images. Applying them in the latent space of pretrained autoencoders allows for near-optimal complexity reduction and detail preservation, significantly improving visual fidelity. Cross-attention layers further enhance LDMs, making them powerful and flexible generators for various inputs and high-resolution synthesis while reducing computational demands compared to pixel-based DMs.
The focus was on the broader implications of prompt engineering beyond text-to-image generation and AI-generated art, with a particular emphasis on Human-AI Interaction (HAI) and receiving special attention. Wang et al. [33] introduced VideoComposer, an innovative framework enabling users to adeptly synthesize videos while considering textual, spatial, and paramountly temporal constraints. Additionally, they devised a Spatio-Temporal Condition encoder (STC-encoder) to function as a cohesive interface, proficiently assimilating the spatial and temporal interdependencies of sequential inputs, thereby optimizing the utilization of temporal conditions within the model. Jabri et al. [34] conducted a comprehensive examination of diffusion models in the context of enabling three-dimensional (3D) scene representation learning models to achieve the rendering of novel views with exceptional visual verisimilitude, all while preserving notable benefits such as object-level scene manipulation. To accomplish this, the researchers devised DORSal, a system that harnesses a video diffusion architecture specifically tailored for object-centric slot-based representations within the domain of 3D scene synthesis. Couairon et al. [35] have devised an innovative approach for zero-shot text-based video editing that ensures temporal and spatial coherence. This method facilitates efficient processing of an entire movie in less than a minute, while maintaining semantic accuracy, image fidelity, and temporal consistency. By employing a distinctive text prompt, the system generates multiple compatible modifications to the video, thereby enabling effective alterations aligned with the intended narrative and visual aesthetics. DreamHuman, a groundbreaking creation by Kolotouros et al. [36], revolutionizes the generation of lifelike, animated 3D human avatars through textual descriptions. While text-to-3D generation techniques have made significant strides, certain limitations persist. However, the visual fidelity achieved by DreamHuman surpasses that of conventional text-to-3D and text-based 3D avatar generators. The resulting 3D models exhibit remarkable diversity in terms of appearances, clothing, skin tones, and body shapes, ensuring a more nuanced and realistic representation. The applications based on diffusion/CLIP models is provided in Table 2.
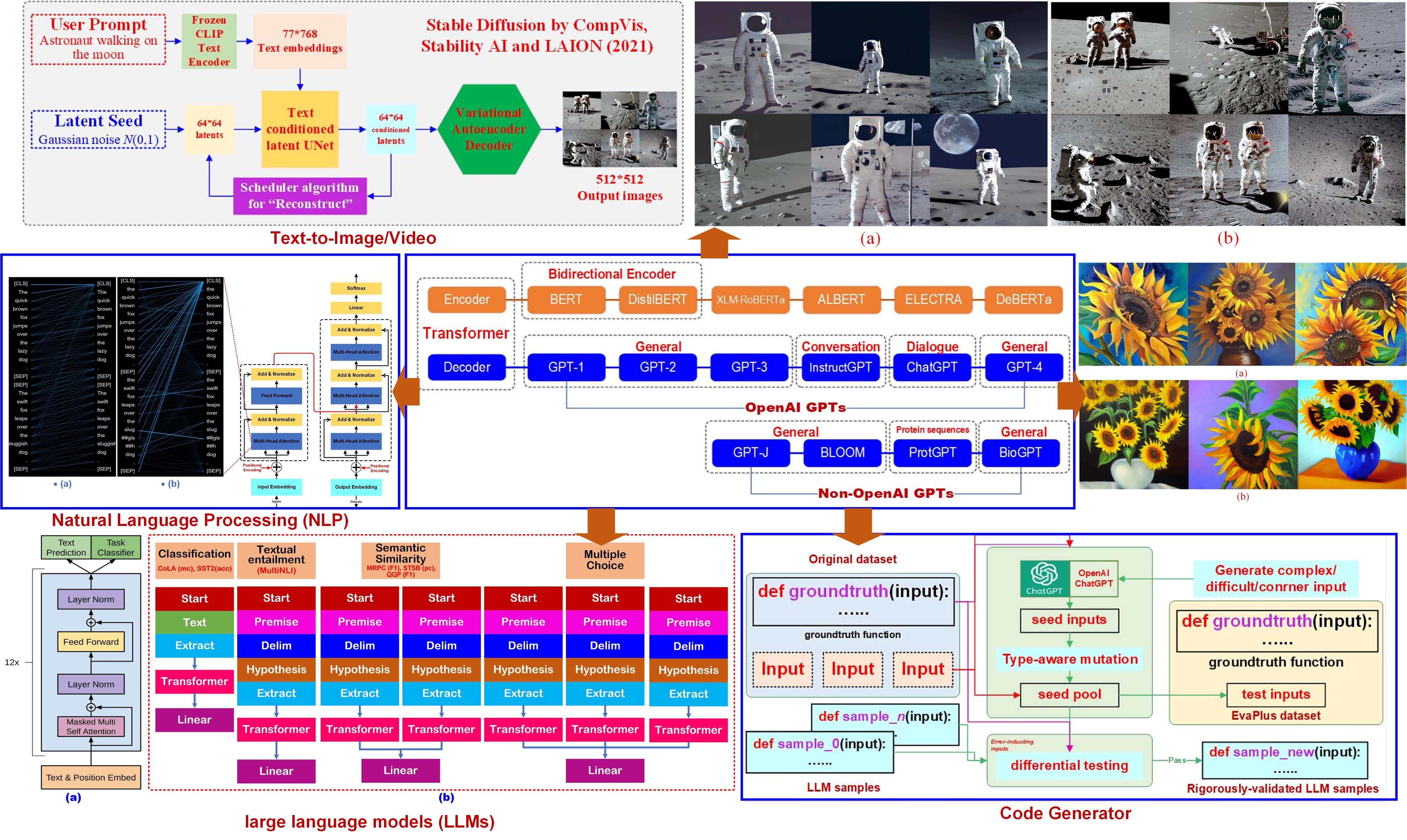
The processing diagram of the stable diffusion (CompVis, Stability AI and LAION) is provided in Fig. 2. The performance comparison of (CLIP-guided and VQGAN CLIP generator text2video) based on the same prompt has been provided in Fig. 3. The generated images based on the DALL E Mini and diffusion-based generative models are shown in Figs. 4–6, respectively. The generated images under different prompts by the DALL E Mini is visualized in Fig. 6. The generated images (abstract scenes) by the DALL E Mini and diffusion-based generative models are shown in Figs. 7–11, respectively.
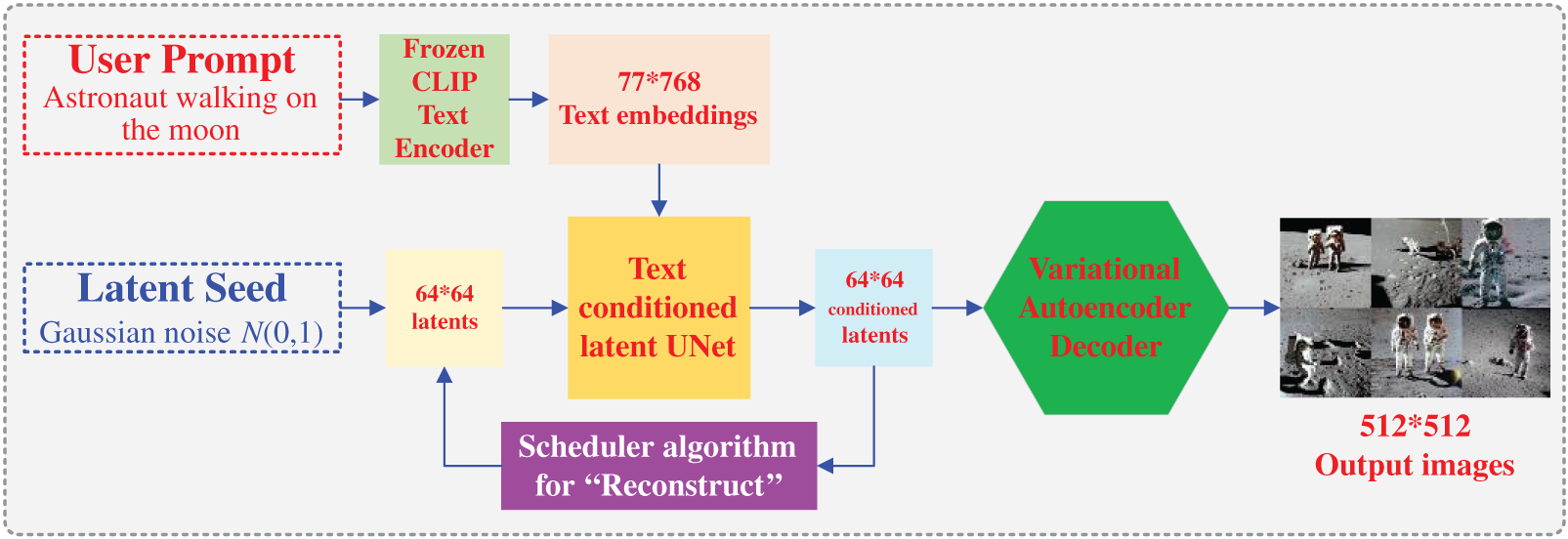
Figure 2: The processing diagram of the stable diffusion


Figure 3: The performance comparison of (CLIP-guided and VQGAN CLIP generator text2video) based on the same prompt: (a) Generated by CLIP-Guided text2video [17]; (b) Generated by VQGAN CLIP GENERATOR text2video [17,19]


Figure 4: The generated images by the DALL E Mini. (a–d): Majestic mountains; (e–h): Flower cake; (i–l): City at night Generated by DALL E Mini [19]

Figure 5: The generated images by the diffusion-based generative models. (a–d): Majestic mountains; (e–h): Flower cake; (i–l): City at night. Generated by diffusion-based generative models [28]

Figure 6: The generated images under different prompts by the DALL E Mini. (a and b): Vincent van Gogh; (c): Robot on the moon; (d): Starry sky at night; (e): Burning straw; (f): Flying fish; (g): Bear playing basketball; (h): Bread robot; (i–l): China’s Jiangnan water town; Generated by DALL E Mini [19]


Figure 7: The generated images under different prompts by the diffusion-based generative models. (a and b): Vincent van Gogh; (c): Robot on the moon; (d): Starry sky at night; (e): Burning straw; (f): Flying fish; (g): Bear playing basketball; (h): Bread robot; (i–l): China’s Jiangnan water town; Generated by diffusion-based generative models [28]

Figure 8: The generated images by the DALL E Mini and diffusion-based generative models. (a) Prompt: Astronaut walking on the moon. Generated by DALL E Mini [19]. (b) Prompt: Astronaut walking on the moon. Generated by diffusion-based generative models [28]

Figure 9: The generated images related to abstract scenes by the DALL E Mini and diffusion-based generative models. (a) Prompt: Butterfly dancing in the moon. Generated by DALL E Mini [19]. (b) Prompt: Butterfly dancing in the moon. Generated by diffusion-based generative models [28]

Figure 10: The generated images related to oil painting style by the DALL E Mini and diffusion-based generative models. (a) Prompt: Sunflowers, oil painting style. Generated by DALL E Mini [19]; (b) Prompt: Sunflowers, oil painting style. Generated by diffusion-based generative models [28]

Figure 11: The generated images comparison of the DALL E Mini and diffusion-based generative models. (a) Prompt: Bubbles in water. Generated by DALL E Mini [19]. (b) Prompt: Bubbles in water. Generated by diffusion-based generative models [28]
Both OpenAI and ChatGPT are excellent at analyzing the ability to determine the target meaning of natural scenery; however, their capacity to scrutinize abstract semantics is somewhat inadequate, particularly with regards to encapsulating regional idiosyncrasies and human-specific terminologies, most notably the extraordinary audacious illusions.
4 Education Assistance Based on ChatGPT
ChatGPT and OpenAI can offer learners assistance in the form of query responses, explanations of subject knowledge, and resource recommendations. They can also be used for language acquisition, providing real-time grammatical correction and vocabulary expansion. In addition, they can facilitate the creation of instructional materials, the production of practice questions, and the evaluation of student work in order to improve the efficacy of instruction. ChatGPT functions as an intelligent learning assistant for educational assistance, facilitating learning and teaching for students and instructors. The probability distribution of Large Language Model (LLM) is given by Eq. (3),
where
where
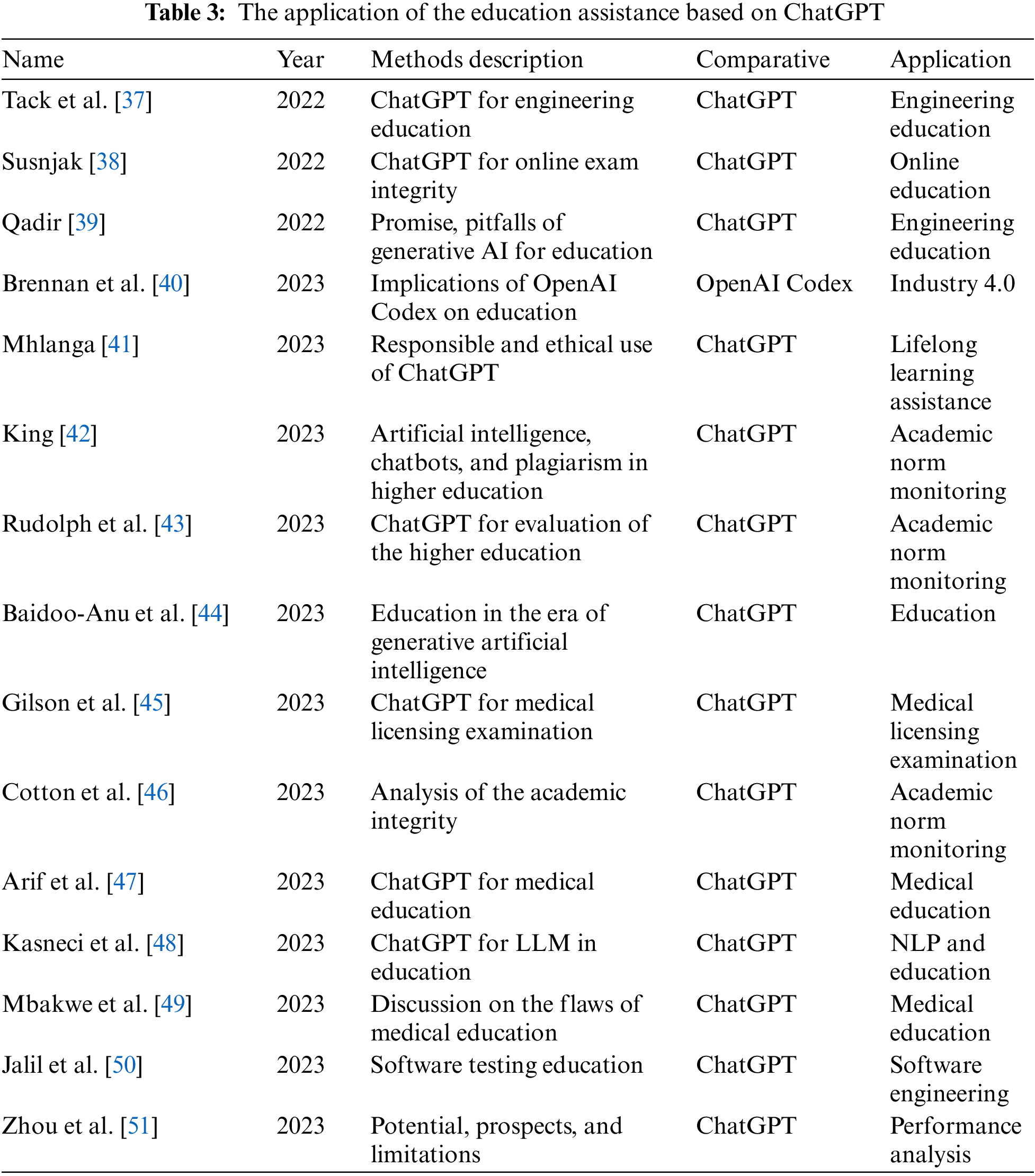
Engineering education is constantly evolving to keep up with new technologies and satisfy the industry’s shifting demands. The application of generative artificial intelligence technologies, such as the ChatGPT conversational agent, could revolutionize the field by making learning more efficient and individualized through feedback, virtual simulations, and hands-on learning. Nonetheless, it is essential to recognize the limitations of this technology, such as its potential to perpetuate biases and generate deceptive information [39]. There are also ethical issues to consider, such as students using it dishonestly or individuals losing their employment due to technological advancements. Even though the current state of generative AI technology is remarkable, engineering instructors must consider what this entails and adapt their teaching practices to maximize the tools’ benefits while minimizing their drawbacks. Brennan et al. [40] conducted a study to determine the effect of OpenAI’s Codex code completion model on teaching and learning in undergraduate engineering programs focusing on industry 4.0. Their evaluation centered on Codex’s ability to generate code in Python’s primary programming paradigms and solve a standard automation and controls programming assignment. The results demonstrated that while Codex can assist with basic code completions, it is not a replacement for a solid understanding of software development principles based on Industry 4.0 standards. The impact of technology and globalization on society, the economy, and the environment has been substantial. Recent AI advancements, such as OpenAI’s ChatGPT, may alter how we teach and learn. However, it is essential that ChatGPT be used responsibly and ethically in education [41]. This requires confidentiality, impartiality, and transparency, among other essential qualities. This essay examines the effects of using ChatGPT in education and demonstrates the importance of taking ethical measures to ensure accountability and adherence to ethical standards in global education. Cotton et al. [46] examined the advantages and disadvantages of the ChatGPT in higher education. In addition, they analyzed the challenges of detecting and preventing academic dishonesty and provided guidance on how institutions can ethically implement these technologies. These strategies include the creation of policies and procedures, the education and assistance of staff members, and the detection and prevention of deception. ChatGPT can provide correct or partially correct answers in 55.6% of cases and correct or partially correct interpretations of answers in 53.0% of cases, according to the findings of Jalil et al. [50]. Using their findings, they assessed the potential benefits and drawbacks of ChatGPT use by students and instructors. In conclusion, it is important to note that OpenAI and ChatGPT have limitations in their understanding of subject domain expertise, which could lead to erroneous or imprecise responses. Additionally, these language models face significant difficulties in adapting to individual students’ unique needs and learning preferences, and they lack personalized teaching support and long-term behavioral analysis capabilities.
5 Clinical Diagnosis and Medical Education Based on ChatGPT
Using OpenAI and ChatGPT, researchers can analyze large experimental datasets to identify patterns and relationships that may not be immediately apparent. These technologies can be used to create clinical diagnostic prediction models that aid in the identification of potential therapeutic targets for a variety of diseases. OpenAI and ChatGPT can accelerate the drug development process by predicting the attributes of potential drug candidates. By analyzing enormous databases of compounds and making predictions about their properties based on their structure and composition, these technologies can be used to rapidly identify viable therapeutic candidates. As shown in Fig. 12 for possible ChatGPT applications, OpenAI and ChatGPT can also be utilized for medical education. The application of clinical diagnosis and medical education based on ChatGPT is provided in Table 4.
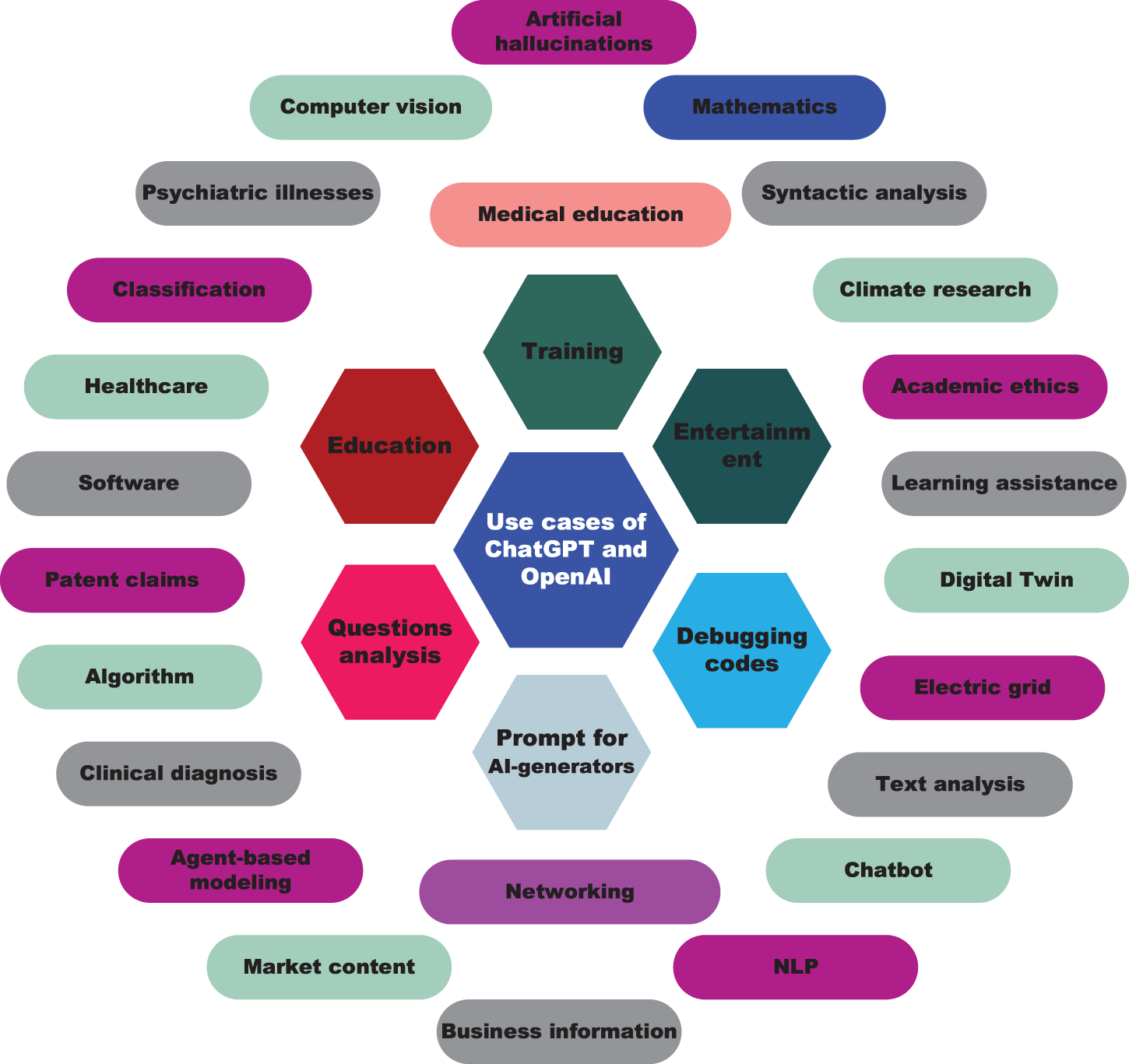
Figure 12: Potential ChatGPT applications
Kung et al. [52] assessed ChatGPT, a large language model, on USMLE Step 1, Step 2CK, and Step 3. ChatGPT passed all three exams untrained. ChatGPT was well-explained. These findings suggest huge language models may improve medical instruction and clinical decision-making. ChatGPT scored 60%. ChatGPT accomplished this feat without human educators. The clarity of ChatGPT’s rationale and clinical insights boosted confidence and comprehension. When Liebrenz et al. [53] examined academic papers about ethical issues in medical publishing with ChatGPT, they discovered that it frequently provided answers without requiring the user to take any action. ChatGPT has thus been used to compose college papers and provide references when requested. Based on a prompt or context, Mijwil et al. [57] discovered that the ChatGPT can generate prose that sounds like it was written by a person. Additionally, it may be modified to generate summaries of articles or product descriptions. It is capable of producing poetry and brief stories. Wang et al. [60] carefully looked at ChatGPT’s ability to withstand attacks from adversarial and out-of-distribution (OOD) points of view. For OOD evaluation, the Flipkart review and DDXPlus medical diagnosis datasets were used. The AdvGLUE (Adversarial GLUE) and ANLI (Adversarial Natural Language Inference) benchmarks were used to measure how strong an adversary is. The study shows that ChatGPT often does better than other well-known foundation models in most adversarial and OOD classification and translation tasks. Lastly, they said that adversarial and OOD robustness are still big problems for foundation models.
Benoit [64] found that ChatGPT can use symptom lists to build vignettes reliably by adding one relevant symptom from outside the list for each condition. In 87.5% of pediatric scenarios with little health literacy, more complicated symptoms were not seen. It was classified as having excellent health literacy in 80% of the vignettes (91.7%). 90% of the problems persisted after rewriting the vignettes between viewings. With first-pass diagnostic accuracy of 75.6% (95% CI, 62.6% to 88.5%) and triage accuracy of 57.8% (95%, 42.9% to 72.7%), ChatGPT identified diseases in 45 vignettes. King [66] were intrigued by the recently released ChatGPT-based natural language chatbot platform for research testing. Examining ChatGPT and encouraging it to produce ingenious, amusing, and helpful comments. Rao et al. [68] evaluated the ChatGPT’s capability for clinical decision support in radiology by identifying the correct imaging modalities for two significant clinical manifestations, cancer screening and breast pain. Based on a patient’s genetic and medical information, OpenAI and ChatGPT can be used to devise individualized treatment regimens. These technologies can be used to develop predictive models that assist physicians in determining the best treatment options for particular patients.
OpenAI and ChatGPT possess inherent limitations in their capacity to interpret and analyze clinical data, thereby potentially yielding erroneous diagnostic outcomes. These models are unable to comprehensively grasp the distinct intricacies of individual patients, rendering them ineffective in incorporating essential factors such as medical history, symptoms, and relevant medical interventions. Furthermore, they fail to account for crucial aspects encompassing legal, ethical, and privacy considerations.
6 Machine Learning Based on ChatGPT
OpenAI and ChatGPT can be used in computer vision and machine learning applications including image recognition, object detection, and facial recognition. Engineers can use these technologies to develop intelligent surveillance systems, autonomous vehicles, and robotics. They can be utilized in data analytics applications such as data mining, predictive analytics, and machine learning. Engineers can utilize these technologies to analyze large datasets and develop predictive models to improve product design, manufacturing processes, and quality control. A common approach to unsupervised text
The language model of the decoder of the multi-layer Transformer is used in the article. This multi-layer structure applies multi-headed self-attention to the feed-forward network that processes the input text plus location information, and the output is the concept distribution of words. In fine-tuning stage, the parameters of the model in the previous stage should be adjusted according to the supervision task. Suppose there is a labeled data set
The final cost function is calculated by Eq. (7), because the language model is added to assist fine-tuning, the results of the supervised model are improved. The application of machine learning based on ChatGPT is given in Table 5.
Dankwa et al. [69] applied the concept of the twin-delayed DDPG (TD3) to eliminate overestimation bias in deep q-learning with discrete actions that are ineffectual in an actor-critical domain environment. Following 500,000 cycles of training, the agent acquired a maximum average reward across a time step of about 1891. The Twin-Delayed Deep Deterministic Policy Gradient (TD3) has significantly enhanced the DDPG’s learning rate and effectiveness in a tough continuous control test. Robotic grasping research has important implications for industries that use robots to speed up processes, like manufacturing and healthcare. Reinforcement learning, which is the study of how agents use incentives to learn how to act, is an effective method for helping robots grasp objects. Nagpal et al. [70] used OpenAI’s Gym’s Pick to test this hypothesis and put environment to engineer rewards and found that Hindsight Experience Replay (HER) is a promising approach for solving sparse reward problems. By tailoring the agent to learn specific rules in a desirable way through reward engineering, it is possible to significantly reduce the learning time, even if it is not the most optimal solution. The VQGAN model can be trained using the available unlabeled image dataset. In [72], the image was displayed as a collection of discrete tokens in the VQGAN codebook space. Srichandan et al. [73] dealt with a clever way to send the angular output from an IMU to a Kalman filter and then send it to the Q-learning input for balancing control on a robot that uses OpenAI. Before the data from the IMU was sent to Q-learning, it was filtered with and without the Kalman filter. This was done to show how well the robot could perform based on how well it could learn and adapt. Ge et al.’s innovative approach [74] used text-to-image synthesis frameworks to automatically generate training data with appropriate labels at scale (e.g., DALL-E, stable diffusion, etc.). The suggested technique divides the training data into the construction of the background (context) and foreground object masks. A straightforward textual template with the object class name was used by DALL-E to generate a variety of foreground images. The advantages were demonstrated using four object detection datasets, including Pascal, VOC, and COCO. Wu et al. [75] made Visual ChatGPT, which uses Visual Foundation Models and lets users connect with ChatGPT by sending and receiving languages, images, and complex visual questions or editing instructions that require the cooperation of several AI models with multiple phases. Suggestions and requests for amended results were considered. The objectives of the topic classification codes and titles proposed by Kashyap et al. [76] in several domains as artificial as ChatGPT were the development of “The Universal Identity” and the adoption of the inclusivity concept. They mathematically proved that starting the process implies unending progress in the search for AI and everything else. Walther et al. [77] discussed the potential negative effects of ChatGPT on how people perceive and interpret men and masculinities and also stressed the significance of understanding whether and how biased ChatGPT is. Also, they offered ChatGPT interactions in an attempt to clarify the caliber and potential biases of the responses from ChatGPT so that one could critically evaluate the output and make inferences for future actions. Lund et al. [78] offered a summary of ChatGPT, a public tool built by OpenAI, and its underlying technology, the generatively trained transformer, as well as their respective important concepts. The language model for ChatGPT was trained using a method called Reinforcement Learning from Human Feedback, making it extremely conversational.
Thorp [79] found that, despite what the website says, “ChatGPT sometimes writes plausible-sounding but wrong or nonsensical answers,” and he gave examples of some of the obvious mistakes it can make, like citing a scientific paper that does not exist. It is the most recent model of its kind to be released by OpenAI, an AI business based in San Francisco, California, and other companies. van Dis et al. [80] found that ChatGPT has caused both interest and disagreement because it is one of the first models that can successfully talk to its users in English, other languages, and on a variety of topics. It is free, user-friendly, and continually learning. The novel approach presented by Zhang et al. [91] known as AutoML-GPT leverages the GPT model to act as a conduit for diverse AI models, allowing for dynamic training with optimized hyperparameters. AutoML-GPT employs an advanced mechanism that extracts user requests from both the model and data cards, generating prompt paragraphs accordingly. This autonomous system seamlessly conducts experiments ranging from data processing to model architecture, hyperparameter tuning, and predicting training logs using the aforementioned query. Remarkably, AutoML-GPT exhibits versatility in handling a variety of complex AI tasks across disparate datasets and domains, including but not limited to computer vision, natural language processing, and other challenging fields. The efficacy of our method is attested to by extensive experiments and ablation studies that demonstrate its generalizability, efficiency, and distinct advantage for a diverse array of AI tasks. The architecture of the AutoML-GPT is shown in Fig. 13.
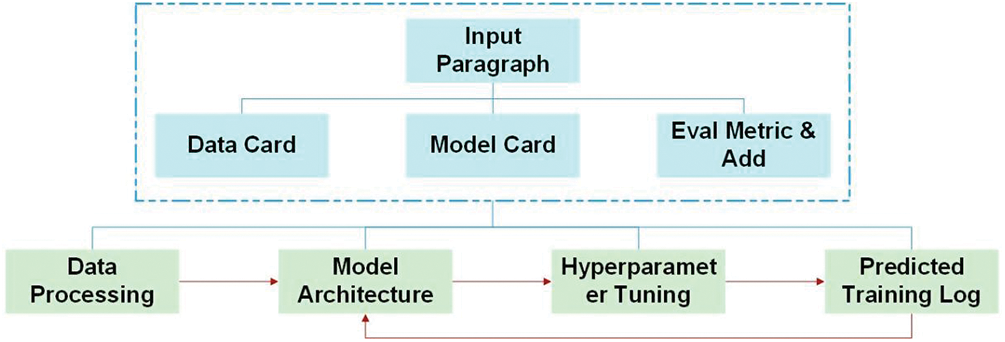
Figure 13: The architecture of the AutoML-GPT [91]
Based on reviews of generated output from finance journal reviewers, the research of Dowling et al. [82] showed that the recently launched AI chatbot ChatGPT can considerably improve finance research. These results ought to hold true for all academic fields. Benefits include data identification and idea formulation. They came to a conclusion by talking about this new technology’s ethical ramifications. Borji [85] analyzed the ChatGPT’s failures, such as reasoning, factual errors, math, coding, and bias are among the eleven failure characteristics. ChatGPT’s hazards, limits, and social effects were also discussed.
The data deviation and sample imbalance of OpenAI and ChatGPT tend to cause their training accuracy to be unstable on new data, and the interpretability and interpretability of the model are limited. It is difficult to understand and explain the model’s prediction and decision-making processes, and its inability to effectively adapt to complex scenarios and diverse computer vision tasks can lead to security risks such as data leakage.
7 Natural Language Processing Based on OpenAI and ChatGPT
OpenAI and ChatGPT are used extensively in Natural Language Processing (NLP) applications in engineering, such as language translation, summarization, and sentiment analysis. Engineers can leverage these technologies to develop more sophisticated chatbots, virtual assistants, and other AI-powered applications. The transformer attention is expressed as Eq. (8),
where
where

GPT-3 made headlines in the mainstream media and got a lot more attention than we would usually expect from an NLP technology improvement. Tobias [95] looked into how OpenAI’s GPT-3 changed how people now see humans (as the only animals who can think and talk) and machines (as things that can not think or talk). Additionally, the discussion of the GPT-3 and other transformer-based language models result based on the structuralist definition of language, has a much broader knowledge of humans and machines than the categories researchers have already known in the past. Classical program synthesis and human-prompt engineering for the generation and selection of instruction were the driving forces behind APE, according to Zhou et al. [97]. Searching for instruction candidates to maximize a scoring function optimizes the “program”. The suggested approach’s automatically generated instructions outperform human annotators on 19 of 24 NLP tasks. The network architecture of transformer is shown in Fig. 14.
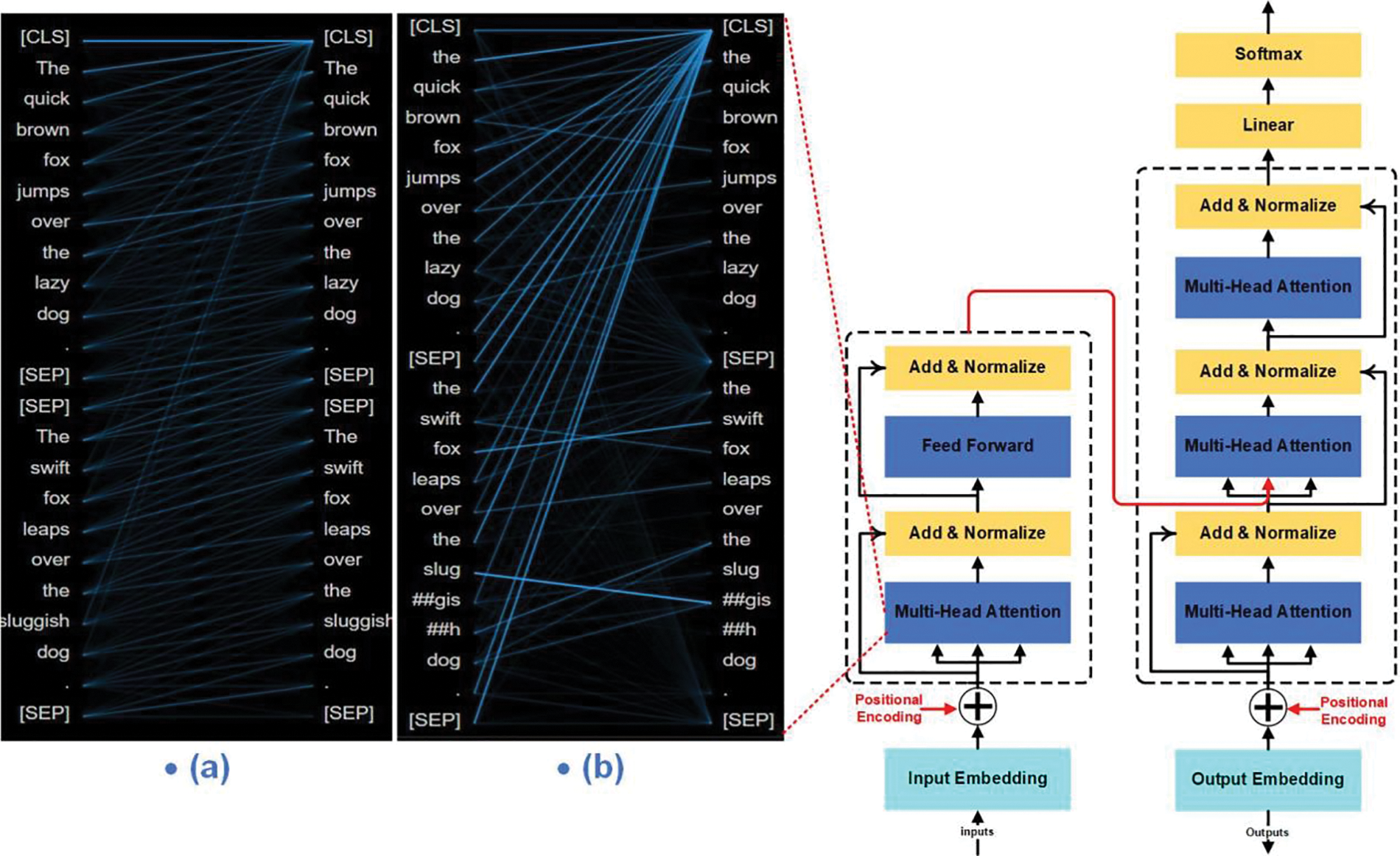
Figure 14: The network architecture of transformer [92]. (a) The attention-head view visualizes attention, Model_type = ‘roberta’, (b) The attention-head view visualizes attention, Model_type = ‘berta’. Prompt_a: The quick brown fox jumps over the lazy dog. Prompt_b: The swift fox leaps over the sluggish dog
Lao Tzu or Laozi, a well-known ancient Chinese philosopher, began his classic Tao Teh Ching or Dao De Jing with six Chinese characters: “Dao ke dao, fei chang dao,” which has been traditionally translated as “The Dao that can be spoken is not the eternal Dao.” Wang et al. [109] investigated this claim by using the ChatGPT. ChatGPT and other advanced language models could change geotechnical engineering by automating data processing, making more information available, improving communication, and making the work go more quickly [110]. GitHub Copilot is a plug-in for Visual Studio Code that uses AI to generate code based on natural language problem descriptions. Since June 2022, concerns have been raised about its impact on beginner programming classes, as it performs well on standard CS1 challenges. To address these concerns, Denny et al. [116] tested Copilot on 166 publicly available programming challenges and found that it solved half of the problems on the first try and 60% with only minor natural language alterations to the problem description. The authors suggest that prompt engineering, which involves interacting with Copilot when it fails, can be a useful learning activity that fosters computational thinking and improves code writing skills. The proposed software tool EvalPlus, as presented by Liu et al. [125], leverages an automated input generation procedure that utilizes both LLM-based and mutation-based input generators to produce a vast number of new test inputs with the aim of validating synthesized code. Building upon a popular benchmark, HUMANEVAL+, their work introduces an extension of this benchmark comprising 81 new exams. The exhaustive evaluation of 14 prominent LLMs reveals that HUMANEVAL+ possesses the capability to effectively identify substantial amounts of erroneous code generated by LLMs. The results obtained with EvalPlus demonstrate that conventional approaches to code synthesis evaluation inadequately capture the performance of LLMs’ code synthesis, and highlight a novel means of enhancing programming benchmarks through automated test input generation. The overview of EvaPlus is showon in Fig. 15.
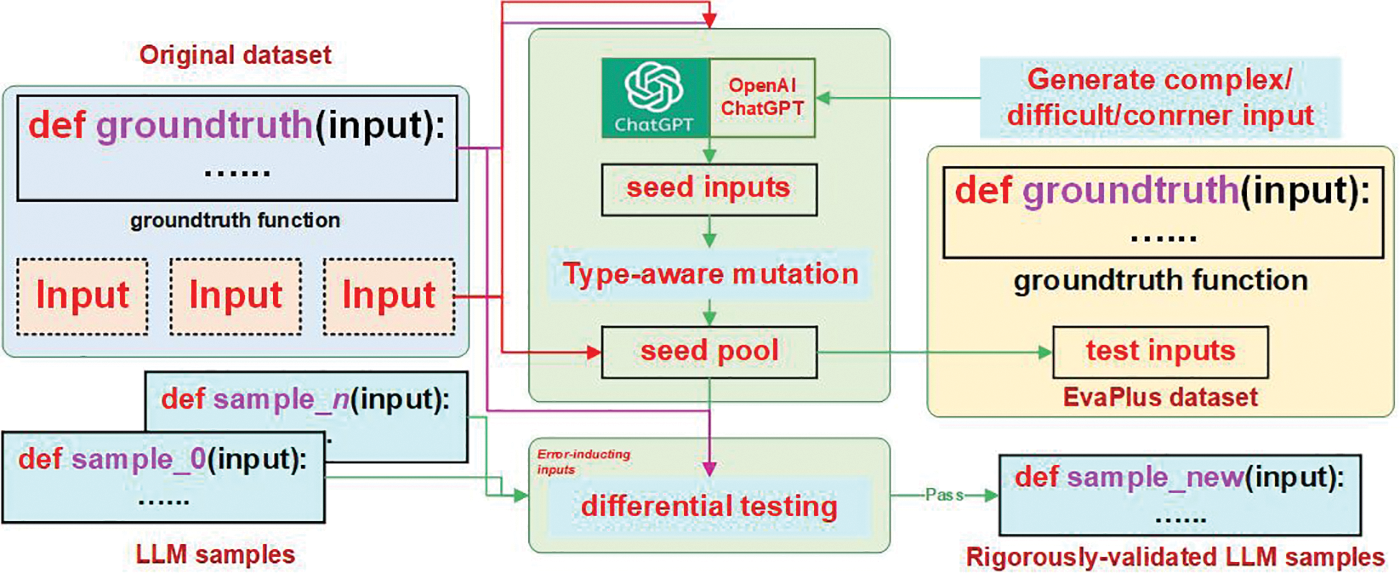
Figure 15: The overview of EvaPlus [125]
ChatGPT demonstrates a constrained comprehension of intricate semantic understanding and contextual nuances, potentially resulting in flawed interpretation and generation of meaning. This limitation is especially pronounced in their analysis capabilities across diverse textual datasets encompassing multiple environments, languages, and cultures. Their inadequate consideration of factors such as emotion and cultural nuances may lead to the propagation of cultural bias and erroneous emotional responses.
8 Hybrid Engineering Application Based on OpenAI and ChatGPT
In May of 2020, OpenAI introduced GPT-3, also known as Generative Pre-trained Transformer 3, a modern artificial intelligence system based on deep learning. This system is designed to generate writing that resembles that of a human in response to user input. Users of the GPT-3 interface input text, and the system generates short stories, novels, reports, academic articles, computer code, mathematical computations, and more. The system is highly adaptable and can generate outputs in a variety of styles that mimic the style of the text input. GPT-3 can also comprehend the text’s content and respond appropriately to queries. It can translate text precisely from one language to another and condense lengthy chapters. The performance of GPT-3 is attributed to its deep neural network-based underlying architecture, which consists of numerous interconnected layers of processing units. The system has been pre-trained on a vast corpus of text data, allowing it to learn linguistic patterns and structures and produce text that is almost identical to human writing. GPT-3 offers enormous potential in a number of areas, including chatbots, virtual assistants, automated content generation, and language translation. It is a huge development in natural language processing overall. The application of hybrid engineering applications based on OpenAI and ChatGPT is shown in Table 7.
In contrast to previous GPT-based methods, Radford et al. [127] used task-aware input transformations during fine-tuning to accomplish effective transfer with minimal model architectural modifications. The experiments’ accuracy improves by 8.9% on the Stories Cloze Test, 5.9% on the RACE test, and 1.5% on the measure of textual entailment (MultiNLI). Jeerige et al. [129] proposed deep reinforcement learning methodologies for constructing intelligent agents by replicating and analyzing prior research. The agent uses deep reinforcement learning to achieve high scores in the Atari 2600 game Breakout. DeepMind’s Asynchronous Advantage actor-critic and Deep Q-Learning are used to train intelligent agents that can communicate with their environment with minimal domain expertise and autonomous feature engineering. ONNX (Open Neural Network eXchange) [131] is an interoperable standard for machine learning frameworks and tools. ONNX-Scala introduces complete ONNX support to the Scala ecosystem, enabling the use of the most advanced deep learning models and numerical computing techniques. ONNX provides two APIs: a black-box API for off-the-shelf models and performance-critical scenarios and a fine-grained API for customized models and internal parameter streaming, both supported by the optimized native CPU/GPU backend ONNX Runtime, with a forthcoming Scala.js backend and NumPy-like API for easy interoperability with other JVM-based products via the ndarray type class. Lee et al. [132] conducted an optimization study of an OpenAI GPT-2 pre-trained model for patent claims. While pre-trained language models have shown success in generating coherent text, patent claim language is challenging to study due to its infrequency. Their study aims to automatically produce logical patent claims and utilized the unique structure and human annotations of patent claims in the fine-tuning process, analyzing the first 100 steps and resulting text to evaluate the approach. Cai et al. [133] proposed a modular software engineering approach for developing robotics with deep reinforcement learning (DRL) that overcomes the difficulties of complex and time-consuming design and limited application. Their approach decouples task, simulator, and hierarchical robot modules from the learning environment, which enables the generation of diverse environments from pre-existing modules. Experimental results demonstrate that the proposed platform enables composable environment design, high module reuse, and effective robot DRL. Moy et al. [134] created a Python framework employing open-source electric grid software (OpenDSS) and deep learning (Open AI) to investigate reinforcement learning applications on distribution grid networks. A reinforcement learning agent was taught to optimally operate capacitor banks in a 13-bus, grid-connected microgrid system in order to maintain system voltage under fluctuating loads. The agent is then evaluated in comparison to optimal control, an OpenDSS-integrated capacitor controller, and a neural network trained under supervision.
Pearce et al. [135] looked into how large language models (LLMs) can be used to fix zero-shot vulnerabilities in code like OpenAI’s Codex and AI21’s Jurassic J-1. Also examined were LLM prompt design problems. The many ways natural languages might phrase crucial information semantically and syntactically make this tough. A large-scale examination of five commercially available, black-box, “off-the-shelf” LLMs, an open-source model, and a locally-trained model on synthetic, hand-crafted, and real-world security bug scenarios is conducted. The LLMs could fix 100% of our synthetically created and handcrafted cases, but a qualitative examination of the model’s effectiveness over a collection of historical actual examples shows limitations in generating functionally correct code. In the study of GPT-3, Thiergart et al. [136] rationalized email communication. Engineers have found it challenging to enable computers to comprehend and produce genuine language. The OpenAI GPT-3 language model and other NLP developments have made both conceivable. The software engineering and data science literature demonstrated the technological potential of email interpretation and response. Technically and commercially, GPT-3 streamlined email communication. The concerns raised by Jayasri et al. [137] can be utilized to identify the type of solution determinant or its characteristics. These concerns can be resolved but cannot be altered. They expanded the scope of the examination to include three moral, mathematical, and semantic assessments, and demonstrated that GPT-3 is not designed to pass them. The industrialization of cost-effective, high-quality semantic artifact production was met with a number of formidable obstacles, which were also discussed. Moroz et al. [138] examined OpenAI’s neural network programmer’s assistant Copilot, which is based on Codex. Analyzing versions of the Codex language model and related systems. Also evaluated are correct command formulation, copyright, safety issues, inefficient code, ethical guidelines, and restrictions. Also recommended were Copilot’s development, progression, and feature enhancements.
Large language models (LLM), such as OpenAI Codex, are being used more frequently in software engineering to write and translate code. A human-centered study found that software developers try to control the properties of generated code in order to get the best results for their code base and the needs of their applications. According to Houde et al.’s analysis of user requirements for programmable code production, human-written code works better than beam-search code derived from a broad language model [139]. The transformer architecture and training objectives is shown in Fig. 16.
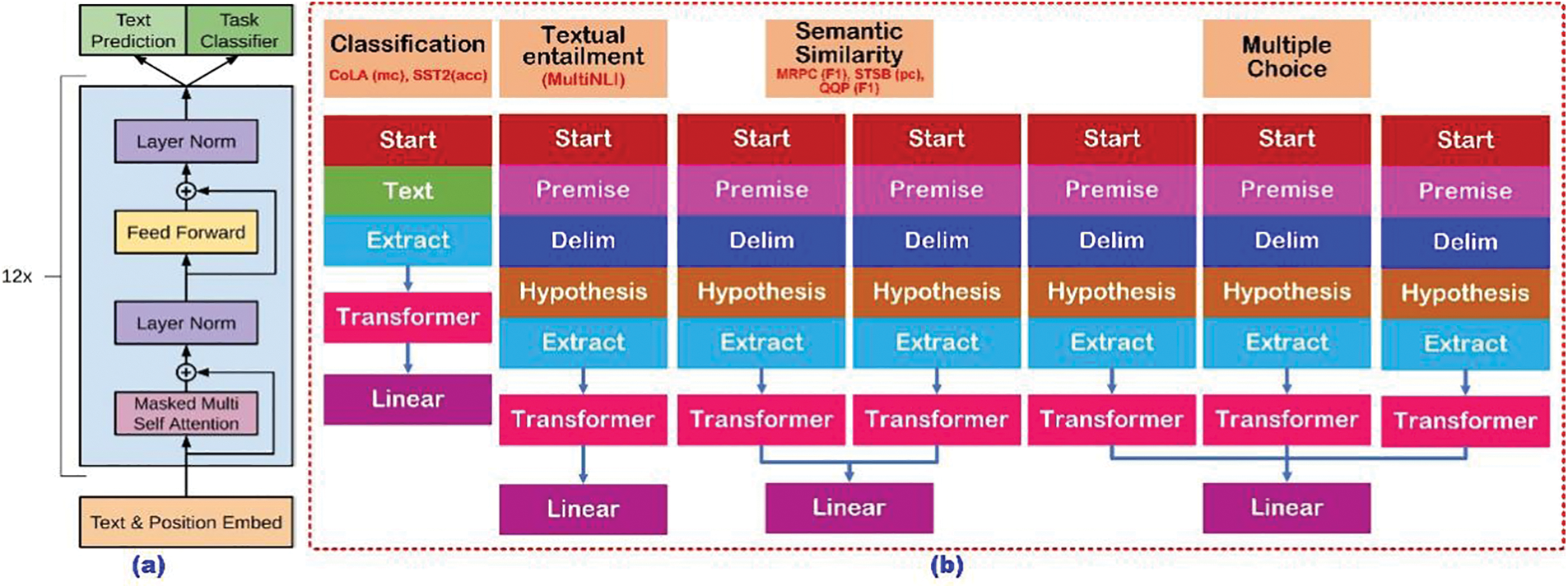
Figure 16: The transformer architecture and training objectives [127]
Aydn et al. [141] conducted a literature review on the development of OpenAI ChatGPT using ChatGPT. Health implications for the Digital Twin were discussed. ChatGPT provided a summary of Google Scholar search results for “Digital twin in healthcare” for 2020–2022. First attempt to demonstrate how AI will accelerate the collection and expression of knowledge. Academics will have more time for research, as publishing will be simplified. Ryu et al. [142] used OpenAI’s Models-as-a-Service (MaaS) offering of GPT-3, which has one of the highest number of parameters, to investigate and mitigate dataset anomalies via the most recent public beta release. The study expands upon previous research demonstrating that cutting-edge NLP models are susceptible to false correlations in training datasets. The massive scope and task-independent pre-training of the GPT-3 made it possible for the authors to evaluate few-shot capabilities and refine natural language inference (NLI) tasks. The study proposes integrating adversarial datasets to reduce dataset artifacts in GPT-3 with minimal performance impact. Haleem et al. [143] conducted research on ChatGPT’s capabilities, issues, and current responsibilities. The neural language models created by Character AI were created specifically for debates. The application uses deep learning to analyze and produce text. The model “understands” natural language with the use of electronic communications. According to Sobania et al. [144], ChatGPT performs much better at repairing bugs than standard program repair techniques while still being on par with the deep learning algorithms CoCoNut and Codex. ChatGPT is a dialogue system that allows users to add more details, like the expected result for a particular input or a noticed error message. With these tips, ChatGPT can solve 31 of 40 problems and outperform the state-of-the-art. Uludag et al. [145] talked about and showed how AI chatbots could be used in the field of psychology. They discovered eight related studies by searching for “ChatGPT.” Frieder et al. [146] evaluated ChatGPT by comparing its performance to that of Minerva and other mathematical corpus models using hand-crafted and publicly available datasets. Examining the value of ChatGPT for professional mathematicians (question responding, theorem searching) by simulating real-world use cases. Experiments demonstrate that ChatGPT comprehends inquiries but cannot respond to them. They ultimately realized that imitating the average classmate is more effective for passing university exams! Du et al. [149] examined ChatGPT from the perspective of IEEE TIV, highlighting its issues and their potential impact on the field of intelligent vehicles. They evaluated ChatGPT’s updating capabilities using basic and complex queries. Initial testing revealed that ChatGPT’s data can be instantaneously updated and corrected, but it can take a while for the changes to be reflected in its responses, meaning it may not always have the most up-to-date subject knowledge. In addition, they highlighted the challenges and potential applications of ChatGPT in intelligent transportation systems, interpersonal behavior, and autonomous driving. Pretrained foundation models, including BERT, GPT-3, MAE, DALLE-E, and ChatGPT, which are trained on vast amounts of data to offer realistic parameter initialization for a variety of downstream applications, were thoroughly surveyed by Zhou et al. [151]. In the use of large models, the concept of pretraining behind PFMs is crucial. They also reviewed the prospects and challenges facing PFMs in text, image, graph, and other data paradigms in the present and future. Xiao et al. [152] have introduced an innovative tri-agent creation pipeline based on ChatGPT. Within this framework, the generator exhibits its prowess by generating an initial output, while the user-specific instructor undertakes the crucial role of producing meticulous editing instructions. These instructions serve as a guiding force for the editor, who subsequently generates an output that intricately aligns with the discerning preferences of the user. A key enhancement incorporated into the pipeline is the utilization of editor-guided reinforcement learning. This strategic approach facilitates the optimization of lesson generation specifically for the instructor, fostering iterative improvements in the overall performance of the system. By seamlessly integrating user-specific input, editing instructions, and reinforcement learning, the proposed tri-agent creation pipeline embodies a cutting-edge paradigm, poised to significantly enhance the tailored output generation process.
OpenAI and ChatGPT have large computing and storage requirements in engineering applications, and there may be performance constraints in resource-constrained environments, making it challenging to meet the requirements of certain real-time application scenarios. Complex business processes and interaction logic cannot be analyzed effectively at this time, and additional customization and adjustment may be necessary to meet the requirements of actual applications.
OpenAI and ChatGPT exhibit remarkable versatility and are well-suited for various engineering applications. Leveraging their capabilities can result in heightened productivity, cost reduction, and improved customer service within organizations. This study undertakes a critical examination of the applications of OpenAI and ChatGPT from multiple perspectives, encompassing text-to-image/video applications, educational assistance, clinical diagnosis, machine learning, natural language processing, and hybrid engineering applications. Through an extensive analysis of relevant literature, this paper delivers a comprehensive and scholarly evaluation of the advancements, potentials, and limitations of these state-of-the-art language models. The findings presented herein aim to inform and benefit academic researchers, industry practitioners, and other interested stakeholders. The meticulous literature review in this paper contributes to the existing knowledge base and holds valuable insights for engineering application practitioners, researchers, and those with a vested interest in the field.
Acknowledgement: Thanks to the help of three anonymous reviewers and journal editors, the logical organization and content quality of this paper have been improved.
Funding Statement: This project is supported by the National Natural Science Foundation of China (No. 62001197).
Author Contributions: The authors confirm contribution to the paper as follows: study conception, design, data collection, analysis and interpretation of results, draft manuscript preparation: Hong Zhang, Haijian Shao. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: This paper is predominantly a review that synthesizes existing methods and literature findings. This investigation utilized only data obtained from publicly accessible sources. These datasets are accessible via the sources listed in the References section of this paper. As the data originates from publicly accessible repositories, its accessibility is unrestricted.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J. et al. (2016). OpenAI Gym. arXiv preprint arXiv:1606.01540. https://doi.org/10.48550/arXiv.1606.01540 [Google Scholar] [CrossRef]
2. Zamora, I., Lopez, N. G., Vilches, V. M., Cordero, A. H. (2016). Extending the OpenAI Gym for robotics: A toolkit for reinforcement learning using ROS and Gazebo. arXiv preprint arXiv:1608.05742. https://doi.org/10.48550/arXiv.1608.05742 [Google Scholar] [CrossRef]
3. Akhtar, E. S. F. (2017). Practical reinforcement learning: Develop self-evolving, intelligent agents with OpenAI Gym, Python and Java. In: Packt publishing. Birmingham, UK: Packt Publishing Press. [Google Scholar]
4. Cullen, M., Davey, B., Friston, K. J., Moran, R. J. (2018). Active inference in OpenAI Gym: A paradigm for computational investigations into psychiatric illness. Biological Psychiatry: Cognitive Neuroscience and Neuroimaging, 3(9), 809–818. [Google Scholar] [PubMed]
5. Kozlowski, N., Unold, O. (2018). Integrating anticipatory classifier systems with OpenAI gym. Proceedings of the Genetic and Evolutionary Computation Conference Companion, pp. 1410–1417. Kyoto, Japan. https://doi.org/10.1145/3205651.3208241 [Google Scholar] [CrossRef]
6. Gawlowicz, P., Zubow, A. (2018). NS3-Gym: Extending OpenAI Gym for networking research. arXiv preprint arXiv:1810.03943. https://doi.org/10.48550/arXiv.1810.03943 [Google Scholar] [CrossRef]
7. Gawlowicz, P., Zubow, A. (2019). NS-3 meets OpenAI Gym: The playground for machine learning in networking research. Proceedings of the 22nd International ACM Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, pp. 113–120. Miami Beach, FL, USA. https://doi.org/10.1145/3345768.3355908 [Google Scholar] [CrossRef]
8. Vázquez-Canteli, J. R., Kämpf, J., Henze, G., Nagy, Z. (2019). Citylearn v1.0: An OpenAI Gym environment for demand response with deep reinforcement learning. Proceedings of the 6th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, pp. 356–357. New York, NY, USA. https://doi.org/10.1145/3360322.3360998 [Google Scholar] [CrossRef]
9. Zielinski, K., Teixeira, M., Ribeiro, R., Casanova, D. (2020). Concept and the implementation of a tool to convert industry 4.0 environments modeled as FSM to an OpenAI Gym wrapper. arXiv preprint arXiv:2006.16035. https://doi.org/10.48550/arXiv.2006.16035 [Google Scholar] [CrossRef]
10. D’Souza, S. (2021). Implementing reinforcement learning algorithms in retail supply chains with OpenAI gym toolkit. arXiv preprint arXiv:2104.14398. https://doi.org/10.48550/arXiv.2104.14398 [Google Scholar] [CrossRef]
11. Schuderer, A., Bromuri, S., van Eekelen, M. (2021). Sim-Env: Decoupling OpenAI gym environments from simulation models. In advances in practical applications of agents, multi-agent systems, and social good. The PAAMS Collection: 19th International Conference, PAAMS 2021, pp. 390–393. Salamanca, Spain, German, Springer International Publishing. [Google Scholar]
12. Nagy, D., Tabi, Z., Hága, P., Kallus, Z., Zimborás, Z. (2021). Photonic quantum policy learning in OpenAI Gym. 2021 IEEE International Conference on Quantum Computing and Engineering (QCE), pp. 123–129. Broomfield, CO, USA, IEEE. https://doi.org/10.48550/arXiv.2108.12926 [Google Scholar] [CrossRef]
13. Vidyadhar, V., Nagaraj, R., Ashoka, D. V. (2021). NetAI-Gym: Customized environment for network to evaluate agent algorithm using reinforcement learning in Open-AI Gym platform. International Journal of Advanced Computer Science and Applications, 12(4). https://doi.org/10.14569/IJACSA.2021.0120423 [Google Scholar] [CrossRef]
14. Gross, D., Jansen, N., Junges, S., Pérez, G. A. (2022). COOL-MC: A comprehensive tool for reinforcement learning and model checking. Dependable Software Engineering. Theories, Tools, and Applications: 8th International Symposium, SETTA 2022, pp. 41–49. Beijing, China, Cham, Springer Nature Switzerland. [Google Scholar]
15. Hsiao, J. Y., Du, Y., Chiang, W. Y., Hsieh, M. H., Goan, H. S. (2022). Unentangled quantum reinforcement learning agents in the OpenAI Gym. arXiv preprint arXiv:2203.14348. https://doi.org/10.48550/arXiv.2203.14348 [Google Scholar] [CrossRef]
16. Biswas, S. S. (2023). Potential use of chat GPT in global warming. Annals of Biomedical Engineering, 1–2. https://doi.org/10.1007/s10439-023-03171-8 [Google Scholar] [CrossRef]
17. Wang, Z., Liu, W., He, Q., Wu, X., Yi, Z. (2022). CLIP-GEN: Language-free training of a text-to-image generator with clip. arXiv preprint arXiv:2203.00386. https://doi.org/10.48550/arXiv.2203.00386 [Google Scholar] [CrossRef]
18. Ding, M., Yang, Z., Hong, W., Zheng, W., Zhou, C. et al. (2021). Cogview: Mastering text-to-image generation via transformers. Advances in Neural Information Processing Systems, 34, 19822–19835. [Google Scholar]
19. Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C. et al. (2021). Zero-shot text-to-image generation. International Conference on Machine Learning, pp. 8821–8831. Hawai, USA: PMLR. [Google Scholar]
20. Huang, Z., Zhang, T., Heng, W., Shi, B., Zhou, S. (2020). Rife: Real-time intermediate flow estimation for video frame interpolation. arXiv preprint arXiv:2011.06294. https://doi.org/10.48550/arXiv.2011.06294 [Google Scholar] [CrossRef]
21. Alec, R., Ilya, S. R., Jong, W. K., Gretchen, K., Sandhini, A. (2021). CLIP: Connecting text and images. https://github.com/openai/CLIP [Google Scholar]
22. Esser, P., Rombach, R., Ommer, B. (2021). Taming transformers for high-resolution image synthesis. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12873–12883. [Google Scholar]
23. Wang, X., Xie, L., Dong, C., Shan, Y. (2021). Real-ESRGAN: Training real-world blind super-resolution with pure synthetic data. Proceedings of the IEEE/CVF International Conference on Computer Vision, October 17, pp. 1905–1914. Montreal, Canada. [Google Scholar]
24. Dayma, B., Patil, S., Cuenca, P., Saifullah, K., Abraham, T. et al. (2021). DALL·E Mini. https://doi.org/10.5281/zenodo.5146400 [Google Scholar] [CrossRef]
25. Vidyadhar, V., Nagaraja, R. (2021). Evaluation of agent-network environment mapping on Open-AI Gym for Q-routing algorithm. International Journal of Advanced Computer Science and Applications, 12(6). https://doi.org/10.14569/issn.2156-5570 [Google Scholar] [CrossRef]
26. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G. et al. (2021). Learning transferable visual models from natural language supervision. International Conference on Machine Learning, pp. 8748–8763. Hawaii, USA, PMLR. [Google Scholar]
27. Schaldenbrand, P., Liu, Z., Oh, J. (2022). Towards real-time Text2Video via CLIP-guided, pixel-level optimization. arXiv preprint arXiv:2210.12826. https://doi.org/10.48550/arXiv.2210.12826 [Google Scholar] [CrossRef]
28. Karras, T., Aittala, M., Aila, T., Laine, S. (2022). Elucidating the design space of diffusion-based generative models. arXiv preprint arXiv:2206.00364. https://doi.org/10.48550/arXiv.2206.00364 [Google Scholar] [CrossRef]
29. Borji, A. (2022). Generated faces in the wild: Quantitative comparison of stable diffusion, midjourney and DALL-E 2. arXiv preprint arXiv:2210.00586. https://doi.org/10.48550/arXiv.2210.00586 [Google Scholar] [CrossRef]
30. Kapelyukh, I., Vosylius, V., Johns, E. (2022). DALL-E-Bot: Introducing web-scale diffusion models to robotics. arXiv preprint arXiv:2210.02438. https://doi.org/10.48550/arXiv.2210.02438 [Google Scholar] [CrossRef]
31. Oppenlaender, J. (2022). Prompt engineering for text-based generative art. arXiv preprint arXiv:2204.13988. https://www.arxiv-vanity.com/papers/2204.13988/ [Google Scholar]
32. Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10684–10695. New Orleans, Louisiana, USA. [Google Scholar]
33. Wang, X., Yuan, H., Zhang, S., Chen, D., Wang, J. et al. (2023). VideoComposer: Compositional video synthesis with motion controllability. arXiv preprint arXiv:2306.02018. https://doi.org/10.48550/arXiv.2306.02018 [Google Scholar] [CrossRef]
34. Jabri, A., Steenkiste, S., Hoogeboom, E., Sajjadi, M., Kipf, T. (2023). DORSal: Diffusion for object-centric representations of Scenes et al. arXiv preprint arXiv:2306.08068. https://doi.org/10.48550/arXiv.2306.08068 [Google Scholar] [CrossRef]
35. Couairon, P., Rambour, C., Haugeard, J., Thome, N. (2023). VidEdit: Zero-shot and spatially aware text-driven video editing. arXiv preprint arXiv:2306.08707. https://doi.org/10.48550/arXiv.2306.08707 [Google Scholar] [CrossRef]
36. Kolotouros, N., Alldieck, T., Zanfir, A., Bazavan, E., Fieraru, M. et al. (2023). DreamHuman: Animatable 3D avatars from text. arXiv preprint arXiv:2306.09329. https://doi.org/10.48550/arXiv.2306.09329 [Google Scholar] [CrossRef]
37. Tack, A., Piech, C. (2022). The AI teacher test: Measuring the pedagogical ability of blender and GPT-3 ineducational dialogues. arXiv preprint arXiv:2205.07540. https://doi.org/10.48550/arXiv.2205.07540 [Google Scholar] [CrossRef]
38. Susnjak, T. (2022). ChatGPT: The end of online exam integrity? arXiv preprint arXiv:2212.09292. https://doi.org/10.48550/arXiv.2212.09292 [Google Scholar] [CrossRef]
39. Qadir, J. (2022). Engineering education in the era of ChatGPT: Promise and pitfalls of generative AI for education. TechRxiv. https://doi.org/10.36227/techrxiv.21789434.v1 [Google Scholar] [CrossRef]
40. Brennan, R. W., Lesage, J. (2023). Exploring the implications of OpenAI codex on education for industry 4.0. in Proc. of Service Oriented, Holonic and Multi-Agent Manufacturing Systems for Industry of the Future, pp. 254–266. Cham, Springer International Publishing. [Google Scholar]
41. Mhlanga, D. (2023). Open AI in education, the responsible and ethical use of ChatGPT towards lifelong learning. https://doi.org/10.2139/ssrn.4354422 [Google Scholar] [CrossRef]
42. King, M. R. (2023). ChatGPT. A conversation on artificial intelligence, chatbots, and plagiarism in higher education. Cellular and Molecular Bioengineering, 16, 1–2. https://doi.org/10.1007/s12195-022-00754-8 [Google Scholar] [CrossRef]
43. Rudolph, J., Tan, S., Tan, S. (2023). ChatGPT: Bullshit spewer or the end of traditional assessments in higher education? Journal of Applied Learning and Teaching, 6(1). https://doi.org/10.37074/jalt.2023.6.1.9 [Google Scholar] [CrossRef]
44. Baidoo-Anu, D., Owusu Ansah, L. (2023). Education in the era of generative artificial intelligence (AIUnderstanding the potential benefits of ChatGPT in promoting teaching and learning. https://doi.org/10.2139/ssrn.4337484 [Google Scholar] [CrossRef]
45. Gilson, A., Safranek, C. W., Huang, T., Socrates, V., Chi, L. et al. (2023). How does CHATGPT perform on the United States medical licensing examination? The implications of large language models for medical education and knowledge assessment. JMIR Medical Education, 9(1), e45312. https://doi.org/10.2196/45312 [Google Scholar] [PubMed] [CrossRef]
46. Cotton, D. R., Cotton, P. A., Shipway, J. R. (2023). Chatting and cheating: Ensuring academic integrity in the era of ChatGPT. Innovations in Education and Teaching International, 1–12. https://doi.org/10.1080/14703297.2023.2190148 [Google Scholar] [CrossRef]
47. Arif, T. B., Munaf, U., Ul-Haque, I. (2023). The future of medical education and research: Is ChatGPT a blessing or blight in disguise? Medical Education Online, 28(1), 2181052. https://doi.org/10.1080/10872981.2023.2181052 [Google Scholar] [PubMed] [CrossRef]
48. Kasneci, E., Seßler, K., Küchemann, S., Bannert, M., Dementieva, D. et al. (2023). ChatGPT for good? On opportunities and challenges of large language models for education. Learning and Individual Differences, 103, 102274. https://doi.org/10.35542/osf.io/5er8f [Google Scholar] [CrossRef]
49. Mbakwe, A. B., Lourentzou, I., Celi, L. A., Mechanic, O. J., Dagan, A. (2023). ChatGPT passing USMLE shines a spotlight on the flaws of medical education. PLoS Digital Health, 2(2), e0000205. https://doi.org/10.1371/journal.pdig.0000205 [Google Scholar] [PubMed] [CrossRef]
50. Jalil, S., Rafi, S., LaToza, T. D., Moran, K., Lam, W. (2023). ChatGPT and software testing education: Promises & perils. arXiv preprint arXiv:2302.03287. https://doi.org/10.48550/arXiv.2302.03287 [Google Scholar] [CrossRef]
51. Zhou, J., Ke, P., Qiu, X., Huang, M., Zhang, J. (2023). ChatGPT: Potential, prospects, and limitations. Frontiers of Information Technology & Electronic Engineering, 1–6. https://doi.org/10.1631/FITEE.2300089 [Google Scholar] [CrossRef]
52. Kung, T. H., Cheatham, M., Medenilla, A., Sillos, C., De Leon, L. et al. (2023). Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digital Health, 2(2), e0000198. https://doi.org/10.1371/journal.pdig.0000198 [Google Scholar] [PubMed] [CrossRef]
53. Liebrenz, M., Schleifer, R., Buadze, A., Bhugra, D., Smith, A. (2023). Generating scholarly content with ChatGPT: Ethical challenges for medical publishing. The Lancet Digital Health, 5(3), e105–e106. [Google Scholar] [PubMed]
54. Biswas, S. (2023). ChatGPT and the future of medical writing. Radiology, 307(2), 223312. https://doi.org/10.1148/radiol.223312 [Google Scholar] [PubMed] [CrossRef]
55. Kitamura, F. C. (2023). ChatGPT is shaping the future of medical writing but still requires human judgment. Radiology, 307(2), 230171. https://doi.org/10.1148/radiol.230171 [Google Scholar] [PubMed] [CrossRef]
56. Koo, M. (2023). The importance of proper use of ChatGPT in medical writing. Radiology, 307(3), 230312. https://doi.org/10.1148/radiol.230312 [Google Scholar] [PubMed] [CrossRef]
57. Mijwil, M., Aljanabi, M., Ali, A. H. (2023). ChatGPT: Exploring the role of cybersecurity in the protection of medical information. Mesopotamian Journal of Cybersecurity, 2023, 18–21. https://doi.org/10.58496/MJCS/2023/004 [Google Scholar] [CrossRef]
58. Ufuk, F. (2023). The role and limitations of large language models such as ChatGPT in clinical settings and medical journalism. Radiology, 307(3), 230276. https://doi.org/10.1148/radiol.230276 [Google Scholar] [PubMed] [CrossRef]
59. Khan, R. A., Jawaid, M., Khan, A. R., Sajjad, M. (2023). ChatGPT-reshaping medical education and clinical management. Pakistan Journal of Medical Sciences, 39(2), 605–607. https://doi.org/10.12669/pjms.39.2.7653 [Google Scholar] [PubMed] [CrossRef]
60. Wang, J., Hu, X., Hou, W., Chen, H., Zheng, R. et al. (2023). On the robustness of ChatGPT: An adversarial and out-of-distribution perspective. arXiv preprint arXiv:2302.12095. https://doi.org/10.48550/arXiv.2302.12095 [Google Scholar] [CrossRef]
61. Patel, S. B., Lam, K., Liebrenz, M. (2023). ChatGPT: Friend or foe. Lancet Digital Health, 5, e102. https://doi.org/10.1016/S2589-7500(23)00023-7 [Google Scholar] [PubMed] [CrossRef]
62. Aljanabi, M. (2023). ChatGPT: Future directions and open possibilities. Mesopotamian Journal of CyberSecurity, 2023, 16–17. https://doi.org/10.58496/MJCS/2023/003 [Google Scholar] [CrossRef]
63. Howard, A., Hope, W., Gerada, A. (2023). ChatGPT and antimicrobial advice: The end of the consulting infection doctor? The Lancet Infectious Diseases, 23(4), 405–406. https://doi.org/10.1016/S1473-3099(23)00113-5 [Google Scholar] [PubMed] [CrossRef]
64. Benoit, J. R. (2023). ChatGPT for clinical vignette generation, revision, and evaluation. medRxiv, 43(7), 677. https://doi.org/10.1101/2023.02.04.23285478 [Google Scholar] [CrossRef]
65. Biswas, S. S. (2023). Role of chat GPT in public health. Annals of Biomedical Engineering, 51(5), 868–869. https://doi.org/10.1007/s10439-023-03172-7 [Google Scholar] [PubMed] [CrossRef]
66. King, M. R. (2023). The future of AI in medicine: A perspective from a Chatbot. Annals of Biomedical Engineering, 51, 291–295. https://doi.org/10.1007/s10439-022-03121-w [Google Scholar] [PubMed] [CrossRef]
67. Patel, S. B., Lam, K. (2023). ChatGPT: The future of discharge summaries? The Lancet Digital Health, 5(3), e107–e108. https://doi.org/10.1016/S2589-7500(23)00021-3 [Google Scholar] [PubMed] [CrossRef]
68. Rao, A., Kim, J., Kamineni, M., Pang, M., Lie, W. et al. (2023). Evaluating ChatGPT as an adjunct for radiologic decision-making. medRxiv. https://doi.org/10.1101/2023.02.02.23285399 [Google Scholar] [CrossRef]
69. Dankwa, S., Zheng, W. (2019). Modeling a continuous locomotion behavior of an intelligent agent using deep reinforcement technique. IEEE 2nd International Conference on Computer and Communication Engineering Technology (CCET), pp. 172–175. Beijing, China, IEEE. https://doi.org/10.1109/CCET48361.2019.8989177 [Google Scholar] [CrossRef]
70. Nagpal, R., Krishnan, A. U., Yu, H. (2020). Reward engineering for object pick and place training. arXiv preprint arXiv:2001.03792. https://doi.org/10.48550/arXiv.2001.03792 [Google Scholar] [CrossRef]
71. Bai, H. X., Thomasian, N. M. (2021). RICORD: A precedent for open AI in COVID-19 image analytics. Radiology, 299(1), E219–E220. https://doi.org/10.1148/radiol.2020204214 [Google Scholar] [PubMed] [CrossRef]
72. Esser, P., Rombach, R., Ommer, B. (2021). Taming transformers for high-resolution image synthesis. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12873–12883. Nashville, Tennessee, USA. [Google Scholar]
73. Srichandan, A., Dhingra, J., Hota, M. K. (2021). An improved Q-learning approach with Kalman filter for self-balancing robot using OpenAI. Journal of Control, Automation and Electrical Systems, 32(6), 1521–1530. https://doi.org/10.1007/s40313-021-00786-x [Google Scholar] [CrossRef]
74. Ge, Y., Xu, J., Zhao, B. N., Itti, L., Vineet, V. (2022). DALL-E for detection: Language-driven context image synthesis for object detection. arXiv preprint arXiv:2206.09592. https://doi.org/10.48550/arXiv.2206.09592 [Google Scholar] [CrossRef]
75. Wu, C., Yin, S., Qi, W., Wang, X., Tang, Z. et al. (2023). Visual ChatGPT: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671. https://doi.org/10.48550/arXiv.2303.04671 [Google Scholar] [CrossRef]
76. Kashyap, R., OpenAI, C. (2023). A first chat with ChatGPT: The first step in the road-map for AI (artificial intelligence). https://ssrn.com/abstract_id=4351637 [Google Scholar]
77. Walther, A., Logoz, F., Eggenberger, L. (2023). The gendered nature of AI: Men and masculinities through the lens of ChatGPT and GPT4. https://doi.org/10.31234/osf.io/6d4ur [Google Scholar] [CrossRef]
78. Lund, B. D., Wang, T., B., D., Wang, T. (2023). Chatting about ChatGPT: How may AI and GPT impact academia and libraries? Library Hi Tech News, 40(3), 26–29. https://doi.org/10.1108/LHTN-01-2023-0009 [Google Scholar] [CrossRef]
79. Thorp, H. H. (2023). ChatGPT is fun, but not an author. Science, 379(6630), 313. https://doi.org/10.1126/science.adg7879 [Google Scholar] [PubMed] [CrossRef]
80. Van Dis, E. A., Bollen, J., Zuidema, W., van Rooij, R., Bockting, C. L. (2023). ChatGPT: Five priorities for research. Nature, 614(7947), 224–226. https://doi.org/10.1038/d41586-023-00288-7 [Google Scholar] [PubMed] [CrossRef]
81. Shen, Y., Heacock, L., Elias, J., Hentel, K. D., Reig, B. et al. (2023). ChatGPT and other large language models are double-edged swords. Radiology, 307(2), 230163. https://doi.org/10.1148/radiol.230163 [Google Scholar] [PubMed] [CrossRef]
82. Dowling, M., Lucey, B. (2023). ChatGPT for (finance) research: The Bananarama conjecture. Finance Research Letters, 103662. https://doi.org/10.1016/j.frl.2023.103662 [Google Scholar] [CrossRef]
83. McGee, R. W. (2023). Is Chat Gpt biased against conservatives? An empirical study. https://doi.org/10.2139/ssrn.4359405 [Google Scholar] [CrossRef]
84. Zhong, Q., Ding, L., Liu, J., Du, B., Tao, D. (2023). Can ChatGPT understand too? a comparative study on ChatGPT and fine-tuned bert. arXiv preprint arXiv:2302.10198. https://doi.org/10.48550/arXiv.2302.10198 [Google Scholar] [CrossRef]
85. Borji, A. (2023). A categorical archive of ChatGPT failures. arXiv preprint arXiv:2302.03494. https://doi.org/10.48550/arXiv.2302.03494 [Google Scholar] [CrossRef]
86. Choi, J. H., Hickman, K. E., Monahan, A., Schwarcz, D. (2023). ChatGPT goes to law school. https://doi.org/10.2139/ssrn.4335905 [Google Scholar] [CrossRef]
87. Lecler, A., Duron, L., Soyer, P. (2023). Revolutionizing radiology with GPT-based models: Current applications, future possibilities and limitations of ChatGPT. Diagnostic and Interventional Imaging, 104(6), 269–274. https://doi.org/10.1016/j.diii.2023.02.003 [Google Scholar] [PubMed] [CrossRef]
88. Helberger, N., Diakopoulos, N. (2023). ChatGPT and the AI act. Internet Policy Review, 12(1), 1–6. https://doi.org/10.14763/2023.1.1682 [Google Scholar] [CrossRef]
89. Ali, M. J., Djalilian, A. (2023). Readership awareness series-paper 4: Chatbots and ChatGPT-ethical considerations in scientific publications. The Ocular Surface, 28, 153–154. https://doi.org/10.1016/j.jtos.2023.04.001 [Google Scholar] [PubMed] [CrossRef]
90. Vaishya, R., Misra, A., Vaish, A. (2023). ChatGPT: Is this version good for healthcare and research? Diabetes & Metabolic Syndrome: Clinical Research & Reviews, 17(4), 102744. https://doi.org/10.1016/j.dsx.2023.102744 [Google Scholar] [PubMed] [CrossRef]
91. Zhang, S., Gong, C., Wu, L., Liu, X., Zhou, M. (2023). AutoML-GPT: Automatic machine learning with GPT. arXiv preprint arXiv:2305.02499. https://doi.org/10.48550/arXiv.2305.02499 [Google Scholar] [CrossRef]
92. Vig, J. (2019). A multiscale visualization of attention in the transformer model. arXiv preprint arXiv:1906.05714. https://doi.org/10.48550/arXiv.1906.05714 [Google Scholar] [CrossRef]
93. Kalyan, K. S., Rajasekharan, A., Sangeetha, S. (2021). AMMUS: A survey of transformer-based pretrained models in natural language processing. arXiv preprint arXiv:2108.05542. https://doi.org/10.48550/arXiv.2108.05542 [Google Scholar] [CrossRef]
94. Abnar, S., Dehghani, M., Neyshabur, B., Sedghi, H. (2021). Exploring the limits of large scale pre-training. arXiv preprint arXiv:2110.02095. https://doi.org/10.48550/arXiv.2110.02095 [Google Scholar] [CrossRef]
95. Rees, T. (2022). Non-human words: On GPT-3 as a philosophical laboratory. Daedalus, 151(2), 168–182. https://doi.org/10.1162/daed_a_01908 [Google Scholar] [CrossRef]
96. Leivada, E., Murphy, E., Marcus, G. (2022). DALL-E 2 fails to reliably capture common syntactic processes. arXiv preprint arXiv:2210. https://doi.org/10.48550/arXiv.2210.12889 [Google Scholar] [CrossRef]
97. Zhou, Y., Muresanu, A. I., Han, Z., Paster, K., Pitis, S. et al. (2022). Large language models are human-level prompt engineers. arXiv preprint arXiv:2211.01910. https://doi.org/10.48550/arXiv.2211.01910 [Google Scholar] [CrossRef]
98. White, J., Fu, Q., Hays, S., Sandborn, M., Olea, C. et al. (2023). A prompt pattern catalog to enhance prompt engineering with ChatGPT. arXiv preprint arXiv:2302.11382. https://doi.org/10.48550/arXiv.2302.11382 [Google Scholar] [CrossRef]
99. Wang, X., Chen, G., Qian, G., Gao, P., Wei, X. Y. et al. (2023). Large-scale multi-modal pre-trained models: A comprehensive survey. arXiv preprint arXiv:2302.10035. https://doi.org/10.48550/arXiv.2302.10035 [Google Scholar] [CrossRef]
100. Qin, C., Zhang, A., Zhang, Z., Chen, J., Yasunaga, M. et al. (2023). Is ChatGPT a general-purpose natural language processing task solver? arXiv preprint arXiv:2302.06476. https://doi.org/10.48550/arXiv.2302.06476 [Google Scholar] [CrossRef]
101. Yang, X., Li, Y., Zhang, X., Chen, H., Cheng, W. (2023). Exploring the limits of ChatGPT for query or aspect-based text summarization. arXiv preprint arXiv:2302.08081. https://doi.org/10.48550/arXiv.2302.08081 [Google Scholar] [CrossRef]
102. Shahriar, S., Hayawi, K. (2023). Let’s have a chat! A conversation with ChatGPT: Technology, applications, and limitations. arXiv preprint arXiv:2302.13817. https://doi.org/10.48550/arXiv.2302.13817 [Google Scholar] [CrossRef]
103. Floridi, L. (2023). AI as agency without intelligence: On ChatGPT, large language models, and other generative models. Philosophy & Technology, 36(1), 15. https://doi.org/10.1007/s13347-023-00621-y [Google Scholar] [CrossRef]
104. Kocoń, J., Cichecki, I., Kaszyca, O., Kochanek, M., Szydło, D. et al. (2023). ChatGPT: Jack of all trades, master of none. arXiv preprint arXiv:2302.10724. https://doi.org/10.48550/arXiv.2302.10724 [Google Scholar] [CrossRef]
105. Huang, F., Kwak, H., An, J. (2023). Is ChatGPT better than human annotators? Potential and limitations of ChatGPT in explaining implicit hate speech. arXiv preprint arXiv:2302.07736. https://doi.org/10.1145/3543873.3587368 [Google Scholar] [CrossRef]
106. Alkaissi, H., McFarlane, S. I. (2023). Artificial hallucinations in ChatGPT: Implications in scientific writing. Cureus, 15(2), 1–4. https://doi.org/10.7759/cureus.35179 [Google Scholar] [PubMed] [CrossRef]
107. Eysenbach, G. (2023). The role of ChatGPT, generative language models, and artificial intelligence in medical education: A conversation with ChatGPT and a call for papers. JMIR Medical Education, 9(1), e46885. https://doi.org/10.2196/46885 [Google Scholar] [PubMed] [CrossRef]
108. Zhuo, T. Y., Huang, Y., Chen, C., Xing, Z. (2023). Exploring AI ethics of ChatGPT: A diagnostic analysis. arXiv preprint arXiv:2301.12867. https://doi.org/10.48550/arXiv.2301.12867 [Google Scholar] [CrossRef]
109. Wang, F. Y., Miao, Q., Li, X., Wang, X., Lin, Y. (2023). What does ChatGPT say: The DAO from algorithmic intelligence to linguistic intelligence. IEEE/CAA Journal of Automatica Sinica, 10(3), 575–579. https://doi.org/10.1109/JAS.2023.123486 [Google Scholar] [CrossRef]
110. Maurer, B. (2023). Geo P. Tech, AI Chatbot geotechnical engineer: How AI language models like “ChatGPT” could change the profession. https://doi.org/10.31224/2858 [Google Scholar] [CrossRef]
111. Yeo-Teh, N. S. L., Tang, B. L. (2023). Letter to editor: NLP systems such as ChatGPT cannot be listed as an author because these cannot fulfill widely adopted authorship criteria. Accountability in Research, 1–3. https://doi.org/10.1080/08989621.2023.2177160 [Google Scholar] [PubMed] [CrossRef]
112. Alberts, I. L., Mercolli, L., Pyka, T., Prenosil, G., Shi, K. et al. (2023). Large language models (LLM) and ChatGPT: What will the impact on nuclear medicine be? European Journal of Nuclear Medicine and Molecular Imaging, 50(6), 1–4. https://doi.org/10.1007/s00259-023-06172-w [Google Scholar] [PubMed] [CrossRef]
113. Jiao, W., Wang, W., Huang, J. T., Wang, X., Tu, Z. (2023). Is ChatGPT a good translator? Yes with GPT-4 as the engine. arXiv preprint arXiv:2301.08745. https://doi.org/10.48550/arXiv.2301.08745 [Google Scholar] [CrossRef]
114. Bang, Y., Cahyawijaya, S., Lee, N., Dai, W., Su, D. et al. (2023). A multitask, multilingual, multimodal evaluation of ChatGPT on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023. https://doi.org/10.48550/arXiv.2302.04023 [Google Scholar] [CrossRef]
115. Newitz, A. (2023). The chatbotpocalypse? New Scientist, 257(3430), 28–29. https://doi.org/10.1016/S0262-4079(23)00476-1 [Google Scholar] [CrossRef]
116. Denny, P., Kumar, V., Giacaman, N. (2023). Conversing with copilot: Exploring prompt engineering for solving cs1 problems using natural language. Proceedings of the 54th ACM Technical Symposium on Computer Science Education V, vol. 1, pp. 1136–1142. Toronto, Ontario, Canada. [Google Scholar]
117. Ram, B., Pratima Verma, P. V. (2023). Artificial intelligence AI-based Chatbot study of ChatGPT, Google AI Bard and Baidu AI. World Journal of Advanced Engineering Technology and Sciences, 8(1), 258–261. https://doi.org/10.30574/wjaets.2023.8.1.0045 [Google Scholar] [CrossRef]
118. Yu, W., Gileadi, N., Fu, C., Kirmani, S., Lee, K. et al. (2023). Language to rewards for robotic skill synthesis. arXiv preprint arXiv:2306.08647. https://doi.org/10.48550/arXiv.2306.08647 [Google Scholar] [CrossRef]
119. Chen, T., Allauzen, C., Huang, Y., Park, D., Rybach, D. et al. (2023). Large-scale language model rescoring on long-form data. Proceedings of 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. Rhodes, Greece, IEEE. [Google Scholar]
120. Yu, J., Wang, X., Tu, S., Cao, S., Zhang-Li, D. et al. (2023). KoLA: Carefully benchmarking world knowledge of large language models. arXiv preprint arXiv:2306.09296. https://doi.org/10.48550/arXiv.2306.09296 [Google Scholar] [CrossRef]
121. Lyu, C., Wu, M., Wang, L., Huang, X., Liu, B. et al. (2023). Macaw-LLM: Multi-modal language modeling with image, audio, video, and text integration. arXiv preprint arXiv:2306.09093. https://doi.org/10.48550/arXiv.2306.09093 [Google Scholar] [CrossRef]
122. Gao, D., Ji, L., Zhou, L., Lin, K., Chen, J. et al. (2023). AssistGPT: A general multi-modal assistant that can plan, execute, inspect, and learn. arXiv preprint arXiv:2306.08640. https://doi.org/10.48550/arXiv.2306.08640 [Google Scholar] [CrossRef]
123. Hu, Z., Iscen, A., Sun, C., Chang, K., Sun, Y. et al. (2023). AVIS: Autonomous visual information seeking with large language models. arXiv preprint arXiv:2306.08129. https://doi.org/10.48550/arXiv.2306.08129 [Google Scholar] [CrossRef]
124. Gu, Y., Dong, L., Wei, F., Huang, M. (2023). Knowledge distillation of large language models. arXiv preprint arXiv:2306.08543. https://doi.org/10.48550/arXiv.2306.08543 [Google Scholar] [CrossRef]
125. Liu, J., Xia, C. S., Wang, Y., Zhang, L. (2023). Is your code generated by ChatGPT really correct? Rigorous evaluation of large language models for code generation. arXiv preprint arXiv:2305.01210. https://doi.org/10.48550/arXiv.2305.01210 [Google Scholar] [CrossRef]
126. Learning, G. M., Fraisse, P. (2016). Supervised models for an OpenAI driving game, pp. 1–6. http://cs229.stanford.edu/proj2017/final-reports/5241842.pdf [Google Scholar]
127. Radford, A., Narasimhan, K., Salimans, T., Sutskever, I. (2018). Improving language understanding by generative pre-training. https://www.mikecaptain.com/resources/pdf/GPT-1.pdf [Google Scholar]
128. Sudmann, A. (2019). On the media-political dimension of artificial intelligence. In: Deep learning as a black box and OpenAI, 223–244. https://doi.org/10.1515/9783839447192-014 [Google Scholar] [CrossRef]
129. Jeerige, A., Bein, D., Verma, A. (2019). Comparison of deep reinforcement learning approaches for intelligent game playing. IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), pp. 0366–0371. Las Vegas, USA, IEEE. [Google Scholar]
130. Peters, C., Stewart, T. C., West, R. L., Esfandiari, B. (2019). Dynamic action selection in openai using spiking neural networks. The Thirty-Second International Flairs Conference, Sarasota, FL, USA. [Google Scholar]
131. Merritt, A. (2020). ONNX-scala: Typeful, functional deep learning/Dotty meets an open AI standard (open-source talk). Proceedings of the 11th ACM SIGPLAN International Symposium on Scala, pp. 33. New York, USA. [Google Scholar]
132. Lee, J. S., Hsiang, J. (2020). Patent claim generation by fine-tuning OpenAI GPT-2. World Patent Information, 62, 101983. https://doi.org/10.1016/j.wpi.2020.101983 [Google Scholar] [CrossRef]
133. Cai, Z., Liang, Z., Ren, J. (2021). MRDRL-ROS: A multi robot deep reinforcement learning platform based on robot operating system. Journal of Physics: Conference Series, 2113(1), 012086. https://doi.org/10.1088/1742-6596/2113/1/012086 [Google Scholar] [CrossRef]
134. Moy, K., Tae, C., Wang, Y., Henri, G., Bambos, N. et al. (2021). An OpenAI-OpenDSS framework for reinforcement learning on distribution-level microgrids. 2021 IEEE Power & Energy Society General Meeting (PESGM), pp. 1–5. Hyatt Regency in Orlando, Florida, USA, IEEE. https://doi.org/10.1109/PESGM46819.2021 [Google Scholar] [CrossRef]
135. Pearce, H., Tan, B., Ahmad, B., Karri, R., Dolan-Gavitt, B. (2021). Can OpenAI codex and other large language models help us fix security bugs? arXiv preprint arXiv:2112.02125. [Google Scholar]
136. Thiergart, J., Huber, S., Übellacker, T. (2021). Understanding emails and drafting responses-An approach using GPT-3. arXiv preprint arXiv:2102.03062. https://doi.org/10.48550/arXiv.2102.03062 [Google Scholar] [CrossRef]
137. Jayasri, T., Heena, S., Amulya, U., Laasya, M. A., Sonia, B. (2021). The attributes, purpose, boundaries, and effects: GPT-3. Mathematical Statistician and Engineering Applications, 70(2), 488–500. [Google Scholar]
138. Moroz, E. A., Grizkevich, V. O., Novozhilov, I. M. (2022). The potential of artificial intelligence as a method of software developer’s productivity improvement. 2022 Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus), pp. 386–390. Petersburg, Russia, IEEE. https://doi.org/10.1109/ElConRus54750.2022.9755659 [Google Scholar] [CrossRef]
139. Houde, S., Radhakrishna, V., Reddy, P., Darwade, J., Hu, H. et al. (2022). User and technical perspectives of controllable code generation. Annual Conference on Neural Information Processing Systems, New Orleans, LA, USA. [Google Scholar]
140. Cotton, P. (2022). Microprediction: Building an Open AI Network, pp. 232. Cambridge: MIT Press. [Google Scholar]
141. Aydin, O., Karaarslan, E. (2022). OpenAI ChatGPT generated literature review: Digital twin in healthcare. In: OpenAI ChatGPT generated literature review: Digital twin in healthcare. Emerging computer technologies, vol. 2, pp. 22–31. izmir Akademi Dernegi. https://doi.org/10.2139/ssrn.4308687 [Google Scholar] [CrossRef]
142. Ryu, M., Nakajima, K. (2022). Analysis and mitigation of dataset artifacts in OpenAI GPT-3, pp. 1–9. https://openreview.net/pdf/9d6face24656ca9850642f9e7fdb3ccffb1d45ca.pdf [Google Scholar]
143. Haleem, A., Javaid, M., Singh, R. P. (2023). An era of ChatGPT as a significant futuristic support tool: A study on features, abilities, and challenges. BenchCouncil Transactions on Benchmarks, Standards and Evaluations, 2(4), 100089. https://doi.org/10.1016/j.tbench.2023.100089 [Google Scholar] [CrossRef]
144. Sobania, D., Briesch, M., Hanna, C., Petke, J. (2023). An analysis of the automatic bug fixing performance of ChatGPT, pp. 1–8. arXiv preprint arXiv:2301.08653. https://doi.org/10.48550/arXiv.2301.08653 [Google Scholar] [CrossRef]
145. Uludag, K. (2023). The use of AI-supported Chatbot in psychology. https://doi.org/10.2139/ssrn.4331367 [Google Scholar] [CrossRef]
146. Frieder, S., Pinchetti, L., Griffiths, R. R., Salvatori, T., Lukasiewicz, T. et al. (2023). Mathematical capabilities of ChatGPT. arXiv preprint arXiv:2301.13867. https://doi.org/10.48550/arXiv.2301.13867 [Google Scholar] [CrossRef]
147. Wang, S., Scells, H., Koopman, B., Zuccon, G. (2023). Can ChatGPT write a good boolean query for systematic review literature search? arXiv preprint arXiv:2302.03495. https://doi.org/10.48550/arXiv.2302.03495 [Google Scholar] [CrossRef]
148. Khalil, M., Er, E. (2023). Will ChatGPT get you caught? Rethinking of plagiarism detection. arXiv preprint arXiv:2302.04335. https://doi.org/10.48550/arXiv.2302.04335 [Google Scholar] [CrossRef]
149. Du, H., Teng, S., Chen, H., Ma, J., Wang, X. et al. (2023). Chat with ChatGPT on intelligent vehicles: An IEEE TIV perspective. IEEE Transactions on Intelligent Vehicles, 1–7. https://doi.org/10.1109/TIV.2023.3253281 [Google Scholar] [CrossRef]
150. Shen, Y., Song, K., Tan, X., Li, D., Lu, W. et al. (2023). HuggingGPT: Solving AI tasks with ChatGPT and its friends in HuggingFace. arXiv preprint arXiv:2303.17580. https://doi.org/10.48550/arXiv.2303.17580 [Google Scholar] [CrossRef]
151. Zhou, C., Li, Q., Li, C., Yu, J., Liu, Y. et al. (2023). A comprehensive survey on pretrained foundation models: A history from bert to ChatGPT. arXiv preprint arXiv:2302.09419. https://doi.org/10.48550/arXiv.2302.09419 [Google Scholar] [CrossRef]
152. Xiao, W., Xie, Y., Carenini, G., He, P. (2023). ChatGPT-steered editing instructor for customization of abstractive summarization. arXiv preprint arXiv:2305.02483. https://doi.org/10.48550/arXiv.2305.02483 [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools