
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Towards Real-Time Multi-Person Pose Estimation via Feature Selection and Sharpening Mechanisms
1 School of Mathematics and Statistics, Huangshan University, Huangshan, China
2 College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, Nanjing, China
3 Huangshan Technology Innovation Center for Digital Economy and Big Data Analysis, Huangshan, China
* Corresponding Author: Jianwei Hu. Email:
Computer Modeling in Engineering & Sciences 2026, 146(3), 32 https://doi.org/10.32604/cmes.2026.079062
Received 14 January 2026; Accepted 03 March 2026; Issue published 30 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Real-time multi-person pose estimation (MPE) built upon neural network architectures aims to simultaneously detect multiple human instances and regress joint coordinates in dynamic scenes. However, due to factors such as high model complexity and limited expression of keypoint information, both the efficiency and accuracy of real-time MPE remain to be improved. To mitigate the adverse impacts caused by the aforementioned issues, this work develops FSEM-Pose, a real-time MPE model rooted in the YOLOv10 framework. In detail, first, FSEM-Pose upgrades the backbone module of the baseline network by introducing the Feature Shuffling-Convolution (FS-Conv), which effectively reduces the backbone size while maximizing the retention of spatial information from the input image. Second, FSEM-Pose incorporates a Feature Saliency Enhancement Module (FSEM) to strengthen the feature encoding of human keypoints, thereby improving the accuracy of pose estimation. Finally, FSEM-Pose further enhances inference efficiency via a lightweight optimization of the head using shared convolutional layers. Our method achieves competitive results across multiple accuracy and efficiency metrics on the MS COCO 2017 and CrowdPose datasets. While being lightweight in design, it improves average precision (AP) by 2.1% and 2.5%, respectively.Keywords
To achieve high-precision pose inference, MPE must overcome occlusion, close interaction, and scale variation—all common in real-world scenes. Real-time Multi-Person Pose Estimation (MPE) aims to detect and reconstruct, from a single image or video, the spatial layout and skeletal connections of keypoints including the head, limbs, and torso that define a person’s pose. Real-time MPE further requires both fast inference and robust multi-person parsing; satisfying these yields structured motion cues for downstream tasks such as activity recognition and human-computer interaction. Its foundational role in movement sensing, human-machine interfaces, mixed reality, and smart surveillance keeps real-time MPE at the center of academic and industrial research, shaping next-generation perception systems.
Deep learning has propelled significant progress in real-time MPE over recent years [1]. Researchers have improved keypoint accuracy and robustness via efficient network backbones [2–5] and refined post-processing strategies [6–8], such as NMS variants or NMS-free designs. To cut computational cost, the community has extensively explored lightweight modules [9,10], weight-sharing (e.g., RepVGG), and multi-scale feature extractors [11,12]. Jointly training MPE with detection or segmentation [13,14] has further broadened its use in complex scenes. Owing to its unmatched inference speed, the YOLO family [13,15–18] has become a mainstream architecture for real-time vision; its pose-specific variants, including YOLO-pose [19–22], achieve competitive accuracy while retaining efficiency. YOLOv10-pose [23], the latest YOLO-based pose estimator, refines the network to boost accuracy without slowing down inference. Its key innovation is a dual-label assignment that enables NMS-free, end-to-end inference, removing post-processing latency entirely. A lightweight classification head and spatially-channel decoupled downsampling further cut parameters and FLOPs, making the model friendlier for edge deployment. Large-kernel convolutions paired with programmable gradient information (PGI) strengthen multi-scale fusion and gradient flow, directly improving feature quality and joint localization. Together, these designs place YOLOv10-pose among the top performers on real-time MPE benchmarks.
Frequent occlusions severely constrain feature representation and push keypoint visibility below a reliable threshold. YOLOv10-pose consequently misses keypoints or produces false positives—a failure pattern Fig. 1 directly visualizes. Its heavy parameter footprint and high FLOPs also stall efficient inference on resource-limited hardware—mobile phones, embedded boards, or edge cameras—sharply curtailing real-world deployability. These two shortcomings reveal that YOLOv10-pose, despite its architectural advances, remains vulnerable to occlusion and edge-device constraints.

Figure 1: Illustration of false and missed detections in MPE based on YOLOv10-pose due to occlusion. Left image: The keypoints in the knee region, marked by the red bounding box, are not correctly detected and regressed, resulting in an incomplete pose estimation. Right image: Due to mutual occlusion of limbs in the area indicated by the red bounding box, keypoint regression is inaccurate, and some keypoints cannot be correctly matched.
To resolve these shortcomings, this work proposes FSEM-Pose, a human pose estimation model drawing on the YOLOv10 architecture. By optimizing its feature extraction mechanism and network structure, the model achieves end-to-end human detection and accurate, fast keypoint regression. To evaluate its performance, we conducted comprehensive comparisons with cutting-edge real-time MPE methodologies on the MS COCO 2017 [24] and CrowdPose [25] datasets. The comprehensive results verify that FSEM-Pose exhibits distinct superiorities in both inference speed and estimation accuracy. The core contributions of this work can be summarized as follows:
• Feature Shuffling-Convolution (FS-Conv): While common lightweight operations tend to sacrifice spatial details, our FS-Conv introduces a new modeling capability: structure-preserving lightweight feature extraction. It actively restructures the feature map prior to convolution, explicitly maintaining fine-grained spatial relationships throughout the dimensionality reduction process. This paradigm ensures that critical spatial cues for keypoint localization are preserved at the source, rather than being recovered later, establishing a more informative foundation for all subsequent stages.
• Feature Saliency Enhancement Module (FSEM): To overcome the limited discriminability of features in occluded or crowded scenes, FSEM provides a targeted, dual-stream enhancement mechanism for sparse keypoints. Its core innovation is the simultaneous and synergistic modeling of two complementary aspects: global spatial dependencies among body parts and local feature sharpening around keypoint boundaries. This integrated “reasoning-and-refining” capability, absent in generic attention modules, delivers task-specific feature enrichment that is essential for precise pose regression.
• Weight-Shared Convolution Head (WSCH): WSCH embodies a higher-level architectural innovation: the shift of model capacity from a complex backend to a strengthened frontend. By leveraging the highly discriminative features produced by FS-Conv and FSEM, we replace the traditional multi-branch head with an extremely lightweight shared-layer design. This demonstrates a new design principle—that superior feature generation enables radical simplification of the prediction head—resulting in a more efficient and balanced overall architecture.
Two-phase methods first run an object detector to propose candidate bounding boxes, then feed each cropped region into a single-person pose estimator. This cascade enables focused per-instance refinement but incurs sequential computation overhead. Single-phase methods [26] skip instance detection altogether. They globally regress dense keypoint heatmaps and resolve human instances through grouping and association—all in a single, parallel forward pass. Two distinct paradigms underpin modern multi-person pose estimation: two-phase and single-phase pipelines, as contrasted in Fig. 2. Each paradigm has merits; however, single-phase designs dominate latency-sensitive applications. Their advantage stems from a detection-free, globally parallel workflow.
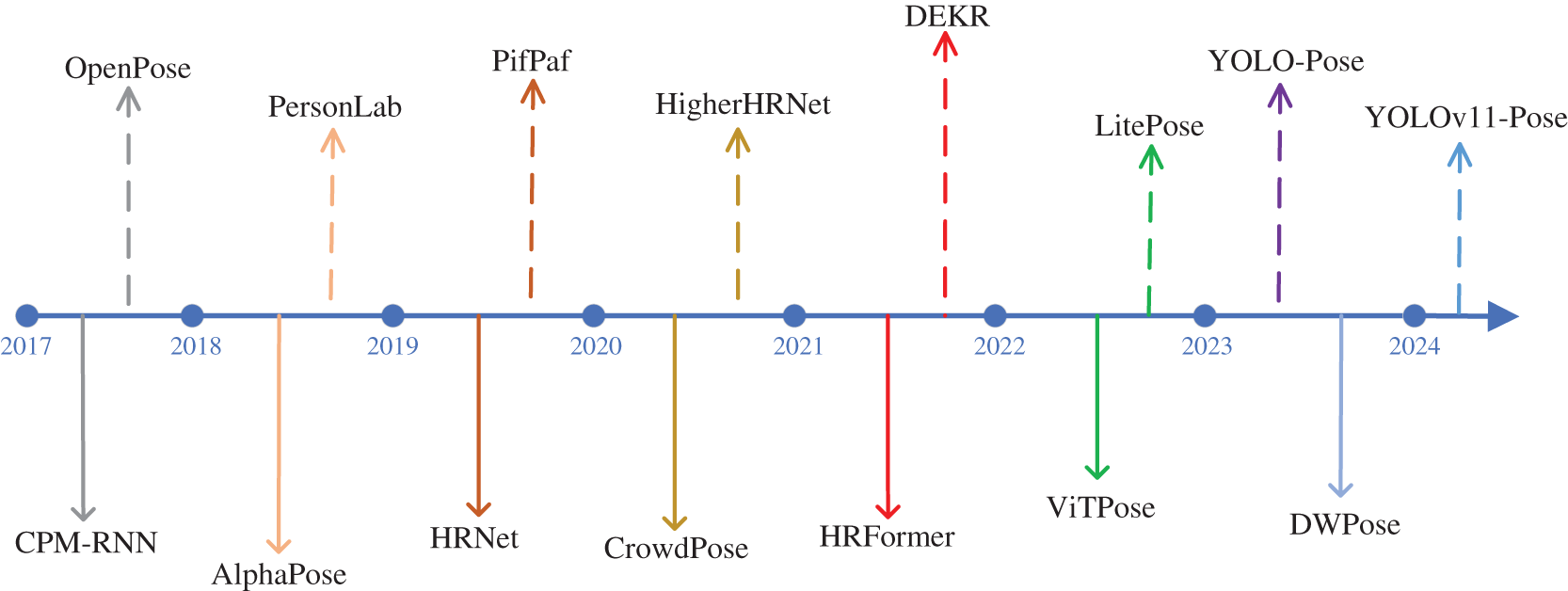
Figure 2: Review of the advancement of MPE paradigms.
2.1 Single-Stage Multi-Person Pose Estimation
DEKR [4] decouples keypoint prediction across independent feature channels, leveraging local context to sharpen feature representation. The design yields strong robustness under occlusion and crowding—yet its parallel decoding structure inflates computational cost. CenterGroup [27] clusters and associates keypoints from predicted human centers, enforcing spatial and feature consistency to reduce matching ambiguity in crowds. However, its accuracy hinges critically on center detection—a fragile link. In ultra-dense scenes, even minor localization errors cascade, causing severe performance drops. RTMPose [28] recasts keypoint estimation as coordinate classification under SimCC, pairing an efficient backbone with attention modules to deliver high precision at low compute. Yet two caveats persist: its accuracy hinges on the upstream detector, and fine-grained keypoint localization often falls short. DWPose [29] pioneers diffusion models for pose estimation, producing keypoint coordinates via iterative denoising. This grants exceptional robustness and accuracy in complex scenes—though at a steep cost. The multi-step inference loop introduces prohibitive latency, barring real-time deployment. AgentPose [30] takes a different route. It bridges the teacher-student capacity gap through diffusion-based progressive distillation, guided by learnable feature agents. The payoff: strong accuracy even under heavy compression. The trade-off? Extra training overhead and sensitive hyperparameter tuning. Collectively, these methods underscore a persistent challenge: balancing efficiency, accuracy, and adaptability across diverse scenarios.
2.2 Multi-Person Pose Estimation Based on Object Detection Architectures
ROI extraction and post-processing have long throttled pose estimation efficiency. FCPose [31] sidesteps both with dynamic instance-aware convolution in a fully convolutional design—eliminating these steps entirely. The payoff: significantly faster inference. The trade-off? Severe occlusion or overlapping often triggers keypoint omissions, dragging down accuracy. Keypoint localization accuracy often suffers from insufficient context. DeepDarts [32] reframes pose estimation as constrained optimization, weaving in contextual cues to sharpen predictions. The result is cleaner keypoint maps—yet the optimizer can stall at local optima, leaving gains on the table. Real-time pose estimation demands end-to-end flow. YOLO-pose [19] and KAPAO [20] deliver exactly that, harnessing the YOLO backbone for simultaneous detection and pose regression—a hallmark of YOLO-based designs. Yet this tight coupling cuts both ways: regression quality hinges on detection box fidelity, and dense crowds expose this fragility. YOLOv9-pose [22] fuses detection and pose estimation in a single network, striking a speed-accuracy balance via multi-task collaborative learning. Still, when occlusion thickens or objects shrink, its fine-grained perception lags behind top-down counterparts—a gap yet to close.
2.3 Feature Enhancement and Model Lightweighting
Scaling depth typically inflates parameters—a dilemma EfficientNetV2 [33] sidesteps with adaptive depth scaling. It lifts accuracy without adding parameters, outrunning traditional CNNs at equal parameter budgets. The catch? Training stretches longer, a cost paid upfront for inference-time efficiency. Standard downsampling leaks fine-grained spatial cues. SPD-Conv [34] rethinks the process: it shrinks spatial maps yet locks in channel-wise integrity. Low-resolution and small objects benefit markedly—but semantic context can blur, sometimes harming recognition of certain targets. Multi-scale feature fusion often remains sparse. UNet 3+ [35] densely weaves encoder features across all scales with same-depth decoder maps, forging richer representations. Boundaries sharpen, detail persists—especially in medical imagery. But dense fusion exacts a toll: complexity and memory soar.
Training power and inference speed often conflict. RepVGG [36] leverages structural reparameterization: multi-branch topologies enrich features during training, then collapse into a single path at inference. Accuracy holds, inference flies—yet training memory swells, a transient but real burden. Predefined pruning ratios often miss the mark. PAGCP [37] derives a gradient-aware criterion: it tracks channel gradient magnitudes during training, pruning redundant channels on the fly. No preset ratios, no complex search—compression becomes adaptive. Still, stability wavers with optimization noise, a side effect of leaning so heavily on training dynamics.
To address the challenges of high computational complexity and insufficient feature representation of keypoints in current real-time multi-person pose estimation methods, this paper proposes an innovative solution named FSEM-Pose. Building upon the foundational architecture of YOLO-Pose [19] and based on the YOLOv10 [23] real-time detection framework, the model constructs an independent keypoint prediction branch, enabling concurrent detection and pose estimation for all individuals within a picture.
Specifically, FSEM-Pose employs the YOLOv10 detector for real-time positioning and identification of human individuals, while adopting the heatmap prediction paradigm to generate all potential human keypoints. A post-processing mechanism based on the Hungarian matching algorithm finally associates the detected keypoints with their corresponding human instances. As illustrated in the system pipeline in Fig. 3, the model outputs a vector of dimension 6 + 3
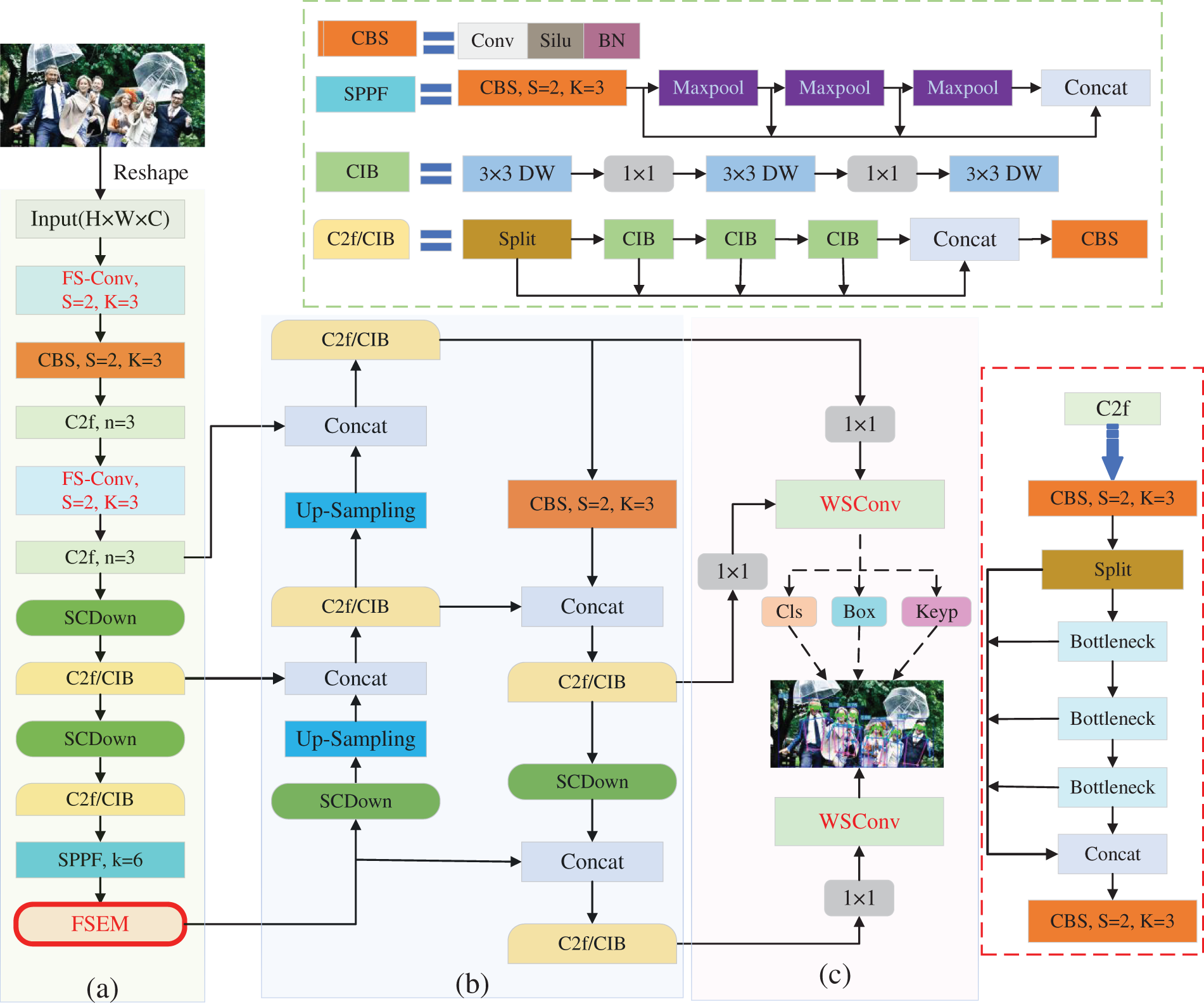
Figure 3: Holistic framework architecture of FSEM-Pose. (a) Backbone: To better facilitate the model’s acquisition of information relevant to human keypoints, FSEM-Pose introduces FS-Conv and FSEM into the CSPDarkNet-53 architecture. These components enhance the feature representation of the backbone while achieving model lightweighting. (b) Neck: FSEM-Pose retains the PANet fusion network from the baseline. Through its ascending pathway enhancement and self-adjusting feature aggregation mechanisms, the architecture’s multi-resolution feature characterization capacity is effectively improved. (c) Head: FSEM-Pose replaces the complex multi-scale convolutional structure in the original YOLO framework with a set of weight-shared convolutional layers, further reducing the model’s size.
3.2 Feature Shuffling-Convolution
Within the backbone architecture of the YOLOv10 reference model, features are extracted through the extensive stacking of
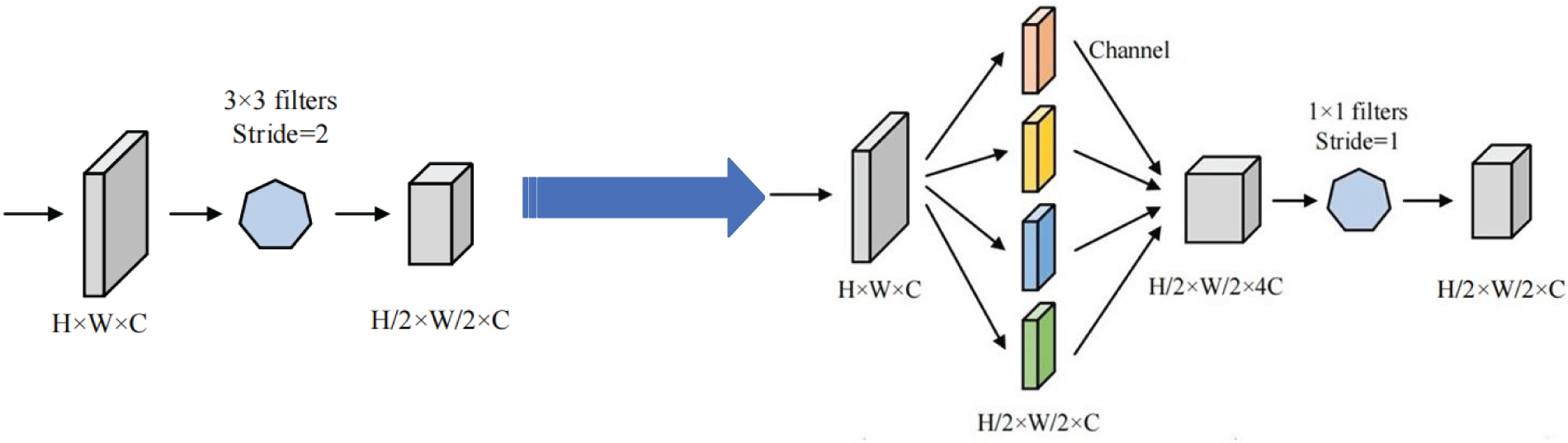
Figure 4: Schematic diagram of the FS-Conv information processing.
In the above formulation, X denotes the incoming feature map, X′ signifies intermediate feature map, and X″ the output feature map.
More precisely, FS-Conv first divides the input feature map into four sub-maps, each being a quarter of the spatial scale of original picture while retaining a matching count of channels. These four sub-maps are then merged along the channel axis, followed by a
where
To address information loss during downsampling, we reframe how spatial details flow into channels—a principle also central to SPD-Conv. Yet their implementations and optimization targets diverge. SPD-Conv opts for a space-to-depth transformation: it packs spatial pixels into channels using a fixed scale factor, then feeds the expanded tensor through a non-strided convolution. Its mission is aggressive—eliminate strided convolutions and pooling altogether to salvage features from low-resolution inputs and tiny objects. FS-Conv instead prioritizes reorganization and lightness. It first splits the feature map channel-wise into several sub-maps—typically four when scale = 2—and then sews them back together using a
The architectural payoff is tangible: where SPD-Conv expands first and transforms later, FS-Conv keeps the pipeline tight. Parameter count drops by 55.6%—yet discriminative capacity holds, and inference speeds up. We therefore position FS-Conv as an evolution of the SPD-Conv paradigm—leaner, more interactive, and tailored for real-time constraints.
3.3 Feature Saliency Enhancement Module
To augment the feature expression associated with input feature maps, the YOLOv10 model incorporates the Polarized Self-Attention (PSA) [38]. By partitioning the feature map along the channel axis and applying the self-attention mechanism only to a subset of branches, the PSA module effectively strengthens the model’s capacity for global context modeling while significantly diminishing computational complexity, thereby attaining a balance among performance and efficiency. Its internal configuration is visualized in Fig. 5.
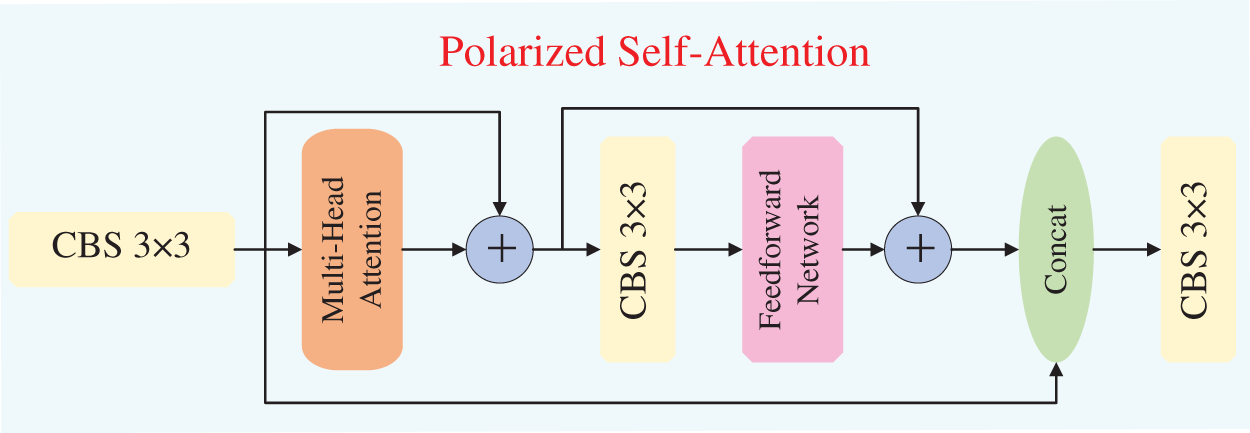
Figure 5: Operational mechanism of the PSA module.
Although the inclusion of PSA can to some extent enhance the feature representation of the baseline model, it still exhibits certain limitations. First, PSA restricts its application to only a specific subset of channels, whereas the critical information requiring long-range dependency modeling may be dynamically distributed across different channels depending on the input image. For tasks such as MPE, where human keypoints are generally discretely distributed across the image, such non-global modeling can easily lead to the loss of important information. Second, self-attention generates weights by computing the similarity between Query and Key vectors, thereby emphasizing regions with higher weights. Typically, texture details related to human keypoints tend to exhibit low contrast against the background, resulting in relatively weak feature responses (i.e., values of Query and Key) for such regions. Therefore, to further optimize the contextual feature representation of the backbone architecture, this work puts forward a Feature Saliency Enhancement Module (FSEM) to substitute the PSA module in the baseline.
The implementation of FSEM primarily consists of two components: Spatial Dependency Modeling (SDM) and Feature Sharpening Modeling (FSM), as depicted in Fig. 6. The entire workflow may be recapitulated as below:
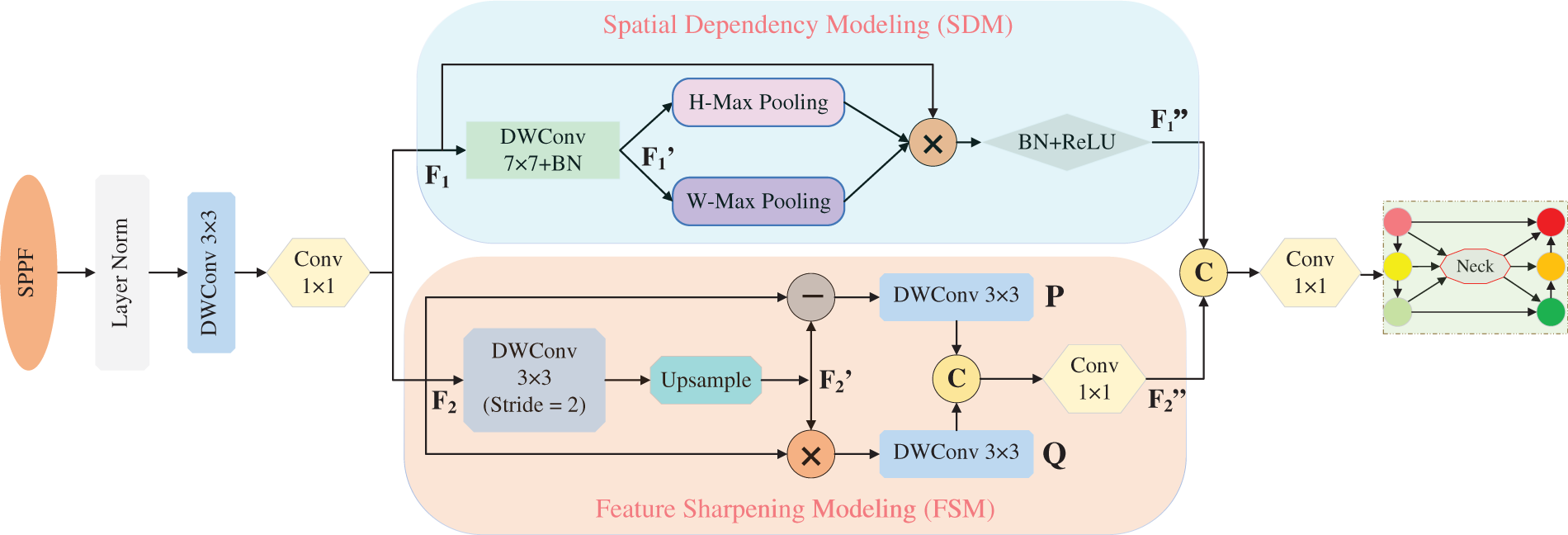
Figure 6: Internal implementation details of the FSEM.
The feature map (
Among them,
Inspired by image sharpening and contrast enhancement techniques [40], the Feature Sharpening Module (FSM) enhances features by performing scale transformation on the incoming feature matrix (
Among them,
In the FSM stage, a matrix subtraction operation is first performed between the detail-smoothed feature matrix
In summary, the FSEM module enhances the feature expression capacity of the feature backbone architecture. Specifically, the Spatial Dependency Modeling (SDM) component establishes long-range spatial dependencies across regions, which is crucial for modeling the discrete distribution characteristics of human keypoints. Meanwhile, the Feature Sharpening Module (FSM) enhances the feature expression of detailed textures and semantic contours, providing richer feature information for the keypoint localization task. To clearly illustrate the module structure, a PyTorch-style implementation is provided in Algorithm 1.
FSEM shares a methodological lineage with CAM in terms of spatial dependency modeling: the SDM component within FSEM adopts the bidirectional feature encoding strategy of CAM, generating orientation-aware attention vectors through global pooling along the height and width dimensions. This enables the network to capture spatial positional information and enhances its ability to localize salient regions. However, the two modules differ fundamentally in both architectural design and functional objectives. CAM operates as a single-path attention mechanism that merely improves spatial sensitivity through feature recalibration. In contrast, FSEM adopts a dual-stream parallel structure: alongside SDM, it introduces a Feature Sharpening FSM that generates blurred feature maps via downsampling-upsampling operations, and subsequently extracts fine-grained texture details and semantic contour information through matrix subtraction and multiplication, respectively. This composite design achieves a joint enhancement of “spatial localization” and “feature sharpening,” enabling FSEM to more effectively address the challenges inherent in human pose estimation—particularly the discrete distribution of keypoints and their low contrast against complex backgrounds—thereby yielding performance gains beyond those attainable by CAM, as empirically validated in our experiments.

3.4 Weight-Shared Convolution Head
The output stage of YOLOv10-pose involves feature maps at three different scales, with each scale further containing three independent output branches (for classification, localization, and keypoints). While this design aids the model in perceiving local features across varying receptive fields, it suffers from low parameter utilization efficiency. Furthermore, despite the differences in the scales of various persons within an image, their low-level features—such as local textures, edges, and structures—exhibit high similarity. Therefore, they can, in theory, be effectively extracted by the same set of convolutional kernels. Based on this insight, this paper proposes a Weight-Shared Convolution Head (WSCH), which replaces the original design with a more compact output head to enhance both parameter utilization and computational efficiency, as visualized in Fig. 7. The implementation of WSCH comprises the subsequent three constituent parts:
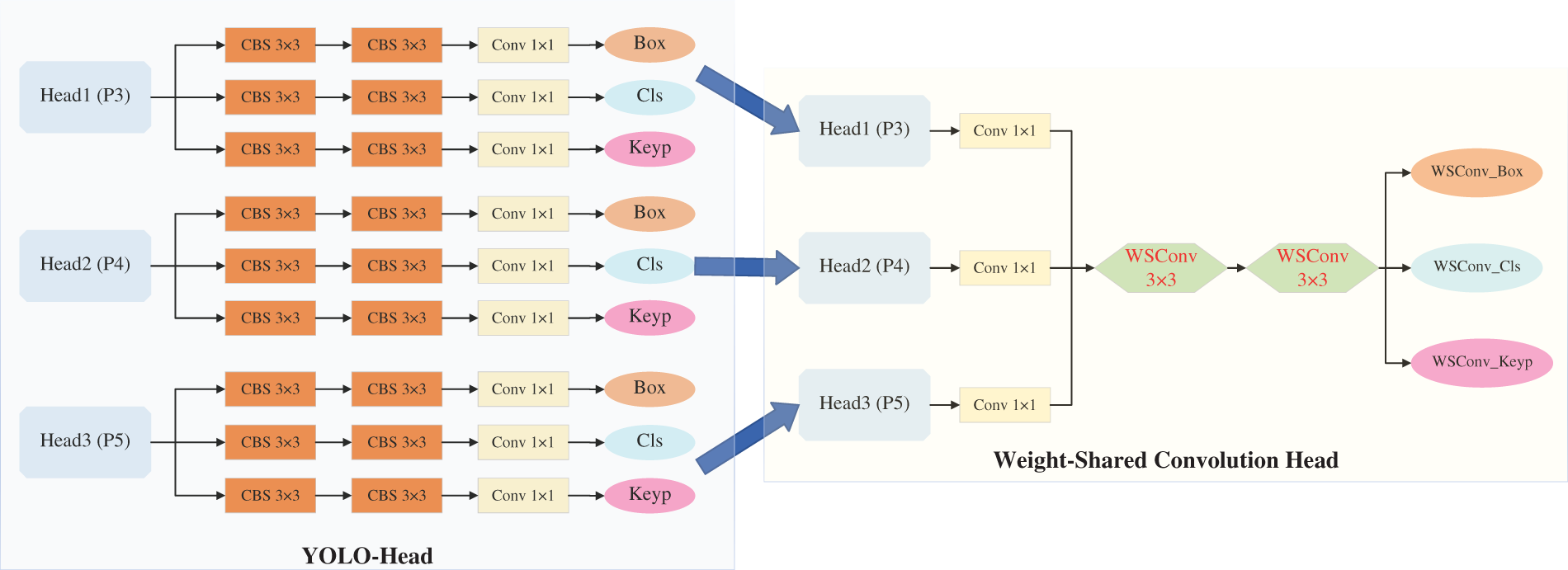
Figure 7: Schematic of head structure lightweighting.
(1) Preprocessing Convolution: This comprises three parallel
The workflow of WSCH can be summarized as follows: Taking the
Finally,
In summary, the traditional YOLOv10-pose output head performs independent convolutional operations on feature maps from different depths, resulting in a complex and cumbersome design. The proposed WSCH mitigates structural redundancy through parameter reuse while maintaining representational capacity. Furthermore, this improvement is not only more efficient in terms of parameters and computation but also guides the network to learn more generalized feature representations by enforcing weight sharing, representing an effective strategy for real-time vision tasks and lightweight deployment.
4 Experimental Studies and Analyses
This chapter conducts a systematic comparative analysis of the proposed FSEM-Pose framework compared with current prevalent MPE paradigms, validating its performance advantages on two public benchmarks: MS COCO 2017 and CrowdPose. To further dissect the contribution of each component, three sets of ablation studies are designed and conducted to individually estimate the impact of different components on the overall functionality. The experimental environment is configured as follows: an NVIDIA RTX 4090 GPU with Ubuntu 18.04 LTS, models are built upon the PyTorch framework, and CUDA is utilized for GPU-accelerated computation.
4.1 Datasets and Evaluation Metrics
(1) For human pose estimation, MS COCO 2017 has become a de facto benchmark—its influence stems from both scale and annotation fidelity. The dataset packs over 250,000 person instances, each annotated, drawn from everyday scenes—indoors, outdoors, varied activities and viewpoints. Annotators label 17 keypoints per instance—from nose to ankles—covering torso, limbs, and face. Evaluation relies on Object Keypoint Similarity (OKS), which normalizes errors by person scale; this yields a metric both scientific and directly comparable across studies. Thanks to its diversity, precise annotations, and rigorous OKS-based evaluation, COCO remains the authoritative testbed—the community trusts it to rank pose estimators reliably.
(2) Dense crowds break generic pose estimators. CrowdPose directly targets this failure mode: 20,000 images, 80,000+ instances, all in crowded scenes. A crowd index—computed from instance overlap—splits samples into easy, medium, and hard. Hard samples alone exceed 40%, filling the gap left by COCO’s sparse crowds. It inherits COCO’s 17-keypoint layout but swaps plain OKS for pose-aware metrics that penalize ID switches and limb-assignment errors—crucial for real-world crowding. For researchers tackling occlusion and instance entanglement, CrowdPose is therefore the benchmark of choice.
In human pose estimation research, Average Precision (AP) based on OKS is the widely adopted performance evaluation metric. This metric comprehensively reflects algorithm performance by calculating the average recognition accuracy across different thresholds and scales. Specifically,
To analyze model adaptability to objects of different scales, the COCO dataset defines
To assess FSEM-Pose holistically, we thus combine accuracy, coverage (AR), speed (Latency), and complexity (GFLOPs)—four dimensions that together reveal trade-offs among precision, robustness, and real-world viability. We measure keypoint coverage completeness via Average Recall (AR), and report Latency—the wall-time from inference start to post-processing end—as a runtime proxy. GFLOPs capture the model’s computational footprint; lower values imply higher efficiency and easier deployment.
FSEM-Pose employs two hybrid augmentations, Mosaic [41] and Mixup [42], at the preprocessing stage—a deliberate choice to improve generalization on small and occluded instances. All input images are first resized to

Figure 8: Pre-processing augmentation strategies.
We substitute Adam with the Lion optimizer [43] when training FSEM-Pose, motivated by Lion’s memory-efficient gradient handling and its reported superiority on vision tasks. Training lasts 240 epochs. The learning rate commences at
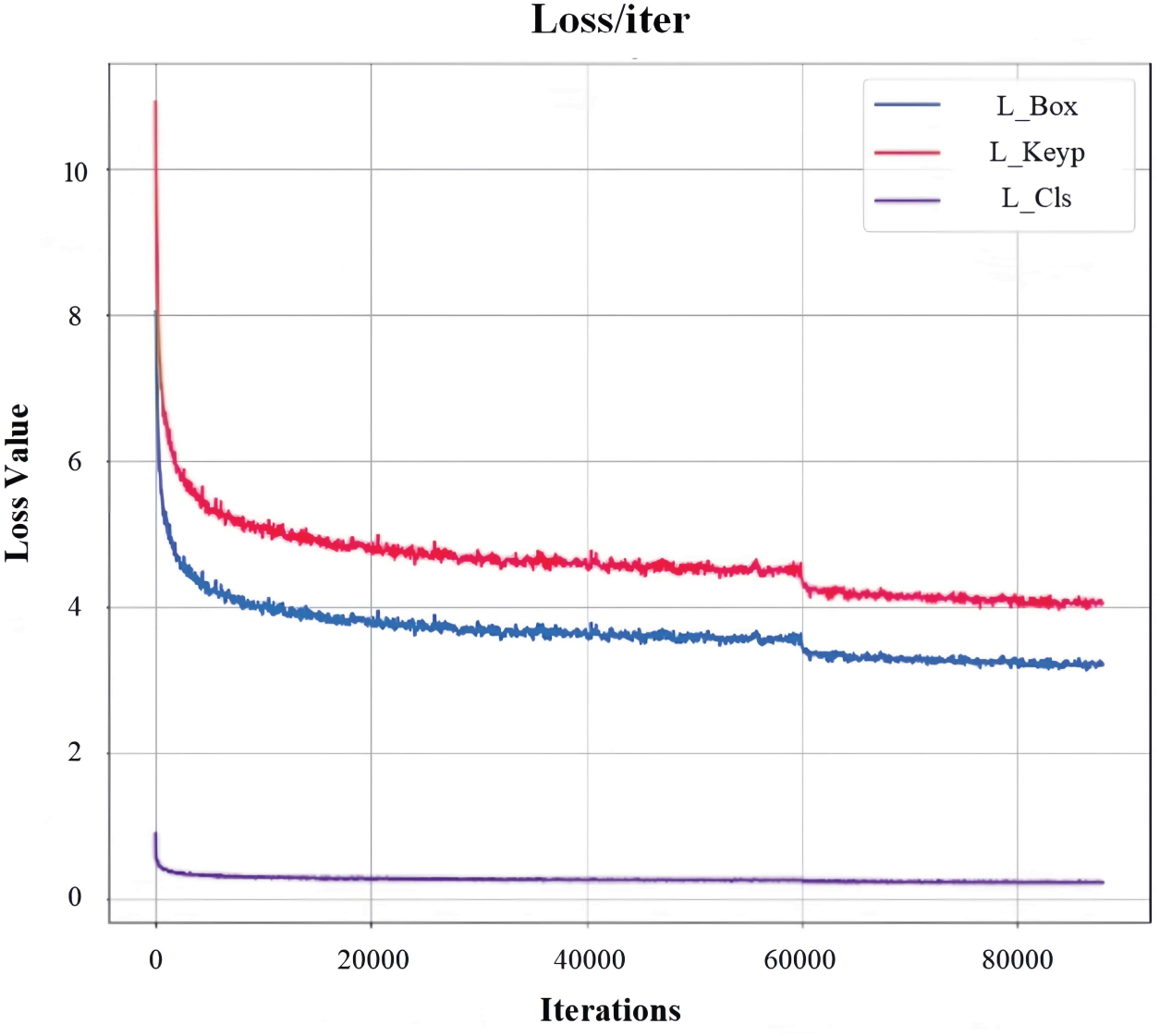
Figure 9: Dynamics of loss components during training.
4.3 Findings from Experiments Using Public Datasets
The FSEM-Pose multi-person pose estimation model is built upon the YOLOv10-pose architecture, inheriting the end-to-end keypoint regression paradigm of YOLO-Pose [19] to realize synchronous detection and pose assessment of multiple human instances within an image. By reconstructing the backbone structure and detection head modules of the baseline network, the model significantly enhances both the correctness and computational performance for real-time pose estimation tasks. As presented in Table 1, a methodical comparative assessment was implemented between FSEM-Pose and current mainstream real-time human pose estimation algorithms on the MS COCO 2017 benchmark dataset.
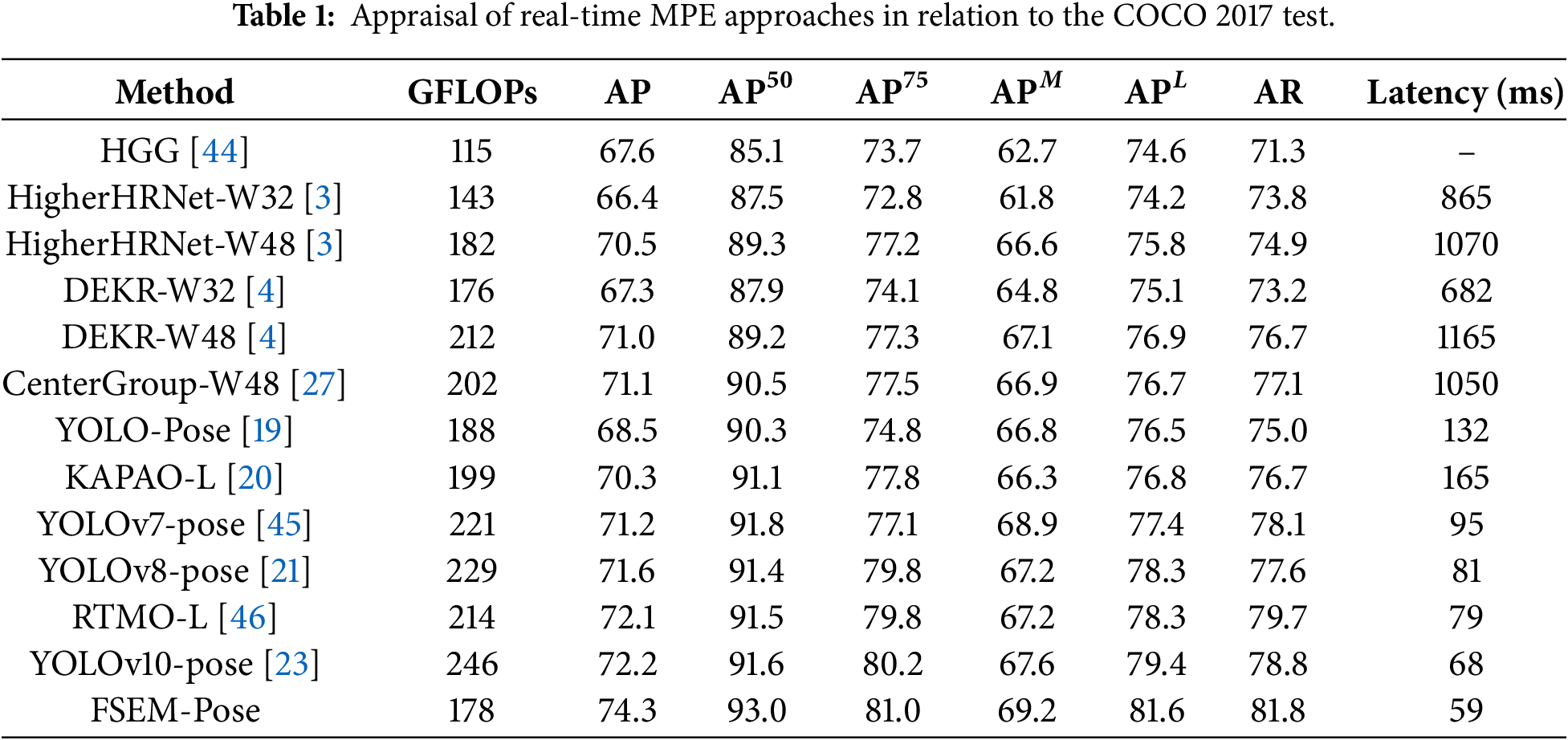
Experimental results demonstrate that FSEM-Pose achieves a pose estimation AP of 74.3% on the COCO 2017 test-dev set, demonstrating all-round competitive advantages in comparison with current leading real-time MPE algorithms [19,21,23,45]. Through structural optimizations, the model achieves a 2.1% improvement in AP and a 3.0% increase in AR over the baseline. Notably, the lightweight design of the backbone network and detection head reduces the model’s computational complexity by approximately 27.8% and improves inference speed by 13.2%, significantly enhancing its real-time processing capability to meet the demands of most practical application scenarios.
In light of the experimental outcomes displayed in Table 2, FSEM-Pose demonstrates excellent keypoint localization accuracy and computational efficiency on the CrowdPose dataset. Compared to the baseline model YOLOv10-pose, the proposed method improves the AP metric by 2.5%. More significantly, FSEM-Pose obtains a notable 4.2% increment in the
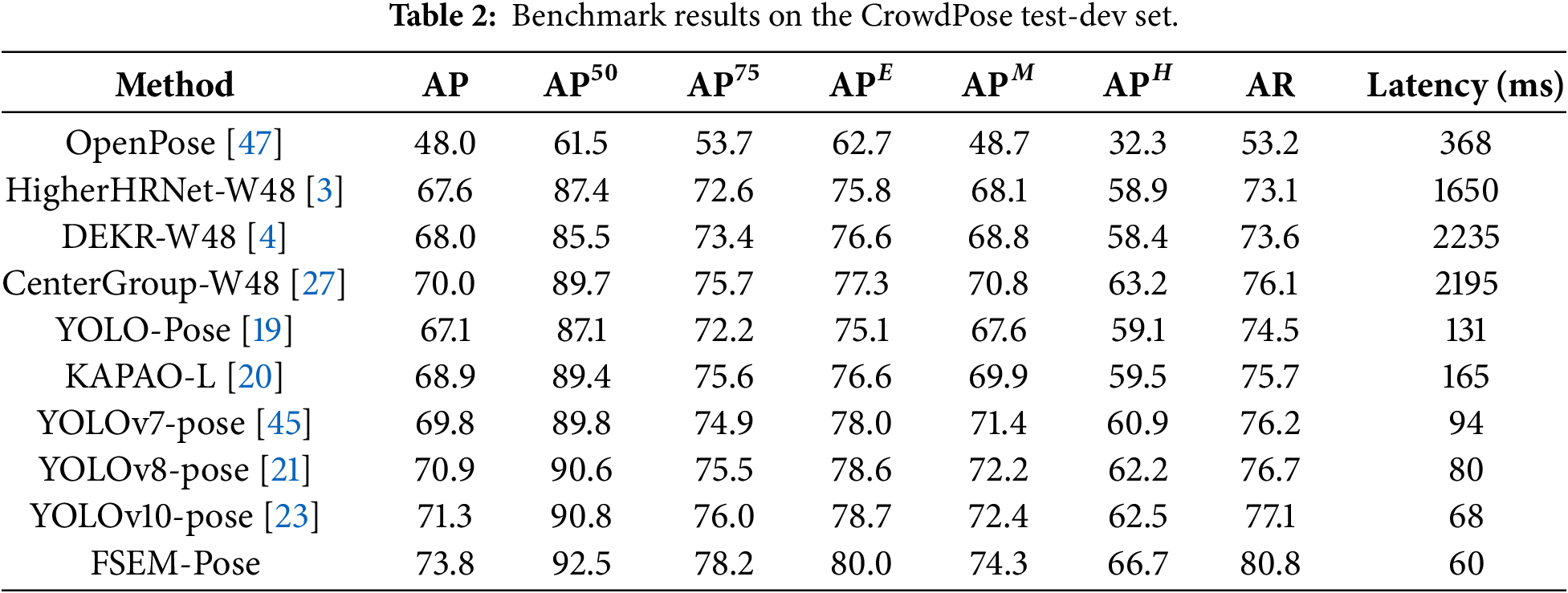
To establish the causal relationship between the proposed modules and performance improvements, this paper designs several sets of component removal analyses on the MS COCO 2017 validation set to individually validate their effectiveness.
4.4.1 Ablation Study on Model Lightweighting
The first part of the experiments focuses on investigating the individual contributions of the two proposed lightweight components—FS-Conv and WSCH. The associated ablation outcomes are synthesized in Table 3. The findings demonstrate that the integration of FS-Conv in the Backbone and WSCH in the Head efficiently decreases the overall count of network parameters, resulting in a model scale reduction of approximately 28.4%. This enhancement is beneficial for deploying real-time MPE models on edge devices. Furthermore, the inclusion of these components also significantly lowers the model’s computational complexity, with GFLOPs decreasing by about 27.8%, thereby further improving inference efficiency. Notably, the accompanying accuracy loss (−0.2%) is nearly negligible.
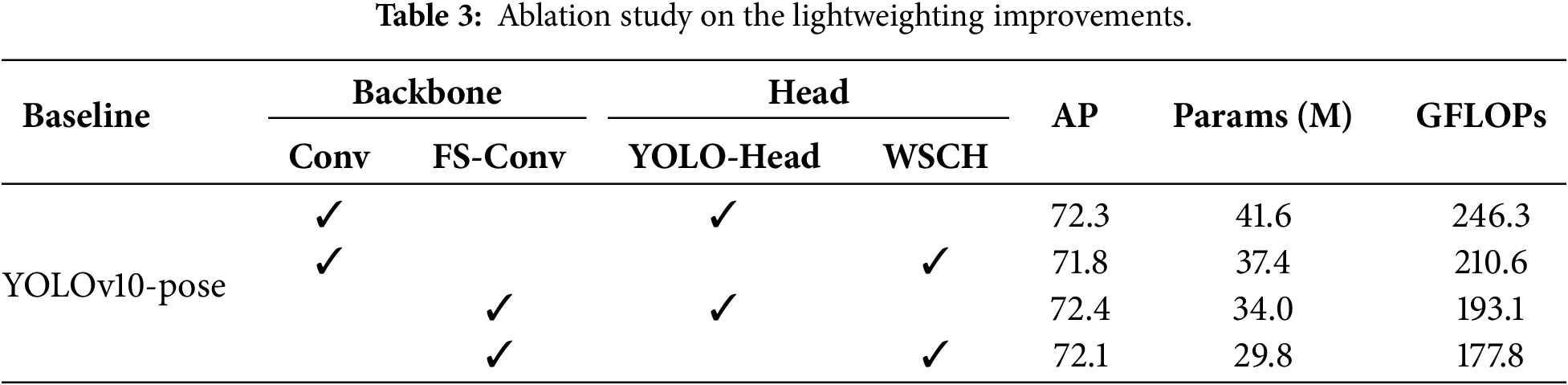
4.4.2 Ablation Analysis on the Feature Enhancement Module
The second part of the experiments focuses on assessing the impact of introducing the FSEM on the accuracy of the MPE task. Additionally, we compare FSEM against several other popular visual attention mechanisms, namely CBAM [48], CA [39], and EMA [49], to verify its superior performance for MPE. Empirical results on COCO val2017 are presented herein Table 4. The ablation analyses demonstrate that the FSEM more effectively augments the feature expressive ability of the backbone architecture, leading to an AP increase of 2.4% and an
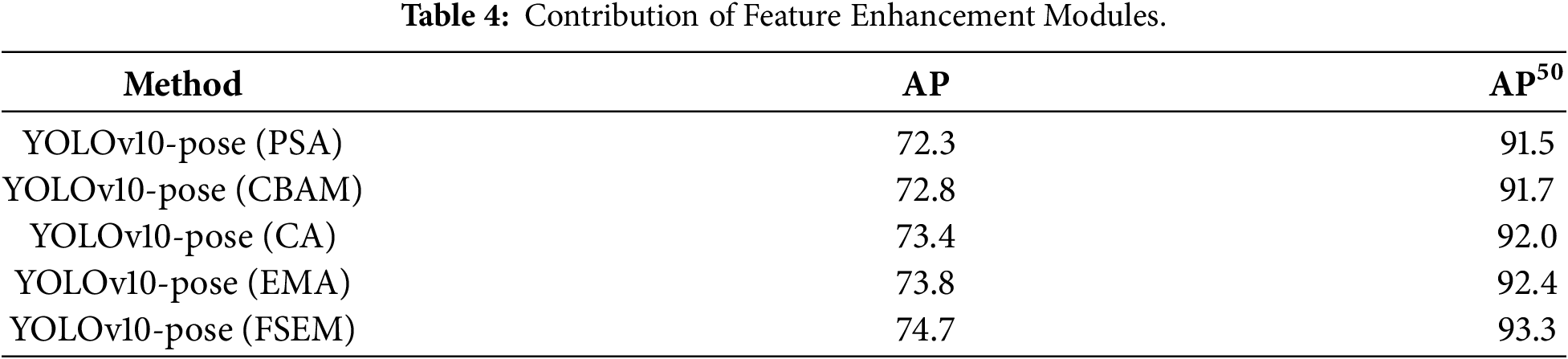

Figure 10: The impact of FSEM integration on human pose estimation accuracy.
Researchers widely adopt Grad-CAM++ [50], a gradient-driven class activation mapping technique, to interpret object detection and image classification models. It renders feature activation distributions into heatmaps, directly revealing which patterns drive model decisions. The mechanism exploits both positive and negative gradient signals—not merely which neurons fire, but also which are suppressed—to localize class-discriminative regions. This yields sharper, more precise activation maps.
We therefore applied Grad-CAM++ to visualize feature activations across several real-time pose estimators. Comparing their heatmaps (Fig. 11), we observe starkly divergent attention patterns. FSEM-Pose, in contrast, consistently activates over anatomically plausible body regions. Background responses drop sharply. This suppression of environmental clutter proves critical: cleaner feature maps translate directly to fewer false positives in joint detection. We attribute much of the model’s performance gain to this focused attention characteristic.

Figure 11: Grad-CAM++ analysis for multi-person pose estimation in YOLO frameworks.
Fig. 12 turns to FSEM-Pose’s actual outputs. The figure also collects representative failure modes. Very small persons, for example, often lose keypoints entirely—the model fails to regress them from insufficient pixel evidence. Limb occlusion or entanglement in multi-person scenes further confuses instance assignment; arms are assigned to wrong torsos, or legs swap identities. These two failure families—tiny instances and crowded occlusion—point to a common bottleneck: insufficient contextual reasoning. Our next step is therefore to strengthen the backbone’s feature representation. Richer context should help the model infer occluded joints from body symmetry and resolve identity across entangled limbs.

Figure 12: Visual interpretation of FSEM-Pose.
Our work addresses the dual challenges of computational efficiency and keypoint localization accuracy in real-time multi-person pose estimation. The conventional cascaded convolutional design in YOLOv10-pose, while effective, results in high parameter counts. This complexity hinders deployment on edge devices, where resources are limited and frame-by-frame processing demands efficiency. Moreover, the fixed receptive field of this architecture—crucial for understanding relationships between distant keypoints, especially under occlusion—limits the model’s ability to integrate broader scene context.
How, then, can we reduce complexity while preserving accuracy? Our solution introduces two lightweight modules: the Feature Shuffling-Convolution (FS-Conv) and the Weight-Shared Convolution Head (WSCH). The former restructures feature maps to enhance information flow with minimal cost; the latter applies a single, optimized convolutional kernel across multiple detection heads. Together, they achieve a significant reduction in both parameters and GFLOPs. Crucially, as our ablation studies (Table 3) confirm, this efficiency gain does not come at the expense of performance; the baseline accuracy is not only preserved but in some settings enhanced. To directly boost the precision of keypoint regression, we developed the Feature Saliency Enhancement Module (FSEM). This module optimizes feature maps by sharpening semantically important regions and suppressing background noise, effectively guiding the network’s focus. This targeted enhancement translates to a measurable +2.4% improvement in Average Precision (AP), a gain quantitatively isolated and reported in Table 4.
We evaluated the integrated FSEM-Pose framework rigorously on the MS COCO 2017 and CrowdPose benchmarks. The results, detailed in Tables 1 and 2, show that our method holds its own against leading real-time pose estimators, achieving competitive trade-offs between accuracy, speed, and model size. The model is built upon the YOLOv10 architecture and integrates a keypoint regression mechanism to achieve end-to-end multi-person detection and pose estimation.
Our ongoing work aims to refine the FSEM-Pose framework for edge deployment. We plan to integrate advanced backbones like ReXNet and apply pruning techniques such as PAGCP, as we believe these methods hold significant potential for further reducing latency without compromising the AP gains demonstrated in this study. The goal is to achieve a more favorable accuracy-efficiency trade-off, enabling deployment across a wider array of resource-constrained devices.
The limitations of this study are as follows. First, the accuracy of our current model has not yet reached the performance level of some advanced two-stage human pose estimation models, indicating room for further improvement. Second, due to the additional feature processing modules introduced, the overall model size and parameter count remain relatively complex. Exploring further compression of the model represents a potential direction for future work.
Beyond pose estimation, a key question is whether the FSEM’s design principle—enhancing salient features—generalizes. We will therefore adapt and evaluate it in related domains where feature discrimination is paramount, notably semantic segmentation and multi-object tracking. Success in these tasks would not only validate the module’s broader utility but also inform its iterative refinement.
Acknowledgement: We sincerely acknowledge the generous support from the Huangshan Technology Innovation Center for Digital Economy and Big Data Analysis for this work.
Funding Statement: This work was primarily supported by the Talent Startup Program of Huangshan University under Grant No. 2025xkjq003. Additional partial funding was gratefully received from the Scientific Research Project of the Anhui Provincial Department of Education under Grant No. 2025AHGXZK40303.
Author Contributions: Chengang Dong performed the preliminary study and composed the outline of the paper and performed the experiments. Yongkang Ding composed the drawings and conducted the experiments, Jianwei Hu prepared the tables and read the proofread of the article. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The datasets analyzed during the current study are available in the repositories of CrowdPose (https://github.com/Jeff-sjtu/CrowdPose.git) and MS COCO (https://cocodataset.org/).
Ethics Approval: Given that this is a computational study relying solely on publicly accessible benchmark datasets, no formal ethical approval was required. The research did not include human participants, animal testing, or the acquisition of confidential data.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Kocabas M, Karagoz S, Akbas E. Multiposenet: fast multi-person pose estimation using pose residual network. In: Proceedings of the European Conference on Computer Vision (ECCV). Cham, Switzerland: Springer; 2018. p. 417–33. [Google Scholar]
2. Papandreou G, Zhu T, Chen LC, Gidaris S, Tompson J, Murphy K. Personlab: person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model. In: Proceedings of the European Conference on Computer Vision (ECCV). Cham, Switzerland: Springer; 2018. p. 269–86. [Google Scholar]
3. Cheng B, Xiao B, Wang J, Shi H, Huang TS, Zhang L. Higherhrnet: scale-aware representation learning for bottom-up human pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2020. p. 5386–95. [Google Scholar]
4. Geng Z, Sun K, Xiao B, Zhang Z, Wang J. Bottom-up human pose estimation via disentangled keypoint regression. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2021. p. 14676–86. [Google Scholar]
5. Wang Y, Li M, Cai H, Chen WM, Han S. Lite pose: efficient architecture design for 2D human pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2022. p. 13126–36. [Google Scholar]
6. Cao Z, Hidalgo G, Simon T, Wei SE, Sheikh Y. Openpose: realtime multi-person 2D pose estimation using part affinity fields. IEEE Trans Pattern Analy Mach Intell. 2019;43(1):172–86. [Google Scholar]
7. Luo Z, Wang Z, Huang Y, Wang L, Tan T, Zhou E. Rethinking the heatmap regression for bottom-up human pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2021. p. 13264–73. [Google Scholar]
8. Tobeta M, Sawada Y, Zheng Z, Takamuku S, Natori N. E2Pose: fully convolutional networks for end-to-end multi-person pose estimation. In: 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway, NJ, USA: IEEE; 2022. p. 532–7. [Google Scholar]
9. Han D, Yun S, Heo B, Yoo Y. Rexnet: diminishing representational bottleneck on convolutional neural network. arXiv:2007.00992. 2020. [Google Scholar]
10. Koonce B. MobileNetV3. In: Convolutional neural networks with swift for tensorflow: image recognition and dataset categorization. Berkeley, CA, USA: Apress; 2021. p. 125–44. [Google Scholar]
11. Huang Z, Wang J, Fu X, Yu T, Guo Y, Wang R. DC-SPP-YOLO: dense connection and spatial pyramid pooling based YOLO for object detection. Inform Sci. 2020;522:241–58. [Google Scholar]
12. Yang G, Lei J, Zhu Z, Cheng S, Feng Z, Liang R. Afpn: asymptotic feature pyramid network for object detection. arXiv:2306.15988. 2023. [Google Scholar]
13. Wang H, Jin Y, Ke H, Zhang X. DDH-YOLOv5: improved YOLOv5 based on double IoU-aware Decoupled Head for object detection. J Real-Time Image Process. 2022;19(6):1023–33. doi:10.1007/s11554-022-01241-z. [Google Scholar] [CrossRef]
14. Shi D, Wei X, Li L, Ren Y, Tan W. End-to-end multi-person pose estimation with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2022. p. 11069–78. [Google Scholar]
15. Bochkovskiy A, Wang CY, Liao HYM. Yolov4: optimal speed and accuracy of object detection. arXiv:2004.10934. 2020. [Google Scholar]
16. Li C, Li L, Jiang H, Weng K, Geng Y, Li L, et al. YOLOv6: a single-stage object detection framework for industrial applications. arXiv:2209.02976. 2022. [Google Scholar]
17. Wang CY, Bochkovskiy A, Liao HYM. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2023. p. 7464–75. [Google Scholar]
18. Aboah A, Wang B, Bagci U, Adu-Gyamfi Y. Real-time multi-class helmet violation detection using few-shot data sampling technique and yolov8. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2023. p. 5349–57. [Google Scholar]
19. Maji D, Nagori S, Mathew M, Poddar D. Yolo-pose: enhancing yolo for multi person pose estimation using object keypoint similarity loss. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2022. p. 2637–46. [Google Scholar]
20. McNally W, Vats K, Wong A, McPhee J. Rethinking keypoint representations: modeling keypoints and poses as objects for multi-person human pose estimation. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2022. p. 37–54. [Google Scholar]
21. Jeon HJ, Lang S, Vogel C, Behrens R. An integrated real-time monocular human pose & shape estimation pipeline for edge devices. In: 2023 IEEE International Conference on Robotics and Biomimetics (ROBIO). Piscataway, NJ, USA: IEEE; 2023. p. 1–6. [Google Scholar]
22. Wang CY, Yeh IH, Mark Liao HY. Yolov9: learning what you want to learn using programmable gradient information. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2025. p. 1–21. [Google Scholar]
23. Wang A, Chen H, Liu L, Chen K, Lin Z, Han J, et al. Yolov10: real-time end-to-end object detection. arXiv:2405.14458. 2024. [Google Scholar]
24. Chowdhury PN, Sain A, Bhunia AK, Xiang T, Gryaditskaya Y, Song YZ. Fs-coco: towards understanding of freehand sketches of common objects in context. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2022. p. 253–70. [Google Scholar]
25. Li J, Wang C, Zhu H, Mao Y, Fang HS, Lu C. Crowdpose: efficient crowded scenes pose estimation and a new benchmark. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2019. p. 10863–72. [Google Scholar]
26. Lin W, Chu J, Leng L, Miao J, Wang L. Feature disentanglement in one-stage object detection. Pattern Recognit. 2024;145(2):109878. doi:10.1016/j.patcog.2023.109878. [Google Scholar] [CrossRef]
27. Brasó G, Kister N, Leal-Taixé L. The center of attention: center-keypoint grouping via attention for multi-person pose estimation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway, NJ, USA: IEEE; 2021. p. 11853–63. [Google Scholar]
28. Jiang T, Lu P, Zhang L, Ma N, Han R, Lyu C, et al. Rtmpose: real-time multi-person pose estimation based on mmpose. arXiv:2303.07399. 2023. [Google Scholar]
29. Liu K, Yang Z, Zhang J, Wang J, Wang S, Yuan C, et al. Boosting pose estimators via cross-representation distillation. In: European Conference on Computer Vision. Cham, Switzerland: Springer; 2024. p. 343–58. [Google Scholar]
30. Zhang F, Liu J, Zhu X, Chen L. AgentPose: progressive distribution alignment via feature agent for human pose distillation. In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Piscataway, NJ, USA: IEEE; 2025. p. 1–5. [Google Scholar]
31. Mao W, Tian Z, Wang X, Shen C. Fcpose: fully convolutional multi-person pose estimation with dynamic instance-aware convolutions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2021. p. 9034–43. [Google Scholar]
32. McNally W, Walters P, Vats K, Wong A, McPhee J. DeepDarts: modeling keypoints as objects for automatic scorekeeping in darts using a single camera. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2021. p. 4547–56. [Google Scholar]
33. Tan M, Le Q. Efficientnetv2: smaller models and faster training. In: International Conference on Machine Learning. London, UK: PMLR; 2021. p. 10096–106. [Google Scholar]
34. Sunkara R, Luo T. No more strided convolutions or pooling: a new CNN building block for low-resolution images and small objects. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Cham, Switzerland: Springer; 2022. p. 443–59. [Google Scholar]
35. Sun F, Han J, Wu W, Sun J, Wang M. A unet-like transformer network for camouflaged object detection. IEEE Trans Multim. 2025;27(2):9267–80. doi:10.1109/tmm.2025.3613076. [Google Scholar] [CrossRef]
36. Goyal A, Bochkovskiy A, Deng J, Koltun V. Non-deep networks. Adv Neural Inform Process Syst. 2022;35:6789–801. doi:10.52202/068431-0492. [Google Scholar] [CrossRef]
37. Ye H, Zhang B, Chen T, Fan J, Wang B. Performance-aware approximation of global channel pruning for multitask CNNs. arXiv:2303.11923. 2023. [Google Scholar]
38. Liu H, Liu F, Fan X, Huang D. Polarized self-attention: towards high-quality pixel-wise mapping. Neurocomputing. 2022;506:158–67. [Google Scholar]
39. Hou Q, Zhou D, Feng J. Coordinate attention for efficient mobile network design. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2021. p. 13713–22. [Google Scholar]
40. Ali M, Javaid M, Noman M, Fiaz M, Khan S. Fanet: feature amplification network for semantic segmentation in cluttered background. In: 2024 IEEE International Conference on Image Processing (ICIP). Piscataway, NJ, USA: IEEE; 2024. p. 2592–8. [Google Scholar]
41. Tan M, Pang R, Le QV. Efficientdet: scalable and efficient object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2020. p. 10781–90. [Google Scholar]
42. Zhang L, Deng Z, Kawaguchi K, Ghorbani A, Zou J. How does mixup help with robustness and generalization? arXiv:2010.04819. 2020. [Google Scholar]
43. Chen X, Liang C, Huang D, Real E, Wang K, Pham H, et al. Symbolic discovery of optimization algorithms. Adv Neural Inform Process Syst. 2023;36:49205–33. doi:10.52202/075280-2140. [Google Scholar] [CrossRef]
44. Jin S, Liu W, Xie E, Wang W, Qian C, Ouyang W, et al. Differentiable hierarchical graph grouping for multi-person pose estimation. In: Computer Vision—ECCV 2020: 16th European Conference. Cham, Switzerland: Springer; 2020. p. 718–34. [Google Scholar]
45. Dong X, Wang X, Li B, Wang H, Chen G, Cai M. YH-Pose: human pose estimation in complex coal mine scenarios. Eng Appl Artif Intell. 2024;127:107338. doi:10.1016/j.engappai.2023.107338. [Google Scholar] [CrossRef]
46. Lu P, Jiang T, Li Y, Li X, Chen K, Yang W. Rtmo: towards high-performance one-stage real-time multi-person pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE; 2024. p. 1491–500. [Google Scholar]
47. Osokin D. Real-time 2D multi-person pose estimation on cpu: lightweight openpose. arXiv:1811.12004. 2018. [Google Scholar]
48. Woo S, Park J, Lee JY, Kweon IS. Cbam: convolutional block attention module. In: Proceedings of the European Conference on Computer Vision (ECCV). Cham, Switzerland: Springer; 2018. p. 3–19. [Google Scholar]
49. Ouyang D, He S, Zhang G, Luo M, Guo H, Zhan J, et al. Efficient multi-scale attention module with cross-spatial learning. In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Piscataway, NJ, USA: IEEE; 2023. p. 1–5. [Google Scholar]
50. Chattopadhay A, Sarkar A, Howlader P, Balasubramanian VN. Grad-cam++: generalized gradient-based visual explanations for deep convolutional networks. In: 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Piscataway, NJ, USA: IEEE; 2018. p. 839–47. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools