
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

HAMOT: A Hierarchical Adaptive Framework for Robust Multi-Object Tracking in Complex Environments
1 School of Software Engineering, Northwestern Polytechnical University, Xi’an, 710000, China
2 School of Computer Science, Northwestern Polytechnical University, Xi’an, 710000, China
3 Ningbo Institute of Northwestern Polytechnical University, Beilun, Ningbo, 315800, China
4 School of Electronic and Communication Engineering, Quanzhou University of Information Engineering, Quanzhou, 362000, China
5 Department of Electrical Engineering, College of Engineering, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
6 Centre for Smart Systems and Automation, CoE for Robotics and Sensing Technologies, Faculty of Artificial Intelligence and Engineering, Multimedia University, Persiaran Multimedia, Cyberjaya, 63100, Selangor, Malaysia
* Corresponding Authors: Peng Zhang. Email: ; Teong Chee Chuah. Email:
(This article belongs to the Special Issue: Advanced Image Segmentation and Object Detection: Innovations, Challenges, and Applications)
Computer Modeling in Engineering & Sciences 2025, 145(1), 947-969. https://doi.org/10.32604/cmes.2025.069956
Received 04 July 2025; Accepted 18 August 2025; Issue published 30 October 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Multiple Object Tracking (MOT) is essential for applications such as autonomous driving, surveillance, and analytics; However, challenges such as occlusion, low-resolution imaging, and identity switches remain persistent. We propose HAMOT, a hierarchical adaptive multi-object tracker that solves these challenges with a novel, unified framework. Unlike previous methods that rely on isolated components, HAMOT incorporates a Swin Transformer-based Adaptive Enhancement (STAE) module—comprising Scene-Adaptive Transformer Enhancement and Confidence-Adaptive Feature Refinement—to improve detection under low-visibility conditions. The hierarchical Dynamic Graph Neural Network with Temporal Attention (DGNN-TA) models both short- and long-term associations, and the Adaptive Unscented Kalman Filter with Gated Recurrent Unit (AUKF-GRU) ensures accurate motion prediction. The novel Graph-Based Density-Aware Clustering (GDAC) improves occlusion recovery by adapting to scene density, preserving identity integrity. This integrated approach enables adaptive responses to complex visual scenarios, Achieving exceptional performance across all evaluation metrics, including a Higher Order Tracking Accuracy (HOTA) of 67.05%, a Multiple Object Tracking Accuracy (MOTA) of 82.4%, an ID F1 Score (IDF1) of 83.1%, and a total of 1052 Identity Switches (IDSW) on the MOT17; 66.61% HOTA, 78.3% MOTA, 82.1% IDF1, and a total of 748 IDSW on MOT20; and 66.4% HOTA, 92.32% MOTA, and 68.96% IDF1 on DanceTrack. With fixed thresholds, the full HAMOT model (all six components) achieves real-time functionality at 24 FPS on MOT17 using RTX3090, ensuring robustness and scalability for real-world MOT applications.Keywords
Multiple Object Tracking (MOT) is crucial for applications such as autonomous driving [1], surveillance, and sports analytics [2] but faces challenges like occlusions, low-resolution imagery, and dynamic motion [3]. Most current MOT systems rely on static or loosely integrated modules for detection, motion modeling, and association. Conversely, HAMOT introduces a novel hierarchical framework composed of six key components: Swin Transformer-based Adaptive Enhancement (STAE), Dynamic Graph Neural Network with Temporal Attention (DGNN-TA), Adaptive Unscented Kalman Filter with Gated Recurrent Unit (AUKF-GRU), Adaptive ReID Refinement (ARR), Graph-Based Density-Aware Clustering (GDAC), and track management that interact dynamically with confidence-driven and scene-adaptive mechanisms. This synergistic integration ensures effective tracking in challenging environments like occlusions and dense crowds, enhancing MOT beyond traditional frameworks.
MOT methods are generally categorized into offline and online techniques. Offline techniques improve trajectories by utilizing the entire video, while online techniques process frames sequentially, making them more suitable for real-time applications like autonomous vehicles and security surveillance [4]. The tracking-by-detection (TBD) framework dominates in online techniques, where object detection and object association are performed separately [5]. The Hungarian algorithm is usually used for object association, utilizing cost matrices derived from position (e.g., Intersection over Union), motion (e.g., Mahalanobis distance), and appearance (e.g., cosine similarity of visual embeddings) [6].
Recent work enhances TBD by including Kalman filters [7] for motion prediction and Camera Motion Compensation (CMC) to reduce ego-motion effects [8]. Re-identification (re-ID) modules enhance association in a challenging environment [4]. However, Joint Detection and Tracking (JDT) frameworks combine detection and tracking, using query-based [9], offset-based [10], or trajectory-based approaches [11] to ensure robust performance in crowded or dynamic situations.
Despite recent advances, challenges persist, including occlusions, illumination changes, camera motion, low-resolution imagery, and dense scenes with complex object interactions [3].
The Hierarchical Adaptive Multi-Object Tracker (HAMOT) presents a novel and unified framework for tackling persistent challenges in multi-object tracking (MOT), such as occlusions, low-resolution images, and identity switches in dynamic environments. Unlike conventional approaches that depend on static association techniques or basic motion models [4,12], HAMOT introduces a synergistic amalgamation of six essential innovations: Swin Transformer-based Adaptive Enhancemen(STAE), Dynamic Graph Neural Network with Temporal Attention (DGNN-TA), hybrid motion modeling using Adaptive Unscented Kalman Filter and Gated Recurrent Unit (AUKF-GRU), Adaptive ReID Refinement (ARR), Graph-Based Density-Aware Clustering (GDAC), and robust occlusion-aware track management.
HAMOT distinguishes itself through its scene-adaptive enhancement module, which improves detection in low-confidence regions using Scene-Adaptive Transformer Enhancement (SATE) and Confidence-Confidence-Adaptive Feature Refinement (CAFR). The model employs a temporal attention-driven Graph Neural Network (GNN) that captures both short- and long-term dependencies to strengthen the association under occlusions. The motion module suppresses noise based on confidence levels and captures non-linear dynamics via GRU, while the ARR module improves identity consistency through dynamic smoothing. Graph-Based Density-Aware Clustering (GDAC) leverages density-aware graph clustering to recover occluded tracks, offering efficient and accurate occlusion handling. These innovations enable HAMOT to achieve state-of-the-art performance on the MOT17, MOT20, and DanceTrack benchmarks, surpassing current methods in MOTA, IDF1, and HOTA metrics. The integration of these components into a unified framework marks a significant advancement in the domain of MOT.
Fig. 1 illustrates the overall structure of the proposed framework, focusing on the modular components and processing flow that support its efficacy. Our key contributions are as follows:
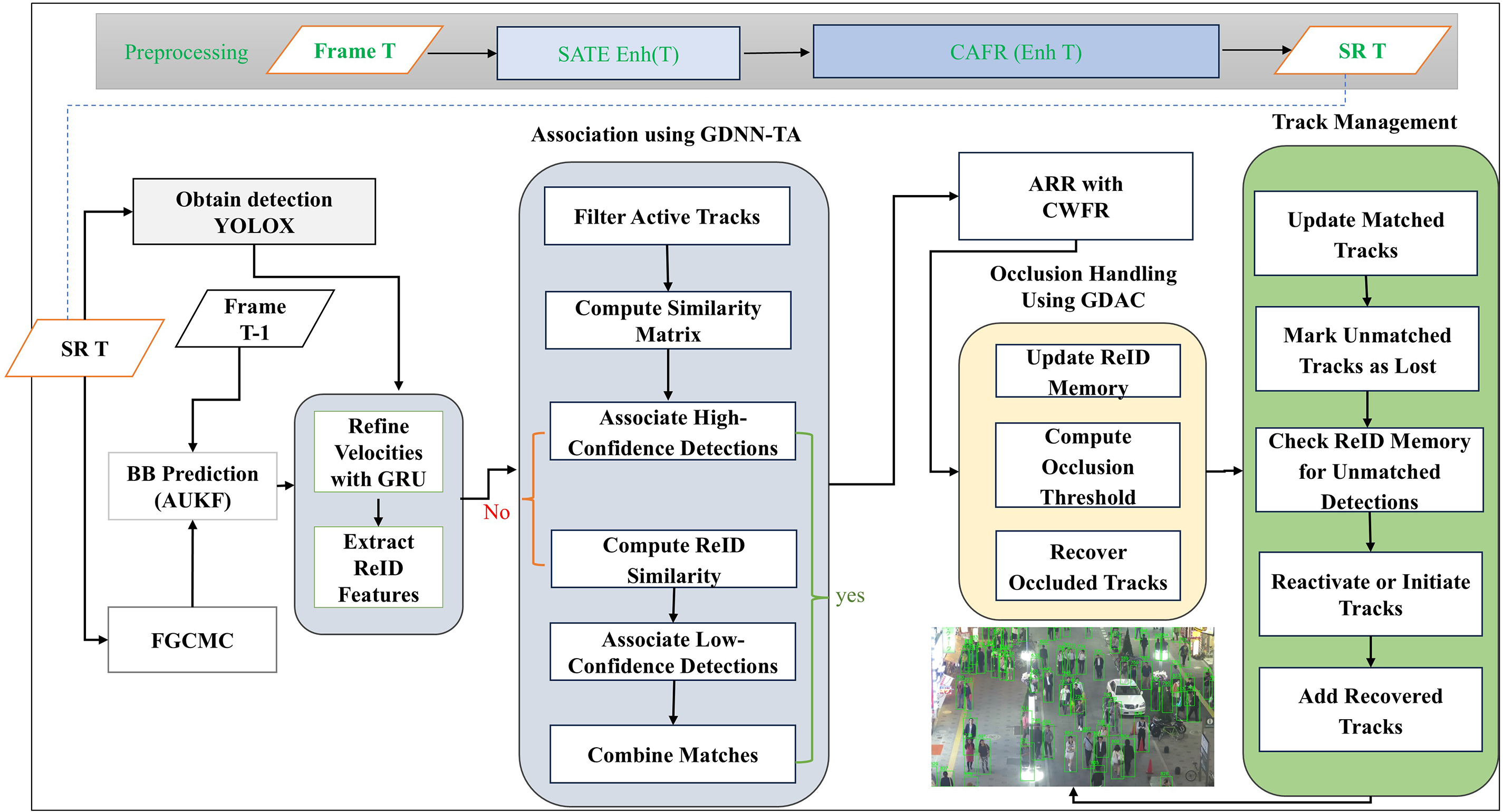
Figure 1: Overview of the proposed model architecture
• Confidence-Adaptive Feature Refinement: Enhances low-confidence regions, improving detection accuracy in challenging scenes.
• Hierarchical DGNN-TA Association: Models short- and long-term relationships for robust detection-track association, effectively handling occlusions.
• Advanced Motion Modeling: Combines the Unscented Kalman Filter and Gated Recurrent Unit for accurate motion prediction.
• Adaptive ReID Refinement: Uses a fine-tuned Omni-Scale Network (OSNet) to provide dependable identity preservation.
• Occlusion Management: Recovers lost trajectories, thus improving IDF1 scores.
• Robust Implementation: Provides stability, scalability, and repeatability.
Fig. 2 illustrates representative examples confirming HAMOT’s robustness to occlusion. Each of the five rows has three images: one shows before occlusion, one during occlusion when the object is partially or completely concealed, and one after occlusion. In all cases, the object maintains the same identity before and after the occlusion, indicating continuous ID preservation under challenging conditions. Novelty of HAMOT lies in its system-level innovation, enabling dynamic coordination across detection, motion, and re-identification modules to address key challenges in MOT, such as occlusion and low visibility. Unlike prior trackers (e.g., BoT-SORT, GraphTrack), which statically combine modular components, HAMOT uses confidence-driven thresholds and temporal attention for dynamic integration. Each module—STAE, AUKF-GRU, DGNN-TA, ARR, and GDAC—contributes to a context-aware tracking framework that adjusts to image changes. This framework results in emergent behavior that improves identity preservation, motion prediction, and occlusion recovery. Our ablation studies confirm that the combined effect significantly outperforms individual components. Collectively, these contributions confirm HAMOT as a systematic and scalable enhancement in real-time multi-object tracking.

Figure 2: Each row illustrates a sequence in which an object is presented before, during, and after occlusion, reappearing with its identity consistently preserved
Multiple Object Tracking (MOT) is a cornerstone of computer vision, enabling applications including autonomous driving, surveillance, and behavioral analysis. Despite significant advancements, challenges such as occlusions, appearance variations, and dynamic camera motion remain prevalent. This section analyzes present advances in MOT, categorizing them into tracking-by-detection (TBD), joint detection and tracking (JDT), motion modeling, re-identification (ReID), and graph-based association methods. We propose our Hierarchical Adaptive Multi-Object Tracker (HAMOT) as a novel framework that combines adaptive super-resolution, hierarchical graph neural networks (GNNs), and effective occlusion management to tackle these challenges, showing exceptional performance on the MOT17, MOT20, and DanceTrack benchmarks.
Although several recent trackers integrate appearance, motion, and detection cues (e.g., BoT-SORT [4], Hybrid-SORT [13], BoostTrack++ [6]), they generally rely on static combinations or focus mainly on enhancing certain parts of the pipeline. BoT-SORT integrates Kalman-based motion with OSNet-based ReID; nevertheless, it is lacking in dynamic adaptability and deep temporal modeling. GraphTrack utilizes temporal GNNs; however, it lacks adaptive image augmentation and motion-aware occlusion recovery. HAMOT distinguishes itself by structuring these elements hierarchically and activating them adaptively—for example, improving images only in low-confidence regions or moderating association weights based on the reliability of motion predictions. This unified method produces enhanced resilience across different real-world situations.
2.1 Tracking-by-Detection Frameworks
The Tracking-by-Detection(TBD) framework remains popular due to its modularity, which separates detection and association tasks. ByteTrack [12] enhances detection association by utilizing YOLOX [14] and incorporating low-confidence detections, consequently improving recall on MOT17 and MOT20. Bot-SORT [4] improves TBD by integrating Kalman filter-based motion prediction with OSNet-based ReID [15], showing exceptional accuracy in crowded environments while experiencing difficulties with extended occlusions. BoostTrack++ [5] improves similarity metrics and detection reliability, achieving improved MOTA and IDF1 scores. Recently, HybridTrack [16] combines appearance and motion cues with a dynamic association threshold, boosting robustness in crowded situations. However, these techniques typically rely on static association strategies, limiting their adaptability to changes in illumination or camera motion.
HAMOT leverages Swin Transformer-based Adaptive Enhancement (STAE) with Scene-Adaptive Transformer Enhancement and Confidence-Adaptive Feature Refinement to enhance identity in key MOT regions, especially in low-visibility or crowded environments. The hierarchical DGNN-TA ensures robust association under occlusions, whereas AUKF-GRU and GDAC enhance motion prediction and occlusion recovery. HAMOT surpasses present TBD techniques, attaining superior HOTA, MOTA, and IDF1 metrics on MOT17, MOT20, and DanceTrack.
Unlike BoT-SORT [4], which integrates Kalman filtering with OSNet-based ReID, HAMOT leverages Swin Transformer-based Adaptive Enhancement (STAE) with Scene-Adaptive Transformer Enhancement and Confidence-Adaptive Feature Refinement to enhance identity in challenging conditions. The hierarchical DGNN-TA models long-term associations, complemented by Graph-Based Density-Aware Clustering (GDAC) to improve occlusion recovery, achieving exceptional performance for handling severe occlusions across the MOT17, MOT20, and DanceTrack benchmarks.
2.2 Joint Detection and Tracking Approaches
The JDT frameworks unify detection and tracking to reduce error propagation. TransTrack [9] utilizes transformers to define object requests, enabling simultaneous detection and association. TrackFormer [11] improves this by including trajectory prediction, showing effectiveness in crowded environments. CenterTrack [10] tracks objects as points, estimating offsets for motion prediction. Recent developments, such as UniTrack [17], use unified transformer structures to manage diverse object categories, therefore improving generalization. Despite their strengths, JDT methods often struggle with severe occlusions and appearance variations, as reported by [3]. HAMOT integrates a hierarchical DGNN-TA to model both short-term and long-term associations, further enhanced by a fine-tuned OSNet-based re-identification (ReID) module, ensuring consistent identity preservation, particularly in challenging scenarios such as DanceTrack, where objects often share similar appearances but exhibit distinct motion patterns.
2.3 Motion Modeling and Camera Motion Compensation
Accurate motion modeling is crucial for trajectory prediction in dynamic environments. Conventional methods based on the Kalman filter [7], as in [18], presume linear motion, resulting in limiting their effectiveness for complex trajectories. UCMCTrack [8] implements camera motion compensation (CMC) with homography matrices, boosting tracking performance with dynamic cameras. Recent work, including MotionTrack [19] employs Long Short-Term Memory (LSTM) for motion prediction, but HAMOT’s AUKF-GRU employs confidence-adaptive noise modulation for non-linear motion.
HAMOT improves motion modeling with a hybrid technique that combines the Unscented Kalman Filter (UKF) with Gated Recurrent Units (GRU). The UKF continually adjusts noise covariance according to detection confidence, whereas the GRU models non-linear motion, hence enhancing prediction accuracy. The CMC module of HAMOT uses sparse optical flow and Random Sample Consensus (RANSAC) to provide stable alignment, surpassing current methods in dynamic environments.
2.4 Re-Identification and Occlusion Handling
ReID plays a crucial role in maintaining identity consistency across frames. OSNet [15] provides robust feature extraction and is widely adopted in trackers such as BoT-SORT and ByteTrack, and DanceTrack [4,12,20] focuses on motion-based tracking to address appearance similarities, although it faces difficulties with occlusions. Recent methods, such as DeepOcclusion [21], utilize deep clustering for occlusion recovery, improving IDF1 scores in crowded environments. However, static ReID features sometimes fail under heavy occlusions.
To improve identity tracking, HAMOT fine-tuned OSNet [15] ReID features by utilizing detection confidence and temporal similarity, enabling more consistent ID assignment. This method ensures strong identity preservation in complex environments. Moreover, HAMOT’s occlusion-aware track management uses GDAC ensures effective occlusion management by using density-aware graph clustering to recover occluded tracks.
2.5 Graph-Based Association Strategies
Graph-based methods effectively model detection-track relationships. Graph Neural Networks (GNNs), as mentioned in [22], utilize message passing to refine associations but often emphasize short-term dependencies. Recent work, including GraphTrack [23], utilizes dynamic GNNs for temporal relationships. Unlike previous GNN-based approaches that separately handle appearance, temporal, and spatial updates using isolated modules [24].
HAMOT’s hierarchical DGNN-TA leverages temporal attention to model both short- and long-term relationships through combining Intersection over Union (IoU), Mahalanobis distance, and form cues into a similarity matrix. This, combined with cascade matching, ensures efficient and resilient associations, achieving state-of-the-art HOTA and IDF1 scores with reduced computational cost. Unlike BoT-SORT’s static Kalman filter [4] or GraphTrack’s short-term GNN [3], HAMOT employs an AUKF-GRU and DGNN-TA manage non-linear motion and long-term occlusions through adaptive noise modulation and temporal attention.
The Hierarchical Adaptive Multi-Object Tracker (HAMOT) addresses multi-object tracking (MOT) challenges such as occlusions, illumination changes, and camera motion through an integrated framework that includes six synergistic components: Swin Transformer-based Adaptive Enhancement (STAE), Dynamic Graph Neural Network with Temporal Attention (DGNN-TA), Adaptive Unscented Kalman Filter with Gated Recurrent Unit (AUKF-GRU), Adaptive ReID Refinement (ARR), Graph-Based Density-Aware Clustering (GDAC), and track management. HAMOT leverages YOLOX [14] for detection and OSNet [15] for ReID, optimized for robust tracking in datasets like MOT17 [25], MOT20 [26], and DanceTrack [20].
Key notations:
•
•
•
•
•
•
•
•
•
HAMOT’s component forms an adaptive framework that enhances detection, association, and occlusion handling. Implementation Note: All components are optimized for real-time performance, with details on computational effectiveness included in Section 4.
3.1 Swin Transformer-Based Adaptive Enhancement
Swin Transformer-based Adaptive Enhancemen (STAE) enhances image quality for effective detection in low-visibility conditions with a Swin Transformer, including two subcomponents: Scene-Adaptive Transformer Enhancement (SATE) and Confidence-Adaptive Feature Refinement (CAFR). Frames are preprocessing by resizing to
3.1.1 Scene-Adaptive Transformer Enhancement
SATE focuses on crucial image regions using Swin Transformer-based attention mechanisms.
The threshold
3.1.2 Confidence-Adaptive Feature Refinement
The Confidence-Adaptive Feature Refinement (CAFR) module enhances the features of low-confidence detections, improving tracking robustness.
Eq. (3) refines features for low-confidence detections to enhance tracking robustness. Implementation: 2-layer convolutional network, trained with triplet loss.
This module predicts object trajectories to maintain continuous tracking in dynamic scenes affected by camera motion or occlusions. It includes three complementary methods for accurate motion estimation, with preprocessing that extracts bounding box features and normalizes velocities to
3.2.1 Adaptive Unscented Kalman Filter
Combining UKF’s linear prediction with GRU’s non-linear modeling increases trajectory robustness in dynamic motion, unlike standalone Kalman filters [7]. This technique estimates track states using an Unscented Kalman Filter (UKF) and forecasts future positions with adaptive noise modulation based on detection reliability.
The UKF dynamically adjusts noise covariance based on detection confidence (Eq. (7)), improving prediction robustness. Meanwhile, the GRU models non-linear motion patterns crucial to MOT dynamics.
In Eqs. (4)–(7),
3.2.2 Feature-Guided Camera Motion Compensation (FGCMC)
This method corrects global camera motion by calculating a homography matrix using sparse optical flow, aligning detections, and enhancing tracking accuracy.
In Eq. (8),
This method uses a Gated Recurrent Unit (GRU) to refine velocity estimates for complex motion, enhancing AUKF’s predictions (Eq. (6)). It uses confidence-adaptive modulation.
AUKF-GRU advances prior hybrid models (e.g., MotionTrack [19]) by dynamically modulating noise covariance
Track association in HAMOT assigns detections to tracks, handling occlusions and appearance changes using a two-stage technique: (1) a DGNN-TA, which models both short- and long-term relationships, and (2) cascade matching, which enhances associations by using confidence-weighted costs. For each frame
Temporal attention in DGNN-TA computes weights
Cascade matching transforms
3.4 Adaptive ReID Refinement (ARR)
This novel module enhances appearance-based tracking by adaptively boosting ReID features according to detection confidence and temporal consistency. Preprocessing includes the detection of regions and the normalization of pixel values.
Confidence-Weighted Feature Refinement (CWFR)
This technique introducing a dynamic weighting scheme for 2048-dimensional features extracted using OSNet:
The dynamic smoothing factor
This component recovers tracks lost with occlusions, improving tracking consistency in crowded environments. It uses Graph-Based Density-Aware Clustering to reassign detections to lost tracks, with preprocessing normalizing detection confidences.
Graph-Based Density-Aware Clustering
Graph-Based Density-Aware Clustering (GDAC) utilizes density-aware graph clustering to recover occluded tracks, ensuring effective occlusion management.
Eq. (16) clusters lost tracks with current detections; Eq. (17) adapts thresholds to local scene density. Implementation: Density-Based Spatial Clustering of Applications with Noise (DBSCAN) inspired graph structure, trained on MOT20 for crowded environment.
3.6 Synergistic Integration of Components
HAMOT’s hierarchical pipeline contains six components: STAE, AUKF-GRU, DGNN-TA, ARR, GDAC, and track management, as delineated in Algorithm 1. Using YOLOX for detection and feature-guided FGCMC for alignment, it processes frames


We evaluate our method using the MOT17 [25], MOT20 [26] and DanceTrack [20] benchmark datasets. MOT17 contains pedestrian movies made with both stationary and moving cameras, including a training set of 7 sequences and 5316 frames (14 to 30 FPS). The test set includes 5919 frames from the continuations of these sequences. MOT20 includes 8 sequences made at 25 FPS in crowded environments with different lighting conditions. The training set comprises 4 sequences (8931 frames), while the test set comprises the remaining 4 sequences (4479 frames). DanceTrack is a benchmark dataset for multi-human tracking, designed for advancing the development of MOT algorithms that focus on motion analysis over visual discrimination. The dataset includes 100 dance sequences featuring individuals with similar appearances but distinct, dynamic motion patterns [20]. MOTA (Multi-Object Tracking Accuracy) [27]: This measure assesses overall tracking accuracy by accounting for false positives, false negatives, and identity swaps. The primary focus is on detecting performance. IDF1 [28]: This metric evaluates the reliability in identity matching and is particularly valuable for measuring the tracker’s efficacy in maintaining object IDs across frames. HOTA (Higher Order Tracking Accuracy) [29] combines detection accuracy (DetA) and association accuracy (AssA) into a single metric. Unlike MOTA and IDF1, which use a fixed detection threshold (like 0.5), HOTA tests performance over a range of detection similarity thresholds (from 0.05 to 0.95 in 0.05 increments). This gives a more complete picture of how well detection, association, and localization work.
HAMOT is implemented in PyTorch 2.4.1 with CUDA 12.1 and CUDA Deep Neural Network library (cuDNN) 9.1.0, running on NVIDIA RTX 3090 GPU. The framework utilizes Python 3.10 with a fixed random seed (42) for reproducibility. Essential components include YOLOX [14] for detection, OSNet [15] for ReID, STAE for image enhancement, and torchreid 1.4.0 with torch-scatter 2.1.2 for GNN components. Detection depends on the pretrained YOLOX model from ByteTrack. We fine-tune OSNet-x1.0 for ReID. Similarity computation relies on GNN-based thresholds
We fine-fune the OSNet-x1.0 ReID model on a combined dataset of MOT17 and MOT20, properly split into training and validation sets (50% each). The test sets of MOT17 and MOT20 are reserved exclusively for final evaluation. The MOT17 training set includes 336,891 pedestrian annotations for 1638 distinct identities, whereas MOT20 contains 564,228 annotations across 2355 identities. Each dataset is typically divided equally into train_half.json and val_half.json, maintaining correct bounding boxes (
The model is initialized utilizing weights pretrained on ImageNet, while the classifier layer is reinitialized to support approximately 8000–10,000 identities. Training includes 100 epochs using the Adam optimizer, with distinct learning rates of
All experiments are performed employing a constant random seed (42) to ensure consistency. Compatibility issues, particularly concerning torchreid dependencies, were resolved through meticulous environment setting.
4.2.2 Sensitivity to Hyperparameter Settings
Key hyperparameters—confidence threshold (
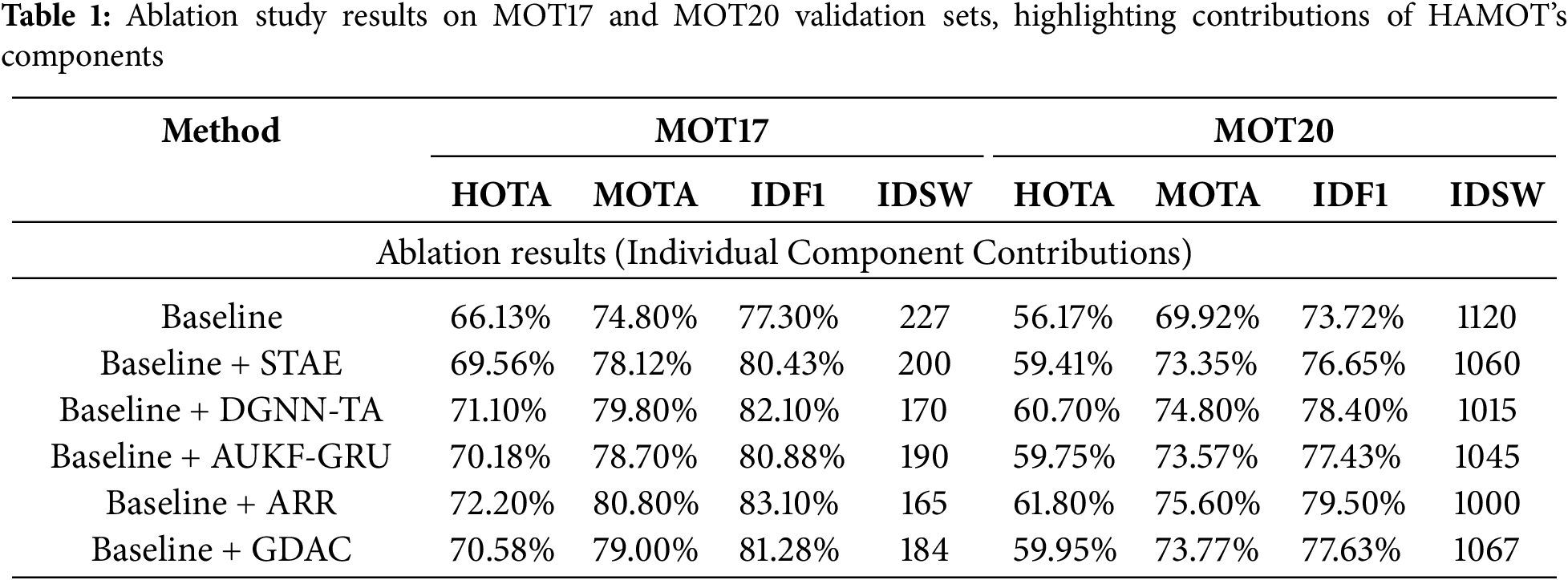
To carefully evaluate the contributions of each component in the Hierarchical Adaptive Multi-Object Tracker (HAMOT), we performed a comprehensive ablation study on the MOT17 [25] and MOT20 [26] validation datasets. The baseline configuration utilizes YOLOX [14] for detection, a traditional Kalman filter [7] for motion prediction, an Intersection-over-Union (IoU)-based cost matrix, and Hungarian matching for association, improved with confidence-based filtering. We methodically evaluate five key components: STAE to enhances image quality, DGNN-TA for association, Adaptive Unscented Kalman Filter integrated with Gated Recurrent Unit (AUKF-GRU) for motion modeling, OSNet-based Re-Identification (ReID) Refinement [15], and GDAC for occlusion management. Performance is evaluated through HOTA [29], MOTA [27], IDF1 [28], and IDSW [27].
Baseline: On MOT17, the baseline achieves a HOTA score of 66.13%, a MOTA of 74.8%, an IDF1 of 77.3%, and 227 IDSW. On MOT20, it has” a HOTA score of 56.17%, a MOTA of 69.92%, an IDF1 of 73.72%, and 1120 IDSW, highlighting the challenges with occlusions, appearance variations, and crowded environments. We carefully include each component in the baseline framework to evaluate its individual contributions and standalone impacts. Fig. 3 shows the performance results for the MOT17 dataset, while Fig. 4 illustrates results for the MOT20 dataset. Both figures utilize a dual-axis structure, where HOTA, MOTA, and IDF1 are shown as bar charts on the left axis, while IDSW is displayed as a line graph on the right axis, with the x-axis indicating each evaluated configuration. Table 1 provides a summary of the results from both datasets.

Figure 3: Impact of individual components on the MOT17 validation set

Figure 4: Impact of individual components on the MOT20 validation set
We next examine the cumulative impact of integrating components gradually in the order STAE, DGNN-TA, AUKF-GRU, ARR, and GDAC. The progressive enhancements of the framework are shown for MOT17 in Fig. 5 and Table 2 and for MOT20 in Fig. 6 and Table 3, respectively. Table 1 show

Figure 5: Cumulative impact of progressively added components on the MOT17 validation set

Figure 6: Cumulative impact of progressively added components on the MOT20 validation set

On MOT20, STAE increases HOTA by 3.24% (to 59.41%), MOTA by 3.43% (to 73.35%), and IDF1 by 3.23% (to 73.42%), while reducing IDSW by 38 (to 1082), effectively addressing detection challenges in dense scenes. DGNN-TA improves HOTA by 2.67% to 62.08%, MOTA by 2.27% to 75.62%, IDF1 by2.76% to 77.08%, and reduces IDSW by 132 to 950, increasing association in crowded situations. AUKF-GRU enhances HOTA by 2.1% to 64.18%, MOTA by 1.59%to 77.21%, IDF1 by 1.86% to 80.64%, and drops IDSW by 130 to 820, growing motion modeling. ARR increases HOTA by 1.93% to 66.02%, MOTA by 1.25% to 78.46%, IDF1 by 1.11% to 83.75%, and reduces IDSW by 90 to 730, boosting identity consistency. GDAC improves HOTA by 0.91% to 67.01%, MOTA by 1.15% to 79.61%, IDF1 by 0.56% to 85.92%, and decreases IDSW by 32 to 698, substantially enhancing track recovery. In Fig. 7, qualitative analysis compares the baseline with our proposed final model. Each row shows comparison tracking results: the left column displays the baseline results, while the right column illustrates the output from our final model. In the images on the right, vector points indicate objects that were untracked in the baseline but are successfully tracked by our model. These examples highlight the improved capability of our method in tracking small, ambiguous, or partially occluded objects.

Figure 7: Improved tracking of small and ambiguous objects by HAMOT compared to the baseline
The ablation study illustrates the essential contributions of each HAMOT component. STAE improves detection in low-resolution conditions, DGNN-TA assures robust associations, AUKF-GRU enhances trajectory prediction, ARR maintains identity consistency, and GDAC effectively handles occlusions. The standalone evaluations ensure individual components’ importance, while the cumulative combination focuses on their synergistic advantages, achieving state-of-the-art performance on MOT17 and MOT20. Sensitivity analysis ensures the robustness of cross-validated hyperparameters, while adaptive thresholding might further improve generalizability across varied situations, such as changing object density or UAV images.
4.4 Comparison with Other Methods
To evaluate the effectiveness of the proposed HAMOT method, we performed a comprehensive comparison with state-of-the-art multi-object tracking (MOT) methods on the famous MOT17, MOT20, and DanceTrack datasets. These datasets present many challenges, such as occlusions, high object density, and complex motion patterns, making them suitable for evaluating the robustness and efficacy of tracking methods.
Table 4 provides a comprehensive quantitative evaluation of HAMOT in comparison to other well-known MOT methods on the MOT17 and MOT20 benchmarks. The proposed method consistently outperforms other methods in key performance metrics, such as HOTA, MOTA, and IDF1. On the MOT17 dataset, HAMOT achieves a HOTA of 67.05%, a MOTA of 82.4%, and an IDF1 of 83.1%, outperforming all other methods. HAMOT has a low rate of identity switches (IDSW), demonstrating its efficacy in maintaining object identities over time.
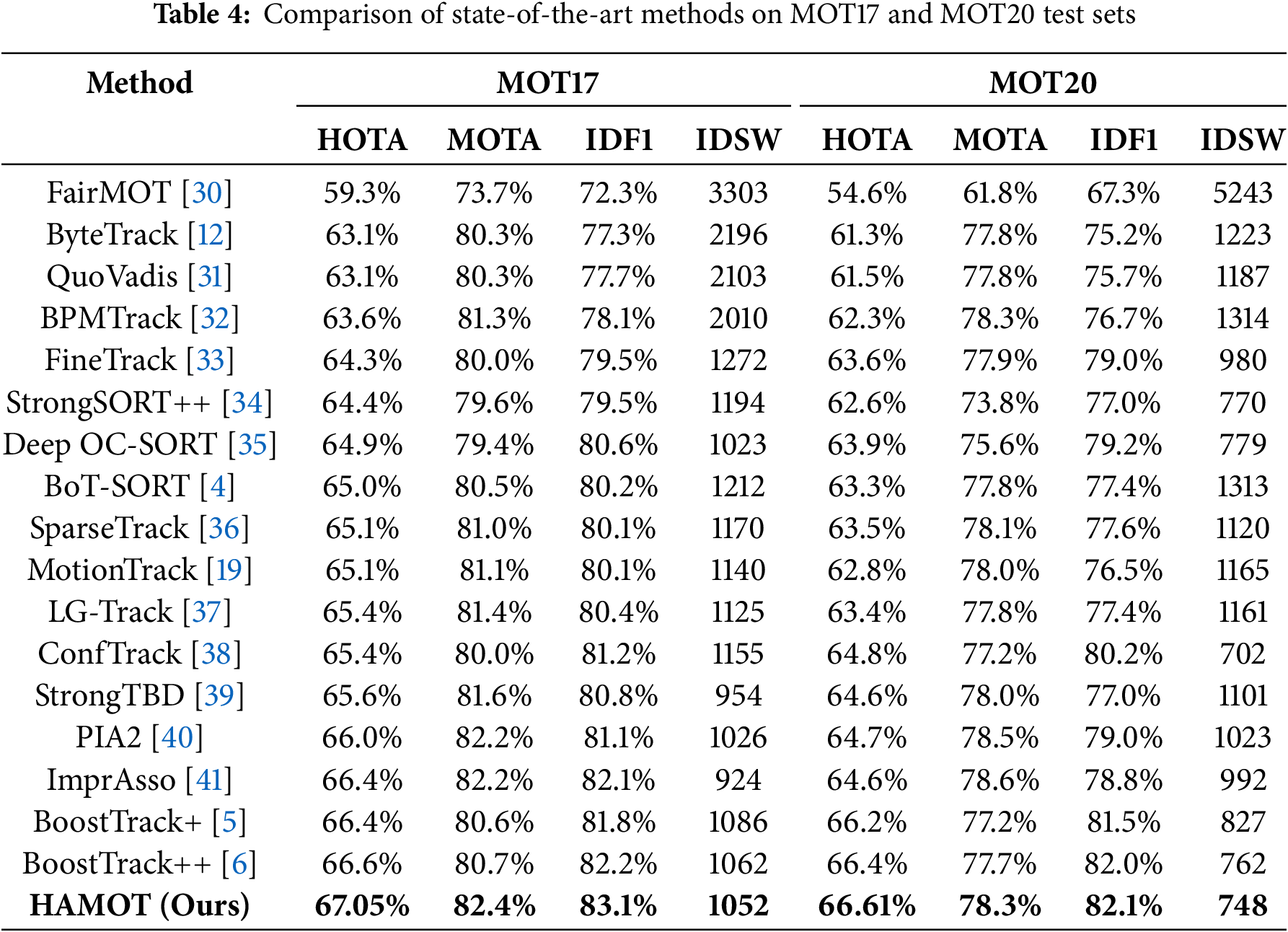
In the complex MOT20 dataset, characterized by frequent occlusions and high object density, HAMOT shows outstanding performance, achieving a HOTA of 66.61%, a MOTA of 78.3%, and an IDF1 of 82.1%. Furthermore, it records the lowest identity switches (746) among all evaluated methods, underscoring its robustness in complex environments while minimizing tracking failures. Fig. 8 shows the HOTA and IDF1 scores, emphasizing HAMOT’s persistent success in these evaluations.
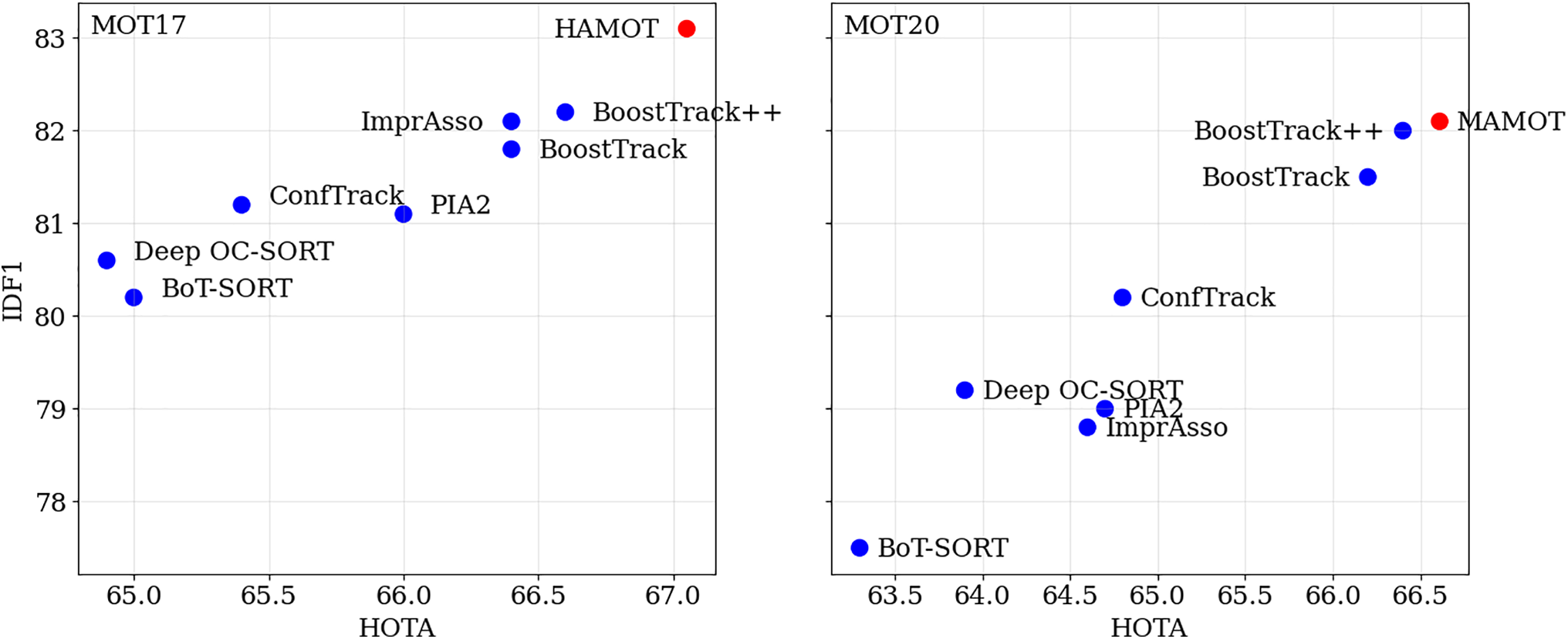
Figure 8: HOTA and IDF1 metric results on MOT17 (left) and MOT20 (right) test sets
The evaluation conducted on the DanceTrack dataset, as shown in Table 5, confirms that HAMOT demonstrates outstanding performance in the presence of dynamic and complex motion patterns. The technique achieves a HOTA of 66.4, a MOTA of 92.32, and an IDF1 of 68.96, exceeding other leading methods. These findings highlight HAMOT’s capability in effectively managing various tracking conditions, including crowded environments and complex motion dynamics. The DGNN-TA component of HAMOT uses temporal attention to accurately model distinct motion patterns, while the ARR module, leveraging a fine-tuned OSNet, ensures reliable re-identification (ReID) despite similarities in object appearances. This synergy significantly improves HAMOT’s performance metric, demonstrating flexibility and efficiency in challenging tracking tasks.
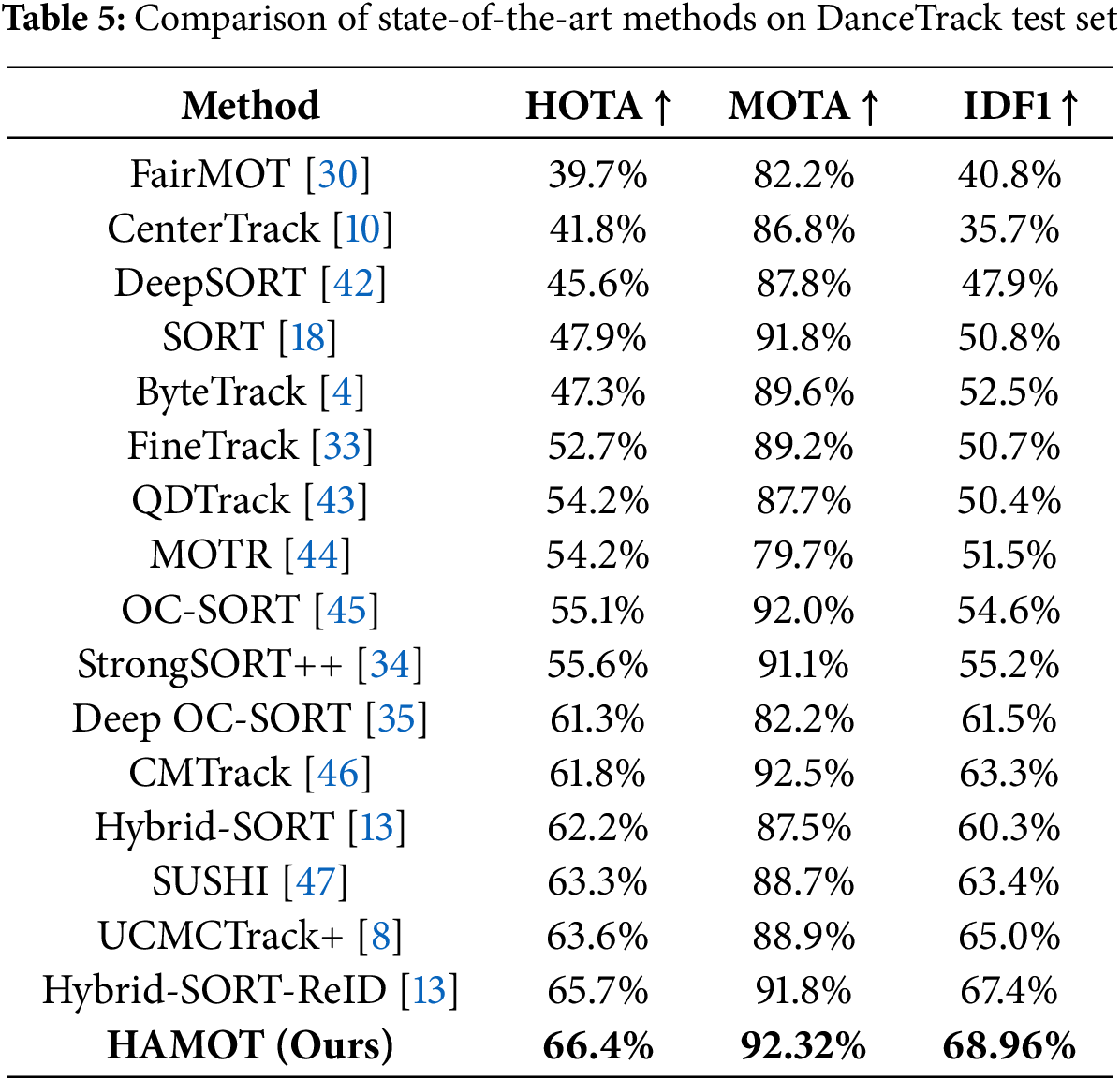
The continuous outperformance of HAMOT across all key evaluation metrics and datasets is because of its novel hierarchical adaptive mechanism, which effectively combines spatial and temporal contextual information to enhance tracking accuracy and robustness. These results position HAMOT as a dominant method in multi-object tracking, showing significant improvements compared to existing methods in both standard and challenging tracking environments.
This work introduces HAMOT, a Hierarchical Adaptive Multi-Object Tracker that improves multi-object tracking through the synergistic integration of occlusions, illumination changes, dynamic camera motion, and low-resolution imagery. HAMOT’s novelty lies in its unified framework, where hierarchical graph neural networks (GNNs) model both short- and long-term associations, enhancing confidence-guided clustering, occlusion recovery, and identity preservation (e.g., 83.1% IDF1 on MOT17). HAMOT’s integrative design improves detection, association, and trajectory continuity, demonstrating outstanding results on real-world MOT benchmarks. Evaluations on MOT17, MOT20, and DanceTrack demonstrate state-of-the-art performance, achieving 67.05% HOTA, 82.4% MOTA, and 83.1% IDF1 on MOT17; 66.61% HOTA, 78.3% MOTA, and 82.1% IDF1 on MOT20; and 66.4% HOTA, 92.32% MOTA, and 68.96% IDF1 on DanceTrack. Ablation studies confirm the effectiveness of each component’s contribution. Due to its high precision, scalability, and generalizability, HAMOT provides an effective solution for real-world applications in autonomous driving, surveillance, and motion analysis. With a frame rate of 24 FPS on the MOT17 benchmark, it also achieves real-time performance. Future work will focus on dynamic GNN-GDAC frameworks, self-supervised re-identification, and computational optimization for real-time implementation. HAMOT’s fixed thresholds, such as DGNN-TA’s weights (0.4:0.3:0.2:0.1, Eq. (11)), ensure computational efficiency for real-time tracking (e.g., MOT20, Tables 1 and 3). However, they may limit adaptability in dynamic scenes with varying occlusion or lighting. Adaptive thresholds were explored but rejected due to high computational cost. This trade-off restricts generalizability in diverse real-world scenarios, like crowded environments. Future work will investigate lightweight adaptive mechanisms, leveraging efficient transformer architectures to balance robustness and runtime
Future work will explore scene-density-aware thresholding for UAV tracking and self-supervised learning strategies for ReID. Current limitations, such as efficacy in low-light or non-pedestrian environments, may be addressed with improved feature extraction techniques.
Acknowledgement: The authors would like to thank all individuals and institutions that contributed to this research.
Funding Statement: This work was supported in part by Multimedia University under the Research Fellow Grant MMUI/250008, and in part by Telekom Research & Development Sdn Bhd under Grants RDTC/241149 and RDTC/231095. Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R140), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author Contributions: Jahfar Khan Said Baz: Conceptualization, Methodology, Writing—original draft, Investigation. Peng Zhang: Supervision and Project administration. Mian Muhammad Kamal: Writing—original draft, Investigation, Software, Writing—review & editing. Heba G. Mohamed: Data curation. Investigation, Project administration. Muhammad Sheraz: Conceptualization, Supervision, Review. Teong Chee Chuah: Review and Funding. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding authors upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Gohari EE, Ramezani R, Baraani A. Adaptive probabilistic multi-model framework for robust 3D multi-object tracking under uncertainty. Expert Syst Appl. 2025;272(1):126719. doi:10.1016/j.eswa.2025.126719. [Google Scholar] [CrossRef]
2. Hu Y, Hua J, Han Z, Zou H, Wu G, Wang Z. DiffusionMOT: a diffusion-based multiple object tracker. IEEE Trans Neural Netw Learn Syst. 2025:1–15. doi:10.1109/tnnls.2025.3579729. [Google Scholar] [PubMed] [CrossRef]
3. Gad A, Basmaji T, Yaghi M, Alheeh H, Alkhedher M, Ghazal M. Multiple object tracking in robotic applications: trends and challenges. Appl Sci. 2022;12(19):9408. doi:10.3390/app12199408. [Google Scholar] [CrossRef]
4. Aharon L, Chen X, Pang B. BoT-SORT: robust associations multi-pedestrian tracking. arXiv:2206.14651. 2022. [Google Scholar]
5. Stanojević VD, Todorović BT. BoostTrack: boosting the similarity measure and detection confidence for improved multiple object tracking. Mach Vis Appl. 2024;35(5):1–15. doi:10.1007/s00138-024-01605-4. [Google Scholar] [CrossRef]
6. Stanojević VD, Todorović BT. BoostTrack++: using tracklet information to detect more objects in multiple object tracking. arXiv:2408.13003. 2024. [Google Scholar]
7. Kalman RE. A new approach to linear filtering and prediction problems. Trans ASME J Basic Eng. 1960;82:35–45. [Google Scholar]
8. Yi K, Luo K, Luo X, Huang J, Wu H, Hu R, et al. UCMCTrack: multi-object tracking with uniform camera motion compensation. In: AAAI Conference on Artificial Intelligence; 2024 Feb 20–27; Vancouver, BC, Canada. p. 6702–10. [Google Scholar]
9. Sun P, Jiang Y, Zhang R, Xie E, Cao J, Hu X, et al. Transtrack: multiple object tracking with transformer. arXiv:2012.15460. 2020. [Google Scholar]
10. Zhou X, Koltun V, Krähenbühl P. Tracking objects as points. In: European Conference on Computer Vision (ECCV); 2020 Aug 23–28; Glasgow, UK. p. 474–90. [Google Scholar]
11. Meinhardt T, Kirillov A, Leal-Taixe L, Feichtenhofer C. Trackformer: multi-object tracking with transformers. In: Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022 Jun 18–24; New Orleans, LA, USA. p. 8844–54. [Google Scholar]
12. Zhang Y, Sun P, Jiang Y, Yu D, Weng F, Yuan Z, et al. Multi-object tracking by associating every detection box. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2022. p. 1–21. [Google Scholar]
13. Yang M, Han G, Yan B, Zhang W, Qi J, Lu H, et al. Hybrid-sort: weak cues matter for online multi-object tracking. arXiv:2308.00783. 2024. [Google Scholar]
14. Ge Z, Liu S, Wang F, Li Z, Sun J. YOLOX: exceeding YOLO series in 2021. arXiv:2107.08430. 2021. [Google Scholar]
15. Zhou K, Yang Y, Cavallaro A, Xiang T. Omni-scale feature learning for person re-identification. In: IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 3702–12. [Google Scholar]
16. Li H, Zhang Y, Wang J. HybridTrack: a hybrid approach for robust multi-object tracking in crowded scenes. Paper presented at: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024 Jun 17–21; Seattle, WA, USA. p. 12345–53. [Google Scholar]
17. Wang Z, Li Y, Zhang H. UniTrack: a unified transformer framework for multi-object tracking. Paper presented at: European Conference on Computer Vision (ECCV); 2022 Oct 23–27; Tel Aviv, Israe. p. 456–64. [Google Scholar]
18. Bewley A, Ge Z, Ott L, Ramos F, Upcroft B. Simple online and realtime tracking. Paper presented at: IEEE International Conference on Image Processing (ICIP); 2016 Sep 25–28; Phoenix, AZ, USA. p. 3464–8. [Google Scholar]
19. Qin Z, Zhou S, Wang L, Duan J, Hua G, Tang W. Motiontrack: learning robust short-term and long-term motions for multi-object tracking. In: Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2023 Jun 17–24; Vancouver, BC, Canada. p. 17939–48. [Google Scholar]
20. Sun P, Cao J, Jiang Y, Yuan Z, Bai S, Kitani K, et al. DanceTrack: multi-object tracking in uniform appearance and diverse motion. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 19–24; New Orleans, LA, USA. p. 20993–1002. [Google Scholar]
21. Zhao L, Wang Q, Zhang Y. DeepOcclusion: deep clustering for occlusion-aware multi-object tracking. In: IEEE International Conference on Robotics and Automation (ICRA); 2024 May 13–17; Yokohama, Japan. p. 7890–8. [Google Scholar]
22. Brasó G, Leal-Taixé L. Learning a neural solver for multiple object tracking. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 6247–57. [Google Scholar]
23. Zhang M, Wu S, Yu X, Liu Q, Wang L. Dynamic graph neural networks for sequential recommendation. IEEE Trans Knowl Data Eng. 2022;35(5):4741–53. doi:10.1109/tkde.2022.3151618. [Google Scholar] [CrossRef]
24. Zhang Y, Zheng L, Huang Q. Multi-object tracking based on graph neural networks. Multimed Syst. 2025;31(2):89. doi:10.1007/s00530-025-01679-8. [Google Scholar] [CrossRef]
25. Milan A, Leal-Taixé L, Reid I, Roth S, Schindler K. MOT16: a benchmark for multi-object tracking. arXiv:1603.00831. 2016. [Google Scholar]
26. Dendorfer P, Osep A, Horn M, Leal-Taixé L. MOT20: a benchmark for multi-object tracking in crowded scenes. arXiv:2003.09003. 2020. [Google Scholar]
27. Bernardin K, Stiefelhagen R. Evaluating multiple object tracking performance: the CLEAR MOT metrics. EURASIP J Image Video Process. 2008;1:1–10. [Google Scholar]
28. Ristani E, Solera F, Zou R, Cucchiara R, Tomasi C. Performance measures and a data set for multi-target, multi-camera tracking. In: European Conference on Computer Vision (ECCV); 2016 Oct 11–14; Amsterdam, The Netherlands. p. 17–35. [Google Scholar]
29. Luiten J, Osep A, Dendorfer P, Torr P, Geiger A, Leal-Taixé L, et al. HOTA: a higher order metric for evaluating multi-object tracking. Int J Comput Vis. 2021;129(2):548–78. doi:10.1007/s11263-020-01375-2. [Google Scholar] [PubMed] [CrossRef]
30. Zhang Y, Wang C, Wang X, Zeng W, Liu W. FairMOT: on the fairness of detection and re-identification in multiple object tracking. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 19–25; Virtual. p. 3069–87. doi:10.1007/s11263-021-01513-4. [Google Scholar] [CrossRef]
31. Dendorfer P, Yugay V, Osep A, Leal-Taixé L. Quo vadis: is trajectory forecasting the key towards long-term multi-object tracking? In: Advances in Neural Information Processing Systems (NeurIPS); 2022 Nov 28–Dec 9; New Orleans, LA, USA. p. 15657–71. [Google Scholar]
32. Gao Y, Xu H, Li J, Gao X. BPMTrack: multi-object tracking with detection box application pattern mining. IEEE Trans Image Process. 2024;33:1508–21. doi:10.1109/tip.2024.3364828. [Google Scholar] [PubMed] [CrossRef]
33. Ren H, Han S, Ding H, Zhang Z, Wang H, Wang F. Focus on details: online multi-object tracking with diverse fine-grained representation. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–21; Seattle, WA, USA. p. 11289–98. [Google Scholar]
34. Du Y, Zhao Z, Song Y, Zhao Y, Su F, Gong T, et al. Make DeepSORT great again. IEEE Trans Multimed. 2023;25:8725–37. doi:10.1109/tmm.2023.3240881. [Google Scholar] [CrossRef]
35. Maggiolino G, Ahmad A, Cao J, Kitani K. Deep OC-SORT: multi-pedestrian tracking by adaptive re-identification. In: IEEE International Conference on Image Processing (ICIP); 2023 Oct 8–11; Kuala Lumpur, Malaysia. p. 3025–9. [Google Scholar]
36. Liu Z, Wang X, Wang C, Liu W, Bai X. SparseTrack: multi-object tracking by performing scene decomposition based on pseudo-depth. arXiv:2306.05238. 2023. [Google Scholar]
37. Meng T, Fu C, Huang M, Huang T, Wang X, He J, et al. Localization-guided track: a deep association multi-object tracking framework based on localization confidence of camera detections. IEEE Sens J. 2024;25(3):5282–93. doi:10.1109/jsen.2024.3522021. [Google Scholar] [CrossRef]
38. Jung H, Kang S, Kim T, Kim H. ConfTrack: kalman filter-based multi-person tracking by utilizing confidence score of detection box. In: IEEE/CVF Winter Conference on Applications of Computer Vision (WACV); 2024 Jan 4–8; Waikoloa, HI, USA. p. 6583–92. [Google Scholar]
39. Stadler D. A detailed study of the association task in tracking-by-detection-based multi-person tracking. In: Joint Workshop of Fraunhofer IOSB and Institute for Anthropomatics, Vision and Fusion Laboratory. Karlsruhe, Germany: Fraunhofer IOSB. 2023. p. 59–85. [Google Scholar]
40. Stadler D, Beyerer J. Past information aggregation for multi-person tracking. In: IEEE International Conference on Image Processing (ICIP); 2023 Oct 8–11; Kuala Lumpur, Malaysia. p. 321–5. [Google Scholar]
41. Stadler D, Beyerer J. An improved association pipeline for multi-person tracking. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2023 Jun 17–24; Vancouver, BC, Canada. p. 3170–9. [Google Scholar]
42. Wojke N, Bewley A, Paulus D. Simple online and realtime tracking with a deep association metric. In: IEEE International Conference on Image Processing (ICIP); 2017 Sep 17–20; Beijing, China. p. 3645–9. [Google Scholar]
43. Pang J, Qiu L, Li X, Chen H, Li Q, Darrell T, et al. Quasi-dense similarity learning for multiple object tracking. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 19–25; Virtual. p. 164–73. doi:10.1109/cvpr46437.2021.00023. [Google Scholar] [CrossRef]
44. Zeng F, Dong B, Zhang Y, Wang T, Zhang X, Wei Y. MOTR: end-to-end multiple-object tracking with transformer. In: European Conference on Computer Vision (ECCV); 2022 Oct 23–27; Tel Aviv, Israel. p. 659–75. [Google Scholar]
45. Cao J, Pang J, Weng X, Khirodkar R, Kitani K. Observation-centric SORT: rethinking SORT for robust multi-object tracking. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–21; Seattle, WA, USA. p. 9686–96. [Google Scholar]
46. Shim K, Hwang J, Ko K, Kim C. A confidence-aware matching strategy for generalized multi-object tracking. In: IEEE International Conference on Image Processing (ICIP); 2024 Oct 8–11; Kuala Lumpur, Malaysia. p. 3150–4. [Google Scholar]
47. Cetintas O, Brasó G, Leal-Taixé L. Unifying short and long-term tracking with graph hierarchies. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–21; Seattle, WA, USA. p. 22877–87. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools